This post is co-written with Jerry Henley, Hans Buchheim and Roy Gunter from Classworks.
Classworks is an online teacher and student platform that includes academic screening, progress monitoring, and specially designed instruction for reading and math for grades K–12. Classworks’s unique ability to ingest student assessment data from various sources, analyze it, and automatically deliver a customized learning progression for each student sets them apart. Although this evidence-based model has significantly impacted student growth, supporting diverse learning needs in a classroom of 25 students working independently remains challenging. Teachers often find themselves torn between assisting individual students and delivering group instruction, ultimately hindering the learning experience for all.
To address the challenges of personalized learning and teacher workload, Classworks introduces Wittly by Classworks, an AI-powered learning assistant built on Amazon Bedrock, a fully managed service that makes it straightforward to build generative AI applications.
Wittly’s innovative approach centers on two key aspects:
- Harnessing Anthropic’s Claude in Amazon Bedrock for advanced AI capabilities – Wittly uses Amazon Bedrock to seamlessly integrate with Anthropic’s Claude Sonnet 3.5, a state-of-the-art large language model (LLM). This powerful combination enables Wittly to provide tailored learning support and foster self-directed learning environments at scale.
- Personalization and teacher empowerment – This comprises two objectives:
- Personalized learning – Through AI-driven differentiated instruction, Wittly adapts to individual student needs, enhancing their learning experience.
- Reduced teacher workload – By reducing the workload, Wittly allows educators to concentrate on high-impact student support, facilitating better educational outcomes.
In this post, we discuss how Classworks uses Amazon Bedrock and Anthropic’s Claude Sonnet to deliver next-generation differentiated learning with Wittly.
Powering differentiated learning with Amazon Bedrock
The ability to deliver differentiated learning to a classroom of diverse learners is transformative. Engaging students with instruction tailored to their current learning skills accelerates mastery and fosters critical thinking and independent problem-solving. However, providing such personalized instruction to an entire classroom is labor-intensive and time-consuming for teachers.
Wittly uses generative AI to offer explanations of each skill at a student’s interest level in various ways. When students encounter challenging concepts, Wittly provides clear, concise guidance tailored to their learning style and language preferences, enabling them to grasp concepts at their own pace and overcome obstacles independently. With the scalable infrastructure of Amazon Bedrock, Wittly handles diverse classroom needs simultaneously, making personalized instruction a reality for every student.
Amazon Bedrock serves as the cornerstone of Wittly’s AI capabilities, offering several key advantages:
- Single API access – Simplifies integration with Anthropic’s Claude foundation models (FMs), allowing for straightforward updates and potential expansion to other models in the future. This unified interface accelerates development cycles by reducing the complexity of working with multiple AI models. It also future proofs Wittly’s AI infrastructure, enabling seamless adoption of new models of capabilities as they become available, without significant code changes.
- Serverless architecture – Eliminates the need for infrastructure management, enabling Classworks to focus on educational content and user experience. This approach provides automatic scaling to handle varying loads, from individual student sessions to entire school districts accessing the platform simultaneously. It also optimizes costs by allocating resources based on actual usage rather than maintaining constant capacity. The reduced operational overhead allows Wittly’s team to dedicate more time and resources to enhancing the core educational features of the platform.
Combining cutting-edge AI technology with thoughtful implementation and robust safeguards, Wittly represents a significant leap forward in personalized digital learning assistance. The system’s architecture, powered by Amazon Bedrock and Anthropic’s Claude Sonnet 3.5, enables Wittly to adapt to individual student needs while maintaining high standards of safety, privacy, and educational efficacy. By integrating these advanced technologies, Wittly not only enhances the learning experience but also makes sure it’s accessible, secure, and tailored to the unique requirements of every student.
Increasing teacher capacity and bandwidth
Meeting the diverse needs of students in a single classroom, particularly during intervention periods or in resource rooms, can be overwhelming. By differentiating instruction for students learning independently, Wittly saves valuable teacher time. Students can seek clarification and guidance from Wittly before asking for the teacher’s help, fostering a self-directed learning environment that eases the teacher’s burden.
This approach is particularly beneficial when a teacher delivers small group lessons while others learn independently. Knowing that interactive explanations are available to students learning each concept is a significant relief for teachers managing diverse ability levels in a classroom. By harnessing the powerful capabilities of Anthropic’s Claude Sonnet 3.5, Wittly creates a more efficient, personalized learning ecosystem that benefits both students and teachers.
Solution overview
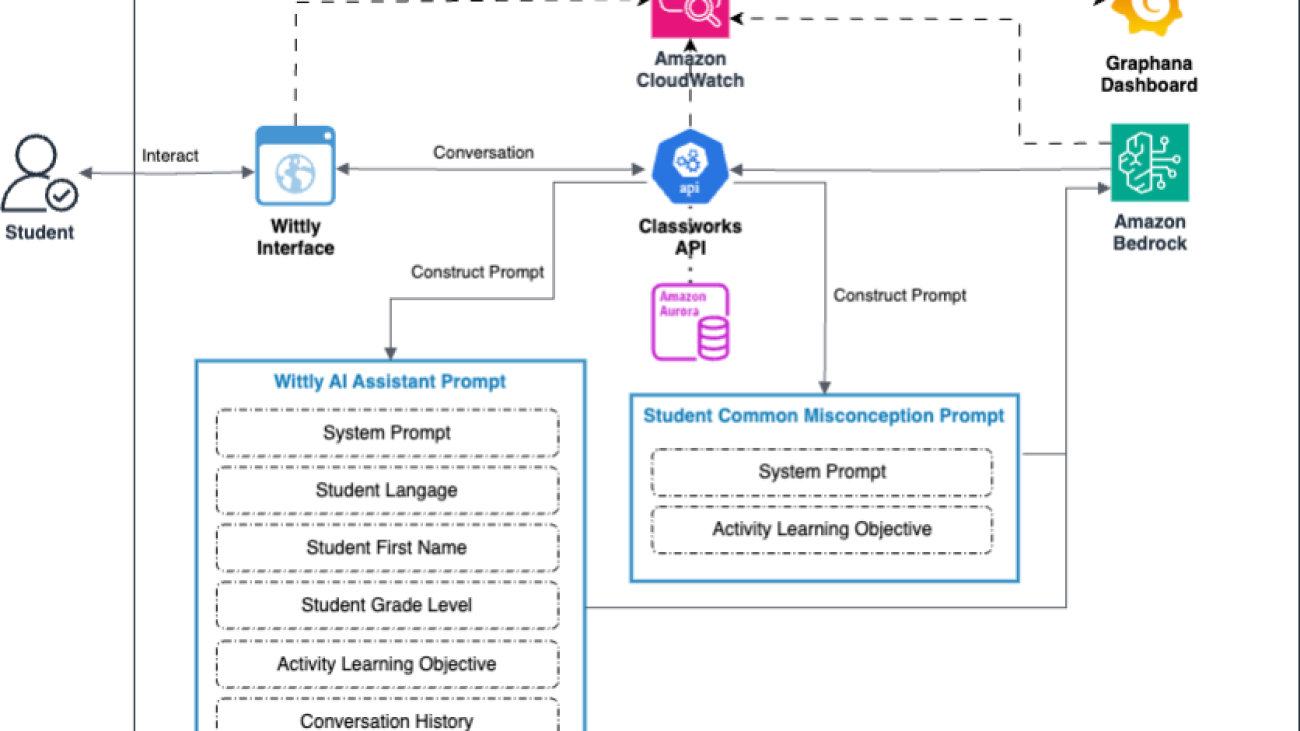
The following diagram illustrates the solution architecture.

The solution consists of the following key components:
- Wittly interface – The frontend component where students interact with the learning assistant is designed to be intuitive and engaging.
- Classworks API – This API manages the data exchange and serves as the central hub for communication between various system components.
- Wittly AI assistant prompt – Students receive a tailored prompt for the AI based on the student’s first name, grade level, learning objectives, and conversation history.
- Student common misconception prompt – This prompt actively identifies potential misconceptions related to the current learning objective, enhancing the student experience.
- Anthropic’s Claude on Amazon Bedrock – Amazon Bedrock orchestrates AI interactions, providing a fully managed service that simplifies the integration of the state-of-the-art Anthropic’s Claude models.
Monitoring the Wittly platform
In the rapidly evolving landscape of AI-powered education, robust monitoring isn’t only beneficial—it’s essential. Classworks recognizes this criticality and has developed a comprehensive monitoring strategy for the Wittly platform. This approach is pivotal in maintaining the highest standards of performance, optimizing resource allocation, and continually refining the user experience. More specifically, the Wittly platform monitors the following metrics:
- Token usage – By tracking overall token consumption and visualizing usage patterns by feature and user type, we can plan resources efficiently and manage costs effectively.
- Request volume – Monitoring API calls helps us detect unusual spikes and analyze usage patterns, enabling predictive scaling decisions and providing system reliability.
- Response times – Measuring and analyzing latency, breaking down response times by query complexity and user segments. This allows us to identify and address performance bottlenecks promptly.
- Costs – Implementing detailed cost tracking and modeling for various usage scenarios supports our budget management and pricing strategies, leading to sustainable growth.
- Quality metrics – Logging and analyzing user feedback, along with correlating satisfaction metrics with model performance, guides our continuous improvement efforts.
- Error tracking – Setting up alerts for critical errors and performing advanced error categorization and trend analysis helps us integrate seamlessly with our development workflow and maintain system integrity.
- User engagement – Visualizing user journeys and feature adoption rates through monitoring feature usage informs our product development priorities, enhancing the overall user experience.
- System health – By tracking overall system performance, we gain a holistic view of system dependencies, supporting proactive maintenance and maintaining a stable platform.
To achieve this, we use Amazon CloudWatch to capture key performance data, such as average latency and token counts. This information is then seamlessly integrated into our Grafana dashboard for real-time visualization and analysis. The following screenshot showcases our monitoring dashboard created using Grafana, which visually represents these critical metrics and provides actionable insights. Grafana is an open-source platform for monitoring and observability, enabling users to query, visualize, and understand their data through customizable dashboards.

This comprehensive monitoring framework enables Classworks to deliver exceptional value to our users by optimizing AI-powered features and maintaining high performance standards. With cutting-edge tools like Grafana for data collection, alerting, and in-depth visualization and analysis, we can adapt and expand our monitoring capabilities in tandem with the growing complexity of our AI integration.
Engaging with Wittly: A student’s experience
As students embark on their Classworks activities, they are greeted by Wittly, their AI-powered learning assistant, integrated seamlessly into the Classworks instructional toolbar. When students encounter challenging concepts or need additional help, they can choose the Wittly icon to open an interactive chat window.
Unlike other AI chat-based systems that rely on open-ended questions, Wittly offers a set of pre-created AI response options. This guided approach makes sure conversations remain focused and relevant to the current activity. When Wittly provides explanations or poses questions, students can select from the provided responses, indicating their understanding or need for further clarification.
The student engagement workflow includes the following steps:
- Wittly is called when a student needs help with a specific activity in Classworks.
- Each Classworks activity focuses on a particular skill or concept, and we’ve tagged all activities with learning objectives for the specific activity.
- When a student accesses Wittly, we send key pieces of information, including the student’s first name, the learning objective of the activity they’re working on, and the language preference of the student.
- Wittly generates a personalized response to help the student. This typically includes a greeting using the student’s name, an explanation of the concept, an example related to the learning objective, and a prompt asking if the explanation helped the student understand the concept.
The following is a sample interaction, starting with the input sent to Wittly:
{
"student_name": "Alex",
"learning_objective": "Identify and use proper punctuation in compound sentences",
"language": "English"
}
Wittly’s output is as follows:
"Hi Alex! Let's work on punctuating compound sentences. Remember to use a comma before coordinating conjunctions like 'and' or 'but'. For example: 'I love pizza, and I enjoy pasta.' Do you understand this? Please reply with 'thumbs up' or 'thumbs down'."
Wittly is designed to adapt to each student’s unique needs. It can communicate in both English and Spanish, and students can choose a voice they find engaging. For those who prefer auditory learning, Wittly reads its answers aloud while highlighting the corresponding text, making the learning experience both dynamic and accessible.
The structured interactions with Wittly are recorded, allowing teachers to monitor student progress and identify areas where additional support may be needed. This makes sure teachers remain actively involved in the learning process and that Wittly’s interactions are always appropriate and aligned with educational objectives.
With Wittly as their learning companion, students can delve into complex concepts in language arts, math, and science through guided, interactive exchanges. Wittly supports their learning journey, making their time in Classworks more engaging and personalized, all within a safe and controlled environment.
The following example showcases the interactive experience with Wittly in action, demonstrating how students engage with personalized learning through guided interactions.
Data privacy and safety considerations
In the era of AI-powered education, protecting student data and providing safe interactions are paramount. Classworks has implemented rigorous measures to uphold the highest standards of privacy and safety in Wittly’s design and operation.
Ethical AI foundation
Classworks employs a human-in-the-loop (HITL) model, combining AI technology with human expertise and insight. Wittly uses advanced AI algorithms, overseen and enhanced by the expertise of human educators and engineers, to generate instructional recommendations.
Student data protection
A core tenet in developing Wittly was achieving personalized learning without compromising student privacy. We don’t share any personally identifiable information with Wittly. Anthropic’s Claude LLM is trained on a dataset of anonymous data, not data from the Classworks platform, providing complete student privacy. Furthermore, when engaging with Wittly, students select from various pre-created responses to indicate whether the differentiated instruction was helpful or if they need further assistance. This approach eliminates the risk of inappropriate conversations, maintaining a safe learning environment.
Amazon Bedrock enhances this protection by encrypting data both in transit and rest and preventing the sharing of prompts with any third parties, including Anthropic. Additionally, Amazon Bedrock doesn’t train models with Classworks’s data, so all interactions remain secure and private.
Conclusion
Amazon Bedrock represents a pivotal advancement in AI technology, offering vast opportunities for innovation and efficiency in education. At Classworks, we’re not just adopting this technology, we’re pioneering its application to craft exceptional, personalized learning experiences. Our commitment extends beyond students to empowering educators with cutting-edge resources that elevate learning outcomes.
Based on Wittly’s capabilities, we estimate that teachers could potentially save 15–25 hours per month. This time savings might come from reduced need for individual student support, decreased time spent on classroom management, and less after-hours support. These efficiency gains significantly enhance the learning environment, allowing teachers to focus more on high impact, tailored educational experiences.
As AI continues to evolve, we’re committed to refining our policies and practices to uphold the highest standards of safety, quality, and efficacy in educational technology. By embracing Amazon Bedrock, we can make sure Classworks remains at the forefront of delivering safe, impactful, and meaningful educational experiences to students and educators alike.
To learn more about how generative AI and Amazon Bedrock can revolutionize your educational platform by delivering personalized learning experiences, enhancing teacher capacity, and enforcing data privacy, visit Amazon Bedrock. Discover how you can use advanced AI to create innovative applications, streamline development processes, and provide impactful data insights for your users.
To learn more about Classworks and our groundbreaking generative AI capabilities, visit our website.
This is a guest post from Classworks. Classworks is an award-winning K–12 special education and tiered intervention platform that uses advanced technology and comprehensive data to deliver superior personalized learning experiences. The comprehensive solution includes academic screeners, math and reading interventions, specially designed instruction, progress monitoring, and powerful data. Validated by the National Center on Intensive Intervention (NCII) and endorsed by The Council of Administrators of Special Education (CASE), Classworks partners with districts nationwide to deliver data-driven personalized learning to students where they are ready to learn.
About the Authors
 Jerry Henley, VP of Technology at Curriculum Advantage, leads the product technical vision, platform services, and support for Classworks. With 18 years in EdTech, he oversees innovation, roadmaps, and AI integration, enhancing personalized learning experiences for students and educators.
Jerry Henley, VP of Technology at Curriculum Advantage, leads the product technical vision, platform services, and support for Classworks. With 18 years in EdTech, he oversees innovation, roadmaps, and AI integration, enhancing personalized learning experiences for students and educators.
 Hans Buchheim, VP of Engineering at Curriculum Advantage, has spent 25 years developing Classworks. He leads software architecture decisions, mentors junior developers, and ensures the product evolves to meet educator needs.
Hans Buchheim, VP of Engineering at Curriculum Advantage, has spent 25 years developing Classworks. He leads software architecture decisions, mentors junior developers, and ensures the product evolves to meet educator needs.
 Roy Gunter, DevOps Engineer at Curriculum Advantage, manages cloud infrastructure and automation for Classworks. He focuses on system reliability, troubleshooting, and performance optimization to deliver an excellent user experience.
Roy Gunter, DevOps Engineer at Curriculum Advantage, manages cloud infrastructure and automation for Classworks. He focuses on system reliability, troubleshooting, and performance optimization to deliver an excellent user experience.
 Gowtham Shankar is a Solutions Architect at Amazon Web Services (AWS). He is passionate about working with customers to design and implement cloud-native architectures to address business challenges effectively. Gowtham actively engages in various open source projects, collaborating with the community to drive innovation.
Gowtham Shankar is a Solutions Architect at Amazon Web Services (AWS). He is passionate about working with customers to design and implement cloud-native architectures to address business challenges effectively. Gowtham actively engages in various open source projects, collaborating with the community to drive innovation.
 Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. She is passionate about researching methodological approaches for machine and human intelligence. Outside of work, she loves hiking, cooking, hunting food, and spending time with friends and families
Dr. Changsha Ma is an AI/ML Specialist at AWS. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. She is passionate about researching methodological approaches for machine and human intelligence. Outside of work, she loves hiking, cooking, hunting food, and spending time with friends and families
Read More











 Asheesh Goja is Principal Solutions Architect at AWS. Prior to AWS, Asheesh worked at prominent organizations such as Cisco and UPS, where he spearheaded initiatives to accelerate the adoption of several emerging technologies. His expertise spans ideation, co-design, incubation, and venture product development. Asheesh holds a wide portfolio of hardware and software patents, including a real-time C++ DSL, IoT hardware devices, Computer Vision and Edge AI prototypes. As an active contributor to the emerging fields of Generative AI and Edge AI, Asheesh shares his knowledge and insights through tech blogs and as a speaker at various industry conferences and forums.
Asheesh Goja is Principal Solutions Architect at AWS. Prior to AWS, Asheesh worked at prominent organizations such as Cisco and UPS, where he spearheaded initiatives to accelerate the adoption of several emerging technologies. His expertise spans ideation, co-design, incubation, and venture product development. Asheesh holds a wide portfolio of hardware and software patents, including a real-time C++ DSL, IoT hardware devices, Computer Vision and Edge AI prototypes. As an active contributor to the emerging fields of Generative AI and Edge AI, Asheesh shares his knowledge and insights through tech blogs and as a speaker at various industry conferences and forums. Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker. Greg Benson is a Professor of Computer Science at the University of San Francisco and Chief Scientist at SnapLogic. He joined the USF Department of Computer Science in 1998 and has taught undergraduate and graduate courses including operating systems, computer architecture, programming languages, distributed systems, and introductory programming. Greg has published research in the areas of operating systems, parallel computing, and distributed systems. Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machine learning. He currently is working on Generative AI for data integration.
Greg Benson is a Professor of Computer Science at the University of San Francisco and Chief Scientist at SnapLogic. He joined the USF Department of Computer Science in 1998 and has taught undergraduate and graduate courses including operating systems, computer architecture, programming languages, distributed systems, and introductory programming. Greg has published research in the areas of operating systems, parallel computing, and distributed systems. Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machine learning. He currently is working on Generative AI for data integration. Aaron Kesler is the Senior Product Manager for AI products and services at SnapLogic, Aaron applies over ten years of product management expertise to pioneer AI/ML product development and evangelize services across the organization. He is the author of the upcoming book “What’s Your Problem?” aimed at guiding new product managers through the product management career. His entrepreneurial journey began with his college startup, STAK, which was later acquired by Carvertise with Aaron contributing significantly to their recognition as Tech Startup of the Year 2015 in Delaware. Beyond his professional pursuits, Aaron finds joy in golfing with his father, exploring new cultures and foods on his travels, and practicing the ukulele.
Aaron Kesler is the Senior Product Manager for AI products and services at SnapLogic, Aaron applies over ten years of product management expertise to pioneer AI/ML product development and evangelize services across the organization. He is the author of the upcoming book “What’s Your Problem?” aimed at guiding new product managers through the product management career. His entrepreneurial journey began with his college startup, STAK, which was later acquired by Carvertise with Aaron contributing significantly to their recognition as Tech Startup of the Year 2015 in Delaware. Beyond his professional pursuits, Aaron finds joy in golfing with his father, exploring new cultures and foods on his travels, and practicing the ukulele. David Dellsperger is a Senior Staff Software Engineer and Technical Lead of the Agent Creator product at SnapLogic. David has been working as a Software Engineer emphasizing in Machine Learning and AI for over a decade previously focusing on AI in Healthcare and now focusing on the SnapLogic Agent Creator. David spends his time outside of work playing video games and spending quality time with his yellow lab, Sudo
David Dellsperger is a Senior Staff Software Engineer and Technical Lead of the Agent Creator product at SnapLogic. David has been working as a Software Engineer emphasizing in Machine Learning and AI for over a decade previously focusing on AI in Healthcare and now focusing on the SnapLogic Agent Creator. David spends his time outside of work playing video games and spending quality time with his yellow lab, Sudo