
NVIDIA kicked off SC24 in Atlanta with a wave of AI and supercomputing tools set to revolutionize industries like biopharma and climate science.
The announcements, delivered by NVIDIA founder and CEO Jensen Huang and Vice President of Accelerated Computing Ian Buck, are rooted in the company’s deep history in transforming computing.
“Supercomputers are among humanity’s most vital instruments, driving scientific breakthroughs and expanding the frontiers of knowledge,” Huang said. “Twenty-five years after creating the first GPU, we have reinvented computing and sparked a new industrial revolution.”
NVIDIA’s journey in accelerated computing began with CUDA in 2006 and the first GPU for scientific computing, Huang said.
Milestones like Tokyo Tech’s Tsubame supercomputer in 2008, the Oak Ridge National Laboratory’s Titan supercomputer in 2012 and the AI-focused NVIDIA DGX-1 delivered to OpenAI in 2016 highlight NVIDIA’s transformative role in the field.
“Since CUDA’s inception, we’ve driven down the cost of computing by a millionfold,” Huang said. “For some, NVIDIA is a computational microscope, allowing them to see the impossibly small. For others, it’s a telescope exploring the unimaginably distant. And for many, it’s a time machine, letting them do their life’s work within their lifetime.”
At SC24, NVIDIA’s announcements spanned tools for next-generation drug discovery, real-time climate forecasting and quantum simulations.
Central to the company’s advancements are CUDA-X libraries, described by Huang as “the engines of accelerated computing,” which power everything from AI-driven healthcare breakthroughs to quantum circuit simulations.
Huang and Buck highlighted examples of real-world impact, including Nobel Prize-winning breakthroughs in neural networks and protein prediction, powered by NVIDIA technology.
“AI will accelerate scientific discovery, transforming industries and revolutionizing every one of the world’s $100 trillion markets,” Huang said.
CUDA-X Libraries Power New Frontiers
At SC24, NVIDIA announced the new cuPyNumeric library, a GPU-accelerated implementation of NumPy, designed to supercharge applications in data science, machine learning and numerical computing.
With over 400 CUDA-X libraries, including cuDNN for deep learning and cuQuantum for quantum circuit simulations, NVIDIA continues to lead in enhancing computing capabilities across various industries.
Real-Time Digital Twins With Omniverse Blueprint
NVIDIA unveiled the NVIDIA Omniverse Blueprint for real-time computer-aided engineering digital twins, a reference workflow designed to help developers create interactive digital twins for industries like aerospace, automotive, energy and manufacturing.
Built on NVIDIA acceleration libraries, physics-AI frameworks and interactive, physically based rendering, the blueprint accelerates simulations by up to 1,200x, setting a new standard for real-time interactivity.
Early adopters, including Siemens, Altair, Ansys and Cadence, are already using the blueprint to optimize workflows, cut costs and bring products to market faster.
Quantum Leap With CUDA-Q
NVIDIA’s focus on real-time, interactive technologies extends across fields, from engineering to quantum simulations.
In partnership with Google, NVIDIA’s CUDA-Q now powers detailed dynamical simulations of quantum processors, reducing weeks-long calculations to minutes.
Buck explained that with CUDA-Q, developers of all quantum processors can perform larger simulations and explore more scalable qubit designs.
AI Breakthroughs in Drug Discovery and Chemistry
With the open-source release of BioNeMo Framework, NVIDIA is advancing AI-driven drug discovery as researchers gain powerful tools tailored specifically for pharmaceutical applications.
BioNeMo accelerates training by 2x compared to other AI software, enabling faster development of lifesaving therapies.
NVIDIA also unveiled DiffDock 2.0, a breakthrough tool for predicting how drugs bind to target proteins — critical for drug discovery.
Powered by the new cuEquivariance library, DiffDock 2.0 is 6x faster than before, enabling researchers to screen millions of molecules with unprecedented speed and accuracy.
And the NVIDIA ALCHEMI NIM microservice, NVIDIA introduces generative AI to chemistry, allowing researchers to design and evaluate novel materials with incredible speed.
Scientists start by defining the properties they want — like strength, conductivity, low toxicity or even color, Buck explained.
A generative model suggests thousands of potential candidates with the desired properties. Then the ALCHEMI NIM sorts candidate compounds for stability by solving for their lowest energy states using NVIDIA Warp.
This microservice is a game-changer for materials discovery, helping developers tackle challenges in renewable energy and beyond.
These innovations demonstrate how NVIDIA is harnessing AI to drive breakthroughs in science, transforming industries and enabling faster solutions to global challenges.
Earth-2 NIM Microservices: Redefining Climate Forecasts in Real Time
Buck also announced two new microservices — CorrDiff NIM and FourCastNet NIM — to accelerate climate change modeling and simulation results by up to 500x in the NVIDIA Earth-2 platform.
Earth-2, a digital twin for simulating and visualizing weather and climate conditions, is designed to empower weather technology companies with advanced generative AI-driven capabilities.
These tools deliver higher-resolution and more accurate predictions, enabling the forecasting of extreme weather events with unprecedented speed and energy efficiency.
With natural disasters causing $62 billion in insured losses in the first half of this year — 70% higher than the 10-year average — NVIDIA’s innovations address a growing need for precise, real-time climate forecasting. These tools highlight NVIDIA’s commitment to leveraging AI for societal resilience and climate preparedness.
Expanding Production With Foxconn Collaboration
As demand for AI systems like the Blackwell supercomputer grows, NVIDIA is scaling production through new Foxconn facilities in the U.S., Mexico and Taiwan.
Foxconn is building the production and testing facilities using NVIDIA Omniverse to bring up the factories as fast as possible.
Scaling New Heights With Hopper
NVIDIA also announced the general availability of the NVIDIA H200 NVL, a PCIe GPU based on the NVIDIA Hopper architecture optimized for low-power, air-cooled data centers.
The H200 NVL offers up to 1.7x faster large language model inference and 1.3x more performance on HPC applications, making it ideal for flexible data center configurations.
It supports a variety of AI and HPC workloads, enhancing performance while optimizing existing infrastructure.
And the GB200 Grace Blackwell NVL4 Superchip integrates four NVIDIA NVLink-connected Blackwell GPUs unified with two Grace CPUs over NVLink-C2C, Buck said. It provides up to 2x performance for scientific computing, training and inference applications over the prior generation. |
The GB200 NVL4 superchip will be available in the second half of 2025.
The talk wrapped up with an invitation to attendees to visit NVIDIA’s booth at SC24 to interact with various demos, including James, NVIDIA’s digital human, the world’s first real-time interactive wind tunnel and the Earth-2 NIM microservices for climate modeling.
Learn more about how NVIDIA’s innovations are shaping the future of science at SC24.


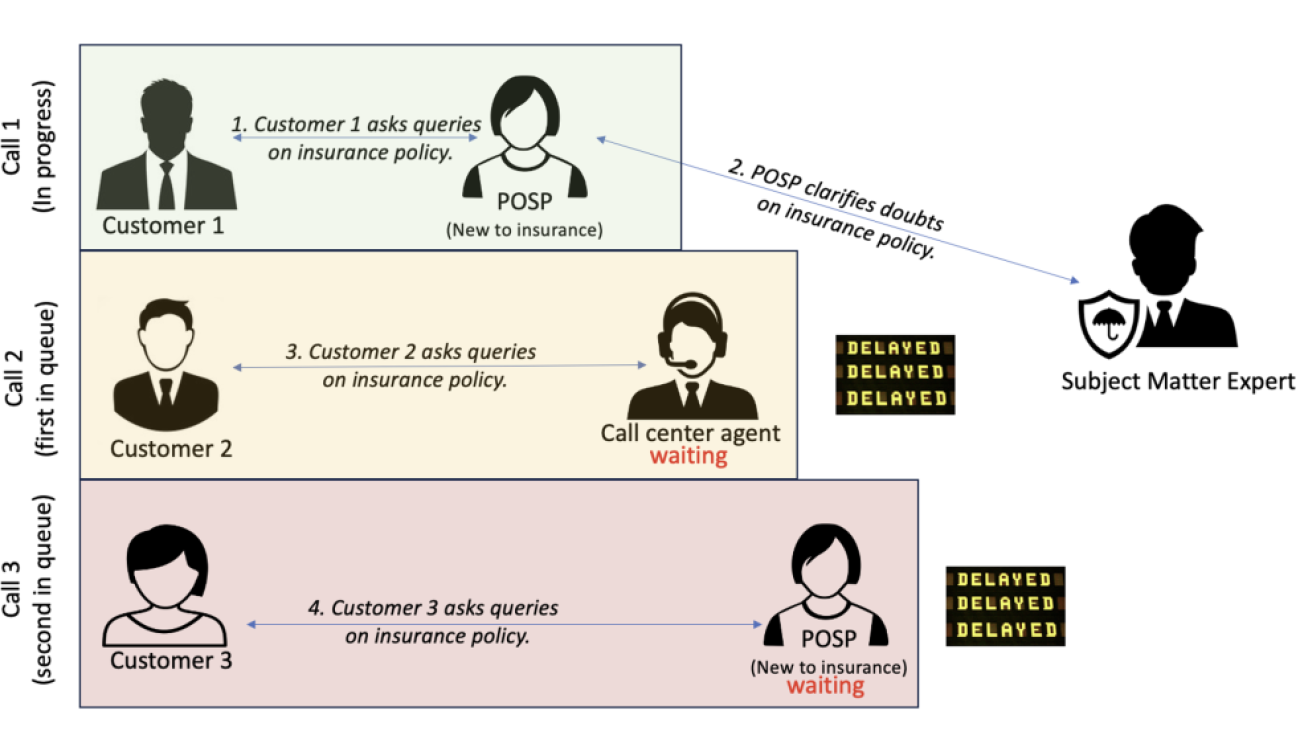


 Vishal Gupta is a Senior Solutions Architect at AWS India, based in Delhi. In his current role at AWS, he works with digital native business customers and enables them to design, architect, and innovate highly scalable, resilient, and cost-effective cloud architectures. An avid blogger and speaker, Vishal loves to share his knowledge with the tech community. Outside of work, he enjoys traveling to new destinations and spending time with his family.
Vishal Gupta is a Senior Solutions Architect at AWS India, based in Delhi. In his current role at AWS, he works with digital native business customers and enables them to design, architect, and innovate highly scalable, resilient, and cost-effective cloud architectures. An avid blogger and speaker, Vishal loves to share his knowledge with the tech community. Outside of work, he enjoys traveling to new destinations and spending time with his family. Nishant Gupta is working as Vice President, Engineering at InsuranceDekho with 14 years of experience. He is passionate about building highly scalable, reliable, and cost-optimized solutions that can handle massive amounts of data efficiently.
Nishant Gupta is working as Vice President, Engineering at InsuranceDekho with 14 years of experience. He is passionate about building highly scalable, reliable, and cost-optimized solutions that can handle massive amounts of data efficiently.




 James Manyika’s opening remarks from the AI for Science Forum.
James Manyika’s opening remarks from the AI for Science Forum.
 Google DeepMind and the Royal Society are co-hosting the AI for Science Forum to explore how AI is rapidly accelerating science.
Google DeepMind and the Royal Society are co-hosting the AI for Science Forum to explore how AI is rapidly accelerating science.
 Google.org announced a $20 million commitment to support AI for scientific breakthroughs. Learn more about what the commitment entails
Google.org announced a $20 million commitment to support AI for scientific breakthroughs. Learn more about what the commitment entails