You can now register machine learning (ML) models in Amazon SageMaker Model Registry with Amazon SageMaker Model Cards, making it straightforward to manage governance information for specific model versions directly in SageMaker Model Registry in just a few clicks.
Model cards are an essential component for registered ML models, providing a standardized way to document and communicate key model metadata, including intended use, performance, risks, and business information. This transparency is particularly important for registered models, which are often deployed in high-stakes or regulated industries, such as financial services and healthcare. By including detailed model cards, organizations can establish the responsible development of their ML systems, enabling better-informed decisions by the governance team.
When solving a business problem with an ML model, customers want to refine their approach and register multiple versions of the model in SageMaker Model Registry to find the best candidate model. To effectively operationalize and govern these various model versions, customers want the ability to clearly associate model cards with a particular model version. This lack of a unified user experience posed challenges for customers, who needed a more streamlined way to register and govern their models.
Because SageMaker Model Cards and SageMaker Model Registry were built on separate APIs, it was challenging to associate the model information and gain a comprehensive view of the model development lifecycle. Integrating model information and then sharing it across different stages became increasingly difficult. This required custom integration efforts, along with complex AWS Identity and Access Management (IAM) policy management, further complicating the model governance process.
With the unification of SageMaker Model Cards and SageMaker Model Registry, architects, data scientists, ML engineers, or platform engineers (depending on the organization’s hierarchy) can now seamlessly register ML model versions early in the development lifecycle, including essential business details and technical metadata. This unification allows you to review and govern models across your lifecycle from a single place in SageMaker Model Registry. By consolidating model governance workflows in SageMaker Model Registry, you can improve transparency and streamline the deployment of models to production environments upon governance officers’ approval.
In this post, we discuss a new feature that supports the integration of model cards with the model registry. We discuss the solution architecture and best practices for managing model cards with a registered model version, and walk through how to set up, operationalize, and govern your models using the integration in the model registry.
Solution overview
In this section, we discuss the solution to address the aforementioned challenges with model governance. First, we introduce the unified model governance solution architecture for addressing the model governance challenges for an end-to-end ML lifecycle in a scalable, well-architected environment. Then we dive deep into the details of the unified model registry and discuss how it helps with governance and deployment workflows.
Unified model governance architecture
ML governance enforces the ethical, legal, and efficient use of ML systems by addressing concerns like bias, transparency, explainability, and accountability. It helps organizations comply with regulations, manage risks, and maintain operational efficiency through robust model lifecycles and data quality management. Ultimately, ML governance builds stakeholder trust and aligns ML initiatives with strategic business goals, maximizing their value and impact. ML governance starts when you want to solve a business use case or problem with ML and is part of every step of your ML lifecycle, from use case inception, model building, training, evaluation, deployment, and monitoring of your production ML system.
Let’s delve into the architecture details of how you can use a unified model registry along with other AWS services to govern your ML use case and models throughout the entire ML lifecycle.
SageMaker Model Registry catalogs your models along with their versions and associated metadata and metrics for training and evaluation. It also maintains audit and inference metadata to help drive governance and deployment workflows.
The following are key concepts used in the model registry:
- Model package group – A model package group or model group solves a business problem with an ML model (for this example, we use the model CustomerChurn). This model group contains all the model versions associated with that ML model.
- Model package version – A model package version or model version is a registered model version that includes the model artifacts and inference code for the model.
- Registered model – This is the model group that is registered in SageMaker Model Registry.
- Deployable model – This is the model version that is deployable to an inference endpoint.
Additionally, this solution uses Amazon DataZone. With the integration of SageMaker and Amazon DataZone, it enables collaboration between ML builders and data engineers for building ML use cases. ML builders can request access to data published by data engineers. Upon receiving approval, ML builders can then consume the accessed data to engineer features, create models, and publish features and models to the Amazon DataZone catalog for sharing across the enterprise. As part of the SageMaker Model Cards and SageMaker Model Registry unification, ML builders can now share technical and business information about their models, including training and evaluation details, as well as business metadata such as model risk, for ML use cases.
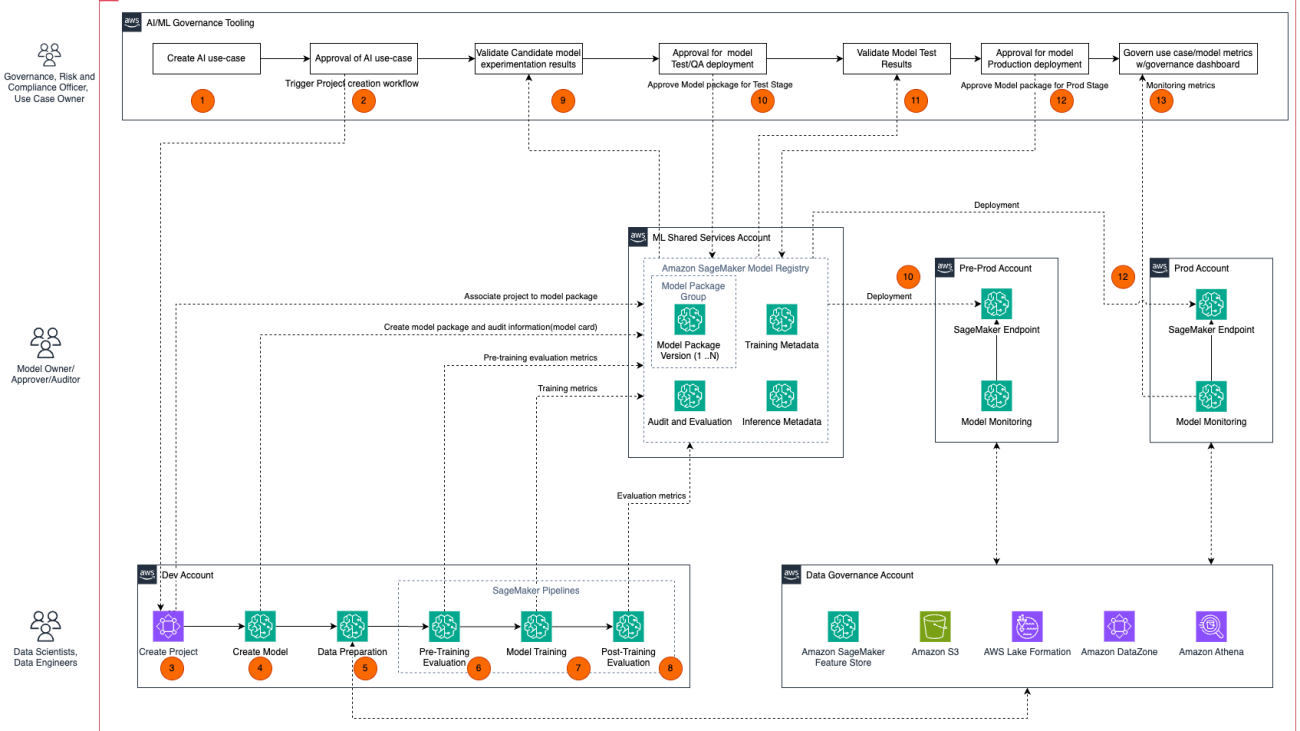
The following diagram depicts the architecture for unified governance across your ML lifecycle.

There are several for implementing secure and scalable end-to-end governance for your ML lifecycle:
- Define your ML use case metadata (name, description, risk, and so on) for the business problem you’re trying to solve (for example, automate a loan application process).
- Set up and invoke your use case approval workflow for building the ML model (for example, fraud detection) for the use case.
- Create an ML project to create a model for the ML use case.
- Create a SageMaker model package group to start building the model. Associate the model to the ML project and record qualitative information about the model, such as purpose, assumptions, and owner.
- Prepare the data to build your model training pipeline.
- Evaluate your training data for data quality, including feature importance and bias, and update the model package version with relevant evaluation metrics.
- Train your ML model with the prepared data and register the candidate model package version with training metrics.
- Evaluate your trained model for model bias and model drift, and update the model package version with relevant evaluation metrics.
- Validate that the candidate model experimentation results meet your model governance criteria based on your use case risk profile and compliance requirements.
- After you receive the governance team’s approval on the candidate model, record the approval on the model package version and invoke an automated test deployment pipeline to deploy the model to a test environment.
- Run model validation tests in a test environment and make sure the model integrates and works with upstream and downstream dependencies similar to a production environment.
- After you validate the model in the test environment and make sure the model complies with use case requirements, approve the model for production deployment.
- After you deploy the model to the production environment, continuously monitor model performance metrics (such as quality and bias) to make sure the model stays in compliance and meets your business use case key performance indicators (KPIs).
Architecture tools, components, and environments
You need to set up several components and environments for orchestrating the solution workflow:
- AI governance tooling – This tooling should be hosted in an isolated environment (a separate AWS account) where your key AI/ML governance stakeholders can set up and operate approval workflows for governing AI/ML use cases across your organization, lines of business, and teams.
- Data governance – This tooling should be hosted in an isolated environment to centralize data governance functions such as setting up data access policies and governing data access for AI/ML use cases across your organization, lines of business, and teams.
- ML shared services – ML shared services components should be hosted in an isolated environment to centralize model governance functions such as accountability through workflows and approvals, transparency through centralized model metadata, and reproducibility through centralized model lineage for AI/ML use cases across your organization, lines of business, and teams.
- ML development – This phase of the ML lifecycle should be hosted in an isolated environment for model experimentation and building the candidate model. Several activities are performed in this phase, such as creating the model, data preparation, model training, evaluation, and model registration.
- ML pre-production – This phase of ML lifecycle should be hosted in an isolated environment for integrating the testing the candidate model with the ML system and validating that the results comply with the model and use case requirements. The candidate model that was built in the ML development phase is deployed to an endpoint for integration testing and validation.
- ML production – This phase of the ML lifecycle should be hosted in an isolated environment for deploying the model to a production endpoint for shadow testing and A/B testing, and for gradually rolling out the model for operations in a production environment.
Integrate a model version in the model registry with model cards
In this section, we provide API implementation details for testing this in your own environment. We walk through an example notebook to demonstrate how you can use this unification during the model development data science lifecycle.
We have two example notebooks in GitHub repository: AbaloneExample and DirectMarketing.
Complete the following steps in the above Abalone example notebook:
- Install or update the necessary packages and library.
- Import the necessary library and instantiate the necessary variables like SageMaker client and Amazon Simple Storage Service (Amazon S3) buckets.
- Create an Amazon DataZone domain and a project within the domain.
You can use an existing project if you already have one. This is an optional step and we will be referencing the Amazon DataZone project ID while creating the SageMaker model package. For overall governance between your data and the model lifecycle, this can help create the correlation between business unit/domain, data and corresponding model.
The following screenshot shows the Amazon DataZone welcome page for a test domain.

In Amazon DataZone, projects enable a group of users to collaborate on various business use cases that involve creating assets in project inventories and thereby making them discoverable by all project members, and then publishing, discovering, subscribing to, and consuming assets in the Amazon DataZone catalog. Project members consume assets from the Amazon DataZone catalog and produce new assets using one or more analytical workflows. Project members can be owners or contributors.
You can gather the project ID on the project details page, as shown in the following screenshot.

In the notebook, we refer to the project ID as follows:
- Prepare a SageMaker model package group.
A model group contains a group of versioned models. We refer to the Amazon DataZone project ID when we create the model package group, as shown in the following screenshot. It’s mapped to the custom_details field.

- Update the details for the model card, including the intended use and owner:
This data is used to update the created model package. The SageMaker model package helps create a deployable model that you can use to get real-time inferences by creating a hosted endpoint or to run batch transform jobs.
The model card information shown as model_card=my_card in the following code snippet can be passed to the pipeline during the model register step:
Alternatively, you can pass it as follows:
The notebook will invoke a run of the SageMaker pipeline (which can also be invoked from an event or from the pipelines UI), which includes preprocessing, training, and evaluation.

After the pipeline is complete, you can navigate to Amazon SageMaker Studio, where you can see a model package on the Models page.

You can view the details like business details, intended use, and more on the Overview tab under Audit, as shown in the following screenshots.



The Amazon DataZone project ID is captured in the Documentation section.

You can view performance metrics under Train as well.

Evaluation details like model quality, bias pre-training, bias post-training, and explainability can be reviewed on the Evaluate tab.




Optionally, you can view the model card details from the model package itself.

Additionally, you can update the audit details of the model by choosing Edit in the top right corner. Once you are done with your changes, choose Save to keep the changes in the model card.

Also, you can update the model’s deploy status.

You can track the different statuses and activity as well.

Lineage
ML lineage is crucial for tracking the origin, evolution, and dependencies of data, models, and code used in ML workflows, providing transparency and traceability. It helps with reproducibility and debugging, making it straightforward to understand and address issues.
Model lineage tracking captures and retains information about the stages of an ML workflow, from data preparation and training to model registration and deployment. You can view the lineage details of a registered model version in SageMaker Model Registry using SageMaker ML lineage tracking, as shown in the following screenshot. ML model lineage tracks the metadata associated with your model training and deployment workflows, including training jobs, datasets used, pipelines, endpoints, and the actual models. You can also use the graph node to view more details, such as dataset and images used in that step.

Clean up
If you created resources while using the notebook in this post, follow the instructions in the notebook to clean up those resources.
Conclusion
In this post, we discussed a solution to use a unified model registry with other AWS services to govern your ML use case and models throughout the entire ML lifecycle in your organization. We walked through an end-to-end architecture for developing an AI use case embedding governance controls, from use case inception to model building, model validation, and model deployment in production. We demonstrated through code how to register a model and update it with governance, technical, and business metadata in SageMaker Model Registry.
We encourage you to try out this solution and share your feedback in the comments section.
About the authors
 Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides his motorcycle and walks with his 3-year-old Sheepadoodle.
Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides his motorcycle and walks with his 3-year-old Sheepadoodle.
 Neelam Koshiya is principal solutions architect (GenAI specialist) at AWS. With a background in software engineering, she moved organically into an architecture role. Her current focus is to help enterprise customers with their ML/ GenAI journeys for strategic business outcomes. Her area of depth is machine learning. In her spare time, she enjoys reading and being outdoors.
Neelam Koshiya is principal solutions architect (GenAI specialist) at AWS. With a background in software engineering, she moved organically into an architecture role. Her current focus is to help enterprise customers with their ML/ GenAI journeys for strategic business outcomes. Her area of depth is machine learning. In her spare time, she enjoys reading and being outdoors.
 Siamak Nariman is a Senior Product Manager at AWS. He is focused on AI/ML technology, ML model management, and ML governance to improve overall organizational efficiency and productivity. He has extensive experience automating processes and deploying various technologies.
Siamak Nariman is a Senior Product Manager at AWS. He is focused on AI/ML technology, ML model management, and ML governance to improve overall organizational efficiency and productivity. He has extensive experience automating processes and deploying various technologies.
 Saumitra Vikaram is a Senior Software Engineer at AWS. He is focused on AI/ML technology, ML model management, ML governance, and MLOps to improve overall organizational efficiency and productivity.
Saumitra Vikaram is a Senior Software Engineer at AWS. He is focused on AI/ML technology, ML model management, ML governance, and MLOps to improve overall organizational efficiency and productivity.


 Luca Guida is a Senior Solutions Architect at AWS; he is based in Milan and he supports independent software vendors in their cloud journey. With an academic background in computer science and engineering, he started developing his AI/ML passion at university; as a member of the natural language processing and generative AI community within AWS, Luca helps customers be successful while adopting AI/ML services.
Luca Guida is a Senior Solutions Architect at AWS; he is based in Milan and he supports independent software vendors in their cloud journey. With an academic background in computer science and engineering, he started developing his AI/ML passion at university; as a member of the natural language processing and generative AI community within AWS, Luca helps customers be successful while adopting AI/ML services. Chiara Relandini is an Associate Solutions Architect at AWS. She collaborates with customers from diverse sectors, including digital native businesses and independent software vendors. After focusing on ML during her studies, Chiara supports customers in using generative AI and ML technologies effectively, helping them extract maximum value from these powerful tools.
Chiara Relandini is an Associate Solutions Architect at AWS. She collaborates with customers from diverse sectors, including digital native businesses and independent software vendors. After focusing on ML during her studies, Chiara supports customers in using generative AI and ML technologies effectively, helping them extract maximum value from these powerful tools. Arian Rezai Tabrizi is an Associate Solutions Architect based in Milan. She supports enterprises across various industries, including retail, fashion, and manufacturing, on their cloud journey. Drawing from her background in data science, Arian assists customers in effectively using generative AI and other AI technologies.
Arian Rezai Tabrizi is an Associate Solutions Architect based in Milan. She supports enterprises across various industries, including retail, fashion, and manufacturing, on their cloud journey. Drawing from her background in data science, Arian assists customers in effectively using generative AI and other AI technologies.


 Jason D’Alba is an AWS Solutions Architect leader focused on enterprise applications, helping customers architect highly available and scalable data & ai solutions.
Jason D’Alba is an AWS Solutions Architect leader focused on enterprise applications, helping customers architect highly available and scalable data & ai solutions.



 Marin Mestrovic is a Partner Solutions Architect at Amazon Web Services, specializing in supporting partner solutions. In his role, he collaborates with leading Global System Integrators (GSIs) and independent software vendors (ISVs) to help design and build cost-efficient, scalable, industry-specific solutions. With his expertise in AWS capabilities, Marin empowers partners to develop innovative solutions that drive business growth for their clients.
Marin Mestrovic is a Partner Solutions Architect at Amazon Web Services, specializing in supporting partner solutions. In his role, he collaborates with leading Global System Integrators (GSIs) and independent software vendors (ISVs) to help design and build cost-efficient, scalable, industry-specific solutions. With his expertise in AWS capabilities, Marin empowers partners to develop innovative solutions that drive business growth for their clients.
 Dilin Joy is a Senior Partner Solutions Architect at Amazon Web Services. In his role, he works with leading independent software vendors (ISVs) and Global System Integrators (GSIs) to provide architectural guidance and support in building strategic industry solutions on the AWS platform. His expertise and collaborative approach help these partners develop innovative cloud-based solutions that drive business success for their clients.
Dilin Joy is a Senior Partner Solutions Architect at Amazon Web Services. In his role, he works with leading independent software vendors (ISVs) and Global System Integrators (GSIs) to provide architectural guidance and support in building strategic industry solutions on the AWS platform. His expertise and collaborative approach help these partners develop innovative cloud-based solutions that drive business success for their clients. Anjan Biswas is a Senior AI Services Solutions Architect who focuses on computer vision, NLP, and generative AI. Anjan is part of the worldwide AI services specialist team and works with customers to help them understand and develop solutions to business problems with AWS AI Services and generative AI.
Anjan Biswas is a Senior AI Services Solutions Architect who focuses on computer vision, NLP, and generative AI. Anjan is part of the worldwide AI services specialist team and works with customers to help them understand and develop solutions to business problems with AWS AI Services and generative AI.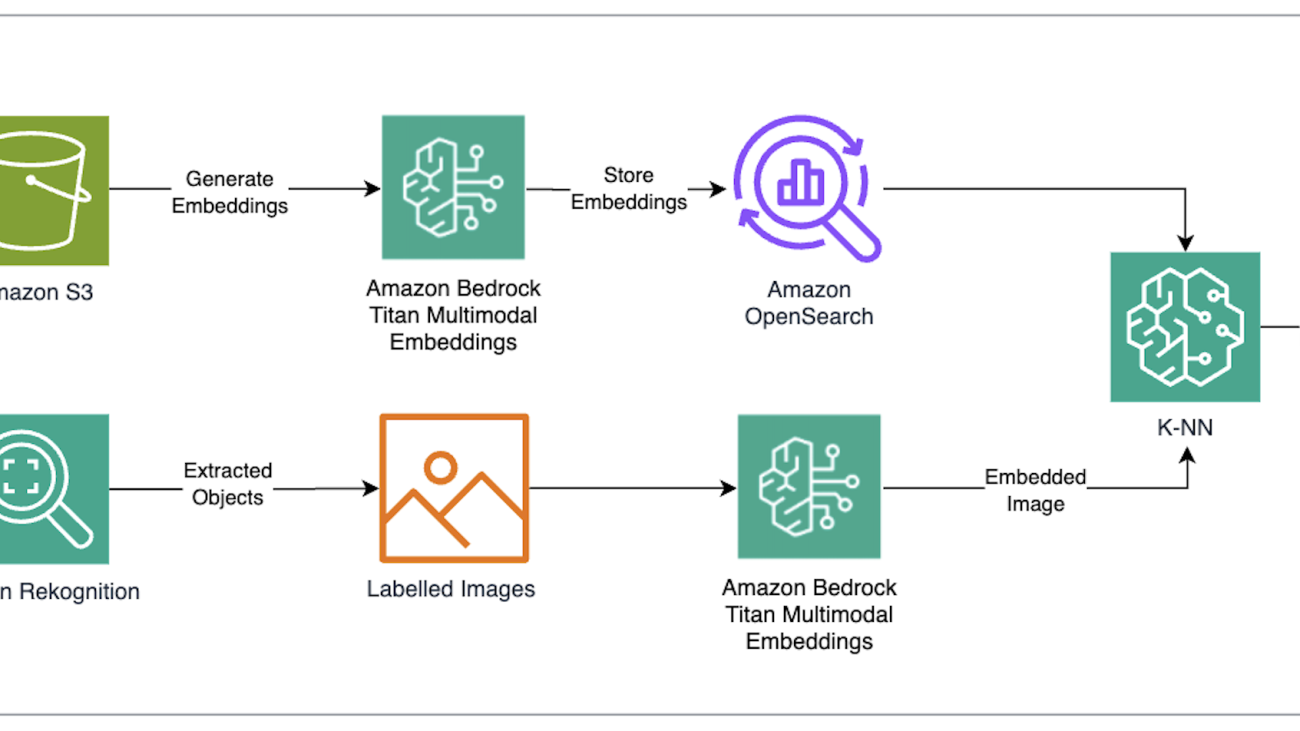
 The steps of the solution include:
The steps of the solution include:








 Nathan Pogue is a Solutions Architect on the Canadian Public Sector Healthcare and Life Sciences team at AWS. Based in Toronto, he focuses on empowering his customers to expand their understanding of AWS and utilize the cloud for innovative use cases. He is particularly passionate about AI/ML and enjoys building proof-of-concept solutions for his customers.
Nathan Pogue is a Solutions Architect on the Canadian Public Sector Healthcare and Life Sciences team at AWS. Based in Toronto, he focuses on empowering his customers to expand their understanding of AWS and utilize the cloud for innovative use cases. He is particularly passionate about AI/ML and enjoys building proof-of-concept solutions for his customers. Waleed Malik is a Solutions Architect with the Canadian Public Sector EdTech team at AWS. He holds six AWS certifications, including the Machine Learning Specialty Certification. Waleed is passionate about helping customers deepen their knowledge of AWS by translating their business challenges into technical solutions.
Waleed Malik is a Solutions Architect with the Canadian Public Sector EdTech team at AWS. He holds six AWS certifications, including the Machine Learning Specialty Certification. Waleed is passionate about helping customers deepen their knowledge of AWS by translating their business challenges into technical solutions.







 Rev Lebaredian
Rev Lebaredian Deepu Talla
Deepu Talla Kevin Levitt
Kevin Levitt Richard Kerris
Richard Kerris Ronnie Vasishta
Ronnie Vasishta Xinzhou Wu
Xinzhou Wu Marc Spieler
Marc Spieler Azita Martin
Azita Martin


