Advancing adaptive AI agents, empowering 3D scene creation, and innovating LLM training for a smarter, safer futureRead More

Advancing adaptive AI agents, empowering 3D scene creation, and innovating LLM training for a smarter, safer futureRead More

Advancing adaptive AI agents, empowering 3D scene creation, and innovating LLM training for a smarter, safer futureRead More

From boardroom to break room, generative AI took this year by storm, stirring discussion across industries about how to best harness the technology to enhance innovation and creativity, improve customer service, transform product development and even boost communication.
The adoption of generative AI and large language models is rippling through nearly every industry, as incumbents and new entrants reimagine products and services to generate an estimated $1.3 trillion in revenue by 2032, according to a report by Bloomberg Intelligence.
Yet, some companies and startups are still slow to adopt AI, sticking to experimentation and siloed projects even as the technology advances at a dizzying pace. That’s partly because AI benefits vary by company, use case and level of investment.
Cautious approaches are giving way to optimism. Two-thirds of the respondents to Forrester Research’s 2024 State of AI Survey believe their organizations would require less than 50% return on investments to consider their AI initiatives successful.
The next big thing on the horizon is agentic AI, a form of autonomous or “reasoning” AI that requires using diverse language models, sophisticated retrieval-augmented generation stacks and advanced data architectures.
NVIDIA experts in industry verticals already shared their expectations for the year ahead. Now, hear from company experts driving innovation in AI across enterprises, research and the startup ecosystem:

IAN BUCK
Vice President of Hyperscale and HPC
Inference drives the AI charge: As AI models grow in size and complexity, the demand for efficient inference solutions will increase.
The rise of generative AI has transformed inference from simple recognition of the query and response to complex information generation — including summarizing from multiple sources and large language models such as OpenAI o1 and Llama 450B — which dramatically increases computational demands. Through new hardware innovations, coupled with continuous software improvements, performance will increase and total cost of ownership is expected to shrink by 5x or more.
Accelerate everything: With GPUs becoming more widely adopted, industries will look to accelerate everything, from planning to production. New architectures will add to that virtuous cycle, delivering cost efficiencies and an order of magnitude higher compute performance with each generation.
As nations and businesses race to build AI factories to accelerate even more workloads, expect many to look for platform solutions and reference data center architectures or blueprints that can get a data center up and running in weeks versus months. This will help them solve some of the world’s toughest challenges, including quantum computing and drug discovery.
Quantum computing — all trials, no errors: Quantum computing will make significant strides as researchers focus on supercomputing and simulation to solve the greatest challenges to the nascent field: errors.
Qubits, the basic unit of information in quantum computing, are susceptible to noise, becoming unstable after performing only thousands of operations. This prevents today’s quantum hardware from solving useful problems. In 2025, expect to see the quantum computing community move toward challenging, but crucial, quantum error correction techniques. Error correction requires quick, low-latency calculations. Also expect to see quantum hardware that’s physically colocated within supercomputers, supported by specialized infrastructure.
AI will also play a crucial role in managing these complex quantum systems, optimizing error correction and enhancing overall quantum hardware performance. This convergence of quantum computing, supercomputing and AI into accelerated quantum supercomputers will drive progress in realizing quantum applications for solving complex problems across various fields, including drug discovery, materials development and logistics.
 BRYAN CATANZARO
BRYAN CATANZARO
Vice President of Applied Deep Learning Research
Putting a face to AI: AI will become more familiar to use, emotionally responsive and marked by greater creativity and diversity. The first generative AI models that drew pictures struggled with simple tasks like drawing teeth. Rapid advances in AI are making image and video outputs much more photorealistic, while AI-generated voices are losing that robotic feel.
These advancements will be driven by the refinement of algorithms and datasets and enterprises’ acknowledgment that AI needs a face and a voice to matter to 8 billion people. This will also cause a shift from turn-based AI interactions to more fluid and natural conversations. Interactions with AI will no longer feel like a series of exchanges but instead offer a more engaging and humanlike conversational experience.
Rethinking industry infrastructure and urban planning: Nations and industries will begin examining how AI automates various aspects of the economy to maintain the current standard of living, even as the global population shrinks.
These efforts could help with sustainability and climate change. For instance, the agriculture industry will begin investing in autonomous robots that can clean fields and remove pests and weeds mechanically. This will reduce the need for pesticides and herbicides, keeping the planet healthier and freeing up human capital for other meaningful contributions. Expect to see new thinking in urban planning offices to account for autonomous vehicles and improve traffic management.
Longer term, AI can help find solutions for reducing carbon emissions and storing carbon, an urgent global challenge.
 KARI BRISKI
KARI BRISKI
Vice President of Generative AI Software
A symphony of agents — AI orchestrators: Enterprises are set to have a slew of AI agents, which are semiautonomous, trained models that work across internal networks to help with customer service, human resources, data security and more. To maximize these efficiencies, expect to see a rise in AI orchestrators that work across numerous agents to seamlessly route human inquiries and interpret collective results to recommend and take actions for users.
These orchestrators will have access to deeper content understanding, multilingual capabilities and fluency with multiple data types, ranging from PDFs to video streams. Powered by self-learning data flywheels, AI orchestrators will continuously refine business-specific insights. For instance, in manufacturing, an AI orchestrator could optimize supply chains by analyzing real-time data and making recommendations on production schedules and supplier negotiations.
This evolution in enterprise AI will significantly boost productivity and innovation across industries while becoming more accessible. Knowledge workers will be more productive because they can tap into a personalized team of AI-powered experts. Developers will be able to build these advanced agents using customizable AI blueprints.
Multistep reasoning amplifies AI insights: AI for years has been good at giving answers to specific questions without having to delve into the context of a given query. With advances in accelerated computing and new model architectures, AI models will tackle increasingly complex problems and respond with greater accuracy and deeper analysis.
Using a capability called multistep reasoning, AI systems increase the amount of “thinking time” by breaking down large, complex questions into smaller tasks — sometimes even running multiple simulations — to problem-solve from various angles. These models dynamically evaluate each step, ensuring contextually relevant and transparent responses. Multistep reasoning also involves integrating knowledge from various sources to enable AI to make logical connections and synthesize information across different domains.
This will likely impact fields ranging from finance and healthcare to scientific research and entertainment. For example, a healthcare model with multistep reasoning could make a number of recommendations for a doctor to consider, depending on the patient’s diagnosis, medications and response to other treatments.
Start your AI query engine: With enterprises and research organizations sitting on petabytes of data, the challenge is gaining quick access to the data to deliver actionable insights.
AI query engines will change how businesses mine that data, and company-specific search engines will be able to sift through structured and unstructured data, including text, images and videos, using natural language processing and machine learning to interpret a user’s intent and provide more relevant and comprehensive results.
This will lead to more intelligent decision-making processes, improved customer experiences and enhanced productivity across industries. The continuous learning capabilities of AI query engines will create self-improving data flywheels that help applications become increasingly effective.
 CHARLIE BOYLE
CHARLIE BOYLE
Vice President of DGX Platforms
Agentic AI makes high-performance inference essential for enterprises: The dawn of agentic AI will drive demand for near-instant responses from complex systems of multiple models. This will make high-performance inference just as important as high-performance training infrastructure. IT leaders will need scalable, purpose-built and optimized accelerated computing infrastructure that can keep pace with the demands of agentic AI to deliver the performance required for real-time decision-making.
Enterprises expand AI factories to process data into intelligence: Enterprise AI factories transform raw data into business intelligence. Next year, enterprises will expand these factories to leverage massive amounts of historical and synthetic data, then generate forecasts and simulations for everything from consumer behavior and supply chain optimization to financial market movements and digital twins of factories and warehouses. AI factories will become a key competitive advantage that helps early adopters anticipate and shape future scenarios, rather than just react to them.
Chill factor — liquid-cooled AI data centers: As AI workloads continue to drive growth, pioneering organizations will transition to liquid cooling to maximize performance and energy efficiency. Hyperscale cloud providers and large enterprises will lead the way, using liquid cooling in new AI data centers that house hundreds of thousands of AI accelerators, networking and software.
Enterprises will increasingly choose to deploy AI infrastructure in colocation facilities rather than build their own — in part to ease the financial burden of designing, deploying and operating intelligence manufacturing at scale. Or, they will rent capacity as needed. These deployments will help enterprises harness the latest infrastructure without needing to install and operate it themselves. This shift will accelerate broader industry adoption of liquid cooling as a mainstream solution for AI data centers.
 GILAD SHAINER
GILAD SHAINER
Senior Vice President of Networking
Goodbye network, hello computing fabric: The term “networking” in the data center will seem dated as data center architecture transforms into an integrated compute fabric that enables thousands of accelerators to efficiently communicate with one another via scale-up and scale-out communications, spanning miles of cabling and multiple data center facilities.
This integrated compute fabric will include NVIDIA NVLink, which enables scale-up communications, as well as scale-out capabilities enabled by intelligent switches, SuperNICs and DPUs. This will help securely move data to and from accelerators and perform calculations on the fly that drastically minimize data movement. Scale-out communication across networks will be crucial to large-scale AI data center deployments — and key to getting them up and running in weeks versus months or years.
As agentic AI workloads grow — requiring communication across multiple interconnected AI models working together rather than monolithic and localized AI models — compute fabrics will be essential to delivering real-time generative AI.
Distributed AI: All data centers will become accelerated as new approaches to Ethernet design emerge that enable hundreds of thousands of GPUs to support a single workload. This will help democratize AI factory rollouts for multi-tenant generative AI clouds and enterprise AI data centers.
This breakthrough technology will also enable AI to expand quickly into enterprise platforms and simplify the buildup and management of AI clouds.
Companies will build data center resources that are more geographically dispersed — located hundreds or even thousands of miles apart — because of power limitations and the need to build closer to renewable energy sources. Scale-out communications will ensure reliable data movement over these long distances.
 LINXI (JIM) FAN
LINXI (JIM) FAN
Senior Research Scientist, AI Agents
Robotics will evolve more into humanoids: Robots will begin to understand arbitrary language commands. Right now, industry robots must be programmed by hand, and they don’t respond intelligently to unpredictable inputs or languages other than those programmed. Multimodal robot foundation models that incorporate vision, language and arbitrary actions will evolve this “AI brain,” as will agentic AI that allows for greater AI reasoning.
To be sure, don’t expect to immediately see intelligent robots in homes, restaurants, service areas and factories. But these use cases may be closer than you think, as governments look for solutions to aging societies and shrinking labor pools. Physical automation is going to happen gradually, in 10 years being as ubiquitous as the iPhone.
AI agents are all about inferencing: In September, OpenAI announced a new large language model trained with reinforcement learning to perform complex reasoning. OpenAI o1, dubbed Strawberry, thinks before it answers: It can produce a long internal chain of thought, correcting mistakes and breaking down tricky steps into simple ones, before responding to the user.
2025 will be the year a lot of computation begins to shift to inference at the edge. Applications will need hundreds of thousands of tokens for a single query, as small language models make one query after another in microseconds before churning out an answer.
Small models will be more energy efficient and will become increasingly important for robotics, creating humanoids and robots that can assist humans in everyday jobs and promoting mobile intelligence applications..
 BOB PETTE
BOB PETTE
Vice President of Enterprise Platforms
Seeking sustainable scalability: As enterprises prepare to embrace a new generation of semiautonomous AI agents to enhance various business processes, they’ll focus on creating robust infrastructure, governance and human-like capabilities for effective large-scale deployment. At the same time, AI applications will increasingly use local processing power to enable more sophisticated AI features to run directly on workstations, including thin, lightweight laptops and compact form factors, and improve performance while reducing latency for AI-driven tasks.
Validated reference architectures, which provide guidance on appropriate hardware and software platforms, will become crucial to optimize performance and accelerate AI deployments. These architectures will serve as essential tools for organizations navigating the complex terrain of AI implementation by helping ensure that their investments align with current needs and future technological advancements.
Revolutionizing construction, engineering and design with AI: Expect to see a rise in generative AI models tailored to the construction, engineering and design industries that will boost efficiency and accelerate innovation.
In construction, agentic AI will extract meaning from massive volumes of construction data collected from onsite sensors and cameras, offering insights that lead to more efficient project timelines and budget management.
AI will evaluate reality capture data (lidar, photogrammetry and radiance fields) 24/7 and derive mission-critical insights on quality, safety and compliance — resulting in reduced errors and worksite injuries.
For engineers, predictive physics based on physics-informed neural networks will accelerate flood prediction, structural engineering and computational fluid dynamics for airflow solutions tailored to individual rooms or floors of a building — allowing for faster design iteration.
In design, retrieval-augmented generation will enable compliance early in the design phase by ensuring that information modeling for designing and constructing buildings complies with local building codes. Diffusion AI models will accelerate conceptual design and site planning by enabling architects and designers to combine keyword prompts and rough sketches to generate richly detailed conceptual images for client presentations. That will free up time to focus on research and design.
 SANJA FIDLER
SANJA FIDLER
Vice President of AI Research
Predicting unpredictability: Expect to see more models that can learn in the everyday world, helping digital humans, robots and even autonomous cars understand chaotic and sometimes unpredictable situations, using very complex skills with little human intervention.
From the research lab to Wall Street, we’re entering a hype cycle similar to the optimism about autonomous driving 5-7 years ago. It took many years for companies like Waymo and Cruise to deliver a system that works — and it’s still not scalable because the troves of data these companies and others, including Tesla, have collected may be applicable in one region but not another.
With models introduced this year, we can now move more quickly — and with much less capital expense — to use internet-scale data to understand natural language and emulate movements by observing human and other actions. Edge applications like robots, cars and warehouse machinery will quickly learn coordination, dexterity and other skills in order to navigate, adapt and interact with the real world.
Will a robot be able to make coffee and eggs in your kitchen, and then clean up after? Not yet. But it may come sooner than you think.
Getting real: Fidelity and realism is coming to generative AI across the graphics and simulation pipeline, leading to hyperrealistic games, AI-generated movies and digital humans.
Unlike with traditional graphics, the vast majority of images will come from generated pixels instead of renderings, resulting in more natural motions and appearances. Tools that develop and iterate on contextual behaviors will result in more sophisticated games for a fraction of the cost of today’s AAA titles.
Industries adopt generative AI: Nearly every industry is poised to use AI to enhance and improve the way people live and play.
Agriculture will use AI to optimize the food chain, improving the delivery of food. For example, AI can be used to predict the greenhouse gas emissions from different crops on individual farms. These analyses can help inform design strategies that help reduce greenhouse gas in supply chains. Meanwhile, AI agents in education will personalize learning experiences, speaking in a person’s native language and asking or answering questions based on level of education in a particular subject.
As next-generation accelerators enter the marketplace, you’ll also see a lot more efficiency in delivering these generative AI applications. By improving the training and efficiency of the models in testing, businesses and startups will see better and faster returns on investment across those applications.
 ANDREW FENG
ANDREW FENG
Vice President of GPU Software
Accelerated data analytics offers insights with no code change: In 2025, accelerated data analytics will become mainstream for organizations grappling with ever-increasing volumes of data.
Businesses generate hundreds of petabytes of data annually, and every company is seeking ways to put it to work. To do so, many will adopt accelerated computing for data analytics.
The future lies in accelerated data analytics solutions that support “no code change” and “no configuration change,” enabling organizations to combine their existing data analytics applications with accelerated computing with minimum effort. Generative AI-empowered analytics technology will further widen the adoption of accelerated data analytics by empowering users — even those who don’t have traditional programming knowledge — to create new data analytics applications.
The seamless integration of accelerated computing, facilitated by a simplified developer experience, will help eliminate adoption barriers and allow organizations to harness their unique data for new AI applications and richer business intelligence.
 NADER KHALIL
NADER KHALIL
Director of Developer Technology
The startup workforce: If you haven’t heard much about prompt engineers or AI personality designers, you will in 2025. As businesses embrace AI to increase productivity, expect to see new categories of essential workers for both startups and enterprises that blend new and existing skills.
A prompt engineer designs and refines precise text strings that optimize AI training and produce desired outcomes based on the creation, testing and iteration of prompt designs for chatbots and agentic AI. The demand for prompt engineers will extend beyond tech companies to sectors like legal, customer support and publishing. As AI agents proliferate, businesses and startups will increasingly lean in to AI personality designers to enhance agents with unique personalities.
Just as the rise of computers spawned job titles like computer scientists, data scientists and machine learning engineers, AI will create different types of work, expanding opportunities for people with strong analytical skills and natural language processing abilities.
Understanding employee efficiency: Startups incorporating AI into their practices increasingly will add revenue per employee (RPE) to their lexicon when talking to investors and business partners.
Instead of a “growth at all costs” mentality, AI supplementation of the workforce will allow startup owners to home in on how hiring each new employee helps everyone else in the business generate more revenue. In the world of startups, RPE fits into discussions about the return on investment in AI and the challenges of filling roles in competition against big enterprises and tech companies.
 Learn more about the latest Pixel and Android updates, featuring the latest in Google AI innovation.Read More
Learn more about the latest Pixel and Android updates, featuring the latest in Google AI innovation.Read More
 Posted by Colby Banbury, Emil Njor, Andrea Mattia Garavagno, Vijay Janapa Reddi
Posted by Colby Banbury, Emil Njor, Andrea Mattia Garavagno, Vijay Janapa Reddi

TinyML is an exciting frontier in machine learning, enabling models to run on extremely low-power devices such as microcontrollers and edge devices. However, the growth of this field has been stifled by a lack of tailored large and high-quality datasets. That’s where Wake Vision comes in—a new dataset designed to accelerate research and development in TinyML.

The development of TinyML requires compact and efficient models, often only a few hundred kilobytes in size. The applications targeted by standard machine learning datasets, like ImageNet, are not well-suited for these highly constrained models.
Existing datasets for TinyML, like Visual Wake Words (VWW), have laid the groundwork for progress in the field. However, their smaller size and inherent limitations pose challenges for training production-grade models. Wake Vision builds upon this foundation by providing a large, diverse, and high-quality dataset specifically tailored for person detection—the cornerstone vision task for TinyML.

Wake Vision is a new, large-scale dataset with roughly 6 million images, almost 100 times larger than VWW, the previous state-of-the-art dataset for person detection in TinyML.
The dataset provides two distinct training sets:
Wake Vision’s comprehensive filtering and labeling process significantly enhances the dataset’s quality.
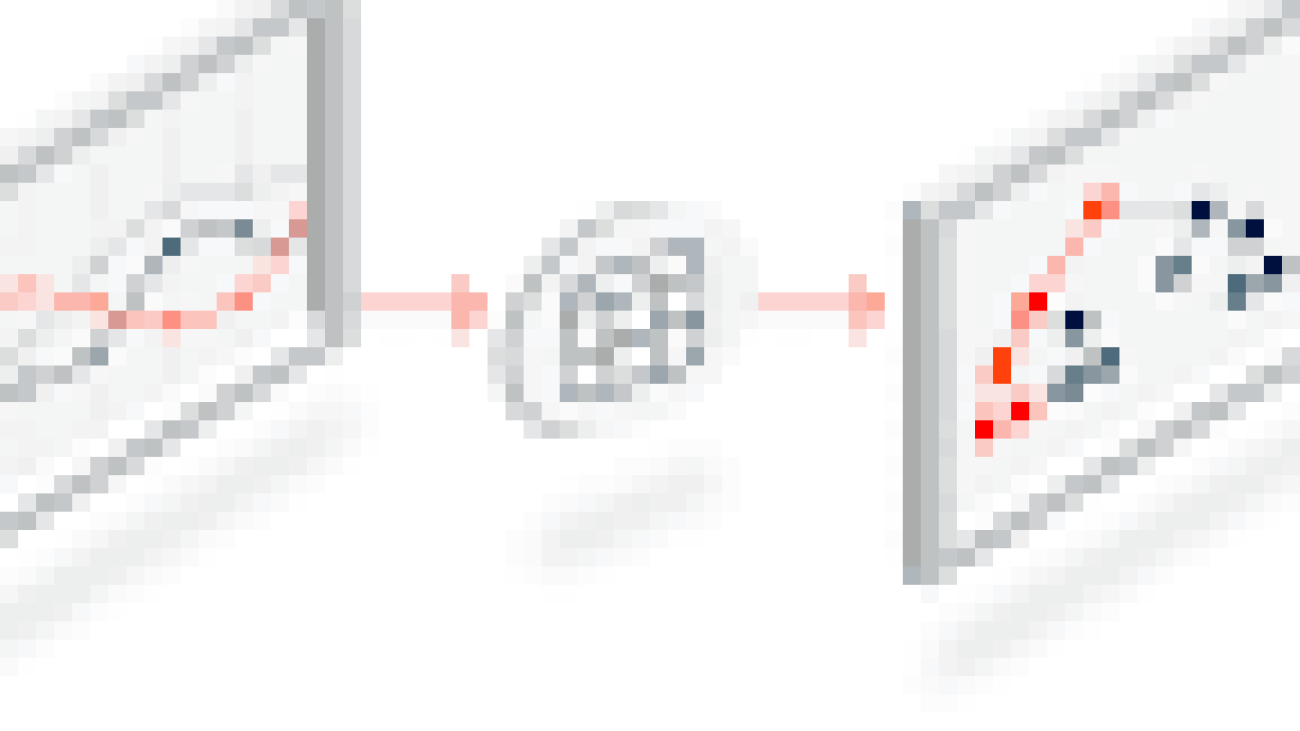
In traditional overparameterized models, it is widely believed that data quantity matters more than data quality, as an overparameterized model can adapt to errors in the training data. But according to the image below, TinyML tells a different story:
 |
The figure above shows that high-quality labels (less error) are more beneficial for under-parameterized models than simply having more data. Larger, error-prone datasets can still be valuable when paired with fine-grained techniques.
By providing two versions of the training set, Wake Vision enables researchers to explore the balance between dataset size and quality effectively.

Unlike many open-source datasets, Wake Vision offers fine-grained benchmarks and detailed tests for real-world applications like those shown in the above figure. These enable the evaluation of model performance in real-world scenarios, such as:
These benchmarks give researchers a nuanced understanding of model performance in specific, real-world contexts and help identify potential biases and limitations early in the design phase.
The performance gains achieved using Wake Vision are impressive:
Furthermore, combining the two Wake Vision training sets, using the larger set for pre-training and the quality set for fine-tuning, yields the best results, highlighting the value of both datasets when used in sophisticated training pipelines.
The Wake Vision website features a Leaderboard, providing a dedicated platform to assess and compare the performance of models trained on the Wake Vision dataset.
The leaderboard enables a clear and detailed view of how models perform under various conditions, with performance metrics like accuracy, error rates, and robustness across diverse real-world scenarios. It’s an excellent resource for both seasoned researchers and newcomers looking to improve and validate their approaches.
Explore the leaderboard to see the current rankings, learn from high-performing models, and submit your own to contribute to advancing the state of the art in TinyML person detection.
Wake Vision is available through popular dataset services such as:
With its permissive license (CC-BY 4.0), researchers and practitioners can freely use and adapt Wake Vision for their TinyML projects.
The Wake Vision team has made the dataset, code, and benchmarks publicly available to accelerate TinyML research and enable the development of better, more reliable person detection models for ultra-low-power devices.
To learn more and access the dataset, visit Wake Vision’s website, where you can also check out a leaderboard of top-performing models on the Wake Vision dataset – and see if you can create better performing models!


Behind every emerging technology is a great idea propelling it forward. In the Microsoft Research Podcast series Ideas, members of the research community at Microsoft discuss the beliefs that animate their research, the experiences and thinkers that inform it, and the positive human impact it targets.
In this episode, host Gretchen Huizinga talks with Senior Principal Research Manager Nicole Immorlica. As Immorlica describes it, when she and others decided to take a computational approach to pushing the boundaries of economic theory, there weren’t many computer scientists doing research in economics. Since then, contributions such as applying approximation algorithms to the classic economic challenge of pricing and work on the stable marriage problem have earned Immorlica numerous honors, including the 2023 Test of Time Award from the ACM Special Interest Group on Economics and Computation and selection as a 2023 Association for Computing Machinery (ACM) Fellow. Immorlica traces the journey back to a graduate market design course and a realization that captivated her: she could use her love of math to help improve the world through systems that empower individuals to make the best decisions possible for themselves.
NICOLE IMMORLICA: So honestly, when generative AI came out, I had a bit of a moment, a like crisis of confidence, so to speak, in the value of theory in my own work. And I decided to dive into a data-driven project, which was not my background at all. As a complete newbie, I was quite shocked by what I found, which is probably common knowledge among experts: data is very messy and very noisy, and it’s very hard to get any signal out of it. Theory is an essential counterpart to any data-driven research. It provides a guiding light. But even more importantly, theory allows us to illuminate things that have not even happened. So with models, we can hypothesize about possible futures and use that to shape what direction we take.
[TEASER ENDS]GRETCHEN HUIZINGA: You’re listening to Ideas, a Microsoft Research Podcast that dives deep into the world of technology research and the profound questions behind the code. I’m Gretchen Huizinga. In this series, we’ll explore the technologies that are shaping our future and the big ideas that propel them forward.
[MUSIC FADES]My guest on this episode is Nicole Immorlica, a senior principal research manager at Microsoft Research New England, where she leads the Economics and Computation Group. Considered by many to be an expert on social networks, matching markets, and mechanism design, Nicole has a long list of accomplishments and honors to her name and some pretty cool new research besides. Nicole Immorlica, I’m excited to get into all the things with you today. Welcome to Ideas!
NICOLE IMMORLICA: Thank you.
HUIZINGA: So before we get into specifics on the big ideas behind your work, let’s find out a little bit about how and why you started doing it. Tell us your research origin story and, if there was one, what big idea or animating “what if” inspired young Nicole and launched a career in theoretical economics and computation research?
IMMORLICA: So I took a rather circuitous route to my current research path. In high school, I thought I actually wanted to study physics, specifically cosmology, because I was super curious about the origins and evolution of the universe. In college, I realized on a day-to-day basis, what I really enjoyed was the math underlying physics, in particular proving theorems. So I changed my major to computer science, which was the closest thing to math that seemed to have a promising career path. [LAUGHTER] But when graduation came, I just wasn’t ready to be a grownup and enter the workforce! So I defaulted to graduate school thinking I’d continue my studies in theoretical computer science. It was in graduate school where I found my passion for the intersection of CS theory and micro-economics. I was just really enthralled with this idea that I could use the math that I so love to understand society and to help shape it in ways that improve the world for everyone in it.
HUIZINGA: I’ve yet to meet an accomplished researcher who didn’t have at least one inspirational “who” behind the “what.” So tell us about the influential people in your life. Who are your heroes, economic or otherwise, and how did their ideas inspire yours and even inform your career?
IMMORLICA: Yeah, of course. So when I was a graduate student at MIT, you know, I was happily enjoying my math, and just on a whim, I decided to take a course, along with a bunch of my other MIT graduate students, at Harvard from Professor Al Roth. And this was a market design course. We didn’t even really know what market design was, but in the context of that course, Al himself and the course content just demonstrated to me the transformative power of algorithms and economics. So, I mean, you might have heard of Al. He eventually won a Nobel Prize in economics for his work using a famous matching algorithm to optimize markets for doctors and separately for kidney exchange programs. And I thought to myself, wow, this is such meaningful work. This is something that I want to do, something I can contribute to the world, you know, something that my skill set is well adapted to. And so I just decided to move on with that, and I’ve never really looked back. It’s so satisfying to do something that’s both … I like both the means and I care very deeply about the ends.
HUIZINGA: So, Nicole, you mentioned you took a course from Al Roth. Did he become anything more to you than that one sort of inspirational teacher? Did you have any interaction with him? And were there any other professors, authors, or people that inspired you in the coursework and graduate studies side of things?
IMMORLICA: Yeah, I mean, Al has been transformative for my whole career. Like, I first met him in the context of that course, but I, and many of the graduate students in my area, have continued to work with him, speak to him at conferences, be influenced by him, so he’s been there throughout my career for me.
HUIZINGA: Right, right, right …
IMMORLICA: In terms of other inspirations, I’ve really admired throughout my career … this is maybe more structurally how different individuals operate their careers. So, for example, Jennifer Chayes, who was the leader of the Microsoft Research lab that I joined …
HUIZINGA: Yeah!
IMMORLICA: … and nowadays Sue Dumais. Various other classic figures like Éva Tardos. Like, all of these are incredibly strong, driven women that have a vision of research, which has been transformative in their individual fields but also care very deeply about the community and the larger context than just themselves and creating spaces for people to really flourish. And I really admire that, as well.
HUIZINGA: Yeah, I’ve had both Sue and Jennifer on the show before, and they are amazing. Absolutely. Well, listen, Nicole, as an English major, I was thrilled—and a little surprised—to hear that literature has influenced your work in economics. I did not have that on my bingo card. Tell us about your interactions with literature and how they broadened your vision of optimization and economic models.
IMMORLICA: Oh, I read a lot, especially fiction. And I care very deeply about being a broad human being, like, with a lot of different facets. And so I seek inspiration not just from my fellow economists and computer scientists but also from artists and writers. One specific example would be Walt Whitman. So I took up this poetry class as an MIT alumni, Walt Whitman, and we, in the context of that course, of course, read his famous poem “Song of Myself.” And I remember one specific verse just really struck me, where he writes, “Do I contradict myself? Very well then I contradict myself, (I am large, I contain multitudes.)” And this just was so powerful because, you know, in traditional economic models, we assume that individuals seek to optimize a single objective function, which we call their utility, but what Whitman is pointing out is that we actually have many different objective functions, which can even conflict with one another, and some at times are more salient than others, and they arise from my many identities as a member of my family, as an American, as you know, a computer scientist, as an economist, and maybe we should actually try to think a little bit more seriously about these multiple identities in the context of our modeling.
HUIZINGA: That just warms my English major heart … [LAUGHS]
IMMORLICA: I’m glad! [LAUGHS]
HUIZINGA: Oh my gosh. And it’s so interesting because, yeah, we always think of, sort of, singular optimization. And so it’s like, how do we expand our horizon on that sort of optimization vision? So I love that. Well, you’ve received what I can only call a flurry of honors and awards last year. Most recently, you were named an ACM Fellow—ACM being Association for Computing Machinery, for those who don’t know—which acknowledges people who bring, and I quote, “transformative contributions to computing science and technology.” Now your citation is for, and I quote again, “contributions to economics and computation, including market design, auctions, and social networks.” That’s a mouthful, but if we’re talking about transformative contributions, how were things different before you brought your ideas to this field, and how were your contributions transformative or groundbreaking?
IMMORLICA: Yeah, so it’s actually a relatively new thing for computer scientists to study economics, and I was among the first cohort to do so seriously. So before our time, economists mostly focused on finding optimal solutions to the problems they posed without regard for the computational or informational requirements therein. But computer scientists have an extensive toolkit to manage such complexities. So, for example, in a paper on pricing, which is a classic economic problem—how do we set up prices for goods in a store?—my coauthors and I used the computer science notion of approximation to show that a very simple menu of prices generates almost optimal revenue for the seller. And prior to this work, economists only knew how to characterize optimal but infinitely large and thereby impractical menus of prices. So this is an example of the kind of work that I and other computer scientists do that can really transform economics.
HUIZINGA: Right. Well, in addition to the ACM fellowship, another honor you received from ACM in 2023 was the Test of Time Award, where the Special Interest Group on Economics and Computation, or SIGecom, recognizes influential papers published between 10 and 25 years ago that significantly impacted research or applications in economics and computation. Now you got this award for a paper you cowrote in 2005 called “Marriage, Honesty, and Stability.” Clearly, I’m not an economist because I thought this was about how to avoid getting a divorce, but actually, it’s about a well-known and very difficult problem called the stable marriage problem. Tell us about this problem and the paper and why, as the award states, it’s stood the test of time.
IMMORLICA: Sure. You’re not the only one to have misinterpreted the title. [LAUGHTER] I remember I gave a talk once and someone came and when they left the talk, they said, I did not think that this was about math! But, you know, math, as I learned, is about life, and the stable marriage problem has, you know, interpretation about marriage and divorce. In particular, the problem asks, how can we match market participants to one another such that no pair prefer each other to their assigned match? So to relate this to the somewhat outdated application of marriage markets, the market participants could be men and women, and the stable marriage problem asks if there is a set of marriages such that no pair of couples seeks a divorce in order to marry each other. And so, you know, that’s not really a problem we solve in real life, but there’s a lot of modern applications of this problem. For example, assigning medical students to hospitals for their residencies, or if you have children, many cities in the United States and around the world use this stable marriage problem to think about the assignment of K-to-12 students to public schools. And so in these applications, the stability property has been shown to contribute to the longevity of the market. And in the 1960s, David Gale and Lloyd Shapley proved, via an algorithm, interestingly, that stable matches exist! Well, in fact, there can be exponentially many stable matches. And so this leads to a very important question for people that want to apply this theory to practice, which is, which stable match should they select among the many ones that exist, and what algorithm should they use to select it? So our work shows that under very natural conditions, namely that preference lists are short and sufficiently random, it doesn’t matter. Most participants have a unique stable match. And so, you know, you can just design your market without worrying too much about what algorithm you use or which match you select because for most people it doesn’t matter. And since our paper, many researchers have followed up on our work studying conditions under which matchings are essentially unique and thereby influencing policy recommendations.
HUIZINGA: Hmm. So this work was clearly focused on the economics side of things like markets. So this seems to have wide application outside of economics. Is that accurate?
IMMORLICA: Well, it depends how you define economics, so I would …
HUIZINGA: I suppose! [LAUGHTER]
IMMORLICA: I define economics as the problem … I mean, Al Roth, for example, wrote a book whose title was Who Gets What—and Why.
HUIZINGA: Ooh.
IMMORLICA: So economics is all about, how do we allocate stuff? How do we allocate scarce resources? And many economic problems are not about spending money. It’s about how do we create outcomes in the world.
HUIZINGA: Yeah.
IMMORLICA: And so I would say all of these problem domains are economics.
HUIZINGA: Well, finally, as regards the “flurry” of honors, besides being named an ACM Fellow and also this Test of Time Award, you were also named an Economic Theory Fellow by the Society for [the] Advancement of Economic Theory, or SAET. And the primary qualification here was to have “substantially or creatively advanced theoretical economics.” So what were the big challenges you tackled, and what big ideas did you contribute to advance economic theory?
IMMORLICA: So as we’ve discussed, I and others with my background have done a lot to advance economic theory through the lens of computational thinking.
HUIZINGA: Mmm …
IMMORLICA: We’ve introduced ideas such as approximation, which we discussed earlier, or machine learning to economic models and proposing them as solution concepts. We’ve also used computer science tools to solve problems within these models. So two examples from my own work include randomized algorithm analysis and stochastic gradient descent. And importantly, we’ve introduced very relevant new settings to the field of economics. So, you know, I’ve worked hard on large-scale auction design and associated auto-bidding algorithms, for instance, which are a primary source of revenue for tech companies these days. I’ve thought a lot about how data enters into markets and how we should think about data in the context of market design. And lately, I’ve spent a lot of time thinking about generative AI and its impact in the economy at both the micro and macro levels.
HUIZINGA: Yeah. Let’s take a detour for a minute and get into the philosophical weeds on this idea of theory. And I want to cite an article that was written way back in 2008 by the editor of Wired magazine at the time, Chris Anderson. He wrote an article titled “The End of Theory,” which was provocative in itself. And he began by quoting the British statistician George Box, who famously said, “All models are wrong, but some are useful.” And then he argued that in an era of massively abundant data, companies didn’t have to settle for wrong models. And then he went even further and attacked the very idea of theory and, citing Google, he said, “Out with every theory of human behavior, from linguistics to sociology. Forget taxonomy, ontology, psychology. Who knows why people do what they do? The point is they do it, and we can track and measure it with unprecedented fidelity.” So, Nicole, from your perch, 15 years later, in the age of generative AI, what did Chris Anderson get right, and what did he get wrong?
IMMORLICA: So, honestly, when generative AI came out, I had a bit of a moment, a like crisis of confidence, so to speak, in the value of theory in my own work.
HUIZINGA: Really!
IMMORLICA: And I decided to dive into a data-driven project, which was not my background at all. As a complete newbie, I was quite shocked by what I found, which is probably common knowledge among experts: data is very messy and very noisy, and it’s very hard to get any signal out of it. Theory is an essential counterpart to any data-driven research. It provides a guiding light. But even more importantly, theory allows us to illuminate things that have not even happened. So with models, we can hypothesize about possible futures and use that to shape what direction we take. Relatedly, what I think that article got most wrong was the statement that correlation supersedes causation, which is actually how the article closes, this idea that causation is dead or dying. I think causation will never become irrelevant. Causation is what allows us to reason about counterfactuals. It’s fundamentally irreplaceable. It’s like, you know, data, you can only see data about things that happened. You can’t see data about things that could happen but haven’t or, you know, about alternative futures.
HUIZINGA: Interesting.
IMMORLICA: And that’s what theory gives you.
HUIZINGA: Yeah. Well, let’s continue on that a little bit because this show is yet another part of our short “series within a series” featuring some of the work going on in the AI, Cognition, and the Economy initiative at Microsoft Research. And I just did an episode with Brendan Lucier and Mert Demirer on the micro- and macro-economic impact of generative AI. And you were part of that project, but another fascinating project you’re involved in right now looks at the impact of generative AI on what you call the “content ecosystem.” So what’s the problem behind this research, and what unique incentive challenges are content creators facing in light of large language and multimodal AI models?
IMMORLICA: Yeah, so this is a project with Brendan, as well, whom you interviewed previously, and also Nageeb Ali, an economist and AICE Fellow at Penn State, and Meena Jagadeesan, who was my intern from Microsoft Research from UC Berkeley. So when you think about content or really any consumption good, there’s often a whole supply chain that produces it. For music, for example, there’s the composition of the song, the recording, the mixing, and finally the delivery to the consumer. And all of these steps involve multiple humans producing things, generating things, getting paid along the way. One way to think about generative AI is that it allows the consumer to bypass this supply chain and just generate the content directly.
HUIZINGA: Right …
IMMORLICA: So, for example, like, I could ask a model, an AI model, to compose and play a song about my cat named Whiskey. [LAUGHTER] And it would do a decent job of it, and it would tailor the song to my specific situation. But there are drawbacks, as well. One thing many researchers fear is that AI needs human-generated content to train. And so if people start bypassing the supply chain and just using AI-generated content, there won’t be any content for AI to train on and AI will cease to improve.
HUIZINGA: Right.
IMMORLICA: Another thing that could be troubling is that there are economies of scale. So there is a nontrivial cost to producing music, even for AI, and if we share that cost among many listeners, it becomes more affordable. But if we each access the content ourselves, it’s going to impose a large per-song cost. And then finally, and this is, I think, most salient to most people, there’s some kind of social benefit to having songs that everyone listens to. It provides a common ground for understanding. It’s a pillar of our culture, right. And so if we bypass that, aren’t we losing something? So for all of these reasons, it becomes very important to understand the market conditions under which people will choose to bypass supply chains and the associated costs and benefits of this. What we show in this work, which is very much work in progress, is that when AI is very costly, neither producers nor consumers will use it, but as it gets cheaper, at first, it actually helps content producers that can leverage it to augment their own ability, creating higher-quality content, more personalized content more cheaply. But then, as the AI gets super cheap, this bypassing behavior starts to emerge, and the content creators are driven out of the market.
HUIZINGA: Right. So what do we do about that?
IMMORLICA: Well, you know, you have to take a stance on whether that’s even a good thing or a bad thing, …
HUIZINGA: Right!
IMMORLICA: … so it could be that we do nothing about it. We could also impose a sort of minimum wage on AI, if you like, to artificially inflate its costs. We could try to amplify the parts of the system that lead towards more human-generated content, like this sociability, the fact that we all are listening to the same stuff. We could try to make that more salient for people. But, you know, generally speaking, I’m not really in a place to take a stance on whether this is a good thing or a bad thing. I think this is for policymakers.
HUIZINGA: It feels like we’re at an inflection point. I’m really interested to see what your research in this arena, the content ecosystem, brings. You know, I’ll mention, too, recently I read a blog written by Yoshua Bengio and Vincent Conitzer, and they acknowledged that the image that they used at the top had been created by an AI bot. And then they said they made a donation to an art museum to say, we’re giving something back to the artistic community that we may have used. Where do you see this, you know, #NoLLM situation coming in this content ecosystem market?
IMMORLICA: Yeah, that’s a very interesting move on their part. I know Vince quite well, actually. I’m not sure that artists of the sort of “art museum nature” suffer, so …
HUIZINGA: Right? [LAUGHS]
IMMORLICA: One of my favorite artists is Laurie Anderson. I don’t know if you’ve seen her work at all …
HUIZINGA: Yeah, I have, yeah.
IMMORLICA: … but she has a piece in the MASS MoCA right now, which is just brilliant, where she actually uses generative AI to create a sequence of images that creates an alternate story about her family history. And it’s just really, really cool. I’m more worried about people who are doing art vocationally, and I think, and maybe you heard some of this from Mert and Brendan, like what’s going to happen is that careers are going to shift and different vocations will become more salient, and we’ve seen this through every technological revolution. People shift their work towards the things that are uniquely human that we can provide and if generating an image at the top of a blog is not one of them, you know, so be it. People will do something else.
HUIZINGA: Right, right, right. Yeah, I just … we’re on the cusp, and there’s a lot of things that are going to happen in the next couple of years, maybe a couple of months, who knows? [LAUGHTER] Well, we hear a lot of dystopian fears—some of them we’ve just referred to—around AI and its impact on humanity, but those fears are often dismissed by tech optimists as what I might call “unwishful thinking.” So your research interests involve the design and use of sociotechnical systems to quote, “explain, predict, and shape behavioral patterns in various online and offline systems, markets, and games.” Now I’m with you on the “explain and predict” but when we get to shaping behavioral patterns, I wonder how we tease out the bad from the good. So, in light of the power of these sociotechnical systems, what could possibly go wrong, Nicole, if in fact you got everything right?
IMMORLICA: Yeah, first I should clarify something. When I say I’m interested in shaping behavioral patterns, I don’t mean that I want to impose particular behaviors on people but rather that I want to design systems that expose to people relevant information and possible actions so that they have the power to shape their own behavior to achieve their own goals. And if we’re able to do that, and do it really well, then things can only really go wrong if you believe people aren’t good at making themselves happy. I mean, there’s certainly evidence of this, like the field of behavioral economics, to which I have contributed some, tries to understand how and when people make mistakes in their behavioral choices. And it proposes ways to help people mitigate these mistakes. But I caution us from going too far in this direction because at the end of the day, I believe people know things about themselves that no external authority can know. And you don’t want to impose constraints that prevent people from acting on that information.
HUIZINGA: Yeah.
IMMORLICA: Another issue here is, of course, externalities. It could be that my behavior makes me happy but makes you unhappy. [LAUGHTER] So another thing that can go wrong is that we, as designers of technology, fail to capture these underlying externalities. I mean, ideally, like an economist would say, well, you should pay with your own happiness for any negative externality you impose on others. And the fields of market and mechanism design have identified very beautiful ways of making this happen automatically in simple settings, such as the famous Vickrey auction. But getting this right in the complex sociotechnical systems of our day is quite a challenge.
HUIZINGA: OK, go back to that auction. What did you call it? The Vickrey auction?
IMMORLICA: Yeah, so Vickrey was an economist, and he proposed an auction format that … so an auction is trying to find a way to allocate goods, let’s say, to bidders such that the bidders that value the goods the most are the ones that win them.
HUIZINGA: Hm.
IMMORLICA: But of course, these bidders are imposing a negative externality on the people who lose, right? [LAUGHTER] And so what Vickrey showed is that a well-designed system of prices can compensate the losers exactly for the externality that is imposed on them. A very simple example of a Vickrey auction is if you’re selling just one good, like a painting, then what you should do, according to Vickrey, is solicit bids, give it to the highest bidder, and charge them the second-highest price.
HUIZINGA: Interesting …
IMMORLICA: And so … that’s going to have good outcomes for society.
HUIZINGA: Yeah, yeah. I want to expand on a couple of thoughts here. One is as you started out to answer this question, you said, well, I’m not interested in shaping behaviors in terms of making you do what I want you to do. But maybe someone else is. What happens if it falls into the wrong hands?
IMMORLICA: Yeah, I mean, there’s definitely competing interests. Everybody has their own objectives, and …
HUIZINGA: Sure, sure.
IMMORLICA: … I might be very fundamentally opposed to some of them, but everybody’s trying to optimize something, and there are competing optimization objectives. And so what’s going to happen if people are leveraging this technology to optimize for themselves and thereby harming me a lot?
HUIZINGA: Right?
IMMORLICA: Ideally, we’ll have regulation to kind of cover that. I think what I’m more worried about is the idea that the technology itself might not be aligned with me, right. Like at the end of the day, there are companies that are producing this technology that I’m then using to achieve my objectives, but the company’s objectives, the creators of the technology, might not be completely aligned with the person’s objectives. And so I’ve looked a little bit in my research about how this potential misalignment might result in outcomes that are not all that great for either party.
HUIZINGA: Wow. Is that stuff that’s in the works?
IMMORLICA: We have a few published papers on the area. I don’t know if you want me to get into them.
HUIZINGA: No, actually, what we’ll probably do is put some in the show notes. We’ll link people to those papers because I think that’s an interesting topic. Listen, most research is incremental in nature, where the ideas are basically iterative steps on existing work. But sometimes there are out-of-the-box ideas that feel like bigger swings or even outrageous, and Microsoft is well known for making room for these. Have you had an idea that felt outrageous, any idea that felt outrageous, or is there anything that you might even consider outrageous now that you’re currently working on or even thinking about?
IMMORLICA: Yeah, well, I mean, this whole moment in history feels outrageous, honestly! [LAUGHTER] It’s like I’m kind of living in the sci-fi novels of my youth.
HUIZINGA: Right?
IMMORLICA: So together with my economics and social science colleagues at Microsoft Research, one thing that we’re really trying to think through is this outrageous idea of agentic AI.
HUIZINGA: Mmm …
IMMORLICA: That is, every single individual and business can have their own AI that acts like their own personal butler that knows them intimately and can take actions on their behalf. In such a world, what will become of the internet, social media, platforms like Amazon, Spotify, Uber? On the one hand, you know, maybe this is good because these individual agentic AIs can just bypass all of these kinds of intermediaries. For example, if I have a busy day of back-to-back meetings at work, my personal AI can notice that I have no time for lunch, contact the AI of some restaurant to order a sandwich for me, make sure that sandwich is tailored to my dietary needs and preferences, and then contact the AI of a delivery service to make sure that sandwich is sitting on my desk when I walk into my noon meeting, right.
HUIZINGA: Right …
IMMORLICA: And this is a huge disruption to how things currently work. It’s shifting the power away from centralized platforms, back to individuals and giving them the agency over their data and the power to leverage it to fulfill their needs. So the, sort of, big questions that we’re thinking about right now is, how will such decentralized markets work? How will they be monetized? Will it be a better world than the one we live in now, or are we losing something? And if it is a better world, how can we get from here to there? And if it’s a worse world, how can we steer the ship in the other direction, you know?
HUIZINGA: Right.
IMMORLICA: These are all very important questions in this time.
HUIZINGA: Does this feel like it’s imminent?
IMMORLICA: I do think it’s imminent. And I think, you know, in life, you can, kind of, decide whether to embrace the good or embrace the bad, see the glass as half-full or half-empty, and …
HUIZINGA: Yeah.
IMMORLICA: … I am hoping that society will see the half-full side of these amazing technologies and leverage them to do really great things in the world.
HUIZINGA: Man, I would love to talk to you for another hour, but we have to close things up. To close this show, I want to do something new with you, a sort of lightning round of short questions with short answers that give us a little window into your life. So are you ready?
IMMORLICA: Yup!
HUIZINGA: OK. First one, what are you reading right now for work?
IMMORLICA: Lots of papers of my students that are on the job market to help prepare recommendation letters. It’s actually very inspiring to see the creativity of the younger generation. In terms of books, I’m reading the Idea Factory, which is about the creation of Bell Labs.
HUIZINGA: Ooh! Interesting!
IMMORLICA: You might be interested in it actually. It actually talks about the value of theory and understanding the fundamentals of a problem space and the sort of business value of that, so it’s very intriguing.
HUIZINGA: OK, second question. What are you reading for pleasure?
IMMORLICA: The book on my nightstand right now is the Epic of Gilgamesh, the graphic novel version. I’m actually quite enthralled by graphic novels ever since I first encountered Maus by Art Spiegelman in the ’90s. But my favorite reading leans towards magic realism, so like Gabriel García Márquez, Italo Calvino, Isabel Allende, and the like. I try to read nonfiction for pleasure, too, but I generally find life is a bit too short for that genre! [LAUGHTER]
HUIZINGA: Well, and I made an assumption that what you were reading for work wasn’t pleasurable, but um, moving on, question number three, what app doesn’t exist but should?
IMMORLICA: Teleportation.
HUIZINGA: Ooh, fascinating. What app exists but shouldn’t?
IMMORLICA: That’s much harder for me. I think all apps within legal bounds should be allowed to exist and the free market should decide which ones survive. Should there be more regulation of apps? Perhaps. But more at the level of giving people tools to manage their consumption at their own discretion and not outlawing specific apps; that just feels too paternalistic to me.
HUIZINGA: Interesting. OK, next question. What’s one thing that used to be very important to you but isn’t so much anymore?
IMMORLICA: Freedom. So by that I mean the freedom to do whatever I want, whenever I want, with whomever I want. This feeling that I could go anywhere at any time without any preparation, that I could be the Paul Erdős of the 21st century, traveling from city to city, living out of a suitcase, doing beautiful math just for the art of it. This feeling that I have no responsibilities. Like, I really bought into that in my 20s.
HUIZINGA: And not so much now?
IMMORLICA: No.
HUIZINGA: OK, so what’s one thing that wasn’t very important to you but is now?
IMMORLICA: Now, as Janis Joplin sang, “Freedom is just another word for nothing left to lose.” [LAUGHTER] And so now it’s important to me to have things to lose—roots, family, friends, pets. I think this is really what gives my life meaning.
HUIZINGA: Yeah, having Janis Joplin cited in this podcast wasn’t on my bingo card either, but that’s great. Well, finally, Nicole, I want to ask you this question based on something we talked about before. Our audience doesn’t know it, but I think it’s funny. What do Norah Jones and oatmeal have in common for you?
IMMORLICA: Yeah, so I use these in conversation as examples of comfort and nostalgia in the categories of music and food because I think they’re well-known examples. But for me personally, comfort is the Brahms Cello Sonata in E Minor, which was in fact my high school cello performance piece, and nostalgia is spaghetti with homemade marinara sauce, either my boyfriend’s version or, in my childhood, my Italian grandma’s version.
HUIZINGA: Man! Poetry, art, cooking, music … who would have expected all of these to come into an economist/computer scientist podcast on the Microsoft Research Podcast. Nicole Immorlica, how fun to have you on the show! Thanks for joining us today on Ideas!
IMMORLICA: Thank you for having me.
[MUSIC]
The post Ideas: Economics and computation with Nicole Immorlica appeared first on Microsoft Research.
GeForce NOW is wrapping a sleigh-full of gaming gifts this month, stuffing members’ cloud gaming stockings with new titles and fresh offers to keep holiday gaming spirits merry and bright.
Adventure calls and whip-cracking action awaits in the highly anticipated Indiana Jones and the Great Circle, streaming in the cloud today during the Advanced Access period for those who have preordered the Premium Edition from Steam or the Microsoft Store.
The title can only be played with RTX ON — GeForce NOW is offering gamers without high-performance hardware the ability to play it with 25% off Ultimate and Performance Day Passes. It’s like finding that extra-special gift hidden behind the tree.
This GFN Thursday also brings a new limited-time offer: 50% off the first month of new Ultimate or Performance memberships — a gift that can keep on giving.
Whether looking to try out GeForce NOW or buckle in for long-term cloud gaming, new members can choose between the Day Pass sale or the new membership offer. There’s a perfect gaming gift for everyone this holiday season.
GFN Thursday also brings 13 new titles in December, with four available this week to get the festivities going.
Plus, the latest update to GeForce NOW — version 2.0.69 — includes expanded support for 10-bit color precision. This feature enhances image quality when streaming on Windows, macOS and NVIDIA SHIELD TVs — and now to Edge and Chrome browsers on Windows devices, as well as to the Chrome browser on Chromebooks, Samsung TVs and LG TVs.
Uncover one of history’s greatest mysteries, streaming Indiana Jones and the Great Circle from the cloud. Members can access it today through Steam’s Advance Access period and will also be able to enjoy it via PC Game Pass on GeForce NOW next week.
The year is 1937, sinister forces are scouring the globe for the secret to an ancient power connected to the Great Circle, and only Indiana Jones can stop them. Experience a thrilling story full of exploration, immersive action and intriguing puzzles. Travel the world, from the pyramids of Egypt to the sunken temples of Sukhothai and beyond. Combine stealth infiltration, melee combat and gunplay to overcome enemies. Use guile and wits to unearth fascinating secrets, solve ancient riddles and survive deadly traps.
Members can indulge their inner explorer by streaming Indiana Jones and the Great Circle on GeForce NOW at release. Enhanced with NVIDIA’s ray-tracing technology, every game scene is bathed in rich, natural light that bounces realistically off surfaces for enhanced immersion.
Ultimate and Performance members can max out their settings for a globe-trotting journey at the highest resolution and lowest latency, even on low-powered devices, thanks to enhancements like NVIDIA DLSS 3 Frame Generation and NVIDIA Reflex. Ultimate members can experience additional perks, like 4K resolution and longer gaming sessions.
This game requires RTX ON, so free members can upgrade today to join in on the action. Take advantage of a limited-time Day Pass sale, with 25% off through Thursday, Dec. 12. Experience all the premium features of GeForce NOW’s Ultimate and Performance tiers with a 24-hour trial before upgrading to a one- or six-month membership.
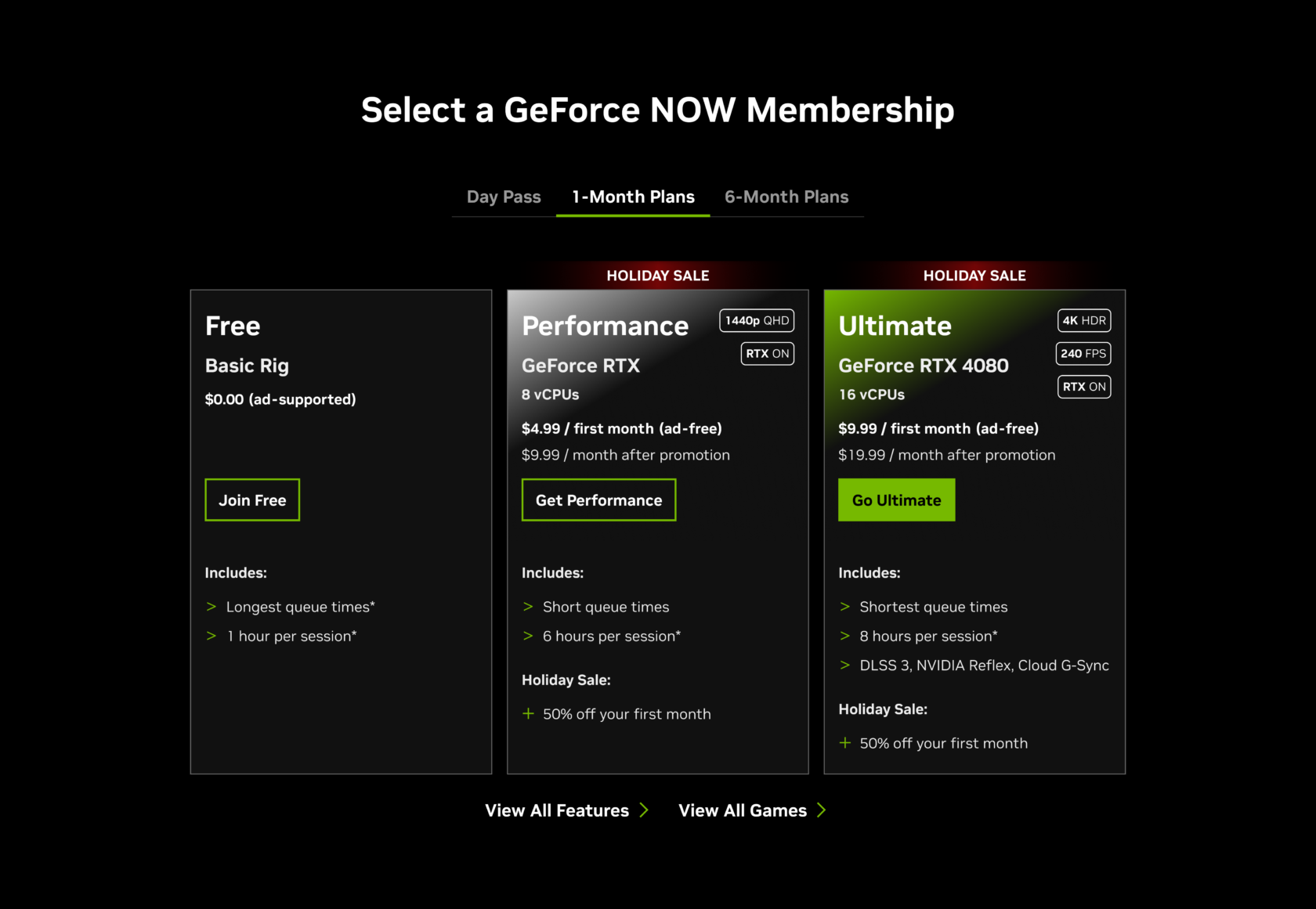
For gamers looking to take their cloud gaming journey even further, unlock the power of GeForce RTX-powered cloud gaming with a monthly GeForce NOW membership. It’s the perfect time to do so, with new members gettings 50% off their first month, now through Monday, Dec. 30.
Experience gaming at its finest with an Ultimate membership by streaming at up to 4K resolution and 120 frames per second, or 1080p at 240 fps. The Performance membership offers an enhanced streaming experience at up to 1440p resolution with ultrawide resolutions for even more immersive gameplay. Both premium tiers provide extended session lengths, priority access to servers and the ability to play the latest and greatest titles with RTX ON.
Whether looking to conquer new worlds, compete at the highest level or unwind with a long-time favorite game, now is an ideal time to join the cloud gaming community. Sign up to transform any device into a powerful gaming rig — just in time for the holiday gaming marathons.

Path of Exile 2 is the highly anticipated sequel to the popular free-to-play action role-playing game from Grinding Gear Games. The game will be available for members to stream Friday, Dec. 6, in early access with a wealth of content to experience.
Explore the three acts of the campaign, six playable character classes and a robust endgame system in the dark world of Wraeclast, a continent populated by unique cultures, ancient secrets and monstrous dangers. A sinister threat, long thought destroyed, has begun creeping back on the edge of civilisation, driving people mad and sickening the land with Corruption. Play Path of Exile 2 solo or grab the squad for online co-op with up to six players.
Look for these games available to stream in the cloud this week:
Here’s what members can expect in December:
In addition to the 17 games announced last month, 13 more joined the GeForce NOW library:
Metal Slug Tactics, Dungeons & Degenerate Gamblers and Headquarters: World War II didn’t make it last month. Stay tuned to future GFN Thursday for updates.
What are you planning to play this weekend? Let us know on X or in the comments below.
There’s no place like the cloud for the holidays.
Unlock the power of GeForce RTX-powered gaming with a GeForce NOW monthly membership — 𝟱𝟬% 𝗼𝗳𝗳 the first month for new members!
RUN
https://t.co/aCfuQ7KtkB pic.twitter.com/8cjY5ZTBPW
—
NVIDIA GeForce NOW (@NVIDIAGFN) December 4, 2024
The remarkable advancements in Multimodal Large Language Models (MLLMs) have not rendered them immune to challenges, particularly in the context of handling deceptive information in prompts, thus producing hallucinated responses under such conditions. To quantitatively assess this vulnerability, we present MAD-Bench, a carefully curated benchmark that contains 1000 test samples divided into 5 categories, such as non-existent objects, count of objects, and spatial relationship. We provide a comprehensive analysis of popular MLLMs, ranging from GPT-4v, Reka, Gemini-Pro, to open-sourced models…Apple Machine Learning Research
*Equal Contributors
Motivated by the problem of next word prediction on user devices we introduce and study the problem of personalized frequency histogram estimation in a federated setting. In this problem, over some domain, each user observes a number of samples from a distribution which is specific to that user. The goal is to compute for all users a personalized estimate of the user’s distribution with error measured in KL divergence. We focus on addressing two central challenges: statistical heterogeneity and protection of user privacy. Our approach to the problem relies on discovering…Apple Machine Learning Research

This post is co-written with Abhishek Sawarkar, Eliuth Triana, Jiahong Liu and Kshitiz Gupta from NVIDIA.
At AWS re:Invent 2024, we are excited to introduce Amazon Bedrock Marketplace. This a revolutionary new capability within Amazon Bedrock that serves as a centralized hub for discovering, testing, and implementing foundation models (FMs). It provides developers and organizations access to an extensive catalog of over 100 popular, emerging, and specialized FMs, complementing the existing selection of industry-leading models in Amazon Bedrock. Bedrock Marketplace enables model subscription and deployment through managed endpoints, all while maintaining the simplicity of the Amazon Bedrock unified APIs.
The NVIDIA Nemotron family, available as NVIDIA NIM microservices, offers a cutting-edge suite of language models now available through Amazon Bedrock Marketplace, marking a significant milestone in AI model accessibility and deployment.
In this post, we discuss the advantages and capabilities of the Bedrock Marketplace and Nemotron models, and how to get started.
Bedrock Marketplace plays a pivotal role in democratizing access to advanced AI capabilities through several key advantages:
At the forefront of the NVIDIA Nemotron model family is Nemotron-4, as stated by NVIDIA, it is a powerful multilingual large language model (LLM) trained on an impressive 8 trillion text tokens, specifically optimized for English, multilingual, and coding tasks. Key capabilities include:
The Nemotron models offer transformative potential for AI developers by addressing critical challenges in AI development:
These capabilities make Nemotron models particularly well-suited for organizations looking to accelerate their AI initiatives while maintaining high standards of performance and security.
To get started with Amazon Bedrock Marketplace, open the Amazon Bedrock console. From there, you can explore Bedrock Marketplace interface, which offers a comprehensive catalog of FMs from various providers. You can browse through the available options to discover different AI capabilities and specializations. This exploration will lead you to find NVIDIA’s model offerings, including Nemotron-4.
We walk you through these steps in the following sections.
Navigating to Amazon Bedrock Marketplace is straightforward:
Upon entering Bedrock Marketplace, you’ll find a well-organized interface with various categories and filters to help you find the right model for your needs. You can browse by providers and modality.

After you’ve located NVIDIA’s model offerings in Bedrock Marketplace, you can narrow down to the Nemotron model. To subscribe to and deploy Nemotron-4, complete the following steps:
Nemotron-4 15B.
On the model details page, you can examine its specifications, capabilities, and pricing details. The Nemotron-4 model offers impressive multilingual and coding capabilities.


The process is user-friendly, allowing you to quickly integrate these powerful AI capabilities into your projects using the Amazon Bedrock APIs.
The launch of NVIDIA Nemotron models on Amazon Bedrock Marketplace marks a significant milestone in making advanced AI capabilities more accessible to developers and organizations. Nemotron-4 15B, with its impressive 15-billion-parameter architecture trained on 8 trillion text tokens, brings powerful multilingual and coding capabilities to the Amazon Bedrock.
Through Bedrock Marketplace, organizations can use Nemotron’s advanced capabilities while benefiting from the scalable infrastructure of AWS and NVIDIA’s robust technologies. We encourage you to start exploring the capabilities of NVIDIA Nemotron models today through Amazon Bedrock Marketplace, and experience firsthand how this powerful language model can transform your AI applications.
 James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends. You can find him on LinkedIn.
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends. You can find him on LinkedIn.
 Saurabh Trikande is a Senior Product Manager for Amazon Bedrock and SageMaker Inference. He is passionate about working with customers and partners, motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, inference with multi-tenant models, cost optimizations, and making the deployment of Generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon Bedrock and SageMaker Inference. He is passionate about working with customers and partners, motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, inference with multi-tenant models, cost optimizations, and making the deployment of Generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
 Melanie Li, PhD, is a Senior Generative AI Specialist Solutions Architect at AWS based in Sydney, Australia, where her focus is on working with customers to build solutions leveraging state-of-the-art AI and machine learning tools. She has been actively involved in multiple Generative AI initiatives across APJ, harnessing the power of Large Language Models (LLMs). Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries.
Melanie Li, PhD, is a Senior Generative AI Specialist Solutions Architect at AWS based in Sydney, Australia, where her focus is on working with customers to build solutions leveraging state-of-the-art AI and machine learning tools. She has been actively involved in multiple Generative AI initiatives across APJ, harnessing the power of Large Language Models (LLMs). Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries.
 Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
 Abhishek Sawarkar is a product manager in the NVIDIA AI Enterprise team working on integrating NVIDIA AI Software in Cloud MLOps platforms. He focuses on integrating the NVIDIA AI end-to-end stack within Cloud platforms & enhancing user experience on accelerated computing.
Abhishek Sawarkar is a product manager in the NVIDIA AI Enterprise team working on integrating NVIDIA AI Software in Cloud MLOps platforms. He focuses on integrating the NVIDIA AI end-to-end stack within Cloud platforms & enhancing user experience on accelerated computing.
 Eliuth Triana is a Developer Relations Manager at NVIDIA empowering Amazon’s AI MLOps, DevOps, Scientists and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing Generative AI Foundation models spanning from data curation, GPU training, model inference and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, tennis and poker player.
Eliuth Triana is a Developer Relations Manager at NVIDIA empowering Amazon’s AI MLOps, DevOps, Scientists and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing Generative AI Foundation models spanning from data curation, GPU training, model inference and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, tennis and poker player.
 Jiahong Liu is a Solutions Architect on the Cloud Service Provider team at NVIDIA. He assists clients in adopting machine learning and AI solutions that leverage NVIDIA-accelerated computing to address their training and inference challenges. In his leisure time, he enjoys origami, DIY projects, and playing basketball.
Jiahong Liu is a Solutions Architect on the Cloud Service Provider team at NVIDIA. He assists clients in adopting machine learning and AI solutions that leverage NVIDIA-accelerated computing to address their training and inference challenges. In his leisure time, he enjoys origami, DIY projects, and playing basketball.
 Kshitiz Gupta is a Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running, hiking, and wildlife watching.
Kshitiz Gupta is a Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running, hiking, and wildlife watching.
