Generating unlimited diverse training environments for future general agentsRead More

Generating unlimited diverse training environments for future general agentsRead More

Generating unlimited diverse training environments for future general agentsRead More

Generating unlimited diverse training environments for future general agentsRead More
Generating unlimited diverse training environments for future general agentsRead More
Amazon Nova Canvas and Amazon Nova Reel use diffusion transformers to deliver studio-quality visual content.Read More
From reinforcement learning and supervised fine-tuning to guardrail models and image watermarking, responsible AI was foundational to the design and development of the Amazon Nova family of models.Read More

 NotebookLM is partnering with Spotify to create a personalized Wrapped AI podcast.Read More
NotebookLM is partnering with Spotify to create a personalized Wrapped AI podcast.Read More
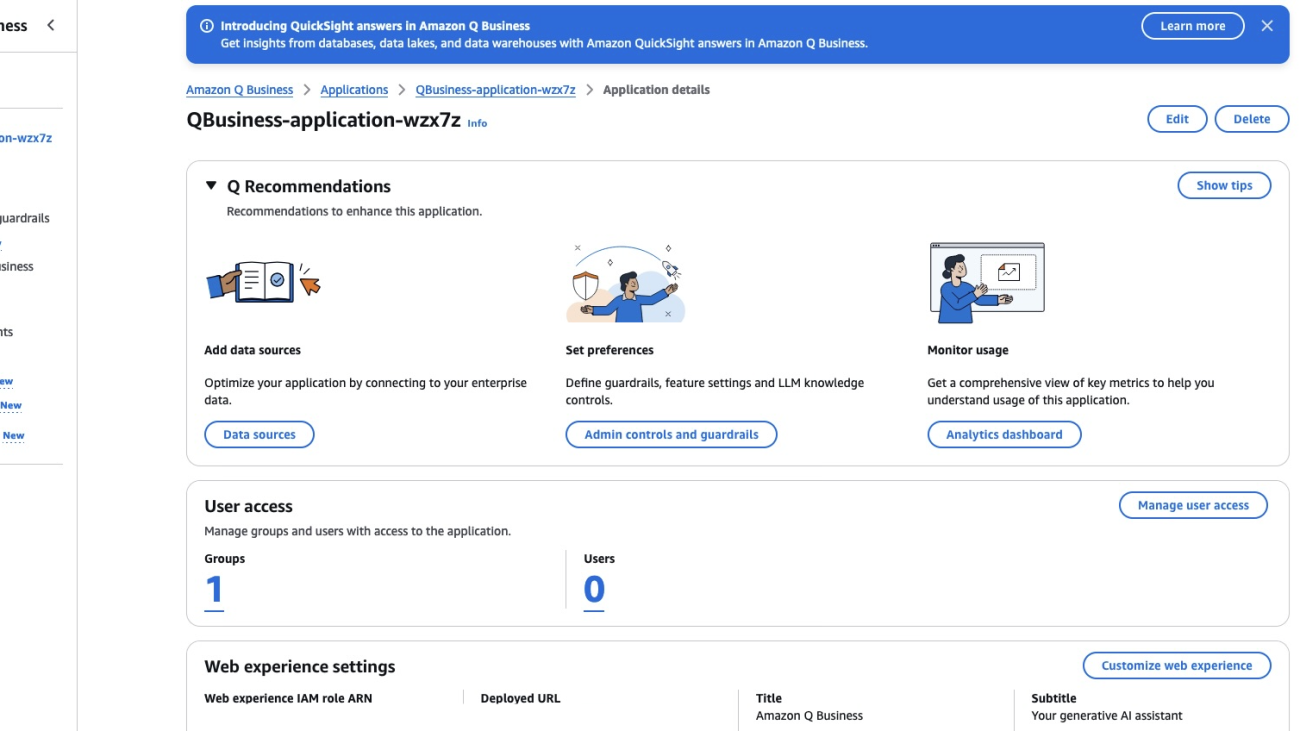
Amazon Q Business is a generative AI-powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. Although generative AI is fueling transformative innovations, enterprises may still experience sharply divided data silos when it comes to enterprise knowledge, in particular between unstructured content (such as PDFs, Word documents, and HTML pages), and structured data (real-time data and reports stored in databases or data lakes). Both categories of data are typically queried and accessed using separate tools, from in-product browse and search functionality for unstructured data, to business intelligence (BI) tools like Amazon QuickSight for structured content.
Amazon Q Business offers an effective solution for quickly building conversational applications over unstructured content, with over 40 data connectors to popular content and storage management systems such as Confluence, SharePoint, and Amazon Simple Storage Service (Amazon S3), to aggregate enterprise knowledge. Customers are also looking for a unified conversational experience across all their knowledge repositories, regardless of the format the content is stored and organized as.
On December 3, 2024, Amazon Q Business announced the launch of its integration with QuickSight, allowing you to quickly connect your structured sources to your Amazon Q Business applications, creating a unified conversational experience for your end-users. The QuickSight integration offers an extensive set of over 20 structured data source connectors, including Amazon Redshift, PostgreSQL, MySQL, and Oracle, enabling you to quickly expand the conversational scope of your Amazon Q Business assistants to cover a wider range of knowledge sources. For the end-users, answers are returned in real time from your structured sources, combined with other relevant information found in unstructured repositories. Amazon Q Business uses the analytics and advanced visualization engine in QuickSight to generate accurate and simple-to-understand answers from structured sources.
In this post, we show you how to configure the QuickSight connection from Amazon Q Business and then ask questions to get real-time data and visualizations from QuickSight for structured data in addition to unstructured content.
The QuickSight feature in Amazon Q Business is available on the Amazon Q Business console as well as through Amazon Q Business APIs. This feature is implemented as a plugin within Amazon Q Business. After it’s enabled, this plugin will behave differently than other Amazon Q Business plugins—it will query QuickSight automatically for every user prompt, looking for relevant answers.
For AWS accounts that aren’t subscribed to QuickSight already, the Amazon Q Business admin completes the following steps:
When the feature is activated, Amazon Q Business will use your unstructured data sources configured in Amazon Q Business, as well as your structured content available using QuickSight, to generate a rich answer that includes narrative and visualizations. Depending on the question and data in QuickSight, Amazon Q Business may generate one or more visualizations as a response.
You should have the following prerequisites:
To use this feature, you need to have an Amazon Q Business application. If you don’t have an existing application, follow the steps in Discover insights from Amazon S3 with Amazon Q S3 connector to create an application along with an Amazon S3 data source. Upload the non-structured document(s) to Amazon S3 and sync the data source.
You can skip this section if you already have an existing QuickSight account. To create a QuickSight account, complete the following steps:



This will create a QuickSight account, assign the IAM Identity Center group as QuickSight Admin Pro, and authorize Amazon Q Business to access QuickSight.

You will see a dashboard with details for QuickSight. Currently, it will show zero datasets and topics.

You can now proceed to the next section to prepare your data.
You can skip this section if you followed the previous steps and created a new QuickSight account.
If your current QuickSight account is not on IAM Identity Center, consider using a different AWS account without a QuickSight subscription for the purpose of testing this feature. From that account, you create an Amazon Q Business application on IAM Identity Center and go through the QuickSight integration setup steps on the Amazon Q Business console that will create the QuickSight account for you in IAM Identity Center. Remember to delete that new QuickSight account and Amazon Q Business application after your testing is done to avoid further billing.
Complete the following steps to set up the QuickSight connector from Amazon Q Business for an existing QuickSight account:



You will see a dashboard with details for QuickSight. If you already have a dataset and topics, they will show up here.

You’re now ready to add a dataset and topics in the next section.
In this section, we create an Amazon Redshift data source. You can instead create a data source from the database of your choice, use files in Amazon S3, or perform a direct upload of CSV files and connect to it. Refer to Creating a dataset from a database for more details.
To configure your data, complete the following steps:
Configuring this connection offers multiple choices; choose the one that best fits your needs.


To start chatting with Amazon Q Business, complete the following steps:
You should see the datasets and topics populated with values.

We uploaded AWS Cost and Usage Reports for a specific AWS account in QuickSight using Amazon Redshift. We also uploaded Amazon service documentation into a data source using Amazon S3 into Amazon Q Business as unstructured data. We will ask questions related to our AWS costs and show how Amazon Q Business answers questions from both structured and unstructured data.
The following screenshot shows an example question that returns a response from only unstructured data.

The following screenshot shows an example question that returns a response from only structured data.

The following screenshot shows an example question that returns a response from both structured and unstructured data.

The following screenshot shows an example question that returns multiple visualizations from both structured and unstructured data.

If you no longer want to use this Amazon Q Business feature, delete the resources you created to avoid future charges:
The process can take up to 15 minutes to complete.
In this post, we showed how to include answers from your structured sources in your Amazon Q Business applications, using the QuickSight integration. This creates a unified conversational experience for your end-users that saves them time, helps them make better decisions through more complete answers, and improves their productivity.
At AWS re:Invent 2024, we also announced a similar unified experience enabling access to insights from unstructured data sources in Amazon Q in QuickSight powered by Amazon Q Business.
To learn about the new capabilities Amazon Q in QuickSight provides, see QuickSight Plugin.
To learn more about Amazon Q Business, refer to the Amazon Q Business User Guide.
To learn more about configuring a QuickSight dataset, see Manage your Amazon QuickSight datasets more efficiently with the new user interface.
QuickSight also offers querying unstructured data. For more details, refer to Integrate unstructured data into Amazon QuickSight using Amazon Q Business.
 Jiten Dedhia is a Sr. AIML Solutions Architect with over 20 years of experience in the software industry. He has helped Fortune 500 companies with their AIML/Generative AI needs.
Jiten Dedhia is a Sr. AIML Solutions Architect with over 20 years of experience in the software industry. He has helped Fortune 500 companies with their AIML/Generative AI needs.
 Jean-Pierre Dodel is a Principal Product Manager for Amazon Q Business, responsible for delivering key strategic product capabilities including structured data support in Q Business, RAG. and overall product accuracy optimizations. He brings extensive AI/ML and Enterprise search experience to the team with over 7 years of product leadership at AWS.
Jean-Pierre Dodel is a Principal Product Manager for Amazon Q Business, responsible for delivering key strategic product capabilities including structured data support in Q Business, RAG. and overall product accuracy optimizations. He brings extensive AI/ML and Enterprise search experience to the team with over 7 years of product leadership at AWS.

Digital experience interruptions can harm customer satisfaction and business performance across industries. Application failures, slow load times, and service unavailability can lead to user frustration, decreased engagement, and revenue loss. The risk and impact of outages increase during peak usage periods, which vary by industry—from ecommerce sales events to financial quarter-ends or major product launches. According to New Relic’s 2024 Observability Forecast, businesses face a median annual downtime of 77 hours from high-impact outages. These outages can cost up to $1.9 million per hour.
New Relic is addressing these challenges by creating the New Relic AI custom plugin for Amazon Q Business. This custom plugin creates a unified solution that combines New Relic AI’s observability insights and recommendations and Amazon Q Business’s Retrieval Augmented Generation (RAG) capabilities, in and a natural language interface for east of use.
The custom plugin streamlines incident response, enhances decision-making, and reduces cognitive load from managing multiple tools and complex datasets. It empowers team members to interpret and act quickly on observability data, improving system reliability and customer experience. By using AI and New Relic’s comprehensive observability data, companies can help prevent issues, minimize incidents, reduce downtime, and maintain high-quality digital experiences.
This post explores the use case, how this custom plugin works, how it can be enabled, and how it can help elevate customers’ digital experiences.
New Relic’s 2024 Observability Forecast highlights three key operational challenges:
The custom plugin for Amazon Q Business addresses these challenges with a unified, natural language interface for critical insights. It uses AI to research and translate findings into clear recommendations, providing quick access to indexed runbooks and post-incident reports. This custom plugin streamlines incident response, enhances decision-making, and reduces effort in managing multiple tools and complex datasets.
The New Relic custom plugin for Amazon Q Business centralizes critical information and actions in one interface, streamlining your workflow. It allows you to inquire about specific services, hosts, or system components directly. For instance, you can investigate a sudden spike in web service response times or a slow database. NR AI responds by analyzing current performance data and comparing it to historical trends and best practices. It then delivers detailed insights and actionable recommendations based on up-to-date production environment information.
The following diagram illustrates the workflow.

When a user asks a question in the Amazon Q interface, such as “Show me problems with the checkout process,” Amazon Q queries the RAG ingested with the customers’ runbooks. Runbooks are troubleshooting guides maintained by operational teams to minimize application interruptions. Amazon Q gains contextual information, including the specific service names and infrastructure information related to the checkout service, and uses the custom plugin to communicate with New Relic AI. New Relic AI initiates a deep dive analysis of monitoring data since the checkout service problems began.
New Relic AI conducts a comprehensive analysis of the checkout service. It examines service performance metrics, forecasts of key indicators like error rates, error patterns and anomalies, security alerts, and overall system status and health. The analysis results in a summarized alert intelligence report that identifies and explains root causes of checkout service issues. This report provides clear, actionable recommendations and includes real-time application performance insights. It also offers direct links to detailed New Relic interfaces. Users can access this comprehensive summary without leaving the Amazon Q interface.
The custom plugin presents information and insights directly within the Amazon Q Business interface, eliminating the need to switch between the New Relic and Amazon Q interfaces, and enabling faster problem resolution.
The New Relic Intelligent Observability platform provides comprehensive incident response and application and infrastructure performance monitoring capabilities for SREs, application engineers, support engineers, and DevOps professionals. Organizations using New Relic report significant improvements in their operations, achieving a 65% reduction in incidents, 10 times more deployments, and 50% faster release times while maintaining 99.99% uptime. When you combine New Relic insights with Amazon Q Business, you can further reduce incidents, deploy higher-quality code more frequently, and create more reliable experiences for your customers:
The New Relic AI custom plugin represents a step forward in digital experience management. By addressing key challenges such as tool fragmentation, knowledge accessibility, and data complexity, this solution empowers teams to deliver superior digital experiences. This collaboration between AWS and New Relic opens up possibilities for building more robust digital infrastructures, advancing innovation in customer-facing technologies, and setting new benchmarks in proactive IT problem-solving.
To learn more about improving your operational efficiency with AI-powered observability, refer to the Amazon Q Business User Guide and explore New Relic AI capabilities. To get started on training, enroll for free Amazon Q training from AWS Training and Certification.
New Relic is a leading cloud-based observability platform that helps businesses optimize the performance and reliability of their digital systems. New Relic processes 3 EB of data annually. Over 5 billion data points are ingested and 2.4 trillion queries are executed every minute across 75,000 active customers. The platform serves over 333 billion web requests each day. The median platform response time is 60 milliseconds.
 Meena Menon is a Sr. Customer Solutions Manager at AWS.
Meena Menon is a Sr. Customer Solutions Manager at AWS.
 Sean Falconer is a Sr. Solutions Architect at AWS.
Sean Falconer is a Sr. Solutions Architect at AWS.
 Nava Ajay Kanth Kota is a Senior Partner Solutions Architect at AWS. He is currently part of the Amazon Partner Network (APN) team that closely works with ISV Storage Partners. Prior to AWS, his experience includes running Storage, Backup, and Hybrid Cloud teams and his responsibilities included creating Managed Services offerings in these areas.
Nava Ajay Kanth Kota is a Senior Partner Solutions Architect at AWS. He is currently part of the Amazon Partner Network (APN) team that closely works with ISV Storage Partners. Prior to AWS, his experience includes running Storage, Backup, and Hybrid Cloud teams and his responsibilities included creating Managed Services offerings in these areas.
 David Girling is a Senior AI/ML Solutions Architect with over 20 years of experience in designing, leading, and developing enterprise systems. David is part of a specialist team that focuses on helping customers learn, innovate, and utilize these highly capable services with their data for their use cases.
David Girling is a Senior AI/ML Solutions Architect with over 20 years of experience in designing, leading, and developing enterprise systems. David is part of a specialist team that focuses on helping customers learn, innovate, and utilize these highly capable services with their data for their use cases.
 Camden Swita is Head of AI and ML Innovation at New Relic specializing in developing compound AI systems, agentic frameworks, and generative user experiences for complex data retrieval, analysis, and actioning.
Camden Swita is Head of AI and ML Innovation at New Relic specializing in developing compound AI systems, agentic frameworks, and generative user experiences for complex data retrieval, analysis, and actioning.
Today, Amazon SageMaker is excited to announce updates to the inference optimization toolkit, providing new functionality and enhancements to help you optimize generative AI models even faster. These updates build on the capabilities introduced in the original launch of the inference optimization toolkit (to learn more, see Achieve up to ~2x higher throughput while reducing costs by ~50% for generative AI inference on Amazon SageMaker with the new inference optimization toolkit – Part 1).
The following are the key additions to the inference optimization toolkit:
These updates build on the toolkit’s existing capabilities, allowing you to reduce the time it takes to optimize generative AI models from months to hours, and achieve best-in-class performance for your use case. Simply choose from the available optimization techniques, apply them to your models, validate the improvements, and deploy the models in just a few clicks through SageMaker.
In this post, we discuss these new features of the toolkit in more detail.
Speculative decoding is an inference technique that aims to speed up the decoding process of large language models (LLMs) for latency-critical applications, without compromising the quality of the generated text. The key idea is to use a smaller, less powerful, but faster language model called the draft model to generate candidate tokens. These candidate tokens are then validated by the larger, more powerful, but slower target model. At each iteration, the draft model generates multiple candidate tokens. The target model verifies the tokens, and if it finds a particular token unacceptable, it rejects it and regenerates that token itself. This allows the larger target model to focus on verification, which is faster than auto-regressive token generation. The smaller draft model can quickly generate all the tokens and send them in batches to the target model for parallel evaluation, significantly speeding up the final response generation.
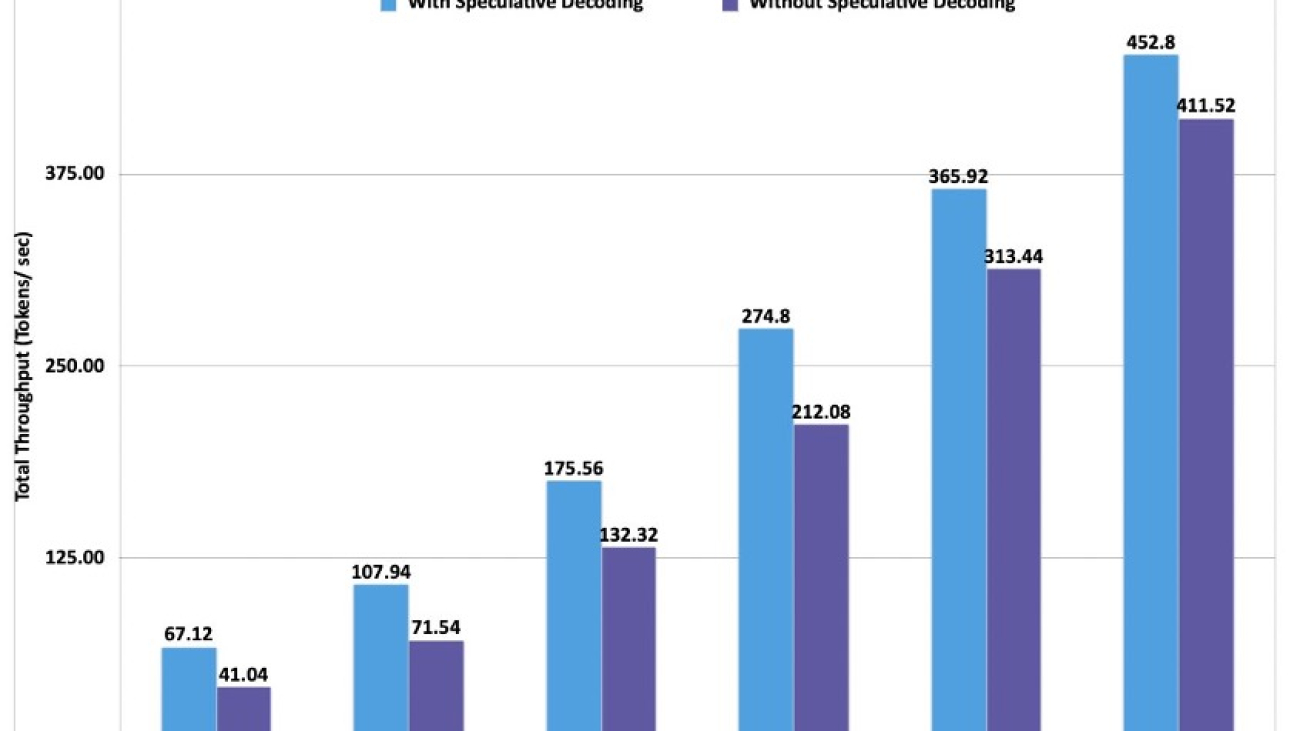
With the updated SageMaker inference toolkit, you get out-of-the-box support for speculative decoding that has been tested for performance at scale on various popular open source LLMs. The toolkit provides a pre-built draft model, eliminating the need to invest time and resources in building your own draft model from scratch. Alternatively, you can also use your own custom draft model, providing flexibility to accommodate your specific requirements. To showcase the benefits of speculative decoding, let’s look at the throughput (tokens per second) for a Meta Llama 3.1 70B Instruct model deployed on an ml.p4d.24xlarge instance using the Meta Llama 3.2 1B Instruct draft model.

Given the increase in throughput that is realized with speculative decoding, we can also see the blended price difference when using speculative decoding vs. when not using speculative decoding. Here we have calculated the blended price as a 3:1 ratio of input to output tokens. The blended price is defined as follows:

Quantization is one of the most popular model compression methods to accelerate model inference. From a technical perspective, quantization has several benefits:
With this launch, the SageMaker inference optimization toolkit now supports FP8 and SmoothQuant (TensorRT-LLM only) quantization. SmoothQuant is a post-training quantization (PTQ) technique for LLMs that reduces memory and speeds up inference without sacrificing accuracy. It migrates quantization difficulty from activations to weights, which are easier to quantize. It does this by introducing a hyperparameter to calculate a per-channel scale that balances the quantization difficulty of activations and weights.
The current generation of instances like p5 and g6 provide support for FP8 using specialized tensor cores. FP8 represents float point numbers in 8 bits instead of the usual 16. At the time of writing, vLLM and TRT-LLM support quantizing the KV cache, attention, and linear layers for text-only LLMs. This reduces memory footprint, increases throughput, and lowers latency. Whereas both weights and activations can be quantized for p5 and g6 instances (W8A8), only weights can be quantized for p4d and g5 instances (W8A16). Though FP8 quantization has minimal impact on accuracy, you should always evaluate the quantized model on your data and for your use case. You can evaluate the quantized model through Amazon SageMaker Clarify. For more details, see Understand options for evaluating large language models with SageMaker Clarify.
The following graph compares the throughput of a FP8 quantized Meta Llama 3.1 70B Instruct model against a non-quantized Meta Llama 3.1 70B Instruct model on an ml.p4d.24xlarge instance.

The quantized model has a smaller memory footprint and it can be deployed to a smaller (and cheaper) instance type. In this post, we have deployed the quantized model on g5.12xlarge.
The following graph shows the price difference per million tokens between the FP8-quantized model deployed on g5.12xlarge and the non-quantized version deployed on p4d.24xlarge.

Our analysis shows a clear price-performance edge for the FP8 quantized model over the non-quantized approach. However, quantization has an impact on model accuracy, so we strongly testing the quantized version of the model on your datasets.
The following is the SageMaker Python SDK code snippet for quantization. You just need to provide the quantization_config attribute in the optimize() function:
Refer to the following code example to learn more about how to enable FP8 quantization and speculative decoding using the optimization toolkit for a pre-trained Amazon SageMaker JumpStart model. If you want to deploy a fine-tuned model with SageMaker JumpStart using speculative decoding, refer to the following notebook.
Compilation optimizes the model to extract the best available performance on the chosen hardware type, without any loss in accuracy. For compilation, the SageMaker inference optimization toolkit provides efficient loading and caching of optimized models to reduce model loading and auto scaling time by up to 40–60 % for Meta Llama 3 8B and 70B.
Model compilation enables running LLMs on accelerated hardware, such as GPUs, while simultaneously optimizing the model’s computational graph for optimal performance on the target hardware. When using the Large Model Inference (LMI) Deep Learning Container (DLC) with the TensorRT-LLM framework, the compiler is invoked from within the framework and creates compiled artifacts. These compiled artifacts are unique for a combination of input shapes, precision of the model, tensor parallel degree, and other framework- or compiler-level configurations. Although the compilation process avoids overhead during inference and enables optimized inference, it can take a lot of time.
To avoid re-compiling every time a model is deployed onto a GPU with the TensorRT-LLM framework, SageMaker introduces the following features:
The following graph illustrates the improvement in model loading time when using pre-compiled artifacts with the SageMaker LMI DLC. The models were compiled with a sequence length of 4096 and a batch size of 16, with Meta Llama 3.1 8B deployed on a g5.12xlarge (tensor parallel degree = 4) and Meta Llama 3.1 70B Instruct on a p4d.24xlarge (tensor parallel degree = 8). As you can see on the graph, the bigger the model, the bigger the benefit of using a pre-compiled model (16% improvement for Meta Llama 3 8B and 43% improvement for Meta Llama 3 70B).

For the SageMaker Python SDK, you can configure the compilation by changing the environment variables in the .optimize() function. For more details on compilation_config, refer to TensorRT-LLM ahead-of-time compilation of models tutorial.
Refer to the following notebook for more information on how to enable TensorRT-LLM compilation using the optimization toolkit for a pre-trained SageMaker JumpStart model.
In this section, let’s walk through the Amazon SageMaker Studio UI experience to run an inference optimization job. In this case, we use the Meta Llama 3.1 70B Instruct model, and for the optimization option, we quantize the model using INT4-AWQ and then use the SageMaker JumpStart suggested draft model Meta Llama 3.2 1B Instruct for speculative decoding.
First, we search for the Meta Llama 3.1 70B Instruct model in the SageMaker JumpStart model hub and choose Optimize on the model card.

The Create inference optimization job page provides you options to choose the type of optimization. In this case, we choose to take advantage of the benefits of both INT4-AWQ quantization and speculative decoding.


For the draft model, you have a choice to use the SageMaker recommended draft model, choose one the SageMaker JumpStart models, or bring your own draft model.

For this scenario, we choose the SageMaker recommended Meta Llama 3.2 1B Instruct model as the draft model and start the optimization job.

When the optimization job is complete, you have an option to evaluate performance or deploy the model onto a SageMaker endpoint for inference.


For compilation and quantization jobs, SageMaker will optimally choose the right instance type, so you don’t have to spend time and effort. You will be charged based on the optimization instance used. To learn more, see Amazon SageMaker pricing. For speculative decoding, there is no additional optimization cost involved; the SageMaker inference optimization toolkit will package the right container and parameters for the deployment on your behalf.
To get started with the inference optimization toolkit, refer to Achieve up to 2x higher throughput while reducing cost by up to 50% for GenAI inference on SageMaker with new inference optimization toolkit: user guide – Part 2. This post will walk you through how to use the inference optimization toolkit when using SageMaker inference with SageMaker JumpStart and the SageMaker Python SDK. You can use the inference optimization toolkit with supported models on SageMaker JumpStart. For the full list of supported models, refer to Inference optimization for Amazon SageMaker models.
 Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
 Dmitry Soldatkin is a Senior AI/ML Solutions Architect at Amazon Web Services (AWS), helping customers design and build AI/ML solutions. Dmitry’s work covers a wide range of ML use cases, with a primary interest in Generative AI, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, utilities, and telecommunications. He has a passion for continuous innovation and using data to drive business outcomes.
Dmitry Soldatkin is a Senior AI/ML Solutions Architect at Amazon Web Services (AWS), helping customers design and build AI/ML solutions. Dmitry’s work covers a wide range of ML use cases, with a primary interest in Generative AI, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, utilities, and telecommunications. He has a passion for continuous innovation and using data to drive business outcomes.
 Raghu Ramesha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
![]() Rishabh Ray Chaudhury is a Senior Product Manager with Amazon SageMaker, focusing on Machine Learning inference. He is passionate about innovating and building new experiences for Machine Learning customers on AWS to help scale their workloads. In his spare time, he enjoys traveling and cooking. You can find him on LinkedIn.
Rishabh Ray Chaudhury is a Senior Product Manager with Amazon SageMaker, focusing on Machine Learning inference. He is passionate about innovating and building new experiences for Machine Learning customers on AWS to help scale their workloads. In his spare time, he enjoys traveling and cooking. You can find him on LinkedIn.
 Lokeshwaran Ravi is a Senior Deep Learning Compiler Engineer at AWS, specializing in ML optimization, model acceleration, and AI security. He focuses on enhancing efficiency, reducing costs, and building secure ecosystems to democratize AI technologies, making cutting-edge ML accessible and impactful across industries.
Lokeshwaran Ravi is a Senior Deep Learning Compiler Engineer at AWS, specializing in ML optimization, model acceleration, and AI security. He focuses on enhancing efficiency, reducing costs, and building secure ecosystems to democratize AI technologies, making cutting-edge ML accessible and impactful across industries.