Our comprehensive benchmark and online leaderboard offer a much-needed measure of how accurately LLMs ground their responses in provided source material and avoid hallucinationsRead More

Our comprehensive benchmark and online leaderboard offer a much-needed measure of how accurately LLMs ground their responses in provided source material and avoid hallucinationsRead More

Our comprehensive benchmark and online leaderboard offer a much-needed measure of how accurately LLMs ground their responses in provided source material and avoid hallucinationsRead More

Our comprehensive benchmark and online leaderboard offer a much-needed measure of how accurately LLMs ground their responses in provided source material and avoid hallucinationsRead More

Our comprehensive benchmark and online leaderboard offer a much-needed measure of how accurately LLMs ground their responses in provided source material and avoid hallucinationsRead More

Our comprehensive benchmark and online leaderboard offer a much-needed measure of how accurately LLMs ground their responses in provided source material and avoid hallucinationsRead More

Our comprehensive benchmark and online leaderboard offer a much-needed measure of how accurately LLMs ground their responses in provided source material and avoid hallucinationsRead More

NVIDIA is taking the wraps off a new compact generative AI supercomputer, offering increased performance at a lower price with a software upgrade.
The new NVIDIA Jetson Orin Nano Super Developer Kit, which fits in the palm of a hand, provides everyone from commercial AI developers to hobbyists and students, gains in generative AI capabilities and performance. And the price is now $249, down from $499.
Available today, it delivers as much as a 1.7x leap in generative AI inference performance, a 70% increase in performance to 67 INT8 TOPS, and a 50% increase in memory bandwidth to 102GB/s compared with its predecessor.
Whether creating LLM chatbots based on retrieval-augmented generation, building a visual AI agent, or deploying AI-based robots, the Jetson Orin Nano Super is an ideal solution to fetch.
The software updates available to the new Jetson Orin Nano Super will also boost generative AI performance for those who already own the Jetson Orin Nano Developer Kit.
Jetson Orin Nano Super is suited for those interested in developing skills in generative AI, robotics or computer vision. As the AI world is moving from task-specific models into foundation models, it also provides an accessible platform to transform ideas into reality.
The enhanced performance of the Jetson Orin Nano Super delivers gains for all popular generative AI models and transformer-based computer vision.
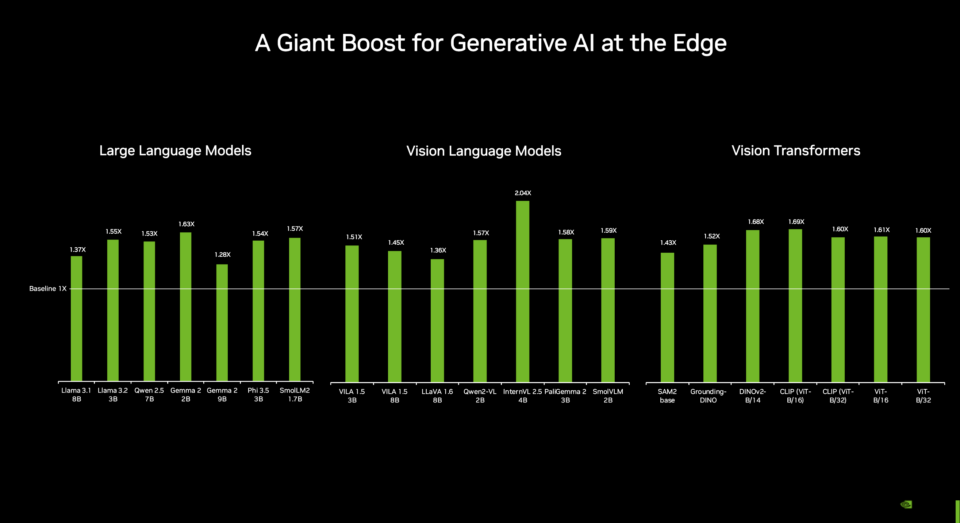
The developer kit consists of a Jetson Orin Nano 8GB system-on-module (SoM) and a reference carrier board, providing an ideal platform for prototyping edge AI applications.
The SoM features an NVIDIA Ampere architecture GPU with tensor cores and a 6-core Arm CPU, facilitating multiple concurrent AI application pipelines and high-performance inference. It can support up to four cameras, offering higher resolution and frame rates than previous versions.
Generative AI is evolving quickly. The NVIDIA Jetson AI lab offers immediate support for those cutting-edge models from the open-source community and provides easy-to-use tutorials. Developers can also get extensive support from the broader Jetson community and inspiration from projects created by developers.
Jetson runs NVIDIA AI software including NVIDIA Isaac for robotics, NVIDIA Metropolis for vision AI and NVIDIA Holoscan for sensor processing. Development time can be reduced with NVIDIA Omniverse Replicator for synthetic data generation and NVIDIA TAO Toolkit for fine-tuning pretrained AI models from the NGC catalog.
Jetson ecosystem partners offer additional AI and system software, developer tools and custom software development. They can also help with cameras and other sensors, as well as carrier boards and design services for product solutions.
The software updates to boost 1.7X generative AI performance will also be available to the Jetson Orin NX and Orin Nano series of systems on modules.

Existing Jetson Orin Nano Developer Kit owners can upgrade the JetPack SDK to unlock boosted performance today.
Learn more about Jetson Orin Nano Super Developer Kit.
See notice regarding software product information.

 Today we’re refreshing Google’s Generative AI Prohibited Use Policy — the rules of the road that help people use the generative AI tools found in our products and servic…Read More
Today we’re refreshing Google’s Generative AI Prohibited Use Policy — the rules of the road that help people use the generative AI tools found in our products and servic…Read More

 Learn more about Google Cloud’s AI predictions for businesses in 2025.Read More
Learn more about Google Cloud’s AI predictions for businesses in 2025.Read More
Today, we are excited to announce that the Llama 3.3 70B from Meta is available in Amazon SageMaker JumpStart. Llama 3.3 70B marks an exciting advancement in large language model (LLM) development, offering comparable performance to larger Llama versions with fewer computational resources.
In this post, we explore how to deploy this model efficiently on Amazon SageMaker AI, using advanced SageMaker AI features for optimal performance and cost management.
Llama 3.3 70B represents a significant breakthrough in model efficiency and performance optimization. This new model delivers output quality comparable to Llama 3.1 405B while requiring only a fraction of the computational resources. According to Meta, this efficiency gain translates to nearly five times more cost-effective inference operations, making it an attractive option for production deployments.
The model’s sophisticated architecture builds upon Meta’s optimized version of the transformer design, featuring an enhanced attention mechanism that can help substantially reduce inference costs. During its development, Meta’s engineering team trained the model on an extensive dataset comprising approximately 15 trillion tokens, incorporating both web-sourced content and over 25 million synthetic examples specifically created for LLM development. This comprehensive training approach results in the model’s robust understanding and generation capabilities across diverse tasks.
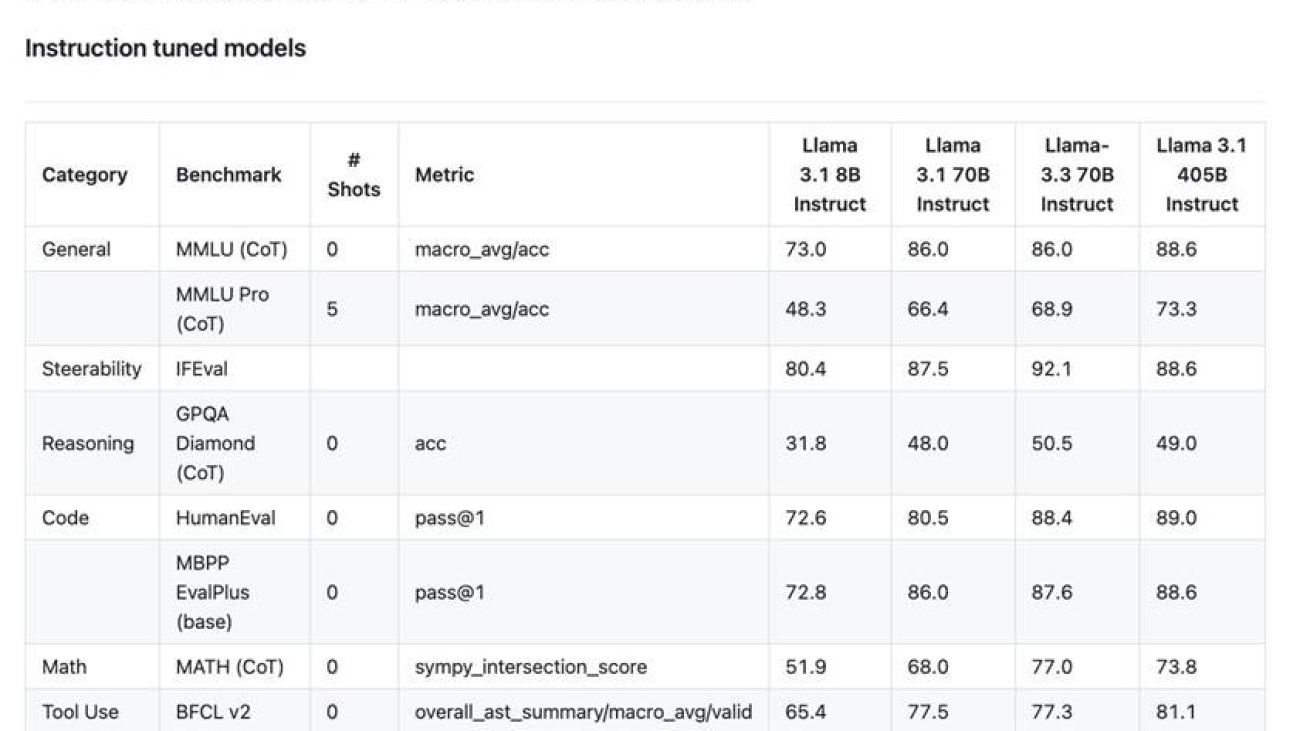
What sets Llama 3.3 70B apart is its refined training methodology. The model underwent an extensive supervised fine-tuning process, complemented by Reinforcement Learning from Human Feedback (RLHF). This dual-approach training strategy helps align the model’s outputs more closely with human preferences while maintaining high performance standards. In benchmark evaluations against its larger counterpart, Llama 3.3 70B demonstrated remarkable consistency, trailing Llama 3.1 405B by less than 2% in 6 out of 10 standard AI benchmarks and actually outperforming it in three categories. This performance profile makes it an ideal candidate for organizations seeking to balance model capabilities with operational efficiency.
The following figure summarizes the benchmark results (source).

SageMaker JumpStart is a machine learning (ML) hub that can help accelerate your ML journey. With SageMaker JumpStart, you can evaluate, compare, and select pre-trained foundation models (FMs), including Llama 3 models. These models are fully customizable for your use case with your data, and you can deploy them into production using either the UI or SDK.
Deploying Llama 3.3 70B through SageMaker JumpStart offers two convenient approaches: using the intuitive SageMaker JumpStart UI or implementing programmatically through the SageMaker Python SDK. Let’s explore both methods to help you choose the approach that best suits your needs.
You can access the SageMaker JumpStart UI through either Amazon SageMaker Unified Studio or Amazon SageMaker Studio. To deploy Llama 3.3 70B using the SageMaker JumpStart UI, complete the following steps:

Alternatively, on the SageMaker Studio console, choose JumpStart in the navigation pane.




Wait until the endpoint status shows as InService. You can now run inference using the model.
For teams looking to automate deployment or integrate with existing MLOps pipelines, you can use the following code to deploy the model using the SageMaker Python SDK:
You can optionally set up auto scaling to scale down to zero after deployment. For more information, refer to Unlock cost savings with the new scale down to zero feature in SageMaker Inference.
SageMaker AI simplifies the deployment of sophisticated models like Llama 3.3 70B, offering a range of features designed to optimize both performance and cost efficiency. With the advanced capabilities of SageMaker AI, organizations can deploy and manage LLMs in production environments, taking full advantage of Llama 3.3 70B’s efficiency while benefiting from the streamlined deployment process and optimization tools of SageMaker AI. Default deployment through SageMaker JumpStart uses accelerated deployment, which uses speculative decoding to improve throughput. For more information on how speculative decoding works with SageMaker AI, see Amazon SageMaker launches the updated inference optimization toolkit for generative AI.
Firstly, the Fast Model Loader revolutionizes the model initialization process by implementing an innovative weight streaming mechanism. This feature fundamentally changes how model weights are loaded onto accelerators, dramatically reducing the time required to get the model ready for inference. Instead of the traditional approach of loading the entire model into memory before beginning operations, Fast Model Loader streams weights directly from Amazon Simple Storage Service (Amazon S3) to the accelerator, enabling faster startup and scaling times.
One SageMaker inference capability is Container Caching, which transforms how model containers are managed during scaling operations. This feature eliminates one of the major bottlenecks in deployment scaling by pre-caching container images, removing the need for time-consuming downloads when adding new instances. For large models like Llama 3.3 70B, where container images can be substantial in size, this optimization significantly reduces scaling latency and improves overall system responsiveness.
Another key capability is Scale to Zero. It introduces intelligent resource management that automatically adjusts compute capacity based on actual usage patterns. This feature represents a paradigm shift in cost optimization for model deployments, allowing endpoints to scale down completely during periods of inactivity while maintaining the ability to scale up quickly when demand returns. This capability is particularly valuable for organizations running multiple models or dealing with variable workload patterns.
Together, these features create a powerful deployment environment that maximizes the benefits of Llama 3.3 70B’s efficient architecture while providing robust tools for managing operational costs and performance.
The combination of Llama 3.3 70B with the advanced inference features of SageMaker AI provides an optimal solution for production deployments. By using Fast Model Loader, Container Caching, and Scale to Zero capabilities, organizations can achieve both high performance and cost-efficiency in their LLM deployments.
We encourage you to try this implementation and share your experiences.
 Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
 Saurabh Trikande is a Senior Product Manager for Amazon Bedrock and SageMaker Inference. He is passionate about working with customers and partners, motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, inference with multi-tenant models, cost optimizations, and making the deployment of Generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon Bedrock and SageMaker Inference. He is passionate about working with customers and partners, motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, inference with multi-tenant models, cost optimizations, and making the deployment of Generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
 Melanie Li, PhD, is a Senior Generative AI Specialist Solutions Architect at AWS based in Sydney, Australia, where her focus is on working with customers to build solutions leveraging state-of-the-art AI and machine learning tools. She has been actively involved in multiple Generative AI initiatives across APJ, harnessing the power of Large Language Models (LLMs). Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries.
Melanie Li, PhD, is a Senior Generative AI Specialist Solutions Architect at AWS based in Sydney, Australia, where her focus is on working with customers to build solutions leveraging state-of-the-art AI and machine learning tools. She has been actively involved in multiple Generative AI initiatives across APJ, harnessing the power of Large Language Models (LLMs). Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries.
 Adriana Simmons is a Senior Product Marketing Manager at AWS.
Adriana Simmons is a Senior Product Marketing Manager at AWS.
 Lokeshwaran Ravi is a Senior Deep Learning Compiler Engineer at AWS, specializing in ML optimization, model acceleration, and AI security. He focuses on enhancing efficiency, reducing costs, and building secure ecosystems to democratize AI technologies, making cutting-edge ML accessible and impactful across industries.
Lokeshwaran Ravi is a Senior Deep Learning Compiler Engineer at AWS, specializing in ML optimization, model acceleration, and AI security. He focuses on enhancing efficiency, reducing costs, and building secure ecosystems to democratize AI technologies, making cutting-edge ML accessible and impactful across industries.
 Yotam Moss is a Software development Manager for Inference at AWS AI.
Yotam Moss is a Software development Manager for Inference at AWS AI.