Untold Studios is a tech-driven, leading creative studio specializing in high-end visual effects and animation. Our commitment to innovation led us to a pivotal challenge: how to harness the power of machine learning (ML) to further enhance our competitive edge while balancing this technological advancement with strict data security requirements and the need to streamline access to our existing internal resources.
To give our artists access to technology, we need to create good user interfaces. This is a challenge, especially if the pool of end-users are diverse in terms of their needs and technological experience. We saw an opportunity to use large language models (LLMs) to create a natural language interface, which makes this challenge easier and takes care of a lot of the heavy lifting.
This post details how we used Amazon Bedrock to create an AI assistant (Untold Assistant), providing artists with a straightforward way to access our internal resources through a natural language interface integrated directly into their existing Slack workflow.
Solution overview
The Untold Assistant serves as a central hub for artists. Besides the common AI functionalities like text and image generation, it allows them to interact with internal data, tools, and workflows through natural language queries.
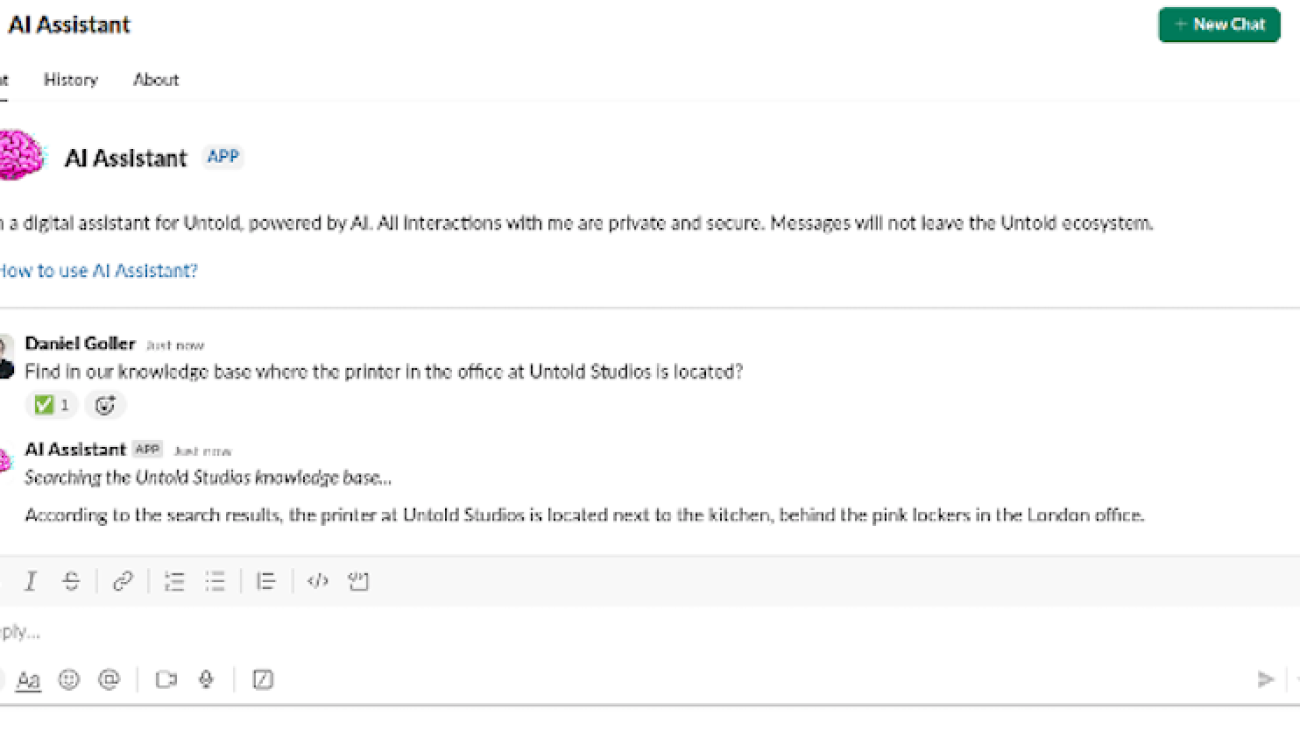
For the UI, we use Slack’s built-in features rather than building custom frontends. Slack already provides applications for workstations and phones, message threads for complex queries, emoji reactions for feedback, and file sharing capabilities. The implementation uses Slack’s event subscription API to process incoming messages and Slack’s Web API to send responses. Users interact with the Untold Assistant through private direct messages or by mentioning it (@-style tagging) in channels for everybody to see. Because our teams already use Slack throughout the day, this eliminates context switching and the need to adopt new software. Every new message is acknowledged by a gear emoji for immediate feedback, which eventually changes to a check mark if the query was successful or an X if an error occurred. The following screenshot shows an example.

With the use of Anthropic’s Claude 3.5 Sonnet model on Amazon Bedrock, the system processes complex requests and generates contextually relevant responses. The serverless architecture provides scalability and responsiveness, and secure storage houses the studio’s vast asset library and knowledge base. Key AWS services used include:
- Amazon Bedrock – Including Anthropic’s Claude 3.5 Sonnet LLM, Stability AI’s Stable Diffusion 3 image generation, and knowledge base connectors
- AWS Lambda – For workflow execution
- Amazon API Gateway – For the Slack event handler
- Amazon Simple Storage Service (Amazon S3) – For arbitrary unstructured data
- Amazon DynamoDB – For persistent storage
The following diagram illustrates the solution architecture.

The main components for this application are the Slack integration, the Amazon Bedrock integration, the Retrieval Augmented Generation (RAG) implementation, user management, and logging.
Slack integration
We use a two-function approach to meet Slack’s 3-second acknowledgment requirement. The incoming event from Slack is sent to an endpoint in API Gateway, and Slack expects a response in less than 3 seconds, otherwise the request fails. The first Lambda function, with reserved capacity, quickly acknowledges the event and forwards the request to the second function, where it can be handled without time restrictions. The setup handles time-sensitive responses while allowing for thorough request processing. We call the second function directly from the first function without using an event with Amazon Simple Notification Service (Amazon SNS) or a queue with Amazon Simple Queue Service (Amazon SQS) in between to keep the latency as low as possible.
Amazon Bedrock integration
Our Untold Assistant uses Amazon Bedrock with Anthropic’s Claude 3.5 Sonnet model for natural language processing. We use the model’s function calling capabilities, enabling the application to trigger specific tools or actions as needed. This allows the assistant to handle both general queries and complex specialized queries or run tasks across our internal systems.
RAG implementation
Our RAG setup uses Amazon Bedrock connectors to integrate with Confluence and Salesforce, tapping into our existing knowledge bases. For other data sources without a pre-built connector available, we export content to Amazon S3 and use the Amazon S3 connector. For example, we export pre-chunked asset metadata from our asset library to Amazon S3, letting Amazon Bedrock handle embeddings, vector storage, and search. This approach significantly decreased development time and complexity, allowing us to focus on improving user experience.
User management
We map Slack user IDs to our internal user pool, currently in DynamoDB (but designed to work with Amazon Cognito). This system tailors the assistant’s capabilities to each user’s role and clearance level, making sure that it operates within the bounds of each user’s authority while maintaining functionality. The access to data sources is controlled using tools. Every tool encapsulates a data source and the LLM’s access to tools is restricted by the user and their role.
Additionally, if a user tells the assistant something that should be remembered, we store this piece of information in a database and add it to the context every time the user initiates a request. This could be, for example, “Keep all your replies as short as possible” or “If I ask for code it’s always Python.”
Logging and monitoring
We use the built-in integration with Amazon CloudWatch in Lambda to track system performance and error states. For monitoring critical errors, we’ve set up direct notifications to a dedicated Slack channel, allowing for immediate awareness and response. Every query and tool invocation is logged to DynamoDB, providing a rich dataset that we use to analyze usage patterns and optimize the system’s performance and functionality.
Function calling with Amazon Bedrock
Like Anthropic’s Claude, most modern LLMs support function calling, which allows us to extend the capabilities of LLMs beyond merely generating text. We can provide a set of function specifications with a description of what the function is going to do and the names and descriptions of the function’s parameters. Based on this information, the LLM decides if an incoming request can be solved directly or if the best next step to solve the query would be a function call. If that’s the case, the model returns the name of the function to call, as well as the parameters and values. It’s then up to us to run the function and initiate the next step. Agents use this system in a loop to call functions and process their output until a success criterion is reached. In our case, we only implement a single pass function call to keep things simple and robust. However, in certain cases, the function itself uses the LLM to process data and format it nicely for the end-user.
Function calling is a very useful feature that helps us convert unstructured user input into structured automatable instructions. We anticipate that over the next couple of months, we will add many more functions to extend the AI assistant’s capabilities and increase its usefulness. Although frameworks like LangChain offer comprehensive solutions for implementing function calling systems, we opted for a lightweight, custom approach tailored to our specific needs. This decision allowed us to maintain a smaller footprint and focus on the essential features for our use case.
The following is a code example of using the AiTool base class for extendability.

All that’s required to add a new function is creating a class like the one in our example. The class will automatically be discovered and the respective specification added to the request to the LLM if the user has access to the function. All the required information to create the function specification is extracted from the code and docstrings:
- NAME – The ID of the function
- PROGRESS_MESSAGE – A message that’s sent to the user through Slack for immediate feedback before the function is run
- EXCLUSIVE_ACCESS_DEPARTMENTS – If set, only users of the specified departments have access to this tool
The tool in this example updates the user memory. For example, the query “Remember to always use Python as a programming language” will trigger the execution of this tool. The LLM will extract the info string from the request, for example, “code should always be Python.” If the existing user memory that is always added to the context already contains a memory about the same topic (for example, “code should always be Java”), the LLM will also provide the memory ID and the existing memory will be overwritten. Otherwise, a new memory with a new ID is created.
Key features and benefits
Slack serves as a single entry point, allowing artists to query diverse internal systems without leaving their familiar workflow. The following features are powered by function calling using Anthropic’s Claude:
- Various knowledge bases for different user roles (Confluence, Salesforce)
- Internal asset library (Amazon S3)
- Image generation powered by Stable Diffusion
- User-specific memory and preferences (for example, default programming languages, default dimensions for image generation, detail level of responses)
By eliminating the need for additional software or context switching, we’ve drastically reduced friction in accessing critical resources. The system is available around the clock for artist queries and tasks, and our framework for function calling with Anthropic’s Claude allows for future expansion of features.
The LLM’s natural language interface is a game changer for user interaction. It’s inherently more flexible and forgiving compared to traditional interfaces, capable of interpreting unstructured input, asking for missing information, and performing tasks like date formatting, unit conversion, and value extraction from natural language descriptions. The system adeptly handles ambiguous queries, extracting relevant information and intent. This means artists can focus on their creative process rather than worrying about precise phrasing or navigating complex menu structures.
Security and control are paramount in our AI adoption strategy. By keeping all data within the AWS ecosystem, we’ve eliminated dependencies on third-party AI tools and mitigated associated risks. This approach allows us to maintain tight control over data access and usage. Additionally, we’ve implemented comprehensive usage analytics, providing insights into adoption patterns and areas for improvement. This data-driven approach makes sure we’re continually refining the tool to meet evolving artist needs.
Impact and future plans
The Untold Assistant currently handles up to 120 queries per day, with about 10–20% of them calling additional tools, like image generation or knowledge base search. Especially for new users who aren’t too familiar with internal workflows and applications yet, it can save a lot of time. Instead of searching in several different Confluence spaces and Slack channels or reaching out to the technology team, they can just ask the Untold Assistant, which acts as a virtual member of the support team. This can cut down the time from minutes to only a few seconds.
Overall, the Untold Assistant, rapidly developed and deployed using AWS services, has delivered several benefits:
- Enhanced discoverability and usage of previously underutilized internal resources
- Significant reduction in time spent searching for information
- Streamlined access to multiple internal systems with an authorization system from a central entry point
- Reduced load on the support and technology team
- Increased speed of adoption of new technologies by providing a framework for user interaction
Building on this success, we’re expanding functionality through additional function calls. A key planned feature is render job error analysis for artists. This tool will automatically fetch logs from recent renders, analyze potential errors using the capabilities of Anthropic’s Claude, and provide users with explanations and solutions by using both internet resources and our internal knowledge base of known errors.
Additionally, we plan to analyze the saved queries using Amazon Titan Text Embeddings and agglomerative clustering to identify semantically similar questions. When the cluster frequency exceeds our defined threshold (for example, more than 10 similar questions from different users within a week), we enhance our knowledge base or update onboarding materials to address these common queries proactively, reducing repetitive questions and improving the assistant’s efficiency.
These initial usage metrics and the planned technical improvements demonstrate the system’s positive impact on our workflows. By automating common support tasks and continuously improving our knowledge base through data-driven analysis, we reduce the technology team’s support load while maintaining high-quality assistance. The modular architecture allows us to quickly integrate new tools as needs arise, to keep up with the astonishing pace of the progress made in AI and ML.
Conclusion
The Untold Assistant demonstrates how Amazon Bedrock enables rapid development of sophisticated AI applications without compromising security or control. Using function calling and pre-built connectors in Amazon Bedrock eliminated the need for complex vector store integrations and custom embedding pipelines, reducing our development time from months to weeks. The modular architecture using Python classes for tools makes the system highly maintainable and extensible.
By automating routine technical tasks and information retrieval, we’ve freed our artists to focus on creative work that drives business value. The solution’s clean separation between the LLM interface and business logic, built entirely within the AWS ecosystem, enables quick integration of new capabilities while maintaining strict data security. The LLM’s ability to interpret unstructured input and handle ambiguous queries creates a more natural and forgiving interface compared to traditional menu-driven systems. This foundation of technical robustness and improved artist productivity positions us to rapidly adopt emerging AI capabilities while keeping our focus on creative innovation.
To explore how to streamline your company’s workflows using Amazon Bedrock, see Getting started with Amazon Bedrock. If you have questions or suggestions, please leave a comment.
About the Authors
 Olivier Vigneresse is a Solutions Architect at AWS. Based in England, he primarily works with SMB Media an&d Entertainment customers. With a background in security and networking, Olivier helps customers achieve success on their cloud journey by providing architectural guidance and best practices; he is also passionate about helping them bring value with Machine Learning and Generative AI use-cases.
Olivier Vigneresse is a Solutions Architect at AWS. Based in England, he primarily works with SMB Media an&d Entertainment customers. With a background in security and networking, Olivier helps customers achieve success on their cloud journey by providing architectural guidance and best practices; he is also passionate about helping them bring value with Machine Learning and Generative AI use-cases.
 Daniel Goller is a Lead R&D Developer at Untold Studios with a focus on cloud infrastructure and emerging technologies. After earning his PhD in Germany, where he collaborated with industry leaders like BMW and Audi, he has spent the past decade implementing software solutions, with a particular emphasis on cloud technology in recent years. At Untold Studios, he leads infrastructure optimisation and AI/ML initiatives, leveraging his technical expertise and background in research to drive innovation in the Media & Entertainment space.
Daniel Goller is a Lead R&D Developer at Untold Studios with a focus on cloud infrastructure and emerging technologies. After earning his PhD in Germany, where he collaborated with industry leaders like BMW and Audi, he has spent the past decade implementing software solutions, with a particular emphasis on cloud technology in recent years. At Untold Studios, he leads infrastructure optimisation and AI/ML initiatives, leveraging his technical expertise and background in research to drive innovation in the Media & Entertainment space.
 Max Barnett is an Account Manager at AWS who specialises in accelerating the cloud journey of Media & Entertainment customers. He has been helping customers at AWS for the past 4.5 years. Max has been particularly involved with customers in the visual effect space, guiding them as they explore generative AI.
Max Barnett is an Account Manager at AWS who specialises in accelerating the cloud journey of Media & Entertainment customers. He has been helping customers at AWS for the past 4.5 years. Max has been particularly involved with customers in the visual effect space, guiding them as they explore generative AI.



 Satveer Khurpa is a Sr. WW Specialist Solutions Architect, Bedrock at Amazon Web Services. In this role, he uses his expertise in cloud-based architectures to develop innovative generative AI solutions for clients across diverse industries. Satveer’s deep understanding of generative AI technologies allows him to design scalable, secure, and responsible applications that unlock new business opportunities and drive tangible value.
Satveer Khurpa is a Sr. WW Specialist Solutions Architect, Bedrock at Amazon Web Services. In this role, he uses his expertise in cloud-based architectures to develop innovative generative AI solutions for clients across diverse industries. Satveer’s deep understanding of generative AI technologies allows him to design scalable, secure, and responsible applications that unlock new business opportunities and drive tangible value. Adewale Akinfaderin is a Sr. Data Scientist–Generative AI, Amazon Bedrock, where he contributes to cutting edge innovations in foundational models and generative AI applications at AWS. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global customers formulate and develop scalable solutions to interdisciplinary problems. He has two graduate degrees in physics and a doctorate in engineering.
Adewale Akinfaderin is a Sr. Data Scientist–Generative AI, Amazon Bedrock, where he contributes to cutting edge innovations in foundational models and generative AI applications at AWS. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global customers formulate and develop scalable solutions to interdisciplinary problems. He has two graduate degrees in physics and a doctorate in engineering. Antonio Rodriguez is a Principal Generative AI Specialist Solutions Architect at Amazon Web Services. He helps companies of all sizes solve their challenges, embrace innovation, and create new business opportunities with Amazon Bedrock. Apart from work, he loves to spend time with his family and play sports with his friends.
Antonio Rodriguez is a Principal Generative AI Specialist Solutions Architect at Amazon Web Services. He helps companies of all sizes solve their challenges, embrace innovation, and create new business opportunities with Amazon Bedrock. Apart from work, he loves to spend time with his family and play sports with his friends.



 Deepti Tirumala is a Senior Solutions Architect at Amazon Web Services, specializing in Machine Learning and Generative AI technologies. With a passion for helping customers advance their AWS journey, she works closely with organizations to architect scalable, secure, and cost-effective solutions that leverage the latest innovations in these areas.
Deepti Tirumala is a Senior Solutions Architect at Amazon Web Services, specializing in Machine Learning and Generative AI technologies. With a passion for helping customers advance their AWS journey, she works closely with organizations to architect scalable, secure, and cost-effective solutions that leverage the latest innovations in these areas. James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries.
James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries. Diwakar Bansal is a Principal GenAI Specialist focused on business development and go-to- market for GenAI and Machine Learning accelerated computing services. Diwakar has led product definition, global business development, and marketing of technology products in the fields of IOT, Edge Computing, and Autonomous Driving focusing on bringing AI and Machine learning to these domains. Diwakar is passionate about public speaking and thought leadership in the Cloud and GenAI space.
Diwakar Bansal is a Principal GenAI Specialist focused on business development and go-to- market for GenAI and Machine Learning accelerated computing services. Diwakar has led product definition, global business development, and marketing of technology products in the fields of IOT, Edge Computing, and Autonomous Driving focusing on bringing AI and Machine learning to these domains. Diwakar is passionate about public speaking and thought leadership in the Cloud and GenAI space.





 Javier Beltrán is a Senior Machine Learning Engineer at Aetion. His career has focused on natural language processing, and he has experience applying machine learning solutions to various domains, from healthcare to social media.
Javier Beltrán is a Senior Machine Learning Engineer at Aetion. His career has focused on natural language processing, and he has experience applying machine learning solutions to various domains, from healthcare to social media. Ornela Xhelili is a Staff Machine Learning Architect at Aetion. Ornela specializes in natural language processing, predictive analytics, and MLOps, and holds a Master’s of Science in Statistics. Ornela has spent the past 8 years building AI/ML products for tech startups across various domains, including healthcare, finance, analytics, and ecommerce.
Ornela Xhelili is a Staff Machine Learning Architect at Aetion. Ornela specializes in natural language processing, predictive analytics, and MLOps, and holds a Master’s of Science in Statistics. Ornela has spent the past 8 years building AI/ML products for tech startups across various domains, including healthcare, finance, analytics, and ecommerce. Prasidh Chhabri is a Product Manager at Aetion, leading the Aetion Evidence Platform, core analytics, and AI/ML capabilities. He has extensive experience building quantitative and statistical methods to solve problems in human health.
Prasidh Chhabri is a Product Manager at Aetion, leading the Aetion Evidence Platform, core analytics, and AI/ML capabilities. He has extensive experience building quantitative and statistical methods to solve problems in human health. Mikhail Vaynshteyn is a Solutions Architect with Amazon Web Services. Mikhail works with healthcare life sciences customers and specializes in data analytics services. Mikhail has more than 20 years of industry experience covering a wide range of technologies and sectors.
Mikhail Vaynshteyn is a Solutions Architect with Amazon Web Services. Mikhail works with healthcare life sciences customers and specializes in data analytics services. Mikhail has more than 20 years of industry experience covering a wide range of technologies and sectors.
 James Manyika and Kent Walker share three scientific imperatives for the AI era.
James Manyika and Kent Walker share three scientific imperatives for the AI era.
 The best of Google AI is now included in Workspace with significant nonprofit discounts.
The best of Google AI is now included in Workspace with significant nonprofit discounts.
 Starting this week, Google Photos will begin using SynthID (a technology that embeds an imperceptible, digital watermark directly into AI-generated images, audio, text o…
Starting this week, Google Photos will begin using SynthID (a technology that embeds an imperceptible, digital watermark directly into AI-generated images, audio, text o…