We’re announcing new updates to Gemini 2.0 Flash, plus introducing Gemini 2.0 Flash-Lite and Gemini 2.0 Pro Experimental.Read More

We’re announcing new updates to Gemini 2.0 Flash, plus introducing Gemini 2.0 Flash-Lite and Gemini 2.0 Pro Experimental.Read More

We’re announcing new updates to Gemini 2.0 Flash, plus introducing Gemini 2.0 Flash-Lite and Gemini 2.0 Pro Experimental.Read More

We’re announcing new updates to Gemini 2.0 Flash, plus introducing Gemini 2.0 Flash-Lite and Gemini 2.0 Pro Experimental.Read More

We’re announcing new updates to Gemini 2.0 Flash, plus introducing Gemini 2.0 Flash-Lite and Gemini 2.0 Pro Experimental.Read More

We’re announcing new updates to Gemini 2.0 Flash, plus introducing Gemini 2.0 Flash-Lite and Gemini 2.0 Pro Experimental.Read More

We’re announcing new updates to Gemini 2.0 Flash, plus introducing Gemini 2.0 Flash-Lite and Gemini 2.0 Pro Experimental.Read More

When non-technical users can create and deploy reliable AI workflows, organizations can do more to serve their clientele
Platforms for developing no- and low-code solutions are bridging the gap between powerful AI models and everyone who’d like to harness them.
Gooey.AI, a member of the NVIDIA Inception program for cutting-edge startups, offers one such platform, enabling teams to tap into multiple AI tools to improve productivity for frontline workers across the globe. Cofounders Sean Blagsvedt and Archana Prasad join the NVIDIA AI Podcast to discuss how the startup’s platform is making AI development accessible to developers and non-coders alike.
The founders detail Gooey.AI’s evolution from a British Council-funded arts project to a comprehensive, open-source, cloud-hosted platform serving over 1 million users in diverse industries like agriculture, healthcare and frontline services. The company’s vision centers on democratizing AI development through shareable AI recipes, as well as helping ensure responsible implementation and representation of historically underserved communities in AI model-building.
Prasad and Blagsvedt discuss unique applications, such as multilingual chatbots that support African farmers via messaging apps and AI assistants that help heating, ventilation, and air conditioning technicians access technical documentation.
Given the rapid adoption of low-code AI platforms is helping organizations of all sizes and charters overcome technical barriers while improving access to expertise, Blagsvedt noted, “You can’t [create] good technology that changes the world just by focusing on the technology — you have to find the problem worth solving.”
Learn more about the latest advancements in AI by registering for NVIDIA GTC, the conference for the era of AI, taking place March 17-21.
00:31 – How a development platform began life as a British Council arts project called Dara.network.
17:53 – Working with the Gates Foundation, DigitalGreen and Opportunity International on agricultural chatbots.
33:21 – The influence of HTML standards and Kubernetes on Gooey.AI’s approach.

NVIDIA’s Louis Stewart on How AI Is Shaping Workforce Development
Louis Stewart, head of strategic initiatives for NVIDIA’s global developer ecosystem, discusses why workforce development is crucial for maximizing AI benefits. He emphasizes the importance of AI education, inclusivity and public-private partnerships in preparing the global workforce for the future. Engaging with AI tools and understanding their impact on the workforce landscape is vital for ensuring these changes benefit everyone.
Living Optics CEO Robin Wang on Democratizing Hyperspectral Imaging
Step into the realm of the unseen with Robin Wang, CEO of Living Optics. Living Optics’ hyperspectral imaging camera, which can capture visual data across 96 colors, reveals details invisible to the human eye. Potential applications are as diverse as monitoring plant health to detecting cracks in bridges. Living Optics aims to empower users across industries to gain new insights from richer, more informative datasets fueled by hyperspectral imaging technology.
Yotta CEO Sunil Gupta on Supercharging India’s Fast-Growing AI Market
India’s AI market is expected to be massive. Yotta Data Services is setting its sights on supercharging it. Sunil Gupta, cofounder, managing director and CEO of Yotta Data Services, details the company’s Shakti Cloud offering, which provides scalable GPU services for enterprises of all sizes. Yotta is the first Indian cloud services provider in the NVIDIA Partner Network, and its Shakti Cloud is India’s fastest AI supercomputing infrastructure, with 16 exaflops of compute capacity supported by over 16,000 NVIDIA H100 GPUs.
Get the AI Podcast through Amazon Music, Apple Podcasts, Google Podcasts, Google Play, Castbox, DoggCatcher, Overcast, PlayerFM, Pocket Casts, Podbay, PodBean, PodCruncher, PodKicker, SoundCloud, Spotify, Stitcher and TuneIn.

NVIDIA’s GeForce RTX 5090 and 5080 GPUs — which are based on the groundbreaking NVIDIA Blackwell architecture —offer up to 8x faster frame rates with NVIDIA DLSS 4 technology, lower latency with NVIDIA Reflex 2 and enhanced graphical fidelity with NVIDIA RTX neural shaders.
These GPUs were built to accelerate the latest generative AI workloads, delivering up to 3,352 AI trillion operations per second (TOPS), enabling incredible experiences for AI enthusiasts, gamers, creators and developers.
To help AI developers and enthusiasts harness these capabilities, NVIDIA at the CES trade show last month unveiled NVIDIA NIM and AI Blueprints for RTX. NVIDIA NIM microservices are prepackaged generative AI models that let developers and enthusiasts easily get started with generative AI, iterate quickly and harness the power of RTX for accelerating AI on Windows PCs. NVIDIA AI Blueprints are reference projects that show developers how to use NIM microservices to build the next generation of AI experiences.
NIM and AI Blueprints are optimized for GeForce RTX 50 Series GPUs. These technologies work together seamlessly to help developers and enthusiasts build, iterate and deliver cutting-edge AI experiences on AI PCs.
While AI model development is rapidly advancing, bringing these innovations to PCs remains a challenge for many people. Models posted on platforms like Hugging Face must be curated, adapted and quantized to run on PC. They also need to be integrated into new AI application programming interfaces (APIs) to ensure compatibility with existing tools, and converted to optimized inference backends for peak performance.
NVIDIA NIM microservices for RTX AI PCs and workstations can ease the complexity of this process by providing access to community-driven and NVIDIA-developed AI models. These microservices are easy to download and connect to via industry-standard APIs and span the key modalities essential for AI PCs. They are also compatible with a wide range of AI tools and offer flexible deployment options, whether on PCs, in data centers, or in the cloud.
NIM microservices include everything needed to run optimized models on PCs with RTX GPUs, including prebuilt engines for specific GPUs, the NVIDIA TensorRT software development kit (SDK), the open-source NVIDIA TensorRT-LLM library for accelerated inference using Tensor Cores, and more.
Microsoft and NVIDIA worked together to enable NIM microservices and AI Blueprints for RTX in Windows Subsystem for Linux (WSL2). With WSL2, the same AI containers that run on data center GPUs can now run efficiently on RTX PCs, making it easier for developers to build, test and deploy AI models across platforms.
In addition, NIM and AI Blueprints harness key innovations of the Blackwell architecture that the GeForce RTX 50 series is built on, including fifth-generation Tensor Cores and support for FP4 precision.
AI calculations are incredibly demanding and require vast amounts of processing power. Whether generating images and videos or understanding language and making real-time decisions, AI models rely on hundreds of trillions of mathematical operations to be completed every second. To keep up, computers need specialized hardware built specifically for AI.

In 2018, NVIDIA GeForce RTX GPUs changed the game by introducing Tensor Cores — dedicated AI processors designed to handle these intensive workloads. Unlike traditional computing cores, Tensor Cores are built to accelerate AI by performing calculations faster and more efficiently. This breakthrough helped bring AI-powered gaming, creative tools and productivity applications into the mainstream.
Blackwell architecture takes AI acceleration to the next level. The fifth-generation Tensor Cores in Blackwell GPUs deliver up to 3,352 AI TOPS to handle even more demanding AI tasks and simultaneously run multiple AI models. This means faster AI-driven experiences, from real-time rendering to intelligent assistants, that pave the way for greater innovation in gaming, content creation and beyond.
Another way to optimize AI performance is through quantization, a technique that reduces model sizes, enabling the models to run faster while reducing the memory requirements.
Enter FP4 — an advanced quantization format that allows AI models to run faster and leaner without compromising output quality. Compared with FP16, it reduces model size by up to 60% and more than doubles performance, with minimal degradation.
For example, Black Forest Labs’ FLUX.1 [dev] model at FP16 requires over 23GB of VRAM, meaning it can only be supported by the GeForce RTX 4090 and professional GPUs. With FP4, FLUX.1 [dev] requires less than 10GB, so it can run locally on more GeForce RTX GPUs.
On a GeForce RTX 4090 with FP16, the FLUX.1 [dev] model can generate images in 15 seconds with just 30 steps. With a GeForce RTX 5090 with FP4, images can be generated in just over five seconds.
FP4 is natively supported by the Blackwell architecture, making it easier than ever to deploy high-performance AI on local PCs. It’s also integrated into NIM microservices, effectively optimizing models that were previously difficult to quantize. By enabling more efficient AI processing, FP4 helps to bring faster, smarter AI experiences for content creation.
NVIDIA AI Blueprints, built on NIM microservices, provide prepackaged, optimized reference implementations that make it easier to develop advanced AI-powered projects — whether for digital humans, podcast generators or application assistants.
At CES, NVIDIA demonstrated PDF to Podcast, a blueprint that allows users to convert a PDF into a fun podcast, and even create a Q&A with the AI podcast host afterwards. This workflow integrates seven different AI models, all working in sync to deliver a dynamic, interactive experience.
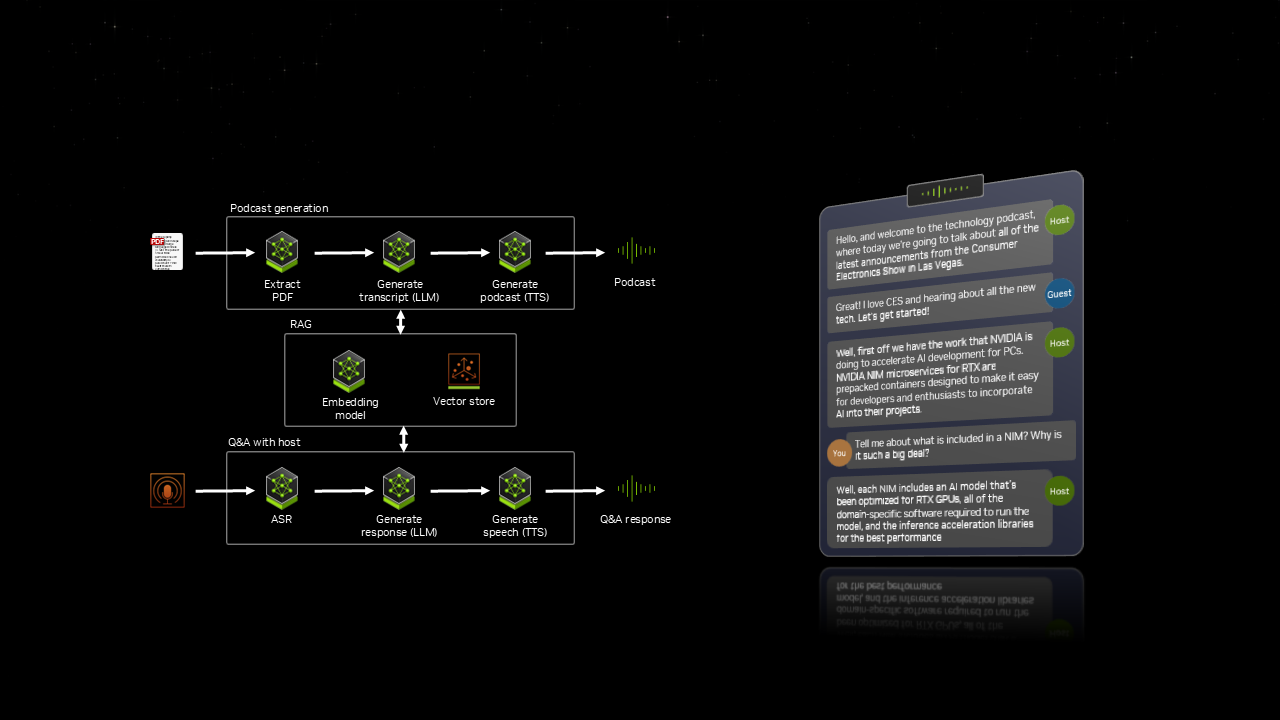
With AI Blueprints, users can quickly go from experimenting with to developing AI on RTX PCs and workstations.
Generative AI is pushing the boundaries of what’s possible across gaming, content creation and more. With NIM microservices and AI Blueprints, the latest AI advancements are no longer limited to the cloud — they’re now optimized for RTX PCs. With RTX GPUs, developers and enthusiasts can experiment, build and deploy AI locally, right from their PCs and workstations.
NIM microservices and AI Blueprints are coming soon, with initial hardware support for GeForce RTX 50 Series, GeForce RTX 4090 and 4080, and NVIDIA RTX 6000 and 5000 professional GPUs. Additional GPUs will be supported in the future.

The financial services industry is reaching an important milestone with AI, as organizations move beyond testing and experimentation to successful AI implementation, driving business results.
NVIDIA’s fifth annual State of AI in Financial Services report shows how financial institutions have consolidated their AI efforts to focus on core applications, signaling a significant increase in AI capability and proficiency.
Companies investing in AI are seeing tangible benefits, including increased revenue and cost savings.
Nearly 70% of respondents report that AI has driven a revenue increase of 5% or more, with a dramatic rise in those seeing a 10-20% revenue boost. In addition, more than 60% of respondents say AI has helped reduce annual costs by 5% or more. Nearly a quarter of respondents are planning to use AI to create new business opportunities and revenue streams.
The top generative AI use cases in terms of return on investment (ROI) are trading and portfolio optimization, which account for 25% of responses, followed by customer experience and engagement at 21%. These figures highlight the practical, measurable benefits of AI as it transforms key business areas and drives financial gains.
Half of management respondents said they’ve deployed their first generative AI service or application, with an additional 28% planning to do so within the next six months. A 50% decline in the number of respondents reporting a lack of AI budget suggests increasing dedication to AI development and resource allocation.
The challenges associated with early AI exploration are also diminishing. The survey revealed fewer companies reporting data issues and privacy concerns, as well as reduced concern over insufficient data for model training. These improvements reflect growing expertise and better data management practices within the industry.
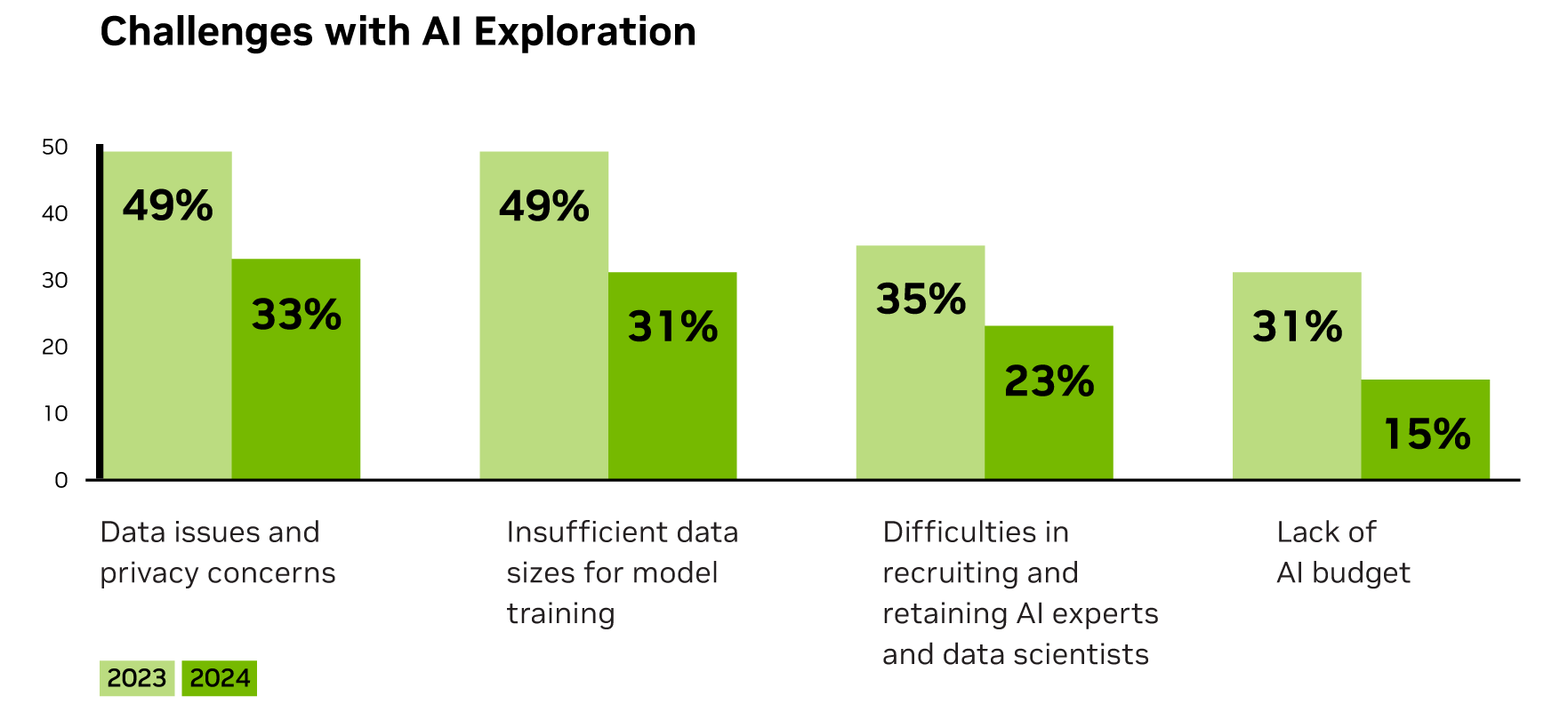
As financial services firms allocate budget and grow more savvy at data management, they can better position themselves to harness AI for enhanced operational efficiency, security and innovation across business functions.
After data analytics, generative AI has emerged as the second-most-used AI workload in the financial services industry. The applications of the technology have expanded significantly, from enhancing customer experience to optimizing trading and portfolio management.
Notably, the use of generative AI for customer experience, particularly via chatbots and virtual assistants, has more than doubled, rising from 25% to 60%. This surge is driven by the increasing availability, cost efficiency and scalability of generative AI technologies for powering more sophisticated and accurate digital assistants that can enhance customer interactions.
More than half of the financial professionals surveyed are now using generative AI to enhance the speed and accuracy of critical tasks like document processing and report generation.
Financial institutions are also poised to benefit from agentic AI — systems that harness vast amounts of data from various sources and use sophisticated reasoning to autonomously solve complex, multistep problems. Banks and asset managers can use agentic AI systems to enhance risk management, automate compliance processes, optimize investment strategies and personalize customer services.
Recognizing the transformative potential of AI, companies are taking proactive steps to build AI factories — specially built accelerated computing platforms equipped with full-stack AI software — through cloud providers or on premises. This strategic focus on implementing high-value AI use cases is crucial to enhancing customer service, boosting revenue and reducing costs.
By tapping into advanced infrastructure and software, companies can streamline the development and deployment of AI models and position themselves to harness the power of agentic AI.
With industry leaders predicting at least 2x ROI on AI investments, financial institutions remain highly motivated to implement their highest-value AI use cases to drive efficiency and innovation.
Download the full report to learn more about how financial services companies are using accelerated computing and AI to transform services and business operations.
Meta: Hongtao Yu, Manman Ren, Bert Maher, Shane Nay
NVIDIA: Gustav Zhu, Shuhao Jiang
Over the past few months, we have been working on enabling advanced GPU features for PyTorch and Triton users through the Triton compiler. One of our key goals has been to introduce warp specialization support on NVIDIA Hopper GPUs. Today, we are thrilled to announce that our efforts have resulted in the rollout of fully automated Triton warp specialization, now available to users in the upcoming release of Triton 3.2, which will ship with PyTorch 2.6. PyTorch users can leverage this feature by implementing user-defined Triton kernels. This work leveraged an initial implementation of warp specialization in Triton by NVIDIA and we look forward to further development with the community in the future.
Warp specialization (WS) is a GPU programming technique where warps (a group of 32 threads on NVIDIA GPUs) within a threadblock are assigned distinct roles or tasks. This approach optimizes performance by enabling efficient execution of workloads that require task differentiation or cooperative processing. It enhances kernel performance by leveraging an asynchronous execution model, where different parts of the kernel are managed by separate hardware units. Data communication between these units, facilitated via shared memory on the NVIDIA H100, is highly efficient. Compared to a uniform warp approach, warp specialization allows the hardware multitasking warp scheduler to operate more effectively, maximizing resource utilization and overall performance.
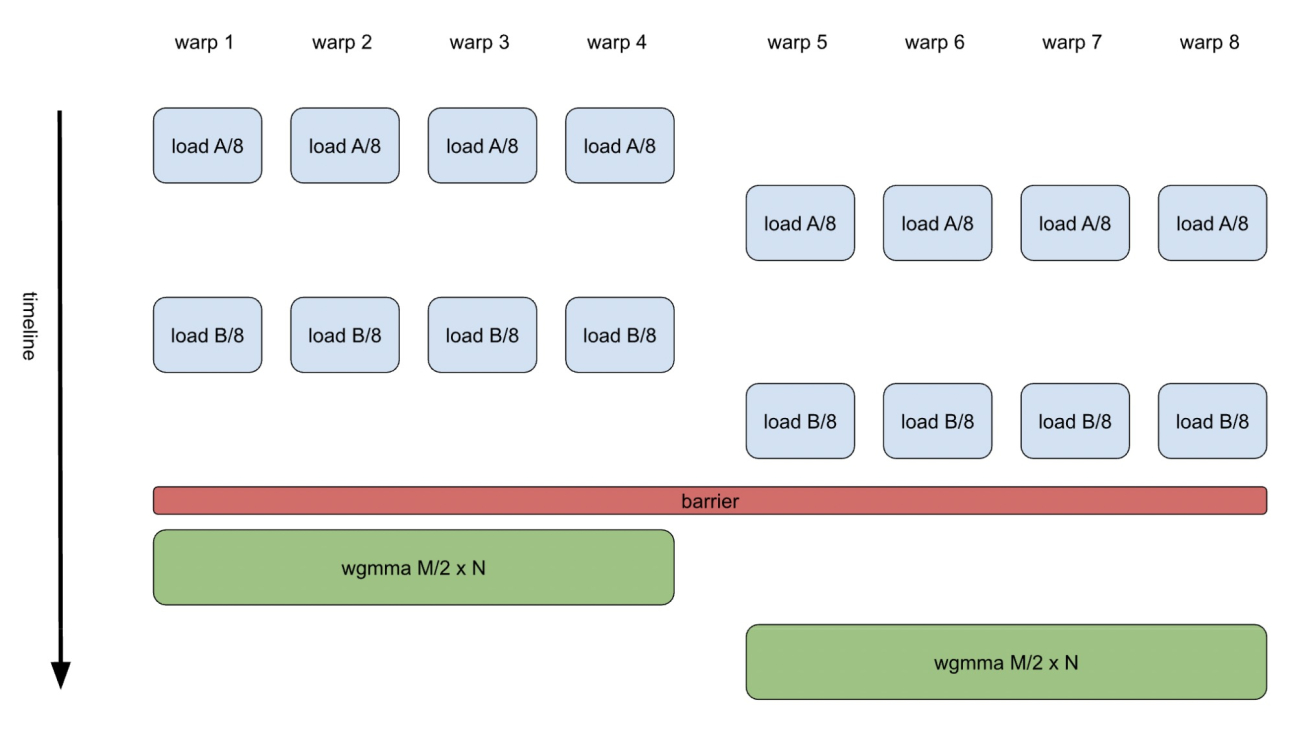
Using GEMM as an example, a typical uniform warp approach on the H100 GPU involves 8 warps per thread block collectively computing a tile of the output tensor. These 8 warps are divided into two warp groups (WG), with each group cooperatively computing half of the tile using efficient warp-group-level MMA (WGMMA) instructions, as illustrated in Figure 1.
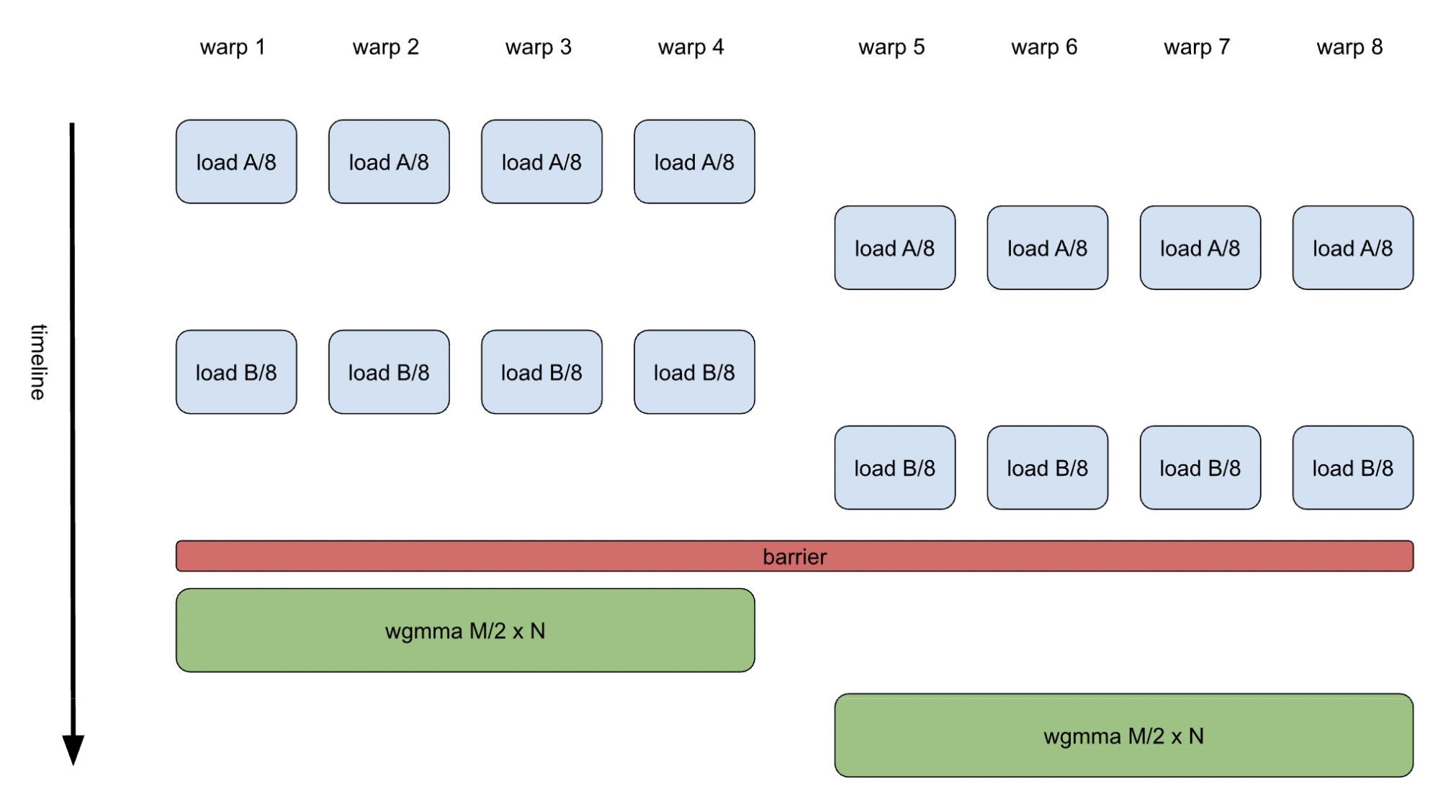
Figure 1. GEMM K-loop Body with Uniform Warps
The implementation is clean, easy to understand, and generally performs well, thanks to an elegant software pipeliner. The pipeliner’s purpose is to enhance instruction-level parallelism by executing non-dependent operations on different hardware units. For instance, load operations from the next loop iteration can be executed simultaneously with WGMMA operations in the current iteration. However, this approach relies heavily on the compiler to craft an instruction sequence that ensures load and WGMMA instructions are issued at precisely the right time. While this is relatively straightforward for GEMM, which involves a limited number of operations, it becomes significantly more challenging for more complex kernels, such as flash attention.
On the other hand, warp specialization addresses programming challenges by separating operations intended to run simultaneously on different hardware units into distinct warps, synchronizing them efficiently using low-cost barriers in shared memory. This allows each warp to have its own instruction sequence, enabling instructions to be issued and executed continuously without being interrupted by other operations, thanks to the multi-way warp scheduler. An illustration of a warp-specialized GEMM can be seen in Figure 2.
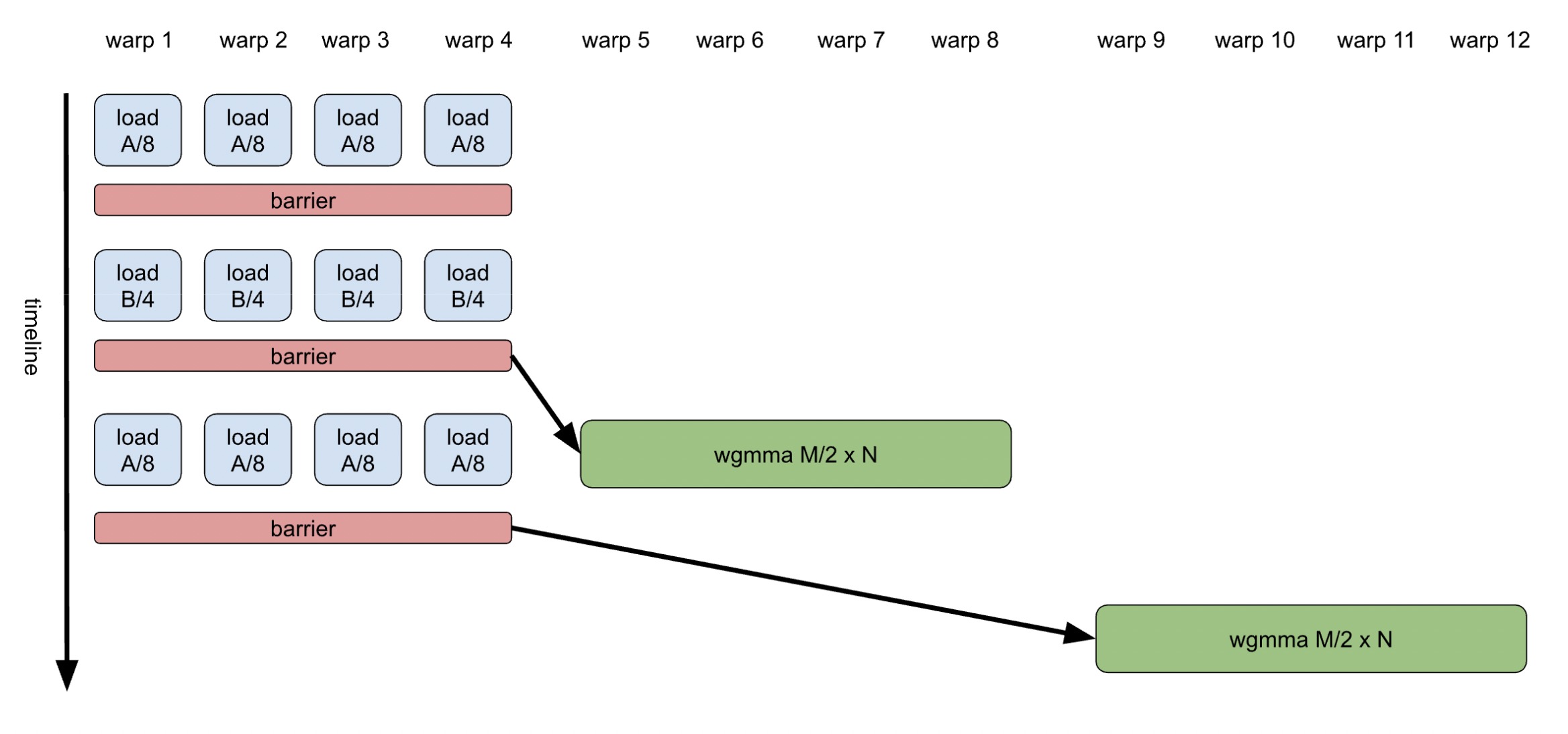
Figure 2. GEMM K-loop Body with Specialized Warps
To enable warp specialization, users simply need to specify two autotune flags: num_consumer_groups and num_buffers_warp_spec. For example, a warp-specialized GEMM implementation might look as shown below. Users can enable warp specialization by setting a non-zero value for num_consumer_groups, which defines the number of consumer warp groups. There is no corresponding flag to set the number of producer warp groups, as currently only one producer is supported. The num_buffers_warp_spec flag specifies the number of buffers the producer warp group will use to communicate with the consumer warp groups. A working example of a warp-specialized kernel is provided in the persistent GEMM tutorial.
@triton.autotune(
configs=[
triton.Config(
{
"BLOCK_SIZE_M": 128,
"BLOCK_SIZE_N": 256,
"BLOCK_SIZE_K": 64,
"GROUP_SIZE_M": 8,
},
num_stages=2,
num_warps=4,
num_consumer_groups=2,
num_buffers_warp_spec=3,
),
],
key=["M", "N", "K"],
)
@triton.jit
def matmul_persistent_ws_kernel(
a_ptr, b_ptr, c_ptr, M, N, K,
stride_am, stride_ak, stride_bk, stride_bn, stride_cm, stride_cn,
BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr, BLOCK_K: tl.constexpr,
):
pid = tl.program_id(axis=0)
num_pid_m = tl.cdiv(M, BLOCK_M)
num_pid_n = tl.cdiv(N, BLOCK_N)
pid_m = pid // num_pid_m
pid_n = pid % num_pid_n
offs_m = pid_m * BLOCK_M + tl.arange(0, BLOCK_M)
offs_n = pid_n * BLOCK_N + tl.arange(0, BLOCK_N)
offs_k = tl.arange(0, BLOCK_K)
a_ptrs = a_ptr + (offs_m[:, None] * stride_am + offs_k[None, :] * stride_ak)
b_ptrs = b_ptr + (offs_k[:, None] * stride_bk + offs_n[None, :] * stride_bn)
acc = tl.zeros((BLOCK_M, BLOCK_N), dtype=tl.float32)
for k in range(0, tl.cdiv(K, BLOCK_K)):
a = tl.load(a_ptrs)
b = tl.load(b_ptrs)
acc += tl.dot(a, b)
a_ptrs += BLOCK_K * stride_ak
b_ptrs += BLOCK_K * stride_bk
c = acc.to(tl.float16)
c_ptrs = c_ptr + stride_cm * offs_m[:, None] + stride_cn * offs_n[None, :]
tl.store(c_ptrs, c)
Warp specialization uses a set of hierarchical compiler transformations and IR changes to translate a user’s non-warp-specialized kernel into warp-specialized machine code. These include:
A along the M dimension, allowing each consumer group to compute half of the output tensor independently. This strategy, known as cooperative partitioning, maximizes efficiency under most conditions. However, if this split leads to inefficiencies—such as producing a workload smaller than the native WGMMA instruction size—the compiler dynamically adjusts and partitions along the N dimension instead.: We introduced four high-level Triton GPU IR (TTGIR) communication operations—ProducerAcquireOp, ProducerCommitOp, ConsumerWaitOp, and ConsumerReleaseOp—to manage pipelined dataflows. These support both TMA and non-TMA memory operations.The warp specialization release introduces a range of Triton compiler transformations that collectively convert user code into warp-specialized kernels. This feature has been applied to several key kernels, including Flash Attention and FP8 row-wise GEMM, resulting in significant performance gains of 10% to 15%. Below, we highlight the latest performance metrics for these high-impact kernels.
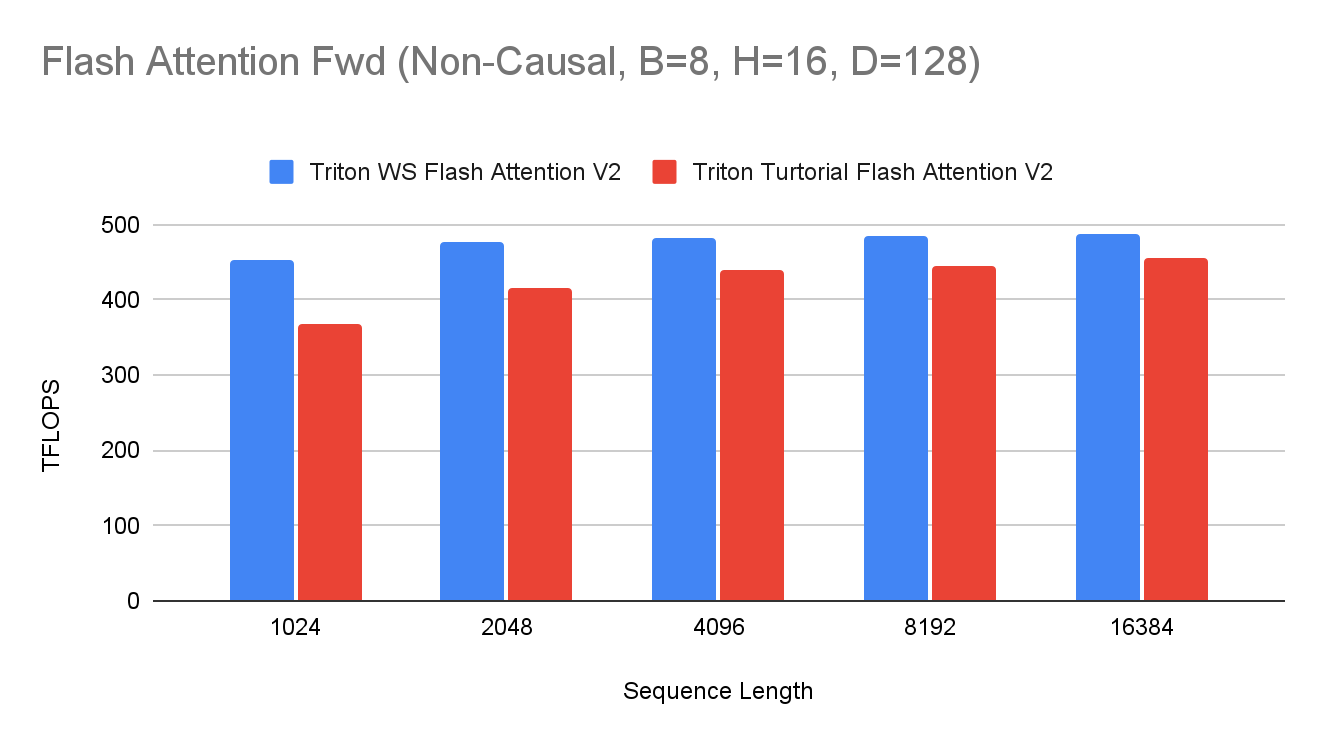
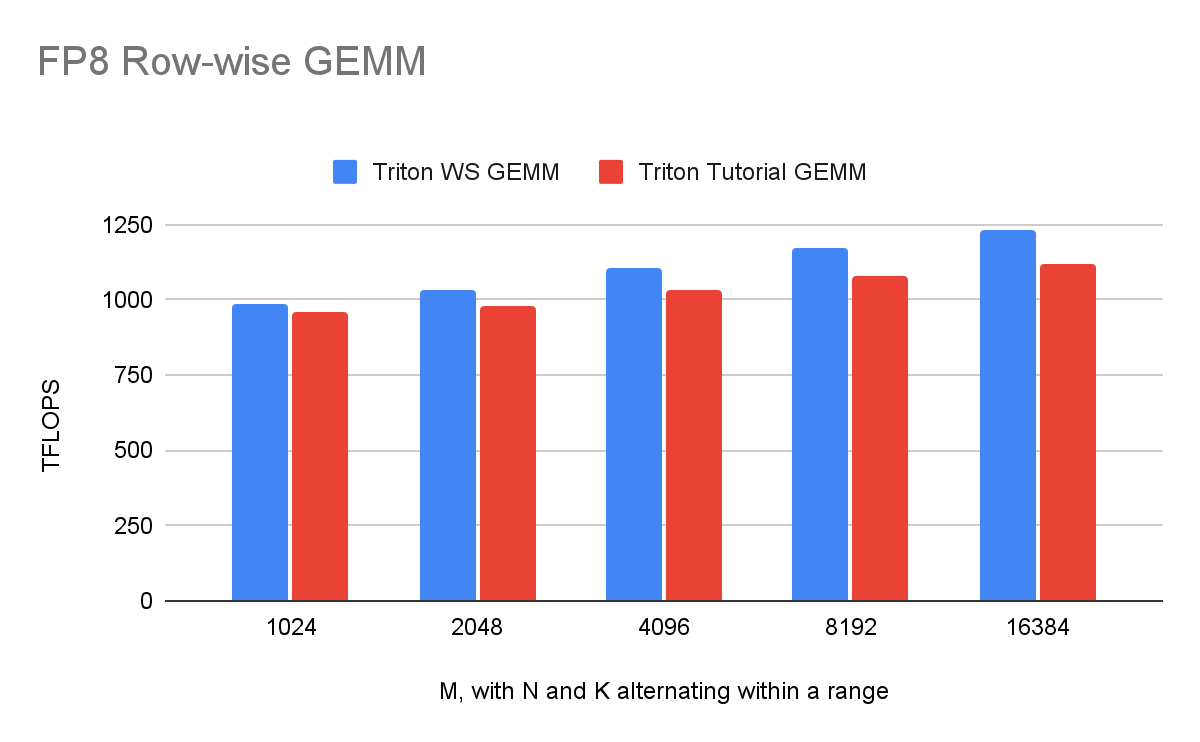
Looking ahead, we plan to further enhance Triton’s warp specialization support by introducing new features such as Ping-Pong scheduling, expanded buffer sharing support, improved transparent handling for TMA, refined partitioning heuristics for upcoming NVIDIA hardware.