Gemini 2.0 Flash-Lite is now generally available in the Gemini API for production use in Google AI Studio and for enterprise customers on Vertex AIRead More
Gemini 2.0 Flash-Lite is now generally available in the Gemini API for production use in Google AI Studio and for enterprise customers on Vertex AIRead More
Gemini 2.0 Flash-Lite is now generally available in the Gemini API for production use in Google AI Studio and for enterprise customers on Vertex AIRead More
Gemini 2.0 Flash-Lite is now generally available in the Gemini API for production use in Google AI Studio and for enterprise customers on Vertex AIRead More
Gemini 2.0 Flash-Lite is now generally available in the Gemini API for production use in Google AI Studio and for enterprise customers on Vertex AIRead More
Gemini 2.0 Flash-Lite is now generally available in the Gemini API for production use in Google AI Studio and for enterprise customers on Vertex AIRead More
Gemini 2.0 Flash-Lite is now generally available in the Gemini API for production use in Google AI Studio and for enterprise customers on Vertex AIRead More

 Technology like AI is changing the ways we prevent, diagnose and treat diseases to make healthcare more accessible and human, putting people at the heart of innovation.T…Read More
Technology like AI is changing the ways we prevent, diagnose and treat diseases to make healthcare more accessible and human, putting people at the heart of innovation.T…Read More
This post is co-written with Xavier Vizcaino, Diego Martín Montoro, and Jordi Sánchez Ferrer from Applus+ Idiada.
In 2021, Applus+ IDIADA, a global partner to the automotive industry with over 30 years of experience supporting customers in product development activities through design, engineering, testing, and homologation services, established the Digital Solutions department. This strategic move aimed to drive innovation by using digital tools and processes. Since then, we have optimized data strategies, developed customized solutions for customers, and prepared for the technological revolution reshaping the industry.
AI now plays a pivotal role in the development and evolution of the automotive sector, in which Applus+ IDIADA operates. Within this landscape, we developed an intelligent chatbot, AIDA (Applus Idiada Digital Assistant)— an Amazon Bedrock powered virtual assistant serving as a versatile companion to IDIADA’s workforce.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
With Amazon Bedrock, AIDA assists with a multitude of tasks, from addressing inquiries to tackling complex technical challenges spanning code, mathematics, and translation. Its capabilities are truly boundless.
With AIDA, we take another step towards our vision of providing global and integrated digital solutions that add value for our customers. Its internal deployment strengthens our leadership in developing data analysis, homologation, and vehicle engineering solutions. Additionally, in the medium term, IDIADA plans to offer AIDA as an integrable product for customers’ environments and develop “light” versions seamlessly integrable into existing systems.
In this post, we showcase the research process undertaken to develop a classifier for human interactions in this AI-based environment using Amazon Bedrock. The objective was to accurately identify the type of interaction received by the intelligent agent to route the request to the appropriate pipeline, providing a more specialized and efficient service.
Built on a flexible and secure architecture, AIDA offers a versatile environment for integrating multiple data sources, including structured data from enterprise databases and unstructured data from internal sources like Amazon Simple Storage Service (Amazon S3). It boasts advanced capabilities like chat with data, advanced Retrieval Augmented Generation (RAG), and agents, enabling complex tasks such as reasoning, code execution, or API calls.
As AIDA’s interactions with humans proliferated, a pressing need emerged to establish a coherent system for categorizing these diverse exchanges.
Initially, users were making simple queries to AIDA, but over time, they started to request more specific and complex tasks. These included document translations, inquiries about IDIADA’s internal services, file uploads, and other specialized requests.
The main reason for this categorization was to develop distinct pipelines that could more effectively address various types of requests. By sorting interactions into categories, AIDA could be optimized to handle specific kinds of tasks more efficiently. This approach allows for tailored responses and processes for different types of user needs, whether it’s a simple question, a document translation, or a complex inquiry about IDIADA’s services.
The primary objective is to offer a more specialized service through the creation of dedicated pipelines for various contexts, such as conversation, document translation, and services to provide more accurate, relevant, and efficient responses to users’ increasingly diverse and specialized requests.
By categorizing the interactions into three main groups—conversation, services, and document translation—the system can better understand the user’s intent and respond accordingly. The Conversation class encompasses general inquiries and exchanges, the Services class covers requests for specific functionalities or support, and the Document_Translation class handles text translation needs.
The specialized pipelines, designed specifically for each use case, allow for a significant increase in efficiency and accuracy of AIDA’s responses. This is achieved in several ways:
The research and development of this large language model (LLM) based classifier is an important step in the continuous improvement of the intelligent agent’s capabilities within the Applus IDIADA environment.
For this occasion, we use a set of 1,668 examples of pre-classified human interactions. These have been divided into 666 for training and 1,002 for testing. A 40/60 split has been applied, giving significant importance to the test set.
The following table shows some examples.
| SAMPLE | CLASS |
| Can you make a summary of this text? “Legislation for the Australian Government’s …” | Conversation |
| No, only focus on this sentence : Braking technique to enable maximum brake application speed | Conversation |
| In a factory give me synonyms of a limiting resource of activities | Conversation |
| We need a translation of the file “Company_Bylaws.pdf” into English, could you handle it? | Document_Translation |
| Please translate the file “Product_Manual.xlsx” into English | Document_Translation |
| Could you convert the document “Data_Privacy_Policy.doc’ into English, please? | Document_Translation |
| Register my username in the IDIADA’s human resources database | Services |
| Send a mail to random_user@mail.com to schedule a meeting for the next weekend | Services |
| Book an electric car charger for me at IDIADA | Services |
We present three different classification approaches: two based on LLMs and one using a classic machine learning (ML) algorithm. The aim is to understand which approach is most suitable for addressing the presented challenge.
In this case, we developed an LLM-based classifier to categorize inputs into three classes: Conversation, Services, and Document_Translation. Instead of relying on predefined, rigid definitions, our approach follows the principle of understanding a set. This principle involves analyzing the common characteristics and patterns present in the examples or instances that belong to each class. By studying the shared traits of inputs within a class, we can derive an understanding of the class itself, without being constrained by preconceived notions.
It’s important to note that the learned definitions might differ from common expectations. For instance, the Conversation class encompasses not only typical conversational exchanges but also tasks like text summarization, which share similar linguistic and contextual traits with conversational inputs.
By following this data-driven approach, the classifier can accurately categorize new inputs based on their similarity to the learned characteristics of each class, capturing the nuances and diversity within each category.
The code consists of the following key components: libraries, a prompt, model invocation, and an output parser.
The programming language used in this code is Python, complemented by the LangChain module, which is specifically designed to facilitate the integration and use of LLMs. This module provides a comprehensive set of tools and abstractions that streamline the process of incorporating and deploying these advanced AI models.
To take advantage of the power of these language models, we use Amazon Bedrock. The integration with Amazon Bedrock is achieved through the Boto3 Python module, which serves as an interface to the AWS, enabling seamless interaction with Amazon Bedrock and the deployment of the classification model.
The task is to assign one of three classes (Conversation, Services, or Document_Translation) to a given sentence, represented by question:
Conversation class, these requests don’t involve summarization. Additionally, the name of the document to be translated and the target language are specified.The prompt suggests a hierarchical approach to the classification process. First, the sentence should be evaluated to determine if it can be classified as a conversation. If the sentence doesn’t fit the Conversation class, one of the other two classes (Services or Document_Translation) should be assigned.
The priority for the Conversation class stems from the fact that 99% of the interactions are actually simple questions regarding various matters.
We use Anthropic’s Claude 3 Sonnet model for the natural language processing task. This LLM model has a context window of 200,000 tokens, enabling it to manage different languages and retrieve highly accurate answers. We use two key parameters:
Another important component is the output parser, which allows us to gather the desired information in JSON format. To achieve this, we use the LangChain parameter output_parsers.
The following code illustrates a simple prompt approach:
We use RAG techniques to enhance the model’s response capabilities. Instead of relying solely on compressed definitions, we provide the model with a quasi-definition by extension. Specifically, we present the model with a diverse set of examples for each class, allowing it to learn the inherent characteristics and patterns that define each category. For instance, in addition to a concise definition of the Conversation class, the model is exposed to various conversational inputs, enabling it to identify common traits such as informal language, open-ended questions, and back-and-forth exchanges. This example-driven approach complements the initial descriptions provided, allowing the model to capture the nuances and diversity within each class. By combining concise definitions with representative examples, the RAG technique helps the model develop a more comprehensive understanding of the classes, enhancing its ability to accurately categorize new inputs based on their inherent nature and characteristics.
The following code provides examples in JSON format for RAG:
The total number of examples provided for each class is as follows:
One of the key challenges with this approach is scalability. Although the model’s performance improves with more training examples, the computational demands quickly become overwhelming for our current infrastructure. The sheer volume of data required can lead to quota issues with Amazon Bedrock and unacceptably long response times. Rapid response times are essential for providing a satisfactory user experience, and this approach falls short in that regard.
In this case, we need to modify the code to embed all the examples. The following code shows the changes applied to the first version of the classifier. The prompt is modified to include all the examples in JSON format under the “Here you have some examples” section.
In this case, we take a different approach by recognizing that despite the multitude of possible interactions, they often share similarities and repetitive patterns. Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearest neighbors (k-NN) to assign a class based on the most similar examples surrounding the input. To make this work, we need to transform the textual interactions into a format that allows algebraic operations. This is where embeddings come into play. Embeddings are vector representations of text that capture semantic and contextual information. We can calculate the semantic similarity between different interactions by converting text into these vector representations and comparing their vectors and determining their proximity in the embedding space.
To accommodate this approach, we need to modify the code accordingly:
We used the Amazon Titan Text Embeddings G1 model, which generates vectors of 1,536 dimensions. This model is trained to accept multiple languages while retaining the semantic meaning of the embedded phrases.
For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module. This method takes a parameter, which we set to 3.
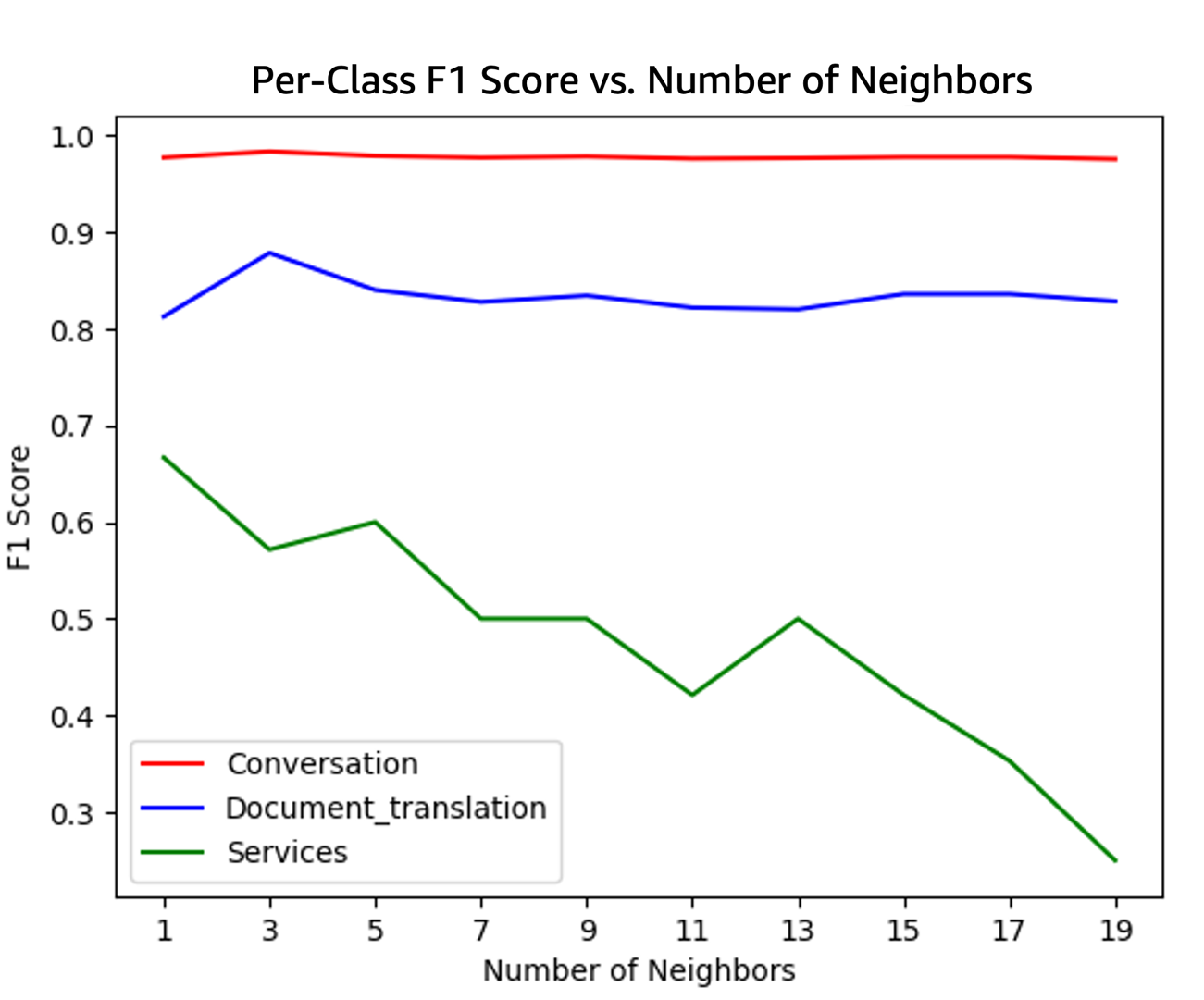
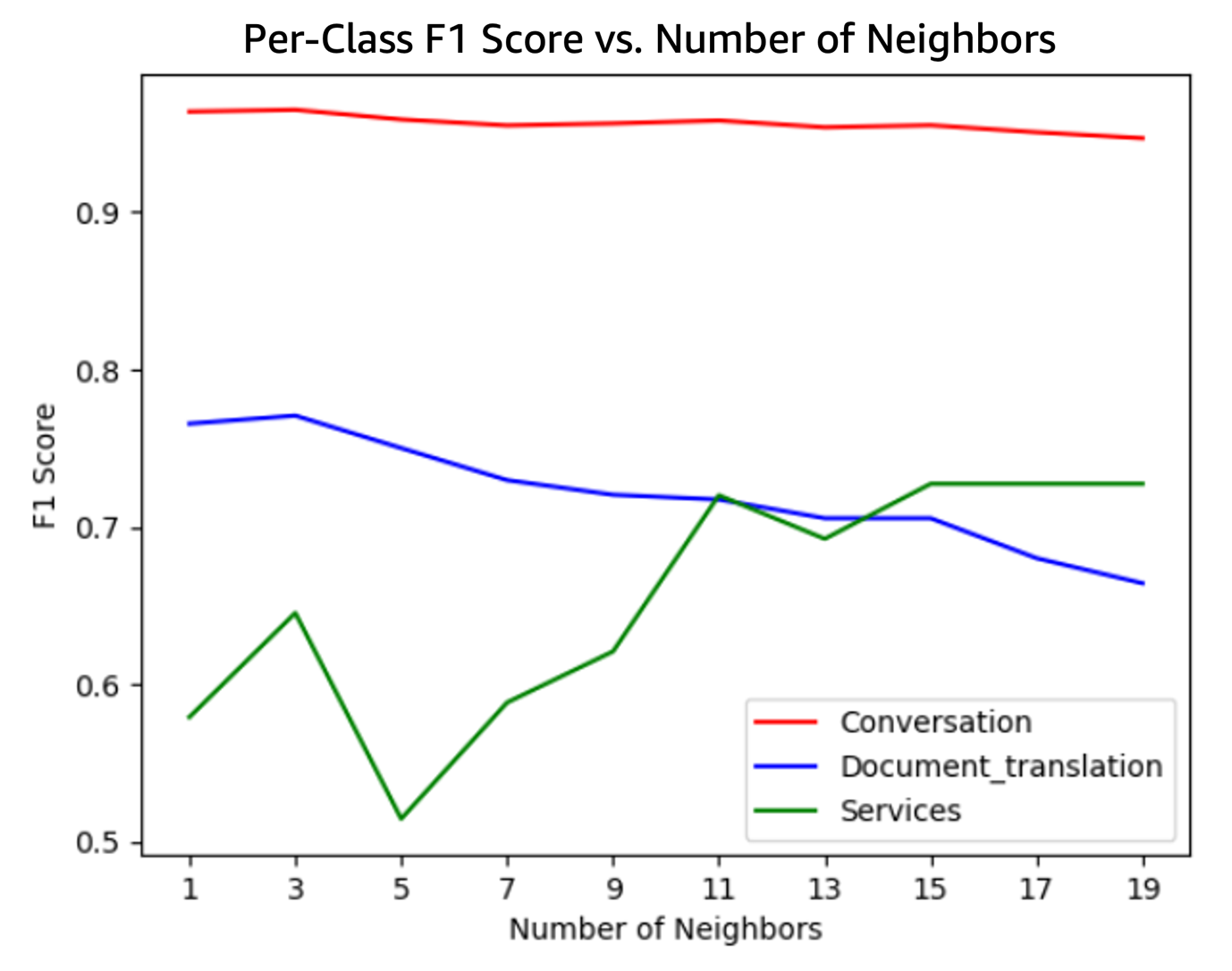
The following figure illustrates the F1 scores for each class plotted against the number of neighbors (k) used in the k-NN algorithm. As the graph shows, the optimal value for k is 3, which yields the highest F1 score for the most prevalent class, Document_Translation. Although it’s not the absolute highest score for the Services class, Document_Translation is significantly more common, making k=3 the best overall choice to maximize performance across all classes.
In the previous section, we used the popular Amazon Titan Text Embeddings G1 model to generate text embeddings. However, other models might offer different advantages. In this section, we explore the use of Cohere’s multilingual model on Amazon Bedrock for generating embeddings. We chose the Cohere model due to its excellent capability in handling multiple languages without compromising the vectorization of phrases. As we will demonstrate, this model doesn’t introduce significant differences in the generated vectors compared to other models, making it more suitable for use in a multilingual environment like AIDA.
To use the Cohere model, we need to change the model_id:
We use Cohere’s multilingual embeddings model to generate vectors with 1,024 dimensions. This model is trained to accept multiple languages and retain the semantic meaning of the embedded phrases.
For the classifier, we employ k-NN, using the scikit-learn Python module. This method takes a parameter, which we have set to 11.
The following figure illustrates the F1 scores for each class plotted against the number of neighbors used. As depicted, the optimal point is k=11, achieving the highest value for Document_Translation and the second-highest for Services. In this instance, the trade-off between Documents_Translation and Services is favorable.
In this section, we delve deeper into the embeddings generated by both models, aiming to understand their nature and consequently comprehend the results obtained. To achieve this, we have performed dimensionality reduction to visualize the vectors obtained in both cases in 2D.
Cohere’s multilingual embeddings model has a limitation on the size of the text it can vectorize, posing a significant constraint. Therefore, in the implementation showcased in the previous section, we applied a filter to only include interactions up to 1,500 characters (excluding cases that exceed this limit).
The following figure illustrates the vector spaces generated in each case.
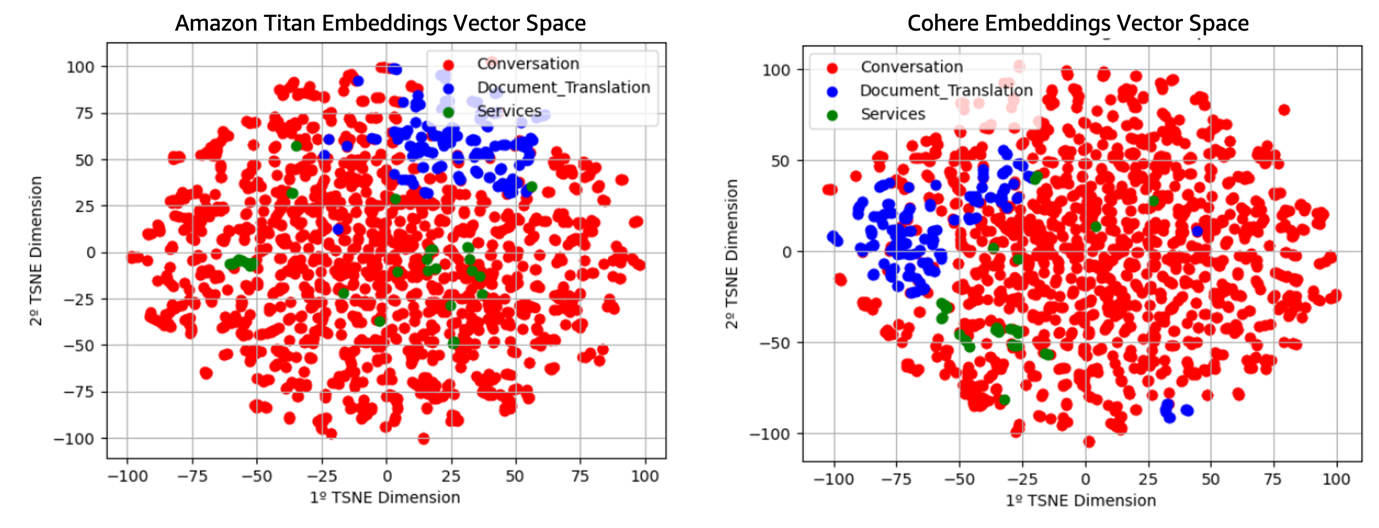
As we can observe, the generated vector spaces are relatively similar, initially appearing to be analogous spaces with a rotation between one another. However, upon closer inspection, it becomes evident that the direction of maximum variance in the case of Cohere’s multilingual embeddings model is distinct (deducible from observing the relative position and shape of the different groups). This type of situation, where high class overlap is observed, presents an ideal case for applying algorithms such as k-NN.
As mentioned in the introduction, most human interactions with AI are very similar to each other within the same class. This would explain why k-NN-based models outperform LLM-based models.
In this scenario, it is likely that user interactions belonging to the three main categories (Conversation, Services, and Document_Translation) form distinct clusters or groups within the embedding space. Each category possesses particular linguistic and semantic characteristics that would be reflected in the geometric structure of the embedding vectors. The previous visualization of the embeddings space displayed only a 2D transformation of this space. This doesn’t imply that clusters coudn’t be highly separable in higher dimensions.
Classification algorithms like support vector machines (SVMs) are especially well-suited to use this implicit geometry of the data. SVMs seek to find the optimal hyperplane that separates the different groups or classes in the embedding space, maximizing the margin between them. This ability of SVMs to use the underlying geometric structure of the data makes them an intriguing option for this user interaction classification problem.
Furthermore, SVMs are a robust and efficient algorithm that can effectively handle high-dimensional datasets, such as text embeddings. This makes them particularly suitable for this scenario, where the embedding vectors of the user interactions are expected to have a high dimensionality.
The following code illustrates the implementation:
We use Amazon Titan Text Embeddings G1. This model generates vectors of 1,536 dimensions, and is trained to accept several languages and to retain the semantic meaning of the phrases embedded.
To implement the classifier, we employed a classic ML algorithm, SVM, using the scikit-learn Python module. The SVM algorithm requires the tuning of several parameters to achieve optimal performance. To determine the best parameter values, we conducted a grid search with 10-fold cross-validation, using the F1 multi-class score as the evaluation metric. This systematic approach allowed us to identify the following set of parameters that yielded the highest performance for our classifier:
None. This parameter adjusts the weights of each class during the training process. Setting class_weight to balanced automatically adjusts the weights inversely proportional to the class frequencies in the input data. This is particularly useful when dealing with imbalanced datasets, where one class is significantly more prevalent than the others. In our case, the value of None for the class_weight parameter suggests that the minor classes don’t have much relevance or impact on the overall classification task. This choice implies that the implicit geometry or decision boundaries learned by the model might not be optimized for separating the different classes effectively.linear. This parameter specifies the type of kernel function to be used by the SVC algorithm. The linear kernel is a simple and efficient choice because it assumes that the decision boundary between classes can be represented by a linear hyperplane in the feature space. This value suggests that, in a higher dimension vector space, the categories could be linearly separated by an hyperplane.The implementation details of the classifier are presented in the following code:
We use the Amazon Titan Text Embeddings G1 model, which generates vectors of 1,536 dimensions. This model is trained to accept multiple languages and retain the semantic meaning of the embedded phrases.
For the classifier, we employ SVM, using the scikit-learn Python module. To obtain the optimal parameters, we performed a grid search with 10-fold cross-validation based on the multi-class F1 score, resulting in the following selected parameters (as detailed in the previous section):
None. A value of None suggests that the minor classes don’t have much relevance, which in turn implies that the implicit geometry might not be suitable for separating the different classes.linear. This value suggests that in a higher-dimensional vector space, the categories could be linearly separated by a hyperplane.Given the promising results obtained with SVMs, we decided to explore another geometry-based method by employing an Artificial Neural Network (ANN) approach.
In this case, we performed normalization of the input vectors to use the advantages of normalization when using neural networks. Normalizing the input data is a crucial step when working with ANNs, because it can help improve the model’s during training. We applied min/max scaling for normalization.
The use of an ANN-based approach provides the ability to capture complex non-linear relationships in the data, which might not be easily modeled using traditional linear methods like SVMs. The combination of the geometric insights and the normalization of inputs can potentially lead to improved predictive accuracy compared to the previous SVM results.
This approach consists of the following parameters:
categorical_crossentropy loss function, the Adam optimizer with a learning rate of 0.01, and the categorical_accuracy. We incorporate an EarlyStopping callback to stop the training if the categorical_accuracy metric doesn’t improve for 25 epochs.categorical_accuracy) obtained during the training.We applied the same methodology, but using the embeddings generated by Cohere’s multilingual embeddings model after being normalized through min/max scaling. In both cases, we employed the same preprocessing steps:
To help avoid ordinal assumptions, we employed a one-hot encoding representation for the output of the network. One-hot encoding doesn’t make any assumptions about the inherent order or hierarchy among the categories. This is particularly useful when the categorical variable doesn’t have a clear ordinal relationship, because the model can learn the relationships without being biased by any assumed ordering.
The following code illustrates the implementation:
We conducted a comparative analysis using the previously presented code and data. The models were assessed based on their F1 scores for the conversation, services, and document translation tasks, as well as their runtimes. The following table summarizes our results.
| MODEL | CONVERSATION F1 | SERVICES F1 | DOCUMENT_ TRANSLATION F1 | RUNTIME (Seconds) |
| LLM | 0.81 | 0.22 | 0.46 | 1.2 |
| LLM with examples | 0.86 | 0.13 | 0.68 | 18 |
| KNN – Amazon Titan Embedding | 0.98 | 0.57 | 0.88 | 0.35 |
| KNN – Cohere Embedding | 0.96 | 0.72 | 0.72 | 0.35 |
| SVM Amazon Titan Embedding | 0.98 | 0.69 | 0.82 | 0.3 |
| SVM Cohere Embedding | 0.99 | 0.80 | 0.93 | 0.3 |
| ANN Amazon Titan Embedding | 0.98 | 0.60 | 0.87 | 0.15 |
| ANN Cohere Embedding | 0.99 | 0.77 | 0.96 | 0.15 |
As illustrated in the table, the SVM and ANN models using Cohere’s multilingual embeddings model demonstrated the strongest overall performance. The SVM with Cohere’s multilingual embeddings model achieved the highest F1 scores in two out of three tasks, reaching 0.99 for Conversation, 0.80 for Services, and 0.93 for Document_Translation. Similarly, the ANN with Cohere’s multilingual embeddings model also performed exceptionally well, with F1 scores of 0.99, 0.77, and 0.96 for the respective tasks.
In contrast, the LLM exhibited relatively lower F1 scores, particularly for the services (0.22) and document translation (0.46) tasks. However, the performance of the LLM improved when provided with examples, with the F1 score for document translation increasing from 0.46 to 0.68.
Regarding runtime, the k-NN, SVM, and ANN models demonstrated significantly faster inference times compared to the LLM. The k-NN and SVM models with both Amazon Titan and Cohere’s multilingual embeddings model had runtimes of approximately 0.3–0.35 seconds. The ANN models were even faster, with runtimes of approximately 0.15 seconds. In contrast, the LLM required approximately 1.2 seconds for inference, and the LLM with examples took around 18 seconds.
These results suggest that the SVM and ANN models using Cohere’s multilingual embeddings model offer the best balance of performance and efficiency for the given tasks. The superior F1 scores of these models, coupled with their faster runtimes, make them promising candidates for application. The potential benefits of providing examples to the LLM model are also noteworthy, because this approach can help improve its performance on specific tasks.
The optimization of AIDA, Applus IDIADA’s intelligent chatbot powered by Amazon Bedrock, has been a resounding success. By developing dedicated pipelines to handle different types of user interactions—from general conversations to specialized service requests and document translations—AIDA has significantly improved its efficiency, accuracy, and overall user experience. The innovative use of LLMs, embeddings, and advanced classification algorithms has allowed AIDA to adapt to the evolving needs of IDIADA’s workforce, providing a versatile and reliable virtual assistant. AIDA now handles over 1,000 interactions per day, with a 95% accuracy rate in routing requests to the appropriate pipeline and driving a 20% increase in their team’s productivity.
Looking ahead, IDIADA plans to offer AIDA as an integrated product for customer environments, further expanding the reach and impact of this transformative technology.
Amazon Bedrock offers a comprehensive approach to security, compliance, and responsible AI development that empowers IDIADA and other customers to harness the full potential of generative AI without compromising on safety and trust. As this advanced technology continues to rapidly evolve, Amazon Bedrock provides the transparent framework needed to build innovative applications that inspire confidence.
Unlock new growth opportunities by creating custom, secure AI models tailored to your organization’s unique needs. Take the first step in your generative AI transformation—connect with an AWS expert today to begin your journey.
 Xavier Vizcaino is the head of the DataLab, in the Digital Solutions department of Applus IDIADA. DataLab is the unit focused on the development of solutions for generating value from the exploitation of data through artificial intelligence.
Xavier Vizcaino is the head of the DataLab, in the Digital Solutions department of Applus IDIADA. DataLab is the unit focused on the development of solutions for generating value from the exploitation of data through artificial intelligence.
 Diego Martín Montoro is an AI Expert and Machine Learning Engineer at Applus+ Idiada Datalab. With a Computer Science degree and a Master’s in Data Science, Diego has built his career in the field of artificial intelligence and machine learning. His experience includes roles as a Machine Learning Engineer at companies like AppliedIT and Applus+ IDIADA, where he has worked on developing advanced AI systems and anomaly detection solutions.
Diego Martín Montoro is an AI Expert and Machine Learning Engineer at Applus+ Idiada Datalab. With a Computer Science degree and a Master’s in Data Science, Diego has built his career in the field of artificial intelligence and machine learning. His experience includes roles as a Machine Learning Engineer at companies like AppliedIT and Applus+ IDIADA, where he has worked on developing advanced AI systems and anomaly detection solutions.
 Jordi Sánchez Ferrer is the current Product Owner of the Datalab at Applus+ Idiada. A Computer Engineer with a Master’s degree in Data Science, Jordi’s trajectory includes roles as a Business Intelligence developer, Machine Learning engineer, and lead developer in Datalab. In his current role, Jordi combines his technical expertise with product management skills, leading strategic initiatives that align data science and AI projects with business objectives at Applus+ Idiada.
Jordi Sánchez Ferrer is the current Product Owner of the Datalab at Applus+ Idiada. A Computer Engineer with a Master’s degree in Data Science, Jordi’s trajectory includes roles as a Business Intelligence developer, Machine Learning engineer, and lead developer in Datalab. In his current role, Jordi combines his technical expertise with product management skills, leading strategic initiatives that align data science and AI projects with business objectives at Applus+ Idiada.
 Daniel Colls is a professional with more than 25 years of experience who has lived through the digital transformation and the transition from the on-premises model to the cloud from different perspectives in the IT sector. For the past 3 years, as a Solutions Architect at AWS, he has made this experience available to his customers, helping them successfully implement or move their workloads to the cloud.
Daniel Colls is a professional with more than 25 years of experience who has lived through the digital transformation and the transition from the on-premises model to the cloud from different perspectives in the IT sector. For the past 3 years, as a Solutions Architect at AWS, he has made this experience available to his customers, helping them successfully implement or move their workloads to the cloud.
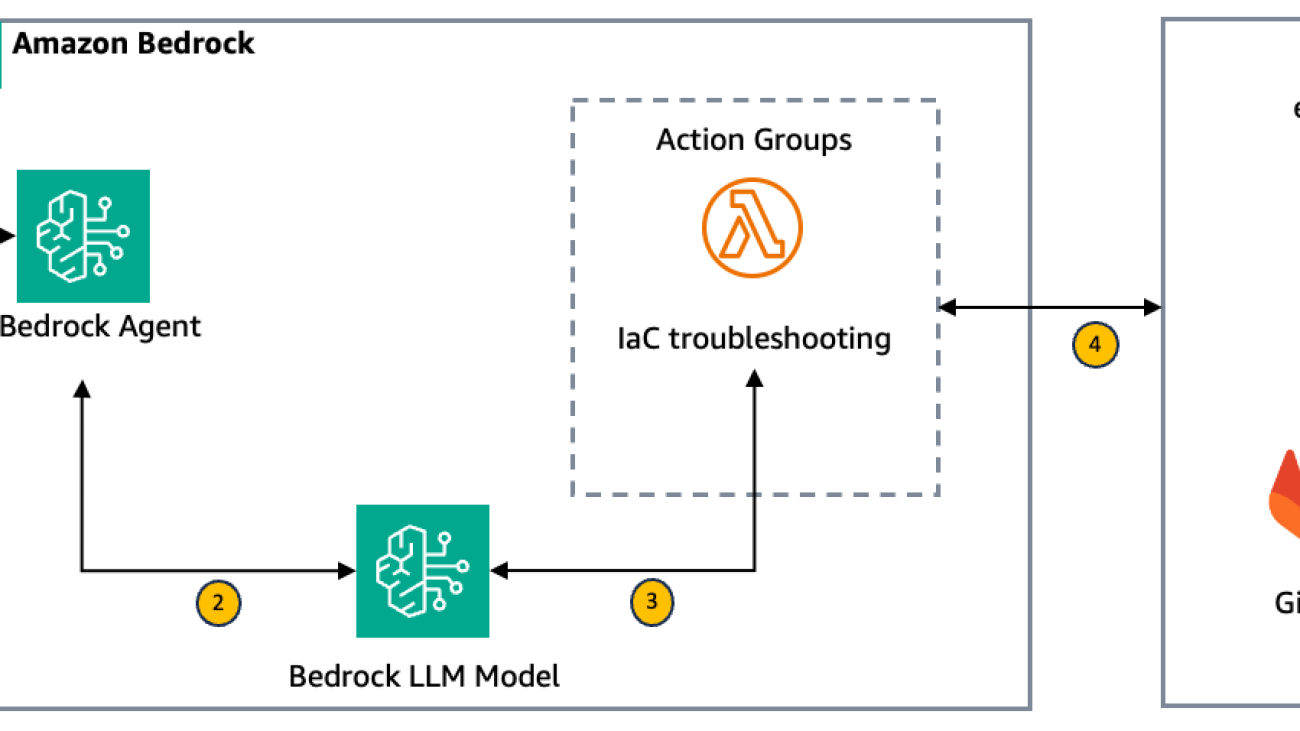
Troubleshooting infrastructure as code (IaC) errors often consumes valuable time and resources. Developers can spend multiple cycles searching for solutions across forums, troubleshooting repetitive issues, or trying to identify the root cause. These delays can lead to missed security errors or compliance violations, especially in complex, multi-account environments.
This post demonstrates how you can use Amazon Bedrock Agents to create an intelligent solution to streamline the resolution of Terraform and AWS CloudFormation code issues through context-aware troubleshooting. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Amazon Bedrock Agents is a fully managed service that helps developers create AI agents that can break down complex tasks into steps and execute them using FMs and APIs to accomplish specific business objectives.
Our solution uses Amazon Bedrock Agents to analyze error messages and code context, generating detailed troubleshooting steps for IaC errors. In organizations with multi-account AWS environments, teams often maintain a centralized AWS environment for developers to deploy applications. This setup makes sure that AWS infrastructure deployments using IaC align with organizational security and compliance measures. For specific IaC errors related to these compliance measures, such as those involving service control policies (SCPs) or resource-based policies, our solution intelligently directs developers to contact appropriate teams like Security or Enablement. This targeted guidance maintains security protocols and makes sure that sensitive issues are handled by the right experts. The solution is flexible and can be adapted for similar use cases beyond these examples.
Although we focus on Terraform Cloud workspaces in this example, the same principles apply to GitLab CI/CD pipelines or other continuous integration and delivery (CI/CD) approaches executing IaC code. By automating initial error analysis and providing targeted solutions or guidance, you can improve operational efficiency and focus on solving complex infrastructure challenges within your organization’s compliance framework.
Before we dive into the deployment process, let’s walk through the key steps of the architecture as illustrated in the following figure.

The workflow for the Terraform solution is as follows:
The following diagram illustrates the step-by-step process of how the solution works.

This solution streamlines the process of resolving Terraform errors, providing immediate, context-aware guidance to developers while making sure that sensitive or complex issues are directed to the appropriate teams. By using the capabilities of Amazon Bedrock Agents, it offers a scalable and intelligent approach to managing IaC challenges in large, multi-account AWS environments.
To implement the solution, you need the following:
To create and configure the Amazon Bedrock agent, complete the following steps:
“You are a terraform code error specialist. Greet the user and ask for terraform workspace url, branch name, code repository url. Once received, trigger troubleshooting action group. Provide the troubleshooting steps to the user.”
After you configure the initial agent and add the preceding instruction to the agent, you need to create two Lambda functions:
After the Terraform workspace error and code details are retrieved, these details will be passed back to the first Lambda function, which will use the Amazon Bedrock API with an FM to generate and provide the appropriate troubleshooting steps based on the error and code information.
Complete the following steps to add the action group to the Amazon Bedrock agent:
For more details, see Define function details for your agent’s action groups in Amazon Bedrock.
This function runs the business logic required when an action is invoked. Make sure to choose the correct version of the first Lambda function. For more details on how to configure Lambda functions for action groups, see Configure Lambda functions to send information that an Amazon Bedrock agent elicits from the user.
|
Name |
Description | Type | Required |
| workspace_url |
Terraform workspace url |
string |
True |
| repo_url |
Code repository URL |
string |
True |
| branch_name | Code repository branch name | string |
True |
The following example is of a Terraform error due to a service control polcy. The troubleshooting steps provided would be aligned to address those specific constraints. The action group triggers the Lambda function, which follows structured single-shot prompting by passing the complete context—such as the error message and repository contents—in a single input to the Amazon Bedrock model to generate precise troubleshooting steps.
Example 1: The following screenshot shows an example of a Terraform error caused by an SCP limitation managed by the security team.

The following screenshot shows an example of the user interaction with Amazon Bedrock Agents and the troubleshooting steps provided.

Example 2: The following screenshot shows an example of a Terraform error due to a missing variable value.

The following screenshot shows an example of the user interaction with Amazon Bedrock Agents and the troubleshooting steps provided.

The services used in this demo can incur costs. Complete the following steps to clean up your resources:
IaC offers flexibility for managing cloud environments, but troubleshooting code errors can be time-consuming, especially in environments with strict organizational guardrails. This post demonstrated how Amazon Bedrock Agents, combined with action groups and generative AI models, streamlines and accelerates the resolution of Terraform errors while maintaining compliance with environment security and operational guidelines.
Using the capabilities of Amazon Bedrock Agents, developers can receive context-aware troubleshooting steps tailored to environment-related issues such as SCP or IAM violations, VPC restrictions, and encryption policies. The solution provides specific guidance based on the error’s context and directs users to the appropriate teams for issues that require further escalation. This reduces the time spent on IaC errors, improves developer productivity, and maintains organizational compliance.
Are you ready to streamline your cloud deployment process with the generative AI of Amazon Bedrock? Start by exploring the Amazon Bedrock User Guide to see how it can facilitate your organization’s transition to the cloud. For specialized assistance, consider engaging with AWS Professional Services to maximize the efficiency and benefits of using Amazon Bedrock.
 Akhil Raj Yallamelli is a Cloud Infrastructure Architect at AWS, specializing in architecting cloud infrastructure solutions for enhanced data security and cost efficiency. He is experienced in integrating technical solutions with business strategies to create scalable, reliable, and secure cloud environments. Akhil enjoys developing solutions focusing on customer business outcomes, incorporating generative AI (Gen AI) technologies to drive innovation and cloud enablement. He holds an MS degree in Computer Science. Outside of his professional work, Akhil enjoys watching and playing sports.
Akhil Raj Yallamelli is a Cloud Infrastructure Architect at AWS, specializing in architecting cloud infrastructure solutions for enhanced data security and cost efficiency. He is experienced in integrating technical solutions with business strategies to create scalable, reliable, and secure cloud environments. Akhil enjoys developing solutions focusing on customer business outcomes, incorporating generative AI (Gen AI) technologies to drive innovation and cloud enablement. He holds an MS degree in Computer Science. Outside of his professional work, Akhil enjoys watching and playing sports.
 Ebbey Thomas is a Senior Generative AI Specialist Solutions Architect at AWS. He designs and implements generative AI solutions that address specific customer business problems. He is recognized for simplifying complexity and delivering measurable business outcomes for clients. Ebbey holds a BS in Computer Engineering and an MS in Information Systems from Syracuse University.
Ebbey Thomas is a Senior Generative AI Specialist Solutions Architect at AWS. He designs and implements generative AI solutions that address specific customer business problems. He is recognized for simplifying complexity and delivering measurable business outcomes for clients. Ebbey holds a BS in Computer Engineering and an MS in Information Systems from Syracuse University.
This blog post is co-written with Gene Arnold from Alation.
To build a generative AI-based conversational application integrated with relevant data sources, an enterprise needs to invest time, money, and people. First, you would need build connectors to the data sources. Next you need to index this data to make it available for a Retrieval Augmented Generation (RAG) approach where relevant passages are delivered with high accuracy to a large language model (LLM). To do this, you need to select an index that provides the capabilities to index the content for semantic and vector search, build the infrastructure to retrieve data, rank the answers, and build a feature rich web application. Additionally, you might need to hire and staff a large team to build, maintain, and manage such a system.
Amazon Q Business is a fully managed generative AI-powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. Amazon Q Business can help you get fast, relevant answers to pressing questions, solve problems, generate content, and take actions using the data and expertise found in your company’s information repositories, code, and enterprise systems. To do this Amazon Q Business provides out-of-the-box native data source connectors that can index content into a built-in retriever and uses an LLM to provide accurate, well written answers. A data source connector is a component of Amazon Q Business that helps to integrate and synchronize data from multiple repositories into one index. Amazon Q Business offers multiple prebuilt connectors to a large number of data sources, including ServiceNow, Atlassian Confluence, Amazon Simple Storage Service (Amazon S3), Microsoft SharePoint, Salesforce, and many more. For a full list of supported data source connectors, see Amazon Q Business connectors.
However, many organizations store relevant information in the form of unstructured data on company intranets or within file systems on corporate networks that are inaccessible to Amazon Q Business using its native data source connectors. You can now use the custom data source connector within Amazon Q Business to upload content to your index from a wider range of data sources.
Using an Amazon Q Business custom data source connector, you can gain insights into your organization’s third party applications with the integration of generative AI and natural language processing. This post shows how to configure an Amazon Q Business custom connector and derive insights by creating a generative AI-powered conversation experience on AWS using Amazon Q Business while using access control lists (ACLs) to restrict access to documents based on user permissions.
Alation is a data intelligence company serving more than 600 global enterprises, including 40% of the Fortune 100. Customers rely on Alation to realize the value of their data and AI initiatives. Headquartered in Redwood City, California, Alation is an AWS Specialization Partner and AWS Marketplace Seller with Data and Analytics Competency. Organizations trust Alation’s platform for self-service analytics, cloud transformation, data governance, and AI-ready data, fostering innovation at scale. In this post, we will showcase a sample of how Alation’s business policies can be integrated with an Amazon Q Business application using a custom data source connector.
After you integrate Amazon Q Business with data sources such as Alation, users can ask questions from the description of the document. For example,
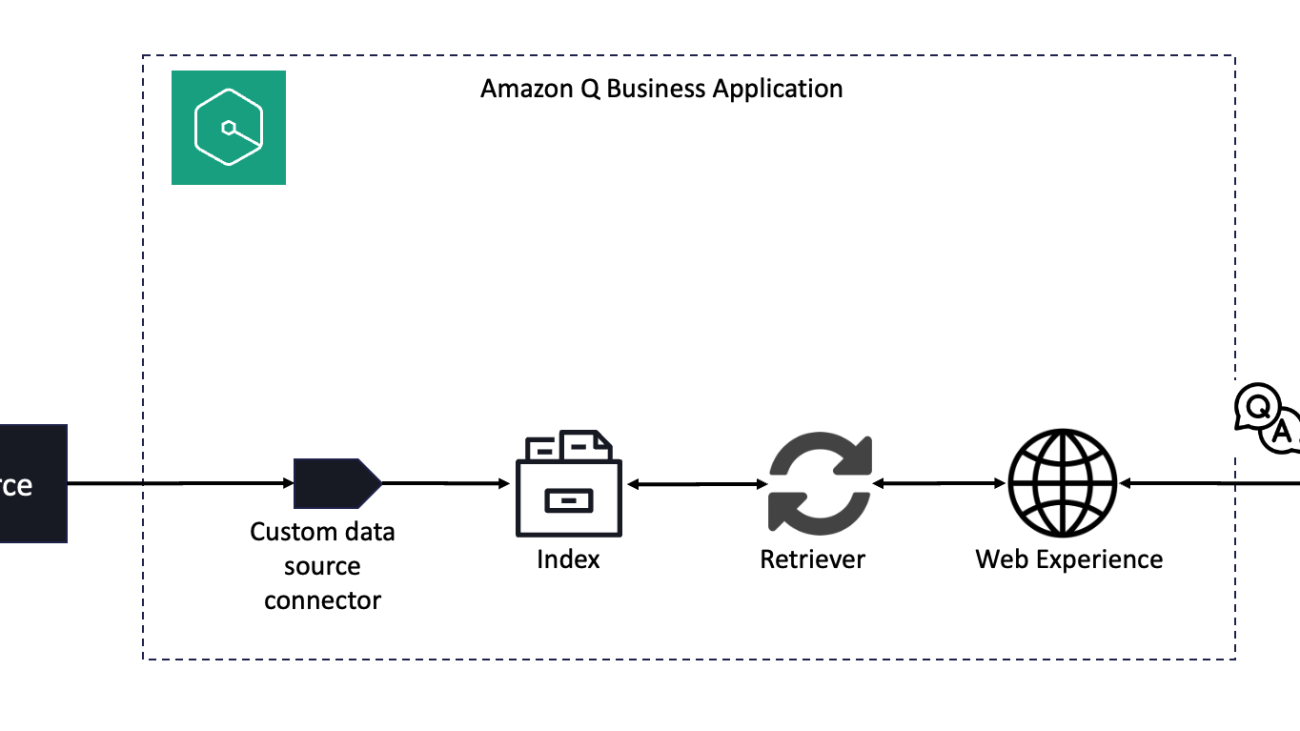
A data source connector is a mechanism for integrating and synchronizing data from multiple repositories into one container index. Amazon Q Business offers multiple pre-built data source connectors that can connect to your data sources and help you create your generative AI solution with minimal configuration. However, if you have valuable data residing in spots for which those pre-built connectors cannot be used, you can use a custom connector.
When you connect Amazon Q Business to a data source and initiate the data synchronization process, Amazon Q Business crawls and adds documents from the data source to its index.
You would typically use an Amazon Q Business custom connector when you have a repository that Amazon Business doesn’t yet provide a data source connector for. Amazon Q Business only provides metric information that you can use to monitor your data source sync jobs. You must create and run the crawler that determines the documents your data source indexes. A simple architectural representation of the steps involved is shown in the following figure.

The solution shown of integrating Alation’s business policies is for demonstration purposes only. We recommend running similar scripts only on your own data sources after consulting with the team who manages them, or be sure to follow the terms of service for the sources that you’re trying to fetch data from. The steps involved for other custom data sources are very similar except the part where we connect to Alation and fetch data from it. To crawl and index contents in Alation you configure an Amazon Q Business custom connector as a data source in your Amazon Q Business application.
For this walkthrough, you should have the following prerequisites:
https://[[your-domain]].alationcloud.com/admin/auth/ and see the OAuth Client Applications. Alation admins can navigate to https://[[your-domain]].alationcloud.com/admin/users/ and change user access if needed.StartDataSourceSyncJob, BatchPutDocument, and StopDataSourceSyncJob permissions) and the AWS Secrets Manager secret (GetSecretValue). Additionally, it’s recommended that the policy restricts access to only the Amazon Q Business application Amazon Resource Name (ARN) and the Secrets Manager secret created in the following steps.In your Alation cloud account, create an OAuth2 client application that can be consumed from an Amazon Q Business application.
https://[[your-domain]].alationcloud.com/admin/auth/).



Client_Id and Client_Secret values copied from the previous step.



In our example, you would create three different sets of Alation policies for a fictional organization named Unicorn Rentals. Grouped as Workplace, HR, and Regulatory, each policy contains a rough two-page summary of crucial organizational items of interest. You can find details on how to create policies on Alation documentation.

On the Amazon Q Business side, let’s assume that we want to ensure that the following access policies are enforced. Users and access are setup via code illustrated in later sections.
| # | First name | Last name | Policies authorized for access |
| 1 | Alejandro | Rosalez | Workplace, HR, and Regulatory |
| 2 | Sofia | Martinez | Workplace and HR |
| 3 | Diego | Ramirez | Workplace and Regulatory |














Now let’s load the Alation data into Amazon Q Business using the correct access permissions. The code examples that follow are also available on the accompanying GitHub code repository.




Now that the data synchronization is complete, you can start exploring insights from Amazon Q Business. With the newly created Amazon Q Business application, select the Web Application settings tab and navigate to the auto-created URL. This will open a new tab with a preview of the user interface and options that you can customize to fit your use case.








If you’re unable to get answers to any of your questions and get the message “Sorry, I could not find relevant information to complete your request,” check to see if any of the following issues apply:
If none of the above are true then open a support case to get this resolved.
To avoid incurring future charges, clean up any resources created as part of this solution. Delete the Amazon Q Business custom connector data source and client application created in Alation and the Amazon Q Business application. Next, delete the Secrets Manager secret with Alation OAuth client application credential data. Also, delete the user management setup in IAM Identity Center and the SageMaker Studio domain.
In this post, we discussed how to configure the Amazon Q Business custom connector to crawl and index tasks from Alation as a sample. We showed how you can use Amazon Q Business generative AI-based search to enable your business leaders and agents discover insights from your enterprise data.
To learn more about the Amazon Q Business custom connector, see the Amazon Q Business developer guide. To learn more about Alation Data Catalog, which is available for purchase through AWS Marketplace. Speak to your Alation account representative for custom purchase options. For any additional information, contact your Alation business partner.

Alation is an AWS Specialization Partner that has pioneered the modern data catalog and is making the leap into a full-service source for data intelligence. Alation is passionate about helping enterprises create thriving data cultures where anyone can find, understand, and trust data.
Contact Alation | Partner Overview | AWS Marketplace
 Gene Arnold is a Product Architect with Alation’s Forward Deployed Engineering team. A curious learner with over 25 years of experience, Gene focuses how to sharpen selling skills and constantly explores new product lines.
Gene Arnold is a Product Architect with Alation’s Forward Deployed Engineering team. A curious learner with over 25 years of experience, Gene focuses how to sharpen selling skills and constantly explores new product lines.
 Prabhakar Chandrasekaran is a Senior Technical Account Manager with AWS Enterprise Support. Prabhakar enjoys helping customers build cutting-edge AI/ML solutions on the cloud. He also works with enterprise customers providing proactive guidance and operational assistance, helping them improve the value of their solutions when using AWS. Prabhakar holds eight AWS and seven other professional certifications. With over 21 years of professional experience, Prabhakar was a data engineer and a program leader in the financial services space prior to joining AWS.
Prabhakar Chandrasekaran is a Senior Technical Account Manager with AWS Enterprise Support. Prabhakar enjoys helping customers build cutting-edge AI/ML solutions on the cloud. He also works with enterprise customers providing proactive guidance and operational assistance, helping them improve the value of their solutions when using AWS. Prabhakar holds eight AWS and seven other professional certifications. With over 21 years of professional experience, Prabhakar was a data engineer and a program leader in the financial services space prior to joining AWS.
 Sindhu Jambunathan is a Senior Solutions Architect at AWS, specializing in supporting ISV customers in the data and generative AI vertical to build scalable, reliable, secure, and cost-effective solutions on AWS. With over 13 years of industry experience, she joined AWS in May 2021 after a successful tenure as a Senior Software Engineer at Microsoft. Sindhu’s diverse background includes engineering roles at Qualcomm and Rockwell Collins, complemented by a Master’s of Science in Computer Engineering from the University of Florida. Her technical expertise is balanced by a passion for culinary exploration, travel, and outdoor activities.
Sindhu Jambunathan is a Senior Solutions Architect at AWS, specializing in supporting ISV customers in the data and generative AI vertical to build scalable, reliable, secure, and cost-effective solutions on AWS. With over 13 years of industry experience, she joined AWS in May 2021 after a successful tenure as a Senior Software Engineer at Microsoft. Sindhu’s diverse background includes engineering roles at Qualcomm and Rockwell Collins, complemented by a Master’s of Science in Computer Engineering from the University of Florida. Her technical expertise is balanced by a passion for culinary exploration, travel, and outdoor activities.
 Prateek Jain is a Sr. Solutions Architect with AWS, based out of Atlanta Georgia. He is passionate about GenAI and helping customers build amazing solutions on AWS. In his free time, he enjoys spending time with Family and playing tennis.
Prateek Jain is a Sr. Solutions Architect with AWS, based out of Atlanta Georgia. He is passionate about GenAI and helping customers build amazing solutions on AWS. In his free time, he enjoys spending time with Family and playing tennis.