Data is the lifeblood of modern applications, driving everything from application testing to machine learning (ML) model training and evaluation. As data demands continue to surge, the emergence of generative AI models presents an innovative solution. These large language models (LLMs), trained on expansive data corpora, possess the remarkable capability to generate new content across multiple media formats—text, audio, and video—and across various business domains, based on provided prompts and inputs.
In this post, we explore how you can use these LLMs with advanced Retrieval Augmented Generation (RAG) to generate high-quality synthetic data for a finance domain use case. You can use the same technique for synthetic data for other business domain use cases as well. For this post, we demonstrate how to generate counterparty risk (CR) data, which would be beneficial for over-the-counter (OTC) derivatives that are traded directly between two parties, without going through a formal exchange.
Solution overview
OTC derivatives are typically customized contracts between counterparties and include a variety of financial instruments, such as forwards, options, swaps, and other structured products. A counterparty is the other party involved in a financial transaction. In the context of OTC derivatives, the counterparty refers to the entity (such as a bank, financial institution, corporation, or individual) with whom a derivative contract is made.
For example, in an OTC swap or option contract, one entity agrees to terms with another party, and each entity becomes the counterparty to the other. The responsibilities, obligations, and risks (such as credit risk) are shared between these two entities according to the contract.
As financial institutions continue to navigate the complex landscape of CR, the need for accurate and reliable risk assessment models has become paramount. For our use case, ABC Bank, a fictional financial services organization, has taken on the challenge of developing an ML model to assess the risk of a given counterparty based on their exposure to OTC derivative data.
Building such a model presents numerous challenges. Although ABC Bank has gathered a large dataset from various sources and in different formats, the data may be biased, skewed, or lack the diversity needed to train a highly accurate model. The primary challenge lies in collecting and preprocessing the data to make it suitable for training an ML model. Deploying a poorly suited model could result in misinformed decisions and significant financial losses.
We propose a generative AI solution that uses the RAG approach. RAG is a widely used approach that enhances LLMs by supplying extra information from external data sources not included in their original training. The entire solution can be broadly divided into three steps: indexing, data generation, and validation.
Data indexing
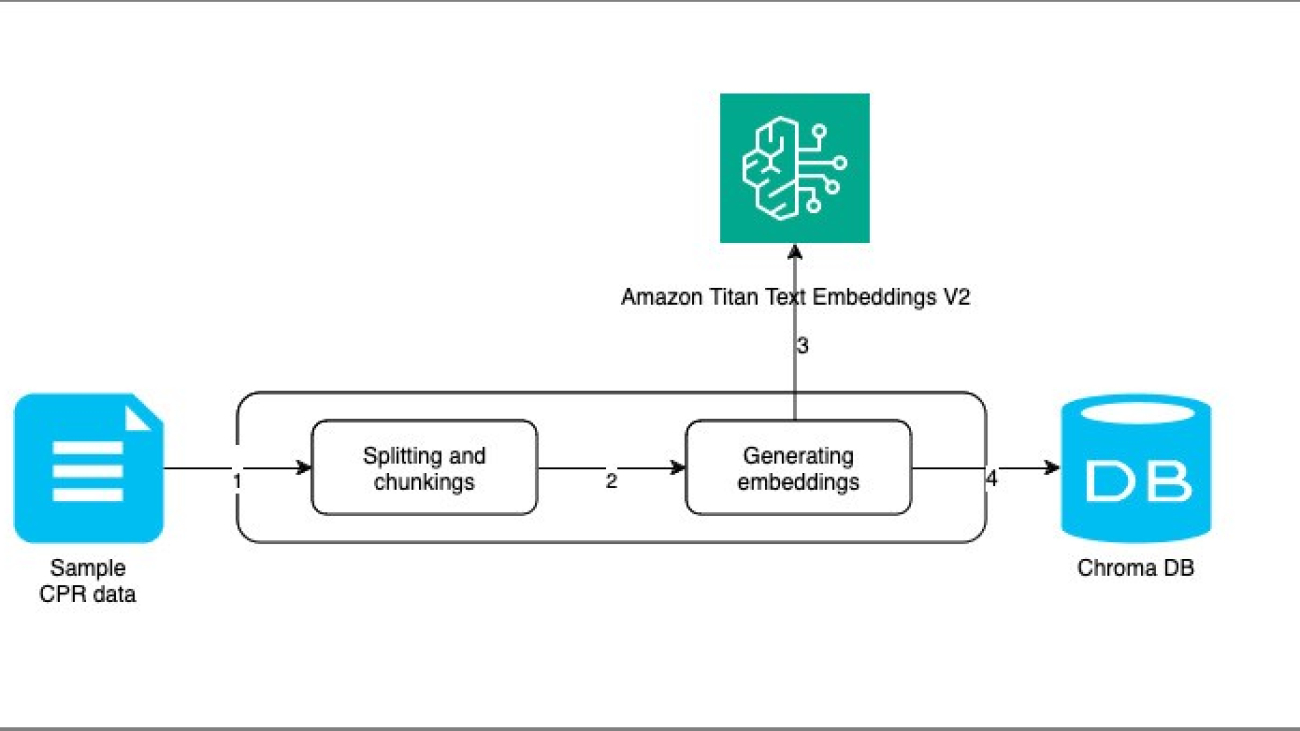
In the indexing step, we parse, chunk, and convert the representative CR data into vector format using the Amazon Titan Text Embeddings V2 model and store this information in a Chroma vector database. Chroma is an open source vector database known for its ease of use, efficient similarity search, and support for multimodal data and metadata. It offers both in-memory and persistent storage options, integrates well with popular ML frameworks, and is suitable for a wide range of AI applications. It is particularly beneficial for smaller to medium-sized datasets and projects requiring local deployment or low resource usage. The following diagram illustrates this architecture.

Here are the steps for data indexing:
- The sample CR data is segmented into smaller, manageable chunks to optimize it for embedding generation.
- These segmented data chunks are then passed to a method responsible for both generating embeddings and storing them efficiently.
- The Amazon Titan Text Embeddings V2 API is called upon to generate high-quality embeddings from the prepared data chunks.
- The resulting embeddings are then stored in the Chroma vector database, providing efficient retrieval and similarity searches for future use.
Data generation
When the user requests data for a certain scenario, the request is converted into vector format and then looked up in the Chroma database to find matches with the stored data. The retrieved data is augmented with the user request and additional prompts to Anthropic’s Claude Haiku on Amazon Bedrock. Anthropic’s Claude Haiku was chosen primarily for its speed, processing over 21,000 tokens per second, which significantly outpaces its peers. Moreover, Anthropic’s Claude Haiku’s efficiency in data generation is remarkable, with a 1:5 input-to-output token ratio. This means it can generate a large volume of data from a relatively small amount of input or context. This capability not only enhances the model’s effectiveness, but also makes it cost-efficient for our application, where we need to generate numerous data samples from a limited set of examples. Anthropic’s Claude Haiku LLM is invoked iteratively to efficiently manage token consumption and help prevent reaching the maximum token limit. The following diagram illustrates this workflow.

Here are the steps for data generation:
- The user initiates a request to generate new synthetic counterparty risk data based on specific criteria.
- The Amazon Titan Text Embeddings V2 LLM is employed to create embeddings for the user’s request prompts, transforming them into a machine-interpretable format.
- These newly generated embeddings are then forwarded to a specialized module designed to identify matching stored data.
- The Chroma vector database, which houses previously stored embeddings, is queried to find data that closely matches the user’s request.
- The identified matching data and the original user prompts are then passed to a module responsible for generating new synthetic data.
- Anthropic’s Claude Haiku 3.0 model is invoked, using both the matching embeddings and user prompts as input to create high-quality synthetic data.
- The generated synthetic data is then parsed and formatted into a .csv file using the Pydantic library, providing a structured and validated output.
- To confirm the quality of the generated data, several statistical methods are applied, including quantile-quantile (Q-Q) plots and correlation heat maps of key attributes, providing a comprehensive validation process.
Data validation
When validating the synthetic CR data generated by the LLM, we employed Q-Q plots and correlation heat maps focusing on key attributes such as cp_exposure, cp_replacement_cost, and cp_settlement_risk. These statistical tools serve crucial roles in promoting the quality and representativeness of the synthetic data. By using the Q-Q plots, we can assess whether these attributes follow a normal distribution, which is often expected in many clinical and financial variables. By comparing the quantiles of our synthetic data against theoretical normal distributions, we can identify significant deviations that might indicate bias or unrealistic data generation.
Simultaneously, the correlation heat maps provide a visual representation of the relationships between these attributes and others in the dataset. This is particularly important because it helps verify that the LLM has maintained the complex interdependencies typically observed in real CR data. For instance, we would expect certain correlations between exposure and replacement cost, or between replacement cost and settlement risk. By making sure these correlations are preserved in our synthetic data, we can be more confident that analyses or models built on this data will yield insights that are applicable to real-world scenarios. This rigorous validation process helps to mitigate the risk of introducing artificial patterns or biases, thereby enhancing the reliability and utility of our synthetic CR dataset for subsequent research or modeling tasks.
We’ve created a Jupyter notebook containing three parts to implement the key components of the solution. We provide code snippets from the notebooks for better understanding.
Prerequisites
To set up the solution and generate test data, you should have the following prerequisites:
- Python 3 must be installed on your machine
- We recommend that an integrated development environment (IDE) that can run Jupyter notebooks be installed
- You can also create a Jupyter notebook instance using Amazon SageMaker from AWS console and develop the code there.
- You need to have an AWS account with access to Amazon Bedrock and the following LLMs enabled (be careful not to share the AWS account credentials):
- Amazon Titan Text Embeddings V2
- Anthropic’s Claude 3 Haiku
Setup
Here are the steps to setup the environment.
import sys!{sys.executable} -m pip install -r requirements.txtThe content of the requirements.txt is given here.
boto3
langchain
langchain-community
streamlit
chromadb==0.4.15
numpy
jq
langchain-aws
seaborn
matplotlib
scipyThe following code snippet will perform all the necessary imports.
from pprint import pprint
from uuid import uuid4
import chromadb
from langchain_community.document_loaders import JSONLoader
from langchain_community.embeddings import BedrockEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitterIndex data in the Chroma database
In this section, we show how indexing of data is done in a Chroma database as a locally maintained open source vector store. This index data is used as context for generating data.
The following code snippet shows the preprocessing steps of loading the JSON data from a file and splitting it into smaller chunks:
def load_using_jsonloaer(path):
loader = JSONLoader(path,
jq_schema=".[]",
text_content=False)
documents = loader.load()
return documents
def split_documents(documents):
doc_list = [item for item in documents]
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1200, chunk_overlap=0)
texts = text_splitter.split_documents(doc_list)
return textsThe following snippet shows how an Amazon Bedrock embedding instance is created. We used the Amazon Titan Embeddings V2 model:
def get_bedrock_embeddings():
aws_region = "us-east-1"
model_id = "amazon.titan-embed-text-v2:0" #look for latest version of model
bedrock_embeddings = BedrockEmbeddings(model_id=model_id, region_name=aws_region)
return bedrock_embeddingsThe following code shows how the embeddings are created and then loaded in the Chroma database:
persistent_client = chromadb.PersistentClient(path="../data/chroma_index")
collection = persistent_client.get_or_create_collection("test_124")
print(collection)
# query the database
vector_store_with_persistent_client = Chroma(collection_name="test_124",
persist_directory="../data/chroma_index",
embedding_function=get_bedrock_embeddings(),
client=persistent_client)
load_json_and_index(vector_store_with_persistent_client)Generate data
The following code snippet shows the configuration used during the LLM invocation using Amazon Bedrock APIs. The LLM used is Anthropic’s Claude 3 Haiku:
config = Config(
region_name='us-east-1',
signature_version='v4',
retries={
'max_attempts': 2,
'mode': 'standard'
}
)
bedrock_runtime = boto3.client('bedrock-runtime', config=config)
model_id = "anthropic.claude-3-haiku-20240307-v1:0" #look for latest version of model
model_kwrgs = {
"temperature": 0,
"max_tokens": 8000,
"top_p": 1.0,
"top_k": 25,
"stop_sequences": ["company-1000"],
}
# Initialize the language model
llm = ChatBedrock(
model_id=model_id,
model_kwargs=model_kwrgs,
client=bedrock_runtime,
)The following code shows how the context is fetched by looking up the Chroma database (where data was indexed) for matching embeddings. We use the same Amazon Titan model to generate the embeddings:
def get_context(scenario):
region_name = 'us-east-1'
credential_profile_name = "default"
titan_model_id = "amazon.titan-embed-text-v2:0"
kb_context = []
be = BedrockEmbeddings(region_name=region_name,
credentials_profile_name=credential_profile_name,
model_id=titan_model_id)
vector_store = Chroma(collection_name="test_124", persist_directory="../data/chroma_index",
embedding_function=be)
search_results = vector_store.similarity_search(scenario, k=3)
for doc in search_results:
kb_context.append(doc.page_content)
return json.dumps(kb_context)The following snippet shows how we formulated the detailed prompt that was passed to the LLM. We provided examples for the context, scenario, start index, end index, records count, and other parameters. The prompt is subjective and can be adjusted for experimentation.
# Create a prompt template
prompt_template = ChatPromptTemplate.from_template(
"You are a financial data expert tasked with generating records "
"representing company OTC derivative data and "
"should be good enough for investor and lending ML model to take decisions "
"and data should accurately represent the scenario: {scenario} n "
"and as per examples given in context: "
"and context is {context} "
"the examples given in context is for reference only, do not use same values while generating dataset."
"generate dataset with the diverse set of samples but record should be able to represent the given scenario accurately."
"Please ensure that the generated data meets the following criteria: "
"The data should be diverse and realistic, reflecting various industries, "
"company sizes, financial metrics. "
"Ensure that the generated data follows logical relationships and correlations between features "
"(e.g., higher revenue typically corresponds to more employees, "
"better credit ratings, and lower risk). "
"And Generate {count} records starting from index {start_index}. "
"generate just JSON as per schema and do not include any text or message before or after JSON. "
"{format_instruction} n"
"If continuing, start after this record: {last_record}n"
"If stopping, do not include this record in the output."
"Please ensure that the generated data is well-formatted and consistent."
)The following code snippet shows the process for generating the synthetic data. You can call this method in an iterative manner to generate more records. The input parameters include scenario, context, count, start_index, and last_record. The response data is also formatted into CSV format using the instruction provided by the following:
output_parser.get_format_instructions():
def generate_records(start_index, count, scenario, context, last_record=""):
try:
response = chain.invoke({
"count": count,
"start_index": start_index,
"scenario": scenario,
"context": context,
"last_record": last_record,
"format_instruction": output_parser.get_format_instructions(),
"data_set_class_schema": DataSet.schema_json()
})
return response
except Exception as e:
print(f"Error in generate_records: {e}")
raise eParsing the output generated by the LLM and representing it in CSV was quite challenging. We used a Pydantic parser to parse the JSON output generated by the LLM, as shown in the following code snippet:
class CustomPydanticOutputParser(PydanticOutputParser):
def parse(self, text: str) -> BaseModel:
# Extract JSON from the text
try:
# Find the first occurrence of '{'
start = text.index('{')
# Find the last occurrence of '}'
end = text.rindex('}') + 1
json_str = text[start:end]
# Parse the JSON string
parsed_json = json.loads(json_str)
# Use the parent class to convert to Pydantic object
return super().parse_with_cls(parsed_json)
except (ValueError, json.JSONDecodeError) as e:
raise ValueError(f"Failed to parse output: {e}")The following code snippet shows how the records are generated in an iterative manner with 10 records in each invocation to the LLM:
def generate_full_dataset(total_records, batch_size, scenario, context):
dataset = []
total_generated = 0
last_record = ""
batch: DataSet = generate_records(total_generated,
min(batch_size, total_records - total_generated),
scenario, context, last_record)
# print(f"batch: {type(batch)}")
total_generated = len(batch.records)
dataset.extend(batch.records)
while total_generated < total_records:
try:
batch = generate_records(total_generated,
min(batch_size, total_records - total_generated),
scenario, context, batch.records[-1].json())
processed_batch = batch.records
if processed_batch:
dataset.extend(processed_batch)
total_generated += len(processed_batch)
last_record = processed_batch[-1].start_index
print(f"Generated {total_generated} records.")
else:
print("Generated an empty or invalid batch. Retrying...")
time.sleep(10)
except Exception as e:
print(f"Error occurred: {e}. Retrying...")
time.sleep(5)
return dataset[:total_records] # Ensure exactly the requested number of recordsVerify the statistical properties of the generated data
We generated Q-Q plots for key attributes of the generated data: cp_exposure, cp_replacement_cost, and cp_settlement_risk, as shown in the following screenshots. The Q-Q plots compare the quantiles of the data distribution with the quantiles of a normal distribution. If the data isn’t skewed, the points should approximately follow the diagonal line.
 |
 |
 |
As the next step of verification, we created a corelation heat map of the following attributes: cp_exposure, cp_replacement_cost, cp_settlement_risk, and risk. The plot is perfectly balanced with the diagonal elements showing a value of 1. The value of 1 indicates the column is perfectly co-related to itself. The following screenshot is the correlation heatmap.

Clean up
It’s a best practice to clean up the resources you created as part of this post to prevent unnecessary costs and potential security risks from leaving resources running. If you created the Jupyter notebook instance in SageMaker please complete the following steps:
- Save and shut down the notebook:
# First save your work # Then close all open notebooks by clicking File -> Close and Halt - Clear the output (if needed before saving):
# Option 1: Using notebook menu # Kernel -> Restart & Clear Output # Option 2: Using code from IPython.display import clear_output clear_output() - Stop and delete the Jupyter notebook instance created in SageMaker:
# Option 1: Using aws cli # Stop the notebook instance when not in use aws sagemaker stop-notebook-instance --notebook-instance-name <your-notebook-name> # If you no longer need the notebook instance aws sagemaker delete-notebook-instance --notebook-instance-name <your-notebook-name> # Option 2: Using Sagemager Console # Amazon Sagemaker -> Notebooks # Select the Notebook and click Actions drop-down and hit Stop. Click Actions drop-down and hit Delete
Responsible use of AI
Responsible AI use and data privacy are paramount when using AI in financial applications. Although synthetic data generation can be a powerful tool, it’s crucial to make sure that no real customer information is used without proper authorization and thorough anonymization. Organizations must prioritize data protection, implement robust security measures, and adhere to relevant regulations. Additionally, when developing and deploying AI models, it’s essential to consider ethical implications, potential biases, and the broader societal impact. Responsible AI practices include regular audits, transparency in decision-making processes, and ongoing monitoring to help prevent unintended consequences. By balancing innovation with ethical considerations, financial institutions can harness the benefits of AI while maintaining trust and protecting individual privacy.
Conclusion
In this post, we showed how to generate a well-balanced synthetic dataset representing various aspects of counterparty data, using RAG-based prompt engineering with LLMs. Counterparty data analysis is imperative for making OTC transactions between two counterparties. Because actual business data in this domain isn’t easily available, using this approach you can generate synthetic training data for your ML models at minimal cost often within minutes. After you train the model, you can use it to make intelligent decisions before entering into an OTC derivative transaction.
For more information about this topic, refer to the following resources:
- What is RAG (Retrieval-Augmented Generation)?
- Retrieval Augmented Generation options and architectures on AWS
- Generate synthetic data for evaluating RAG systems using Amazon Bedrock
- Amazon Titan Text Embeddings models
- Claude 3 Haiku: our fastest model yet
About the Authors
 Santosh Kulkarni is a Senior Moderation Architect with over 16 years of experience, specialized in developing serverless, container-based, and data architectures for clients across various domains. Santosh’s expertise extends to machine learning, as a certified AWS ML specialist. Currently, engaged in multiple initiatives leveraging AWS Bedrock and hosted Foundation models.
Santosh Kulkarni is a Senior Moderation Architect with over 16 years of experience, specialized in developing serverless, container-based, and data architectures for clients across various domains. Santosh’s expertise extends to machine learning, as a certified AWS ML specialist. Currently, engaged in multiple initiatives leveraging AWS Bedrock and hosted Foundation models.
 Joyanta Banerjee is a Senior Modernization Architect with AWS ProServe and specializes in building secure and scalable cloud native application for customers from different industry domains. He has developed an interest in the AI/ML space particularly leveraging Gen AI capabilities available on Amazon Bedrock.
Joyanta Banerjee is a Senior Modernization Architect with AWS ProServe and specializes in building secure and scalable cloud native application for customers from different industry domains. He has developed an interest in the AI/ML space particularly leveraging Gen AI capabilities available on Amazon Bedrock.
 Mallik Panchumarthy is a Senior Specialist Solutions Architect for generative AI and machine learning at AWS. Mallik works with customers to help them architect efficient, secure and scalable AI and machine learning applications. Mallik specializes in generative AI services Amazon Bedrock and Amazon SageMaker.
Mallik Panchumarthy is a Senior Specialist Solutions Architect for generative AI and machine learning at AWS. Mallik works with customers to help them architect efficient, secure and scalable AI and machine learning applications. Mallik specializes in generative AI services Amazon Bedrock and Amazon SageMaker.



 Sajin Jacob is the Director of Software Engineering at Verisk, where he leads the Premium Audit Advisory Service (PAAS) development team. In this role, Sajin plays a crucial part in designing the architecture and providing strategic guidance to eight development teams, optimizing their efficiency and ensuring the maintainability of all solutions. He holds an MS in Software Engineering from Periyar University, India.
Sajin Jacob is the Director of Software Engineering at Verisk, where he leads the Premium Audit Advisory Service (PAAS) development team. In this role, Sajin plays a crucial part in designing the architecture and providing strategic guidance to eight development teams, optimizing their efficiency and ensuring the maintainability of all solutions. He holds an MS in Software Engineering from Periyar University, India. Jerry Chen is a Lead Software Developer at Verisk, based in Jersey City. He leads the GenAi development team, working on solutions for projects within the Verisk Underwriting department to enhance application functionalities and accessibility. Within PAAS, he has worked on the implementation of the conversational RAG architecture with enhancements such as hybrid search, guardrails, and response evaluations. Jerry holds a degree in Computer Science from Stevens Institute of Technology.
Jerry Chen is a Lead Software Developer at Verisk, based in Jersey City. He leads the GenAi development team, working on solutions for projects within the Verisk Underwriting department to enhance application functionalities and accessibility. Within PAAS, he has worked on the implementation of the conversational RAG architecture with enhancements such as hybrid search, guardrails, and response evaluations. Jerry holds a degree in Computer Science from Stevens Institute of Technology. Sid Mohanram is the Senior Vice President of Core Lines Technology at Verisk. His area of expertise includes data strategy, analytics engineering, and digital transformation. Sid is head of the technology organization with global teams across five countries. He is also responsible for leading the technology transformation for the multi-year Core Lines Reimagine initiative. Sid holds an MS in Information Systems from Stevens Institute of Technology.
Sid Mohanram is the Senior Vice President of Core Lines Technology at Verisk. His area of expertise includes data strategy, analytics engineering, and digital transformation. Sid is head of the technology organization with global teams across five countries. He is also responsible for leading the technology transformation for the multi-year Core Lines Reimagine initiative. Sid holds an MS in Information Systems from Stevens Institute of Technology. Luis Barbier is the Chief Technology Officer (CTO) of Verisk Underwriting at Verisk. He provides guidance to the development teams’ architectures to maximize efficiency and maintainability for all underwriting solutions. Luis holds an MBA from Iona University.
Luis Barbier is the Chief Technology Officer (CTO) of Verisk Underwriting at Verisk. He provides guidance to the development teams’ architectures to maximize efficiency and maintainability for all underwriting solutions. Luis holds an MBA from Iona University. Kristen Chenowith, MSMSL, CPCU, WCP, APA, CIPA, AIS, is PAAS Product Manager at Verisk. She is currently the product owner for the Premium Audit Advisory Service (PAAS) product suite, including PAAS AI, a first to market generative AI chat tool for premium audit that accelerates research for many consultative questions by 98% compared to traditional methods. Kristen holds an MS in Management, Strategy and Leadership at Michigan State University and a BS in Business Administration at Valparaiso University. She has been in the commercial insurance industry and premium audit field since 2006.
Kristen Chenowith, MSMSL, CPCU, WCP, APA, CIPA, AIS, is PAAS Product Manager at Verisk. She is currently the product owner for the Premium Audit Advisory Service (PAAS) product suite, including PAAS AI, a first to market generative AI chat tool for premium audit that accelerates research for many consultative questions by 98% compared to traditional methods. Kristen holds an MS in Management, Strategy and Leadership at Michigan State University and a BS in Business Administration at Valparaiso University. She has been in the commercial insurance industry and premium audit field since 2006. Michelle Stahl, MBA, CPCU, AIM, API, AIS, is a Digital Product Manager with Verisk. She has over 20 years of experience building and transforming technology initiatives for the insurance industry. She has worked as a software developer, project manager, and product manager throughout her career.
Michelle Stahl, MBA, CPCU, AIM, API, AIS, is a Digital Product Manager with Verisk. She has over 20 years of experience building and transforming technology initiatives for the insurance industry. She has worked as a software developer, project manager, and product manager throughout her career. Arun Pradeep Selvaraj is a Senior Solutions Architect at AWS. Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build, and reinvent. He is creative, fast-paced, deeply customer-obsessed, and uses the working backward process to build modern architectures to help customers solve their unique challenges. Connect with him on
Arun Pradeep Selvaraj is a Senior Solutions Architect at AWS. Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build, and reinvent. He is creative, fast-paced, deeply customer-obsessed, and uses the working backward process to build modern architectures to help customers solve their unique challenges. Connect with him on  Ryan Doty is a Solutions Architect Manager at AWS, based out of New York. He helps financial services customers accelerate their adoption of the AWS Cloud by providing architectural guidelines to design innovative and scalable solutions. Coming from a software development and sales engineering background, the possibilities that the cloud can bring to the world excite him.
Ryan Doty is a Solutions Architect Manager at AWS, based out of New York. He helps financial services customers accelerate their adoption of the AWS Cloud by providing architectural guidelines to design innovative and scalable solutions. Coming from a software development and sales engineering background, the possibilities that the cloud can bring to the world excite him. Apoorva Kiran, PhD, is a Senior Solutions Architect at AWS, based out of New York. He is aligned with the financial service industry, and is responsible for providing architectural guidelines to design innovative and scalable fintech solutions. He specializes in developing and commercializing artificial intelligence and machine learning products. Connect with him on
Apoorva Kiran, PhD, is a Senior Solutions Architect at AWS, based out of New York. He is aligned with the financial service industry, and is responsible for providing architectural guidelines to design innovative and scalable fintech solutions. He specializes in developing and commercializing artificial intelligence and machine learning products. Connect with him on 










 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN)