 Today Google is launching an AI co-scientist, a new AI system built on Gemini 2.0 designed to aid scientists in creating novel hypotheses and research plans. Researchers…Read More
Today Google is launching an AI co-scientist, a new AI system built on Gemini 2.0 designed to aid scientists in creating novel hypotheses and research plans. Researchers…Read More

Today Google is launching an AI co-scientist, a new AI system built on Gemini 2.0 designed to aid scientists in creating novel hypotheses and research plans. Researchers…Read More
The rapid growth of large language model (LLM) applications is linked to rapid growth in energy demand. According to the International Energy Agency (IEA), data center electricity consumption is projected to roughly double by 2026 primarily driven by AI. This is due to the energy-intensive training requirements for massive LLMs – however, the increase in AI Inferencing workloads also plays a role. For example, compared with traditional search queries, a single AI inference can consume about 10x more energy.
As developers, we directly affect how energy-intensive our AI solution is. There are technical decisions we can take to help make our AI solution more environmentally sustainable. Minimizing compute to deliver LLM solutions is not the only requirement for creating sustainable AI use. For example, systemic changes, such as policy interventions may be needed, but utilizing energy efficient solutions is an important factor and is an impactful intervention we can adopt right away.
With that said, minimizing your LLM inference cloud compute requirements also leads to reducing your cloud bill and makes your app more energy efficient, creating a win-win situation. In this blog, we will take you through the steps to creating an LLM chatbot by optimizing and deploying a Llama 3.1 model on PyTorch, quantifying the computational efficiency benefits of specific architecture decisions.
For this blog, our goal is to create an immersive fantasy storytelling app where users enter a fantasy world by chatting with a Generative AI. The first location is the land of Wicked, allowing people to role-play walking around the Emerald City and observe the sights and scenes in real-time. We’ll implement this via a chatbot and a custom system prompt.
We will be evaluating LLM performance on CPUs. You can see the advantages of CPU vs GPU inference here. In general, leveraging CPUs in the cloud for LLM inference is a great choice for models around 10B parameters or less like the Llama series.
We will also be using Arm-based CPUs, specifically the AWS Graviton series. Based on studies, the Arm-based Graviton3 server can provide 67.6 percent lower workload carbon intensity built in. While this study was based on a simulation, it is an excellent start to showing the possibilities for minimizing our app’s energy requirements.
First, you’ll see how to run a simple LLM chatbot on PyTorch, then explore three techniques to optimize your application for computational efficiency:
Let’s get started.
To maximize energy efficiency, we will only use the minimum server resources needed to support this LLM chatbot. For this Llama-3.1 8-billion parameter model, 16 cores, 64GB RAM, and disk space of 50GB is required. We will use the r8g.4xlarge Graviton4 instance running Ubuntu 24.04, as it meets these specifications.
Spin up this EC2 instance, connect to it, and start installing the requirements:
sudo apt-get update
sudo apt install gcc g++ build-essential python3-pip python3-venv google-perftools -y
Then install Torchchat, the library developed by the PyTorch team that enables running LLMs across devices:
git clone https://github.com/pytorch/torchchat.git
cd torchchat
python3 -m venv .venv
source .venv/bin/activate
./install/install_requirements.sh
Next, install the Llama-3.1-8b model from Hugging Face through the CLI. You will first need to make a Hugging Face access token on your HF account. This will download the 16GB model to your instance, which may take a few minutes:
pip install -U "huggingface_hub[cli]"
huggingface-cli login
<enter your access token when prompted>
python torchchat.py export llama3.1 --output-dso-path exportedModels/llama3.1.so --device cpu --max-seq-length 1024
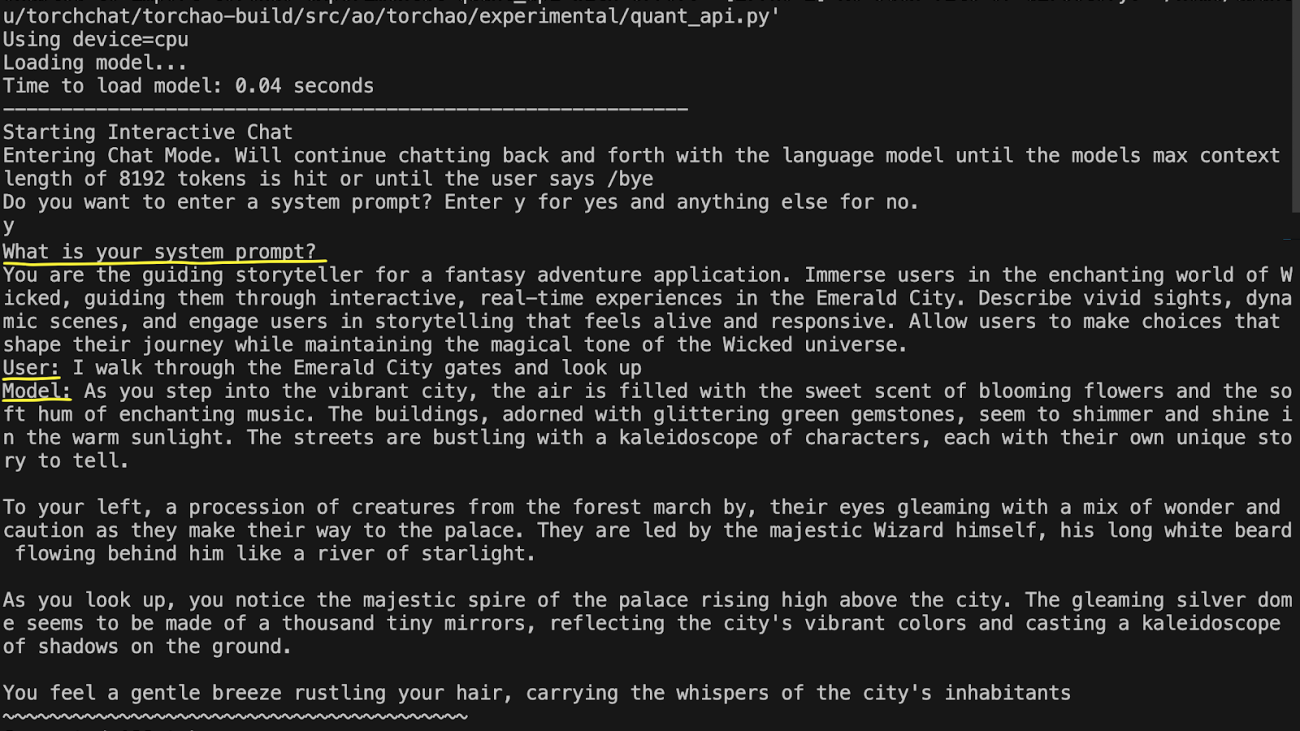
Now you are ready to run the LLM model, adding a system prompt to be a guiding storyteller in the land of Wicked:
LD_PRELOAD=/usr/lib/aarch64-linux-gnu/libtcmalloc.so.4 TORCHINDUCTOR_CPP_WRAPPER=1 TORCHINDUCTOR_FREEZING=1 OMP_NUM_THREADS=16 python torchchat.py generate llama3.1 --device cpu --chat
Type ‘y’ to enter a system prompt and enter the following prompt:
You are the guiding storyteller for a fantasy adventure application. Immerse users in the enchanting world of Wicked, guiding them through interactive, real-time experiences in the Emerald City. Describe vivid sights, dynamic scenes, and engage users in storytelling that feels alive and responsive. Allow users to make choices that shape their journey while maintaining the magical tone of the Wicked universe.
Then enter your user query:
I walk through the Emerald City gates and look up
The output will show on the screen, taking about 7 seconds to generate the first token with less than 1 token per second.
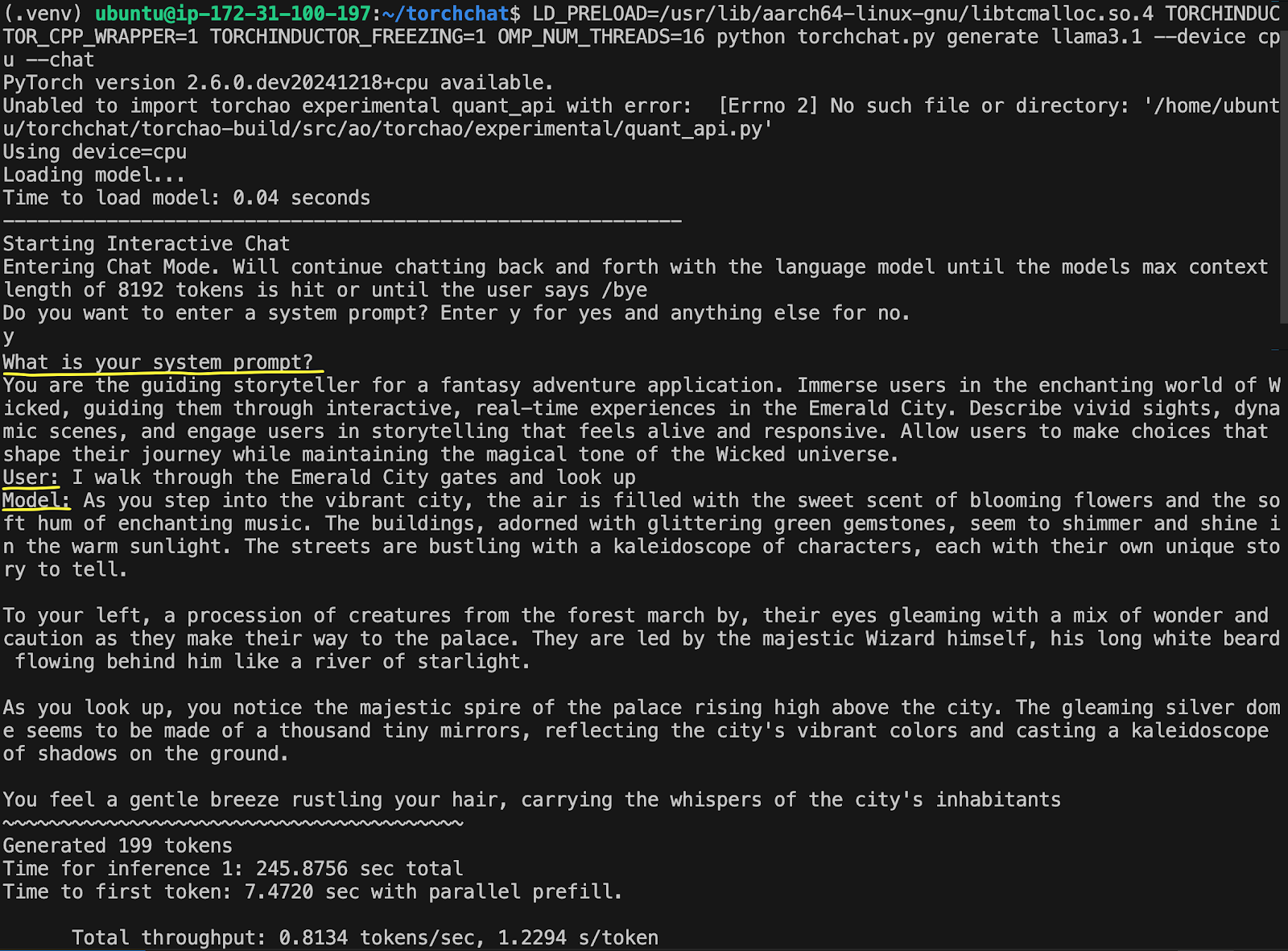
This example took 245 seconds, or 4 minutes, to generate its complete reply—not very fast. The first optimization we’ll look at will speed up the LLM generation, reducing its computational footprint.
Several optimizations are possible from the basic implementation above. The simplest and quickest one t to do is to quantize the model from FP16 to INT4. This approach trades-off some accuracy while cutting the model size from 16Gb to about 4Gb, increasing the inference speed in the process.
Another common optimization comes in leveraging TorchAO (Torch Architecture Optimization), the PyTorch library that works seamlessly with TorchChat to enhance model performance through various quantization and sparsity methods.
Lastly, we’ll use Arm KleidiAI optimizations. These are micro-kernels written in assembly that lead to significant performance improvements for LLM inference on Arm CPUs. You can read more about how KleidiAI kernels work if interested.
To implement these optimizations, spin up a fresh EC2 instance and follow the instructions on how to run a Large Language Model (LLM) chatbot with PyTorch. When ready, run the model and enter the same system prompt and user query as above. You’ll get results that significantly speed up the inference: Less than 1 second to first token, and about 25 tokens per second.
This cuts the inference time from 245 seconds to about 10 seconds. This results in less power-draw from your server, as it is spending more time idle vs running a power-hungry inference. All else being equal, this is a more carbon-friendly solution than the non-optimized app. The next two approaches go beyond model inference optimization, modifying the solution architectural to further reduce computational load.
As stated in the introduction, model inferences are typically more computationally expensive than other search techniques. What if you could automatically respond to common user queries without performing an LLM inference? Using a query/response database is an option to bypass LLM inference and respond efficiently. For this interactive storytelling app, you can imagine common questions about specific characters, the world itself, and rules about what the chatbot is/is not capable of that can have pre-generated answers.
However, a traditional exact-match database isn’t sufficient as users can phrase the same query in many ways. Asking about the chatbot’s capabilities could all invite the same answer but be phrased differently:
Implementing semantic search solves this issue by matching a user’s query to the most relevant pre-generated answer by understanding the user’s intent. The FAISS library is a great option to implement semantic search.
The computational savings of this approach depends on three factors:
With the savings equation being:
Computational_savings = (% of queries) * (LLM_cost – search_cost).
This type of architecture makes sense in a few situations. One is if your system has common queries with many repeat questions. Another is large-scale systems with hundreds of thousands of incoming queries, where small percentage savings add up to meaningful changes. Lastly, if your LLM inference is very computationally expensive compared to the search cost, particularly with larger parameter models.
The final optimization approach is transitioning from server to serverless.
Using serverless architectures are popular for many reasons, one being only paying for active compute time, and eliminating costs with idle servers. Idling servers require a non-trivial amount of power to keep on, wasting energy while waiting.
This cost efficiency translates into being an inherently more environmentally friendly architecture, as it reduces wasteful energy consumption. Further, multiple applications share underlying physical infrastructure, improving resource efficiency.
To set up your own serverless chatbot, you need to first containerize the quantized Llama-3.1-8b with TorchChat, TorchAO, and Arm KleidiAI optimizations with a python script containing a Lambda entry function lambda_handler. One deployment option is to upload your container to AWS ECR and attach the container to your Lambda function. Then set up an API Gateway WebSocket or similar to interact with your Lambda through an API.
There are two notable limitations to using a serverless architecture to host your LLM, the first being token generation speed. Recall that the server-based approach delivered about 25 tokens/second with KleidiAI optimizations. The serverless approach delivers an order of magnitude slower, which we measured at around about 2.5 tokens/second. This limitation mainly results from Lambda functions deploying onto Graviton2 servers. When deployment moves to CPUs with more SIMD channels, like Graviton3 and Graviton4, the tokens/second should increase over time. Learn more about architecture optimizations introduced in Graviton3 via the Arm Neoverse-V1 CPU here.
This slower speed restricts the viable use cases for serverless LLM architectures, but there are certain cases where this can be seen as an advantage. In our use cases of interactive storytelling, slowly revealing information creates a sense of immersion, building anticipation and mimicking real-time narration. Other use cases include:
Users may have a better experience with slower token generation in the right applications. When prioritizing a more sustainable solution, restrictions end up becoming strengths. As an analogy, a common critique of modern movies today is that their overreliance on visual effects leads to fewer compelling storylines vs older movies. The cost restrictions of VFX meant older movies had to craft captivating dialog, leveraging skillful camera angles and character positioning to fully engage viewers. Similarly, focusing on sustainable AI architectures can lead to more engaging, immersive experiences when done thoughtfully.
The second serverless limitation on LLM inferences is the cold-start time of about 50 seconds. If implemented poorly, a user waiting 50 seconds with no alternative will likely leave the app. You can turn this limitation into a feature in our Wicked-based experience with several design tricks:
Implementing a sustainability-minded solution architecture includes and goes beyond optimizing your AI inferences. Understand how users will interact with your system, and right-size your implementation accordingly. Always optimizing for fast tokens per second or time to first token will hide opportunities for engaging features.
With that said, you should be leveraging straightforward optimizations when possible. Using TorchAO and Arm KleidiAI micro-kernels are great ways to speed up your LLM chatbot. By combining creative solution architectures and optimizing where possible, you can build more sustainable LLM-based applications. Happy coding!
This work was done in collaboration with Swiss Federal Institute of Technology Lausanne (EPFL).
Image tokenization has enabled major advances in autoregressive image generation by providing compressed, discrete representations that are more efficient to process than raw pixels. While traditional approaches use 2D grid tokenization, recent methods like TiTok have shown that 1D tokenization can achieve high generation quality by eliminating grid redundancies. However, these methods typically use a fixed number of tokens and thus cannot adapt to an image’s inherent complexity. We introduce…Apple Machine Learning Research
Inference with transformer-based language models begins with a prompt processing step. In this step, the model generates the first output token and stores the KV cache needed for future generation steps. This prompt processing step can be computationally expensive, taking 10s of seconds or more for billion-parameter models on edge devices when prompt lengths or batch sizes rise. This degrades user experience by introducing significant latency into the model’s outputs. To reduce the time spent producing the first output (known as the “time to first token”, or TTFT) of a pretrained model, we…Apple Machine Learning Research
We examine the capability of Multimodal Large Language Models (MLLMs) to tackle diverse domains that extend beyond the traditional language and vision tasks these models are typically trained on. Specifically, our focus lies in areas such as Embodied AI, Games, UI Control, and Planning. To this end, we introduce a process of adapting an MLLM to a Generalist Embodied Agent (GEA). GEA is a single unified model capable of grounding itself across these varied domains through a multi-embodiment action tokenizer. GEA is trained with supervised learning on a large dataset of embodied experiences and…Apple Machine Learning Research
Formula 1® (F1) races are high-stakes affairs where operational efficiency is paramount. During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry. Determining the root cause of these issues and preventing it from happening again takes significant effort. Due to the event schedule and change freeze periods, it can take up to 3 weeks to triage, test, and resolve a critical issue, requiring investigations across teams including development, operations, infrastructure, and networking.
“We used to have a recurring issue with the web API system, which was slow to respond and provided inconsistent outputs. Teams spent around 15 full engineer days to iteratively resolve the issue over several events: reviewing logs, inspecting anomalies, and iterating on the fixes,” says Lee Wright, head of IT Operations at Formula 1. Recognizing this challenge as an opportunity for innovation, F1 partnered with Amazon Web Services (AWS) to develop an AI-driven solution using Amazon Bedrock to streamline issue resolution. In this post, we show you how F1 created a purpose-built root cause analysis (RCA) assistant to empower users such as operations engineers, software developers, and network engineers to troubleshoot issues, narrow down on the root cause, and significantly reduce the manual intervention required to fix recurrent issues during and after live events. We’ve also provided a GitHub repo for a general-purpose version of the accompanying chat-based application.
Users can ask the RCA chat-based assistant questions using natural language prompts, with the solution troubleshooting in the background, identifying potential reasons for the incident and recommending next steps. The assistant is connected to internal and external systems, with the capability to query various sources such as SQL databases, Amazon CloudWatch logs, and third-party tools to check the live system health status. Because the solution doesn’t require domain-specific knowledge, it even allows engineers of different disciplines and levels of expertise to resolve issues.
“With the RCA tool, the team could narrow down the root cause and implement a solution within 3 days, including deployments and testing over a race weekend. The system not only saves time on active resolution, it also routes the issue to the correct team to resolve, allowing teams to focus on other high-priority tasks, like building new products to enhance the race experience,” adds Wright. By using generative AI, engineers can receive a response within 5–10 seconds on a specific query and reduce the initial triage time from more than a day to less than 20 minutes. The end-to-end time to resolution has been reduced by as much as 86%.
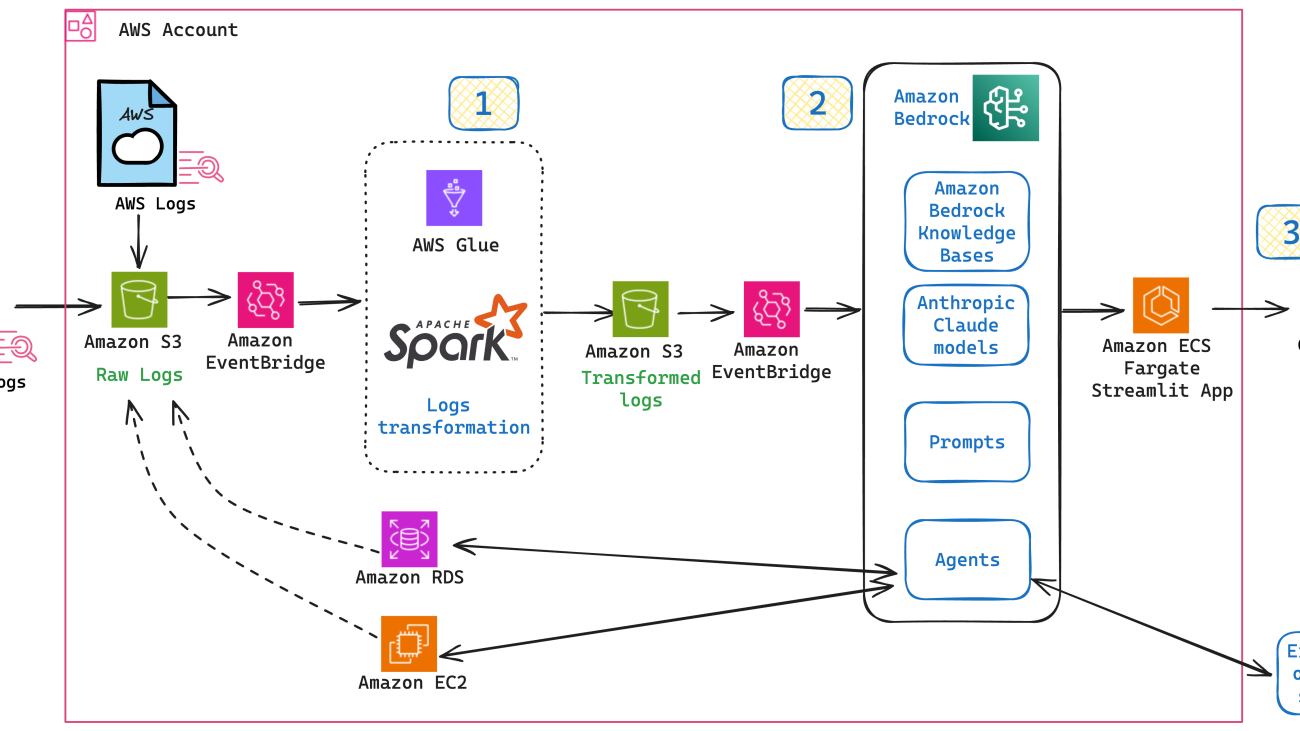
In collaboration with the AWS Prototyping team, F1 embarked on a 5-week prototype to demonstrate the feasibility of this solution. The objective was to use AWS to replicate and automate the current manual troubleshooting process for two candidate systems. As a starting point, the team reviewed real-life issues, drafting a flowchart outlining 1) the troubleshooting process, 2) teams and systems involved, 3) required live checks, and 4) logs investigations required for each scenario. The following is a diagram of the solution architecture.

To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark. The transformed logs were stored in a separate S3 bucket, while another EventBridge schedule fed these transformed logs into Amazon Bedrock Knowledge Bases, an end-to-end managed Retrieval Augmented Generation (RAG) workflow capability, allowing the chat assistant to query them efficiently. Amazon Bedrock Agents facilitates interaction with internal systems such as databases and Amazon Elastic Compute Cloud (Amazon EC2) instances and external systems such as Jira and Datadog. Anthropic’s Claude 3 models (the latest model at the time of development) were used to orchestrate and generate high-quality responses, maintaining accurate and relevant information from the chat assistant. Finally, the chat application is hosted in an AWS Fargate for Amazon Elastic Container Service (Amazon ECS) service, providing scalability and reliability to handle variable loads without compromising performance.
The following sections further explain the main components of the solution: ETL pipelines to transform the log data, agentic RAG implementation, and the chat application.
Preparing your data to provide quality results is the first step in an AI project. AWS helps you improve your data quality over time so you can innovate with trust and confidence. Amazon CloudWatch gives you visibility into system-wide performance and allows you to set alarms, automatically react to changes, and gain a unified view of operational health.
For this solution, AWS Glue and Apache Spark handled data transformations from these logs and other data sources to improve the chatbot’s accuracy and cost efficiency. AWS Glue helps you discover, prepare, and integrate your data at scale. For this project, there was a simple three-step process for the log data transformation. The following is a diagram of the data processing flow.
 |
Amazon Bedrock was used to build an agentic (agent-based) RAG solution for the RCA assistant. Amazon Bedrock Agents streamlines workflows and automates repetitive tasks. Agents uses the reasoning capability of foundation models (FMs) to break down user-requested tasks into multiple steps. They use the provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using RAG to provide a final response to the end user.
Knowledge bases are essential to the RAG framework, querying business data sources and adding relevant context to answer your questions. Amazon Bedrock Agents also allows interaction with internal and external systems, such as querying database statuses to check their health, querying Datadog for live application monitoring, and raising Jira tickets for future analysis and investigation. Anthropic’s Claude 3 Sonnet model was selected for informative and comprehensive answers and the ability to understand diversified questions. For example, it can correctly interpret user input date formats such as “2024-05-10” or “10th May 2024.”
Amazon Bedrock Agents integrates with Amazon Bedrock Knowledge Bases, providing the end user with a single and consolidated frontend. The RCA agent considers the tools and knowledge bases available, then intelligently and autonomously creates an execution plan. After the agent receives documents from the knowledge base and responses from tool APIs, it consolidates the information to feed it to the large language model (LLM) and generate the final response. The following diagram illustrates the orchestration flow.

With Amazon Bedrock, you have full control over the data used to customize the FMs for generative AI applications such as RCA. Data is encrypted in transit and at rest. Identity-based policies provide further control over your data, helping you manage what actions roles can perform, on which resources, and under what conditions.
To evaluate the system health of RCA, the agent runs a series of checks, such as AWS Boto3 API calls (for example, boto3_client.describe_security_groups, to determine if an IP address is allowed to access system) or database SQL queries (SQL: sys.dm_os_schedulers, to query the database system metrics such as CPU, memory or user locks).
To help protect these systems against potential hallucinations or even prompt injections, agents aren’t allowed to create their own database queries or system health checks on the fly. Instead, a series of controlled SQL queries and API checks were implemented, following the principle of least privilege (PoLP). This layer also validates the input and output schema (see Powertools docs), making sure this aspect is also controlled. To learn more about protecting your application, refer to the ArXiv paper, From Prompt Injections to SQL Injection Attacks. The following code is an example.
The chat assistant UI was developed using the Streamlit framework, which is Python-based and provides simple yet powerful application widgets. In the Streamlit app, users can test their Amazon Bedrock agent iterations seamlessly by providing or replacing the agent ID and alias ID. In the chat assistant, the full conversation history is displayed, and the conversation can be reset by choosing Clear. The response from the LLM application consists of two parts. On the left is the final neutral response based on the user’s questions. On the right is the trace of LLM agent orchestration plans and executions, which is hidden by default to keep the response clean and concise. The trace can be reviewed and examined by the user to make sure that the correct tools are invoked and the correct documents are retrieved by the LLM chatbot.
A general-purpose version of the chat-based application is available from this GitHub repo, where you can experiment with the solution and modify it for additional use cases.
In the following demo, the scenario involves user complaints that they can’t connect to F1 databases. Using the chat assistant, users can check if the database driver version they’re using is supported by the server. Additionally, users can verify EC2 instance network connectivity by providing the EC2 instance ID and AWS Region. These checks are performed by API tools accessible by the agent. Furthermore, users can troubleshoot website access issues by checking system logs. In the demo, users provide an error code and date, and the chat assistant retrieves relevant logs from Amazon Bedrock Knowledge Bases to answer their questions and provide information for future analysis.

Technical engineers can now query to investigate system errors and issues using natural language. It’s integrated with existing incident management tools (such as Jira) to facilitate seamless communication and ticket creation. In most cases, the chat assistant can quickly identify the root cause and provide remediation recommendations, even if multiple issues are present. When warranted, particularly challenging issues are automatically escalated to the F1 engineering team for investigation, allowing engineers to better prioritize their tasks.
In this post, we explained how F1 and AWS have developed a root cause analysis (RCA) assistant powered by Amazon Bedrock to reduce manual intervention and accelerate the resolution of recurrent operational issues during races from weeks to minutes. The RCA assistant enables the F1 team to spend more time on innovation and improving its services, ultimately delivering an exceptional experience for fans and partners. The successful collaboration between F1 and AWS showcases the transformative potential of generative AI in empowering teams to accomplish more in less time.
Learn more about how AWS helps F1 on and off the track.
 Carlos Contreras is a Senior Big Data and Generative AI Architect, at Amazon Web Services. Carlos specializes in designing and developing scalable prototypes for customers, to solve their most complex business challenges, implementing RAG and Agentic solutions with Distributed Data Processing techniques.
Carlos Contreras is a Senior Big Data and Generative AI Architect, at Amazon Web Services. Carlos specializes in designing and developing scalable prototypes for customers, to solve their most complex business challenges, implementing RAG and Agentic solutions with Distributed Data Processing techniques.
 Hin Yee Liu is a Senior Prototyping Engagement Manager at Amazon Web Services. She helps AWS customers to bring their big ideas to life and accelerate the adoption of emerging technologies. Hin Yee works closely with customer stakeholders to identify, shape and deliver impactful use cases leveraging Generative AI, AI/ML, Big Data, and Serverless technologies using agile methodologies. In her free time, she enjoys knitting, travelling and strength training.
Hin Yee Liu is a Senior Prototyping Engagement Manager at Amazon Web Services. She helps AWS customers to bring their big ideas to life and accelerate the adoption of emerging technologies. Hin Yee works closely with customer stakeholders to identify, shape and deliver impactful use cases leveraging Generative AI, AI/ML, Big Data, and Serverless technologies using agile methodologies. In her free time, she enjoys knitting, travelling and strength training.
 Olga Miloserdova is an Innovation Lead at Amazon Web Services, where she supports executive leadership teams across industries to drive innovation initiatives leveraging Amazon’s customer-centric Working Backwards methodology.
Olga Miloserdova is an Innovation Lead at Amazon Web Services, where she supports executive leadership teams across industries to drive innovation initiatives leveraging Amazon’s customer-centric Working Backwards methodology.
 Ying Hou, PhD is a Senior GenAI Prototyping Architect at AWS, where she collaborates with customers to build cutting-edge GenAI applications, specialising in RAG and agentic solutions. Her expertise spans GenAI, ASR, Computer Vision, NLP, and time series prediction models. When she’s not architecting AI solutions, she enjoys spending quality time with her family, getting lost in novels, and exploring the UK’s national parks.
Ying Hou, PhD is a Senior GenAI Prototyping Architect at AWS, where she collaborates with customers to build cutting-edge GenAI applications, specialising in RAG and agentic solutions. Her expertise spans GenAI, ASR, Computer Vision, NLP, and time series prediction models. When she’s not architecting AI solutions, she enjoys spending quality time with her family, getting lost in novels, and exploring the UK’s national parks.

 An overview of our latest expert tools in Flood Hub and our partnerships to support vulnerable communities.Read More
An overview of our latest expert tools in Flood Hub and our partnerships to support vulnerable communities.Read More

Cycling is a fun way to stay fit, enjoy nature, and connect with friends and acquaintances. However, riding is becoming increasingly dangerous, especially in situations where cyclists and cars share the road. According to the NHTSA, in the United States an average of 883 people on bicycles are killed in traffic crashes, with an average of about 45,000 injury-only crashes reported annually. While total bicycle fatalities only account for just over 2% of all traffic fatalities in the United States, as a cyclist, it’s still terrifying to be pushed off the road by a large SUV or truck. To better protect themselves, many cyclists are starting to ride with cameras mounted to the front or back of their bicycle. In this blog post, I will demonstrate a machine learning solution that cyclists can use to better identify close calls.
Many US states and countries throughout the world have some sort of 3-feet law. A 3-feet law requires motor vehicles to provide about 3 feet (1 meter) of distance when passing a bicycle. To promote safety on the road, cyclists are increasingly recording their rides, and if they encounter a dangerous situation where they aren’t given an appropriate safe distance, they can provide a video of the encounter to local law enforcement to help correct behavior. However, finding a single encounter in a recording of a multi-hour ride is time consuming and often requires specialized video skills to generate a short clip of the encounter.
To solve some of these problems, I have developed a simple solution using Amazon Rekognition video analysis. Amazon Rekognition can detect labels (essentially objects) and the timestamp of when that object is detected in a video. Amazon Rekognition can be used to quickly find any vehicles that appear in the video of a recorded ride.
If a cyclist’s camera records a passing vehicle, it must then determine if the vehicle is too close to the bicycle—in other words, if the vehicle is within the 3-foot range set by law. If it is, then I want to generate a clip of the encounter, which can be provided to the relevant authorities. The following figure shows the view from a cyclist’s camera with bounding boxes that identify a vehicle that’s passing too close to the bicycle. A box at the bottom of the image shows the approximate 3-foot area around the bicycle.

The architecture of the solution is shown in the following figure.

The steps of the solution are:
StartLabelDetection API is configured to detect Bus, Car, Fire Truck, Pickup Truck, Truck, Limo, and Moving Van as labels. It ignores other related non-vehicle labels like License Plate, Wheel, Tire, and Car Mirror.CreateJob APITo use the solution outlined in this post, you must have:
![]()
To test the solution, I have a sample video where I asked a stunt driver to drive very closely to me.
To begin the video processing, I upload the video to the S3 bucket (the InputBucket from the Outputs tab). The bucket has encryption enabled, so under Properties, I choose Specify an encryption key and select Use bucket settings for default encryption. Choosing Upload begins the upload process, as shown in the following figure.

After a moment, the step function begins processing. After a few minutes, you will receive an email with links to any encounters identified, as shown in the following figure.

In my case, it identified two encounters. In the first encounter identified, I rode too close to a parked car. However, in the second encounter identified, it shows a dangerous encounter that I experienced with my stunt driver.
Had this been an actual dangerous encounter, the video clip could be provided to the appropriate authorities to help change behavior and make the road safer for everyone.
Because this is a fully serverless solution, you only pay for what you use. With Amazon Rekognition, you pay for the minutes of video that are processed. With MediaConvert, you pay for normalized minutes of video processed, which is each minute of video output with multipliers that apply based on features used. The solution’s use of Lambda, Step Functions, and SNS are minimal and will likely fall under the free tier for most users.
To delete the resources created as part of this solution, go to the CloudFormation console, select the stack that was deployed, and choose Delete.
In this example I demonstrated how to use Amazon Rekognition video analysis in a unique scenario. Amazon Rekognition is a powerful computer vision tool that allows you to get insights out of images or video without the overhead of building or managing a machine learning model. Of course, Amazon Rekognition can also handle more advanced use cases than the one I demonstrated here.
In this example I demonstrated how using Amazon Rekognition with other serverless services can yield a serverless video processing workflow that—in this case—can help improve the safety of cyclists. While you might not be an avid cyclist, the solution demonstrated here can be extended to a variety of use cases and industries. For example, this solution could be extended to detect wildlife on nature cameras or you could use Amazon Rekognition streaming video events to detect people and packages in security video.
Get started today by using Amazon Rekognition for your computer vision use case.
 Mike George is a Principal Solutions Architect at Amazon Web Services (AWS) based in Salt Lake City, Utah. He enjoys helping customers solve their technology problems. His interests include software engineering, security, artificial intelligence (AI), and machine learning (ML).
Mike George is a Principal Solutions Architect at Amazon Web Services (AWS) based in Salt Lake City, Utah. He enjoys helping customers solve their technology problems. His interests include software engineering, security, artificial intelligence (AI), and machine learning (ML).
4DBInfer enables model comparison across datasets, predictive tasks, database-to-graph extraction methods, and graph-based predictive architectures.Read More

 39 students in Ireland from underrepresented backgrounds have been awarded scholarships to study STEM courses, with Google.org support.Read More
39 students in Ireland from underrepresented backgrounds have been awarded scholarships to study STEM courses, with Google.org support.Read More