In recent years, graph neural network (GNN) based models showed promising results in simulating complex physical systems. However, training dedicated graph network simulator can be costly, as most models are confined to fully supervised training. Extensive data generated from traditional simulators is required to train the model. It remained unexplored how transfer learning could be applied to improve the model performance and training efficiency. In this work, we introduce a pretraining and transfer learning paradigm for graph network simulator.
First, We proposed the scalable graph U-net…Apple Machine Learning Research
Build a dynamic, role-based AI agent using Amazon Bedrock inline agents
AI agents continue to gain momentum, as businesses use the power of generative AI to reinvent customer experiences and automate complex workflows. We are seeing Amazon Bedrock Agents applied in investment research, insurance claims processing, root cause analysis, advertising campaigns, and much more. Agents use the reasoning capability of foundation models (FMs) to break down user-requested tasks into multiple steps. They use developer-provided instructions to create an orchestration plan and carry out that plan by securely invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to accurately handle the user’s request.
Although organizations see the benefit of agents that are defined, configured, and tested as managed resources, we have increasingly seen the need for an additional, more dynamic way to invoke agents. Organizations need solutions that adjust on the fly—whether to test new approaches, respond to changing business rules, or customize solutions for different clients. This is where the new inline agents capability in Amazon Bedrock Agents becomes transformative. It allows you to dynamically adjust your agent’s behavior at runtime by changing its instructions, tools, guardrails, knowledge bases, prompts, and even the FMs it uses—all without redeploying your application.
In this post, we explore how to build an application using Amazon Bedrock inline agents, demonstrating how a single AI assistant can adapt its capabilities dynamically based on user roles.
Inline agents in Amazon Bedrock Agents
This runtime flexibility enabled by inline agents opens powerful new possibilities, such as:
- Rapid prototyping – Inline agents minimize the time-consuming create/update/prepare cycles traditionally required for agent configuration changes. Developers can instantly test different combinations of models, tools, and knowledge bases, dramatically accelerating the development process.
- A/B testing and experimentation – Data science teams can systematically evaluate different model-tool combinations, measure performance metrics, and analyze response patterns in controlled environments. This empirical approach enables quantitative comparison of configurations before production deployment.
- Subscription-based personalization – Software companies can adapt features based on each customer’s subscription level, providing more advanced tools for premium users.
- Persona-based data source integration – Institutions can adjust content complexity and tone based on the user’s profile, providing persona-appropriate explanations and resources by changing the knowledge bases associated to the agent on the fly.
- Dynamic tool selection – Developers can create applications with hundreds of APIs, and quickly and accurately carry out tasks by dynamically choosing a small subset of APIs for the agent to consider for a given request. This is particularly helpful for large software as a service (SaaS) platforms needing multi-tenant scaling.
Inline agents expand your options for building and deploying agentic solutions with Amazon Bedrock Agents. For workloads needing managed and versioned agent resources with a pre-determined and tested configuration (specific model, instructions, tools, and so on), developers can continue to use InvokeAgent on resources created with CreateAgent. For workloads that need dynamic runtime behavior changes for each agent invocation, you can use the new InvokeInlineAgent API. With either approach, your agents will be secure and scalable, with configurable guardrails, a flexible set of model inference options, native access to knowledge bases, code interpretation, session memory, and more.
Solution overview
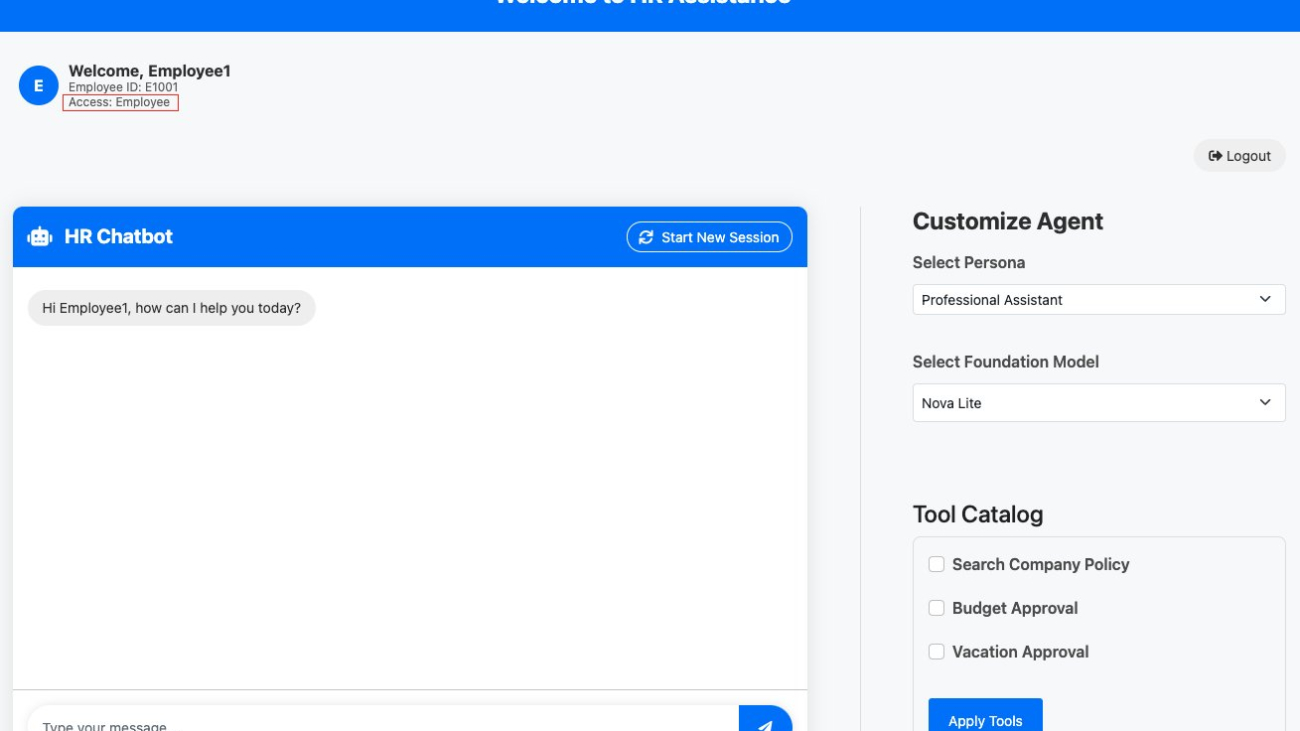
Our HR assistant example shows how to build a single AI assistant that adapts to different user roles using the new inline agent capabilities in Amazon Bedrock Agents. When users interact with the assistant, the assistant dynamically configures agent capabilities (such as model, instructions, knowledge bases, action groups, and guardrails) based on the user’s role and their specific selections. This approach creates a flexible system that adjusts its functionality in real time, making it more efficient than creating separate agents for each user role or tool combination. The complete code for this HR assistant example is available on our GitHub repo.
This dynamic tool selection enables a personalized experience. When an employee logs in without direct reports, they see a set of tools that they have access to based on their role. They can select from options like requesting vacation time, checking company policies using the knowledge base, using a code interpreter for data analysis, or submitting expense reports. The inline agent assistant is then configured with only these selected tools, allowing it to assist the employee with their chosen tasks. In a real-world example, the user would not need to make the selection, because the application would make that decision and automatically configure the agent invocation at runtime. We make it explicit in this application so that you can demonstrate the impact.
Similarly, when a manager logs in to the same system, they see an extended set of tools reflecting their additional permissions. In addition to the employee-level tools, managers have access to capabilities like running performance reviews. They can select which tools they want to use for their current session, instantly configuring the inline agent with their choices.
The inclusion of knowledge bases is also adjusted based on the user’s role. Employees and managers see different levels of company policy information, with managers getting additional access to confidential data like performance review and compensation details. For this demo, we’ve implemented metadata filtering to retrieve only the appropriate level of documents based on the user’s access level, further enhancing efficiency and security.
Let’s look at how the interface adapts to different user roles.
The employee view provides access to essential HR functions like vacation requests, expense submissions, and company policy lookups. Users can select which of these tools they want to use for their current session.

The manager view extends these options to include supervisory functions like compensation management, demonstrating how the inline agent can be configured with a broader set of tools based on user permissions.

The manager view extends these capabilities to include supervisory functions like compensation management, demonstrating how the inline agent dynamically adjusts its available tools based on user permissions. Without inline agents, we would need to build and maintain two separate agents.
As shown in the preceding screenshots, the same HR assistant offers different tool selections based on the user’s role. An employee sees options like Knowledge Base, Apply Vacation Tool, and Submit Expense, whereas a manager has additional options like Performance Evaluation. Users can select which tools they want to add to the agent for their current interaction.
This flexibility allows for quick adaptation to user needs and preferences. For instance, if the company introduces a new policy for creating business travel requests, the tool catalog can be quickly updated to include a Create Business Travel Reservation tool. Employees can then choose to add this new tool to their agent configuration when they need to plan a business trip, or the application could automatically do so based on their role.
With Amazon Bedrock inline agents, you can create a catalog of actions that is dynamically selected by the application or by users of the application. This increases the level of flexibility and adaptability of your solutions, making them a perfect fit for navigating the complex, ever-changing landscape of modern business operations. Users have more control over their AI assistant’s capabilities, and the system remains efficient by only loading the necessary tools for each interaction.
Technical foundation: Dynamic configuration and action selection
Inline agents allow dynamic configuration at runtime, enabling a single agent to effectively perform the work of many. By specifying action groups and modifying instructions on the fly, even within the same session, you can create versatile AI applications that adapt to various scenarios without multiple agent deployments.
The following are key points about inline agents:
- Runtime configuration – Change the agent’s configuration, including its FM, at runtime. This enables rapid experimentation and adaptation without redeploying the application, reducing development cycles.
- Governance at tool level – Apply governance and access control at the tool level. With agents changing dynamically at runtime, tool-level governance helps maintain security and compliance regardless of the agent’s configuration.
- Agent efficiency – Provide only necessary tools and instructions at runtime to reduce token usage and improve the agent accuracy. With fewer tools to choose from, it’s less complicated for the agent to select the right one, reducing hallucinations in the tool selection process. This approach can also lead to lower costs and improved latency compared to static agents because removing unnecessary tools, knowledge bases, and instructions reduces the number of input and output tokens being processed by the agent’s large language model (LLM).
- Flexible action catalog – Create reusable actions for dynamic selection based on specific needs. This modular approach simplifies maintenance, updates, and scalability of your AI applications.
The following are examples of reusable actions:
- Enterprise system integration – Connect with systems like Salesforce, GitHub, or databases
- Utility tools – Perform common tasks such as sending emails or managing calendars
- Team-specific API access – Interact with specialized internal tools and services
- Data processing – Analyze text, structured data, or other information
- External services – Fetch weather updates, stock prices, or perform web searches
- Specialized ML models – Use specific machine learning (ML) models for targeted tasks
When using inline agents, you configure parameters for the following:
- Contextual tool selection based on user intent or conversation flow
- Adaptation to different user roles and permissions
- Switching between communication styles or personas
- Model selection based on task complexity
The inline agent uses the configuration you provide at runtime, allowing for highly flexible AI assistants that efficiently handle various tasks across different business contexts.
Building an HR assistant using inline agents
Let’s look at how we built our HR Assistant using Amazon Bedrock inline agents:
- Create a tool catalog – We developed a demo catalog of HR-related tools, including:
- Knowledge Base – Using Amazon Bedrock Knowledge Bases for accessing company policies and guidelines based on the role of the application user. In order to filter the knowledge base content based on the user’s role, you also need to provide a metadata file specifying the type of employee’s roles that can access each file
- Apply Vacation – For requesting and tracking time off.
- Expense Report – For submitting and managing expense reports.
- Code Interpreter – For performing calculations and data analysis.
- Compensation Management – for conducting and reviewing employee compensation assessments (manager only access).
- Set conversation tone – We defined multiple conversation tones to suit different interaction styles:
- Professional – For formal, business-like interactions.
- Casual – For friendly, everyday support.
- Enthusiastic – For upbeat, encouraging assistance.
- Implement access control – We implemented role-based access control. The application backend checks the user’s role (employee or manager) and provides access to appropriate tools and information and passes this information to the inline agent. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses. The system allows for dynamic tool use at runtime. Users can switch personas or add and remove tools during their session, allowing the agent to adapt to different conversation needs in real time.
- Integrate the agent with other services and tools – We connected the inline agent to:
- Amazon Bedrock Knowledge Bases for company policies, with metadata filtering for role-based access.
- AWS Lambda functions for executing specific actions (such as submitting vacation requests or expense reports).
- A code interpreter tool for performing calculations and data analysis.
- Create the UI – We created a Flask-based UI that performs the following actions:
- Displays available tools based on the user’s role.
- Allows users to select different personas.
- Provides a chat window for interacting with the HR assistant.
To understand how this dynamic role-based functionality works under the hood, let’s examine the following system architecture diagram.

As shown in preceding architecture diagram, the system works as follows:
- The end-user logs in and is identified as either a manager or an employee.
- The user selects the tools that they have access to and makes a request to the HR assistant.
- The agent breaks down the problems and uses the available tools to solve for the query in steps, which may include:
- Amazon Bedrock Knowledge Bases (with metadata filtering for role-based access).
- Lambda functions for specific actions.
- Code interpreter tool for calculations.
- Compensation tool (accessible only to managers to submit base pay raise requests).
- The application uses the Amazon Bedrock inline agent to dynamically pass in the appropriate tools based on the user’s role and request.
- The agent uses the selected tools to process the request and provide a response to the user.
This approach provides a flexible, scalable solution that can quickly adapt to different user roles and changing business needs.
Conclusion
In this post, we introduced the Amazon Bedrock inline agent functionality and highlighted its application to an HR use case. We dynamically selected tools based on the user’s roles and permissions, adapted instructions to set a conversation tone, and selected different models at runtime. With inline agents, you can transform how you build and deploy AI assistants. By dynamically adapting tools, instructions, and models at runtime, you can:
- Create personalized experiences for different user roles
- Optimize costs by matching model capabilities to task complexity
- Streamline development and maintenance
- Scale efficiently without managing multiple agent configurations
For organizations demanding highly dynamic behavior—whether you’re an AI startup, SaaS provider, or enterprise solution team—inline agents offer a scalable approach to building intelligent assistants that grow with your needs. To get started, explore our GitHub repo and HR assistant demo application, which demonstrate key implementation patterns and best practices.
To learn more about how to be most successful in your agent journey, read our two-part blog series:
- Best practices for building robust generative AI applications with Amazon Bedrock Agents – Part 1
- Best practices for building robust generative AI applications with Amazon Bedrock Agents – Part 2
To get started with Amazon Bedrock Agents, check out the following GitHub repository with example code.
About the authors
 Ishan Singh is a Generative AI Data Scientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value. Outside of work, he enjoys playing volleyball, exploring local bike trails, and spending time with his wife and dog, Beau.
Ishan Singh is a Generative AI Data Scientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value. Outside of work, he enjoys playing volleyball, exploring local bike trails, and spending time with his wife and dog, Beau.
 Maira Ladeira Tanke is a Senior Generative AI Data Scientist at AWS. With a background in machine learning, she has over 10 years of experience architecting and building AI applications with customers across industries. As a technical lead, she helps customers accelerate their achievement of business value through generative AI solutions on Amazon Bedrock. In her free time, Maira enjoys traveling, playing with her cat, and spending time with her family someplace warm.
Maira Ladeira Tanke is a Senior Generative AI Data Scientist at AWS. With a background in machine learning, she has over 10 years of experience architecting and building AI applications with customers across industries. As a technical lead, she helps customers accelerate their achievement of business value through generative AI solutions on Amazon Bedrock. In her free time, Maira enjoys traveling, playing with her cat, and spending time with her family someplace warm.
 Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build generative AI solutions. His focus since early 2023 has been leading solution architecture efforts for the launch of Amazon Bedrock, the flagship generative AI offering from AWS for builders. Mark’s work covers a wide range of use cases, with a primary interest in generative AI, agents, and scaling ML across the enterprise. He has helped companies in insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services. Mark holds six AWS certifications, including the ML Specialty Certification.
Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build generative AI solutions. His focus since early 2023 has been leading solution architecture efforts for the launch of Amazon Bedrock, the flagship generative AI offering from AWS for builders. Mark’s work covers a wide range of use cases, with a primary interest in generative AI, agents, and scaling ML across the enterprise. He has helped companies in insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services. Mark holds six AWS certifications, including the ML Specialty Certification.
 Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS, experienced in Software Engineering, Enterprise Architecture, and AI/ML. He is deeply passionate about exploring the possibilities of generative AI. He collaborates with customers to help them build well-architected applications on the AWS platform, and is dedicated to solving technology challenges and assisting with their cloud journey.
Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS, experienced in Software Engineering, Enterprise Architecture, and AI/ML. He is deeply passionate about exploring the possibilities of generative AI. He collaborates with customers to help them build well-architected applications on the AWS platform, and is dedicated to solving technology challenges and assisting with their cloud journey.
 Ashrith Chirutani is a Software Development Engineer at Amazon Web Services (AWS). He specializes in backend system design, distributed architectures, and scalable solutions, contributing to the development and launch of high-impact systems at Amazon. Outside of work, he spends his time playing ping pong and hiking through Cascade trails, enjoying the outdoors as much as he enjoys building systems.
Ashrith Chirutani is a Software Development Engineer at Amazon Web Services (AWS). He specializes in backend system design, distributed architectures, and scalable solutions, contributing to the development and launch of high-impact systems at Amazon. Outside of work, he spends his time playing ping pong and hiking through Cascade trails, enjoying the outdoors as much as he enjoys building systems.
 Shubham Divekar is a Software Development Engineer at Amazon Web Services (AWS), working in Agents for Amazon Bedrock. He focuses on developing scalable systems on the cloud that enable AI applications frameworks and orchestrations. Shubham also has a background in building distributed, scalable, high-volume-high-throughput systems in IoT architectures.
Shubham Divekar is a Software Development Engineer at Amazon Web Services (AWS), working in Agents for Amazon Bedrock. He focuses on developing scalable systems on the cloud that enable AI applications frameworks and orchestrations. Shubham also has a background in building distributed, scalable, high-volume-high-throughput systems in IoT architectures.
 Vivek Bhadauria is a Principal Engineer for Amazon Bedrock. He focuses on building deep learning-based AI and computer vision solutions for AWS customers. Oustide of work, Vivek enjoys trekking and following cricket.
Vivek Bhadauria is a Principal Engineer for Amazon Bedrock. He focuses on building deep learning-based AI and computer vision solutions for AWS customers. Oustide of work, Vivek enjoys trekking and following cricket.
Use language embeddings for zero-shot classification and semantic search with Amazon Bedrock
In this post, we discuss what embeddings are, show how to practically use language embeddings, and explore how to use them to add functionality such as zero-shot classification and semantic search. We then use Amazon Bedrock and language embeddings to add these features to a really simple syndication (RSS) aggregator application.
Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using Amazon Web Services (AWS) services without having to manage infrastructure. For this post, we use the Cohere v3 Embed model on Amazon Bedrock to create our language embeddings.
Use case: RSS aggregator
To demonstrate some of the possible uses of these language embeddings, we developed an RSS aggregator website. RSS is a web feed that allows publications to publish updates in a standardized, computer-readable way. On our website, users can subscribe to an RSS feed and have an aggregated, categorized list of the new articles. We use embeddings to add the following functionalities:
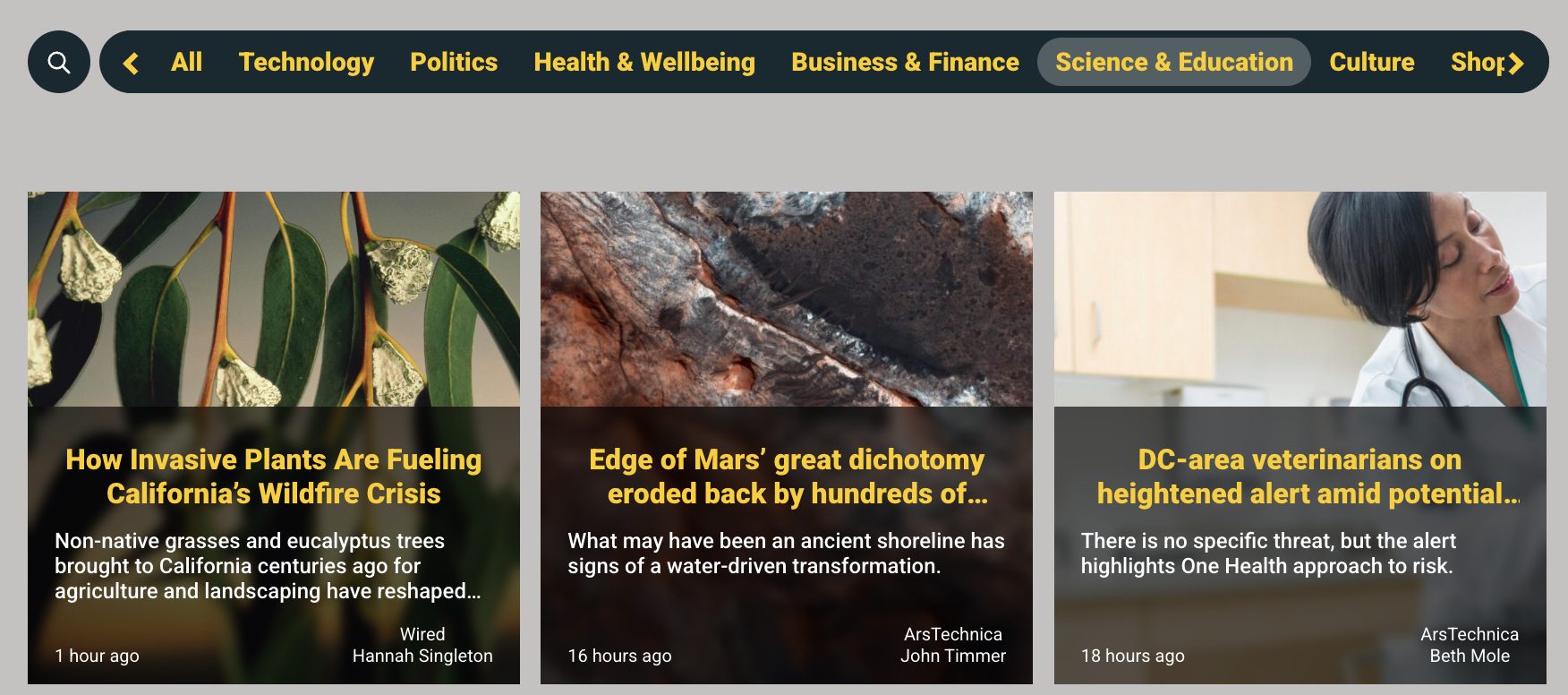
- Zero-shot classification – Articles are classified between different topics. There are some default topics, such as Technology, Politics, and Health & Wellbeing, as shown in the following screenshot. Users can also create their own topics.
- Semantic search – Users can search their articles using semantic search, as shown in the following screenshot. Users can not only search for a specific topic but also narrow their search by factors such as tone or style.
This post uses this application as a reference point to discuss the technical implementation of the semantic search and zero-shot classification features.
Solution overview
This solution uses the following services:
- Amazon API Gateway – The API is accessible through Amazon API Gateway. Caching is performed on Amazon CloudFront for certain topics to ease the database load.
- Amazon Bedrock with Cohere v3 Embed – The articles and topics are converted into embeddings with the help of Amazon Bedrock and Cohere v3 Embed.
- Amazon CloudFront and Amazon Simple Storage Service (Amazon S3) – The single-page React application is hosted using Amazon S3 and Amazon CloudFront.
- Amazon Cognito – Authentication is done using Amazon Cognito user pools.
- Amazon EventBridge – Amazon EventBridge and EventBridge schedules are used to coordinate new updates.
- AWS Lambda – The API is a Fastify application written in TypeScript. It’s hosted on AWS Lambda.
- Amazon Aurora PostgreSQL-Compatible Edition and pgvector – Amazon Aurora PostgreSQL-Compatible is used as the database, both for the functionality of the application itself and as a vector store using pgvector.
- Amazon RDS Proxy – Amazon RDS Proxy is used for connection pooling.
- Amazon Simple Queue Service (Amazon SQS) – Amazon SQS is used to queue events. It consumes one event at a time so it doesn’t hit the rate limit of Cohere in Amazon Bedrock.
The following diagram illustrates the solution architecture.

What are embeddings?
This section offers a quick primer on what embeddings are and how they can be used.
Embeddings are numerical representations of concepts or objects, such as language or images. In this post, we discuss language embeddings. By reducing these concepts to numerical representations, we can then use them in a way that a computer can understand and operate on.
Let’s take Berlin and Paris as an example. As humans, we understand the conceptual links between these two words. Berlin and Paris are both cities, they’re capitals of their respective countries, and they’re both in Europe. We understand their conceptual similarities almost instinctively, because we can create a model of the world in our head. However, computers have no built-in way of representing these concepts.
To represent these concepts in a way a computer can understand, we convert them into language embeddings. Language embeddings are high dimensional vectors that learn their relationships with each other through the training of a neural network. During training, the neural network is exposed to enormous amounts of text and learns patterns based on how words are colocated and relate to each other in different contexts.
Embedding vectors allow computers to model the world from language. For instance, if we embed “Berlin” and “Paris,” we can now perform mathematical operations on these embeddings. We can then observe some fairly interesting relationships. For instance, we could do the following: Paris – France + Germany ~= Berlin. This is because the embeddings capture the relationships between the words “Paris” and “France” and between “Germany” and “Berlin”—specifically, that Paris and Berlin are both capital cities of their respective countries.
The following graph shows the word vector distance between countries and their respective capitals.

Subtracting “France” from “Paris” removes the country semantics, leaving a vector representing the concept of a capital city. Adding “Germany” to this vector, we are left with something closely resembling “Berlin,” the capital of Germany. The vectors for this relationship are shown in the following graph.

For our use case, we use the pre-trained Cohere Embeddings model in Amazon Bedrock, which embeds entire texts rather than a single word. The embeddings represent the meaning of the text and can be operated on using mathematical operations. This property can be useful to map relationships such as similarity between texts.
Zero-shot classification
One way in which we use language embeddings is by using their properties to calculate how similar an article is to one of the topics.
To do this, we break down a topic into a series of different and related embeddings. For instance, for culture, we have a set of embeddings for sports, TV programs, music, books, and so on. We then embed the incoming title and description of the RSS articles, and calculate the similarity against the topic embeddings. From this, we can assign topic labels to an article.
The following figure illustrates how this works. The embeddings that Cohere generates are highly dimensional, containing 1,024 values (or dimensions). However, to demonstrate how this system works, we use an algorithm designed to reduce the dimensionality of the embeddings, t-distributed Stochastic Neighbor Embedding (t-SNE), so that we can view them in two dimensions. The following image uses these embeddings to visualize how topics are clustered based on similarity and meaning.

You can use the embedding of an article and check the similarity of the article against the preceding embeddings. You can then say that if an article is clustered closely to one of these embeddings, it can be classified with the associated topic.
This is the k-nearest neighbor (k-NN) algorithm. This algorithm is used to perform classification and regression tasks. In k-NN, you can make assumptions around a data point based on its proximity to other data points. For instance, you can say that an article that has proximity to the music topic shown in the preceding diagram can be tagged with the culture topic.
The following figure demonstrates this with an ArsTechnica article. We plot against the embedding of an article’s title and description: (The climate is changing so fast that we haven’t seen how bad extreme weather could get: Decades-old statistics no longer represent what is possible in the present day).

The advantage of this approach is that you can add custom, user-generated topics. You can create a topic by first creating a series of embeddings of conceptually related items. For instance, an AI topic would be similar to the embeddings for AI, Generative AI, LLM, and Anthropic, as shown in the following screenshot.

In a traditional classification system, we’d be required to train a classifier—a supervised learning task where we’d need to provide a series of examples to establish whether an article belongs to its respective topic. Doing so can be quite an intensive task, requiring labeled data and training the model. For our use case, we can provide examples, create a cluster, and tag articles without having to provide labeled examples or train additional models. This is shown in the following screenshot of results page of our website.
In our application, we ingest new articles on a schedule. We use EventBridge schedules to periodically call a Lambda function, which checks if there are new articles. If there are, it creates an embedding from them using Amazon Bedrock and Cohere.
We calculate the article’s distance to the different topic embeddings, and can then determine whether the article belongs to that category. This is done with Aurora PostgreSQL with pgvector. We store the embeddings of the topics and then calculate their distance using the following SQL query:
The <-> operator in the preceding code calculates the Euclidean distance between the article and the topic embedding. This number allows us to understand how close an article is to one of the topics. We can then determine the appropriateness of a topic based on this ranking.
We then tag the article with the topic. We do this so that the subsequent request for a topic is as computationally as light as possible; we do a simple join rather than calculating the Euclidean distance.
We also cache a specific topic/feed combination because these are calculated hourly and aren’t expected to change in the interim.
Semantic search
As previously discussed, the embeddings produced by Cohere contain a multitude of features; they embed the meanings and semantics of a word of phrase. We’ve also found that we can perform mathematical operations on these embeddings to do things such as calculate the similarity between two phrases or words.
We can use these embeddings and calculate the similarity between a search term and an embedding of an article with the k-NN algorithm to find articles that have similar semantics and meanings to the search term we’ve provided.
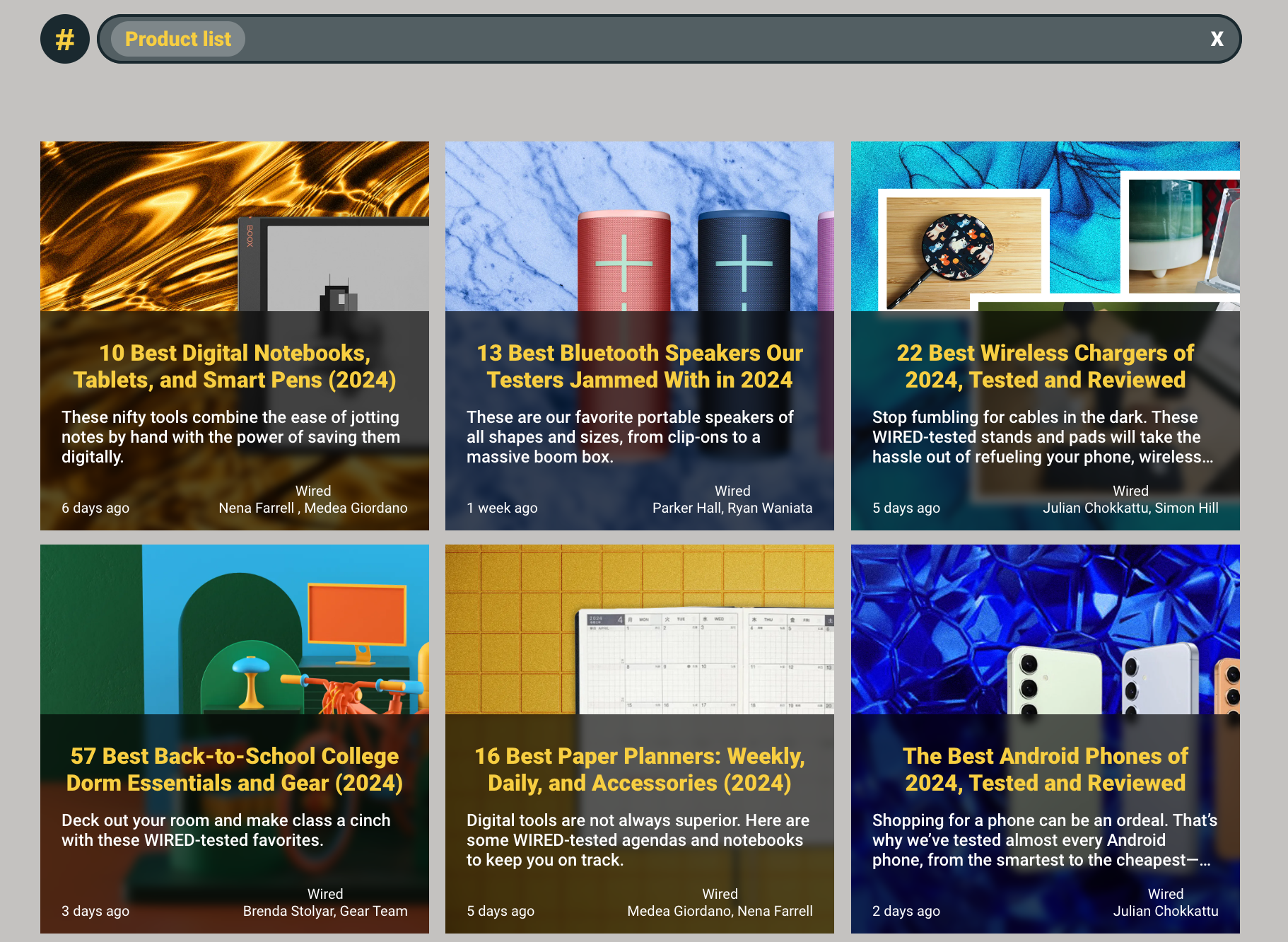
For example, in one of our RSS feeds, we have a lot of different articles that rate products. In a traditional search system, we’d rely on keyword matches to provide relevant results. Although it might be simple to find a specific article (for example, by searching “best digital notebooks”), we would need a different method to capture multiple product list articles.
In a semantic search system, we first transform the term “Product list” in an embedding. We can then use the properties of this embedding to perform a search within our embedding space. Using the k-NN algorithm, we can find articles that are semantically similar. As shown in the following screenshot, despite not containing the text “Product list” in either the title or description, we’ve been able to find articles that contain a product list. This is because we were able to capture the semantics of the query and match it to the existing embeddings we have for each article.
In our application, we store these embeddings using pgvector on Aurora PostgreSQL. pgvector is an open source extension that enables vector similarity search in PostgreSQL. We transform our search term into an embedding using Amazon Bedrock and Cohere v3 Embed.
After we’ve converted the search term to an embedding, we can compare it with the embeddings on the article that have been saved during the ingestion process. We can then use pgvector to find articles that are clustered together. The SQL code for that is as follows:
This code calculates the distance between the topics, and the embedding of this article as “similarity.” If this distance is close, then we can assume that the topic of the article is related, and we therefore attach the topic to the article.
Prerequisites
To deploy this application in your own account, you need the following prerequisites:
- An active AWS account.
- Model access for Cohere Embed English. On the Amazon Bedrock console, choose Model access in the navigation pane, then choose Manage model access. Select the FMs of your choice and request access.

- The AWS Cloud Development Kit (AWS CDK) set up. For installation instructions, refer to Getting started with the AWS CDK.
- A virtual private cloud (VPC) set up with access to private VPCs. For more information, refer to Create a VPC.
Deploy the AWS CDK stack
When the prerequisite steps are complete, you’re ready to set up the solution:
- Clone the GitHub repository containing the solution files:
git clone https://github.com/aws-samples/rss-aggregator-using-cohere-embeddings-bedrock
- Navigate to the solution directory:
cd infrastructure
- In your terminal, export your AWS credentials for a role or user in ACCOUNT_ID. The role needs to have all necessary permissions for AWS CDK deployment:
- export AWS_REGION=”<region>”
– The AWS Region you want to deploy the application to - export AWS_ACCESS_KEY_ID=”<access-key>”
– The access key of your role or user - export AWS_SECRET_ACCESS_KEY=”<secret-key>”
– The secret key of your role or user
- export AWS_REGION=”<region>”
- If you’re deploying the AWS CDK for the first time, run the following command:
cdk bootstrap
- To synthesize the AWS CloudFormation template, run the following command:
cdk synth -c vpc_id=<ID Of your VPC>
- To deploy, use the following command:
cdk deploy -c vpc_id=<ID Of your VPC>
When deployment is finished, you can check these deployed stacks by visiting the AWS CloudFormation console, as shown in the following screenshot.

Clean up
Run the following command in the terminal to delete the CloudFormation stack provisioned using the AWS CDK:
cdk destroy --all
Conclusion
In this post, we explored what language embeddings are and how they can be used to enhance your application. We’ve learned how, by using the properties of embeddings, we can implement a real-time zero-shot classifier and can add powerful features such as semantic search.
The code for this application can be found on the accompanying GitHub repo. We encourage you to experiment with language embeddings and find out what powerful features they can enable for your applications!
About the Author
 Thomas Rogers is a Solutions Architect based in Amsterdam, the Netherlands. He has a background in software engineering. At AWS, Thomas helps customers build cloud solutions, focusing on modernization, data, and integrations.
Thomas Rogers is a Solutions Architect based in Amsterdam, the Netherlands. He has a background in software engineering. At AWS, Thomas helps customers build cloud solutions, focusing on modernization, data, and integrations.

Physicists Tap James Web Space Telescope to Track New Asteroids and City-Killer Rock
Asteroids were responsible for extinction events hundreds of millions of years ago on Earth, providing no shortage of doomsday film plots for Hollywood.
But researchers focused on asteroid tracking are on a mission to locate them for today’s real-world concerns: planetary defense.
The new and unexpected discovery tool applied in this research is NASA’s James Web Space Telescope (JWST), which was tapped for views of these asteroids from previous research and enabled by NVIDIA accelerated computing.
An international team of researchers, led by MIT physicists, reported on the cover of Nature this week how the new method was able to spot 10-meter asteroids within the main asteroid belt located between Jupiter and Mars.
These rocks in space can range from the size of a bus to several Costco stores in width and deliver destruction to cities on Earth.
The finding of more than 100 space rocks of this size marks the smallest asteroids ever detected in the main asteroid belt. Previously, the smallest asteroids spotted measured more than half a mile in diameter.
Researchers say the novel method — tapping into previous studies, asteroid synthetic movement tracking and infrared observations — will help identify and track orbital movements of asteroids likely to approach Earth, supporting asteroid defense efforts.
“We have been able to detect near-Earth objects down to 10 meters in size when they are really close to Earth,” Artem Burdanov, the study’s co-lead author and a research scientist in MIT’s Department of Earth, Atmospheric and Planetary Sciences, told MIT News. “We now have a way of spotting these small asteroids when they are much farther away, so we can do more precise orbital tracking, which is key for planetary defense.”
New research has also supported follow-up observations on asteroid 2024YR4, which is on a potential collision course with Earth by 2032.
Capturing Asteroid Images With Infrared JWST Driven by NVIDIA GPUs
Observatories typically look at the reflected light off asteroids to determine their size, which can be inaccurate. Using a telescope with infrared, like the JWST, can help track the thermal signals of asteroids for a more precise way at gauging their size.

Asteroid hunters focused on planetary defense are looking out for near-Earth asteroids. These rocks have orbits around the Sun that are within 28 million miles of Earth’s orbit. And any asteroid around 450 feet long is capable of demolishing a sizable city.
The asteroid paper’s co-authors included MIT professors of planetary science co-lead Julien de Wit and Richard Binzel. Contributions from international institutions included the University of Liege in Belgium, Charles University in the Czech Republic, the European Space Agency, and institutions in Germany including the Max Planck Institute for Extraterrestrial Physics and the University of Oldenburg.
The work was supported by the NVIDIA Academic Grant Program.
Harnessing GPUs to Save the Planet From Asteroids
The 2024YR4 near-Earth asteroid — estimated as wide as 300 feet and capable of destroying a city the size of New York — has a 2.3% chance of striking Earth.
Movies like Armageddon provide fictional solutions, like implanting a nuclear bomb, but it’s unclear how this could play out off screen.
The JWST technology will soon be the only telescope capable of tracking the space rock as it moves away from Earth before coming back.
The new study used the JWST, the best-ever telescope in the infrared, on images of TRAPPIST-1, a star studied to search for signs of atmospheres around its seven terrestrial planets and located about 40 light years from Earth. The data include more than 10,000 images of the star.
After processing the images from JWST to study TRAPPIST-1’s planets, the researchers considered whether they could do more with the datasets. They’re looking at if they can search for otherwise undetectable asteroids using JWST’s infrared capabilities and a new detection technique they had deployed on other datasets called synthetic tracking.
The researchers applied synthetic tracking methods, which doesn’t require previous information on an asteroid’s motion. Instead it does “fully blind” search by testing possible shifts, like velocity vectors.
Such techniques are computationally intense, and they created bottlenecks until NVIDIA GPUs were applied to such work in recent years. Harnessing GPU-based synthetic tracking increases the scientific return on resources when conducting exoplanet transit-search surveys by recovering serendipitous asteroid detections, the study said.
After applying their GPU-based framework for detecting asteroids in targeted exoplanet surveys, the researchers were able to detect eight known and 139 unknown asteroids, the paper’s authors noted.
“Today’s GPU technology was key to unlocking the scientific achievement of detecting the small-asteroid population of the main belt, but there is more to it in the form of planetary-defense efforts,” said de Wit. “Since our study, the potential Earth-impactor 2024YR4 has been detected, and we now know that JWST can observe such an asteroid all the way out to the main belt as they move away from Earth before coming back. And in fact, JWST will do just that soon.”
Gif attribution: https://en.wikipedia.org/wiki/2024_YR4#/media/File:2024_YR4_ESO-VLT.gif
GeForce NOW Welcomes Warner Bros. Games to the Cloud With ‘Batman: Arkham’ Series
It’s a match made in heaven — GeForce NOW and Warner Bros. Games are collaborating to bring the beloved Batman: Arkham series to the cloud as part of GeForce NOW’s fifth-anniversary celebration. Just in time for Valentine’s Day, gamers can fall in love all over again with Gotham City’s Dark Knight, streaming his epic adventures from anywhere, on nearly any device.
The sweet treats don’t end there. GeForce NOW also brings the launch of the highly anticipated Sid Meier’s Civilization VII.
It’s all part of the lovable lineup of seven games joining the cloud this week.
A Match Made in Gotham City
GeForce NOW is welcoming Warner Bros. Games to the cloud with the Batman: Arkham series, including Arkham Asylum Game of the Year Edition, Batman: Arkham City Game of the Year Edition and Batman: Arkham Knight Premium. Don the cape and cowl of the world’s greatest detective, bringing justice to the streets of Gotham City with bone-crushing combat and ingenious gadgets.

Experience the dark and gritty world of Gotham City’s infamous asylum in the critically acclaimed action-adventure game Batman: Arkham Asylum. The Game of the Year (GOTY) Edition enhances the original title with additional challenge maps, allowing players to test their skills as the Dark Knight. Unravel the Joker’s sinister plot, face off against iconic villains and harness Batman’s gadgets and detective abilities in this groundbreaking title.

Members can expand their crimefighting horizons in the open-world sequel, Batman: Arkham City. The GOTY Edition includes the full game, plus all downloadable content, featuring Catwoman, Nightwing and Robin as playable characters. Explore the sprawling super-prison of Arkham City, confront a rogues’ gallery of villains and uncover the mysteries behind Hugo Strange’s Protocol 10. With enhanced gameplay and an even larger arsenal of gadgets, Batman: Arkham City elevates the Batman experience to new heights.

Conclude the Batman: Arkham trilogy in style with Batman: Arkham Knight. The Premium Edition includes the base game and season pass, offering new story missions, additional DC Super-Villains, legendary Batmobiles, advanced challenge maps and alternative character skins. Take control of a fully realized Gotham City, master the iconic Batmobile and face off against the Scarecrow and the mysterious Arkham Knight in this epic finale. With stunning visuals and refined gameplay, Batman: Arkham Knight delivers the ultimate Batman experience.
It’s the ideal time for members to be swept off their feet by the Caped Crusader. Stream the Batman: Arkham series with a GeForce NOW Ultimate membership and experience these iconic titles in stunning 4K resolution at up to 120 frames per second. Feel the heartbeat of Gotham City, the rush of grappling between skyscrapers and the thrill of outsmarting Gotham’s most notorious villains — all from the cloud.
Build an Empire in the Cloud
GeForce NOW’s fifth-anniversary celebration continues this week with the gift of Sid Meier’s Civilization VII in the cloud at launch.

2K Games’ highly anticipated sequel comes to the cloud with innovative gameplay mechanics. This latest installment introduces a dynamic three-Age structure — Antiquity, Exploration and Modern — allowing players to evolve their civilizations throughout history and transition between civilizations with the flexibility to shape empires’ destinies.
Explore unknown lands, expand territories, engage in diplomacy or battle with rival nations. Sid Meier’s Civilization VII introduces a crisis-event system at the end of each era, bringing challenges for players to navigate.
With its refined gameplay and bold new features, the title offers both longtime fans and newcomers a fresh and engaging take on the classic formula that has defined the series for decades.
Prepare for New Games

Legacy: Steel & Sorcery is an action-packed player vs. player vs. environment extraction role-playing game (RPG) set in the fantasy world of Mithrigarde by Notorious Studios, former World of Warcraft developers. Choose from distinctive classes like Warrior, Hunter, Rogue and Priest, each with unique abilities and environmental interactions. The game features a dynamic combat system emphasizing skill-based PvP, a full-loot system and RPG progression elements. Explore expansive outdoor zones solo or team up with friends to search for treasures, complete quests and battle both AI-controlled foes and rival players for an immersive fantasy RPG experience with a fresh twist on the extraction genre.
Look for the following games available to stream in the cloud this week:
- Sid Meier’s Civilization VII (New release on Steam and Epic Games Store, Feb. 11)
- Legacy: Steel & Sorcery (New release on Steam, Feb. 12)
- F1 Manager 2024 (New release on Epic Games Store, Free Feb. 13)
- Tomb Raider IV-VI Remastered (New release on Steam, Feb. 14)
- Batman: Arkham Asylum – Game of the Year Edition (Steam and Epic Games Store)
- Batman: Arkham City – Game of the Year Edition (Steam and Epic Games Store)
- Batman: Arkham Knight (Steam and Epic Games Store)
What are you planning to play this weekend? Let us know on X or in the comments below.
Guess who?
#5YearsOfGFN
—
NVIDIA GeForce NOW (@NVIDIAGFN) February 12, 2025
ARMOR: Egocentric Perception for Humanoid Robot Collision Avoidance and Motion Planning
Humanoid robots have significant gaps in their sensing and perception, making it hard to perform motion planning in dense environments. To address this, we introduce ARMOR, a novel egocentric perception system that integrates both hardware and software, specifically incorporating wearable-like depth sensors for humanoid robots. Our distributed perception approach enhances the robot’s spatial awareness, and facilitates more agile motion planning. We also train a transformer-based imitation learning (IL) policy in simulation to perform dynamic collision avoidance, by leveraging around 86 hours…Apple Machine Learning Research
Robust Autonomy Emerges from Self-Play
Self-play has powered breakthroughs in two-player and multi-player games. Here we show that self-play is a surprisingly effective strategy in another domain. We show that robust and naturalistic driving emerges entirely from self-play in simulation at unprecedented scale — 1.6~billion~km of driving. This is enabled by GigaFlow, a batched simulator that can synthesize and train on 42 years of subjective driving experience per hour on a single 8-GPU node. The resulting policy achieves state-of-the-art performance on three independent autonomous driving benchmarks. The policy outperforms the…Apple Machine Learning Research

How Gemini added a new dimension to our I/O 2025 save the date puzzle
 Here’s how Google built the I/O 2025 puzzle save the date, including a Gemini integration.Read More
Here’s how Google built the I/O 2025 puzzle save the date, including a Gemini integration.Read More

Microsoft Research and Physics Wallah team up to enhance AI-based tutoring

In India, limited resources, geographical constraints, and economic factors present barriers to quality higher education for some students.
A shortage of teachers, particularly in remote or low-income areas, makes it harder for students to receive the guidance they need to prepare for highly competitive professional and academic programs. Microsoft Research is developing new algorithms and techniques that are enabling Physics Wallah (opens in new tab), a growing educational company, to make its AI-based tutoring services more accurate and reliable, to better support students on their education journey.
As in other countries, many Indian students purchase coaching and tutoring services to prepare for entrance exams at top institutions. This includes offline coaching, where hundreds of students meet in a classroom staffed by teachers covering a structured curriculum. Online coaching enables students to learn remotely in a virtual classroom. Hybrid coaching delivers virtual lessons in a physical classroom.
Offline courses can cost as much as 100,000 Indian rupees a year—equivalent to hundreds of U.S. dollars. This puts them out of reach for many lower income students living in smaller and mid-sized Indian cities, as well as rural villages. Online courses are much more affordable. They allow students to work at their own pace by providing high-quality web-based content supported by teachers who work remotely.

Meeting this need is the mission of Physics Wallah. The company uses AI to offer on-demand tutoring at scale, curating volumes of standard science- and math-related content to provide the best answers. Some 2 million students use the Physics Wallah platform every day, at a fraction of the cost of offline tutoring. For example, its prep courses for the Joint Entrance Examination (JEE), which is required for admission to engineering and technology programs, and the National Eligibility cum Entrance Test (NEET), a required entrance exam for medical and dental school candidates, cost between 4,200 and 4,500 rupees per year. That’s roughly 50 U.S. dollars.
“The mantra here really is how do we provide quality education in an affordable manner and accessible to every student, regardless of who they are or where they come from.”
—Vineet Govil, Chief Technology and Product Officer, Physics Wallah

Microsoft Research India’s collaboration with Physics Wallah is part of a 20-year legacy of supporting emerging Indian companies, underscored by the January 2025 announcement that Microsoft will invest $3 billion (opens in new tab) in cloud and AI infrastructure to accelerate the adoption of AI, skilling, and innovation.
Physics Wallah has developed an AI-driven educational suite, Alakh AI, leveraging OpenAI’s GPT-4o model through Microsoft Azure OpenAI Service. Alakh AI’s flagship offerings include AI Guru and the Smart Doubt Engine, both designed to transform the learning experience in and beyond the classroom.
- AI Guru acts as a personal academic tutor, delivering adaptive guidance based on a student’s progress, real-time question-solving, and customized content that evolves with their learning journey.
- Smart Doubt Engine is an AI tool through which students can ask questions (also known as “doubts” in Indian English) during live classes and receive instant responses.
Additionally, the Alakh AI suite includes:
- AI Grader for subjective answer evaluation without human intervention
- Sahayak for crafting hyper-personalized learning paths tailored to individual students’ needs
This innovative ecosystem elevates learning efficiency and accessibility for students.


How does AI Guru work?
Let’s say a student had a question about Newton’s laws of motion, a core concept in physics. She would type her query into the AI Guru chat window (she could also just talk to it or upload an image from a textbook) and receive a text answer plus images derived from standard textbooks and curated content, typically in just a few seconds. AI Guru also provides a short video where a teacher offers additional context.
Getting the technology right
The Alakh AI suite is powered by OpenAI’s foundational models GPT-4 and GPT-4o, integrated with a retrieval-augmented generation (RAG) architecture. It leverages Physics Wallah’s rich repository of high-quality curated content—developed and refined over several years—along with continuous updates from subject matter experts to ensure new materials, textbooks, tutorials, and question banks are seamlessly incorporated. Despite considerable progress, the existing AI sometimes falters when navigating complex academic problems.
“The accuracy level of today’s large language models (LLMs) is not up to the mark where we can provide reliable and satisfactory answers to the students all the time—specifically, if it’s a hard mathematical problem involving complex equations,” Govil said.
That’s one important focus of the collaboration. Researchers from Microsoft Research are developing new algorithms and techniques to enhance the accuracy and reasoning capabilities of AI models. They are now collaborating with Physics Wallah to apply these advancements to the Alakh AI suite, improving its ability to solve complex problems and provide more reliable, step-by-step guidance to students. A key challenge is the nature of student queries, which are often ambiguous and involve multimodal inputs—text, images, videos, or audio—requiring unified capabilities to address the problem. Many STEM problems require breaking down complex queries into logical sub-problems and applying high-order, step-by-step reasoning for consistency. Additionally, integrating domain-specific knowledge in advanced math, physics, chemistry, and biology requires contextualization and seamless retrieval of specialized, grade-appropriate information.
Microsoft Research is working with Physics Wallah to move beyond traditional next-token prediction and develop AI systems that approach reliable, systematic, step-by-step problem-solving.
That includes ongoing work to enhance the model’s reasoning capabilities and deliver more accurate query answers on complex JEE math problems. Instead of just providing the final answer, the underlying models now break problems into step-by-step solutions. That helps students learn how to solve the actual problems. The AI can also review student answers, detect mistakes, and give detailed feedback, acting as a personal tutor to guide students, improve their understanding, and enhance their learning experience.
Microsoft research podcast

Collaborators: Silica in space with Richard Black and Dexter Greene
College freshman Dexter Greene and Microsoft research manager Richard Black discuss how technology that stores data in glass is supporting students as they expand earlier efforts to communicate what it means to be human to extraterrestrials.
Solving complex problems requires enhancing the reasoning capabilities of both large and small language models by training them to not just generate answers, but to systematically think through and reason about complex problems. This requires high-quality reasoning traces—detailed, step-by-step breakdowns of logical problem-solving processes.
To enable this, researchers collaborated with Physics Wallah to curate a dataset of 150,000 high-quality math reasoning traces. These traces serve as the foundation for training specialized small language models (SLMs) using supervised fine-tuning (SFT). Model performance is further refined through training on carefully curated on-policy preference data, ensuring alignment with high-quality reasoning standards. The team’s current Phi-based models have already outperformed leading LLMs and other baselines on complex math problems.
“Building AI systems capable of human-like thinking and reasoning represents a significant challenge.”
—Akshay Nambi, Principal Researcher at Microsoft Research India
The next step is to develop a self-evolving learning pipeline using online reinforcement learning techniques, allowing the model to continuously generate high-quality synthetic data that further enhances its capabilities. Additionally, researchers are building a reward model and integrating it with Monte Carlo Tree Search (MCTS) to optimize reasoning and improve inference-time decision-making.
“The goal is to develop tools that complement education. To do this, we are enhancing the model’s capabilities to process, break down, and solve problems step-by-step. We do this by incorporating high-quality data into training to teach the model how to approach such tasks, alongside algorithmic innovations that enable the model to think and reason more effectively.”
Listen or read along as Microsoft Research Podcast guest Akshay Nambi shares how his passion for tackling real-world challenges across various domains fuels his work in building reliable and robust AI systems.

Opening new doors for students

Getting an education at a top university can be life changing for anyone. For Chandramouleswar Parida, it could change the lives of everyone in his home village in Baniatangi, Khordha, Odisha State, India. Chandra decided to become a doctor after watching his grandfather die from a heart attack. The nearest doctor who could have treated him was at a regional hospital 65 kilometers away.
“He could have been saved if certain procedures had been followed,” Chandra said. He wants to study medicine, perhaps receiving advanced training overseas, and then return home. “I want to be a doctor here in our village and serve our people, because there is a lack of treatment. Being a doctor is a very noble kind of job in this society.”
Chandra is the only student in Baniatangi Village, Khordha, Odisha, currently preparing for the NEET. Without Physics Wallah, students like Chandra would likely have no access to the support and resources that can’t be found locally.

Another student, Anushka Sunil Dhanwade, is optimistic that Physics Wallah will help her dramatically improve her initial score on the NEET exam. While in 11th class, or grade, she joined an online NEET prep class with 800 students. But she struggled to follow the coursework, as the teachers tailored the content to the strongest students. After posting a low score on the NEET exam, her hopes of becoming a doctor were fading.
But after a serious stomach illness reminded her of the value of having a doctor in her family, she tried again, this time with Physics Wallah and AI Guru. After finishing 12th class, she began preparing for NEET and plans to take the exams again in May, confident that she will increase her score.
“AI Guru has made my learning so smooth and easy because it provides me answers related to my study and study-related doubt just within a click.”
—Anushka Sunil Dhanwade, Student
Next steps in the collaboration
The collaboration between Microsoft Research and Physics Wallah aims to apply the advancements in solving math problems across additional subjects, ultimately creating a unified education LLM with enhanced reasoning capabilities and improved accuracy to support student learning.
“We’re working on an education-specific LLM that will be fine-tuned using the extensive data we’ve gathered and enriched by Microsoft’s expertise in LLM training and algorithms. Our goal is to create a unified model that significantly improves accuracy and raises student satisfaction rates to 95% and beyond,” Govil explained.
The teams are also integrating a new tool from Microsoft Research called PromptWizard (opens in new tab), an automated framework for optimizing the instructions given to a model, into Physics Wallah’s offerings. New prompts can now be generated in minutes, eliminating months of manual work, while providing more accurate and aligned answers for students.
For Nambi and the Microsoft Research India team, the collaboration is the latest example of their deep commitment to cultivating the AI ecosystem in India and translating new technology from the lab into useful business applications.
“By leveraging advanced reasoning techniques and domain expertise, we are transforming how AI addresses challenges across multiple subjects. This represents a key step in building AI systems that act as holistic personal tutors, enhancing student understanding and creating a more engaging learning experience,” Nambi said.
Explore more



-

Video
Shiksha copilot demo
The post Microsoft Research and Physics Wallah team up to enhance AI-based tutoring appeared first on Microsoft Research.
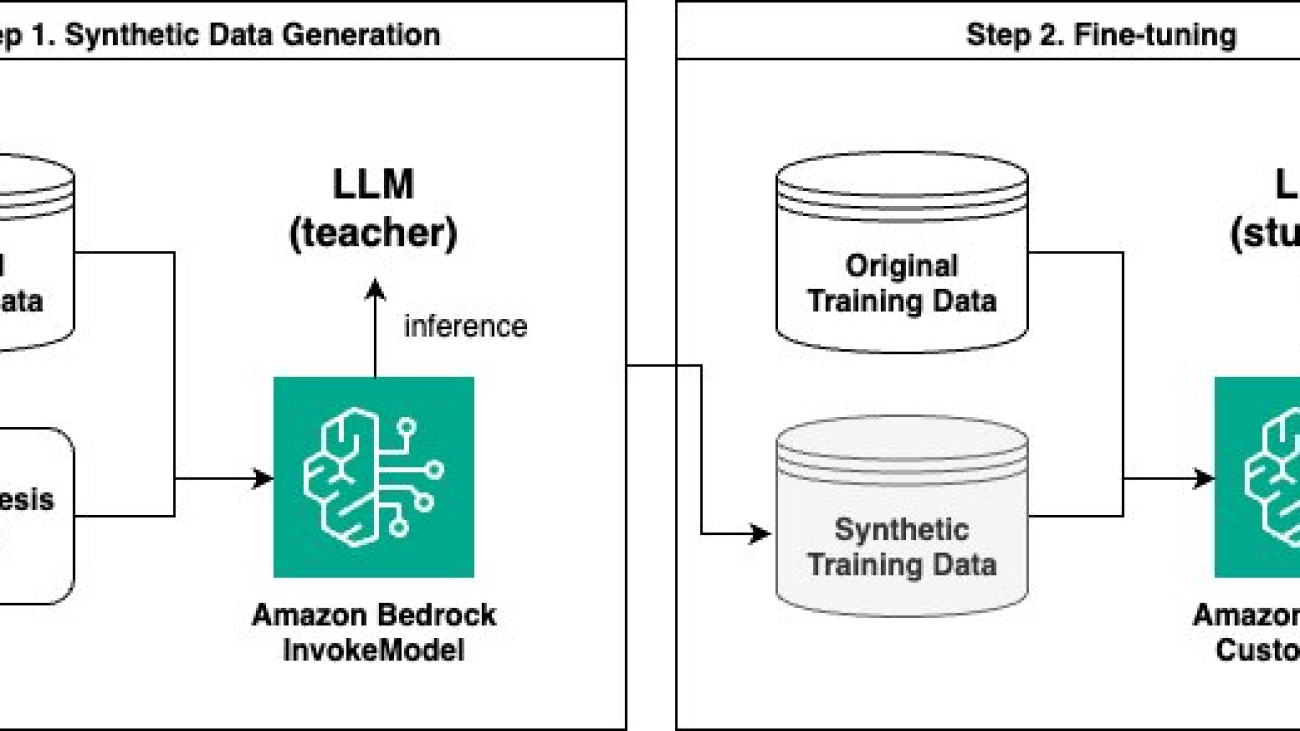
Fine-tune LLMs with synthetic data for context-based Q&A using Amazon Bedrock
There’s a growing demand from customers to incorporate generative AI into their businesses. Many use cases involve using pre-trained large language models (LLMs) through approaches like Retrieval Augmented Generation (RAG). However, for advanced, domain-specific tasks or those requiring specific formats, model customization techniques such as fine-tuning are sometimes necessary. Amazon Bedrock provides you with the ability to customize leading foundation models (FMs) such as Anthropic’s Claude 3 Haiku and Meta’s Llama 3.1.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage any infrastructure.
Fine-tuning is a supervised training process where labeled prompt and response pairs are used to further train a pre-trained model to improve its performance for a particular use case. One consistent pain point of fine-tuning is the lack of data to effectively customize these models. Gathering relevant data is difficult, and maintaining its quality is another hurdle. Furthermore, fine-tuning LLMs requires substantial resource commitment. In such scenarios, synthetic data generation offers a promising solution. You can create synthetic training data using a larger language model and use it to fine-tune a smaller model, which has the benefit of a quicker turnaround time.
In this post, we explore how to use Amazon Bedrock to generate synthetic training data to fine-tune an LLM. Additionally, we provide concrete evaluation results that showcase the power of synthetic data in fine-tuning when data is scarce.
Solution overview
The solution comprises two main steps:
- Generate synthetic data using the Amazon Bedrock InvokeModel API.
- Fine-tune using an Amazon Bedrock custom model.
For synthetic data generation, we use a larger language model (such as Anthropic’s Claude 3 Sonnet on Amazon Bedrock) as the teacher model, and a smaller language model (such as Anthropic’s Claude Instant 1.2 or Claude 3 Haiku on Amazon Bedrock) as the student model for fine-tuning. We use the larger teacher model to generate new data based on its knowledge, which is then used to train the smaller student model. This concept is similar to knowledge distillation used in deep learning, except that we’re using the teacher model to generate a new dataset from its knowledge rather than directly modifying the architecture of the student model.
The following diagram illustrates the overall flow of the solution.

Finally, we share our experiment results, where we compare the performance of the model fine-tuned with synthetic data to the baseline (not fine-tuned) model and to a model fine-tuned with an equal amount of original training data.
Prerequisites
To generate synthetic data and fine-tune models using Amazon Bedrock, you first need to create an AWS Identity and Access Management (IAM) service role with the appropriate permissions. This role is used by Amazon Bedrock to access the necessary resources on your behalf.
For instructions on creating the service role, refer to Create a service role for model customization. Also, make sure the role has the permission for the bedrock:InvokeModel action.
If you’re running this code using an Amazon SageMaker notebook instance, edit the IAM role that’s attached to the notebook (for example, AmazonSageMaker-ExecutionRole-XXX) instead of creating a new role. Follow Create a service role for model customization to modify the trust relationship and add the S3 bucket permission. Additionally, on the role’s Permissions tab, create the following inline policies:
- Policy name: bedrock-customization
- Policy name: iam-pass-role
The final permission policies for the SageMaker execution role should look like the following, which include AmazonSageMaker-ExecutionPolicy, AmazonSageMakerFullAccess, bedrock-customization, and iam-pass-role.

Generate synthetic data using the Amazon Bedrock InvokeModel API
We use the Amazon Bedrock InvokeModel API to generate synthetic data for fine-tuning. You can use the API to programmatically send an inference (text generation) request to the model of your choice. All you need is a well-crafted prompt tailored for data synthesis. We used the following sample prompt for our use case:
The goal of our use case was to fine-tune a model to generate a relevant and coherent answer based on a given reference document and a question. RAG is a popular technique used for such Q&A tasks; however, one significant challenge with RAG is the potential for retrieving unrelated or irrelevant documents, which can lead to inaccurate responses. You can apply fine-tuning to guide the model to better focus on the relevance of the documents to the question instead of using the provided documents without context to answer the question.
Our dataset includes Q&A pairs with reference documents regarding AWS services. Each sample has up to five reference documents as context, and a single-line question follows. The following table shows an example.
| document |
Context: Document 1: Step 1: Prepare to work with AWS CodeStar projects In this step, you create an AWS CodeStar service role and an Amazon EC2 key pair, so that you can begin creating and working with AWS CodeStar projects. If you have used AWS CodeStar before, skip ahead to Step 2 Step 2: Create a Project in AWS CodeStar. For this step, follow the instructions in Setting Up AWS CodeStar in the AWS CodeStar User Guide. Do not create a new AWS account, IAM user, or IAM group as part of those instructions. Use the ones you created or identified in Team Setup for AWS Cloud9. When you finish following those instructions, return to this topic. Document 2: Setting Up AWS CodeStar Before you can start using AWS CodeStar, you must complete the following steps. Topics: Step 1: Create an account Step 2: Create the AWS CodeStar Service Role Step 3: Configure the User’s IAM Permissions Step 4: Create an Amazon EC2 Key Pair for AWS CodeStar Projects Step 5: Open the AWS CodeStar Console Next Steps Document 3: How Do I Get Started with AWS CodeStar? To get started with AWS CodeStar: Prepare to use AWS CodeStar by following the steps in Setting Up AWS CodeStar. Experiment with AWS CodeStar by following the steps in the Getting Started with AWS CodeStar tutorial. Share your project with other developers by following the steps in Add Team Members to an AWS CodeStar Project. Integrate your favorite IDE by following the steps in Use an IDE with AWS CodeStar. Document 4: Step 2: Create a project in AWS CodeStar In this step, you create a project in AWS CodeStar. If you already have a project in AWS CodeStar you want to use, skip ahead to Step 3: Create an AWS Cloud9 Development Environment and Connect It to the Project. For this step, follow the instructions in Create a Project in AWS CodeStar in the AWS CodeStar User Guide. In the AWS CodeStar create project wizard, when you get to the Setup tools page or Connect to your source repository page, choose Skip, and then return to this topic. Document 5: Create a Project in AWS CodeStar You use the AWS CodeStar console to create a project. If you use a project template, it sets up the required resources for you. The template also includes sample code that you can use to start coding. To create a project, sign in to the AWS Management Console with an IAM user that has the AWSCodeStarFullAccess policy or equivalent permissions. For more information, see Setting Up AWS CodeStar. Note: You must complete the steps in Setting Up AWS CodeStar before you can complete the procedures in this topic. Topics Create a Project in AWS CodeStar (Console) Create a Project in AWS CodeStar (AWS CLI) Answer the following question to the best of your ability. Use and paraphrase the information in the context, if it answers the question. Otherwise, rely on your knowledge and memory. |
| question | How do I get started with AWS CodeStar? |
| answer |
To get started with AWS CodeStar, follow these steps: 1. Prepare to work with AWS CodeStar projects: a. Create an AWS CodeStar service role by following the instructions in “Setting Up AWS CodeStar” (Document 2) in the AWS CodeStar User Guide [1]. b. Create an Amazon EC2 key pair for AWS CodeStar projects, as described in the same guide [1]. 2. Create a project in AWS CodeStar: a. Sign in to the AWS Management Console with an IAM user that has the AWSCodeStarFullAccess policy or equivalent permissions [2]. b. In the AWS CodeStar console, select one of the available project templates, which will automatically provision all the required resources for your project [3]. c. Once your project is provisioned, you can see your running application from the Application endpoints tile [3]. 3. Connect to the AWS CodeCommit source repository for your project: a. Use the steps provided in the CodeStar console to connect to the AWS CodeCommit source repository for your project [3]. b. Begin coding and making changes to your project’s source code. 4. Track and manage changes in the release process: a. Use the project dashboard to track and manage changes in the release process [3]. b. View the most recent project activity on the dashboard. 5. Share your project with other developers: a. Follow the steps in “Add Team Members to an AWS CodeStar Project” to share your project with other developers [3]. 6. Integrate your favorite IDE: a. Follow the steps in “Use an IDE with AWS CodeStar” to integrate your preferred Integrated Development Environment (IDE) with AWS CodeStar [3]. [1] https://docs.aws.amazon.com/codestar/latest/userguide/setting-up.html [2] https://docs.aws.amazon.com/codestar/latest/userguide/create-project.html [3] https://docs.aws.amazon.com/codestar/latest/userguide/getting-started.html |
For data synthesis, we asked the model to generate three new Q&A pairs per reference document. However, you can adjust the number as needed. The crucial part is to make the model think deeply about a variety of topics. Because the purpose of generating synthetic data is to enrich the training dataset, it’s more beneficial to have the model look at different parts of the documents and create Q&A pairs with different topics than the original.
The following example shows how to generate synthetic data with the Amazon Bedrock InvokeModel API. We tested the preceding prompt with Anthropic’s Claude 3 Sonnet. If you want to test a different model, retrieve the corresponding model ID from Amazon Bedrock model IDs, and replace the modelId variable in the function.
The preceding function returns three JSONL records in strings with question, answer, and topic as keys. The following parse_llm_output function loads the strings and uses regular expressions to retrieve the generated questions and answers. Then, the create_synthetic_samples function combines those two functionalities to produce the final synthetic training samples.
The following script combines all of the preceding functions and gives you the final training set with both original and synthetic samples. We convert the samples into the format required by the customization job using the to_customization_format function and save them as train.jsonl. Assume the input data is a CSV file with three columns: document, question, and answer.
Fine-tune using an Amazon Bedrock custom model
Now that you have the synthetic data generated by the teacher model along with your original data, it’s time to train the student model. We fine-tune the student model using the Amazon Bedrock custom model functionality.
Model customization is the process of providing training data to an FM to improve its performance for specific use cases. Amazon Bedrock offers three model customization methods as of this writing:
- Fine-tuning
- Continued pre-training
- Distillation (preview).
You can create your own custom model using any of these methods through the Amazon Bedrock console or API. For more information on supported models and AWS Regions with various customization methods, please see User guide for model customization. In this section, we focus on how to fine-tune a model using the API.
To create a fine-tuning job in Amazon Bedrock, complete the following prerequisite steps:
- Create an Amazon Simple Storage Service (Amazon S3) bucket for your training data and another one for your output data (the names must be unique).
- Upload the jsonl file to the training data bucket.
- Make sure that you have created an IAM role, as described in the Prerequisites
When these steps are complete, run the following code to submit a new fine-tuning job. In our use case, the student model was Anthropic’s Claude Instant 1.2. At the time of writing, Anthropic’s Claude 3 Haiku is generally available, and we recommend following the rest of the code using Anthropic’s Claude 3 Haiku. For the release announcement, see Fine-tuning for Anthropic’s Claude 3 Haiku in Amazon Bedrock is now generally available.
If you want to try different models, you must check the model provider’s terms of service yourself. Many providers restrict using their models to train competing models. For the latest model support information, see Supported Regions and models for model customization, and replace baseModelIdentifier accordingly. Different models have different hyperparameters. For more information, see Custom model hyperparameters.
When the status changes to Completed, your fine-tuned student model is ready for use. To run an inference with this custom model, you need to purchase provisioned throughput. A flexible No commitment option is available for custom models, which can be turned off when not in use and billed by the hour. A cost estimate is provided on the console prior to purchasing provisioned throughput.
On the Amazon Bedrock console, choose Custom models in the navigation pane. Select the model you fine-tuned and choose Purchase provisioned throughput.

The model name and type are automatically selected for you. Select No commitment for Commitment term. After you make this selection, the estimated cost is shown. If you’re okay with the pricing, choose Confirm purchase.

When the Provisioned Throughput becomes available, retrieve the ARN of the provisioned custom model and run the inference:
Evaluate
In this section, we share our experiment results to provide data points on how the synthetic data generated by a teacher model can improve the performance of a student model. For evaluation methods, we used an LLM-as-a-judge approach, where a judge model compares responses from two different models and picks a better response. Additionally, we conducted a manual evaluation on a small subset to assess whether the LLM-as-a-judge and human judges have aligned preferences.
We carried out controlled experiments where we compared four different models as follows: 1,500 synthetic training samples for the 4th model were generated by Anthropic’s Claude 3 Sonnet, and we created three synthetic samples per one original reference document (3 samples * 500 original reference documents = 1,500 synthetic samples).
| Instant base model | Anthropic’s Claude Instant without any customization |
| Fine-tuned 500 original | Anthropic’s Claude Instant fine-tuned with 500 original training samples |
| Fine-tuned 2,000 original | Anthropic’s Claude Instant fine-tuned with 2,000 original training samples |
| Fine-tuned with synthetic | Anthropic’s Claude Instant fine-tuned with 500 original training samples plus 1,500 synthetic training samples |
LLM-as-a-judge results
LLM output evaluation is an important step in developing generative AI applications, but it is expensive and takes considerable time if done manually. An alternative solution to systematically evaluate output quality in large volume is the LLM-as-a-judge approach, where an LLM is used to evaluate another LLM’s responses.
For our use case, we used Anthropic’s Claude 3 Sonnet and Meta Llama 3 70B as the judges. We asked the LLM judges to compare outputs from two different models and choose one over the other or state a tie. The following chart summarizes the judges’ decisions. Each number represents the percentage of times when the respective model was selected as providing a better answer, excluding tie cases. The test set contained 343 samples.

As shown in the preceding chart, the Anthropic’s Claude 3 Sonnet judge preferred the response from the fine-tuned model with synthetic examples over the Anthropic’s Claude Instant base model (84.8% preference) and the fine-tuned model with original 500 samples (72.3% preference). However, the judge concluded that the fine-tuned model with 2,000 original examples was preferred over the fine-tuned model with synthetic examples (32.3% preference). This aligns with the expectation that when large, high-quality original data is available, it’s better to use the large training data that accurately reflects the target data distribution.

The Meta Llama judge reached a similar conclusion. As shown in the preceding chart, it preferred the response from the fine-tuned model with synthetic samples over the Anthropic’s Claude Instant base model (75.6% preference) and the fine-tuned model with original 500 examples (76.4% preference), but the fine-tuned model with 2,000 original examples was the ultimate winner.
Human evaluation results
To complement the LLM-as-a-judge result, we conducted manual evaluation with two human judges. We asked the two human evaluators to perform the same pairwise comparison task as the LLM judge, but for 20 examples. The following chart summarizes the results.

As shown in the preceding chart, the two human evaluators reached a similar conclusion, reinforcing the LLM-as-a-judge result. The fine-tuned model with synthetic examples produced outputs that were more preferable than the Anthropic’s Claude Instant base model and the fine-tuned model with the original 500 examples; however, it didn’t outperform the fine-tuned model with the 2,000 original examples.
These comparative evaluation results from both the LLM judges and human judges strongly demonstrate the power and potential of using data synthesis when training data is scarce. Moreover, by using high-quality data from the teacher model, we can effectively train the student model, which is lightweight and cost-effective for deployment in a production environment.
Amazon Bedrock evaluations
Running LLM-as-a-judge and human evaluation has become much easier with Amazon Bedrock. Model evaluation on Amazon Bedrock allows you to evaluate, compare, and select the best FMs for your use case. Human evaluation workflows can use your own employees or an AWS-managed team as reviewers. For more information on how to set up a human evaluation workflow, see Creating your first model evaluation that uses human workers. The latest feature, LLM-as-a-judge, is now in preview and allows you to assess multiple quality dimensions including correctness, helpfulness, and responsible AI criteria such as answer refusal and harmfulness. For step-by-step instructions, see New RAG evaluation and LLM-as-a-judge capabilities in Amazon Bedrock.
Clean up
Make sure to delete the following resources to avoid incurring cost:
- Provisioned throughput for the custom model
- The training_bucket and output_bucket S3 buckets
Conclusion
In this post, we explored how to use Amazon Bedrock to generate synthetic training data using a large teacher language model and fine-tune a smaller student model with synthetic data. We provided instructions on generating synthetic data using the Amazon Bedrock InvokeModel API and fine-tuning the student model using an Amazon Bedrock custom model. Our evaluation results, based on both an LLM-as-a-judge approach and human evaluation, demonstrated the effectiveness of synthetic data in improving the student model’s performance when original training data is limited.
Although fine-tuning with a large amount of high-quality original data remains the ideal approach, our findings highlight the promising potential of synthetic data generation as a viable solution when dealing with data scarcity. This technique can enable more efficient and cost-effective model customization for domain-specific or specialized use cases.
If you’re interested in working with the AWS Generative AI Innovation Center and learning more about LLM customization and other generative AI use cases, visit Generative AI Innovation Center.
About the Author
 Sujeong Cha is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she specializes in model customization and optimization. She has extensive hands-on experience in solving customers’ business use cases by utilizing generative AI as well as traditional AI/ML solutions. Sujeong holds a M.S. degree in Data Science from New York University.
Sujeong Cha is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she specializes in model customization and optimization. She has extensive hands-on experience in solving customers’ business use cases by utilizing generative AI as well as traditional AI/ML solutions. Sujeong holds a M.S. degree in Data Science from New York University.
 Arijit Ghosh Chowdhury is a Scientist with the AWS Generative AI Innovation Center, where he works on model customization and optimization. In his role, he works on applied research in fine-tuning and model evaluations to enable GenAI for various industries. He has a Master’s degree in Computer Science from the University of Illinois at Urbana Champaign, where his research focused on question answering, search and domain adaptation.
Arijit Ghosh Chowdhury is a Scientist with the AWS Generative AI Innovation Center, where he works on model customization and optimization. In his role, he works on applied research in fine-tuning and model evaluations to enable GenAI for various industries. He has a Master’s degree in Computer Science from the University of Illinois at Urbana Champaign, where his research focused on question answering, search and domain adaptation.
 Sungmin Hong is a Senior Applied Scientist at Amazon Generative AI Innovation Center where he helps expedite the variety of use cases of AWS customers. Before joining Amazon, Sungmin was a postdoctoral research fellow at Harvard Medical School. He holds Ph.D. in Computer Science from New York University. Outside of work, Sungmin enjoys hiking, reading and cooking.
Sungmin Hong is a Senior Applied Scientist at Amazon Generative AI Innovation Center where he helps expedite the variety of use cases of AWS customers. Before joining Amazon, Sungmin was a postdoctoral research fellow at Harvard Medical School. He holds Ph.D. in Computer Science from New York University. Outside of work, Sungmin enjoys hiking, reading and cooking.
 Yiyue Qian is an Applied Scientist II at the AWS Generative AI Innovation Center, where she develops generative AI solutions for AWS customers. Her expertise encompasses designing and implementing innovative AI-driven and deep learning techniques, focusing on natural language processing, computer vision, multi-modal learning, and graph learning. Yiyue holds a Ph.D. in Computer Science from the University of Notre Dame, where her research centered on advanced machine learning and deep learning methodologies. Outside of work, she enjoys sports, hiking, and traveling.
Yiyue Qian is an Applied Scientist II at the AWS Generative AI Innovation Center, where she develops generative AI solutions for AWS customers. Her expertise encompasses designing and implementing innovative AI-driven and deep learning techniques, focusing on natural language processing, computer vision, multi-modal learning, and graph learning. Yiyue holds a Ph.D. in Computer Science from the University of Notre Dame, where her research centered on advanced machine learning and deep learning methodologies. Outside of work, she enjoys sports, hiking, and traveling.
 Wei-Chih Chen is a Machine Learning Engineer at the AWS Generative AI Innovation Center, where he works on model customization and optimization for LLMs. He also builds tools to help his team tackle various aspects of the LLM development life cycle—including fine-tuning, benchmarking, and load-testing—that accelerating the adoption of diverse use cases for AWS customers. He holds an M.S. degree in Computer Science from UC Davis.
Wei-Chih Chen is a Machine Learning Engineer at the AWS Generative AI Innovation Center, where he works on model customization and optimization for LLMs. He also builds tools to help his team tackle various aspects of the LLM development life cycle—including fine-tuning, benchmarking, and load-testing—that accelerating the adoption of diverse use cases for AWS customers. He holds an M.S. degree in Computer Science from UC Davis.
 Hannah Marlowe is a Senior Manager of Model Customization at the AWS Generative AI Innovation Center. Her team specializes in helping customers develop differentiating Generative AI solutions using their unique and proprietary data to achieve key business outcomes. She holds a Ph.D in Physics from the University of Iowa, with a focus on astronomical X-ray analysis and instrumentation development. Outside of work, she can be found hiking, mountain biking, and skiing around the mountains in Colorado.
Hannah Marlowe is a Senior Manager of Model Customization at the AWS Generative AI Innovation Center. Her team specializes in helping customers develop differentiating Generative AI solutions using their unique and proprietary data to achieve key business outcomes. She holds a Ph.D in Physics from the University of Iowa, with a focus on astronomical X-ray analysis and instrumentation development. Outside of work, she can be found hiking, mountain biking, and skiing around the mountains in Colorado.