Inaugural global university competition focused on advancing secure, trusted AI-assisted software development.Read More
When Does a Predictor Know Its Own Loss?
Given a predictor and a loss function, how well can we predict the loss that the predictor will incur on an input? This is the problem of loss prediction, a key computational task associated with uncertainty estimation for a predictor. In a classification setting, a predictor will typically predict a distribution over labels and hence have its own estimate of the loss that it will incur, given by the entropy of the predicted distribution. Should we trust this estimate? In other words, when does the predictor know what it knows and what it does not know?
In this work we study the theoretical…Apple Machine Learning Research
Accelerating insurance policy reviews with generative AI: Verisk’s Mozart companion
This post is co-authored with Sundeep Sardana, Malolan Raman, Joseph Lam, Maitri Shah and Vaibhav Singh from Verisk.
Verisk (Nasdaq: VRSK) is a leading strategic data analytics and technology partner to the global insurance industry, empowering clients to strengthen operating efficiency, improve underwriting and claims outcomes, combat fraud, and make informed decisions about global risks. Through advanced data analytics, software, scientific research, and deep industry knowledge, Verisk helps build global resilience across individuals, communities, and businesses. At the forefront of using generative AI in the insurance industry, Verisk’s generative AI-powered solutions, like Mozart, remain rooted in ethical and responsible AI use. Mozart, the leading platform for creating and updating insurance forms, enables customers to organize, author, and file forms seamlessly, while its companion uses generative AI to compare policy documents and provide summaries of changes in minutes, cutting the change adoption time from days or weeks to minutes.
The generative AI-powered Mozart companion uses sophisticated AI to compare legal policy documents and provides essential distinctions between them in a digestible and structured format. The new Mozart companion is built using Amazon Bedrock. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. The Mozart application rapidly compares policy documents and presents comprehensive change details, such as descriptions, locations, excerpts, in a tracked change format.
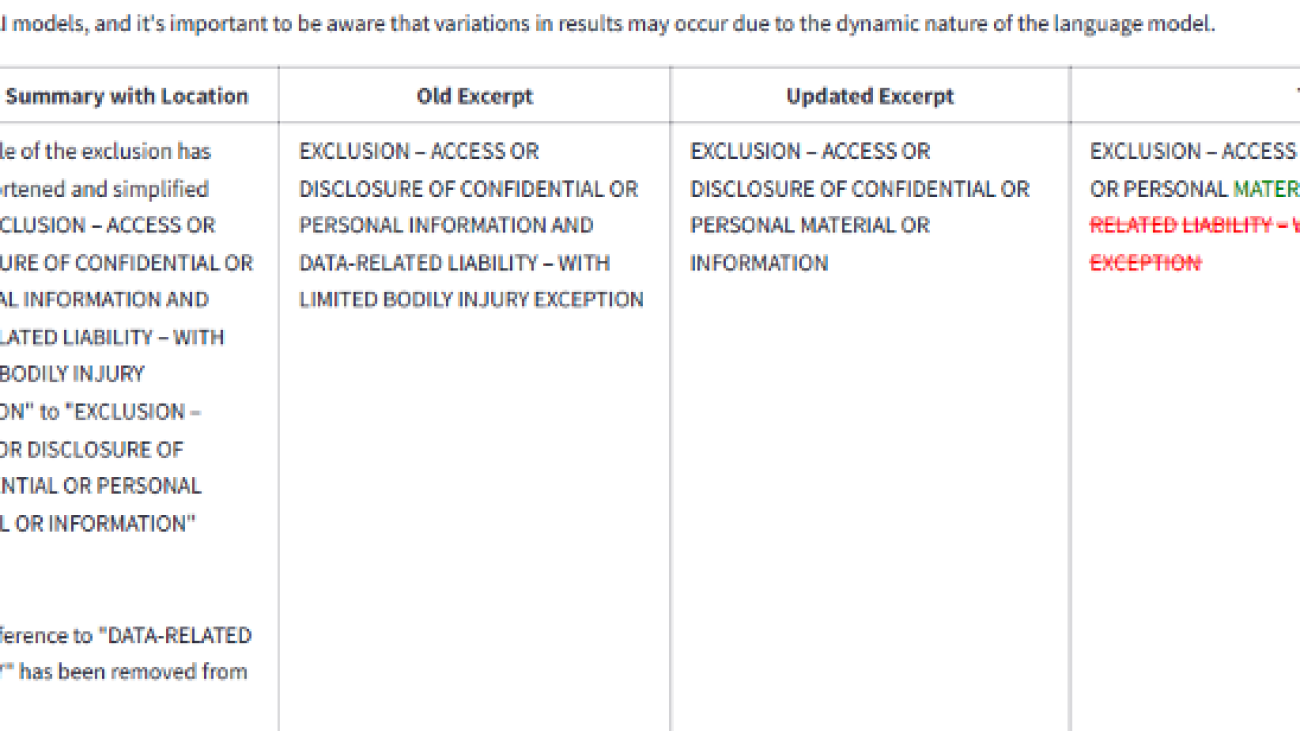
The following screenshot shows an example of the output of the Mozart companion displaying the summary of changes between two legal documents, the excerpt from the original document version, the updated excerpt in the new document version, and the tracked changes represented with redlines.

In this post, we describe the development journey of the generative AI companion for Mozart, the data, the architecture, and the evaluation of the pipeline.
Data: Policy forms
Mozart is designed to author policy forms like coverage and endorsements. These documents provide information about policy coverage and exclusions (as shown in the following screenshot) and help in determining the risk and premium associated with an insurance policy.

Solution overview
The policy documents reside in Amazon Simple Storage Service (Amazon S3) storage. An AWS Batch job reads these documents, chunks them into smaller slices, then creates embeddings of the text chunks using the Amazon Titan Text Embeddings model through Amazon Bedrock and stores them in an Amazon OpenSearch Service vector database. Along with each document slice, we store the metadata associated with it using an internal Metadata API, which provides document characteristics like document type, jurisdiction, version number, and effective dates. This process has been implemented as a periodic job to keep the vector database updated with new documents. During the solution design process, Verisk also considered using Amazon Bedrock Knowledge Bases because it’s purpose built for creating and storing embeddings within Amazon OpenSearch Serverless. In the future, Verisk intends to use the Amazon Titan Embeddings V2 model.
The user can pick the two documents that they want to compare. This action invokes an AWS Lambda function to retrieve the document embeddings from the OpenSearch Service database and present them to Anthropic’s Claude 3 Sonnet FM, which is accessed through Amazon Bedrock. The results are stored in a JSON structure and provided using the API service to the UI for consumption by the end-user.
The following diagram illustrates the solution architecture.

Security and governance
Generative AI is very new technology and brings with it new challenges related to security and compliance. Verisk has a governance council that reviews generative AI solutions to make sure that they meet Verisk’s standards of security, compliance, and data use. Verisk also has a legal review for IP protection and compliance within their contracts. It’s important that Verisk makes sure the data that is shared by the FM is transmitted securely and the FM doesn’t retain any of their data or use it for its own training. The quality of the solution, speed, cost, and ease of use were the key factors that led Verisk to pick Amazon Bedrock and Anthropic’s Claude Sonnet within their generative AI solution.
Evaluation criteria
To assess the quality of the results produced by generative AI, Verisk evaluated based on the following criteria:
- Accuracy
- Consistency
- Adherence to context
- Speed and cost
To assess the generative AI results’ accuracy and consistency, Verisk designed human evaluation metrics with the help of in-house insurance domain experts. Verisk conducted multiple rounds of human evaluation of the generated results. During these tests, in-house domain experts would grade accuracy, consistency, and adherence to context on a manual grading scale of 1–10. The Verisk team measured how long it took to generate the results by tracking latency. Feedback from each round of tests was incorporated in subsequent tests.
The initial results that Verisk got from the model were good but not close to the desired level of accuracy and consistency. The development process underwent iterative improvements that included redesign, making multiple calls to the FM, and testing various FMs. The primary metric used to evaluate the success of FM and non-FM solutions was a manual grading system where business experts would grade results and compare them. FM solutions are improving rapidly, but to achieve the desired level of accuracy, Verisk’s generative AI software solution needed to contain more components than just FMs. To achieve the desired accuracy, consistency, and efficiency, Verisk employed various techniques beyond just using FMs, including prompt engineering, retrieval augmented generation, and system design optimizations.
Prompt optimization
The change summary is different than showing differences in text between the two documents. The Mozart application needs to be able to describe the material changes and ignore the noise from non-meaningful changes. Verisk created prompts using the knowledge of their in-house domain experts to achieve these objectives. With each round of testing, Verisk added detailed instructions to the prompts to capture the pertinent information and reduce possible noise and hallucinations. The added instructions would be focused on reducing any issues identified by the business experts reviewing the end results. To get the best results, Verisk needed to adjust the prompts based on the FM used—there are differences in how each FM responds to prompts, and using the prompts specific to the given FM provides better results. Through this process, Verisk instructed the model on the role it is playing along with the definition of common terms and exclusions. In addition to optimizing prompts for the FMs, Verisk also explored techniques for effectively splitting and processing the document text itself.
Splitting document pages
Verisk tested multiple strategies for document splitting. For this use case, a recursive character text splitter with a chunk size of 500 characters with 15% overlap provided the best results. This splitter is part of the LangChain framework; it’s a semantic splitter that considers semantic similarities in the text. Verisk also considered the NLTK splitter. With an effective approach for splitting the document text into processable chunks, Verisk then focused on enhancing the quality and relevance of the summarized output.
Quality of summary
The quality assessment starts with confirming that the correct documents are picked for comparison. Verisk enhanced the quality of the solution by using document metadata to narrow the search results by specifying which documents to include or exclude from a query, resulting in more relevant responses generated by the FM. For the generative AI description of change, Verisk wanted to capture the essence of the change instead of merely highlighting the differences. The results were reviewed by their in-house policy authoring experts and their feedback was used to determine the prompts, document splitting strategy, and FM. With techniques in place to enhance output quality and relevance, Verisk also prioritized optimizing the performance and cost-efficiency of their generative AI solution. These techniques were specific to prompt engineering; some examples are few-shot prompting, chain of thought prompting, and the needle in a haystack approach.
Price-performance
To achieve lower cost, Verisk regularly evaluated various FM options and changed them as new options with lower cost and better performance were released. During the development process, Verisk redesigned the solution to reduce the number of calls to the FM and wherever possible used non-FM based options.
As mentioned earlier, the overall solution consists of a few different components:
- Location of the change
- Excerpts of the changes
- Change summary
- Changes shown in the tracked change format
Verisk reduced the FM load and improved accuracy by identifying the sections that contained differences and then passing these sections to the FM to generate the change summary. For constructing the tracked difference format, containing redlines, Verisk used a non-FM based solution. In addition to optimizing performance and cost, Verisk also focused on developing a modular, reusable architecture for their generative AI solution.
Reusability
Good software development practices apply to the development of generative AI solutions too. You can create a decoupled architecture with reusable components. The Mozart generative AI companion is provided as an API, which decouples it from the frontend development and allows for reusability of this capability. Similarly, the API consists of many reusable components like common prompts, common definitions, retrieval service, embedding creation, and persistence service. Through their modular, reusable design approach and iterative optimization process, Verisk was able to achieve highly satisfactory results with their generative AI solution.
Results
Based on Verisk’s evaluation template questions and rounds of testing, they concluded that the results generated over 90% good or acceptable summaries. Testing was done by providing results of the solution to business experts, and having these experts grade the results using a grading scale.
Business impact
Verisk’s customers spend significant time regularly to review changes to the policy forms. The generative AI-powered Mozart companion can simplify the review process by ingesting these complex and unstructured policy documents and providing a summary of changes in minutes. This enables Verisk’s customers to cut the change adoption time from days to minutes. The improved adoption speed not only increases productivity, but also enable timely implementation of changes.
Conclusion
Verisk’s generative AI-powered Mozart companion uses advanced natural language processing and prompt engineering techniques to provide rapid and accurate summaries of changes between insurance policy documents. By harnessing the power of large language models like Anthropic’s Claude 3 Sonnet while incorporating domain expertise, Verisk has developed a solution that significantly accelerates the policy review process for their customers, reducing change adoption time from days or weeks to just minutes. This innovative application of generative AI delivers tangible productivity gains and operational efficiencies to the insurance industry. With a strong governance framework promoting responsible AI use, Verisk is at the forefront of unlocking generative AI’s potential to transform workflows and drive resilience across the global risk landscape.
For more information, see the following resources:
- Explore generative AI on AWS
- Learn about unlocking the business value of generative AI
- Learn more about Anthropic’s Claude 3 models on Amazon Bedrock
- Learn about Amazon Bedrock and how to build and scale generative AI applications with FMs
- Explore other use cases for generative AI with Amazon Bedrock
About the Authors
 Sundeep Sardana is the Vice President of Software Engineering at Verisk Analytics, based in New Jersey. He leads the Reimagine program for the company’s Rating business, driving modernization across core services such as forms, rules, and loss costs. A dynamic change-maker and technologist, Sundeep specializes in building high-performing teams, fostering a culture of innovation, and leveraging emerging technologies to deliver scalable, enterprise-grade solutions. His expertise spans cloud computing, Generative AI, software architecture, and agile development, ensuring organizations stay ahead in an evolving digital landscape. Connect with him on LinkedIn.
Sundeep Sardana is the Vice President of Software Engineering at Verisk Analytics, based in New Jersey. He leads the Reimagine program for the company’s Rating business, driving modernization across core services such as forms, rules, and loss costs. A dynamic change-maker and technologist, Sundeep specializes in building high-performing teams, fostering a culture of innovation, and leveraging emerging technologies to deliver scalable, enterprise-grade solutions. His expertise spans cloud computing, Generative AI, software architecture, and agile development, ensuring organizations stay ahead in an evolving digital landscape. Connect with him on LinkedIn.
 Malolan Raman is a Principal Engineer at Verisk, based out of New Jersey specializing in the development of Generative AI (GenAI) applications. With extensive experience in cloud computing and artificial intelligence, He has been at the forefront of integrating cutting-edge AI technologies into scalable, secure, and efficient cloud solutions.
Malolan Raman is a Principal Engineer at Verisk, based out of New Jersey specializing in the development of Generative AI (GenAI) applications. With extensive experience in cloud computing and artificial intelligence, He has been at the forefront of integrating cutting-edge AI technologies into scalable, secure, and efficient cloud solutions.
 Joseph Lam is the senior director of commercial multi-lines that include general liability, umbrella/excess, commercial property, businessowners, capital assets, crime and inland marine. He leads a team responsible for research, development, and support of commercial casualty products, which mostly consist of forms and rules. The team is also tasked with supporting new and innovative solutions for the emerging marketplace.
Joseph Lam is the senior director of commercial multi-lines that include general liability, umbrella/excess, commercial property, businessowners, capital assets, crime and inland marine. He leads a team responsible for research, development, and support of commercial casualty products, which mostly consist of forms and rules. The team is also tasked with supporting new and innovative solutions for the emerging marketplace.
 Maitri Shah is a Software Development Engineer at Verisk with over two years of experience specializing in developing innovative solutions in Generative AI (GenAI) on Amazon Web Services (AWS). With a strong foundation in machine learning, cloud computing, and software engineering, Maitri has successfully implemented scalable AI models that drive business value and enhance user experiences.
Maitri Shah is a Software Development Engineer at Verisk with over two years of experience specializing in developing innovative solutions in Generative AI (GenAI) on Amazon Web Services (AWS). With a strong foundation in machine learning, cloud computing, and software engineering, Maitri has successfully implemented scalable AI models that drive business value and enhance user experiences.
 Vaibhav Singh is a Product Innovation Analyst at Verisk, based out of New Jersey. With a background in Data Science, engineering, and management, he works as a pivotal liaison between technology and business, enabling both sides to build transformative products & solutions that tackle some of the current most significant challenges in the insurance domain. He is driven by his passion for leveraging data and technology to build innovative products that not only address the current obstacles but also pave the way for future advancements in that domain.
Vaibhav Singh is a Product Innovation Analyst at Verisk, based out of New Jersey. With a background in Data Science, engineering, and management, he works as a pivotal liaison between technology and business, enabling both sides to build transformative products & solutions that tackle some of the current most significant challenges in the insurance domain. He is driven by his passion for leveraging data and technology to build innovative products that not only address the current obstacles but also pave the way for future advancements in that domain.
 Ryan Doty is a Solutions Architect Manager at AWS, based out of New York. He helps financial services customers accelerate their adoption of the AWS Cloud by providing architectural guidelines to design innovative and scalable solutions. Coming from a software development and sales engineering background, the possibilities that the cloud can bring to the world excite him.
Ryan Doty is a Solutions Architect Manager at AWS, based out of New York. He helps financial services customers accelerate their adoption of the AWS Cloud by providing architectural guidelines to design innovative and scalable solutions. Coming from a software development and sales engineering background, the possibilities that the cloud can bring to the world excite him.
 Tarik Makota is a Sr. Principal Solutions Architect with Amazon Web Services. He provides technical guidance, design advice, and thought leadership to AWS’ customers across the US Northeast. He holds an M.S. in Software Development and Management from Rochester Institute of Technology.
Tarik Makota is a Sr. Principal Solutions Architect with Amazon Web Services. He provides technical guidance, design advice, and thought leadership to AWS’ customers across the US Northeast. He holds an M.S. in Software Development and Management from Rochester Institute of Technology.
 Alex Oppenheim is a Senior Sales Leader at Amazon Web Services, supporting consulting and services customers. With extensive experience in the cloud and technology industry, Alex is passionate about helping enterprises unlock the power of AWS to drive innovation and digital transformation.
Alex Oppenheim is a Senior Sales Leader at Amazon Web Services, supporting consulting and services customers. With extensive experience in the cloud and technology industry, Alex is passionate about helping enterprises unlock the power of AWS to drive innovation and digital transformation.
Announcing general availability of Amazon Bedrock Knowledge Bases GraphRAG with Amazon Neptune Analytics
Today, Amazon Web Services (AWS) announced the general availability of Amazon Bedrock Knowledge Bases GraphRAG (GraphRAG), a capability in Amazon Bedrock Knowledge Bases that enhances Retrieval-Augmented Generation (RAG) with graph data in Amazon Neptune Analytics. This capability enhances responses from generative AI applications by automatically creating embeddings for semantic search and generating a graph of the entities and relationships extracted from ingested documents. The graph, stored in Amazon Neptune Analytics, provides enriched context during the retrieval phase to deliver more comprehensive, relevant, and explainable responses tailored to customer needs. Developers can enable GraphRAG with just a few clicks on the Amazon Bedrock console to boost the accuracy of generative AI applications without any graph modeling expertise.
In this post, we discuss the benefits of GraphRAG and how to get started with it in Amazon Bedrock Knowledge Bases.
Enhance RAG with graphs for more comprehensive and explainable GenAI applications
Generative AI is transforming how humans interact with technology by having natural conversations that provide helpful, nuanced, and insightful responses. However, a key challenge facing current generative AI systems is providing responses that are comprehensive, relevant, and explainable because data is stored across multiple documents. Without effectively mapping shared context across input data sources, responses risk being incomplete and inaccurate.
To address this, AWS announced a public preview of GraphRAG at re:Invent 2024, and is now announcing its general availability. This new capability integrates the power of graph data modeling with advanced natural language processing (NLP). GraphRAG automatically creates graphs which capture connections between related entities and sections across documents. More specifically, the graph created will connect chunks to documents, and entities to chunks.
During response generation, GraphRAG first does semantic search to find the top k most relevant chunks, and then traverses the surrounding neighborhood of those chunks to retrieve the most relevant content. By linking this contextual information, the generative AI system can provide responses that are more complete, precise, and grounded in source data. Whether answering complex questions across topics or summarizing key details from lengthy reports, GraphRAG delivers the comprehensive and explainable responses needed to enable more helpful, reliable AI conversations.
GraphRAG boosts relevance and accuracy when relevant information is dispersed across multiple sources or documents, which can be seen in the following three use cases.
Streamlining market research to accelerate business decisions
A leading global financial institution sought to enhance insight extraction from its proprietary research. With a vast repository of economic and market research reports, the institution wanted to explore how GraphRAG could improve information retrieval and reasoning for complex financial queries. To evaluate this, they added their proprietary research papers, focusing on critical market trends and economic forecasts.
To evaluate the effectiveness of GraphRAG, the institution partnered with AWS to build a proof-of-concept using Amazon Bedrock Knowledge Bases and Amazon Neptune Analytics. The goal was to determine if GraphRAG could more effectively surface insights compared to traditional retrieval methods. GraphRAG structures knowledge into interconnected entities and relationships, enabling multi-hop reasoning across documents. This capability is crucial for answering intricate questions such as “What are some headwinds and tailwinds to capex growth in the next few years?” or “What is the impact of the ILA strike on international trade?”. Rather than relying solely on keyword matching, GraphRAG allows the model to trace relationships between economic indicators, policy changes, and industry impacts, ensuring responses are contextually rich and data-driven.
When comparing the quality of responses from GraphRAG and other retrieval methods, notable differences emerged in their comprehensiveness, clarity, and relevance. While other retrieval methods delivered straightforward responses, they often lacked deeper insights and broader context. GraphRAG instead provided more nuanced answers by incorporating related factors and offering additional relevant information, which made the responses more comprehensive than the other retrieval methods.
Improving data-driven decision-making in automotive manufacturing
An international auto company manages a large dataset, supporting thousands of use cases across engineering, manufacturing, and customer service. With thousands of users querying different datasets daily, making sure insights are accurate and connected across sources has been a persistent challenge.
To address this, the company worked with AWS to prototype a graph that maps relationships between key data points, such as vehicle performance, supply chain logistics, and customer feedback. This structure allows for more precise results across datasets, rather than relying on disconnected query results.
With Amazon Bedrock Knowledge Bases GraphRAG with Amazon Neptune Analytics automatically constructing a graph from ingested documents, the company can surface relevant insights more efficiently in their RAG applications. This approach helps teams identify patterns in manufacturing quality, predict maintenance needs, and improve supply chain resilience, making data analysis more effective and scalable across the organization.
Enhancing cybersecurity incident analysis
A cybersecurity company is using GraphRAG to improve how its AI-powered assistant analyzes security incidents. Traditional detection methods rely on isolated alerts, often missing the broader context of an attack.
By using a graph, the company connects disparate security signals, such as login anomalies, malware signatures, and network traffic patterns, into a structured representation of threat activity. This allows for faster root cause analysis and more comprehensive security reporting.
Amazon Bedrock Knowledge Bases and Neptune Analytics enable this system to scale while maintaining strict security controls, providing resource isolation. With this approach, the company’s security teams can quickly interpret threats, prioritize responses, and reduce false positives, leading to more efficient incident handling.
Solution overview
In this post, we provide a walkthrough to build Amazon Bedrock Knowledge Bases GraphRAG with Amazon Neptune Analytics, using files in an Amazon Simple Storage Service (Amazon S3) bucket. Running this example will incur costs in Amazon Neptune Analytics, Amazon S3, and Amazon Bedrock. Amazon Neptune Analytics costs for this example will be approximately $0.48 per hour. Amazon S3 costs will vary depending on how large your dataset is, and more details on Amazon S3 pricing can be found here. Amazon Bedrock costs will vary depending on the embeddings model and chunking strategy you select, and more details on Bedrock pricing can be found here.
Prerequisites
To follow along with this post, you need an AWS account with the necessary permissions to access Amazon Bedrock, and an Amazon S3 bucket containing data to serve as your knowledge base. Also ensure that you have enabled model access to Claude 3 Haiku (anthropic.claude-3-haiku-20240307-v1:0) and any other models that you wish to use as your embeddings model. For more details on how to enable model access, refer to the documentation here.
Build Amazon Bedrock Knowledge Bases GraphRAG with Amazon Neptune Analytics
To get started, complete the following steps:
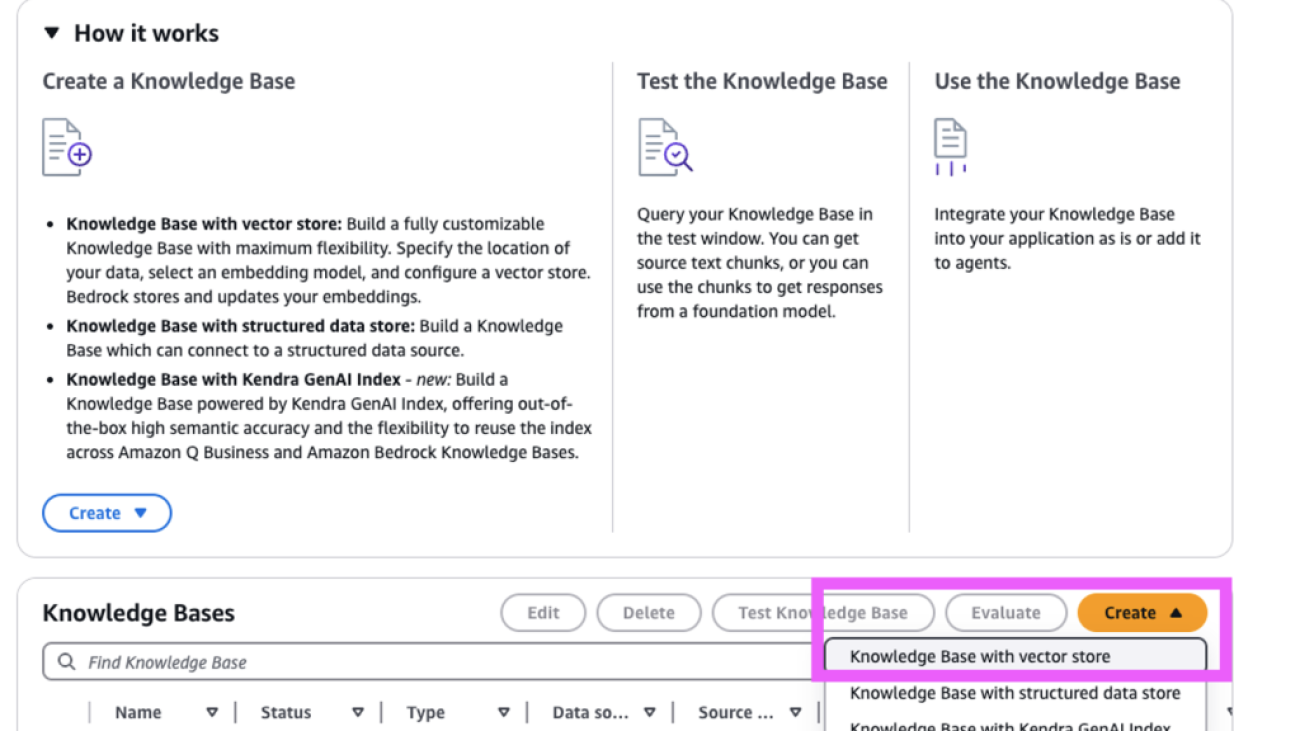
- On the Amazon Bedrock console, choose Knowledge Bases under Builder tools in the navigation pane.
- In the Knowledge Bases section, choose Create and Knowledge Base with vector store.

- For Knowledge Base details, enter a name and an optional description.
- For IAM permissions, select Create and use a new service role to create a new AWS Identity and Access Management (IAM) role.

- For Data source details, select Amazon S3 as your data source.
- Choose Next.
- For S3 URI, choose Browse S3 and choose the appropriate S3 bucket.
- For Parsing strategy, select Amazon Bedrock default parser.
- For Chunking strategy, choose Default chunking (recommended for GraphRAG) or any other strategy as you wish.
- Choose Next.

- For Embeddings model, choose an embeddings model, such as Amazon Titan Text Embeddings v2.
- For Vector database, select Quick create a new vector store and then select Amazon Neptune Analytics (GraphRAG).
- Choose Next.

- Review the configuration details and choose Create Knowledge Base.
Sync the data source
- Once the knowledge base is created, click Sync under the Data source section. The data sync can take a few minutes to a few hours, depending on how many source documents you have and how big each one is.

Test the knowledge base
Once the data sync is complete:
- Choose the expansion icon to expand the full view of the testing area.

- Configure your knowledge base by adding filters or guardrails.
- We encourage you to enable reranking (For information about pricing for reranking models, see Amazon Bedrock Pricing) to fully take advantage of the capabilities of GraphRAG. Reranking allows GraphRAG to refine and optimize search results.
- You can also supply a custom metadata file (each up to 10 KB) for each document in the knowledge base. You can apply filters to your retrievals, instructing the vector store to pre-filter based on document metadata and then search for relevant documents. This way, you have control over the retrieved documents, especially if your queries are ambiguous. Note that the
listtype is not supported.
- Use the chat area in the right pane to ask questions about the documents from your Amazon S3 bucket.
The responses will use GraphRAG and provide references to chunks and documents in their response.

Now that you’ve enabled GraphRAG, test it out by querying your generative AI application and observe how the responses have improved compared to baseline RAG approaches. You can monitor the Amazon CloudWatch logs for performance metrics on indexing, query latency, and accuracy.
Clean up
When you’re done exploring the solution, make sure to clean up by deleting any resources you created. Resources to clean up include the Amazon Bedrock knowledge base, the associated AWS IAM role that the Amazon Bedrock knowledge base uses, and the Amazon S3 bucket that was used for the source documents.
You will also need to separately delete the Amazon Neptune Analytics graph that was created on your behalf, by Amazon Bedrock Knowledge Bases.
Conclusion
In this post, we discussed how to get started with Amazon Bedrock Knowledge Bases GraphRAG with Amazon Neptune. For further experimentation, check out the Amazon Bedrock Knowledge Bases Retrieval APIs to use the power of GraphRAG in your own applications. Refer to our documentation for code samples and best practices.
About the authors
 Denise Gosnell is a Principal Product Manager for Amazon Neptune, focusing on generative AI infrastructure and graph data applications that enable scalable, cutting-edge solutions across industry verticals.
Denise Gosnell is a Principal Product Manager for Amazon Neptune, focusing on generative AI infrastructure and graph data applications that enable scalable, cutting-edge solutions across industry verticals.
 Melissa Kwok is a Senior Neptune Specialist Solutions Architect at AWS, where she helps customers of all sizes and verticals build cloud solutions according to best practices. When she’s not at her desk you can find her in the kitchen experimenting with new recipes or reading a cookbook.
Melissa Kwok is a Senior Neptune Specialist Solutions Architect at AWS, where she helps customers of all sizes and verticals build cloud solutions according to best practices. When she’s not at her desk you can find her in the kitchen experimenting with new recipes or reading a cookbook.
 Ozan Eken is a Product Manager at AWS, passionate about building cutting-edge Generative AI and Graph Analytics products. With a focus on simplifying complex data challenges, Ozan helps customers unlock deeper insights and accelerate innovation. Outside of work, he enjoys trying new foods, exploring different countries, and watching soccer.
Ozan Eken is a Product Manager at AWS, passionate about building cutting-edge Generative AI and Graph Analytics products. With a focus on simplifying complex data challenges, Ozan helps customers unlock deeper insights and accelerate innovation. Outside of work, he enjoys trying new foods, exploring different countries, and watching soccer.
 Harsh Singh is a Principal Product Manager Technical at AWS AI. Harsh enjoys building products that bring AI to software developers and everyday users to improve their productivity.
Harsh Singh is a Principal Product Manager Technical at AWS AI. Harsh enjoys building products that bring AI to software developers and everyday users to improve their productivity.
 Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High-Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High-Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.

Powering AI with PyTorch, Fedora, and Open Source Communities

At DevConf.IN 2025 in Pune, I had the opportunity to host a PyTorch Meetup on February 28th. The session, titled “Powering AI with PyTorch, Fedora, and Open Source Communities” was aimed at introducing PyTorch to students and professionals, explaining why PyTorch+Fedora form an ideal AI development platform. The other key aspect I covered was collaboration between open source communities.
Introduction to PyTorch
The Power of Deep Learning made simple
With the explosion of GPTs, there is a renowned interest in the field of AI and ML. The myth of developing AI/ML technologies and its applications is rocket science and far-fetched, needs correction. Only open source has the power to demystify this myth and further evolve the technology to make it versatile and developer friendly. Since its inception, PyTorch has evolved and has been a driving force to make AI/ML development extremely simple. I covered the aspects of PyTorch key components, its features and why PyTorch is the best choice as a deep learning framework.

The codewalk through was designed to showcase how easy and simple it is to utilise the power of GPUs, creating a simple neural network and training the model. The code walkthrough was very well received and it was great to hear back from the attendees that they never knew how powerful PyTorch is for deep learning. The real world examples sighted how this powerful framework can be used beyond the common GPTs and has the power to influence across a broad spectrum of applications.
Fedora+PyTorch the Ideal AI/ML Development Platform


One of the highlights of the event was the discussion on Fedora’s role as an AI platform. Fedora’s reliability, flexibility, and strong community support make it an ideal partner for PyTorch, allowing developers to focus on model-building without worrying about infrastructure. The students were intrigued by the idea of contributing to Fedora’s AI/ML ecosystem while building their own projects. Sumantro Mukherjee spoke about the AI policy in Fedora and how one can start contributing to the AI/ML using Fedora as a platform. He highlighted how Fedora is evolving to meet the needs of AI practitioners. The idea that an open-source operating system could provide the perfect foundation for AI research sparked an engaging conversation.
Innovation in Open Source When Communities Come Together
It is important that we learn from history and repeat the good things! When open source communities come together they can create seismic shifts in the industry. To drive this home, I took the audience on a journey through history, revisiting a pivotal moment when Apache and Linux came together, solving common problems and fundamentally reshaping enterprise computing. That moment was not just about technology; it was about collaboration. It was about two powerful communities recognizing that they were stronger together. Today, we stand at the cusp of another such moment – PyTorch and Linux, particularly Fedora, are coming together to shape the future of AI/ML. This is not just an opportunity but a responsibility for contributors, developers, and AI/ML enthusiasts to be part of this movement.
Looking Ahead

One of the best parts of the event was the enthusiasm it generated. Diverse audience, including students, AI enthusiasts, and industry professionals. Notably, Vincent Caldeira (CTO, APAC, Red Hat) and Chris Butler (Senior Principal Chief Architect, Red Hat) were present, reinforcing the growing interest in open-source AI/ML. Many students were eager to explore PyTorch and Fedora, contribute to open-source AI projects, and start their own AI experiments. Industry experts saw the potential for scalable, community-driven AI innovation. The session sparked curiosity and conversations that continued long after the event ended.
Towards AI-Driven Sign Language Generation with Non-Manual Markers
Sign languages are essential for the Deaf and Hard-of-Hearing (DHH) community. Sign language generation systems have the potential to support communication by translating from written languages, such as English, into signed videos. However, current systems often fail to meet user needs due to poor translation of grammatical structures, the absence of facial cues and body language, and insufficient visual and motion fidelity. We address these challenges by building on recent advances in LLMs and video generation models to translate English sentences into natural-looking AI ASL signers. The text…Apple Machine Learning Research

Oscars Gold: NVIDIA Researchers Honored for Advancing the Art and Science of Filmmaking
For the past 16 years, NVIDIA technologies have been working behind the scenes of every Academy Award-nominated film for Best Visual Effects.
This year, three NVIDIA researchers — Essex Edwards, Fabrice Rousselle and Timo Aila — have been honored with Scientific and Technical Awards by the Academy of Motion Picture Arts and Sciences for their groundbreaking contributions to the film industry. Their innovations in simulation, denoising and rendering are helping shape the future of visual storytelling, empowering filmmakers to create even more breathtaking and immersive worlds.

Ziva VFX: Bringing Digital Characters to Life
Essex Edwards received a Technical Achievement Award, alongside James Jacobs, Jernej Barbic, Crawford Doran and Andrew van Straten, for his design and development of Ziva VFX. This cutting-edge system allows artists to construct and simulate human muscles, fat, fascia and skin for digital characters with an intuitive, physics-based approach.
Providing a robust solver and an artist-friendly interface, Ziva VFX transformed the ways studios bring photorealistic and animated characters to the big screen and beyond.
Award-winning visuals effect and animation studio DNEG is continuing to develop Ziva VFX to further enhance its creature pipeline.
“Ziva VFX was the result of a team of artists and engineers coming together and making thousands of really good small design decisions over and over for years,” said Edwards.
Disney’s ML Denoiser: Revolutionizing Rendering
Fabrice Rousselle was honored with a Scientific and Engineering Award, alongside Thijs Vogels, David Adler, Gerhard Röthlin and Mark Meyer, for his work on Disney’s ML Denoiser. This advanced machine learning denoiser introduced a pioneering kernel-predicting convolutional network, ensuring temporal stability in rendered images for higher-quality graphics.
Originally developed to enhance the quality of animated films, this breakthrough technology has since become an essential tool in live-action visual effects and high-end rendering workflows. It helps remove noise, sharpens images and speeds up rendering, allowing artists to work faster while achieving higher quality.
Since 2018, Disney’s state-of-the-art denoiser powered by machine learning (ML) has been used in over 100 films, including “Toy Story 4,” “Ralph Breaks the Internet,” and “Avengers: Endgame.”
The denoiser was developed by Disney Research, ILM, Pixar and Walt Disney Animation — the result of a massive cross-studio effort helping to push the boundaries of visual storytelling for studios across the industry.
In this extreme example of four samples average per pixel, Disney’s ML Denoiser does a remarkable job. Inside Out 2 © Disney/Pixar
Intel Open Image Denoise: Advancing AI-Powered Image Processing
Timo Aila received a Technical Achievement Award, alongside Attila T. Áfra, for his pioneering contributions to AI image denoising. Aila’s early work at NVIDIA focused on the U-Net architecture, which Áfra used in Intel Open Image Denoise — an open-source library that provides an efficient, high-quality solution for AI-driven denoising in rendering.
By preserving fine details while significantly reducing noise, Intel Open Image Denoise has become a vital component in real-time and offline rendering across the industry.
“Path tracing has an inherent noise problem, and in the early days of deep learning, we started looking for architectures that could help,” Aila said. “We turned to denoising autoencoders, and the pivotal moment was when we introduced skip connections. Everything began to work, from fixing JPEG compression artifacts to eliminating the kind of Monte Carlo noise that occurs in path-traced computer graphics. This breakthrough led to the production of cleaner, more realistic images in rendering pipelines.”
Pushing the Boundaries of Visual Storytelling
With these latest honors, Edwards, Rousselle and Aila join the many NVIDIA researchers who have been recognized by the Academy for their pioneering contributions to filmmaking.

Over the years, 14 additional NVIDIA researchers have received Scientific and Technical Awards, reflecting NVIDIA’s significant contributions to the art and science of motion pictures through cutting-edge research in AI, simulation and real-time rendering.
This group includes Christian Rouet, Runa Loeber and NVIDIA’s advanced rendering team, Michael Kass, Jos Stam, Jonathan Cohen, Michael Kowalski, Matt Pharr, Joe Mancewicz, Ken Museth, Charles Loop, Ingo Wald, Dirk Van Gelder, Gilles Daviet, Luca Fascione and Christopher Jon Horvath.
The awards ceremony will take place on Tuesday, April 29, at the Academy Museum of Motion Pictures in Los Angeles.
Learn more about NVIDIA Research, AI, simulation and rendering at NVIDIA GTC, a global AI conference taking place March 17-21 at the San Jose Convention Center and online. Register now to join a conference track dedicated to media and entertainment.
Main feature courtesy of DNEG © 2024 Warner Bros. Ent. and Legendary. All Rights Reserved. GODZILLA TM & © Toho Co., Ltd.

Google for Startups Accelerator: AI for Energy applications are open
 Learn more about the first-ever Google for Startups Accelerator: AI for Energy.Read More
Learn more about the first-ever Google for Startups Accelerator: AI for Energy.Read More
Build a Multi-Agent System with LangGraph and Mistral on AWS
Agents are revolutionizing the landscape of generative AI, serving as the bridge between large language models (LLMs) and real-world applications. These intelligent, autonomous systems are poised to become the cornerstone of AI adoption across industries, heralding a new era of human-AI collaboration and problem-solving. By using the power of LLMs and combining them with specialized tools and APIs, agents can tackle complex, multistep tasks that were previously beyond the reach of traditional AI systems. The Multi-Agent City Information System demonstrated in this post exemplifies the potential of agent-based architectures to create sophisticated, adaptable, and highly capable AI applications.
As we look to the future, agents will have a very important role to play in:
- Improving decision-making with deeper, context-aware information
- Automating complex workflows across various domains, from customer service to scientific research
- Enabling more natural and intuitive human-AI interactions
- Generating new ideas by bringing together diverse data sources and specialized knowledge
- Addressing ethical concerns by providing more transparent and explainable AI systems
Building and deploying multi-agent systems like the one in this post is a step toward unlocking the full potential of generative AI. As these systems evolve, they will transform industries, expand possibilities, and open new doors for artificial intelligence.
Solution overview
In this post, we explore how to use LangGraph and Mistral models on Amazon Bedrock to create a powerful multi-agent system that can handle sophisticated workflows through collaborative problem-solving. This integration enables the creation of AI agents that can work together to solve complex problems, mimicking humanlike reasoning and collaboration.
The result is a system that delivers comprehensive details about events, weather, activities, and recommendations for a specified city, illustrating how stateful, multi-agent applications can be built and deployed on Amazon Web Services (AWS) to address real-world challenges.
LangGraph is essential to our solution by providing a well-organized method to define and manage the flow of information between agents. It provides built-in support for state management and checkpointing, providing smooth process continuity. This framework also allows for straightforward visualization of the agentic workflows, enhancing clarity and understanding. It integrates easily with LLMs and Amazon Bedrock, providing a versatile and powerful solution. Additionally, its support for conditional routing allows for dynamic workflow adjustments based on intermediate results, providing flexibility in handling different scenarios.
The multi-agent architecture we present offers several key benefits:
- Modularity – Each agent focuses on a specific task, making the system easier to maintain and extend
- Flexibility – Agents can be quickly added, removed, or modified without affecting the entire system
- Complex workflow handling – The system can manage advanced and complex workflows by distributing tasks among multiple agents
- Specialization – Each agent is optimized for its specific task, improving latency, accuracy, and overall system efficiency
- Security – The system enhances security by making sure that each agent only has access to the tools necessary for its task, reducing the potential for unauthorized access to sensitive data or other agents’ tasks
How our multi-agent system works
In this section, we explore how our Multi-Agent City Information System works, based on the multi-agent LangGraph Mistral Jupyter notebook available in the Mistral on AWS examples for Bedrock & SageMaker repository on GitHub.
This agentic workflow takes a city name as input and provides detailed information, demonstrating adaptability in handling different scenarios:
- Events – It searches a local database and online sources for upcoming events in the city. Whenever local database information is unavailable, it triggers an online search using the Tavily API. This makes sure that users receive up-to-date event information, regardless of whether it’s stored locally or needs to be retrieved from the web
- Weather – The system fetches current weather data using the OpenWeatherMap API, providing accurate and timely weather information for the queried location. Based on the weather, the system also offers outfit and activity recommendations tailored to the conditions, providing relevant suggestions for each city
- Restaurants – Recommendations are provided through a Retrieval Augmented Generation (RAG) system. This method combines prestored information with real-time generation to offer relevant and up-to-date dining suggestions
The system’s ability to work with varying levels of information is showcased through its adaptive approach, which means that users receive the most comprehensive and up-to-date information possible, regardless of the varying availability of data for different cities. For instance:
- Some cities might require the use of the search tool for event information when local database data is unavailable
- Other cities might have data available in the local database, providing quick access to event information without needing an online search
- In cases where restaurant recommendations are unavailable for a particular city, the system can still provide valuable insights based on the available event and weather data
The following diagram is the solution’s reference architecture:

Data sources
The Multi-Agent City Information System can take advantage of two sources of data.
Local events database
This SQLite database is populated with city events data from a JSON file, providing quick access to local event information that ranges from community happenings to cultural events and citywide activities. This database is used by the events_database_tool() for efficient querying and retrieval of city event details, including location, date, and event type.
Restaurant RAG system
For restaurant recommendations, the generate_restaurants_dataset() function generates synthetic data, creating a custom dataset specifically tailored to our recommendation system. The create_restaurant_vector_store() function processes this data, generates embeddings using Amazon Titan Text Embeddings, and builds a vector store with Facebook AI Similarity Search (FAISS). Although this approach is suitable for prototyping, for a more scalable and enterprise-grade solution, we recommend using Amazon Bedrock Knowledge Bases.
Building the multi-agent architecture
At the heart of our Multi-Agent City Information System lies a set of specialized functions and tools designed to gather, process, and synthesize information from various sources. They form the backbone of our system, enabling it to provide comprehensive and up-to-date information about cities. In this section, we explore the key components that drive our system: the generate_text() function, which uses Mistral model, and the specialized data retrieval functions for local database queries, online searches, weather information, and restaurant recommendations. Together, these functions and tools create a robust and versatile system capable of delivering valuable insights to users.
Text generation function
This function serves as the core of our agents, allowing them to generate text using the Mistral model as needed. It uses the Amazon Bedrock Converse API, which supports text generation, streaming, and external function calling (tools).
The function works as follows:
- Sends a user message to the Mistral model using the Amazon Bedrock Converse API
- Invokes the appropriate tool and incorporates the results into the conversation
- Continues the conversation until a final response is generated
Here’s the implementation:
def generate_text(bedrock_client, model_id, tool_config, input_text):
......
while True:
response = bedrock_client.converse(**kwargs)
output_message = response['output']['message']
messages.append(output_message) # Add assistant's response to messages
stop_reason = response.get('stopReason')
if stop_reason == 'tool_use' and tool_config:
tool_use = output_message['content'][0]['toolUse']
tool_use_id = tool_use['toolUseId']
tool_name = tool_use['name']
tool_input = tool_use['input']
try:
if tool_name == 'get_upcoming_events':
tool_result = local_info_database_tool(tool_input['city'])
json_result = json.dumps({"events": tool_result})
elif tool_name == 'get_city_weather':
tool_result = weather_tool(tool_input['city'])
json_result = json.dumps({"weather": tool_result})
elif tool_name == 'search_and_summarize_events':
tool_result = search_tool(tool_input['city'])
json_result = json.dumps({"events": tool_result})
else:
raise ValueError(f"Unknown tool: {tool_name}")
tool_response = {
"toolUseId": tool_use_id,
"content": [{"json": json.loads(json_result)}]
}
......
messages.append({
"role": "user",
"content": [{"toolResult": tool_response}]
})
# Update kwargs with new messages
kwargs["messages"] = messages
else:
break
return output_message, tool_resultLocal database query tool
The events_database_tool() queries the local SQLite database for events information by connecting to the database, executing a query to fetch upcoming events for the specified city, and returning the results as a formatted string. It’s used by the events_database_agent() function. Here’s the code:
def events_database_tool(city: str) -> str:
conn = sqlite3.connect(db_path)
query = """
SELECT event_name, event_date, description
FROM local_events
WHERE city = ?
ORDER BY event_date
LIMIT 3
"""
df = pd.read_sql_query(query, conn, params=(city,))
conn.close()
print(df)
if not df.empty:
events = df.apply(
lambda row: (
f"{row['event_name']} on {row['event_date']}: {row['description']}"
),
axis=1
).tolist()
return "n".join(events)
else:
return f"No upcoming events found for {city}."Weather tool
The weather_tool() fetches current weather data for the specified city by calling the OpenWeatherMap API. It’s used by the weather_agent() function. Here’s the code:
def weather_tool(city: str) -> str:
weather = OpenWeatherMapAPIWrapper()
tool_result = weather.run("Tampa")
return tool_resultOnline search tool
When local event information is unavailable, the search_tool() performs an online search using the Tavily API to find upcoming events in the specified city and return a summary. It’s used by the search_agent() function. Here’s the code:
def search_tool(city: str) -> str:
client = TavilyClient(api_key=os.environ['TAVILY_API_KEY'])
query = f"What are the upcoming events in {city}?"
response = client.search(query, search_depth="advanced")
results_content = "nn".join([result['content'] for result in response['results']])
return results_content Restaurant recommendation function
The query_restaurants_RAG() function uses a RAG system to provide restaurant recommendations by performing a similarity search in the vector database for relevant restaurant information, filtering for highly rated restaurants in the specified city and using Amazon Bedrock with the Mistral model to generate a summary of the top restaurants based on the retrieved information. It’s used by the query_restaurants_agent() function.
For the detailed implementation of these functions and tools, environment setup, and use cases, refer to the Multi-Agent LangGraph Mistral Jupyter notebook.
Implementing AI agents with LangGraph
Our multi-agent system consists of several specialized agents. Each agent in this architecture is represented by a Node in LangGraph, which, in turn, interacts with the tools and functions defined previously. The following diagram shows the workflow:

The workflow follows these steps:
- Events database agent (events_database_agent) – Uses the
events_database_tool()to query a local SQLite database and find local event information - Online search agent (search_agent) – Whenever local event information is unavailable in the database, this agent uses the
search_tool()to find upcoming events by searching online for a given city - Weather agent (weather_agent) – Fetches current weather data using the
weather_tool()for the specified city - Restaurant recommendation agent (query_restaurants_agent) – Uses the
query_restaurants_RAG()function to provide restaurant recommendations for a specified city - Analysis agent (analysis_agent) – Aggregates information from other agents to provide comprehensive recommendations
Here’s an example of how we created the weather agent:
def weather_agent(state: State) -> State:
......
tool_config = {
"tools": [
{
"toolSpec": {
"name": "get_city_weather",
"description": "Get current weather information for a specific city",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "The name of the city to look up weather for"
}
},
"required": ["city"]
}
}
}
}
]
}
input_text = f"Get current weather for {state.city}"
output_message, tool_result = generate_text(bedrock_client, DEFAULT_MODEL, tool_config, input_text)
if tool_result:
state.weather_info = {"city": state.city, "weather": tool_result}
else:
state.weather_info = {"city": state.city, "weather": "Weather information not available."}
print(f"Weather info set to: {state.weather_info}")
return stateOrchestrating agent collaboration
In the Multi-Agent City Information System, several key primitives orchestrate agent collaboration. The build_graph() function defines the workflow in LangGraph, utilizing nodes, routes, and conditions. The workflow is dynamic, with conditional routing based on event search results, and incorporates memory persistence to store the state across different executions of the agents. Here’s an overview of the function’s behavior:
- Initialize workflow – The function begins by creating a StateGraph object called
workflow, which is initialized with a State. In LangGraph, theStaterepresents the data or context that is passed through the workflow as the agents perform their tasks. In our example, the state includes things like the results from previous agents (for example, event data, search results, and weather information), input parameters (for example, city name), and other relevant information that the agents might need to process:
# Define the graph
def build_graph():
workflow = StateGraph(State)
...- Add nodes (agents) – Each agent is associated with a specific function, such as retrieving event data, performing an online search, fetching weather information, recommending restaurants, or analyzing the gathered information:
workflow.add_node("Events Database Agent", events_database_agent)
workflow.add_node("Online Search Agent", search_agent)
workflow.add_node("Weather Agent", weather_agent)
workflow.add_node("Restaurants Recommendation Agent", query_restaurants_agent)
workflow.add_node("Analysis Agent", analysis_agent)- Set entry point and conditional routing – The entry point for the workflow is set to the
Events Database Agent, meaning the execution of the workflow starts from this agent. Also, the function defines a conditional route using theadd_conditional_edgesmethod. Theroute_events()function decides the next step based on the results from theEvents Database Agent:
workflow.set_entry_point("Events Database Agent")
def route_events(state):
print(f"Routing events. Current state: {state}")
print(f"Events content: '{state.events_result}'")
if f"No upcoming events found for {state.city}" in state.events_result:
print("No events found in local DB. Routing to Online Search Agent.")
return "Online Search Agent"
else:
print("Events found in local DB. Routing to Weather Agent.")
return "Weather Agent"
workflow.add_conditional_edges(
"Events Database Agent",
route_events,
{
"Online Search Agent": "Online Search Agent",
"Weather Agent": "Weather Agent"
}
)- Add Edges between agents – These edges define the order in which agents interact in the workflow. The agents will proceed in a specific sequence: from
Online Search AgenttoWeather Agent, fromWeather AgenttoRestaurants Recommendation Agent, and from there toAnalysis Agent, before finally reaching theEND:
workflow.add_edge("Online Search Agent", "Weather Agent")
workflow.add_edge("Weather Agent", "Restaurants Recommendation Agent")
workflow.add_edge("Restaurants Recommendation Agent", "Analysis Agent")
workflow.add_edge("Analysis Agent", END)- Initialize memory for state persistence – The
MemorySaverclass is used to make sure that the state of the workflow is preserved between runs. This is especially useful in multi-agent systems where the state of the system needs to be maintained as the agents interact:
# Initialize memory to persist state between graph runs
checkpointer = MemorySaver()- Compile the workflow and visualize the graph – The workflow is compiled, and the memory-saving object (
checkpointer) is included to make sure that the state is persisted between executions. Then, it outputs a graphical representation of the workflow:
# Compile the workflow
app = workflow.compile(checkpointer=checkpointer)
# Visualize the graph
display(
Image(
app.get_graph().draw_mermaid_png(
draw_method=MermaidDrawMethod.API
)
)
)The following diagram illustrates these steps:

Results and analysis
To demonstrate the versatility of our Multi-Agent City Information System, we run it for three different cities: Tampa, Philadelphia, and New York. Each example showcases different aspects of the system’s functionality.
The used function main() orchestrates the entire process:
- Calls the
build_graph()function, which implements the agentic workflow - Initializes the state with the specified city
- Streams the events through the workflow
- Retrieves and displays the final analysis and recommendations
To run the code, do the following:
if __name__ == "__main__":
cities = ["Tampa", "Philadelphia", "New York"]
for city in cities:
print(f"nStarting script execution for city: {city}")
main(city)Three example use cases
For Example 1 (Tampa), the following diagram shows how the agentic workflow produces the output in response to the user’s question, “What’s happening in Tampa and what should I wear?”

The system produced the following results:
- Events – Not found in the local database, triggering the search tool which called the Tavily API to find several upcoming events
- Weather – Retrieved from weather tool. Current conditions include moderate rain, 28°C, and 87% humidity
- Activities – The system suggested various indoor and outdoor activities based on the events and weather
- Outfit recommendations – Considering the warm, humid, and rainy conditions, the system recommended light, breathable clothing and rain protection
- Restaurants – Recommendations provided through the RAG system
For Example 2 (Philadelphia), the agentic workflow identified events in the local database, including cultural events and festivals. It retrieved weather data from the OpenWeatherMap API, then suggested activities based on local events and weather conditions. Outfit recommendations were made in line with the weather forecast, and restaurant recommendations were provided through the RAG system.
For Example 3 (New York), the workflow identified events such as Broadway shows and city attractions in the local database. It retrieved weather data from the OpenWeatherMap API and suggested activities based on the variety of local events and weather conditions. Outfit recommendations were tailored to New York’s weather and urban environment. However, the RAG system was unable to provide restaurant recommendations for New York because the synthetic dataset created earlier hadn’t included any restaurants from this city.
These examples demonstrate the system’s ability to adapt to different scenarios. For detailed output of these examples, refer to the Results and Analysis section of the Multi-Agent LangGraph Mistral Jupyter notebook.
Conclusion
In the Multi-Agent City Information System we developed, agents integrate various data sources and APIs within a flexible, modular framework to provide valuable information about events, weather, activities, outfit recommendations, and dining options across different cities. Using Amazon Bedrock and LangGraph, we’ve created a sophisticated agent-based workflow that adapts seamlessly to varying levels of available information, switching between local and online data sources as needed. These agents autonomously gather, process, and consolidate data into actionable insights, orchestrating and automating business logic to streamline processes and provide real-time insights. As a result, this multi-agent approach enables the creation of robust, scalable, and intelligent agentic systems that push the boundaries of what’s possible with generative AI.
Want to dive deeper? Explore the implementation of Multi-Agent Collaboration and Orchestration using LangGraph for Mistral Models on GitHub to observe the code in action and try out the solution yourself. You’ll find step-by-step instructions for setting up and running the multi-agent system, along with code for interacting with data sources, agents, routing data, and visualizing the workflow.
About the Author
 Andre Boaventura is a Principal AI/ML Solutions Architect at AWS, specializing in generative AI and scalable machine learning solutions. With over 25 years in the high-tech software industry, he has deep expertise in designing and deploying AI applications using AWS services such as Amazon Bedrock, Amazon SageMaker, and Amazon Q. Andre works closely with global system integrators (GSIs) and customers across industries to architect and implement cutting-edge AI/ML solutions to drive business value. Outside of work, Andre enjoys practicing Brazilian Jiu-Jitsu with his son (often getting pinned or choked by a teenager), cheering for his daughter at her dance competitions (despite not knowing ballet terms—he claps enthusiastically anyway), and spending ‘quality time’ with his wife—usually in shopping malls, pretending to be interested in clothes and shoes while secretly contemplating a new hobby.
Andre Boaventura is a Principal AI/ML Solutions Architect at AWS, specializing in generative AI and scalable machine learning solutions. With over 25 years in the high-tech software industry, he has deep expertise in designing and deploying AI applications using AWS services such as Amazon Bedrock, Amazon SageMaker, and Amazon Q. Andre works closely with global system integrators (GSIs) and customers across industries to architect and implement cutting-edge AI/ML solutions to drive business value. Outside of work, Andre enjoys practicing Brazilian Jiu-Jitsu with his son (often getting pinned or choked by a teenager), cheering for his daughter at her dance competitions (despite not knowing ballet terms—he claps enthusiastically anyway), and spending ‘quality time’ with his wife—usually in shopping malls, pretending to be interested in clothes and shoes while secretly contemplating a new hobby.

Evaluate RAG responses with Amazon Bedrock, LlamaIndex and RAGAS
In the rapidly evolving landscape of artificial intelligence, Retrieval Augmented Generation (RAG) has emerged as a game-changer, revolutionizing how Foundation Models (FMs) interact with organization-specific data. As businesses increasingly rely on AI-powered solutions, the need for accurate, context-aware, and tailored responses has never been more critical.
Enter the powerful trio of Amazon Bedrock, LlamaIndex, and RAGAS– a cutting-edge combination that’s set to redefine the evaluation and optimization of RAG responses. This blog post delves into how these innovative tools synergize to elevate the performance of your AI applications, ensuring they not only meet but exceed the exacting standards of enterprise-level deployments.
Whether you’re a seasoned AI practitioner or a business leader exploring the potential of generative AI, this guide will equip you with the knowledge and tools to:
- Harness the full potential of Amazon Bedrock robust foundation models
- Utilize RAGAS’s comprehensive evaluation metrics for RAG systems
In this post, we’ll explore how to leverage Amazon Bedrock, LlamaIndex, and RAGAS to enhance your RAG implementations. You’ll learn practical techniques to evaluate and optimize your AI systems, enabling more accurate, context-aware responses that align with your organization’s specific needs. Let’s dive in and discover how these powerful tools can help you build more effective and reliable AI-powered solutions.
RAG Evaluation
RAG evaluation is important to ensure that RAG models produce accurate, coherent, and relevant responses. By analyzing the retrieval and generator components both jointly and independently, RAG evaluation helps identify bottlenecks, monitor performance, and improve the overall system. Current RAG pipelines frequently employ similarity-based metrics such as ROUGE, BLEU, and BERTScore to assess the quality of the generated responses, which is essential for refining and enhancing the model’s capabilities.
Above mentioned probabilistic metrics ROUGE, BLEU, and BERTScore have limitations in assessing relevance and detecting hallucinations. More sophisticated metrics are needed to evaluate factual alignment and accuracy.
Evaluate RAG components with Foundation models
We can also use a Foundation Model as a judge to compute various metrics for both retrieval and generation. Here are some examples of these metrics:
- Retrieval component
- Context precision – Evaluates whether all of the ground-truth relevant items present in the contexts are ranked higher or not.
- Context recall – Ensures that the context contains all relevant information needed to answer the question.
- Generator component
- Faithfulness – Verifies that the generated answer is factually accurate based on the provided context, helping to identify errors or “hallucinations.”
- Answer relavancy : Measures how well the answer matches the question. Higher scores mean the answer is complete and relevant, while lower scores indicate missing or redundant information.

Overview of solution
This post guides you through the process of assessing quality of RAG response with evaluation framework such as RAGAS and LlamaIndex with Amazon Bedrock.
In this post, we are also going to leverage Langchain to create a sample RAG application.
Amazon Bedrock is a fully managed service that offers a choice of high-performing Foundation Models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
The Retrieval Augmented Generation Assessment (RAGAS) framework offers multiple metrics to evaluate each part of the RAG system pipeline, identifying areas for improvement. It utilizes foundation models to test individual components, aiding in pinpointing modules for development to enhance overall results.
LlamaIndex is a framework for building LLM applications. It simplifies data integration from various sources and provides tools for data indexing, engines, agents, and application integrations. Optimized for search and retrieval, it streamlines querying LLMs and retrieving documents. This blog post focuses on using its Observability/Evaluation modules.
LangChain is an open-source framework that simplifies the creation of applications powered by foundation models. It provides tools for chaining LLM operations, managing context, and integrating external data sources. LangChain is primarily used for building chatbots, question-answering systems, and other AI-driven applications that require complex language processing capabilities.
Diagram Architecture
The following diagram is a high-level reference architecture that explains how you can evaluate the RAG solution with RAGAS or LlamaIndex.
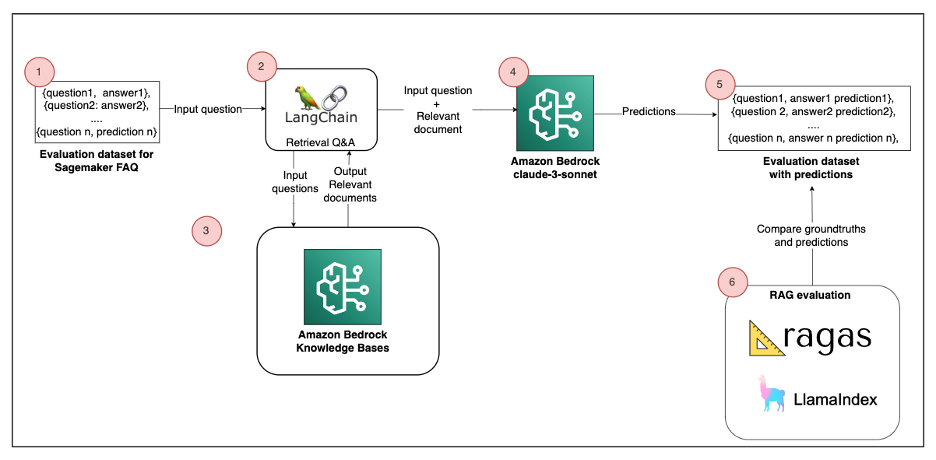
The solution consists of the following components:
- Evaluation dataset – The source data for the RAG comes from the Amazon SageMaker FAQ, which represents 170 question-answer pairs. This corresponds to Step 1 in the architecture diagram.
- Build sample RAG – Documents are segmented into chunks and stored in an Amazon Bedrock Knowledge Bases (Steps 2–4). We use Langchain Retrieval Q&A to answer user queries. This process retrieves relevant data from an index at runtime and passes it to the Foundation Model (FM).
- RAG evaluation – To assess the quality of the Retrieval-Augmented Generation (RAG) solution, we can use both RAGAS and LlamaIndex. An LLM performs the evaluation by comparing its predictions with ground truths (Steps 5–6).
You must follow the provided notebook to reproduce the solution. We elaborate on the main code components in this post.
Prerequisites
To implement this solution, you need the following:
- An AWS accountwith privileges to create AWS Identity and Access Management (IAM) roles and policies. For more information, see Overview of access management: Permissions and policies.
- Access enabled for the Amazon Titan Embeddings G1 – Text model and Anthropic Claude 3 Sonnet on Amazon Bedrock. For instructions, see Model access.
- Run the prerequisite code provided in the Python
Ingest FAQ data
The first step is to ingest the SageMaker FAQ data. For this purpose, LangChain provides a WebBaseLoader object to load text from HTML webpages into a document format. Then we split each document in multiple chunks of 2,000 tokens with a 100-token overlap. See the following code below:
text_chunks = split_document_from_url(SAGEMAKER_URL, chunck_size= 2000, chunk_overlap=100)
retriever_db= get_retriever(text_chunks, bedrock_embeddings)Set up embeddings and LLM with Amazon Bedrock and LangChain
In order to build a sample RAG application, we need an LLM and an embedding model:
- LLM – Anthropic Claude 3 Sonnet
- Embedding – Amazon Titan Embeddings – Text V2
This code sets up a LangChain application using Amazon Bedrock, configuring embeddings with Titan and a Claude 3 Sonnet model for text generation with specific parameters for controlling the model’s output. See the following code below from the notebook :
from botocore.client import Config
from langchain.llms.bedrock import Bedrock
from langchain_aws import ChatBedrock
from langchain.embeddings import BedrockEmbeddings
from langchain.retrievers.bedrock import AmazonKnowledgeBasesRetriever
from langchain.chains import RetrievalQA
import nest_asyncio
nest_asyncio.apply()
#URL to fetch the document
SAGEMAKER_URL="https://aws.amazon.com/sagemaker/faqs/"
#Bedrock parameters
EMBEDDING_MODEL="amazon.titan-embed-text-v2:0"
BEDROCK_MODEL_ID="anthropic.claude-3-sonnet-20240229-v1:0"
bedrock_embeddings = BedrockEmbeddings(model_id=EMBEDDING_MODEL,client=bedrock_client)
model_kwargs = {
"temperature": 0,
"top_k": 250,
"top_p": 1,
"stop_sequences": ["\n\nHuman:"]
}
llm_bedrock = ChatBedrock(
model_id=BEDROCK_MODEL_ID,
model_kwargs=model_kwargs
)Set up Knowledge Bases
We will create Amazon Bedrock knowledgebases Web Crawler datasource and process Sagemaker FAQ data.
In the code below, we load the embedded documents in Knowledge bases and we set up the retriever with LangChain:
from utils import split_document_from_url, get_bedrock_retriever
from botocore.exceptions import ClientError
text_chunks = split_document_from_url(SAGEMAKER_URL, chunck_size= 2000, chunk_overlap=100)
retriever_db= get_bedrock_retriever(text_chunks, region)Build a Q&A chain to query the retrieval API
After the database is populated, create a Q&A retrieval chain to perform question answering with context extracted from the vector store. You also define a prompt template following Claude prompt engineering guidelines. See the following code below from the notebook:
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
system_prompt = (
"Use the given context to answer the question. "
"If you don't know the answer, say you don't know. "
"Use three sentence maximum and keep the answer concise and short. "
"Context: {context}"
)
prompt_template = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{input}")
]
)
question_answer_chain = create_stuff_documents_chain(llm_bedrock, prompt_template)
chain = create_retrieval_chain(retriever_db, question_answer_chain)Build Dataset to evaluate RAG application
To evaluate a RAG application, we need a combination of the following datasets:
- Questions – The user query that serves as input to the RAG pipeline
- Context – The information retrieved from enterprise or external data sources based on the provided query
- Answers – The responses generated by LLMs
- Ground truths – Human-annotated, ideal responses for the questions that can be used as the benchmark to compare against the LLM-generated answers
We are ready to evaluate the RAG application. As describe in the introduction, we select 3 metrics to assess our RAG solution:
- Faithfulness
- Answer Relevancy
- Answer Correctness
For more information, refer to Metrics.
This step involves defining an evaluation dataset with a set of ground truth questions and answers. For this post, we choose four random questions from the SageMaker FAQ. See the following code below from the notebook:
EVAL_QUESTIONS = [
"Can I stop a SageMaker Autopilot job manually?",
"Do I get charged separately for each notebook created and run in SageMaker Studio?",
"Do I get charged for creating and setting up an SageMaker Studio domain?",
"Will my data be used or shared to update the base model that is offered to customers using SageMaker JumpStart?",
]
#Defining the ground truth answers for each question
EVAL_ANSWERS = [
"Yes. You can stop a job at any time. When a SageMaker Autopilot job is stopped, all ongoing trials will be stopped and no new trial will be started.",
"""No. You can create and run multiple notebooks on the same compute instance.
You pay only for the compute that you use, not for individual items.
You can read more about this in our metering guide.
In addition to the notebooks, you can also start and run terminals and interactive shells in SageMaker Studio, all on the same compute instance.""",
"No, you don’t get charged for creating or configuring an SageMaker Studio domain, including adding, updating, and deleting user profiles.",
"No. Your inference and training data will not be used nor shared to update or train the base model that SageMaker JumpStart surfaces to customers."
]Evaluation of RAG with RAGAS
Evaluating the RAG solution requires to compare LLM predictions with ground truth answers. To do so, we use the batch() function from LangChain to perform inference on all questions inside our evaluation dataset.
Then we can use the evaluate() function from RAGAS to perform evaluation on each metric (answer relevancy, faithfulness and answer corectness). It uses an LLM to compute metrics. Feel free to use other Metrics from RAGAS.
See the following code below from the notebook:
from ragas.metrics import answer_relevancy, faithfulness, answer_correctness
from ragas import evaluate
#Batch invoke and dataset creation
result_batch_questions = chain.batch([{"input": q} for q in EVAL_QUESTIONS])
dataset= build_dataset(EVAL_QUESTIONS,EVAL_ANSWERS,result_batch_questions, text_chunks)
result = evaluate(dataset=dataset, metrics=[ answer_relevancy, faithfulness, answer_correctness ],llm=llm_bedrock, embeddings=bedrock_embeddings, raise_exceptions=False )
df = result.to_pandas()
df.head()
The following screenshot shows the evaluation results and the RAGAS answer relevancy score.
Answer Relevancy
In the answer_relevancy_score column, a score closer to 1 indicates the response generated is relevant to the input query.
Faithfulness
In the second column, the first query result has a lower faithfulness_score (0.2), which indicates the responses are not derived from the context and are hallucinations. The rest of the query results have a higher faithfulness_score (1.0), which indicates the responses are derived from the context.
Answer Correctness
In the last column answer_correctness, the second and last row have high answer correctness, meaning that answer provided by the LLM is closer to to from the groundtruth.
Evaluation of RAG with LlamaIndex
LlamaIndex, similar to Ragas, provides a comprehensive RAG (Retrieval-Augmented Generation) evaluation module. This module offers a variety of metrics to assess the performance of your RAG system. The evaluation process generates two key outputs:
- Feedback: The judge LLM (Language Model) provides detailed evaluation feedback in the form of a string, offering qualitative insights into the system’s performance.
- Score: This numerical value indicates how well the answer meets the evaluation criteria. The scoring system varies depending on the specific metric being evaluated. For example, metrics like Answer Relevancy and Faithfulness are typically scored on a scale from 0 to 1.
These outputs allow for both qualitative and quantitative assessment of your RAG system’s performance, enabling you to identify areas for improvement and track progress over time.
The following is a code sample from the notebook:
from llama_index.llms.bedrock import Bedrock
from llama_index.core.evaluation import (
AnswerRelevancyEvaluator,
CorrectnessEvaluator,
FaithfulnessEvaluator
)
from utils import evaluate_llama_index_metric
bedrock_llm_llama = Bedrock(model=BEDROCK_MODEL_ID)
faithfulness= FaithfulnessEvaluator(llm=bedrock_llm_llama)
answer_relevancy= AnswerRelevancyEvaluator(llm=bedrock_llm_llama)
correctness= CorrectnessEvaluator(llm=bedrock_llm_llama)Answer Relevancy
df_answer_relevancy= evaluate_llama_index_metric(answer_relevancy, dataset)
df_answer_relevancy.head()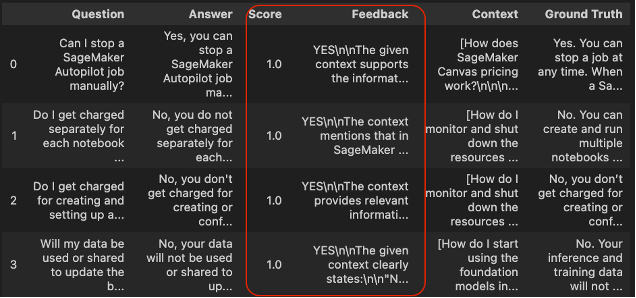
The column Score defines the result for the answer_relevancy evaluation criteria. All passing values are set to 1, meaning that all predictions are relevant with the context retrieved.
Additionally, the column Feedback provides a clear explanation of the result of the passing score. We can observe that all answers align with the context extracted from the retriever.
Answer Correctness
df_correctness= evaluate_llama_index_metric(correctness, dataset)
df_correctness.head()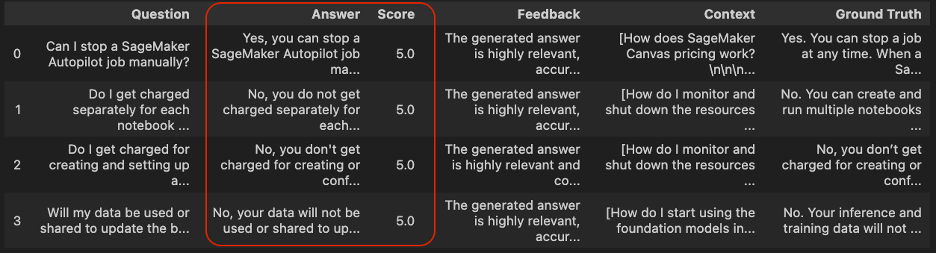
All values from the column Score are set to 5.0, meaning that all predictions are coherent with ground truth answers.
Faithfulness
The following screenshot shows the evaluation results for answer faithfulness.
df_faithfulness= evaluate_llama_index_metric(faithfulness, dataset)
df_faithfulness.head()
All values from the Score column are set to 1.0, which means all answers generated by LLM are coherent given the context retrieved.
Conclusion
While Foundation Models offer impressive generative capabilities, their effectiveness in addressing organization-specific queries has been a persistent challenge. The Retrieval Augmented Generation framework emerges as a powerful solution, bridging this gap by enabling LLMs to leverage external, organization-specific data sources.
To truly unlock the potential of RAG pipelines, the RAGAS framework, in conjunction with LlamaIndex, provides a comprehensive evaluation solution. By meticulously assessing both retrieval and generation components, this approach empowers organizations to pinpoint areas for improvement and refine their RAG implementations. The result? Responses that are not only factually accurate but also highly relevant to user queries.
By adopting this holistic evaluation approach, enterprises can fully harness the transformative power of generative AI applications. This not only maximizes the value derived from these technologies but also paves the way for more intelligent, context-aware, and reliable AI systems that can truly understand and address an organization’s unique needs.
As we continue to push the boundaries of what’s possible with AI, tools like Amazon Bedrock, LlamaIndex, and RAGAS will play a pivotal role in shaping the future of enterprise AI applications. By embracing these innovations, organizations can confidently navigate the exciting frontier of generative AI, unlocking new levels of efficiency, insight, and competitive advantage.
For further exploration, readers interested in enhancing the reliability of AI-generated content may want to look into Amazon Bedrock’s Guardrails feature, which offers additional tools like the Contextual Grounding Check.
About the authors
 Madhu is a Senior Partner Solutions Architect specializing in worldwide public sector cybersecurity partners. With over 20 years in software design and development, he collaborates with AWS partners to ensure customers implement solutions that meet strict compliance and security objectives. His expertise lies in building scalable, highly available, secure, and resilient applications for diverse enterprise needs.
Madhu is a Senior Partner Solutions Architect specializing in worldwide public sector cybersecurity partners. With over 20 years in software design and development, he collaborates with AWS partners to ensure customers implement solutions that meet strict compliance and security objectives. His expertise lies in building scalable, highly available, secure, and resilient applications for diverse enterprise needs.
 Babu Kariyaden Parambath is a Senior AI/ML Specialist at AWS. At AWS, he enjoys working with customers in helping them identify the right business use case with business value and solve it using AWS AI/ML solutions and services. Prior to joining AWS, Babu was an AI evangelist with 20 years of diverse industry experience delivering AI driven business value for customers.
Babu Kariyaden Parambath is a Senior AI/ML Specialist at AWS. At AWS, he enjoys working with customers in helping them identify the right business use case with business value and solve it using AWS AI/ML solutions and services. Prior to joining AWS, Babu was an AI evangelist with 20 years of diverse industry experience delivering AI driven business value for customers.