Increasingly, organizations across industries are turning to generative AI foundation models (FMs) to enhance their applications. To achieve optimal performance for specific use cases, customers are adopting and adapting these FMs to their unique domain requirements. This need for customization has become even more pronounced with the emergence of new models, such as those released by DeepSeek.
However, customizing DeepSeek models effectively while managing computational resources remains a significant challenge. Tuning model architecture requires technical expertise, training and fine-tuning parameters, and managing distributed training infrastructure, among others. This often forces companies to choose between model performance and practical implementation constraints, creating a critical need for more accessible and streamlined model customization solutions.
In this two-part series, we discuss how you can reduce the DeepSeek model customization complexity by using the pre-built fine-tuning workflows (also called “recipes”) for both DeepSeek-R1 model and its distilled variations, released as part of Amazon SageMaker HyperPod recipes.
In this first post, we will build a solution architecture for fine-tuning DeepSeek-R1 distilled models and demonstrate the approach by providing a step-by-step example on customizing the DeepSeek-R1 Distill Qwen 7b model using recipes, achieving an average of 25% on all the Rouge scores, with a maximum of 49% on Rouge 2 score with both SageMaker HyperPod and SageMaker training jobs. The second part of the series will focus on fine-tuning the DeepSeek-R1 671b model itself.
At the time of this writing, the DeepSeek-R1 model and its distilled variations for Llama and Qwen were the latest released recipe. Check out sagemaker-hyperpod-recipes on GitHub for the latest released recipes, including support for fine-tuning the DeepSeek-R1 671b parameter model.
Amazon SageMaker HyperPod recipes
At re:Invent 2024, we announced the general availability of Amazon SageMaker HyperPod recipes. SageMaker HyperPod recipes help data scientists and developers of all skill sets to get started training and fine-tuning popular publicly available generative AI models in minutes with state-of-the-art training performance. These recipes include a training stack validated by Amazon Web Services (AWS), which removes the tedious work of experimenting with different model configurations, minimizing the time it takes for iterative evaluation and testing. They automate several critical steps, such as loading training datasets, applying distributed training techniques, automating checkpoints for faster recovery from faults, and managing the end-to-end training loop.
Recipes, paired with the resilient infrastructure of AWS, (Amazon SageMaker HyperPod and Amazon SageMaker Model Training) provide a resilient training environment for fine-tuning FMs such as DeepSeek-R1 with out-of-the-box customization.
To help customers quickly use DeepSeek’s powerful and cost-efficient models to accelerate generative AI innovation, we released new recipes to fine-tune six DeepSeek models, including DeepSeek-R1 distilled Llama and Qwen models using supervised fine-tuning (SFT), Quantized Low-Rank Adaptation (QLoRA), Low-Rank Adaptation (LoRA) techniques. In this post, we introduce these new recipes and walk you through a solution to fine-tune a DeepSeek Qwen 7b model for an advanced medical reasoning use case.
Solution overview
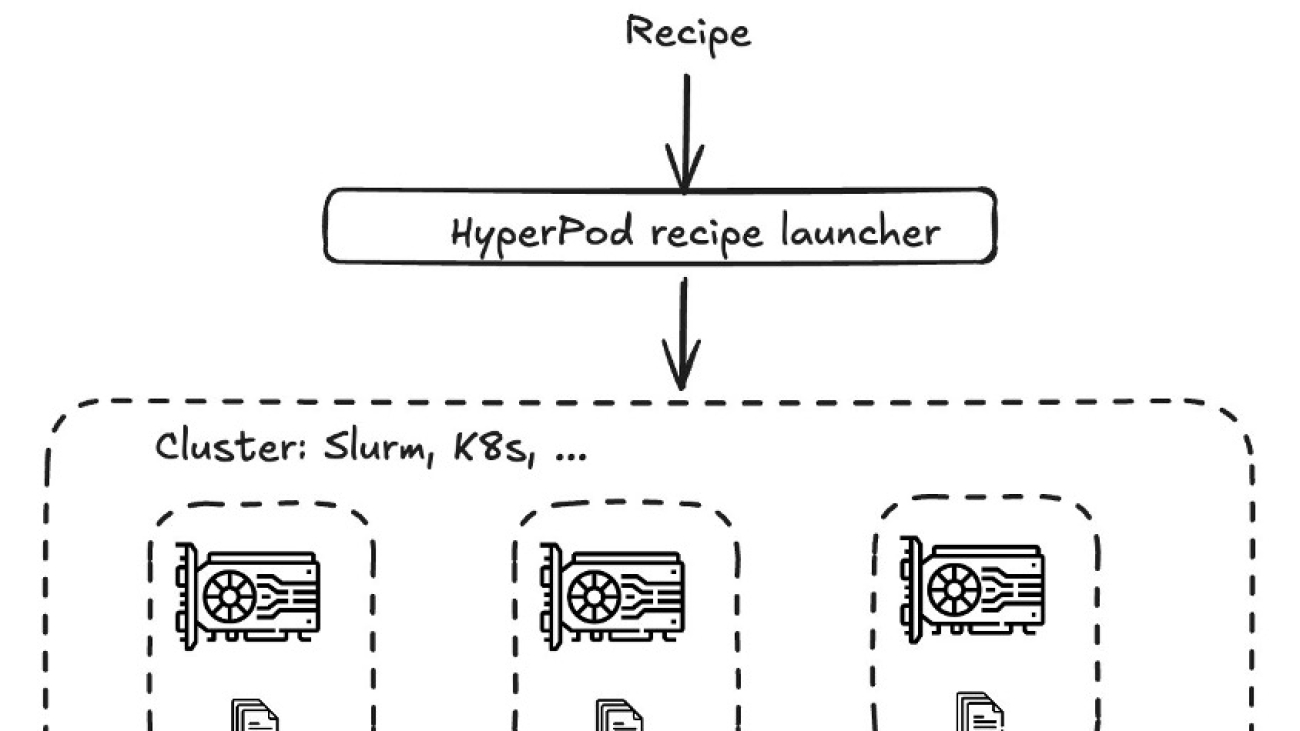
At its core, as depicted in the following diagram, the recipe architecture implements a hierarchical workflow that begins with a recipe specification that covers a comprehensive configuration defining the training parameters, model architecture, and distributed training strategies. These recipes are processed through the HyperPod recipe launcher, which serves as the orchestration layer responsible for launching a job on the corresponding architecture. The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. It’s a familiar NeMo-style launcher with which you can choose a recipe and run it on your infrastructure of choice (SageMaker HyperPod or training).
For example, after choosing your recipe, you can pre-train or fine-tune a model by running python3 main.py recipes=recipe-name. Alternatively, you can use a launcher script, which is a bash script that is preconfigured to run the chosen training or fine-tuning job on your cluster. You can check out main.py (NeMo style launcher) and launcher scripts for DeepSeek on the GitHub repository hosting SageMaker HyperPod recipes.
A key component of this architecture is the HyperPod training adapter for NeMo, which is built on the NVIDIA NeMo framework and Neuronx Distributed training package, which loads data, creates models, and facilitates efficient data parallelism, model parallelism, and hybrid parallelism strategies, which enables optimal utilization of computational resources across the distributed infrastructure. The architecture’s modular design allows for scalability and flexibility, making it particularly effective for training LLMs that require distributed computing capabilities.

You can run these recipes using SageMaker HyperPod or as SageMaker training jobs. For organizations that require granular control over training infrastructure and extensive customization options, SageMaker HyperPod is the ideal choice. SageMaker training jobs, on the other hand, is tailored for organizations that want a fully managed experience for their training workflows. To learn more details about these service features, refer to Generative AI foundation model training on Amazon SageMaker.
In the next sections, we go over the solution architecture for these services before presenting a step-by-step implementation example for each.
SageMaker HyperPod
To submit jobs using SageMaker HyperPod, you can use the HyperPod recipes launcher, which provides an straightforward mechanism to run recipes on both Slurm and Kubernetes. After you choose your orchestrator, you can choose your recipe’s launcher and have it run on your HyperPod cluster. The launcher will interface with your cluster with Slurm or Kubernetes native constructs. For this post, we use the HyperPod recipes launcher mechanism to run the training on a Slurm cluster. The following image shows the solution architecture for SageMaker HyperPod.

SageMaker training jobs
The workflow for SageMaker training jobs begins with an API request that interfaces with the SageMaker control plane, which manages the orchestration of training resources. The system uses the training jobs launcher to efficiently run workloads on a managed cluster.
The architecture uses Amazon Elastic Container Registry (Amazon ECR) for container image management. Training jobs are executed across a distributed cluster, with seamless integration to multiple storage solutions, including Amazon Simple Storage Service (Amazon S3), Amazon Elastic File Storage (Amazon EFS), and Amazon FSx for Lustre. All of this runs under the SageMaker managed environment, providing optimal resource utilization and security.
This design simplifies the complexity of distributed training while maintaining the flexibility needed for diverse machine learning (ML) workloads, making it an ideal solution for enterprise AI development. The following image shows the solution architecture for SageMaker training jobs.

Solution walkthrough
For this solution, consider a use case for a healthcare industry startup that aims to create an accurate, medically verified chat assistant application that bridges complex medical information with patient-friendly explanations. By fine-tuning DeepSeek-R1 Distill Qwen 7b using the FreedomIntelligence/medical-o1-reasoning-SFT dataset, you can use its medical reasoning capabilities to produce content that maintains clinical accuracy.
Prerequisites
You need to complete the following prerequisites before you can run the DeepSeek-R1 Distill Qwen 7B model fine-tuning notebook.
- Make the following quota increase requests for SageMaker. You need to request a minimum of one
p4d.24xlarge instance (with 8 x NVIDIA A100 GPUs) ranging to a maximum of two p4d.24xlarge instances (depending on time-to-train and cost-to-train trade-offs for your use case).
On the Service Quotas console, request the following SageMaker quotas:
-
- P4 instances (
p4d.24xlarge) for training job usage: 1–2
- P4 instances (
p4d.24xlarge) for HyperPod clusters (“ml.p4d.24xlarge for cluster usage“): 1-2
- If you choose to use HyperPod clusters to run your training, set up a HyperPod Slurm cluster following the documentation at Tutuorial for getting started with SageMaker HyperPod. Alternatively, you can use the AWS CloudFormation template provided in the AWS Workshop Studio at Amazon SageMaker HyperPod Own Account and follow the instructions to set up a cluster and a development environment to access and submit jobs to the cluster.
- (Optional) If you choose to use SageMaker training jobs, you can create an Amazon SageMaker Studio domain (refer to Use quick setup for Amazon SageMaker AI) to access Jupyter notebooks with the preceding role. (You can use JupyterLab in your local setup, too.)
- Clone the GitHub repository with the assets for this deployment. This repository consists of a notebook that references training assets:
git clone https://github.com/aws-samples/sagemaker-distributed-training-workshop.git
cd 18_sagemaker_training_recipes/ft_deepseek_qwen_lora
Next, we run the model_trainer_deepseek_r1_recipe_lora.ipynb notebook to fine-tune the DeepSeek-R1 model using QLoRA on SageMaker.
Prepare the dataset
To prepare the dataset, you need to load the FreedomIntelligence/medical-o1-reasoning-SFT dataset, tokenize and chunk the dataset, and configure the data channels for SageMaker training on Amazon S3. Complete the following steps:
- Format the dataset by applying the prompt format for DeepSeek-R1 Distill Qwen 7B:
def generate_prompt(data_point):
full_prompt = f"""
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{data_point["Question"]}
### Response:
{data_point["Complex_CoT"]}
"""
return {"prompt": full_prompt.strip()}
- Load the FreedomIntelligence/medical-o1-reasoning-SFT dataset and split it into training and validation datasets:
# Load dataset from the hub
train_set = load_dataset(dataset_name, 'en', split="train[5%:]")
test_set = load_dataset(dataset_name, 'en', split="train[:5%]")
...
train_dataset = train_set.map(
generate_and_tokenize_prompt,
remove_columns=columns_to_remove,
batched=False
)
test_dataset = test_set.map(
generate_and_tokenize_prompt,
remove_columns=columns_to_remove,
batched=False
)
- Load the DeepSeek-R1 Distill Qwen 7B tokenizer from the Hugging Face Transformers library and generate tokens for the train and validation datasets:
model_id = "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"
max_seq_length=1024
# Initialize a tokenizer by loading a pre-trained tokenizer configuration, using the fast tokenizer implementation if available.
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)
...
train_dataset = train_dataset.map(tokenize, remove_columns=["prompt"])
test_dataset = test_dataset.map(tokenize, remove_columns=["prompt"])
- Prepare the training and validation datasets for SageMaker training by saving them as
arrow files, which is required by SageMaker HyperPod recipes, and constructing the S3 paths where these files will be uploaded:
train_dataset_s3_path = f"s3://{bucket_name}/{input_path}/train"
val_dataset_s3_path = f"s3://{bucket_name}/{input_path}/test"
train_dataset.save_to_disk(train_dataset_s3_path)
val_dataset.save_to_disk(val_dataset_s3_path)
The dataset above will be used in the examples for both SageMaker training jobs and SageMaker HyerPod.
Option A: Fine-tune using SageMaker training jobs
To fine-tune the model using SageMaker training jobs with recipes, this example uses the ModelTrainer class.
The ModelTrainer class is a newer and more intuitive approach to model training that significantly enhances user experience and supports distributed training, Build Your Own Container (BYOC), and recipes. For additional information about ModelTrainer, you can refer to Accelerate your ML lifecycle using the new and improved Amazon SageMaker Python SDK – Part 1: ModelTrainer
To set up the fine-tuning workload, complete the following steps:
- Select the instance type, the container image for the training job, and define the checkpoint path where the model will be stored:
instance_type = "ml.p4d.24xlarge"
image_uri = (
f"658645717510.dkr.ecr.{sagemaker_session.boto_session.region_name}.amazonaws.com/smdistributed-modelparallel:2.4.1-gpu-py311-cu121"
)
checkpoint_s3_path = f"s3://{bucket_name}/deepseek-r1-distilled-qwen-7b-recipe-lora/checkpoints"
- Create the ModelTrainer function to encapsulate the training setup from a selected recipe:
from sagemaker.modules.configs import CheckpointConfig, Compute, InputData, SourceCode, StoppingCondition
from sagemaker.modules.distributed import Torchrun
from sagemaker.modules.train import ModelTrainer
instance_count = 1
# Working override for custom dataset
recipe_overrides = {
...
"trainer": {
"num_nodes": instance_count,
...
},
...
"use_smp_model": False, # Required for PEFT
"model": {
"hf_model_name_or_path": model_id,
"data": {
"train_dir": "/opt/ml/input/data/train",
"val_dir": "/opt/ml/input/data/test",
},
},
}
# Define the compute
compute_configs = Compute(
instance_type=instance_type,
instance_count=instance_count,
keep_alive_period_in_seconds=0
)
model_trainer = ModelTrainer.from_recipe(
training_image=image_uri,
training_recipe="fine-tuning/deepseek/hf_deepseek_r1_distilled_qwen_7b_seq8k_gpu_lora",
recipe_overrides=recipe_overrides,
requirements="./requirements.txt",
compute=compute_configs,
...
checkpoint_config=CheckpointConfig(
s3_uri=f"{checkpoint_s3_path}/{job_prefix}"
),
)
You can point to the specific recipe with the training_recipe argument and override the recipe arguments by providing a dictionary as argument of recipe_overrides. In the previous example:
num_nodes: Indicates the number of instances that will be used for the fine-tuning executioncheckpoint_dir: Location in the container where the job will save model checkpoints
The ModelTrainer class simplifies the experience by encapsulating code and training setup directly from the selected recipe. In this example:
training_recipe: hf_deepseek_r1_distilled_qwen_7b_seq8k_gpu_lora is defining fine-tuning setup for the LoRA technique
- Set up the input channels for ModelTrainer by creating an InputData objects from the provided S3 bucket paths for the training and test and validation datasets
- Submit the training job:
# starting the train job with our uploaded datasets as input
model_trainer.train(input_data_config=data, wait=True)
Option B: Fine-tune using SageMaker HyperPod with Slurm
To fine-tune the model using HyperPod, make sure your cluster is up and ready by following the prerequisites. To access the login or head node of the HyperPod Slurm cluster from your development environment, follow the login instructions at Log in to your cluster in the Amazon SageMaker HyperPod workshop.
Alternatively, you can also use AWS Systems Manager and run a command like the following to start the session. You can find the cluster ID, instance group name, and instance ID on the Amazon SageMaker console.
aws ssm start-session --target sagemaker-cluster:[cluster-id]_[instance-group-name]-[instance-id] --region region_name
- In the cluster’s login or head node, run the following commands to set up the environment. Run
sudo su - ubuntu to run the remaining commands as the root user unless you have a specific user ID to access the cluster and your POSIX user is created through a lifecycle script on the cluster. Refer to the multi-user setup for more details.
# create a virtual environment
python3 -m venv ${PWD}/venv
source venv/bin/activate
# clone the recipes repository and set up the environment
git clone --recursive https://github.com/aws/sagemaker-hyperpod-recipes.git
cd sagemaker-hyperpod-recipes
pip3 install -r requirements.txt
- Create a squash file using Enroot to run the job on the cluster. Enroot runtime offers GPU acceleration, rootless container support, and seamless integration with high performance computing (HPC) environments, making it ideal for running our workflows securely.
# create a squash file using Enroot
REGION=<region>
IMAGE="658645717510.dkr.ecr.${REGION}.amazonaws.com/smdistributed-modelparallel:2.4.1-gpu-py311-cu121"
aws ecr get-login-password --region "${REGION}" | docker login --username AWS --password-stdin 658645717510.dkr.ecr.${REGION}.amazonaws.com
enroot import -o $PWD/smdistributed-modelparallel.sqsh dockerd://${IMAGE}
- After you’ve created the squash file, update the
recipes_collection/config.yaml file with the absolute path to the squash file (created in the preceding step), and update the instance_type if needed. The final config file should have the following parameters:
...
cluster_type: slurm
...
instance_type: p4d.24xlarge
...
container: /fsx/<path-to-smdistributed-modelparallel>.sqsh
...
- Download the prepared dataset that you uploaded to S3 into the FSx for Lustre volume attached to the cluster. Run the following commands to download the files from Amazon S3:
aws s3 cp s3://{bucket_name}/{input_path}/train /fsx/ubuntu/deepseek/data/train --recursive
aws s3 cp s3://{bucket_name}/{input_path}/test /fsx/ubuntu/deepseek/data/test --recursive
- Update the launcher script for fine-tuning the DeepSeek-R1 Distill Qwen 7B model. The launcher scripts serve as convenient wrappers for executing the training script
main.py file), which streamlines the process of fine-tuning and parameter adjustment. For fine-tuning the DeepSeek-R1 Qwen 7B model, you can find the specific script at:
launcher_scripts/deepseek/run_hf_deepseek_r1_qwen_7b_seq16k_gpu_fine_tuning.sh
- Before running the script, you need to modify the location of the training and validation files and update the HuggingFace model ID and optionally the access token for private models and datasets. The script should look like the following (update
recipes.trainer.num_nodes if you’re using a multi-node cluster):
SAGEMAKER_TRAINING_LAUNCHER_DIR=${SAGEMAKER_TRAINING_LAUNCHER_DIR:-"$(pwd)"}
HF_MODEL_NAME_OR_PATH="deepseek-ai/DeepSeek-R1-Distill-Qwen-7B" # HuggingFace pretrained model name or path
HF_ACCESS_TOKEN="hf_xxxx" # Optional HuggingFace access token
TRAIN_DIR="/fsx/ubuntu/deepseek/data/train" # Location of training dataset
VAL_DIR="/fsx/ubuntu/deepseek/data/test" # Location of validation dataset
EXP_DIR="/fsx/ubuntu/deepseek/results" # Location to save experiment info including logging, checkpoints, etc
HYDRA_FULL_ERROR=1 python3 "${SAGEMAKER_TRAINING_LAUNCHER_DIR}/main.py"
recipes=fine-tuning/deepseek/hf_deepseek_r1_distilled_qwen_7b_seq16k_gpu_fine_tuning
base_results_dir="${SAGEMAKER_TRAINING_LAUNCHER_DIR}/results"
recipes.run.name="hf-deepseek-r1-distilled-qwen-7b-fine-tuning"
recipes.exp_manager.exp_dir="$EXP_DIR"
recipes.trainer.num_nodes=1
recipes.model.data.train_dir="$TRAIN_DIR"
recipes.model.data.val_dir="$VAL_DIR"
recipes.model.hf_model_name_or_path="$HF_MODEL_NAME_OR_PATH"
recipes.model.hf_access_token="$HF_ACCESS_TOKEN"
You can view the recipe for this fine-tuning task under, overriding any additional parameters as needed:
recipes_collection/recipes/fine-tuning/deepseek/hf_deepseek_r1_distilled_qwen_7b_seq16k_gpu_fine_tuning.yaml
- Submit the job by running the launcher script:
bash launcher_scripts/deepseek/run_hf_deepseek_r1_qwen_7b_seq16k_gpu_fine_tuning.sh
You can monitor the job using Slurm commands such as squeue and scontrol show to view the status of the job and the corresponding logs. After the job is complete, the trained model will also be available in the results folder, as shown in the following code:
cd results
ls -R
.:
checkpoints experiment
./checkpoints:
full
./checkpoints/full:
steps_50
./checkpoints/full/steps_50:
config.json pytorch_model.bin
./experiment:
...
- Upload the fine-tuned model checkpoint to Amazon S3 for evaluating the model using the validation data:
aws s3 cp /fsx/<path_to_checkpoint> s3://{bucket_name}/{model_prefix}/qwen7b --recursive
Evaluate the fine-tuned model
To objectively evaluate your fine-tuned model, you can run an evaluation job on the validation portion of the dataset.
You can run a SageMaker training job and use ROUGE metrics (ROUGE-1, ROUGE-2, ROUGE-L, and ROUGE-L-Sum), which measure the similarity between machine-generated text and human-written reference text. The SageMaker training job will compute ROUGE metrics for both the base DeepSeek-R1 Distill Qwen 7B model and the fine-tuned one. You can access the code sample for ROUGE evaluation in the sagemaker-distributed-training-workshop on GitHub. Please refer this notebook for details.
Complete the following steps:
- Define the S3 path where the fine-tuned checkpoints are stored, the instance_type, and the image uri to use in the training job:
trained_model = <S3_PATH>
instance_type = "ml.p4d.24xlarge"
image_uri = sagemaker.image_uris.retrieve(
framework="pytorch",
region=sagemaker_session.boto_session.region_name,
version="2.4",
instance_type=instance_type,
image_scope="training"
)
#763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-training:2.4-gpu-py311
- Create the ModelTrainer function to encapsulate the evaluation script and define the input data:
from sagemaker.modules.configs import Compute, InputData, OutputDataConfig, SourceCode, StoppingCondition
from sagemaker.modules.distributed import Torchrun
from sagemaker.modules.train import ModelTrainer
# Define the script to be run
source_code = SourceCode(
source_dir="./scripts",
requirements="requirements.txt",
entry_script="evaluate_recipe.py",
)
# Define the compute
...
# Define the ModelTrainer
model_trainer = ModelTrainer(
training_image=image_uri,
source_code=source_code,
compute=compute_configs,
...
hyperparameters={
"model_id": model_id, # Hugging Face model id
"dataset_name": dataset_name
}
)
# Pass the input data
train_input = InputData(
channel_name="adapterdir",
data_source=trained_model,
)
test_input = InputData(
channel_name="testdata",
data_source=test_dataset_s3_path, # S3 path where training data is stored
)
# Check input channels configured
data = [train_input, test_input]
- Submit the training job:
# starting the train job with our uploaded datasets as input
model_trainer.train(input_data_config=data, wait=True)
The following table shows the task output for the fine-tuned model and the base model.
| Model |
Rouge 1 |
Rouge 2 |
Rouge L |
Rouge L Sum |
| Base |
0.36362 |
0.08739 |
0.16345 |
0.3204 |
| Fine-tuned |
0.44232 |
0.13022 |
0.17769 |
0.38989 |
| % Difference |
21.64207 |
49.01703 |
8.7121 |
21.68871 |
Our fine-tuned model demonstrates remarkable efficiency, achieving about 22% overall improvement on the reasoning task after only one training epoch. The most significant gain appears in Rouge 2 scores—which measure bigram overlap—with about 49% increase, indicating better alignment between generated and reference summaries.
Notably, preliminary experiments suggest these results could be further enhanced by extending the training duration. Increasing the number of epochs shows promising potential for additional performance gains while maintaining computational efficiency.
Clean up
To clean up your resources to avoid incurring any more charges, follow these steps:
- Delete any unused SageMaker Studio resources
- (Optional) Delete the SageMaker Studio domain
- Verify that your training job isn’t running anymore. To do so, on your SageMaker console, choose Training and check Training jobs.
- If you created a HyperPod cluster, delete the cluster to stop incurring costs. If you created the networking stack from the HyperPod workshop, delete the stack as well to clean up the virtual private cloud (VPC) resources and the FSx for Lustre volume.
Conclusion
In the first post of this two-part DeepSeek-R1 series, we discussed how SageMaker HyperPod recipes provide a powerful yet accessible solution for organizations to scale their AI model training capabilities with large language models (LLMs) including DeepSeek. The architecture streamlines complex distributed training workflows through its intuitive recipe-based approach, reducing setup time from weeks to minutes.
We recommend starting your LLM customization journey by exploring our sample recipes in the Amazon SageMaker HyperPod documentation. The AWS AI/ML community offers extensive resources, including workshops and technical guidance, to support your implementation journey.
To begin using the SageMaker HyperPod recipes, visit the sagemaker-hyperpod-recipes repo on GitHub for comprehensive documentation and example implementations. Our team continues to expand the recipe ecosystem based on customer feedback and emerging ML trends, making sure that you have the tools needed for successful AI model training.
In our second post, we discuss how these recipes could further be used to fine-tune DeepSeek-R1 671b model. Stay tuned!
About the Authors
 Kanwaljit Khurmi is a Principal Worldwide Generative AI Solutions Architect at AWS. He collaborates with AWS product teams, engineering departments, and customers to provide guidance and technical assistance, helping them enhance the value of their hybrid machine learning solutions on AWS. Kanwaljit specializes in assisting customers with containerized applications and high-performance computing solutions.
Kanwaljit Khurmi is a Principal Worldwide Generative AI Solutions Architect at AWS. He collaborates with AWS product teams, engineering departments, and customers to provide guidance and technical assistance, helping them enhance the value of their hybrid machine learning solutions on AWS. Kanwaljit specializes in assisting customers with containerized applications and high-performance computing solutions.
 Bruno Pistone is a Senior World Wide Generative AI/ML Specialist Solutions Architect at AWS based in Milan, Italy. He works with AWS product teams and large customers to help them fully understand their technical needs and design AI and Machine Learning solutions that take full advantage of the AWS cloud and Amazon Machine Learning stack. His expertise includes: End-to-end Machine Learning, model customization, and generative AI. He enjoys spending time with friends, exploring new places, and traveling to new destinations.
Bruno Pistone is a Senior World Wide Generative AI/ML Specialist Solutions Architect at AWS based in Milan, Italy. He works with AWS product teams and large customers to help them fully understand their technical needs and design AI and Machine Learning solutions that take full advantage of the AWS cloud and Amazon Machine Learning stack. His expertise includes: End-to-end Machine Learning, model customization, and generative AI. He enjoys spending time with friends, exploring new places, and traveling to new destinations.
 Arun Kumar Lokanatha is a Senior ML Solutions Architect with the Amazon SageMaker team. He specializes in large language model training workloads, helping customers build LLM workloads using SageMaker HyperPod, SageMaker training jobs, and SageMaker distributed training. Outside of work, he enjoys running, hiking, and cooking.
Arun Kumar Lokanatha is a Senior ML Solutions Architect with the Amazon SageMaker team. He specializes in large language model training workloads, helping customers build LLM workloads using SageMaker HyperPod, SageMaker training jobs, and SageMaker distributed training. Outside of work, he enjoys running, hiking, and cooking.
 Durga Sury is a Senior Solutions Architect on the Amazon SageMaker team. Over the past 5 years, she has worked with multiple enterprise customers to set up a secure, scalable AI/ML platform built on SageMaker.
Durga Sury is a Senior Solutions Architect on the Amazon SageMaker team. Over the past 5 years, she has worked with multiple enterprise customers to set up a secure, scalable AI/ML platform built on SageMaker.
 Aman Shanbhag is an Associate Specialist Solutions Architect on the ML Frameworks team at Amazon Web Services, where he helps customers and partners with deploying ML training and inference solutions at scale. Before joining AWS, Aman graduated from Rice University with degrees in computer science, mathematics, and entrepreneurship.
Aman Shanbhag is an Associate Specialist Solutions Architect on the ML Frameworks team at Amazon Web Services, where he helps customers and partners with deploying ML training and inference solutions at scale. Before joining AWS, Aman graduated from Rice University with degrees in computer science, mathematics, and entrepreneurship.
 Anirudh Viswanathan is a Sr Product Manager, Technical – External Services with the SageMaker AI Training team. He holds a Masters in Robotics from Carnegie Mellon University, an MBA from the Wharton School of Business, and is named inventor on over 40 patents. He enjoys long-distance running, visiting art galleries, and Broadway shows.
Anirudh Viswanathan is a Sr Product Manager, Technical – External Services with the SageMaker AI Training team. He holds a Masters in Robotics from Carnegie Mellon University, an MBA from the Wharton School of Business, and is named inventor on over 40 patents. He enjoys long-distance running, visiting art galleries, and Broadway shows.
Read More





 Here are Google’s latest AI updates from February 2025
Here are Google’s latest AI updates from February 2025


 Nima Seifi is a Solutions Architect at AWS, based in Southern California, where he specializes in SaaS and LLMOps. He serves as a technical advisor to startups building on AWS. Prior to AWS, he worked as a DevOps architect in the e-commerce industry for over 5 years, following a decade of R&D work in mobile internet technologies. Nima has authored 20+ technical publications and holds 7 U.S. patents. Outside of work, he enjoys reading, watching documentaries, and taking beach walks.
Nima Seifi is a Solutions Architect at AWS, based in Southern California, where he specializes in SaaS and LLMOps. He serves as a technical advisor to startups building on AWS. Prior to AWS, he worked as a DevOps architect in the e-commerce industry for over 5 years, following a decade of R&D work in mobile internet technologies. Nima has authored 20+ technical publications and holds 7 U.S. patents. Outside of work, he enjoys reading, watching documentaries, and taking beach walks. Nelson Ong is a Solutions Architect at Amazon Web Services. He works with early stage startups across industries to accelerate their cloud adoption.
Nelson Ong is a Solutions Architect at Amazon Web Services. He works with early stage startups across industries to accelerate their cloud adoption.










 Deepesh Dhapola is a Senior Solutions Architect at AWS India, where he assists financial services and fintech clients in scaling and optimizing their applications on the AWS platform. He specializes in core machine learning and generative AI. Outside of work, Deepesh enjoys spending time with his family and experimenting with various cuisines.
Deepesh Dhapola is a Senior Solutions Architect at AWS India, where he assists financial services and fintech clients in scaling and optimizing their applications on the AWS platform. He specializes in core machine learning and generative AI. Outside of work, Deepesh enjoys spending time with his family and experimenting with various cuisines. Preston Tuggle is a Sr. Specialist Solutions Architect working on generative AI.
Preston Tuggle is a Sr. Specialist Solutions Architect working on generative AI. Shane Rai is a Principal GenAI Specialist with the AWS World Wide Specialist Organization (WWSO). He works with customers across industries to solve their most pressing and innovative business needs using AWS’s breadth of cloud-based AI/ML services including model offerings from top tier foundation model providers.
Shane Rai is a Principal GenAI Specialist with the AWS World Wide Specialist Organization (WWSO). He works with customers across industries to solve their most pressing and innovative business needs using AWS’s breadth of cloud-based AI/ML services including model offerings from top tier foundation model providers. John Liu has 14 years of experience as a product executive and 10 years of experience as a portfolio manager. At AWS, John is a Principal Product Manager for Amazon Bedrock. Previously, he was the Head of Product for AWS Web3 / Blockchain. Prior to AWS, John held various product leadership roles at public blockchain protocols and fintech companies, and also spent 9 years as a portfolio manager at various hedge funds.
John Liu has 14 years of experience as a product executive and 10 years of experience as a portfolio manager. At AWS, John is a Principal Product Manager for Amazon Bedrock. Previously, he was the Head of Product for AWS Web3 / Blockchain. Prior to AWS, John held various product leadership roles at public blockchain protocols and fintech companies, and also spent 9 years as a portfolio manager at various hedge funds.
 Learn more about Google for Startups Accelerator: AI for Nature and Climate, as well as other new efforts to use technology to preserve our environment.
Learn more about Google for Startups Accelerator: AI for Nature and Climate, as well as other new efforts to use technology to preserve our environment.





 Google Cloud and healthcare organizations share new partnerships at HIMSS 2025.
Google Cloud and healthcare organizations share new partnerships at HIMSS 2025.