In this work, we dive into the fundamental challenges of evaluating Text2SQL solutions and highlight potential failure causes and the potential risks of relying on aggregate metrics in existing benchmarks. We identify two largely unaddressed limitations in current open benchmarks: (1) data quality issues in the evaluation data mainly attributed to the lack of capturing the probabilistic nature of translating a natural language description into a structured query (e.g., NL ambiguity), and (2) the bias that using different match functions as approximations for SQL equivalence can introduce.
To…Apple Machine Learning Research
UniVG: A Generalist Diffusion Model for Unified Image Generation and Editing
Text-to-Image (T2I) diffusion models have shown impressive results in generating visually compelling images following user prompts. Building on this, various methods further fine-tune the pre-trained T2I model for specific tasks. However, this requires separate model architectures, training designs, and multiple parameter sets to handle different tasks. In this paper, we introduce UniVG, a generalist diffusion model capable of supporting a diverse range of image generation tasks with a single set of weights. UniVG treats multi-modal inputs as unified conditions to enable various downstream…Apple Machine Learning Research
Build a generative AI enabled virtual IT troubleshooting assistant using Amazon Q Business
Today’s organizations face a critical challenge with the fragmentation of vital information across multiple environments. As businesses increasingly rely on diverse project management and IT service management (ITSM) tools such as ServiceNow, Atlassian Jira and Confluence, employees find themselves navigating a complex web of systems to access crucial data.
This isolated approach leads to several challenges for IT leaders, developers, program managers, and new employees. For example:
- Inefficiency: Employees need to access multiple systems independently to gather data insights and remediation steps during incident troubleshooting
- Lack of integration: Information is isolated across different environments, making it difficult to get a holistic view of ITSM activities
- Time-consuming: Searching for relevant information across multiple systems is time-consuming and reduces productivity
- Potential for inconsistency: Using multiple systems increases the risk of inconsistent data and processes across the organization.
Amazon Q Business is a fully managed, generative artificial intelligence (AI) powered assistant that can address challenges such as inefficient, inconsistent information access within an organization by providing 24/7 support tailored to individual needs. It handles a wide range of tasks such as answering questions, providing summaries, generating content, and completing tasks based on data in your organization. Amazon Q Business offers over 40 data source connectors that connect to your enterprise data sources and help you create a generative AI solution with minimal configuration. Amazon Q Business also supports over 50 actions across popular business applications and platforms. Additionally, Amazon Q Business offers enterprise-grade data security, privacy, and built-in guardrails that you can configure.
This blog post explores an innovative solution that harnesses the power of generative AI to bring value to your organization and ITSM tools with Amazon Q Business.
Solution overview
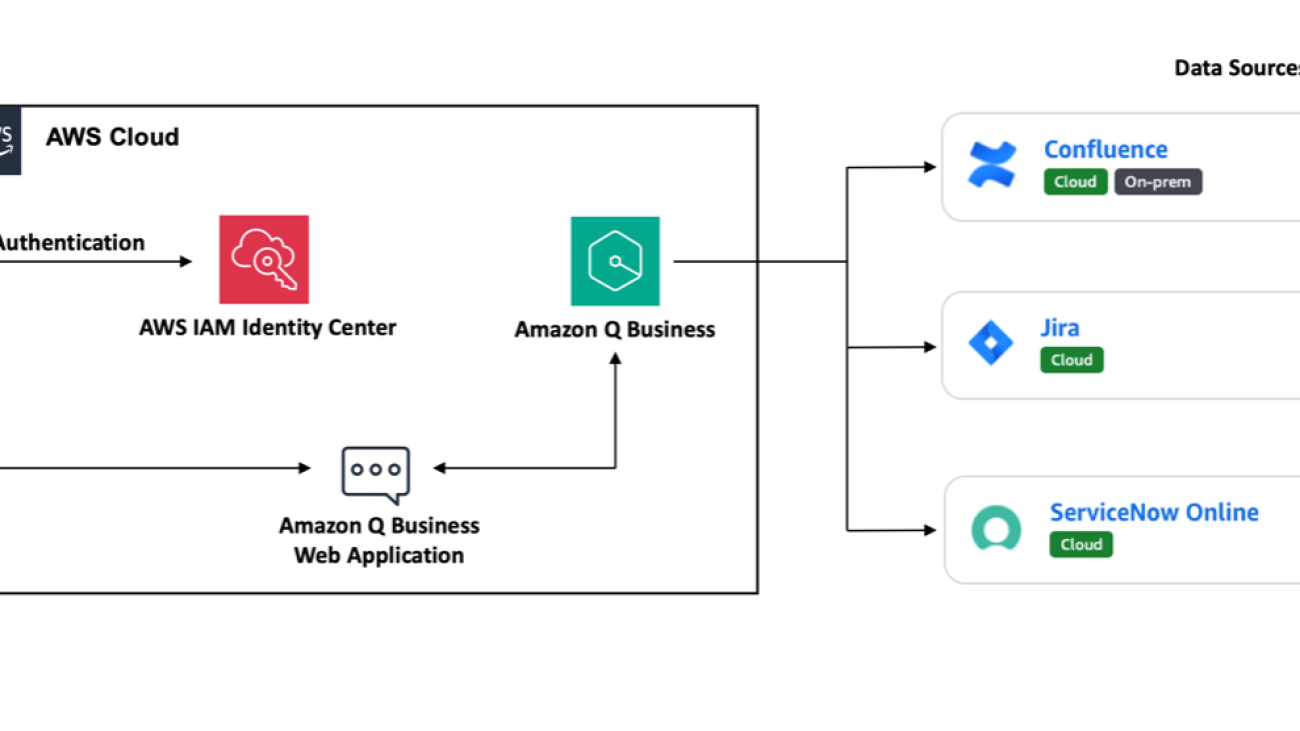
The solution architecture shown in the following figure demonstrates how to build a virtual IT troubleshooting assistant by integrating with multiple data sources such as Atlassian Jira, Confluence, and ServiceNow. This solution helps streamline information retrieval, enhance collaboration, and significantly boost overall operational efficiency, offering a glimpse into the future of intelligent enterprise information management.

This solution integrates with ITSM tools such as ServiceNow Online and project management software such as Atlassian Jira and Confluence using the Amazon Q Business data source connectors. You can use a data source connector to combine data from different places into a central index for your Amazon Q Business application. For this demonstration, we use the Amazon Q Business native index and retriever. We also configure an application environment and grant access to users to interact with an application environment using AWS IAM Identity Center for user management. Then, we provision subscriptions for IAM Identity Center users and groups.
Authorized users interact with the application environment through a web experience. You can share the web experience endpoint URL with your users so they can open the URL and authenticate themselves to start chatting with the generative AI application powered by Amazon Q Business.
Deployment
Start by setting up the architecture and data needed for the demonstration.
- We’ve provided an AWS CloudFormation template in our GitHub repository that you can use to set up the environment for this demonstration. If you don’t have existing Atlassian Jira, Confluence, and ServiceNow accounts follow these steps to create trial accounts for the demonstration
- Once step 1 is complete, open the AWS Management Console for Amazon Q Business. On the Applications tab, open your application to see the data sources. See Best practices for data source connector configuration in Amazon Q Business to understand best practices

- To improve retrieved results and customize the end user chat experience, use Amazon Q to map document attributes from your data sources to fields in your Amazon Q index. Choose the Atlassian Jira, Confluence Cloud and ServiceNow Online links to learn more about their document attributes and field mappings. Select the data source to edit its configurations under Actions. Select the appropriate fields that you think would be important for your search needs. Repeat the process for all of the data sources. The following figure is an example of some of the Atlassian Jira project field mappings that we selected

- Sync mode enables you to choose how you want to update your index when your data source content changes. Sync run schedule sets how often you want Amazon Q Business to synchronize your index with the data source. For this demonstration, we set the Sync mode to Full Sync and the Frequency to Run on demand. Update Sync mode with your changes and choose Sync Now to start syncing data sources. When you initiate a sync, Amazon Q will crawl the data source to extract relevant documents, then sync them to the Amazon Q index, making them searchable

- After syncing data sources, you can configure the metadata controls in Amazon Q Business. An Amazon Q Business index has fields that you can map your document attributes to. After the index fields are mapped to document attributes and are search-enabled, admins can use the index fields to boost results from specific sources, or by end users to filter and scope their chat results to specific data. Boosting chat responses based on document attributes helps you rank sources that are more authoritative higher than other sources in your application environment. See Boosting chat responses using metadata boosting to learn more about metadata boosting and metadata controls. The following figure is an example of some of the metadata controls that we selected

- For the purposes of the demonstration, use the Amazon Q Business web experience. Select your application under Applications and then select the Deployed URL link in the web experience settings

- Enter the same username, password and multi-factor authentication (MFA) authentication for the user that you created previously in IAM Identity Center to sign in to the Amazon Q Business web experience generative AI assistant

Demonstration
Now that you’ve signed in to the Amazon Q Business web experience generative AI assistant (shown in the previous figure), let’s try some natural language queries.
IT leaders: You’re an IT leader and your team is working on a critical project that needs to hit the market quickly. You can now ask questions in natural language to Amazon Q Business to get answers based on your company data.
Developers: Developers who want to know information such as the tasks that are assigned to them, specific tasks details, or issues in a particular sub segment. They can now get these questions answered from Amazon Q Business without necessarily signing in to either Atlassian Jira or Confluence.
Project and program managers: Project and program managers can monitor the activities or developments in their projects or programs from Amazon Q Business without having to contact various teams to get individual status updates.
New employees or business users: A newly hired employee who’s looking for information to get started on a project or a business user who needs tech support can use the generative AI assistant to get the information and support they need.
Benefits and outcomes
From the demonstrations, you saw that various users whether they are leaders, managers, developers, or business users can benefit from using a generative AI solution like our virtual IT assistant built using Amazon Q Business. It removes the undifferentiated heavy lifting of having to navigate multiple solutions and cross-reference multiple items and data points to get answers. Amazon Q Business can use the generative AI to provide responses with actionable insights in just few seconds. Now, let’s dive deeper into some of the additional benefits that this solution provides.
- Increased efficiency: Centralized access to information from ServiceNow, Atlassian Jira, and Confluence saves time and reduces the need to switch between multiple systems.
- Enhanced decision-making: Comprehensive data insights from multiple systems leads to better-informed decisions in incident management and problem-solving for various users across the organization.
- Faster incident resolution: Quick access to enterprise data sources and knowledge and AI-assisted remediation steps can significantly reduce mean time to resolutions (MTTR) for cases with elevated priorities.
- Improved knowledge management: Access to Confluence’s architectural documents and other knowledge bases such as ServiceNow’s Knowledge Articles promotes better knowledge sharing across the organization. Users can now get responses based on information from multiple systems.
- Seamless integration and enhanced user experience: Better integration between ITSM processes, project management, and software development streamlines operations. This is helpful for organizations and teams that incorporate agile methodologies.
- Cost savings: Reduction in time spent searching for information and resolving incidents can lead to significant cost savings in IT operations.
- Scalability: Amazon Q Business can grow with the organization, accommodating future needs and additional data sources as required. Organization can create more Amazon Q Business applications and share purpose-built Amazon Q Business apps within their organizations to manage repetitive tasks.
Clean up
After completing your exploration of the virtual IT troubleshooting assistant, delete the CloudFormation stack from your AWS account. This action terminates all resources created during deployment of this demonstration and prevents unnecessary costs from accruing in your AWS account.
Conclusion
By integrating Amazon Q Business with enterprise systems, you can create a powerful virtual IT assistant that streamlines information access and improves productivity. The solution presented in this post demonstrates the power of combining AI capabilities with existing enterprise systems to create powerful unified ITSM solutions and more efficient and user-friendly experiences.
We provide the sample virtual IT assistant using an Amazon Q Business solution as open source—use it as a starting point for your own solution and help us make it better by contributing fixes and features through GitHub pull requests. Visit the GitHub repository to explore the code, choose Watch to be notified of new releases, and check the README for the latest documentation updates.
Learn more:
For expert assistance, AWS Professional Services, AWS Generative AI partner solutions, and AWS Generative AI Competency Partners are here to help.
We’d love to hear from you. Let us know what you think in the comments section, or use the issues forum in the GitHub repository.
About the Authors
 Jasmine Rasheed Syed is a Senior Customer Solutions manager at AWS, focused on accelerating time to value for the customers on their cloud journey by adopting best practices and mechanisms to transform their business at scale. Jasmine is a seasoned, result oriented leader with 20+ years of progressive experience in Insurance, Retail & CPG with exemplary track record spanning across Business Development, Cloud/Digital Transformation, Delivery, Operational & Process Excellence and Executive Management.
Jasmine Rasheed Syed is a Senior Customer Solutions manager at AWS, focused on accelerating time to value for the customers on their cloud journey by adopting best practices and mechanisms to transform their business at scale. Jasmine is a seasoned, result oriented leader with 20+ years of progressive experience in Insurance, Retail & CPG with exemplary track record spanning across Business Development, Cloud/Digital Transformation, Delivery, Operational & Process Excellence and Executive Management.
 Suprakash Dutta is a Sr. Solutions Architect at Amazon Web Services. He focuses on digital transformation strategy, application modernization and migration, data analytics, and machine learning. He is part of the AI/ML community at AWS and designs Generative AI and Intelligent Document Processing(IDP) solutions.
Suprakash Dutta is a Sr. Solutions Architect at Amazon Web Services. He focuses on digital transformation strategy, application modernization and migration, data analytics, and machine learning. He is part of the AI/ML community at AWS and designs Generative AI and Intelligent Document Processing(IDP) solutions.
 Joshua Amah is a Partner Solutions Architect at Amazon Web Services, specializing in supporting SI partners with a focus on AI/ML and generative AI technologies. He is passionate about guiding AWS Partners in using cutting-edge technologies and best practices to build innovative solutions that meet customer needs. Joshua provides architectural guidance and strategic recommendations for both new and existing workloads.
Joshua Amah is a Partner Solutions Architect at Amazon Web Services, specializing in supporting SI partners with a focus on AI/ML and generative AI technologies. He is passionate about guiding AWS Partners in using cutting-edge technologies and best practices to build innovative solutions that meet customer needs. Joshua provides architectural guidance and strategic recommendations for both new and existing workloads.
 Brad King is an Enterprise Account Executive at Amazon Web Services specializing in translating complex technical concepts into business value and making sure that clients achieve their digital transformation goals efficiently and effectively through long term partnerships.
Brad King is an Enterprise Account Executive at Amazon Web Services specializing in translating complex technical concepts into business value and making sure that clients achieve their digital transformation goals efficiently and effectively through long term partnerships.
 Joseph Mart is an AI/ML Specialist Solutions Architect at Amazon Web Services (AWS). His core competence and interests lie in machine learning applications and generative AI. Joseph is a technology addict who enjoys guiding AWS customers on architecting their workload in the AWS Cloud. In his spare time, he loves playing soccer and visiting nature.
Joseph Mart is an AI/ML Specialist Solutions Architect at Amazon Web Services (AWS). His core competence and interests lie in machine learning applications and generative AI. Joseph is a technology addict who enjoys guiding AWS customers on architecting their workload in the AWS Cloud. In his spare time, he loves playing soccer and visiting nature.
Process formulas and charts with Anthropic’s Claude on Amazon Bedrock
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data. However, by using Anthropic’s Claude on Amazon Bedrock, researchers and engineers can now automate the indexing and tagging of these technical documents. This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata.
Amazon Bedrock is a fully managed service that provides a single API to access and use various high-performing foundation models (FMs) from leading AI companies. It offers a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI practices. Anthropic’s Claude 3 Sonnet offers best-in-class vision capabilities compared to other leading models. It can accurately transcribe text from imperfect images—a core capability for retail, logistics, and financial services, where AI might glean more insights from an image, graphic, or illustration than from text alone. The latest of Anthropic’s Claude models demonstrate a strong aptitude for understanding a wide range of visual formats, including photos, charts, graphs and technical diagrams. With Anthropic’s Claude, you can extract more insights from documents, process web UIs and diverse product documentation, generate image catalog metadata, and more.
In this post, we explore how you can use these multi-modal generative AI models to streamline the management of technical documents. By extracting and structuring the key information from the source materials, the models can create a searchable knowledge base that allows you to quickly locate the data, formulas, and visualizations you need to support your work. With the document content organized in a knowledge base, researchers and engineers can use advanced search capabilities to surface the most relevant information for their specific needs. This can significantly accelerate research and development workflows, because professionals no longer have to manually sift through large volumes of unstructured data to find the references they need.
Solution overview
This solution demonstrates the transformative potential of multi-modal generative AI when applied to the challenges faced by scientific and engineering communities. By automating the indexing and tagging of technical documents, these powerful models can enable more efficient knowledge management and accelerate innovation across a variety of industries.
In addition to Anthropic’s Claude on Amazon Bedrock, the solution uses the following services:
- Amazon SageMaker JupyterLab – The SageMakerJupyterLab application is a web-based interactive development environment (IDE) for notebooks, code, and data. JupyterLab application’s flexible and extensive interface can be used to configure and arrange machine learning (ML) workflows. We use JupyterLab to run the code for processing formulae and charts.
- Amazon Simple Storage Service (Amazon S3) – Amazon S3 is an object storage service built to store and protect any amount of data. We use Amazon S3 to store sample documents that are used in this solution.
- AWS Lambda –AWS Lambda is a compute service that runs code in response to triggers such as changes in data, changes in application state, or user actions. Because services such as Amazon S3 and Amazon Simple Notification Service (Amazon SNS) can directly trigger a Lambda function, you can build a variety of real-time serverless data-processing systems.
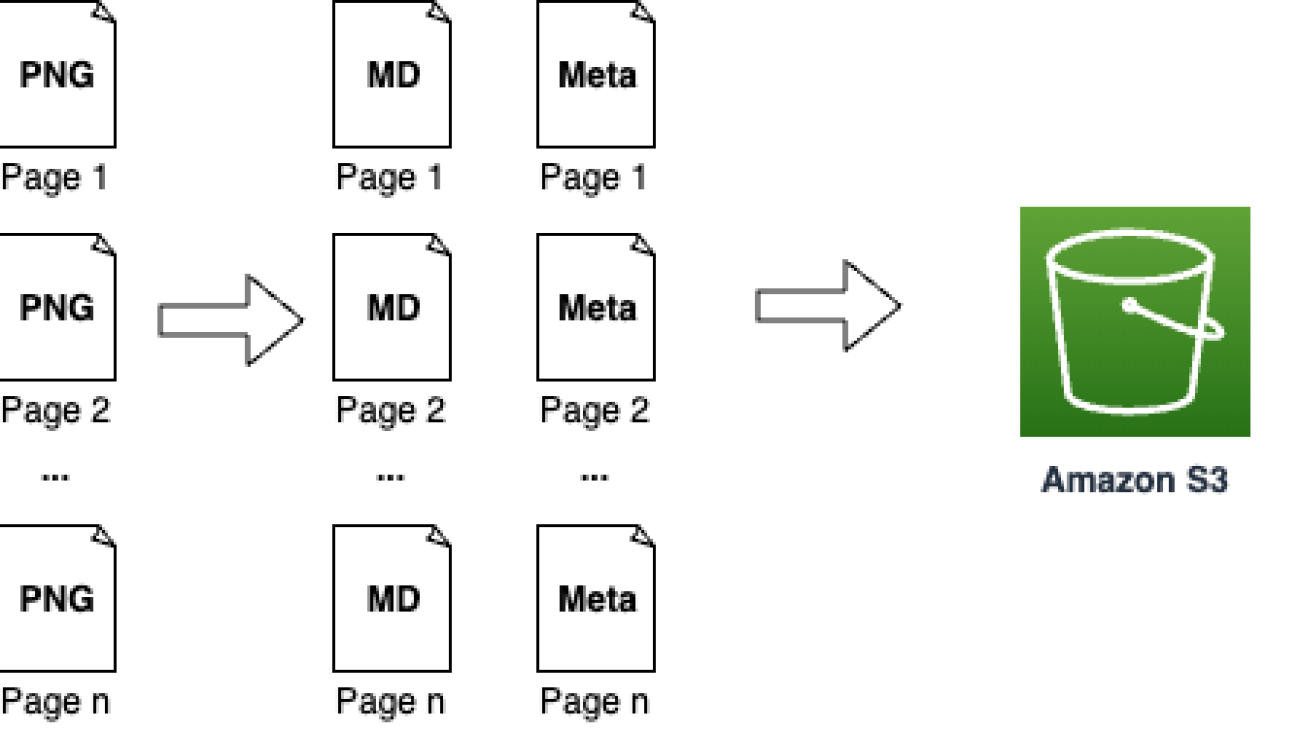
The solution workflow contains the following steps:
- Split the PDF into individual pages and save them as PNG files.
- With each page:
- Extract the original text.
- Render the formulas in LaTeX.
- Generate a semantic description of each formula.
- Generate an explanation of each formula.
- Generate a semantic description of each graph.
- Generate an interpretation for each graph.
- Generate metadata for the page.
- Generate metadata for the full document.
- Upload the content and metadata to Amazon S3.
- Create an Amazon Bedrock knowledge base.
The following diagram illustrates this workflow.

Prerequisites
- If you’re new to AWS, you first need to create and set up an AWS account.
- Additionally, in your account under Amazon Bedrock, request access to
anthropic.claude-3-5-sonnet-20241022-v2:0if you don’t have it already.
Deploy the solution
Complete the following steps to set up the solution:
- Launch the AWS CloudFormation template by choosing Launch Stack (this creates the stack in the
us-east-1AWS Region):
![]()
- When the stack deployment is complete, open the Amazon SageMaker AI
- Choose Notebooks in the navigation pane.
- Locate the notebook
claude-scientific-docs-notebookand choose Open JupyterLab.

- In the notebook, navigate to
notebooks/process_scientific_docs.ipynb.

- Choose conda_python3 as the kernel, then choose Select.

- Walk through the sample code.
Explanation of the notebook code
In this section, we walk through the notebook code.
Load data
We use example research papers from arXiv to demonstrate the capability outlined here. arXiv is a free distribution service and an open-access archive for nearly 2.4 million scholarly articles in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance, statistics, electrical engineering and systems science, and economics.
We download the documents and store them under a samples folder locally. Multi-modal generative AI models work well with text extraction from image files, so we start by converting the PDF to a collection of images, one for each page.
Get Metadata from formulas
After the image documents are available, you can use Anthropic’s Claude to extract formulas and metadata with the Amazon Bedrock Converse API. Additionally, you can use the Amazon Bedrock Converse API to obtain an explanation of the extracted formulas in plain language. By combining the formula and metadata extraction capabilities of Anthropic’s Claude with the conversational abilities of the Amazon Bedrock Converse API, you can create a comprehensive solution for processing and understanding the information contained within the image documents.
We start with the following example PNG file.

We use the following request prompt:
We get the following response, which shows the extracted formula converted to LaTeX format and described in plain language, enclosed in double dollar signs.

Get metadata from charts
Another useful capability of multi-modal generative AI models is the ability to interpret graphs and generate summaries and metadata. The following is an example of how you can obtain metadata of the charts and graphs using simple natural language conversation with models. We use the following graph.

We provide the following request:
The response returned provides its interpretation of the graph explaining the color-coded lines and suggesting that overall, the DSC model is performing well on the training data, achieving a high Dice coefficient of around 0.98. However, the lower and fluctuating validation Dice coefficient indicates potential overfitting and room for improvement in the model’s generalization performance.

Generate metadata
Using natural language processing, you can generate metadata for the paper to aid in searchability.
We use the following request:
We get the following response, including formula markdown and a description.
Use your extracted data in a knowledge base
Now that we’ve prepared our data with formulas, analyzed charts, and metadata, we will create an Amazon Bedrock knowledge base. This will make the information searchable and enable question-answering capabilities.
Prepare your Amazon Bedrock knowledge base
To create a knowledge base, first upload the processed files and metadata to Amazon S3:
When your files have finished uploading, complete the following steps:
- Create an Amazon Bedrock knowledge base.
- Create an Amazon S3 data source for your knowledge base, and specify hierarchical chunking as the chunking strategy.
Hierarchical chunking involves organizing information into nested structures of child and parent chunks.
The hierarchical structure allows for faster and more targeted retrieval of relevant information, first by performing semantic search on the child chunk and then returning the parent chunk during retrieval. By replacing the children chunks with the parent chunk, we provide large and comprehensive context to the FM.
Hierarchical chunking is best suited for complex documents that have a nested or hierarchical structure, such as technical manuals, legal documents, or academic papers with complex formatting and nested tables.
Query the knowledge base
You can query the knowledge base to retrieve information from the extracted formula and graph metadata from the sample documents. With a query, relevant chunks of text from the source of data are retrieved and a response is generated for the query, based off the retrieved source chunks. The response also cites sources that are relevant to the query.
We use the custom prompt template feature of knowledge bases to format the output as markdown:
We get the following response, which provides information on when the Focal Tversky Loss is used.

Clean up
To clean up and avoid incurring charges, run the cleanup steps in the notebook to delete the files you uploaded to Amazon S3 along with the knowledge base. Then, on the AWS CloudFormation console, locate the stack claude-scientific-doc and delete it.
Conclusion
Extracting insights from complex scientific documents can be a daunting task. However, the advent of multi-modal generative AI has revolutionized this domain. By harnessing the advanced natural language understanding and visual perception capabilities of Anthropic’s Claude, you can now accurately extract formulas and data from charts, enabling faster insights and informed decision-making.
Whether you are a researcher, data scientist, or developer working with scientific literature, integrating Anthropic’s Claude into your workflow on Amazon Bedrock can significantly boost your productivity and accuracy. With the ability to process complex documents at scale, you can focus on higher-level tasks and uncover valuable insights from your data.
Embrace the future of AI-driven document processing and unlock new possibilities for your organization with Anthropic’s Claude on Amazon Bedrock. Take your scientific document analysis to the next level and stay ahead of the curve in this rapidly evolving landscape.
For further exploration and learning, we recommend checking out the following resources:
- Prompt engineering techniques and best practices: Learn by doing with Anthropic’s Claude 3 on Amazon Bedrock
- Intelligent document processing using Amazon Bedrock and Anthropic Claude
- Automate document processing with Amazon Bedrock Prompt Flows (preview)
About the Authors
 Erik Cordsen is a Solutions Architect at AWS serving customers in Georgia. He is passionate about applying cloud technologies and ML to solve real life problems. When he is not designing cloud solutions, Erik enjoys travel, cooking, and cycling.
Erik Cordsen is a Solutions Architect at AWS serving customers in Georgia. He is passionate about applying cloud technologies and ML to solve real life problems. When he is not designing cloud solutions, Erik enjoys travel, cooking, and cycling.
 Renu Yadav is a Solutions Architect at Amazon Web Services (AWS), where she works with enterprise-level AWS customers providing them with technical guidance and help them achieve their business objectives. Renu has a strong passion for learning with her area of specialization in DevOps. She leverages her expertise in this domain to assist AWS customers in optimizing their cloud infrastructure and streamlining their software development and deployment processes.
Renu Yadav is a Solutions Architect at Amazon Web Services (AWS), where she works with enterprise-level AWS customers providing them with technical guidance and help them achieve their business objectives. Renu has a strong passion for learning with her area of specialization in DevOps. She leverages her expertise in this domain to assist AWS customers in optimizing their cloud infrastructure and streamlining their software development and deployment processes.
 Venkata Moparthi is a Senior Solutions Architect at AWS who empowers financial services organizations and other industries to navigate cloud transformation with specialized expertise in Cloud Migrations, Generative AI, and secure architecture design. His customer-focused approach combines technical innovation with practical implementation, helping businesses accelerate digital initiatives and achieve strategic outcomes through tailored AWS solutions that maximize cloud potential.
Venkata Moparthi is a Senior Solutions Architect at AWS who empowers financial services organizations and other industries to navigate cloud transformation with specialized expertise in Cloud Migrations, Generative AI, and secure architecture design. His customer-focused approach combines technical innovation with practical implementation, helping businesses accelerate digital initiatives and achieve strategic outcomes through tailored AWS solutions that maximize cloud potential.
Automate IT operations with Amazon Bedrock Agents
IT operations teams face the challenge of providing smooth functioning of critical systems while managing a high volume of incidents filed by end-users. Manual intervention in incident management can be time-consuming and error prone because it relies on repetitive tasks, human judgment, and potential communication gaps. Using generative AI for IT operations offers a transformative solution that helps automate incident detection, diagnosis, and remediation, enhancing operational efficiency.
AI for IT operations (AIOps) is the application of AI and machine learning (ML) technologies to automate and enhance IT operations. AIOps helps IT teams manage and monitor large-scale systems by automatically detecting, diagnosing, and resolving incidents in real time. It combines data from various sources—such as logs, metrics, and events—to analyze system behavior, identify anomalies, and recommend or execute automated remediation actions. By reducing manual intervention, AIOps improves operational efficiency, accelerates incident resolution, and minimizes downtime.
This post presents a comprehensive AIOps solution that combines various AWS services such as Amazon Bedrock, AWS Lambda, and Amazon CloudWatch to create an AI assistant for effective incident management. This solution also uses Amazon Bedrock Knowledge Bases and Amazon Bedrock Agents. The solution uses the power of Amazon Bedrock to enable the deployment of intelligent agents capable of monitoring IT systems, analyzing logs and metrics, and invoking automated remediation processes.
Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading AI startups and Amazon available through a single API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage the infrastructure. Amazon Bedrock Knowledge Bases is a fully managed capability with built-in session context management and source attribution that helps you implement the entire Retrieval Augmented Generation (RAG) workflow, from ingestion to retrieval and prompt augmentation, without having to build custom integrations to data sources and manage data flows. Amazon Bedrock Agents is a fully managed capability that make it straightforward for developers to create generative AI-based applications that can complete complex tasks for a wide range of use cases and deliver up-to-date answers based on proprietary knowledge sources.
Generative AI is rapidly transforming businesses and unlocking new possibilities across industries. This post highlights the transformative impact of large language models (LLMs). With the ability to encode human expertise and communicate in natural language, generative AI can help augment human capabilities and allow organizations to harness knowledge at scale.
Challenges in IT operations with runbooks
Runbooks are detailed, step-by-step guides that outline the processes, procedures, and tasks needed to complete specific operations, typically in IT and systems administration. They are commonly used to document repetitive tasks, troubleshooting steps, and routine maintenance. By standardizing responses to issues and facilitating consistency in task execution, runbooks help teams improve operational efficiency and streamline workflows. Most organizations rely on runbooks to simplify complex processes, making it straightforward for teams to handle routine operations and respond effectively to system issues. For organizations, managing hundreds of runbooks, monitoring their status, keeping track of failures, and setting up the right alerting can become difficult. This creates visibility gaps for IT teams. When you have multiple runbooks for various processes, managing the dependencies and run order between them can become complex and tedious. It’s challenging to handle failure scenarios and make sure everything runs in the right sequence.
The following are some of the challenges that most organizations face with manual IT operations:
- Manual diagnosis through run logs and metrics
- Runbook dependency and sequence mapping
- No automated remediation processes
- No real-time visibility into runbook progress
Solution overview
Amazon Bedrock is the foundation of this solution, empowering intelligent agents to monitor IT systems, analyze data, and automate remediation. The solution provides sample AWS Cloud Development Kit (AWS CDK) code to deploy this solution. The AIOps solution provides an AI assistant using Amazon Bedrock Agents to help with operations automation and runbook execution.
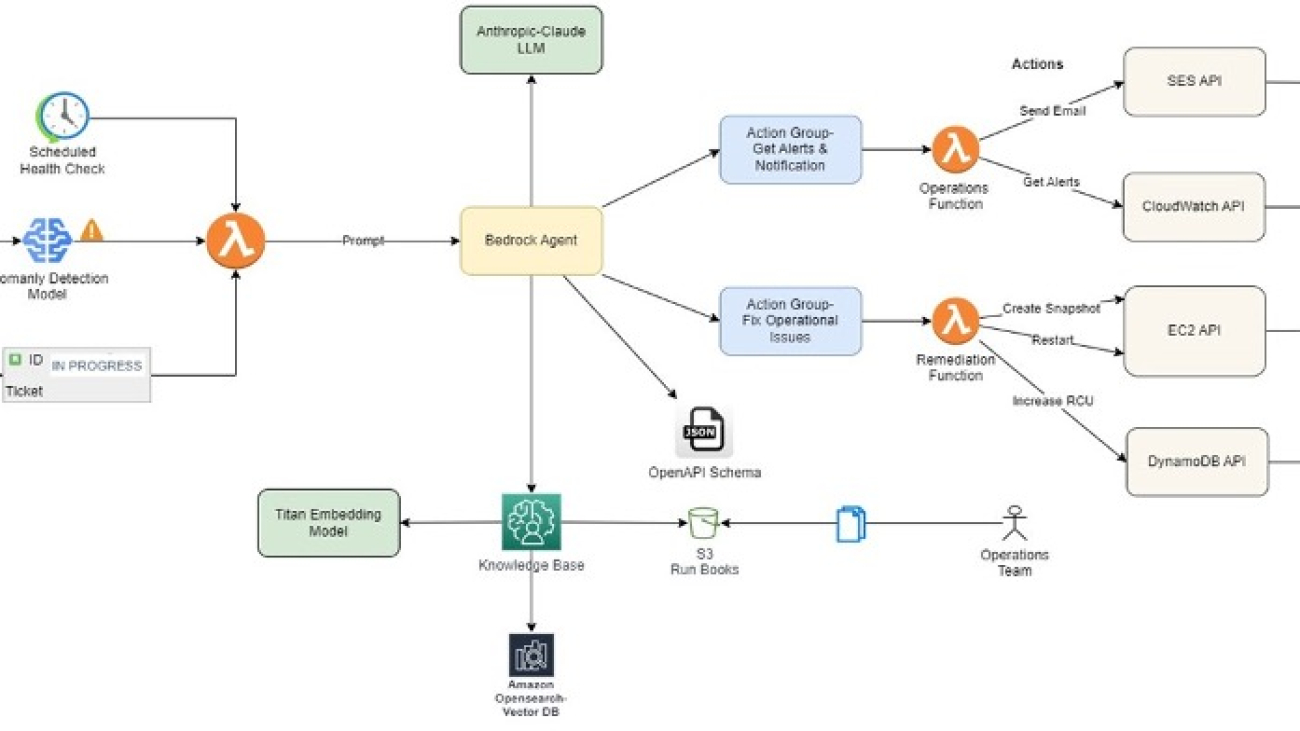
The following architecture diagram explains the overall flow of this solution.

The agent uses Anthropic’s Claude LLM available on Amazon Bedrock as one of the FMs to analyze incident details and retrieve relevant information from the knowledge base, a curated collection of runbooks and best practices. This equips the agent with business-specific context, making sure responses are precise and backed by data from Amazon Bedrock Knowledge Bases. Based on the analysis, the agent dynamically generates a runbook tailored to the specific incident and invokes appropriate remediation actions, such as creating snapshots, restarting instances, scaling resources, or running custom workflows.
Amazon Bedrock Knowledge Bases create an Amazon OpenSearch Serverless vector search collection to store and index incident data, runbooks, and run logs, enabling efficient search and retrieval of information. Lambda functions are employed to run specific actions, such as sending notifications, invoking API calls, or invoking automated workflows. The solution also integrates with Amazon Simple Email Service (Amazon SES) for timely notifications to stakeholders.
The solution workflow consists of the following steps:
- Existing runbooks in various formats (such as Word documents, PDFs, or text files) are uploaded to Amazon Simple Storage Service (Amazon S3).
- Amazon Bedrock Knowledge Bases converts these documents into vector embeddings using a selected embedding model, configured as part of the knowledge base setup.
- These vector embeddings are stored in OpenSearch Serverless for efficient retrieval, also configured during the knowledge base setup.
- Agents and action groups are then set up with the required APIs and prompts for handling different scenarios.
- The OpenAPI specification defines which APIs need to be called, along with their input parameters and expected output, allowing Amazon Bedrock Agents to make informed decisions.
- When a user prompt is received, Amazon Bedrock Agents uses RAG, action groups, and the OpenAPI specification to determine the appropriate API calls. If more details are needed, the agent prompts the user for additional information.
- Amazon Bedrock Agents can iterate and call multiple functions as needed until the task is successfully complete.
Prerequisites
To implement this AIOps solution, you need an active AWS account and basic knowledge of the AWS CDK and the following AWS services:
- Amazon Bedrock
- Amazon CloudWatch
- AWS Lambda
- Amazon OpenSearch Serverless
- Amazon SES
- Amazon S3
Additionally, you need to provision the required infrastructure components, such as Amazon Elastic Compute Cloud (Amazon EC2) instances, Amazon Elastic Block Store (Amazon EBS) volumes, and other resources specific to your IT operations environment.
Build the RAG pipeline with OpenSearch Serverless
This solution uses a RAG pipeline to find relevant content and best practices from operations runbooks to generate responses. The RAG approach helps make sure the agent generates responses that are grounded in factual documentation, which avoids hallucinations. The relevant matches from the knowledge base guide Anthropic’s Claude 3 Haiku model so it focuses on the relevant information. The RAG process is powered by Amazon Bedrock Knowledge Bases, which stores information that the Amazon Bedrock agent can access and use. For this use case, our knowledge base contains existing runbooks from the organization with step-by-step procedures to resolve different operational issues on AWS resources.
The pipeline has the following key tasks:
- Ingest documents in an S3 bucket – The first step ingests existing runbooks into an S3 bucket to create a searchable index with the help of OpenSearch Serverless.
- Monitor infrastructure health using CloudWatch – An Amazon Bedrock action group is used to invoke Lambda functions to get CloudWatch metrics and alerts for EC2 instances from an AWS account. These specific checks are then used as Anthropic’s Claude 3 Haiku model inputs to form a health status overview of the account.
Configure Amazon Bedrock Agents
Amazon Bedrock Agents augment the user request with the right information from Amazon Bedrock Knowledge Bases to generate an accurate response. For this use case, our knowledge base contains existing runbooks from the organization with step-by-step procedures to resolve different operational issues on AWS resources.
By configuring the appropriate action groups and populating the knowledge base with relevant data, you can tailor the Amazon Bedrock agent to assist with specific tasks or domains and provide accurate and helpful responses within its intended scopes.
Amazon Bedrock agents empower Anthropic’s Claude 3 Haiku to use tools, overcoming LLM limitations like knowledge cutoffs and hallucinations, for enhanced task completion through API calls and other external interactions.
The agent’s workflow is to check for resource alerts using an API, then if found, fetch and execute the relevant runbook’s steps (for example, create snapshots, restart instances, and send emails).
The overall system enables automated detection and remediation of operational issues on AWS while enforcing adherence to documented procedures through the runbook approach.
To set up this solution using Amazon Bedrock Agents, refer to the GitHub repo that provisions the following resources. Make sure to verify the AWS Identity and Access Management (IAM) permissions and follow IAM best practices while deploying the code. It is advised to apply least-privilege permissions for IAM policies.
- S3 bucket
- Amazon Bedrock agent
- Action group
- Amazon Bedrock agent IAM role
- Amazon Bedrock agent action group
- Lambda function
- Lambda service policy permission
- Lambda IAM role
Benefits
With this solution, organizations can automate their operations and save a lot of time. The automation is also less prone to errors compared to manual execution. It offers the following additional benefits:
- Reduced manual intervention – Automating incident detection, diagnosis, and remediation helps minimize human involvement, reducing the likelihood of errors, delays, and inconsistencies that often arise from manual processes.
- Increased operational efficiency – By using generative AI, the solution speeds up incident resolution and optimizes operational workflows. The automation of tasks such as runbook execution, resource monitoring, and remediation allows IT teams to focus on more strategic initiatives.
- Scalability – As organizations grow, managing IT operations manually becomes increasingly complex. Automating operations using generative AI can scale with the business, managing more incidents, runbooks, and infrastructure without requiring proportional increases in personnel.
Clean up
To avoid incurring unnecessary costs, it’s recommended to delete the resources created during the implementation of this solution when not in use. You can do this by deleting the AWS CloudFormation stacks deployed as part of the solution, or manually deleting the resources on the AWS Management Console or using the AWS Command Line Interface (AWS CLI).
Conclusion
The AIOps pipeline presented in this post empowers IT operations teams to streamline incident management processes, reduce manual interventions, and enhance operational efficiency. With the power of AWS services, organizations can automate incident detection, diagnosis, and remediation, enabling faster incident resolution and minimizing downtime.
Through the integration of Amazon Bedrock, Anthropic’s Claude on Amazon Bedrock, Amazon Bedrock Agents, Amazon Bedrock Knowledge Bases, and other supporting services, this solution provides real-time visibility into incidents, automated runbook generation, and dynamic remediation actions. Additionally, the solution provides timely notifications and seamless collaboration between AI agents and human operators, fostering a more proactive and efficient approach to IT operations.
Generative AI is rapidly transforming how businesses can take advantage of cloud technologies with ease. This solution using Amazon Bedrock demonstrates the immense potential of generative AI models to enhance human capabilities. By providing developers expert guidance grounded in AWS best practices, this AI assistant enables DevOps teams to review and optimize cloud architecture across of AWS accounts.
Try out the solution yourself and leave any feedback or questions in the comments.
About the Authors
 Upendra V is a Sr. Solutions Architect at Amazon Web Services, specializing in Generative AI and cloud solutions. He helps enterprise customers design and deploy production-ready Generative AI workloads, implement Large Language Models (LLMs) and Agentic AI systems, and optimize cloud deployments. With expertise in cloud adoption and machine learning, he enables organizations to build and scale AI-driven applications efficiently.
Upendra V is a Sr. Solutions Architect at Amazon Web Services, specializing in Generative AI and cloud solutions. He helps enterprise customers design and deploy production-ready Generative AI workloads, implement Large Language Models (LLMs) and Agentic AI systems, and optimize cloud deployments. With expertise in cloud adoption and machine learning, he enables organizations to build and scale AI-driven applications efficiently.
 Deepak Dixit is a Solutions Architect at Amazon Web Services, specializing in Generative AI and cloud solutions. He helps enterprises architect scalable AI/ML workloads, implement Large Language Models (LLMs), and optimize cloud-native applications.
Deepak Dixit is a Solutions Architect at Amazon Web Services, specializing in Generative AI and cloud solutions. He helps enterprises architect scalable AI/ML workloads, implement Large Language Models (LLMs), and optimize cloud-native applications.
Empowering disaster preparedness: AI’s role in navigating complex climate risks
AI systems that integrate meteorological, geospatial, and socioeconomic data can deliver warnings that are more localized and more timely.Read More

OpenReg: A Self-Contained PyTorch Out-of-Tree Backend Implementation Using “PrivateUse1” Mechanism
OpenReg is a self-contained demonstration of a PyTorch out-of-tree backend implementation utilizing the core framework’s “PrivateUse1” mechanism. This implementation serves two primary purposes:
- Reference Implementation: Provides a practical template for third-party device vendors integrating with PyTorch through PrivateUse1.
- CI Testing Infrastructure: Enables device-agnostic testing capabilities for continuous integration pipelines.
Usage
Module Installation
cd {project}/test/cpp_extensions/open_registration_extension
python setup.py install
Use Case
import torch
import pytorch_openreg
if __name__ == "__main__":
print(torch.ones(1, 2, device='openreg'))
Architectural Overview
Process Management
OpenReg implements virtual device isolation by spawning N independent subprocesses, each maintaining dedicated request/response queues for inter-process communication. The parent process driver encapsulates device operations into command packets that are:
- Dispatched to target devices via request queues
- Processed asynchronously with results returned through response queues
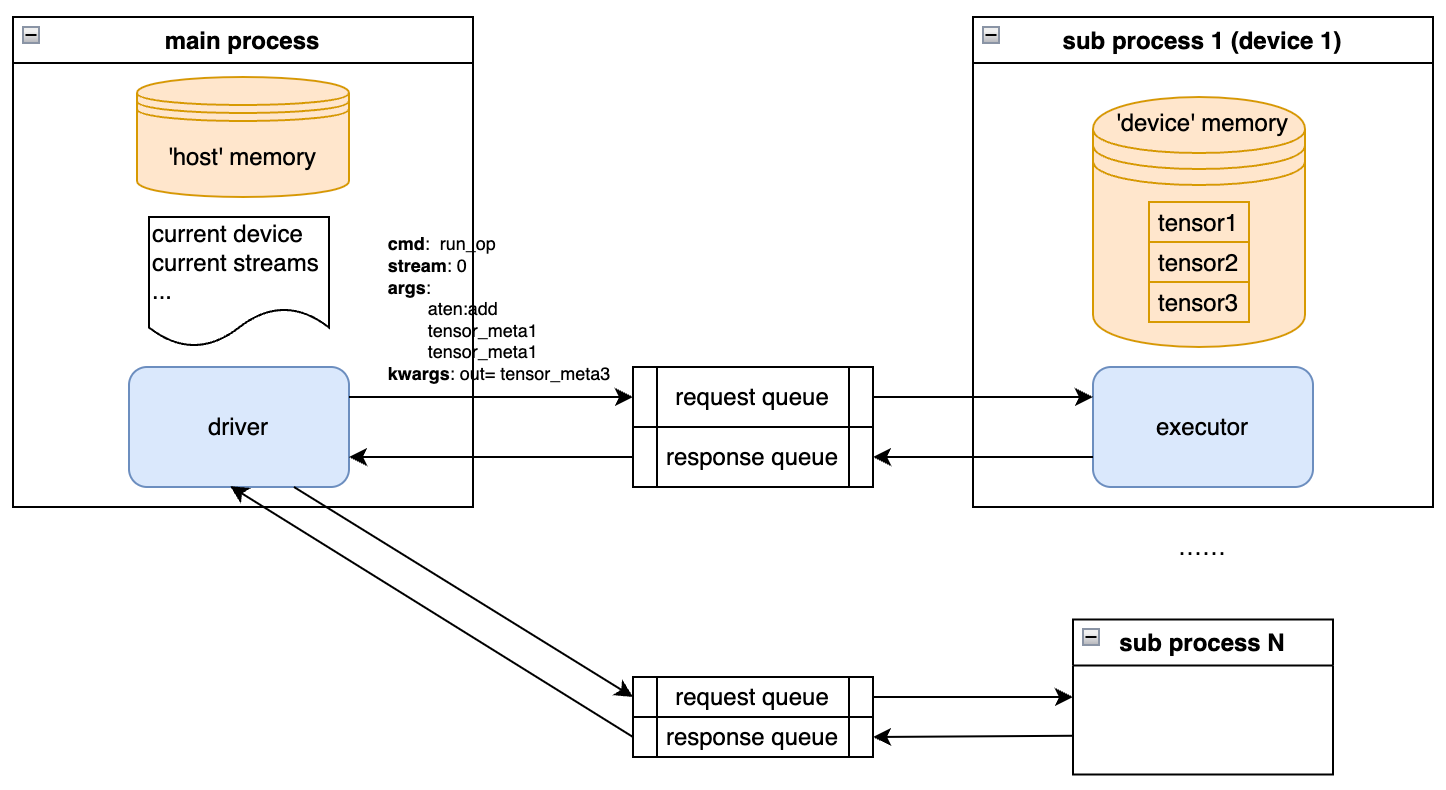
Figure: Parent-Subprocess Communication Flow
Memory Management
Device memory allocations occur within individual subprocesses to ensure:
- Strict memory isolation between devices
- Realistic simulation of physical device constraints
Component Breakdown
_aten_impl.py
This module handles dual responsibilities:
- Hook Registration:
- Utilizes _IMPL_REGISTRY to bind C++ backend hooks (e.g., getDevice, getStream) to device driver implementations
- Fallback Mechanism:
- Define a new
torch.Librarythat registers a fallback that will be called whenever a backend kernel for PrivateUse1 is called. It contains the logic to handle all kind of native functions, computing the output metadata, allocating it and only calling into the device daemon to perform computation
- Define a new
_device_daemon.py
Core Subsystems
- Allocators:
HostAllocator: Manages pinned memory in parent processDeviceAllocator: Handles device memory with tensor reconstruction capabilities
- Driver (Parent Process):
- Maintains device context (active device/streams)
- Implements device control operations:
- setDevice/getDevice
- deviceCount
- exchangeStream
- Orchestrates command execution through queue-based IPC
- Executor (Subprocess):
- Processes command types:
- Memory operations (
malloc/free) - Tensor computations (
run_op) - Data transfers (
send_data/recv_data) - Stream/event management (primarily no-op due to CPU sync nature)
- Memory operations (
- Processes command types:
_meta_parser.py
Key Features:
- Implements serialization utilities for cross-process object transfer
- OpenRegTensorMeta class encapsulates complete tensor metadata for:
- Output tensor reconstruction
- Device-side computation preparation
Design Considerations
Execution Characteristics
- Synchronous Computation: CPU operator execution necessitates synchronous processing
- Stream/Event Semantics: Implemented as no-ops due to synchronous execution model
- Memory Isolation: Strict per-device memory boundaries enforced through subprocess allocation
This architecture enables realistic simulation of device integration while maintaining PyTorch compatibility through standard backend interfaces.

The reality of generative AI in the clinic

Two years ago, OpenAI’s GPT-4 kick-started a new era in AI. In the months leading up to its public release, Peter Lee, president of Microsoft Research, cowrote a book full of optimism for the potential of advanced AI models to transform the world of healthcare. What has happened since? In this special podcast series—The AI Revolution in Medicine, Revisited—Lee revisits the book, exploring how patients, providers, and other medical professionals are experiencing and using generative AI today while examining what he and his coauthors got right—and what they didn’t foresee.
In this episode, Dr. Christopher Longhurst (opens in new tab) and Dr. Sara Murray (opens in new tab), leading experts in healthcare AI implementation, join Lee to discuss the current state and future of AI in clinical settings. Longhurst, chief clinical and innovation officer at UC San Diego Health and executive director of the Jacobs Center for Health Innovation, details his healthcare system’s collaboration with Epic and Microsoft to integrate GPT into their electronic health record system, offering clinicians support in responding to patient messages. Dr. Murray, chief health AI officer at UC San Francisco Health, discusses AI’s integration into clinical workflows, the promise and risks of AI-driven decision-making, and how generative AI is reshaping patient care and physician workload.
Learn more:
Large Language Models for More Efficient Reporting of Hospital Quality Measures (opens in new tab)
Publication | October 2024
Generative artificial intelligence responses to patient messages in the electronic health record: early lessons learned (opens in new tab)
Publication | July 2024
The Chief Health AI Officer — An Emerging Role for an Emerging Technology (opens in new tab)
Publication | June 2024
AI-Generated Draft Replies Integrated Into Health Records and Physicians’ Electronic Communication (opens in new tab)
Publication | April 2024
Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum (opens in new tab)
Publication | April 2023
The AI Revolution in Medicine: GPT-4 and Beyond
Book | April 2023
Transcript
[MUSIC] [BOOK PASSAGE]PETER LEE: “The workload on healthcare workers in the United States has increased dramatically over the past 20 years, and in the worst way possible. … Far too much of the practical, day-to-day work of healthcare has evolved into a crushing slog of filling out and handling paperwork. … GPT-4 indeed looks very promising as a foundational technology for relieving doctors of many of the most taxing and burdensome aspects of their daily jobs.”
[END OF BOOK PASSAGE] [THEME MUSIC]This is The AI Revolution in Medicine, Revisited. I’m your host, Peter Lee.
Shortly after OpenAI’s GPT-4 was publicly released, Carey Goldberg, Dr. Zak Kohane, and I published The AI Revolution in Medicine to help educate the world of healthcare and medical research about the transformative impact this new generative AI technology could have. But because we wrote the book when GPT-4 was still a secret, we had to speculate. Now, two years later, what did we get right, and what did we get wrong?
In this series, we’ll talk to clinicians, patients, hospital administrators, and others to understand the reality of AI in the field and where we go from here.
[THEME MUSIC FADES]
What I read there at the top is a passage from Chapter 2 of the book, which captures part of what we’re going to cover in this episode.
In our book, we predicted how AI would be leveraged in the clinic. Some of those predictions, I felt, were slam dunks, for example, AI being used to listen to doctor-patient conversations and write clinical notes. There were already early products coming out in the world not using generative AI that were doing just that. But other predictions we made were bolder, for instance, on the use of generative AI as a second set of eyes, to look over the shoulder of a doctor or a nurse or a patient and spot mistakes.
In this episode, I’m pleased to welcome Dr. Chris Longhurst and Dr. Sara Murray to talk about how clinicians in their respective systems are using AI, their reactions to it, and what’s ahead. Chris is the chief clinical and innovation officer at UC San Diego Health, and he is also the executive director of the Joan & Irwin Jacobs Center for Health Innovation. He’s in charge of UCSD Health’s digital strategy, including the integration of new technologies from bedside to bench and reaching across UCSD Health, the School of Medicine, and the Jacobs School of Engineering. Chris is a board-certified pediatrician and clinical informaticist.
Sara is vice president and chief health AI officer at UC San Francisco Health. Sara is an internal medicine specialist and associate professor of clinical medicine. A doctor, a professor of medicine, and a strategic health system leader, she builds infrastructure and governance processes to ensure that UCSF’s deployment of AI, including both AI procured from companies as well as AI-powered tools developed in-house, are trustworthy and ethical.
I’ve known Chris and Sara for years, and what’s really impressed me about their work—and frankly, the work of all the guests we’ll have on the show—is that they’ve all done something significant to advance the use of AI in healthcare.
[TRANSITION MUSIC]Here’s my conversation with Dr. Chris Longhurst:
LEE: Chris, thank you so much for joining us today.
CHRISTOPHER LONGHURST: Peter, it’s a pleasure to be here. Really appreciate it.
LEE: We’re going to get into, you know, what’s happening in the clinic with AI. But I think we need to find out a little bit more about you first. I introduced you as a person with a fancy title, chief clinical and innovation officer. What is that exactly, and how do you spend a typical day at work?
LONGHURST: Well, I have a little bit of a unicorn job because my portfolio includes information technology, and I’m a recovering CIO after spending seven years in that role. It also includes quality patient safety, case management, and the office of our chief medical officer.
And so I’m really trying to unify our mission to deliver highly reliable care with these new tools in a way that allows us to transform that care. One good analogy, I think, is it’s about the game, right. Our job is not only to play the game and win the game using the existing tools but also to change the game by leveraging these new tools and showing the rest of the country how that can be done.
LEE: And so as you’re doing that, I can understand, of course, you’re working at a very, kind of, senior executive level. But, you know, when I’ve visited you at UCSD Health, you’re also working with clinicians, doctors, and nurses all the time. In a way, I viewed you as, sort of, connective tissue between these things. Is that accurate?
LONGHURST: Well, sure. And we’ve got, you know, several physicians who are part of the executive team who are also continuing to practice, and I think that’s one of the ways in which doctors on the executive team can bring value, is being that connective tissue, being the ears on the ground and a little dose of reality.
LEE: [LAUGHS] Well, in fact, that reality is really what I want to delve into. But I just want to, before getting into that, talk a little bit about AI and your encounters with AI. And I think we have to do it in two stages because there is AI and machine learning and data analytics prior to the rise of generative AI and then, of course, after. And so tell us a little bit about, you know, what got you into health informatics and AI to begin with.
LONGHURST: Well, Peter, I know that you play video games, and I did too for many years. So I was an early John Carmack id Software, Castle Wolfenstein, and Doom fan.
LEE: Love it.
LONGHURST: And that kept me occupied because I lived out in the country on 50 acres of almond trees. And so it was computer gaming that first got me into computers.
But during medical school, I decided to pursue graduate work in this field called health informatics. And actually my master’s thesis was using machine learning to help identify and distinguish innocent from pathologic heart murmurs in children. And I worked with Dr. Nancy Reed at UC Davis, who had programmed using Lisp, a really fancy tool to do exactly that.
And I will tell you that if I never see another parentheses in Lisp code again, it’ll be too soon. So I spent a solid year on that.
LEE: [LAUGHS] No, no, but you should wear that as a badge of honor. And I will guess that no other guest on this podcast series will have programmed in Lisp. So kudos to you.
LONGHURST: [LAUGHS] Well, it was a lot of work, and I learned a lot, but as you can imagine, it wasn’t highly successful at the time. And fast forward, we’ve had lots of traditional machine learning kind of activities using discrete data for predictive analytics to help predict flow in the hospital and even sepsis, which we can talk about. But as you said, the advent of generative AI in the fall of 2022 was a real game-changer.
LEE: Well, you have this interest in technology, and, in fact, I do know you as a fairly intensely geeky person. Really, I think maybe that’s one reason why we’ve been attracted to each other. But you also got drawn into medicine. Where did that come from?
LONGHURST: So my father was a practicing cardiologist and scientist. He was MD, PhD trained, and he really shared with me both a love of medicine but also science. I worked in his lab for three summers, and it was during college I decided I wanted to apply to medical school because the human side of the science really drew me in.
But my father was the one who really identified it was important to cross-train. And that’s why I decided to take time off to do that master’s degree in health informatics and see if I could figure out how to take two disparate fields and really combine them into one.
I actually went down to Stanford to become a pediatrician because they have a standalone children’s hospital that’s one of the best in the country. And I still practice pediatrics and see newborns, and it’s a passion for me and part of my identity.
LEE: Well, I’m just endlessly fascinated and impressed with people who can span these two worlds in the way that you’ve done. So now, you know, 2022, in November, ChatGPT gets released to the world, and then, you know, a few months later, GPT-4, and then, of course, in the last two years, so much has happened. But what was your first encounter with what we now know of as generative AI?
LONGHURST: So I remember when ChatGPT was released, and, you know, some of my computer science-type of nerd friends, we were on text threads, you know, with a lot of mind-blowing emojis. But when it really hit medicine was when I got a call right after Thanksgiving in 2022 from my colleague. He was playing with ChatGPT, and he said to me, Chris, I’ve been feeding it patient questions and you wouldn’t believe the responses. And he emailed some of the examples to me, and my mind was blown.
And so that’s when I became one of the reviewers on the paper that was published in April of 2023 that showed not only could ChatGPT help answer questions from patients in a high-quality way, but it also expressed a tremendous amount of empathy.[1] And in fact, in our review, the clickbait headlines that came out of the paper were that the chatbot was both higher quality and more empathetic than doctors.
But that wasn’t my takeaway at all. In fact, I’ll take my doctors any day and put them against your chatbot if you give them an hour to Google and construct a really long, thoughtful response. To me, part of the takeaway was that this was really an opportunity to improve efficiency and save time. And so I called up our colleagues at Epic. I think it was right around December of 2022. And I said, Sumit, have you seen this? I’d like to share some results with you. And I showed him the data from our paper before we had actually had it published. And he said, “Well, that’s great because we’re working with Peter Lee and the team at Microsoft to integrate GPT into Epic.”
And so, of course, that’s how we became one of the first two sites in the country to roll out GPT inside our electronic health record to help draft answers to patient questions.
LEE: And, you know, one thing that’s worth emphasizing in the story that you’ve just told is that there is no other major health system that has been confronting the reality of generative AI longer than UC San Diego Health—and I think largely because of your drive and early adoption.
And many listeners of this podcast will know what Epic is, but many will not. And so it’s worth saying that Epic is a very important creator of an electronic health records system. And of course, UC San Diego Health uses Epic to store all of the clinical data for its patients.
And then Sumit is, of course, Sumit Rana, who is president at Epic.
LONGHURST: So in partnership with Epic, we decided to tackle a really important challenge in healthcare today, which is, particularly since the pandemic and the increase in virtual and telehealth care, our clinicians get more messages than ever from patients. But answering those asynchronous messages is an unreimbursed, noncompensated activity that can often take time after hours—what we call “pajama time”—for our doctors.
And in truth, you know, health systems that have thought through this, most of the answers are not actually generated by the doctors themselves. Many times, it’s mid-level providers, protocol schedulers, other things, because the questions can be about anything from rescheduling an appointment to a medication refill. They don’t all require doctors.
When they do, it’s a more complicated question, and sometimes can require a more complicated answer. And in many cases, the clinicians will see a long complex question, and rather than typing an answer, they’ll say, “You know, this is complicated. Why don’t you schedule a visit with me so we can talk about it more?”
LEE: Yeah, so now you’ve made a decision to contact people at Epic to what … posit the idea that AI might be able to make responding to patient queries easier? Is that the story here?
LONGHURST: That’s exactly right. And Sumit knew well that this is a challenge across many organizations. This is not unique to UC San Diego or Stanford. And there’s been a lot of publications about it. It’s even been in the lay press. So our hypothesis was that using GPT to help draft responses for doctors would save them time, make it easier, and potentially result in higher-quality, more empathetic answers to patients.
LEE: And so now the thing that I was so impressed with is you actually did a carefully controlled study to try to understand how well does that work. So tell us a little bit first about the results of that study but then how you set it up.
LONGHURST: Sure. Well, first, I want to acknowledge something you said at the beginning, which is one of my hats is the executive director of the Joan & Irwin Jacobs Center for Health Innovation. And we’re incredibly grateful to the Jacobs for their gift, which has allowed us to not only implement AI as part of hospital operations but also to have resources that other health systems may not have to be able to study outcomes. And so that really enabled what we’re going to talk about here.
LEE: Right. By the way, one of the things I was personally so fascinated by is, of course, in our book, we speculated that things like after-visit notes to patients, responding to patient queries might be something that happens. And you, at the same time we were writing the book, were actually actively trying to make that real, which is just incredible and for me, and I think my coauthors, pretty affirming.
LONGHURST: I think you guys were really prescient in your vision. The book is tremendous. I have a signed copy of Peter’s book, and I recommend it for all your listeners. [LAUGHTER]
LEE: All right, so now what have you found about …
LONGHURST: Yeah.
LEE: … generative AI?
LONGHURST: Yeah. Well, first to understand what we found, you have to understand how we built [the AI inbox response tool]. And so Stanford and UC San Diego really collaborated with Epic on designing what this would look like. So doctor gets that patient message. We feed some information to GPT that’s not only the message but also some information about the patient—their problems and medications and past medical and surgical history and that sort of thing.
LEE: Is there a privacy concern that patients should be worried about when that happens?
LONGHURST: Yeah, it’s a really good question. There’s not because we’re operating in partnership with Epic and Microsoft in a HIPAA-compliant cloud. And so that data is not only secure and private, but that’s our top priority, is keeping it that way.
LEE: Great.
LONGHURST: So once we feed that into GPT, of course, we very quickly get a draft message that we could send to a patient. But we chose not to just send that message to a patient. So part of our AI governance is keeping a human in the loop. And there’s two buttons that allow that clinician to review the message. One button says Edit draft message, and the other button says Start new blank message. So there’s no button that says just Send now. And that really is illustrative of the approach that we took. The second thing, though, that we chose to do I think is really interesting from a conversation standpoint is that our AI governance, as they were looking at this, said, “You know, AI is new and novel. It can be scary to patients. And if we want to maximize trust with our patients, we should maximize transparency.” And so anytime a clinician uses the button that says Edit draft response, we automatically append something in the message that says, “This message was automatically generated and reviewed and edited by your doctor.” We felt strongly that was the right approach, and we’ve had a lot of positive feedback.
LEE: And so we’ll want to get into, you know, how good these messages are, whether there are issues with bias or hallucination, but before doing that, you know, on this human in loop, this was another theme in our book. And in fact, we recommended this. But there were other health systems around the country that were also later experimenting with similar ideas. And some have taken different approaches. In fact, as time has gone on, if anything, it seems like it’s become a little bit less clear, this sort of labeling idea. Has your view on this evolved at all over the last two years?
LONGHURST: First of all, I’m glad that we did it. I think it was the right choice for University of California, and in fact, the other four UC sites are all doing this, as well. There is variability across the organizations that are using this functionality, and as you suggest, there’s tens of thousands of physicians and hundreds of thousands if not millions of patients receiving these messages. And it’s been highlighted a bit in the press.
I can tell you that talking about our approach to transparency, one of our lawmakers in the state of California heard about this and actually proposed a bill that was signed into legislation by our governor so that effective Jan. 1, any communication with patients that uses AI has to be disclosed with those patients. And so there is some thought that this is perhaps the right approach.
I don’t think that it’s a perfect approach, though. We’re using AI in more and more ways, and it’s not as if we’re going to be able to disclose every single time that we’re doing it to prioritize, you know, scheduling for the sickest patients or to help operationally on billing or something else. And so I think that there are other ways we need to figure it out. But we have called on national societies and others to try to create some guidelines around this because we should be as transparent as we can with our patients.
LEE: Obviously, one of the issues—and we highlighted this a lot in our book—is the problem of hallucination. And surely this must be an issue when you’re having AI draft these notes to patients. What have you found?
LONGHURST: We were worried about that when we rolled it out. And what we found is not only were there very few hallucinations, in some cases, our doctors were learning from the GPT. And I can give you an example. When a patient who had had a visit wrote their doctor afterwards and said, “Doc, I’ve been thinking a lot about what we discussed in quitting smoking marijuana.” And the GPT draft reply said something to the effect of, “That’s great news. Here’s a bunch of evidence on how smoking marijuana can harm your lungs and cause other effects. And by the way, since you live in the state of California, here’s the marijuana quitters helpline.” And the doctor who was sending this called me up to tell me about it. And I said, well, is there a marijuana quitters helpline in the state of California? And he said, “I didn’t know, so I Googled it. And yeah, there is.” And so that’s an example of the GPT actually having more information than, you know, a primary care clinician might have. And so there are cases clearly where the GPT can help us increase the quality. In addition, some of the feedback that we’ve been getting both anecdotally and now measuring is that these draft responses do carry that tone of empathy that Dr. [John] Ayers [2] and I saw in the original manuscript. And we’ve heard from our clinicians that it’s reminding them to be empathetic because you don’t always have that time when you’re hammering out a quick short message, right?
LEE: You know, I think the thing that we’ve observed, and we’ve discussed this also, is exactly that reminding thing. There might be in the encounter between a doctor and patient, maybe a conversation about, you know, going to a football game for the first time. That could be part of the conversation. But in a busy doctor’s life, when writing a note, you might forget about that. And, of course, an AI has the endless ability to remember that it might be friendly to send well wishes.
LONGHURST: Exactly right, Peter. In fact, one of the findings in Dr. Ayers’s manuscript that didn’t get as much attention but I think is really important was the difference in length between the responses. So I was one of the putatively blinded reviewers, but as I was looking at the questions and answers, it was really obvious which ones were the chatbot and which ones were the doctors because the chatbot was always, you know, three or four paragraphs and the doctor was three or four sentences, right. It’s about time. And so we saw that in the results of our study.
LEE: All right, so now let’s get into those results.
LONGHURST: OK. Well, first of all, my hypothesis was that this would help us save time, and I was wrong. It turns out a busy primary care clinician might get about 30 messages a day from patients, and each one of those messages might take about 30 seconds to type a quick response, a two-sentence response, a dot phrase, a macro. Your labs are normal. No need to worry. I’ll call you if anything comes up. After we implemented the AI tool, it still took about 30 seconds per message to respond. But we saw that the responses were two to three times longer on average, and they carried a more empathetic tone. [3] And our physicians told us it decreased cognitive burden, which is not surprising because any of you have written know that it’s much easier to edit somebody else’s copy than it is to face a blank screen, right. That’s why I like to be senior author, not lead author.
And so the tool actually helped quite a bit, but it didn’t help in the ways that we had expected necessarily. There are some other sites that have now found a little bit of time savings, but it’s really nominal overall. The Stanford study (opens in new tab) that was done at the same time—and we actually had some shared coauthors—measured physician burnout using a validated survey, and they saw a decrease in measured physician burnout. And so there are clear advantages to this, and we’re still learning more.
In fact, we’ve now rolled this out not only to all of our physicians, but to all of our nurses who help answer those messages in many different clinics. And one of the things that we’re finding—and Dr. CT Lin at University of Colorado recently published (opens in new tab)—is that this tool might actually help those mid-level providers even more because it’s really good at protocolized responses. I mentioned at the beginning, some of the questions that come to the physicians may be more the edge cases that require a little bit less protocolized kind of answers. And so as we get into academic subspecialties like gynecology oncology, the GPT might not be dishing up a draft message that’s quite as useful. But if you’re a nurse in obstetrics and you’re getting very routine pregnancy questions, it could save a ton of time. And so we’ve rolled this out broadly.
I want to acknowledge the partnership with Seth Hain and the team at Epic, who’ve just been fantastic. And we’re finding all sorts of new ways to integrate the GPT tools into our electronic health record, as well.
LEE: Yeah. Certainly the doctors and nurses that I’ve encountered that have access to this feature, they just don’t want to give it up. But it’s so interesting that it actually doesn’t really save time. Is that a problem? Because, of course, you know, there seems to be a workforce shortage in healthcare, a need to lower costs and have greater efficiencies. You know, how do you think about that?
LONGHURST: Great question. There are so many opportunities, as you’ve kind of mentioned. I mean, healthcare is full of waste and inefficiency, and I am super bullish on how these generative AI tools are going to help us reduce some of that inefficiency.
So everything from revenue cycle to our call centers to operations efficiency, I think, can be positively impacted, and those things make more resources available for clinicians and others. When we think about, you know, saving clinicians time, I don’t think it’s necessarily, sort of, the communicating with patients where you want to save that time actually. I think what we want to do is we want to offload some of those administrative tasks that, you know, take a lot of time for our physicians.
So we’ve measured “pajama time” in our doctors, and on average, a busy primary care clinician can spend one to two hours after clinic doing things. But only about 15 minutes is answering messages from patients. Actually, the bulk of the time after hours is documenting the notes that are required from those visits, right. And those notes are used for a number of different purposes, not only communicating to the next doctor who sees the patient but also for billing purposes and compliance purposes and medical legal purposes. So another really exciting area is AI scribes.
LEE: Yeah. And so, you know, we’ll get into scribes and actually other possibilities. I wonder, though, about this empathy issue. Because as computer scientists, we know that you can fall into traps if you anthropomorphize these AI systems or any machine. So in this study, how was that measured, and how real do think that is?
LONGHURST: So in the study, you’ll see anecdotal or qualitative evidence about empathy. We have a follow-up study that will be published soon where we’ve actually measured empathy using some more quantitative tools, and there is no doubt that the chatbot-generated drafts are coming through with more empathy. And we’ve heard this from a number of our doctors, so it’s not surprising. Here’s one of the more surprising things though. I published a paper last year with Dr. Sally Baxter (opens in new tab), one of our ophthalmologists, and she actually looked at messages with a negative tone. It turns out, not surprisingly, healthcare can be frustrating. And stressed patients can send some pretty nasty messages to their care teams. [LAUGHTER] And you can imagine being a busy, …
LEE: I’ve done it. [LAUGHS]
LONGHURST: … tired, exhausted clinician, and receiving a bit of a nasty gram from one of your patients can be pretty frustrating. And the GPT is actually really helpful in those instances in helping draft a pretty empathetic response when I think the human instinct would be a pretty nasty one. [LAUGHTER] I should probably use it in my email, Peter.
LEE: And is the patient experience, the actually lived experience of patients when they receive these notes, are you absolutely convinced and certain that they are also benefiting from this empathetic tone?
LONGHURST: I am. In fact, in our paper, we also found that the messages going to patients that had been drafted with the AI tool were two to three times longer (opens in new tab) than the messages going to patients that weren’t using the drafts. And so it’s clear there’s more content going and that content is either contributing to a greater sense of empathy and relationship among the patients as well as the clinicians, and/or in some cases, that content may be educating the patients or even reducing the need for follow-up visits.
LEE: Yeah, so now I think an important thing to share with the audience here is, you know, healthcare, of course, is a very highly regulated industry for good reasons. There are issues of safety and privacy that have to be guarded very, very carefully and thoroughly. And for that reason, clinical studies oftentimes have very carefully developed controls and randomization setups. And so to what extent was that done in this case? Because here, it’s not like you’re testing a new drug. It’s something that’s a little fuzzier, isn’t it?
LONGHURST: Yeah, that’s right, Peter. And credit to the lead author, Dr. Ming Tai-Seale, we actually did randomize. And so that’s unusual in these type of studies. We actually got IRB [institutional review board] exemption to do this as a randomized QI study. And it was a crossover study because all the doctors wanted the functionality. So what we tested was the early adopters versus the late adopters. And we compared at the same time the early adopters to those who weren’t using the functionality and then later the late adopters to the folks that weren’t using the functionality.
LEE: And in that type of study, you might also, depending on how the randomization is set up, also have to have doctors some days using it and some days not having access. Did that also happen?
LONGHURST: We did, but it wasn’t on a day-to-day basis. It was more a month-to-month basis.
LEE: Uh-huh. And what kind of conversation do you have with a doctor that might be attached to a technology and then be told for the next month you don’t get to use it?
LONGHURST: [LAUGHS] The good news is because of a doctor’s medical training, they all understood the need for it. And the conversation was sort of, hey, we’re going to need you to stop using that for a month so that we can compare it, but we’ll give it back to you afterwards.
LEE: [LAUGHS] OK, great. All right. So now we made some other predictions. So we talked about, you know, responding to patients. You briefly mentioned clinical note-taking. We also made guesses about other types of paperwork, you know, filling out prior authorization requests or referral letters, maybe for a doctor to refer to a specialist. We even made some guesses about a second set of eyes on medications, on various treatment options, diagnoses. What of these things have happened and what hasn’t happened, at least in your clinical experience?
LONGHURST: Your guesses were spot on. And I would say almost all of them have already happened and are happening today at UC San Diego and many other health systems. We have a HIPAA-compliant GPT instance that can be used for things like generating patient letters, generating referral letters, even generating patient education with patient-friendly language. And that’s a common use case. The second set of eyes on medications is something that we’re exploring but have not yet rolled out. One of the areas I’m really excited about is reporting. So Johns Hopkins did a study a couple of years ago that showed an average academic medical center our size spends about $5 million annually (opens in new tab) just reporting on quality measures that are regulatory requirements. And that’s about accurate for us.
We published a paper just last fall showing that large language models could help to pre-populate quality data (opens in new tab) for things like sepsis reporting in a really effective way. It was like 91% accurate. And so that’s a huge time savings and efficiency opportunity. Again, allows us to redeploy those qualities staff. We’re now looking at things like how do we use large language models to review charts for peer review to help ensure ongoing, you know, accuracy and mitigate risk. I’m really passionate about the whole space of using AI to improve quality and patient safety in particular.
Your readers may be familiar with the famous report in 1999, “To Err is Human (opens in new tab),” that suggests a hundred thousand Americans die on an annual basis from medical errors. And unfortunately the data shows we really haven’t made great progress in 25 years, but these new tools give us the opportunity to impact that in a really meaningful way. This is a turning point in healthcare.
LEE: Yeah, medication errors—actually, all manner of medical errors—I think has been just such a frustrating problem. And, you know, I think this gives us some new hope. Well, let’s look ahead a little bit. And just to be a little bit provocative, you know, one question that I get asked a lot by both patients and clinicians is, you know, “Will AI replace doctors sometime in the future?” What are your thoughts?
LONGHURST: So the pat response is AI won’t replace doctors, but AI will replace doctors who don’t use AI. And the implication there, of course, is that a doctor using AI will end up being a more effective practitioner than a doctor who doesn’t. And I think that’s absolutely true. From a medical legal standpoint, what is standard of care today and what is standard of care five or 10 years from now will be different. And I think there will be a point where doctors who aren’t using AI regularly, it would almost be unconscionable.
LEE: Yeah, I think there are already some areas where we’ve seen this happen. My favorite example is with the technology of ultrasound, where if you’re a gynecologist or some part of internal medicine, there are some diagnostic procedures where it would really be malpractice not to use ultrasound. Whereas in the late 1950s, the safety and also the doctor training to read ultrasound images were all called into question. And so let’s look ahead two years from now, five years from now, 10 years from now. And on those three time frames, you know, what do you think—based on the practice of medicine today, what doctors and nurses are doing in clinic every day today—what do you think the biggest differences will be two years from now, five years from now, and 10 years from now?
LONGHURST: Great question, Peter. So first of all, 10 years from now, I think that patients will be still coming to clinic. Doctors will still be seeing them. Hopefully we’ll have more house calls and care occurring outside the clinic with remote monitoring and things like that. But the most important part of healthcare is the humanism. And so what I’m really excited about is AI helping to restore humanism in medical care. Because we’ve lost some of it over the last 20, 30 years as healthcare has become more corporate.
So in the next two to five years, some things I expect to see is AI baked into more workflows. So AI scribes are going to become incredibly commonplace. I also think that there are huge opportunities to use those scribes to help reduce errors in diagnosis. So five or seven years from now, I think that when you’re speaking to your physician about your symptoms and other things, the scribe is going to be developing a differential diagnosis and helping recommend not only the right follow-up tests or imaging but even the physical exam findings that the doctor might want to look for in particular to help make a diagnosis.
Dirty secret in healthcare, Peter, is that 50% of doctors are below average. It’s just math. And I think that the AI can help raise all of our doctors. So it’s like Lake Wobegon. They’re all above average. It has important implications for the workforce as you were saying. Do we need all visits to be with primary care doctors? Will mid-level providers augmented by AI be able to do as great a job as many of our physicians do? I think these are unanswered questions today that need to be explored. And then there was a really stimulating editorial in The New York Times recently by Dr. Eric Topol (opens in new tab), and he was waxing philosophic about a recent study that showed AI could interpret X-rays with 90% accuracy and radiologists actually achieve about 72% accuracy (opens in new tab).
LEE: Right.
LONGHURST: The study looked at, how did the radiologists do with AI working together? And they got about 74% accuracy. So the doctors didn’t believe the AI. They thought that they were in the right, and the inference that Eric took that I agree with is that rather than always looking for ways to combine the two, we should be thinking about those tasks that are amenable to automation that could be offloaded with AI. So that our physicians are focused on the things that they’re great at, which is not only the humanism in healthcare but a lot of those edge cases we talked about. So let’s take mammogram screening as an example, chest X-ray screening. There’s going to be a point in the next five years where all first reads are being done by AI, and then it’s a subset of those that are positive that need to be reviewed by physicians. And that helps free up radiologists to do a lot of other things that we need them to do.
LEE: Wow, that is really just such a great vision for the future. And I call some of this the flip, where even patient expectations on the use of technology flips from fear and uncertainty to, you know, you would try to do this without the technology? And I think you just really put a lot of color and detail on that. Well, Chris, thank you so much for this. On that groundbreaking paper from April of 2023, we’ll put a link to it. It’s a really great thing to read. And of course, you’ve published extensively since then. But I can’t thank you enough for just all the great work that you’re doing. It’s really changing medicine.
[TRANSITION MUSIC]LONGHURST: Peter, can’t thank you enough for the opportunity to be here today and the partnership with Microsoft to make this all possible.
LEE: I always love talking to Chris because he really is a prime example of an important breed of doctor, a doctor who has clinical experience but is also world-class tech geek. [LAUGHS] You know, it’s surprising to me, and pleasantly so, that the traditional gold standard of randomized trials that Chris has employed can be used to assess the viability of generative AI, not just for things like medical diagnosis, but even for seemingly mundane things like writing email notes to patients.
The other surprise is that the use of AI, at least in the in-basket task, which involves doctors having to respond to emails from patients, doesn’t seem to save much time for doctors, even though the AI is drafting those notes. Doctors seem to love the reduced cognitive burden, and patients seem to appreciate the greater detail and friendliness that AI provides, but it’s not yet a big timesaver. And of course, the biggest surprise out of the conversation with Chris was his celebrated paper back two years ago now on the idea that AI notes are perceived by patients as being more empathetic than notes written by human doctors. Wow.
Let’s go ahead to my conversation with Dr. Sara Murray:
LEE: Sara, I’m thrilled you’re here. Welcome.
SARA MURRAY: Thank you so much for having me.
LEE: You know, you have actually a lot of roles, and I know that’s not so uncommon for people at the leading academic medical institutions. But, you know, I think for our audience, understanding what a chief health AI officer does, an associate professor of clinical medicine—what does it all mean? And so to start, when you talk to someone, say, like your parents, how do you describe your job? You know, how do you spend a typical day at work?
MURRAY: So first and foremost, I do always introduce myself as a physician because that’s how I identify, that’s how I trained. But in my current role, as the chief health AI officer, I’m really responsible for the vision and strategy for how we use trustworthy AI at scale to solve the biggest problems in our health system. And so I think there’s a couple key important points about that. One is that we have to be very careful that everything we’re doing in healthcare is trustworthy, meaning it’s safe, it’s ethical, it’s doing what we hope it’s doing, and it’s not causing any unexpected harm.
And then, you know, second, we really want to be doing things that affect, you know, the population at large of the patients we’re taking care of. And so I think if you look historically at what’s happened with AI in healthcare, you’ve seen little studies here and there, but nothing broadly affecting or transforming how we deliver care. And I think now that we’re in this generative AI era, we have the tools to start thinking about how we’re doing that. And so that’s part of my role.
LEE: And I’m assuming a chief health AI officer is not a role that has been around for a long time. Is this fairly new at UCSF, or has this particular job title been around?
MURRAY: No, it’s a relatively new role, actually. I came into this role about 18 months ago. I am the first chief health AI officer at UCSF, and I actually wrote the paper defining the role (opens in new tab) with Dr. Ashley Beecy, Dr. Chris Longhurst, Dr. Karandeep Singh, and Dr. Bob Wachter where we discuss what is this role in healthcare, why do we actually need it now, and what is this person accountable for. And I think it’s very important that as we roll these technologies out in health systems, we have someone who’s really accountable for thinking about, you know, whether we’re selecting the right tools and whether they’re being used in the right ways to impact our patients.
LEE: It’s so interesting because I would say in the old days, you know, like five years ago, [LAUGHS] information technology in a hospital or health-system setting might be under the control and responsibility of a chief information officer, a CIO, or an IT, you know, chief. Or if it’s maybe some sort of medical device technology integration, maybe it’s some engineering-type of leader, a chief technology officer. But you’re different, and in fact the role that I think I would credit you with, sort of, making the blueprint for seems different because it’s actually doctors, practicing clinicians, who tend to inhabit these roles. Is there a reason why it’s different that way? Like, a typical CIO is not a clinician.
MURRAY: Yeah, so I report to our CIO. And I think that there’s a recognition that you need a clinician who really understands in practice how the tools can be deployed effectively. So it’s not enough to just understand the technology, but you really have to understand the use cases. And I think when you’re seeing physician chief health AI officers pop up around the country, it’s because they’re people who both understand the technology—not to the level you do obviously—but to some sufficient level and then understand how to use these tools in clinical care and where they can drive value and what the risks are in clinical care and that type of thing. And so I think it’d be hard for it not to be some type of clinician in this role.
LEE: So I’m going to want to get into, you know, what’s really happening in clinic, but before that, I’ve been asking our guests about their “stages of AI grief,” [LAUGHS] as I like to put it. And for most people, I’ve been talking about the experiences and encounters with machine learning and AI before ChatGPT and then afterwards. And so can you tell us a little bit about, you know, how did you get into AI in the first place and what were your first encounters like?
MURRAY: Yeah. So I actually started out as a health services researcher, and this was before we had electronic health records [EHR], when we were still writing our notes on carbon copy in the elevators, and a lot of the data we used was actually from claims data. And that was the kind of rich data source at the time, but as you know, that was very limited.
And so when we went live with our electronic health record, I realized there was this tremendous opportunity to really use rich clinical data for research. And so I initially started collaborating with folks down at Stanford to do machine learning to identify, you know, rare diseases like lupus in the electronic health record but quickly realized there was this real gap in the health system for using data in an actionable way.
And so I built what was initially our advanced analytics team, grew into our data science team, and is now our health AI team as our ability to use the data in more sophisticated ways evolved. But if we think about, I guess, the pre-generative era and my first encounter with AI or at least AI deployment in healthcare, you know, we initially, gosh, it was probably eight or nine years ago where we got access through our EHR vendor to some initial predictive tools, and these were relatively simple tools, but they were predicting things we care about in healthcare, like who’s not going make it to a clinic visit or how long patients are going stay in the hospital.
And so there’s a lot of interest in, you know, predicting who might not make it to a clinic visit because we have big access issues with it being difficult for patients to get appointments, and the idea was that if you knew who wouldn’t show, you could actually put someone else in that slot, and it’s called overbooking. And so when we looked at the initial model, it was striking to me how risky it was for vulnerable patient populations because immediately it was obvious that this model was likely to overbook people by race, by body weight, by things that were clearly protected patient characteristics.
And so we did a lot of work initially with that model and a lot of education around how these tools could be biased. But the risk existed, and as we continued to look at more of these models, we found there were a lot of issues with trustworthiness. You know, there was a length-of-stay prediction model that my team was able to outperform with a pair of dice. And when I talked to other systems about not implementing this model, you know, folks said, but it must be useful a little bit. I was like, actually, you know, if the dice is better, it’s not useful at all. [LAUGHS]
LEE: Right!
MURRAY: And so there was very little out there to frame this, but we quickly realized we have to start putting something together because there’s a lot of hype and there’s a lot of hope, but there’s also a lot of risk here. And so that was my pre-generative moment.
LEE: You know, just before I get to your post-generative moment, you know, this story that you told, I sometimes refer to it as the healthcare IT world’s version of irrational exuberance. Because I think one thing that I’ve learned, and I have to say I’ve been guilty personally as a techie, you look at some of the problems that the world of healthcare faces, and to a techie first encountering this, a lot of it looks like common sense. Of course, we can build a model and predict these things.
And you sort of don’t understand some of the realities, as you’ve described, that make this complicated. And at the same time, from healthcare professionals, I sometimes think they look at all of this dazzling machine learning magic and also are kind of overly optimistic that it can solve so many problems.
And it does create this danger, this irrational exuberance, that both sides kind of get into a reinforcing cycle where they’re too quick to adopt technologies without thinking through the implications more carefully. I don’t know if that resonates with you at all.
MURRAY: Yeah, totally. I think there’s a real educational opportunity here because it’s the “you don’t know what you don’t know” phenomenon. And so I do think there is a lot of work in healthcare to be done around, you know, people understanding the strengths and limitations of these tools because they’re not magic, but they are perceived to be magic.
And likewise, you know, I think the tech world often doesn’t understand, you know, how healthcare is practiced and doesn’t think through these risks in the same way we do, right. So I know that some of the vulnerable patients who might’ve been overbooked by that algorithm are the people who I most need to see in clinic and are the people who would be, you know, most slighted if that they show up and the other patient shows up and now you have an overworked clinician. But I just think those are stages, you know, further down the pathway of utilization of these algorithms that people don’t think of when they’re initially developing them.
And so one of the things we actually, you know, require in our AI oversight process is when folks come to the table with a tool, they have to have a plan for how it’s going to be used and operationalized. And a lot of things die right there, honestly, because folks have built a cool tool, but they don’t know who’s going to use it in clinic, who the clinical champions are, how it’ll be acted on, and you can’t really evaluate whether these tools are trustworthy unless you’ve thought through all of that.
Because you can imagine using the same algorithm in dramatically different ways, right. If you’re using the no-show model to do targeted outreach and send people a free Lyft if they have transportation issues, that’s going to have very different outcomes than overbooking folks.
LEE: It’s so interesting and I’m going to want to get back to this topic because I think it also speaks to the challenges of how do you integrate technologies into the daily workflow of a clinic. And I know this is something you think about a lot, but let’s get back now to my original question about your AI moments. So now November 2022, ChatGPT happens, and what is your encounter with this new technology?
MURRAY: Yeah. So I used to be on MedTwitter, or I still am actually; it’s just not as active anymore. But I would say, you know, MedTwitter went crazy after ChatGPT was initially released and it was largely filled with catchy poems and people, you know, having fun …
LEE: [LAUGHS] Guilty.
MURRAY: Yeah, exactly. I still use poems. And people having fun trying to make it hallucinate. And so, you know, I went—I was guilty of that, as well—and so one of the things I initially did was I asked it to do something crazy. So I asked it, draft me a letter for a prior authorization request for a drug called Apixaban, which is a blood thinner, to treat insomnia. And if you practice clinical medicine, you know that we would never use a blood thinner to treat insomnia. But it wrote me such a compelling letter that I actually went back to PubMed and I made sure that I wasn’t missing anything, like some unexpected side effect. I wasn’t missing anything and in fact it was hallucination. And so at that moment I said, this is very promising technology, but this is still a party trick.
LEE: Yeah.
MURRAY: A few months later, I went and did the exact same prompt, and I got a lecture, instead of a draft, about how it would be unethical [LAUGHTER] and unsafe for me to draft such a request. And so, you know, I realized these tools were rapidly evolving, and the game was just going to be changing very quickly. I think the other thing that, you know, we’ve never seen before is the deployment of a technology at scale like we have with AI scribes.
So this is a technology that was in its infancy, you know, two years ago, and is now largely a commodity deployed at scale across many health systems. A very short period of time. There’s been no government incentives for people to do this. And so it clearly works well enough to be used in clinics. And I think these tools, you know, like AI scribes, have the opportunity to really undo a lot of the harm that the electronic health record implementations were perceived to have caused.
LEE: What is a scribe, first off?
MURRAY: Yeah, so AI scribes or, as we’re now calling them, AI assistants or ambient assistants, are tools that essentially listen to your clinical interaction. We record them with the permission of a patient, with consent, and then they draft a clinical note, and they can also draft other things like the patient instructions. And the idea is those drafts are very helpful to clinicians, and they have to review them and edit them, but it saves a lot of the furious typing that was previously happening during patient encounters.
LEE: We have been talking also to Chris Longhurst, your colleague at UC San Diego, and, you know, he mentions also the importance of having appropriate billing codes in those notes, which is yet another burden. Of course, when Carey, Zak, and I wrote our book, we predicted that AI scribes would get better and would find wider use because of the improvement in technology. Let me start by asking, do you yourself use an AI scribe?
MURRAY: So I do not use it yet because I’m an inpatient doctor, and we have deployed them to all ambulatory clinic doctors because that’s where the technology is tried and true. So we’re looking now to deploy it in the inpatient setting, but we’re doing very initial testing.
LEE: And what are the reasons for not integrating it into the inpatient setting?
MURRAY: Well, there’s two things actually. Most inpatient documentation work, I would say, is follow-up documentation. And so you’re often taking your prior notes and making small changes to it as you change the care from day to day. And so the tools are just, all of the companies are working on this, but right now they don’t really incorporate your prior documentation or note when they draft your note for today.
The second reason is that a lot of the decision-making that we do in the inpatient setting is asynchronous with the patient. So we’ll often have a conversation in the morning with the patient in their room, and then I’ll see some labs come back and I’ll make decisions and act on those labs and give the patient a call later and let them know what’s going on. And so it’s not a very succinct encounter, and so the technology is going to have to be a little bit different to work in that case, I think.
LEE: Right, and so these are distinct workflows from the ambulatory setting, where it is the classic, you’re sitting with a patient in an exam room having an encounter.
MURRAY: Mm-hmm. Exactly. And all your decisions are made there. And I would say it’s also different from nursing. We’re also looking at deploying these tools to nurses. But a lot of their documentation is in something called flowsheets. They write in columns, you know, specific numbers, and so for them to use these tools, they’d have to start saying to the patient, sounds like your pain is a five. Your blood pressure is 120 over 60. And so those are different workflows they’d have to adopt to use the tools.
LEE: So you’ve been in the position of having to oversee the integration of AI scribes into UCSF health. From your perspective how were clinical staff actually viewing all of this?
MURRAY: So I would say clinical staff are largely very excited, receptive, and would like us to move faster. And in fact, I gave a town hall to UCSF, and all of the comments were, when is this coming for APPs [advanced practice providers]? When is this coming for allied health professionals? And so people want this across healthcare. It’s not just doctors. But at the same time, you know, I think there’s a technology adoption curve, and about half of our ambulatory clinicians have signed up and about a third of them are now using the tool. And so we are now doing outreach to figure out who is not using it, why aren’t they using it, and what can we do to increase adoption. Or are there true barriers that we need to help folks overcome?
LEE: And when you do these things, of course, there are risks. And as you were mentioning several times before, you were really concerned about hallucinations, about trustworthiness. So what were the steps that you took at UCSF to make these integrations happen?
MURRAY: Yeah, so we have a AI oversight process for all tools that come into our healthcare with AI, regardless of where they’re coming from. So industry tools, internally developed tools, and research tools come through the same process. And we have a committee that is quite multidisciplinary. We have health system leaders, data scientists, bioethicists, researchers, health-equity experts. And through our process, we break down the AI lifecycle to a couple key places where these tools come for committee review. And so for every AI deployment, we expect people to establish performance metrics, fairness metrics, and we help them with figuring out what those things should be.
We were also fortunate to receive a donation to build a AI monitoring platform, which we’re working on now at UCSF. We call it our Impact Monitoring Platform for AI and Clinical Care, IMPACC, and AI scribes is actually our first use case. And so on that platform, we have a metric adjudication process where we’ve established, you know, what do we really care about for our health system executive leaders, what do we really care about for, you know, ensuring safety and trustworthiness, and then, you know, what are our patients going to want to know? Because we want to also be transparent with our patients about the use of these tools. And so we have processes for doing all this work.
I think the challenge is actually how we scale these processes as more and more tools come through because as you could imagine, a lot of conversation with a lot of stakeholders to figure out what and how we measure things right now.
LEE: And so there’s so much to get into there, but I actually want to zoom in on the actual experience that doctors, nurses, and patients are having. And, you know, do you find that AI is meeting expectations? Is it making a difference, positive or negative, in people’s lives? And what kinds of potential surprises are people encountering?
MURRAY: Mm-hmm. So we’re collecting data in a couple of ways. First, we’re surveying clinicians before and after their experience, and we are hearing from folks that they feel like their clinic work is more manageable, that they’re more able to finish their documentation in a timely fashion.
And then we’re looking at actual metrics that we can extract from the EHR around how long people are spending doing things. And that data is largely aligning with what people are reporting, although the caveat is they’re not saving enough time for us to have them see more patients. And so we’ve been very explicit at UCSF around making it clear that this is a tool to improve experience and not to improve efficiency.
So we’re not expecting for people to see more patients as a result of using this tool. We want their clinic experience to be more meaningful. But then the other thing that’s interesting that folks share is this tremendous relief of cognitive burden that folks feel when using this tool. So they may have been really efficient before. You know, they could get all their work done. They could type while they were talking to their patients. But they didn’t actually, you know, get to look at their patients eye to eye and have the meaningful conversation that people went into medicine for. And so we’re hearing that, as well.
And I think one of the things that’s going to be important to us is actually measuring that moving forward. And that is matched by some of the feedback we’re getting from patients. So we have quotes from patients where they’ve said, you know, my doctor is using this new tool and it’s amazing. We’re just having eye-to-eye conversations. Keep using it. So I think that’s really important.
LEE: I’ve been pushing my own primary care doctor to get into this because I really depend on her. I love her dearly, but we never … I’m always looking at her back as she’s typing at a computer during our encounters. [LAUGHS]
So, Sara, while we’re talking about efficiency, and at least the early evidence doesn’t show clear efficiency gains, it does actually beg the question about how or why health systems, many of which are financially, you know, not swimming in money, how or why they could adopt these things.
And then we could also even imagine that there are even more important applications in the future that, you know, might require quite a bit of expense on developers as well as procurers of these things. You know, what’s your point of view on the I guess we would call this the ROI question about AI?
MURRAY: Mm-hmm. I think this is a really challenging area because return on investment is very important to health systems that are trying to figure out how to spend a limited budget to improve care delivery. And so I think we’ve started to see a lot of small use cases that prove this technology could likely be beneficial.
So there are use cases that you may have heard of from Dr. Longhurst around drafting responses to patient messages, for example, where we’ve seen that this technology is helpful but doesn’t get us all the way there. And that’s because these technologies are actually quite expensive. And when you want to process large amounts of data, that’s called tokens, and tokens cost money.
And so I think one of the challenges when we envision the future of healthcare, we’re not really envisioning the expense of querying the entire medical record through a large language model. And we’re going to have to build systems from a technology standpoint that can do that work in a more affordable way for us to be able to deliver really high-value use cases to clinicians that involve processing that.
And so those are use cases like summarizing large parts of the patient’s medical record, providing really meaningful clinical decision support that takes into account the patient’s entire medical history. We haven’t seen those types of use cases really come into being yet, largely because, you know, they’re technically a bit more complex to do well and they’re expensive, but they’re completely feasible.
LEE: Yeah. You know, what you’re saying really resonates so strongly from the tech industry’s perspective. You know, one way that that problem manifests itself is shareholders in big tech companies like ours more or less expect … they’re paying a high premium—a high multiple on the share price—because they’re expecting our revenues to grow at very spectacular rates, double digit rates. But that isn’t obviously compatible with how healthcare works and the healthcare business works. It doesn’t grow, you know, at 30% year over year or anything like that.
And so how to make these things financially make sense for all comers. And it’s sort of part and parcel also with the problem that sometimes efficiency gains in healthcare just translate into heavier caseloads for doctors, which isn’t obviously the best outcome either. And so in a way, I think it’s another aspect of the work on impact and trustworthiness when we think about technology, at all, in healthcare.
MURRAY: Mm-hmm. I think that’s right. And I think, you know, if you look at the difference between the AI scribe market and the rest of the summarization work that’s largely happening within the electronic health record, in the AI scribe market, you have a lot of independent companies, and they all are competing to be the best. And so because of that, we’re seeing the technology get more efficient, cheaper. There’s just a lot of investment in that space.
Whereas like with the electronic health record providers, they’re also invested in really providing us with these tools, but it’s not their main priority. They’re delivering an entire electronic health record, and they also have to do it in a way that is affordable for, you know, all kinds of health systems, big UCSF health systems, smaller settings, and so there’s a real tension, I think, between delivering good-enough tools and truly transformative tools.
LEE: So I want to go back for a minute to this idea of cognitive burden that you described. When we talk about cognitive burden, it’s often in the context of paperwork, right. There are maybe referral letters, after-visit notes, all of these things. How do you see these AI tools progressing with respect to that stream of different administrative tasks?
MURRAY: These tools are going to continue to be optimized to do more and more tasks for us. So with AI scribes, for example, you know, we’re starting to look at whether it can draft the billing and coding information for the clinician, which is a tedious task with many clicks.
These tools are poised to start pending orders based on the conversation. Again, a tedious task. All of this with clinician oversight. But I think as we move from them being AI scribes to AI assistants, it’s going to be like a helper on the side for clinicians doing more and more work so they can really focus on the conversations, the shared decision-making, and the reason they went into medicine really.
LEE: Yeah, let me, since you mentioned AI assistants and that’s such an interesting word and it does connect with something that was apparent to us even, you know, as we were writing the book, which is this phenomenon that these AI systems might make mistakes.
They might be guilty of making biased decisions or showing bias, and yet they at the same time seem incredibly effective at spotting other people’s mistakes or other people’s biased decisions. And so is there a point where these AI scribes do become AI assistants, that they’re sort of looking over a doctor’s shoulder and saying, “Hey, did you think about something else?” or “Hey, you know, maybe you’re wrong about a certain diagnosis?”
MURRAY: Mm-hmm. I mean, absolutely. You’re just really talking about combining technologies that already exist into a more streamlined clinical care experience, right. So you can—and I already do this when I’m on rounds—I’ll kind of give the case to ChatGPT if it’s a complex case, and I’ll say, “Here’s how I’m thinking about it; are there other things?” And it’ll give me additional ideas that are sometimes useful and sometimes not but often useful, and I’ll integrate them into my conversation about the patient.
I think all of these companies are thinking about that. You know, how do we integrate more clinical decision-making into the process? I think it’s just, you know, healthcare is always a little bit behind the technology industry in general, to say the least. And so it’s kind of one step at a time, and all of these use cases need a lot of validation. There’s regulatory issues, and so I think it’s going to take time for us to get there.
LEE: Should I be impressed or concerned that the chief health AI officer at UC San Francisco Health is using ChatGPT off label?
MURRAY: [LAUGHS] Well, I actually, every time I go on service, I encourage my residents to use it because I think we need to learn how to use these technologies. And, you know, when our medical education leaders start thinking about how do we teach students to use these, we don’t know how to teach students to use them if we’re not using them ourselves, right. And so I’ve learned a lot about what I perceive the strengths and limitations of the tools are.
And I think … but you know, one of the things that we’ve learned is—and you’ve written about this in your book—but the prompting really matters. And so I had a resident ask it for a differential for abnormal liver tests. But in asking for that differential, there is a key important blood finding, something called eosinophilia. It’s a type of blood cell that was mildly, mildly elevated, and they didn’t know it. So they didn’t give it in the prompt, and as a result, they didn’t get the right differential, but it wasn’t actually ChatGPT’s fault. It just didn’t get the right information because the trainee didn’t recognize the right information. And so I think there’s a lot to learn as we practice using these tools clinically. So I’m not ashamed of it. [LAUGHS]
LEE: [LAUGHS] Yeah. Well, in fact, I think my coauthor Carey Goldberg would find what you said really validating because in our book, she actually wrote this fictional account of what it might be like in the future. And this medical resident was also using an AI chatbot off label for pretty much the same kinds of purposes. And it’s these kinds of things that, you know, it seems like might be coming next.
MURRAY: I mean, medicine, the practice of medicine, is a very imperfect science, and so, you know, when we have a difficult case, I might sit in the workroom with my colleagues and run it by people. And everyone has different thoughts and opinions on, you know, things I should check for. And so I think this is just one other resource where you can kind of run cases, obviously, just reviewing all of the outputs yourself.
LEE: All right, so we’re running short on time and so I want to be a little provocative at the end here. And since we’ve gotten into AI assistants, two questions: First off, do we get to a point in the near future when it would be unthinkable and maybe even bordering on malpractice for a doctor not to use AI assistants in his or her daily work?
MURRAY: So it’s possible that we see that in the future. We don’t see it right now. And that’s part of the reason we don’t force this on people. So we see AI scribes or AI assistants as a tool we offer to people to improve their daily work because we don’t have sufficient data that the outcomes are markedly better from using these tools.
I think there is a future where specific, you know, tools do actually improve outcomes. And then their use should be incentivized either through, you know, CMS [Centers for Medicare & Medicaid Services] or other systems to ensure that, you know, we’re delivering standard of care. But we’re not yet at the place where any of these tools are standard of care, which means they should be used to practice good medicine.
LEE: And I think I would say that it’s the work of people like you that would make it possible for these things to become standard of care. And so now, final provocation. It must have crossed your mind through all of this, the possibility that AI might replace doctors in some ways. What are your thoughts?
MURRAY: I think we’re a long way from that happening, honestly. And I think even when I talk to my colleagues in radiology about this, where I perceive, as an internist, they might be the most replaceable, there’s a million reasons why that’s not the case. And so I think these tools are going to augment our work. They’re going to help us streamline access for patients. They’re going to maybe change what clinicians have to do, but I don’t think they’re going fully replace doctors. There’s just too much complexity and nuance in providing clinical care for these tools to do that work fully.
LEE: Yeah, I think you’re right. And actually, you know, I think there’s plenty of evidence because in the history of modern medicine, we actually haven’t seen technology replace human doctors. Maybe you could say that we don’t use barbers for bloodletting anymore because of technology. But I think, as you say, we’re at least a long ways away.
MURRAY: Yeah.
LEE: Sara, this has been just a great conversation. And thank you for the great work that you’re doing, you know, and for being so open with us on your personal use of AI, but also how you see the adoption of AI in our health system.
[TRANSITION MUSIC]MURRAY: Thank you, it was really great talking with you.
LEE: I get so much out of talking to Sara. Every time, she manages to get me refocused on two things: the quality of the user experience and the importance of trust in any new technology that is brought into the clinic. I felt like there were several good takeaways from the conversation. One is that she really validated some predictions that Carey, Zak, and I made in our book, first and foremost, that automated note taking would be a highly desirable and practical reality. The other validation is Sara revealing that even she uses ChatGPT as a daily assistant in her clinical work, something that we guessed would happen in the book, but we weren’t really sure since health systems oftentimes are very locked down when it comes to the use of technological tools.
And of course, maybe the biggest thing about Sara’s work is her role in defining a new type of job in healthcare, the health AI officer. This is something that Carey, Zak, and I didn’t see coming at all, but in retrospect, makes all the sense in the world. Taken together, these two conversations really showed that we were on the right track in the book. AI has made its way into day-to-day life and work in the clinic, and both doctors and patients seem to be appreciating it.
[MUSIC TRANSITIONS TO THEME]I’d like to extend another big thank you to Chris and Sara for joining me on the show and sharing their insights. And to our listeners, thank you for coming along for the ride. We have some really great conversations planned for the coming episodes. We’ll delve into how patients are using generative AI for their own healthcare, the hype and reality of AI drug discovery, and more. We hope you’ll continue to tune in. Until next time.
[MUSIC FADES]
The post The reality of generative AI in the clinic appeared first on Microsoft Research.
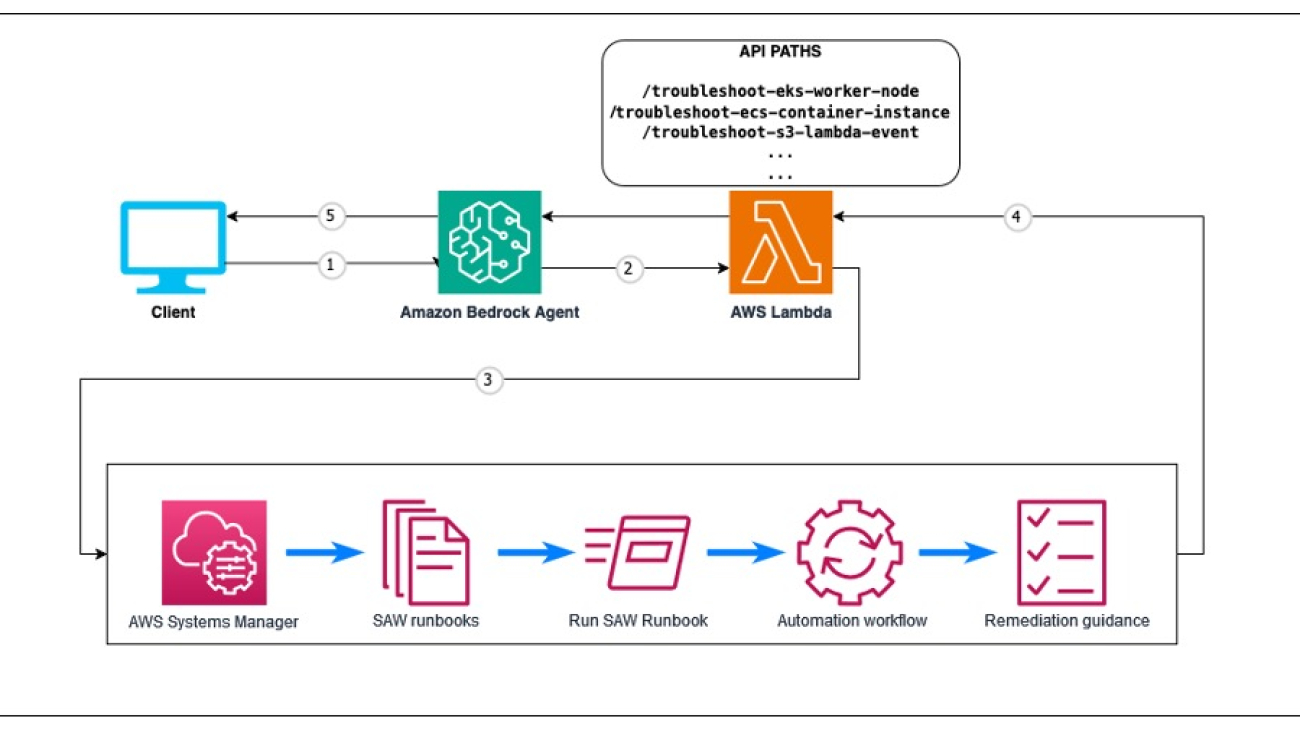
Streamline AWS resource troubleshooting with Amazon Bedrock Agents and AWS Support Automation Workflows
As AWS environments grow in complexity, troubleshooting issues with resources can become a daunting task. Manually investigating and resolving problems can be time-consuming and error-prone, especially when dealing with intricate systems. Fortunately, AWS provides a powerful tool called AWS Support Automation Workflows, which is a collection of curated AWS Systems Manager self-service automation runbooks. These runbooks are created by AWS Support Engineering with best practices learned from solving customer issues. They enable AWS customers to troubleshoot, diagnose, and remediate common issues with their AWS resources.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Using Amazon Bedrock, you can experiment with and evaluate top FMs for your use case, privately customize them with your data using techniques such as fine-tuning and Retrieval Augmented Generation (RAG), and build agents that execute tasks using your enterprise systems and data sources. Because Amazon Bedrock is serverless, you don’t have to manage infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with.
In this post, we explore how to use the power of Amazon Bedrock Agents and AWS Support Automation Workflows to create an intelligent agent capable of troubleshooting issues with AWS resources.
Solution overview
Although the solution is versatile and can be adapted to use a variety of AWS Support Automation Workflows, we focus on a specific example: troubleshooting an Amazon Elastic Kubernetes Service (Amazon EKS) worker node that failed to join a cluster. The following diagram provides a high-level overview of troubleshooting agents with Amazon Bedrock.

Our solution is built around the following key components that work together to provide a seamless and efficient troubleshooting experience:
- Amazon Bedrock Agents – Amazon Bedrock Agents acts as the intelligent interface between users and AWS Support Automation Workflows. It processes natural language queries to understand the issue context and manages conversation flow to gather required information. The agent uses Anthropic’s Claude 3.5 Sonnet model for advanced reasoning and response generation, enabling natural interactions throughout the troubleshooting process.
- Amazon Bedrock agent action groups – These action groups define the structured API operations that the Amazon Bedrock agent can invoke. Using OpenAPI specifications, they define the interface between the agent and AWS Lambda functions, specifying the available operations, required parameters, and expected responses. Each action group contains the API schema that tells the agent how to properly format requests and interpret responses when interacting with Lambda functions.
- Lambda Function – The Lambda function acts as the integration layer between the Amazon Bedrock agent and AWS Support Automation Workflows. It validates input parameters from the agent and initiates the appropriate SAW runbook execution. It monitors the automation progress while processing the technical output into a structured format. When the workflow is complete, it returns formatted results back to the agent for user presentation.
- IAM role – The AWS Identity and Access Management (IAM) role provides the Lambda function with the necessary permissions to execute AWS Support Automation Workflows and interact with required AWS services. This role follows the principle of least privilege to maintain security best practices.
- AWS Support Automation Workflows – These pre-built diagnostic runbooks are developed by AWS Support Engineering. The workflows execute comprehensive system checks based on AWS best practices in a standardized, repeatable manner. They cover a wide range of AWS services and common issues, encapsulating AWS Support’s extensive troubleshooting expertise.
The following steps outline the workflow of our solution:
- Users start by describing their AWS resource issue in natural language through the Amazon Bedrock chat console. For example, “Why isn’t my EKS worker node joining the cluster?”
- The Amazon Bedrock agent analyzes the user’s question and matches it to the appropriate action defined in its OpenAPI schema. If essential information is missing, such as a cluster name or instance ID, the agent engages in a natural conversation to gather the required parameters. This makes sure that necessary data is collected before proceeding with the troubleshooting workflow.
- The Lambda function receives the validated request and triggers the corresponding AWS Support Automation Workflow. These SAW runbooks contain comprehensive diagnostic checks developed by AWS Support Engineering to identify common issues and their root causes. The checks run automatically without requiring user intervention.
- The SAW runbook systematically executes its diagnostic checks and compiles the findings. These results, including identified issues and configuration problems, are structured in JSON format and returned to the Lambda function.
- The Amazon Bedrock agent processes the diagnostic results using chain of thought (CoT) reasoning, based on the ReAct (synergizing reasoning and acting) technique. This enables the agent to analyze the technical findings, identify root causes, generate clear explanations, and provide step-by-step remediation guidance.
During the reasoning phase of the agent, the user is able to view the reasoning steps.
Troubleshooting examples
Let’s take a closer look at a common issue we mentioned earlier and how our agent can assist in troubleshooting it.
EKS worker node failed to join EKS cluster
When an EKS worker node fails to join an EKS cluster, our Amazon Bedrock agent can be invoked with the relevant information: cluster name and worker node ID. The agent will execute the corresponding AWS Support Automation Workflow, which will perform checks like verifying the worker node’s IAM role permissions and verifying the necessary network connectivity.
The automation workflow will run all the checks. Then Amazon Bedrock agent will ingest the troubleshooting, explain the root cause of the issue to the user, and suggest remediation steps based on the AWSSupport-TroubleshootEKSWorkerNode output, such as updating the worker node’s IAM role or resolving network configuration issues, enabling them to take the necessary actions to resolve the problem.
OpenAPI example
When you create an action group in Amazon Bedrock, you must define the parameters that the agent needs to invoke from the user. You can also define API operations that the agent can invoke using these parameters. To define the API operations, we will create an OpenAPI schema in JSON:
"Body_troubleshoot_eks_worker_node_troubleshoot_eks_worker_node_post": {
"properties": {
"cluster_name": {
"type": "string",
"title": "Cluster Name",
"description": "The name of the EKS cluster"
},
"worker_id": {
"type": "string",
"title": "Worker Id",
"description": "The ID of the worker node"
}
},
"type": "object",
"required": [
"cluster_name",
"worker_id"
],
"title": "Body_troubleshoot_eks_worker_node_troubleshoot_eks_worker_node_post"
}
The schema consists of the following components:
- Body_troubleshoot_eks_worker_node_troubleshoot_eks_worker_node_post – This is the name of the schema, which corresponds to the request body for the
troubleshoot-eks-worker_nodePOST endpoint. - Properties – This section defines the properties (fields) of the schema:
- “cluster_name” – This property represents the name of the EKS cluster. It is a string type and has a title and description.
- “worker_id” – This property represents the ID of the worker node. It is also a string type and has a title and description.
- Type – This property specifies that the schema is an “object” type, meaning it is a collection of key-value pairs.
- Required – This property lists the required fields for the schema, which in this case are “cluster_name” and “worker _id”. These fields must be provided in the request body.
- Title – This property provides a human-readable title for the schema, which can be used for documentation purposes.
The OpenAPI schema defines the structure of the request body. To learn more, see Define OpenAPI schemas for your agent’s action groups in Amazon Bedrock and OpenAPI specification.
Lambda function code
Now let’s explore the Lambda function code:
@app.post("/troubleshoot-eks-worker-node")
@tracer.capture_method
def troubleshoot_eks_worker_node(
cluster_name: Annotated[str, Body(description="The name of the EKS cluster")],
worker_id: Annotated[str, Body(description="The ID of the worker node")]
) -> dict:
"""
Troubleshoot EKS worker node that failed to join the cluster.
Args:
cluster_name (str): The name of the EKS cluster.
worker_id (str): The ID of the worker node.
Returns:
dict: The output of the Automation execution.
"""
return execute_automation(
automation_name='AWSSupport-TroubleshootEKSWorkerNode',
parameters={
'ClusterName': [cluster_name],
'WorkerID': [worker_id]
},
execution_mode='TroubleshootWorkerNode'
)
The code consists of the following components
- app.post(“/troubleshoot-eks-worker-node”, description=”Troubleshoot EKS worker node failed to join the cluster”) – This is a decorator that sets up a route for a POST request to the
/troubleshoot-eks-worker-nodeendpoint. The description parameter provides a brief explanation of what this endpoint does. - @tracer.capture_method – This is another decorator that is likely used for tracing or monitoring purposes, possibly as part of an application performance monitoring (APM) tool. It captures information about the execution of the function, such as the duration, errors, and other metrics.
- cluster_name: str = Body(description=”The name of the EKS cluster”), – This parameter specifies that the
cluster_nameis a string type and is expected to be passed in the request body. The Body decorator is used to indicate that this parameter should be extracted from the request body. The description parameter provides a brief explanation of what this parameter represents. - worker_id: str = Body(description=”The ID of the worker node”) – This parameter specifies that the
worker_idis a string type and is expected to be passed in the request body. - -> Annotated[dict, Body(description=”The output of the Automation execution”)] – This is the return type of the function, which is a dictionary. The Annotated type is used to provide additional metadata about the return value, specifically that it should be included in the response body. The description parameter provides a brief explanation of what the return value represents.
To link a new SAW runbook in the Lambda function, you can follow the same template.
Prerequisites
Make sure you have the following prerequisites:
- An AWS account
- Access for Anthropic’s Claude 3.5 Sonnet model enabled in Amazon Bedrock
- Your credentials configured in the AWS Command Line Interface (AWS CLI)
- Javascript installed
- The AWS Cloud Development Kit (AWS CDK) 143.0
Deploy the solution
Complete the following steps to deploy the solution:
- Clone the GitHub repository and go to the root of your downloaded repository folder:
$ git clone https://github.com/aws-samples/sample-bedrock-agent-for-troubleshooting-aws-resources.git$ cd bedrock-agent-for-troubleshooting-aws-resources- Install local dependencies:
$ npm install- Sign in to your AWS account using the AWS CLI by configuring your credential file (replace <PROFILE_NAME> with the profile name of your deployment AWS account):
$ export AWS_PROFILE=PROFILE_NAME- Bootstrap the AWS CDK environment (this is a one-time activity and is not needed if your AWS account is already bootstrapped):
$ cdk bootstrap- Run the script to replace the placeholders for your AWS account and AWS Region in the config files:
$ cdk deploy --allTest the agent
Navigate to the Amazon Bedrock Agents console in your Region and find your deployed agent. You will find the agent ID in the cdk deploy command output.
You can now interact with the agent and test troubleshooting a worker node not joining an EKS cluster. The following are some example questions:
- I want to troubleshoot why my Amazon EKS worker node is not joining the cluster. Can you help me?
- Why this instance <instance_ID> is not able to join the EKS cluster <Cluster_Name>?
The following screenshot shows the console view of the agent.

The agent understood the question and mapped it with the right action group. It also spotted that the parameters needed are missing in the user prompt. It came back with a follow-up question to require the Amazon Elastic Compute Cloud (Amazon EC2) instance ID and EKS cluster name.

We can see the agent’s thought process in the trace step 1. The agent assesses the next step as ready to call the right Lambda function and right API path.

With the results coming back from the runbook, the agent now reviews the troubleshooting outcome. It goes through the information and will start writing the solution where it provides the instructions for the user to follow.
In the answer provided, the agent was able to spot all the issues and transform that into solution steps. We can also see the agent mentioning the right information like IAM policy and the required tag.
Clean up
When implementing Amazon Bedrock Agents, there are no additional charges for resource construction. However, costs are incurred for embedding model and text model invocations on Amazon Bedrock, with charges based on the pricing of each FM used. In this use case, you will also incur costs for Lambda invocations.
To avoid incurring future charges, delete the created resources by the AWS CDK. From the root of your repository folder, run the following command:
$ npm run cdk destroy --allConclusion
Amazon Bedrock Agents and AWS Support Automation Workflows are powerful tools that, when combined, can revolutionize AWS resource troubleshooting. In this post, we explored a serverless application built with the AWS CDK that demonstrates how these technologies can be integrated to create an intelligent troubleshooting agent. By defining action groups within the Amazon Bedrock agent and associating them with specific scenarios and automation workflows, we’ve developed a highly efficient process for diagnosing and resolving issues such as Amazon EKS worker node failures.
Our solution showcases the potential for automating complex troubleshooting tasks, saving time and streamlining operations. Powered by Anthropic’s Claude 3.5 Sonnet, the agent demonstrates improved understanding and responding in languages other than English, such as French, Japanese, and Spanish, making it accessible to global teams while maintaining its technical accuracy and effectiveness. The intelligent agent quickly identifies root causes and provides actionable insights, while automatically executing relevant AWS Support Automation Workflows. This approach not only minimizes downtime, but also scales effectively to accommodate various AWS services and use cases, making it a versatile foundation for organizations looking to enhance their AWS infrastructure management.
Explore the AWS Support Automation Workflow for additional use cases and consider using this solution as a starting point for building more comprehensive troubleshooting agents tailored to your organization’s needs. To learn more about using agents to orchestrate workflows, see Automate tasks in your application using conversational agents. For details about using guardrails to safeguard your generative AI applications, refer to Stop harmful content in models using Amazon Bedrock Guardrails.
Happy coding!
Acknowledgements
The authors thank all the reviewers for their valuable feedback.
About the Authors
 Wael Dimassi is a Technical Account Manager at AWS, building on his 7-year background as a Machine Learning specialist. He enjoys learning about AWS AI/ML services and helping customers meet their business outcomes by building solutions for them.
Wael Dimassi is a Technical Account Manager at AWS, building on his 7-year background as a Machine Learning specialist. He enjoys learning about AWS AI/ML services and helping customers meet their business outcomes by building solutions for them.
 Marwen Benzarti is a Senior Cloud Support Engineer at AWS Support where he specializes in Infrastructure as Code. With over 4 years at AWS and 2 years of previous experience as a DevOps engineer, Marwen works closely with customers to implement AWS best practices and troubleshoot complex technical challenges. Outside of work, he enjoys playing both competitive multiplayer and immersive story-driven video games.
Marwen Benzarti is a Senior Cloud Support Engineer at AWS Support where he specializes in Infrastructure as Code. With over 4 years at AWS and 2 years of previous experience as a DevOps engineer, Marwen works closely with customers to implement AWS best practices and troubleshoot complex technical challenges. Outside of work, he enjoys playing both competitive multiplayer and immersive story-driven video games.
Create generative AI agents that interact with your companies’ systems in a few clicks using Amazon Bedrock in Amazon SageMaker Unified Studio
Today we are announcing that general availability of Amazon Bedrock in Amazon SageMaker Unified Studio.
Companies of all sizes face mounting pressure to operate efficiently as they manage growing volumes of data, systems, and customer interactions. Manual processes and fragmented information sources can create bottlenecks and slow decision-making, limiting teams from focusing on higher-value work. Generative AI agents offer a powerful solution by automatically interfacing with company systems, executing tasks, and delivering instant insights, helping organizations scale operations without scaling complexity.
Amazon Bedrock in SageMaker Unified Studio addresses these challenges by providing a unified service for building AI-driven solutions that centralize customer data and enable natural language interactions. It integrates with existing applications and includes key Amazon Bedrock features like foundation models (FMs), prompts, knowledge bases, agents, flows, evaluation, and guardrails. Users can access these AI capabilities through their organization’s single sign-on (SSO), collaborate with team members, and refine AI applications without needing AWS Management Console access.
Generative AI-powered agents for automated workflows
Amazon Bedrock in SageMaker Unified Studio allows you to create and deploy generative AI agents that integrate with organizational applications, databases, and third-party systems, enabling natural language interactions across the entire technology stack. The chat agent bridges complex information systems and user-friendly communication. By using Amazon Bedrock functions and Amazon Bedrock Knowledge Bases, the agent can connect with data sources like JIRA APIs for real-time project status tracking, retrieve customer information, update project tasks, and manage preferences.
Sales and marketing teams can quickly access customer information and their meeting preferences, and project managers can efficiently manage JIRA tasks and timelines. This streamlined process enhances productivity and customer interactions across the organization.
The following diagram illustrates the generative AI agent solution workflow.

Solution overview
Amazon Bedrock provides a governed collaborative environment to build and share generative AI applications within SageMaker Unified Studio. Let’s look at an example solution for implementing a customer management agent:
- An agentic chat can be built with Amazon Bedrock chat applications, and integrated with functions that can be quickly built with other AWS services such as AWS Lambda and Amazon API Gateway.
- SageMaker Unified Studio, using Amazon DataZone, provides a comprehensive data management solution through its integrated services. Organization administrators can control member access to Amazon Bedrock models and features, maintaining secure identity management and granular access control.
Before we dive deep into the deployment of the AI agent, let’s walk through the key steps of the architecture, as shown in the following diagram.

The workflow is as follows:
- The user logs into SageMaker Unified Studio using their organization’s SSO from AWS IAM Identity Center. Then the user interacts with the chat application using natural language.
- The Amazon Bedrock chat application uses a function to retrieve JIRA status and customer information from the database through the endpoint using API Gateway.
- The chat application authenticates with API Gateway to securely access the endpoint with the random API key from AWS Secrets Manager, and triggers the Lambda function based on the user’s request.
- The Lambda function performs the actions by calling the JIRA API or database with the required parameters provided from the agent. The agent has the capability to:
-
- Provide a brief customer overview.
- List recent customer interactions.
- Retrieve the meeting preferences for a customer.
- Retrieve open JIRA tickets for a project.
- Update the due date for a JIRA ticket.
Prerequisites
You need the following prerequisites to follow along with this solution implementation:
- An AWS account
- User access to Amazon Bedrock in SageMaker Unified Studio
- Model access to Amazon Nova Pro on Amazon Bedrock in a supported AWS Region
- A JIRA application, JIRA URL, and a JIRA API token to your account
We assume you are familiar with fundamental serverless constructs on AWS, such as API Gateway, Lambda functions, and IAM Identity Center. We don’t focus on defining these services in this post, but we do use them to show use cases for the new Amazon Bedrock features within SageMaker Unified Studio.
Deploy the solution
Complete the following deployment steps:
- Download the code from GitHub.
- Get the value of JIRA_API_KEY_ARN, JIRA_URL, and JIRA_USER_NAME for the Lambda function.
- Use the following AWS CloudFormation template, and refer to Create a stack from the CloudFormation console to launch the stack in your preferred AWS Region.
- After the stack is deployed, note down the API Gateway URL value from the CloudFormation Outputs tab (
ApiInvokeURL). - On the Secrets Manager console, find the secrets for JIRA_API_KEY_ARN, JIRA_URL, and JIRA_USER_NAME.
- Choose Retrieve secret and copy the variables from Step 2 to the secret plaintext string.
- Sign in to SageMaker Unified Studio using your organization’s SSO.

Create a new project
Complete the following steps to create a new project:
- On the SageMaker Unified Studio landing page, create a new project.
- Give the project a name (for example,
crm-agent). - Choose Generative AI application development profile and continue.
- Use the default settings and continue.
- Review and choose Create project to confirm.

Build the chat agent application
Complete the following steps to build the chat agent application:
- Under the New section located to the right of the crm-agent project landing page, choose Chat agent.
It has a list of configurations for your agent application.
- Under the model section, choose a desired FM supported by Amazon Bedrock. For this crm-agent, we choose Amazon Nova Pro.
- In the system prompt section, add the following prompt. Optionally, you could add examples of user input and model responses to improve it.
You are a customer relationship management agent tasked with helping a sales person plan their work with customers. You are provided with an API endpoint. This endpoint can provide information like company overview, company interaction history (meeting times and notes), company meeting preferences (meeting type, day of week, and time of day). You can also query Jira tasks and update their timeline. After receiving a response, clean it up into a readable format. If the output is a numbered list, format it as such with newline characters and numbers.

- In the Functions section, choose Create a new function.
- Give the function a name, such as
crm_agent_calling. - For Function schema, use the OpenAPI definition from the GitHub repo.
- For Authentication method, choose API Keys (Max. 2 Keys)and enter the following details:
- For Key sent in, choose Header.
- For Key name, enter
x-api-key. - For Key value, enter the Secrets Manager api Key
- In the API servers section, input the endpoint URL.
- Choose Create to finish the function creation.
- In the Functions section of the chat agent application, choose the function you created and choose Save to finish the application creation.

Example interactions
In this section, we explore two example interactions.
Use case 1: CRM analyst can retrieve customer details stored in the database with natural language.
For this use case, we ask the following questions in the chat application:
- Give me a brief overview of customer C-jkl101112.
- List the last 2 recent interactions for customer C-def456.
- What communication method does customer C-mno131415 prefer?
- Recommend optimal time and contact channel to reach out to C-ghi789 based on their preferences and our last interaction.
The response from the chat application is shown in the following screenshot. The agent successfully retrieves the customer’s information from the database. It understands the user’s question and queries the database to find corresponding answers.

Use case 2: Project managers can list and update the JIRA ticket.
In this use case, we ask the following questions:
- What are the open JIRA Tasks for project id CRM?
- Please update JIRA Task CRM-3 to 1 weeks out.
The response from the chat application is shown in the following screenshot. Similar to the previous use case, the agent accesses the JIRA board and fetches the JIRA project information. It provides a list of open JIRA tasks and updates the timeline of the task following the user’s request.

Clean up
To avoid incurring additional costs, complete the following steps:
- Delete the CloudFormation stack.
- Delete the function component in Amazon Bedrock.
- Delete the chat agent application in Amazon Bedrock.
- Delete the domains in SageMaker Unified Studio.
Cost
Amazon Bedrock in SageMaker Unified Studio doesn’t incur separate charges, but you will be charged for the individual AWS services and resources utilized within the service. You only pay for the Amazon Bedrock resources you use, without minimum fees or upfront commitments.
If you need further assistance with pricing calculations or have questions about optimizing costs for your specific use case, please reach out to AWS Support or consult with your account manager.
Conclusion
In this post, we demonstrated how to use Amazon Bedrock in SageMaker Unified Studio to build a generative AI application to integrate with an existing endpoint and database.
The generative AI features of Amazon Bedrock transform how organizations build and deploy AI solutions by enabling rapid agent prototyping and deployment. Teams can swiftly create, test, and launch chat agent applications, accelerating the implementation of AI solutions that automate complex tasks and enhance decision-making capabilities. The solution’s scalability and flexibility allow organizations to seamlessly integrate advanced AI capabilities into existing applications, databases, and third-party systems.
Through a unified chat interface, agents can handle project management, data retrieval, and workflow automation—significantly reducing manual effort while enhancing user experience. By making advanced AI capabilities more accessible and user-friendly, Amazon Bedrock in SageMaker Unified Studio empowers organizations to achieve new levels of productivity and customer satisfaction in today’s competitive landscape.
Try out Amazon Bedrock in SageMaker Unified Studio for your own use case, and share your questions in the comments.
About the Authors
 Jady Liu is a Senior AI/ML Solutions Architect on the AWS GenAI Labs team based in Los Angeles, CA. With over a decade of experience in the technology sector, she has worked across diverse technologies and held multiple roles. Passionate about generative AI, she collaborates with major clients across industries to achieve their business goals by developing scalable, resilient, and cost-effective generative AI solutions on AWS. Outside of work, she enjoys traveling to explore wineries and distilleries.
Jady Liu is a Senior AI/ML Solutions Architect on the AWS GenAI Labs team based in Los Angeles, CA. With over a decade of experience in the technology sector, she has worked across diverse technologies and held multiple roles. Passionate about generative AI, she collaborates with major clients across industries to achieve their business goals by developing scalable, resilient, and cost-effective generative AI solutions on AWS. Outside of work, she enjoys traveling to explore wineries and distilleries.
 Justin Ossai is a GenAI Labs Specialist Solutions Architect based in Dallas, TX. He is a highly passionate IT professional with over 15 years of technology experience. He has designed and implemented solutions with on-premises and cloud-based infrastructure for small and enterprise companies.
Justin Ossai is a GenAI Labs Specialist Solutions Architect based in Dallas, TX. He is a highly passionate IT professional with over 15 years of technology experience. He has designed and implemented solutions with on-premises and cloud-based infrastructure for small and enterprise companies.