Today, we are excited to announce that the NeMo Retriever Llama3.2 Text Embedding and Reranking NVIDIA NIM microservices are available in Amazon SageMaker JumpStart. With this launch, you can now deploy NVIDIA’s optimized reranking and embedding models to build, experiment, and responsibly scale your generative AI ideas on AWS.
In this post, we demonstrate how to get started with these models on SageMaker JumpStart.
About NVIDIA NIM on AWS
NVIDIA NIM microservices integrate closely with AWS managed services such as Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Kubernetes Service (Amazon EKS), and Amazon SageMaker to enable the deployment of generative AI models at scale. As part of NVIDIA AI Enterprise available in AWS Marketplace, NIM is a set of user-friendly microservices designed to streamline and accelerate the deployment of generative AI. These prebuilt containers support a broad spectrum of generative AI models, from open source community models to NVIDIA AI foundation models (FMs) and custom models. NIM microservices provide straightforward integration into generative AI applications using industry-standard APIs and can be deployed with just a few lines of code, or with a few clicks on the SageMaker JumpStart console. Engineered to facilitate seamless generative AI inferencing at scale, NIM helps you deploy your generative AI applications.
Overview of NVIDIA NeMo Retriever NIM microservices
In this section, we provide an overview of the NVIDIA NeMo Retriever NIM microservices discussed in this post.
NeMo Retriever text embedding NIM
The NVIDIA NeMo Retriever Llama3.2 embedding NIM is optimized for multilingual and cross-lingual text question-answering retrieval with support for long documents (up to 8,192 tokens) and dynamic embedding size (Matryoshka Embeddings). This model was evaluated on 26 languages: English, Arabic, Bengali, Chinese, Czech, Danish, Dutch, Finnish, French, German, Hebrew, Hindi, Hungarian, Indonesian, Italian, Japanese, Korean, Norwegian, Persian, Polish, Portuguese, Russian, Spanish, Swedish, Thai, and Turkish. In addition to enabling multilingual and cross-lingual question-answering retrieval, this model reduces the data storage footprint by 35-fold through dynamic embedding sizing and support for longer token length, making it feasible to handle large-scale datasets efficiently.
NeMo Retriever text reranking NIM
The NVIDIA NeMo Retriever Llama3.2 reranking NIM is optimized for providing a logit score that represents how relevant a document is to a given query. The model was fine-tuned for multilingual, cross-lingual text question-answering retrieval, with support for long documents (up to 8,192 tokens). This model was evaluated on the same 26 languages mentioned earlier.
SageMaker JumpStart overview
SageMaker JumpStart is a fully managed service that offers state-of-the-art FMs for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval. It provides a collection of pre-trained models that you can deploy quickly, accelerating the development and deployment of ML applications. One of the key components of SageMaker JumpStart is model hubs, which offer a vast catalog of pre-trained models, such as Mistral, for a variety of tasks.
Solution overview
You can now discover and deploy the NeMo Retriever text embedding and reranking NIM microservices in Amazon SageMaker Studio or programmatically through the Amazon SageMaker Python SDK, enabling you to derive model performance and MLOps controls with SageMaker features such as Amazon SageMaker Pipelines, Amazon SageMaker Debugger, or container logs. The model is deployed in a secure AWS environment and in your virtual private cloud (VPC), helping to support data security for enterprise security needs.
In the following sections, we demonstrate how to deploy these microservices and run real-time and batch inference.
Make sure your SageMaker AWS Identity and Access Management (IAM) service role has the AmazonSageMakerFullAccess permission policy attached.
To deploy NeMo Retriever Llama3.2 embedding and reranking microservices successfully, confirm one of the following:
- Make sure your IAM role has the following permissions and you have the authority to make AWS Marketplace subscriptions in the AWS account used:
aws-marketplace:ViewSubscriptionsaws-marketplace:Unsubscribeaws-marketplace:Subscribe
- Alternatively, confirm your AWS account has a subscription to the model. If so, you can skip the following deployment instructions and start at the Subscribe to the model package section.
Deploy NeMo Retriever microservices on SageMaker JumpStart
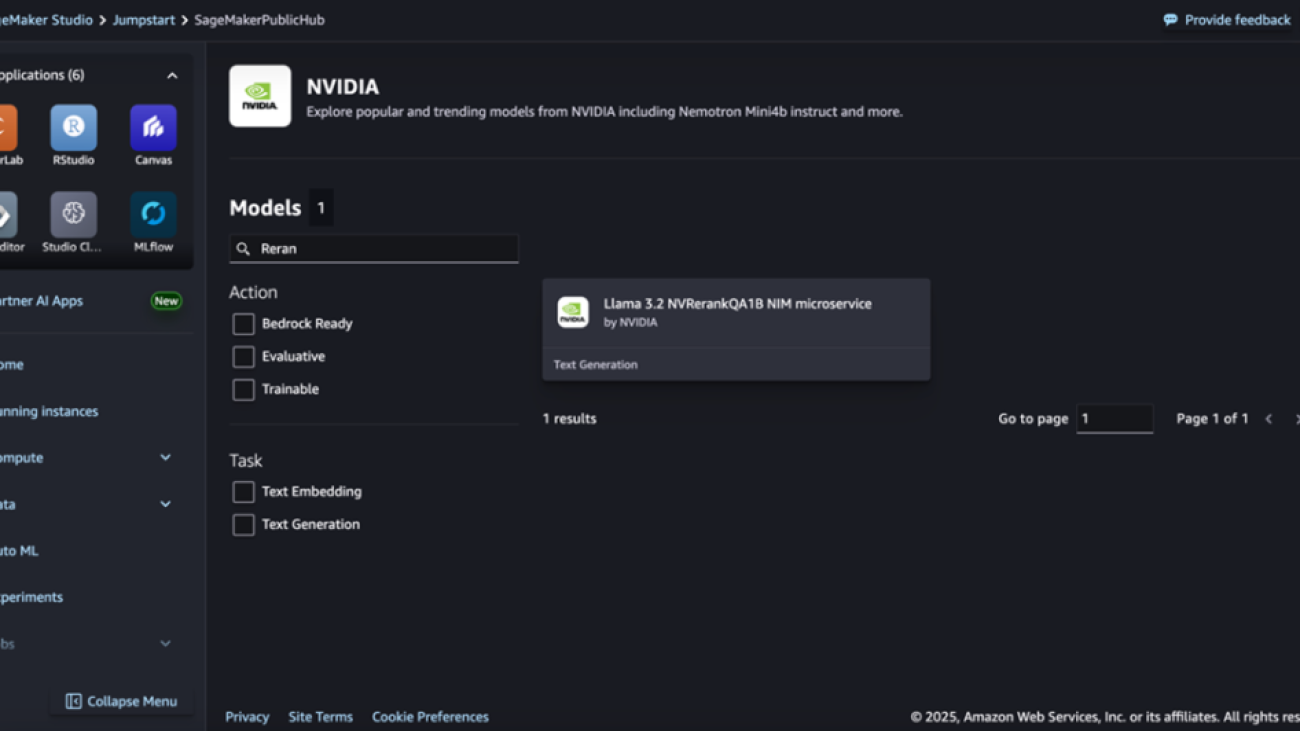
For those new to SageMaker JumpStart, we demonstrate using SageMaker Studio to access models on SageMaker JumpStart. The following screenshot shows the NeMo Retriever text embedding and reranking microservices available on SageMaker JumpStart.

Deployment starts when you choose the Deploy option. You might be prompted to subscribe to this model through AWS Marketplace. If you are already subscribed, then you can move forward with choosing the second Deploy button. After deployment finishes, you will see that an endpoint is created. You can test the endpoint by passing a sample inference request payload or by selecting the testing option using the SDK.

Subscribe to the model package
To subscribe to the model package, complete the following steps
- Depending on the model you want to deploy, open the model package listing page for Llama-3.2-NV-EmbedQA-1B-v2 or Llama-3.2-NV-RerankQA-1B-v2.
- On the AWS Marketplace listing, choose Continue to subscribe.
- On the Subscribe to this software page, review and choose Accept Offer if you and your organization agree with EULA, pricing, and support terms.
- Choose Continue to configuration and then choose an AWS Region.
A product Amazon Resource Name (ARN) will be displayed. This is the model package ARN that you need to specify while creating a deployable model using Boto3.
Deploy NeMo Retriever microservices using the SageMaker SDK
In this section, we walk through deploying the NeMo Retriever text embedding NIM through the SageMaker SDK. A similar process can be followed for deploying the NeMo Retriever text reranking NIM as well.
Define the SageMaker model using the model package ARN
To deploy the model using the SDK, copy the product ARN from the previous step and specify it in the model_package_arn in the following code:
# Define the model details
model_package_arn = "Specify the model package ARN here"
sm_model_name = "nim-llama-3-2-nv-embedqa-1b-v2"
# Create the SageMaker model
create_model_response = sm.create_model(
ModelName=sm_model_name,
PrimaryContainer={
'ModelPackageName': model_package_arn
},
ExecutionRoleArn=role,
EnableNetworkIsolation=True
)
print("Model Arn: " + create_model_response["ModelArn"])
Create the endpoint configuration
Next, we create an endpoint configuration specifying instance type; in this case, we are using an ml.g5.2xlarge instance type accelerated by NVIDIA A10G GPUs. Make sure you have the account-level service limit for using ml.g5.2xlarge for endpoint usage as one or more instances. To request a service quota increase, refer to AWS service quotas. For further performance improvements, you can use NVIDIA Hopper GPUs (P5 instances) on SageMaker.
# Create the endpoint configuration
endpoint_config_name = sm_model_name
create_endpoint_config_response = sm.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
'VariantName': 'AllTraffic',
'ModelName': sm_model_name,
'InitialInstanceCount': 1,
'InstanceType': 'ml.g5.xlarge',
'InferenceAmiVersion': 'al2-ami-sagemaker-inference-gpu-2',
'RoutingConfig': {'RoutingStrategy': 'LEAST_OUTSTANDING_REQUESTS'},
'ModelDataDownloadTimeoutInSeconds': 3600, # Specify the model download timeout in seconds.
'ContainerStartupHealthCheckTimeoutInSeconds': 3600, # Specify the health checkup timeout in seconds
}
]
)
print("Endpoint Config Arn: " + create_endpoint_config_response["EndpointConfigArn"])
Create the endpoint
Using the preceding endpoint configuration, we create a new SageMaker endpoint and wait for the deployment to finish. The status will change to InService after the deployment is successful.
# Create the endpoint
endpoint_name = endpoint_config_name
create_endpoint_response = sm.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name
)
print("Endpoint Arn: " + create_endpoint_response["EndpointArn"])
Deploy the NIM microservice
Deploy the NIM microservice with the following code:
resp = sm.describe_endpoint(EndpointName=endpoint_name)
status = resp["EndpointStatus"]
print("Status: " + status)
while status == "Creating":
time.sleep(60)
resp = sm.describe_endpoint(EndpointName=endpoint_name)
status = resp["EndpointStatus"]
print("Status: " + status)
print("Arn: " + resp["EndpointArn"])
print("Status: " + status)
We get the following output:
Status: Creating
Status: Creating
Status: Creating
Status: Creating
Status: Creating
Status: Creating
Status: InService
Arn: arn:aws:sagemaker:us-west-2:611951037680:endpoint/nim-llama-3-2-nv-embedqa-1b-v2
Status: InService
After you deploy the model, your endpoint is ready for inference. In the following section, we use a sample text to do an inference request. For inference request format, NIM on SageMaker supports the OpenAI API inference protocol (at the time of writing). For an explanation of supported parameters, see Create an embedding vector from the input text.
Inference example with NeMo Retriever text embedding NIM microservice
The NVIDIA NeMo Retriever Llama3.2 embedding model is optimized for multilingual and cross-lingual text question-answering retrieval with support for long documents (up to 8,192 tokens) and dynamic embedding size (Matryoshka Embeddings). In this section, we provide examples of running real-time inference and batch inference.
Real-time inference example
The following code example illustrates how to perform real-time inference using the NeMo Retriever Llama3.2 embedding model:
import pprint
pp1 = pprint.PrettyPrinter(indent=2, width=80, compact=True, depth=3)
input_embedding = '''{
"model": "nvidia/llama-3.2-nv-embedqa-1b-v2",
"input": ["Sample text 1", "Sample text 2"],
"input_type": "query"
}'''
print("Example input data for embedding model endpoint:")
print(input_embedding)
response = client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/json",
Accept="application/json",
Body=input_embedding
)
print("nEmbedding endpoint response:")
response = json.load(response["Body"])
pp1.pprint(response)
We get the following output:
Example input data for embedding model endpoint:
{
"model": "nvidia/llama-3.2-nv-embedqa-1b-v2",
"input": ["Sample text 1", "Sample text 2"],
"input_type": "query"
}
Embedding endpoint response:
{ 'data': [ {'embedding': [...], 'index': 0, 'object': 'embedding'},
{'embedding': [...], 'index': 1, 'object': 'embedding'}],
'model': 'nvidia/llama-3.2-nv-embedqa-1b-v2',
'object': 'list',
'usage': {'prompt_tokens': 14, 'total_tokens': 14}}
Batch inference example
When you have many documents, you can vectorize each of them with a for loop. This will often result in many requests. Alternatively, you can send requests consisting of batches of documents to reduce the number of requests to the API endpoint. We use the following example with a dataset of 10 documents. Let’s test the model with a number of documents in different languages:
documents = [
"El futuro de la computación cuántica en aplicaciones criptográficas.",
"L’application des réseaux neuronaux dans les systèmes de véhicules autonomes.",
"Analyse der Rolle von Big Data in personalisierten Gesundheitslösungen.",
"L’evoluzione del cloud computing nello sviluppo di software aziendale.",
"Avaliando o impacto da IoT na infraestrutura de cidades inteligentes.",
"Потенциал граничных вычислений для обработки данных в реальном времени.",
"评估人工智能在欺诈检测系统中的有效性。",
"倫理的なAIアルゴリズムの開発における課題と機会。",
"دمج تقنية الجيل الخامس (5G) في تعزيز الاتصال بالإنترنت للأشياء (IoT).",
"सुरक्षित लेनदेन के लिए बायोमेट्रिक प्रमाणीकरण विधियों में प्रगति।"
]
The following code demonstrates how to group the documents into batches and invoke the endpoint repeatedly to vectorize the whole dataset. Specifically, the example code loops over the 10 documents in batches of size 5 (batch_size=5).
pp2 = pprint.PrettyPrinter(indent=2, width=80, compact=True, depth=2)
encoded_data = []
batch_size = 5
# Loop over the documents in increments of the batch size
for i in range(0, len(documents), batch_size):
input = json.dumps({
"input": documents[i:i+batch_size],
"input_type": "passage",
"model": "nvidia/llama-3.2-nv-embedqa-1b-v2",
})
response = client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/json",
Accept="application/json",
Body=input,
)
response = json.load(response["Body"])
# Concatenating vectors into a single list; preserve original index
encoded_data.extend({"embedding": data[1]["embedding"], "index": data[0] } for
data in zip(range(i,i+batch_size), response["data"]))
# Print the response data
pp2.pprint(encoded_data)
We get the following output:
[ {'embedding': [...], 'index': 0}, {'embedding': [...], 'index': 1},
{'embedding': [...], 'index': 2}, {'embedding': [...], 'index': 3},
{'embedding': [...], 'index': 4}, {'embedding': [...], 'index': 5},
{'embedding': [...], 'index': 6}, {'embedding': [...], 'index': 7},
{'embedding': [...], 'index': 8}, {'embedding': [...], 'index': 9}]
Inference example with NeMo Retriever text reranking NIM microservice
The NVIDIA NeMo Retriever Llama3.2 reranking NIM microservice is optimized for providing a logit score that represents how relevant a documents is to a given query. The model was fine-tuned for multilingual, cross-lingual text question-answering retrieval, with support for long documents (up to 8,192 tokens).
In the following example, we create an input payload for a list of emails in multiple languages:
payload_model = "nvidia/llama-3.2-nv-rerankqa-1b-v2"
query = {"text": "What emails have been about returning items?"}
documents = [
{"text":"Contraseña incorrecta. Hola, llevo una hora intentando acceder a mi cuenta y sigue diciendo que mi contraseña es incorrecta. ¿Puede ayudarme, por favor?"},
{"text":"Confirmation Email Missed. Hi, I recently purchased a product from your website but I never received a confirmation email. Can you please look into this for me?"},
{"text":"أسئلة حول سياسة الإرجاع. مرحبًا، لدي سؤال حول سياسة إرجاع هذا المنتج. لقد اشتريته قبل بضعة أسابيع وهو معيب"},
{"text":"Customer Support is Busy. Good morning, I have been trying to reach your customer support team for the past week but I keep getting a busy signal. Can you please help me?"},
{"text":"Falschen Artikel erhalten. Hallo, ich habe eine Frage zu meiner letzten Bestellung. Ich habe den falschen Artikel erhalten und muss ihn zurückschicken."},
{"text":"Customer Service is Unavailable. Hello, I have been trying to reach your customer support team for the past hour but I keep getting a busy signal. Can you please help me?"},
{"text":"Return Policy for Defective Product. Hi, I have a question about the return policy for this product. I purchased it a few weeks ago and it is defective."},
{"text":"收到错误物品. 早上好,关于我最近的订单,我有一个问题。我收到了错误的商品,需要退货。"},
{"text":"Return Defective Product. Hello, I have a question about the return policy for this product. I purchased it a few weeks ago and it is defective."}
]
payload = {
"model": payload_model,
"query": query,
"passages": documents,
"truncate": "END"
}
response = client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/json",
Body=json.dumps(payload)
)
output = json.loads(response["Body"].read().decode("utf8"))
print(f'Documents: {response}')
print(json.dumps(output, indent=2))
In this example, the relevance (logit) scores are normalized to be in the range [0, 1]. Scores close to 1 indicate a high relevance to the query, and scores closer to 0 indicate low relevance.
Documents: {'ResponseMetadata': {'RequestId': 'a3f19e06-f468-4382-a927-3485137ffcf6', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': 'a3f19e06-f468-4382-a927-3485137ffcf6', 'x-amzn-invoked-production-variant': 'AllTraffic', 'date': 'Tue, 04 Mar 2025 21:46:39 GMT', 'content-type': 'application/json', 'content-length': '349', 'connection': 'keep-alive'}, 'RetryAttempts': 0}, 'ContentType': 'application/json', 'InvokedProductionVariant': 'AllTraffic', 'Body': <botocore.response.StreamingBody object at 0x7fbb00ff94b0>}
{
"rankings": [
{
"index": 4,
"logit": 0.0791015625
},
{
"index": 8,
"logit": -0.1904296875
},
{
"index": 7,
"logit": -2.583984375
},
{
"index": 2,
"logit": -4.71484375
},
{
"index": 6,
"logit": -5.34375
},
{
"index": 1,
"logit": -5.64453125
},
{
"index": 5,
"logit": -11.96875
},
{
"index": 3,
"logit": -12.2265625
},
{
"index": 0,
"logit": -16.421875
}
],
"usage": {
"prompt_tokens": 513,
"total_tokens": 513
}
}
Let’s see the top-ranked document for our query:
# 1. Extract the array of rankings
rankings = output["rankings"] # or output.get("rankings", [])
# 2. Get the top-ranked entry (highest logit)
top_ranked_entry = rankings[0]
top_index = top_ranked_entry["index"] # e.g. 4 in your example
# 3. Retrieve the corresponding document
top_document = documents[top_index]
print("Top-ranked document:")
print(top_document)
The following is the top-ranked document based on the provided relevance scores:
Top-ranked document:
{'text': 'Falschen Artikel erhalten. Hallo, ich habe eine Frage zu meiner letzten Bestellung. Ich habe den falschen Artikel erhalten und muss ihn zurückschicken.'}
This translates to the following:
"Wrong item received. Hello, I have a question about my last order. I received the wrong item and need to return it."
Based on the preceding results from the model, we see that a higher logit indicates stronger alignment with the query, whereas lower (or more negative) values indicate lower relevance. In this case, the document discussing receiving the wrong item (in German) was ranked first with the highest logit, confirming that the model quickly and effectively identified it as the most relevant passage regarding product returns.
Clean up
To clean up your resources, use the following commands:
sm.delete_model(ModelName=sm_model_name)
sm.delete_endpoint_config(EndpointConfigName=endpoint_config_name)
sm.delete_endpoint(EndpointName=endpoint_name)
Conclusion
The NVIDIA NeMo Retriever Llama 3.2 NIM microservices bring powerful multilingual capabilities to enterprise search and retrieval systems. These models excel in diverse use cases, including cross-lingual search applications, enterprise knowledge bases, customer support systems, and content recommendation engines. The text embedding NIM’s dynamic embedding size (Matryoshka Embeddings) reduces storage footprint by 35-fold while supporting 26 languages and documents up to 8,192 tokens. The reranking NIM accurately scores document relevance across languages, enabling precise information retrieval even for multilingual content. For organizations managing global knowledge bases or customer-facing search experiences, these NVIDIA-optimized microservices provide a significant advantage in latency, accuracy, and efficiency, allowing developers to quickly deploy sophisticated search capabilities without compromising on performance or linguistic diversity.
SageMaker JumpStart provides a straightforward way to use state-of-the-art large language FMs for text embedding and reranking. Through the UI or just a few lines of code, you can deploy a highly accurate text embedding model to generate dense vector representations that capture semantic meaning and a reranking model to find semantic matches and retrieve the most relevant information from various data stores at scale and cost-efficiently.
About the Authors
 Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s in Computer Science and Bioinformatics.
Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s in Computer Science and Bioinformatics.
 Greeshma Nallapareddy is a Sr. Business Development Manager at AWS working with NVIDIA on go-to-market strategy to accelerate AI solutions for customers at scale. Her experience includes leading solutions architecture teams focused on working with startups.
Greeshma Nallapareddy is a Sr. Business Development Manager at AWS working with NVIDIA on go-to-market strategy to accelerate AI solutions for customers at scale. Her experience includes leading solutions architecture teams focused on working with startups.
 Abhishek Sawarkar is a product manager in the NVIDIA AI Enterprise team working on integrating NVIDIA AI Software in Cloud MLOps platforms. He focuses on integrating the NVIDIA AI end-to-end stack within cloud platforms and enhancing user experience on accelerated computing.
Abhishek Sawarkar is a product manager in the NVIDIA AI Enterprise team working on integrating NVIDIA AI Software in Cloud MLOps platforms. He focuses on integrating the NVIDIA AI end-to-end stack within cloud platforms and enhancing user experience on accelerated computing.
 Abdullahi Olaoye is a Senior AI Solutions Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and products with cloud AI services and open source tools to optimize AI model deployment, inference, and generative AI workflows. He collaborates with AWS to enhance AI workload performance and drive adoption of NVIDIA-powered AI and generative AI solutions.
Abdullahi Olaoye is a Senior AI Solutions Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and products with cloud AI services and open source tools to optimize AI model deployment, inference, and generative AI workflows. He collaborates with AWS to enhance AI workload performance and drive adoption of NVIDIA-powered AI and generative AI solutions.
 Banu Nagasundaram leads product, engineering, and strategic partnerships for Amazon SageMaker JumpStart, the machine learning and generative AI hub provided by Amazon SageMaker. She is passionate about building solutions that help customers accelerate their AI journey and unlock business value.
Banu Nagasundaram leads product, engineering, and strategic partnerships for Amazon SageMaker JumpStart, the machine learning and generative AI hub provided by Amazon SageMaker. She is passionate about building solutions that help customers accelerate their AI journey and unlock business value.
 Chase Pinkerton is a Startups Solutions Architect at Amazon Web Services. He holds a Bachelor’s in Computer Science with a minor in Economics from Tufts University. He’s passionate about helping startups grow and scale their businesses. When not working, he enjoys road cycling, hiking, playing volleyball, and photography.
Chase Pinkerton is a Startups Solutions Architect at Amazon Web Services. He holds a Bachelor’s in Computer Science with a minor in Economics from Tufts University. He’s passionate about helping startups grow and scale their businesses. When not working, he enjoys road cycling, hiking, playing volleyball, and photography.
 Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA, empowering Amazon’s AI MLOps, DevOps, scientists, and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing generative AI foundation models spanning from data curation, GPU training, model inference, and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, and tennis and poker player.
Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA, empowering Amazon’s AI MLOps, DevOps, scientists, and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing generative AI foundation models spanning from data curation, GPU training, model inference, and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, and tennis and poker player.
Read More





 Jose Navarro is an AI/ML Specialist Solutions Architect at AWS, based in Spain. Jose helps AWS customers—from small startups to large enterprises—architect and take their end-to-end machine learning use cases to production.
Jose Navarro is an AI/ML Specialist Solutions Architect at AWS, based in Spain. Jose helps AWS customers—from small startups to large enterprises—architect and take their end-to-end machine learning use cases to production. Morgan Dutton is a Senior Technical Program Manager at AWS, Amazon Q Business based in Seattle.
Morgan Dutton is a Senior Technical Program Manager at AWS, Amazon Q Business based in Seattle. Eva Pagneux is a Principal Product Manager at AWS, Amazon Q Business, based in San Francisco.
Eva Pagneux is a Principal Product Manager at AWS, Amazon Q Business, based in San Francisco. Wesleigh Roeca is a Senior Worldwide Gen AI/ML Specialist at AWS, Amazon Q Business, based in Santa Monica.
Wesleigh Roeca is a Senior Worldwide Gen AI/ML Specialist at AWS, Amazon Q Business, based in Santa Monica.













 Abdullahi Olaoye is a Senior AI Solutions Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and products with cloud AI services and open-source tools to optimize AI model deployment, inference, and generative AI workflows. He collaborates with AWS to enhance AI workload performance and drive adoption of NVIDIA-powered AI and generative AI solutions.
Abdullahi Olaoye is a Senior AI Solutions Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and products with cloud AI services and open-source tools to optimize AI model deployment, inference, and generative AI workflows. He collaborates with AWS to enhance AI workload performance and drive adoption of NVIDIA-powered AI and generative AI solutions. Greeshma Nallapareddy is a Sr. Business Development Manager at AWS working with NVIDIA on go-to-market strategy to accelerate AI solutions for customers at scale. Her experience includes leading solutions architecture teams focused on working with startups.
Greeshma Nallapareddy is a Sr. Business Development Manager at AWS working with NVIDIA on go-to-market strategy to accelerate AI solutions for customers at scale. Her experience includes leading solutions architecture teams focused on working with startups. Akshit Arora is a senior data scientist at NVIDIA, where he works on deploying conversational AI models on GPUs at scale. He’s a graduate of University of Colorado at Boulder, where he applied deep learning to improve knowledge tracking on a K-12 online tutoring service. His work spans multilingual text-to-speech, time series classification, ed-tech, and practical applications of deep learning.
Akshit Arora is a senior data scientist at NVIDIA, where he works on deploying conversational AI models on GPUs at scale. He’s a graduate of University of Colorado at Boulder, where he applied deep learning to improve knowledge tracking on a K-12 online tutoring service. His work spans multilingual text-to-speech, time series classification, ed-tech, and practical applications of deep learning. Ankur Srivastava is a Sr. Solutions Architect in the ML Frameworks Team. He focuses on helping customers with self-managed distributed training and inference at scale on AWS. His experience includes industrial predictive maintenance, digital twins, probabilistic design optimization and has completed his doctoral studies from Mechanical Engineering at Rice University and post-doctoral research from Massachusetts Institute of Technology.
Ankur Srivastava is a Sr. Solutions Architect in the ML Frameworks Team. He focuses on helping customers with self-managed distributed training and inference at scale on AWS. His experience includes industrial predictive maintenance, digital twins, probabilistic design optimization and has completed his doctoral studies from Mechanical Engineering at Rice University and post-doctoral research from Massachusetts Institute of Technology. Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA empowering Amazon AI MLOps, DevOps, Scientists, and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing generative AI foundation models spanning from data curation, GPU training, model inference, and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, tennis and poker player.
Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA empowering Amazon AI MLOps, DevOps, Scientists, and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing generative AI foundation models spanning from data curation, GPU training, model inference, and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, tennis and poker player.