Large language models (LLMs) have demonstrated remarkable capabilities in reasoning, language understanding, and even creative tasks. Yet, a key challenge persists: how to efficiently integrate external knowledge.
Traditional methods such as fine-tuning and Retrieval-Augmented Generation (RAG) come with trade-offs—fine-tuning demands costly retraining, while RAG introduces separate retrieval modules that increase complexity and prevent seamless, end-to-end training. In-context learning, on the other hand, becomes increasingly inefficient as knowledge bases grow, facing quadratic computational scaling that hinders its ability to handle large repositories. A comparison of these approaches can be seen in Figure 1.
A new way to integrate knowledge
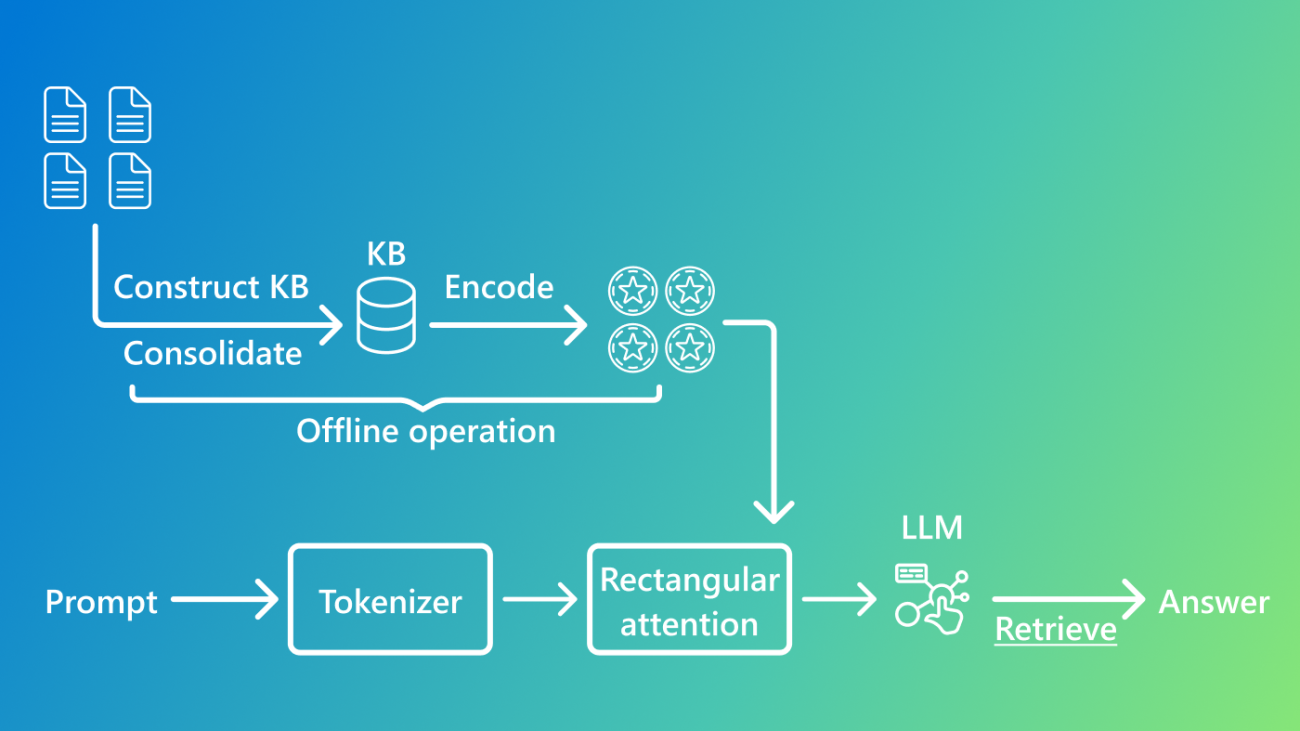
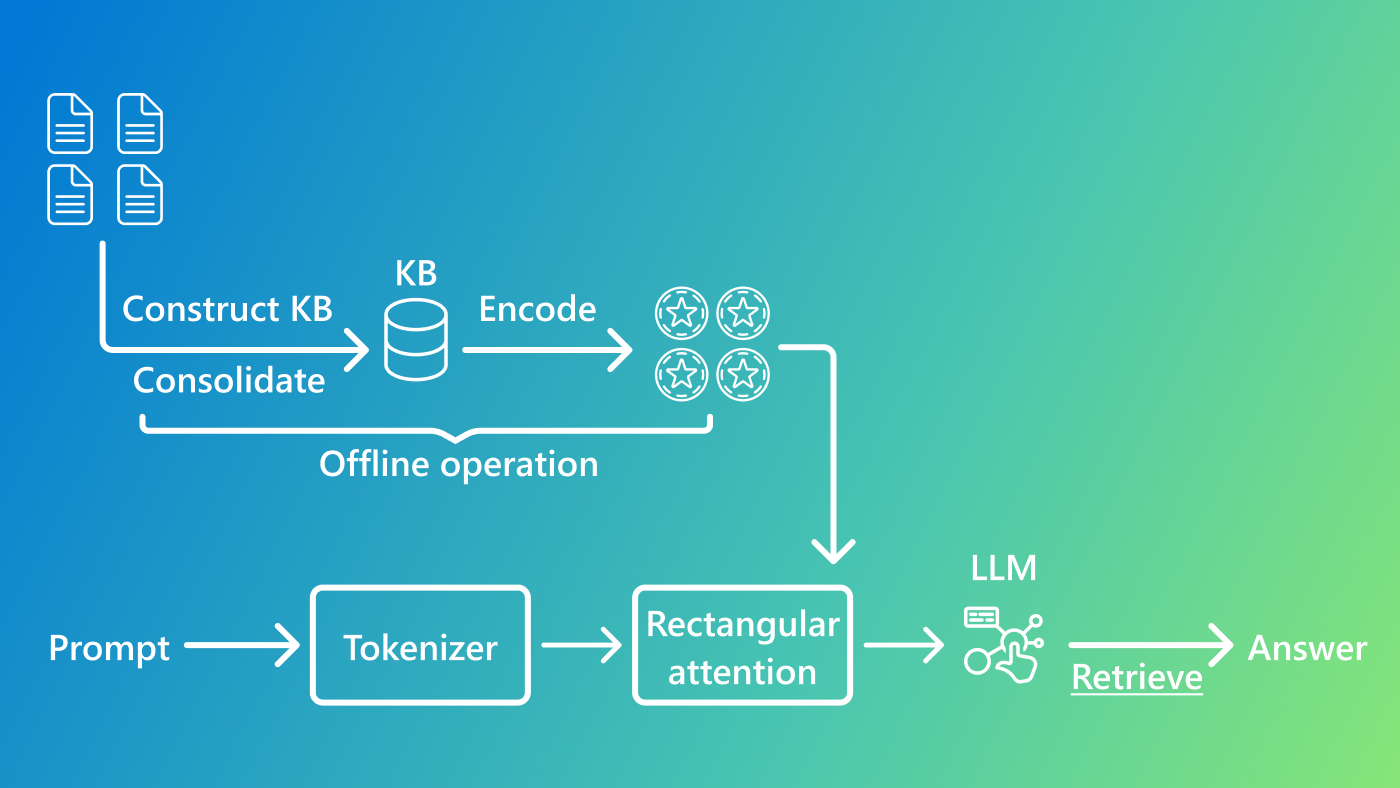
To address these challenges, we introduce the Knowledge Base-Augmented Language Model (KBLaM) —a novel approach that integrates structured knowledge bases into pre-trained LLMs. Instead of relying on external retrieval modules or costly fine-tuning, KBLaM encodes knowledge into continuous key-value vector pairs, efficiently embedding them within the model’s attention layers using a specialized rectangular attention mechanism, which implicitly performs retrieval in an integrated manner.
We use structured knowledge bases to represent the data, allowing us to consolidate knowledge and leverage structure. This design allows it to scale linearly with the size of the knowledge base while maintaining dynamic updates without retraining, making it far more efficient than existing methods.
Microsoft research podcast

NeurIPS 2024: The co-evolution of AI and systems with Lidong Zhou
Just after his NeurIPS 2024 keynote on the co-evolution of systems and AI, Microsoft CVP Lidong Zhou joins the podcast to discuss how rapidly advancing AI impacts the systems supporting it and the opportunities to use AI to enhance systems engineering itself.
Scalable, efficient, and future-ready
At its core, KBLaM is designed to integrate structured knowledge into LLMs, making them more efficient and scalable. It achieves this by converting external knowledge bases—collections of facts structured as triples consisting of an entity, a property, and a value—into a format that LLMs can process naturally. Such knowledge bases allow for consolidated, reliable sources of knowledge.
To create these knowledge bases, we first extract structured data in JSON format using small language models. We then apply Project Alexandria’s probabilistic clustering. Once we have this structured knowledge base, KBLaM follows a three-step pipeline:
- Knowledge Encoding: Each knowledge triple is mapped into a key-value vector pair using a pre-trained sentence encoder with lightweight linear adapters. The key vector, derived from the entity name and property, encodes “index information,” while the value vector captures the corresponding property value. This allows us to create continuous, learnable key-value representations.
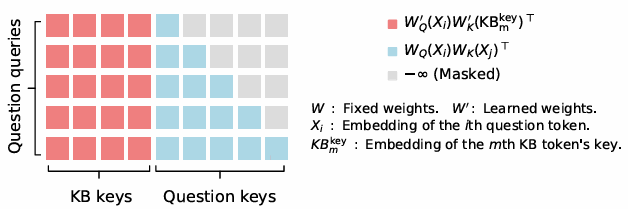
- Integration with LLMs: These key-value pairs, or knowledge tokens, are augmented into the model’s attention layers using a specialized rectangular attention structure. Unlike traditional transformer models that process all tokens equally and come with quadratic cost—such as GPT-4, Phi, and Llama—rectangular attention enables the model to attend over knowledge with linear cost, as illustrated in Figure 2. Compared to standard attention mechanisms in generative language models, where each token attends to all preceding tokens, our approach introduces a more efficient structure. In this setup, language tokens (such as those from a user’s question) attend to all knowledge tokens. However, knowledge tokens do not attend to one another, nor do they attend back to the language tokens. This selective attention pattern significantly reduces computational cost while preserving the model’s ability to incorporate external knowledge effectively.
This linear cost, which is crucial for the efficiency of KBLaM, effectively amounts to treating each fact independently—an assumption that holds for most facts. For example, the model’s name, KBLaM, and the fact that the research was conducted at Microsoft Research are very weakly correlated. This rectangular attention is implemented as an extension of standard attention. During training, we keep the base model’s weights frozen, ensuring that when no knowledge tokens are provided, the model functions exactly as it did originally.
- Efficient Knowledge Retrieval: Through this rectangular attention, the model learns to dynamically retrieve relevant knowledge tokens during inference, eliminating the need for separate retrieval steps.
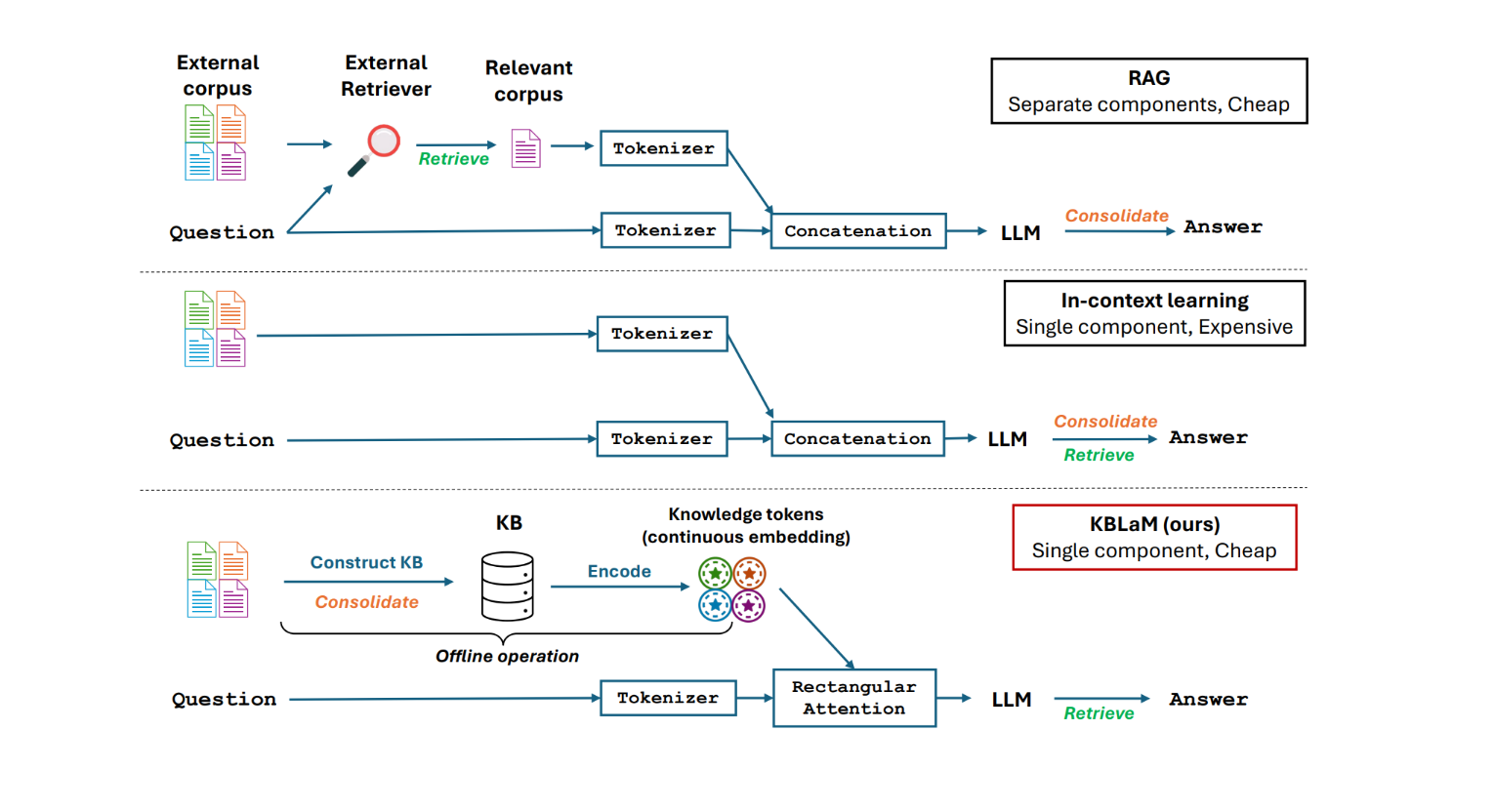
Unlike RAG, which appends retrieved document chunks to prompts, KBLaM allows for direct integration of knowledge into the model. Compared to in-context learning, KBLaM’s rectangular attention maintains a linear memory footprint, making it vastly more scalable for large knowledge bases.
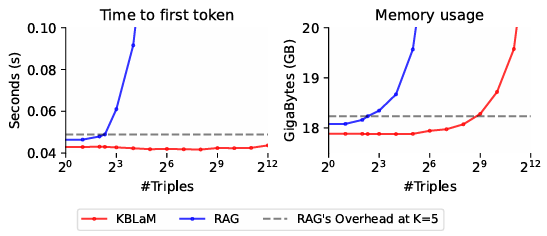
Its efficiency is a game-changer. While traditional in-context learning methods struggle with quadratic memory growth due to self-attention overhead, KBLaM’s linear overhead means we can store much more knowledge in the context. In practice, this means KBLaM can store and process over 10,000 knowledge triples, the equivalent of approximately 200,000 text tokens on a single GPU—a feat that would be computationally prohibitive with conventional in-context learning. The results across a wide range of triples and can be seen in Figure 3. Remarkably, it achieves this while extending a base model that has a context length of only 8K tokens. Additionally, KBLaM enables dynamic updates: modifying a single knowledge triple does not require retraining or re-computation of the entire knowledge base.
Enhancing interpretability and reliability
Another major benefit of KBLaM is its interpretability. Unlike in-context learning, where knowledge injection is opaque, KBLAM’s attention weights provide clear insights into how the model utilizes knowledge tokens. Experiments show that KBLaM assigns high attention scores to relevant knowledge triples, effectively mimicking a soft retrieval process.
Furthermore, KBLaM enhances model reliability by learning through its training examples when not to answer a question if the necessary information is missing from the knowledge base. In particular, with knowledge bases larger than approximately 200 triples, we found that the model refuses to answer questions it has no knowledge about more precisely than a model given the information as text in context. This feature helps reduce hallucinations, a common problem in LLMs that rely on internal knowledge alone, making responses more accurate and trustworthy.
The future of knowledge-augmented AI
KBLaM represents a major step forward in integrating structured knowledge into LLMs. By offering a scalable, efficient, and interpretable alternative to existing techniques, it paves the way for AI systems that can stay up to date and provide reliable, knowledge-driven responses. In fields where accuracy and trust are critical—such as medicine, finance, and scientific research—this approach has the potential to transform how language models interact with real-world information.
As AI systems increasingly rely on dynamic knowledge rather than static model parameters, we hope KBLaM will serve as a bridge between raw computational power and real-world understanding.
However, there is still work to be done before it can be deployed at scale. Our current model has been trained primarily on factual question-answer pairs, and further research is needed to expand its capabilities across more complex reasoning tasks and diverse knowledge domains.
To accelerate progress, we are releasing KBLaM’s code and datasets (opens in new tab) to the research community, and we are planning integrations with the Hugging Face transformers library. By making these resources available, we hope to inspire further research and adoption of scalable, efficient knowledge augmentation for LLMs. The future of AI isn’t just about generating text—it’s about generating knowledge that is accurate, adaptable, and deeply integrated with the evolving world. KBLaM is a step in that direction.
The post Introducing KBLaM: Bringing plug-and-play external knowledge to LLMs appeared first on Microsoft Research.

 At The Check Up, we unveil how we’re using AI to reshape what’s possible in health and help people live healthier lives.
At The Check Up, we unveil how we’re using AI to reshape what’s possible in health and help people live healthier lives.
 Ubie, a health tech startup in Japan, is using Google AI to change patient — and healthcare worker — experiences for the better.
Ubie, a health tech startup in Japan, is using Google AI to change patient — and healthcare worker — experiences for the better.





 Learn more about Google Research’s FireSat project, built to detect small wildfires.
Learn more about Google Research’s FireSat project, built to detect small wildfires.
 Learn how our AI Collaboratives for wildfires and food security are taking a new funding approach to help people around the world.
Learn how our AI Collaboratives for wildfires and food security are taking a new funding approach to help people around the world.
 The first satellite for the FireSat constellation officially made contact with Earth. This satellite is the first of more than 50 in a first-of-its-kind constellation de…
The first satellite for the FireSat constellation officially made contact with Earth. This satellite is the first of more than 50 in a first-of-its-kind constellation de…