The AI landscape is rapidly evolving, and more organizations are recognizing the power of synthetic data to drive innovation. However, enterprises looking to use AI face a major roadblock: how to safely use sensitive data. Stringent privacy regulations make it risky to use such data, even with robust anonymization. Advanced analytics can potentially uncover hidden correlations and reveal real data, leading to compliance issues and reputational damage. Additionally, many industries struggle with a scarcity of high-quality, diverse datasets needed for critical processes like software testing, product development, and AI model training. This data shortage can hinder innovation, slowing down development cycles across various business operations.
Organizations need innovative solutions to unlock the potential of data-driven processes without compromising ethics or data privacy. This is where synthetic data comes in—a solution that mimics the statistical properties and patterns of real data while being entirely fictitious. By using synthetic data, enterprises can train AI models, conduct analyses, and develop applications without the risk of exposing sensitive information. Synthetic data effectively bridges the gap between data utility and privacy protection. However, creating high-quality synthetic data comes with significant challenges:
- Data quality – Making sure synthetic data accurately reflects real-world statistical properties and nuances is difficult. The data might not capture rare edge cases or the full spectrum of human interactions.
- Bias management – Although synthetic data can help reduce bias, it can also inadvertently amplify existing biases if not carefully managed. The quality of synthetic data heavily depends on the model and data used to generate it.
- Privacy vs. utility – Balancing privacy preservation with data utility is complex. There’s a risk of reverse engineering or data leakage if not properly implemented.
- Validation challenges – Verifying the quality and representation of synthetic data often requires comparison with real data, which can be problematic when working with sensitive information.
- Reality gap – Synthetic data might not fully capture the dynamic nature of the real world, potentially leading to a disconnect between model performance on synthetic data and real-world applications.
In this post, we explore how to use Amazon Bedrock for synthetic data generation, considering these challenges alongside the potential benefits to develop effective strategies for various applications across multiple industries, including AI and machine learning (ML). Amazon Bedrock offers a broad set of capabilities to build generative AI applications with a focus on security, privacy, and responsible AI. Built within the AWS landscape, Amazon Bedrock is designed to help maintain the security and compliance standards required for enterprise use.
Attributes of high-quality synthetic data
To be truly effective, synthetic data must be both realistic and reliable. This means it should accurately reflect the complexities and nuances of real-world data while maintaining complete anonymity. A high-quality synthetic dataset exhibits several key characteristics that facilitate its fidelity to the original data:
- Data structure – The synthetic data should maintain the same structure as the real data, including the same number of columns, data types, and relationships between different data sources
- Statistical properties – The synthetic data should mimic the statistical properties of the real data, such as mean, median, standard deviation, correlation between variables, and distribution patterns.
- Temporal patterns – If the real data exhibits temporal patterns (for example, diurnal or seasonal patterns), the synthetic data should also reflect these patterns.
- Anomalies and outliers – Real-world data often contains anomalies and outliers. The synthetic data should also include a similar proportion and distribution of anomalies and outliers to accurately represent the real-world scenario.
- Referential integrity – If the real data has relationships and dependencies between different data sources, the synthetic data should maintain these relationships to facilitate referential integrity.
- Consistency – The synthetic data should be consistent across different data sources and maintain the relationships and dependencies between them, facilitating a coherent and unified representation of the dataset.
- Scalability – The synthetic data generation process should be scalable to handle large volumes of data and support the generation of synthetic data for different scenarios and use cases.
- Diversity – The synthetic data should capture the diversity present in the real data.
Solution overview
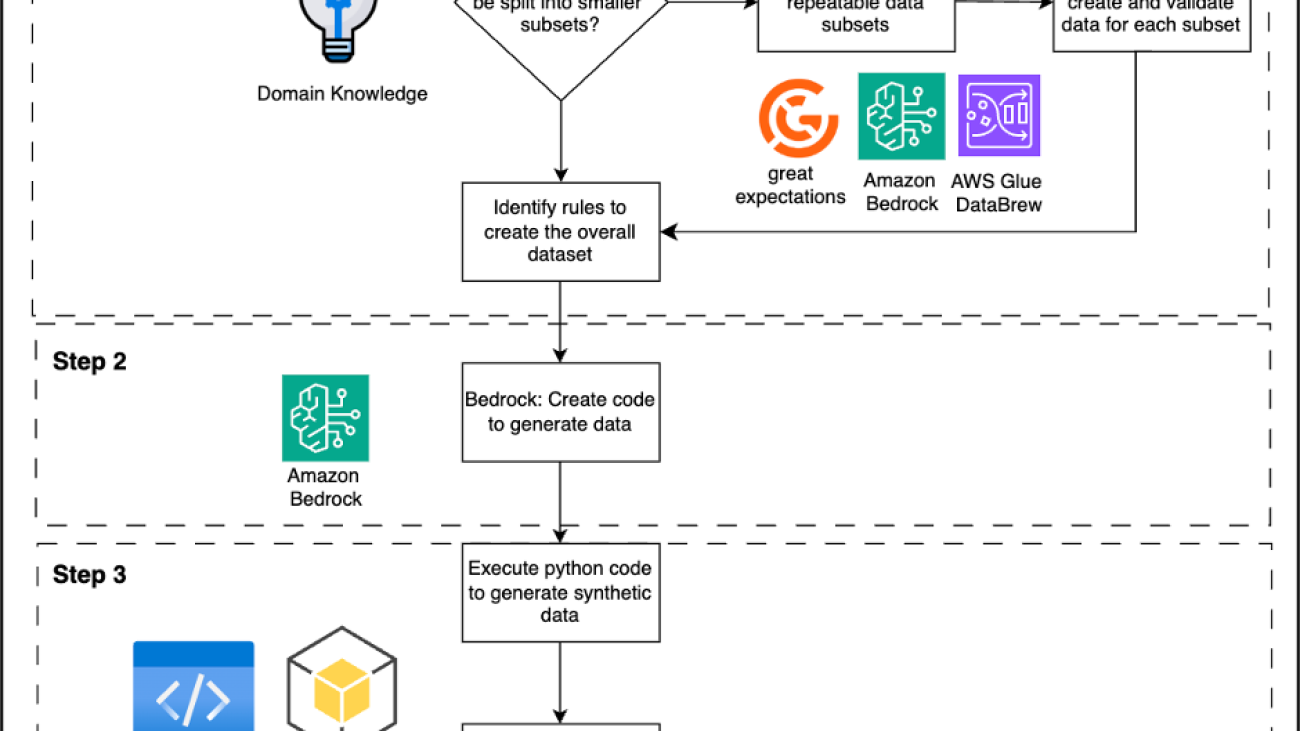
Generating useful synthetic data that protects privacy requires a thoughtful approach. The following figure represents the high-level architecture of the proposed solution. The process involves three key steps:
- Identify validation rules that define the structure and statistical properties of the real data.
- Use those rules to generate code using Amazon Bedrock that creates synthetic data subsets.
- Combine multiple synthetic subsets into full datasets.

Let’s explore these three key steps for creating useful synthetic data in more detail.
Step 1: Define data rules and characteristics
- To create synthetic datasets, start by establishing clear rules that capture the essence of your target data:
- Use domain-specific knowledge to identify key attributes and relationships.
- Study existing public datasets, academic resources, and industry documentation.
- Use tools like AWS Glue DataBrew, Amazon Bedrock, or open source alternatives (such as Great Expectations) to analyze data structures and patterns.
- Develop a comprehensive rule-set covering:
- Data types and value ranges
- Inter-field relationships
- Quality standards
- Domain-specific patterns and anomalies
This foundational step makes sure your synthetic data accurately reflects real-world scenarios in your industry.
Step 2: Generate code with Amazon Bedrock
Transform your data rules into functional code using Amazon Bedrock language models:
- Choose an appropriate Amazon Bedrock model based on code generation capabilities and domain relevance.
- Craft a detailed prompt describing the desired code output, including data structures and generation rules.
- Use the Amazon Bedrock API to generate Python code based on your prompts.
- Iteratively refine the code by:
- Reviewing for accuracy and efficiency
- Adjusting prompts as needed
- Incorporating developer input for complex scenarios
The result is a tailored script that generates synthetic data entries matching your specific requirements and closely mimicking real-world data in your domain.
Step 3: Assemble and scale the synthetic dataset
Transform your generated data into a comprehensive, real-world representative dataset:
- Use the code from Step 2 to create multiple synthetic subsets for various scenarios.
- Merge subsets based on domain knowledge, maintaining realistic proportions and relationships.
- Align temporal or sequential components and introduce controlled randomness for natural variation.
- Scale the dataset to required sizes, reflecting different time periods or populations.
- Incorporate rare events and edge cases at appropriate frequencies.
- Generate accompanying metadata describing dataset characteristics and the generation process.
The end result is a diverse, realistic synthetic dataset for uses like system testing, ML model training, or data analysis. The metadata provides transparency into the generation process and data characteristics. Together, these measures result in a robust synthetic dataset that closely parallels real-world data while avoiding exposure of direct sensitive information. This generalized approach can be adapted to various types of datasets, from financial transactions to medical records, using the power of Amazon Bedrock for code generation and the expertise of domain knowledge for data validation and structuring.
Importance of differential privacy in synthetic data generation
Although synthetic data offers numerous benefits for analytics and machine learning, it’s essential to recognize that privacy concerns persist even with artificially generated datasets. As we strive to create high-fidelity synthetic data, we must also maintain robust privacy protections for the original data. Although synthetic data mimics patterns in actual data, if created improperly, it risks revealing details about sensitive information in the source dataset. This is where differential privacy enters the picture. Differential privacy is a mathematical framework that provides a way to quantify and control the privacy risks associated with data analysis. It works by injecting calibrated noise into the data generation process, making it virtually impossible to infer anything about a single data point or confidential information in the source dataset.
Differential privacy protects against re-identification exploits by adversaries attempting to extract details about data. The carefully calibrated noise added to synthetic data makes sure that even if an adversary tries, it is computationally infeasible to tie an output back to specific records in the original data, while still maintaining the overall statistical properties of the dataset. This allows the synthetic data to closely reflect real-world characteristics and remain useful for analytics and modeling while protecting privacy. By incorporating differential privacy techniques into the synthetic data generation process, you can create datasets that not only maintain statistical properties of the original data but also offer strong privacy guarantees. It enables organizations to share data more freely, collaborate on sensitive projects, and develop AI models with reduced risk of privacy breaches. For instance, in healthcare, differentially private synthetic patient data can accelerate research without compromising individual patient confidentiality.
As we continue to advance in the field of synthetic data generation, the incorporation of differential privacy is becoming not just a best practice, but a necessary component for responsible data science. This approach paves the way for a future where data utility and privacy protection coexist harmoniously, fostering innovation while safeguarding individual rights. However, although differential privacy offers strong theoretical guarantees, its practical implementation can be challenging. Organizations must carefully balance the trade-off between privacy and utility, because increasing privacy protection often comes at the cost of reduced data utility.
Build synthetic datasets for Trusted Advisor findings with Amazon Bedrock
In this post, we guide you through the process of creating synthetic datasets for AWS Trusted Advisor findings using Amazon Bedrock. Trusted Advisor provides real-time guidance to optimize your AWS environment, improving performance, security, and cost-efficiency through over 500 checks against AWS best practices. We demonstrate the synthetic data generation approach using the “Underutilized Amazon EBS Volumes” check (checkid: DAvU99Dc4C) as an example.
By following this post, you will gain practical knowledge on:
- Defining data rules for Trusted Advisor findings
- Using Amazon Bedrock to generate data creation code
- Assembling and scaling synthetic datasets
This approach can be applied across over 500 Trusted Advisor checks, enabling you to build comprehensive, privacy-aware datasets for testing, training, and analysis. Whether you’re looking to enhance your understanding of Trusted Advisor recommendations or develop new optimization strategies, synthetic data offers powerful possibilities.
Prerequisites
To implement this approach, you must have an AWS account with the appropriate permissions.
- AWS Account Setup:
- IAM permissions for:
- Amazon Bedrock
- AWS Trusted Advisor
- Amazon EBS
- IAM permissions for:
- AWS Service Access:
- Access enabled for Amazon Bedrock in your Region
- Access to Anthropic Claude model in Amazon Bedrock
- Enterprise or Business support plan for full Trusted Advisor access
- Development Environment:
- Python 3.8 or later installed
- Required Python packages:
- pandas
- numpy
- random
- boto3
- Knowledge Requirements:
- Basic understanding of:
- Python programming
- AWS services (especially EBS and Trusted Advisor)
- Data analysis concepts
- JSON/YAML file format
- Basic understanding of:
Define Trusted Advisor findings rules
Begin by examining real Trusted Advisor findings for the “Underutilized Amazon EBS Volumes” check. Analyze the structure and content of these findings to identify key data elements and their relationships. Pay attention to the following:
- Standard fields – Check ID, volume ID, volume type, snapshot ID, and snapshot age
- Volume attributes – Size, type, age, and cost
- Usage metrics – Read and write operations, throughput, and IOPS
- Temporal patterns – Volume type and size variations
- Metadata – Tags, creation date, and last attached date
As you study these elements, note the typical ranges, patterns, and distributions for each attribute. For example, observe how volume sizes correlate with volume types, or how usage patterns differ between development and production environments. This analysis will help you create a set of rules that accurately reflect real-world Trusted Advisor findings.
After analyzing real Trusted Advisor outputs for the “Underutilized Amazon EBS Volumes” check, we identified the following crucial patterns and rules:
- Volume type – Consider gp2, gp3, io1, io2, and st1 volume types. Verify the volume sizes are valid for volume types.
- Criteria – Represent multiple AWS Regions, with appropriate volume types. Correlate snapshot ages with volume ages.
- Data structure – Each finding should include the same columns.
The following is an example ruleset:
Generate code with Amazon Bedrock
With your rules defined, you can now use Amazon Bedrock to generate Python code for creating synthetic Trusted Advisor findings.
The following is an example prompt for Amazon Bedrock:
You can submit this prompt to the Amazon Bedrock chat playground using Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock, and receive generated Python code. Review this code carefully, verifying it meets all specifications and generates realistic data. If necessary, iterate on your prompt or make manual adjustments to the code to address any missing logic or edge cases.
The resulting code will serve as the foundation for creating varied and realistic synthetic Trusted Advisor findings that adhere to the defined parameters. By using Amazon Bedrock in this way, you can quickly develop sophisticated data generation code that would otherwise require significant manual effort and domain expertise to create.
Create data subsets
With the code generated by Amazon Bedrock and refined with your custom functions, you can now create diverse subsets of synthetic Trusted Advisor findings for the “Underutilized Amazon EBS Volumes” check. This approach allows you to simulate a wide range of real-world scenarios. In the following sample code, we have customized the volume_id and snapshot_id format to begin with vol-9999 and snap-9999, respectively:
This code creates subsets that include:
- Various volume types and instance types
- Different levels of utilization
- Occasional misconfigurations (for example, underutilized volumes)
- Diverse regional distribution
Combine and scale the dataset
The process of combining and scaling synthetic data involves merging multiple generated datasets while introducing realistic anomalies to create a comprehensive and representative dataset. This step is crucial for making sure that your synthetic data reflects the complexity and variability found in real-world scenarios. Organizations typically introduce controlled anomalies at a specific rate (usually 5–10% of the dataset) to simulate various edge cases and unusual patterns that might occur in production environments. These anomalies help in testing system responses, developing monitoring solutions, and training ML models to identify potential issues.
When generating synthetic data for underutilized EBS volumes, you might introduce anomalies such as oversized volumes (5–10 times larger than needed), volumes with old snapshots (older than 365 days), or high-cost volumes with low utilization. For instance, a synthetic dataset might include a 1 TB gp2 volume that’s only using 100 GB of space, simulating a real-world scenario of overprovisioned resources. See the following code:
The following screenshot shows an example of sample rows generated.

Validate the synthetic Trusted Advisor findings
Data validation is a critical step that verifies the quality, reliability, and representativeness of your synthetic data. This process involves performing rigorous statistical analysis to verify that the generated data maintains proper distributions, relationships, and patterns that align with real-world scenarios. Validation should include both quantitative metrics (statistical measures) and qualitative assessments (pattern analysis). Organizations should implement comprehensive validation frameworks that include distribution analysis, correlation checks, pattern verification, and anomaly detection. Regular visualization of the data helps in identifying inconsistencies or unexpected patterns.
For EBS volume data, validation might include analyzing the distribution of volume sizes across different types (gp2, gp3, io1), verifying that cost correlations match expected patterns, and making sure that introduced anomalies (like underutilized volumes) maintain realistic proportions. For instance, validating that the percentage of underutilized volumes aligns with typical enterprise environments (perhaps 15–20% of total volumes) and that the cost-to-size relationships remain realistic across volume types.
The following figures show examples of our validation checks.
- The following screenshot shows statistics of the generated synthetic datasets.

- The following figure shows the proportion of underutilized volumes in the generated synthetic datasets.

- The following figure shows the distribution of volume sizes in the generated synthetic datasets.

- The following figure shows the distribution of volume types in the generated synthetic datasets.

- The following figure shows the distribution of snapshot ages in the generated synthetic datasets.

Enhancing synthetic data with differential privacy
After exploring the steps to create synthetic datasets for the Trusted Advisor “Underutilized Amazon EBS Volumes” check, it’s worth revisiting how differential privacy strengthens this approach. When a cloud consulting firm analyzes aggregated Trusted Advisor data across multiple clients, differential privacy through OpenDP provides the critical privacy-utility balance needed. By applying carefully calibrated noise to computations of underutilized volume statistics, consultants can generate synthetic datasets that preserve essential patterns across Regions and volume types while mathematically guaranteeing individual client confidentiality. This approach verifies that the synthetic data maintains sufficient accuracy for meaningful trend analysis and recommendations, while eliminating the risk of revealing sensitive client-specific infrastructure details or usage patterns—making it an ideal complement to our synthetic data generation pipeline.
Conclusion
In this post, we showed how to use Amazon Bedrock to create synthetic data for enterprise needs. By combining language models available in Amazon Bedrock with industry knowledge, you can build a flexible and secure way to generate test data. This approach helps create realistic datasets without using sensitive information, saving time and money. It also facilitates consistent testing across projects and avoids ethical issues of using real user data. Overall, this strategy offers a solid solution for data challenges, supporting better testing and development practices.
In part 2 of this series, we will demonstrate how to use pattern recognition for different datasets to automate rule-set generation needed for the Amazon Bedrock prompts to generate corresponding synthetic data.
About the authors
 Devi Nair is a Technical Account Manager at Amazon Web Services, providing strategic guidance to enterprise customers as they build, operate, and optimize their workloads on AWS. She focuses on aligning cloud solutions with business objectives to drive long-term success and innovation.
Devi Nair is a Technical Account Manager at Amazon Web Services, providing strategic guidance to enterprise customers as they build, operate, and optimize their workloads on AWS. She focuses on aligning cloud solutions with business objectives to drive long-term success and innovation.
 Vishal Karlupia is a Senior Technical Account Manager/Lead at Amazon Web Services, Toronto. He specializes in generative AI applications and helps customers build and scale their AI/ML workloads on AWS. Outside of work, he enjoys being outdoors and keeping bonfires alive.
Vishal Karlupia is a Senior Technical Account Manager/Lead at Amazon Web Services, Toronto. He specializes in generative AI applications and helps customers build and scale their AI/ML workloads on AWS. Outside of work, he enjoys being outdoors and keeping bonfires alive.
 Srinivas Ganapathi is a Principal Technical Account Manager at Amazon Web Services. He is based in Toronto, Canada, and works with games customers to run efficient workloads on AWS.
Srinivas Ganapathi is a Principal Technical Account Manager at Amazon Web Services. He is based in Toronto, Canada, and works with games customers to run efficient workloads on AWS.
 Nicolas Simard is a Technical Account Manager based in Montreal. He helps organizations accelerate their AI adoption journey through technical expertise, architectural best practices, and enables them to maximize business value from AWS’s Generative AI capabilities.
Nicolas Simard is a Technical Account Manager based in Montreal. He helps organizations accelerate their AI adoption journey through technical expertise, architectural best practices, and enables them to maximize business value from AWS’s Generative AI capabilities.




 Learn how Google DeepMind and Google Cloud are helping to bring a cinema classic to larger-than-life in Las Vegas.
Learn how Google DeepMind and Google Cloud are helping to bring a cinema classic to larger-than-life in Las Vegas.









 Banu Nagasundaram leads product, engineering, and strategic partnerships for Amazon SageMaker JumpStart, the SageMaker machine learning and generative AI hub. She is passionate about building solutions that help customers accelerate their AI journey and unlock business value.
Banu Nagasundaram leads product, engineering, and strategic partnerships for Amazon SageMaker JumpStart, the SageMaker machine learning and generative AI hub. She is passionate about building solutions that help customers accelerate their AI journey and unlock business value.


 John Liu has 14 years of experience as a product executive and 10 years of experience as a portfolio manager. At AWS, John is a Principal Product Manager for Amazon Bedrock. Previously, he was the Head of Product for AWS Web3 and Blockchain. Prior to AWS, John held various product leadership roles at public blockchain protocols and fintech companies, and also spent 9 years as a portfolio manager at various hedge funds.
John Liu has 14 years of experience as a product executive and 10 years of experience as a portfolio manager. At AWS, John is a Principal Product Manager for Amazon Bedrock. Previously, he was the Head of Product for AWS Web3 and Blockchain. Prior to AWS, John held various product leadership roles at public blockchain protocols and fintech companies, and also spent 9 years as a portfolio manager at various hedge funds.






 Breanne Warner
Breanne Warner Justin Lin
Justin Lin Chloe Gorgen
Chloe Gorgen