Helping music professionals explore the potential of generative AIRead More

Helping music professionals explore the potential of generative AIRead More

Helping music professionals explore the potential of generative AIRead More
Get the controllers ready and clear the calendar — it’s a jam-packed GFN Thursday.
Time to revisit a timeless classic for a dose of remastered nostalgia. GeForce NOW is bringing members a surprise from Bethesda — The Elder Scrolls IV: Oblivion Remastered is now available in the cloud.
Clair Obscur: Expedition 33, the spellbinding turn-based role-playing game, is ready to paint its adventure across GeForce NOW for members to stream in style.
Sunderfolk, from Dreamhaven’s Secret Door studio, launches on GeForce NOW, following an exclusive First Look Demo for members.
And get ready to crack the case with the sharpest minds in the business — Capcom’s Ace Attorney Investigations Collection heads to the cloud this week, offering members the thrilling adventures of prosecutor Miles Edgeworth.
Stream it all across devices, along with eight other games added to the cloud this week, including Zenless Zone Zero’s latest update.

Step back into the world of Cyrodiil in style with the award-winning The Elder Scrolls IV: Oblivion Remastered in the cloud. The revitalization of the iconic 2006 role-playing game offers updated visuals, gameplay and plenty of more content.
Explore a meticulously recreated world, navigate story paths as diverse character archetypes and engage in an epic quest to save Tamriel from a Daedric invasion. The remaster includes all previously released expansions — Shivering Isles, Knights of the Nine and additional downloadable content — providing a comprehensive experience for new and returning fans.
Rediscover the vast landscape of Cyrodiil like never before with a GeForce NOW membership and stop the forces of Oblivion from overtaking the land. Ultimate and Performance members enjoy higher resolutions and longer gaming sessions for immersive gaming anytime, anywhere.
Sunderfolk is a turn-based tactical role-playing adventure for up to four players that offers an engaging couch co-op experience. Control characters using a smartphone app, which serves as both a controller and a hub for cards, inventory and rules.

In the underground fantasy world of Arden, take on the roles of anthropomorphic animal heroes tasked with defending their town from the corruption of shadowstone. Six unique classes — from the fiery Pyromancer salamander to the tactical Bard bat — are equipped with distinct skill cards. Missions range from combat and exploration to puzzles and rescues, requiring teamwork and coordination.
Get into the mischief streaming it on GeForce NOW. Gather the squad and rekindle the spirit of game night from the comfort of the couch, streaming on the big screen with GeForce NOW and using a mobile device as a controller for a unique, immersive co-op experience.

Experience both Ace Attorney Investigations games in one gorgeous collection, stepping into the shoes of Miles Edgeworth, the prosecutor of prosecutors from the Ace Attorney mainline games.
Leave the courtroom behind and walk with Edgeworth around the crime scene to gather evidence and clues, including by talking with persons of interest. Solve tough, intriguing cases through wit, logic and deduction.
Members can level up their detective work across devices with a premium GeForce NOW membership. Ultimate and Performance members get extended session times to crack cases without interruptions.

Zenless Zone Zero v1.7, “Bury Your Tears With the Past,” marks the dramatic conclusion of the first season’s storyline. Team with a special investigator to infiltrate enemy ranks, uncover the truth behind the Exaltists’ conspiracy and explore the mysteries of the Sacrifice Core, adding new depth to the game’s lore and characters.
The update also introduces two new S-Rank Agents — Vivian, a versatile Ether Anomaly fighter, and Hugo, an Ice Attack specialist — each bringing unique combat abilities to the roster. Alongside limited-time events, quality-of-life improvements and more, the update offers fresh gameplay modes and exclusive rewards.

Clair Obscur: Expedition 33 is a visually stunning, dark fantasy role-playing game available now for members to stream. A mysterious entity called the Paintress erases everyone of a certain age each year after painting their number on a monolith. Join a desperate band of survivors — most with only a year left to live — on the 33rd expedition to end this cycle of death by confronting the Paintress and her monstrous creations. Dodge, parry and counterattack in battle while exploring a richly imagined world inspired by French Belle Époque art and filled with complex, emotionally driven characters.
Look for the following games available to stream in the cloud this week:
What are you planning to play this weekend? Let us know on X or in the comments below.
What’s a game on GFN that deserves more love?
—
NVIDIA GeForce NOW (@NVIDIAGFN) April 22, 2025

Advancing AI requires a full-stack approach, with a powerful foundation of computing infrastructure — including accelerated processors and networking technologies — connected to optimized compilers, algorithms and applications.
NVIDIA Research is innovating across this spectrum, supporting virtually every industry in the process. At this week’s International Conference on Learning Representations (ICLR), taking place April 24-28 in Singapore, more than 70 NVIDIA-authored papers introduce AI developments with applications in autonomous vehicles, healthcare, multimodal content creation, robotics and more.
“ICLR is one of the world’s most impactful AI conferences, where researchers introduce important technical innovations that move every industry forward,” said Bryan Catanzaro, vice president of applied deep learning research at NVIDIA. “The research we’re contributing this year aims to accelerate every level of the computing stack to amplify the impact and utility of AI across industries.”
Several NVIDIA-authored papers at ICLR cover groundbreaking work in multimodal generative AI and novel methods for AI training and synthetic data generation, including:
Discover the latest work from NVIDIA Research, a global team of around 400 experts in fields including computer architecture, generative AI, graphics, self-driving cars and robotics.

We are excited to announce the release of PyTorch® 2.7 (release notes)! This release features:
This release is composed of 3262 commits from 457 contributors since PyTorch 2.6. We want to sincerely thank our dedicated community for your contributions. As always, we encourage you to try these out and report any issues as we improve 2.7. More information about how to get started with the PyTorch 2-series can be found at our Getting Started page.
| Beta | Prototype |
| Torch.Compile support for Torch Function Modes | NVIDIA Blackwell Architecture Support |
| Mega Cache | PyTorch Native Context Parallel |
| Enhancing Intel GPU Acceleration | |
| FlexAttention LLM first token processing on x86 CPUs | |
| FlexAttention LLM throughput mode optimization on x86 CPUs | |
| Foreach Map | |
| Flex Attention for Inference | |
| Prologue Fusion Support in Inductor |
*To see a full list of public feature submissions click here.
This feature enables users to override any *torch.** operation to implement custom user-defined behavior. For example, ops can be rewritten to accommodate a specific backend. This is used in FlexAttention to re-write indexing ops.
See the tutorial for more information.
Mega Cache allows users to have end-to-end portable caching for torch. The intended use case is after compiling and executing a model, the user calls torch.compiler.save_cache_artifacts() which will return the compiler artifacts in a portable form. Later, potentially on a different machine, the user may call torch.compiler.load_cache_artifacts() with these artifacts to pre-populate the torch.compile caches in order to jump-start their cache.
See the tutorial for more information.
PyTorch 2.7 introduces support for NVIDIA’s new Blackwell GPU architecture and ships pre-built wheels for CUDA 12.8. For more details on CUDA 12.8 see CUDA Toolkit Release.
More context can also be found here.
PyTorch Context Parallel API allows users to create a Python context so that every *torch.nn.functional.scaled_dot_product_attention() *call within will run with context parallelism. Currently, PyTorch Context Parallel supports 3 attention backends: 1. Flash attention; 2. Efficient attention; and 3. cuDNN attention.
As an example, this is used within TorchTitan as the Context Parallel solution for LLM training.
See tutorial here.
This latest release introduces enhanced performance optimizations for Intel GPU architectures. These improvements accelerate workloads across various Intel GPUs through the following key enhancements:
 Ultra Series 2 with Intel® Arc Graphics, and Intel® Arc B-Series graphics on both Windows and Linux.
Ultra Series 2 with Intel® Arc Graphics, and Intel® Arc B-Series graphics on both Windows and Linux.For more information regarding Intel GPU support, please refer to Getting Started Guide.
See also the tutorials here and here.
FlexAttention x86 CPU support was first introduced in PyTorch 2.6, offering optimized implementations — such as PageAttention, which is critical for LLM inference—via the TorchInductor C++ backend. In PyTorch 2.7, more attention variants for first token processing of LLMs are supported. With this feature, users can have a smoother experience running FlexAttention on x86 CPUs, replacing specific scaled_dot_product_attention operators with a unified FlexAttention API, and benefiting from general support and good performance when using torch.compile.
The performance of FlexAttention on x86 CPUs for LLM inference throughput scenarios has been further improved by adopting the new C++ micro-GEMM template ability. This addresses the performance bottlenecks for large batch size scenarios present in PyTorch 2.6. With this enhancement, users can transparently benefit from better performance and a smoother experience when using FlexAttention APIs and torch.compile for LLM throughput serving on x86 CPUs.
This feature uses torch.compile to allow users to apply any pointwise or user-defined function (e.g. torch.add) to lists of tensors, akin to the existing *torch.foreach** ops. The main advantage over the existing *torch.foreach** ops is that any mix of scalars or lists of tensors can be supplied as arguments, and even user-defined python functions can be lifted to apply to lists of tensors. Torch.compile will automatically generate a horizontally fused kernel for optimal performance.
See tutorial here.
In release 2.5.0, FlexAttention* torch.nn.attention.flex_attention* was introduced for ML researchers who’d like to customize their attention kernels without writing kernel code. This update introduces a decoding backend optimized for inference, supporting GQA and PagedAttention, along with feature updates including nested jagged tensor support, performance tuning guides and trainable biases support.
Prologue fusion optimizes matrix multiplication (matmul) operations by fusing operations that come before the matmul into the matmul kernel itself, improving performance by reducing global memory bandwidth.

We are excited to announce the release of PyTorch® 2.7 (release notes)! This release features:
This release is composed of 3262 commits from 457 contributors since PyTorch 2.6. We want to sincerely thank our dedicated community for your contributions. As always, we encourage you to try these out and report any issues as we improve 2.7. More information about how to get started with the PyTorch 2-series can be found at our Getting Started page.
| Beta | Prototype |
| Torch.Compile support for Torch Function Modes | NVIDIA Blackwell Architecture Support |
| Mega Cache | PyTorch Native Context Parallel |
| Enhancing Intel GPU Acceleration | |
| FlexAttention LLM first token processing on x86 CPUs | |
| FlexAttention LLM throughput mode optimization on x86 CPUs | |
| Foreach Map | |
| Flex Attention for Inference | |
| Prologue Fusion Support in Inductor |
*To see a full list of public feature submissions click here.
This feature enables users to override any *torch.** operation to implement custom user-defined behavior. For example, ops can be rewritten to accommodate a specific backend. This is used in FlexAttention to re-write indexing ops.
See the tutorial for more information.
Mega Cache allows users to have end-to-end portable caching for torch. The intended use case is after compiling and executing a model, the user calls torch.compiler.save_cache_artifacts() which will return the compiler artifacts in a portable form. Later, potentially on a different machine, the user may call torch.compiler.load_cache_artifacts() with these artifacts to pre-populate the torch.compile caches in order to jump-start their cache.
See the tutorial for more information.
PyTorch 2.7 introduces support for NVIDIA’s new Blackwell GPU architecture and ships pre-built wheels for CUDA 12.8. For more details on CUDA 12.8 see CUDA Toolkit Release.
More context can also be found here.
PyTorch Context Parallel API allows users to create a Python context so that every *torch.nn.functional.scaled_dot_product_attention() *call within will run with context parallelism. Currently, PyTorch Context Parallel supports 3 attention backends: 1. Flash attention; 2. Efficient attention; and 3. cuDNN attention.
As an example, this is used within TorchTitan as the Context Parallel solution for LLM training.
See tutorial here.
This latest release introduces enhanced performance optimizations for Intel GPU architectures. These improvements accelerate workloads across various Intel GPUs through the following key enhancements:
Ultra Series 2 with Intel® Arc Graphics, and Intel® Arc B-Series graphics on both Windows and Linux.For more information regarding Intel GPU support, please refer to Getting Started Guide.
See also the tutorials here and here.
FlexAttention x86 CPU support was first introduced in PyTorch 2.6, offering optimized implementations — such as PageAttention, which is critical for LLM inference—via the TorchInductor C++ backend. In PyTorch 2.7, more attention variants for first token processing of LLMs are supported. With this feature, users can have a smoother experience running FlexAttention on x86 CPUs, replacing specific scaled_dot_product_attention operators with a unified FlexAttention API, and benefiting from general support and good performance when using torch.compile.
The performance of FlexAttention on x86 CPUs for LLM inference throughput scenarios has been further improved by adopting the new C++ micro-GEMM template ability. This addresses the performance bottlenecks for large batch size scenarios present in PyTorch 2.6. With this enhancement, users can transparently benefit from better performance and a smoother experience when using FlexAttention APIs and torch.compile for LLM throughput serving on x86 CPUs.
This feature uses torch.compile to allow users to apply any pointwise or user-defined function (e.g. torch.add) to lists of tensors, akin to the existing *torch.foreach** ops. The main advantage over the existing *torch.foreach** ops is that any mix of scalars or lists of tensors can be supplied as arguments, and even user-defined python functions can be lifted to apply to lists of tensors. Torch.compile will automatically generate a horizontally fused kernel for optimal performance.
See tutorial here.
In release 2.5.0, FlexAttention* torch.nn.attention.flex_attention* was introduced for ML researchers who’d like to customize their attention kernels without writing kernel code. This update introduces a decoding backend optimized for inference, supporting GQA and PagedAttention, along with feature updates including nested jagged tensor support, performance tuning guides and trainable biases support.
Prologue fusion optimizes matrix multiplication (matmul) operations by fusing operations that come before the matmul into the matmul kernel itself, improving performance by reducing global memory bandwidth.
Ratings and reviews are an invaluable resource for users exploring an app on the App Store, providing insights into how others have experienced the app. With review summaries now available in iOS 18.4, users can quickly get a high-level overview of what other users think about an app, while still having the option to dive into individual reviews for more detail. This feature is powered by a novel, multi-step LLM-based system that periodically summarizes user reviews.
Our goal in producing review summaries is to ensure they are inclusive, balanced, and accurately reflect the user’s voice. To…Apple Machine Learning Research
As statistical analyses become more central to science, industry and society, there is a growing need to ensure correctness of their results. Approximate correctness can be verified by replicating the entire analysis, but can we verify without replication? Building on a recent line of work, we study proof-systems that allow a probabilistic verifier to ascertain that the results of an analysis are approximately correct, while drawing fewer samples and using less computational resources than would be needed to replicate the analysis. We focus on distribution testing problems: verifying that an…Apple Machine Learning Research
Archival data in research institutions and national laboratories represents a vast repository of historical knowledge, yet much of it remains inaccessible due to factors like limited metadata and inconsistent labeling. Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights.
To address these challenges, a U.S. National Laboratory has implemented an AI-driven document processing platform that integrates named entity recognition (NER) and large language models (LLMs) on Amazon SageMaker AI. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization. By using Mixtral-8x7B for abstractive summarization and title generation, alongside a BERT-based NER model for structured metadata extraction, the system significantly improves the organization and retrieval of scanned documents.
Designed with a serverless, cost-optimized architecture, the platform provisions SageMaker endpoints dynamically, providing efficient resource utilization while maintaining scalability. The integration of modern natural language processing (NLP) and LLM technologies enhances metadata accuracy, enabling more precise search functionality and streamlined document management. This approach supports the broader goal of digital transformation, making sure that archival data can be effectively used for research, policy development, and institutional knowledge retention.
In this post, we discuss how you can build an AI-powered document processing platform with open source NER and LLMs on SageMaker.
The NER & LLM Gen AI Application is a document processing solution built on AWS that combines NER and LLMs to automate document analysis at scale. The system addresses the challenges of processing large volumes of textual data by using two key models: Mixtral-8x7B for text generation and summarization, and a BERT NER model for entity recognition.
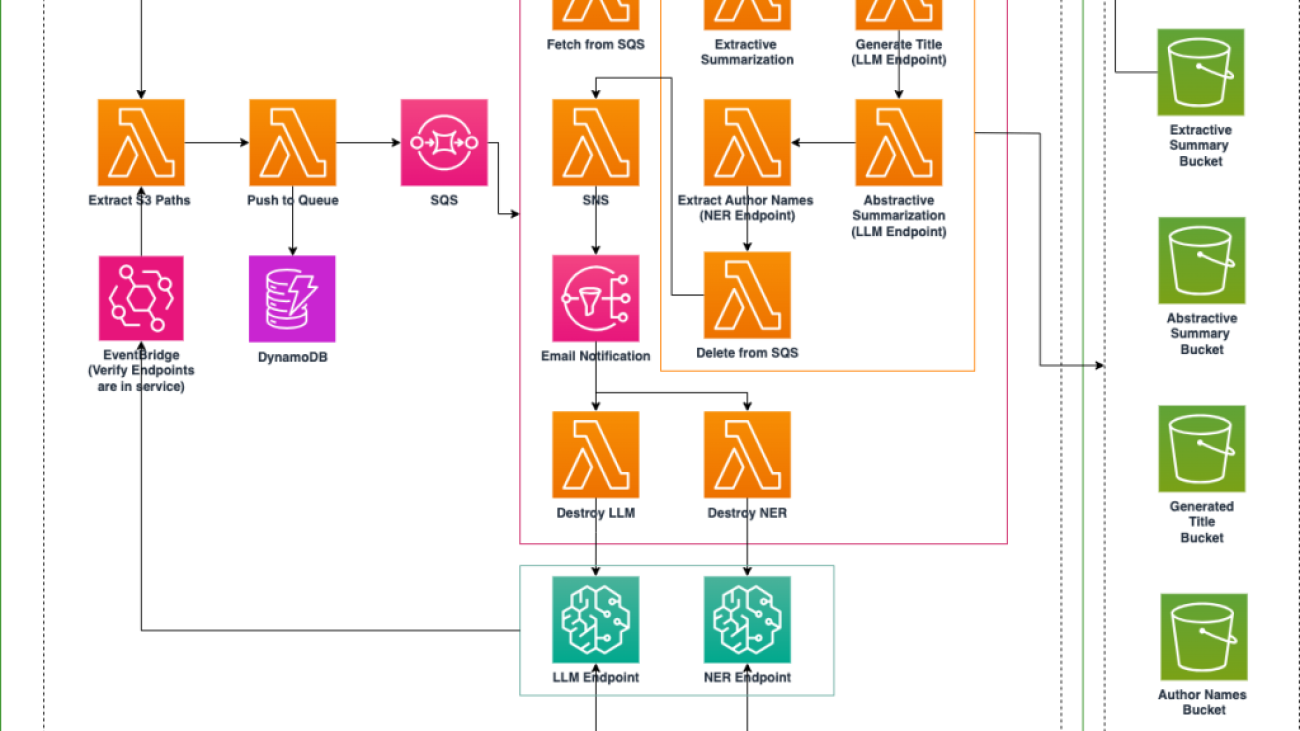
The following diagram illustrates the solution architecture.

The architecture implements a serverless design with dynamically managed SageMaker endpoints that are created on demand and destroyed after use, optimizing performance and cost-efficiency. The application follows a modular structure with distinct components handling different aspects of document processing, including extractive summarization, abstractive summarization, title generation, and author extraction. These modular pieces can be removed, replaced, duplicated, and patterned against for optimal reusability.
The processing workflow begins when documents are detected in the Extracts Bucket, triggering a comparison against existing processed files to prevent redundant operations. The system then orchestrates the creation of necessary model endpoints, processes documents in batches for efficiency, and automatically cleans up resources upon completion. Multiple specialized Amazon Simple Storage Service Buckets (Amazon S3 Bucket) store different types of outputs.
Click here to open the AWS console and follow along.
The application uses a multi-bucket Amazon S3 storage architecture designed for clarity, efficient processing tracking, and clear separation of document processing stages. Each bucket serves a specific purpose in the pipeline, providing organized data management and simplified access control. Amazon DynamoDB is used to track the processing of each document.
The bucket types are as follows:
The SageMaker endpoints in this application represent a dynamic, cost-optimized approach to machine learning (ML) model deployment. Rather than maintaining constantly running endpoints, the system creates them on demand when document processing begins and automatically stops them upon completion. Two primary endpoints are managed: one for the Mixtral-8x7B LLM, which handles text generation tasks including abstractive summarization and title generation, and another for the BERT-based NER model responsible for author extraction. This endpoint based architecture provides decoupling between the other processing, allowing independent scaling, versioning, and maintenance of each component. The decoupled nature of the endpoints also provides flexibility to update or replace individual models without impacting the broader system architecture.
The endpoint lifecycle is orchestrated through dedicated AWS Lambda functions that handle creation and deletion. When processing is triggered, endpoints are automatically initialized and model artifacts are downloaded from Amazon S3. The LLM endpoint is provisioned on ml.p4d.24xlarge (GPU) instances to provide sufficient computational power for the LLM operations. The NER endpoint is deployed on a ml.c5.9xlarge instance (CPU), which is sufficient to support this language model. To maximize cost-efficiency, the system processes documents in batches while the endpoints are active, allowing multiple documents to be processed during a single endpoint deployment cycle and maximizing the usage of the endpoints.
For usage awareness, the endpoint management system includes notification mechanisms through Amazon Simple Notification Service (Amazon SNS). Users receive notifications when endpoints are destroyed, providing visibility that a large instance is destroyed and not idling. The entire endpoint lifecycle is integrated into the broader workflow through AWS Step Functions, providing coordinated processing across all components of the application.
The following figure illustrates the Step Functions workflow.

The application implements a processing pipeline through AWS Step Functions, orchestrating a series of Lambda functions that handle distinct aspects of document analysis. Multiple documents are processed in batches while endpoints are active, maximizing resource utilization. When processing is complete, the workflow automatically triggers endpoint deletion, preventing unnecessary resource consumption.
The highly modular Lambda functions are designed for flexibility and extensibility, enabling their adaptation for diverse use cases beyond their default implementations. For example, the abstractive summarization can be reused to do QnA or other forms of generation, and the NER model can be used to recognize other entity types such as organizations or locations.
The document processing workflow orchestrates multiple stages of analysis that operate both in parallel and sequential patterns. The Step Functions coordinates the movement of documents through extractive summarization, abstractive summarization, title generation, and author extraction processes. Each stage is managed as a discrete step, with clear input and output specifications, as illustrated in the following figure.
In the following sections, we look at each step of the logical flow in more detail.

The extractive summarization process employs the TextRank algorithm, powered by sumy and NLTK libraries, to identify and extract the most significant sentences from source documents. This approach treats sentences as nodes within a graph structure, where the importance of each sentence is determined by its relationships and connections to other sentences. The algorithm analyzes these interconnections to identify key sentences that best represent the document’s core content, functioning similarly to how an editor would select the most important passages from a text. This method preserves the original wording while reducing the document to its most essential components.
The title generation process uses the Mixtral-8x7B model but focuses on creating concise, descriptive titles that capture the document’s main theme. It uses the extractive summary as input to provide efficiency and focus on key content. The LLM is prompted to analyze the main topics and themes present in the summary and generate an appropriate title that effectively represents the document’s content. This approach makes sure that generated titles are both relevant and informative, providing users with a quick understanding of the document’s subject matter without needing to read the full text.
Abstractive summarization also uses the Mixtral-8x7B LLM to generate entirely new text that captures the essence of the document. Unlike extractive summarization, this method doesn’t simply select existing sentences, but creates new content that paraphrases and restructures the information. The process takes the extractive summary as input, which helps reduce computation time and costs by focusing on the most relevant content. This approach results in summaries that read more naturally and can effectively condense complex information into concise, readable text.
Author extraction employs a BERT NER model to identify and classify author names within documents. The process specifically focuses on the first 1,500 characters of each document, where author information typically appears. The system follows a three-stage process: first, it detects potential name tokens with confidence scoring; second, it assembles related tokens into complete names; and finally, it validates the assembled names to provide proper formatting and eliminate false positives. The model can recognize various entity types (PER, ORG, LOC, MISC) but is specifically tuned to identify person names in the context of document authorship.
The solution achieves remarkable throughput by processing 100,000 documents within a 12-hour window. Key architectural decisions drive both performance and cost optimization. By implementing extractive summarization as an initial step, the system reduces input tokens by 75-90% (depending on the size of the document), substantially decreasing the workload for downstream LLM processing. The implementation of a dedicated NER model for author extraction yields an additional 33% reduction in LLM calls by bypassing the need for the more resource-intensive language model. These strategic optimizations create a compound effect – accelerating processing speeds while simultaneously reducing operational costs – establishing the platform as an efficient and cost-effective solution for enterprise-scale document processing needs. To estimate cost for processing 100,000 documents, multiply 12 by the cost per hour of the ml.p4d.24xlarge instance in your AWS region. It’s important to note that instance costs vary by region and may change over time, so current pricing should be consulted for accurate cost projections.
To deploy follow along the instruction in the GitHub repo.
Clean up instructions can be found in this section.
The NER & LLM Gen AI Application represents an organizational advancement in automated document processing, using powerful language models in an efficient serverless architecture. Through its implementation of both extractive and abstractive summarization, named entity recognition, and title generation, the system demonstrates the practical application of modern AI technologies in handling complex document analysis tasks. The application’s modular design and flexible architecture enable organizations to adapt and extend its capabilities to meet their specific needs, while the careful management of AWS resources through dynamic endpoint creation and deletion maintains cost-effectiveness. As organizations continue to face growing demands for efficient document processing, this solution provides a scalable, maintainable and customizable framework for automating and streamlining these workflows.
 Nick Biso is a Machine Learning Engineer at AWS Professional Services. He solves complex organizational and technical challenges using data science and engineering. In addition, he builds and deploys AI/ML models on the AWS Cloud. His passion extends to his proclivity for travel and diverse cultural experiences.
Nick Biso is a Machine Learning Engineer at AWS Professional Services. He solves complex organizational and technical challenges using data science and engineering. In addition, he builds and deploys AI/ML models on the AWS Cloud. His passion extends to his proclivity for travel and diverse cultural experiences.
 Dr. Ian Lunsford is an Aerospace Cloud Consultant at AWS Professional Services. He integrates cloud services into aerospace applications. Additionally, Ian focuses on building AI/ML solutions using AWS services.
Dr. Ian Lunsford is an Aerospace Cloud Consultant at AWS Professional Services. He integrates cloud services into aerospace applications. Additionally, Ian focuses on building AI/ML solutions using AWS services.
 Max Rathmann is a Senior DevOps Consultant at Amazon Web Services, where she specializes in architecting cloud-native, server-less applications. She has a background in operationalizing AI/ML solutions and designing MLOps solutions with AWS Services.
Max Rathmann is a Senior DevOps Consultant at Amazon Web Services, where she specializes in architecting cloud-native, server-less applications. She has a background in operationalizing AI/ML solutions and designing MLOps solutions with AWS Services.
 Michael Massey is a Cloud Application Architect at Amazon Web Services, where he specializes in building frontend and backend cloud-native applications. He designs and implements scalable and highly-available solutions and architectures that help customers achieve their business goals.
Michael Massey is a Cloud Application Architect at Amazon Web Services, where he specializes in building frontend and backend cloud-native applications. He designs and implements scalable and highly-available solutions and architectures that help customers achieve their business goals.
 Jeff Ryan is a DevOps Consultant at AWS Professional Services, specializing in AI/ML, automation, and cloud security implementations. He focuses on helping organizations leverage AWS services like Bedrock, Amazon Q, and SageMaker to build innovative solutions. His expertise spans MLOps, GenAI, serverless architectures, and Infrastructure as Code (IaC).
Jeff Ryan is a DevOps Consultant at AWS Professional Services, specializing in AI/ML, automation, and cloud security implementations. He focuses on helping organizations leverage AWS services like Bedrock, Amazon Q, and SageMaker to build innovative solutions. His expertise spans MLOps, GenAI, serverless architectures, and Infrastructure as Code (IaC).
 Dr. Brian Weston is a research manager at the Center for Applied Scientific Computing, where he is the AI/ML Lead for the Digital Twins for Additive Manufacturing Strategic Initiative, a project focused on building digital twins for certification and qualification of 3D printed components. He also holds a program liaison role between scientists and IT staff, where Weston champions the integration of cloud computing with digital engineering transformation, driving efficiency and innovation for mission science projects at the laboratory.
Dr. Brian Weston is a research manager at the Center for Applied Scientific Computing, where he is the AI/ML Lead for the Digital Twins for Additive Manufacturing Strategic Initiative, a project focused on building digital twins for certification and qualification of 3D printed components. He also holds a program liaison role between scientists and IT staff, where Weston champions the integration of cloud computing with digital engineering transformation, driving efficiency and innovation for mission science projects at the laboratory.
 Ian Thompson is a Data Engineer at Enterprise Knowledge, specializing in graph application development and data catalog solutions. His experience includes designing and implementing graph architectures that improve data discovery and analytics across organizations. He is also the #1 Square Off player in the world.
Ian Thompson is a Data Engineer at Enterprise Knowledge, specializing in graph application development and data catalog solutions. His experience includes designing and implementing graph architectures that improve data discovery and analytics across organizations. He is also the #1 Square Off player in the world.
 Anna D’Angela is a Data Engineer at Enterprise Knowledge within the Semantic Engineering and Enterprise AI practice. She specializes in the design and implementation of knowledge graphs.
Anna D’Angela is a Data Engineer at Enterprise Knowledge within the Semantic Engineering and Enterprise AI practice. She specializes in the design and implementation of knowledge graphs.
Retrieval Augmented Generation (RAG) applications have become increasingly popular due to their ability to enhance generative AI tasks with contextually relevant information. Implementing RAG-based applications requires careful attention to security, particularly when handling sensitive data. The protection of personally identifiable information (PII), protected health information (PHI), and confidential business data is crucial because this information flows through RAG systems. Failing to address these security considerations can lead to significant risks and potential data breaches. For healthcare organizations, financial institutions, and enterprises handling confidential information, these risks can result in regulatory compliance violations and breach of customer trust. See the OWASP Top 10 for Large Language Model Applications to learn more about the unique security risks associated with generative AI applications.
Developing a comprehensive threat model for your generative AI applications can help you identify potential vulnerabilities related to sensitive data leakage, prompt injections, unauthorized data access, and more. To assist in this effort, AWS provides a range of generative AI security strategies that you can use to create appropriate threat models.
Amazon Bedrock Knowledge Bases is a fully managed capability that simplifies the management of the entire RAG workflow, empowering organizations to give foundation models (FMs) and agents contextual information from your private data sources to deliver more relevant and accurate responses tailored to your specific needs. Additionally, with Amazon Bedrock Guardrails, you can implement safeguards in your generative AI applications that are customized to your use cases and responsible AI policies. You can redact sensitive information such as PII to protect privacy using Amazon Bedrock Guardrails.
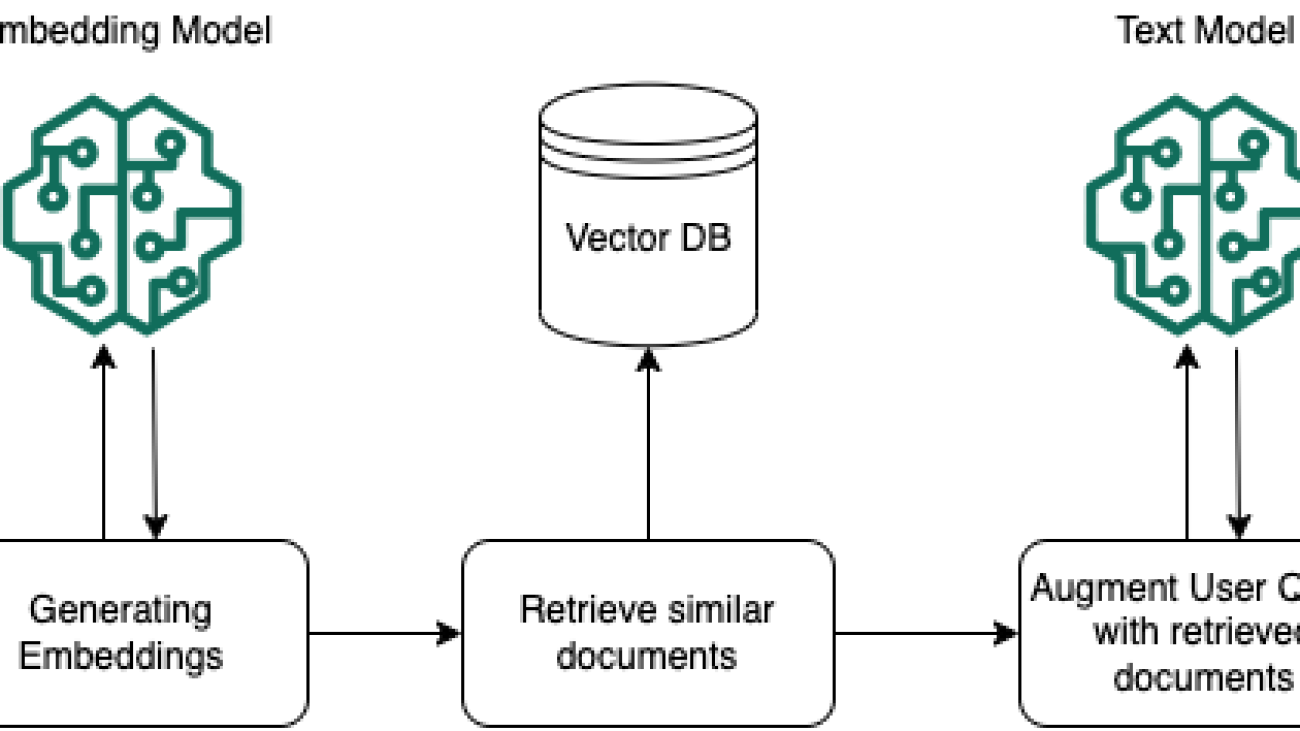
RAG consists of two major steps:
The following diagram shows the architectural workflow of a RAG system, illustrating how a user’s query is processed through multiple stages to generate an informed response

In this post we present two architecture patterns: data redaction at storage level and role-based access, for protecting sensitive data when building RAG-based applications using Amazon Bedrock Knowledge Bases.
Data redaction at storage level – Identifying and redacting (or masking) sensitive data before storing them to the vector store (ingestion) using Amazon Bedrock Knowledge Bases. This zero-trust approach to data sensitivity reduces the risk of sensitive information being inadvertently disclosed to unauthorized users.
Role-based access to sensitive data – Controlling selective access to sensitive information based on user roles and permissions during retrieval. This approach is best in situations where sensitive data needs to be stored in the vector store, such as in healthcare settings with distinct user roles like administrators (doctors) and non-administrators (nurses or support personnel).
For all data stored in Amazon Bedrock, the AWS shared responsibility model applies.
Let’s dive in to understand how to implement the data redaction at storage level and role-based access architecture patterns effectively.
The ingestion flow implements a four-step process to help protect sensitive data when building RAG applications with Amazon Bedrock:
This multi-layered approach focuses on securing text content while highlighting the importance of implementing additional safeguards for image processing. Organizations should evaluate their multi-modal document requirements and extend the security framework accordingly.
The following illustration demonstrates a secure document processing pipeline for handling sensitive data before ingestion into Amazon Bedrock Knowledge Bases.

The high-level steps are as follows:
inputs folder in the source bucket. An EventBridge rule triggers a Lambda function (ComprehendLambda).ComprehendLambda function monitors for new files in the inputs folder of the source bucket and moves landed files to a processing folder. It then launches an asynchronous Amazon Comprehend PII redaction analysis job and records the job ID and status in an Amazon DynamoDB JobTracking table for monitoring job completion. The Amazon Comprehend PII redaction job automatically redacts and masks sensitive elements such as names, addresses, phone numbers, Social Security numbers, driver’s license IDs, and banking information with the entity type. The job replaces these identified PII entities with placeholder tokens, such as [NAME], [SSN] etc. The entities to mask can be configured using RedactionConfig. For more information, see Redacting PII entities with asynchronous jobs (API). The MaskMode in RedactionConfig is set to REPLACE_WITH_PII_ENTITY_TYPE instead of MASK; redacting with a MaskCharacter would affect the quality of retrieved documents because many documents could contain the same MaskCharacter, thereby affecting the retrieval quality. After completion, the redacted files move to the for_macie_scan folder for secondary scanning.MacieLambda) monitors the completion of the Amazon Comprehend PII redaction job. When the job is complete, the function triggers a Macie one-time sensitive data detection job with files in the for_macie_scan folder.quarantine folder for human review by authorized personnel with appropriate permissions and access controls, whereas files with low severity ratings are moved to a designated redacted bucket, which then triggers a data ingestion job to the Amazon Bedrock knowledge base.This process helps prevent sensitive details from being exposed when the model generates responses based on retrieved data.
The augmented retrieval flow diagram shows how user queries are processed securely. It illustrates the complete workflow from user authentication through Amazon Cognito to response generation with Amazon Bedrock, including guardrail interventions that help prevent policy violations in both inputs and outputs.

The high-level steps are as follows:
To deploy Scenario 1, find the instructions here on Github
In this scenario, we demonstrate a comprehensive security approach that combines role-based access control (RBAC) with intelligent PII guardrails for RAG applications. It integrates Amazon Bedrock with AWS identity services to automatically enforce security through different guardrail configurations for admin and non-admin users.
The solution uses the metadata filtering capabilities of Amazon Bedrock Knowledge Bases to dynamically filter documents during similarity searches using metadata attributes assigned before ingestion. For example, admin and non-admin metadata attributes are created and attached to relevant documents before the ingestion process. During retrieval, the system returns only the documents with metadata matching the user’s security role and permissions and applies the relevant guardrail policies to either mask or block sensitive data detected on the LLM output.
This metadata-driven approach, combined with features like custom guardrails, real-time PII detection, masking, and comprehensive access logging creates a robust framework that maintains the security and utility of the RAG application while enforcing RBAC.
The following diagram illustrates how RBAC works with metadata filtering in the vector database.

For a detailed understanding of how metadata filtering works, see Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy.
The augmented retrieval flow diagram shows how user queries are processed securely based on role-based access.

The workflow consists of the following steps:
To deploy Scenario 2, find the instructions here on Github
This security architecture combines Amazon Bedrock guardrails with granular access controls to automatically manage sensitive information exposure based on user permissions. The multi-layered approach makes sure organizations maintain security compliance while fully utilizing their knowledge base, proving security and functionality can coexist.
The solution offers several customization points to enhance its flexibility and adaptability:
With these customization options, you can tailor the solution to your specific needs, providing a robust and flexible security framework for your RAG applications. This approach not only protects sensitive data but also maintains the utility and efficiency of the knowledge base, allowing users to interact with the system while automatically enforcing role-appropriate information access and PII handling.
At AWS, security is our top priority and security in the cloud is a shared responsibility between AWS and our customers. With AWS, you control your data by using AWS services and tools to determine where your data is stored, how it is secured, and who has access to it. Services such as AWS Identity and Access Management (IAM) provide robust mechanisms for securely controlling access to AWS services and resources.
To enhance your security posture further, services like AWS CloudTrail and Amazon Macie offer advanced compliance, detection, and auditing capabilities. When it comes to encryption, AWS CloudHSM and AWS Key Management Service (KMS) enable you to generate and manage encryption keys with confidence.
For organizations seeking to establish governance and maintain data residency controls, AWS Control Tower offers a comprehensive solution. For more information on Data protection and Privacy, refer to Data Protection and Privacy at AWS.
While our solution demonstrates the use of PII detection and redaction techniques, it does not provide an exhaustive list of all PII types or detection methods. As a customer, you bear the responsibility for implementing the appropriate PII detection types and redaction methods using AWS services, including Amazon Bedrock Guardrails and other open-source libraries. The regular expressions configured in Bedrock Guardrails within this solution serve as a reference example only and do not cover all possible variations for detecting PII types. For instance, date of birth (DOB) formats can vary widely. Therefore, it falls on you to configure Bedrock Guardrails and policies to accurately detect the PII types relevant to your use case. Amazon Bedrock maintains strict data privacy standards. The service does not store or log your prompts and completions, nor does it use them to train AWS models or share them with third parties. We implement this through our Model Deployment Account architecture – each AWS Region where Amazon Bedrock is available has a dedicated deployment account per model provider, managed exclusively by the Amazon Bedrock service team. Model providers have no access to these accounts. When a model is delivered to AWS, Amazon Bedrock performs a deep copy of the provider’s inference and training software into these controlled accounts for deployment, making sure that model providers cannot access Amazon Bedrock logs or customer prompts and completions.
Ultimately, while we provide the tools and infrastructure, the responsibility for securing your data using AWS services rests with you, the customer. This shared responsibility model makes sure that you have the flexibility and control to implement security measures that align with your unique requirements and compliance needs, while we maintain the security of the underlying cloud infrastructure. For comprehensive information about Amazon Bedrock security, please refer to the Amazon Bedrock Security documentation.
In this post, we explored two approaches for securing sensitive data in RAG applications using Amazon Bedrock. The first approach focused on identifying and redacting sensitive data before ingestion into an Amazon Bedrock knowledge base, and the second demonstrated a fine-grained RBAC pattern for managing access to sensitive information during retrieval. These solutions represent just two possible approaches among many for securing sensitive data in generative AI applications.
Security is a multi-layered concern that requires careful consideration across all aspects of your application architecture. Looking ahead, we plan to dive deeper into RBAC for sensitive data within structured data stores when used with Amazon Bedrock Knowledge Bases. This can provide additional granularity and control over data access patterns while maintaining security and compliance requirements. Securing sensitive data in RAG applications requires ongoing attention to evolving security best practices, regular auditing of access patterns, and continuous refinement of your security controls as your applications and requirements grow.
To enhance your understanding of Amazon Bedrock security implementation, explore these additional resources:
The complete source code and deployment instructions for these solutions are available in our GitHub repository.
We encourage you to explore the repository for detailed implementation guidance and customize the solutions based on your specific requirements using the customization points discussed earlier.
 Praveen Chamarthi brings exceptional expertise to his role as a Senior AI/ML Specialist at Amazon Web Services, with over two decades in the industry. His passion for Machine Learning and Generative AI, coupled with his specialization in ML inference on Amazon SageMaker and Amazon Bedrock, enables him to empower organizations across the Americas to scale and optimize their ML operations. When he’s not advancing ML workloads, Praveen can be found immersed in books or enjoying science fiction films. Connect with him on LinkedIn to follow his insights.
Praveen Chamarthi brings exceptional expertise to his role as a Senior AI/ML Specialist at Amazon Web Services, with over two decades in the industry. His passion for Machine Learning and Generative AI, coupled with his specialization in ML inference on Amazon SageMaker and Amazon Bedrock, enables him to empower organizations across the Americas to scale and optimize their ML operations. When he’s not advancing ML workloads, Praveen can be found immersed in books or enjoying science fiction films. Connect with him on LinkedIn to follow his insights.
 Srikanth Reddy is a Senior AI/ML Specialist with Amazon Web Services. He is responsible for providing deep, domain-specific expertise to enterprise customers, helping them use AWS AI and ML capabilities to their fullest potential. You can find him on LinkedIn.
Srikanth Reddy is a Senior AI/ML Specialist with Amazon Web Services. He is responsible for providing deep, domain-specific expertise to enterprise customers, helping them use AWS AI and ML capabilities to their fullest potential. You can find him on LinkedIn.
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing and artificial intelligence. He focuses on deep learning, including NLP and computer vision domains. He helps customers achieve high-performance model inference on Amazon SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing and artificial intelligence. He focuses on deep learning, including NLP and computer vision domains. He helps customers achieve high-performance model inference on Amazon SageMaker.
 Vivek Bhadauria is a Principal Engineer at Amazon Bedrock with almost a decade of experience in building AI/ML services. He now focuses on building generative AI services such as Amazon Bedrock Agents and Amazon Bedrock Guardrails. In his free time, he enjoys biking and hiking.
Vivek Bhadauria is a Principal Engineer at Amazon Bedrock with almost a decade of experience in building AI/ML services. He now focuses on building generative AI services such as Amazon Bedrock Agents and Amazon Bedrock Guardrails. In his free time, he enjoys biking and hiking.
 Brandon Rooks Sr. is a Cloud Security Professional with 20+ years of experience in the IT and Cybersecurity field. Brandon joined AWS in 2019, where he dedicates himself to helping customers proactively enhance the security of their cloud applications and workloads. Brandon is a lifelong learner, and holds the CISSP, AWS Security Specialty, and AWS Solutions Architect Professional certifications. Outside of work, he cherishes moments with his family, engaging in various activities such as sports, gaming, music, volunteering, and traveling.
Brandon Rooks Sr. is a Cloud Security Professional with 20+ years of experience in the IT and Cybersecurity field. Brandon joined AWS in 2019, where he dedicates himself to helping customers proactively enhance the security of their cloud applications and workloads. Brandon is a lifelong learner, and holds the CISSP, AWS Security Specialty, and AWS Solutions Architect Professional certifications. Outside of work, he cherishes moments with his family, engaging in various activities such as sports, gaming, music, volunteering, and traveling.
 Vikash Garg is a Principal Engineer at Amazon Bedrock with almost 4 years of experience in building AI/ML services. He has a decade of experience in building large-scale systems. He now focuses on building the generative AI service AWS Bedrock Guardrails. In his free time, he enjoys hiking and traveling.
Vikash Garg is a Principal Engineer at Amazon Bedrock with almost 4 years of experience in building AI/ML services. He has a decade of experience in building large-scale systems. He now focuses on building the generative AI service AWS Bedrock Guardrails. In his free time, he enjoys hiking and traveling.
