CMU researchers are presenting 143 papers at the Thirteenth International Conference on Learning Representations (ICLR 2025), held from April 24 – 28 at the Singapore EXPO. Here is a quick overview of the areas our researchers are working on:

And here are our most frequent collaborator institutions:

Table of Contents
- Oral Papers
- Spotlight Papers
- Poster Papers
- Alignment, Fairness, Safety, Privacy, And Societal Considerations
- Applications to Computer Vision, Audio, Language, And Other Modalities
- Applications to Neuroscience & Cognitive Science
- Applications to Physical Sciences (Physics, Chemistry, Biology, Etc.)
- Applications to Robotics, Autonomy, Planning
- Causal Reasoning
- Datasets and Benchmarks
- Foundation or Frontier Models, Including LLMs
- Generative Models
- Infrastructure, Software Libraries, Hardware, Systems, etc.
- Interpretability and Explainable AI
- Learning on Graphs and Other Geometries & Topologies
- Learning Theory
- Neurosymbolic & Hybrid AI Systems (Physics-Informed, Logic & Formal Reasoning, etc.)
- Optimization
- Other Topics in Machine Learning (i.e., none of the above)
- Probabilistic Methods (Bayesian Methods, Variational Inference, Sampling, Uncertainty Quantification, etc.)
- Reinforcement Learning
- Transfer Learning, Meta Learning, and Lifelong Learning
- Unsupervised, Self-supervised, Semi-supervised, and Supervised Representation Learning
Oral Papers
Backtracking Improves Generation Safety
Authors: Yiming Zhang, Jianfeng Chi, Hailey Nguyen, Kartikeya Upasani, Daniel M. Bikel, Jason E Weston, Eric Michael Smith
This paper introduces backtracking, a new technique that allows language models to recover from unsafe text generation by using a special [RESET] token to “undo” problematic outputs. Unlike traditional safety methods that aim to prevent harmful responses outright, backtracking trains the model to self-correct mid-generation. The authors demonstrate that backtracking significantly improves safety without sacrificing helpfulness, and it also provides robustness against several adversarial attacks.
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Authors: Terry Yue Zhuo, Vu Minh Chien, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, Simon Brunner, Chen Gong, James Hoang, Armel Randy Zebaze, Xiaoheng Hong, Wen-ding Li, Jean Kaddour, Ming Xu, Zhihan Zhang, Prateek Yadav, Naman Jain, Alex Gu, Zhoujun Cheng, Jiawei Liu, Qian Liu, Zijian Wang, David Lo, Binyuan Hui, Niklas Muennighoff, Daniel Fried, Xiaoning Du, Harm De Vries, Leandro Von Werra
Recent advances in LLMs have enabled task automation through Python code, but existing benchmarks mainly focus on simple, self-contained tasks. To assess LLMs’ ability to handle more practical challenges requiring diverse and compositional function use, the authors introduce BigCodeBench—a benchmark covering 1,140 tasks across 139 libraries and 7 domains. Each task includes rigorous testing with high branch coverage, and a variant, BigCodeBench-Instruct, reformulates instructions for natural language evaluation. Results from testing 60 LLMs reveal significant performance gaps, highlighting that current models struggle to follow complex instructions and compose function calls accurately compared to human performance.
Context-Parametric Inversion: Why Instruction Finetuning May Not Actually Improve Context Reliance
Authors: Sachin Goyal, Christina Baek, J Zico Kolter, Aditi Raghunathan
LLMs are expected to follow user-provided context, especially when they contain new or conflicting information. While instruction finetuning should improve this ability, the authors uncover a surprising failure mode called context-parametric inversion: models initially rely more on input context, but this reliance decreases as finetuning continues—even as benchmark performance improves. Through controlled experiments and theoretical analysis, the authors trace the cause to training examples where context aligns with pretraining knowledge, reinforcing parametric reliance. They suggest mitigation strategies and highlight this as a key challenge in instruction tuning.
EmbodiedSAM: Online Segment Any 3D Thing in Real Time
Authors: Xiuwei Xu, Huangxing Chen, Linqing Zhao, Ziwei Wang, Jie Zhou, Jiwen Lu
Embodied tasks demand fine-grained 3D perception, which is difficult to achieve due to limited high-quality 3D data. To address this, the authors propose a method that leverages the Segment Anything Model (SAM) for online 3D instance segmentation by transforming 2D masks into 3D-aware queries. Their approach enables real-time object matching across video frames and efficient inference using a similarity matrix. Experiments across multiple datasets show that the method outperforms offline alternatives and generalizes well to new settings with minimal data.
LLM-SR: Scientific Equation Discovery via Programming with Large Language Models
Authors: Parshin Shojaee, Kazem Meidani, Shashank Gupta, Amir Barati Farimani, Chandan K. Reddy
Mathematical equations are remarkably effective at describing natural phenomena, but discovering them from data is challenging due to vast combinatorial search spaces. Existing symbolic regression methods often overlook domain knowledge and rely on limited representations. To address this, the authors propose LLM-SR, a novel approach that uses Large Language Models to generate equation hypotheses informed by scientific priors and refines them through evolutionary search. Evaluated across multiple scientific domains, LLM-SR outperforms existing methods, particularly in generalization, by efficiently exploring the equation space and producing accurate, interpretable models.
Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models
Authors: Yuda Song, Hanlin Zhang, Udaya Ghai, Carson Eisenach, Sham M. Kakade, Dean Foster
Self-improvement in Large Language Models involves the model verifying its outputs, filtering data accordingly, and using the refined data for further learning. While effective in practice, there has been little theoretical grounding for this technique. This work presents a comprehensive study of LLM self-improvement, introducing a formal framework centered on the generation-verification gap—a key quantity that governs self-improvement. Experiments reveal that this gap scales consistently with pretraining FLOPs across tasks and model families. The authors also explore when and how iterative self-improvement works and offer insights and strategies to enhance it.
On the Benefits of Memory for Modeling Time-Dependent PDEs
Authors: Ricardo Buitrago, Tanya Marwah, Albert Gu, Andrej Risteski
Data-driven methods offer an efficient alternative to traditional numerical solvers for PDEs, but most existing approaches assume Markovian dynamics, limiting their effectiveness when input signals are distorted. Inspired by the Mori-Zwanzig theory, the authors propose MemNO, a Memory Neural Operator that explicitly incorporates past states using structured state-space models and the Fourier Neural Operator. MemNO demonstrates strong performance on various PDE families, especially on low-resolution inputs, achieving over six times lower error than memoryless baselines.
On the Identification of Temporal Causal Representation with Instantaneous Dependence
Authors: Zijian Li, Yifan Shen, Kaitao Zheng, Ruichu Cai, Xiangchen Song, Mingming Gong, Guangyi Chen, Kun Zhang
This work introduces IDOL (Identification framework for Instantaneous Latent dynamics), a method designed to identify latent causal processes in time series data, even when instantaneous relationships are present. Unlike existing methods that require interventions or grouping of observations, IDOL imposes a sparse influence constraint, allowing both time-delayed and instantaneous causal relations to be captured. Through a temporally variational inference architecture and gradient-based sparsity regularization, IDOL effectively estimates latent variables. Experimental results show that IDOL can identify latent causal processes in simulations and real-world human motion forecasting tasks, demonstrating its practical applicability.
Progressive distillation induces an implicit curriculum
Authors: Abhishek Panigrahi, Bingbin Liu, Sadhika Malladi, Andrej Risteski, Surbhi Goel
This work explores the concept of progressive distillation, where a student model learns from intermediate checkpoints of a teacher model, rather than just the final model. The authors identify an “implicit curriculum” that emerges through these intermediate checkpoints, which accelerates the student’s learning and provides a sample complexity benefit. Using sparse parity as a sandbox, they demonstrate that this curriculum imparts valuable learning steps that are unavailable from the final teacher model. The study extends this idea to Transformers trained on probabilistic context-free grammars (PCFGs) and real-world datasets, showing that the teacher progressively teaches the student to capture longer contexts. Both theoretical and empirical results highlight the effectiveness of progressive distillation across different tasks.
Scaling Laws for Precision
Authors: Tanishq Kumar, Zachary Ankner, Benjamin Frederick Spector, Blake Bordelon, Niklas Muennighoff, Mansheej Paul, Cengiz Pehlevan, Christopher Re, Aditi Raghunathan
This work introduces precision-aware scaling laws that extend traditional scaling frameworks to account for the effects of low-precision training and inference in language models. The authors show that lower precision effectively reduces a model’s usable parameter count, enabling predictions of performance degradation due to quantization. For inference, they find that post-training quantization causes increasing degradation with more pretraining data, potentially making additional training counterproductive. Their unified framework predicts loss across varying precisions and suggests that training larger models in lower precision may be more compute-efficient. These predictions are validated on over 465 pretraining runs, including models up to 1.7B parameters.
Self-Improvement in Language Models: The Sharpening Mechanism
Authors: Audrey Huang, Adam Block, Dylan J Foster, Dhruv Rohatgi, Cyril Zhang, Max Simchowitz, Jordan T. Ash, Akshay Krishnamurthy
This paper presents a theoretical framework for understanding how LLMs can self-improve by using themselves as verifiers to refine their own outputs; a process the authors call “sharpening.” The key insight is that LLMs are often better at judging response quality than generating high-quality responses outright, so sharpening helps concentrate probability mass on better sequences. The paper analyzes two families of self-improvement algorithms: one based on supervised fine-tuning (SFT) and one on reinforcement learning (RLHF). They show that while the SFT-based approach is optimal under certain conditions, the RLHF-based approach can outperform it by actively exploring beyond the model’s existing knowledge.
When Selection meets Intervention: Additional Complexities in Causal Discovery
Authors: Haoyue Dai, Ignavier Ng, Jianle Sun, Zeyu Tang, Gongxu Luo, Xinshuai Dong, Peter Spirtes, Kun Zhang
This work tackles the often-overlooked issue of selection bias in interventional studies, where participants are selectively included based on specific criteria. Existing causal discovery methods typically ignore this bias, leading to inaccurate conclusions. To address this, the authors introduce a novel graphical model that distinguishes between the observed world with interventions and the counterfactual world where selection occurs. They develop a sound algorithm that identifies both causal relationships and selection mechanisms, demonstrating its effectiveness through experiments on both synthetic and real-world data.
miniCTX: Neural Theorem Proving with (Long-)Contexts
Authors: Jiewen Hu, Thomas Zhu, Sean Welleck
Real-world formal theorem proving relies heavily on rich contextual information, which is often absent from traditional benchmarks. To address this, the authors introduce miniCTX, a benchmark designed to test models’ ability to prove theorems using previously unseen, extensive context from real Lean projects and textbooks. Unlike prior benchmarks, miniCTX includes large repositories with relevant definitions, lemmas, and structures. Baseline experiments show that models conditioned on this broader context significantly outperform those relying solely on the local state. The authors also provide a toolkit to facilitate the expansion of the benchmark.
Spotlight Papers
ADIFF: Explaining audio difference using natural language
Authors: Soham Deshmukh, Shuo Han, Rita Singh, Bhiksha Raj
This paper tackles the novel task of explaining differences between audio recordings, which is important for applications like audio forensics, quality assessment, and generative audio systems. The authors introduce two new datasets and propose a three-tiered explanation framework—ranging from concise event descriptions to rich, emotionally grounded narratives—generated using large language models. They present ADIFF, a new method that improves on baselines by incorporating audio cross-projection, position-aware captioning, and multi-stage training, and show that it significantly outperforms existing audio-language models both quantitatively and via human evaluation.
Better Instruction-Following Through Minimum Bayes Risk
Authors: Ian Wu, Patrick Fernandes, Amanda Bertsch, Seungone Kim, Sina Khoshfetrat Pakazad, Graham Neubig
This paper explores how LLMs can be used as judges to evaluate and improve other LLMs. The authors show that using a method called Minimum Bayes Risk (MBR) decoding—where an LLM judge selects the best output from a set—can significantly improve model performance compared to standard decoding methods. They also find that training models on these high-quality outputs can lead to strong gains even without relying on MBR at test time, making the models faster and more efficient while maintaining or exceeding previous performance.
DeFT: Decoding with Flash Tree-attention for Efficient Tree-structured LLM Inference
Authors: Jinwei Yao, Kaiqi Chen, Kexun Zhang, Jiaxuan You, Binhang Yuan, Zeke Wang, Tao Lin
This paper introduces DeFT, a new algorithm that speeds up how large language models handle tasks involving tree-like structures with shared text prefixes, such as multi-step reasoning or few-shot prompting. Existing methods waste time and memory by repeatedly accessing the same data and poorly distributing the workload across the GPU. DeFT solves this by smartly grouping and splitting memory usage to avoid redundant operations and better balance the work, leading to up to 3.6x faster performance on key tasks compared to current approaches.
Holistically Evaluating the Environmental Impact of Creating Language Models
Authors: Jacob Morrison, Clara Na, Jared Fernandez, Tim Dettmers, Emma Strubell, Jesse Dodge
This paper estimates the full environmental impact of developing large language models, including not just the final training runs but also model development and hardware manufacturing—areas typically underreported. The authors found that training a series of models released 493 metric tons of carbon emissions and used 2.769 million liters of water, even in a highly efficient data center. Notably, around half of the carbon emissions came from the development phase alone, and power usage during training varied significantly, raising concerns for energy grid planning as AI systems grow.
Language Model Alignment in Multilingual Trolley Problems
Authors: Zhijing Jin, Max Kleiman-weiner, Giorgio Piatti, Sydney Levine, Jiarui Liu, Fernando Gonzalez Adauto, Francesco Ortu, András Strausz, Mrinmaya Sachan, Rada Mihalcea, Yejin Choi, Bernhard Schölkopf
This paper evaluates how well LLMs align with human moral preferences across languages using multilingual trolley problems. The authors introduce MultiTP, a new dataset of moral dilemmas in over 100 languages based on the Moral Machine experiment, enabling cross-lingual analysis of LLM decision-making. By assessing 19 models across six moral dimensions and examining demographic correlations and prompt consistency, they uncover significant variation in moral alignment across languages—highlighting ethical biases and the need for more inclusive, multilingual approaches to responsible AI development.
Lean-STaR: Learning to Interleave Thinking and Proving
Authors: Haohan Lin, Zhiqing Sun, Sean Welleck, Yiming Yang
This paper introduces Lean-STaR, a framework that improves language model-based theorem proving by incorporating informal “thoughts” before each proof step. Unlike traditional approaches that rely solely on formal proof data, Lean-STaR generates synthetic thought processes using retrospective proof tactics during training. At inference time, the model generates these thoughts to guide its next action, and expert iteration further refines its performance using the Lean theorem prover. This approach boosts proof success rates and offers new insights into how structured reasoning improves formal mathematical problem solving.
MagicPIG: LSH Sampling for Efficient LLM Generation
Authors: Zhuoming Chen, Ranajoy Sadhukhan, Zihao Ye, Yang Zhou, Jianyu Zhang, Niklas Nolte, Yuandong Tian, Matthijs Douze, Leon Bottou, Zhihao Jia, Beidi Chen
This paper introduces MagicPIG, a new system that speeds up LLM inference by approximating attention more efficiently. While many methods assume attention is sparse and use TopK approximations, the authors show this isn’t always accurate and can hurt performance. Instead, MagicPIG uses a sampling method backed by theoretical guarantees and accelerates it using Locality Sensitive Hashing, offloading computations to the CPU to support longer inputs and larger batches without sacrificing accuracy.
Multi-Robot Motion Planning with Diffusion Models
Authors: Yorai Shaoul, Itamar Mishani, Shivam Vats, Jiaoyang Li, Maxim Likhachev
This paper introduces a method for planning coordinated, collision-free movements for many robots using only data from individual robots. The authors combine learned diffusion models with classical planning algorithms to generate realistic, safe multi-robot trajectories. Their approach, called Multi-robot Multi-model planning Diffusion, also scales to large environments by stitching together multiple diffusion models, showing strong results in simulated logistics scenarios.
Reinforcement Learning for Control of Non-Markovian Cellular Population Dynamics
Authors: Josiah C Kratz, Jacob Adamczyk
This paper explores how reinforcement learning can be used to develop drug dosing strategies for controlling cell populations that adapt over time, such as cancer cells switching between resistant and susceptible states. Traditional methods struggle when the system’s dynamics are unknown or involve memory of past environments, making optimal control difficult. The authors show that deep RL can successfully learn effective strategies even in complex, memory-based systems, offering a promising approach for real-world biomedical applications.
Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning
Authors: Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, Aviral Kumar
This paper explores how to improve large language models’ reasoning by giving feedback at each step of their thinking process, rather than only at the final answer. The authors introduce a method where feedback—called a process reward—is based on whether a step helps make a correct final answer more likely, as judged by a separate model (a “prover”) that can recognize progress better than the model being trained. They show both theoretically and experimentally that this strategy makes learning more efficient, leading to significantly better and faster results than traditional outcome-based feedback methods.
SVDQuant: Absorbing Outliers by Low-Rank Component for 4-Bit Diffusion Models
Authors: Muyang Li, Yujun Lin, Zhekai Zhang, Tianle Cai, Junxian Guo, Xiuyu Li, Enze Xie, Chenlin Meng, Jun-yan Zhu, Song Han
This paper introduces SVDQuant, a method for significantly speeding up diffusion models by quantizing both weights and activations to 4 bits. Since such aggressive quantization can hurt image quality, the authors use a clever technique: they shift problematic “outlier” values into a separate low-rank component handled with higher precision, while the rest is processed with efficient low-bit operations. To avoid slowing things down due to extra computation, they also design a custom inference engine called Nunchaku, which merges the processing steps to minimize memory access. Together, these techniques reduce memory usage and deliver over 3x speedups without sacrificing image quality.
Stabilizing Reinforcement Learning in Differentiable Multiphysics Simulation
Authors: Eliot Xing, Vernon Luk, Jean Oh
This paper tackles the challenge of applying reinforcement learning (RL) to soft-body robotics, where simulations are usually too slow for data-hungry RL algorithms. The authors introduce SAPO, a new model-based RL algorithm that efficiently learns from differentiable simulations using analytic gradients. The authors also present Rewarped, a fast, parallel simulation platform that supports both rigid and deformable materials, demonstrating that their approach outperforms existing methods on complex manipulation and locomotion tasks.
Streaming Algorithms For $ell_p$ Flows and $ell_p$ Regression
Authors: Amit Chakrabarti, Jeffrey Jiang, David Woodruff, Taisuke Yasuda
This paper investigates how to solve underdetermined linear regression problems in a streaming setting, where the data arrives one column at a time and storing the full dataset is impractical. The authors develop algorithms that approximate the regression cost or output a near-optimal solution using much less memory than storing the entire dataset—particularly relevant for applications like computing flows on large graphs. They also establish space lower bounds, showing the limitations of what’s possible, and provide the first algorithms that achieve nontrivial approximations using sublinear space in various settings.
Poster Papers
Alignment, Fairness, Safety, Privacy, And Societal Considerations
AgentHarm: Benchmarking Robustness of LLM Agents on Harmful Tasks
Authors: Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, J Zico Kolter, Matt Fredrikson, Yarin Gal, Xander Davies
Aligned LLMs Are Not Aligned Browser Agents
Authors: Priyanshu Kumar, Elaine Lau, Saranya Vijayakumar, Tu Trinh, Elaine T Chang, Vaughn Robinson, Shuyan Zhou, Matt Fredrikson, Sean M. Hendryx, Summer Yue, Zifan Wang
Toward Robust Defenses Against LLM Weight Tampering Attacks
Authors: Rishub Tamirisa, Bhrugu Bharathi, Long Phan, Andy Zhou, Alice Gatti, Tarun Suresh, Maxwell Lin, Justin Wang, Rowan Wang, Ron Arel, Andy Zou, Dawn Song, Bo Li, Dan Hendrycks, Mantas Mazeika
Applications To Computer Vision, Audio, Language, And Other Modalities
Fugatto 1: Foundational Generative Audio Transformer Opus 1
Authors: Rafael Valle, Rohan Badlani, Zhifeng Kong, Sang-gil Lee, Arushi Goel, Joao Felipe Santos, Aya Aljafari, Sungwon Kim, Shuqi Dai, Siddharth Gururani, Alexander H. Liu, Kevin J. Shih, Ryan Prenger, Wei Ping, Chao-han Huck Yang, Bryan Catanzaro
MetaDesigner: Advancing Artistic Typography through AI-Driven, User-Centric, and Multilingual WordArt Synthesis
Authors: Jun-yan He, Zhi-qi Cheng, Chenyang Li, Jingdong Sun, Qi He, Wangmeng Xiang, Hanyuan Chen, Jin-peng Lan, Xianhui Lin, Kang Zhu, Bin Luo, Yifeng Geng, Xuansong Xie, Alexander G Hauptmann
Applications To Neuroscience & Cognitive Science
Applications To Physical Sciences (Physics, Chemistry, Biology, Etc.)
Causal Representation Learning from Multimodal Biological Observations
Authors: Yuewen Sun, Lingjing Kong, Guangyi Chen, Loka Li, Gongxu Luo, Zijian Li, Yixuan Zhang, Yujia Zheng, Mengyue Yang, Petar Stojanov, Eran Segal, Eric P. Xing, Kun Zhang
Applications To Robotics, Autonomy, Planning
Causal Reasoning
Datasets And Benchmarks
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Authors: Chien-yu Huang, Wei-chih Chen, Shu-wen Yang, Andy T. Liu, Chen-an Li, Yu-xiang Lin, Wei-cheng Tseng, Anuj Diwan, Yi-jen Shih, Jiatong Shi, William Chen, Xuanjun Chen, Chi-yuan Hsiao, Puyuan Peng, Shih-heng Wang, Chun-yi Kuan, Ke-han Lu, Kai-wei Chang, Chih-kai Yang, Fabian Alejandro Ritter Gutierrez, Huang Kuan-po, Siddhant Arora, You-kuan Lin, Chuang Ming To, Eunjung Yeo, Kalvin Chang, Chung-ming Chien, Kwanghee Choi, Cheng-hsiu Hsieh, Yi-cheng Lin, Chee-en Yu, I-hsiang Chiu, Heitor Guimarães, Jionghao Han, Tzu-quan Lin, Tzu-yuan Lin, Homu Chang, Ting-wu Chang, Chun Wei Chen, Shou-jen Chen, Yu-hua Chen, Hsi-chun Cheng, Kunal Dhawan, Jia-lin Fang, Shi-xin Fang, Kuan Yu Fang Chiang, Chi An Fu, Hsien-fu Hsiao, Ching Yu Hsu, Shao-syuan Huang, Lee Chen Wei, Hsi-che Lin, Hsuan-hao Lin, Hsuan-ting Lin, Jian-ren Lin, Ting-chun Liu, Li-chun Lu, Tsung-min Pai, Ankita Pasad, Shih-yun Shan Kuan, Suwon Shon, Yuxun Tang, Yun-shao Tsai, Wei Jui Chiang, Tzu-chieh Wei, Chengxi Wu, Dien-ruei Wu, Chao-han Huck Yang, Chieh-chi Yang, Jia Qi Yip, Shao-xiang Yuan, Haibin Wu, Karen Livescu, David Harwath, Shinji Watanabe, Hung-yi Lee
Scalable Benchmarking and Robust Learning for Noise-Free Ego-Motion and 3D Reconstruction from Noisy Video
Authors: Xiaohao Xu, Tianyi Zhang, Shibo Zhao, Xiang Li, Sibo Wang, Yongqi Chen, Ye Li, Bhiksha Raj, Matthew Johnson-roberson, Sebastian Scherer, Xiaonan Huang
Foundation Or Frontier Models, Including Llms
Diversity Empowers Intelligence: Integrating Expertise of Software Engineering Agents
Authors: Kexun Zhang, Weiran Yao, Zuxin Liu, Yihao Feng, Zhiwei Liu, Rithesh R N, Tian Lan, Lei Li, Renze Lou, Jiacheng Xu, Bo Pang, Yingbo Zhou, Shelby Heinecke, Silvio Savarese, Huan Wang, Caiming Xiong
Generative Models
Linear Combination of Saved Checkpoints Makes Consistency and Diffusion Models Better
Authors: Enshu Liu, Junyi Zhu, Zinan Lin, Xuefei Ning, Shuaiqi Wang, Matthew B. Blaschko, Sergey Yekhanin, Shengen Yan, Guohao Dai, Huazhong Yang, Yu Wang
RAG-DDR: Optimizing Retrieval-Augmented Generation Using Differentiable Data Rewards
Authors: Xinze Li, Sen Mei, Zhenghao Liu, Yukun Yan, Shuo Wang, Shi Yu, Zheni Zeng, Hao Chen, Ge Yu, Zhiyuan Liu, Maosong Sun, Chenyan Xiong
Infrastructure, Software Libraries, Hardware, Systems, Etc.
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Authors: Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, Graham Neubig
Interpretability And Explainable Ai
Learning On Graphs And Other Geometries & Topologies
Learning Theory
Neurosymbolic & Hybrid Ai Systems (Physics-informed, Logic & Formal Reasoning, Etc.)
Optimization
Other Topics In Machine Learning (I.e., None Of The Above)
Zeroth-Order Fine-Tuning of LLMs with Transferable Static Sparsity
Authors: Wentao Guo, Jikai Long, Yimeng Zeng, Zirui Liu, Xinyu Yang, Yide Ran, Jacob R. Gardner, Osbert Bastani, Christopher De Sa, Xiaodong Yu, Beidi Chen, Zhaozhuo Xu
Probabilistic Methods (Bayesian Methods, Variational Inference, Sampling, Uq, Etc.)
Reinforcement Learning
Transfer Learning, Meta Learning, And Lifelong Learning
Unsupervised, Self-supervised, Semi-supervised, And Supervised Representation Learning
Memory Mosaics
Authors: Jianyu Zhang, Niklas Nolte, Ranajoy Sadhukhan, Beidi Chen, Leon Bottou
Read More


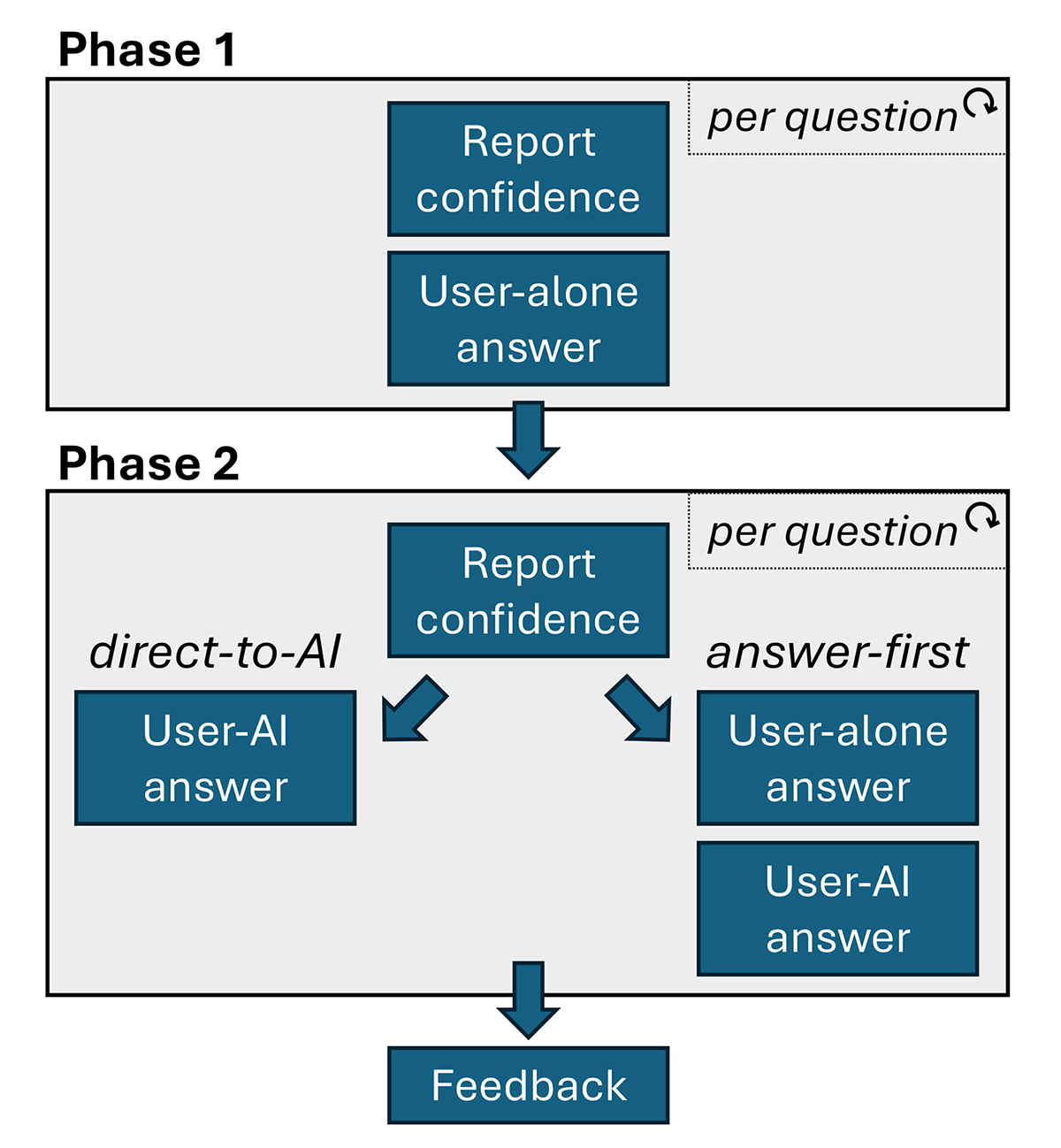




 Vivek Gangasani is a Lead Specialist Solutions Architect for Inference at AWS. He helps emerging generative AI companies build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of large language models. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines.
Vivek Gangasani is a Lead Specialist Solutions Architect for Inference at AWS. He helps emerging generative AI companies build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of large language models. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines. Siddharth Venkatesan is a Software Engineer in AWS Deep Learning. He currently focusses on building solutions for large model inference. Prior to AWS he worked in the Amazon Grocery org building new payment features for customers world-wide. Outside of work, he enjoys skiing, the outdoors, and watching sports.
Siddharth Venkatesan is a Software Engineer in AWS Deep Learning. He currently focusses on building solutions for large model inference. Prior to AWS he worked in the Amazon Grocery org building new payment features for customers world-wide. Outside of work, he enjoys skiing, the outdoors, and watching sports. Felipe Lopez is a Senior AI/ML Specialist Solutions Architect at AWS. Prior to joining AWS, Felipe worked with GE Digital and SLB, where he focused on modeling and optimization products for industrial applications.
Felipe Lopez is a Senior AI/ML Specialist Solutions Architect at AWS. Prior to joining AWS, Felipe worked with GE Digital and SLB, where he focused on modeling and optimization products for industrial applications. Banu Nagasundaram leads product, engineering, and strategic partnerships for Amazon SageMaker JumpStart, the SageMaker machine learning and generative AI hub. She is passionate about building solutions that help customers accelerate their AI journey and unlock business value.
Banu Nagasundaram leads product, engineering, and strategic partnerships for Amazon SageMaker JumpStart, the SageMaker machine learning and generative AI hub. She is passionate about building solutions that help customers accelerate their AI journey and unlock business value. Dmitry Soldatkin is a Senior AI/ML Solutions Architect at Amazon Web Services (AWS), helping customers design and build AI/ML solutions. Dmitry’s work covers a wide range of ML use cases, with a primary interest in Generative AI, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, utilities, and telecommunications. You can connect with Dmitry on
Dmitry Soldatkin is a Senior AI/ML Solutions Architect at Amazon Web Services (AWS), helping customers design and build AI/ML solutions. Dmitry’s work covers a wide range of ML use cases, with a primary interest in Generative AI, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, utilities, and telecommunications. You can connect with Dmitry on 






 Rui Cardoso is a partner solutions architect at Amazon Web Services (AWS). He is focusing on AI/ML and IoT. He works with AWS Partners and support them in developing solutions in AWS. When not working, he enjoys cycling, hiking and learning new things.
Rui Cardoso is a partner solutions architect at Amazon Web Services (AWS). He is focusing on AI/ML and IoT. He works with AWS Partners and support them in developing solutions in AWS. When not working, he enjoys cycling, hiking and learning new things. Julia Hu is a Sr. AI/ML Solutions Architect at Amazon Web Services. She is specialized in Generative AI, Applied Data Science and IoT architecture. Currently she is part of the Amazon Bedrock team, and a Gold member/mentor in Machine Learning Technical Field Community. She works with customers, ranging from start-ups to enterprises, to develop AWSome generative AI solutions. She is particularly passionate about leveraging Large Language Models for advanced data analytics and exploring practical applications that address real-world challenges.
Julia Hu is a Sr. AI/ML Solutions Architect at Amazon Web Services. She is specialized in Generative AI, Applied Data Science and IoT architecture. Currently she is part of the Amazon Bedrock team, and a Gold member/mentor in Machine Learning Technical Field Community. She works with customers, ranging from start-ups to enterprises, to develop AWSome generative AI solutions. She is particularly passionate about leveraging Large Language Models for advanced data analytics and exploring practical applications that address real-world challenges. Amit Gupta is a Senior Q Business Solutions Architect Solutions Architect at AWS. He is passionate about enabling customers with well-architected generative AI solutions at scale.
Amit Gupta is a Senior Q Business Solutions Architect Solutions Architect at AWS. He is passionate about enabling customers with well-architected generative AI solutions at scale. Neil Desai is a technology executive with over 20 years of experience in artificial intelligence (AI), data science, software engineering, and enterprise architecture. At AWS, he leads a team of Worldwide AI services specialist solutions architects who help customers build innovative Generative AI-powered solutions, share best practices with customers, and drive product roadmap. He is passionate about using technology to solve real-world problems and is a strategic thinker with a proven track record of success.
Neil Desai is a technology executive with over 20 years of experience in artificial intelligence (AI), data science, software engineering, and enterprise architecture. At AWS, he leads a team of Worldwide AI services specialist solutions architects who help customers build innovative Generative AI-powered solutions, share best practices with customers, and drive product roadmap. He is passionate about using technology to solve real-world problems and is a strategic thinker with a proven track record of success. Ricardo Aldao is a Senior Partner Solutions Architect at AWS. He is a passionate AI/ML enthusiast who focuses on supporting partners in building generative AI solutions on AWS.
Ricardo Aldao is a Senior Partner Solutions Architect at AWS. He is a passionate AI/ML enthusiast who focuses on supporting partners in building generative AI solutions on AWS.








 Shreyas Subramanian is a Principal Data Scientist and helps customers by using generative AI and deep learning to solve their business challenges using AWS services. Shreyas has a background in large-scale optimization and ML and in the use of ML and reinforcement learning for accelerating optimization tasks.
Shreyas Subramanian is a Principal Data Scientist and helps customers by using generative AI and deep learning to solve their business challenges using AWS services. Shreyas has a background in large-scale optimization and ML and in the use of ML and reinforcement learning for accelerating optimization tasks. Balasubramaniam Srinivasan is a Senior Applied Scientist at Amazon AWS, working on post training methods for generative AI models. He enjoys enriching ML models with domain-specific knowledge and inductive biases to delight customers. Outside of work, he enjoys playing and watching tennis and football (soccer).
Balasubramaniam Srinivasan is a Senior Applied Scientist at Amazon AWS, working on post training methods for generative AI models. He enjoys enriching ML models with domain-specific knowledge and inductive biases to delight customers. Outside of work, he enjoys playing and watching tennis and football (soccer). Yun Zhou is an Applied Scientist at AWS where he helps with research and development to ensure the success of AWS customers. He works on pioneering solutions for various industries using statistical modeling and machine learning techniques. His interest includes generative models and sequential data modeling.
Yun Zhou is an Applied Scientist at AWS where he helps with research and development to ensure the success of AWS customers. He works on pioneering solutions for various industries using statistical modeling and machine learning techniques. His interest includes generative models and sequential data modeling. Haibo Ding is a senior applied scientist at Amazon Machine Learning Solutions Lab. He is broadly interested in Deep Learning and Natural Language Processing. His research focuses on developing new explainable machine learning models, with the goal of making them more efficient and trustworthy for real-world problems. He obtained his Ph.D. from University of Utah and worked as a senior research scientist at Bosch Research North America before joining Amazon. Apart from work, he enjoys hiking, running, and spending time with his family.
Haibo Ding is a senior applied scientist at Amazon Machine Learning Solutions Lab. He is broadly interested in Deep Learning and Natural Language Processing. His research focuses on developing new explainable machine learning models, with the goal of making them more efficient and trustworthy for real-world problems. He obtained his Ph.D. from University of Utah and worked as a senior research scientist at Bosch Research North America before joining Amazon. Apart from work, he enjoys hiking, running, and spending time with his family.