Gemini 2.5 Flash is our first fully hybrid reasoning model, giving developers the ability to turn thinking on or off.Read More

Gemini 2.5 Flash is our first fully hybrid reasoning model, giving developers the ability to turn thinking on or off.Read More

Gemini 2.5 Flash is our first fully hybrid reasoning model, giving developers the ability to turn thinking on or off.Read More

Gemini 2.5 Flash is our first fully hybrid reasoning model, giving developers the ability to turn thinking on or off.Read More

Gemini 2.5 Flash is our first fully hybrid reasoning model, giving developers the ability to turn thinking on or off.Read More

 Imagine being able to ask a cell how it’s feeling, what it’s doing or how it might respond to a drug — and receiving an answer back in plain English. Today, in partnersh…Read More
Imagine being able to ask a cell how it’s feeling, what it’s doing or how it might respond to a drug — and receiving an answer back in plain English. Today, in partnersh…Read More
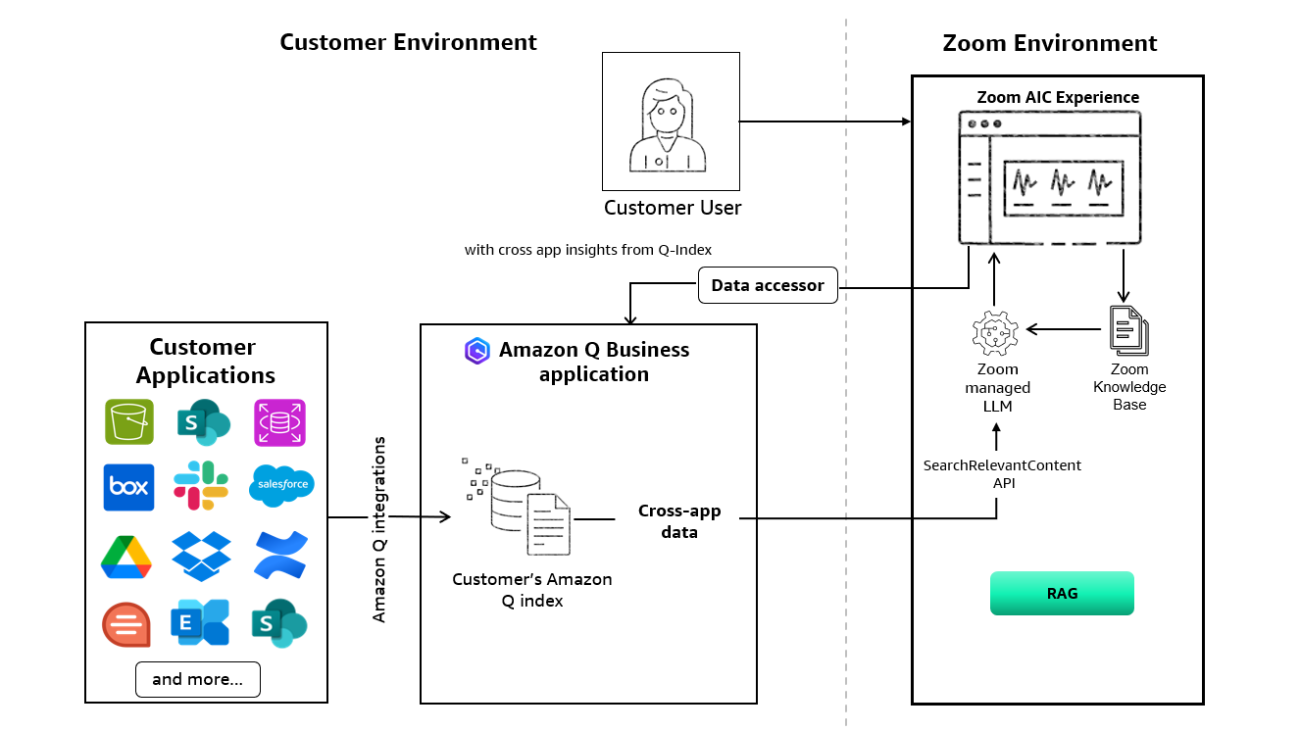
For many organizations, vast amounts of enterprise knowledge are scattered across diverse data sources and applications. Organizations across industries seek to use this cross-application enterprise data from within their preferred systems while adhering to their established security and governance standards.
This post demonstrates how Zoom users can access their Amazon Q Business enterprise data directly within their Zoom interface, alleviating the need to switch between applications while maintaining enterprise security boundaries. Organizations can now configure Zoom as a data accessor in Amazon Q Business, enabling seamless integration between their Amazon Q index and Zoom AI Companion. This integration allows users to access their enterprise knowledge in a controlled manner directly within the Zoom platform.
The Amazon Q Business data accessor is a core component within Amazon Q Business. It manages and controls access to data stored in an enterprise’s internal knowledge repositories on Amazon Q Business from an external independent software vendor (ISV) such as Zoom while maintaining security and data access compliance. This feature allows Zoom to retrieve relevant content, enhancing the Zoom AI Companion’s knowledge. It serves as an intermediary that enforces access control lists (ACLs), defining both data source permissions and user access rights to the existing Amazon Q Business index.
Zoom AI Companion, the foundation of Zoom’s AI-first work platform, enhances human connection by working behind the scenes to boost productivity, improve work quality, and strengthen relationships. This April, Zoom launched the Custom AI Companion add-on, enabling organizations to customize AI agents and skills to help meet their specific needs and drive company-wide efficiency. Through its partnership with Amazon Q Business, customers can now connect their indexed data in Amazon Q index to Zoom AI Companion, providing enhanced knowledge and contextual insights.
As an Amazon Q Business data accessor, Zoom AI Companion can interact with the enterprise Amazon Q index in a managed way, enriching content beyond what’s available in Zoom alone. Enterprise users can retrieve contextual information from their Amazon Q index’s multiple connected data sources directly within Zoom, with results seamlessly presented through Zoom AI Companion. Zoom AI Companion can access Amazon Q index data with its native data sources, such as previous call transcripts, to quickly surface relevant information to users. This integration alleviates the need to manually switch between various enterprise systems like Google Drive, Confluence, Salesforce, and more, saving time and reducing workflow disruptions.
For example, while preparing for a Zoom call, users can quickly find answers to questions like “When is customer AnyCustomer’s contract up for renewal, and who signed the last one?” The Amazon Q index processes these queries and delivers results through Zoom AI Companion in real time.
The following diagram is a high-level architecture that explains how enterprises can set up and access Amazon Q Business indexed data from within the Zoom AI Companion application.

In the following sections, we demonstrate how to configure Zoom as a data accessor and get started using Zoom AI Companion.
To implement this solution, you need an AWS account with appropriate permissions.
To access indexed data from Amazon Q Business through Zoom AI Companion, organizations must first set up their Amazon Q Business application. The application must be configured with AWS IAM Identity Center to enable the Zoom data accessor functionality. For detailed guidance on creating an Amazon Q Business application, refer to Configure application.
Through IAM Identity Center, Amazon Q Business uses trusted identity propagation to provide proper authentication and fine-grained authorization based on user ID and group-based resources, making sure access to sensitive data is tightly controlled and document ACLs are enforced. The ISV is only permitted to access this index using the assigned data accessor.
If you’re using an identity provider (IdP) such as Okta, CyberArk, or others, you can add the IdP to IAM Identity Center as a trusted token issuer. For additional information, see Configure Amazon Q Business with AWS IAM Identity Center trusted identity propagation.
For more information on IAM Identity Center, refer to IAM Identity Center identity source tutorials.
After creating an Amazon Q Business application with IAM Identity Center, administrators can configure Zoom as a data accessor through the Amazon Q Business console. Complete the following steps:


You can select specific data sources to be available through the data accessor. This allows you to control which content is surfaced in the ISV environment. You can use Amazon Q Business pre-built connectors to synchronize content from various systems. For more information, refer to Supported connectors.
This option enables you to configure granular permissions for data accessor accessibility and manage organizational access controls.
For more information about data access, refer to Accessing a customer’s Amazon Q index as a data accessor using cross-account access.

Administrators can modify data accessor settings at any time after implementation. You can adjust user access permissions, update available data sources, and change the scope of accessibility. To revoke access, complete the following steps:
Removing a data accessor from a data source immediately cancels the ISV’s access to your organization’s Amazon Q index.
To start using Zoom as a data accessor for your Amazon Q Business index, the following information from your enterprise Amazon Q Business application must be shared with Zoom:
For more information, refer to Accessing a customer’s Amazon Q index as a data accessor using cross-account access.
After you add Zoom as a data accessor, a pop-up window will appear on the Amazon Q Business console. This pop-up contains the required parameters, as shown in the following screenshot.

Navigate to the Zoom App Marketplace to configure Amazon Q in Zoom, and enter the information you collected.

After you submit this information, you’re ready to access Amazon Q index data from Zoom AI Companion.
With AI Companion connected to Amazon Q index, you have the information you need instantly. For example, you could make AI Companion aware of your organization’s IT troubleshooting guides so employees could quickly get help with questions like “How do I fix a broken keyboard?”

When an enterprise customer with an Amazon Q index enables a data accessor, it allows authenticated Amazon Q Business users to search and retrieve relevant content in real time while using external ISV platforms (like Zoom). This functionality is achieved through the ISV calling the Amazon Q index SearchRelevantContent API as an external data accessor across accounts. The SearchRelevantContent API is specifically designed to return search results from the Amazon Q index, which can be further enhanced by the ISV’s generative AI stack. By using the Amazon Q index SearchRelevantContent API, Zoom and other ISVs can integrate query results directly into their environment.
The SearchRelevantContent API is an identity-aware API, which means it operates with knowledge of the user’s identity and associated information (such as email and group membership) through the credentials used to call the API. This identity awareness is a prerequisite for using the API. When querying the index, it reconciles document access controls against the authenticated user’s permissions. As a result, users can only retrieve results from content they are authorized to access.
When an ISV calls the SearchRelevantContent API as a data accessor, both sparse and dense searches are applied to the Amazon Q index, combining keyword search and vector embedding proximity. Results are ranked before being returned to the ISV interface.
For example, if you ask in Zoom, “What is Company XYZ’s engagement on the cancer moonshot project?”, Zoom AI Companion triggers a call to the SearchRelevantContent API as a data accessor.
For a more comprehensive code example, see the notebook in Module 2 – Amazon Q cross-app index.
The following is a code snippet in Python showing what that search request might look like:
The search response will contain an array of results with relevant chunks of text, along with source information, document attributes, and confidence scores. The following is a snippet from the SearchRelevantContent API response. This is an example of results you might see from the web crawler data connector used with Amazon Q Business.
The SearchRelevantContent API has a rich set of optional parameters available that ISVs can choose to use. For example, document attributes can be used as filters. If documents with meta attributes have been indexed, and one of these attributes contains the author, it would be possible for an ISV to apply a filter where you can specify an author name. In the following example, results returned are constrained to only documents that have the specified attribute author name “John Smith.”
For a more comprehensive reference on what is available in the SearchRelevantContent API request object, refer to search_relevant_content.
When you’re done using this solution, clean up the resources you created.
Deleting the Amazon Q Business application will remove the associated index and data source connectors, and prevent incurring additional costs.
Amazon Q indexes offers a transformative approach to workplace efficiency. By creating a centralized, secure repository for your organization’s data, you can seamlessly integrate vital information with your everyday productivity tools like Zoom AI Companion.
In this post, we explored how Amazon Q Business enterprise users can add data accessors to integrate with external parties like Zoom AI Companion, allowing users to access their enterprise knowledge in a managed way directly from within those platforms.
Ready to supercharge your workforce’s productivity? Start your Amazon Q Business journey today alongside Zoom. To learn more about Amazon Q Business data accessors, see Enhance enterprise productivity for your LLM solution by becoming an Amazon Q Business data accessor.
 David Girling is a Senior AI/ML Solutions Architect with over 20 years of experience in designing, leading, and developing enterprise systems. David is part of a specialist team that focuses on helping customers learn, innovate, and utilize these highly capable services with their data for their use cases.
David Girling is a Senior AI/ML Solutions Architect with over 20 years of experience in designing, leading, and developing enterprise systems. David is part of a specialist team that focuses on helping customers learn, innovate, and utilize these highly capable services with their data for their use cases.
 Chinmayee Rane is a Generative AI Specialist Solutions Architect at AWS, with a core focus on generative AI. She helps Independent Software Vendors (ISVs) accelerate the adoption of generative AI by designing scalable and impactful solutions. With a strong background in applied mathematics and machine learning, she specializes in intelligent document processing and AI-driven innovation. Outside of work, she enjoys salsa and bachata dancing.
Chinmayee Rane is a Generative AI Specialist Solutions Architect at AWS, with a core focus on generative AI. She helps Independent Software Vendors (ISVs) accelerate the adoption of generative AI by designing scalable and impactful solutions. With a strong background in applied mathematics and machine learning, she specializes in intelligent document processing and AI-driven innovation. Outside of work, she enjoys salsa and bachata dancing.
 Sonali Sahu is leading the Generative AI Specialist Solutions Architecture team in AWS. She is an author, thought leader, and passionate technologist. Her core area of focus is AI and ML, and she frequently speaks at AI and ML conferences and meetups around the world. She has both breadth and depth of experience in technology and the technology industry, with industry expertise in healthcare, the financial sector, and insurance.
Sonali Sahu is leading the Generative AI Specialist Solutions Architecture team in AWS. She is an author, thought leader, and passionate technologist. Her core area of focus is AI and ML, and she frequently speaks at AI and ML conferences and meetups around the world. She has both breadth and depth of experience in technology and the technology industry, with industry expertise in healthcare, the financial sector, and insurance.
This post is co-written with Ameet Deshpande and Vatsal Saglani from Qyrus.
As businesses embrace accelerated development cycles to stay competitive, maintaining rigorous quality standards can pose a significant challenge. Traditional testing methods, which occur late in the development cycle, often result in delays, increased costs, and compromised quality.
Shift-left testing, which emphasizes earlier testing in the development process, aims to address these issues by identifying and resolving problems sooner. However, effectively implementing this approach requires the right tools. By using advanced AI models, QyrusAI improves testing throughout the development cycle—from generating test cases during the requirements phase to uncovering unexpected issues during application exploration.
In this post, we explore how QyrusAI and Amazon Bedrock are revolutionizing shift-left testing, enabling teams to deliver better software faster. Amazon Bedrock is a fully managed service that allows businesses to build and scale generative AI applications using foundation models (FMs) from leading AI providers. It enables seamless integration with AWS services, offering customization, security, and scalability without managing infrastructure.
QyrusAI is a suite of AI-driven testing tools that enhances the software testing process across the entire software development lifecycle (SDLC). Using advanced large language models (LLMs) and vision-language models (VLMs) through Amazon Bedrock, QyrusAI provides a suite of capabilities designed to elevate shift-left testing. Let’s dive into each agent and the cutting-edge models that power them.
TestGenerator generates initial test cases based on requirements using a suite of advanced models:
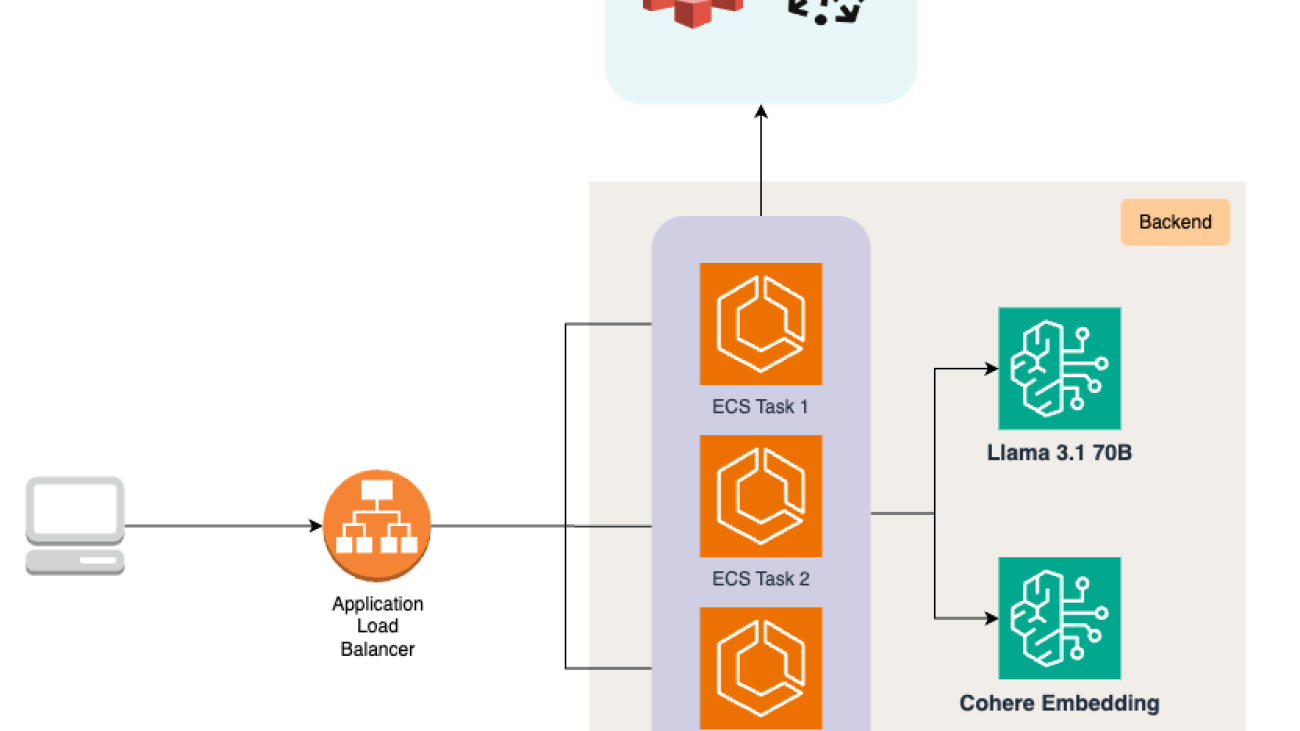
The following diagram shows how TestGenerator is deployed on AWS using Amazon Elastic Container Service (Amazon ECS) tasks exposed through Application Load Balancer, using Amazon Bedrock, Amazon Simple Storage Service (Amazon S3), and Pinecone for embedding storage and retrieval to generate comprehensive test cases.

VisionNova is QyrusAI’s design test case generator that crafts design-based test cases using Anthropic’s Claude 3.5 Sonnet. The model is used to analyze design documents and generate precise, relevant test cases. This workflow specializes in understanding UX/UI design documents and translating visual elements into testable scenarios.
The following diagram shows how VisionNova is deployed on AWS using ECS tasks exposed through Application Load Balancer, using Anthropic’s Claude 3 and Claude 3.5 Sonnet models on Amazon Bedrock for image understanding, and using Amazon S3 for storing images, to generate design-based test cases for validating UI/UX elements.

UXtract is QyrusAI’s agentic workflow that converts Figma prototypes into test scenarios and steps based on the flow of screens in the prototype.
Figma prototype graphs are used to create detailed test cases with step-by-step instructions. The graph is analyzed to understand the different flows and make sure transitions between elements are validated. Anthropic’s Claude 3 Opus is used to process these transitions to identify potential actions and interactions, and Anthropic’s Claude 3.5 Sonnet is used to generate detailed test steps and instructions based on the transitions and higher-level objectives. This layered approach makes sure that UXtract captures both the functional accuracy of each flow and the granularity needed for effective testing.
The following diagram illustrates how UXtract uses ECS tasks, connected through Application Load Balancer, along with Amazon Bedrock models and Amazon S3 storage, to analyze Figma prototypes and create detailed, step-by-step test cases.

API Builder creates virtualized APIs for early frontend testing by using various LLMs from Amazon Bedrock. These models interpret API specifications and generate accurate mock responses, facilitating effective testing before full backend implementation.
The following diagram illustrates how API Builder uses ECS tasks, connected through Application Load Balancer, along with Amazon Bedrock models and Amazon S3 storage, to create a virtualized and high-scalable microservice with dynamic data provisions using Amazon Elastic File System (Amazon EFS) on AWS Lambda compute.

QyrusAI offers a range of additional agents that further enhance the testing process:
These agents, powered by Amazon Bedrock, collaborate to deliver a robust, AI-driven shift-left testing strategy throughout the SDLC.
At the core of QyrusAI’s integration with Amazon Bedrock is our custom-developed qai package, which builds upon aiobotocore, aioboto3, and boto3. This unified interface enables our AI agents to seamlessly access the diverse array of LLMs, VLMs, and embedding models available on Amazon Bedrock. The qai package is essential to our AI-powered testing ecosystem, offering several key benefits:
Function calling and JSON mode were critical requirements for our AI workflows and agents. To maximize compatibility across diverse array of models available on Amazon Bedrock, we implemented consistent interfaces for these features in our QAI package. Because prompts for generating structured data can differ among LLMs and VLMs, specialized classes were created for various models and model families to provide consistent function calling and JSON mode capabilities. This approach provides a unified interface across the agents, streamlining interactions and enhancing overall efficiency.
The following code is a simplified overview of how we use the qai package to interact with LLMs and VLMs on Amazon Bedrock:
Shift-left testing allows teams to catch issues sooner and reduce risk. Here’s how QyrusAI agents facilitate the shift-left approach:
The following diagram visually represents how QyrusAI agents integrate throughout the SDLC, from requirement analysis to maintenance, enabling a shift-left testing approach that makes sure issues are caught early and quality is maintained continuously.
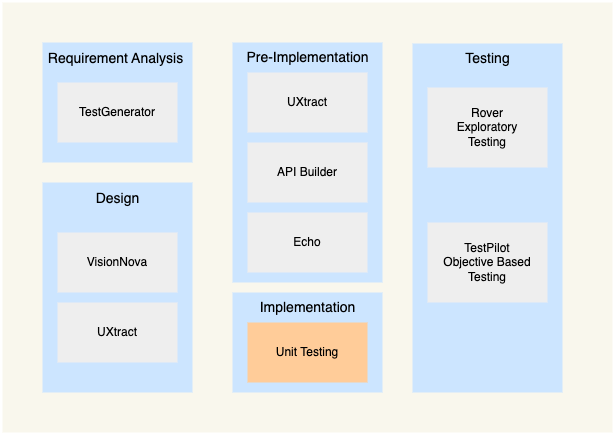
QyrusAI’s integrated approach makes sure that testing is proactive, continuous, and seamlessly aligned with every phase of the SDLC. With this approach, teams can:
This shift-left strategy, powered by QyrusAI and Amazon Bedrock, enables teams to deliver higher-quality software faster and more efficiently.
To make this more tangible, let’s walk through how QyrusAI and Amazon Bedrock can help create and refine test cases from a sample requirements document:
By following these steps, teams can get ahead of potential issues, creating a safety net that improves both the quality and speed of software development.
Our data—collected from early adopters of QyrusAI—demonstrates the significant benefits of our AI-driven shift-left approach:
These metrics have been gathered through a combination of internal testing and pilot programs with select customers. The results consistently show that incorporating AI early in the SDLC can lead to a significant reduction in defects, development costs, and time to market.
Shift-left testing, powered by QyrusAI and Amazon Bedrock, is set to revolutionize the software development landscape. By integrating AI-driven testing across the entire SDLC—from requirements analysis to maintenance—QyrusAI helps teams:
Amazon Bedrock provides the essential foundation with its advanced language and vision models, offering unparalleled flexibility and capability in software testing. This integration, along with seamless connectivity to other AWS services, enhances scalability, security, and cost-effectiveness.
As the software industry advances, the collaboration between QyrusAI and Amazon Bedrock positions teams at the cutting edge of AI-driven quality assurance. By adopting this shift-left, AI-powered approach, organizations can not only keep pace with today’s fast-moving digital world, but also set new benchmarks in software quality and development efficiency.
If you’re looking to revolutionize your software testing processes, we invite you to reach out to our team and learn more about QyrusAI. Let’s work together to build better software, faster.
To see how QyrusAI can enhance your development workflow, get in touch today at support@qyrus.com. Let’s redefine your software quality with AI-driven shift-left testing.
 Ameet Deshpande is Head of Engineering at Qyrus and leads innovation in AI-driven, codeless software testing solutions. With expertise in quality engineering, cloud platforms, and SaaS, he blends technical acumen with strategic leadership. Ameet has spearheaded large-scale transformation programs and consulting initiatives for global clients, including top financial institutions. An electronics and communication engineer specializing in embedded systems, he brings a strong technical foundation to his leadership in delivering transformative solutions.
Ameet Deshpande is Head of Engineering at Qyrus and leads innovation in AI-driven, codeless software testing solutions. With expertise in quality engineering, cloud platforms, and SaaS, he blends technical acumen with strategic leadership. Ameet has spearheaded large-scale transformation programs and consulting initiatives for global clients, including top financial institutions. An electronics and communication engineer specializing in embedded systems, he brings a strong technical foundation to his leadership in delivering transformative solutions.
 Vatsal Saglani is a Data Science and Generative AI Lead at Qyrus, where he builds generative AI-powered test automation tools and services using multi-agent frameworks, large language models, and vision-language models. With a focus on fine-tuning advanced AI systems, Vatsal accelerates software development by empowering teams to shift testing left, enhancing both efficiency and software quality.
Vatsal Saglani is a Data Science and Generative AI Lead at Qyrus, where he builds generative AI-powered test automation tools and services using multi-agent frameworks, large language models, and vision-language models. With a focus on fine-tuning advanced AI systems, Vatsal accelerates software development by empowering teams to shift testing left, enhancing both efficiency and software quality.
 Siddan Korbu is a Customer Delivery Architect with AWS. He works with enterprise customers to help them build AI/ML and generative AI solutions using AWS services.
Siddan Korbu is a Customer Delivery Architect with AWS. He works with enterprise customers to help them build AI/ML and generative AI solutions using AWS services.
Contextual advertising, a strategy that matches ads with relevant digital content, has transformed digital marketing by delivering personalized experiences to viewers. However, implementing this approach for streaming video-on-demand (VOD) content poses significant challenges, particularly in ad placement and relevance. Traditional methods rely heavily on manual content analysis. For example, a content analyst might spend hours watching a romantic drama, placing an ad break right after a climactic confession scene, but before the resolution. Then, they manually tag the content with metadata such as romance, emotional, or family-friendly to verify appropriate ad matching. Although this manual process helps create a seamless viewer experience and maintains ad relevance, it proves highly impractical at scale.
Recent advancements in generative AI, particularly multimodal foundation models (FMs), demonstrate advanced video understanding capabilities and offer a promising solution to these challenges. We previously explored this potential in the post Media2Cloud on AWS Guidance: Scene and ad-break detection and contextual understanding for advertising using generative AI, where we demonstrated custom workflows using Amazon Titan Multimodal embeddings G1 models and Anthropic’s Claude FMs from Amazon Bedrock. In this post, we’re introducing an even simpler way to build contextual advertising solutions.
Amazon Bedrock Data Automation (BDA) is a new managed feature powered by FMs in Amazon Bedrock. BDA extracts structured outputs from unstructured content—including documents, images, video, and audio—while alleviating the need for complex custom workflows. In this post, we demonstrate how BDA automatically extracts rich video insights such as chapter segments and audio segments, detects text in scenes, and classifies Interactive Advertising Bureau (IAB) taxonomies, and then uses these insights to build a nonlinear ads solution to enhance contextual advertising effectiveness. A sample Jupyter notebook is available in the following GitHub repository.
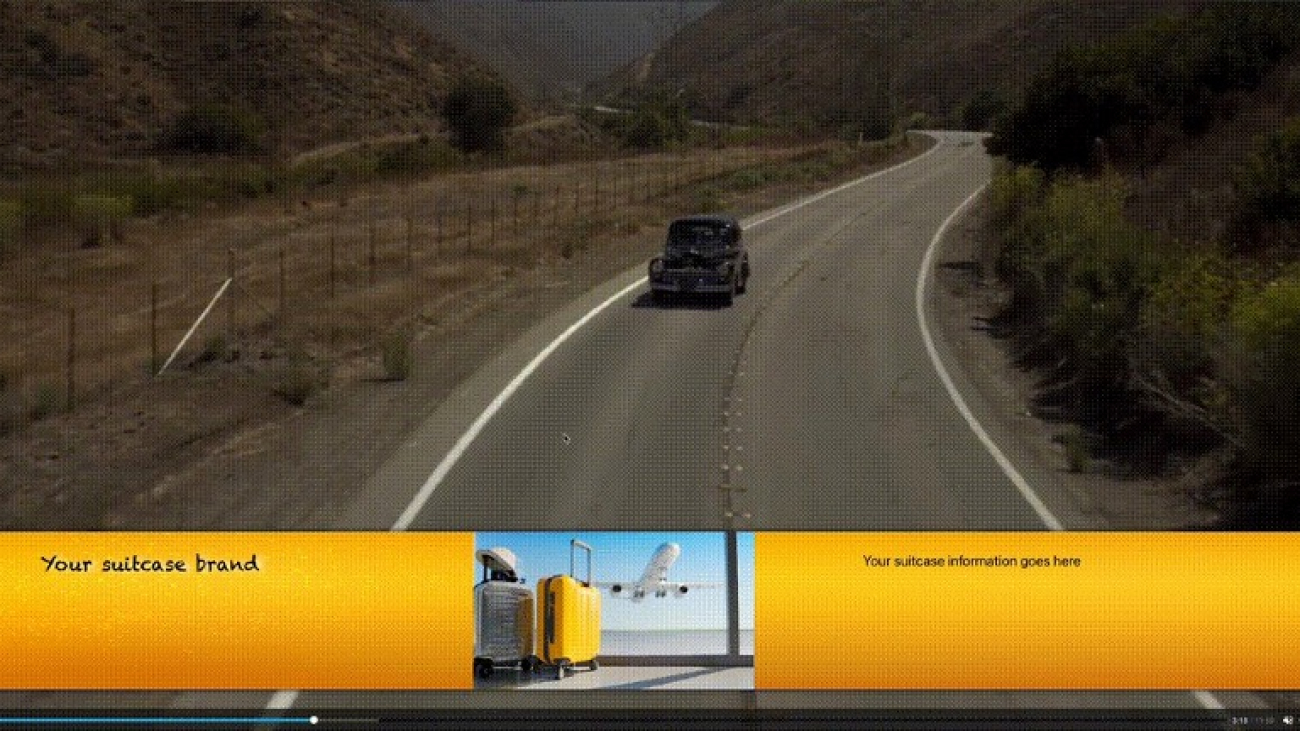
Nonlinear ads are digital video advertisements that appear simultaneously with the main video content without interrupting playback. These ads are displayed as overlays, graphics, or rich media elements on top of the video player, typically appearing at the bottom of the screen. The following screenshot is an illustration of the final linear ads solution we will implement in this post.

The following diagram presents an overview of the architecture and its key components.

The workflow is as follows:
For simplicity in our notebook example, we provide a dictionary that maps the metadata to a set of local ad inventory files to be displayed with the video segments. This simulates how MediaTailor interacts with content manifest files and requests replacement ads from the Ad Decision Service.
The following prerequisites are needed to run the notebooks and follow along with the examples in this post:
Thanks to BDA, processing and analyzing videos has become significantly simpler. The workflow consists of three main steps: creating a project, invoking the analysis, and retrieving analysis results. The first step—creating a project—establishes a reusable configuration template for your analysis tasks. Within the project, you define the types of analyses you want to perform and how you want the results structured. To create a project, use the create_data_automation_project API from the BDA boto3 client. This function returns a dataAutomationProjectArn, which you will need to include with each runtime invocation.
Upon project completion (status: COMPLETED), you can use the invoke_data_automation_async API from the BDA runtime client to start video analysis. This API requires input/output S3 locations and a cross-Region profile ARN in your request. BDA requires cross-Region inference support for all file processing tasks, automatically selecting the optimal AWS Region within your geography to maximize compute resources and model availability. This mandatory feature helps provide optimal performance and customer experience at no additional cost. You can also optionally configure Amazon EventBridge notifications for job tracking (for more details, see Tutorial: Send an email when events happen using Amazon EventBridge). After it’s triggered, the process immediately returns a job ID while continuing processing in the background.
Let’s explore the outputs from BDA for video analysis. Understanding these outputs is essential to understand what type of insights BDA provides and how to use them to build our contextual advertising solution. The following diagram is an illustration of key components of a video, and each defines a granularity level you need to analyze the video content.

The key components are as follows:
Now that we defined the video granularity terms, let’s examine the insights BDA provides. At full video level, BDA generates a comprehensive summary that delivers a concise overview of the video’s key themes and main content. The system also includes speaker identification, a process that attempts to derive speakers’ names based on audible cues (For example, “I’m Jane Doe”) or visual cues on the screen whenever possible. To illustrate this capability, we can examine the following full video summary that BDA generated for the short film Meridian:
In a series of mysterious disappearances along a stretch of road above El Matador Beach, three seemingly unconnected men vanished without a trace. The victims – a school teacher, an insurance salesman, and a retiree – shared little in common except for being divorced, with no significant criminal records or ties to criminal organizations…Detective Sullivan investigates the cases, initially dismissing the possibility of suicide due to the absence of bodies. A key breakthrough comes from a credible witness who was walking his dog along the bluffs on the day of the last disappearance. The witness described seeing a man atop a massive rock formation at the shoreline, separated from the mainland. The man appeared to be searching for something or someone when suddenly, unprecedented severe weather struck the area with thunder and lightning….The investigation takes another turn when Captain Foster of the LAPD arrives at the El Matador location, discovering that Detective Sullivan has also gone missing. The case becomes increasingly complex as the connection between the disappearances, the mysterious woman, and the unusual weather phenomena remains unexplained.
Along with the summary, BDA generates a complete audio transcript that includes speaker identification. This transcript captures the spoken content while noting who is speaking throughout the video. The following is an example of a transcript generated by BDA from the Meridian short film:
[spk_0]: So these guys just disappeared.
[spk_1]: Yeah, on that stretch of road right above El Matador. You know it. With the big rock. That’s right, yeah.
[spk_2]: You know, Mickey Cohen used to take his associates out there, get him a bond voyage.
…
BDA performs detailed analysis at the chapter level by generating comprehensive chapter summaries. Each chapter summary includes specific start and end timestamps to precisely mark the chapter’s duration. Additionally, when relevant, BDA applies IAB categories to classify the chapter’s content. These IAB categories are part of a standardized classification system created for organizing and mapping publisher content, which serves multiple purposes, including advertising targeting, internet security, and content filtering. The following example demonstrates a typical chapter-level analysis:
[00:00:20;04 – 00:00:23;01] Automotive, Auto Type
The video showcases a vintage urban street scene from the mid-20th century. The focal point is the Florentine Gardens building, an ornate structure with a prominent sign displaying “Florentine GARDENS” and “GRUEN Time”. The building’s facade features decorative elements like columns and arched windows, giving it a grand appearance. Palm trees line the sidewalk in front of the building, adding to the tropical ambiance. Several vintage cars are parked along the street, including a yellow taxi cab and a black sedan. Pedestrians can be seen walking on the sidewalk, contributing to the lively atmosphere. The overall scene captures the essence of a bustling city environment during that era.
For a comprehensive list of supported IAB taxonomy categories, see Videos.
Also at the chapter level, BDA produces detailed audio transcriptions with precise timestamps for each spoken segment. These granular transcriptions are particularly useful for closed captioning and subtitling tasks. The following is an example of a chapter-level transcription:
[26.85 – 29.59] So these guys just disappeared.
[30.93 – 34.27] Yeah, on that stretch of road right above El Matador.
[35.099 – 35.959] You know it.
[36.49 – 39.029] With the big rock. That’s right, yeah.
[40.189 – 44.86] You know, Mickey Cohen used to take his associates out there, get him a bond voyage.
…
At a more granular level, BDA provides frame-accurate timestamps for shot boundaries. The system also performs text detection and logo detection on individual frames, generating bounding boxes around detected text and logo along with confidence scores for each detection. The following image is an example of text bounding boxes extracted from the Meridian video.

Let’s apply the insights extracted from BDA to power nonlinear ad solutions. Unlike traditional linear advertising that relies on predetermined time slots, nonlinear advertising enables dynamic ad placement based on content context. At the chapter level, BDA automatically segments videos and provides detailed insights including content summaries, IAB categories, and precise timestamps. These insights serve as intelligent markers for ad placement opportunities, allowing advertisers to target specific chapters that align with their promotional content.
In this example, we prepared a list of ad images and mapped them each to specific IAB categories. When BDA identifies IAB categories at the chapter level, the system automatically matches and selects the most relevant ad from the list to display as an overlay banner during that chapter. In the following example, when BDA identifies a scene with a car driving on a country road (IAB category: Automotive, Travel), the system selects and displays a suitcase at an airport from the pre-mapped ad database. This automated matching process promotes precise ad placement while maintaining optimal viewer experience.
Follow the instructions in the cleanup section of the notebook to delete the projects and resources provisioned to avoid unnecessary charges. Refer to Amazon Bedrock pricing for details regarding BDA cost.
Amazon Bedrock Data Automation, powered by foundation models from Amazon Bedrock, marks a significant advancement in video analysis. BDA minimizes the complex orchestration layers previously required for extracting deep insights from video content, transforming what was once a sophisticated technical challenge into a streamlined, managed solution. This breakthrough empowers media companies to deliver more engaging, personalized advertising experiences while significantly reducing operational overhead. We encourage you to explore the sample Jupyter notebook provided in the GitHub repository to experience BDA firsthand and discover additional BDA use cases across other modalities in the following resources:
 James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries
James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries
 Alex Burkleaux is a Senior AI/ML Specialist Solution Architect at AWS. She helps customers use AI Services to build media solutions using Generative AI. Her industry experience includes over-the-top video, database management systems, and reliability engineering.
Alex Burkleaux is a Senior AI/ML Specialist Solution Architect at AWS. She helps customers use AI Services to build media solutions using Generative AI. Her industry experience includes over-the-top video, database management systems, and reliability engineering.
This post is a joint collaboration between Salesforce and AWS and is being cross-published on both the Salesforce Engineering Blog and the AWS Machine Learning Blog.
The Salesforce AI Model Serving team is working to push the boundaries of natural language processing and AI capabilities for enterprise applications. Their key focus areas include optimizing large language models (LLMs) by integrating cutting-edge solutions, collaborating with leading technology providers, and driving performance enhancements that impact Salesforce’s AI-driven features. The AI Model Serving team supports a wide range of models for both traditional machine learning (ML) and generative AI including LLMs, multi-modal foundation models (FMs), speech recognition, and computer vision-based models. Through innovation and partnerships with leading technology providers, this team enhances performance and capabilities, tackling challenges such as throughput and latency optimization and secure model deployment for real-time AI applications. They accomplish this through evaluation of ML models across multiple environments and extensive performance testing to achieve scalability and reliability for inferencing on AWS.
The team is responsible for the end-to-end process of gathering requirements and performance objectives, hosting, optimizing, and scaling AI models, including LLMs, built by Salesforce’s data science and research teams. This includes optimizing the models to achieve high throughput and low latency and deploying them quickly through automated, self-service processes across multiple AWS Regions.
In this post, we share how the AI Model Service team achieved high-performance model deployment using Amazon SageMaker AI.
The team faces several challenges in deploying models for Salesforce. An example would be balancing latency and throughput while achieving cost-efficiency when scaling these models based on demand. Maintaining performance and scalability while minimizing serving costs is vital across the entire inference lifecycle. Inference optimization is a crucial aspect of this process, because the model and their hosting environment must be fine-tuned to meet price-performance requirements in real-time AI applications. Salesforce’s fast-paced AI innovation requires the team to constantly evaluate new models (proprietary, open source, or third-party) across diverse use cases. They then have to quickly deploy these models to stay in cadence with their product teams’ go-to-market motions. Finally, the models must be hosted securely, and customer data must be protected to abide by Salesforce’s commitment to providing a trusted and secure platform.
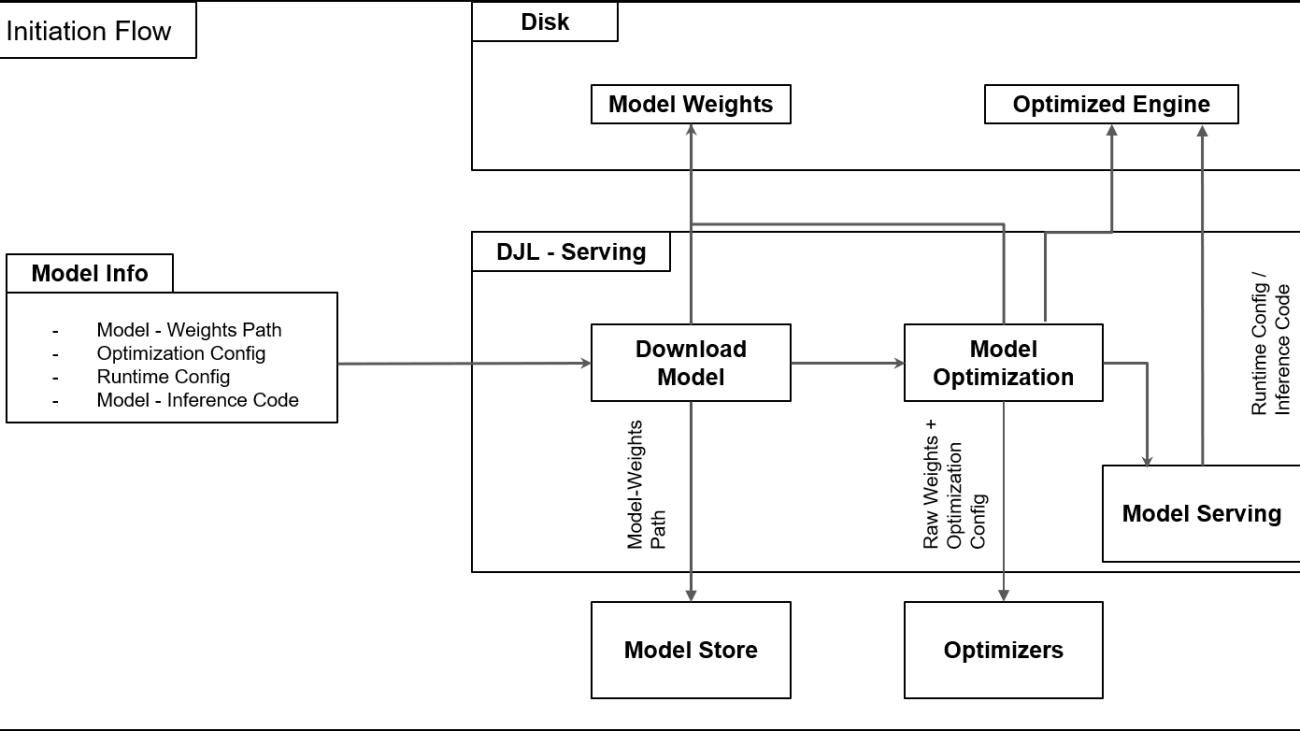
To support such a critical function for Salesforce AI, the team developed a hosting framework on AWS to simplify their model lifecycle, allowing them to quickly and securely deploy models at scale while optimizing for cost. The following diagram illustrates the solution workflow.

Managing scalability in the project involves balancing performance with efficiency and resource management. With SageMaker AI, the team supports distributed inference and multi-model deployments, preventing memory bottlenecks and reducing hardware costs. SageMaker AI provides access to advanced GPUs, supports multi-model deployments, and enables intelligent batching strategies to balance throughput with latency. This flexibility makes sure performance improvements don’t compromise scalability, even in high-demand scenarios. To learn more, see Revolutionizing AI: How Amazon SageMaker Enhances Einstein’s Large Language Model Latency and Throughput.
SageMaker AI Deep Learning Containers (DLCs) play a crucial role in accelerating model development and deployment. These pre-built containers come with optimized deep learning frameworks and best-practice configurations, providing a head start for AI teams. DLCs provide optimized library versions, preconfigured CUDA settings, and other performance enhancements that improve inference speeds and efficiency. This significantly reduces the setup and configuration overhead, allowing engineers to focus on model optimization rather than infrastructure concerns.
A key advantage of using SageMaker AI is the best practice configurations for deployment. SageMaker AI provides default parameters for setting GPU utilization and memory allocation, which simplifies the process of configuring high-performance inference environments. These features make it straightforward to deploy optimized models with minimal manual intervention, providing high availability and low-latency responses.
The team uses the DLC’s rolling-batch capability, which optimizes request batching to maximize throughput while maintaining low latency. SageMaker AI DLCs expose configurations for rolling batch inference with best-practice defaults, simplifying the implementation process. By adjusting parameters such as max_rolling_batch_size and job_queue_size, the team was able to fine-tune performance without extensive custom engineering. This streamlined approach provides optimal GPU utilization while maintaining real-time response requirements.
SageMaker AI provides elastic load balancing, instance scaling, and real-time model monitoring, and provides Salesforce control over scaling and routing strategies to suit their needs. These measures maintain consistent performance across environments while optimizing scalability, performance, and cost-efficiency.
Because the team supports multiple simultaneous deployments across projects, they needed to make sure enhancements in each project didn’t compromise others. To address this, they adopted a modular development approach. The SageMaker AI DLC architecture is designed with modular components such as the engine abstraction layer, model store, and workload manager. This structure allows the team to isolate and optimize individual components on the container, like rolling batch inference for throughput, without disrupting critical functionality such as latency or multi-framework support. This allows project teams to work on individual projects such as performance tuning while allowing others to focus on enabling other functionalities such as streaming in parallel.
This cross-functional collaboration is complemented by comprehensive testing. The Salesforce AI model team implemented continuous integration (CI) pipelines using a mix of internal and external tools such as Jenkins and Spinnaker to detect any unintended side effects early. Regression testing made sure that optimizations, such as deploying models with TensorRT or vLLM, didn’t negatively impact scalability or user experience. Regular reviews, involving collaboration between the development, foundation model operations (FMOps), and security teams, made sure that optimizations aligned with project-wide objectives.
Configuration management is also part of the CI pipeline. To be precise, configuration is stored in git alongside inference code. Configuration management using simple YAML files enabled rapid experimentation across optimizers and hyperparameters without altering the underlying code. These practices made sure that performance or security improvements were well-coordinated and didn’t introduce trade-offs in other areas.
Balancing rapid deployment with high standards of trust and security requires embedding security measures throughout the development and deployment lifecycle. Secure-by-design principles are adopted from the outset, making sure that security requirements are integrated into the architecture. Rigorous testing of all models is conducted in development environments alongside performance testing to provide scalable performance and security before production.
To maintain these high standards throughout the development process, the team employs several strategies:
Frequent automated testing for both performance and security is employed through small incremental deployments, allowing for early issue identification while minimizing risks. Collaboration with cloud providers and continuous monitoring of deployments maintain compliance with the latest security standards and make sure rapid deployment aligns seamlessly with robust security, trust, and reliability.
As Salesforce’s generative AI needs scale, and with the ever-changing model landscape, the team continually works to improve their deployment infrastructure—ongoing research and development efforts are centered on enhancing the performance, scalability, and efficiency of LLM deployments. The team is exploring new optimization techniques with SageMaker, including:
The team is also investigating emerging technologies like AWS AI chips (AWS Trainium and AWS Inferentia) and AWS Graviton processors to further improve cost and energy efficiency. Collaboration with open source communities and public cloud providers like AWS makes sure that the latest advancements are incorporated into deployment pipelines while also pushing the boundaries further. Salesforce is collaborating with AWS to include advanced features into DJL, which makes the usage even better and more robust, such as additional configuration parameters, environment variables, and more granular metrics for logging. A key focus is refining multi-framework support and distributed inference capabilities to provide seamless model integration across various environments.
Efforts are also underway to enhance FMOps practices, such as automated testing and deployment pipelines, to expedite production readiness. These initiatives aim to stay at the forefront of AI innovation, delivering cutting-edge solutions that align with business needs and meet customer expectations. They are in close collaboration with the SageMaker team to continue to explore potential features and capabilities to support these areas.
Though exact metrics vary by use case, the Salesforce AI Model Serving team saw substantial improvements in terms of deployment speed and cost-efficiency with their strategy on SageMaker AI. They experienced faster iteration cycles, measured in days or even hours instead of weeks. With SageMaker AI, they reduced their model deployment time by as much as 50%.
To learn more about how SageMaker AI enhances Einstein’s LLM latency and throughput, see Revolutionizing AI: How Amazon SageMaker Enhances Einstein’s Large Language Model Latency and Throughput. For more information on how to get started with SageMaker AI, refer to Guide to getting set up with Amazon SageMaker AI.
 Sai Guruju is working as a Lead Member of Technical Staff at Salesforce. He has over 7 years of experience in software and ML engineering with a focus on scalable NLP and speech solutions. He completed his Bachelor’s of Technology in EE from IIT-Delhi, and has published his work at InterSpeech 2021 and AdNLP 2024.
Sai Guruju is working as a Lead Member of Technical Staff at Salesforce. He has over 7 years of experience in software and ML engineering with a focus on scalable NLP and speech solutions. He completed his Bachelor’s of Technology in EE from IIT-Delhi, and has published his work at InterSpeech 2021 and AdNLP 2024.
 Nitin Surya is working as a Lead Member of Technical Staff at Salesforce. He has over 8 years of experience in software and machine learning engineering, completed his Bachelor’s of Technology in CS from VIT University, with an MS in CS (with a major in Artificial Intelligence and Machine Learning) from the University of Illinois Chicago. He has three patents pending, and has published and contributed to papers at the CoRL Conference.
Nitin Surya is working as a Lead Member of Technical Staff at Salesforce. He has over 8 years of experience in software and machine learning engineering, completed his Bachelor’s of Technology in CS from VIT University, with an MS in CS (with a major in Artificial Intelligence and Machine Learning) from the University of Illinois Chicago. He has three patents pending, and has published and contributed to papers at the CoRL Conference.
 Srikanta Prasad is a Senior Manager in Product Management specializing in generative AI solutions, with over 20 years of experience across semiconductors, aerospace, aviation, print media, and software technology. At Salesforce, he leads model hosting and inference initiatives, focusing on LLM inference serving, LLMOps, and scalable AI deployments. Srikanta holds an MBA from the University of North Carolina and an MS from the National University of Singapore.
Srikanta Prasad is a Senior Manager in Product Management specializing in generative AI solutions, with over 20 years of experience across semiconductors, aerospace, aviation, print media, and software technology. At Salesforce, he leads model hosting and inference initiatives, focusing on LLM inference serving, LLMOps, and scalable AI deployments. Srikanta holds an MBA from the University of North Carolina and an MS from the National University of Singapore.
 Rielah De Jesus is a Principal Solutions Architect at AWS who has successfully helped various enterprise customers in the DC, Maryland, and Virginia area move to the cloud. In her current role, she acts as a customer advocate and technical advisor focused on helping organizations like Salesforce achieve success on the AWS platform. She is also a staunch supporter of women in IT and is very passionate about finding ways to creatively use technology and data to solve everyday challenges.
Rielah De Jesus is a Principal Solutions Architect at AWS who has successfully helped various enterprise customers in the DC, Maryland, and Virginia area move to the cloud. In her current role, she acts as a customer advocate and technical advisor focused on helping organizations like Salesforce achieve success on the AWS platform. She is also a staunch supporter of women in IT and is very passionate about finding ways to creatively use technology and data to solve everyday challenges.
Gold prospecting in Venezuela has led to a malaria resurgence, but researchers have developed AI to take a bite out of the problem.
In Venezuela’s Bolivar state, deforestation for gold mining in waters has disturbed mosquito populations, which are biting miners and infecting them with the deadly parasite.
Venezuela was certified as malaria-free in 1961 by the World Health Organization. It’s estimated that worldwide there were 263 million cases of malaria and 597,000 deaths in 2023, according to the WHO.
In the Venezuelan outbreak, the area affected is rural and has limited access to medical clinics, so detection with microscopy by trained professionals is lacking.
But researchers at the intersection of medicine and technology have tapped AI and NVIDIA GPUs to come up with a solution. They recently published a paper in Nature, describing the development of a convolutional neural network (CNN) for automatically detecting malaria parasites in blood samples.
“At some point in Venezuela, malaria was almost eradicated,” said 25-year-old Diego Ramos-Briceño, who has a bachelor’s in engineering that he earned while also pursuing a doctorate in medicine. “I believe it was around 135,000 cases last year.”
The researchers — Ramos-Briceño, Alessandro Flammia-D’Aleo, Gerardo Fernández-López, Fhabián Carrión-Nessi and David Forero-Peña — used the CNN to identify Plasmodium falciparum and Plasmodium vivax in thick blood smears, achieving 99.51% accuracy.
To develop the model, the team acquired a dataset of 5,941 labeled thick blood smear microscope images from the Chittagong Medical College Hospital, in Bangladesh. They processed this dataset to create nearly 190,000 labeled images.
“What we wanted for the neural network to learn is the morphology of the parasite, so from out of the nearly 6,000 microscope level images, we extracted every single parasite, and from all that data augmentation and segmentation, we ended up having almost 190,000 images for model training,” said Ramos-Briceño.
The model comes as traditional microscopy methods are also challenged by limitations in accuracy and consistency, according to the research paper.
To run model training, the malaria paper’s team tapped into an RTX 3060 GPU from a computer science teacher mentoring their research.
“We used PyTorch Lightning with NVIDIA CUDA acceleration that enabled us to do efficient parallel computation that significantly sped up the matrix operations and the preparations of the neural network compared with what a CPU would have done,” said Ramos-Briceño.
For inference, malaria determinations from blood samples can be made within several seconds, he said, using such GPUs.
Clinics lacking trained microscopists could use the model and introduce their own data for transfer learning so that the model performs optimally with the types of images they submit, handling the lighting conditions and other factors, he said.
“For communities that are far away from the urban setting, where there’s more access to resources, this could be a way to approach the malaria problem,” said Ramos-Briceño.