We’re extending Gemini to become a world model that can make plans and imagine new experiences by simulating aspects of the world.Read More

We’re extending Gemini to become a world model that can make plans and imagine new experiences by simulating aspects of the world.Read More

Gemini 2.5 Pro continues to be loved by developers as the best model for coding, and 2.5 Flash is getting even better with a new update. We’re bringing new capabilities to our models, including Deep Think, an experimental enhanced reasoning mode for 2.5 Pro.Read More
 We’re launching the new NotebookLM app, designed to help people understand anything, anywhere.Read More
We’re launching the new NotebookLM app, designed to help people understand anything, anywhere.Read More

Agentic AI is redefining scientific discovery and unlocking research breakthroughs and innovations across industries. Through deepened collaboration, NVIDIA and Microsoft are delivering advancements that accelerate agentic AI-powered applications from the cloud to the PC.
At Microsoft Build, Microsoft unveiled Microsoft Discovery, an extensible platform built to empower researchers to transform the entire discovery process with agentic AI. This will help research and development departments across various industries accelerate the time to market for new products, as well as speed and expand the end-to-end discovery process for all scientists.
Microsoft Discovery will integrate the NVIDIA ALCHEMI NIM microservice, which optimizes AI inference for chemical simulations, to accelerate materials science research with property prediction and candidate recommendation. The platform will also integrate NVIDIA BioNeMo NIM microservices, tapping into pretrained AI workflows to speed up AI model development for drug discovery. These integrations equip researchers with accelerated performance for faster scientific discoveries.
In testing, researchers at Microsoft used Microsoft Discovery to detect a novel coolant prototype with promising properties for immersion cooling in data centers in under 200 hours, rather than months or years with traditional methods.
Microsoft is rapidly deploying tens of thousands of NVIDIA GB200 NVL72 rack-scale systems across its Azure data centers, boosting both performance and efficiency.
Azure’s ND GB200 v6 virtual machines — built on a rack-scale architecture with up to 72 NVIDIA Blackwell GPUs per rack and advanced liquid cooling — deliver up to 35x more inference throughput compared with previous ND H100 v5 VMs accelerated by eight NVIDIA H100 GPUs, setting a new benchmark for AI workloads.
These innovations are underpinned by custom server designs, high-speed NVIDIA NVLink interconnects and NVIDIA Quantum InfiniBand networking — enabling seamless scaling to tens of thousands of Blackwell GPUs for demanding generative and agentic AI applications.
Microsoft chairman and CEO Satya Nadella and NVIDIA founder and CEO Jensen Huang also highlighted how Microsoft and NVIDIA’s collaboration is compounding performance gains through continuous software optimizations across NVIDIA architectures on Azure. This approach maximizes developer productivity, lowers total cost of ownership and accelerates all workloads, including AI and data processing — all while driving greater efficiency per dollar and per watt for customers.
Building on the NIM integration in Azure AI Foundry, announced at NVIDIA GTC, Microsoft and NVIDIA are expanding the platform with the NVIDIA Llama Nemotron family of open reasoning models and NVIDIA BioNeMo NIM microservices, which deliver enterprise-grade, containerized inferencing for complex decision-making and domain-specific AI workloads.
Developers can now access optimized NIM microservices for advanced reasoning in Azure AI Foundry. These include the NVIDIA Llama Nemotron Super and Nano models, which offer advanced multistep reasoning, coding and agentic capabilities, delivering up to 20% higher accuracy and 5x faster inference than previous models.
Healthcare-focused BioNeMo NIM microservices like ProteinMPNN, RFDiffusion and OpenFold2 address critical applications in digital biology, drug discovery and medical imaging, enabling researchers and clinicians to accelerate protein science, molecular modeling and genomic analysis for improved patient care and faster scientific innovation.
This expanded integration empowers organizations to rapidly deploy high-performance AI agents, connecting to these models and other specialized healthcare solutions with robust reliability and simplified scaling.
Generative AI is reshaping PC software with entirely new experiences — from digital humans to writing assistants, intelligent agents and creative tools. NVIDIA RTX AI PCs make it easy to get it started with experimenting with generative AI and unlock greater performance on Windows 11.
At Microsoft Build, NVIDIA and Microsoft are unveiling an AI inferencing stack to simplify development and boost inference performance for Windows 11 PCs.
NVIDIA TensorRT has been reimagined for RTX AI PCs, combining industry-leading TensorRT performance with just-in-time, on-device engine building and an 8x smaller package size for seamless AI deployment to the more than 100 million RTX AI PCs.
Announced at Microsoft Build, TensorRT for RTX is natively supported by Windows ML — a new inference stack that provides app developers with both broad hardware compatibility and state-of-the-art performance. TensorRT for RTX is available in the Windows ML preview starting today, and will be available as a standalone software development kit from NVIDIA Developer in June.
Learn more about how TensorRT for RTX and Windows ML are streamlining software development. Explore new NIM microservices and AI Blueprints for RTX, and RTX-powered updates from Autodesk, Bilibili, Chaos, LM Studio and Topaz in the RTX AI PC blog, and join the community discussion on Discord.
Explore sessions, hands-on workshops and live demos at Microsoft Build to learn how Microsoft and NVIDIA are accelerating agentic AI.
This blog post is co-written with Jonas Neuman from HERE Technologies.
HERE Technologies, a 40-year pioneer in mapping and location technology, collaborated with the AWS Generative AI Innovation Center (GenAIIC) to enhance developer productivity with a generative AI-powered coding assistant. This innovative tool is designed to enhance the onboarding experience for HERE’s self-service Maps API for JavaScript. HERE’s use of generative AI empowers its global developer community to quickly translate natural language queries into interactive map visualizations, streamlining the evaluation and adaptation of HERE’s mapping services.
New developers who try out these APIs for the first time often begin with questions such as “How can I generate a walking route from point A to B?” or “How can I display a circle around a point?” Although HERE’s API documentation is extensive, HERE recognized that accelerating the onboarding process could significantly boost developer engagement. They aim to enhance retention rates and create proficient product advocates through personalized experiences.
To create a solution, HERE collaborated with the GenAIIC. Our joint mission was to create an intelligent AI coding assistant that could provide explanations and executable code solutions in response to users’ natural language queries. The requirement was to build a scalable system that could translate natural language questions into HTML code with embedded JavaScript, ready for immediate rendering as an interactive map that users can see on screen.
The team needed to build a solution that accomplished the following:
Together, HERE and the GenAIIC built a solution based on Amazon Bedrock that balanced goals with inherent trade-offs. Amazon Bedrock is a fully managed service that provides access to foundation models (FMs) from leading AI companies through a single API, along with a broad set of capabilities, enabling you to build generative AI applications with built-in security, privacy, and responsible AI features. The service allows you to experiment with and privately customize different FMs using techniques like fine-tuning and Retrieval Augmented Generation (RAG), and build agents that execute tasks. Amazon Bedeck is serverless, alleviates infrastructure management needs, and seamlessly integrates with existing AWS services.
Built on the comprehensive suite of AWS managed and serverless services, including Amazon Bedrock FMs, Amazon Bedrock Knowledge Bases for RAG implementation, Amazon Bedrock Guardrails for content filtering, and Amazon DynamoDB for conversation management, the solution delivers a robust and scalable coding assistant without the overhead of infrastructure management. The result is a practical, user-friendly tool that can enhance the developer experience and provide a novel way for API exploration and fast solutioning of location and navigation experiences.
In this post, we describe the details of how this was accomplished.
We used the following resources as part of this solution:
To develop the coding assistant, we designed and implemented a RAG workflow. Although standard LLMs can generate code, they often work with outdated knowledge and can’t adapt to the latest HERE Maps API for JavaScript changes or best practices. HERE Maps API for JavaScript documentation can significantly enhance coding assistants by providing accurate, up-to-date context. The storage of HERE Maps API for JavaScript documentation in a vector database allows the coding assistant to retrieve relevant snippets for user queries. This allows the LLM to ground its responses in official documentation rather than potentially outdated training data, leading to more accurate code suggestions.
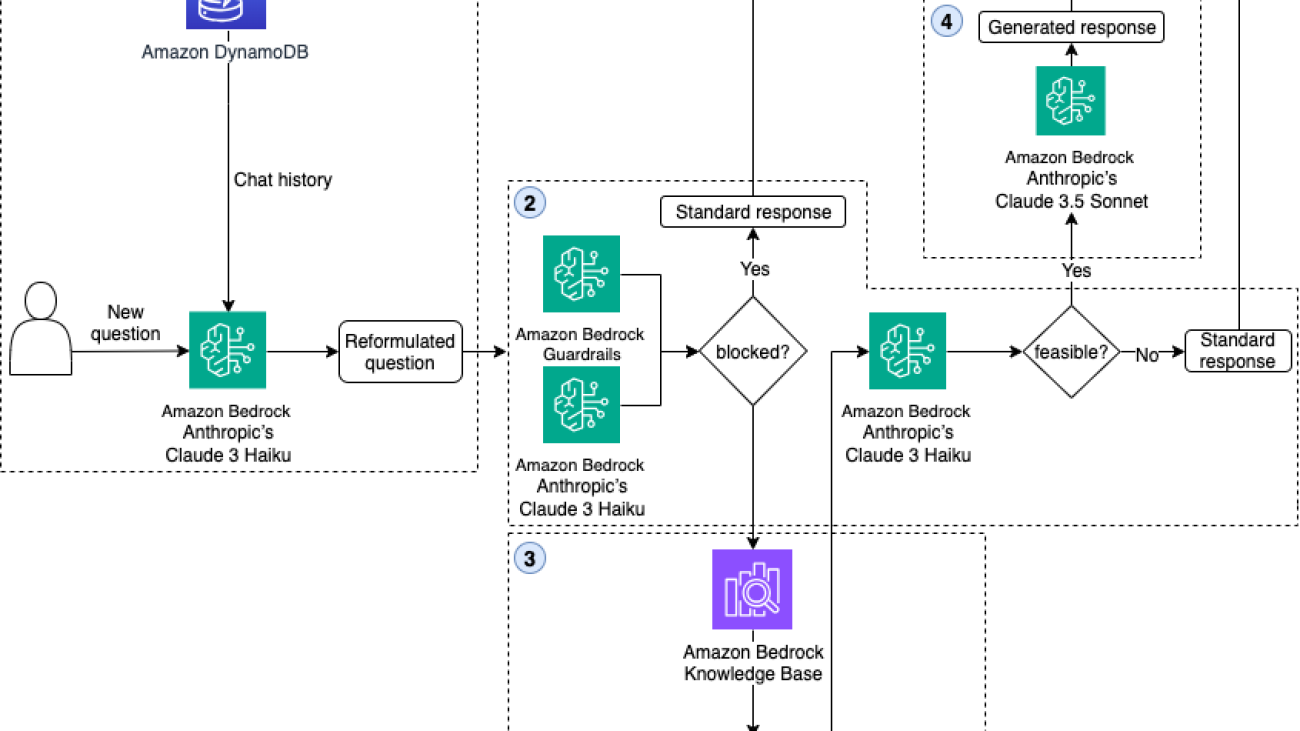
The following diagram illustrates the overall architecture.

The solution architecture comprises four key modules:
Each module discussed in the previous section was decomposed into smaller sub-tasks. This allowed us to model the functionality and various decision points within the system as a Directed Acyclic Graph (DAG) using LangGraph. A DAG is a graph where nodes (vertices) are connected by directed edges (arrows) that represent relationships, and crucially, there are no cycles (loops) in the graph. A DAG allows the representation of dependencies with a guaranteed order, and it helps enable safe and efficient execution of tasks. LangGraph orchestration has several benefits, such as parallel task execution, code readability, and maintainability through state management and streaming support.
The following diagram illustrates the coding assistant workflow.

When a user submits a question, a workflow is invoked, starting at the Reformulate Question node. This node handles the implementation of the follow-up question module (Module 1). The Apply Guardrail, Retrieve Documents, and Review Question nodes run in parallel, using the reformulated input question. The Apply Guardrail node uses denied topics from Amazon Bedrock Guardrails to enforce boundaries and apply safeguards against harmful inputs, and the Review Question node filters out-of-scope inquiries using Anthropic’s Claude 3 Haiku (Module 2). The Retrieve Documents node retrieves relevant documents from the Amazon Bedrock knowledge base to provide the language model with necessary information (Module 3).
The outputs of the Apply Guardrail and Review Question nodes determine the next node invocation. If the input passes both checks, the Review Documents node assesses the question’s feasibility by analyzing if it can be answered with the retrieved documents (Module 2). If feasible, the Generate Response node answers the question and the code and description are streamed to the UI, allowing the user to start getting feedback from the system within seconds (Module 4). Otherwise, the Block Response node returns a predefined answer. Finally, the Update Chat History node persistently maintains the conversation history for future reference (Module 1).
This pipeline backs the code assistant chatbot capability, providing an efficient and user-friendly experience for developers seeking guidance on implementing the HERE Maps API for JavaScript. The following code and screenshot is an example of the model generated code and code rendered map for the query “How to open an infobubble when clicking on a marker?

To improve final code generation accuracy, we employed extensive prompt engineering for the response generation module. The final prompt incorporated the following components:
The following is the core structure of the prompt and the components discussed:
We manually evaluated the accuracy of code generation for each question in the test set. Our evaluation focused on two key criteria:
Code samples that satisfied both criteria were classified as correct. In addition to accuracy, we also evaluated latency, including both overall latency and time to first token. Overall latency refers to the total time taken to generate the full response. To improve user experience and avoid having users wait without visible output, we employed response streaming. Time to first token measures how long it takes for the system to generate the first token of the response. The evaluation results, based on 20 samples from the testing dataset, are as follows:
The high accuracy makes sure that the code assistant generates correct code to answer the user’s question. The low overall latency and quick time to first token significantly reduces customer waiting time, enhancing the overall user experience.
Security is our top priority at AWS. For the scope of this post, we shared how we used Amazon Bedrock Guardrails to build responsible AI application. Safety and security is critical for every application. For in-depth guidance on AWS’s approach to secure and responsible AI development, refer to Securing generative AI and the AWS Whitepaper Navigating the security landscape of generative AI.
The following two areas are worth exploring to improve overall system accuracy and improve the current mechanism for evaluating the LLM response:
The outcome of this solution is a fast, practical, user-friendly coding assistant that enhances the developer experience for the HERE Maps API for JavaScript. Through iterative evolution of a RAG approach and prompt engineering techniques, the team surpassed target accuracy and latency without relying on fine-tuning. This means the solution can be expanded to other HERE offerings beyond the HERE Maps API for JavaScript. Additionally, the LLMs backing the assistant can be upgraded as higher-performant FMs are made available on Amazon Bedrock.
Key highlights of the solution include the use of a map initialization code template in the prompt, a modular and maintainable architecture orchestrated by LangGraph, and response streaming capabilities that start displaying generated code in under 8 seconds. The careful selection and combination of language models, optimized for specific tasks, further contributed to the overall performance and cost-effectiveness of the solution.
Overall, the outcomes of this proof of concept were made possible through the partnership between the GenAIIC and HERE Technologies. The coding assistant has laid a solid foundation for HERE Technologies to significantly enhance developer productivity, accelerate API adoption, and drive growth in its developer landscape.
Explore how Amazon Bedrock makes it straightforward to build generative AI applications with model choice and features like Amazon Bedrock Knowledge Bases and Amazon Bedrock Guardrails. Get started with Amazon Bedrock Knowledge Bases to implement RAG-based solutions that can transform your developer experience and boost productivity.
 Gan is an Applied Scientist on the AWS Generative AI Innovation and Delivery team. He is passionate about leveraging generative AI techniques to help customers solve real-world business problems.
Gan is an Applied Scientist on the AWS Generative AI Innovation and Delivery team. He is passionate about leveraging generative AI techniques to help customers solve real-world business problems.
 Grace Lang is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she designs and implements advanced AI solutions across industries. Driven by a passion for solving complex technical challenges, Grace partners with customers to develop innovative machine learning applications.
Grace Lang is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she designs and implements advanced AI solutions across industries. Driven by a passion for solving complex technical challenges, Grace partners with customers to develop innovative machine learning applications.
 Julia Wagner is a Senior AI Strategist at AWS’s Generative AI Innovation Center. With her background in product management, she helps teams develop AI solutions focused on customer and business needs. Outside of work, she enjoys biking and mountain activities.
Julia Wagner is a Senior AI Strategist at AWS’s Generative AI Innovation Center. With her background in product management, she helps teams develop AI solutions focused on customer and business needs. Outside of work, she enjoys biking and mountain activities.
 Jonas Neuman is an Engineering Manager at HERE Technologies, based in Berlin, Germany. He is passionate about building great customer-facing applications. Together with his team, Jonas delivers features that help customers sign up for HERE Services and SDKs, manage access, and monitor their usage.
Jonas Neuman is an Engineering Manager at HERE Technologies, based in Berlin, Germany. He is passionate about building great customer-facing applications. Together with his team, Jonas delivers features that help customers sign up for HERE Services and SDKs, manage access, and monitor their usage.
 Sibasankar is a Senior Solutions Architect at AWS in the Automotive and Manufacturing team. He is passionate about AI, data and security. In his free time, he loves spending time with his family and reading non-fiction books.
Sibasankar is a Senior Solutions Architect at AWS in the Automotive and Manufacturing team. He is passionate about AI, data and security. In his free time, he loves spending time with his family and reading non-fiction books.
 Jared Kramer is an Applied Science Manager at Amazon Web Services based in Seattle. Jared joined Amazon 11 years ago as an ML Science intern. After 6 years in Customer Service Technologies and 4 years in Sustainability Science and Innovation, he now leads of team of Applied Scientists and Deep Learning Architects in the Generative AI Innovation Center. Jared specializes in designing and delivering industry NLP applications and is on the Industry Track program committee for ACL and EMNLP.
Jared Kramer is an Applied Science Manager at Amazon Web Services based in Seattle. Jared joined Amazon 11 years ago as an ML Science intern. After 6 years in Customer Service Technologies and 4 years in Sustainability Science and Innovation, he now leads of team of Applied Scientists and Deep Learning Architects in the Generative AI Innovation Center. Jared specializes in designing and delivering industry NLP applications and is on the Industry Track program committee for ACL and EMNLP.

Generative AI is transforming PC software into breakthrough experiences — from digital humans to writing assistants, intelligent agents and creative tools.
NVIDIA RTX AI PCs are powering this transformation with technology that makes it simpler to get started experimenting with generative AI and unlock greater performance on Windows 11.
NVIDIA TensorRT has been reimagined for RTX AI PCs, combining industry-leading TensorRT performance with just-in-time, on-device engine building and an 8x smaller package size for seamless AI deployment to more than 100 million RTX AI PCs.
Announced at Microsoft Build, TensorRT for RTX is natively supported by Windows ML — a new inference stack that provides app developers with both broad hardware compatibility and state-of-the-art performance.
For developers looking for AI features ready to integrate, NVIDIA software development kits (SDKs) offer a wide array of options, from NVIDIA DLSS to multimedia enhancements like NVIDIA RTX Video. This month, top software applications from Autodesk, Bilibili, Chaos, LM Studio and Topaz Labs are releasing updates to unlock RTX AI features and acceleration.
AI enthusiasts and developers can easily get started with AI using NVIDIA NIM — prepackaged, optimized AI models that can run in popular apps like AnythingLLM, Microsoft VS Code and ComfyUI. Releasing this week, the FLUX.1-schnell image generation model will be available as a NIM microservice, and the popular FLUX.1-dev NIM microservice has been updated to support more RTX GPUs.
Those looking for a simple, no-code way to dive into AI development can tap into Project G-Assist — the RTX PC AI assistant in the NVIDIA app — to build plug-ins to control PC apps and peripherals using natural language AI. New community plug-ins are now available, including Google Gemini web search, Spotify, Twitch, IFTTT and SignalRGB.
Today’s AI PC software stack requires developers to compromise on performance or invest in custom optimizations for specific hardware.
Windows ML was built to solve these challenges. Windows ML is powered by ONNX Runtime and seamlessly connects to an optimized AI execution layer provided and maintained by each hardware manufacturer.
For GeForce RTX GPUs, Windows ML automatically uses the TensorRT for RTX inference library for high performance and rapid deployment. Compared with DirectML, TensorRT delivers over 50% faster performance for AI workloads on PCs.
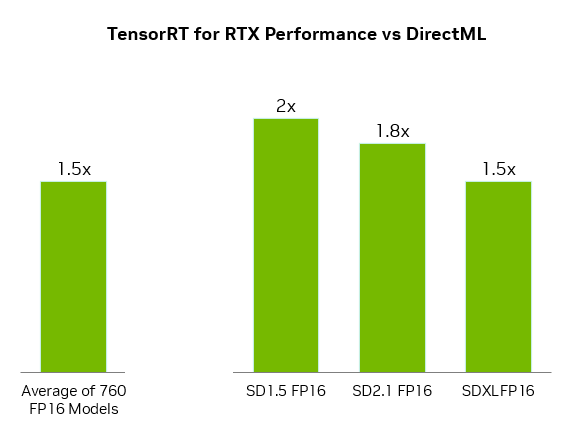
Windows ML also delivers quality-of-life benefits for developers. It can automatically select the right hardware — GPU, CPU or NPU — to run each AI feature, and download the execution provider for that hardware, removing the need to package those files into the app. This allows for the latest TensorRT performance optimizations to be delivered to users as soon as they’re ready.
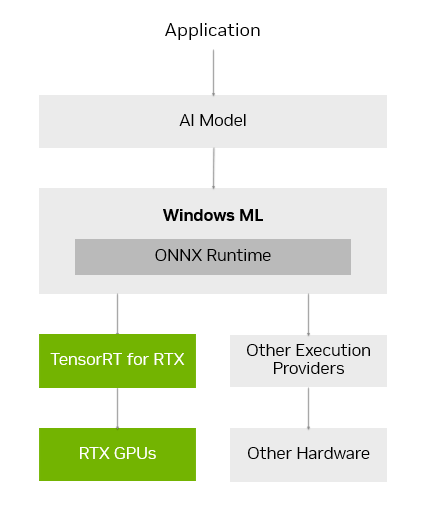
TensorRT, a library originally built for data centers, has been redesigned for RTX AI PCs. Instead of pre-generating TensorRT engines and packaging them with the app, TensorRT for RTX uses just-in-time, on-device engine building to optimize how the AI model is run for the user’s specific RTX GPU in mere seconds. And the library’s packaging has been streamlined, reducing its file size significantly by 8x.
TensorRT for RTX is available to developers through the Windows ML preview today, and will be available as a standalone SDK at NVIDIA Developer in June.
Developers can learn more in the TensorRT for RTX launch blog or Microsoft’s Windows ML blog.
Developers looking to add AI features or boost app performance can tap into a broad range of NVIDIA SDKs. These include NVIDIA CUDA and TensorRT for GPU acceleration; NVIDIA DLSS and Optix for 3D graphics; NVIDIA RTX Video and Maxine for multimedia; and NVIDIA Riva and ACE for generative AI.
Top applications are releasing updates this month to enable unique features using these NVIDIA SDKs, including:
NVIDIA looks forward to continuing to work with Microsoft and top AI app developers to help them accelerate their AI features on RTX-powered machines through the Windows ML and TensorRT integration.
Getting started with developing AI on PCs can be daunting. AI developers and enthusiasts have to select from over 1.2 million AI models on Hugging Face, quantize it into a format that runs well on PC, find and install all the dependencies to run it, and more.
NVIDIA NIM makes it easy to get started by providing a curated list of AI models, prepackaged with all the files needed to run them and optimized to achieve full performance on RTX GPUs. And since they’re containerized, the same NIM microservice can be run seamlessly across PCs or the cloud.
NVIDIA NIM microservices are available to download through build.nvidia.com or through top AI apps like Anything LLM, ComfyUI and AI Toolkit for Visual Studio Code.
During COMPUTEX, NVIDIA will release the FLUX.1-schnell NIM microservice — an image generation model from Black Forest Labs for fast image generation — and update the FLUX.1-dev NIM microservice to add compatibility for a wide range of GeForce RTX 50 and 40 Series GPUs.
These NIM microservices enable faster performance with TensorRT and quantized models. On NVIDIA Blackwell GPUs, they run over twice as fast as running them natively, thanks to FP4 and RTX optimizations.
AI developers can also jumpstart their work with NVIDIA AI Blueprints — sample workflows and projects using NIM microservices.
NVIDIA last month released the NVIDIA AI Blueprint for 3D-guided generative AI, a powerful way to control composition and camera angles of generated images by using a 3D scene as a reference. Developers can modify the open-source blueprint for their needs or extend it with additional functionality.
NVIDIA recently released Project G-Assist as an experimental AI assistant integrated into the NVIDIA app. G-Assist enables users to control their GeForce RTX system using simple voice and text commands, offering a more convenient interface compared to manual controls spread across numerous legacy control panels.
Developers can also use Project G-Assist to easily build plug-ins, test assistant use cases and publish them through NVIDIA’s Discord and GitHub.
The Project G-Assist Plug-in Builder — a ChatGPT-based app that allows no-code or low-code development with natural language commands — makes it easy to start creating plug-ins. These lightweight, community-driven add-ons use straightforward JSON definitions and Python logic.
New open-source plug-in samples are available now on GitHub, showcasing diverse ways on-device AI can enhance PC and gaming workflows. They include:
Explore the GitHub repository for more examples — including hands-free music control via Spotify, livestream status checks with Twitch, and more.
Companies are adopting AI as the new PC interface. For example, SignalRGB is developing a G-Assist plug-in that enables unified lighting control across multiple manufacturers. Users will soon be able to install this plug-in directly from the SignalRGB app.
Starting this week, the AI community will also be able to use G-Assist as a custom component in Langflow — enabling users to integrate function-calling capabilities in low-code or no-code workflows, AI applications and agentic flows.
Enthusiasts interested in developing and experimenting with Project G-Assist plug-ins are invited to join the NVIDIA Developer Discord channel to collaborate, share creations and gain support.
Each week, the RTX AI Garage blog series features community-driven AI innovations and content for those looking to learn more about NIM microservices and AI Blueprints, as well as building AI agents, creative workflows, digital humans, productivity apps and more on AI PCs and workstations.
Plug in to NVIDIA AI PC on Facebook, Instagram, TikTok and X — and stay informed by subscribing to the RTX AI PC newsletter.
Follow NVIDIA Workstation on LinkedIn and X.
See notice regarding software product information.

Modern productivity is rooted in the web—from searching for information and filling in forms to navigating dashboards. Yet, many of these tasks remain manual and repetitive. Today, we are introducing Magentic-UI, a new open-source research prototype of a human-centered agent that is meant to help researchers study open questions on human-in-the-loop approaches and oversight mechanisms for AI agents. This prototype collaborates with users on web-based tasks and operates in real time over a web browser. Unlike other computer use agents that aim for full autonomy, Magentic-UI offers a transparent and controllable experience for tasks that are action-oriented and require activities beyond just performing simple web searches.
Magentic-UI builds on Magentic-One (opens in new tab), a powerful multi-agent team we released last year, and is powered by AutoGen (opens in new tab), our leading agent framework. It is available under MIT license at https://github.com/microsoft/Magentic-UI (opens in new tab) and on Azure AI Foundry Labs (opens in new tab), the hub where developers, startups, and enterprises can explore groundbreaking innovations from Microsoft Research. Magentic-UI is integrated with Azure AI Foundry models and agents. Learn more about how to integrate Azure AI agents into the Magentic-UI multi-agent architecture by following this code sample (opens in new tab).
Magentic-UI can perform tasks that require browsing the web, writing and executing Python and shell code, and understanding files. Its key features include:

While many web agents promise full autonomy, in practice users can be left unsure of what the agent can do, what it is currently doing, and whether they have enough control to intervene when something goes wrong or doesn’t occur as expected. By contrast, Magentic-UI considers user needs at every stage of interaction. We followed a human-centered design methodology in building Magentic-UI by prototyping and obtaining feedback from pilot users during its design.
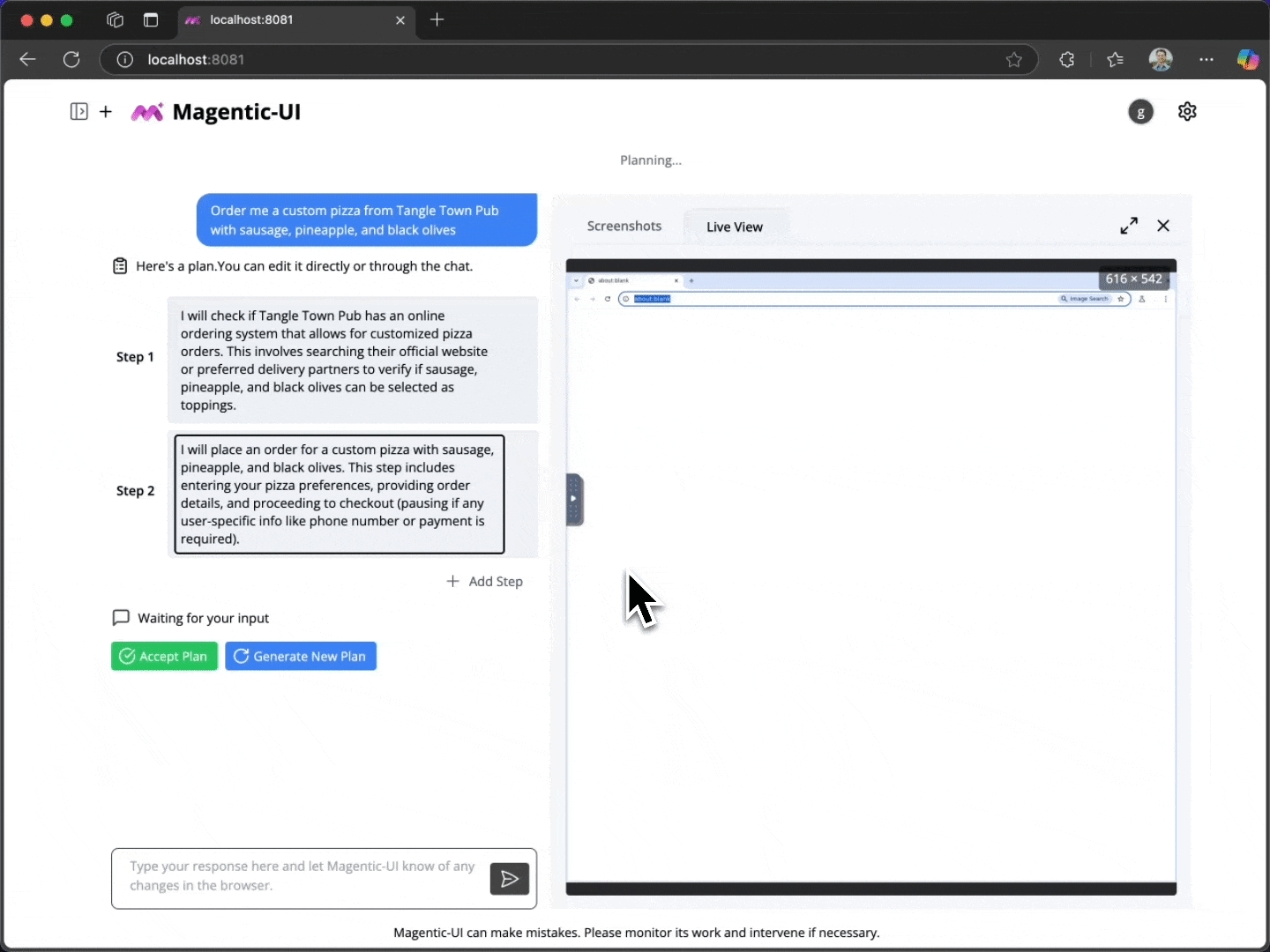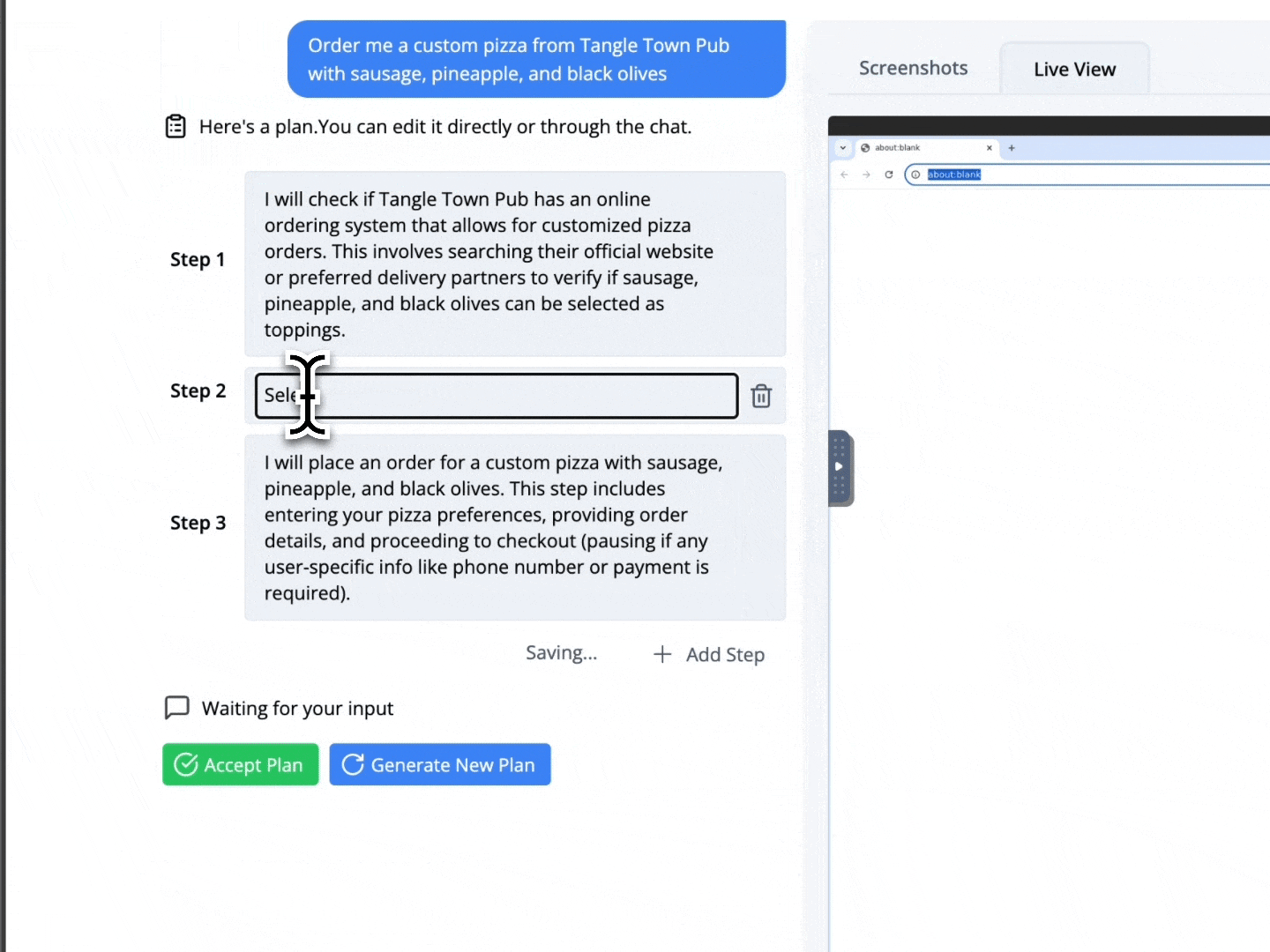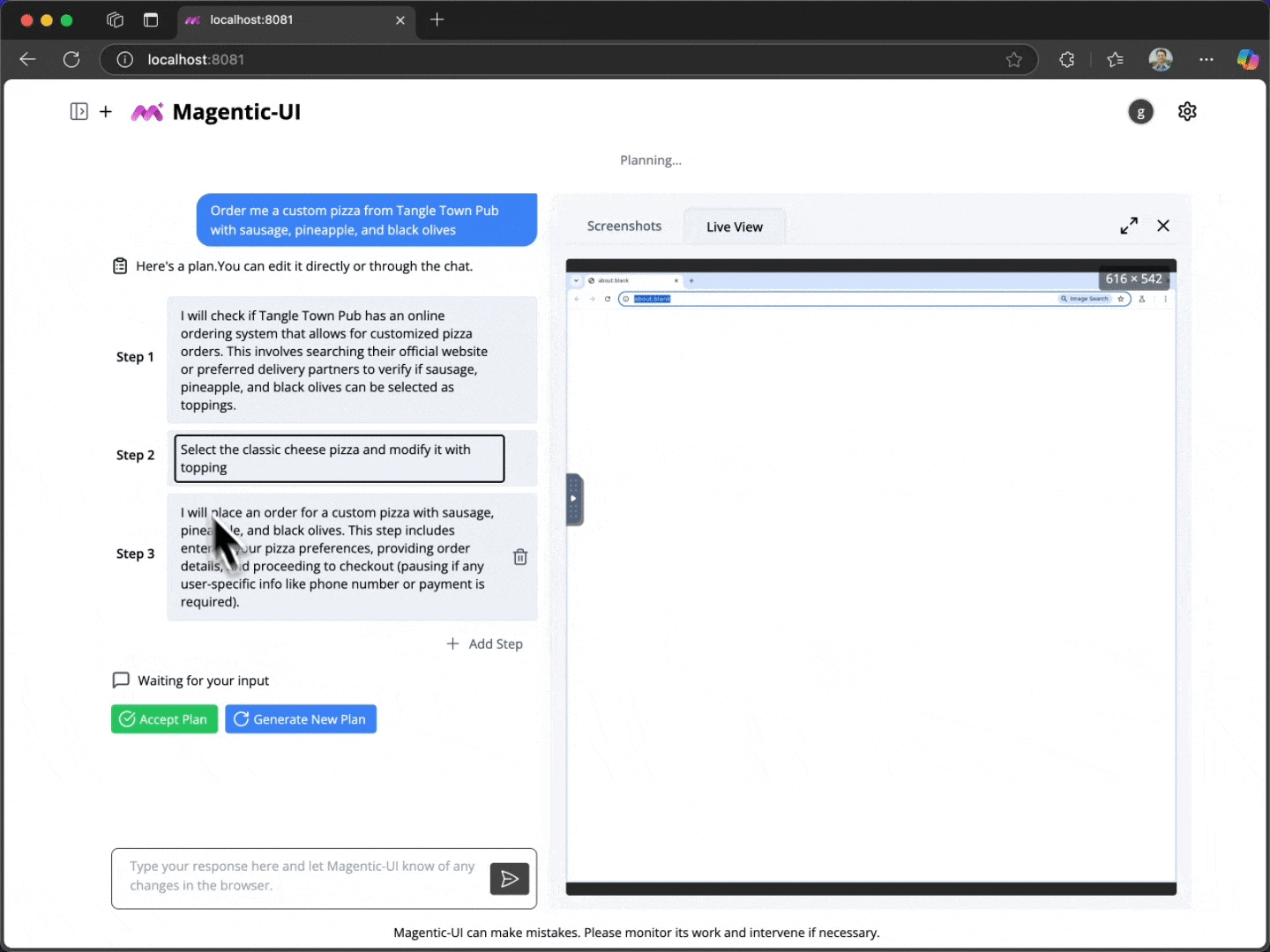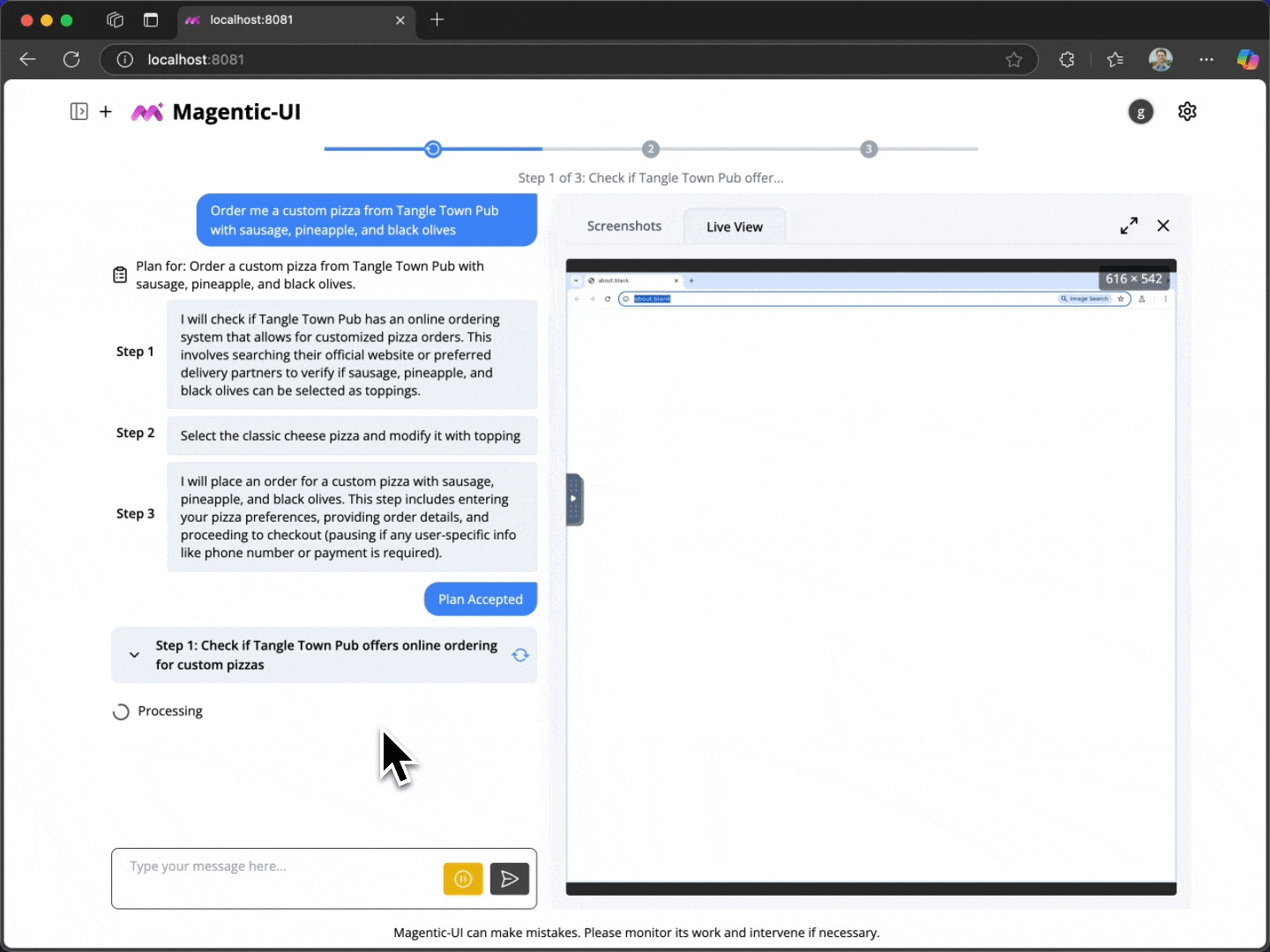
For example, after a person specifies and before Magentic-UI even begins to execute, it creates a clear step-by-step plan that outlines what it would do to accomplish the task. People can collaborate with Magentic-UI to modify this plan and then give final approval for Magentic-UI to begin execution. This is crucial as users may have expectations of how the task should be completed; communicating that information could significantly improve agent performance. We call this feature co-planning.
During execution, Magentic-UI shows in real time what specific actions it’s about to take. For example, whether it is about to click on a button or input a search query. It also shows in real time what it observed on the web pages it is visiting. Users can take control of the action at any point in time and give control back to the agent. We call this feature co-tasking.


Additionally, Magentic-UI asks for user permission before performing actions that are deemed irreversible, such as closing a tab or clicking a button with side effects. We call these “action guards”. The user can also configure Magentic-UI’s action guards to always ask for permission before performing any action. If the user deems an action risky (e.g., paying for an item), they can reject it.


After execution, the user can ask Magentic-UI to reflect on the conversation and infer and save a step-by-step plan for future similar tasks. Users can view and modify saved plans for Magentic-UI to reuse in the future in a saved-plans gallery. In a future session, users can launch Magentic-UI with the saved plan to either execute the same task again, like checking the price of a specific flight, or use the plan as a guide to help complete similar tasks, such as checking the price of a different type of flight.
Combined, these four features—co-planning, co-tasking, action guards, and plan learning—enable users to collaborate effectively with Magentic-UI.
Magentic-UI’s underlying system is a team of specialized agents adapted from AutoGen’s Magentic-One system. The agents work together to create a modular system:

To interact with Magentic-UI, users can enter a text message and attach images. In response, Magentic-UI creates a natural-language step-by-step plan with which users can interact through a plan-editing interface. Users can add, delete, edit, regenerate steps, and write follow-up messages to iterate on the plan. While the user editing the plan adds an upfront cost to the interaction, it can potentially save a significant amount of time in the agent executing the plan and increase its chance at success.
The plan is stored inside the Orchestrator and is used to execute the task. For each step of the plan, the Orchestrator determines which of the agents (WebSurfer, Coder, FileSurfer) or the user should complete the step. Once that decision is made, the Orchestrator sends a request to one of the agents or the user and waits for a response. After the response is received, the Orchestrator decides whether that step is complete. If it is, the Orchestrator moves on to the following step.
Once all steps are completed, the Orchestrator generates a final answer that is presented to the user. If, while executing any of the steps, the Orchestrator decides that the plan is inadequate (for example, because a certain website is unreachable), the Orchestrator can replan with user permission and start executing a new plan.
All intermediate progress steps are clearly displayed to the user. Furthermore, the user can pause the execution of the plan and send additional requests or feedback. The user can also configure through the interface whether agent actions (e.g., clicking a button) require approval.
Magentic-UI innovates through its ability to integrate human feedback in its planning and execution of tasks. We performed a preliminary automated evaluation to showcase this ability on the GAIA benchmark (opens in new tab) for agents with a user-simulation experiment.

GAIA is a benchmark for general AI assistants, with multimodal question-answer pairs that are challenging, requiring the agents to navigate the web, process files, and execute code. The traditional evaluation setup with GAIA assumes the system will autonomously complete the task and return an answer, which is compared to the ground-truth answer.
To evaluate the human-in-the-loop capabilities of Magentic-UI, we transform GAIA into an interactive benchmark by introducing the concept of a simulated user. Simulated users provide value in two ways: by having specific expertise that the agent may not possess, and by providing guidance on how the task should be performed.
We experiment with two types of simulated users to show the value of human-in-the-loop: (1) a simulated user that is more intelligent than the Magentic-UI agents and (2) a simulated user with the same intelligence as Magentic-UI agents but with additional information about the task. During co-planning, Magentic-UI takes feedback from this simulated user to improve its plan. During co-tasking, Magentic-UI can ask the (simulated) user for help when it gets stuck. Finally, if Magentic-UI does not provide a final answer, then the simulated user provides an answer instead.
The simulated user is an LLM without any tools, instructed to interact with Magentic-UI the way we expect a human would act. The first type of simulated user relies on OpenAI’s o4-mini, more performant at many tasks than the one powering the Magentic-UI agents (GPT-4o). For the second type of simulated user, we use GPT-4o for both the simulated user and the rest of the agents, but the user has access to side information about each task. Each task in GAIA has side information, which includes a human-written plan to solve the task. While this plan is not used as input in the traditional benchmark, in our interactive setting we provide this information to the second type of simulated user,which is powered by an LLM so that it can mimic a knowledgeable user. Importantly, we tuned our simulated user so as not to reveal the ground-truth answer directly as the answer is usually found inside the human written plan. Instead, it is prompted to guide Magentic-UI indirectly. We found that this tuning prevented the simulated user from inadvertently revealing the answer in all but 6% of tasks when Magentic-UI provides a final answer.
On the validation subset of GAIA (162 tasks), we show the results of Magentic-One operating in autonomous mode, Magentic-UI operating in autonomous mode (without the simulated user), Magentic-UI with simulated user (1) (smarter model), Magentic-UI with simulated user (2) (side-information), and human performance. We first note that Magentic-UI in autonomous mode is within a margin of error of the performance of Magentic-One. Note that the same LLM (GPT-4o) is used for Magentic-UI and Magentic-One.
Magentic-UI with the simulated user that has access to side information improves the accuracy of autonomous Magentic-UI by 71%, from a 30.3% task-completion rate to a 51.9% task-completion rate. Moreover, Magentic-UI only asks for help from the simulated user in 10% of tasks and relies on the simulated user for the final answer in 18% of tasks. And in those tasks where it does ask for help, it asks for help on average 1.1 times. Magentic-UI with the simulated user powered by a smarter model improves to 42.6% where Magentic-UI asks for help in only 4.3% of tasks, asking for help an average of 1.7 times in those tasks. This demonstrates the potential of even lightweight human feedback for improving performance (e.g., task completion) of autonomous agents, especially at a fraction of the cost compared to people completing tasks entirely manually.
As described above, once Magentic-UI completes a task, users have the option for Magentic-UI to learn a plan based on the execution of the task. These plans are saved in a plan gallery, which users and Magentic-UI can access in the future.
The user can select a plan from the plan gallery, which is displayed by clicking on the Saved Plans button. Alternatively, as a user enters a task that closely matches a previous task, the saved plan will be displayed even before the user is done typing. If no identical task is found, Magentic-UI can use AutoGen’s Task-Centric Memory (opens in new tab) to retrieve plans for any similar tasks. Our preliminary evaluations show that this retrieval is highly accurate, and when recalling a saved plan can be around 3x faster than generating a new plan. Once a plan is recalled or generated, the user can always accept it, modify it, or ask Magentic-UI to modify it for the specific task at hand.
Magentic-UI can surf the live internet and execute code. With such capabilities, we need to ensure that Magentic-UI acts in a safe and secure manner. The following features, design decisions, and evaluations were made to ensure this:
In addition to the above design decisions, we performed a red-team evaluation of Magentic-UI on a set of internal scenarios, which we developed to challenge the security and safety of Magentic-UI. Such scenarios include cross-site prompt injection attacks, where web pages contain malicious instructions distinct from the user’s original intent (e.g., to execute risky code, access sensitive files, or perform actions on other websites). It also contains scenarios comparable to phishing, which try to trick Magentic-UI into entering sensitive information, or granting permissions on impostor sites (e.g., a synthetic website that asks Magentic-UI to log in and enter Google credentials to read an article). In our preliminary evaluations, we found that Magentic-UI either refuses to complete the requests, stops to ask the user, or, as a final safety measure, is eventually unable to complete the request due to Docker sandboxing. We have found that this layered approach is effective for thwarting these attacks.
We have also released transparency notes, which can be found at: https://github.com/microsoft/magentic-ui/blob/main/TRANSPARENCY_NOTE.md (opens in new tab)
Magentic-UI provides a tool for researchers to study critical questions in agentic systems and particularly on human-agent interaction. In a previous report (opens in new tab), we outlined 12 questions for human-agent communication, and Magentic-UI provides a vehicle to study these questions in a realistic setting. A key question among these is how we enable humans to efficiently intervene and provide feedback to the agent while executing a task. Humans should not have to constantly watch the agent. Ideally, the agent should know when to reach out for help and provide the necessary context for the human to assist it. A second question is about safety. As agents interact with the live web, they may become prone to attacks from malicious actors. We need to study what necessary safeguards are needed to protect the human from side effects without adding a heavy burden on the human to verify every agent action. There are also many other questions surrounding security, personalization, and learning that Magentic-UI can help with studying.
Magentic-UI is an open-source agent prototype that works with people to complete complex tasks that require multi-step planning and browser use. As agentic systems expand in the scope of tasks they can complete, Magentic-UI’s design enables better transparency into agent actions and enables human control to ensure safety and reliability. Moreover, by facilitating human intervention, we can improve performance while still reducing human cost in completing tasks on aggregate. Today we have released the first version of Magentic-UI. Looking ahead, we plan to continue developing it in the open with the goal of improving its capabilities and answering research questions on human-agent collaboration. We invite the research community to extend and reuse Magentic-UI for their scientific explorations and domains.
The post Magentic-UI, an experimental human-centered web agent appeared first on Microsoft Research.

Across robot training and development, NVIDIA Research is uncovering breakthroughs in areas such as multimodal generative AI and synthetic data generation.
The team’s latest innovations will be spotlighted at the International Conference on Robotics and Automation (ICRA), running May 19-23 in Atlanta.
“ICRA has played a pivotal role in shaping the direction of robotics and automation, marking key milestones in the field’s evolution and celebrating achievements that have had a lasting impact on technology and society,” said Dieter Fox, senior director of robotics research at NVIDIA. “The research we’re contributing this year will further advance the development of autonomous vehicles and humanoid robots by helping close the data gap and improve robot safety and control.”
NVIDIA-authored papers showcased at ICRA give a glimpse into the future of robotics. They include:
Robotics workshops at ICRA featuring NVIDIA speakers include:
Explore the latest work from NVIDIA Research, and check out the Robotics Research and Development Digest (R²D²), which gives developers deeper insight into the latest physical AI and robotics breakthroughs.

Electricity. The Internet. Now it’s time for another major technology, AI, to sweep the globe.
NVIDIA founder and CEO Jensen Huang took the stage at a packed Taipei Music Center Monday to kick off COMPUTEX 2025, captivating the audience of more than 4,000 with a vision for a technology revolution that will sweep every country, every industry and every company.
“AI is now infrastructure, and this infrastructure, just like the internet, just like electricity, needs factories,” Huang said. “These factories are essentially what we build today.”
“They’re not data centers of the past,” Huang added. “These AI data centers, if you will, are improperly described. They are, in fact, AI factories. You apply energy to it, and it produces something incredibly valuable, and these things are called tokens.”
NVIDIA CUDA-X Everywhere: After showing a towering wall of partner logos, Huang described how companies are using NVIDIA’s CUDA-X platform for a dizzying array of applications, how NVIDIA and its partners are building 6G using AI, and revealed NVIDIA’s latest work to accelerate quantum supercomputing.
“The larger the install base, the more developers want to create libraries, the more libraries, the more amazing things are done,” Huang said, describing CUDA-X’s growing popularity and power. “Better applications, more benefits to users.”
More’s coming, Huang said, describing the growing power of AI to reason and perceive. That leads us to agentic AI — AI able to understand, think and act. Beyond that is physical AI — AI that understands the world. The phase after that, he said, is general robotics.
All of this has created demand for much more computing power. To meet those needs, Huang detailed the latest NVIDIA innovations from Grace Blackwell NVL72 systems to advanced networking technology, and detailed huge new AI installations from CoreWeave, Oracle, Microsoft, xAI and others across the globe.
“These are gigantic factory investments, and the reason why people build factories is because you know, you know the answer,” Huang said with a grin. “The more you buy, the more you make.”
Building AI for Taiwan: It all starts in Taiwan, Huang said, highlighting the key role Taiwan plays in the global technology ecosystem. But Taiwan isn’t just building AI for the world; NVIDIA is helping build AI for Taiwan. Huang announced that NVIDIA and Foxconn Hon Hai Technology Group are deepening their longstanding partnership and are working with the Taiwan government to build an AI factory supercomputer that will deliver state-of-the-art NVIDIA Blackwell infrastructure to researchers, startups and industries – including TSMC.
“Having a world-class AI infrastructure here in Taiwan is really important,” Huang said.
NVIDIA NVLink Fusion: And moving to help its partners scale up their systems however they choose, Huang announced NVLink Fusion, a new architecture that enables hyperscalers to create semi-custom compute solutions with NVIDIA’s NVLink interconnect.
This technology aims to break down traditional data center bottlenecks, enabling a new level of AI scale and more flexible, optimized system designs tailored to specific AI workloads.
“This incredible body of work now becomes flexible and open for anybody to integrate into,” Huang said.
Blackwell Everywhere: And the engine now powering this entire AI ecosystem is NVIDIA Blackwell, with Huang showing a slide explaining how NVIDIA offers “one architecture,” from cloud AI to enterprise AI, from personal AI to edge AI.
Physical AI: Agents are “essentially digital robots,” Huang said, able to “perceive, understand and plan.” To speed up the development of physical robots, the industry needs to train robots in a simulated environment. Huang said that NVIDIA partnered with DeepMind and Disney to build Newton, the world’s most advanced physics training engine for robotics.
NVIDIA Constellation: Lastly, building anticipation, Huang introduced a dramatic video showing NVIDIA’s Santa Clara office launching into space and landing in Taiwan. The big reveal: NVIDIA Constellation, a brand new Taiwan office for NVIDIA’s growing Taiwan workforce.
In closing, Huang emphasized that the work Taiwanese companies are doing has changed the world. He thanked NVIDIA’s ecosystem partners and described the industry’s opportunity as “extraordinary” and “once in a lifetime.”
“We are in fact creating a whole new industry to support AI factories, AI agents, and robotics, with one architecture,” Huang said.
