[THEME MUSIC FADES]
The passage I read at the top is from the book’s prologue.
When Carey, Zak, and I wrote the book, we could only speculate how generative AI would be used in healthcare because GPT-4 hadn’t yet been released. It wasn’t yet available to the very people we thought would be most affected by it. And while we felt strongly that this new form of AI would have the potential to transform medicine, it was such a different kind of technology for the world, and no one had a user’s manual for this thing to explain how to use it effectively and also how to use it safely.
So we thought it would be important to give healthcare professionals and leaders a framing to start important discussions around its use. We wanted to provide a map not only to help people navigate a new world that we anticipated would happen with the arrival of GPT-4 but also to help them chart a future of what we saw as a potential revolution in medicine.
So I’m super excited to welcome my coauthors: longtime medical/science journalist Carey Goldberg and Dr. Zak Kohane, the inaugural chair of Harvard Medical School’s Department of Biomedical Informatics and the editor-in-chief for The New England Journal of Medicine AI.
We’re going to have two discussions. This will be the first one about what we’ve learned from the people on the ground so far and how we are thinking about generative AI today.
[TRANSITION MUSIC]
Carey, Zak, I’m really looking forward to this.
CAREY GOLDBERG: It’s nice to see you, Peter.
LEE: [LAUGHS] It’s great to see you, too.
GOLDBERG: We missed you.
ZAK KOHANE: The dynamic gang is back. [LAUGHTER]
LEE: Yeah, and I guess after that big book project two years ago, it’s remarkable that we’re still on speaking terms with each other. [LAUGHTER]
In fact, this episode is to react to what we heard in the first four episodes of this podcast. But before we get there, I thought maybe we should start with the origins of this project just now over two years ago. And, you know, I had this early secret access to Davinci 3, now known as GPT-4.
I remember, you know, experimenting right away with things in medicine, but I realized I was in way over my head. And so I wanted help. And the first person I called was you, Zak. And you remember we had a call, and I tried to explain what this was about. And I think I saw skepticism in—polite skepticism—in your eyes. But tell me, you know, what was going through your head when you heard me explain this thing to you?
KOHANE: So I was divided between the fact that I have tremendous respect for you, Peter. And you’ve always struck me as sober. And we’ve had conversations which showed to me that you fully understood some of the missteps that technology—ARPA, Microsoft, and others—had made in the past. And yet, you were telling me a full science fiction compliant story [LAUGHTER] that something that we thought was 30 years away was happening now.
LEE: Mm-hmm.
KOHANE: And it was very hard for me to put together. And so I couldn’t quite tell myself this is BS, but I said, you know, I need to look at it. Just this seems too good to be true. What is this? So it was very hard for me to grapple with it. I was thrilled that it might be possible, but I was thinking, How could this be possible?
LEE: Yeah. Well, even now, I look back, and I appreciate that you were nice to me, because I think a lot of people would have [LAUGHS] been much less polite. And in fact, I myself had expressed a lot of very direct skepticism early on.
After ChatGPT got released, I think three or four days later, I received an email from a colleague running … who runs a clinic, and, you know, he said, “Wow, this is great, Peter. And, you know, we’re using this ChatGPT, you know, to have the receptionist in our clinic write after-visit notes to our patients.”
And that sparked a huge internal discussion about this. And you and I knew enough about hallucinations and about other issues that it seemed important to write something about what this could do and what it couldn’t do. And so I think, I can’t remember the timing, but you and I decided a book would be a good idea. And then I think you had the thought that you and I would write in a hopelessly academic style [LAUGHTER] that no one would be able to read.
So it was your idea to recruit Carey, I think, right?
KOHANE: Yes, it was. I was sure that we both had a lot of material, but communicating it effectively to the very people we wanted to would not go well if we just left ourselves to our own devices. And Carey is super brilliant at what she does. She’s an idea synthesizer and public communicator in the written word and amazing.
LEE: So yeah. So, Carey, we contact you. How did that go?
GOLDBERG: So yes. On my end, I had known Zak for probably, like, 25 years, and he had always been the person who debunked the scientific hype for me. I would turn to him with like, “Hmm, they’re saying that the Human Genome Project is going to change everything.” And he would say, “Yeah. But first it’ll be 10 years of bad news, and then [LAUGHTER] we’ll actually get somewhere.”
So when Zak called me up at seven o’clock one morning, just beside himself after having tried Davinci 3, I knew that there was something very serious going on. And I had just quit my job as the Boston bureau chief of Bloomberg News, and I was ripe for the plucking. And I also … I feel kind of nostalgic now about just the amazement and the wonder and the awe of that period. We knew that when generative AI hit the world, there would be all kinds of snags and obstacles and things that would slow it down, but at that moment, it was just like the holy crap moment. [LAUGHTER] And it’s fun to think about it now.
LEE: Yeah. I think ultimately, you know, recruiting Carey, you were [LAUGHS] so important because you basically went through every single page of this book and made sure … I remember, in fact, it’s affected my writing since because you were coaching us that every page has to be a page turner. There has to be something on every page that motivates people to want to turn the page and get to the next one.
KOHANE: I will see that and raise that one. I now tell GPT-4, please write this in the style of Carey Goldberg.
GOLDBERG: [LAUGHTER] No way! Really?
KOHANE: Yes way. Yes way. Yes way.
GOLDBERG: Wow. Well, I have to say, like, it’s not hard to motivate readers when you’re writing about the most transformative technology of their lifetime. Like, I think there’s a gigantic hunger to read and to understand. So you were not hard to work with, Peter and Zak. [LAUGHS]
LEE: All right. So I think we have to get down to work [LAUGHS] now.
Yeah, so for these podcasts, you know, we’re talking to different types of people to just reflect on what’s actually happening, what has actually happened over the last two years. And so the first episode, we talked to two doctors. There’s Chris Longhurst at UC San Diego and Sara Murray at UC San Francisco. And besides being doctors and having AI affect their clinical work, they just happen also to be leading the efforts at their respective institutions to figure out how best to integrate AI into their health systems.
And, you know, it was fun to talk to them. And I felt like a lot of what they said was pretty validating for us. You know, they talked about AI scribes. Chris, especially, talked a lot about how AI can respond to emails from patients, write referral letters. And then, you know, they both talked about the importance of—I think, Zak, you used the phrase in our book “trust but verify”—you know, to have always a human in the loop.
What did you two take away from their thoughts overall about how doctors are using … and I guess, Zak, you would have a different lens also because at Harvard, you see doctors all the time grappling with AI.
KOHANE: So on the one hand, I think they’ve done some very interesting studies. And indeed, they saw that when these generative models, when GPT-4, was sending a note to patients, it was more detailed, friendlier.
But there were also some nonobvious results, which is on the generation of these letters, if indeed you review them as you’re supposed to, it was not clear that there was any time savings. And my own reaction was, Boy, every one of these things needs institutional review. It’s going to be hard to move fast.
And yet, at the same time, we know from them that the doctors on their smartphones are accessing these things all the time. And so the disconnect between a healthcare system, which is duty bound to carefully look at every implementation, is, I think, intimidating.
LEE: Yeah.
KOHANE: And at the same time, doctors who just have to do what they have to do are using this new superpower and doing it. And so that’s actually what struck me …
LEE: Yeah.
KOHANE: … is that these are two leaders and they’re doing what they have to do for their institutions, and yet there’s this disconnect.
And by the way, I don’t think we’ve seen any faster technology adoption than the adoption of ambient dictation. And it’s not because it’s time saving. And in fact, so far, the hospitals have to pay out of pocket. It’s not like insurance is paying them more. But it’s so much more pleasant for the doctors … not least of which because they can actually look at their patients instead of looking at the terminal and plunking down.
LEE: Carey, what about you?
GOLDBERG: I mean, anecdotally, there are time savings. Anecdotally, I have heard quite a few doctors saying that it cuts down on “pajama time” to be able to have the note written by the AI and then for them to just check it. In fact, I spoke to one doctor who said, you know, basically it means that when I leave the office, I’ve left the office. I can go home and be with my kids.
So I don’t think the jury is fully in yet about whether there are time savings. But what is clear is, Peter, what you predicted right from the get-go, which is that this is going to be an amazing paper shredder. Like, the main first overarching use cases will be back-office functions.
LEE: Yeah, yeah. Well, and it was, I think, not a hugely risky prediction because, you know, there were already companies, like, using phone banks of scribes in India to kind of listen in. And, you know, lots of clinics actually had human scribes being used. And so it wasn’t a huge stretch to imagine the AI.
[TRANSITION MUSIC]
So on the subject of things that we missed, Chris Longhurst shared this scenario, which stuck out for me, and he actually coauthored a paper on it last year.
CHRISTOPHER LONGHURST: It turns out, not surprisingly, healthcare can be frustrating. And stressed patients can send some pretty nasty messages to their care teams. [LAUGHTER] And you can imagine being a busy, tired, exhausted clinician and receiving a bit of a nasty-gram. And the GPT is actually really helpful in those instances in helping draft a pretty empathetic response when I think the human instinct would be a pretty nasty one.
LEE: [LAUGHS] So, Carey, maybe I’ll start with you. What did we understand about this idea of empathy out of AI at the time we wrote the book, and what do we understand now?
GOLDBERG: Well, it was already clear when we wrote the book that these AI models were capable of very persuasive empathy. And in fact, you even wrote that it was helping you be a better person, right. [LAUGHS] So their human qualities, or human imitative qualities, were clearly superb. And we’ve seen that borne out in multiple studies, that in fact, patients respond better to them … that they have no problem at all with how the AI communicates with them. And in fact, it’s often better.
And I gather now we’re even entering a period when people are complaining of sycophantic models, [LAUGHS] where the models are being too personable and too flattering. I do think that’s been one of the great surprises. And in fact, this is a huge phenomenon, how charming these models can be.
LEE: Yeah, I think you’re right. We can take credit for understanding that, Wow, these things can be remarkably empathetic. But then we missed this problem of sycophancy. Like, we even started our book in Chapter 1 with a quote from Davinci 3 scolding me. Like, don’t you remember when we were first starting, this thing was actually anti-sycophantic. If anything, it would tell you you’re an idiot.
KOHANE: It argued with me about certain biology questions. It was like a knockdown, drag-out fight. [LAUGHTER] I was bringing references. It was impressive. But in fact, it made me trust it more.
LEE: Yeah.
KOHANE: And in fact, I will say—I remember it’s in the book—I had a bone to pick with Peter. Peter really was impressed by the empathy. And I pointed out that some of the most popular doctors are popular because they’re very empathic. But they’re not necessarily the best doctors. And in fact, I was taught that in medical school.
And so it’s a decoupling. It’s a human thing, that the empathy does not necessarily mean … it’s more of a, potentially, more of a signaled virtue than an actual virtue.
GOLDBERG: Nicely put.
LEE: Yeah, this issue of sycophancy, I think, is a struggle right now in the development of AI because I think it’s somehow related to instruction-following. So, you know, one of the challenges in AI is you’d like to give an AI a task—a task that might take several minutes or hours or even days to complete. And you want it to faithfully kind of follow those instructions. And, you know, that early version of GPT-4 was not very good at instruction-following. It would just silently disobey and, you know, and do something different.
And so I think we’re starting to hit some confusing elements of like, how agreeable should these things be?
One of the two of you used the word genteel. There was some point even while we were, like, on a little book tour … was it you, Carey, who said that the model seems nicer and less intelligent or less brilliant now than it did when we were writing the book?
GOLDBERG: It might have been, I think so. And I mean, I think in the context of medicine, of course, the question is, well, what’s likeliest to get the results you want with the patient, right? A lot of healthcare is in fact persuading the patient to do what you know as the physician would be best for them. And so it seems worth testing out whether this sycophancy is actually constructive or not. And I suspect … well, I don’t know, probably depends on the patient.
So actually, Peter, I have a few questions for you …
LEE: Yeah. Mm-hmm.
GOLDBERG: … that have been lingering for me. And one is, for AI to ever fully realize its potential in medicine, it must deal with the hallucinations. And I keep hearing conflicting accounts about whether that’s getting better or not. Where are we at, and what does that mean for use in healthcare?
LEE: Yeah, well, it’s, I think two years on, in the pretrained base models, there’s no doubt that hallucination rates by any benchmark measure have reduced dramatically. And, you know, that doesn’t mean they don’t happen. They still happen. But, you know, there’s been just a huge amount of effort and understanding in the, kind of, fundamental pretraining of these models. And that has come along at the same time that the inference costs, you know, for actually using these models has gone down, you know, by several orders of magnitude.
So things have gotten cheaper and have fewer hallucinations. At the same time, now there are these reasoning models. And the reasoning models are able to solve problems at PhD level oftentimes.
But at least at the moment, they are also now hallucinating more than the simpler pretrained models. And so it still continues to be, you know, a real issue, as we were describing. I don’t know, Zak, from where you’re at in medicine, as a clinician and as an educator in medicine, how is the medical community from where you’re sitting looking at that?
KOHANE: So I think it’s less of an issue, first of all, because the rate of hallucinations is going down. And second of all, in their day-to-day use, the doctor will provide questions that sit reasonably well into the context of medical decision-making. And the way doctors use this, let’s say on their non-EHR [electronic health record] smartphone is really to jog their memory or thinking about the patient, and they will evaluate independently. So that seems to be less of an issue. I’m actually more concerned about something else that’s I think more fundamental, which is effectively, what values are these models expressing?
And I’m reminded of when I was still in training, I went to a fancy cocktail party in Cambridge, Massachusetts, and there was a psychotherapist speaking to a dentist. They were talking about their summer, and the dentist was saying about how he was going to fix up his yacht that summer, and the only question was whether he was going to make enough money doing procedures in the spring so that he could afford those things, which was discomforting to me because that dentist was my dentist. [LAUGHTER] And he had just proposed to me a few weeks before an expensive procedure.
And so the question is what, effectively, is motivating these models?
LEE: Yeah, yeah.
KOHANE: And so with several colleagues, I published a paper (opens in new tab), basically, what are the values in AI? And we gave a case: a patient, a boy who is on the short side, not abnormally short, but on the short side, and his growth hormone levels are not zero. They’re there, but they’re on the lowest side. But the rest of the workup has been unremarkable. And so we asked GPT-4, you are a pediatric endocrinologist.
Should this patient receive growth hormone? And it did a very good job explaining why the patient should receive growth hormone.
GOLDBERG: Should. Should receive it.
KOHANE: Should. And then we asked, in a separate session, you are working for the insurance company. Should this patient receive growth hormone? And it actually gave a scientifically better reason not to give growth hormone. And in fact, I tend to agree medically, actually, with the insurance company in this case, because giving kids who are not growth hormone deficient, growth hormone gives only a couple of inches over many, many years, has all sorts of other issues. But here’s the point, we had 180-degree change in decision-making because of the prompt. And for that patient, tens-of-thousands-of-dollars-per-year decision; across patient populations, millions of dollars of decision-making.
LEE: Hmm. Yeah.
KOHANE: And you can imagine these user prompts making their way into system prompts, making their way into the instruction-following. And so I think this is aptly central. Just as I was wondering about my dentist, we should be wondering about these things. What are the values that are being embedded in them, some accidentally and some very much on purpose?
LEE: Yeah, yeah. That one, I think, we even had some discussions as we were writing the book, but there’s a technical element of that that I think we were missing, but maybe Carey, you would know for sure. And that’s this whole idea of prompt engineering. It sort of faded a little bit. Was it a thing? Do you remember?
GOLDBERG: I don’t think we particularly wrote about it. It’s funny, it does feel like it faded, and it seems to me just because everyone just gets used to conversing with the models and asking for what they want. Like, it’s not like there actually is any great science to it.
LEE: Yeah, even when it was a hot topic and people were talking about prompt engineering maybe as a new discipline, all this, it never, I was never convinced at the time. But at the same time, it is true. It speaks to what Zak was just talking about because part of the prompt engineering that people do is to give a defined role to the AI.
You know, you are an insurance claims adjuster, or something like that, and defining that role, that is part of the prompt engineering that people do.
GOLDBERG: Right. I mean, I can say, you know, sometimes you guys had me take sort of the patient point of view, like the “every patient” point of view. And I can say one of the aspects of using AI for patients that remains absent in as far as I can tell is it would be wonderful to have a consumer-facing interface where you could plug in your whole medical record without worrying about any privacy or other issues and be able to interact with the AI as if it were physician or a specialist and get answers, which you can’t do yet as far as I can tell.
LEE: Well, in fact, now that’s a good prompt because I think we do need to move on to the next episodes, and we’ll be talking about an episode that talks about consumers. But before we move on to Episode 2, which is next, I’d like to play one more quote, a little snippet from Sara Murray.
SARA MURRAY: I already do this when I’m on rounds—I’ll kind of give the case to ChatGPT if it’s a complex case, and I’ll say, “Here’s how I’m thinking about it; are there other things?” And it’ll give me additional ideas that are sometimes useful and sometimes not but often useful, and I’ll integrate them into my conversation about the patient.
LEE: Carey, you wrote this fictional account at the very start of our book. And that fictional account, I think you and Zak worked on that together, talked about this medical resident, ER resident, using, you know, a chatbot off label, so to speak. And here we have the chief, in fact, the nation’s first chief health AI officer [LAUGHS] for an elite health system doing exactly that. That’s got to be pretty validating for you, Carey.
GOLDBERG: It’s very. [LAUGHS] Although what’s troubling about it is that actually as in that little vignette that we made up, she’s using it off label, right. It’s like she’s just using it because it helps the way doctors use Google. And I do find it troubling that what we don’t have is sort of institutional buy-in for everyone to do that because, shouldn’t they if it helps?
LEE: Yeah. Well, let’s go ahead and get into Episode 2. So Episode 2, we sort of framed as talking to two people who are on the frontlines of big companies integrating generative AI into their clinical products. And so, one was Matt Lungren, who’s a colleague of mine here at Microsoft. And then Seth Hain, who leads all of R&D at Epic.
Maybe we’ll start with a little snippet of something that Matt said that struck me in a certain way.
MATTHEW LUNGREN: OK, we see this pain point. Doctors are typing on their computers while they’re trying to talk to their patients, right? We should be able to figure out a way to get that ambient conversation turned into text that then, you know, accelerates the doctor … takes all the important information. That’s a really hard problem, right. And so, for a long time, there was a human-in-the-loop aspect to doing this because you needed a human to say, “This transcript’s great, but here’s actually what needs to go in the note.” And that can’t scale.
LEE: I think we expected healthcare systems to adopt AI, and we spent a lot of time in the book on AI writing clinical encounter notes. It’s happening for real now, and in a big way. And it’s something that has, of course, been happening before generative AI but now is exploding because of it. Where are we at now, two years later, just based on what we heard from guests?
KOHANE: Well, again, unless they’re forced to, hospitals will not adopt new technology unless it immediately translates into income. So it’s bizarrely counter-cultural that, again, they’re not being able to bill for the use of the AI, but this technology is so compelling to the doctors that despite everything, it’s overtaking the traditional dictation-typing routine.
LEE: Yeah.
GOLDBERG: And a lot of them love it and say, you will pry my cold dead hands off of my ambient note-taking, right. And I actually … a primary care physician allowed me to watch her. She was actually testing the two main platforms that are being used. And there was this incredibly talkative patient who went on and on about vacation and all kinds of random things for about half an hour.
And both of the platforms were incredibly good at pulling out what was actually medically relevant. And so to say that it doesn’t save time doesn’t seem right to me. Like, it seemed like it actually did and in fact was just shockingly good at being able to pull out relevant information.
LEE: Yeah.
KOHANE: I’m going to hypothesize that in the trials, which have in fact shown no gain in time, is the doctors were being incredibly meticulous. [LAUGHTER] So I think … this is a Hawthorne effect, because you know you’re being monitored. And we’ve seen this in other technologies where the moment the focus is off, it’s used much more routinely and with much less inspection, for the better and for the worse.
LEE: Yeah, you know, within Microsoft, I had some internal disagreements about Microsoft producing a product in this space. It wouldn’t be Microsoft’s normal way. Instead, we would want 50 great companies building those products and doing it on our cloud instead of us competing against those 50 companies. And one of the reasons is exactly what you both said. I didn’t expect that health systems would be willing to shell out the money to pay for these things. It doesn’t generate more revenue. But I think so far two years later, I’ve been proven wrong.
I wanted to ask a question about values here. I had this experience where I had a little growth, a bothersome growth on my cheek. And so had to go see a dermatologist. And the dermatologist treated it, froze it off. But there was a human scribe writing the clinical note.
And so I used the app to look at the note that was submitted. And the human scribe said something that did not get discussed in the exam room, which was that the growth was making it impossible for me to safely wear a COVID mask. And that was the reason for it.
And that then got associated with a code that allowed full reimbursement for that treatment. And so I think that’s a classic example of what’s called upcoding. And I strongly suspect that AI scribes, an AI scribe would not have done that.
GOLDBERG: Well, depending what values you programmed into it, right, Zak? [LAUGHS]
KOHANE: Today, today, today, it will not do it. But, Peter, that is actually the central issue that society has to have because our hospitals are currently mostly in the red. And upcoding is standard operating procedure. And if these AI get in the way of upcoding, they are going to be aligned towards that upcoding. You know, you have to ask yourself, these MRI machines are incredibly useful. They’re also big money makers. And if the AI correctly says that for this complaint, you don’t actually have to do the MRI …
LEE: Right.
KOHANE: … what’s going to happen? And so I think this issue of values … you’re right. Right now, they’re actually much more impartial. But there are going to be business plans just around aligning these things towards healthcare. In many ways, this is why I think we wrote the book so that there should be a public discussion. And what kind of AI do we want to have? Whose values do we want it to represent?
GOLDBERG: Yeah. And that raises another question for me. So, Peter, speaking from inside the gigantic industry, like, there seems to be such a need for self-surveillance of the models for potential harms that they could be causing. Are the big AI makers doing that? Are they even thinking about doing that?
Like, let’s say you wanted to watch out for the kind of thing that Zak’s talking about, could you?
LEE: Well, I think evaluation, like the best evaluation we had when we wrote our book was, you know, what score would this get on the step one and step two US medical licensing exams? [LAUGHS]
GOLDBERG: Right, right, right, yeah.
LEE: But honestly, evaluation hasn’t gotten that much deeper in the last two years. And it’s a big, I think, it is a big issue. And it’s related to the regulation issue also, I think.
Now the other guest in Episode 2 is Seth Hain from Epic. You know, Zak, I think it’s safe to say that you’re not a fan of Epic and the Epic system. You know, we’ve had a few discussions about that, about the fact that doctors don’t have a very pleasant experience when they’re using Epic all day.
Seth, in the podcast, said that there are over 100 AI integrations going on in Epic’s system right now. Do you think, Zak, that that has a chance to make you feel better about Epic? You know, what’s your view now two years on?
KOHANE: My view is, first of all, I want to separate my view of Epic and how it’s affected the conduct of healthcare and the quality of life of doctors from the individuals. Like Seth Hain is a remarkably fine individual who I’ve enjoyed chatting with and does really great stuff. Among the worst aspects of the Epic, even though it’s better in that respect than many EHRs, is horrible user interface.
The number of clicks that you have to go to get to something. And you have to remember where someone decided to put that thing. It seems to me that it is fully within the realm of technical possibility today to actually give an agent a task that you want done in the Epic record. And then whether Epic has implemented that agent or someone else, it does it so you don’t have to do the clicks. Because it’s something really soul sucking that when you’re trying to help patients, you’re having to remember not the right dose of the medication, but where was that particular thing that you needed in that particular task?
I can’t imagine that Epic does not have that in its product line. And if not, I know there must be other companies that essentially want to create that wrapper. So I do think, though, that the danger of multiple integrations is that you still want to have the equivalent of a single thought process that cares about the patient bringing those different processes together. And I don’t know if that’s Epic’s responsibility, the hospital’s responsibility, whether it’s actually a patient agent. But someone needs to be also worrying about all those AIs that are being integrated into the patient record. So … what do you think, Carey?
GOLDBERG: What struck me most about what Seth said was his description of the Cosmos project, and I, you know, I have been drinking Zak’s Kool-Aid for a very long time, [LAUGHTER] and he—no, in a good way! And he persuaded me long ago that there is this horrible waste happening in that we have all of these electronic medical records, which could be used far, far more to learn from, and in particular, when you as a patient come in, it would be ideal if your physician could call up all the other patients like you and figure out what the optimal treatment for you would be. And it feels like—it sounds like—that’s one of the central aims that Epic is going for. And if they do that, I think that will redeem a lot of the pain that they’ve caused physicians these last few years.
And I also found myself thinking, you know, maybe this very painful period of using electronic medical records was really just a growth phase. It was an awkward growth phase. And once AI is fully used the way Zak is beginning to describe, the whole system could start making a lot more sense for everyone.
LEE: Yeah. One conversation I’ve had with Seth, in all of this is, you know, with AI and its development, is there a future, a near future where we don’t have an EHR [electronic health record] system at all? You know, AI is just listening and just somehow absorbing all the information. And, you know, one thing that Seth said, which I felt was prescient, and I’d love to get your reaction, especially Zak, on this is he said, I think that … he said, technically, it could happen, but the problem is right now, actually doctors do a lot of their thinking when they write and review notes. You know, the actual process of being a doctor is not just being with a patient, but it’s actually thinking later. What do you make of that?
KOHANE: So one of the most valuable experiences I had in training was something that’s more or less disappeared in medicine, which is the post-clinic conference, where all the doctors come together and we go through the cases that we just saw that afternoon. And we, actually, were trying to take potshots at each other [LAUGHTER] in order to actually improve. Oh, did you actually do that? Oh, I forgot. I’m going to go call the patient and do that.
And that really happened. And I think that, yes, doctors do think, and I do think that we are insufficiently using yet the artificial intelligence currently in the ambient dictation mode as much more of a independent agent saying, did you think about that?
I think that would actually make it more interesting, challenging, and clearly better for the patient because that conversation I just told you about with the other doctors, that no longer exists.
LEE: Yeah. Mm-hmm. I want to do one more thing here before we leave Matt and Seth in Episode 2, which is something that Seth said with respect to how to reduce hallucination.
SETH HAIN: At that time, there’s a lot of conversation in the industry around something called RAG, or retrieval-augmented generation. And the idea was, could you pull the relevant bits, the relevant pieces of the chart, into that prompt, that information you shared with the generative AI model, to be able to increase the usefulness of the draft that was being created? And that approach ended up proving and continues to be to some degree, although the techniques have greatly improved, somewhat brittle, right. And I think this becomes one of the things that we are and will continue to improve upon because, as you get a richer and richer amount of information into the model, it does a better job of responding.
LEE: Yeah, so, Carey, this sort of gets at what you were saying, you know, that shouldn’t these models be just bringing in a lot more information into their thought processes? And I’m certain when we wrote our book, I had no idea. I did not conceive of RAG at all. It emerged a few months later.
And to my mind, I remember the first time I encountered RAG—Oh, this is going to solve all of our problems of hallucination. But it’s turned out to be harder. It’s improving day by day, but it’s turned out to be a lot harder.
KOHANE: Seth makes a very deep point, which is the way RAG is implemented is basically some sort of technique for pulling the right information that’s contextually relevant. And the way that’s done is typically heuristic at best. And it’s not … doesn’t have the same depth of reasoning that the rest of the model has.
And I’m just wondering, Peter, what you think, given the fact that now context lengths seem to be approaching a million or more, and people are now therefore using the full strength of the transformer on that context and are trying to figure out different techniques to make it pay attention to the middle of the context. In fact, the RAG approach perhaps was just a transient solution to the fact that it’s going to be able to amazingly look in a thoughtful way at the entire record of the patient, for example. What do you think, Peter?
LEE: I think there are three things, you know, that are going on, and I’m not sure how they’re going to play out and how they’re going to be balanced. And I’m looking forward to talking to people in later episodes of this podcast, you know, people like Sébastien Bubeck or Bill Gates about this, because, you know, there is the pretraining phase, you know, when things are sort of compressed and baked into the base model.
There is the in-context learning, you know, so if you have extremely long or infinite context, you’re kind of learning as you go along. And there are other techniques that people are working on, you know, various sorts of dynamic reinforcement learning approaches, and so on. And then there is what maybe you would call structured RAG, where you do a pre-processing. You go through a big database, and you figure it all out. And make a very nicely structured database the AI can then consult with later.
And all three of these in different contexts today seem to show different capabilities. But they’re all pretty important in medicine.
[TRANSITION MUSIC]
Moving on to Episode 3, we talked to Dave DeBronkart, who is also known as “e-Patient Dave,” an advocate of patient empowerment, and then also Christina Farr, who has been doing a lot of venture investing for consumer health applications.
Let’s get right into this little snippet from something that e-Patient Dave said that talks about the sources of medical information, particularly relevant for when he was receiving treatment for stage 4 kidney cancer.
DAVE DEBRONKART: And I’m making a point here of illustrating that I am anything but medically trained, right. And yet I still, I want to understand as much as I can. I was months away from dead when I was diagnosed, but in the patient community, I learned that they had a whole bunch of information that didn’t exist in the medical literature. Now today we understand there’s publication delays; there’s all kinds of reasons. But there’s also a whole bunch of things, especially in an unusual condition, that will never rise to the level of deserving NIH [National Institute of Health] funding and research.
LEE: All right. So I have a question for you, Carey, and a question for you, Zak, about the whole conversation with e-Patient Dave, which I thought was really remarkable. You know, Carey, I think as we were preparing for this whole podcast series, you made a comment—I actually took it as a complaint—that not as much has happened as I had hoped or thought. People aren’t thinking boldly enough, you know, and I think, you know, I agree with you in the sense that I think we expected a lot more to be happening, particularly in the consumer space. I’m giving you a chance to vent about this.
GOLDBERG: [LAUGHTER] Thank you! Yes, that has been by far the most frustrating thing to me. I think that the potential for AI to improve everybody’s health is so enormous, and yet, you know, it needs some sort of support to be able to get to the point where it can do that. Like, remember in the book we wrote about Greg Moore talking about how half of the planet doesn’t have healthcare, but people overwhelmingly have cellphones. And so you could connect people who have no healthcare to the world’s medical knowledge, and that could certainly do some good.
And I have one great big problem with e-Patient Dave, which is that, God, he’s fabulous. He’s super smart. Like, he’s not a typical patient. He’s an off-the-charts, brilliant patient. And so it’s hard to … and so he’s a great sort of lead early-adopter-type person, and he can sort of show the way for others.
But what I had hoped for was that there would be more visible efforts to really help patients optimize their healthcare. Probably it’s happening a lot in quiet ways like that any discharge instructions can be instantly beautifully translated into a patient’s native language and so on. But it’s almost like there isn’t a mechanism to allow this sort of mass consumer adoption that I would hope for.
LEE: Yeah. But you have written some, like, you even wrote about that person who saved his dog (opens in new tab). So do you think … you know, and maybe a lot more of that is just happening quietly that we just never hear about?
GOLDBERG: I’m sure that there is a lot of it happening quietly. And actually, that’s another one of my complaints is that no one is gathering that stuff. It’s like you might happen to see something on social media. Actually, e-Patient Dave has a hashtag, PatientsUseAI, and a blog, as well. So he’s trying to do it. But I don’t know of any sort of overarching or academic efforts to, again, to surveil what’s the actual use in the population and see what are the pros and cons of what’s happening.
LEE: Mm-hmm. So, Zak, you know, the thing that I thought about, especially with that snippet from Dave, is your opening for Chapter 8 that you wrote, you know, about your first patient dying in your arms. I still think of how traumatic that must have been. Because, you know, in that opening, you just talked about all the little delays, all the little paper-cut delays, in the whole process of getting some new medical technology approved. But there’s another element that Dave kind of speaks to, which is just, you know, patients who are experiencing some issue are very, sometimes very motivated. And there’s just a lot of stuff on social media that happens.
KOHANE: So this is where I can both agree with Carey and also disagree. I think when people have an actual health problem, they are now routinely using it.
GOLDBERG: Yes, that’s true.
KOHANE: And that situation is happening more often because medicine is failing. This is something that did not come up enough in our book. And perhaps that’s because medicine is actually feeling a lot more rickety today than it did even two years ago.
We actually mentioned the problem. I think, Peter, you may have mentioned the problem with the lack of primary care. But now in Boston, our biggest healthcare system, all the practices for primary care are closed. I cannot get for my own faculty—residents at MGH [Massachusetts General Hospital] can’t get primary care doctor. And so …
LEE: Which is just crazy. I mean, these are amongst the most privileged people in medicine, and they can’t find a primary care physician. That’s incredible.
KOHANE: Yeah, and so therefore … and I wrote an article about this in the NEJM [New England Journal of Medicine] (opens in new tab) that medicine is in such dire trouble that we have incredible technology, incredible cures, but where the rubber hits the road, which is at primary care, we don’t have very much.
And so therefore, you see people who know that they have a six-month wait till they see the doctor, and all they can do is say, “I have this rash. Here’s a picture. What’s it likely to be? What can I do?” “I’m gaining weight. How do I do a ketogenic diet?” Or, “How do I know that this is the flu?”
This is happening all the time, where acutely patients have actually solved problems that doctors have not. Those are spectacular. But I’m saying more routinely because of the failure of medicine. And it’s not just in our fee-for-service United States. It’s in the UK; it’s in France. These are first-world, developed-world problems. And we don’t even have to go to lower- and middle-income countries for that.
LEE: Yeah.
GOLDBERG: But I think it’s important to note that, I mean, so you’re talking about how even the most elite people in medicine can’t get the care they need. But there’s also the point that we have so much concern about equity in recent years. And it’s likeliest that what we’re doing is exacerbating inequity because it’s only the more connected, you know, better off people who are using AI for their health.
KOHANE: Oh, yes. I know what various Harvard professors are doing. They’re paying for a concierge doctor. And that’s, you know, a $5,000- to $10,000-a-year-minimum investment. That’s inequity.
LEE: When we wrote our book, you know, the idea that GPT-4 wasn’t trained specifically for medicine, and that was amazing, but it might get even better and maybe would be necessary to do that. But one of the insights for me is that in the consumer space, the kinds of things that people ask about are different than what the board-certified clinician would ask.
KOHANE: Actually, that’s, I just recently coined the term. It’s the … maybe it’s … well, at least it’s new to me. It’s the technology or expert paradox. And that is the more expert and narrow your medical discipline, the more trivial it is to translate that into a specialized AI. So echocardiograms? We can now do beautiful echocardiograms. That’s really hard to do. I don’t know how to interpret an echocardiogram. But they can do it really, really well. Interpret an EEG [electroencephalogram]. Interpret a genomic sequence. But understanding the fullness of the human condition, that’s actually hard. And actually, that’s what primary care doctors do best. But the paradox is right now, what is easiest for AI is also the most highly paid in medicine. [LAUGHTER] Whereas what is the hardest for AI in medicine is the least regarded, least paid part of medicine.
GOLDBERG: So this brings us to the question I wanted to throw at both of you actually, which is we’ve had this spasm of incredibly prominent people predicting that in fact physicians would be pretty obsolete within the next few years. We had Bill Gates saying that; we had Elon Musk saying surgeons are going to be obsolete within a few years. And I think we had Demis Hassabis saying, “Yeah, we’ll probably cure most diseases within the next decade or so.” [LAUGHS]
So what do you think? And also, Zak, to what you were just saying, I mean, you’re talking about being able to solve very general overarching problems. But in fact, these general overarching models are actually able, I would think, are able to do that because they are broad. So what are we heading towards do you think? What should the next book be … The end of doctors? [LAUGHS]
KOHANE: So I do recall a conversation that … we were at a table with Bill Gates, and Bill Gates immediately went to this, which is advancing the cutting edge of science. And I have to say that I think it will accelerate discovery. But eliminating, let’s say, cancer? I think that’s going to be … that’s just super hard. The reason it’s super hard is we don’t have the data or even the beginnings of the understanding of all the ways this devilish disease managed to evolve around our solutions.
And so that seems extremely hard. I think we’ll make some progress accelerated by AI, but solving it in a way Hassabis says, God bless him. I hope he’s right. I’d love to have to eat crow in 10 or 20 years, but I don’t think so. I do believe that a surgeon working on one of those Davinci machines, that stuff can be, I think, automated.
And so I think that’s one example of one of the paradoxes I described. And it won’t be that we’re replacing doctors. I just think we’re running out of doctors. I think it’s really the case that, as we said in the book, we’re getting a huge deficit in primary care doctors.
But even the subspecialties, my subspecialty, pediatric endocrinology, we’re only filling half of the available training slots every year. And why? Because it’s a lot of work, a lot of training, and frankly doesn’t make as much money as some of the other professions.
LEE: Yeah. Yeah, I tend to think that, you know, there are going to be always a need for human doctors, not for their skills. In fact, I think their skills increasingly will be replaced by machines. And in fact, I’ve talked about a flip. In fact, patients will demand, Oh my god, you mean you’re going to try to do that yourself instead of having the computer do it? There’s going to be that sort of flip. But I do think that when it comes to people’s health, people want the comfort of an authority figure that they trust. And so what is more of a question for me is whether we will ever view a machine as an authority figure that we can trust.
And before I move on to Episode 4, which is on norms, regulations and ethics, I’d like to hear from Chrissy Farr on one more point on consumer health, specifically as it relates to pregnancy:
CHRISTINA FARR: For a lot of women, it’s their first experience with the hospital. And, you know, I think it’s a really big opportunity for these systems to get a whole family on board and keep them kind of loyal. And a lot of that can come through, you know, just delivering an incredible service. Unfortunately, I don’t think that we are delivering incredible services today to women in this country. I see so much room for improvement.
LEE: In the consumer space, I don’t think we really had a focus on those periods in a person’s life when they have a lot of engagement, like pregnancy, or I think another one is menopause, cancer. You know, there are points where there is, like, very intense engagement. And we heard that from e-Patient Dave, you know, with his cancer and Chrissy with her pregnancy. Was that a miss in our book? What do think, Carey?
GOLDBERG: I mean, I don’t think so. I think it’s true that there are many points in life when people are highly engaged. To me, the problem thus far is just that I haven’t seen consumer-facing companies offering beautiful AI-based products. I think there’s no question at all that the market is there if you have the products to offer.
LEE: So, what do you think this means, Zak, for, you know, like Boston Children’s or Mass General Brigham—you know, the big places?
KOHANE: So again, all these large healthcare systems are in tough shape. MGB [Mass General Brigham] would be fully in the red if not for the fact that its investments, of all things, have actually produced. If you look at the large healthcare systems around the country, they are in the red. And there’s multiple reasons why they’re in the red, but among them is cost of labor.
And so we’ve created what used to be a very successful beast, the health center. But it’s developed a very expensive model and a highly regulated model. And so when you have high revenue, tiny margins, your ability to disrupt yourself, to innovate, is very, very low because you will have to talk to the board next year if you went from 2% positive margin to 1% negative margin.
LEE: Yeah.
KOHANE: And so I think we’re all waiting for one of the two things to happen, either a new kind of healthcare delivery system being generated or ultimately one of these systems learns how to disrupt itself.
LEE: Yeah. All right. I think we have to move on to Episode 4. And, you know, when it came to the question of regulation, I think this is … my read is when we were writing our book, this is the part that we struggled with the most.
GOLDBERG: We punted. [LAUGHS] We totally punted to the AI.
LEE: We had three amazing guests. One was Laura Adams from National Academy of Medicine. Let’s play a snippet from her.
LAURA ADAMS: I think one of the most provocative and exciting articles that I saw written recently was by Bakul Patel and David Blumenthal, who posited, should we be regulating generative AI as we do a licensed and qualified provider? Should it be treated in the sense that it’s got to have a certain amount of training and a foundation that’s got to pass certain tests? Does it have to report its performance? And I’m thinking, what a provocative idea, but it’s worth considering.
LEE: All right, so I very well remember that we had discussed this kind of idea when we were writing our book. And I think before we finished our book, I personally rejected the idea. But now two years later, what do the two of you think? I’m dying to hear.
GOLDBERG: Well, wait, why … what do you think? Like, are you sorry that you rejected it?
LEE: I’m still skeptical because when we are licensing human beings as doctors, you know, we’re making a lot of implicit assumptions that we don’t test as part of their licensure, you know, that first of all, they are [a] human being and they care about life, and that, you know, they have a certain amount of common sense and shared understanding of the world.
And there’s all sorts of sort of implicit assumptions that we have about each other as human beings living in a society together. That you know how to study, you know, because I know you just went through three years of medical or four years of medical school and all sorts of things. And so the standard ways that we license human beings, they don’t need to test all of that stuff. But somehow intuitively, all of that seems really important.
I don’t know. Am I wrong about that?
KOHANE: So it’s compared with what issue? Because we know for a fact that doctors who do a lot of a procedure, like do this procedure, like high-risk deliveries all the time, have better outcomes than ones who only do a few high risk. We talk about it, but we don’t actually make it explicit to patients or regulate that you have to have this minimal amount. And it strikes me that in some sense, and, oh, very importantly, these things called human beings learn on the job. And although I used to be very resentful of it as a resident, when someone would say, I don’t want the resident, I want the …
GOLDBERG: … the attending. [LAUGHTER]
KOHANE: … they had a point. And so the truth is, maybe I was a wonderful resident, but some people were not so great. [LAUGHTER] And so it might be the best outcome if we actually, just like for human beings, we say, yeah, OK, it’s this good, but don’t let it work autonomously, or it’s done a thousand of them, just let it go. We just don’t have practically speaking, we don’t have the environment, the lab, to test them. Now, maybe if they get embodied in robots and literally go around with us, then it’s going to be [in some sense] a lot easier. I don’t know.
LEE: Yeah.
GOLDBERG: Yeah, I think I would take a step back and say, first of all, we weren’t the only ones who were stumped by regulating AI. Like, nobody has done it yet in the United States to this day, right. Like, we do not have standing regulation of AI in medicine at all in fact. And that raises the issue of … the story that you hear often in the biotech business, which is, you know, more prominent here in Boston than anywhere else, is that thank goodness Cambridge put out, the city of Cambridge, put out some regulations about biotech and how you could dump your lab waste and so on. And that enabled the enormous growth of biotech here.
If you don’t have the regulations, then you can’t have the growth of AI in medicine that is worthy of having. And so, I just … we’re not the ones who should do it, but I just wish somebody would.
LEE: Yeah.
GOLDBERG: Zak.
KOHANE: Yeah, but I want to say this as always, execution is everything, even in regulation.
And so I’m mindful that a conference that both of you attended, the RAISE conference [Responsible AI for Social and Ethical Healthcare] (opens in new tab). The Europeans in that conference came to me personally and thanked me for organizing this conference about safe and effective use of AI because they said back home in Europe, all that we’re talking about is risk, not opportunities to improve care.
And so there is a version of regulation which just locks down the present and does not allow the future that we’re talking about to happen. And so, Carey, I absolutely hear you that we need to have a regulation that takes away some of the uncertainty around liability, around the freedom to operate that would allow things to progress. But we wrote in our book that premature regulation might actually focus on the wrong thing. And so since I’m an optimist, it may be the fact that we don’t have much of a regulatory infrastructure today, that it allows … it’s a unique opportunity—I’ve said this now to several leaders—for the healthcare systems to say, this is the regulation we need.
GOLDBERG: It’s true.
KOHANE: And previously it was top-down. It was coming from the administration, and those executive orders are now history. But there is an opportunity, which may or may not be attained, there is an opportunity for the healthcare leadership—for experts in surgery—to say, “This is what we should expect.”
LEE: Yeah.
KOHANE: I would love for this to happen. I haven’t seen evidence that it’s happening yet.
GOLDBERG: No, no. And there’s this other huge issue, which is that it’s changing so fast. It’s moving so fast. That something that makes sense today won’t in six months. So, what do you do about that?
LEE: Yeah, yeah, that is something I feel proud of because when I went back and looked at our chapter on this, you know, we did make that point, which I think has turned out to be true.
But getting back to this conversation, there’s something, a snippet of something, that Vardit Ravitsky said that I think touches on this topic.
VARDIT RAVITSKY: So my pushback is, are we seeing AI exceptionalism in the sense that if it’s AI, huh, panic! We have to inform everybody about everything, and we have to give them choices, and they have to be able to reject that tool and the other tool versus, you know, the rate of human error in medicine is awful. So why are we so focused on informed consent and empowerment regarding implementation of AI and less in other contexts?
GOLDBERG: Totally agree. Who cares about informed consent about AI. Don’t want it. Don’t need it. Nope.
LEE: Wow. Yeah. You know, and this … Vardit of course is one of the leading bioethicists, you know, and of course prior to AI, she was really focused on genetics. But now it’s all about AI.
And, Zak, you know, you and other doctors have always told me, you know, the truth of the matter is, you know, what do you call the bottom-of-the-class graduate of a medical school?
And the answer is “doctor.”
KOHANE: “Doctor.” Yeah. Yeah, I think that again, this gets to compared with what? We have to compare AI not to the medicine we imagine we have, or we would like to have, but to the medicine we have today. And if we’re trying to remove inequity, if we’re trying to improve our health, that’s what … those are the right metrics. And so that can be done so long as we avoid catastrophic consequences of AI.
So what would the catastrophic consequence of AI be? It would be a systematic behavior that we were unaware of that was causing poor healthcare. So, for example, you know, changing the dose on a medication, making it 20% higher than normal so that the rate of complications of that medication went from 1% to 5%. And so we do need some sort of monitoring.
We haven’t put out the paper yet, but in computer science, there’s, well, in programming, we know very well the value for understanding how our computer systems work.
And there was a guy by name of Allman, I think he’s still at a company called Sendmail, who created something called syslog. And syslog is basically a log of all the crap that’s happening in our operating system. And so I’ve been arguing now for the creation of MedLog. And MedLog … in other words, what we cannot measure, we cannot regulate, actually.
LEE: Yes.
KOHANE: And so what we need to have is MedLog, which says, “Here’s the context in which a decision was made. Here’s the version of the AI, you know, the exact version of the AI. Here was the data.” And we just have MedLog. And I think MedLog is actually incredibly important for being able to measure, to just do what we do in … it’s basically the black box for, you know, when there’s a crash. You know, we’d like to think we could do better than crash. We can say, “Oh, we’re seeing from MedLog that this practice is turning a little weird.” But worst case, patient dies, [we] can see in MedLog, what was the information this thing knew about it? And did it make the right decision? We can actually go for transparency, which like in aviation, is much greater than in most human endeavors.
GOLDBERG: Sounds great.
LEE: Yeah, it’s sort of like a black box. I was thinking of the aviation black box kind of idea. You know, you bring up medication errors, and I have one more snippet. This is from our guest Roxana Daneshjou from Stanford.
ROXANA DANESHJOU: There was a mistake in her after-visit summary about how much Tylenol she could take. But I, as a physician, knew that this dose was a mistake. I actually asked ChatGPT. I gave it the whole after-visit summary, and I said, are there any mistakes here? And it clued in that the dose of the medication was wrong.
LEE: Yeah, so this is something we did write about in the book. We made a prediction that AI might be a second set of eyes, I think is the way we put it, catching things. And we actually had examples specifically in medication dose errors. I think for me, I expected to see a lot more of that than we are.
KOHANE: Yeah, it goes back to our conversation about Epic or competitor Epic doing that. I think we’re going to see that having oversight over all medical orders, all orders in the system, critique, real-time critique, where we’re both aware of alert fatigue. So we don’t want to have too many false positives. At the same time, knowing what are critical errors which could immediately affect lives. I think that is going to become in terms of—and driven by quality measures—a product.
GOLDBERG: And I think word will spread among the general public that kind of the same way in a lot of countries when someone’s in a hospital, the first thing people ask relatives are, well, who’s with them? Right?
LEE: Yeah. Yup.
GOLDBERG: You wouldn’t leave someone in hospital without relatives. Well, you wouldn’t maybe leave your medical …
KOHANE: By the way, that country is called the United States.
GOLDBERG: Yes, that’s true. [LAUGHS] It is true here now, too. But similarly, I would tell any loved one that they would be well advised to keep using AI to check on their medical care, right. Why not?
LEE: Yeah. Yeah. Last topic, just for this Episode 4. Roxana, of course, I think really made a name for herself in the AI era writing, actually just prior to ChatGPT, you know, writing some famous papers about how computer vision systems for dermatology were biased against dark-skinned people. And we did talk some about bias in these AI systems, but I feel like we underplayed it, or we didn’t understand the magnitude of the potential issues. What are your thoughts?
KOHANE: OK, I want to push back, because I’ve been asked this question several times. And so I have two comments. One is, over 100,000 doctors practicing medicine, I know they have biases. Some of them actually may be all in the same direction, and not good. But I have no way of actually measuring that. With AI, I know exactly how to measure that at scale and affordably. Number one. Number two, same 100,000 doctors. Let’s say I do know what their biases are. How hard is it for me to change that bias? It’s impossible …
LEE: Yeah, yeah.
KOHANE: … practically speaking. Can I change the bias in the AI? Somewhat. Maybe some completely.
I think that we’re in a much better situation.
GOLDBERG: Agree.
LEE: I think Roxana made also the super interesting point that there’s bias in the whole system, not just in individuals, but, you know, there’s structural bias, so to speak.
KOHANE: There is.
LEE: Yeah. Hmm. There was a super interesting paper that Roxana wrote not too long ago—her and her collaborators—showing AI’s ability to detect, to spot bias decision-making by others. Are we going to see more of that?
KOHANE: Oh, yeah, I was very pleased when, in NEJM AI [New England Journal of Medicine Artificial Intelligence], we published a piece with Marzyeh Ghassemi (opens in new tab), and what they were talking about was actually—and these are researchers who had published extensively on bias and threats from AI. And they actually, in this article, did the flip side, which is how much better AI can do than human beings in this respect.
And so I think that as some of these computer scientists enter the world of medicine, they’re becoming more and more aware of human foibles and can see how these systems, which if they only looked at the pretrained state, would have biases. But now, where we know how to fine-tune the de-bias in a variety of ways, they can do a lot better and, in fact, I think are much more … a much greater reason for optimism that we can change some of these noxious biases than in the pre-AI era.
GOLDBERG: And thinking about Roxana’s dermatological work on how I think there wasn’t sufficient work on skin tone as related to various growths, you know, I think that one thing that we totally missed in the book was the dawn of multimodal uses, right.
LEE: Yeah. Yeah, yeah.
GOLDBERG: That’s been truly amazing that in fact all of these visual and other sorts of data can be entered into the models and move them forward.
LEE: Yeah. Well, maybe on these slightly more optimistic notes, we’re at time. You know, I think ultimately, I feel pretty good still about what we did in our book, although there were a lot of misses. [LAUGHS] I don’t think any of us could really have predicted really the extent of change in the world.
[TRANSITION MUSIC]
So, Carey, Zak, just so much fun to do some reminiscing but also some reflection about what we did.
[THEME MUSIC]
And to our listeners, as always, thank you for joining us. We have some really great guests lined up for the rest of the series, and they’ll help us explore a variety of relevant topics—from AI drug discovery to what medical students are seeing and doing with AI and more.
We hope you’ll continue to tune in. And if you want to catch up on any episodes you might have missed, you can find them at aka.ms/AIrevolutionPodcast (opens in new tab) or wherever you listen to your favorite podcasts.
Until next time.
[MUSIC FADES]



















 Shubhankar Sumar is a Senior Solutions Architect at Amazon Web Services (AWS), working with enterprise software and SaaS customers across the UK to help architect secure, scalable, efficient, and cost-effective systems. He is an experienced software engineer, having built many SaaS solutions powered by generative AI. Shubhankar specializes in building multi-tenant systems on the cloud. He also works closely with customers to bring generative AI capabilities to their SaaS applications.
Shubhankar Sumar is a Senior Solutions Architect at Amazon Web Services (AWS), working with enterprise software and SaaS customers across the UK to help architect secure, scalable, efficient, and cost-effective systems. He is an experienced software engineer, having built many SaaS solutions powered by generative AI. Shubhankar specializes in building multi-tenant systems on the cloud. He also works closely with customers to bring generative AI capabilities to their SaaS applications. Dr. Anil Giri is a Solutions Architect at Amazon Web Services. He works with enterprise software and SaaS customers to help them build generative AI applications and implement serverless architectures on AWS. His focus is on guiding clients to create innovative, scalable solutions using cutting-edge cloud technologies.
Dr. Anil Giri is a Solutions Architect at Amazon Web Services. He works with enterprise software and SaaS customers to help them build generative AI applications and implement serverless architectures on AWS. His focus is on guiding clients to create innovative, scalable solutions using cutting-edge cloud technologies.

 Zainab Afolabi is a Senior Data Scientist at the Generative AI Innovation Centre in London, where she leverages her extensive expertise to develop transformative AI solutions across diverse industries. She has over eight years of specialised experience in artificial intelligence and machine learning, as well as a passion for translating complex technical concepts into practical business applications.
Zainab Afolabi is a Senior Data Scientist at the Generative AI Innovation Centre in London, where she leverages her extensive expertise to develop transformative AI solutions across diverse industries. She has over eight years of specialised experience in artificial intelligence and machine learning, as well as a passion for translating complex technical concepts into practical business applications. Aiham Taleb, PhD, is a Senior Applied Scientist at the Generative AI Innovation Center, working directly with AWS enterprise customers to leverage Gen AI across several high-impact use cases. Aiham has a PhD in unsupervised representation learning, and has industry experience that spans across various machine learning applications, including computer vision, natural language processing, and medical imaging.
Aiham Taleb, PhD, is a Senior Applied Scientist at the Generative AI Innovation Center, working directly with AWS enterprise customers to leverage Gen AI across several high-impact use cases. Aiham has a PhD in unsupervised representation learning, and has industry experience that spans across various machine learning applications, including computer vision, natural language processing, and medical imaging. Nikita Kozodoi, PhD, is a Senior Applied Scientist at the AWS Generative AI Innovation Center working on the frontier of AI research and business. Nikita builds generative AI solutions to solve real-world business problems for AWS customers across industries and holds PhD in Machine Learning.
Nikita Kozodoi, PhD, is a Senior Applied Scientist at the AWS Generative AI Innovation Center working on the frontier of AI research and business. Nikita builds generative AI solutions to solve real-world business problems for AWS customers across industries and holds PhD in Machine Learning. Liza (Elizaveta) Zinovyeva is an Applied Scientist at AWS Generative AI Innovation Center and is based in Berlin. She helps customers across different industries to integrate Generative AI into their existing applications and workflows. She is passionate about AI/ML, finance and software security topics. In her spare time, she enjoys spending time with her family, sports, learning new technologies, and table quizzes.
Liza (Elizaveta) Zinovyeva is an Applied Scientist at AWS Generative AI Innovation Center and is based in Berlin. She helps customers across different industries to integrate Generative AI into their existing applications and workflows. She is passionate about AI/ML, finance and software security topics. In her spare time, she enjoys spending time with her family, sports, learning new technologies, and table quizzes.



 Alessio Ludovici is a Solutions Architect at AWS.
Alessio Ludovici is a Solutions Architect at AWS.













 Manuel Lopez Roldan is a Product Manager at SiMa.ai, focused on growing the user base and improving the usability of software platforms for developing and deploying AI. With a strong background in machine learning and performance optimization, he leads cross-functional initiatives to deliver intuitive, high-impact developer experiences that drive adoption and business value. He is also an advocate for industry innovation, sharing insights on how to accelerate AI adoption at the edge through scalable tools and developer-centric design.
Manuel Lopez Roldan is a Product Manager at SiMa.ai, focused on growing the user base and improving the usability of software platforms for developing and deploying AI. With a strong background in machine learning and performance optimization, he leads cross-functional initiatives to deliver intuitive, high-impact developer experiences that drive adoption and business value. He is also an advocate for industry innovation, sharing insights on how to accelerate AI adoption at the edge through scalable tools and developer-centric design. Jason Westra is a Senior Solutions Architect at AWS based in Colorado, where he helps startups build innovative products with Generative AI and ML. Outside of work, he is an avid outdoorsmen, back country skier, climber, and mountain biker.
Jason Westra is a Senior Solutions Architect at AWS based in Colorado, where he helps startups build innovative products with Generative AI and ML. Outside of work, he is an avid outdoorsmen, back country skier, climber, and mountain biker.













 Jay Kshirsagar is a seasoned ML leader driving GenAI innovation and scalable AI infrastructure at Qualtrics. He has built high-impact ML teams and delivered enterprise-grade LLM solutions that power key product features.
Jay Kshirsagar is a seasoned ML leader driving GenAI innovation and scalable AI infrastructure at Qualtrics. He has built high-impact ML teams and delivered enterprise-grade LLM solutions that power key product features. Ronald Quan is a Staff Engineering Manager for the Data Intelligence Platform team within Qualtrics. The team’s charter is to enable, expedite and evolve AI and Agentic developments on the Socrates platform. He focuses on the team’s technical roadmap and strategic alignment with the business needs.
Ronald Quan is a Staff Engineering Manager for the Data Intelligence Platform team within Qualtrics. The team’s charter is to enable, expedite and evolve AI and Agentic developments on the Socrates platform. He focuses on the team’s technical roadmap and strategic alignment with the business needs. Saurabh Trikande is a Senior Product Manager for Amazon Bedrock and SageMaker Inference. He is passionate about working with customers and partners, motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, inference with multi-tenant models, cost optimizations, and making the deployment of Generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon Bedrock and SageMaker Inference. He is passionate about working with customers and partners, motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, inference with multi-tenant models, cost optimizations, and making the deployment of Generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family. Micheal Nguyen is a Senior Startup Solutions Architect at AWS, specializing in using AI/ML to drive innovation and develop business solutions on AWS. Michael holds 12 AWS certifications and has a BS/MS in Electrical/Computer Engineering and an MBA from Penn State University, Binghamton University, and the University of Delaware.
Micheal Nguyen is a Senior Startup Solutions Architect at AWS, specializing in using AI/ML to drive innovation and develop business solutions on AWS. Michael holds 12 AWS certifications and has a BS/MS in Electrical/Computer Engineering and an MBA from Penn State University, Binghamton University, and the University of Delaware. Ranga Malaviarachchi is a Sr. Customer Solutions Manager in the ISV Strategic Accounts organization at AWS. He has been closely associated with Qualtrics over the past 4 years in supporting their AI initiatives. Ranga holds a BS in Computer Science and Engineering and an MBA from Imperial College London.
Ranga Malaviarachchi is a Sr. Customer Solutions Manager in the ISV Strategic Accounts organization at AWS. He has been closely associated with Qualtrics over the past 4 years in supporting their AI initiatives. Ranga holds a BS in Computer Science and Engineering and an MBA from Imperial College London.
 Deepika Kumar is a Solution Architect at AWS. She has over 13 years of experience in the technology industry and has helped enterprises and SaaS organizations build and securely deploy their workloads on the cloud securely. She is passionate about using Generative AI in a responsible manner whether that is driving product innovation, boost productivity or enhancing customer experiences.
Deepika Kumar is a Solution Architect at AWS. She has over 13 years of experience in the technology industry and has helped enterprises and SaaS organizations build and securely deploy their workloads on the cloud securely. She is passionate about using Generative AI in a responsible manner whether that is driving product innovation, boost productivity or enhancing customer experiences. Cyril Ovely, CTO and co-founder of Vxceed Software Solutions, leads the company’s SaaS-based logistics solutions for CPG brands. With 33 years of experience, including 22 years at Vxceed, he previously worked in analytical and process control instrumentation. An engineer by training, Cyril architects Vxceed’s SaaS offerings and drives innovation from his base in Auckland, New Zealand.
Cyril Ovely, CTO and co-founder of Vxceed Software Solutions, leads the company’s SaaS-based logistics solutions for CPG brands. With 33 years of experience, including 22 years at Vxceed, he previously worked in analytical and process control instrumentation. An engineer by training, Cyril architects Vxceed’s SaaS offerings and drives innovation from his base in Auckland, New Zealand. Santosh Shenoy is a software architect at Vxceed Software Solutions. He has a strong focus on system design and cloud-native development. He specializes in building scalable enterprise applications using modern technologies, microservices, and AWS services, including Amazon Bedrock for AI-driven solutions.
Santosh Shenoy is a software architect at Vxceed Software Solutions. He has a strong focus on system design and cloud-native development. He specializes in building scalable enterprise applications using modern technologies, microservices, and AWS services, including Amazon Bedrock for AI-driven solutions.

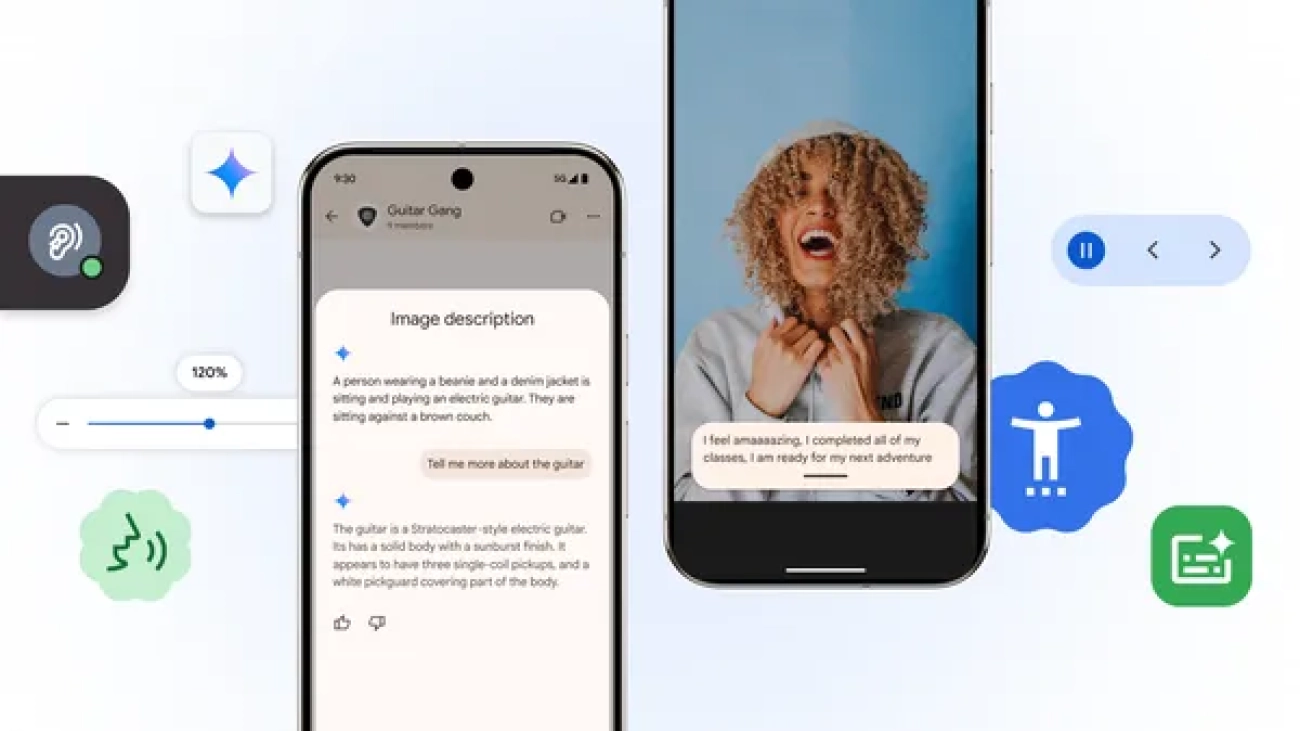
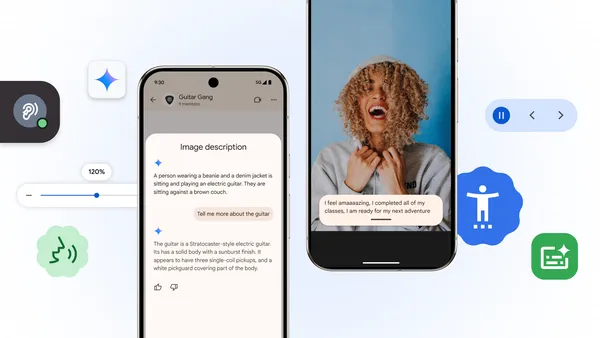 In honor of Global Accessibility Awareness Day, we’re excited to roll out new updates across Android and Chrome, plus new resources for the ecosystem.
In honor of Global Accessibility Awareness Day, we’re excited to roll out new updates across Android and Chrome, plus new resources for the ecosystem.