Mixture-of-Experts (MoE) is a popular model architecture for large language models (LLMs). Although it reduces computation in training and inference by activating fewer parameters per token, it imposes additional challenges in achieving optimal computation efficiency with high memory and communication pressure, as well as the complexity to handle the dynamism and sparsity nature of the model. Here we introduce a new MoE inference solution, MetaShuffling, which enables us to efficiently deploy Llama 4 models for production inference.
Llama 4 Architecture
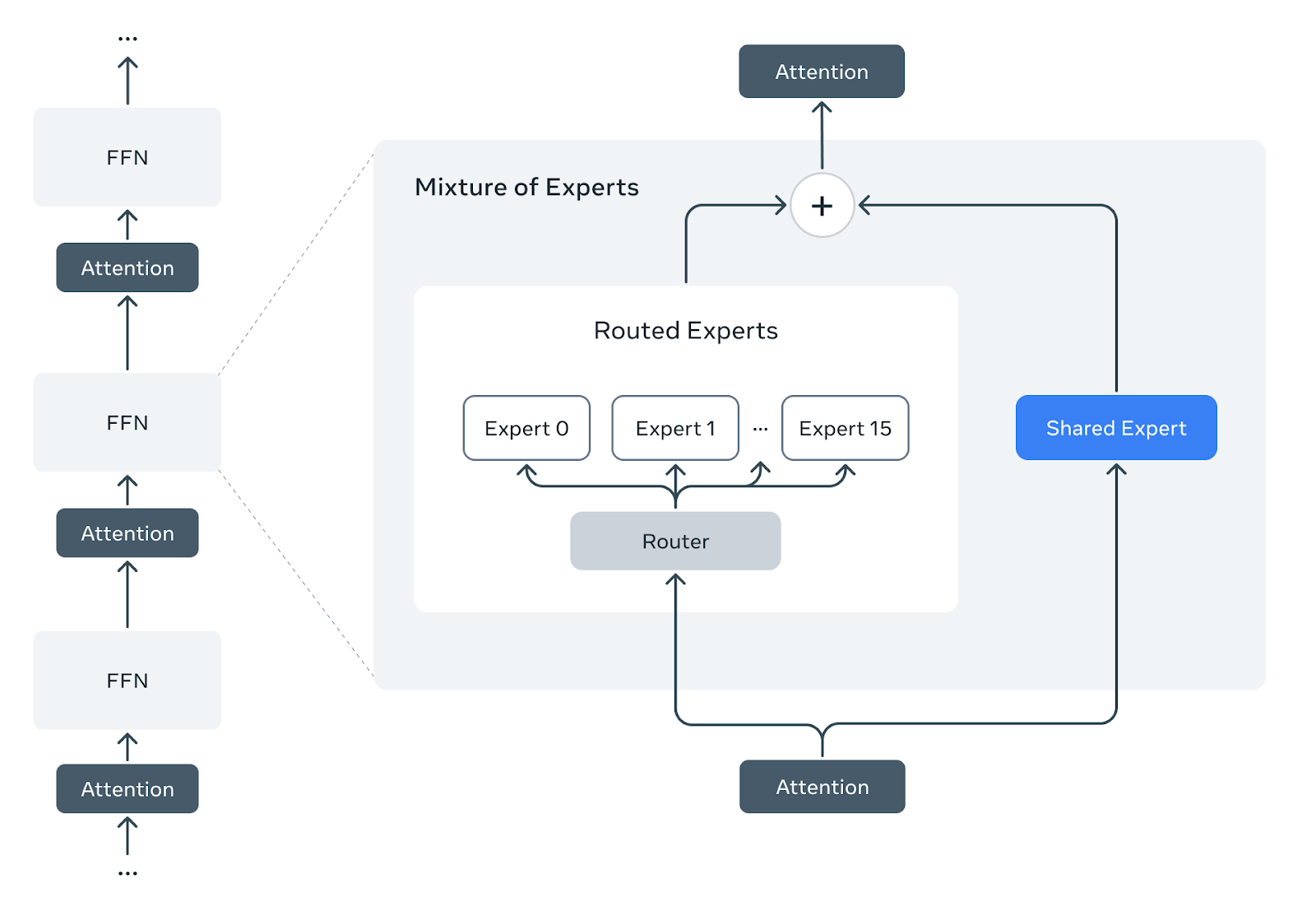
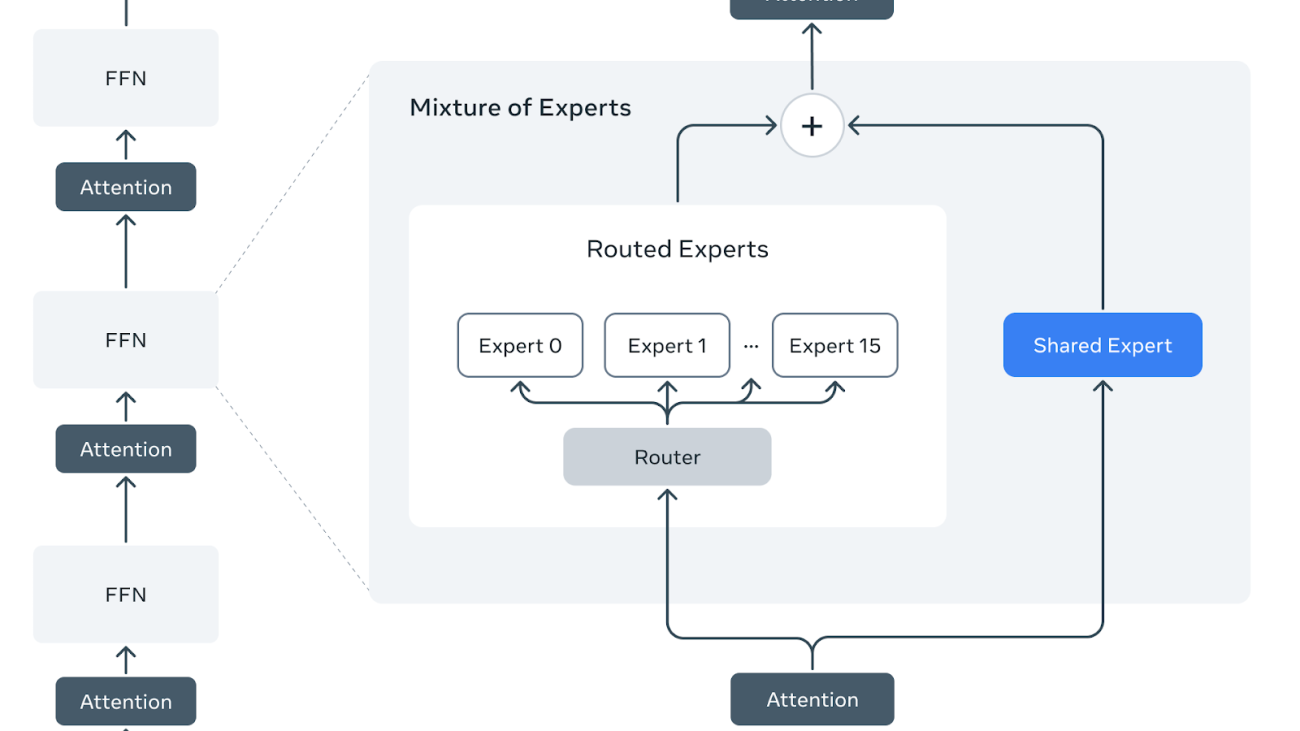
Llama 4 Scout and Maverick models are officially released. Scout / Maverick has a shared expert and 16 / 128 routed experts with dropless token-choice routing and Top-1 selection for each MoE layer. Besides, both shared and routed experts use SwiGLU activation with 3 linear layers. Please refer to The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation for more information about the model.
Key Concept
There are multiple common solutions to handle dynamism and sparsity problems introduced in MoE layers. Here we demonstrate different solutions of token-choice routing with Top-1 selection.
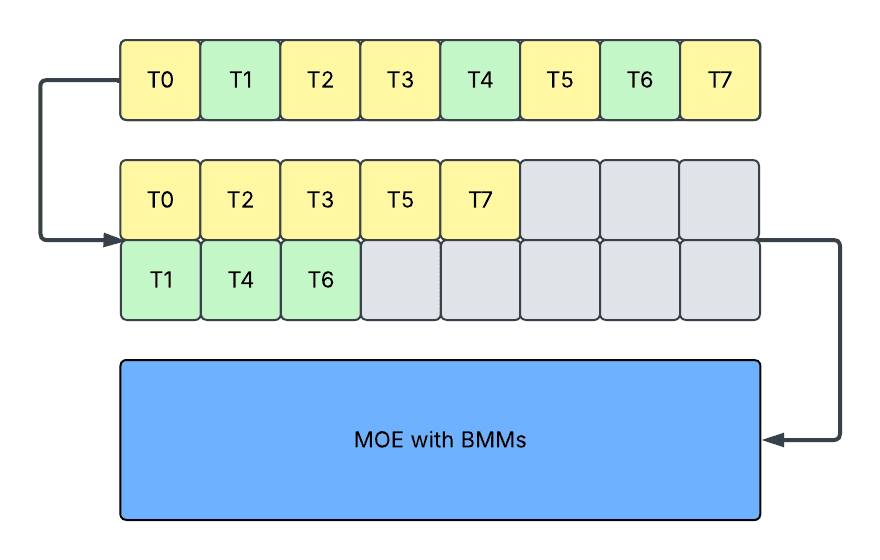
The above diagram shows the padding design. Each box represents a token, and the yellow / green color represents valid tokens with different routed experts, and the grey color represents padded tokens. Each row of boxes in the second step represents different routed experts. Ti represents the i-th token from the current rank of the data parallel group.
- Padding: In this approach, we pad activation to maximum sequence length for each expert and run a single batched matrix multiplication (BMM). It incurs:
- Increased memory on holding paddings.
- Increased latency on processing paddings. Note that it is possible to avoid processing padding through jagged kernels, but jagged kernels may also incur high overhead when the number of experts is large.
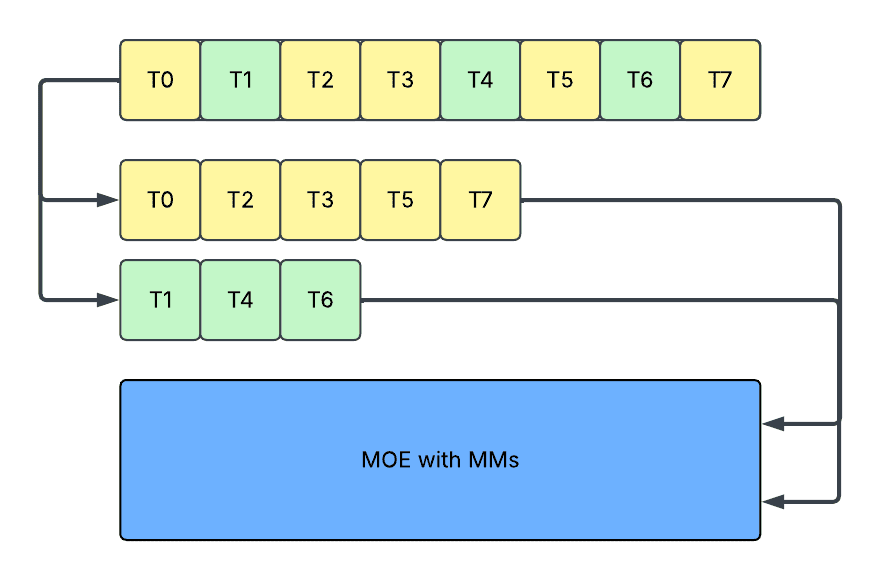
- Slicing: In this approach, we slice activation to exact sequence length for each expert and run multiple matrix multiplications (MM). It avoids the problems in padding, but it incurs:
- Reduced kernel efficiency, caused by repeated kernel launches on small shapes.
- Reduced device utilization, caused by frequent host and device synchronizations on dynamic shapes, plus extra kernel launch overheads, as it is incompatible with graph capturing mechanisms (e.g. CUDAGraph and torch.compile).
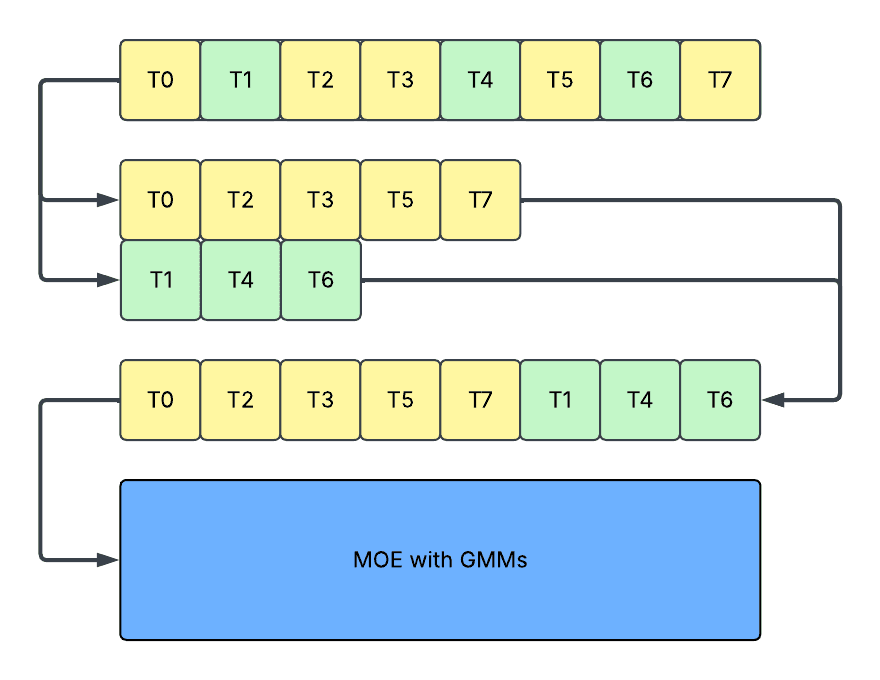
- Concatenation: In this approach, we further concatenate the activations after slicing and run a single grouped matrix multiplication (GMM). It avoids the kernel efficiency problem in slicing, but still incurs
- Reduced device utilization, as it still requires host and device synchronization, and still incompatible with graph capturing mechanisms.
To further improve the solution, we propose a shuffling-based mechanism:
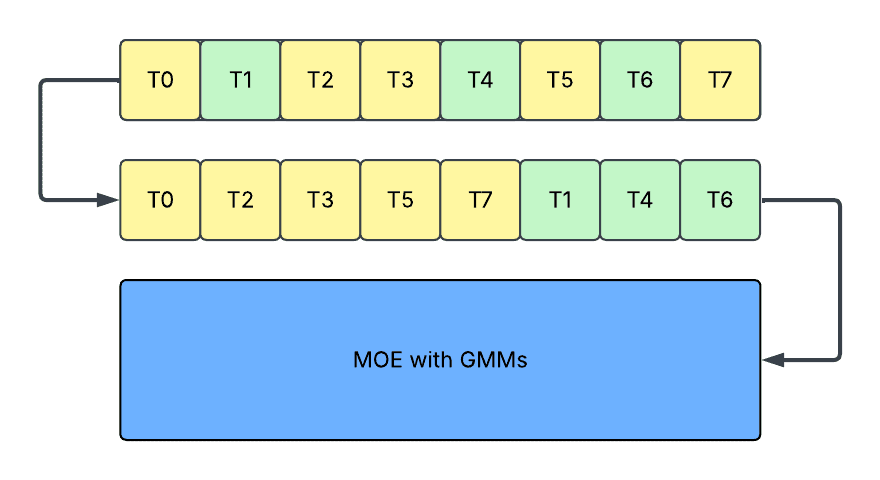
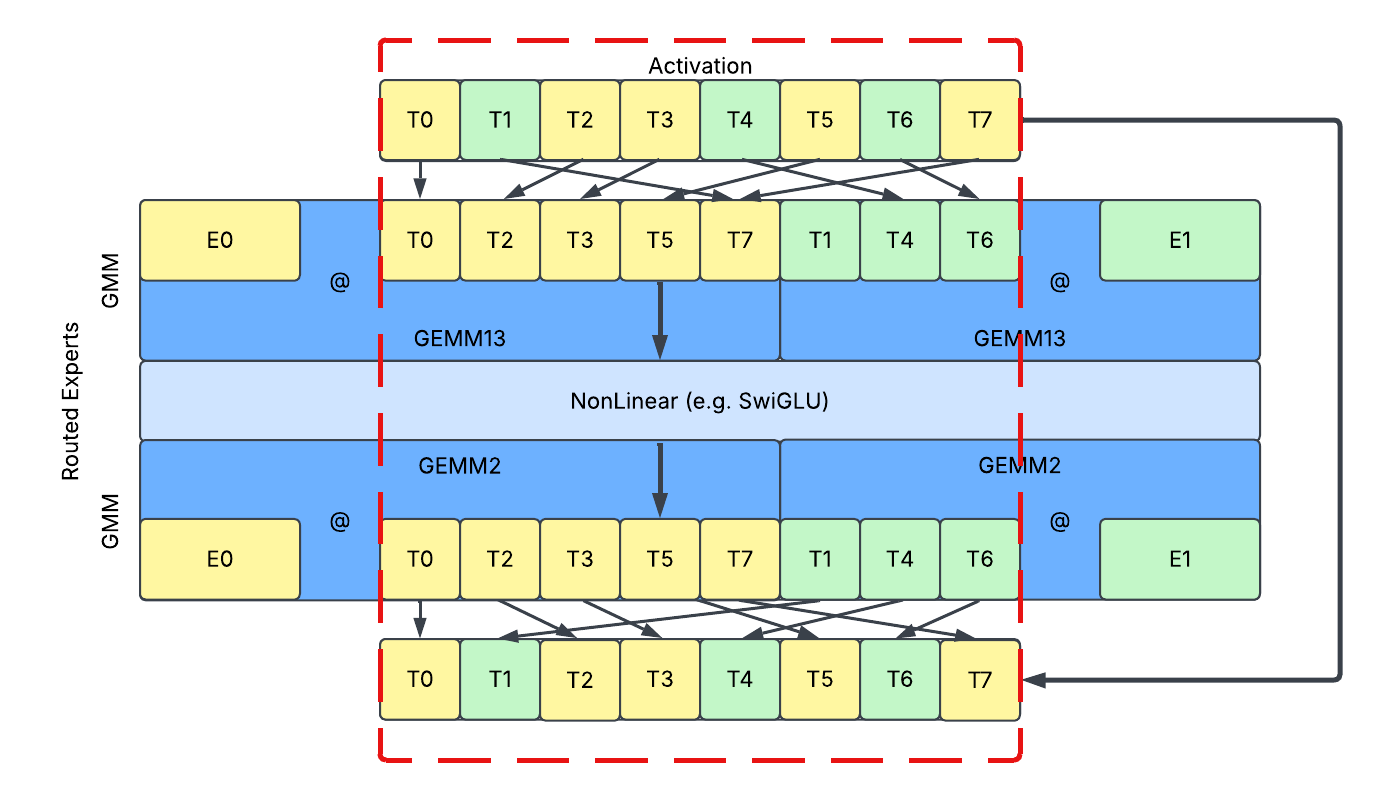
- Shuffling: In this approach, we directly sort the tokens so that routed tokens are ordered by routed expert’s ID. By doing so, no padding or splitting is introduced, and tokens assigned to the same experts are stored together and can be processed together inside GroupedGEMM. It provides a dense model interface and avoids all the problems mentioned above.
- No paddings as the activation remains a dense tensor.
- No host and device synchronization, as the activation remains a static-shaped tensor.
We built an end-to-end MoE inference solution, MetaShuffling, based on this design.
Runtime Design
No Parallelism for Single-GPU Inference
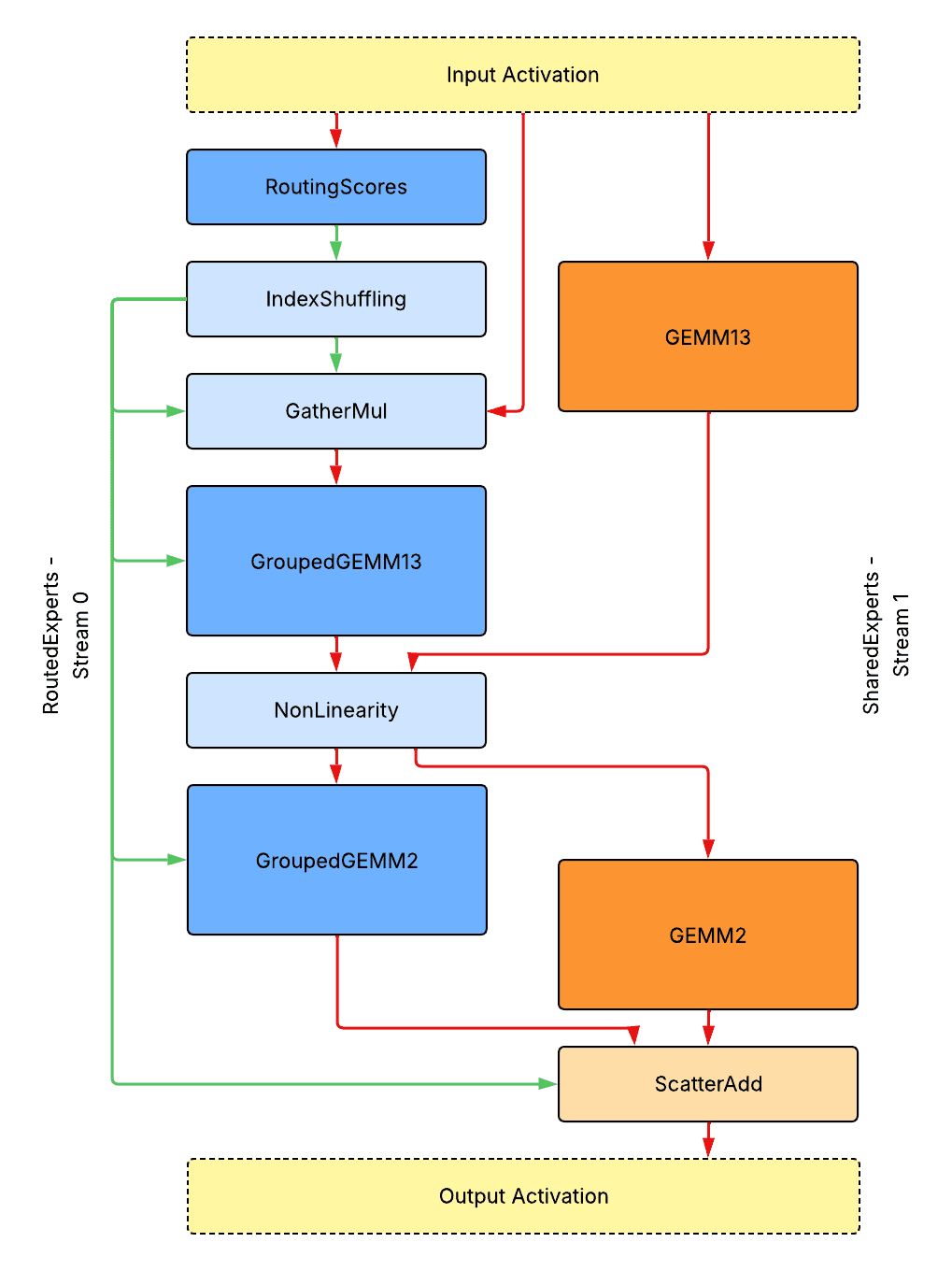
Above is the overall runtime design for single-GPU inference without model parallelism. Note that, to optimize performance, the first and third linear layers of SwiGLU activation are merged together as GroupedGEMM13 / GEMM13.
- Solid dark blue/orange boxes represent tensor core heavy kernels on routed/shared expert streams.
- Solid light blue/orange boxes represent CUDA core or memory traffic-heavy kernels on routed/shared expert streams.
- Red arrows represent data flows of activation tensors.
- Green arrows represent data flows of metadata tensors.
All metadata tensors are placed on the device. There is no blocking device to host synchronization. All kernels are launched back to back without bubbles. The diagram shows data flows only, not a demonstration of actual profiling traces.
Kernel Interfaces And Data Flows
- RoutingScores: A function or fused kernel that handles routing scores calculation.
- Input: input_tokens: [T, D] (T: number of tokens; D: feature dimension); router_weights: [D, E] (E: number of experts); router_biases: [E];
- Output: routing_scores: [T, E]; scaling_factors: [T, E];
- IndexShuffling: A fused kernel that handles shuffling and sorting of indices. We will introduce an optimized implementation in the Kernel Design section.
- Input: routing_scores: [T, E]; K (threshold for top-k routing);
- Output: routed_token_indices: [K * T]; routed_expert_indices: [K * T]; routed_token_counts_per_expert: [E];
- GatherMul: A fused kernel that shuffles tokens based on sorted indices and scales them.
- Input: input_tokens: [T, D]; routed_token_indices: [K * T]; routed_expert_indices: [K * T]; scaling_factors: [T, E];
- Output: scaled_routed_tokens: [K * T, D]
- GroupedGEMM: An optimized GroupedGEMM kernel that handles on-device shape information about batches along M dimension without restrictions. We will introduce an optimized implementation in the Kernel Design section.
- Input: tokens: [K * T, D]; weights: [E, D, HD] (HD: hidden dimension); routed_token_counts_per_expert: [E];
- Output: tokens: [K * T, HD]
- GEMM: An optimized GEMM kernel. Similar interface to dense model.
- NonLinearity: A fused kernel that handles non-linearity. Similar interface to dense model.
- ScatterAdd: An optimized kernel that reverses token shuffling based on sorted indices and directly performs scatter add to shared expert output without materializing an unshuffled tensor.
- Input: shared_output_tokens: [T, D]; routed_output_tokens: [K * T, D]; routed_token_indices: [K * T];
- Output: combined_output_tokens: [T, D]
Note that if quantization is applied, then activation quantization kernels are fused into the preceding non-GEMM kernels, which means fusing into GatherMul for GroupedGEMM13 and fusing into NonLinearity for GroupedGEMM2, etc.
Note if using a large K * T, the GatherMul and ScatterAdd operation can be further fused into following/proceeding GroupedGEMM operations, which should be complete as global memory to shared memory/registers or shared memory to global memory step in prologue/epilogue, however, it adds additional challenge on overlapping with tensor core execution at the kernel design level. Besides, fusing ScatterAdd requires shared experts to complete before routed experts, which might not be a good design choice if these kernels can be used to hide AlltoAll latency.
Tensor Parallelism for Single-Host Inference
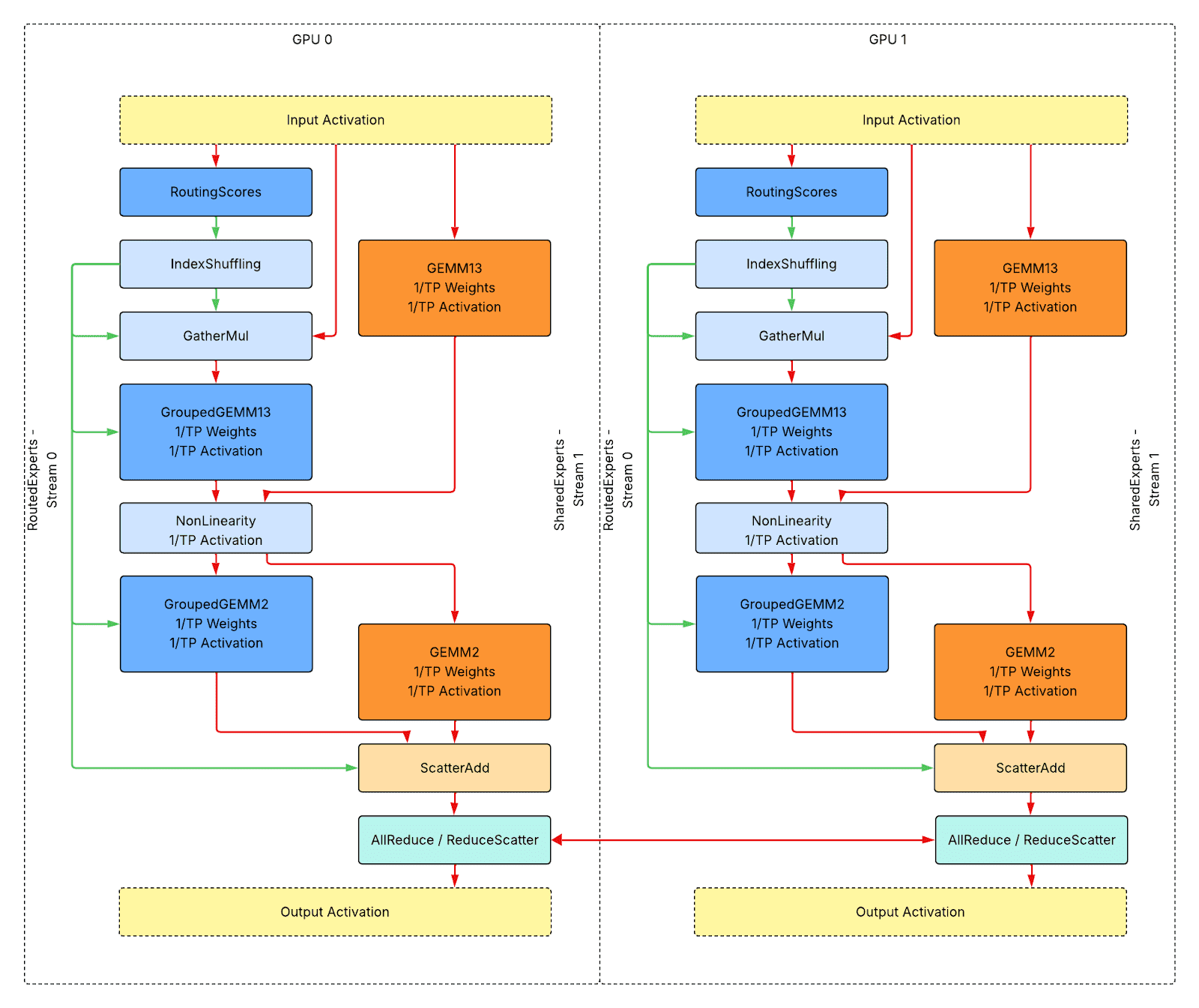
Above is the overall runtime design for single-host inference with tensor parallelism (TP). Compared to single-GPU inference, the additional step is:
- Solid light mint boxes represent network traffic-heavy communication kernels.
Still, all metadata tensors are placed on the device, there is no device to host synchronization. All kernels are launched back to back without bubbles. The diagram shows data flows only, not a demonstration of actual profiling traces.
Workload Sharding and Additional Kernels
No additional custom kernel is introduced compared to the single GPU inference use case. For GEMM, GroupedGEMM, and non-linearity kernels, the activation and weights are both shared to 1/TP along different dimensions, and the computation/memory overhead is also shared to 1/TP.
The final step should be AllReduce if only tensor parallelism is applied. Alternatively, ReduceScatter if tensor parallelism is applied with sequence parallelism.
Expert Parallelism for Multi-Host Inference
To enable expert parallelism (EP), we swap data parallelism dimension out of the routed expert as the expert parallelism dimension inside the routed expert. Note that tensor parallelism can be further swapped with expert parallelism for better GEMM efficiency with increased routing imbalance risk, but we won’t cover this design in this blog.
If expert parallelism is enabled with token-choice routing, then we must decide between using dense tensors or using static shapes, because the number of routed tokens to different expert groups is dynamic.
- We use dense tensors and dynamic shapes when using eager mode is preferred to avoid waste on network traffic and memory space caused by running unpadded AlltoAll.
- We use sparse tensors and static shapes when using graph mode is preferred to avoid generating GPU bubbles caused by CPU launch overheads and device-to-host synchronization through running with CUDAGraph.
Note that wasted network traffic with padded activations can also be avoided using a custom AlltoAll implementation, but we won’t cover any topics on custom communication or communication and computation fusion kernels in this blog.
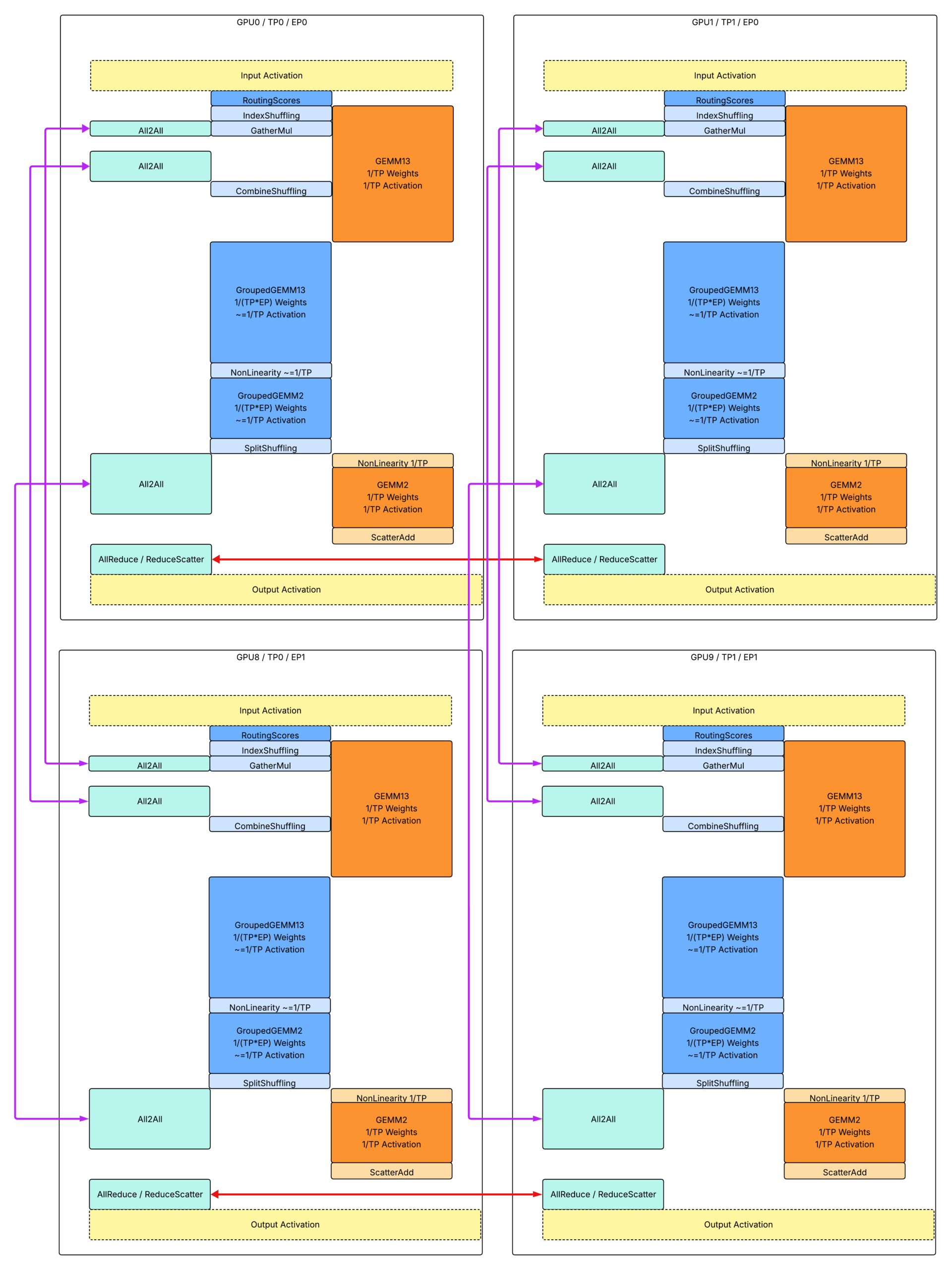
Above is the overall runtime design for multi-host inference with tensor parallelism and expert parallelism. Compared to single-host inference with tensor parallelism.
- Solid red arrows represent intra-node communication.
- Solid purple arrows represent inter-node communication.
Kernel Interfaces And Data Flows
For added expert parallelism-based communication, we use 3-shot All2All communication to exchange shapes and tokens:
- 1st A2A: Exchange on-device metadata tensor about number of tokens routed to each expert, which is `routed_token_counts_per_expert: [E]`, the output generated from IndexShuffling kernel.
- 2nd A2A: Exchange tokens from data parallelism based to expert parallelism based, dispatching to different EP ranks based on routing.
- 3rd A2A: Exchange tokens from expert parallelism based to data parallelism based, combining from different EP ranks based on routing.
Besides, we added 2 additional shuffling kernels and 1 special scatter kernel:
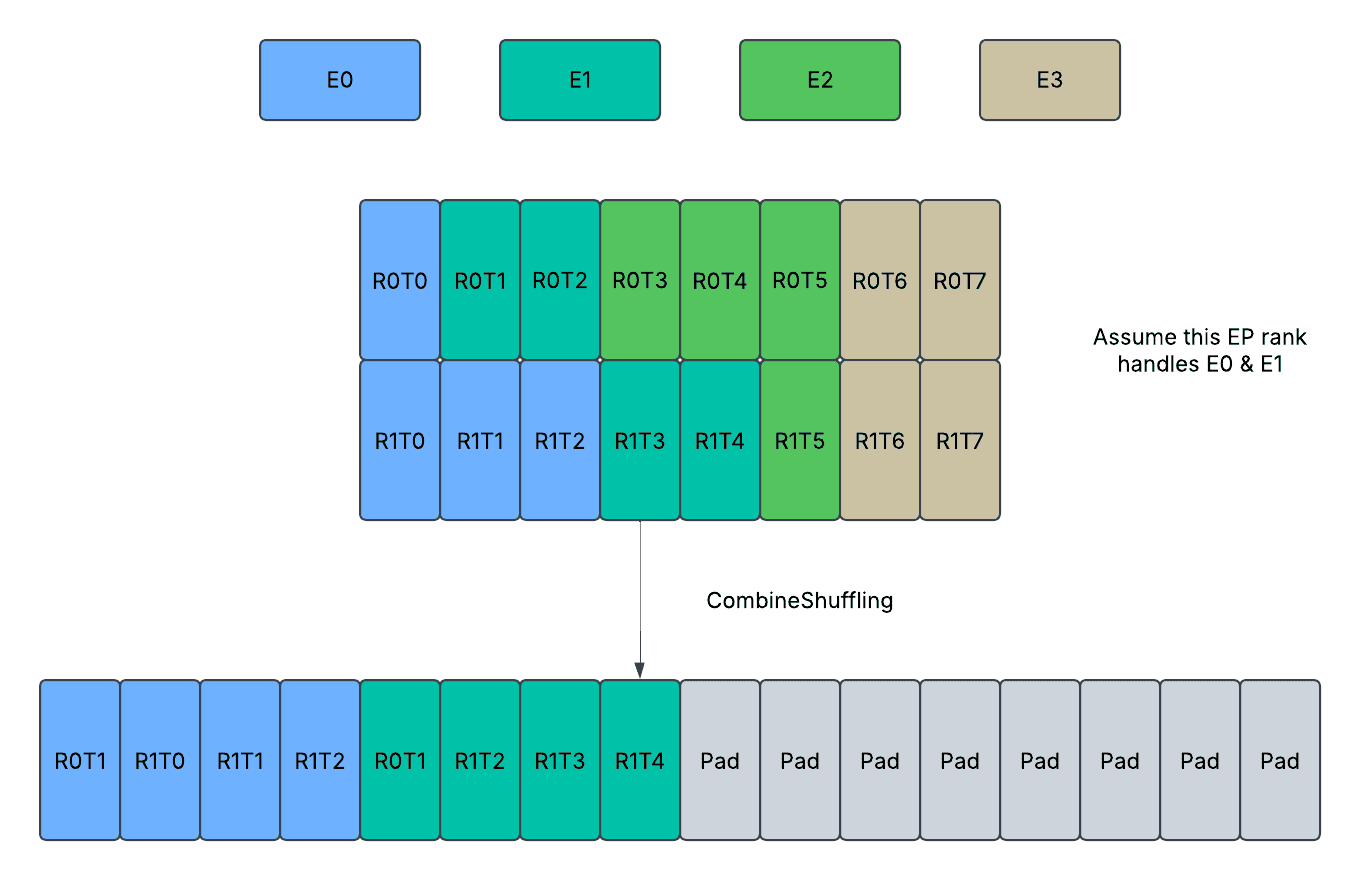
- CombineShuffling (Dense or Padded): Reshuffles received tokens from rank first order to expert first order. Following T* indicates the number of total tokens received from all peers, which can be further interpreted as a jagged dimension with shape information from routed_token_counts_per_rank_per_expert tensor.
- Input: received_tokens: [T*, D] (first ordered by dp ranks, then ordered by expert indices); routed_token_counts_per_rank_per_expert: [EP, E // EP];
- Output: reshuffled_tokens: [T*, D] (first ordered by expert indices, then ordered by dp ranks); routed_token_counts_per_expert: [E // EP];
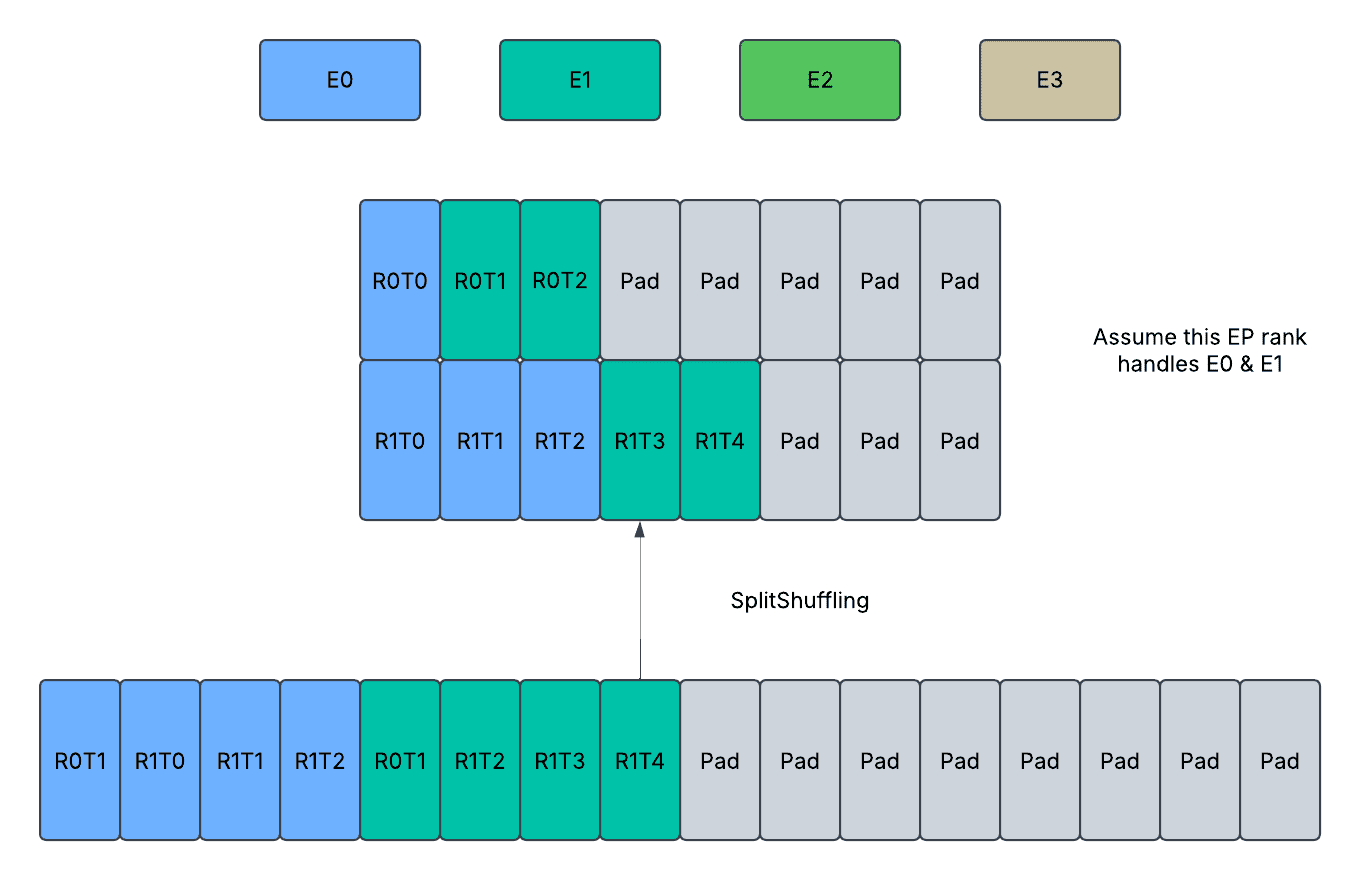
- SplitShuffling (Dense or Padded): Reverse process of CombineShuffling. Reshuffles to-send tokens from expert first order to rank first order.
- Input: reshuffuled_tokens: [T*, D] (first ordered by expert indices, then ordered by dp ranks); routed_token_counts_per_rank_per_expert: [EP, E // EP];
- Output: to_send_tokens: [T*, D] (first ordered by dp ranks, then ordered by expert indices);
- ScatterAdd (Padded): Scatter adds validate tokens from padded tensors.
- Input: shared_output_tokens: [T, D]; received_padded_routed_output_tokens: [EP, K*T, D]; routed_token_indices: [K * T]; routed_token_counts_per_expert: [E];
- Output: combined_output_tokens: [T, D]
We will provide a better demonstration of the above kernels in detail in the `Padded Communication with Static Shapes In Graph Mode` section.
Unpadded Communication with Dynamic Shapes In Eager Mode
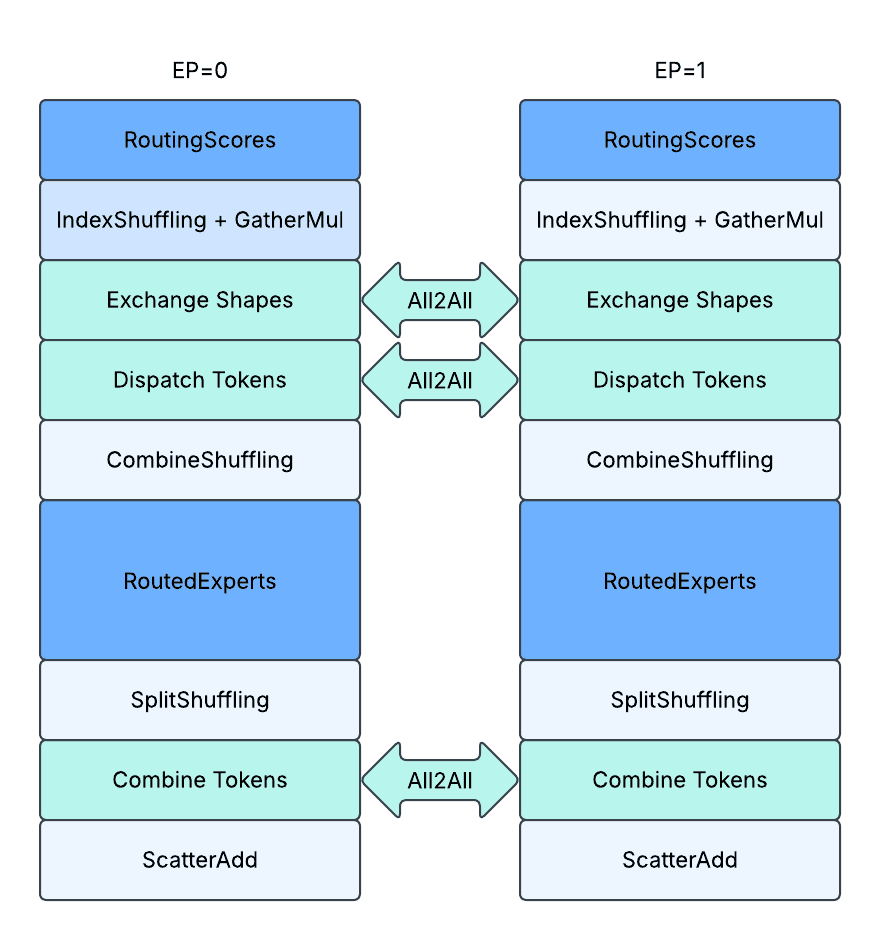
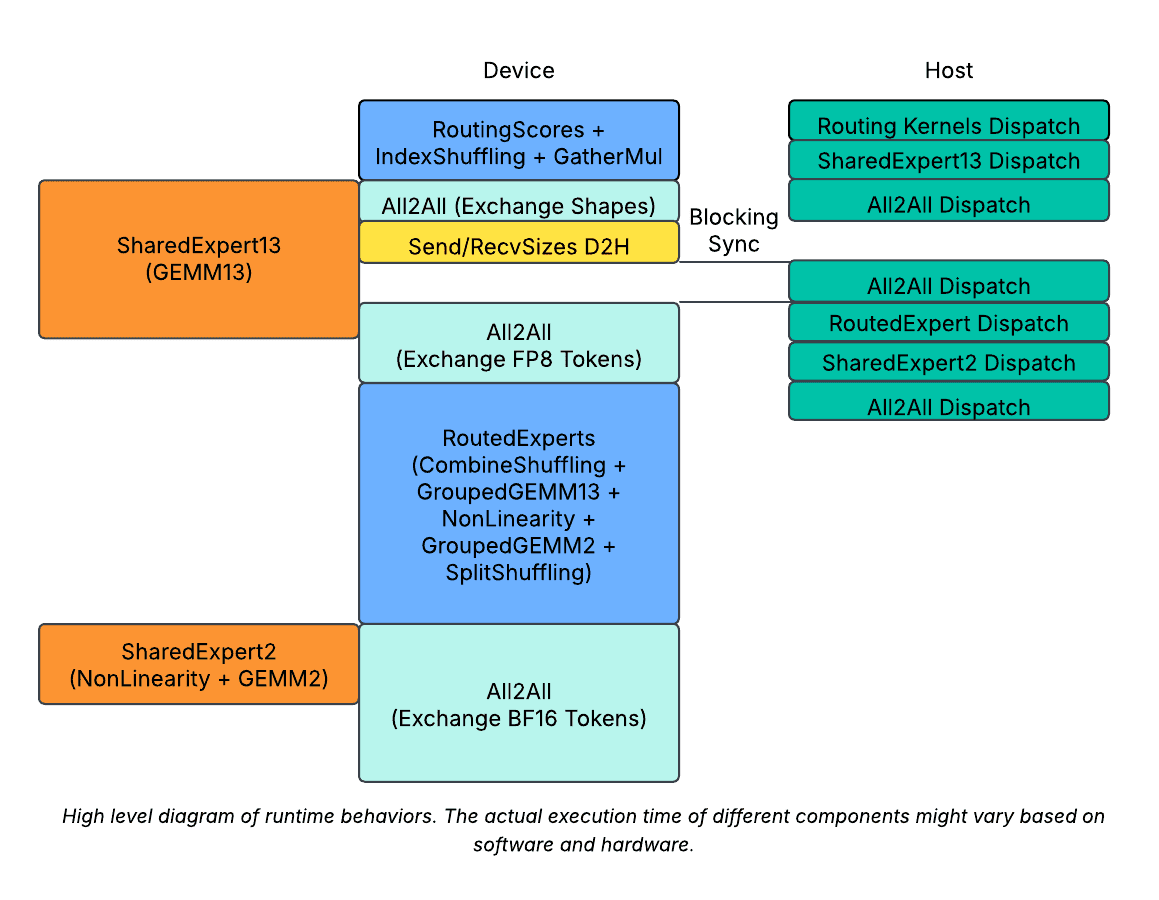
High-level diagram on runtime behavior. The actual runtime of different components might vary based on software and hardware.
Minimize Usage of Dynamic Shapes
As the routing is dynamic per MoE layer, the minimal amount of device/host synchronization required is once per layer. To achieve this, we made a delay of the D2H copy of `send_sizes`, and concatenated it with `recv_sizes` to transfer them together with a single D2H copy. It reduces the device/host synchronization to once per layer.
Minimize Negative Impact on Dynamic Shapes
To further hide the device/host synchronization overhead, we further split the shared experts into 2 parts.
- We had the first part dispatched right after routing, but before dispatch A2As. Then, when the device/host synchronization happens, the device is still kept busy running shared experts.
- We have the second part dispatched right after MoE but before combining A2A. This will further help overlapping the second A2A.
Padded Communication with Static Shapes In Graph Mode
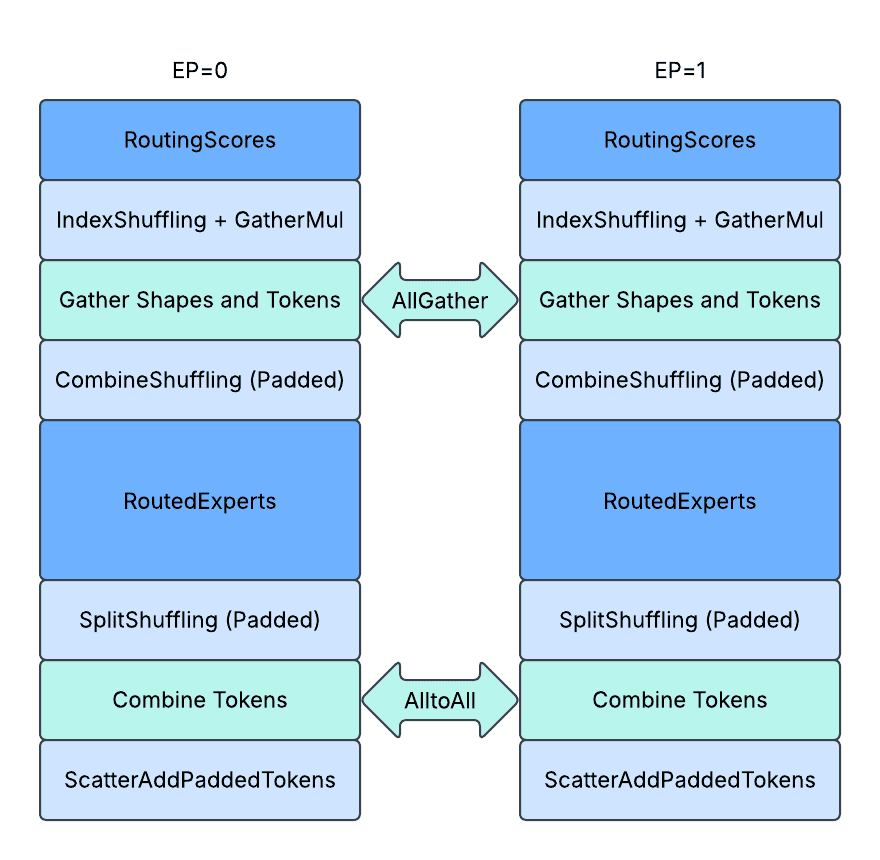
Minimize Usage of Padding
With a dropless token choice design, the maximum possible number of tokens routed to any single expert is T. However, if we group multiple experts together and place them on a single GPU through expert parallelism sharding, for TopK routing,
- The maximum number of tokens routed to 1 expert is T.
- The maximum number of tokens routed to 2 expert is 2 * T.
- …
- The maximum number of tokens routed to K experts is K * T.
- The maximum number of tokens routed to K + 1 experts is, still, K * T.
- …
So the maximum number of tokens routed to an expert group of N experts will be capped at min(N, K) * T tokens.
For Top1 routing, the number of tokens routed to an expert group of any size will always be capped at T tokens, and the minimal required memory to allocate and hold for dynamic tokens is EP * T tokens, as there are EP expert groups.
To achieve the minimal required padding, we directly use AllGather to gather all active tokens from different EP ranks and then splits and reshuffles routed tokens locally through custom kernels. The activation size is compressed to 1 / (E // EP), which corresponds to reductions in memory and network traffic.
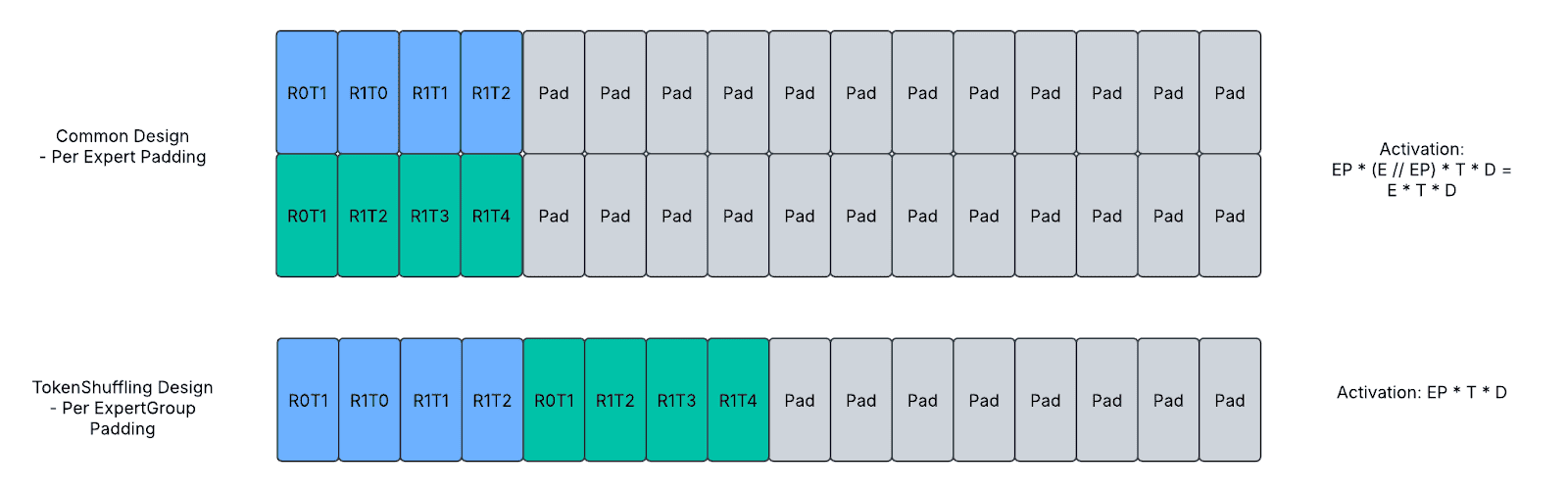
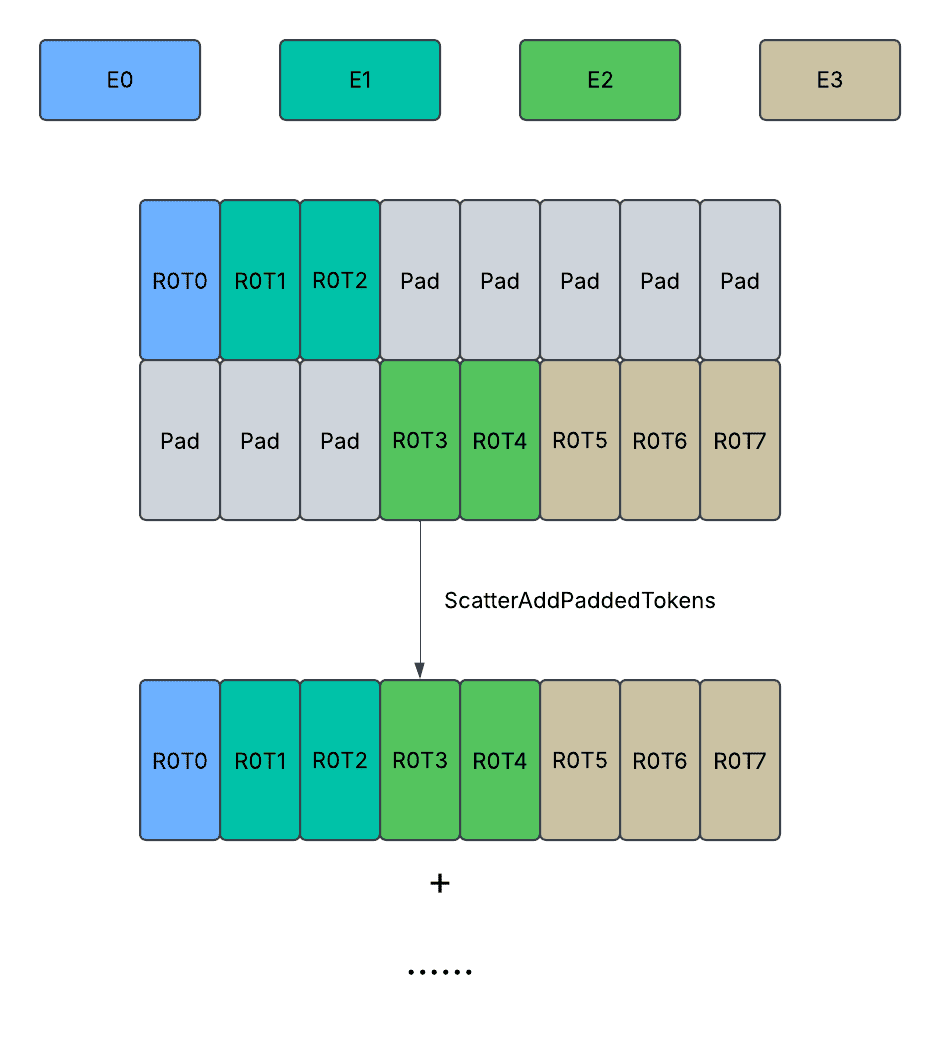
The above diagram shows the padding design. Each box represents a token, the blue / green color represents valid tokens with expert assignments and the grey color represents padded tokens. RiTj represents the j-th token from the i-th rank of expert parallelism group.
Minimize Negative Impact on Padding
Even though the paddings are reduced to minimal allowance, we also ensure that the paddings only cause memory space (allocation) and network traffic (communication), but not cause redundant computation (GroupedGEMM / NonLinear), redundant memory bandwidth (CombineShuffling / SplitShuffling / ScatterAdd) through taking on device shape information `routed_token_counts_per_expert` or `routed_token_counts_per_rank_per_expert`.
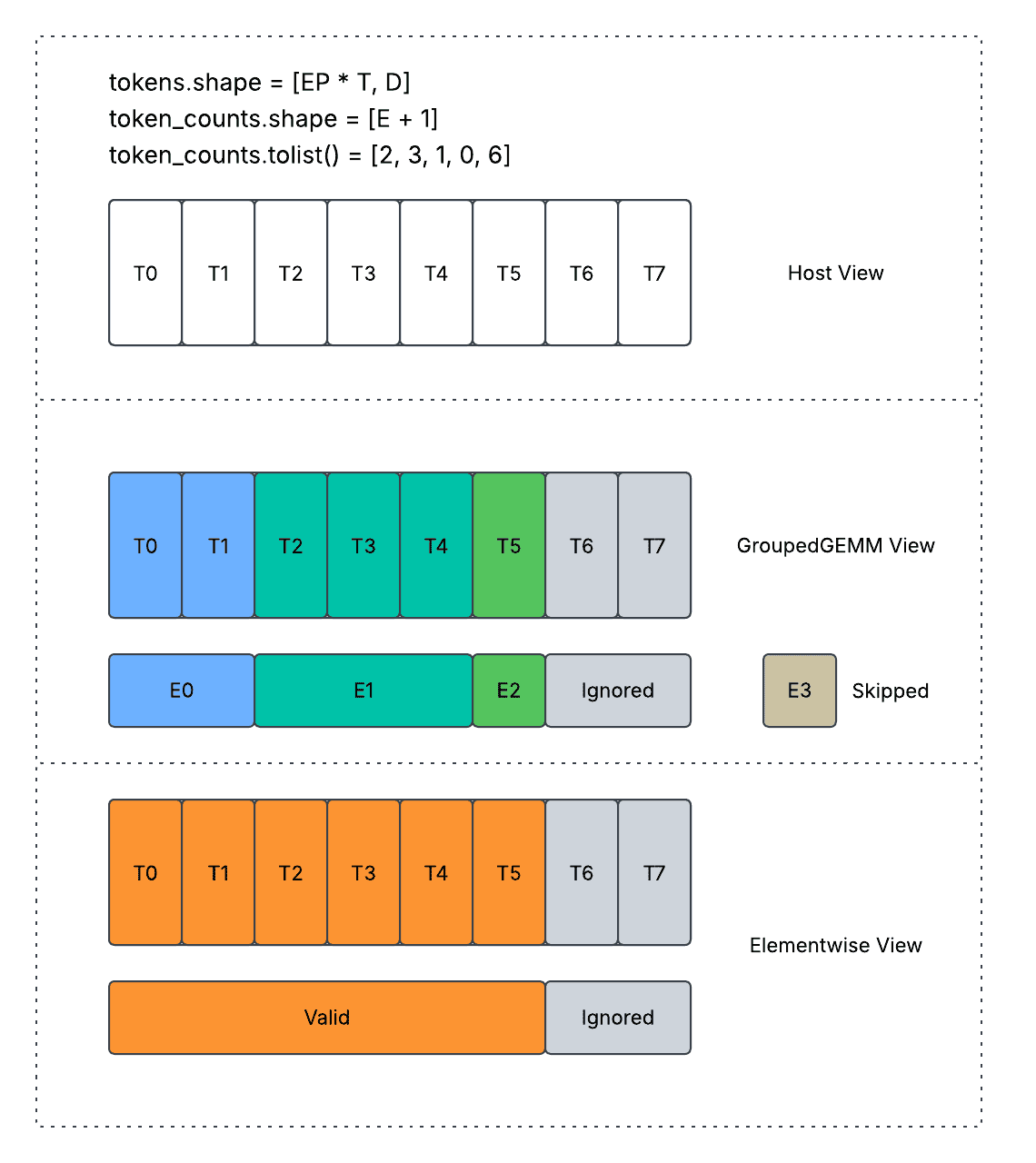
Activation Conceptional Interpretation
Most importantly,
- When the total number of active tokens is small across all EP ranks, it is important to do so to avoid activating redundant experts in GroupedGEMM and causing extra memory traffic.
- When the total number of active tokens is large across all EP ranks, it is also important to do so to avoid converting GroupedGEMM from memory bound to compute bound.
CombineShuffling: The tokens assigned to the current EP rank are reshuffled from expert first order to rank first order right after AllGather. The tokens not assigned are not copied, and the remaining allocated memory space at the end of the tensor remains untouched.
SplitShuffling: The tokens assigned to the current EP rank are reshuffled from rank-first order to expert-first order right before AlltoAll. The tokens not assigned are not copied, and the reshuffled tensors have paddings stored in an interleaved fashion.
ScatterAdd (Padded): Each EP rank finally receives activations computed from all other ranks, it will understand where are the valid tokens and where are the padded tokens, and then only read the valid tokens to do scatter_add with.
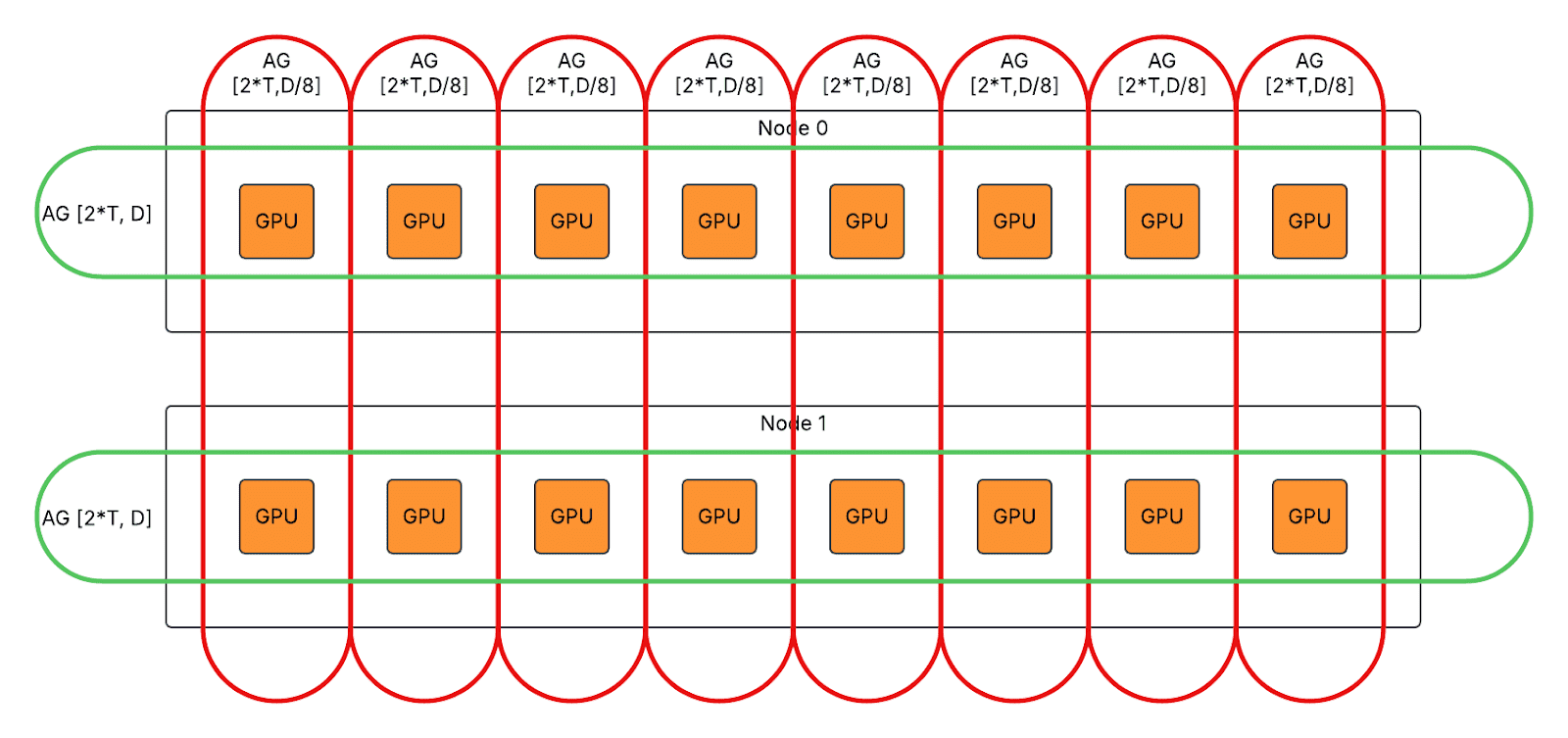
Communication Deduplication
Different tensor parallelism ranks have the same activation before 1st GroupedGEMM and after 2nd GroupedGEMM, so the same tokens are exchanged across nodes repeatedly.
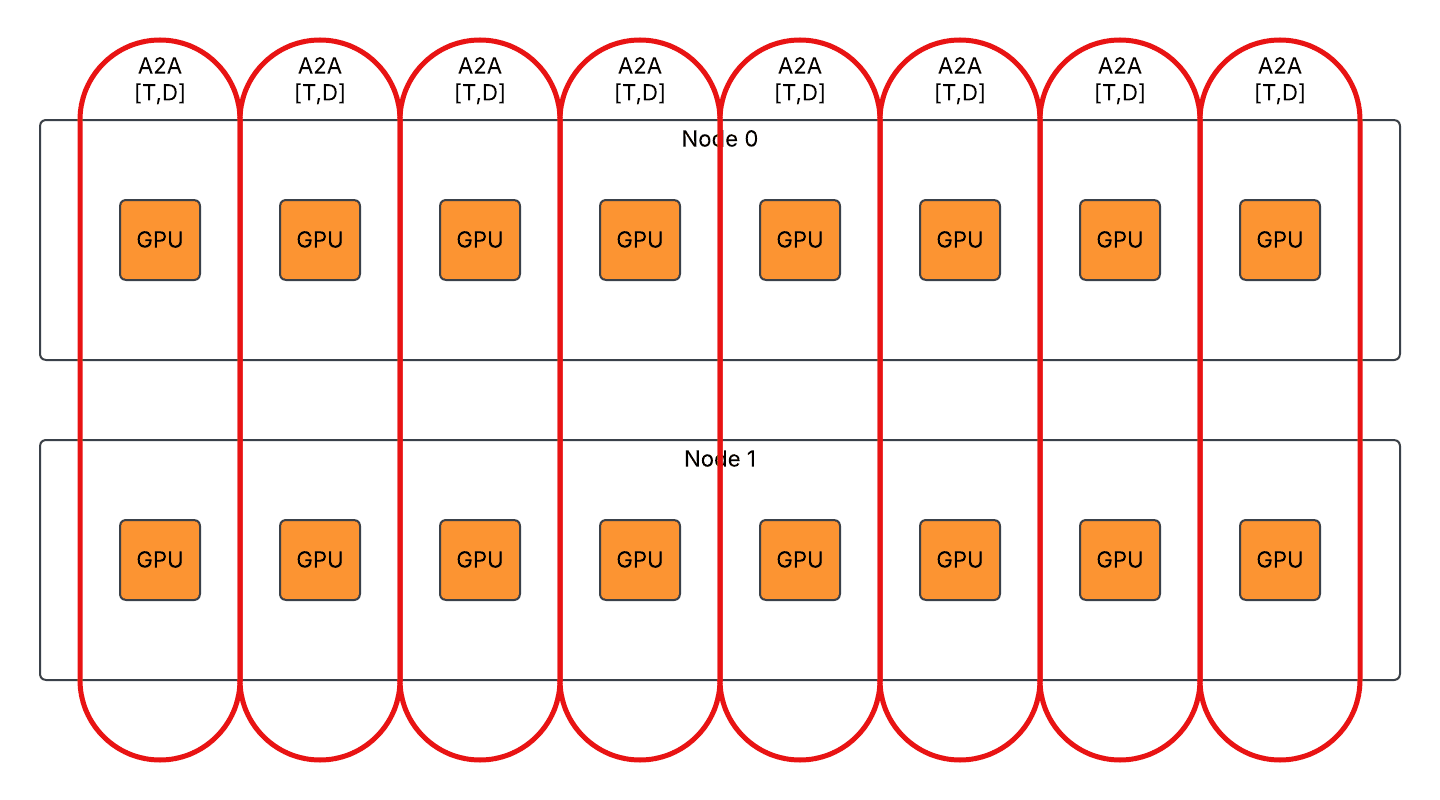
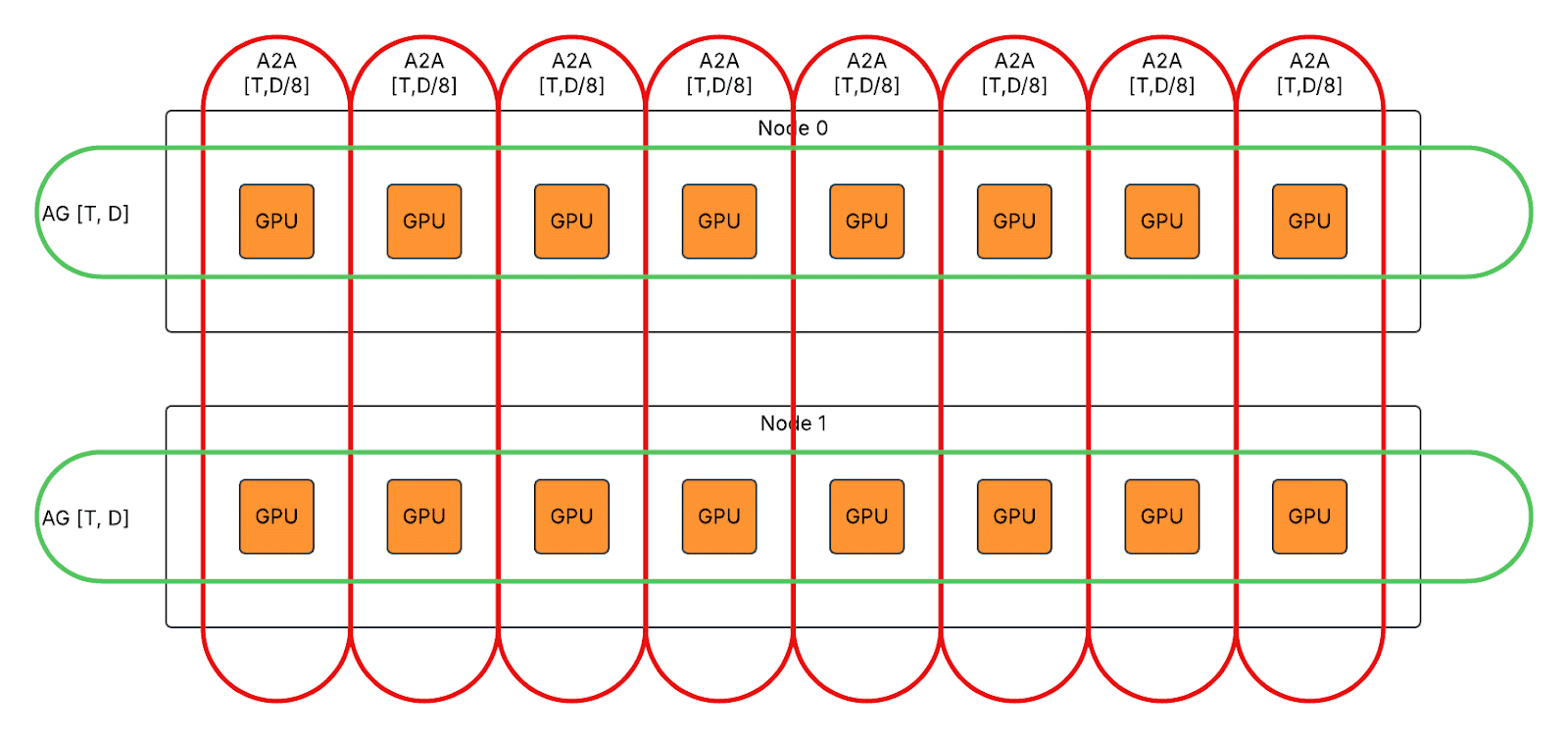
We enabled communication deduplication to evenly distribute the inter-node communication workload to different ranks with extra intra-node communication introduced. Example of DP2/TP8/EP2:
- For first AlltoAll in eager mode, split T*D inter-node AlltoAll to T*D/8 inter-node AlltoAll and T*D intra-node AllGather.
- For second AlltoAll in eager / graph mode, split T*D inter-node AlltoAll to T*D/8 intra-node ReduceScatter and T*D/8 inter-node AlltoAll.
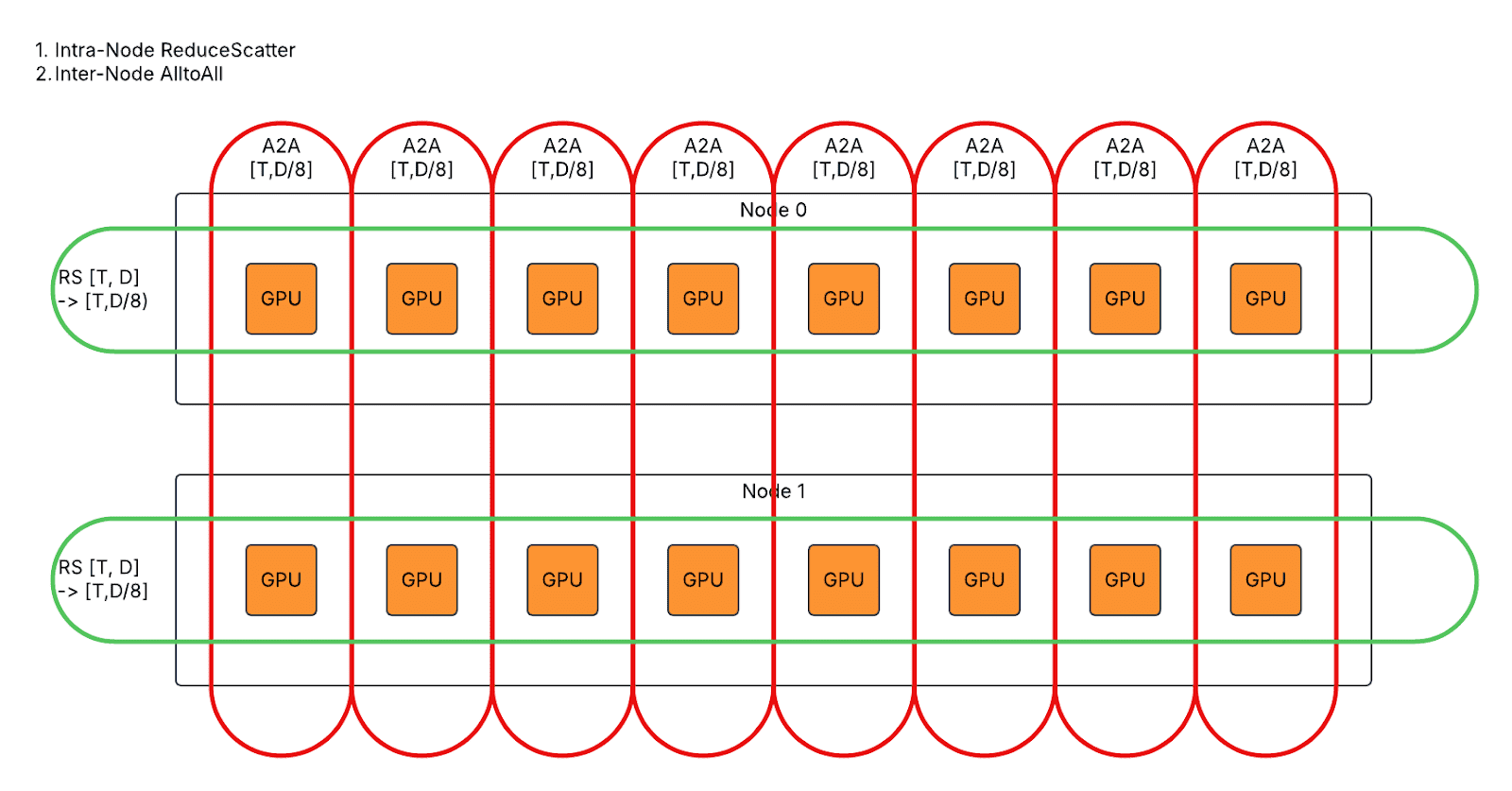
- For first AllGather in graph mode, split 2*T*D inter-node AlltoAll to 2*T*D/8 inter-node AllGather and 2*T*D intra-node AllGather.
Kernel Design
We implemented more than 10 custom kernels to support MetaShuffling MoE inference design in different use cases running on both Nvidia H100 GPU and AMD MI300X GPU. We open sourced all computation kernels as PyTorch operators in FBGEMM Generative AI Kernel Library. We hope it can help users efficiently serve Llama 4 models in their preferred framework and preferred accelerators, for example, vLLM / SGLang. In this blog, we will focus on the 2 most interesting kernels designs as the key to improve inference performance, GroupedGEMM and IndexShuffling.
GroupedGEMM
We implemented Triton-based GroupedGEMM kernels for BF16 / FP16 / FP8 Rowwise.
Interface
def grouped_gemm_fp8_rowwise(
x: torch.Tensor, # shape: [M, K]
w: torch.Tensor, # shape: [G*N, K]
m_sizes: torch.Tensor, # shape: [G]
x_scales: torch.Tensor, # shape: [M]
w_scales: torch.Tensor, # shape: [G*N]
) -> torch.Tensor: # shape: [M, N]
...
The interface is quite similar to single GEMM in that it takes a single LHS, a single RHS tensor, and produces a single output. There is no dynamism or sparsity from the runtime point of view.
However, the kernel dynamically splits the M dimension of the LHS tensor using the data of `m_sizes` and statically splits the N dimension of the RHS tensor using the shape of `m_sizes`. This design has several advantages:
- No additional padding or alignment requirement within different batches of Ms. So `m_sizes` can store any non-negative values as long as its total does not exceed `M`.
- The `m_sizes` can be zero values to skip loading weights of unactivated experts.
- The `m_sizes` can have a total sum less than `M` to skip computation on padded tokens at the end without extra overhead.
- The `m_sizes`, or the splitting of the LHS activation, is known to the device but unknown to the host. So it supports dynamic routing information without incurring device-to-host synchronization.
Workload Partition
We adopt the persistent kernel design to launch 1 CTA per SM and have all the CTAs running through all the partitioned tiles in an interleaved fashion. Conceptually, the workload partition happens as follows.
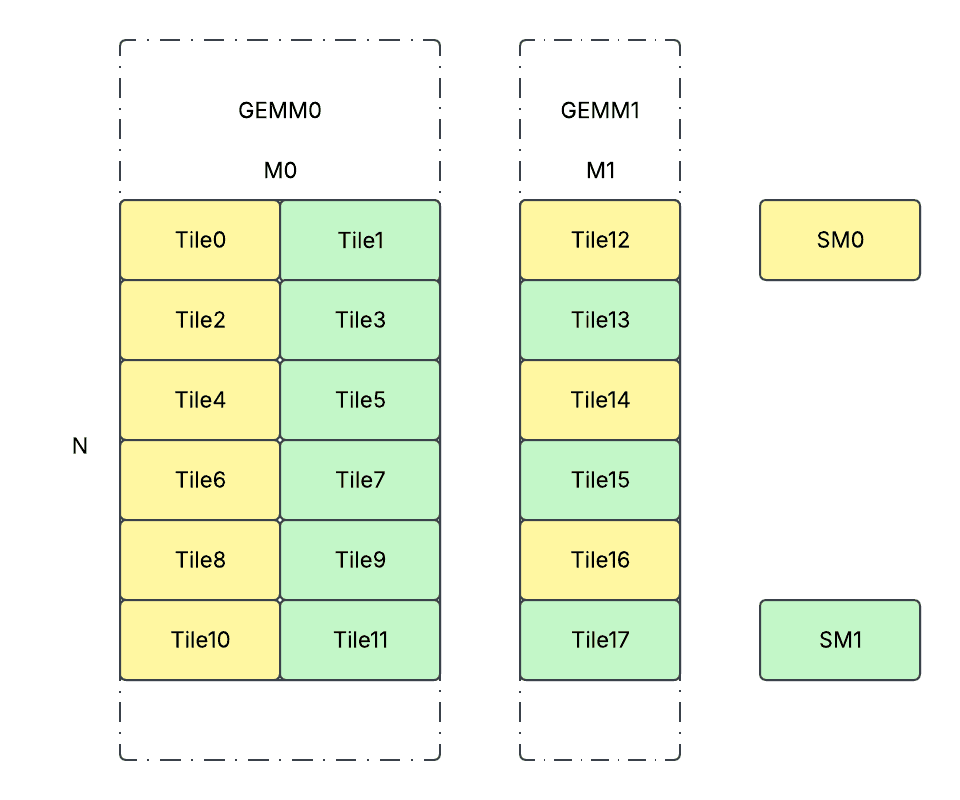
def partition_workload(G: int, Ms: List[int], N: int):
partitions = []
for g in range(G):
for n in range(0, N, BLOCK_N):
for m in range(0, Ms[g], BLOCK_M):
partitions.append((g, m, n))
paritions_per_cta = [[] for _ in NUM_SMS]
for i, part in enumerate(partitions):
paritions_per_cta[i % NUM_SMS].append(part)
The partitions are dynamically calculated on the device side at runtime with a small overhead. However, by doing so, we can achieve:
- Balanced workload across different SMs.
- Small launching overhead as each SM will only launch 1 CTA.
- High L2 cache hit rate. The order of workload partition makes sure the weights/activations will most likely be loaded once from HBM and cached on L2. Because usages of the same weight/activation tile will almost always happen concurrently / consecutively from different SMs.
Persistent Kernel with Warp Specialization
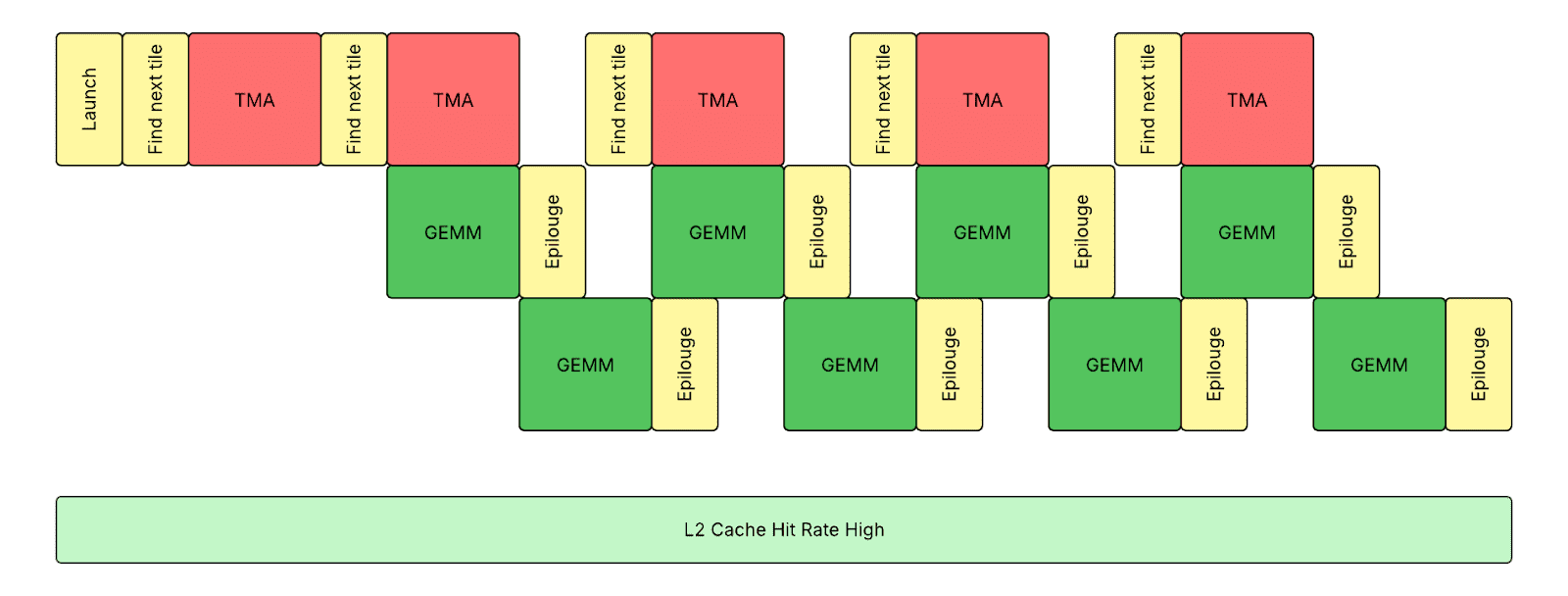
We adopted host-side tensor map-based loading of activations and weights, and optional device-side tensor map-based storing of outputs, to reduce memory transfer overhead on Hopper GPUs. With a contiguous storage format of activations, we can use a single host-side TMA (Tensor Memory Accelerator) descriptor to load activations and mask out the tokens that belong to other experts. However, we need to create multiple device-side TMA descriptors to store outputs without dynamic masking support.
We adopted a warp specialization-based kernel design to have the kernel running in a truly persistent fashion that each SM switches between 3 warp groups (1 producer and 2 consumers). This design keeps TMA engine, Tensor core, and CUDA core execution overlapping with each other, utilizing asynchronous TMA instructions and WGMMA (Asynchronous Warpgroup Level Matrix Multiply-Accumulate) instructions with memory barriers on shared memory. We received tremendous help from our Meta’s Triton compiler team to enable it. It is only possible to hide prologue and epilogue with warp specialization, as the traditional software pipeline approach cannot handle complicated control flows with pointer chasing.
IndexShuffling
We implemented CUDA / HIP-based index shuffling kernels.
Interface
def index_shuffling(
scores: torch.Tensor, # shape: [T, E]
):
token_counts: torch.Tensor = ... # shape: [E]
expert_indices: torch.Tensor = ... # shape: [T]
token_indices: torch.Tensor = ... # shape: [T]
return token_counts, expert_indices, token_indices
The kernel takes routing scores of all tokens on all experts, figures out the specific expert each token is routed to, reorders the token indices such that all the tokens routed to the same expert are placed contiguously, and returns:
- `token_counts`: As the number of tokens routed to each expert. It will be fed into the GroupedGEMM kernel discussed above.
- `expert_indices`: As the expert index each shuffled token belongs to. It will be fed into the GatherMul kernel discussed above.
- `token_indices`: As the original token index each shuffled token belongs to. It will be fed into the GatherMul and ScatterAdd kernel discussed above.
Cooperative Kernel
We adopted the cooperative kernel design, and split the kernel into 2 major phases, top-k reduction phase and bucket sort phase, with a global synchronization in the middle.
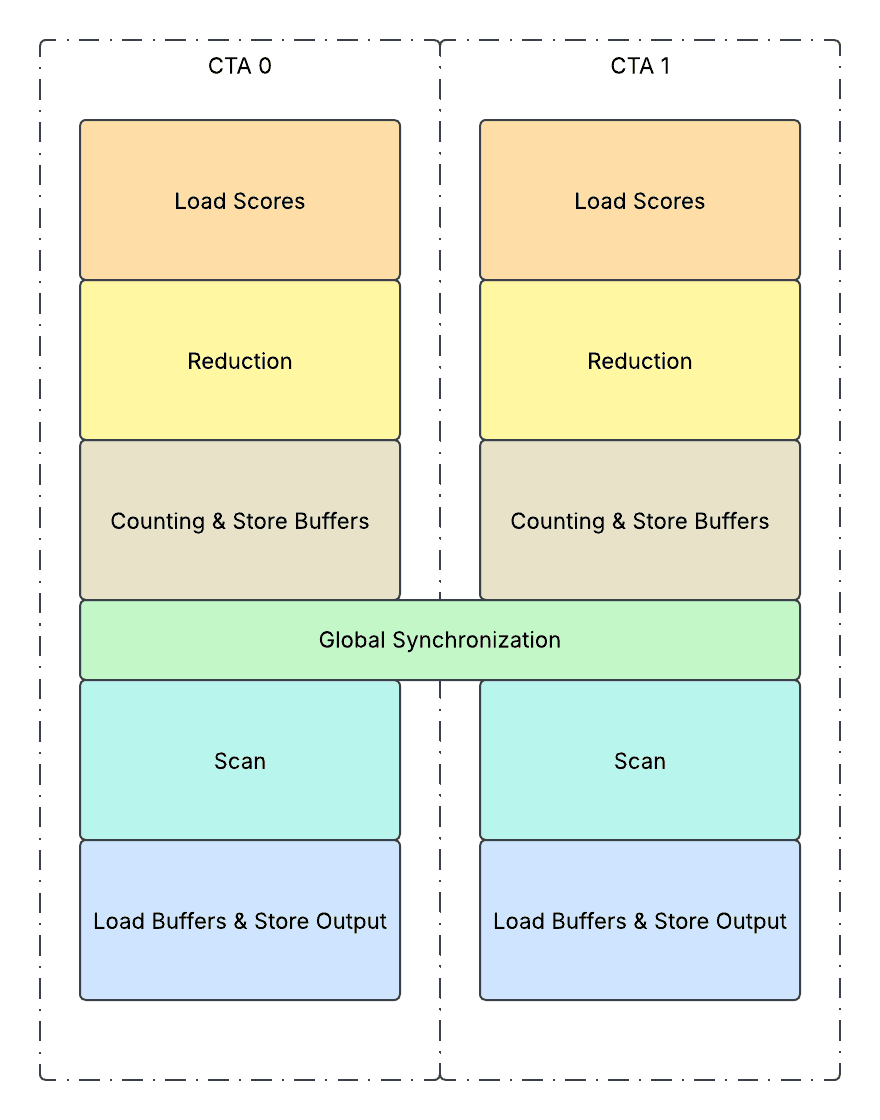
- 1. Load scores:
- It loads a tile of routing scores from global memory (HBM) to shared memory (SMEM) and stores associated expert indices along with it on SMEM.
- 2. Reduction:
- Performs TopK reduction on SMEM across E dimension. For Llama 4 use cases, it performs ArgMax sorting as Top1 reduction, which includes a 2D parallel tree reduction on the scores and associated expert indices on SMEM. Between different tree reduction phases,
- All threads will concurrently work on reductions of multiple tokens on SMEM.
- Each thread will sequentially work on reductions of multiple tokens on SMEM.
- 3. Counting & Store Buffers:
- It iterates all the tokens on the tile, getting the selected expert index from SMEM, storing it to the buffer (`buf_expert_index`) on HBM, and performs an `atomicAdd` operation on the output counter (`token_counts`) on HBM.
- The interesting part is, the `atomicAdd` operation will return the value previously on the memory location, which indicates the place of the token within the group, and we will store this value inside a buffer (`buf_local_token_index`) and use it to determine the global order among all the tokens.
- Repeat 1-3 iteratively until all the tokens assigned to the CTA are processed.
- 4. Global Synchronization:
- It performs an `atomicAdd` operation on the global counter on HBM. Afterwards, all CTAs will wait until the global counter reaches the number of total tokens, with a `st.release` + `ld.aquire` barrier guarding preceding store operations and following load operations to ensure correctness.
- 5. Scan:
- It performs a simple load and prefix sum of `token_counts` and transforms it into `token_counts_cumsums` on SMEM.
- 6. Load Buffer & Store Output:
- It iterates all the tokens assigned to this CTA. For each token, it loads the expert index the token is assigned to from `buf_expert_index`, and then figure out the new token index after shuffling as a sum of
- The number of tokens before it that belong to previous experts, using the SMEM tensor `token_counts_cumsums`.
- The number of tokens before it that belong to the same expert, using the HBM tensor `buf_local_token_index`.
- Afterwards, it simply does a direct store on `expert_indices` and `token_indices` output at the new token index after shuffling.
Performance
Example Kernel Performance
Our setup used H100 80GB SMX5 HBM3 700W SKUs, Python 3.12, and CUDA 12.8. The theoretical peak HBM memory bandwidth on a single H100 is 3.35 TB/s.
GroupedGEMM
Prefill Performance
The following table shows the prefill performance of the kernel on Llama 4 Scout and Maverick single host serving. The experiment setup assumes 16,384 total number of tokens and tensor parallelism sharding.
| Precision |
G |
M |
N |
K |
Time
(us)
|
Compute
(TFlops)
|
Memory
(GB/s)
|
| BF16 |
16 |
1,024 |
2,048 |
5,120 |
523.85 |
655.90 |
1,088.90 |
| BF16 |
16 |
1,024 |
5,120 |
1,024 |
294.95 |
582.46 |
1,251.39 |
| BF16 |
128 |
128 |
2,048 |
5,120 |
975.41 |
352.26 |
2,992.82 |
| BF16 |
128 |
128 |
5,120 |
1,024 |
510.78 |
336.35 |
3,021.86 |
| FP8 |
16 |
1,024 |
2,048 |
5,120 |
286.89 |
1,197.64 |
1,111.10 |
| FP8 |
16 |
1,024 |
5,120 |
1,024 |
182.41 |
941.83 |
1,471.62 |
| FP8 |
128 |
128 |
2,048 |
5,120 |
517.16 |
664.40 |
2,887.28 |
| FP8 |
128 |
128 |
5,120 |
1,024 |
290.25 |
591.90 |
2,947.93 |
Note: G indicates the number of groups. M indicates the number of tokens per group. N indicates the output feature dimension per group. K indicates the input feature dimension per group. FP8 indicates FP8 rowwise scaling (per-token scaling on activation and per-channel scaling on weight) with fast accumulation. Quantization kernels are not included in benchmarking. Scales are not included in memory bandwidth calculation. Benchmarked with rotating buffers and CUDAGraphs.
Decode Performance
The following table shows the decode performance of the kernel on Llama 4 Scout and Maverick single host serving. The experiment setup assumes 128 total number of tokens and tensor parallelism sharding.
| Precision |
G |
M |
N |
K |
Time
(us)
|
Compute
(TFlops)
|
Memory
(GB/s)
|
| BF16 |
16 |
8 |
2,048 |
5,120 |
112.54 |
23.85 |
2,997.82 |
| BF16 |
16 |
8 |
5,120 |
1,024 |
60.00 |
22.37 |
2,822.50 |
| BF16 |
128 |
1 |
2,048 |
5,120 |
861.22 |
3.12 |
3,119.07 |
| BF16 |
128 |
1 |
5,120 |
1,024 |
433.15 |
3.10 |
3,102.26 |
| FP8 |
16 |
8 |
2,048 |
5,120 |
59.81 |
44.88 |
2,824.60 |
| FP8 |
16 |
8 |
5,120 |
1,024 |
34.86 |
38.50 |
2,447.64 |
| FP8 |
128 |
1 |
2,048 |
5,120 |
440.53 |
6.09 |
3,049.44 |
| FP8 |
128 |
1 |
5,120 |
1,024 |
225.14 |
5.96 |
2,987.15 |
IndexShuffling
The following table shows the performance of the kernel on Llama 4 Scout and Maverick single-host serving, comparing against native PyTorch implementations.
| Num Tokens |
Num Experts |
IndexShuffling (us) |
Unfused Ops (us) |
Speedup |
| 128 |
16 |
5.08 |
36.71 |
722.53% |
| 128 |
128 |
8.95 |
34.36 |
384.05% |
| 2048 |
16 |
7.06 |
57.10 |
808.51% |
| 2048 |
128 |
13.53 |
69.84 |
516.18% |
| 4096 |
16 |
7.42 |
68.96 |
929.98% |
| 4096 |
128 |
18.89 |
87.46 |
463.09% |
| 8192 |
16 |
9.26 |
123.94 |
1339.16% |
| 8192 |
128 |
30.56 |
165.21 |
540.71% |
Note: Benchmarked with rotating buffers and CUDAGraphs.
Example Trace Analysis
Llama 4 Scout BF16 Decode
Here is an example decoding trace of Llama 4 Scout BF16 with 64 tokens using our MetaShuffling MoE inference solution.
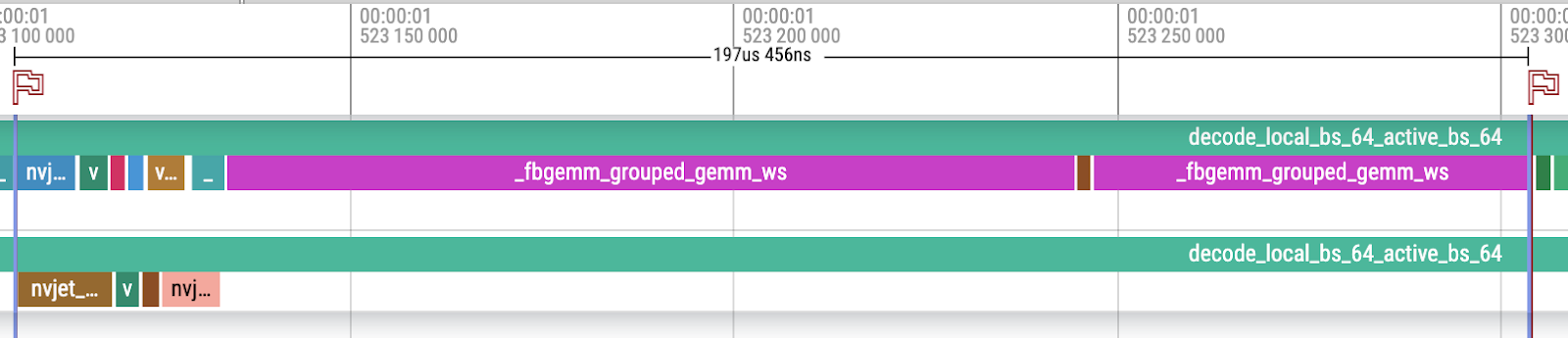
- The total memory traffic of MoE is (ignoring activations):
- Router: 5120x16x2 = 163,840 Bytes
- Shared Experts: (2048×5120 + 5120×1024)x2=31,457,280 Bytes
- Routed Experts: 16x(2048×5120 + 5120×1024)x2=503,316,480 Bytes
- Total combined: 163,840 + 31,457,280 + 503,316,480=534,937,600 Bytes
- The total execution time of MoE is 197.456usThe memory bandwidth achieved is 534,937,600 / (197.456 * 10^-6)=2,709,148,367,231 Bytes/s ~= 2.71 TB/s, which is 80.90% of the theoretical peak HBM memory bandwidth of H100 80GB SMX5 HBM3 as 3.35 TB/s.
Here is a breakdown of different components of the trace.

First is the breakdown of routing and shared experts. Both components are running concurrently on 2 different streams to achieve better resource utilization.
For the router stream (marked with red boxes):
- 1. Router GEMM: CuBLAS-based GEMM with a split-k design. It launches 2 kernels with the second kernel being the reduction kernel.
- 2. Sigmoid (Router Activation): PyTorch native sigmoid.
- 3. IndexShuffling: FBGEMM-based index shuffling with a cooperative kernel design. It can be viewed as a fusion of 3 operations, topk, bincount, and sort. It launches 2 kernels with the first kernel being the setup kernel.
- 4. GatherMul: FBGEMM-based gather scaling. It can be viewed as a fusion of 3 operations: gather (tokens), gather (scores), and mul operations.
For the shared expert stream (marked with orange boxes):
- 5. SharedExpert GEMM13: CuBLAS-based GEMM with a split-k design. It launches 2 kernels, with the second kernel being the reduction kernel.
- 6. SwiGLU: Fused SwiGLU. It can be viewed as a fusion of 2 operations, sigmoid and mul.
- 7. SharedExpert GEMM2: CuBLAS based GEMM.

Second is the breakdown of routed experts. This component is running exclusively on 1 stream to let the GroupedGEMM kernels take full ownership of all SMs.
For the routed expert stream (marked with red boxes):
- 8. RoutedExperts GroupedGEMM13: FBGEMM-based GroupedGEMM with a persistent kernel design.
- 9. SwiGLU: Fused SwiGLU. As mentioned in 6.
- 10. RoutedExperts GroupedGEMM2: FBGEMM-based GroupedGEMM with a persistent kernel design, fused with scatter add in the epilogue.
The decoding step is running on dense tensors with static shapes using CUDAGraph.
Llama 4 Maverick FP8 Prefill
Here is an example prefill trace of Llama 4 Maverick FP8 with 5000 tokens using our MetaShuffling MoE inference solution. Note FP8 rowwise scaling for routed experts, and BF16 for router and shared experts.

Compared to the decode trace:
- It uses a single stream to avoid interactions of kernels between router and shared experts. As the kernels are working on a large enough problem size that can saturate compute resources, having additional overlapping simply causes contentions, especially on L2 cache.
- It runs on dense tensors with static shapes, but in eager mode. As the kernel execution time is large enough and there is no device/host synchronization, the kernels can be launched back to back without bubbles.
Here we highlight the kernel difference between these two traces, except for execution time.
- Router GEMM and SharedExpertGEMM13: CuBLAS-based GEMM without using split-k design. So it launches 1 kernel instead of 2.
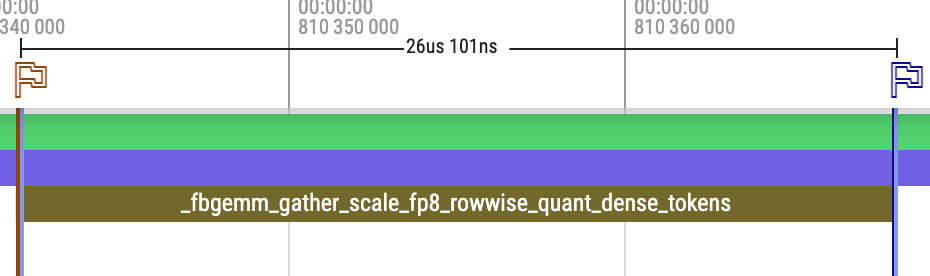
- 4. GatherMul (FP8 Rowwise Quantize): FBGEMM-based gather scaling and quantization. It can be viewed as a fusion of 8 operations: gather (tokens), gather (scores), mul, max, divide, mul, clamp, and typecast.
- 9. SwiGLU (FP8 Rowwise Quantize): Fused SwiGLU and quantization. It can be viewed as a fusion of 7 operations: sigmoid and mul, max, divide, mul, clamp, and typecast.

Takeaway
We take the following steps progressively to optimize the inference performance of our MoE solution:
-
- Improve device-level utilization by avoiding host and device synchronization.
- Reduce wasted resources by removing paddings or avoiding processing paddings.
- Reduce kernel launch and I/O overhead by aggressive kernel fusion.
- Improve computation and memory efficiency by various kernel optimizations, pushing performance towards hardware limits.
- Improve hardware component level utilization by concurrent execution of computation, memory traffic, or network traffic heavy kernels, but avoiding undesirable contention at the same time.
Single Host Serving
We benchmarked the single-host serving performance of Llama 4 Maverick and Llama 4 Scout with our internal MetaShuffling-based MoE inference stack using 1000 requests with random prompts. To compare against openly available data from vLLM and SGLang, we adopted the same experiment setup (i.e., Maverick with FP8, Scout with BF16, on a 8xH100 host with maximum batch size 64). Our setup used H100 80GB SMX5 HBM3 700W SKUs, Python 3.12, and CUDA 12.8. We open sourced all computation kernels used in the MetaShuffling MoE inference stack on FBGEMM and an example implementation of MetaShuffling as a reference.
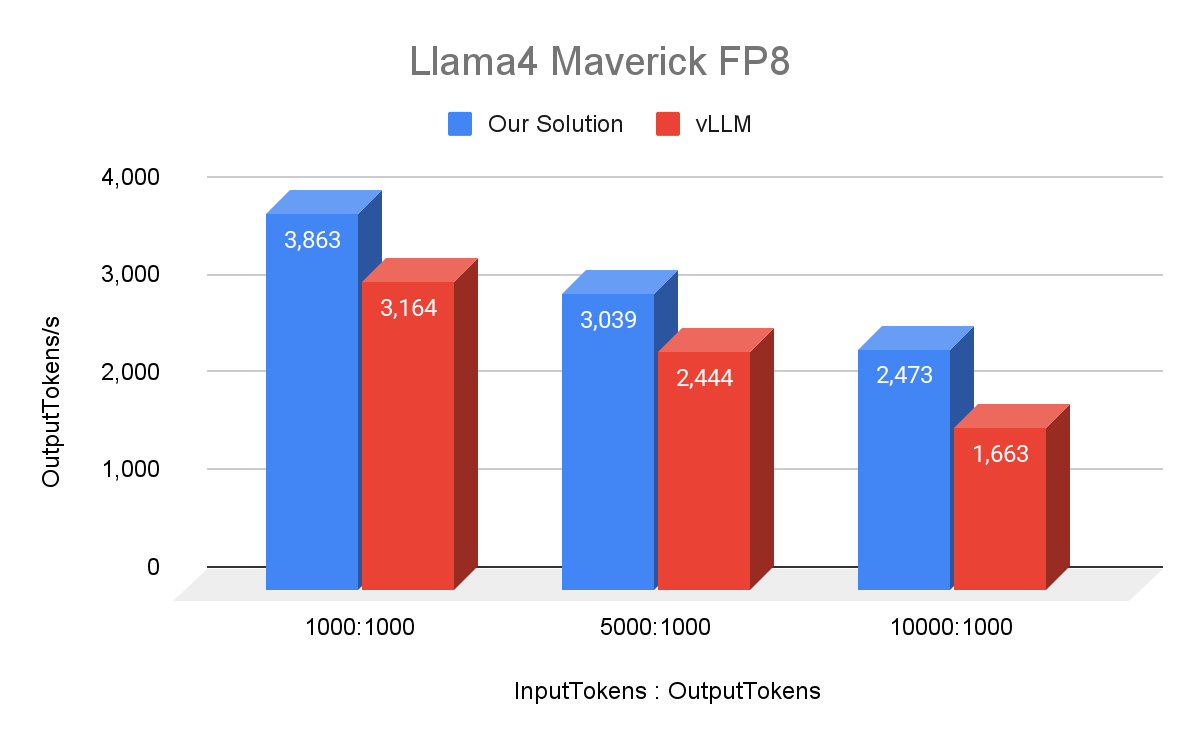
To keep the best accuracy, we benchmarked Llama 4 Maverick with FP8 precision on routed experts. BF16 precision on attention linear, attention, shared experts, router, and KV cache.
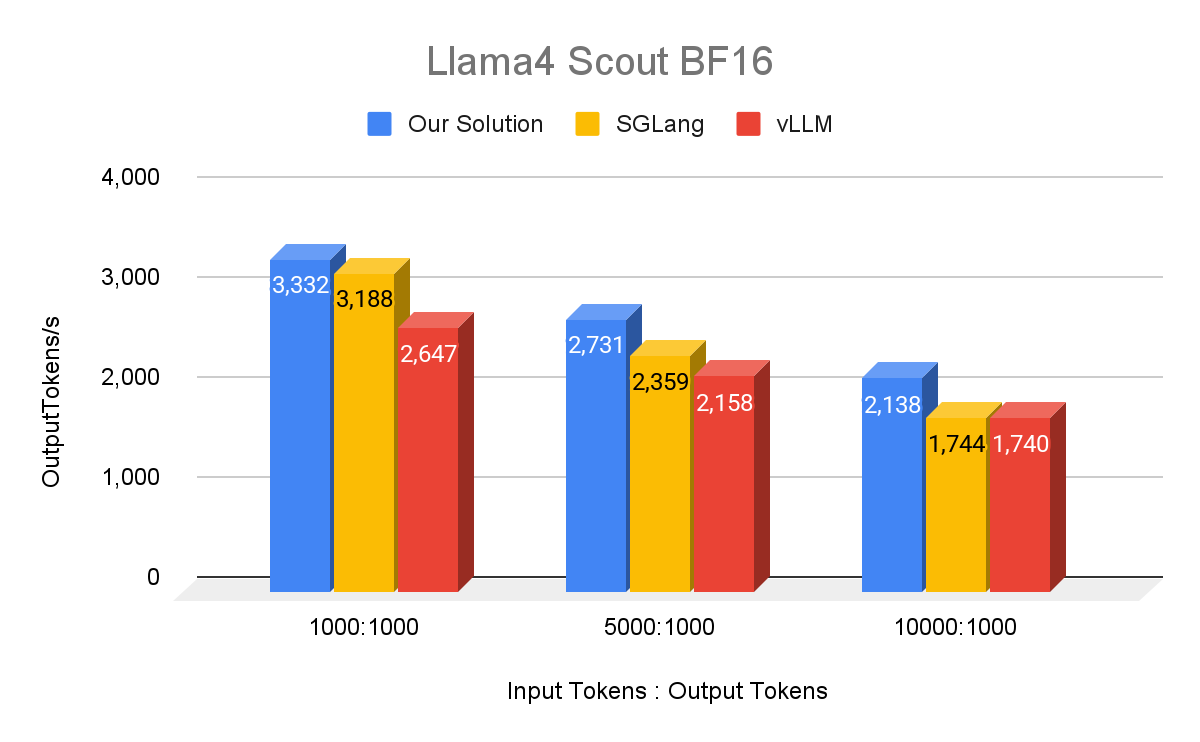
To match external benchmark numbers, we benchmarked Llama 4 Scout with BF16 precision on all linear layers (attention linear, shared experts, router, and routed experts), attention, and KV cache.
Disclaimer: Here we use datapoints released from official channels as a reference. However, as all inference frameworks are rapidly evolving, they might already be outdated at the time of publication. We hope the community can continuously break records in improving the efficiency of serving Llama 4 models.
Acknowledgement
We would like to thank Jing Zhang, Ying Zhang, and Manman Ren for providing technical review and guidance.
We would also like to thank Bradley Davis, Yan Cui, Rengan Xu, Josh Fromm, Jiawen Liu, Sarunya Pumma, Jie Wang, Xinfeng Xie, Benson Ma, Michael Shu, Bingzhe Liu, Jingyi Yang, Min Si, Pavan Balaji, Dhruva Kaushal. for contributions to this project.
Read More









 Learn more and register at
Learn more and register at












































 The AI Futures Fund is a new initiative from Google that invests in and works with startups.
The AI Futures Fund is a new initiative from Google that invests in and works with startups.










 Arghya Banerjee is a Sr. Solutions Architect at AWS in the San Francisco Bay Area, focused on helping customers adopt and use the AWS Cloud. He is focused on big data, data lakes, streaming and batch analytics services, and generative AI technologies.
Arghya Banerjee is a Sr. Solutions Architect at AWS in the San Francisco Bay Area, focused on helping customers adopt and use the AWS Cloud. He is focused on big data, data lakes, streaming and batch analytics services, and generative AI technologies. Dhara Vaishnav is Solution Architecture leader at AWS and provides technical advisory to enterprise customers to use cutting-edge technologies in generative AI, data, and analytics. She provides mentorship to solution architects to design scalable, secure, and cost-effective architectures that align with industry best practices and customers’ long-term goals.
Dhara Vaishnav is Solution Architecture leader at AWS and provides technical advisory to enterprise customers to use cutting-edge technologies in generative AI, data, and analytics. She provides mentorship to solution architects to design scalable, secure, and cost-effective architectures that align with industry best practices and customers’ long-term goals. Mayank Agrawal is a Senior Customer Solutions Manager at AWS in San Francisco, dedicated to maximizing enterprise cloud success through strategic transformation. With over 20 years in tech and a computer science background, he transforms businesses through strategic cloud adoption. His expertise in HR systems, digital transformation, and previous leadership at Accenture helps organizations across healthcare and professional services modernize their technology landscape.
Mayank Agrawal is a Senior Customer Solutions Manager at AWS in San Francisco, dedicated to maximizing enterprise cloud success through strategic transformation. With over 20 years in tech and a computer science background, he transforms businesses through strategic cloud adoption. His expertise in HR systems, digital transformation, and previous leadership at Accenture helps organizations across healthcare and professional services modernize their technology landscape. Namita Mathew is a Solutions Architect at AWS, where she works with enterprise ISV customers to build and innovate in the cloud. She is passionate about generative AI and IoT technologies and how to solve emerging business challenges.
Namita Mathew is a Solutions Architect at AWS, where she works with enterprise ISV customers to build and innovate in the cloud. She is passionate about generative AI and IoT technologies and how to solve emerging business challenges. Wesley Petry is a Solutions Architect based in the NYC area, specialized in serverless and edge computing. He is passionate about building and collaborating with customers to create innovative AWS-powered solutions that showcase the art of the possible. He frequently shares his expertise at trade shows and conferences, demonstrating solutions and inspiring others across industries.
Wesley Petry is a Solutions Architect based in the NYC area, specialized in serverless and edge computing. He is passionate about building and collaborating with customers to create innovative AWS-powered solutions that showcase the art of the possible. He frequently shares his expertise at trade shows and conferences, demonstrating solutions and inspiring others across industries.