 Google and Kaggle’s Gen AI Intensive course, had more than 280,000 signups in just 20 days.Read More
Google and Kaggle’s Gen AI Intensive course, had more than 280,000 signups in just 20 days.Read More

Google and Kaggle’s Gen AI Intensive course, had more than 280,000 signups in just 20 days.Read More


The PyTorch Foundation is proud to launch the PyTorch Ambassador Program, an initiative that recognizes and supports individuals who are passionate about building, educating, and advocating for PyTorch in impactful ways.
From organizing local events to mentoring new users, creating technical tutorials, and speaking at global conferences, PyTorch Ambassadors play a critical role in growing and supporting the global PyTorch ecosystem. The first official cohort of Ambassadors will launch in June 2025, with nominations open from May 7 to June 7, 2025.
The PyTorch Ambassador Program highlights independent, trusted voices in the PyTorch community. These leaders help others get started with PyTorch, contribute to the ecosystem, and promote its use across industry, academia, and research.
The program is designed to:
Ambassadors are active contributors who:
Ambassadors are expected to participate in at least one of these focus areas on a regular basis and commit to a one-year term.
The Ambassador Program provides a range of resources and opportunities to help community leaders make a lasting impact:
Nominations are open now through June 7, 2025. Individuals can nominate themselves or someone else. All applications will be reviewed by the PyTorch Foundation team, and selected Ambassadors will be invited to participate in onboarding and training sessions beginning in June.
To apply, visit the PyTorch Ambassador Program Application Page and click on the button that says Learn More and Apply.
To be eligible, nominees must:
Ambassador nominations will be evaluated on the following criteria:
The PyTorch Foundation is seeking Ambassadors from all regions to build a globally representative program. Nominees will be asked to share their location to help identify opportunities for regional engagement and support.
The inaugural cohort of PyTorch Ambassadors will be announced in June 2025. Their stories, events, and contributions will be featured on the PyTorch Foundation website and shared across community channels.
The PyTorch Ambassador Program is an exciting new chapter in our community’s growth. We invite you to join us in building an even more connected, inclusive, and global ecosystem.

May 09, 09:38 AMMay 09, 09:38 AM
This week, at Amazons Delivering the Future symposium in Dortmund, Germany, Amazon announced that its Vulcan robots, which stow items into and pick items from fabric storage pods in Amazon fulfillment centers (FCs), have completed a pilot trial and are ready to move into beta testing.

Amazon FCs already use robotic arms to retrieve packages and products from conveyor belts and open-topped bins. But a fabric pod is more like a set of cubbyholes, accessible only from the front, and the items in the individual cubbies are randomly assorted and stacked and held in place by elastic bands. Its nearly impossible to retrieve an item from a cubby or insert one into it without coming into physical contact with other items and the pod walls.
The Vulcan robots thus have end-of-arm tools grippers or suction tools equipped with sensors that measure force and torque along all six axes. Unlike the robot arms currently used in Amazon FCs, the Vulcan robots are designed to make contact with random objects in their work environments; the tool sensors enable them to gauge how much force they are exerting on those objects and to back off before the force becomes excessive.
A lot of traditional industrial automation think of welding robots or even the other Amazon manipulation projects are moving through free space, so the robot arms are either touching the top of a pile, or they’re not touching anything at all, says Aaron Parness, a director of applied science with Amazon Robotics, who leads the Vulcan project. Traditional industrial automation, going back to the 90s, is built around preventing contact, and the robots operate using only vision and knowledge of where their joints are in space.
What’s really new and unique and exciting is we are using a sense of touch in addition to vision. One of the examples I give is when you as a person pick up a coin off a table, you don’t command your fingers to go exactly to the specific point where you grab the coin. You actually touch the table first, and then you slide your fingers along the table until you contact the coin, and when you feel the coin, that’s your trigger to rotate the coin up into your grasp. You’re using contact both in the way you plan the motion and in the way you control the motion, and our robots are doing the same thing.
The Vulcan pilot involved six Vulcan Stow robots in an FC in Spokane, Washington; the beta trial will involve another 30 robots in the same facility, to be followed by an even larger deployment at a facility in Germany, with Vulcan Stow and Vulcan Pick working together.
Vulcan Stow
When new items arrive at an FC, they are stowed in fabric pods at a stowing station; when a customer places an order, the corresponding items are picked from pods at a picking station. Autonomous robots carry the pods between the FCs storage area and the stations. Picked items are sorted into totes and sent downstream for packaging.

The allocation of items to pods and pod shelves is fairly random. This may seem counterintuitive, but in fact it maximizes the efficiency of the picking and stowing operations. An FC might have 250 stowing stations and 100 picking stations. Random assortment minimizes the likelihood that any two picking or stowing stations will require the same pod at the same time.
To reach the top shelves of a pod, a human worker needs to climb a stepladder. The plan is for the Vulcan robots to handle the majority of stow and pick operations on the highest and lowest shelves, while humans will focus on the middle shelves and on more challenging operations involving densely packed bins or items, such as fluid containers, that require careful handling.
The Vulcan robots’ main hardware innovation is the end-of-arm tools (EOATs) they use to perform their specialized tasks.
The pick robots EOAT is a suction device. It also has a depth camera to provide real-time feedback on the way in which the contents of the bin have shifted in response to the pick operation.

The stow EOAT is a gripper with two parallel plates that sandwich the item to be stowed. Each plate has a conveyer belt built in, and after the gripper moves into position, it remains stationary as the conveyer belts slide the item into position. The stow EOAT also has an extensible aluminum attachment thats rather like a kitchen spatula, which it uses to move items in the bin aside to make space for the item being stowed.

Both the pick and stow robots have a second arm whose EOAT is a hook, which is used to pull down or push up the elastic bands covering the front of the storage bin.

As a prelude to the stow operation, the stow robots EOAT receives an item from a conveyor belt. The width of the gripper opening is based on a computer vision system’s inference of the item’s dimensions.

The stow system has three pairs of stereo cameras mounted on a tower, and their redundant stereo imaging allows it to build up a precise 3-D model of the pod and its contents.
At the beginning of a stow operation, the robot must identify a pod bin with enough space for the item to be stowed. A pods elastic bands can make imaging the items in each bin difficult, so the stow robots imaging algorithm was trained on synthetic bin images in which elastic bands were added by a generative-AI model.
The imaging algorithm uses three different deep-learning models to segment the bin image in three different ways: one model segments the elastic bands; one model segments the bins; and the third segments the objects inside the bands. These segments are then projected onto a three-dimensional point cloud captured by the stereo cameras to produce a composite 3-D segmentation of the bin.

The stow algorithm then computes bounding boxes indicating the free space in each bin. If the sum of the free-space measurements for a particular bin is adequate for the item to be stowed, the algorithm selects the bin for insertion. If the bounding boxes are non-contiguous, the stow robot will push items to the side to free up space.
The algorithm uses convolution to identify space in a 2-D image in which an item can be inserted: that is, it steps through the image applying the same kernel which represents the space necessary for an insertion to successive blocks of pixels until it finds a match. It then projects the convolved 2-D image onto the 3-D model, and a machine learning model generates a set of affordances indicating where the item can be inserted and, if necessary, where the EOATs extensible blade can be inserted to move objects in the bin to the side.
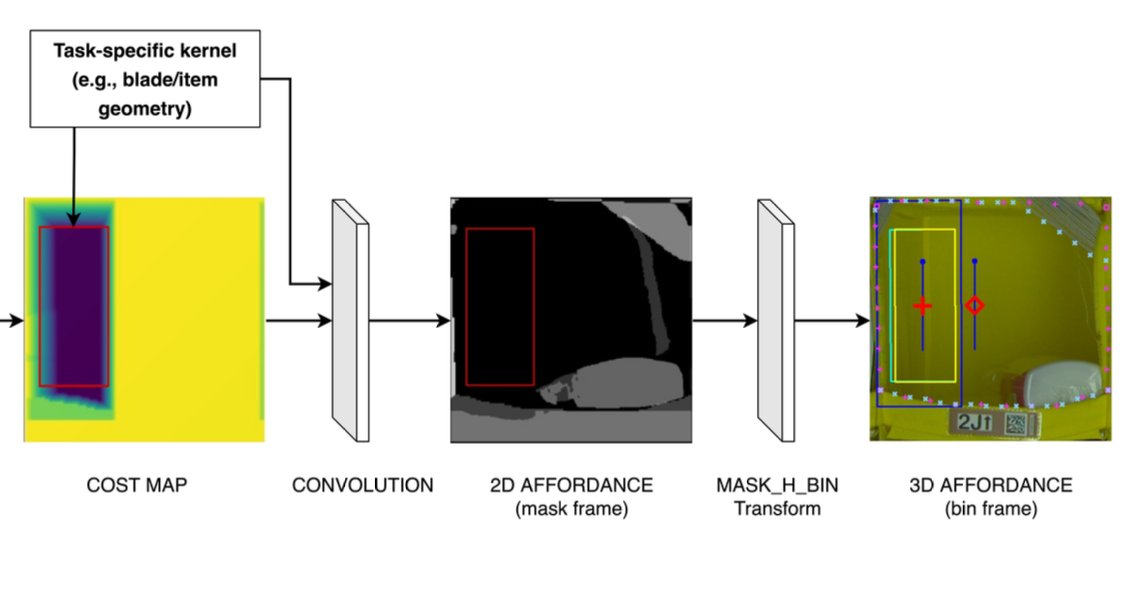
Based on the affordances, the stow algorithm then strings together a set of control primitives such as approach, extend blade, sweep, and eject_item to execute the stow. If necessary, the robot can insert the blade horizontally and rotate an object 90 degrees to clear space for an insertion.
It’s not just about creating a world model, Parness explains. It’s not just about doing 3-D perception and saying, Here’s where everything is. Because we’re interacting with the scene, we have to predict how that pile of objects will shift if we sweep them over to the side. And we have to think about like the physics of If I collide with this T-shirt, is it going to be squishy, or is it going to be rigid? Or if I try and push on this bowling ball, am I going to have to use a lot of force? Versus a set of ping pong balls, where I’m not going to have to use a lot of force. That reasoning layer is also kind of unique.
The first step in executing a pick operation is determining bin contents eligibility for robotic extraction: if a target object is obstructed by too many other objects in the bin, its passed to human pickers. The eligibility check is based on images captured by the FCs existing imaging systems and augmented with metadata about the bins contents, which helps the imaging algorithm segment the bin contents.

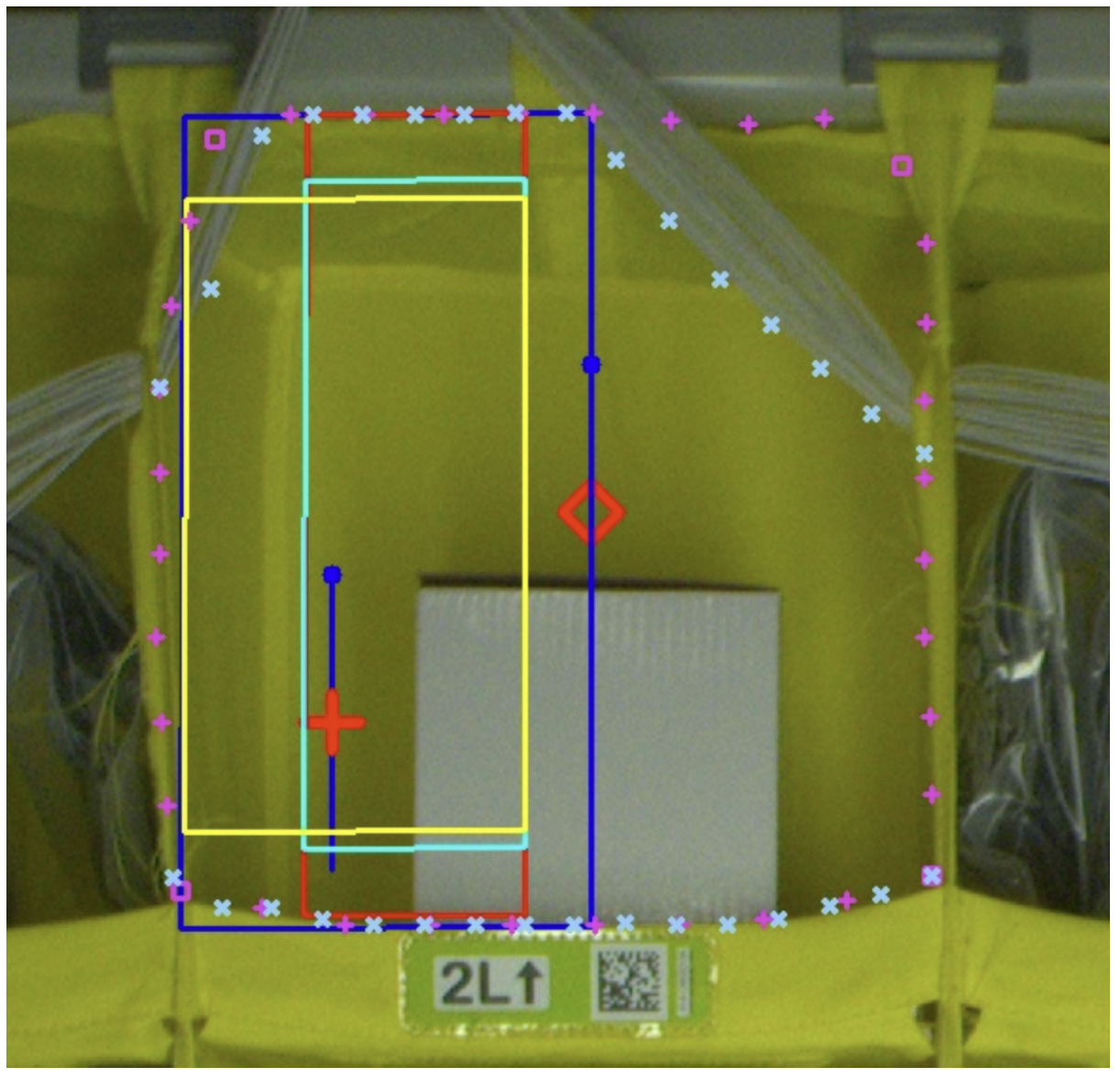
The pick operation itself uses the EOATs built-in camera, which uses structured light an infrared pattern projected across the objects in the cameras field of view to gauge depth. Like the stow operation, the pick operation begins by segmenting the image, but the segmentation is performed by a single MaskDINO neural model. Parnesss team, however, added an extra layer to the MaskDINO model, which classifies the segmented objects into four categories: (1) not an item (e.g., elastic bands or metal bars), (2) an item in good status (not obstructed), (3) an item below others, or (4) an item blocked by others.
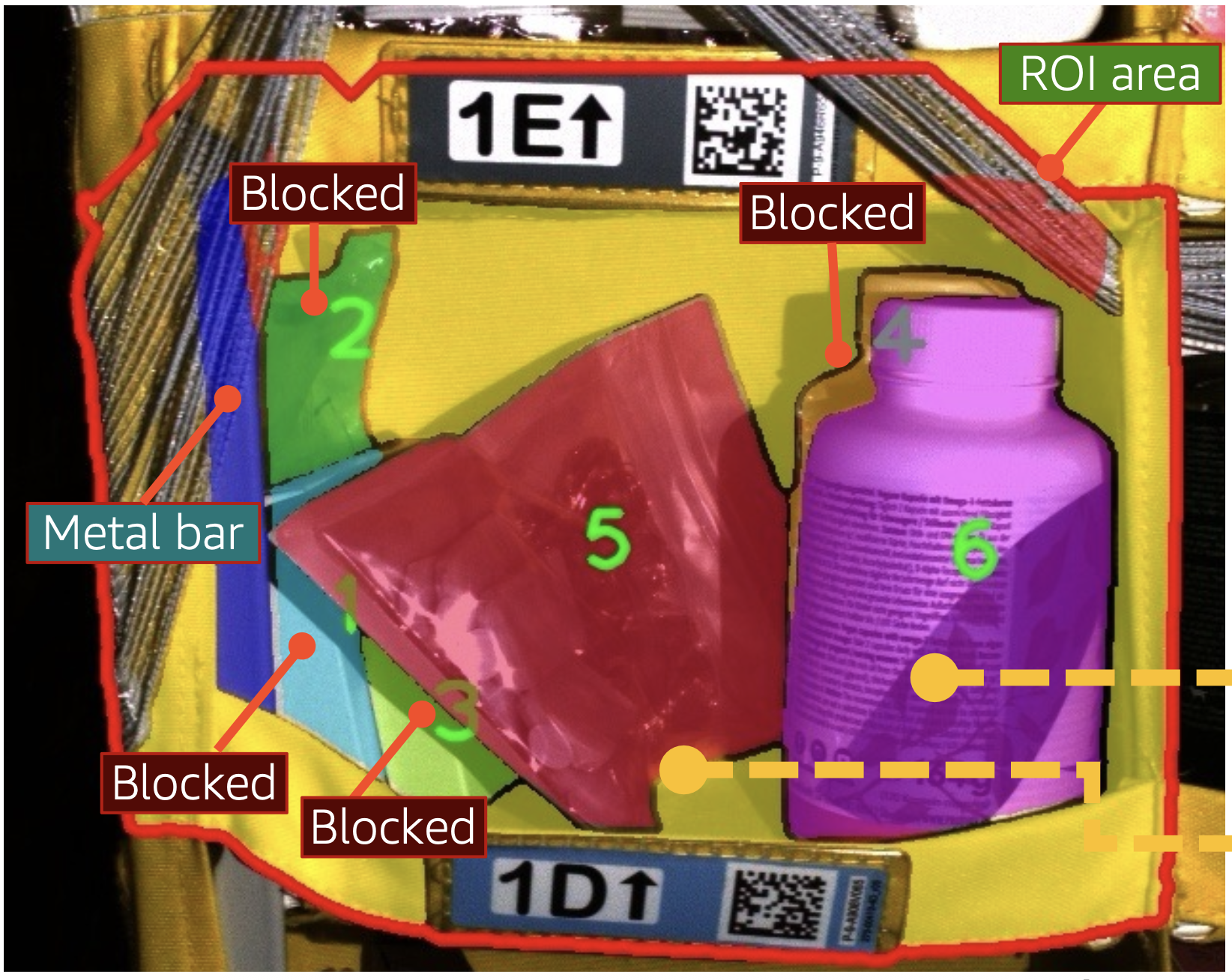
Like the stow algorithm, the pick algorithm projects the segmented image onto a point cloud indicating the depths of objects in the scene. The algorithm also uses a signed distance function to characterize the three-dimensional scene: free space at the front of a bin is represented with positive distance values, and occupied space behind a segmented surface is represented with negative distance values.
Next without scanning barcodes the algorithm must identify the object to be picked. Since the products in Amazons catalogue are constantly changing, and the lighting conditions under which objects are imaged can vary widely, the object identification compares target images on the fly to sample product images captured during other FC operations.
The product-matching model is trained through contrastive learning: its fed pairs of images, either same product photographed from different angles and under different lighting conditions, or two different products; it learns to minimize the distance between representations of the same object in the representational space and to maximize the distance between representations of different objects. It thus becomes a general-purpose product matcher.

Using the 3-D composite, the algorithm identifies relatively flat surfaces of the target item that promise good adhesion points for the suction tool. Candidate surfaces are then ranked according to the signed distances of the regions around them, which indicate the likelihood of collisions during extraction.
Finally, the suction tool is deployed to affix itself to the highest-ranked candidate surface. During the extraction procedure, the suction pressure is monitored to ensure a secure hold, and the camera captures 10 low-res images per second to ensure that the extraction procedure hasnt changed the geometry of the bin. If the initial pick point fails, the robot tries one of the other highly ranked candidates. In the event of too many failures, it passes the object on for human extraction.
I really think of this as a new paradigm for robotic manipulation, Parness says. Getting out of the I can only move through free space or Touch the thing that’s on the top of the pile to the new paradigm where I can handle all different kinds of items, and I can dig around and find the toy that’s at the bottom of the toy chest, or I can handle groceries and pack groceries that are fragile in a bag. I think there’s maybe 20 years of applications for this force-in-the-loop, high-contact style of manipulation.
For more information about the Vulcan Pick and Stow robots, see the associated research papers: Pick | Stow.
Research areas: Robotics
Tags: Robotic manipulation , Human-robot interaction , Autonomous robotics
We present Matrix3D, a unified model that performs several photogrammetry subtasks, including pose estimation, depth prediction, and novel view synthesis using just the same model. Matrix3D utilizes a multi-modal diffusion transformer (DiT) to integrate transformations across several modalities, such as images, camera parameters, and depth maps. The key to Matrix3D’s large-scale multi-modal training lies in the incorporation of a mask learning strategy. This enables full-modality model training even with partially complete data, such as bi-modality data of image-pose and image-depth pairs…Apple Machine Learning Research

 Google Research teams are using AI to address fundamental scientific questions and advance research across disciplines from quantum computing to genomics and neuroscienc…Read More
Google Research teams are using AI to address fundamental scientific questions and advance research across disciplines from quantum computing to genomics and neuroscienc…Read More

Artificial intelligence is helping identify and treat diseases faster with better results for humankind. Natural disasters like wildfires are next.
Fires in the Los Angeles area have claimed more than 16,000 homes and other structures so far this year. Damages in January were estimated as high as $164 billion, making it potentially the worst natural disaster financially in U.S. history, according to Bloomberg.
The U.S. Department of Agriculture and the U.S. Forest Service have reportedly been redirecting resources in recent months toward beneficial fires to reduce overgrowth.
AI enables fire departments to keep more eyes on controlled burns, making them safer and more accepted in communities, say industry experts.
“This is just like cancer treatment,” said Sonia Kastner, CEO and founder of Pano AI, based in San Francisco. “You can do early screening, catch it when it’s in phase one, and hit it with really aggressive treatment so it doesn’t progress — what we’ve seen this fire season is proof that our customers across the country use our solution in this way.”
San Ramon, California-based Green Grid, which specializes in AI for utility companies, in September alerted its customer at a Big Bear resort that a fire started in the San Bernardino National Forest was near, said Chinmoy Saha, the company’s CEO. By acting early, the resort customer was able to prepare for the needed suppression measures for the fire before it reached and became uncontrollable, he said. Due to the favorable weather conditions, the fire did not reach the customer territory.
In the recent Los Angeles area fires, Saha said he had been in discussion with a customer seeking to bring AI to cameras located at the site of the now-devasted Eaton fire that has claimed 17 lives and more than 9,000 buildings.
“If we had our system there, this fire could have been mitigated,” said Saha. “Early detection is the key, so the fire is contained and it doesn’t become a catastrophic wildfire.”
Pano’s service provides human-in-the-loop AI-driven fire detection and alerts that have enabled fire departments to act faster than from 911 calls, accelerating containment efforts, said Kastner.
The company’s Pano Station uses two ultra-high-definition cameras mounted on top of mountains like a cell tower, rotating 360 degrees every minute to capture views 10 miles in all directions. Those images are transmitted to the cloud every minute, where AI models running on GPUs do inference for smoke detection.

Pano has a daytime smoke detection model and a nighttime near infrared model looking for smoke, as well as a nighttime geostationary satellite model. It has a human in the loop for verifying the detections, and it can be confirmed using digital zoom and time-lapse imagery.
It trains on NVIDIA GPUs locally and runs inference on NVIDIA GPUs in the cloud.
California Department of Forestry and Fire Protection (CAL FIRE) is carrying out prescribed fires, or controlled burns, to reduce dry vegetation that creates fuel for wildfires.
“Controlled burns are necessary, and we didn’t do a good job in California for the past 30 or 40 years,” said Saha. Green Grid has deployed its trailer mounted AI camera sensors for monitoring fires and control burns before they go out of control.
Pano can be used by fire departments to monitor controlled burn zones with its AI-driven cameras to make sure that plumes of smoke don’t appear outside of the permitted zone, maintaining safety.
The company has its cameras stationed at Rancho Palos Verdes, south of the recent Los Angeles area fires.
“The area around the palisades fire was a very overgrown forest, and with a lot of dead fuels, so our hope is that there is going to be more focus on prescribed fires,” said Kastner.
CAL FIRE is partnered with Alert California and UC San Diego for a network of cameras owned by investor-owned utilities, CAL FIRE, U.S. Forest Service and other U.S. Department of the Interior agencies.
Through that network, they’ve implemented an AI program that looks for new fire starts. It pans every two minutes and continuously updates, and Alert California has the most up-to-date information from this network.
If AI can enable fire departments to get to the scene of a fire when it’s just a few acres, it’s a lot easier to control than if it’s 50 or more acres, said David Acuna, battalion chief at CAL FIRE, Clovis, California. This is particularly important in remote areas where it might take hours before a human sees and reports a fire, he added.
“They use AI to determine if this looks like a new start,” said Acuna. “Now the key here is the program will then send an email to the relevant emergency command center, saying ‘Hey, I think we spotted a new start, what do you think?’ And it has to be verified by a human.”


Members of the research community at Microsoft work continuously to advance their respective fields. Abstracts bring its audience to the cutting edge with them through short, compelling conversations about new and noteworthy achievements.
In this episode, senior researcher Hongxia Hao (opens in new tab), and physics professor Bing Lv (opens in new tab), join host Gretchen Huizinga to talk about how they are using deep learning techniques to probe the upper limits of heat transfer in inorganic crystals, discover novel materials with exceptional thermal conductivity, and rewrite the rulebook for designing high-efficiency electronics and sustainable energy.
GRETCHEN HUIZINGA: Welcome to Abstracts, a Microsoft Research Podcast that puts the spotlight on world-class research in brief. I’m Gretchen Huizinga. In this series, members of the research community at Microsoft give us a quick snapshot – or a podcast abstract – of their new and noteworthy papers.
Today I’m talking to two researchers, Hongxia Hao, a senior researcher at Microsoft Research AI for Science, and Bing Lv, an associate professor in physics at the University of Texas at Dallas. Hongxia and Bing are co-authors of a paper called Probing the Limit of Heat Transfer in Inorganic Crystals with Deep Learning. I’m excited to learn more about this! Hongxia and Bing, it’s great to have you both on Abstracts!
HONGXIA HAO: Nice to be here.
BING LV: Nice to be here, too.
HUIZINGA: So Hongxia, let’s start with you and a brief overview of this paper. In just a few sentences. Tell us about the problem your research addresses and more importantly, why we should care about it.
HAO: Let me start with a very simple yet profound question. What’s the fastest the heat can travel through a solid material? This is not just an academic curiosity, but it’s a question that touched the bottom of how we build technologies around us. So from the moment when you tap your smartphone, and the moment where the laptop is turned on and functioning, heat is always flowing. So we’re trying to answer the question of a century-old mystery of the upper limit of heat transfer in solids. So we care about this not just because it’s a fundamental problem in physics and material science, but because solving it could really rewrite the rulebook for designing high-efficiency electronics and sustainable energy, etc. And nowadays, with very cutting-edge nanometer chips or very fancy technologies, we are packing more computing power into smaller space, but the faster and denser we build, the harder it becomes to remove the heat. So in many ways, thermal bottlenecks, not just transistor density, are now the ceiling of the Moore’s Law. And also the stakes are very enormous. We really wish to bring more thermal solutions by finding more high thermal conductor choices from the perspective of materials discovery with the help of AI.
LV: So I think one of the biggest things as Hongxia said, right? Thermal solutions will become, eventually become, a bottleneck for all type of heterogeneous integration of the materials. So from this perspective, so how people actually have been finding out previously, all the thermal was the last solution to solve. But now people actually more and more realize all these things have to be upfront. This co-design, all these things become very important. So I think what we are doing right now, integrated with AI, helping to identify the large space of the materials, identify fundamentally what will be the limit of this material, will become very important for the society.
HUIZINGA: Hmm. Yeah. Hongxia, did you have anything to add to that?
HAO: Yes, so previously many people are working on exploring these material science questions through experimental tradition and the past few decades people see a new trend using computational materials discovery. Like for example, we do the fundamental solving of the Schrödinger equation using Density Functional Theory [DFT]. Actually, this brings us a lot of opportunities. The question here is, as the theory is getting more and more developed, it’s too expensive for us to make it very large scale and to study tons of materials. Think about this. The bottleneck here, now, is not just about having a very good theory, it’s about the scale. So, this is where AI, specifically now we are using deep learning, comes into play.
HUIZINGA: Well, Hongxia, let’s stay with you for a minute and talk about methodology. How did you do this research and what was the methodology you employed?
HAO: So here we, for this question, we built a pipeline that spans the AI, the quantum mechanics, and computational brute-force with a blend of efficiency and accuracy. It begins with generating an enormous chemical and structure design space because this is inspired by Slack’s principle. We focus first on simple crystals, and there are the systems most likely to have low and harmonious state, fewer phononic scattering events, and therefore potentially have high thermal conductivities. But we didn’t stop here. We also included a huge pool of more complex and higher energy structures to ensure diversity and avoid bias. And for each candidate, we first run like a structure relaxation using MatterSim, which is a deep learning foundational model for material science for us to characterize the properties of materials. And we use that screen for dynamic stability. And now it’s about 200K structures past this filter. And then came another real challenge: calculating the thermal conductivity. We try to solve this problem using the Boltzmann transport equation and the three-phonon scattering process. The twist here is all of this was not done by traditional DFT solvers, but with our deep learning model, the MatterSim. It’s trained to predict energy, force, and stress. And we can get second- and third-order interatomic force constants directly from here, which can guarantee the accuracy of the solution. And finally, to validate the model’s predictions, we performed full DFT-based calculations on the top candidates that we found, some of which even include higher-order scattering mechanism, electron phonon coupling effect, etc. And this rigorous validation gave us confidence in the speed and accuracy trade-offs and revealed a spectrum of materials that had either previously been overlooked or were never before conceived.
HUIZINGA: So Bing, let’s talk about your research findings. How did things work out for you on this project and what did you find?
LV: I think one of the biggest things for this paper is it creates a very large material base. Basically, you can say it’s a smart database which eventually will be made accessible to the public. I think that’s a big achievement because people who actually if they have to look into it, they actually can go search Microsoft database, finding out, oh, this material does have this type of thermal properties. This is actually, this database can send about 230,000 materials. And one of the things we confirm is the highest thermal conductivity material based on all the wisdom of Slack criteria, predicted diamond would have the highest thermal conductivity. We more or less really very solidly prove diamond, at this stage, will remain with the highest thermal conductivity. We have a lot of new materials, exotic materials, which some of them, Hongxia can elaborate a little bit more. So, which having all this very exotic combination of properties, thermal with other properties, which could actually provide a new insight for new physics development, new material development, and a new device perspective. All of this combined will have actually a very profound impact to society.
HUIZINGA: Yeah, Hongxia, go a little deeper on that because that was an interesting part of the paper when you talked about diamond still being the sort of “gold standard,” to mix metaphors! But you’ve also found some other materials that are remarkable compared to silicon.
HAO: Yeah, yeah. Among this search space, even though we didn’t find like something that’s higher than diamonds, but we do discover more than like twenty new materials with thermal conductivity exceeding that of silicon. And silicon is something like a benchmark for criteria that we think we want to compare with because it’s a backbone of modern electronics. More interestingly, I think, is the manganese vanadium. It shows some very interesting and surprising phenomena. Like it’s a metallic compound, but with very high lattice thermal connectivity. And this is the first time discovered by, like, through our search pattern, and it’s something that cannot be easily discovered without the hope with AI. And right now, think Bing can explain more on this, and show some interesting results.
HUIZINGA: Yeah, go ahead Bing.
LV: So this is actually very surprising to me as an experimentalist because of when Hongxia presented their theory work to me, this material, magnesium vanadium, it’s discovered back in 1938, almost 100 years ago, but there’s no more than twenty papers talking about this! A lot of them was on theory, okay, not even on experimental part. We actually did quite a bit of work on this. We actually are in the process; will characterize this and then moving forward even for the thermal conductivity measurements. So that will be hopefully, will be adding to the value of these things, showing you, Hey, AI does help to predict the materials could really generate the new materials with very good high thermal conductivity.
HUIZINGA: Yeah, so Bing, stay with you for a minute. I want you to talk about some kind of real-world applications of this. I know you alluded to a couple of things, but how is this work significant in that respect, and who might be most excited about it, aside from the two of you? [LAUGHS]
LV: So I think as I mentioned before, the first thing is this database. I believe that’s the first ever large material database regarding to the thermal conductivity. And it has, as I said, 230,000 materials with AI-predicted thermal connectivity. This will provide not only science but engineering with a vastly expanding catalog of candidate materials for the future roadmap of integration, material integration, and all these bottlenecks we are talking about, the thermal solution for the semiconductors or for even beyond the semiconductor integration, people actually can have a database to looking for. So these things, it will become very important, and I believe over a long time it will generate a very long impact for the research community, for the society development.
HUIZINGA: Yeah. Hongxia, did you have anything to add to that one too?
HAO: Yeah, so this study reshapes how we think about limits. I like the sentence that the only way to discover the limits of possible is to go beyond them into the impossible. In this case, we tried, but we didn’t break the diamond limit. But we proved it even more rigorously than ever before. In doing so, we also uncovered some uncharted peaks in the thermal conductivity landscape. This would not happen without new AI capabilities for material science. I think in the long run, I believe researchers could benefit from using this AI design and shift their way on how to do materials research with AI.
HUIZINGA: Yeah, it’ll be interesting to see if anyone ever does break the diamond limit with the new tools that are available, but…
HAO: Yeah!
HUIZINGA: So this is the part of the abstracts podcast where I like to ask for sort of a golden nugget, a one sentence takeaway that listeners might get from this paper. If you had one Hongxia, what would it be? And then I’ll ask Bing to maybe give his.
HAO: Yes. AI is no longer just a tool. It’s becoming a critical partner for us in scientific discovery. So our work proved that the large-scale data-driven science can now approach long-standing and fundamental questions with very fresh eyes. When trained well, and guided with physical intuition, models like MatterSim can really realize a full in-silico characterization for materials and don’t just simulate some known materials, but really trying to imagine what nature hasn’t yet revealed. Our work points to a path forward, not just incrementally better materials, but entirely new class of high-performance compounds where we could never have guessed without AI.
HUIZINGA: Yeah. Bing, what’s your one takeaway?
LV: I think I want to add a few things on top of Hongxia’s comments because I think Hongxia has very good critical words I would like to emphasize. When we train the AI well, if we guide the AI well, it could be very useful to become our partner. So I think all in all, our human being’s intellectual merit here is still going to play a significantly important role, okay? We are generating this AI, we should really train the AI, we should be using our human being intellectual merit to guide them to be useful for our human being society advancement. Now with all these AI tools, I think it’s a very golden time right now. Experimentalists could work very closely with like Hongxia, who’s a good theorist who has very good intellectual merits, and then we actually now incorporate with AI, then combine all pieces together, hopefully we’re really able to accelerating material discovery in a much faster pace than ever which the whole society will eventually get a benefit from it.
HUIZINGA: Yeah. Well, as we close, Bing, I want you to go a little further and talk about what’s next then, research wise. What are the open questions or outstanding challenges that remain in this field and what’s on your research agenda to address them?
LV: So first of all, I think this paper is addressing primarily on these crystalline ordered inorganic bulk materials. And also with the condition we are targeting at ambient pressure, room temperature, because that’s normally how the instrument is working, right? But what if under extreme conditions? We want to go to space, right? There we’ll have extreme conditions, some very… sometimes very cold, sometimes very hot. We have some places with extremely probably quite high pressure. Or we have some conditions that are highly radioactive. So under that condition, there’s going to be a new database could be emerged. Can we do something beyond that? Another good important thing is we are targeting this paper on high thermal conductivity. What about extremely low thermal conductivity? Those will actually bring a very good challenge for theorists and also the machine learning approach. I think that’s something Hongxia probably is very excited to work on in that direction. I know since she’s ambitious, she wants to do something more than beyond what we actually achieved so far.
HUIZINGA: Yeah, so Hongxia, how would you encapsulate what your dream research is next?
HAO: Yeah, so I think besides all of these exciting research directions, on my end, another direction is perhaps kind of exciting is we want to move from search to design. So right now we are kind of good at asking like what exists by just doing a forward prediction and brute force. But with generative AI, we can start asking what should exist? In the future, we can have an incorporation between forward prediction and backwards generative design to really tackle questions. If you have materials like you want to have desired like properties, how would you design the problems?
HUIZINGA: Well, it sounds like there’s a full plate of research agenda goodness going forward in this field, both with human brains and AI. So, Hongxia Hao and Bing Lv, thanks for joining us today. And to our listeners, thanks for tuning in. If you want to read this paper, you can find a link at aka.ms/Abstracts, or you can read a pre-print of it on arXiv. See you next time on Abstracts!
The post Abstracts: Heat Transfer and Deep Learning with Hongxia Hao and Bing Lv appeared first on Microsoft Research.
As AI use cases continue to expand — from document summarization to custom software agents — developers and enthusiasts are seeking faster, more flexible ways to run large language models (LLMs).
Running models locally on PCs with NVIDIA GeForce RTX GPUs enables high-performance inference, enhanced data privacy and full control over AI deployment and integration. Tools like LM Studio — free to try — make this possible, giving users an easy way to explore and build with LLMs on their own hardware.
LM Studio has become one of the most widely adopted tools for local LLM inference. Built on the high-performance llama.cpp runtime, the app allows models to run entirely offline and can also serve as OpenAI-compatible application programming interface (API) endpoints for integration into custom workflows.
The release of LM Studio 0.3.15 brings improved performance for RTX GPUs thanks to CUDA 12.8, significantly improving model load and response times. The update also introduces new developer-focused features, including enhanced tool use via the “tool_choice” parameter and a redesigned system prompt editor.
The latest improvements to LM Studio improve its performance and usability — delivering the highest throughput yet on RTX AI PCs. This means faster responses, snappier interactions and better tools for building and integrating AI locally.
LM Studio is built for flexibility — suited for both casual experimentation or full integration into custom workflows. Users can interact with models through a desktop chat interface or enable developer mode to serve OpenAI-compatible API endpoints. This makes it easy to connect local LLMs to workflows in apps like VS Code or bespoke desktop agents.
For example, LM Studio can be integrated with Obsidian, a popular markdown-based knowledge management app. Using community-developed plug-ins like Text Generator and Smart Connections, users can generate content, summarize research and query their own notes — all powered by local LLMs running through LM Studio. These plug-ins connect directly to LM Studio’s local server, enabling fast, private AI interactions without relying on the cloud.
The 0.3.15 update adds new developer capabilities, including more granular control over tool use via the “tool_choice” parameter and an upgraded system prompt editor for handling longer or more complex prompts.
The tool_choice parameter lets developers control how models engage with external tools — whether by forcing a tool call, disabling it entirely or allowing the model to decide dynamically. This added flexibility is especially valuable for building structured interactions, retrieval-augmented generation (RAG) workflows or agent pipelines. Together, these updates enhance both experimentation and production use cases for developers building with LLMs.
LM Studio supports a broad range of open models — including Gemma, Llama 3, Mistral and Orca — and a variety of quantization formats, from 4-bit to full precision.
Common use cases span RAG, multi-turn chat with long context windows, document-based Q&A and local agent pipelines. And by using local inference servers powered by the NVIDIA RTX-accelerated llama.cpp software library, users on RTX AI PCs can integrate local LLMs with ease.
Whether optimizing for efficiency on a compact RTX-powered system or maximizing throughput on a high-performance desktop, LM Studio delivers full control, speed and privacy — all on RTX.
At the core of LM Studio’s acceleration is llama.cpp — an open-source runtime designed for efficient inference on consumer hardware. NVIDIA partnered with the LM Studio and llama.cpp communities to integrate several enhancements to maximize RTX GPU performance.
Key optimizations include:
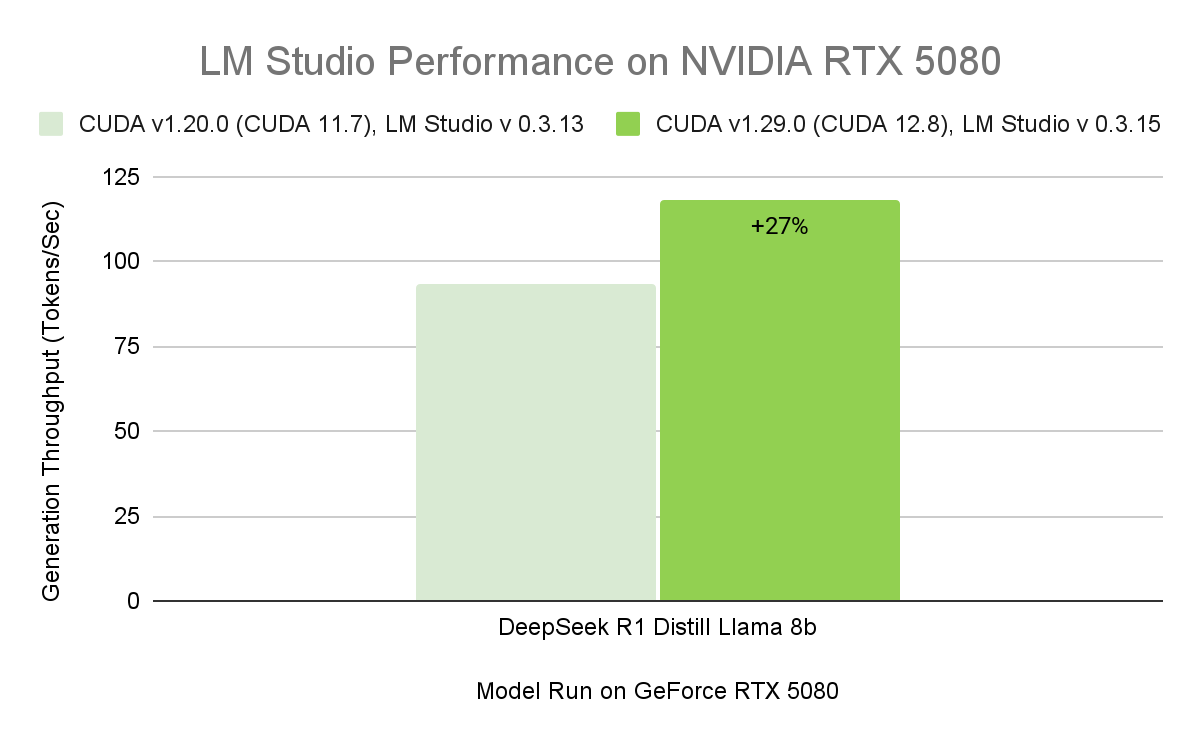
With a compatible driver, LM Studio automatically upgrades to the CUDA 12.8 runtime, enabling significantly faster model load times and higher overall performance.
These enhancements deliver smoother inference and faster response times across the full range of RTX AI PCs — from thin, light laptops to high-performance desktops and workstations.
LM Studio is free to download and runs on Windows, macOS and Linux. With the latest 0.3.15 release and ongoing optimizations, users can expect continued improvements in performance, customization and usability — making local AI faster, more flexible and more accessible.
Users can load a model through the desktop chat interface or enable developer mode to expose an OpenAI-compatible API.
To quickly get started, download the latest version of LM Studio and open up the application.
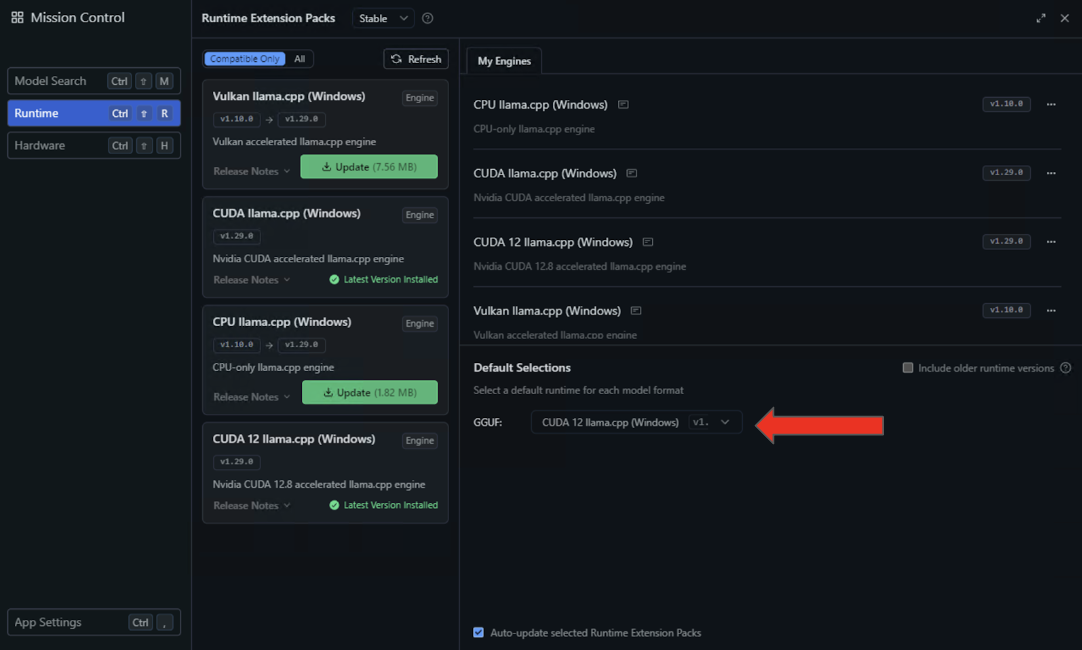

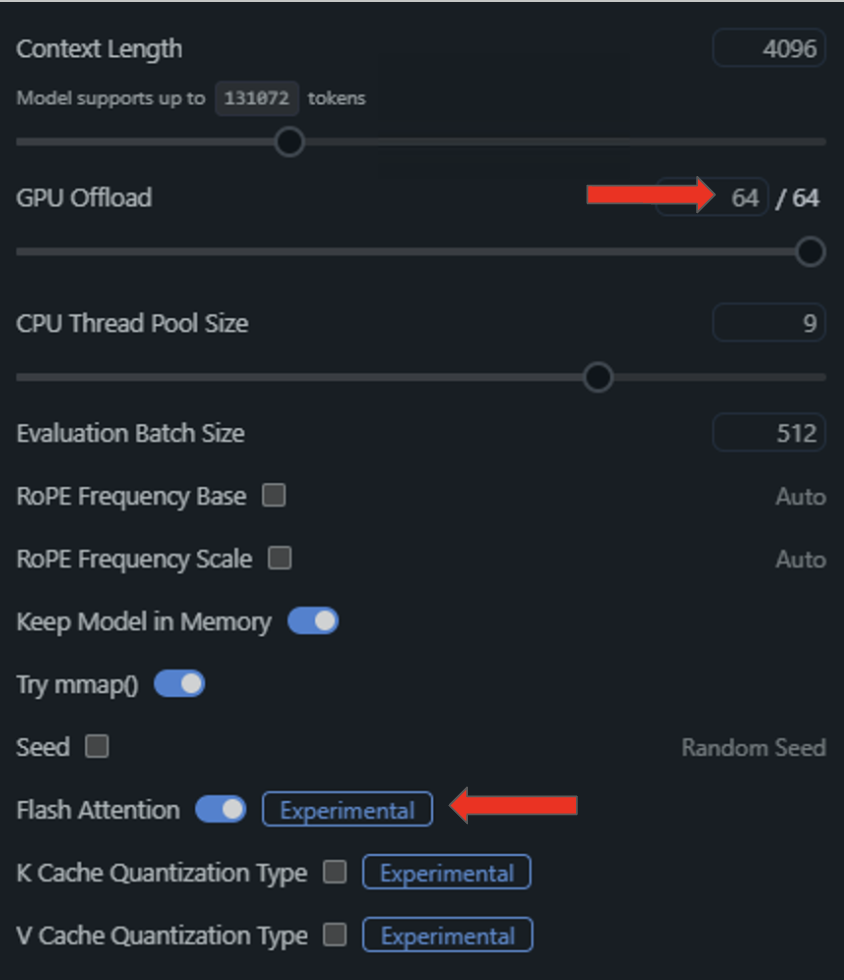
Once these features are enabled and configured, running NVIDIA GPU inference on a local setup is good to go.
LM Studio supports model presets, a range of quantization formats and developer controls like tool_choice for fine-tuned inference. For those looking to contribute, the llama.cpp GitHub repository is actively maintained and continues to evolve with community- and NVIDIA-driven performance enhancements.
Each week, the RTX AI Garage blog series features community-driven AI innovations and content for those looking to learn more about NVIDIA NIM microservices and AI Blueprints, as well as building AI agents, creative workflows, digital humans, productivity apps and more on AI PCs and workstations.
Plug in to NVIDIA AI PC on Facebook, Instagram, TikTok and X — and stay informed by subscribing to the RTX AI PC newsletter.
Calling all wiseguys — 2K’s acclaimed Mafia franchise is available to stream from the cloud.
Step into the gritty underworld of organized crime and experience the cinematic storytelling and action-packed gameplay that made the Mafia franchise a classic, captivating both newcomers and longtime fans of the saga.
It’s all part of nine games joining the cloud family this week, including Towerborne from Stoic and Xbox Game Studios.
Plus, the family is waiting — the Mafia saga’s highly anticipated prequel, Mafia: The Old Country, will join the cloud at launch.
Step into the world of organized crime with Mafia, Mafia: Definitive Edition, Mafia II and Mafia III now streaming on GeForce NOW for those new and returning to the family. Experience the gritty underworld drama and cinematic storytelling that made Mafia a legend — no need to wait for a sitdown with the don.

Start with the first game in the series, Mafia. An inadvertent brush with the mob thrusts cab driver Tommy Angelo into the world of organized crime. He’s initially uneasy about falling in with the Salieri family, but the rewards become too big to ignore. Plus, check out Mafia: Definitive Edition, a remake from the ground up of the classic first title, with an expanded story, gameplay and original score.

Years later, the criminal legacy continues with Mafia II. Vito Scaletta has started to make a name for himself on the streets of Empire Bay as someone who can be trusted to get a job done. Together with his buddy Joe, he’s working to prove himself to the mafia, quickly climbing the family ladder with crimes of larger reward, status and consequence — the life as a wise guy isn’t quite as untouchable as it seems.

The saga expands to 1968 New Bordeaux in Mafia III: Definitive Edition. After years of combat in Vietnam, Lincoln Clay knows this truth: family isn’t who you’re born with, it’s who you die for. When his surrogate family is wiped out by the Italian mafia, Lincoln builds a new family and blazes a path of revenge through the mafioso responsible.
Step into the tailored suits and fedoras of the criminal underworld with the Mafia series on GeForce NOW. Play anytime, anywhere across devices, just like a true mobster on the move.

From Stoic and Xbox Game Studios comes Towerborne, a new kind of looter brawler, combining side-scrolling combat with action role-playing game loot progression and customization — available in the cloud at high performance for GeForce NOW members.
Take on the role of an Ace — a hero reborn from the spirit realm — to protect the last bastion of humanity, the Belfry, from monstrous threats. Embark on a series of daring expeditions beyond the city’s walls and into the wilds. Engage in fast-paced, combo-driven combat and experiment with different weapon classes like the heavy-hitting Rockbreaker, agile Shadowstriker and more.
Experience the vibrant, action-packed world of Towerborne on GeForce NOW, with high dynamic range support for richer colors and deeper contrast. Defend the Belfry on a Performance or Ultimate membership to get immersed in stunning, high-contrast visuals that bring explosive battles to life. Members can adventure solo or team with up to three friends for co-op action and stream the game instantly from the cloud, no downloads required.

Genshin Impact version 5.6, called “Paralogism,” brings a new story chapter in which players return to the city of Mondstadt and help solve a mysterious crisis involving the character Albedo. The update also introduces an event in the city of Fontaine, where players can build and run their own amusement park. Plus, two new characters join the game: Escoffier, a chef who uses cryo elemental power, and Ifa, an Saurian veterinarian who fights alongside his Saurian companion, Cacucu. Catch it in the cloud without waiting for downloads.
Look for the following games available to stream in the cloud this week:
What are you planning to play this weekend? Let us know on X or in the comments below.
Storage full?
*laughs in cloud*
—
NVIDIA GeForce NOW (@NVIDIAGFN) May 6, 2025
In this issue:
New research on compound AI systems and causal verification of the Confidential Consortium Framework; release of Phi-4-reasoning; enriching tabular data with semantic structure, and more.


This research introduces Murakkab, a prototype system built on a declarative workflow that reimagines how compound AI systems are built and managed to significantly improve resource efficiency. Compound AI systems integrate multiple interacting components like language models, retrieval engines, and external tools. They are essential for addressing complex AI tasks. However, current implementations could benefit from greater efficiencies in resource utilization, with improvements to tight coupling between application logic and execution details, better connections between orchestration and resource management layers, and bridging gaps between efficiency and quality.
Murakkab addresses critical inefficiencies in current AI architectures and offers a new approach that unifies workflow orchestration and cluster resource management for better performance and sustainability. In preliminary evaluations, it demonstrates speedups up to ∼ 3.4× in workflow completion times while delivering ∼ 4.5× higher energy efficiency, showing promise in optimizing resources and advancing AI system design.

This work presents a new, pragmatic verification technique that improves the trustworthiness of distributed systems like the Confidential Consortium Framework (CCF) and proves its effectiveness by catching critical bugs before deployment. Smart casual verification is a novel hybrid verification approach to validating CCF, an open-source platform for developing trustworthy and reliable cloud applications which underpins Microsoft’s Azure Confidential Ledger service.
The researchers apply smart casual verification to validate the correctness of CCF’s novel distributed protocols, focusing on its unique distributed consensus protocol and its custom client consistency model. This hybrid approach combines the rigor of formal specification and model checking with the pragmatism of automated testing, specifically binding the formal specification in TLA+ to the C++ implementation. While traditional formal methods are often one-off efforts by domain experts, the researchers have integrated smart casual verification into CCF’s continuous integration pipeline, allowing contributors to continuously validate CCF as it evolves.

This report introduces Phi-4-reasoning (opens in new tab), a 14-billion parameter model optimized for complex reasoning tasks. It is trained via supervised fine-tuning of Phi-4 using a carefully curated dataset of high-quality prompts and reasoning demonstrations generated by o3-mini. These prompts span diverse domains—including math, science, coding, and spatial reasoning—and are selected to challenge the base model near its capability boundaries.
Building on recent findings that reinforcement learning (RL) can further improve smaller models, the team developed Phi-4-reasoning-plus, which incorporates an additional outcome-based RL phase using verifiable math problems. This enhances the model’s ability to generate longer, more effective reasoning chains.
Despite its smaller size, the Phi-4-reasoning family outperforms significantly larger open-weight models such as DeepSeekR1-Distill-Llama-70B and approaches the performance of full-scale frontier models like DeepSeek R1. It excels in tasks requiring multi-step problem solving, logical inference, and goal-directed planning.
The work highlights the combined value of supervised fine-tuning and reinforcement learning for building efficient, high-performing reasoning models. It also offers insights into training data design, methodology, and evaluation strategies. Phi-4-reasoning contributes to the growing class of reasoning-specialized language models and points toward more accessible, scalable AI for science, education, and technical domains.

This research introduces a practical, cost-effective solution for enriching tabular data with semantic structure, making it more useful for downstream analysis and insights—which is especially valuable in business intelligence, data cleaning, and automated analytics workflows. This approach outperforms baseline models and naive LLM applications on converted text classification benchmarks.
Extracting structured insights from free-text columns in tables—such as product reviews or user feedback—can be time-consuming and error-prone, especially when relying on traditional syntactic methods that often miss semantic meaning. This research introduces the semantic text column featurization problem, which aims to assign meaningful, context-aware labels to each entry in a text column.
The authors propose a scalable, efficient method that combines the power of LLMs with text embeddings. Instead of labeling an entire column manually or applying LLMs to every cell—an expensive process—this new method intelligently samples a diverse subset of entries, uses an LLM to generate semantic labels for just that subset, and then propagates those labels to the rest of the column using embedding similarity.

This work introduces ARTIST (Agentic Reasoning and Tool Integration in Self-improving Transformers), a new paradigm for LLM reasoning that expands beyond traditional language-only inference.
While LLMs have made considerable strides in complex reasoning tasks, they remain limited by their reliance on static internal knowledge and text-only reasoning. Real-world problem solving often demands dynamic, multi-step reasoning, adaptive decision making, and the ability to interact with external tools and environments. In this research, ARTIST brings together agentic reasoning, reinforcement learning (RL), and tool integration, designed to enable LLMs to autonomously decide when and how to invoke internal tools within multi-turn reasoning chains. ARTIST leverages outcome-based reinforcement learning to learn robust strategies for tool use and environment interaction without requiring step-level supervision.
Extensive experiments on mathematical reasoning and multi-turn function calling benchmarks show that ARTIST consistently outperforms state-of-the-art baselines, with up to 22% absolute improvement over base models and strong gains on the most challenging tasks. Detailed studies show that agentic RL training leads to deeper reasoning, more effective tool use, and higher-quality solutions.
What if you could find materials with tailored properties without ever entering the lab? The Materialism Podcast, which is dedicated to exploring materials science and engineering, talks with Tian Xie from Microsoft Research to discuss MatterGen, an AI tool which accelerates materials science discovery. Tune in to hear a discussion of the new Azure AI Foundry, where MatterGen will interact with and support MatterSim, an advanced deep learning model designed to simulate the properties of materials across a wide range of elements, temperatures, and pressures.
Quanta Magazine | April 30, 2025
Large language models are everywhere, igniting discovery, disruption and debate in whatever scientific community they touch. But the one they touched first — for better, worse and everything in between — was natural language processing. What did that impact feel like to the people experiencing it firsthand?
To tell that story, Quanta interviewed 19 NLP experts, including Kalika Bali, senior principal researcher at Microsoft Research. From researchers to students, tenured academics to startup founders, they describe a series of moments — dawning realizations, elated encounters and at least one “existential crisis” — that changed their world. And ours.
The post Research Focus: Week of May 7, 2025 appeared first on Microsoft Research.