This post is co-written with Kilian Zimmerer and Daniel Ringler from Deutsche Bahn.
Every day, Deutsche Bahn (DB) moves over 6.6 million passengers across Germany, requiring precise time series forecasting for a wide range of purposes. However, building accurate forecasting models traditionally required significant expertise and weeks of development time.
Today, we’re excited to explore how the time series foundation model Chronos-Bolt, recently launched on Amazon Bedrock Marketplace and available through Amazon SageMaker JumpStart, is revolutionizing time series forecasting by enabling accurate predictions with minimal effort. Whereas traditional forecasting methods typically rely on statistical modeling, Chronos treats time series data as a language to be modeled and uses a pre-trained FM to generate forecasts — similar to how large language models (LLMs) generate texts. Chronos helps you achieve accurate predictions faster, significantly reducing development time compared to traditional methods.
In this post, we share how Deutsche Bahn is redefining forecasting using Chronos models, and provide an example use case to demonstrate how you can get started using Chronos.
Chronos: Learning the language of time series
The Chronos model family represents a breakthrough in time series forecasting by using language model architectures. Unlike traditional time series forecasting models that require training on specific datasets, Chronos can be used for forecasting immediately. The original Chronos model quickly became the number #1 most downloaded model on Hugging Face in 2024, demonstrating the strong demand for FMs in time series forecasting.
Building on this success, we recently launched Chronos-Bolt, which delivers higher zero-shot accuracy compared to original Chronos models. It offers the following improvements:
- Up to 250 times faster inference
- 20 times better memory efficiency
- CPU deployment support, making hosting costs up to 10 times less expensive
Now, you can use Amazon Bedrock Marketplace to deploy Chronos-Bolt. Amazon Bedrock Marketplace is a new capability in Amazon Bedrock that enables developers to discover, test, and use over 100 popular, emerging, and specialized FMs alongside the current selection of industry-leading models in Amazon Bedrock.
The challenge
Deutsche Bahn, Germany’s national railway company, serves over 1.8 billion passengers annually in long distance and regional rail passenger transport, making it one of the world’s largest railway operators. For more than a decade, Deutsche Bahn has been innovating together with AWS. AWS is the primary cloud provider for Deutsche Bahn and a strategic partner of DB Systel, a wholly owned subsidiary of DB AG that drives digitalization across all group companies.
Previously, Deutsche Bahn’s forecasting processes were highly heterogeneous across teams, requiring significant effort for each new use case. Different data sources required using multiple specialized forecasting methods, resulting in cost- and time-intensive manual effort. Company-wide, Deutsche Bahn identified dozens of different and independently operated forecasting processes. Smaller teams found it hard to justify developing customized forecasting solutions for their specific needs.
For example, the data analysis platform for passenger train stations of DB InfraGO AG integrates and analyzes diverse data sources, from weather data and SAP Plant Maintenance information to video analytics. Given the diverse data sources, a forecast method that was designed for one data source was usually not transferable to the other data sources.
To democratize forecasting capabilities across the organization, Deutsche Bahn needed a more efficient and scalable approach to handle various forecasting scenarios. Using Chronos, Deutsche Bahn demonstrates how cutting-edge technology can transform enterprise-scale forecasting operations.
Solution overview
A team enrolled in Deutsche Bahn’s accelerator program Skydeck, the innovation lab of DB Systel, developed a time series FM forecasting system using Chronos as the underlying model, in partnership with DB InfraGO AG. This system offers a secured internal API that can be used by Deutsche Bahn teams across the organization for efficient and simple-to-use time series forecasts, without the need to develop customized software.
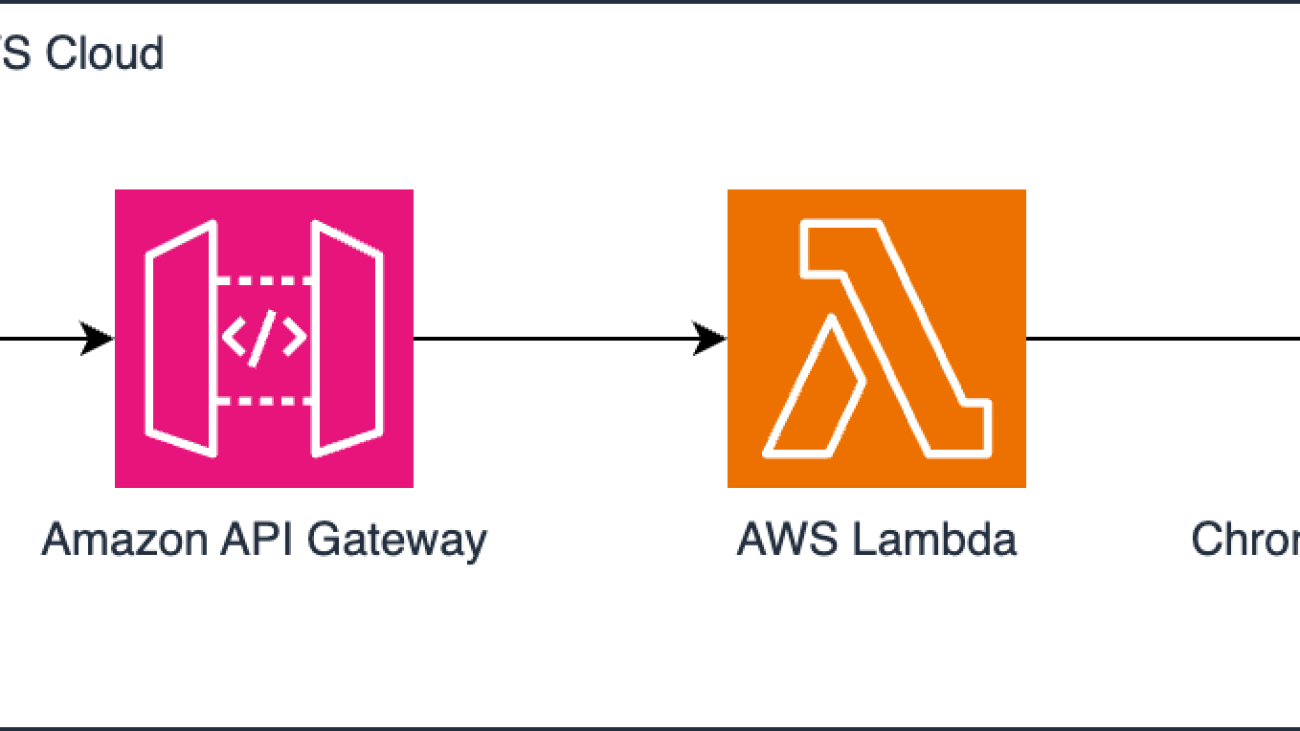
The following diagram shows a simplified architecture of how Deutsche Bahn uses Chronos.

In the solution workflow, a user can pass timeseries data to Amazon API Gateway which serves as a secure front door for API calls, handling authentication and authorization. For more information on how to limit access to an API to authorized users only, refer to Control and manage access to REST APIs in API Gateway. Then, an AWS Lambda function is used as serverless compute for processing and passing requests to the Chronos model for inference. The fastest way to host a Chronos model is by using Amazon Bedrock Marketplace or SageMaker Jumpstart.
Impact and future plans
Deutsche Bahn tested the service on multiple use cases, such as predicting actual costs for construction projects and forecasting monthly revenue for retail operators in passenger stations. The implementation with Chronos models revealed compelling outcomes. The following table depicts the achieved results. In the first use case, we can observe that in zero-shot scenarios (meaning that the model has never seen the data before), Chronos models can achieve accuracy superior to established statistical methods like AutoARIMA and AutoETS, even though these methods were specifically trained on the data. Additionally, in both use cases, Chronos inference time is up to 100 times faster, and when fine-tuned, Chronos models outperform traditional approaches in both scenarios. For more details on fine-tuning Chronos, refer to Forecasting with Chronos – AutoGluon.
| . |
Model |
Error (Lower is Better) |
Prediction Time (seconds) |
Training Time (seconds) |
| Deutsche Bahn test use case 1 |
AutoArima |
0.202 |
40 |
. |
| AutoETS |
0.2 |
9.1 |
. |
| Chronos Bolt Small (Zero Shot) |
0.195 |
0.4 |
. |
| Chronos Bolt Base (Zero Shot) |
0.198 |
0.6 |
. |
| Chronos Bolt Small (Fine-Tuned) |
0.181 |
0.4 |
650 |
| Chronos Bolt Base (Fine-Tuned) |
0.186 |
0.6 |
1328 |
| Deutsche Bahn test use case 2 |
AutoArima |
0.13 |
100 |
. |
| AutoETS |
0.136 |
18 |
. |
| Chronos Bolt Small (Zero Shot) |
0.197 |
0.7 |
. |
| Chronos Bolt Base (Zero Shot) |
0.185 |
1.2 |
. |
| Chronos Bolt Small (Fine-Tuned) |
0.134 |
0.7 |
1012 |
| Chronos Bolt Base (Fine-Tuned) |
0.127 |
1.2 |
1893 |
Error is measured in SMAPE. Finetuning was stopped after 10,000 steps.
Based on the successful prototype, Deutsche Bahn is developing a company-wide forecasting service accessible to all DB business units, supporting different forecasting scenarios. Importantly, this will democratize the usage of forecasting across the organization. Previously resource-constrained teams are now empowered to generate their own forecasts, and forecast preparation time can be reduced from weeks to hours.
Example use case
Let’s walk through a practical example of using Chronos-Bolt with Amazon Bedrock Marketplace. We will forecast passenger capacity utilization at German long-distance and regional train stations using publicly available data.
Prerequisites
For this, you will use the AWS SDK for Python (Boto3) to programmatically interact with Amazon Bedrock. As prerequisites, you need to have the Python libraries boto3, pandas, and matplotlib installed. In addition, configure a connection to an AWS account such that Boto3 can use Amazon Bedrock. For more information on how to setup Boto3, refer to Quickstart – Boto3. If you are using Python inside an Amazon SageMaker notebook, the necessary packages are already installed.
Forecast passenger capacity
First, load the data with the historical passenger capacity utilization. For this example, focus on train station 239:
import pandas as pd
# Load data
df = pd.read_csv(
"https://mobilithek.info/mdp-api/files/aux/573351169210855424/benchmark_personenauslastung_bahnhoefe_training.csv"
)
df_train_station = df[df["train_station"] == 239].reset_index(drop=True)
Next, deploy an endpoint on Amazon Bedrock Marketplace containing Chronos-Bolt. This endpoint acts as a hosted service, meaning that it can receive requests containing time series data and return forecasts in response.
Amazon Bedrock will assume an AWS Identity and Access Management (IAM) role to provision the endpoint. Modify the following code to reference your role. For a tutorial on creating an execution role, refer to How to use SageMaker AI execution roles.
import boto3
import time
def describe_endpoint(bedrock_client, endpoint_arn):
return bedrock_client.get_marketplace_model_endpoint(endpointArn=endpoint_arn)[
"marketplaceModelEndpoint"
]
def wait_for_endpoint(bedrock_client, endpoint_arn):
endpoint = describe_endpoint(bedrock_client, endpoint_arn)
while endpoint["endpointStatus"] in ["Creating", "Updating"]:
print(
f"Endpoint {endpoint_arn} status is still {endpoint['endpointStatus']}."
"Waiting 10 seconds before continuing..."
)
time.sleep(10)
endpoint = describe_endpoint(bedrock_client, endpoint_arn)
print(f"Endpoint status: {endpoint['status']}")
bedrock_client = boto3.client(service_name="bedrock")
region_name = bedrock_client.meta.region_name
executionRole = "arn:aws:iam::account-id:role/ExecutionRole" # Change to your role
# Deploy Endpoint
body = {
"modelSourceIdentifier": f"arn:aws:sagemaker:{region_name}:aws:hub-content/SageMakerPublicHub/Model/autogluon-forecasting-chronos-bolt-base/2.0.0",
"endpointConfig": {
"sageMaker": {
"initialInstanceCount": 1,
"instanceType": "ml.m5.xlarge",
"executionRole": executionRole,
}
},
"endpointName": "brmp-chronos-endpoint",
"acceptEula": True,
}
response = bedrock_client.create_marketplace_model_endpoint(**body)
endpoint_arn = response["marketplaceModelEndpoint"]["endpointArn"]
# Wait until the endpoint is created. This will take a few minutes.
wait_for_endpoint(bedrock_client, endpoint_arn)
Then, invoke the endpoint to make a forecast. Send a payload to the endpoint, which includes historical time series values and configuration parameters, such as the prediction length and quantile levels. The endpoint processes this input and returns a response containing the forecasted values based on the provided data.
import json
# Query endpoint
bedrock_runtime_client = boto3.client(service_name="bedrock-runtime")
body = json.dumps(
{
"inputs": [
{"target": df_train_station["capacity"].values.tolist()},
],
"parameters": {
"prediction_length": 64,
"quantile_levels": [0.1, 0.5, 0.9],
}
}
)
response = bedrock_runtime_client.invoke_model(modelId=endpoint_arn, body=body)
response_body = json.loads(response["body"].read())
Now you can visualize the forecasts generated by Chronos-Bolt.
import matplotlib.pyplot as plt
# Plot forecast
forecast_index = range(len(df_train_station), len(df_train_station) + 64)
low = response_body["predictions"][0]["0.1"]
median = response_body["predictions"][0]["0.5"]
high = response_body["predictions"][0]["0.9"]
plt.figure(figsize=(8, 4))
plt.plot(df_train_station["capacity"], color="royalblue", label="historical data")
plt.plot(forecast_index, median, color="tomato", label="median forecast")
plt.fill_between(
forecast_index,
low,
high,
color="tomato",
alpha=0.3,
label="80% prediction interval",
)
plt.legend(loc='upper left')
plt.grid()
plt.show()
The following figure shows the output.

As we can see on the right-hand side of the preceding graph in red, the model is able to pick up the pattern that we can visually recognize on the left part of the plot (in blue). The Chronos model predicts a steep decline followed by two smaller spikes. It is worth highlighting that the model successfully predicted this pattern using zero-shot inference, that is, without being trained on the data. Going back to the original prediction task, we can interpret that this particular train station is underutilized on weekends.
Clean up
To avoid incurring unnecessary costs, use the following code to delete the model endpoint:
bedrock_client.delete_marketplace_model_endpoint(endpointArn=endpoint_arn)
# Confirm that endpoint is deleted
time.sleep(5)
try:
endpoint = describe_endpoint(bedrock_client, endpoint_arn=endpoint_arn)
print(endpoint["endpointStatus"])
except ClientError as err:
assert err.response['Error']['Code'] =='ResourceNotFoundException'
print(f"Confirmed that endpoint {endpoint_arn} was deleted")
Conclusion
The Chronos family of models, particularly the new Chronos-Bolt model, represents a significant advancement in making accurate time series forecasting accessible. Through the simple deployment options with Amazon Bedrock Marketplace and SageMaker JumpStart, organizations can now implement sophisticated forecasting solutions in hours rather than weeks, while achieving state-of-the-art accuracy.
Whether you’re forecasting retail demand, optimizing operations, or planning resource allocation, Chronos models provide a powerful and efficient solution that can scale with your needs.
About the authors
 Kilian Zimmerer is an AI and DevOps Engineer at DB Systel GmbH in Berlin. With his expertise in state-of-the-art machine learning and deep learning, alongside DevOps infrastructure management, he drives projects, defines their technical vision, and supports their successful implementation within Deutsche Bahn.
Kilian Zimmerer is an AI and DevOps Engineer at DB Systel GmbH in Berlin. With his expertise in state-of-the-art machine learning and deep learning, alongside DevOps infrastructure management, he drives projects, defines their technical vision, and supports their successful implementation within Deutsche Bahn.
 Daniel Ringler is a software engineer specializing in machine learning at DB Systel GmbH in Berlin. In addition to his professional work, he is a volunteer organizer for PyData Berlin, contributing to the local data science and Python programming community.
Daniel Ringler is a software engineer specializing in machine learning at DB Systel GmbH in Berlin. In addition to his professional work, he is a volunteer organizer for PyData Berlin, contributing to the local data science and Python programming community.
 Pedro Eduardo Mercado Lopez is an Applied Scientist at Amazon Web Services, where he works on time series forecasting for labor planning and capacity planning with a focus on hierarchical time series and foundation models. He received a PhD from Saarland University, Germany, doing research in spectral clustering for signed and multilayer graphs.
Pedro Eduardo Mercado Lopez is an Applied Scientist at Amazon Web Services, where he works on time series forecasting for labor planning and capacity planning with a focus on hierarchical time series and foundation models. He received a PhD from Saarland University, Germany, doing research in spectral clustering for signed and multilayer graphs.
 Simeon Brüggenjürgen is a Solutions Architect at Amazon Web Services based in Munich, Germany. With a background in Machine Learning research, Simeon supported Deutsche Bahn on this project.
Simeon Brüggenjürgen is a Solutions Architect at Amazon Web Services based in Munich, Germany. With a background in Machine Learning research, Simeon supported Deutsche Bahn on this project.
 John Liu has 15 years of experience as a product executive and 9 years of experience as a portfolio manager. At AWS, John is a Principal Product Manager for Amazon Bedrock. Previously, he was the Head of Product for AWS Web3 / Blockchain. Prior to AWS, John held various product leadership roles at public blockchain protocols, fintech companies and also spent 9 years as a portfolio manager at various hedge funds.
John Liu has 15 years of experience as a product executive and 9 years of experience as a portfolio manager. At AWS, John is a Principal Product Manager for Amazon Bedrock. Previously, he was the Head of Product for AWS Web3 / Blockchain. Prior to AWS, John held various product leadership roles at public blockchain protocols, fintech companies and also spent 9 years as a portfolio manager at various hedge funds.
 Michael Bohlke-Schneider is an Applied Science Manager at Amazon Web Services. At AWS, Michael works on machine learning and forecasting, with a focus on foundation models for structured data and AutoML. He received his PhD from the Technical University Berlin, where he worked on protein structure prediction.
Michael Bohlke-Schneider is an Applied Science Manager at Amazon Web Services. At AWS, Michael works on machine learning and forecasting, with a focus on foundation models for structured data and AutoML. He received his PhD from the Technical University Berlin, where he worked on protein structure prediction.
 Florian Saupe is a Principal Technical Product Manager at AWS AI/ML research supporting science teams like the graph machine learning group, and ML Systems teams working on large scale distributed training, inference, and fault resilience. Before joining AWS, Florian lead technical product management for automated driving at Bosch, was a strategy consultant at McKinsey & Company, and worked as a control systems and robotics scientist—a field in which he holds a PhD.
Florian Saupe is a Principal Technical Product Manager at AWS AI/ML research supporting science teams like the graph machine learning group, and ML Systems teams working on large scale distributed training, inference, and fault resilience. Before joining AWS, Florian lead technical product management for automated driving at Bosch, was a strategy consultant at McKinsey & Company, and worked as a control systems and robotics scientist—a field in which he holds a PhD.
Read More




 For more than a decade, Google Research has been using AI to precisely map the connections between every cell in the brain in an endeavor called connectomics. Now, in co…
For more than a decade, Google Research has been using AI to precisely map the connections between every cell in the brain in an endeavor called connectomics. Now, in co…





















 Shreyas Subramanian is a Principal Data Scientist and helps customers by using generative AI and deep learning to solve their business challenges using AWS services. Shreyas has a background in large-scale optimization and ML and in the use of ML and reinforcement learning for accelerating optimization tasks.
Shreyas Subramanian is a Principal Data Scientist and helps customers by using generative AI and deep learning to solve their business challenges using AWS services. Shreyas has a background in large-scale optimization and ML and in the use of ML and reinforcement learning for accelerating optimization tasks.



 Here are Google’s latest AI updates from April 2025
Here are Google’s latest AI updates from April 2025