The book passage I read at the top is from “Chapter 4: Trust but Verify,” which was written by Zak.
You know, it’s no secret that in the US and elsewhere shortages in medical staff and the rise of clinician burnout are affecting the quality of patient care for the worse. In our book, we predicted that generative AI would be something that might help address these issues.
So in this episode, we’ll delve into how individual performance gains that our previous guests have described might affect the healthcare workforce as a whole, and on the patient side, we’ll look into the influence of generative AI on the consumerization of healthcare. Now, since all of this consumes such a huge fraction of the overall economy, we’ll also get into what a general-purpose technology as disruptive as generative AI might mean in the context of labor markets and beyond.
To help us do that, I’m pleased to welcome Ethan Mollick and Azeem Azhar.
Ethan Mollick is the Ralph J. Roberts Distinguished Faculty Scholar, a Rowan Fellow, and an associate professor at the Wharton School of the University of Pennsylvania. His research into the effects of AI on work, entrepreneurship, and education is applied by organizations around the world, leading him to be named one of Time magazine’s most influential people in AI for 2024. He’s also the author of the New York Times best-selling book Co-Intelligence.
Azeem Azhar is an author, founder, investor, and one of the most thoughtful and influential voices on the interplay between disruptive emerging technologies and business and society. In his best-selling book, The Exponential Age, and in his highly regarded newsletter and podcast, Exponential View, he explores how technologies like AI are reshaping everything from healthcare to geopolitics.
Ethan and Azeem are two leading thinkers on the ways that disruptive technologies—and especially AI—affect our work, our jobs, our business enterprises, and whole industries. As economists, they are trying to work out whether we are in the midst of an economic revolution as profound as the shift from an agrarian to an industrial society.
[TRANSITION MUSIC]
Here is my interview with Ethan Mollick:
LEE: Ethan, welcome.
ETHAN MOLLICK: So happy to be here, thank you.
LEE: I described you as a professor at Wharton, which I think most of the people who listen to this podcast series know of as an elite business school. So it might surprise some people that you study AI. And beyond that, you know, that I would seek you out to talk about AI in medicine. [LAUGHTER] So to get started, how and why did it happen that you’ve become one of the leading experts on AI?
MOLLICK: It’s actually an interesting story. I’ve been AI-adjacent my whole career. When I was [getting] my PhD at MIT, I worked with Marvin Minsky (opens in new tab) and the MIT [Massachusetts Institute of Technology] Media Labs AI group. But I was never the technical AI guy. I was the person who was trying to explain AI to everybody else who didn’t understand it.
And then I became very interested in, how do you train and teach? And AI was always a part of that. I was building games for teaching, teaching tools that were used in hospitals and elsewhere, simulations. So when LLMs burst into the scene, I had already been using them and had a good sense of what they could do. And between that and, kind of, being practically oriented and getting some of the first research projects underway, especially under education and AI and performance, I became sort of a go-to person in the field.
And once you’re in a field where nobody knows what’s going on and we’re all making it up as we go along—I thought it’s funny that you led with the idea that you have a couple of months head start for GPT-4, right. Like that’s all we have at this point, is a few months’ head start. [LAUGHTER] So being a few months ahead is good enough to be an expert at this point. Whether it should be or not is a different question.
LEE: Well, if I understand correctly, leading AI companies like OpenAI, Anthropic, and others have now sought you out as someone who should get early access to really start to do early assessments and gauge early reactions. How has that been?
MOLLICK: So, I mean, I think the bigger picture is less about me than about two things that tells us about the state of AI right now.
One, nobody really knows what’s going on, right. So in a lot of ways, if it wasn’t for your work, Peter, like, I don’t think people would be thinking about medicine as much because these systems weren’t built for medicine. They weren’t built to change education. They weren’t built to write memos. They, like, they weren’t built to do any of these things. They weren’t really built to do anything in particular. It turns out they’re just good at many things.
And to the extent that the labs work on them, they care about their coding ability above everything else and maybe math and science secondarily. They don’t think about the fact that it expresses high empathy. They don’t think about its accuracy and diagnosis or where it’s inaccurate. They don’t think about how it’s changing education forever.
So one part of this is the fact that they go to my Twitter feed or ask me for advice is an indicator of where they are, too, which is they’re not thinking about this. And the fact that a few months’ head start continues to give you a lead tells you that we are at the very cutting edge. These labs aren’t sitting on projects for two years and then releasing them. Months after a project is complete or sooner, it’s out the door. Like, there’s very little delay. So we’re kind of all in the same boat here, which is a very unusual space for a new technology.
LEE: And I, you know, explained that you’re at Wharton. Are you an odd fit as a faculty member at Wharton, or is this a trend now even in business schools that AI experts are becoming key members of the faculty?
MOLLICK: I mean, it’s a little of both, right. It’s faculty, so everybody does everything. I’m a professor of innovation-entrepreneurship. I’ve launched startups before and working on that and education means I think about, how do organizations redesign themselves? How do they take advantage of these kinds of problems? So medicine’s always been very central to that, right. A lot of people in my MBA class have been MDs either switching, you know, careers or else looking to advance from being sort of individual contributors to running teams. So I don’t think that’s that bad a fit. But I also think this is general-purpose technology; it’s going to touch everything. The focus on this is medicine, but Microsoft does far more than medicine, right. It’s … there’s transformation happening in literally every field, in every country. This is a widespread effect.
So I don’t think we should be surprised that business schools matter on this because we care about management. There’s a long tradition of management and medicine going together. There’s actually a great academic paper that shows that teaching hospitals that also have MBA programs associated with them have higher management scores and perform better (opens in new tab). So I think that these are not as foreign concepts, especially as medicine continues to get more complicated.
LEE: Yeah. Well, in fact, I want to dive a little deeper on these issues of management, of entrepreneurship, um, education. But before doing that, if I could just stay focused on you. There is always something interesting to hear from people about their first encounters with AI. And throughout this entire series, I’ve been doing that both pre-generative AI and post-generative AI. So you, sort of, hinted at the pre-generative AI. You were in Minsky’s lab. Can you say a little bit more about that early encounter? And then tell us about your first encounters with generative AI.
MOLLICK: Yeah. Those are great questions. So first of all, when I was at the media lab, that was pre-the current boom in sort of, you know, even in the old-school machine learning kind of space. So there was a lot of potential directions to head in. While I was there, there were projects underway, for example, to record every interaction small children had. One of the professors was recording everything their baby interacted with in the hope that maybe that would give them a hint about how to build an AI system.
There was a bunch of projects underway that were about labeling every concept and how they relate to other concepts. So, like, it was very much Wild West of, like, how do we make an AI work—which has been this repeated problem in AI, which is, what is this thing?
The fact that it was just like brute force over the corpus of all human knowledge turns out to be a little bit of like a, you know, it’s a miracle and a little bit of a disappointment in some ways [LAUGHTER] compared to how elaborate some of this was. So, you know, I think that, that was sort of my first encounters in sort of the intellectual way.
The generative AI encounters actually started with the original, sort of, GPT-3, or, you know, earlier versions. And it was actually game-based. So I played games like AI Dungeon. And as an educator, I realized, oh my gosh, this stuff could write essays at a fourth-grade level. That’s really going to change the way, like, middle school works, was my thinking at the time. And I was posting about that back in, you know, 2021 that this is a big deal. But I think everybody was taken surprise, including the AI companies themselves, by, you know, ChatGPT, by GPT-3.5. The difference in degree turned out to be a difference in kind.
LEE: Yeah, you know, if I think back, even with GPT-3, and certainly this was the case with GPT-2, it was, at least, you know, from where I was sitting, it was hard to get people to really take this seriously and pay attention.
MOLLICK: Yes.
LEE: You know, it’s remarkable. Within Microsoft, I think a turning point was the use of GPT-3 to do code completions. And that was actually productized as GitHub Copilot (opens in new tab), the very first version. That, I think, is where there was widespread belief. But, you know, in a way, I think there is, even for me early on, a sense of denial and skepticism. Did you have those initially at any point?
MOLLICK: Yeah, I mean, it still happens today, right. Like, this is a weird technology. You know, the original denial and skepticism was, I couldn’t see where this was going. It didn’t seem like a miracle because, you know, of course computers can complete code for you. Like, what else are they supposed to do? Of course, computers can give you answers to questions and write fun things. So there’s difference of moving into a world of generative AI. I think a lot of people just thought that’s what computers could do. So it made the conversations a little weird. But even today, faced with these, you know, with very strong reasoner models that operate at the level of PhD students, I think a lot of people have issues with it, right.
I mean, first of all, they seem intuitive to use, but they’re not always intuitive to use because the first use case that everyone puts AI to, it fails at because they use it like Google or some other use case. And then it’s genuinely upsetting in a lot of ways. I think, you know, I write in my book about the idea of three sleepless nights. That hasn’t changed. Like, you have to have an intellectual crisis to some extent, you know, and I think people do a lot to avoid having that existential angst of like, “Oh my god, what does it mean that a machine could think—apparently think—like a person?”
So, I mean, I see resistance now. I saw resistance then. And then on top of all of that, there’s the fact that the curve of the technology is quite great. I mean, the price of GPT-4 level intelligence from, you know, when it was released has dropped 99.97% at this point, right.
LEE: Yes. Mm-hmm.
MOLLICK: I mean, I could run a GPT-4 class system basically on my phone. Microsoft’s releasing things that can almost run on like, you know, like it fits in almost no space, that are almost as good as the original GPT-4 models. I mean, I don’t think people have a sense of how fast the trajectory is moving either.
LEE: Yeah, you know, there’s something that I think about often. There is this existential dread, or will this technology replace me? But I think the first people to feel that are researchers—people encountering this for the first time. You know, if you were working, let’s say, in Bayesian reasoning or in traditional, let’s say, Gaussian mixture model based, you know, speech recognition, you do get this feeling, Oh, my god, this technology has just solved the problem that I’ve dedicated my life to. And there is this really difficult period where you have to cope with that. And I think this is going to be spreading, you know, in more and more walks of life. And so this … at what point does that sort of sense of dread hit you, if ever?
MOLLICK: I mean, you know, it’s not even dread as much as like, you know, Tyler Cowen wrote that it’s impossible to not feel a little bit of sadness as you use these AI systems, too. Because, like, I was talking to a friend, just as the most minor example, and his talent that he was very proud of was he was very good at writing limericks for birthday cards. He’d write these limericks. Everyone was always amused by them. [LAUGHTER]
And now, you know, GPT-4 and GPT-4.5, they made limericks obsolete. Like, anyone can write a good limerick, right. So this was a talent, and it was a little sad. Like, this thing that you cared about mattered.
You know, as academics, we’re a little used to dead ends, right, and like, you know, some getting the lap. But the idea that entire fields are hitting that way. Like in medicine, there’s a lot of support systems that are now obsolete. And the question is how quickly you change that. In education, a lot of our techniques are obsolete.
What do you do to change that? You know, it’s like the fact that this brute force technology is good enough to solve so many problems is weird, right. And it’s not just the end of, you know, of our research angles that matter, too. Like, for example, I ran this, you know, 14-person-plus, multimillion-dollar effort at Wharton to build these teaching simulations, and we’re very proud of them. It took years of work to build one.
Now we’ve built a system that can build teaching simulations on demand by you talking to it with one team member. And, you know, you literally can create any simulation by having a discussion with the AI. I mean, you know, there’s a switch to a new form of excitement, but there is a little bit of like, this mattered to me, and, you know, now I have to change how I do things. I mean, adjustment happens. But if you haven’t had that displacement, I think that’s a good indicator that you haven’t really faced AI yet.
LEE: Yeah, what’s so interesting just listening to you is you use words like sadness, and yet I can see the—and hear the—excitement in your voice and your body language. So, you know, that’s also kind of an interesting aspect of all of this.
MOLLICK: Yeah, I mean, I think there’s something on the other side, right. But, like, I can’t say that I haven’t had moments where like, ughhhh, but then there’s joy and basically like also, you know, freeing stuff up. I mean, I think about doctors or professors, right. These are jobs that bundle together lots of different tasks that you would never have put together, right. If you’re a doctor, you would never have expected the same person to be good at keeping up with the research and being a good diagnostician and being a good manager and being good with people and being good with hand skills.
Like, who would ever want that kind of bundle? That’s not something you’re all good at, right. And a lot of our stress of our job comes from the fact that we suck at some of it. And so to the extent that AI steps in for that, you kind of feel bad about some of the stuff that it’s doing that you wanted to do. But it’s much more uplifting to be like, I don’t have to do this stuff I’m bad anymore, or I get the support to make myself good at it. And the stuff that I really care about, I can focus on more. Well, because we are at kind of a unique moment where whatever you’re best at, you’re still better than AI. And I think it’s an ongoing question about how long that lasts. But for right now, like you’re not going to say, OK, AI replaces me entirely in my job in medicine. It’s very unlikely.
But you will say it replaces these 17 things I’m bad at, but I never liked that anyway. So it’s a period of both excitement and a little anxiety.
LEE: Yeah, I’m going to want to get back to this question about in what ways AI may or may not replace doctors or some of what doctors and nurses and other clinicians do. But before that, let’s get into, I think, the real meat of this conversation. In previous episodes of this podcast, we talked to clinicians and healthcare administrators and technology developers that are very rapidly injecting AI today to do various forms of workforce automation, you know, automatically writing a clinical encounter note, automatically filling out a referral letter or request for prior authorization for some reimbursement to an insurance company.
And so these sorts of things are intended not only to make things more efficient and lower costs but also to reduce various forms of drudgery, cognitive burden on frontline health workers. So how do you think about the impact of AI on that aspect of workforce, and, you know, what would you expect will happen over the next few years in terms of impact on efficiency and costs?
MOLLICK: So I mean, this is a case where I think we’re facing the big bright problem in AI in a lot of ways, which is that this is … at the individual level, there’s lots of performance gains to be gained, right. The problem, though, is that we as individuals fit into systems, in medicine as much as anywhere else or more so, right. Which is that you could individually boost your performance, but it’s also about systems that fit along with this, right.
So, you know, if you could automatically, you know, record an encounter, if you could automatically make notes, does that change what you should be expecting for notes or the value of those notes or what they’re for? How do we take what one person does and validate it across the organization and roll it out for everybody without making it a 10-year process that it feels like IT in medicine often is? Like, so we’re in this really interesting period where there’s incredible amounts of individual innovation in productivity and performance improvements in this field, like very high levels of it, but not necessarily seeing that same thing translate to organizational efficiency or gains.
And one of my big concerns is seeing that happen. We’re seeing that in nonmedical problems, the same kind of thing, which is, you know, we’ve got research showing 20 and 40% performance improvements, like not uncommon to see those things. But then the organization doesn’t capture it; the system doesn’t capture it. Because the individuals are doing their own work and the systems don’t have the ability to, kind of, learn or adapt as a result.
LEE: You know, where are those productivity gains going, then, when you get to the organizational level?
MOLLICK: Well, they’re dying for a few reasons. One is, there’s a tendency for individual contributors to underestimate the power of management, right.
Practices associated with good management increase happiness, decrease, you know, issues, increase success rates. In the same way, about 40%, as far as we can tell, of the US advantage over other companies, of US firms, has to do with management ability. Like, management is a big deal. Organizing is a big deal. Thinking about how you coordinate is a big deal.
At the individual level, when things get stuck there, right, you can’t start bringing them up to how systems work together. It becomes, How do I deal with a doctor that has a 60% performance improvement? We really only have one thing in our playbook for doing that right now, which is, OK, we could fire 40% of the other doctors and still have a performance gain, which is not the answer you want to see happen.
So because of that, people are hiding their use. They’re actually hiding their use for lots of reasons.
And it’s a weird case because the people who are able to figure out best how to use these systems, for a lot of use cases, they’re actually clinicians themselves because they’re experimenting all the time. Like, they have to take those encounter notes. And if they figure out a better way to do it, they figure that out. You don’t want to wait for, you know, a med tech company to figure that out and then sell that back to you when it can be done by the physicians themselves.
So we’re just not used to a period where everybody’s innovating and where the management structure isn’t in place to take advantage of that. And so we’re seeing things stalled at the individual level, and people are often, especially in risk-averse organizations or organizations where there’s lots of regulatory hurdles, people are so afraid of the regulatory piece that they don’t even bother trying to make change.
LEE: If you are, you know, the leader of a hospital or a clinic or a whole health system, how should you approach this? You know, how should you be trying to extract positive success out of AI?
MOLLICK: So I think that you need to embrace the right kind of risk, right. We don’t want to put risk on our patients … like, we don’t want to put uninformed risk. But innovation involves risk to how organizations operate. They involve change. So I think part of this is embracing the idea that R&D has to happen in organizations again.
What’s happened over the last 20 years or so has been organizations giving that up. Partially, that’s a trend to focus on what you’re good at and not try and do this other stuff. Partially, it’s because it’s outsourced now to software companies that, like, Salesforce tells you how to organize your sales team. Workforce tells you how to organize your organization. Consultants come in and will tell you how to make change based on the average of what other people are doing in your field.
So companies and organizations and hospital systems have all started to give up their ability to create their own organizational change. And when I talk to organizations, I often say they have to have two approaches. They have to think about the crowd and the lab.
So the crowd is the idea of how to empower clinicians and administrators and supporter networks to start using AI and experimenting in ethical, legal ways and then sharing that information with each other. And the lab is, how are we doing R&D about the approach of how to [get] AI to work, not just in direct patient care, right. But also fundamentally, like, what paperwork can you cut out? How can we better explain procedures? Like, what management role can this fill?
And we need to be doing active experimentation on that. We can’t just wait for, you know, Microsoft to solve the problems. It has to be at the level of the organizations themselves.
LEE: So let’s shift a little bit to the patient. You know, one of the things that we see, and I think everyone is seeing, is that people are turning to chatbots, like ChatGPT, actually to seek healthcare information for, you know, their own health or the health of their loved ones.
And there was already, prior to all of this, a trend towards, let’s call it, consumerization of healthcare. So just in the business of healthcare delivery, do you think AI is going to hasten these kinds of trends, or from the consumer’s perspective, what … ?
MOLLICK: I mean, absolutely, right. Like, all the early data that we have suggests that for most common medical problems, you should just consult AI, too, right. In fact, there is a real question to ask: at what point does it become unethical for doctors themselves to not ask for a second opinion from the AI because it’s cheap, right? You could overrule it or whatever you want, but like not asking seems foolish.
I think the two places where there’s a burning almost, you know, moral imperative is … let’s say, you know, I’m in Philadelphia, I’m a professor, I have access to really good healthcare through the Hospital University of Pennsylvania system. I know doctors. You know, I’m lucky. I’m well connected. If, you know, something goes wrong, I have friends who I can talk to. I have specialists. I’m, you know, pretty well educated in this space.
But for most people on the planet, they don’t have access to good medical care, they don’t have good health. It feels like it’s absolutely imperative to say when should you use AI and when not. Are there blind spots? What are those things?
And I worry that, like, to me, that would be the crash project I’d be invoking because I’m doing the same thing in education, which is this system is not as good as being in a room with a great teacher who also uses AI to help you, but it’s better than not getting an, you know, to the level of education people get in many cases. Where should we be using it? How do we guide usage in the right way? Because the AI labs aren’t thinking about this. We have to.
So, to me, there is a burning need here to understand this. And I worry that people will say, you know, everything that’s true—AI can hallucinate, AI can be biased. All of these things are absolutely true, but people are going to use it. The early indications are that it is quite useful. And unless we take the active role of saying, here’s when to use it, here’s when not to use it, we don’t have a right to say, don’t use this system. And I think, you know, we have to be exploring that.
LEE: What do people need to understand about AI? And what should schools, universities, and so on be teaching?
MOLLICK: Those are, kind of, two separate questions in lot of ways. I think a lot of people want to teach AI skills, and I will tell you, as somebody who works in this space a lot, there isn’t like an easy, sort of, AI skill, right. I could teach you prompt engineering in two to three classes, but every indication we have is that for most people under most circumstances, the value of prompting, you know, any one case is probably not that useful.
A lot of the tricks are disappearing because the AI systems are just starting to use them themselves. So asking good questions, being a good manager, being a good thinker tend to be important, but like magic tricks around making, you know, the AI do something because you use the right phrase used to be something that was real but is rapidly disappearing.
So I worry when people say teach AI skills. No one’s been able to articulate to me as somebody who knows AI very well and teaches classes on AI, what those AI skills that everyone should learn are, right.
I mean, there’s value in learning a little bit how the models work. There’s a value in working with these systems. A lot of it’s just hands on keyboard kind of work. But, like, we don’t have an easy slam dunk “this is what you learn in the world of AI” because the systems are getting better, and as they get better, they get less sensitive to these prompting techniques. They get better prompting themselves. They solve problems spontaneously and start being agentic. So it’s a hard problem to ask about, like, what do you train someone on? I think getting people experience in hands-on-keyboards, getting them to … there’s like four things I could teach you about AI, and two of them are already starting to disappear.
But, like, one is be direct. Like, tell the AI exactly what you want. That’s very helpful. Second, provide as much context as possible. That can include things like acting as a doctor, but also all the information you have. The third is give it step-by-step directions—that’s becoming less important. And the fourth is good and bad examples of the kind of output you want. Those four, that’s like, that’s it as far as the research telling you what to do, and the rest is building intuition.
LEE: I’m really impressed that you didn’t give the answer, “Well, everyone should be teaching my book, Co-Intelligence.” [LAUGHS]
MOLLICK: Oh, no, sorry! Everybody should be teaching my book Co-Intelligence. I apologize. [LAUGHTER]
LEE: It’s good to chuckle about that, but actually, I can’t think of a better book, like, if you were to assign a textbook in any professional education space, I think Co-Intelligence would be number one on my list. Are there other things that you think are essential reading?
MOLLICK: That’s a really good question. I think that a lot of things are evolving very quickly. I happen to, kind of, hit a sweet spot with Co-Intelligence to some degree because I talk about how I used it, and I was, sort of, an advanced user of these systems.
So, like, it’s, sort of, like my Twitter feed, my online newsletter. I’m just trying to, kind of, in some ways, it’s about trying to make people aware of what these systems can do by just showing a lot, right. Rather than picking one thing, and, like, this is a general-purpose technology. Let’s use it for this. And, like, everybody gets a light bulb for a different reason. So more than reading, it is using, you know, and that can be Copilot or whatever your favorite tool is.
But using it. Voice modes help a lot. In terms of readings, I mean, I think that there is a couple of good guides to understanding AI that were originally blog posts. I think Tim Lee has one called Understanding AI (opens in new tab), and it had a good overview …
LEE: Yeah, that’s a great one.
MOLLICK: … of that topic that I think explains how transformers work, which can give you some mental sense. I think [Andrej] Karpathy (opens in new tab) has some really nice videos of use that I would recommend.
Like on the medical side, I think the book that you did, if you’re in medicine, you should read that. I think that that’s very valuable. But like all we can offer are hints in some ways. Like there isn’t … if you’re looking for the instruction manual, I think it can be very frustrating because it’s like you want the best practices and procedures laid out, and we cannot do that, right. That’s not how a system like this works.
LEE: Yeah.
MOLLICK: It’s not a person, but thinking about it like a person can be helpful, right.
LEE: One of the things that has been sort of a fun project for me for the last few years is I have been a founding board member of a new medical school at Kaiser Permanente. And, you know, that medical school curriculum is being formed in this era. But it’s been perplexing to understand, you know, what this means for a medical school curriculum. And maybe even more perplexing for me, at least, is the accrediting bodies, which are extremely important in US medical schools; how accreditors should think about what’s necessary here.
Besides the things that you’ve … the, kind of, four key ideas you mentioned, if you were talking to the board of directors of the LCME [Liaison Committee on Medical Education] accrediting body, what’s the one thing you would want them to really internalize?
MOLLICK: This is both a fast-moving and vital area. This can’t be viewed like a usual change, which [is], “Let’s see how this works.” Because it’s, like, the things that make medical technologies hard to do, which is like unclear results, limited, you know, expensive use cases where it rolls out slowly. So one or two, you know, advanced medical facilities get access to, you know, proton beams or something else at multi-billion dollars of cost, and that takes a while to diffuse out. That’s not happening here. This is all happening at the same time, all at once. This is now … AI is part of medicine.
I mean, there’s a minor point that I’d make that actually is a really important one, which is large language models, generative AI overall, work incredibly differently than other forms of AI. So the other worry I have with some of these accreditors is they blend together algorithmic forms of AI, which medicine has been trying for long time—decision support, algorithmic methods, like, medicine more so than other places has been thinking about those issues. Generative AI, even though it uses the same underlying techniques, is a completely different beast.
So, like, even just take the most simple thing of algorithmic aversion, which is a well-understood problem in medicine, right. Which is, so you have a tool that could tell you as a radiologist, you know, the chance of this being cancer; you don’t like it, you overrule it, right.
We don’t find algorithmic aversion happening with LLMs in the same way. People actually enjoy using them because it’s more like working with a person. The flaws are different. The approach is different. So you need to both view this as universal applicable today, which makes it urgent, but also as something that is not the same as your other form of AI, and your AI working group that is thinking about how to solve this problem is not the right people here.
LEE: You know, I think the world has been trained because of the magic of web search to view computers as question-answering machines. Ask a question, get an answer.
MOLLICK: Yes. Yes.
LEE: Write a query, get results. And as I have interacted with medical professionals, you can see that medical professionals have that model of a machine in mind. And I think that’s partly, I think psychologically, why hallucination is so alarming. Because you have a mental model of a computer as a machine that has absolutely rock-solid perfect memory recall.
But the thing that was so powerful in Co-Intelligence, and we tried to get at this in our book also, is that’s not the sweet spot. It’s this sort of deeper interaction, more of a collaboration. And I thought your use of the term Co-Intelligence really just even in the title of the book tried to capture this. When I think about education, it seems like that’s the first step, to get past this concept of a machine being just a question-answering machine. Do you have a reaction to that idea?
MOLLICK: I think that’s very powerful. You know, we’ve been trained over so many years at both using computers but also in science fiction, right. Computers are about cold logic, right. They will give you the right answer, but if you ask it what love is, they explode, right. Like that’s the classic way you defeat the evil robot in Star Trek, right. “Love does not compute.” [LAUGHTER]
Instead, we have a system that makes mistakes, is warm, beats doctors in empathy in almost every controlled study on the subject, right. Like, absolutely can outwrite you in a sonnet but will absolutely struggle with giving you the right answer every time. And I think our mental models are just broken for this. And I think you’re absolutely right. And that’s part of what I thought your book does get at really well is, like, this is a different thing. It’s also generally applicable. Again, the model in your head should be kind of like a person even though it isn’t, right.
There’s a lot of warnings and caveats to it, but if you start from person, smart person you’re talking to, your mental model will be more accurate than smart machine, even though both are flawed examples, right. So it will make mistakes; it will make errors. The question is, what do you trust it on? What do you not trust it? As you get to know a model, you’ll get to understand, like, I totally don’t trust it for this, but I absolutely trust it for that, right.
LEE: All right. So we’re getting to the end of the time we have together. And so I’d just like to get now into something a little bit more provocative. And I get the question all the time. You know, will AI replace doctors? In medicine and other advanced knowledge work, project out five to 10 years. What do think happens?
MOLLICK: OK, so first of all, let’s acknowledge systems change much more slowly than individual use. You know, doctors are not individual actors; they’re part of systems, right. So not just the system of a patient who like may or may not want to talk to a machine instead of a person but also legal systems and administrative systems and systems that allocate labor and systems that train people.
So, like, it’s hard to imagine that in five to 10 years medicine being so upended that even if AI was better than doctors at every single thing doctors do, that we’d actually see as radical a change in medicine as you might in other fields. I think you will see faster changes happen in consulting and law and, you know, coding, other spaces than medicine.
But I do think that there is good reason to suspect that AI will outperform people while still having flaws, right. That’s the difference. We’re already seeing that for common medical questions in enough randomized controlled trials that, you know, best doctors beat AI, but the AI beats the mean doctor, right. Like, that’s just something we should acknowledge is happening at this point.
Now, will that work in your specialty? No. Will that work with all the contingent social knowledge that you have in your space? Probably not.
Like, these are vignettes, right. But, like, that’s kind of where things are. So let’s assume, right … you’re asking two questions. One is, how good will AI get?
LEE: Yeah.
MOLLICK: And we don’t know the answer to that question. I will tell you that your colleagues at Microsoft and increasingly the labs, the AI labs themselves, are all saying they think they’ll have a machine smarter than a human at every intellectual task in the next two to three years. If that doesn’t happen, that makes it easier to assume the future, but let’s just assume that that’s the case. I think medicine starts to change with the idea that people feel obligated to use this to help for everything.
Your patients will be using it, and it will be your advisor and helper at the beginning phases, right. And I think that I expect people to be better at empathy. I expect better bedside manner. I expect management tasks to become easier. I think administrative burden might lighten if we handle this right way or much worse if we handle it badly. Diagnostic accuracy will increase, right.
And then there’s a set of discovery pieces happening, too, right. One of the core goals of all the AI companies is to accelerate medical research. How does that happen and how does that affect us is a, kind of, unknown question. So I think clinicians are in both the eye of the storm and surrounded by it, right. Like, they can resist AI use for longer than most other fields, but everything around them is going to be affected by it.
LEE: Well, Ethan, this has been really a fantastic conversation. And, you know, I think in contrast to all the other conversations we’ve had, this one gives especially the leaders in healthcare, you know, people actually trying to lead their organizations into the future, whether it’s in education or in delivery, a lot to think about. So I really appreciate you joining.
MOLLICK: Thank you.
[TRANSITION MUSIC]
I’m a computing researcher who works with people who are right in the middle of today’s bleeding-edge developments in AI. And because of that, I often lose sight of how to talk to a broader audience about what it’s all about. And so I think one of Ethan’s superpowers is that he has this knack for explaining complex topics in AI in a really accessible way, getting right to the most important points without making it so simple as to be useless. That’s why I rarely miss an opportunity to read up on his latest work.
One of the first things I learned from Ethan is the intuition that you can, sort of, think of AI as a very knowledgeable intern. In other words, think of it as a persona that you can interact with, but you also need to be a manager for it and to always assess the work that it does.
In our discussion, Ethan went further to stress that there is, because of that, a serious education gap. You know, over the last decade or two, we’ve all been trained, mainly by search engines, to think of computers as question-answering machines. In medicine, in fact, there’s a question-answering application that is really popular called UpToDate (opens in new tab). Doctors use it all the time. But generative AI systems like ChatGPT are different. There’s therefore a challenge in how to break out of the old-fashioned mindset of search to get the full value out of generative AI.
The other big takeaway for me was that Ethan pointed out while it’s easy to see productivity gains from AI at the individual level, those same gains, at least today, don’t often translate automatically to organization-wide or system-wide gains. And one, of course, has to conclude that it takes more than just making individuals more productive; the whole system also has to adjust to the realities of AI.
Here’s now my interview with Azeem Azhar:
LEE: Azeem, welcome.
AZEEM AZHAR: Peter, thank you so much for having me.
LEE: You know, I think you’re extremely well known in the world. But still, some of the listeners of this podcast series might not have encountered you before.
And so one of the ways I like to ask people to introduce themselves is, how do you explain to your parents what you do every day?
AZHAR: Well, I’m very lucky in that way because my mother was the person who got me into computers more than 40 years ago. And I still have that first computer, a ZX81 with a Z80 chip …
LEE: Oh wow.
AZHAR: … to this day. It sits in my study, all seven and a half thousand transistors and Bakelite plastic that it is. And my parents were both economists, and economics is deeply connected with technology in some sense. And I grew up in the late ’70s and the early ’80s. And that was a time of tremendous optimism around technology. It was space opera, science fiction, robots, and of course, the personal computer and, you know, Bill Gates and Steve Jobs. So that’s where I started.
And so, in a way, my mother and my dad, who passed away a few years ago, had always known me as someone who was fiddling with computers but also thinking about economics and society. And so, in a way, it’s easier to explain to them because they’re the ones who nurtured the environment that allowed me to research technology and AI and think about what it means to firms and to the economy at large.
LEE: I always like to understand the origin story. And what I mean by that is, you know, what was your first encounter with generative AI? And what was that like? What did you go through?
AZHAR: The first real moment was when Midjourney and Stable Diffusion emerged in that summer of 2022. I’d been away on vacation, and I came back—and I’d been off grid, in fact—and the world had really changed.
Now, I’d been aware of GPT-3 and GPT-2, which I played around with and with BERT, the original transformer paper about seven or eight years ago, but it was the moment where I could talk to my computer, and it could produce these images, and it could be refined in natural language that really made me think we’ve crossed into a new domain. We’ve gone from AI being highly discriminative to AI that’s able to explore the world in particular ways. And then it was a few months later that ChatGPT came out—November, the 30th.
And I think it was the next day or the day after that I said to my team, everyone has to use this, and we have to meet every morning and discuss how we experimented the day before. And we did that for three or four months. And, you know, it was really clear to me in that interface at that point that, you know, we’d absolutely pass some kind of threshold.
LEE: And who’s the we that you were experimenting with?
AZHAR: So I have a team of four who support me. They’re mostly researchers of different types. I mean, it’s almost like one of those jokes. You know, I have a sociologist, an economist, and an astrophysicist. And, you know, they walk into the bar, [LAUGHTER] or they walk into our virtual team room, and we try to solve problems.
LEE: Well, so let’s get now into brass tacks here. And I think I want to start maybe just with an exploration of the economics of all this and economic realities. Because I think in a lot of your work—for example, in your book—you look pretty deeply at how automation generally and AI specifically are transforming certain sectors like finance, manufacturing, and you have a really, kind of, insightful focus on what this means for productivity and which ways, you know, efficiencies are found.
And then you, sort of, balance that with risks, things that can and do go wrong. And so as you take that background and looking at all those other sectors, in what ways are the same patterns playing out or likely to play out in healthcare and medicine?
AZHAR: I’m sure we will see really remarkable parallels but also new things going on. I mean, medicine has a particular quality compared to other sectors in the sense that it’s highly regulated, market structure is very different country to country, and it’s an incredibly broad field. I mean, just think about taking a Tylenol and going through laparoscopic surgery. Having an MRI and seeing a physio. I mean, this is all medicine. I mean, it’s hard to imagine a sector that is [LAUGHS] more broad than that.
So I think we can start to break it down, and, you know, where we’re seeing things with generative AI will be that the, sort of, softest entry point, which is the medical scribing. And I’m sure many of us have been with clinicians who have a medical scribe running alongside—they’re all on Surface Pros I noticed, right? [LAUGHTER] They’re on the tablet computers, and they’re scribing away.
And what that’s doing is, in the words of my friend Eric Topol, it’s giving the clinician time back (opens in new tab), right. They have time back from days that are extremely busy and, you know, full of administrative overload. So I think you can obviously do a great deal with reducing that overload.
And within my team, we have a view, which is if you do something five times in a week, you should be writing an automation for it. And if you’re a doctor, you’re probably reviewing your notes, writing the prescriptions, and so on several times a day. So those are things that can clearly be automated, and the human can be in the loop. But I think there are so many other ways just within the clinic that things can help.
So, one of my friends, my friend from my junior school—I’ve known him since I was 9—is an oncologist who’s also deeply into machine learning, and he’s in Cambridge in the UK. And he built with Microsoft Research a suite of imaging AI tools from his own discipline, which they then open sourced.
So that’s another way that you have an impact, which is that you actually enable the, you know, generalist, specialist, polymath, whatever they are in health systems to be able to get this technology, to tune it to their requirements, to use it, to encourage some grassroots adoption in a system that’s often been very, very heavily centralized.
LEE: Yeah.
AZHAR: And then I think there are some other things that are going on that I find really, really exciting. So one is the consumerization of healthcare. So I have one of those sleep tracking rings, the Oura (opens in new tab).
LEE: Yup.
AZHAR: That is building a data stream that we’ll be able to apply more and more AI to. I mean, right now, it’s applying traditional, I suspect, machine learning, but you can imagine that as we start to get more data, we start to get more used to measuring ourselves, we create this sort of pot, a personal asset that we can turn AI to.
And there’s still another category. And that other category is one of the completely novel ways in which we can enable patient care and patient pathway. And there’s a fantastic startup in the UK called Neko Health (opens in new tab), which, I mean, does physicals, MRI scans, and blood tests, and so on.
It’s hard to imagine Neko existing without the sort of advanced data, machine learning, AI that we’ve seen emerge over the last decade. So, I mean, I think that there are so many ways in which the temperature is slowly being turned up to encourage a phase change within the healthcare sector.
And last but not least, I do think that these tools can also be very, very supportive of a clinician’s life cycle. I think we, as patients, we’re a bit … I don’t know if we’re as grateful as we should be for our clinicians who are putting in 90-hour weeks. [LAUGHTER] But you can imagine a world where AI is able to support not just the clinicians’ workload but also their sense of stress, their sense of burnout.
So just in those five areas, Peter, I sort of imagine we could start to fundamentally transform over the course of many years, of course, the way in which people think about their health and their interactions with healthcare systems
LEE: I love how you break that down. And I want to press on a couple of things.
You also touched on the fact that medicine is, at least in most of the world, is a highly regulated industry. I guess finance is the same way, but they also feel different because the, like, finance sector has to be very responsive to consumers, and consumers are sensitive to, you know, an abundance of choice; they are sensitive to price. Is there something unique about medicine besides being regulated?
AZHAR: I mean, there absolutely is. And in finance, as well, you have much clearer end states. So if you’re not in the consumer space, but you’re in the, you know, asset management space, you have to essentially deliver returns against the volatility or risk boundary, right. That’s what you have to go out and do. And I think if you’re in the consumer industry, you can come back to very, very clear measures, net promoter score being a very good example.
In the case of medicine and healthcare, it is much more complicated because as far as the clinician is concerned, people are individuals, and we have our own parts and our own responses. If we didn’t, there would never be a need for a differential diagnosis. There’d never be a need for, you know, Let’s try azithromycin first, and then if that doesn’t work, we’ll go to vancomycin, or, you know, whatever it happens to be. You would just know. But ultimately, you know, people are quite different. The symptoms that they’re showing are quite different, and also their compliance is really, really different.
I had a back problem that had to be dealt with by, you know, a physio and extremely boring exercises four times a week, but I was ruthless in complying, and my physio was incredibly surprised. He’d say well no one ever does this, and I said, well you know the thing is that I kind of just want to get this thing to go away.
LEE: Yeah.
AZHAR: And I think that that’s why medicine is and healthcare is so different and more complex. But I also think that’s why AI can be really, really helpful. I mean, we didn’t talk about, you know, AI in its ability to potentially do this, which is to extend the clinician’s presence throughout the week.
LEE: Right. Yeah.
AZHAR: The idea that maybe some part of what the clinician would do if you could talk to them on Wednesday, Thursday, and Friday could be delivered through an app or a chatbot just as a way of encouraging the compliance, which is often, especially with older patients, one reason why conditions, you know, linger on for longer.
LEE: You know, just staying on the regulatory thing, as I’ve thought about this, the one regulated sector that I think seems to have some parallels to healthcare is energy delivery, energy distribution.
Because like healthcare, as a consumer, I don’t have choice in who delivers electricity to my house. And even though I care about it being cheap or at least not being overcharged, I don’t have an abundance of choice. I can’t do price comparisons.
And there’s something about that, just speaking as a consumer of both energy and a consumer of healthcare, that feels similar. Whereas other regulated industries, you know, somehow, as a consumer, I feel like I have a lot more direct influence and power. Does that make any sense to someone, you know, like you, who’s really much more expert in how economic systems work?
AZHAR: I mean, in a sense, one part of that is very, very true. You have a limited panel of energy providers you can go to, and in the US, there may be places where you have no choice.
I think the area where it’s slightly different is that as a consumer or a patient, you can actually make meaningful choices and changes yourself using these technologies, and people used to joke about you know asking Dr. Google. But Dr. Google is not terrible, particularly if you go to WebMD. And, you know, when I look at long-range change, many of the regulations that exist around healthcare delivery were formed at a point before people had access to good quality information at the touch of their fingertips or when educational levels in general were much, much lower. And many regulations existed because of the incumbent power of particular professional sectors.
I’ll give you an example from the United Kingdom. So I have had asthma all of my life. That means I’ve been taking my inhaler, Ventolin, and maybe a steroid inhaler for nearly 50 years. That means that I know … actually, I’ve got more experience, and I—in some sense—know more about it than a general practitioner.
LEE: Yeah.
AZHAR: And until a few years ago, I would have to go to a general practitioner to get this drug that I’ve been taking for five decades, and there they are, age 30 or whatever it is. And a few years ago, the regulations changed. And now pharmacies can … or pharmacists can prescribe those types of drugs under certain conditions directly.
LEE: Right.
AZHAR: That was not to do with technology. That was to do with incumbent lock-in. So when we look at the medical industry, the healthcare space, there are some parallels with energy, but there are a few little things that the ability that the consumer has to put in some effort to learn about their condition, but also the fact that some of the regulations that exist just exist because certain professions are powerful.
LEE: Yeah, one last question while we’re still on economics. There seems to be a conundrum about productivity and efficiency in healthcare delivery because I’ve never encountered a doctor or a nurse that wants to be able to handle even more patients than they’re doing on a daily basis.
And so, you know, if productivity means simply, well, your rounds can now handle 16 patients instead of eight patients, that doesn’t seem necessarily to be a desirable thing. So how can we or should we be thinking about efficiency and productivity since obviously costs are, in most of the developed world, are a huge, huge problem?
AZHAR: Yes, and when you described doubling the number of patients on the round, I imagined you buying them all roller skates so they could just whizz around [LAUGHTER] the hospital faster and faster than ever before.
We can learn from what happened with the introduction of electricity. Electricity emerged at the end of the 19th century, around the same time that cars were emerging as a product, and car makers were very small and very artisanal. And in the early 1900s, some really smart car makers figured out that electricity was going to be important. And they bought into this technology by putting pendant lights in their workshops so they could “visit more patients.” Right?
LEE: Yeah, yeah.
AZHAR: They could effectively spend more hours working, and that was a productivity enhancement, and it was noticeable. But, of course, electricity fundamentally changed the productivity by orders of magnitude of people who made cars starting with Henry Ford because he was able to reorganize his factories around the electrical delivery of power and to therefore have the moving assembly line, which 10xed the productivity of that system.
So when we think about how AI will affect the clinician, the nurse, the doctor, it’s much easier for us to imagine it as the pendant light that just has them working later …
LEE: Right.
AZHAR: … than it is to imagine a reconceptualization of the relationship between the clinician and the people they care for.
And I’m not sure. I don’t think anybody knows what that looks like. But, you know, I do think that there will be a way that this changes, and you can see that scale out factor. And it may be, Peter, that what we end up doing is we end up saying, OK, because we have these brilliant AIs, there’s a lower level of training and cost and expense that’s required for a broader range of conditions that need treating. And that expands the market, right. That expands the market hugely. It’s what has happened in the market for taxis or ride sharing. The introduction of Uber and the GPS system …
LEE: Yup.
AZHAR: … has meant many more people now earn their living driving people around in their cars. And at least in London, you had to be reasonably highly trained to do that.
So I can see a reorganization is possible. Of course, entrenched interests, the economic flow … and there are many entrenched interests, particularly in the US between the health systems and the, you know, professional bodies that might slow things down. But I think a reimagining is possible.
And if I may, I’ll give you one example of that, which is, if you go to countries outside of the US where there are many more sick people per doctor, they have incentives to change the way they deliver their healthcare. And well before there was AI of this quality around, there was a few cases of health systems in India—Aravind Eye Care (opens in new tab) was one, and Narayana Hrudayalaya [now known as Narayana Health (opens in new tab)] was another. And in the latter, they were a cardiac care unit where you couldn’t get enough heart surgeons.
LEE: Yeah, yep.
AZHAR: So specially trained nurses would operate under the supervision of a single surgeon who would supervise many in parallel. So there are ways of increasing the quality of care, reducing the cost, but it does require a systems change. And we can’t expect a single bright algorithm to do it on its own.
LEE: Yeah, really, really interesting. So now let’s get into regulation. And let me start with this question. You know, there are several startup companies I’m aware of that are pushing on, I think, a near-term future possibility that a medical AI for consumer might be allowed, say, to prescribe a medication for you, something that would normally require a doctor or a pharmacist, you know, that is certified in some way, licensed to do. Do you think we’ll get to a point where for certain regulated activities, humans are more or less cut out of the loop?
AZHAR: Well, humans would have been in the loop because they would have provided the training data, they would have done the oversight, the quality control. But to your question in general, would we delegate an important decision entirely to a tested set of algorithms? I’m sure we will. We already do that. I delegate less important decisions like, What time should I leave for the airport to Waze. I delegate more important decisions to the automated braking in my car. We will do this at certain levels of risk and threshold.
If I come back to my example of prescribing Ventolin. It’s really unclear to me that the prescription of Ventolin, this incredibly benign bronchodilator that is only used by people who’ve been through the asthma process, needs to be prescribed by someone who’s gone through 10 years or 12 years of medical training. And why that couldn’t be prescribed by an algorithm or an AI system.
LEE: Right. Yep. Yep.
AZHAR: So, you know, I absolutely think that that will be the case and could be the case. I can’t really see what the objections are. And the real issue is where do you draw the line of where you say, “Listen, this is too important,” or “The cost is too great,” or “The side effects are too high,” and therefore this is a point at which we want to have some, you know, human taking personal responsibility, having a liability framework in place, having a sense that there is a person with legal agency who signed off on this decision. And that line I suspect will start fairly low, and what we’d expect to see would be that that would rise progressively over time.
LEE: What you just said, that scenario of your personal asthma medication, is really interesting because your personal AI might have the benefit of 50 years of your own experience with that medication. So, in a way, there is at least the data potential for, let’s say, the next prescription to be more personalized and more tailored specifically for you.
AZHAR: Yes. Well, let’s dig into this because I think this is super interesting, and we can look at how things have changed. So 15 years ago, if I had a bad asthma attack, which I might have once a year, I would have needed to go and see my general physician.
In the UK, it’s very difficult to get an appointment. I would have had to see someone privately who didn’t know me at all because I’ve just walked in off the street, and I would explain my situation. It would take me half a day. Productivity lost. I’ve been miserable for a couple of days with severe wheezing. Then a few years ago the system changed, a protocol changed, and now I have a thing called a rescue pack, which includes prednisolone steroids. It includes something else I’ve just forgotten, and an antibiotic in case I get an upper respiratory tract infection, and I have an “algorithm.” It’s called a protocol. It’s printed out. It’s a flowchart
I answer various questions, and then I say, “I’m going to prescribe this to myself.” You know, UK doctors don’t prescribe prednisolone, or prednisone as you may call it in the US, at the drop of a hat, right. It’s a powerful steroid. I can self-administer, and I can now get that repeat prescription without seeing a physician a couple of times a year. And the algorithm, the “AI” is, it’s obviously been done in PowerPoint naturally, and it’s a bunch of arrows. [LAUGHS]
Surely, surely, an AI system is going to be more sophisticated, more nuanced, and give me more assurance that I’m making the right decision around something like that.
LEE: Yeah. Well, at a minimum, the AI should be able to make that PowerPoint the next time. [LAUGHS]
AZHAR: Yeah, yeah. Thank god for Clippy. Yes.
LEE: So, you know, I think in our book, we had a lot of certainty about most of the things we’ve discussed here, but one chapter where I felt we really sort of ran out of ideas, frankly, was on regulation. And, you know, what we ended up doing for that chapter is … I can’t remember if it was Carey’s or Zak’s idea, but we asked GPT-4 to have a conversation, a debate with itself [LAUGHS], about regulation. And we made some minor commentary on that.
And really, I think we took that approach because we just didn’t have much to offer. By the way, in our defense, I don’t think anyone else had any better ideas anyway.
AZHAR: Right.
LEE: And so now two years later, do we have better ideas about the need for regulation, the frameworks around which those regulations should be developed, and, you know, what should this look like?
AZHAR: So regulation is going to be in some cases very helpful because it provides certainty for the clinician that they’re doing the right thing, that they are still insured for what they’re doing, and it provides some degree of confidence for the patient. And we need to make sure that the claims that are made stand up to quite rigorous levels, where ideally there are RCTs [randomized control trials], and there are the classic set of processes you go through.
You do also want to be able to experiment, and so the question is: as a regulator, how can you enable conditions for there to be experimentation? And what is experimentation? Experimentation is learning so that every element of the system can learn from this experience.
So finding that space where there can be bit of experimentation, I think, becomes very, very important. And a lot of this is about experience, so I think the first digital therapeutics have received FDA approval, which means there are now people within the FDA who understand how you go about running an approvals process for that, and what that ends up looking like—and of course what we’re very good at doing in this sort of modern hyper-connected world—is we can share that expertise, that knowledge, that experience very, very quickly.
So you go from one approval a year to a hundred approvals a year to a thousand approvals a year. So we will then actually, I suspect, need to think about what is it to approve digital therapeutics because, unlike big biological molecules, we can generate these digital therapeutics at the rate of knots [very rapidly].
LEE: Yes.
AZHAR: Every road in Hayes Valley in San Francisco, right, is churning out new startups who will want to do things like this. So then, I think about, what does it mean to get approved if indeed it gets approved? But we can also go really far with things that don’t require approval.
I come back to my sleep tracking ring. So I’ve been wearing this for a few years, and when I go and see my doctor or I have my annual checkup, one of the first things that he asks is how have I been sleeping. And in fact, I even sync my sleep tracking data to their medical record system, so he’s saying … hearing what I’m saying, but he’s actually pulling up the real data going, This patient’s lying to me again. Of course, I’m very truthful with my doctor, as we should all be. [LAUGHTER]
LEE: You know, actually, that brings up a point that consumer-facing health AI has to deal with pop science, bad science, you know, weird stuff that you hear on Reddit. And because one of the things that consumers want to know always is, you know, what’s the truth?
AZHAR: Right.
LEE: What can I rely on? And I think that somehow feels different than an AI that you actually put in the hands of, let’s say, a licensed practitioner. And so the regulatory issues seem very, very different for these two cases somehow.
AZHAR: I agree, they’re very different. And I think for a lot of areas, you will want to build AI systems that are first and foremost for the clinician, even if they have patient extensions, that idea that the clinician can still be with a patient during the week.
And you’ll do that anyway because you need the data, and you also need a little bit of a liability shield to have like a sensible person who’s been trained around that. And I think that’s going to be a very important pathway for many AI medical crossovers. We’re going to go through the clinician.
LEE: Yeah.
AZHAR: But I also do recognize what you say about the, kind of, kooky quackery that exists on Reddit. Although on Creatine, Reddit may yet prove to have been right. [LAUGHTER]
LEE: Yeah, that’s right. Yes, yeah, absolutely. Yeah.
AZHAR: Sometimes it’s right. And I think that it serves a really good role as a field of extreme experimentation. So if you’re somebody who makes a continuous glucose monitor traditionally given to diabetics but now lots of people will wear them—and sports people will wear them—you probably gathered a lot of extreme tail distribution data by reading the Reddit/biohackers …
LEE: Yes.
AZHAR: … for the last few years, where people were doing things that you would never want them to really do with the CGM [continuous glucose monitor]. And so I think we shouldn’t understate how important that petri dish can be for helping us learn what could happen next.
LEE: Oh, I think it’s absolutely going to be essential and a bigger thing in the future. So I think I just want to close here then with one last question. And I always try to be a little bit provocative with this.
And so as you look ahead to what doctors and nurses and patients might be doing two years from now, five years from now, 10 years from now, do you have any kind of firm predictions?
AZHAR: I’m going to push the boat out, and I’m going to go further out than closer in.
LEE: OK. [LAUGHS]
AZHAR: As patients, we will have many, many more touch points and interaction with our biomarkers and our health. We’ll be reading how well we feel through an array of things. And some of them we’ll be wearing directly, like sleep trackers and watches.
And so we’ll have a better sense of what’s happening in our lives. It’s like the moment you go from paper bank statements that arrive every month to being able to see your account in real time.
LEE: Yes.
AZHAR: And I suspect we’ll have … we’ll still have interactions with clinicians because societies that get richer see doctors more, societies that get older see doctors more, and we’re going to be doing both of those over the coming 10 years. But there will be a sense, I think, of continuous health engagement, not in an overbearing way, but just in a sense that we know it’s there, we can check in with it, it’s likely to be data that is compiled on our behalf somewhere centrally and delivered through a user experience that reinforces agency rather than anxiety.
And we’re learning how to do that slowly. I don’t think the health apps on our phones and devices have yet quite got that right. And that could help us personalize problems before they arise, and again, I use my experience for things that I’ve tracked really, really well. And I know from my data and from how I’m feeling when I’m on the verge of one of those severe asthma attacks that hits me once a year, and I can take a little bit of preemptive measure, so I think that that will become progressively more common and that sense that we will know our baselines.
I mean, when you think about being an athlete, which is something I think about, but I could never ever do, [LAUGHTER] but what happens is you start with your detailed baselines, and that’s what your health coach looks at every three or four months. For most of us, we have no idea of our baselines. You we get our blood pressure measured once a year. We will have baselines, and that will help us on an ongoing basis to better understand and be in control of our health. And then if the product designers get it right, it will be done in a way that doesn’t feel invasive, but it’ll be done in a way that feels enabling. We’ll still be engaging with clinicians augmented by AI systems more and more because they will also have gone up the stack. They won’t be spending their time on just “take two Tylenol and have a lie down” type of engagements because that will be dealt with earlier on in the system. And so we will be there in a very, very different set of relationships. And they will feel that they have different ways of looking after our health.
LEE: Azeem, it’s so comforting to hear such a wonderfully optimistic picture of the future of healthcare. And I actually agree with everything you’ve said.
Let me just thank you again for joining this conversation. I think it’s been really fascinating. And I think somehow the systemic issues, the systemic issues that you tend to just see with such clarity, I think are going to be the most, kind of, profound drivers of change in the future. So thank you so much.
AZHAR: Well, thank you, it’s been my pleasure, Peter, thank you.
[TRANSITION MUSIC]
I always think of Azeem as a systems thinker. He’s always able to take the experiences of new technologies at an individual level and then project out to what this could mean for whole organizations and whole societies.
In our conversation, I felt that Azeem really connected some of what we learned in a previous episode—for example, from Chrissy Farr—on the evolving consumerization of healthcare to the broader workforce and economic impacts that we’ve heard about from Ethan Mollick.
Azeem’s personal story about managing his asthma was also a great example. You know, he imagines a future, as do I, where personal AI might assist and remember decades of personal experience with a condition like asthma and thereby know more than any human being could possibly know in a deeply personalized and effective way, leading to better care. Azeem’s relentless optimism about our AI future was also so heartening to hear.
Both of these conversations leave me really optimistic about the future of AI in medicine. At the same time, it is pretty sobering to realize just how much we’ll all need to change in pretty fundamental and maybe even in radical ways. I think a big insight I got from these conversations is how we interact with machines is going to have to be altered not only at the individual level, but at the company level and maybe even at the societal level.
Since my conversation with Ethan and Azeem, there have been some pretty important developments that speak directly to this. Just last week at Build (opens in new tab), which is Microsoft’s yearly developer conference, we announced a slew of AI agent technologies. Our CEO, Satya Nadella, in fact, started his keynote by going online in a GitHub developer environment and then assigning a coding task to an AI agent, basically treating that AI as a full-fledged member of a development team. Other agents, for example, a meeting facilitator, a data analyst, a business researcher, travel agent, and more were also shown during the conference.
But pertinent to healthcare specifically, what really blew me away was the demonstration of a healthcare orchestrator agent. And the specific thing here was in Stanford’s cancer treatment center, when they are trying to decide on potentially experimental treatments for cancer patients, they convene a meeting of experts. That is typically called a tumor board. And so this AI healthcare orchestrator agent actually participated as a full-fledged member of a tumor board meeting to help bring data together, make sure that the latest medical knowledge was brought to bear, and to assist in the decision-making around a patient’s cancer treatment. It was pretty amazing.
[THEME MUSIC]
A big thank-you again to Ethan and Azeem for sharing their knowledge and understanding of the dynamics between AI and society more broadly. And to our listeners, thank you for joining us. I’m really excited for the upcoming episodes, including discussions on medical students’ experiences with AI and AI’s influence on the operation of health systems and public health departments. We hope you’ll continue to tune in.
Until next time.
[MUSIC FADES]
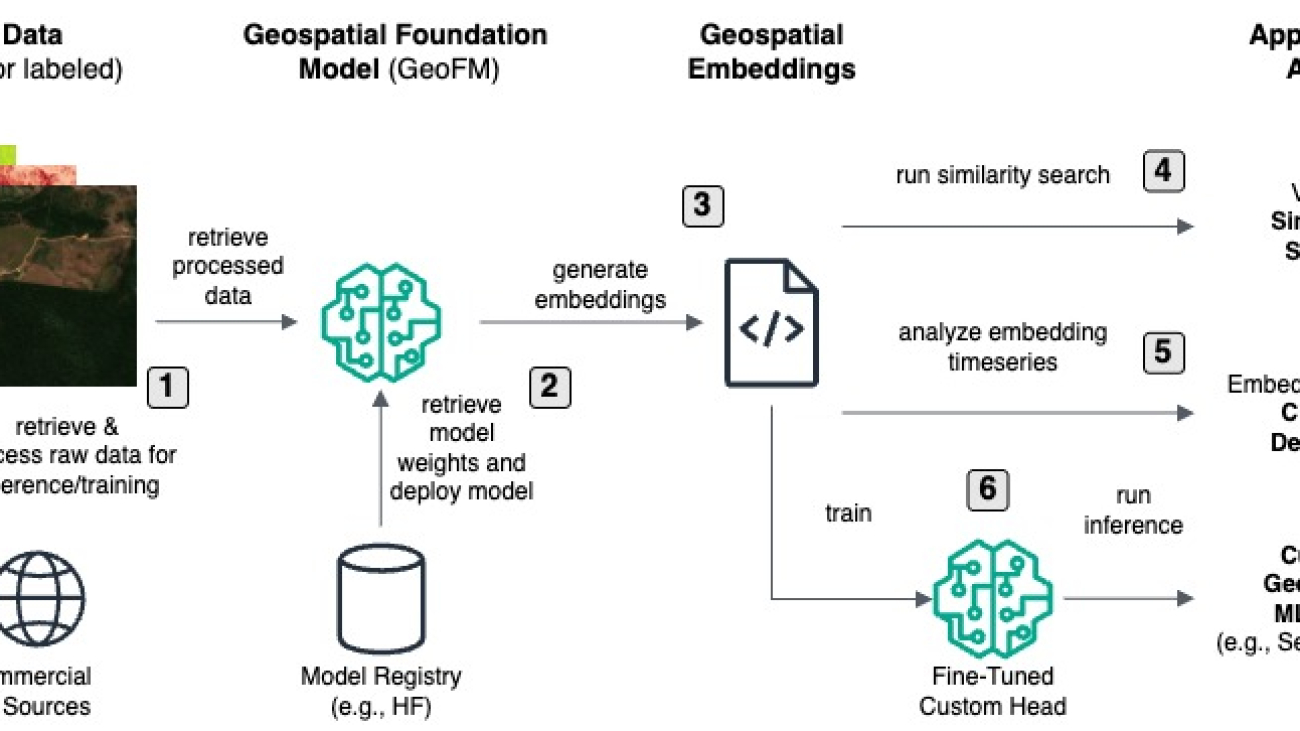






 Dr. Karsten Schroer is a Senior Machine Learning (ML) Prototyping Architect at AWS, focused on helping customers leverage artificial intelligence (AI), ML, and generative AI technologies. With deep ML expertise, he collaborates with companies across industries to design and implement data- and AI-driven solutions that generate business value. Karsten holds a PhD in applied ML.
Dr. Karsten Schroer is a Senior Machine Learning (ML) Prototyping Architect at AWS, focused on helping customers leverage artificial intelligence (AI), ML, and generative AI technologies. With deep ML expertise, he collaborates with companies across industries to design and implement data- and AI-driven solutions that generate business value. Karsten holds a PhD in applied ML. is a Senior ML Prototyping Architect at AWS with over a decade of experience in software engineering and AI/ML. Specializing in GenAI, LLMs, NLP, CV, and GeoSpatial ML, he collaborates with AWS customers to build solutions for challenging problems through co-development. His expertise accelerates customers’ journey from concept to production, tackling complex use cases across various industries. In his free time, he enjoys hiking, traveling, and spending time with family and friends.
is a Senior ML Prototyping Architect at AWS with over a decade of experience in software engineering and AI/ML. Specializing in GenAI, LLMs, NLP, CV, and GeoSpatial ML, he collaborates with AWS customers to build solutions for challenging problems through co-development. His expertise accelerates customers’ journey from concept to production, tackling complex use cases across various industries. In his free time, he enjoys hiking, traveling, and spending time with family and friends. Dr. Iza Moise is a Senior Machine Learning (ML) Prototyping Architect at AWS, with expertise in both traditional ML and advanced techniques like foundation models and vision transformers. She focuses on applied ML across diverse scientific fields, publishing and reviewing at Amazon’s internal ML conferences. Her strength lies in translating theoretical advances into practical solutions that deliver measurable impact through thoughtful implementation.
Dr. Iza Moise is a Senior Machine Learning (ML) Prototyping Architect at AWS, with expertise in both traditional ML and advanced techniques like foundation models and vision transformers. She focuses on applied ML across diverse scientific fields, publishing and reviewing at Amazon’s internal ML conferences. Her strength lies in translating theoretical advances into practical solutions that deliver measurable impact through thoughtful implementation.


 Ying Hou, PhD, is a Sr. Specialist Solution Architect for Gen AI at AWS, where she collaborates with model providers to onboard the latest and most intelligent AI models onto AWS platforms. With deep expertise in Gen AI, ASR, computer vision, NLP, and time-series forecasting models, she works closely with customers to design and build cutting-edge ML and GenAI applications. Outside of architecting innovative AI solutions, she enjoys spending quality time with her family, getting lost in novels, and exploring the UK’s national parks.
Ying Hou, PhD, is a Sr. Specialist Solution Architect for Gen AI at AWS, where she collaborates with model providers to onboard the latest and most intelligent AI models onto AWS platforms. With deep expertise in Gen AI, ASR, computer vision, NLP, and time-series forecasting models, she works closely with customers to design and build cutting-edge ML and GenAI applications. Outside of architecting innovative AI solutions, she enjoys spending quality time with her family, getting lost in novels, and exploring the UK’s national parks. Preston Tuggle is a Sr. Specialist Solutions Architect with the Third-Party Model Provider team at AWS. He focuses on working with model providers across Amazon Bedrock and Amazon SageMaker, helping them accelerate their go-to-market strategies through technical scaling initiatives and customer engagement.
Preston Tuggle is a Sr. Specialist Solutions Architect with the Third-Party Model Provider team at AWS. He focuses on working with model providers across Amazon Bedrock and Amazon SageMaker, helping them accelerate their go-to-market strategies through technical scaling initiatives and customer engagement.







































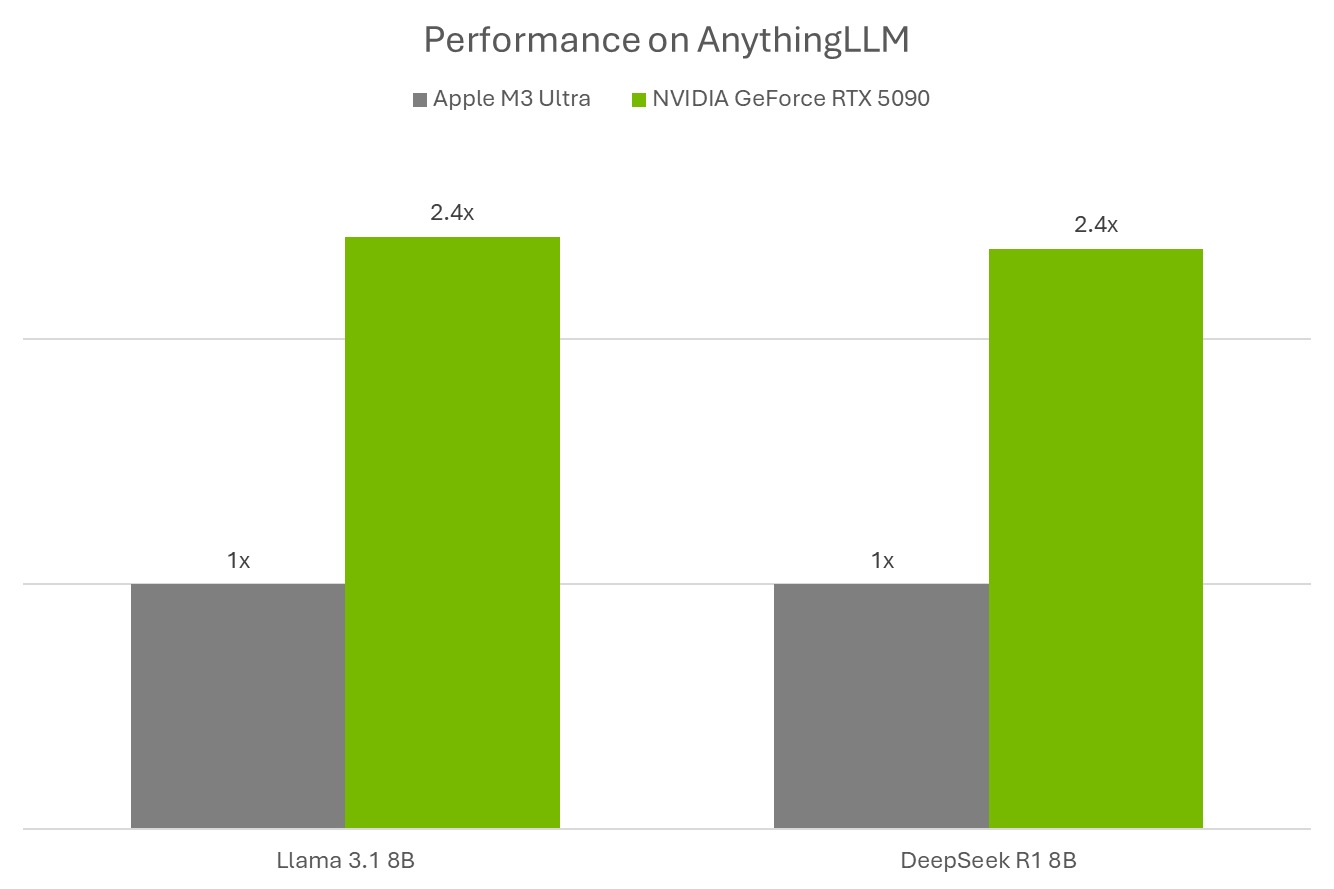


 Sovik Kumar Nath is an AI/ML and Generative AI senior solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
Sovik Kumar Nath is an AI/ML and Generative AI senior solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies. Lucas Banerji is an AI/ML and GenAI specialist Solutions Architect at AWS. He is passionate about building agentic AI systems and exploring the frontier of what’s possible with intelligent automation. Lucas holds a degree in Computer Science from the University of Virginia. Outside of work, he enjoys running, practicing Muay Thai, and traveling the world.
Lucas Banerji is an AI/ML and GenAI specialist Solutions Architect at AWS. He is passionate about building agentic AI systems and exploring the frontier of what’s possible with intelligent automation. Lucas holds a degree in Computer Science from the University of Virginia. Outside of work, he enjoys running, practicing Muay Thai, and traveling the world. Mohan Musti is a Principal Technical Account Manger based out of Dallas. Mohan helps customers architect and optimize applications on AWS. Mohan has Computer Science and Engineering from JNT University, India. In his spare time, he enjoys spending time with his family and camping.
Mohan Musti is a Principal Technical Account Manger based out of Dallas. Mohan helps customers architect and optimize applications on AWS. Mohan has Computer Science and Engineering from JNT University, India. In his spare time, he enjoys spending time with his family and camping.