Our updated version of Gemini 2.5 Pro Preview has improved capabilities for coding.Read More

Our updated version of Gemini 2.5 Pro Preview has improved capabilities for coding.Read More

Our updated version of Gemini 2.5 Pro Preview has improved capabilities for coding.Read More

Our updated version of Gemini 2.5 Pro Preview has improved capabilities for coding.Read More

Our updated version of Gemini 2.5 Pro Preview has improved capabilities for coding.Read More


The PyTorch Foundation is excited to welcome DeepSpeed, a deep learning optimization library, as a PyTorch Foundation-hosted project. Contributed by Microsoft, DeepSpeed empowers developers to streamline distributed training and inference, making it easier to scale AI models efficiently while minimizing costs and operational complexity. Since inception, DeepSpeed has leveraged core PyTorch functionalities as the foundation for building deep learning features and optimizations.
The PyTorch Foundation recently announced its expansion to an umbrella foundation to accelerate AI innovation and is pleased to welcome DeepSpeed as one of the first new projects. Foundation-Hosted Projects are projects that fall under the umbrella, they are officially governed and administered under the PyTorch Foundation’s neutral and transparent governance model.
DeepSpeed is designed to optimize deep learning workflows, providing a robust set of features that enhance the performance, scalability, and cost-efficiency of AI model training and deployment. It enables seamless scaling across thousands of GPUs while also optimizing resource utilization for constrained systems, addressing key technical challenges in AI development.
Key features of DeepSpeed include:
DeepSpeed’s addition as a PyTorch Foundation strengthens the foundation’s mission to accelerate open source AI. By joining PyTorch Foundation, DeepSpeed gains access to a thriving ecosystem of open source projects, a global network of contributors, and robust technical and operational resources. This collaboration enables the DeepSpeed community to scale its efforts, enhance interoperability with other projects, and drive broader adoption of its optimization library. Additionally, PyTorch Foundation’s focus on open governance and community-driven development ensures that DeepSpeed’s growth aligns with the shared goals of transparency, inclusivity, and innovation in the AI space.
Learn more about DeepSpeed and how to get involved by visiting the DeepSpeed website.


When we look back at the early days of PyTorch, our main focus was initially on accelerated training and developer experience for AI researchers. We wanted to empower researchers to easily express their ideas (no matter how crazy they were) and accelerate training, enabling them to quickly validate those ideas. This evolved to be broader when we established PyTorch 1.0, brought in Caffe2 and expanded the mission to become ‘research to production’. With PyTorch 2.0, the scope and vision yet again expanded to include a major focus on performance, including an expansion in our compiler investments, heterogenous hardware support, which has led to torch.compile, TorchInductor and investment in the Triton project. Throughout all of this, we maintained a design philosophy that values: (1) Usability over performance; (2) Simple over easy; and (3) Python first with a focus on language interoperability.
Moreover, when we first put the 3 year vision together for PyTorch back in 2020, the goals we set were:
With the PyTorch Foundation joining the Linux Foundation in 2022, this set the stage for the next phase of growth for the project. If we fast forward to today, the foundation is rapidly growing with 13 Premier members and a total of 30 member organizations, more diverse contributors than ever and a growing ecosystem. The PyTorch Foundation is well-positioned to continue to play a leadership role in the rapidly evolving field of AI.
All of that said, we yet again have a major opportunity to evolve PyTorch to play a much more integral role in setting the direction of open source AI and the industry at large.
Over the past two years, the AI landscape has undergone a remarkable transformation. Large Language Models (LLMs) have moved to the forefront, powering applications like ChatGPT and driving an open revolution of models spearheaded by Llama. Now, we’re witnessing agentic systems entering the mainstream. Despite these advances, significant challenges persist as we transition into a generative AI and agent-first world. To better understand the nature of these challenges, we should consider several key questions:
These challenging questions require a collective community working towards common goals to address them effectively. By bringing together diverse perspectives, we can build a comprehensive framework that integrates all layers of AI development—from hardware acceleration primitives to sophisticated agentic development, evaluation, and deployment practices. What we’re envisioning transcends typical technological initiatives; it’s more akin to developing a new language or operating system—a foundational infrastructure that enables entirely new possibilities.
One way to frame a broader vision for PyTorch is for it to be “The Open Language of AI”.
Modulo some wordsmithing, it feels like we should consider adding an additional goal for PyTorch:
Viewed as a foundational operating system: PyTorch powers the foundation of AI systems throughout the industry
As the depth of the AI stack expands, the reach of the PyTorch Foundation is also set to grow and expand.The PyTorch Foundation has thus just evolved into an umbrella foundation that expands the scope and impact of PyTorch well beyond its traditional roots as an AI framework, and allows the foundation to host high value projects in the AI landscape.
In welcoming new projects to the PyTorch Foundation, we will look to uphold the same design principles that have guided PyTorch to this day.
Starting with vLLM and DeepSpeed, we are going to bring together some of the most innovative communities in AI development and in the process building a broader and more comprehensive stack for AI developers.
Look for more project announcements coming very soon!
As we move forward here in 2025, the core PyTorch project continues to make progress across a number of areas. Some of the high-level themes include:
You can dig into the published roadmaps here for more details.
With the PyTorch Foundation now an umbrella foundation, we are focused on bringing in high-quality and complementary projects that extend the scope and vision of PyTorch. You will see projects announced over the weeks and months joining the foundation that will strengthen the PyTorch vision and create a rich portfolio of AI projects that integrate well and create a frictionless user experience. Our focus is on creating a trusted landscape of projects that are open source, have demonstrable value to the community and solve problems in the AI lifecycle.
Additionally, our community continues to grow rapidly, with 3 PyTorch Days announced for 2025 in Asia, Europe and India and our keystone event, the PyTorch Conference coming October 22nd and 23rd in the middle of Open Source AI Week 2025. The conference will also add an extra day this year with the Startup Showcase, Measuring Intelligence Summit, AI Infra Summit, hackathons, co-located open source AI events and networking opportunities. We’re excited about this awesome celebration of open source AI innovation and hope you’ll join us!
Cheers,
Joe & Luca


Expanded Foundation will Provide a Trusted and Vendor-Neutral Home for High-Impact and Innovative Open Source AI Projects
PyTorch Day France, Paris, France – May 7, 2025 – The PyTorch Foundation, a community-driven hub for open source AI, today announced its expansion into an umbrella foundation. As part of this milestone, two leading open source AI projects—vLLM and DeepSpeed—have been accepted into the foundation by the Technical Advisory Council. This expansion positions the PyTorch Foundation as the trusted home for a broad range of community-driven AI projects spanning the entire AI lifecycle—from training and inference and domain-specific applications to agentic frameworks.
As artificial intelligence becomes a critical driver of global innovation and competitive advantage, enterprises are under pressure to adopt scalable, secure, and future-focused AI solutions. With global GenAI spending forecasted to hit $644 billion this year, and demand growing for open source AI alternatives, the PyTorch Foundation is positioning itself as a vendor-neutral home for trusted and innovative new AI projects. The foundation will support the development of the next generation of open source AI tooling, ensuring interoperability, reducing vendor lock-in, and enabling faster integration of trusted, production-grade technologies. With transparent governance and broad industry collaboration, the PyTorch Foundation is playing a crucial role in shaping the infrastructure enterprises rely on to build and deploy responsible AI at scale.
“This is an exciting new chapter for the PyTorch Foundation and the broader open source AI ecosystem,” said Matt White, Executive Director of the PyTorch Foundation. “By transitioning to an umbrella foundation, we’re not only formalizing the momentum we’ve built across the PyTorch ecosystem—we’re creating space for new projects and innovators to thrive within a vendor-neutral, open governance environment.”
The decision to expand to an umbrella foundation is a natural evolution of the PyTorch Foundation’s rapid growth and global momentum. In just two and a half years, the organization has grown to include over 30 member companies and 120 vibrant ecosystem projects, and PyTorch itself has become the preferred framework for AI research and deployment. The new umbrella structure will support a broader portfolio of high-impact projects, foster deeper collaboration across domains, and help scale innovation throughout the AI lifecycle.
The PyTorch Foundation’s expanded scope allows it to host two new categories of projects:
Projects accepted under the PyTorch Foundation benefit from neutral IP governance, strategic support, increased visibility, and a global community of contributors. The PyTorch Foundation distinguishes between ecosystem projects, which remain independently governed, and foundation-hosted projects, which adopt the foundation’s open governance model and receive comprehensive operational support.
The first two projects accepted into the PyTorch Foundation as hosted projects are:
The PyTorch Foundation is committed to fostering the growth and adoption of open source AI solutions and tooling. Communities interested in joining the PyTorch Foundation’s expanding ecosystem can learn more about the process for becoming a project here.
“AMD has been a consistent supporter of open source software and the community of open source AI projects. We are excited about this expansion of the PyTorch Foundation, which provides a great opportunity for important AI projects to mature in an open and vendor-neutral ecosystem.”
– Ramine Roane, Corporate Vice President of AI Product Management, AMD
“At Arm, we believe collaboration is essential to empower developers and accelerate AI innovation from cloud to edge. The expansion of the PyTorch Foundation is a major milestone for the open source AI community—by providing a trusted home for projects like vLLM and DeepSpeed, the PyTorch Foundation is helping to unlock scalable, efficient AI and we’re proud to support this important evolution.”
– Alex Spinelli, Senior Vice President, AI and Developer Platforms and Services, Arm
“Open source frameworks are essential to advancing AI development, which is why AWS has been committed to the long-term success of the PyTorch ecosystem since its early days and through our continued support of the PyTorch Foundation. Expanding to an umbrella foundation highlights the rapid growth of this community and will make it easier to support a broader portfolio of high-impact projects, foster deeper collaboration across domains, and help scale innovation throughout the AI lifecycle.”
– Brian Granger, Senior Principal Technologist of AI Platforms, Amazon Web Services
“DeepSpeed is delighted to become a hosted Platform project in the PyTorch Foundation. From inception, DeepSpeed has built on PyTorch, with critical dependencies on features such as Module, Tensor, Distributed, and Compiler. We are eager to leverage this closer integration with the PyTorch ecosystem to achieve our goal of providing open and democratized access to state-of-the-art AI technologies for all.“
– Olatunji Ruwase, Project Lead, DeepSpeed
“Google congratulates the PyTorch Foundation on its expansion into an umbrella foundation. This evolution is poised to not only champion important open-source AI projects like vLLM and DeepSpeed, but is also a significant step forward in cultivating deeper collaboration and driving innovation within the AI community. We look forward to continuing to collaborate with the foundation and contributing to the expanded ecosystem.”
– Joe Pamer, Senior Director, ML Frameworks and Compilers, Google
“As a significant contributor to vLLM, DeepSpeed and PyTorch, Huawei welcomes their move to the foundation. We believe the professional services offered under the umbrella model will foster continued growth and value for users and developers.”
– Li Yongle, General Manager of Open Source Development, Huawei’s Computing Product Line
“Super excited for vLLM and DeepSpeed to join the PyTorch Foundation as it becomes an umbrella foundation. These packages are essential tools in the deep learning stack and integrate seamlessly with PyTorch. This is a strategic move that ensures future growth and maintenance for them.”
– Lysandre Debut, Chief Open-Source Officer, Hugging Face
“As a pivotal member of the PyTorch community for years, IBM applauds the expansion of the PyTorch Foundation to an umbrella foundation. This shift provides opportunities to support projects such as vLLM and others across the entire AI model lifecycle, from training to tuning to inference. An umbrella organization structure will support new workstreams underpinned by essential AI governance principles, accelerating performance in a new era of open, responsible AI.”
– Sriram Raghavan, VP, IBM Research AI
“As a premier member of the PyTorch Foundation, Intel is excited about the foundation’s expansion into an umbrella model. This strategy empowers developers with essential resources and support, enabling them to create innovative, community-driven AI projects that tackle real-world challenges.”
– Kismat Singh, VP, Engineering for AI Frameworks, Intel Corporation
“PyTorch sits at the very core of AI today. Meanwhile, the depth of the AI stack has grown dramatically—evolving from enabling accelerated compute to powering fully autonomous systems. Broadening the PyTorch Foundation is a key step in keeping the AI revolution open and accessible to all, across the stack and aligned with the principles PyTorch was built on.”
– Luca Antiga, CTO, Lightning AI
“Today PyTorch plays such a fundamental role in the AI space underpinning Llama, ChatGPT and so many other influential projects. This move to create an umbrella foundation enables PyTorch to significantly expand its ecosystem both horizontally and vertically in this era of agentic systems. I really believe this will usher in a new wave of innovation, and I’m especially excited about vLLM and DeepSpeed joining. These projects have a strong history of being critical to AI’s advances and it’s exciting that we are joining forces to grow this amazing community!”
– Joe Spisak, Product Director for PyTorch, Meta
“The PyTorch Foundation plays a vital role in advancing the PyTorch ecosystem by driving innovation, supporting education, and fostering community collaboration. Its expansion to an umbrella foundation helps ensure the long-term success of open source tools and creates the conditions necessary to welcome new projects that are essential to the future of open source AI.”
– Ujval Kapasi, VP of Deep Learning Software, NVIDIA
“At Snowflake, we believe that empowering the AI community is fundamental, and strengthening the open, vendor-neutral foundation around pivotal projects like these is crucial for progress. It’s truly exciting to witness the PyTorch Foundation evolve into an umbrella organization and welcome essential projects like DeepSpeed and vLLM. Having been part of the PyTorch ecosystem, I deeply appreciate the significance of this strategic move. We eagerly anticipate the accelerated innovation this closer collaboration within the PyTorch Foundation will bring.”
– Dwarak Rajagopal, VP of AI Engineering and Research, Snowflake
“We’re excited that vLLM is one of the first Platform Projects joining the PyTorch Foundation. vLLM is built on top of PyTorch with deep integration such as Torch Compile and multi-hardware support. We look forward to further collaborating with the ecosystem that powers innovations in open source and vendor neural technologies for AI.“
– Simon Mo, Project Co-Lead, vLLM
###
The PyTorch Foundation is a community-driven hub supporting the open source PyTorch framework and a broader portfolio of innovative open source AI projects. Hosted by the Linux Foundation, the PyTorch Foundation provides a vendor-neutral, trusted home for collaboration across the AI lifecycle—from model training and inference, to domain-specific applications. Through open governance, strategic support, and a global contributor community, the PyTorch Foundation empowers developers, researchers, and enterprises to build and deploy responsible AI at scale. Learn more at https://pytorch.org/foundation.
The Linux Foundation has registered trademarks and uses trademarks. For a list of trademarks of The Linux Foundation, please see our trademark usage page. Linux is a registered trademark of Linus Torvalds.
Media Contact
Natasha Woods
The Linux Foundation
nwoods@linuxfoundation.org


The PyTorch Foundation is excited to welcome vLLM as a PyTorch Foundation-hosted project. Contributed by the University of California – Berkeley, vLLM is a high-throughput, memory-efficient inference and serving engine designed for LLMs. vLLM has always had a strong connection with the PyTorch project. It is deeply integrated into PyTorch, leveraging it as a unified interface to support a wide array of hardware backends. These include NVIDIA GPUs, AMD GPUs, Google Cloud TPUs, Intel GPUs, Intel CPUs, Intel Gaudi HPUs, and AWS Neuron, among others. This tight coupling with PyTorch ensures seamless compatibility and performance optimization across diverse hardware platforms.
The PyTorch Foundation recently announced its expansion to an umbrella foundation to accelerate AI innovation and is pleased to welcome vLLM as one of the first new projects. Foundation-Hosted Projects are projects that fall under the umbrella, they are officially governed and administered under the PyTorch Foundation’s neutral and transparent governance model.
Running large language models (LLMs) is both resource-intensive and complex, especially as these models scale to hundreds of billions of parameters. That’s where vLLM comes in. Originally built around the innovative PagedAttention algorithm, vLLM has grown into a comprehensive, state-of-the-art inference engine. A thriving community is also continuously adding new features and optimizations to vLLM, including pipeline parallelism, chunked prefill, speculative decoding, and disaggregated serving.
Since its release, vLLM has garnered significant attention, achieving over 46,500 GitHub stars and over 1000 contributors—a testament to its popularity and thriving community. This milestone marks an exciting chapter for vLLM as we continue to empower developers and researchers with cutting-edge tools for efficient and scalable AI deployment. Welcome to the next era of LLM inference!
By becoming a PyTorch Foundation project, vLLM will collaborate with the PyTorch team closely on feature development. For example:
The partnership creates significant mutual advantages for both vLLM and PyTorch core. vLLM gains a committed steward in the Foundation, ensuring long-term codebase maintenance, production stability, and transparent community governance. Meanwhile, PyTorch benefits from vLLM’s ability to dramatically expand PyTorch adoption across diverse accelerator platforms while driving innovation in cutting-edge features that enhance the entire ecosystem.

At the end of March, the PyTorch Korea User Group hosted a special meetup that brought together prominent speakers for deep discussions on the PyTorch core and its broader ecosystem. With the event more than doubling in size compared to past gatherings, we were able to connect with even more developers and share insights. Huge thanks to goorm for sponsoring the fantastic venue! 

This recap is for those who couldn’t attend in person, as well as for participants who want to revisit the energy and insights of the day. The event featured experts in core PyTorch, AI accelerators, inference optimization, and large language model development. Below is a quick overview of the key sessions that anchored the conference.
Representing the PyTorch Foundation, part of the Linux Foundation, Jaeung provided an overview of how PyTorch is driving core open source technologies forward. He shared PyTorch’s growth story, the many global projects currently in motion, and the ecosystem’s impressive 20%+ annual growth. The session also covered how the foundation operates, how member organizations are involved, and upcoming plans that are particularly useful for practitioners.

Alban shared the design philosophy behind PyTorch and Meta’s official contribution roadmap (link). He provided a deep technical dive into the differences between Eager and Compiled modes, especially breaking down the backend architecture of device Eager execution. Practical tools and improvements were also introduced—such as memory profilers, enhanced custom operator support, and pinned memory optimizations.

Rebellions is building runtime integration for their proprietary NPU architecture, fully aligned with the structural changes in PyTorch 2.0. This talk introduced the performance and scalability of their upcoming chip, their integration strategy with the PyTorch runtime, and challenges in supporting Eager Mode. Hongseok also previewed their roadmap toward releasing these features within the year.

Backend.AI abstracts and integrates various AI accelerators into a unified workflow. As the diversity of accelerator architectures grows, the need for portability and infrastructure unification becomes even more important. This session showcased features across development and operations—from NPU scheduling and resource allocation to monitoring. Backend.AI currently supports accelerators from NVIDIA, Intel, Tenstorrent, Rebellions, and more.

This talk focused on the challenges of inference in real-world industrial applications of AI models. As new state-of-the-art models emerge rapidly, there’s a growing need for environments that can quickly validate device compatibility—ideally with one-click ease. NetsPresso is actively working on a static graph representation compatible with PyTorch, offering efficient support for model development, optimization, and testing.

Jungyeop took us through his journey of reproducing Deepseek, a large language model—an effort that involved 201 experiments. He shared real-world lessons from training with Korean data, tokenizer modifications, and fine-tuning strategies. His practical insights and next steps were especially valuable for those building or re-implementing large models from scratch.

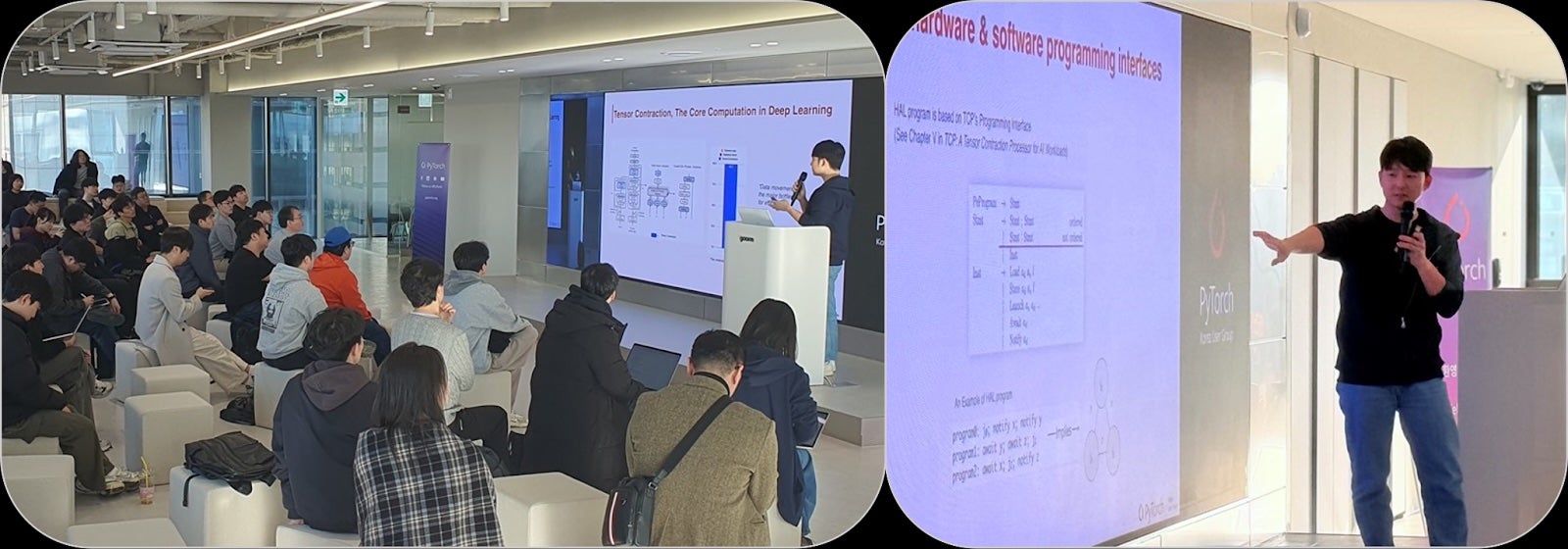
Sol presented an integrated optimization approach to deploying large models using the TCP(Tensor Contraction Processor) architecture, which supports tensor contraction at the hardware level. The talk highlighted optimization techniques built on hardware abstraction layers (HALs) and bottom-up integration strategies with PyTorch—offering a hybrid hardware-software perspective.
 Panel Talk & Q&A
Panel Talk & Q&A The event wrapped up with an engaging panel discussion. Attendees asked sharp questions, and the speakers offered insightful answers. It was a powerful moment that captured the community’s enthusiasm for PyTorch and their hunger for deeper technical understanding.

Since our first offline meetup in October 2022, the PyTorch Korea User Group has held five major technical conferences. Each event deepens our appreciation for the scale and depth of the PyTorch ecosystem. With perspectives from users, contributors, and ecosystem builders, the stories we share are only growing—and we’re committed to continuing this journey together.
See you at the next conference—with even more exciting talks to come! 

At the end of March, the PyTorch Korea User Group hosted a special meetup that brought together prominent speakers for deep discussions on the PyTorch core and its broader ecosystem. With the event more than doubling in size compared to past gatherings, we were able to connect with even more developers and share insights. Huge thanks to goorm for sponsoring the fantastic venue!

This recap is for those who couldn’t attend in person, as well as for participants who want to revisit the energy and insights of the day. The event featured experts in core PyTorch, AI accelerators, inference optimization, and large language model development. Below is a quick overview of the key sessions that anchored the conference.
Representing the PyTorch Foundation, part of the Linux Foundation, Jaeung provided an overview of how PyTorch is driving core open source technologies forward. He shared PyTorch’s growth story, the many global projects currently in motion, and the ecosystem’s impressive 20%+ annual growth. The session also covered how the foundation operates, how member organizations are involved, and upcoming plans that are particularly useful for practitioners.

Alban shared the design philosophy behind PyTorch and Meta’s official contribution roadmap (link). He provided a deep technical dive into the differences between Eager and Compiled modes, especially breaking down the backend architecture of device Eager execution. Practical tools and improvements were also introduced—such as memory profilers, enhanced custom operator support, and pinned memory optimizations.

Rebellions is building runtime integration for their proprietary NPU architecture, fully aligned with the structural changes in PyTorch 2.0. This talk introduced the performance and scalability of their upcoming chip, their integration strategy with the PyTorch runtime, and challenges in supporting Eager Mode. Hongseok also previewed their roadmap toward releasing these features within the year.

Backend.AI abstracts and integrates various AI accelerators into a unified workflow. As the diversity of accelerator architectures grows, the need for portability and infrastructure unification becomes even more important. This session showcased features across development and operations—from NPU scheduling and resource allocation to monitoring. Backend.AI currently supports accelerators from NVIDIA, Intel, Tenstorrent, Rebellions, and more.

This talk focused on the challenges of inference in real-world industrial applications of AI models. As new state-of-the-art models emerge rapidly, there’s a growing need for environments that can quickly validate device compatibility—ideally with one-click ease. NetsPresso is actively working on a static graph representation compatible with PyTorch, offering efficient support for model development, optimization, and testing.

Jungyeop took us through his journey of reproducing Deepseek, a large language model—an effort that involved 201 experiments. He shared real-world lessons from training with Korean data, tokenizer modifications, and fine-tuning strategies. His practical insights and next steps were especially valuable for those building or re-implementing large models from scratch.

Sol presented an integrated optimization approach to deploying large models using the TCP(Tensor Contraction Processor) architecture, which supports tensor contraction at the hardware level. The talk highlighted optimization techniques built on hardware abstraction layers (HALs) and bottom-up integration strategies with PyTorch—offering a hybrid hardware-software perspective.

Panel Talk & Q&A The event wrapped up with an engaging panel discussion. Attendees asked sharp questions, and the speakers offered insightful answers. It was a powerful moment that captured the community’s enthusiasm for PyTorch and their hunger for deeper technical understanding.

Since our first offline meetup in October 2022, the PyTorch Korea User Group has held five major technical conferences. Each event deepens our appreciation for the scale and depth of the PyTorch ecosystem. With perspectives from users, contributors, and ecosystem builders, the stories we share are only growing—and we’re committed to continuing this journey together.
See you at the next conference—with even more exciting talks to come!