[THEME MUSIC FADES]
The passage I read at the top there is from Chapter 9, “Safety First.”
One needs only to look at examples such as laws mandating seatbelts in cars and, more recently, internet regulation to know that policy and oversight are often playing catch-up with emerging technologies. When we were writing our book, Carey, Zak, and I didn’t claim that putting frameworks in place to allow for innovation and adoption while prioritizing inclusiveness and protecting patients from hallucination and other harms would be easy. In fact, in our writing, we posed more questions than answers in the hopes of highlighting the complexities at hand and supporting constructive discussion and action in this space.
In this episode, I’m pleased to welcome three experts who have been thinking deeply about these matters: Laura Adams, Vardit Ravitsky, and Dr. Roxana Daneshjou.
Laura is an expert in AI, digital health, and human-centered care. As a senior advisor at the National Academy of Medicine, or NAM, she guides strategy for the academy’s science and technology portfolio and leads the Artificial Intelligence Code of Conduct national initiative.
Vardit is president and CEO of The Hastings Center for Bioethics, a bioethics and health policy institute. She leads research projects funded by the National Institutes of Health, is a member of the committee developing the National Academy of Medicine’s AI Code of Conduct, and is a senior lecturer at Harvard Medical School.
Roxana is a board-certified dermatologist and an assistant professor of both dermatology and biomedical data science at Stanford University. Roxana is among the world’s thought leaders in AI, healthcare, and medicine, thanks in part to groundbreaking work on AI biases and trustworthiness.
One of the good fortunes I’ve had in my career is the chance to work with both Laura and Vardit, mainly through our joint work with the National Academy of Medicine. They’re both incredibly thoughtful and decisive leaders working very hard to help the world of healthcare—and healthcare regulators—come to grips with generative AI. And over the past few years, I’ve become an avid reader of all of Roxana’s research papers. Her work is highly technical, super influential but also informative in a way that spans computer science, medicine, bioethics, and law.
These three leaders—one from the medical establishment, one from the bioethics field, and the third from clinical research—provide insights into three incredibly important dimensions of the issues surrounding regulations, norms, and ethics of AI in medicine.
[TRANSITION MUSIC]
Here is my interview with Laura Adams:
LEE: Laura, I’m just incredibly honored and excited that you’re joining us here today, so welcome.
ADAMS: Thank you, Peter, my pleasure. Excited to be here.
LEE: So, Laura, you know, I’ve been working with you at the NAM for a while, and you are a strategic advisor at the NAM. But I think a lot of our listeners might not know too much about the National Academy of Medicine and then, within the National Academy of Medicine, what a strategic advisor does.
So why don’t we start there. You know, how would you explain to a person’s mother or father what the National Academy of Medicine is?
ADAMS: Sure. National Academy was formed more than 50 years ago. It was formed by the federal government, but it is not the federal government. It was formed as an independent body to advise the nation and the federal government on issues of science and primarily technology-related issues, as well.
So with that 50 years, some probably know of the National Academy of Medicine when it was the Institute of Medicine and produced such publications as To Err is Human (opens in new tab) and Crossing the Quality Chasm (opens in new tab), both of which were seminal publications that I think had a dramatic impact on quality, safety, and how we saw our healthcare system and what we saw in terms of its potential.
LEE: So now, for your role within NAM, what does the senior advisor do? What do you do?
ADAMS: What I do there is in the course of leading the AI Code of Conduct project, my role there was in framing the vision for that project, really understanding what did we want it to do, what impact did we want it to make.
So for example, some thought that it might be that we wanted everyone to use our code of conduct. And my advice on that was let’s use this as a touchstone. We want people to think about their own codes of conduct for their use of AI. That’s a valuable exercise, to decide what you value, what your aspirations are.
I also then do a lot of the field alignment around that work. So I probably did 50 talks last year—conference presentations, webinars, different things—where the code of conduct was presented so that the awareness could be raised around it so people could see the practicality of using that tool.
Especially the six commitments that were based on the idea of complex adaptive systems simple rules, where we could recall those in the heat of decision-making around AI, in the heat of application, or even in the planning and strategic thinking around it.
LEE: All right, we’re going to want to really break into a lot of details here.
But I would just like to rewind the clock a little bit and talk about your first encounters with AI. And there’s sort of, I guess, two eras. There’s the era of AI and machine learning before ChatGPT, before the generative AI era, and then afterwards.
Before the era of generative AI, what was your relationship with the idea of artificial intelligence? Was it a big part of your role and something you thought about, or was it just one of many technologies that you considered?
ADAMS: It was one of many.
LEE: Yeah.
ADAMS: Watching it help us evolve from predictive analytics to predictive AI, which of course I was fascinated by the fact that it could use structured and unstructured data, that it could learn from its own processes. These things were really quite remarkable, but my sense about it was that it was one of many.
We were looking at telemedicine. We were looking at [a] variety of other things, particularly wearables and things that were affecting and empowering patients to take better care of themselves and take more … have more agency around their own care. So I saw it as one of many.
And then the world changed in 2022, changed dramatically.
LEE: [LAUGHS] OK. Right. OK, so November 2022, ChatGPT. Later in the spring of 2023, GPT-4. And so, you know, what were your first encounters, and what were you feeling? What were you experiencing?
ADAMS: At the time, I was curious, and I thought, I think I’m seeing four things here that make this way different.
And one was, and it proved to be true over time, the speed with which this evolved. And I was watching it evolve very, very quickly and thinking, this is almost, this is kind of mind blowing how fast this is getting better.
And then this idea that, you know, we could scale this. As we were watching the early work with ambient listening, I was working with a group of physicians that were lamenting the cost and the unavailability of scribes. They wanted to use scribes. And I’m thinking, We don’t have to incur the cost of that. We don’t have to struggle with the unavailability of that type of … someone in the workforce.
And then I started watching the ubiquity, and I thought, Oh, my gosh, this is unlike any other technology that we’ve seen. Because with electronic health records, for example, it’s had its place, but it was over here. We had another digital technology, maybe telehealth, over here. This was one, and I thought, there will be no aspect of healthcare that will be left untouched by AI. That blew my mind.
LEE: Yeah.
ADAMS: And then I think the last thing was the democratization. And I realized: Wow, anyone with a smartphone has access to the most powerful large language models in the world.
And I thought, This, to me, is a revolution in cheap expertise. Those were the things that really began to stun me, and I just knew that we were in a way different era.
LEE: It’s interesting that you first talked about ambient listening. Why was that of particular initial interest to you specifically?
ADAMS: It was because one of the things that we were putting together in our code of conduct, which began pre-generative AI, was the idea that we wanted to renew the moral well-being and the sense of shared purpose to the healthcare workforce. That’s one of the six principles.
And I knew that the cognitive burden was becoming unbearable. When we came out of COVID, it was such a huge wake-up call to understand exactly what was going on at that point of care and how challenging it had become because information overload is astonishing in and of itself. And that idea that we have so much in the way of documentation that needed to be done and how much of a clinician’s time was taken up doing that rather than doing the thing that they went into the profession to do. And that was interact with people, that was to heal, that was to develop human connection that had a healing effect, and they just … so much of the time was taken away from that activity.
I also looked at it and because I studied diffusion of innovations theory and understand what causes something to move rapidly across a social system and get adopted, it has to have a clear relative advantage. It has to be compatible with the way that processes work.
So I didn’t see that this was going to be a hugely disruptive activity to workflow, which is a challenge of most digital tools, is that they’re designed without that sense of, how does this impact the workflow? And then I just thought that it was going to be a front runner in adoption, and it might then start to create that tsunami, that wave of interest in this, and I don’t think I was wrong.
LEE: I have to ask you, because I’ve been asking every guest, there must have been moments early on in the encounter with generative AI where you felt doubt or skepticism. Is that true, or did you immediately think, Wow, this is something very important?
ADAMS: No, I did feel doubt and skepticism.
My understanding tells me of it, and told me of it in the very beginning, that this is trained on the internet with all of its flaws. When we think about AI, we think about it being very futuristic, but it’s trained on data from the past. I’m well aware of how flawed that data, how biased that data is, mostly men, mostly white men, when we think about it during a certain age grouping of.
So I knew that we had inherent massive flaws in the training data and that concerned me. I saw other things about it that also concerned me. I saw that … its difficulty in beginning to use it and govern it effectively.
You really do have to put a good governance system in if you’re going to put this into a care delivery system. And I began to worry about widening a digital divide that already was a chasm. And that was between those well-resourced, usually urban, hospitals and health systems that are serving the well-resourced, and the inner-city hospital in Chicago or the rural hospital in Nebraska or the Mississippi community health center.
LEE: Yes. So I think this skepticism about technology, new technologies, in healthcare is very well-earned. So you’ve zeroed in on this issue of technology where oftentimes we hope it’ll reduce or eliminate biases but actually seems to oftentimes have the opposite effect.
And maybe this is a good segue then into this really super-important national effort that you’re leading on the AI code of conduct. Because in a way, I think those failures of the past and even just the idea—the promise—that technology should make a doctor or a nurse’s job easier, not harder, even that oftentimes seems not to have panned out in the way that we hope.
And then there’s, of course, the well-known issue of hallucinations or of mistakes being made. You know, how did those things inform this effort around a code of conduct, and why a code of conduct?
ADAMS: Those things weighed heavily on me as the initiative leader because I had been deeply involved in the spread of electronic health records, not really knowing and understanding that electronic health records were going to have the effect that they had on the providers that use them.
Looking back now, I think that there could have been design changes, but we probably didn’t have as much involvement of providers in the design. And in some cases, we did. We just didn’t understand what it would take to work it into their workflows.
So I wanted to be sure that the code of conduct took into consideration and made explicit some of the things that I believe would have helped us had we had those guardrails or those guidelines explicit for us.
And those are things like our first one is to protect and advance human health and connection.
We also wanted to see things about openly sharing and monitoring because we know that for this particular technology, it’s emergent. We’re going to have to do a much better job at understanding whether what we’re doing works and works in the real world.
So the reason for a code of conduct was we knew that … the good news, when the “here comes AI and it’s barreling toward us,” the good news was that everybody was putting together guidelines, frameworks, and principle sets. The bad news was same. That everybody was putting together their own guideline, principle, and framework set.
And I thought back to how much I struggled when I worked in the world of health information exchange and built a statewide health information exchange and then turned to try to exchange that data across the nation and realized that we had a patchwork of privacy laws and regulations across the state; it was extremely costly to try to move data.
And I thought we actually need, in addition to data interoperability, we need governance interoperability, where we can begin to agree on a core set of principles that will more easily allow us to move ahead and achieve some of the potential and the vision that we have for AI if we are not working with a patchwork of different guidelines, principles, and frameworks.
So that was the impetus behind it. Of course, we again want it to be used as a touchstone, not everybody wholesale adopt what we’ve said.
LEE: Right.
ADAMS: We want people to think about this and think deeply about it.
LEE: Yeah, Laura, I always am impressed with just how humble you are. You were indeed, you know, one of the prime instigators of the digitization of health records leading to electronic health record systems. And I don’t think you need to feel bad about that. That was a tremendous advance. I mean, moving a fifth of the US economy to be digital, I think, is significant.
Also, our listeners might want to know that you led something called the Rhode Island Quality Institute, which was really, I think, maybe the, arguably, the most important early kind of examples that set a pattern for how and why health data might actually lead very directly to improvements in human health at a statewide level or at a population level. And so I think your struggles and frustrations on, you know, how to expand that nationwide, I think, are really, really informative.
So let’s get into what these principles are, you know, what’s in the code of conduct.
ADAMS: Yeah, the six simple rules were derived out of a larger set of principles that we pulled together. And the origin of all of this was we did a fairly extensive landscape review. We looked at least at 60 different sets of these principles, guidelines, and frameworks. We looked for areas of real convergence. We looked for areas where there was inconsistencies. And we looked for out-and-out gaps.
The out-and-out gaps that we saw at the time were things like a dearth of references to advancing human health as the priority. Also monitoring post-implementation. So at the time, we were watching these evolve and we thought these are very significant gaps. Also, the impact on the environment was a significant gap, as well. And so when we pull that together, we developed a set of principles and cross-walked those with learning health system principles (opens in new tab).
And then once we got that, we again wanted to distill that down into a set of commitments which we knew that people could find accessible. And we published that draft set of principles (opens in new tab) last year. And we have a new publication that will be coming out in the coming months that will be the revised set of principles and code commitments that we got because we took this out publicly.
So we opened it up for public comment once we did the draft last year. Again, many of those times that I spoke about this, almost all of those times came with an invitation for feedback, and conversations that we had with people shaped it. And it is in no way, shape, or form a final code of conduct, this set of principles and commitments, because we see this as dynamic. But what we also knew about this was that we wanted to build this with a super solid foundation, a set of immutables, the things that don’t change at some vicissitudes or the whims of this or the whims of that. We wanted those things that were absolutely foundational.
LEE: Yeah, so we’ll provide a link to the documents that describe the current state of this, but can we give an example of one or two of these principles and one or two of the commitments?
ADAMS: Sure. I’ve mentioned the “protect and advance human health and connection” as the primary aim. We also want to ensure the equitable distribution of risks and benefits, and that equitable distribution of risks and benefits is something that I was referring to earlier about when I see well-resourced organizations. And one that’s particularly important to me is engaging people as partners with agency at every stage of the AI lifecycle.
That one matters because this one talks about and speaks to the idea that we want to begin bringing in those that are affected by AI, those on whom AI is used, into the early development and conceptualization of what we want this new tool, this new application, to do. So that includes the providers that use it, the patients. And we find that when we include them—the ethicists that come along with that—we develop much better applications, much more targeted applications that do what we intend them to do in a more precise way.
The other thing about that engaging with agency, by agency we mean that person, that participant can affect the decisions and they can affect the outcome. So it isn’t that they’re sort of a token person coming into the table and we’ll allow you to tell your story or so, but this is an active participant.
We practiced what we preached when we developed the code of conduct, and we brought patient advocates in to work with us on the development of this, work with us on our applications, that first layer down of what the applications would look like, which is coming out in this new paper.
We really wanted that component of this because I’m also seeing that patients are definitely not passive users of this, and they’re having an agency moment, let’s say, with generative AI because they’ve discovered a new capacity to gain information, to—in many ways—claim some autonomy in all of this.
And I think that there is a disruption underway right now, a big one that has been in the works for many years, but it feels to me like AI may be the tipping point for that disruption of the delivery system as we know it.
LEE: Right. I think it just exudes sort of inclusivity and thoughtfulness in the whole process. During this process, were there surprises, things that you didn’t expect? Things about AI technology itself that surprised you?
ADAMS: The surprises that came out of this process for me, one of them was I surprised myself. We were working on the commentary paper, and Steven Lin from Stanford had strong input into that paper. And when we looked at what we thought were missing, he said, “Let’s make sure we have the environmental impact.” And I said, “Oh, really, Steven, we really want to think about things that are more directly aligned with health,” which I couldn’t believe came out of my own mouth. [LAUGHTER]
And Steven, without saying, “Do you hear yourself?” I mean, I think he could have said that. But he was more diplomatic than that. And he persisted a bit longer and said, “I think it’s actually the greatest threat to human health.” And I said, “Of course, you’re right.” [LAUGHS]
But that was surprising and embarrassing for me. But it was eye-opening in that even when I thought that I had understood the gaps and the using this as a touchstone. So the learning that took place and how rapidly that learning was happening among people involved in this.
The other thing that was surprising for me was the degree at which patients became vastly facile with using it to the extent that it helped them begin to, again, build their own capacity.
The #PatientsUseAI from Dave deBronkart—watch that one. This is more revolutionary than we think. And so I watched that, the swell of that happening, and it sort of shocked me because I was envisioning this as, again, a tool for use in the clinical setting.
LEE: Yeah. OK, so we’re running now towards the end of our time together. And I always like to end our conversations with a more provocative topic. And I thought for you, I’d like to use the very difficult word regulation.
And when I think about the book that Carey, Zak, and I wrote, we have a chapter on regulation, but honestly, we didn’t have ideas. We couldn’t understand how this would be regulated. And so we just defaulted to publishing a conversation about regulation with GPT-4. And in a way, I think … I don’t know that I or my coauthors were satisfied with that.
In your mind, where do we stand two years later now when we think about the need or not to regulate AI, particularly in its application to healthcare, and where has the thinking evolved to?
ADAMS: There are two big differences that I see in that time that has elapsed. And the first one is we have understood the insufficiency of simply making sure that AI-enabled devices are safe prior to going out into implementation settings.
We recognize now that there’s got to be this whole other aspect of regulation and assurance that these things are functioning as intended and we have the capacity to do that in the point of care type of setting. So that’s been one of the major ones. The other thing is how wickedly challenging it is to regulate generative AI.
I think one of the most provocative and exciting articles (opens in new tab) that I saw written recently was by Bakul Patel and David Blumenthal, who posited, should we be regulating generative AI as we do a licensed and qualified provider?
Should it be treated in the sense that it’s got to have a certain amount of training and a foundation that’s got to pass certain tests? It has to demonstrate that it’s improving and keeping up with current literature. Does it … be responsible for mistakes that it makes in some way, shape, or form? Does it have to report its performance?
And I’m thinking, what a provocative idea …
LEE: Right.
ADAMS: … but it’s worth considering. I chair the Global Opportunities Group for a regulatory and innovation AI sandbox in the UK. And we’re hard at work thinking about, how do you regulate something as unfamiliar and untamed, really, as generative AI?
So I’d like to see us think more about this idea of sandboxes, more this idea of should we be just completely rethinking the way that we regulate. To me, that’s where the new ideas will come because the danger, of course, in regulating in the old way … first of all, we haven’t kept up over time, even with predictive AI; even with pre-generative AI, we haven’t kept up.
And what worries me about continuing on in that same vein is that we will stifle innovation …
LEE: Yes.
ADAMS: … and we won’t protect from potential harms. Nobody wants an AI Chernobyl, nobody.
LEE: Right
ADAMS: But I worry that if we use those old tools on the new applications that we will not only not regulate, then we’ll stifle innovation. And when I see all of the promise coming out of this for things that we thought were unimaginable, then that would be a tragedy.
LEE: You know, I think the other reflection I’ve had on this is the consumer aspect of it, because I think a lot of our current regulatory frameworks are geared towards experts using the technology.
ADAMS: Yes.
LEE: So when you have a medical device, you know you have a trained, board-certified doctor or licensed nurse using the technology. But when you’re putting things in the hands of a consumer, I think somehow the surface area of risk seems wider to me. And so I think that’s another thing that somehow our current regulatory concepts aren’t really ready for.
ADAMS: I would agree with that. I think a few things to consider, vis-a-vis that, is that this revolution of patients using it is unstoppable. So it will happen. But we’re considering a project here at the National Academy about patients using AI and thinking about: let’s explore all the different facets of that. Let’s understand, what does safe usage look like? What might we do to help this new development enhance the patient-provider relationship and not erode it as we saw, “Don’t confuse your Google search with my medical degree” type of approach.
Thinking about: how does it change the identity of the provider? How does it … what can we do to safely build a container in which patients can use this without giving them the sense that it’s being taken away, or that … because I just don’t see that happening. I don’t think they’re going to let it happen.
That, to me, feels extremely important for us to explore all the dimensions of that. And that is one project that I hope to be following on to the AI Code of Conduct and applying the code of conduct principles with that project.
LEE: Well, Laura, thank you again for joining us. And thank you even more for your tremendous national, even international, leadership on really helping mobilize the greatest institutions in a diverse way to fully confront the realities of AI in healthcare. I think it’s tremendously important work.
ADAMS: Peter, thank you for having me. This has been an absolute pleasure.
[TRANSITION MUSIC]
I’ve had the opportunity to watch Laura in action as she leads a national effort to define an AI code of conduct. And our conversation today has only heightened my admiration for her as a national leader.
What impresses me is Laura’s recognition that technology adoption in healthcare has had a checkered history and furthermore oftentimes not accommodated the huge diversity of stakeholders that are affected equally.
The concept of an AI code of conduct seems straightforward in some ways, but you can tell that every word in the emerging code has been chosen carefully. And Laura’s tireless engagement traveling to virtually every corner of the United States, as well as to several other countries, shows real dedication.
And now here’s my conversation with Vardit Ravitsky:
LEE: Vardit, thank you so much for joining.
RAVITSKY: It’s a real pleasure. I’m honored that you invited me.
LEE: You know, we’ve been lucky. We’ve had a few chances to interact and work together within the National Academy of Medicine and so on. But I think for many of the normal subscribers to the Microsoft Research Podcast, they might not know what The Hastings Center for Bioethics is and then what you as the leader of The Hastings Center do every day. So I’d like to start there, first off, with what is The Hastings Center?
RAVITSKY: Mostly, we’re a research center. We’ve been around for more than 55 years. And we’re considered one of the organizations that actually founded the field known today as bioethics, which is the field that explores the policy implications, the ethical, social issues in biomedicine. So we look at how biotechnology is rolled out; we look at issues of equity, of access to care. We look at issues at the end of life, the beginning of life, how our natural environment impacts our health. Any aspect of the delivery of healthcare, the design of the healthcare system, and biomedical research leading to all this. Any aspect that has an ethical implication is something that we’re happy to explore.
We try to have broad conversations with many, many stakeholders, people from different disciplines, in order to come up with guidelines and recommendations that would actually help patients, families, communities.
We also have an editorial department. We publish academic journals. We publish a blog. And we do a lot of public engagement activities—webinars, in-person events. So, you know, we just try to promote the thinking of the public and of experts on the ethical aspects of health and healthcare.
LEE: One thing I’ve been impressed with, with your work and the work of The Hastings Center is it really confronts big questions but also gets into a lot of practical detail. And so we’ll get there. But before that just a little bit about you then. The way I like to ask this question is: how do you explain to your parents what you do every day? [LAUGHS]
RAVITSKY: Funny that you brought my parents into this, Peter, because I come from a family of philosophers. Everybody in my family is in humanities, in academia. When I was 18, I thought that that was the only profession [LAUGHTER] and that I absolutely had to become a philosopher, or else what else can you do with your life?
I think being a bioethicist is really about, on one hand, keeping an eye constantly on the science as it evolves. When a new scientific development occurs, you have to understand what’s happening so that you can translate that outside of science. So if we can now make a gamete from a skin cell so that babies will be created differently, you have to understand how that’s done, what that means, and how to talk about it.
The second eye you keep on the ethics literature. What ethical frameworks, theories, principles have we developed over the last decades that are now relevant to this technology. So you’re really a bridge between science, biomedicine on one hand and humanities on the other hand.
LEE: OK. So let’s shift to AI. And here I’d like to start with a kind of an origin story because I’m assuming before generative AI and ChatGPT became widely known and available, you must have had some contact with ideas in data science, in machine learning, and, you know, in the concept of AI before ChatGPT. Is that true? And, you know, what were some of those early encounters like for you?
RAVITSKY: The earlier issues that I heard people talk about in the field were really around diagnostics and reading images and, Ooh, it looks like machines could perform better than radiologists. And, Oh, what if women preferred that their mammographies be read by these algorithms? And, Does that threaten us clinicians? Because it sort of highlights our limitations and weaknesses as, you know, the weakness of the human eye and the human brain.
So there were early concerns about, will this outperform the human and potentially take away our jobs? Will it impact our authority with patients? What about de-skilling clinicians or radiologists or any type of diagnostician losing the ability … some abilities that they’ve had historically because machines take over? So those were the early-day reflections and interestingly some of them remain even now with generative AI.
All those issues of the standing of a clinician, and what sets us apart, and will a machine ever be able to perform completely autonomously, and what about empathy, and what about relationships? Much of that translated later on into the, you know, more advanced technology.
LEE: I find it interesting that you use words like our and we to implicitly refer to humans, homo sapiens, to human beings. And so do you see a fundamental distinction, a hard distinction that separates humans from machines? Or, you know, how … if there are replacements of some human capabilities or some things that human beings do by machines, you know, how do you think about that?
RAVITSKY: Ooh, you’re really pushing hard on the philosopher in me here. [LAUGHTER] I’ve read books and heard lectures by those who think that the line is blurred, and I don’t buy that. I think there’s a clear line between human and machine.
I think the issue of AGI—of artificial general intelligence—and will that amount to consciousness … again, it’s such a profound, deep philosophical challenge that I think it would take a lot of conceptual work to get there. So how do we define consciousness? How do we define morality? The way it stands now, I look into the future without being a technologist, without being an AI developer, and I think, maybe I hope, that the line will remain clear. That there’s something about humanity that is irreplaceable.
But I’m also remembering that Immanuel Kant, the famous German philosopher, when he talked about what it means to be a part of the moral universe, what it means to be a moral agent, he talked about rationality and the ability to implement what he called the categorical imperative. And he said that would apply to any creature, not just humans.
And that’s so interesting. It’s always fascinated me that so many centuries ago, he said such a progressive thing.
LEE: That’s amazing, yeah.
RAVITSKY: It is amazing because I often, as an ethicist, I don’t just ask myself, What makes us human? I ask myself, What makes us worthy of moral respect? What makes us holders of rights? What gives us special status in the universe that other creatures don’t have? And I know this has been challenged by people like Peter Singer who say [that] some animals should have the same respect. “And what about fetuses and what about people in a coma?” I know the landscape is very fraught.
But the notion of what makes humans deserving of special moral treatment to me is the core question of ethics. And if we think that it’s some capacities that give us this respect, that make us hold that status, then maybe it goes beyond human. So it doesn’t mean that the machine is human, but maybe at [a] certain point, these machines will deserve a certain type of moral respect that … it’s hard for us right now to think of a machine as deserving that respect. That I can see.
But completely collapsing the distinction between human and machine? I don’t think so, and I hope not.
LEE: Yeah. Well, you know, in a way I think it’s easier to entertain this type of conversation post-ChatGPT. And so now, you know, what was your first personal encounter with what we now call generative AI, and what went through your mind as you had that first encounter?
RAVITSKY: No one’s ever asked me this before, Peter. It almost feels exposing to share your first encounter. [LAUGHTER]
So I just logged on, and I asked a simple question, but it was an ethical question. I framed an ethical dilemma because I thought, if I ask it to plan a trip, like all my friends already did, it’s less interesting to me.
And within seconds, a pretty thoughtful, surprisingly nuanced analysis was kind of trickling down my screen, and I was shocked. I was really taken aback. I was almost sad because I think my whole life I was hoping that only humans can generate this kind of thinking using moral and ethical terms.
And then I started tweaking my question, and I asked for specific philosophical approaches to this. And it just kept surprising me in how well it performed.
So I literally had to catch my breath and, you know, sit down and go, OK, this is a new world, something very important and potentially scary is happening here. How is this going to impact my teaching? How is this going to impact my writing? How is this going to impact health? Like, it was really a moment of shock.
LEE: I think the first time I had the privilege of meeting you, I heard you speak and share some of your initial framing of how, you know, how to think about the potential ethical implications of AI and the human impacts of AI in the future. Keeping in mind that people listening to this podcast will tend to be technologists and computer scientists as well as some medical educators and practicing clinicians, you know, what would you like them to know or understand most about your thoughts?
RAVITSKY: I think from early on, Peter, I’ve been an advocate in favor of bioethics as a field positioning itself to be a facilitator of implementing AI. I think on one hand, if we remain the naysayers as we have been regarding other technologies, we will become irrelevant. Because it’s happening, it’s happening fast, we have to keep our eye on the ball, and not ask, “Should we do it?” But rather ask, “How should we do it?”
And one of the reasons that bioethics is going to be such a critical player is that the stakes are so high. The risk of making a mistake in diagnostics is literally life and death; the risk of breaches of privacy that would lead to patients losing trust and refusing to use these tools; the risk of clinicians feeling overwhelmed and replaceable. The risks are just too high.
And therefore, creating guardrails, creating frameworks with principles that sensitize us to the ethical aspects, that is critically important for AI and health to succeed. And I’m saying it as someone who wants it very badly to succeed.
LEE: You are actually seeing a lot of healthcare organizations adopting and deploying AI. Has any aspect of that been surprising to you? Have you expected it to be happening faster or slower or unfolding in a different way?
RAVITSKY: One thing that surprises me is how it seems to be isolated. Different systems, different institutions making their own, you know, decisions about what to acquire and how to implement. I’m not seeing consistency. And I’m not even seeing anybody at a higher level collecting all the information about who’s buying and implementing what under what types of principles and what are their outcomes? What are they seeing?
It seems to be just siloed and happening everywhere. And I wish we collected all this data, even about how the decision is made at the executive level to buy a certain tool, to implement it, where, why, by whom. So that’s one thing that surprised me.
The speed is not surprising me because it really solves problems that healthcare systems have been struggling with. What seems to be one of the more popular uses, and again, you know this better than I do, is the help with scribes with taking notes, ambient recording. This seems to be really desired because of burnout that clinicians face around this whole issue of note taking.
And it’s also seen as a way to allow clinicians to do more human interaction, you know, …
LEE: Right.
RAVITSKY: … look at the patient, talk to the patient, …
LEE: Yep.
RAVITSKY: … listen, rather than focus on the screen. We’ve all sat across the desk with a doctor that never looks at us because they only look at the screen. So there’s a real problem here, and there’s a real solution and therefore it’s hitting the ground quickly.
But what’s surprising to me is how many places don’t think that it’s their responsibility to inform patients that this is happening. So some places do; some places don’t. And to me, this is a fundamental ethical issue of patient autonomy and empowerment. And it’s also pragmatically the fear of a crisis of trust. People don’t like being recorded without their consent. Surprise, surprise.
LEE: Mm-hmm. Yeah, yeah.
RAVITSKY: People worry about such a recording of a very private conversation that they consider to be confidential, such a recording ending up in the wrong hands or being shared externally or going to a commercial entity. People care; patients care.
So what is our ethical responsibility to tell them? And what is the institutional responsibility to implement these wonderful tools? I’m not against them, I’m totally in favor—implement these great tools in a way that respects long-standing ethical principles of informed consent, transparency, accountability for, you know, change in practice? And, you know, bottom line: patients right to know what’s happening in their care.
LEE: You actually recently had a paper in a medical journal (opens in new tab) that touched on an aspect of this, which I think was not with scribes, but with notes, you know, …
RAVITSKY: Yep.
LEE: … that doctors would send to patients. And in fact, in previous episodes of this podcast, we actually talked to both the technology developers of that type of feature as well as doctors who were using that feature. And in fact, even in those previous conversations, there was the question, “Well, what does the patient need to know about how this note was put together?” So you and your coauthors had a very interesting recent paper about this.
RAVITSKY: Yeah, so the trigger for the paper was that patients seemed to really like being able to send electronic messages to clinicians.
LEE: Yes.
RAVITSKY: We email and text all day long. Why not in health, right? People are used to communicating in that way. It’s efficient; it’s fast.
So we asked ourselves, “Wait, what if an AI tool writes the response?” Because again, this is a huge burden on clinicians, and it’s a real issue of burnout.
We surveyed hundreds of respondents, and basically what we discovered is that there was a statistically significant difference in their level of satisfaction when they got an answer from a human clinician, when they got an answer, again, electronic message from AI.
And it turns out that they preferred the messages written by AI. They were longer, more detailed, even conveyed more empathy. You know, AI has all the time in the world [LAUGHS] to write you a text. It’s not rushing to the next one.
But then when we disclosed who wrote the message, they were less satisfied when they were told it was AI.
So the ethical question that that raises is the following: if your only metric is patient satisfaction, the solution is to respond using AI but not tell them that.
Now when we compared telling them that it was AI or human or not telling them anything, their satisfaction remained high, which means that if they were not told anything, they probably assumed that it was a human clinician writing, because their satisfaction for human clinician or no disclosure was the same.
So basically, if we say nothing and just send back an AI-generated response, they will be more satisfied because the response is nicer, but they won’t be put off by the fact that it was written by AI. And therefore, hey presto, optimal satisfaction. But we challenge that, and we say, it’s not just about satisfaction.
It’s about long-term trust. It’s about your right to know. It’s about empowering you to make decisions about how you want to communicate.
So we push back against this notion that we’re just there to optimize patient satisfaction, and we bring in broader ethical considerations that say, “No, patients need to know.” If it’s not the norm yet to get your message from AI, …
LEE: Yeah.
RAVITSKY: … they should know that this is happening. And I think, Peter, that maybe we’re in a transition period.
It could be that in two years, maybe less than that, most of our communication will come back from AI, and we will just take it for granted …
LEE: Right.
RAVITSKY: … that that’s the case. And at that point, maybe disclosure is not necessary because many, many surveys will show us that patients assume that, and therefore they are informed. But at this point in time, when it’s transition and it’s not the norm yet, I firmly think that ethics requires that we inform patients.
LEE: Let me push on this a little bit because I think this final point that you just made is, I think is so interesting. Does it matter what kind of information is coming from a human or AI? Is there a time when patients will have different expectations for different types of information from their doctors?
RAVITSKY: I think, Peter, that you’re asking the right question because it’s more nuanced. And these are the kinds of empirical questions that we will be exploring in the coming months and years. Our recent paper showed that there was no difference regarding the content. If the message was about what we call the “serious” matter or a less “serious” matter, the preferences were the same. But we didn’t go deep enough into that. That would require a different type of design of study. And you just said, you know, there are different types of information. We need to categorize them.
LEE: Yeah.
RAVITSKY: What types of information and what degree of impact on your life? Is it a life-and-death piece of information? Is it a quality-of-life piece of information? How central is it to your care and to your thinking? So all of that would have to be mapped out so that we can design these studies.
But you know, you pushed back in that way, and I want to push back in a different direction that to me is more fundamental and philosophical. How much do we know now? You know, I keep saying, oh, patients deserve a chance for informed consent, …
LEE: Right.
RAVITSKY: … and they need to be empowered to make decisions. And if they don’t want that tool used in their care, then they should be able to say, “No.” Really? Is that the world we live in now? [LAUGHTER] Do I have access to the black box that is my doctor’s brain? Do I know how they performed on this procedure in the last year?
Do I know whether they’re tired? Do I know if they’re up to speed on the literature with this? We already deal with black boxes, except they’re not AI. And I think the evidence emerges that AI outperforms the humans in so many of these tasks.
So my pushback is, are we seeing AI exceptionalism in the sense that if it’s AI, Huh, panic! We have to inform everybody about everything, and we have to give them choices, and they have to be able to reject that tool and the other tool versus, you know, the rate of human error in medicine is awful. People don’t know the numbers. The annual deaths attributed to medical error is outrageous.
So why are we so focused on informed consent and empowerment regarding implementation of AI and less in other contexts. Is it just because it’s new? Is it because it is some sort of existential threat, …
LEE: Yep, yeah.
RAVITSKY: … not just a matter of risk? I don’t know the answer, but I don’t want us to suffer from AI exceptionalism, and I don’t want us to hold AI to such a high standard that we won’t be able to benefit from it. Whereas, again, we’re dealing with black boxes already in medicine.
LEE: Just to stay on this topic, though, one more question, which is, maybe, almost silly in how hypothetical it is. If instead of email, it were a Teams call or a Zoom call, doctor-patient, except that the doctor is not the real doctor, but it’s a perfect replica of the doctor designed to basically fool the patient that this is the real human being and having that interaction. Does that change the bioethical considerations at all?
RAVITSKY: I think it does because it’s always a question of, are we really misleading? Now if you get a text message in an environment that, you know, people know AI is already integrated to some extent, maybe not your grandmother, but the younger generation is aware of this implementation, then maybe you can say, “Hmm. It was implied. I didn’t mean to mislead the patient.”
If the patient thinks they’re talking to a clinician, and they’re seeing, like—what if it’s not you now, Peter? What if I’m talking to an avatar [LAUGHS] or some representation of you? Would I feel that I was misled in recording this podcast? Yeah, I would. Because you really gave me good reasons to assume that it was you.
So it’s something deeper about trust, I think. And it touches on the notion of empathy. A lot of literature is being developed now on the issue of: what will remain the purview of the human clinician? What are humans good for [LAUGHS] when AI is so successful and especially in medicine?
And if we see that the text messages are read as conveying more empathy and more care and more attention, and if we then move to a visual representation, facial expressions that convey more empathy, we really need to take a hard look at what we mean by care. What about then the robots, right, that we can touch, that can hug us?
I think we’re really pushing the frontier of what we mean by human interaction, human connectedness, care, and empathy. This will be a lot of material for philosophers to ask themselves the fundamental question you asked me at first: what does it mean to be human?
But this time, what does it mean to be two humans together and to have a connection?
And if we can really be replaced in the sense that patients will feel more satisfied, more heard, more cared for, do we have ethical grounds for resisting that? And if so, why?
You’re really going deep here into the conceptual questions, but bioethics is already looking at that.
LEE: Vardit, it’s just always amazing to talk to you. The incredible span of what you think about from those fundamental philosophical questions all the way to the actual nitty gritty, like, you know, what parts of an email from a doctor to a patient should be marked as AI. I think that span is just incredible and incredibly needed and useful today. So thank you for all that you do.
RAVITSKY: Thank you so much for inviting me.
[TRANSITION MUSIC]
The field of bioethics, and this is my take, is all about the adoption of disruptive new technologies into biomedical research and healthcare. And Vardit is able to explain this with such clarity. I think one of the reasons that AI has been challenging for many people is that its use spans the gamut from the nuts and bolts of how and when to disclose to patients that AI is being used to craft an email, all the way to, what does it mean to be a human being caring for another human?
What I learned from the conversation with Vardit is that bioethicists are confronting head-on the issue of AI in medicine and not with an eye towards restricting it, but recognizing that the technology is real, it’s arrived, and needs to be harnessed now for maximum benefit.
And so now, here’s my conversation with Dr. Roxana Daneshjou:
LEE: Roxana, I’m just thrilled to have this chance to chat with you.
ROXANA DANESHJOU: Thank you so much for having me on today. I’m looking forward to our conversation.
LEE: In Microsoft Research, of course, you know, we think about healthcare and biomedicine a lot, but I think there’s less of an understanding from our audience what people actually do in their day-to-day work. And of course, you have such a broad background, both on the science side with a PhD and on the medical side. So what’s your typical work week like?
DANESHJOU: I spend basically 90% of my time working on running my research lab (opens in new tab) and doing research on how AI interacts with medicine, how we can implement it to fix the pain points in medicine, and how we can do that in a fair and responsible way. And 10% of my time, I am in clinic. So I am a practicing dermatologist at Stanford, and I see patients half a day a week.
LEE: And your background, it’s very interesting. There’s always been these MD-PhDs in the world, but somehow, especially right now with what’s happening in AI, people like you have become suddenly extremely important because it suddenly has become so important to be able to combine these two things. Did you have any inkling about that when you started, let’s say, on your PhD work?
DANESHJOU: So I would say that during my—[LAUGHS] because I was in training for so long—during … my PhD was in computational genomics, and I still have a significant interest in precision medicine, and I think AI is going to be central to that.
But I think the reason I became interested in AI initially is that I was thinking about how we associate genetic factors with patient phenotypes. Patient phenotypes being, How does the disease present? What does the disease look like? And I thought, you know, AI might be a good way to standardize phenotypes from images of, say, skin disease, because I was interested in dermatology at that time. And, you know, the part about phenotyping disease was a huge bottleneck because you would have humans sort of doing the phenotyping.
And so in my head, when I was getting into the space, I was thinking I’ll bring together, you know, computer vision and genetics to try to, you know, make new discoveries about how genetics impacts human disease. And then when I actually started my postdoc to learn computer vision, I went down this very huge rabbit hole, which I am still, I guess, falling down, where I realized, you know, about biases in computer vision and how much work needed to be done for generalizability.
And then after that, large language models came out, and, like, everybody else became incredibly interested in how this could help in healthcare and now also vision language models and multimodal models. So, you know, we’re just tumbling down the rabbit hole.
LEE: Indeed, I think you really made a name for yourself by looking at the issues of biases, for example, in training datasets. And that was well before large language models were a thing. Maybe our audience would like to hear a little bit more about that earlier work.
DANESHJOU: So as I mentioned, my PhD was in computational genetics. In genetics, what has happened during the genetic revolution is these large-scale studies to discover how genetic variation impacts human disease and human response to medication, so that’s what pharmacogenomics is, is human response to medications. And as I got, you know, entrenched in that world, I came to realize that I wasn’t really represented in the data. And it was because the majority of these genetic studies were on European ancestry individuals. You weren’t represented either.
LEE: Right, yeah.
DANESHJOU: Many diverse global populations were completely excluded from these studies, and genetic variation is quite diverse across the globe. And so you’re leaving out a large portion of genetic variation from these research studies. Now things have improved. It still needs work in genetics. But definitely there has been many amazing researchers, you know, sounding the alarm in that space. And so during my PhD, I actually focused on doing studies of pharmacogenomics in non-European ancestry populations. So when I came to computer vision and in particular dermatology, where there were a lot of papers being published about how AI models perform at diagnosing skin disease and several papers essentially saying, oh, it’s equivalent to a dermatologist—of course, that’s not completely true because it’s a very sort of contrived, you know, setting of diagnosis— …
LEE: Right, right.
DANESHJOU: … but my first inkling was, well, are these models going to be able to perform well across skin tones? And one of our, you know, landmark papers, which was in Science Advances (opens in new tab), showed … we created a diverse dataset, our own diverse benchmark of skin disease, and showed that the models performed significantly worse on brown and black skin. And I think the key here is we also showed that it was an addressable problem because when we fine-tuned on diverse skin tones, you could make that bias go away. So it was really, in this case, about what data was going into the training of these computer vision models.
LEE: Yeah, and I think if you’re listening to this conversation, if you haven’t read that paper, I think it’s really must reading. It was not only, Roxana, it wasn’t only just a landmark scientifically and medically, but it also sort of crossed the chasm and really became a subject of public discourse and debate, as well. And I think you really changed the public discourse around AI.
So now I want to get into generative AI. I always like to ask, what was your first encounter with generative AI personally? And what went through your head? You know, what was that experience like for you?
DANESHJOU: Yeah, I mean, I actually tell this story a lot because I think it’s a fun story. So I would say that I had played with, you know, GPT-3 prior and wasn’t particularly, you know, impressed …
LEE: Yeah.
DANESHJOU: … by how it was doing. And I was at NeurIPS [Conference on Neural Information Processing Systems] in New Orleans, and I was … we were walking back from a dinner. I was with Andrew Beam from Harvard. I was with his group.
And we were just, sort of, you know, walking along, enjoying the sites of New Orleans, chatting. And one of his students said, “Hey, OpenAI just released this thing called ChatGPT.”
LEE: So this would be New Orleans in December …
DANESHJOU: 2022.
LEE: 2022, right? Yes. Uh-huh. OK.
DANESHJOU: So I went back to my hotel room. I was very tired. But I, you know, went to the website to see, OK, like, what is this thing? And I started to ask it medical questions, and I started all of a sudden thinking, “Uh-oh, we have made … we have made a leap here; something has changed.”
LEE: So it must have been very intense for you from then because months later, you had another incredibly impactful, or landmark, paper basically looking at biases, race-based medicine in large language models (opens in new tab). So can you say more about that?
DANESHJOU: Yes. I work with a very diverse team, and we have thought about bias in medicine, not just with technology but also with humans. Humans have biases, too. And there’s this whole debate around, is the technology going to be more biased than the humans? How do we do that? But at the same time, like, the technology actually encodes the biases of humans.
And there was a paper in the Proceedings of the National Academy of Sciences (opens in new tab), which did not look at technology at all but actually looked at the race-based biases of medical trainees that were untrue and harmful in that they perpetuated racist beliefs.
And so we thought, if medical trainees and humans have these biases, why don’t we see if the models carry them forward? And we added a few more questions that we, sort of, brainstormed as a team, and we started asking the models those questions. And …
LEE: And by this time, it was GPT-4?
DANESHJOU: We did include GPT-4 because GPT-4 came out, as well. And we also included other models, as well, such as Claude, because we wanted to look across the board. And what we found is that all of the models had instances of perpetuating race-based medicine. And actually, the GPT models had one of the most, I think, one of the most egregious responses—and, again, this is 3.5 and 4; we haven’t, you know, fully checked to see what things look like, because there have been newer models—in that they said that we should use race in calculating kidney function because there were differences in muscle mass between the races. And this is sort of a racist trope in medicine that is not true because race is not based on biology; it’s a social construct.
So, yeah, that was that study. And that one did spur a lot of public conversation.
LEE: Your work there even had the issue of bias overtake hallucination, you know, as really the most central and most difficult issue. So how do you think about bias in LLMs, and does that in your mind disqualify the use of large language models from particular uses in medicine?
DANESHJOU: Yeah, I think that the hallucinations are an issue, too. And in some senses, they might even go with one another, right. Like, if it’s hallucinating information that’s not true but also, like, biased.
So I think these are issues that we have to address with the use of LLMs in healthcare. But at the same time, things are moving very fast in this space. I mean, we have a secure instance of several large language models within our healthcare system at Stanford so that you could actually put secure patient information in there.
So while I acknowledge that bias and hallucinations are a huge issue, I also acknowledge that the healthcare system is quite broken and needs to be improved, needs to be streamlined. Physicians are burned out; patients are not getting access to care in the appropriate ways. And I have a really great story about that, which I can share with you later.
So in 2024, we did a study asking dermatologists, are they using large language models (opens in new tab) in their clinical practice? And I think this percentage has probably gone up since then: 65% of dermatologists reported using large language models in their practices on tasks such as, you know, writing insurance authorization letters, you know, writing information sheets for the patient, even, sort of, using them to educate themselves, which makes me a little nervous because in my mind, the best use of large language models right now are cases where you can verify facts easily.
So, for example, I did show and teach my nurse how to use our secure large language model in our healthcare system to write rebuttal letters to the insurance. I told her, “Hey, you put in these bullet points that you want to make, and you ask it to write the letter, and you can verify that the letter contains the facts which you want and which are true.”
LEE: Yes.
DANESHJOU: And we have also done a lot of work to try to stress test models because we want them to be better. And so we held this red-teaming event at Stanford where we brought together 80 physicians, computer scientists, engineers and had them write scenarios and real questions that they might ask on a day to day or tasks that they might actually ask AI to do.
And then we had them grade the performance. And we did this with the GPT models. At the time, we were doing it with GPT-3.5, 4, and 4 with internet. But before the paper (opens in new tab) came out, we then ran the dataset on newer models.
And we made the dataset public (opens in new tab) because I’m a big believer in public data. So we made the dataset public so that others could use this dataset, and we labeled what the issues were in the responses, whether it was bias, hallucination, like, a privacy issue, those sort of things.
LEE: If I think about the hits or misses in our book, you know, we actually wrote a little bit, not too much, about noticing biases. I think we underestimated the magnitude of the issue in our book. And another element that we wrote about in our book is that we noticed that the language model, if presented with some biased decision-making, more often than not was able to spot that the decision-making was possibly being influenced by some bias. What do you make of that?
DANESHJOU: So funny enough, I think we had … we had a—before I moved from Twitter to Bluesky—but we had a little back and forth on Twitter about this, which actually inspired us to look into this as a research, and we have a preprint up on it of actually using other large language models to identify bias and then to write critiques that the original model can incorporate and improve its answer upon.
I mean, we’re moving towards this sort of agentic systems framework rather than a singular large language model, and people, of course, are talking about also retrieval-augmented generation, where you sort of have this corpus of, you know, text that you trust and find trustworthy and have that incorporated into the response of the model.
And so you could build systems essentially where you do have other models saying, “Hey, specifically look for bias.” And then it will sort of focus on that task. And you can even, you know, give it examples of what bias is within context learning now. So I do think that we are going to be improving in this space. And actually, my team is … most recently, we’re working on building patient-facing chatbots. That’s where my, like, patient story comes in. But we’re building patient-facing chatbots. And we’re using, you know, we’re using prompt-engineering tools. We’re using automated eval tools. We’re building all of these things to try to make it more accurate and less bias. So it’s not just like one LLM spitting out an answer. It’s a whole system.
LEE: All right. So let’s get to your patient-facing story.
DANESHJOU: Oh, of course. Over the summer, my 6-year-old fell off the monkey bars and broke her arm. And I picked her up from school. She’s crying so badly. And I just look at her, and I know that we’re in trouble.
And I said, OK, you know, we’re going straight to the emergency room. And we went straight to the emergency room. She’s crying the whole time. I’m almost crying because it’s just, like, she doesn’t even want to go into the hospital. And so then my husband shows up, and we also had the baby, and the baby wasn’t allowed in the emergency room, so I had to step out.
And thanks to the [21st Century] Cures Act (opens in new tab), I’m getting, like, all the information, you know, as it’s happening. Like, I’m getting the x-ray results, and I’m looking at it. And I can tell there’s a fracture, but I can’t, you know, tell, like, how bad it is. Like, is this something that’s going to need surgery?
And I’m desperately texting, like, all the orthopedic folks I know, the pediatricians I know. [LAUGHTER] “Hey, what does this mean?” Like, getting real-time information. And later in the process, there was a mistake in her after-visit summary about how much Tylenol she could take. But I, as a physician, knew that this dose was a mistake.
I actually asked ChatGPT. I gave it the whole after-visit summary, and I said, are there any mistakes here? And it clued in that the dose of the medication was wrong. So again, I—as a physician with all these resources—have difficulty kind of navigating the healthcare system; understanding what’s going on in x-ray results that are showing up on my phone; can personally identify medication dose mistakes, but you know, most people probably couldn’t. And it could be very … I actually, you know, emailed the team and let them know, to give feedback.
So we have a healthcare system that is broken in so many ways, and it’s so difficult to navigate. So I get it. And so that’s been, you know, a big impetus for me to work in this space and try to make things better.
LEE: That’s an incredible story. It’s also validating because, you know, one of the examples in our book was the use of an LLM to spot a medication error that a doctor or a nurse might make. You know, interestingly, we’re finding no sort of formalized use of AI right now in the field. But anecdotes like this are everywhere. So it’s very interesting.
All right. So we’re starting to run short on time. So I want to ask you a few quick questions and a couple that might be a little provocative.
DANESHJOU: Oh boy. [LAUGHTER] Well, I don’t run away … I don’t run away from controversy.
LEE: So, of course, with that story you just told, I can see that you use AI yourself. When you are actually in clinic, when you are being a dermatologist …
DANESHJOU: Yeah.
LEE: … and seeing patients, are you using generative AI?
DANESHJOU: So I do not use it in clinic except for the situation of the insurance authorization letters. And even, I was offered, you know, sort of an AI-based scribe, which many people are using. There have been some studies that show that they can make mistakes. I have a human scribe. To me, writing the notes is actually part of the thinking process. So when I write my notes at the end of the day, there have been times that I’ve all of a sudden had an epiphany, particularly on a complex case. But I have used it to write, you know, sort of these insurance authorization letters. I’ve also used it in grant writing. So as a scientist, I have used it a lot more.
LEE: Right. So I don’t know of anyone who has a more nuanced and deeper understanding of the issues of biases in AI in medicine than you. Do you think [these] biases can be repaired in AI, and if not, what are the implications?
DANESHJOU: So I think there are several things here, and I just want to be thoughtful about it. One, I think, the bias in the technology comes from bias in the system and bias in medicine, which very much exists and is incredibly problematic. And so I always tell people, like, it doesn’t matter if you have the most perfect, fair AI. If you have a biased human and you add those together, because you’re going to have this human-AI interaction, you’re still going to have a problem.
And there is a paper that I’m on with Dr. Matt Groh (opens in new tab), which looked at looking at dermatology diagnosis across skin tones and then with, like, AI assistance. And we found there’s a bias gap, you know, with even physicians. So it’s not just an AI problem; humans have the problem, too. And…
LEE: Hmm. Yup.
DANESHJOU: … we also looked at when you have the human-AI system, how that impacts the gap because you want to see the gap close. And it was kind of a mixed result in the sense that there was actually situations where, like, the accuracy increased in both groups, but the gap actually also increased because they were actually, even though they knew it was a fair AI, for some reason, they were relying upon the AI more often when … or they were trusting it more often on diagnoses on white skin—maybe they’d read my papers, who knows? [LAUGHTER]—even though we had told them, you know, it was a fair model.
So I think for me, the important thing is understanding how the AI model works with the physician at the task. And what I would like to see is it improve the overall bias and disparities with that unit.
And at the same time, I tell human physicians, we have to work on ourselves. We have to work on our system, you know, our medical system that has systemic issues of access to care or how patients get treated based on what they might look like or other parts of their background.
LEE: All right, final question. So we started off with your stories about imaging in dermatology. And of course, Geoff Hinton, Turing winner and one of the grandfathers of the AI revolution, famously had predicted many years ago that by 2018 or something like that, we wouldn’t need human radiologists because of AI.
That hasn’t come to pass, but since you work in a field that also is very dependent on imaging technologies, do you see a future when radiologists or, for that matter, dermatologists might be largely replaced by machines?
DANESHJOU: I think that’s a complex question. Let’s say you have the most perfect AI systems. I think there’s still a lot of nuance in how these, you know, things get done. I’m not a radiologist, so I don’t want to speak to what happens in radiology. But in dermatology, it ends up being quite complex, the process.
LEE: Yeah.
DANESHJOU: You know, I don’t just look at lesions and make diagnoses. Like, I do skin exams to first identify the lesions of concern. So maybe if we had total-body photography that could help, like, catch which lesions would be of concern, which people have worked on, that would be step, sort of, step one.
And then the second thing is, you know, it’s … I have to do the biopsy. So, you know, the robot’s not going to be doing the biopsy. [LAUGHTER]
And then the pathology for skin cancer is sometimes very clear, but there’s also, like, intermediate-type lesions where we have to make a decision bringing all that information together. For rashes, it can be quite complex. And then we have to kind of think about what other tests we’re going to order, what therapeutics we might try first, that sort of stuff.
So, you know, there is a thought that you might have AI that could reason through all of those steps maybe, but I just don’t feel like we’re anywhere close to that at all. I think the other thing is AI does a lot better on sort of, you know, tasks that are well defined. And a lot of things in medicine, like, it would be hard to train the model on because it’s not well defined. Even human physicians would disagree on the next best step.
LEE: Well, Roxana, for whatever it’s worth, I can’t even begin to imagine anything replacing you. I think your work has been just so—I think you used the word, and I agree with it— landmark, and multiple times. So thank you for all that you’re doing and thank you so much for joining this podcast.
DANESHJOU: Thanks for having me. This was very fun.
[TRANSITION MUSIC]
The issue of bias in AI has been the subject of truly landmark work by Roxana and her collaborators. And this includes biases in large language models.
This was something that in our writing of the book, Carey, Zak, and I recognized and wrote about. But in fairness, I don’t think Carey, Zak, or I really understood the full implications of it. And this is where Roxana’s work has been so illuminating and important.
Roxana’s practical prescriptions around red teaming have proven to be important in practice, and equally important were Roxana’s insights into how AI might always be guilty of the same biases, not only of individuals but also of whole healthcare organizations. But at the same time, AI might also be a potentially powerful tool to detect and help mitigate against such biases.
When I think about the book that Carey, Zak, and I wrote, I think when we talked about laws, norms, ethics, regulations, it’s the place that we struggled the most. And in fact, we actually relied on a conversation with GPT-4 in order to tease out some of the core issues. Well, moving on from that conversation with an AI to a conversation with three deep experts who have dedicated their careers to making sure that we can harness all of the goodness while mitigating against the risks of AI, it’s been both fulfilling, very interesting, and a great learning experience.
[THEME MUSIC]
I’d like to say thank you again to Laura, Vardit, and Roxana for sharing their stories and insights. And to our listeners, thank you for joining us. We have some really great conversations planned for the coming episodes, including an examination on the broader economic impact of AI in health and a discussion on AI drug discovery. We hope you’ll continue to tune in.
Until next time.
[MUSIC FADES]





 5. Stand Out by Being Proactive
5. Stand Out by Being Proactive
















 Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things.
Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things. Ishan Singh is a Generative AI Data Scientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value. Outside of work, he enjoys playing volleyball, exploring local bike trails, and spending time with his wife and dog, Beau.
Ishan Singh is a Generative AI Data Scientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value. Outside of work, he enjoys playing volleyball, exploring local bike trails, and spending time with his wife and dog, Beau. Sovik Kumar Nath is an AI/ML and Generative AI senior solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
Sovik Kumar Nath is an AI/ML and Generative AI senior solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies. Karel Mundnich is a Sr. Applied Scientist in AWS Agentic AI. He has previously worked in AWS Lex and AWS Bedrock, where he worked in speech recognition, speech LLMs, and LLM fine-tuning. He holds a PhD in Electrical Engineering from the University of Southern California. In his free time, he enjoys skiing, hiking, and cycling.
Karel Mundnich is a Sr. Applied Scientist in AWS Agentic AI. He has previously worked in AWS Lex and AWS Bedrock, where he worked in speech recognition, speech LLMs, and LLM fine-tuning. He holds a PhD in Electrical Engineering from the University of Southern California. In his free time, he enjoys skiing, hiking, and cycling. Marcelo Aberle is a Sr. Research Engineer at AWS Bedrock. In recent years, he has been working at the intersection of science and engineering to enable new AWS service launches. This includes various LLM projects across Titan, Bedrock, and other AWS organizations. Outside of work, he keeps himself busy staying up-to-date on the latest GenAI startups in his adopted home city of San Francisco, California.
Marcelo Aberle is a Sr. Research Engineer at AWS Bedrock. In recent years, he has been working at the intersection of science and engineering to enable new AWS service launches. This includes various LLM projects across Titan, Bedrock, and other AWS organizations. Outside of work, he keeps himself busy staying up-to-date on the latest GenAI startups in his adopted home city of San Francisco, California. Jiayu Li is an Applied Scientist at AWS Bedrock, where he contributes to the development and scaling of generative AI applications using foundation models. He holds a Ph.D. and a Master’s degree in computer science from Syracuse University. Outside of work, Jiayu enjoys reading and cooking.
Jiayu Li is an Applied Scientist at AWS Bedrock, where he contributes to the development and scaling of generative AI applications using foundation models. He holds a Ph.D. and a Master’s degree in computer science from Syracuse University. Outside of work, Jiayu enjoys reading and cooking. Fang Liu is a principal machine learning engineer at Amazon Web Services, where he has extensive experience in building AI/ML products using cutting-edge technologies. He has worked on notable projects such as Amazon Transcribe and Amazon Bedrock. Fang Liu holds a master’s degree in computer science from Tsinghua University.
Fang Liu is a principal machine learning engineer at Amazon Web Services, where he has extensive experience in building AI/ML products using cutting-edge technologies. He has worked on notable projects such as Amazon Transcribe and Amazon Bedrock. Fang Liu holds a master’s degree in computer science from Tsinghua University.







 Mona Mona currently works as a Sr World Wide Gen AI Specialist Solutions Architect at Amazon focusing on Gen AI Solutions. She was a Lead Generative AI specialist in Google Public Sector at Google before joining Amazon. She is a published author of two books – Natural Language Processing with AWS AI Services and Google Cloud Certified Professional Machine Learning Study Guide. She has authored 19 blogs on AI/ML and cloud technology and a co-author on a research paper on CORD19 Neural Search which won an award for Best Research Paper at the prestigious AAAI (Association for the Advancement of Artificial Intelligence) conference.
Mona Mona currently works as a Sr World Wide Gen AI Specialist Solutions Architect at Amazon focusing on Gen AI Solutions. She was a Lead Generative AI specialist in Google Public Sector at Google before joining Amazon. She is a published author of two books – Natural Language Processing with AWS AI Services and Google Cloud Certified Professional Machine Learning Study Guide. She has authored 19 blogs on AI/ML and cloud technology and a co-author on a research paper on CORD19 Neural Search which won an award for Best Research Paper at the prestigious AAAI (Association for the Advancement of Artificial Intelligence) conference. Davide Gallitelli is a Senior Worldwide Specialist Solutions Architect for Generative AI at AWS, where he empowers global enterprises to harness the transformative power of AI. Based in Europe but with a worldwide scope, Davide partners with organizations across industries to architect custom AI agents that solve complex business challenges using AWS ML stack. He is particularly passionate about democratizing AI technologies and enabling teams to build practical, scalable solutions that drive organizational transformation.
Davide Gallitelli is a Senior Worldwide Specialist Solutions Architect for Generative AI at AWS, where he empowers global enterprises to harness the transformative power of AI. Based in Europe but with a worldwide scope, Davide partners with organizations across industries to architect custom AI agents that solve complex business challenges using AWS ML stack. He is particularly passionate about democratizing AI technologies and enabling teams to build practical, scalable solutions that drive organizational transformation. Surya Kari is a Senior Generative AI Data Scientist at AWS, specializing in developing solutions leveraging state-of-the-art foundation models. He has extensive experience working with advanced language models including DeepSeek-R1, the Llama family, and Qwen, focusing on their fine-tuning and optimization for specific scientific applications. His expertise extends to implementing efficient training pipelines and deployment strategies using AWS SageMaker, enabling the scaling of foundation models from development to production. He collaborates with customers to design and implement generative AI solutions, helping them navigate model selection, fine-tuning approaches, and deployment strategies to achieve optimal performance for their specific use cases.
Surya Kari is a Senior Generative AI Data Scientist at AWS, specializing in developing solutions leveraging state-of-the-art foundation models. He has extensive experience working with advanced language models including DeepSeek-R1, the Llama family, and Qwen, focusing on their fine-tuning and optimization for specific scientific applications. His expertise extends to implementing efficient training pipelines and deployment strategies using AWS SageMaker, enabling the scaling of foundation models from development to production. He collaborates with customers to design and implement generative AI solutions, helping them navigate model selection, fine-tuning approaches, and deployment strategies to achieve optimal performance for their specific use cases. Giuseppe Zappia is a Principal Solutions Architect at AWS, with over 20 years of experience in full stack software development, distributed systems design, and cloud architecture. In his spare time, he enjoys playing video games, programming, watching sports, and building things.
Giuseppe Zappia is a Principal Solutions Architect at AWS, with over 20 years of experience in full stack software development, distributed systems design, and cloud architecture. In his spare time, he enjoys playing video games, programming, watching sports, and building things.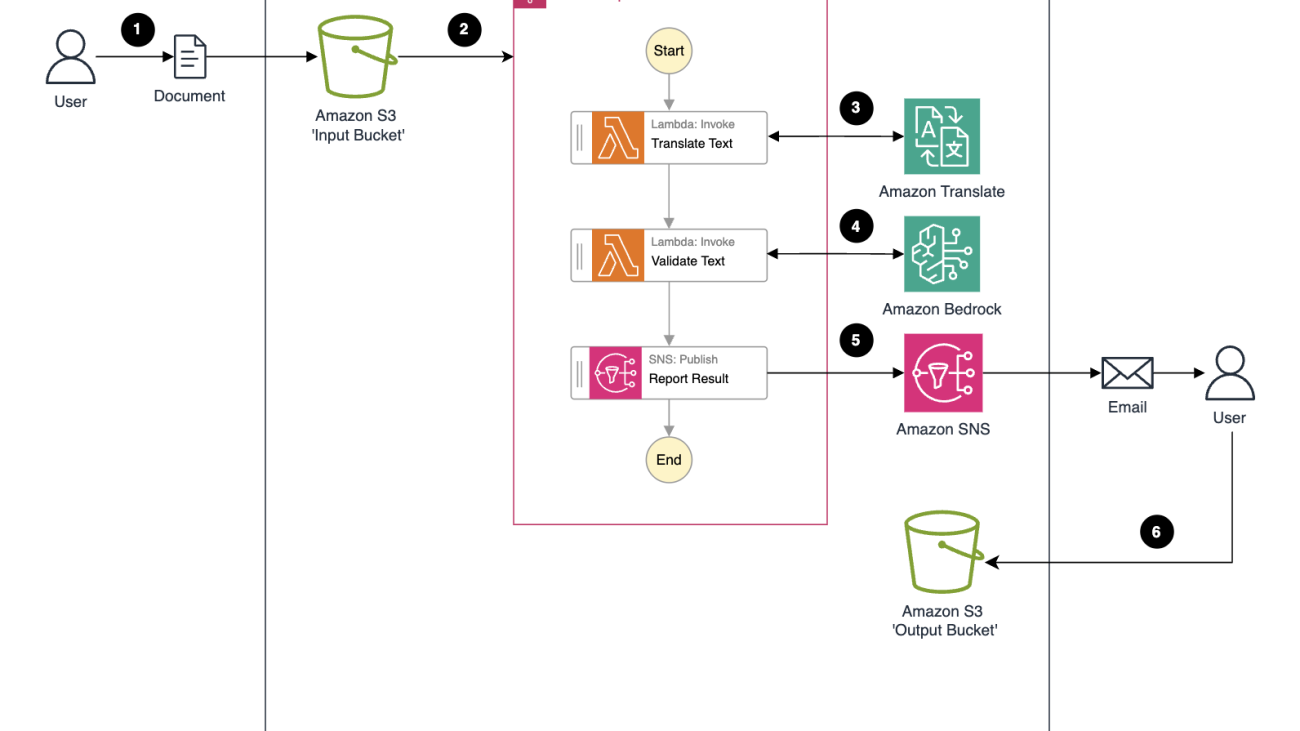









 Nadhya Polanco is an Associate Solutions Architect at AWS based in Brussels, Belgium. In this role, she supports organizations looking to incorporate AI and Machine Learning into their workloads. In her free time, Nadhya enjoys indulging in her passion for coffee and exploring new destinations.
Nadhya Polanco is an Associate Solutions Architect at AWS based in Brussels, Belgium. In this role, she supports organizations looking to incorporate AI and Machine Learning into their workloads. In her free time, Nadhya enjoys indulging in her passion for coffee and exploring new destinations. Steve Bell is a Senior Solutions Architect at AWS based in Amsterdam, Netherlands. He helps enterprise organizations navigate the complexities of migration, modernization and multicloud strategy. Outside of work he loves walking his labrador, Lily, and practicing his amateur BBQ skills.
Steve Bell is a Senior Solutions Architect at AWS based in Amsterdam, Netherlands. He helps enterprise organizations navigate the complexities of migration, modernization and multicloud strategy. Outside of work he loves walking his labrador, Lily, and practicing his amateur BBQ skills.











 Wrick Talukdar is a Tech Lead – Generative AI Specialist focused on Intelligent Document Processing. He leads machine learning initiatives and projects across business domains, leveraging multimodal AI, generative models, computer vision, and natural language processing. He speaks at conferences such as AWS re:Invent, IEEE, Consumer Technology Society(CTSoc), YouTube webinars, and other industry conferences like CERAWEEK and ADIPEC. In his free time, he enjoys writing and birding photography.
Wrick Talukdar is a Tech Lead – Generative AI Specialist focused on Intelligent Document Processing. He leads machine learning initiatives and projects across business domains, leveraging multimodal AI, generative models, computer vision, and natural language processing. He speaks at conferences such as AWS re:Invent, IEEE, Consumer Technology Society(CTSoc), YouTube webinars, and other industry conferences like CERAWEEK and ADIPEC. In his free time, he enjoys writing and birding photography. Jady Liu is a Senior AI/ML Solutions Architect on the AWS GenAI Labs team based in Los Angeles, CA. With over a decade of experience in the technology sector, she has worked across diverse technologies and held multiple roles. Passionate about generative AI, she collaborates with major clients across industries to achieve their business goals by developing scalable, resilient, and cost-effective generative AI solutions on AWS. Outside of work, she enjoys traveling to explore wineries and distilleries.
Jady Liu is a Senior AI/ML Solutions Architect on the AWS GenAI Labs team based in Los Angeles, CA. With over a decade of experience in the technology sector, she has worked across diverse technologies and held multiple roles. Passionate about generative AI, she collaborates with major clients across industries to achieve their business goals by developing scalable, resilient, and cost-effective generative AI solutions on AWS. Outside of work, she enjoys traveling to explore wineries and distilleries. Farshad Bidanjiri is a Solutions Architect focused on helping startups build scalable, cloud-native solutions. With over a decade of IT experience, he specializes in container orchestration and Kubernetes implementations. As a passionate advocate for generative AI, he helps emerging companies leverage cutting-edge AI technologies to drive innovation and growth.
Farshad Bidanjiri is a Solutions Architect focused on helping startups build scalable, cloud-native solutions. With over a decade of IT experience, he specializes in container orchestration and Kubernetes implementations. As a passionate advocate for generative AI, he helps emerging companies leverage cutting-edge AI technologies to drive innovation and growth. Keith Mascarenhas leads worldwide GTM strategy for Generative AI at AWS, developing enterprise use cases and adoption frameworks for Amazon Bedrock. Prior to this, he drove AI/ML solutions and product growth at AWS, and held key roles in Business Development, Solution Consulting and Architecture across Analytics, CX and Information Security.
Keith Mascarenhas leads worldwide GTM strategy for Generative AI at AWS, developing enterprise use cases and adoption frameworks for Amazon Bedrock. Prior to this, he drove AI/ML solutions and product growth at AWS, and held key roles in Business Development, Solution Consulting and Architecture across Analytics, CX and Information Security. Jessie-Lee Fry is a Product and Go-to Market (GTM) Strategy executive specializing in Generative AI and Machine Learning, with over 15 years of global leadership experience in Strategy, Product, Customer success, Business Development, Business Transformation and Strategic Partnerships. Jessie has defined and delivered a broad range of products and cross-industry go- to-market strategies driving business growth, while maneuvering market complexities and C-Suite customer groups. In her current role, Jessie and her team focus on helping AWS customers adopt Amazon Bedrock at scale enterprise use cases and adoption frameworks, meeting customers where they are in their Generative AI Journey.
Jessie-Lee Fry is a Product and Go-to Market (GTM) Strategy executive specializing in Generative AI and Machine Learning, with over 15 years of global leadership experience in Strategy, Product, Customer success, Business Development, Business Transformation and Strategic Partnerships. Jessie has defined and delivered a broad range of products and cross-industry go- to-market strategies driving business growth, while maneuvering market complexities and C-Suite customer groups. In her current role, Jessie and her team focus on helping AWS customers adopt Amazon Bedrock at scale enterprise use cases and adoption frameworks, meeting customers where they are in their Generative AI Journey. Raj Jayaraman is a Senior Generative AI Solutions Architect at AWS, bringing over a decade of experience in helping customers extract valuable insights from data. Specializing in AWS AI and generative AI solutions, Raj’s expertise lies in transforming business solutions through the strategic application of AWS’s AI capabilities, ensuring customers can harness the full potential of generative AI in their unique contexts. With a strong background in guiding customers across industries in adopting AWS Analytics and Business Intelligence services, Raj now focuses on assisting organizations in their generative AI journey—from initial demonstrations to proof of concepts and ultimately to production implementations.
Raj Jayaraman is a Senior Generative AI Solutions Architect at AWS, bringing over a decade of experience in helping customers extract valuable insights from data. Specializing in AWS AI and generative AI solutions, Raj’s expertise lies in transforming business solutions through the strategic application of AWS’s AI capabilities, ensuring customers can harness the full potential of generative AI in their unique contexts. With a strong background in guiding customers across industries in adopting AWS Analytics and Business Intelligence services, Raj now focuses on assisting organizations in their generative AI journey—from initial demonstrations to proof of concepts and ultimately to production implementations.
 Anyone in the U.S. can now get immediate access to AI Mode in Labs.
Anyone in the U.S. can now get immediate access to AI Mode in Labs.
