NVIDIA and Google share a long-standing relationship rooted in advancing AI innovation and empowering the global developer community. This partnership goes beyond infrastructure, encompassing deep engineering collaboration to optimize the computing stack.
The latest innovations stemming from this partnership include significant contributions to community software efforts like JAX, OpenXLA, MaxText and llm-d. These foundational optimizations directly support serving of Google’s cutting-edge Gemini models and Gemma family of open models.
Additionally, performance-optimized NVIDIA AI software like NVIDIA NeMo, NVIDIA TensorRT-LLM, NVIDIA Dynamo and NVIDIA NIM microservices are tightly integrated across Google Cloud, including Vertex AI, Google Kubernetes Engine (GKE) and Cloud Run, to accelerate performance and simplify AI deployments.
NVIDIA Blackwell in Production on Google Cloud
Google Cloud was the first cloud service provider to offer both NVIDIA HGX B200 and NVIDIA GB200 NVL72 with its A4 and A4X virtual machines (VMs).
These new VMs with Google Cloud’s AI Hypercomputer architecture are accessible through managed services like Vertex AI and GKE, enabling organizations to choose the right path to develop and deploy agentic AI applications at scale. Google Cloud’s A4 VMs, accelerated by NVIDIA HGX B200, are now generally available.
Google Cloud’s A4X VMs deliver over one exaflop of compute per rack and support seamless scaling to tens of thousands of GPUs, enabled by Google’s Jupiter network fabric and advanced networking with NVIDIA ConnectX-7 NICs. Google’s third-generation liquid cooling infrastructure delivers sustained, efficient performance even for the largest AI workloads.
Google Gemini Can Now Be Deployed On-Premises With NVIDIA Blackwell on Google Distributed Cloud
Gemini’s advanced reasoning capabilities are already powering cloud-based agentic AI applications — however, some customers in public sector, healthcare and financial services with strict data residency, regulatory or security requirements have yet been unable to tap into the technology.
With NVIDIA Blackwell platforms coming to Google Distributed Cloud — Google Cloud’s fully managed solution for on-premises, air-gapped environments and edge — organizations will now be able to deploy Gemini models securely within their own data centers, unlocking agentic AI for these customers
NVIDIA Blackwell’s unique combination of breakthrough performance and confidential computing capabilities makes this possible — ensuring that user prompts and fine-tuning data remain protected. This enables customers to innovate with Gemini while maintaining full control over their information, meeting the highest standards of privacy and compliance. Google Distributed Cloud expands the reach of Gemini, empowering more organizations than ever to tap into next-generation agentic AI.
Optimizing AI Inference Performance for Google Gemini and Gemma
Designed for the agentic era, the Gemini family of models represent Google’s most advanced and versatile AI models to date, excelling at complex reasoning, coding and multimodal understanding.
NVIDIA and Google have worked on performance optimizations to ensure that Gemini-based inference workloads run efficiently on NVIDIA GPUs, particularly within Google Cloud’s Vertex AI platform. This enables Google to serve a significant amount of user queries for Gemini models on NVIDIA-accelerated infrastructure across Vertex AI and Google Distributed Cloud.
In addition, the Gemma family of lightweight, open models have been optimized for inference using the NVIDIA TensorRT-LLM library and are expected to be offered as easy-to-deploy NVIDIA NIM microservices. These optimizations maximize performance and make advanced AI more accessible to developers to run their workloads on various deployment architectures across data centers to local NVIDIA RTX-powered PCs and workstations.
Building a Strong Developer Community and Ecosystem
NVIDIA and Google Cloud are also supporting the developer community by optimizing open-source frameworks like JAX for seamless scaling and breakthrough performance on Blackwell GPUs — enabling AI workloads to run efficiently across tens of thousands of nodes.
The collaboration extends beyond technology, with the launch of a new joint Google Cloud and NVIDIA developer community that brings experts and peers together to accelerate cross-skilling and innovation.
By combining engineering excellence, open-source leadership and a vibrant developer ecosystem, the companies are making it easier than ever for developers to build, scale and deploy the next generation of AI applications.
See notice regarding software product information.
Over a century ago, Henry Ford pioneered the mass production of cars and engines to provide transportation at an affordable price. Today, the technology industry manufactures the engines for a new kind of factory — those that produce intelligence.
As companies and countries increasingly focus on AI, and move from experimentation to implementation, the demand for AI technologies continues to grow exponentially. Leading system builders are racing to ramp up production of the servers for AI factories – the engines of AI factories – to meet the world’s exploding demand for intelligence and growth.
Dell Technologies is a leader in this renaissance. Dell and NVIDIA have partnered for decades and continue to push the pace of innovation. In its last earnings call, Dell projected that its AI server business will grow at least $15 billion this year.
“We’re on a mission to bring AI to millions of customers around the world,” said Michael Dell, chairman and chief executive officer, Dell Technologies, in a recent announcement at Dell Technologies World. “With the Dell AI Factory with NVIDIA, enterprises can manage the entire AI lifecycle across use cases, from training to deployment, at any scale.”
The latest Dell AI servers, powered by NVIDIA Blackwell, offer up to 50x more AI reasoning inference output and 5x improvement in throughput compared with the Hopper platform. Customers use them to generate tokens for new AI applications that will help solve some of the world’s biggest challenges, from disease prevention to advanced manufacturing.
Dell servers with NVIDIA GB200 are shipping at scale for a variety of customers, such as CoreWeave’s new NVIDIA GB200 NVL72 system. One of Dell’s U.S. factories can ship thousands of NVIDIA Blackwell GPUs to customers in a week. It’s why they were chosen by one of their largest customers to deploy 100,000 NVIDIA GPUs in just six weeks.
But how is an AI server made? We visited a facility to find out.
Building the Engines of Intelligence
We visited one of Dell’s U.S. facilities that builds the most compute-dense NVIDIA Blackwell generation servers ever manufactured.
Modern automobile engines have more than 200 major components and take three to seven years to roll out to market. NVIDIA GB200 NVL72 servers have 1.2 million parts and were designed just a year ago.
Amid a forest of racks, grouped by phases of assembly, Dell employees quickly slide in GB200 trays, NVLink Switch networking trays and then test the systems. The company said its ability to engineer the compute, network and storage assembly under one roof and fine tune, deploy and integrate complete systems is a powerful differentiator. Speed also matters. The Dell team can build, test, ship – test again on site at a customer location – and turn over a rack in 24 hours.
The servers are destined for state-of-the-art data centers that require a dizzying quantity of cables, pipes and hoses to operate. One data center can have 27,000 miles of network cable — enough to wrap around the Earth. It can pack about six miles of water pipes, 77 miles of rubber hoses, and is capable of circulating 100,000 gallons of water per minute for cooling.
With new AI factories being announced each week – the European Union has plans for seven AI factories, while India, Japan, Saudi Arabia, the UAE and Norway are also developing them – the demand for these engines of intelligence will only grow in the months and years ahead.
Organizations across a wide range of industries are struggling to process massive amounts of unstructured video and audio content to support their core business applications and organizational priorities. Amazon Bedrock Data Automation helps them meet this challenge by streamlining application development and automating workflows that use content from documents, images, audio, and video. Recently, we announced two new capabilities that you can use to get custom insights from video and audio. You can streamline development and boost efficiency through consistent, multimodal analytics that can be seamlessly customized to their specific business needs.
Amazon Bedrock Data Automation accelerates development time from months to minutes through prepackaged foundation models (FMs), eliminating the need for multiple task-specific models and complex processing logic. Now developers can eliminate the time-consuming heavy lifting of unstructured multimodal content processing at scale, whether analyzing petabytes of video or processing millions of customer conversations. Developers can use natural language instructions to generate insights that meet the needs of their downstream systems and applications. Media and entertainment users can unlock custom insights from movies, television shows, ads, and user-generated video content. Customer-facing teams can generate new insights from audio—analyzing client consultations to identify best practices, categorize conversation topics, and extract valuable customer questions for training.
Customizing insights with Amazon Bedrock Data Automation for videos
Amazon Bedrock Data Automation makes it painless for you to tailor your generative AI–powered insights generated from video. You can specify which fields you want to generate from videos, such as scene context or summary, data format, and the natural language instructions for each field. You can customize Amazon Bedrock Data Automation output by generating specific insights in consistent formats for AI-powered multimedia analysis applications. For example, you can use Amazon Bedrock Data Automation to extract scene summaries, identify visually prominent objects, and detect logos in movies, television shows, and social media content. With Amazon Bedrock Data Automation, you can create new custom video output in minutes. Or you can select from a catalog of pre-built solutions—including advertisement analysis, media search, and more. Read the following example to understand how a customer is using Amazon Bedrock Data Automation for video analysis.
Air is an AI-based software product that helps businesses automate how they collect, approve, and share content. Creative teams love Air because they can replace their digital asset management (DAM), cloud storage solution, and workflow tools with Air’s creative operations system. Today, Air manages more than 250M images and videos for global brands such as Google, P&G, and Sweetgreen. Air’s product launched in March 2021, and they’ve raised $70M from world class venture capital firms. Air uses Amazon Bedrock Data Automation to help creative teams quickly organize their content.
“At Air, we are using Amazon Bedrock Data Automation to process tens of millions of images and videos. Amazon Bedrock Data Automation allows us to extract specific, tailored insights from content (such as video chapters, transcription, optical character recognition) in a matter of seconds. This was a virtually impossible task for us earlier. The new Amazon Bedrock Data Automation powered functionality on Air enables creative and marketing teams with critical business insights. With Amazon Bedrock Data Automation, Air has cut down search and organization time for its users by 90%. Today, every company needs to operate like a media company. Businesses are prioritizing the ability to generate original and unique creative work: a goal achievable through customization. Capabilities like Amazon Bedrock Data Automation allow Air to customize the extraction process for every customer, based on their specific goals and needs.”
—Shane Hedge, Co-Founder and CEO at Air
Extracting focused insights with Amazon Bedrock Data Automation for audio
The new Amazon Bedrock Data Automation capabilities make it faster and more streamlined for you to extract customized generative AI–powered insights from audio. You can specify the desired output configuration in natural language. And you can extract custom insights—such as summaries, key topics, and intents—from customer calls, clinical discussions, meetings, and other audio. You can use the audio insights in Amazon Bedrock Data Automation to improve productivity, enhance customer experience, ensure regulatory compliance, among others. For example, sales agents can improve their productivity by extracting insights such as summaries, key action items, and next steps from conversations between sales agents with clients.
Getting started with the new Amazon Bedrock Data Automation video and audio capabilities
To analyze your video and audio assets, follow these steps:
On the Amazon Bedrock console, choose Data Automation in the navigation pane. The following screenshot shows the Data Automation page.
In the Create a new BDA Project screen under BDA Project name, enter a name. Select Create project, as shown in the following screenshot.
Choose a Sample Blueprint or create a Blueprint
To use a blueprint, follow these steps:
You can choose a sample blueprint or you can create a new one.
To create a blueprint, on the Amazon Bedrock Data Automation console in the navigation pane under Data Automation, select custom output.
Choose Create blueprint and select the tile for the video or audio file you want to create a blueprint for, as shown in the following screenshot.
Choosing a sample blueprint for video modality
Creating a new blueprint for audio modality
Generate results for custom output
On the video asset, within the blueprint, you can choose Generate results to see the detailed analysis.
Choose Edit field – In the Edit fields pane, enter a field name. Under Instructions, provide clear, step-by-step guidance for how to identify and classify the field’s data during the extraction process.
Choose Save blueprint.
Conclusion
The new video and audio capabilities in Amazon Bedrock Data Automation represent a significant step forward in helping you unlock the value of their unstructured content at scale. By streamlining application development and automating workflows that use content from documents, images, audio, and video, organizations can now quickly generate custom insights. Whether you’re analyzing customer conversations to improve sales effectiveness, extracting insights from media content, or processing video feeds, Amazon Bedrock Data Automation provides the flexibility and customization options you need while eliminating the undifferentiated heavy lifting of processing multimodal content. To learn more about these new capabilities, visit the Amazon Bedrock Data Automation documentation, and start building your first video or audio analysis project today.
Resources
To learn more about the new Amazon Bedrock Data Automation capabilities, visit:
The What’s New post for the new video capability in Amazon Bedrock Data Automation
The What’s New post for the new audio capability in Amazon Bedrock Data Automation
About the author
Ashish Lal is an AI/ML Senior Product Marketing Manager for Amazon Bedrock. He has 11+ years of experience in product marketing and enjoys helping customers accelerate time to value and reduce their AI lifecycle cost.
This blog post is co-written with Heidi Vogel Brockmann and Ronald Brockmann from GuardianGamer.
Millions of families face a common challenge: how to keep children safe in online gaming without sacrificing the joy and social connection these games provide.
In this post, we share how GuardianGamer—a member of the AWS Activate startup community—has built a cloud gaming platform that helps parents better understand and engage with their children’s gaming experiences using AWS services. Built specifically for families with children under 13, GuardianGamer uses AWS services including Amazon Nova and Amazon Bedrock to deliver a scalable and efficient supervision platform. The team uses Amazon Nova for intelligent narrative generation to provide parents with meaningful insights into their children’s gaming activities and social interactions, while maintaining a non-intrusive approach to monitoring.
The challenge: Monitoring children’s online gaming experiences
Monitoring children’s online gaming activities has been overwhelming for parents, offering little visibility and limited control. GuardianGamer fills a significant void in the market for parents to effectively monitor their children’s gaming activities without being intrusive.
Traditional parental controls were primarily focused on blocking content rather than providing valuable data related to their children’s gaming experiences and social interactions. This led GuardianGamer’s founders to develop a better solution—one that uses AI to summarize gameplay and chat interactions, helping parents better understand and engage with their children’s gaming activities in a non-intrusive way, by using short video reels, while also helping identify potential safety concerns.
Creating connected experiences for parent and child
GuardianGamer is a cloud gaming platform built specifically for families with pre-teen children under 13, combining seamless gaming experiences with comprehensive parental insights. Built on AWS and using Amazon Nova for intelligent narrative generation, the platform streams popular games while providing parents with much-desired visibility into their children’s gaming activities and social interactions. The service prioritizes both safety and social connection through integrated private voice chat, delivering a positive gaming environment that keeps parents informed in a non-invasive way.
There are two connected experiences offered in the platform: one for parents to stay informed and one for kids to play in a highly trusted and safe GuardianGamer space.
For parents, GuardianGamer offers a comprehensive suite of parental engagement tools and insights, empowering them to stay informed and involved in their children’s online activities. Insights are generated from gaming and video understanding, and texted to parents to foster positive conversations between parents and kids. Through these tools, parents can actively manage their child’s gaming experience, enjoying a safe and balanced approach to online entertainment.
For kids, GuardianGamer offers uninterrupted gameplay with minimal latency, all while engaging in social interactions. The platform makes it possible for children to connect and play exclusively within a trusted circle of friends—each vetted and approved by parents—creating a secure digital extension of their real-world relationships. This transforms gaming sessions into natural extensions of friendships formed through school, sports, and community activities, all enhanced by advanced parental AI insights.
By seamlessly blending technology, community, and family, GuardianGamer creates a safer and enriching digital space, called “The Trusted Way for Kids to Play.”
Solution overview
When the GuardianGamer team set out to build a platform that would help parents supervise their children’s gaming experiences across Minecraft, Roblox, and beyond, they knew they needed a cloud infrastructure partner with global reach and proven scalability. Having worked with AWS on previous projects, the team found it to be the natural choice for their ambitious vision.
“Our goal was to build a solution that could scale from zero to millions of users worldwide while maintaining low latency and high reliability—all with a small, nimble engineering team. AWS serverless architecture gave us exactly what we needed without requiring a massive DevOps investment.”
– Heidi Vogel Brockmann, founder and CEO of GuardianGamer.
The following diagram illustrates the backend’s AWS architecture.
GuardianGamer’s backend uses a fully serverless stack built on AWS Lambda, Amazon DynamoDB, Amazon Cognito, Amazon Simple Storage Service (Amazon S3), and Amazon Simple Notification Service (Amazon SNS), making it possible to expand the platform effortlessly as user adoption grows while keeping operational overhead minimal. This architecture enables the team to focus on their core innovation: AI-powered game supervision for parents, rather than infrastructure management.
The cloud gaming component presented unique challenges, requiring low-latency GPU resources positioned close to users around the world.
“Gaming is an inherently global activity, and latency can make or break the user experience. The extensive Regional presence and diverse Amazon Elastic Compute Cloud (Amazon EC2) instance types give us the flexibility to deploy gaming servers where our users are.”
For the AI analysis capabilities that form the heart of GuardianGamer’s parental supervision features, the team relies on AWS Batch to coordinate analysis jobs, and Amazon Bedrock provides access to powerful large language models (LLMs).
“We’re currently using Amazon Nova Lite for summary generation and highlight video selection, which helps parents quickly understand what’s happening in their children’s gameplay without watching hours of content, just a few minutes a day to keep up to date and start informed conversations with their child,”
– Heidi Vogel Brockmann.
Results
Together, AWS and GuardianGamer have successfully scaled GuardianGamer’s cloud gaming platform to handle thousands of concurrent users across multiple game environments. The company’s recent expansion to support Roblox—in addition to its existing Minecraft capabilities—has broadened its serviceable addressable market to 160 million children and their families.
“What makes our implementation special is how we use Amazon Nova to maintain a continuous record of each child’s gaming activities across sessions. When a parent opens our app, they see a comprehensive view of their child’s digital journey, not just isolated moments.”
– Ronald Brockmann, CTO of GuardianGamer.
Conclusion
GuardianGamer demonstrates how a small, agile team can use AWS services to build a sophisticated, AI-powered gaming platform that prioritizes both child safety and parent engagement. By combining cloud gaming infrastructure across multiple Regions with the capabilities of Amazon Bedrock and Amazon Nova, GuardianGamer is pioneering a new approach to family-friendly gaming. Through continuous parent feedback and responsible AI practices, the platform delivers safer, more transparent gaming experiences while maintaining rapid innovation.
“AWS has been exceptional at bringing together diverse teams and technologies across the company to support our vision. Our state-of-the-art architecture leverages several specialized AI components, including speech analysis, video processing, and game metadata collection. We’re particularly excited about incorporating Amazon Nova, which helps us transform complex gaming data into coherent narratives for parents. With AWS as our scaling partner, we’re confident we can deliver our service to millions of families worldwide.”
Heidi Vogel Brockmann is the CEO & Founder at GuardianGamer AI. Heidi is an engineer and a proactive mom of four with a mission to transform digital parenting in the gaming space. Frustrated by the lack of tools available for parents with gaming kids, Heidi built the platform to enable fun for kids and peace of mind for parents.
Ronald Brockmann is the CTO of GuardianGamer AI. With extensive expertise in cloud technology and video streaming, Ronald brings decades of experience in building scalable, secure systems. A named inventor on dozens of patents, he excels at building high-performance teams and deploying products at scale. His leadership combines innovative thinking with precise execution to drive GuardianGamer’s technical vision.
Raechel Frick is a Sr Product Marketing Manager at AWS. With over 20 years of experience in the tech industry, she brings a customer-first approach and growth mindset to building integrated marketing programs. Based in the greater Seattle area, Raechel balances her professional life with being a soccer mom and after-school carpool manager, demonstrating her ability to excel both in the corporate world and family life.
John D’Eufemia is an Account Manager at AWS supporting customers within Media, Entertainment, Games, and Sports. With an MBA from Clark University, where he graduated Summa Cum Laude, John brings entrepreneurial spirit to his work, having co-founded multiple ventures at Femia Holdings. His background includes significant leadership experience through his 8-year involvement with DECA Inc., where he served as both an advisor and co-founder of Clark University’s DECA chapter.
On May 17, the PyTorch Meetup was successfully held in Hangzhou, drawing nearly 60 developers and industry experts from companies including Huawei, Tencent, Ant Group, and ByteDance. The event focused on the development of the PyTorch ecosystem, AI acceleration technologies, and industry practices. Through keynote speeches and technical sessions, in-depth discussions were held with participants, providing a valuable platform for exchange and collaboration.
Session Highlights:
Latest Developments in the PyTorch Community and Ecosystem Outlook
Yikun Jiang, a member of the PyTorch Technical Advisory Council (TAC), shared the latest updates from the PyTorch community. Topics included the general progress of PyTorch, PyTorch Foundation Expands to an Umbrella Foundation, the Ambassador Program, and PyTorch Conference planning. He emphasized how PyTorch continues to drive innovation and real-world adoption of AI open source technologies through technical iteration, ecosystem expansion, and global collaboration. He called on developers to actively engage in community building and help shape the future of the AI open source ecosystem.
Torchair: A torch.compile Backend Optimized for Ascend NPU
Peng Xue, Senior Engineer at Huawei, presented technical practices around graph mode optimization on Ascend NPUs. He introduced the two Torchair modes—Reduce-overhead and Max-autotune—and detailed deep optimizations in memory management, dynamic shapes, multi-stream parallelism, and compile-time caching. These improvements aim to enhance model training and inference performance while maintaining ease of use.
PyTorch Ecosystem on Ascend
Yuanhao Ji, Software Engineer at Huawei, discussed support for PyTorch ecosystem projects on Ascend NPUs. Focusing on model training, fine-tuning, and inference, he introduced TorchTitan, TorchTune, and vLLM as case studies. He explained their core features and adaptation strategies for Ascend, offering practical guidance for deploying PyTorch projects on this hardware.
Production Prefill/Decode Disaggregation Based on vLLM at Tencent
Chao Zhang, Senior Engineer at Tencent, presented the practice of Prefill/Decode (PD) separation in large model inference. This technique decouples the compute-intensive prefill stage from the memory-intensive decode stage, significantly improving system throughput and resource utilization. His talk covered key technical implementations such as KV cache transmission optimization, intelligent load balancing, and multi-turn dialogue caching. Real-world deployments on both homogeneous GPUs and heterogeneous setups like Ascend A2 + H20 showed performance improvements of 20%–50%. Tencent has further optimized the vLLM framework for CPUs, GPUs, and uses pipeline decomposition, low-precision KV caches, and graph compilers to enhance adaptability and performance across hardware platforms.
Key Reinforcement Learning (RL) Acceleration Techniques and Training Practices
Chenyi Pan, Senior Engineer at Huawei, shared Ascend’s breakthroughs in reinforcement learning and ecosystem development. Addressing the challenge of low resource utilization in RL systems, introduced a training-inference co-card solution that allows for efficient switching between the two tasks. This approach not only saves 50% in compute resources but also doubles single-card throughput and improves inference memory availability by 80%. To enrich the technical ecosystem, Ascend also launched TransferDock, a streaming data engine that employs dynamic load balancing strategies to improve task efficiency by over 10% compared to traditional caching mechanisms.
On the framework side, MindSpeed-RL combines the MindSpeed training backend with the vLLM inference engine, supporting dynamic weight partitioning and time-sharing of cluster resources while maintaining compatibility with mainstream open source ecosystems. Benchmarks using the Qwen2.5-32B model showed that this setup outperformed the SimpleRL-Zoo baseline on evaluations such as MATH500, demonstrating its technical leadership.
Ray’s Practice and Exploration in Ant Group’s AI Infra Ecosystem
Senlin Zhu, Senior Technical Expert at Ant Group and Head of Ant Ray, shared the practice and exploration of Ray within Ant’s AI Infra ecosystem. He outlined Ray’s architectural design and programming paradigm. Over time, Ray has evolved into critical infrastructure for AI systems, supporting training, inference, hyperparameter tuning, and reinforcement learning.
Since 2017, Ant Group has continuously invested in Ray, which now supports applications at the scale of 2 million cores. Ant has also contributed key features to the community, such as multi-tenancy support and the Flow Insight visual debugging tool. Flow Insight, in particular, has alleviated “black box” issues in complex AI systems and significantly improved observability and deployment efficiency at scale.
Challenges and Standardization in PyTorch Ecosystem Accelerator Development
Zesheng Zong, a community developer from Huawei, provided a systematic overview of the challenges, solutions, and case studies in developing accelerators for the PyTorch ecosystem. Developers integrating out-of-tree hardware face version compatibility issues and a lack of standardized quality benchmarks, making it hard to quantify new device support. In early 2025, a new exploration group was formed in the PyTorch community to tackle these challenges.
Key improvements include: Establishing a standardized testing framework using the public repository pytorch-fdn/oota for daily plugin testing. Developing the OpenReg module to simulate backend behavior and validate with test cases. Optimizing the PrivateUse1 plugin mechanism to reduce integration complexity. Supporting automatic plugin loading to simplify device access. Improving the torch.accelerator device-agnostic API for broader compatibility.
Intel’s community developer Chuanqi Wang followed up with a case study on integrating and running CI infrastructure using Intel Gaudi. He described how to leverage CI from code compilation and unit testing to TorchBench automated benchmarking, ensuring quality for new backend integrations. He also noted plans to reduce testing time, clarify required test items, and define quality standards to improve ecosystem compatibility and development efficiency.
This PyTorch Meetup served as a technical bridge for in-depth developer exchanges and demonstrated the vibrant energy of the PyTorch ecosystem in AI’s cutting-edge domains. Through diverse perspectives, the attendees sketched a picture of how open source collaboration drives technological progress. We look forward to more developers joining this open and thriving wave of innovation, where each exchange can spark new ideas in the age of intelligence.
In this post, we describe FrodoKEM, a key encapsulation protocol that offers a simple design and provides strong security guarantees even in a future with powerful quantum computers.
The quantum threat to cryptography
For decades, modern cryptography has relied on mathematical problems that are practically impossible for classical computers to solve without a secret key. Cryptosystems like RSA, Diffie-Hellman key-exchange, and elliptic curve-based schemes—which rely on the hardness of the integer factorization and (elliptic curve) discrete logarithm problems—secure communications on the internet, banking transactions, and even national security systems. However, the emergence ofquantum computing poses a significant threat to these cryptographic schemes.
Quantum computers leverage the principles of quantum mechanics to perform certain calculations exponentially faster than classical computers. Their ability to solve complex problems, such as simulating molecular interactions, optimizing large-scale systems, and accelerating machine learning, is expected to have profound and beneficial implications for fields ranging from chemistry and material science to artificial intelligence.
At the same time, quantum computing is poised to disrupt cryptography. In particular, Shor’s algorithm, a quantum algorithm developed in 1994, can efficiently factor large numbers and compute discrete logarithms—the very problems that underpin the security of RSA, Diffie-Hellman, and elliptic curve cryptography. This means that once large-scale, fault-tolerant quantum computers become available, public-key protocols based on RSA, ECC, and Diffie-Hellman will become insecure, breaking a sizable portion of the cryptographic backbone of today’s digital world. Recent advances in quantum computing, such as Microsoft’s Majorana 1 (opens in new tab), the first quantum processor powered by topological qubits, represent major steps toward practical quantum computing and underscore the urgency of transitioning to quantum-resistant cryptographic systems.
To address this looming security crisis, cryptographers and government agencies have been working on post-quantum cryptography (PQC)—new cryptographic algorithms that can resist attacks from both classical and quantum computers.
The NIST Post-Quantum Cryptography Standardization effort
In 2017, the U.S. National Institute of Standards and Technology (NIST) launched the Post-Quantum Cryptography Standardization project (opens in new tab) to evaluate and select cryptographic algorithms capable of withstanding quantum attacks. As part of this initiative, NIST sought proposals for two types of cryptographic primitives: key encapsulation mechanisms (KEMs)—which enable two parties to securely derive a shared key to establish an encrypted connection, similar to traditional key exchange schemes—and digital signature schemes.
This initiative attracted submissions from cryptographers worldwide, and after multiple evaluation rounds, NIST selected CRYSTALS-Kyber, a KEM based on structured lattices, and standardized it as ML-KEM (opens in new tab). Additionally, NIST selected three digital signature schemes: CRYSTALS-Dilithium, now called ML-DSA; SPHINCS+, now called SLH-DSA; and Falcon, now called FN-DSA.
While ML-KEM provides great overall security and efficiency, some governments and cryptographic researchers advocate for the inclusion and standardization of alternative algorithms that minimize reliance on algebraic structure. Reducing algebraic structure might prevent potential vulnerabilities and, hence, can be considered a more conservative design choice. One such algorithm is FrodoKEM.
International standardization of post-quantum cryptography
Beyond NIST, other international standardization bodies have been actively working on quantum-resistant cryptographic solutions. The International Organization for Standardization (ISO) is leading a global effort to standardize additional PQC algorithms. Notably, European government agencies—including Germany’s BSI (opens in new tab), the Netherlands’ NLNCSA and AIVD (opens in new tab), and France’s ANSSI (opens in new tab)—have shown strong support for FrodoKEM, recognizing it as a conservative alternative to structured lattice-based schemes.
As a result, FrodoKEM is undergoing standardization at ISO. Additionally, ISO is standardizing ML-KEM and a conservative code-based KEM called Classic McEliece. These three algorithms are planned for inclusion in ISO/IEC 18033-2:2006 as Amendment 2 (opens in new tab).
What is FrodoKEM?
FrodoKEM is a key encapsulation mechanism (KEM) based on the Learning with Errors (LWE) problem, a cornerstone of lattice-based cryptography. Unlike structured lattice-based schemes such as ML-KEM, FrodoKEM is built on generic, unstructured lattices, i.e., it is based on the plain LWE problem.
Why unstructured lattices?
Structured lattice-based schemes introduce additional algebraic properties that could potentially be exploited in future cryptanalytic attacks. By using unstructured lattices, FrodoKEM eliminates these concerns, making it a safer choice in the long run, albeit at the cost of larger key sizes and lower efficiency.
It is important to emphasize that no particular cryptanalytic weaknesses are currently known for recommended parameterizations of structured lattice schemes in comparison to plain LWE. However, our current understanding of the security of these schemes could potentially change in the future with cryptanalytic advances.
Lattices and the Learning with Errors (LWE) problem
Lattice-based cryptography relies on the mathematical structure of lattices, which are regular arrangements of points in multidimensional space. A lattice is defined as the set of all integer linear combinations of a set of basis vectors. The difficulty of certain computational problems on lattices, such as the Shortest Vector Problem (SVP) and the Learning with Errors (LWE) problem, forms the basis of lattice-based schemes.
The Learning with Errors (LWE) problem
The LWE problem is a fundamental hard problem in lattice-based cryptography. It involves solving a system of linear equations where some small random error has been added to each equation, making it extremely difficult to recover the original secret values. This added error ensures that the problem remains computationally infeasible, even for quantum computers. Figure 1 below illustrates the LWE problem, specifically, the search version of the problem.
As can be seen in Figure 1, for the setup of the problem we need a dimension (n) that defines the size of matrices, a modulus (q) that defines the value range of the matrix coefficients, and a certain error distribution (chi) from which we sample (textit{“small”}) matrices. We sample two matrices from (chi), a small matrix (text{s}) and an error matrix (text{e}) (for simplicity in the explanation, we assume that both have only one column); sample an (n times n) matrix (text{A}) uniformly at random; and compute (text{b} = text{A} times text{s} + text{e}). In the illustration, each matrix coefficient is represented by a colored square, and the “legend of coefficients” gives an idea of the size of the respective coefficients, e.g., orange squares represent the small coefficients of matrix (text{s}) (small relative to the modulus (q)). Finally, given (text{A}) and (text{b}), the search LWE problem consists in finding (text{s}). This problem is believed to be hard for suitably chosen parameters (e.g., for dimension (n) sufficiently large) and is used at the core of FrodoKEM.
In comparison, the LWE variant used in ML-KEM—called Module-LWE (M-LWE)—has additional symmetries, adding mathematical structure that helps improve efficiency. In a setting similar to that of the search LWE problem above, the matrix (text{A}) can be represented by just a single row of coefficients.
FIGURE 1: Visualization of the (search) LWE problem.
LWE is conjectured to be quantum-resistant, and FrodoKEM’s security is directly tied to its hardness. In other words, cryptanalysts and quantum researchers have not been able to devise an efficient quantum algorithm capable of solving the LWE problem and, hence, FrodoKEM. In cryptography, absolute security can never be guaranteed; instead, confidence in a problem’s hardness comes from extensive scrutiny and its resilience against attacks over time.
How FrodoKEM Works
FrodoKEM follows the standard paradigm of a KEM, which consists of three main operations—key generation, encapsulation, and decapsulation—performed interactively between a sender and a recipient with the goal of establishing a shared secret key:
Key generation (KeyGen), computed by the recipient
Generates a public key and a secret key.
The public key is sent to the sender, while the private key remains secret.
Encapsulation (Encapsulate), computed by the sender
Generates a random session key.
Encrypts the session key using the recipient’s public key to produce a ciphertext.
Produces a shared key using the session key and the ciphertext.
The ciphertext is sent to the recipient.
Decapsulation (Decapsulate), computed by the recipient
Decrypts the ciphertext using their secret key to recover the original session key.
Reproduces the shared key using the decrypted session key and the ciphertext.
The shared key generated by the sender and reconstructed by the recipient can then be used to establish secure symmetric-key encryption for further communication between the two parties.
Figure 2 below shows a simplified view of the FrodoKEM protocol. As highlighted in red, FrodoKEM uses at its core LWE operations of the form “(text{b} = text{A} times text{s} + text{e})”, which are directly applied within the KEM paradigm.
FIGURE 2: Simplified overview of FrodoKEM.
Performance: Strong security has a cost
Not relying on additional algebraic structure certainly comes at a cost for FrodoKEM in the form of increased protocol runtime and bandwidth. The table below compares the performance and key sizes corresponding to the FrodoKEM level 1 parameter set (variant called “FrodoKEM-640-AES”) and the respective parameter set of ML-KEM (variant called “ML-KEM-512”). These parameter sets are intended to match or exceed the brute force security of AES-128. As can be seen, the difference in speed and key sizes between FrodoKEM and ML-KEM is more than an order of magnitude. Nevertheless, the runtime of the FrodoKEM protocol remains reasonable for most applications. For example, on our benchmarking platform clocked at 3.2GHz, the measured runtimes are 0.97 ms, 1.9 ms, and 3.2 ms for security levels 1, 2, and 3, respectively.
For security-sensitive applications, a more relevant comparison is with Classic McEliece, a post-quantum code-based scheme also considered for standardization. In this case, FrodoKEM offers several efficiency advantages. Classic McEliece’s public keys are significantly larger—well over an order of magnitude greater than FrodoKEM’s—and its key generation is substantially more computationally expensive. Nonetheless, Classic McEliece provides an advantage in certain static key-exchange scenarios, where its high key generation cost can be amortized across multiple key encapsulation executions.
TABLE 1: Comparison of key sizes and performance on an x86-64 processor for NIST level 1 parameter sets.
A holistic design made with security in mind
FrodoKEM’s design principles support security beyond its reliance on generic, unstructured lattices to minimize the attack surface of potential future cryptanalytic threats. Its parameters have been carefully chosen with additional security margins to withstand advancements in known attacks. Furthermore, FrodoKEM is designed with simplicity in mind—its internal operations are based on straightforward matrix-vector arithmetic using integer coefficients reduced modulo a power of two. These design decisions facilitate simple, compact and secure implementations that are also easier to maintain and to protect against side-channel attacks.
Conclusion
After years of research and analysis, the next generation of post-quantum cryptographic algorithms has arrived. NIST has chosen strong PQC protocols that we believe will serve Microsoft and its customers well in many applications. For security-sensitive applications, FrodoKEM offers a secure yet practical approach for post-quantum cryptography. While its reliance on unstructured lattices results in larger key sizes and higher computational overhead compared to structured lattice-based alternatives, it provides strong security assurances against potential future attacks. Given the ongoing standardization efforts and its endorsement by multiple governmental agencies, FrodoKEM is well-positioned as a viable alternative for organizations seeking long-term cryptographic resilience in a post-quantum world.
Further Reading
For those interested in learning more about FrodoKEM, post-quantum cryptography, and lattice-based cryptography, the following resources provide valuable insights:
A comprehensive survey on lattice-based cryptography: Peikert, C. “A Decade of Lattice Cryptography.” Foundations and Trends in Theoretical Computer Science. (2016)
A comprehensive tutorial on modern lattice-based schemes, including ML-KEM and ML-DSA: Lyubashevsky, V. “Basic Lattice Cryptography: The concepts behind Kyber (ML-KEM) and Dilithium (ML-DSA).” https://eprint.iacr.org/2024/1287 (opens in new tab). (2024)
Mixture-of-Experts (MoE) models are crucial for scaling model capacity while controlling inference costs. While integrating MoE into multimodal models like CLIP improves performance, training these models is notoriously challenging and expensive. We propose CLIP-Upcycling (CLIP-UP), an efficient alternative training strategy that converts a pre-trained dense CLIP model into a sparse MoE architecture. Through extensive experimentation with various settings and auxiliary losses, we demonstrate that CLIP-UP significantly reduces training complexity and cost. Remarkably, our sparse CLIP B/16…Apple Machine Learning Research
This post was cowritten by Mulay Ahmed, Assistant Director of Engineering, and Ruby Donald, Assistant Director of Engineering at Principal Financial Group. The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
Principal Financial Group® is an integrated global financial services company with specialized solutions helping people, businesses, and institutions reach their long-term financial goals and access greater financial security.
With US contact centers that handle millions of customer calls annually, Principal® wanted to further modernize their customer call experience. With a robust AWS Cloud infrastructure already in place, they selected a cloud-first approach to create a more personalized and seamless experience for their customers that would:
Understand customer intents through natural language (vs. touch tone experiences)
Assist customers with self-service offerings where possible
Accurately route customer calls based on business rules
Assist engagement center agents with contextual data
Initially, Principal developed a voice Virtual Assistant (VA) using an Amazon Lex bot to recognize customer intents. The VA can perform self-service transactions or route customers to specific call center queues in the Genesys Cloud contact center platform, based on customer intents and business rules.
As customers interact with the VA, it’s essential to continuously monitor its health and performance. This allows Principal to identify opportunities for fine-tuning, which can enhance the VA’s ability to understand customer intents. Consequently, this will reduce fallback intent rates, improve functional intent fulfillment rates, and lead to better customer experiences.
In this post, we explore how Principal used this opportunity to build an integrated voice VA reporting and analytics solution using an Amazon QuickSight dashboard.
Amazon Lex is a service for building conversational interfaces using voice and text. It provides high-quality speech recognition and language understanding capabilities, enabling the addition of sophisticated, natural language chatbots to new and existing applications.
Genesys Cloud, an omni-channel orchestration and customer relationship platform, provides a contact center platform in a public cloud model that enables quick and simple integration of AWS Contact Center Intelligence (AWS CCI). As part of AWS CCI, Genesys Cloud integrates with Amazon Lex, which enables self-service, intelligent routing, and data collection capabilities.
QuickSight is a unified business intelligence (BI) service that makes it straightforward within an organization to build visualizations, perform ad hoc analysis, and quickly get business insights from their data.
Solution overview
Principal required a reporting and analytics solution that would monitor VA performance based on customer interactions at scale, enabling Principal to improve the Amazon Lex bot performance.
Reporting requirements included customer and VA interaction and Amazon Lex bot performance (target metrics and intent fulfillment) analytics to identify and implement tuning and training opportunities.
The solution used a QuickSight dashboard that derives these insights from the following customer interaction data used to measure VA performance:
Genesys Cloud data such as queues and data actions
Business-specific data such as product and call center operations data
Business API-specific data and metrics such as API response codes
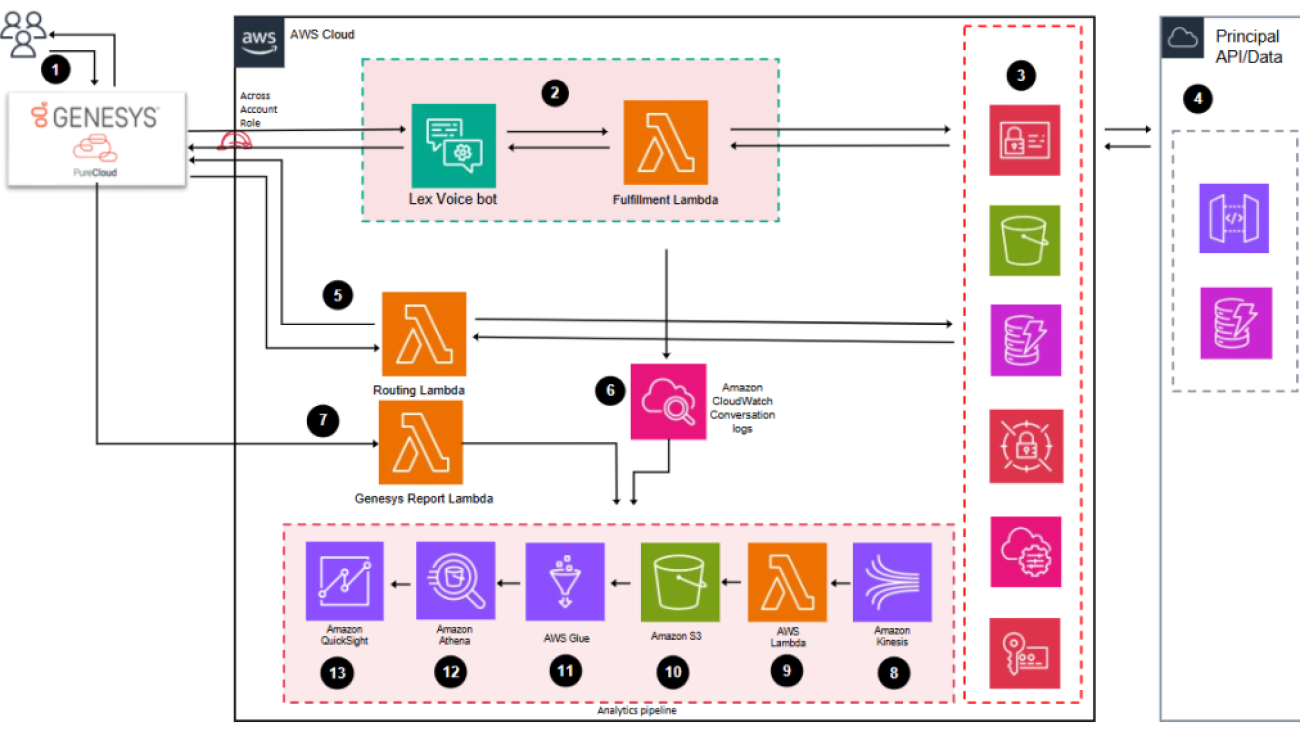
The following diagram shows the solution architecture using Genesys, Amazon Lex, and QuickSight.
The solution workflow involves the following steps:
Users call in and interact with Genesys Cloud.
Genesys Cloud calls an AWS Lambda routing function. This function will return a response to Genesys Cloud with the necessary data, to route the customer call. To generate a response, the function fetches routing data from an Amazon DynamoDB table, and requests an Amazon Lex V2 bot to provide an answer on the user intent.
The Amazon Lex V2 bot processes the customer intent and calls a Lambda fulfillment function to fulfill the intent.
The fulfillment function executes custom logic (routing and session variables logic) and calls necessary APIs to fetch the data required to fulfill the intent.
The APIs process and return the data requested (such as data to perform a self-service transaction).
The Amazon Lex V2 bot’s conversation logs are sent to Amazon CloudWatch (these logs will be used for business analytics, operational monitoring, and alerts).
Genesys Cloud calls a third Lambda function to send customer interaction reports. The Genesys report function pushes these reports to an Amazon Simple Storage Service (Amazon S3) bucket (these reports will be used for business analytics).
An Amazon Data Firehose delivery stream ships the conversation logs from CloudWatch to an S3 bucket.
The Firehose delivery stream transforms the logs in Parquet or CSV format using a Lambda function.
Logging and monitoring – The solution monitors AWS resources with CloudWatch and uses alerts to receive notification upon failure events.
Least privilege access – The solution uses IAM roles and policies to grant the minimum necessary permissions to uses and services.
Data privacy – The solution handles customer sensitive data such as personally identifiable information (PII) according to compliance and data protection requirements. It implements data masking when applicable and appropriate.
Secure APIs – APIs implemented in this solution are protected and designed according to compliance and security requirements.
Data types – The solution defines data types, such as time stamps, in the Data Catalog (and Athena) in order to refresh data (SPICE data) in QuickSight on a schedule.
DevOps – The solution is version controlled, and changes are deployed using pipelines, to enable faster release cycles.
Analytics on Amazon Lex – Analytics on Amazon Lex empowers teams with data-driven insights to improve the performance of their bots. The overview dashboard provides a single snapshot of key metrics such as the total number of conversations and intent recognition rates. Principal does not use this capability due to the following reasons:
The dashboard can’t integrate with external data:
Genesys Cloud data (such as queues and data actions)
Business-specific data (such as product and call center operations data)
Business API-specific data and metrics (such as response codes)
The dashboard can’t be customized to add additional views and data.
Sample dashboard
With this reporting and analytics solution, Principal can consolidate data from multiple sources and visualize the performance of the VA to identify areas of opportunities for improvement. The following screenshot shows an example of their QuickSight dashboard for illustrative purposes.
Conclusion
In this post, we presented how Principal created a report and analytics solution for their VA solution using Genesys Cloud and Amazon Lex, along with QuickSight to provide customer interaction insights.
The VA solution allowed Principal to maintain its existing contact center solution with Genesys Cloud and achieve better customer experiences. It offers other benefits such as the ability for a customer to receive support on some inquiries without requiring an agent on the call (self-service). It also provides intelligent routing capabilities, leading to reduced call time and increased agent productivity.
With the implementation of this solution, Principal can monitor and derive insights from its VA solution and fine-tune accordingly its performance.
In its 2025 roadmap, Principal will continue to strengthen the foundation of the solution described in this post. In a second post, Principal will present how they automate the deployment and testing of new Amazon Lex bot versions.
AWS and Amazon are not affiliates of any company of the Principal Financial Group®. This communication is intended to be educational in nature and is not intended to be taken as a recommendation.
Mulay Ahmed is an Assistant Director of Engineering at Principal and well-versed in architecting and implementing complex enterprise-grade solutions on AWS Cloud.
Ruby Donald is an Assistant Director of Engineering at Principal and leads the Enterprise Virtual Assistants Engineering Team. She has extensive experience in building and delivering software at enterprise scale.
Open source licensing revolutionized software development, creating a thriving ecosystem built on shared innovation and collaboration. Licenses like MIT and Apache-2.0 gave developers a standard, legally robust way to share code, reducing friction and accelerating adoption.
Today, we stand at a similar inflection point with open AI models. These models, increasingly foundational to research and industry, lack an equivalent licensing standard. Existing open source software licenses weren’t designed with AI models in mind, while most model-specific licenses are either too complex, overly restrictive, or legally ambiguous.
To fully unlock the potential of open AI, we need a license purpose-built for the realities of machine learning. That’s where OpenMDW comes in.
Why AI Models Need a New License
AI models differ fundamentally from traditional software. They are:
Composites of multiple types of components: including code, architecture, training data, weights, documentation, and evaluation protocols.
Subject to overlapping IP regimes: such as copyright, database rights, and trade secrets, which vary across jurisdictions.
Distributed without a consistent definition of “open”: resulting in a fragmented licensing landscape.
This complexity has led to a proliferation of bespoke, incompatible licenses that often:
Limit redistribution, reuse, or modification.
Fail to address legal nuances unique to models.
Create uncertainty for developers and adopters alike.
The result? Friction in open ecosystems, legal ambiguity, and a significant barrier to collaboration and innovation.
The Origins of OpenMDW
OpenMDW, short for Open Model, Data and Weights License was born out of the effort to implement the Model Openness Framework (MOF). The MOF is a 3-tier classification system that defines what it means for a model to be truly “open”— not just available with limitations or use restrictions, but licensed openly across its code, architecture, parameters, training data, and documentation.
To make MOF practical, model developers needed a simple, standard license they could drop into any repository, just like Apache-2.0 or MIT is used in software. Something purpose-built for many types of content including models, not just code.
What Makes OpenMDW Different
OpenMDW is the first truly permissive license designed from the ground up for machine learning models. Here’s what sets it apart:
Covers the Entire Model Stack
It’s designed to apply to all components of a model release:
Model architecture
Parameters and checkpoints
Training and inference code
Preprocessing and evaluation data
Documentation (e.g., model cards, data cards)
Importantly, OpenMDW does not require inclusion of all components. It applies only to what is distributed, while remaining compatible with many other licenses that may govern certain parts of the repository.
(OpenMDW users will of course have to continue to comply with any other third-party licenses that apply to other pre-existing materials in their repos, such as by providing license text and notices, source code where applicable, etc.)
Comprehensive and Legally Grounded
OpenMDW grants expansive permissions including under copyright, patent, database, and trade secret law, a broad legal spectrum of rights relevant to AI artifacts.
It also includes:
A patent litigation termination clauses to deter patent assertions by users of the model’s materials
Attribution requirements to maintain provenance and trust
Compatible with Policy and Open Source Principles
Intended to be fully aligned with the EU AI Act’s references to “free and open-source licenses”
Supports the Open Source Initiative (OSI) 10 principles, including free redistribution, source availability, derived works and no discrimination against persons or groups
Designed for Simplicity
One license, one file, one place: a LICENSE file at the root of your repo
No complex licensing matrix: no confusion for downstream users
Easy integration into any repo: just like MIT or Apache-2.0.
Understanding the OpenMDW License
Definitions and Scope
Model Materials under OpenMDW include:
Model architecture and trained parameters; and
all other related materials provided under OpenMDW, which can include:
Preprocessing, training and inference code
Datasets and evaluation scripts
Documentation, metadata, and tools
This comprehensive scope maps directly to the Model Openness Framework (MOF), ensuring that all critical elements of a model are covered if they are included with the distribution.
The Model Materials are not intended to be a requirement of what has to be included in the distribution. It only specifies that what is included in the distribution is covered by the license, and excludes anything covered by other licenses in the distribution.
Grant of Rights
OpenMDW grants broad rights to “deal in the Model Materials without restriction,” including for example:
Use, modify and distribute the Model Materials
Operate under copyright, patent, database, and trade secret laws
These rights are granted free of charge, with no field-of-use restrictions, removing ambiguity for developers and enterprises alike.
Attribution, Not Copyleft
OpenMDW imposes only minimal obligations:
Retain the license text
Preserve original copyright and attribution notices
There are no copyleft or share-alike conditions, meaning derivative models and integrations can remain fully permissive. This allows for maximum reuse and interoperability.
Patent Protection
To prevent misuse of the commons, OpenMDW includes a patent-litigation termination clause: if a licensee initiates offensive patent litigation over the Model Materials, their license is revoked.
This mirrors best practices in open source software and helps preserve a collaborative ecosystem.
Outputs Are Unrestricted
A major innovation: outputs generated by using a model under OpenMDW are completely free of licensing restrictions imposed by the provider of the Model Materials.
This eliminates confusion over whether generated text, images, code or predictions are encumbered by the model provider— a common point of uncertainty in existing licenses.
How to Adopt OpenMDW
Adopting OpenMDW is straightforward:
Add the OpenMDW-1.0 license file to your repository: LICENSE
Clearly indicate that your release is under OpenMDW-1.0 in the README
Ensure all components of the model package are covered and disclosed, including prominently highlighting any components that are subject to other licenses
Why This Matters Now
The AI community is reaching an inflection point. Open models from AI2’s Molmo to Mistral, and open reasoning models like DeepSeek’s R1 to multimodal agents are reshaping what’s possible in the open. But their licensing status remains hard to characterize, since software licenses may not map cleanly onto AI models.
Some open weights models which use restrictive licenses have become gradually more permissive; but without a strong legal framework available for licensing, model producers have been forced to err towards the side of caution in designing their own licenses.
In his recent post, Nathan Lambert of AI2 rightly notes: “One of the long standing todo items for open-source AI is better licenses”, OpenMDW helps to fill that need.
Just as Apache-2.0 and MIT became foundational licenses for open source software, OpenMDW is positioned to become the standard for open models. Its clarity, scope, and permissiveness lower barriers for developers and create certainty for companies and researchers looking to build responsibly on open foundations.
This isn’t just about legal clarity, it’s about enabling an innovation-rich and open source AI ecosystem.
Visit openmdw.ai for more details including the FAQ.
Featured Sessions: Exploring Innovation at PyTorch Day China 2025
PyTorch Day China 2025, proudly hosted by the PyTorch Foundation, will take place on June 7 in Beijing, China collocated with the BAAI Conference. This will be the second event in the new PyTorch Day series, following the inaugural PyTorch Day France last month in Paris., PyTorch Days are focused on regional communities and provide a forum for sharing technical advances, project updates and tutorials, and showcasing impactful innovations across research and industry.
PyTorch Day China will highlight cutting-edge tools, frameworks, and practices across the PyTorch ecosystem. The full-day event will feature insightful talks across a multitude of domains and technical discussions on the most cutting-edge and relevant challenges and projects in the open source AI lifecycle.
torch.accelerator: A Unified Runtime API for Accelerators Yu Guangye, AI Framework Engineer, Intel Learn how Intel is helping unify PyTorch’s runtime interface across diverse hardware accelerators, streamlining portable and scalable AI workloads.
vLLM: Easy, Fast, and Cheap LLM Serving for Everyone Kaichao You, Tsinghua University Explore the design and performance of vLLM, a popular open-source project for efficient inference and serving of large language models.
This is just a sample of what PyTorch Day China will offer. To explore the full agenda, visit the BAAI Conference event page.
Whether you’re contributing to the PyTorch ecosystem or deploying it at scale, PyTorch Day China is an opportunity to connect with a growing community and shape the future of AI development.








 Ashish Lal is an AI/ML Senior Product Marketing Manager for Amazon Bedrock. He has 11+ years of experience in product marketing and enjoys helping customers accelerate time to value and reduce their AI lifecycle cost.
Ashish Lal is an AI/ML Senior Product Marketing Manager for Amazon Bedrock. He has 11+ years of experience in product marketing and enjoys helping customers accelerate time to value and reduce their AI lifecycle cost.


 Heidi Vogel Brockmann is the CEO & Founder at GuardianGamer AI. Heidi is an engineer and a proactive mom of four with a mission to transform digital parenting in the gaming space. Frustrated by the lack of tools available for parents with gaming kids, Heidi built the platform to enable fun for kids and peace of mind for parents.
Heidi Vogel Brockmann is the CEO & Founder at GuardianGamer AI. Heidi is an engineer and a proactive mom of four with a mission to transform digital parenting in the gaming space. Frustrated by the lack of tools available for parents with gaming kids, Heidi built the platform to enable fun for kids and peace of mind for parents. Ronald Brockmann is the CTO of GuardianGamer AI. With extensive expertise in cloud technology and video streaming, Ronald brings decades of experience in building scalable, secure systems. A named inventor on dozens of patents, he excels at building high-performance teams and deploying products at scale. His leadership combines innovative thinking with precise execution to drive GuardianGamer’s technical vision.
Ronald Brockmann is the CTO of GuardianGamer AI. With extensive expertise in cloud technology and video streaming, Ronald brings decades of experience in building scalable, secure systems. A named inventor on dozens of patents, he excels at building high-performance teams and deploying products at scale. His leadership combines innovative thinking with precise execution to drive GuardianGamer’s technical vision. Raechel Frick is a Sr Product Marketing Manager at AWS. With over 20 years of experience in the tech industry, she brings a customer-first approach and growth mindset to building integrated marketing programs. Based in the greater Seattle area, Raechel balances her professional life with being a soccer mom and after-school carpool manager, demonstrating her ability to excel both in the corporate world and family life.
Raechel Frick is a Sr Product Marketing Manager at AWS. With over 20 years of experience in the tech industry, she brings a customer-first approach and growth mindset to building integrated marketing programs. Based in the greater Seattle area, Raechel balances her professional life with being a soccer mom and after-school carpool manager, demonstrating her ability to excel both in the corporate world and family life. John D’Eufemia is an Account Manager at AWS supporting customers within Media, Entertainment, Games, and Sports. With an MBA from Clark University, where he graduated Summa Cum Laude, John brings entrepreneurial spirit to his work, having co-founded multiple ventures at Femia Holdings. His background includes significant leadership experience through his 8-year involvement with DECA Inc., where he served as both an advisor and co-founder of Clark University’s DECA chapter.
John D’Eufemia is an Account Manager at AWS supporting customers within Media, Entertainment, Games, and Sports. With an MBA from Clark University, where he graduated Summa Cum Laude, John brings entrepreneurial spirit to his work, having co-founded multiple ventures at Femia Holdings. His background includes significant leadership experience through his 8-year involvement with DECA Inc., where he served as both an advisor and co-founder of Clark University’s DECA chapter.