This paper was accepted at the CV4Metaverse Workshop at CVPR 2025.
With rapid advancements in virtual reality (VR) headsets, effectively measuring stereoscopic quality of experience (SQoE) has become essential for delivering immersive and comfortable 3D experiences. However, most existing stereo metrics focus on isolated aspects of the viewing experience such as visual discomfort or image quality, and have traditionally faced data limitations. To address these gaps, we present SCOPE (Stereoscopic COntent Preference Evaluation), a new dataset comprised of real and synthetic stereoscopic images…Apple Machine Learning Research

100 things we announced at I/O
 Learn more about the biggest announcements and launches from Google’s 2025 I/O developer conference.Read More
Learn more about the biggest announcements and launches from Google’s 2025 I/O developer conference.Read More
Integrate Amazon Bedrock Agents with Slack
As companies increasingly adopt generative AI applications, AI agents capable of delivering tangible business value have emerged as a crucial component. In this context, integrating custom-built AI agents within chat services such as Slack can be transformative, providing businesses with seamless access to AI assistants powered by sophisticated foundation models (FMs). After an AI agent is developed, the next challenge lies in incorporating it in a way that provides straightforward and efficient use. Organizations have several options: integration into existing web applications, development of custom frontend interfaces, or integration with communication services such as Slack. The third option—integrating custom AI agents with Slack—offers a simpler and quicker implementation path you can follow to summon the AI agent on-demand within your familiar work environment.
This solution drives team productivity through faster query responses and automated task handling, while minimizing operational overhead. The pay-per-use model optimizes cost as your usage scales, making it particularly attractive for organizations starting their AI journey or expanding their existing capabilities.
There are numerous practical business use cases for AI agents, each offering measurable benefits and significant time savings compared to traditional approaches. Examples include a knowledge base agent that instantly surfaces company documentation, reducing search time from minutes to seconds. A compliance checker agent that facilitates policy adherence in real time, potentially saving hours of manual review. Sales analytics agents provide immediate insights, alleviating the need for time consuming data compilation and analysis. AI agents for IT support help with common technical issues, often resolving problems faster than human agents.
These AI-powered solutions enhance user experience through contextual conversations, providing relevant assistance based on the current conversation and query context. This natural interaction model improves the quality of support and helps drive user adoption across the organization. You can follow this implementation approach to provide the solution to your Slack users in use cases where quick access to AI-powered insights would benefit team workflows. By integrating custom AI agents, organizations can track improvements in key performance indicators (KPIs) such as mean time to resolution (MTTR), first-call resolution rates, and overall productivity gains, demonstrating the practical benefits of AI agents powered by large language models (LLMs).
In this post, we present a solution to incorporate Amazon Bedrock Agents in your Slack workspace. We guide you through configuring a Slack workspace, deploying integration components in Amazon Web Services (AWS), and using this solution.
Solution overview
The solution consists of two main components: the Slack to Amazon Bedrock Agents integration infrastructure and either your existing Amazon Bedrock agent or a sample agent we provide for testing. The integration infrastructure handles the communication between Slack and the Amazon Bedrock agent, and the agent processes and responds to the queries.
The solution uses Amazon API Gateway, AWS Lambda, AWS Secrets Manager, and Amazon Simple Queue Service (Amazon SQS) for a serverless integration. This alleviates the need for always-on infrastructure, helping to reduce overall costs because you only pay for actual usage.
Amazon Bedrock agents automate workflows and repetitive tasks while securely connecting to your organization’s data sources to provide accurate responses.
An action group defines actions that the agent can help the user perform. This way, you can integrate business logic with your backend services by having your agent process and manage incoming requests. The agent also maintains context throughout conversations, uses the process of chain of thought, and enables more personalized interactions.
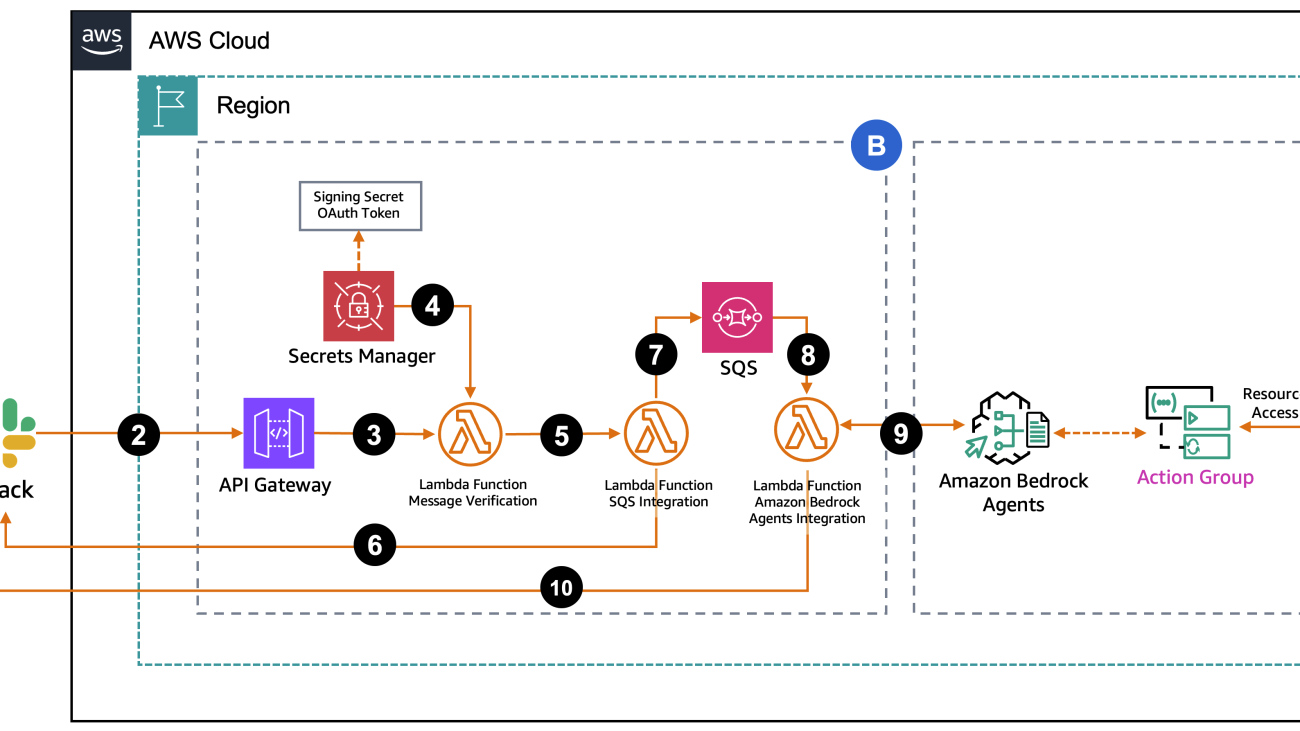
The following diagram represents the solution architecture, which contains two key sections:
- Section A – The Amazon Bedrock agent and its components are included in this section. With this part of the solution, you can either connect your existing agent or deploy our sample agent using the provided AWS CloudFormation template
- Section B – This section contains the integration infrastructure (API Gateway, Secrets Manager, Lambda, and Amazon SQS) that’s deployed by a CloudFormation template.

The request flow consists of the following steps:
- A user sends a message in Slack to the bot by using
@appname. - Slack sends a webhook POST request to the API Gateway endpoint.
- The request is forwarded to the verification Lambda function.
- The Lambda function retrieves the Slack signing secret and bot token to verify request authenticity.
- After verification, the message is sent to a second Lambda function.
- Before putting the message in the SQS queue, the Amazon SQS integration Lambda function sends a “
 Processing your request…” message to the user in Slack within a thread under the original message.
Processing your request…” message to the user in Slack within a thread under the original message. - Messages are sent to the FIFO (First-In-First-Out) queue for processing, using the channel and thread ID to help prevent message duplication.
- The SQS queue triggers the Amazon Bedrock integration Lambda function.
- The Lambda function invokes the Amazon Bedrock agent with the user’s query, and the agent processes the request and responds with the answer.
- The Lambda function updates the initial “ Processing your request…” message in the Slack thread with either the final agent’s response or, if debug mode is enabled, the agent’s reasoning process.
Prerequisites
You must have the following in place to complete the solution in this post:
- An AWS account
- A Slack account (two options):
- For company Slack accounts, work with your administrator to create and publish the integration application, or you can use a sandbox organization
- Alternatively, create your own Slack account and workspace for testing and experimentation
- Model access in Amazon Bedrock for Anthropic’s Claude 3.5 Sonnet in the same AWS Region where you’ll deploy this solution (if using your own agent, you can skip this requirement)
- The accompanying CloudFormation templates provided in GitHub repo:
- Sample Amazon Bedrock agent (
virtual-meteorologist) - Slack integration to Amazon Bedrock Agents
- Sample Amazon Bedrock agent (
Create a Slack application in your workspace
Creating applications in Slack requires specific permissions that vary by organization. If you don’t have the necessary access, you’ll need to contact your Slack administrator. The screenshots in this walkthrough are from a personal Slack account and are intended to demonstrate the implementation process that can be followed for this solution.
- Go to Slack API and choose Create New App

- In the Create an app pop-up, choose From scratch

- For App Name, enter
virtual-meteorologist - For Pick a workspace to develop your app in, choose the workspace where you want to use this application
- Choose Create App

After the application is created, you’ll be taken to the Basic Information page.
- In the navigation pane under Features, choose OAuth & Permissions
- Navigate to the Scopes section and under Bot Tokens Scopes, add the following scopes by choosing Add an OAuth Scope and entering
im:read,im:write, andchat:write

- On the OAuth & Permissions page, navigate to the OAuth Tokens section and choose Install to {Workspace}
- On the following page, choose Allow to complete the process

- On the OAuth & Permissions page, navigate to OAuth Tokens and copy the value for Bot User OAuth Token that has been created. Save this in a notepad to use later when you’re deploying the CloudFormation template.

- In the navigation pane under Settings, choose Basic Information
- Navigate to Signing Secret and choose Show
- Copy and save this value to your notepad to use later when you’re deploying the CloudFormation template

Deploy the sample Amazon Bedrock agent resources with AWS CloudFormation
If you already have an Amazon Bedrock agent configured, you can copy its ID and alias from the agent details. If you don’t, then when you run the CloudFormation template for the sample Amazon Bedrock agent (virtual-meteorologist), the following resources are deployed (costs will be incurred for the AWS resources used):
- Lambda functions:
- GeoCoordinates – Converts location names to latitude and longitude coordinates
- Weather – Retrieves weather information using coordinates
- DateTime – Gets current date and time for specific time zones
- AWS Identity and Access Management IAM roles:
- GeoCoordinatesRole – Role for
GeoCoordinatesLambda function - WeatherRole – Role for
WeatherLambda function - DateTimeRole – Role for
DateTimeLambda function - BedrockAgentExecutionRole – Role for Amazon Bedrock agent execution
- GeoCoordinatesRole – Role for
- Lambda permissions:
- GeoCoordinatesLambdaPermission – Allows Amazon Bedrock to invoke the
GeoCoordinatesLambda function - WeatherLambdaPermission – Allows Amazon Bedrock to invoke the
WeatherLambda function - DateTimeLambdaPermission – Allows Amazon Bedrock to invoke the
DateTimeLambda function
- GeoCoordinatesLambdaPermission – Allows Amazon Bedrock to invoke the
- Amazon Bedrock agent:
- BedrockAgent – Virtual meteorologist agent configured with three action groups
- Amazon Bedrock agent action groups:
obtain-latitude-longitude-from-place-nameobtain-weather-information-with-coordinatesget-current-date-time-from-timezone
Choose Launch Stack to deploy the resources:
![]()
After deployment is complete, navigate to the Outputs tab and copy the BedrockAgentId and BedrockAgentAliasID values. Save these to a notepad to use later when deploying the Slack integration to Amazon Bedrock Agents CloudFormation template.

Deploy the Slack integration to Amazon Bedrock Agents resources with AWS CloudFormation
When you run the CloudFormation template to integrate Slack with Amazon Bedrock Agents, the following resources are deployed (costs will be incurred for the AWS resources used):
- API Gateway:
- SlackAPI – A REST API for Slack interactions
- Lambda functions:
- MessageVerificationFunction – Verifies Slack message signatures and tokens
- SQSIntegrationFunction – Handles message queueing to Amazon SQS
- BedrockAgentsIntegrationFunction – Processes messages with the Amazon Bedrock agent
- IAM roles:
- MessageVerificationFunctionRole – Role for
MessageVerificationFunctionLambda function permissions - SQSIntegrationFunctionRole – Role for
SQSIntegrationFunctionLambda function permissions - BedrockAgentsIntegrationFunctionRole – Role for
BedrockAgentsIntegrationFunctionLambda function permissions
- MessageVerificationFunctionRole – Role for
- SQS queues:
- ProcessingQueue – FIFO queue for ordered message processing
- DeadLetterQueue – FIFO queue for failed message handling
- Secrets Manager secret:
- SlackBotTokenSecret – Stores Slack credentials securely
Choose Launch Stack to deploy these resources:
![]()
Provide your preferred stack name. When deploying the CloudFormation template, you’ll need to provide four values: the Slack bot user OAuth token, the signing secret from your Slack configuration, and the BedrockAgentId and BedrockAgentAliasID values saved earlier. If your agent is in draft version, use TSTALIASID as the BedrockAgentAliasID. Although our example uses a draft version, you can use the alias ID of your published version if you’ve already published your agent.

Keep SendAgentRationaleToSlack set to False by default. However, if you want to troubleshoot or observe how Amazon Bedrock Agents processes your questions, you can set this to True. This way, you can receive detailed processing information in the Slack thread where you invoked the Slack application.
When deployment is complete, navigate to the Outputs tab and copy the WebhookURL value. Save this to your notepad to use in your Slack configuration in the next step.

Integrate Amazon Bedrock Agents with your Slack workspace
Complete the following steps to integrate Amazon Bedrock Agents with your Slack workspace:
- Go to Slack API and choose the
virtual-meteorologistapplication

- In the navigation pane, choose Event Subscriptions
- On the Event Subscriptions page, turn on Enable Events
- Enter your previously copied API Gateway URL for Request URL—verification will happen automatically
- For Subscribe to bot events, select Add Bot User Event button and add
app_mentionandmessage.im - Choose Save Changes
- Choose Reinstall your app and choose Allow on the following page

Test the Amazon Bedrock Agents bot application in Slack
Return to Slack and locate virtual-meteorologist in the Apps section. After you add this application to your channel, you can interact with the Amazon Bedrock agent by using @virtual-meteorologist to get weather information.

Let’s test it with some questions. When we ask about today’s weather in Chicago, the application first sends a “ Processing your request…” message as an initial response. After the Amazon Bedrock agent completes its analysis, this temporary message is replaced with the actual weather information.

You can ask follow-up questions within the same thread, and the Amazon Bedrock agent will maintain the context from your previous conversation. To start a new conversation, use @virtual-meteorologist in the main channel instead of the thread.

Clean up
If you decide to stop using this solution, complete the following steps to remove it and its associated resources deployed using AWS CloudFormation:
- Delete the Slack integration CloudFormation stack:
- On the AWS CloudFormation console, choose Stacks in the navigation pane
- Locate the stack you created for the Slack integration for Amazon Bedrock Agents during the deployment process (you assigned a name to it)
- Select the stack and choose Delete
- If you deployed the sample Amazon Bedrock agent (
virtual-meteorologist), repeat these steps to delete the agent stack
Considerations
When designing serverless architectures, separating Lambda functions by purpose offers significant advantages in terms of maintenance and flexibility. This design pattern allows for straightforward behavior modifications and customizations without impacting the overall system logic. Each request involves two Lambda functions: one for token validation and another for SQS payload processing. During high-traffic periods, managing concurrent executions across both functions requires attention to Lambda concurrency limits. For use cases where scaling is a critical concern, combining these functions into a single Lambda function might be an alternative approach, or you could consider using services such as Amazon EventBridge to help manage the event flow between components. Consider your use case and traffic patterns when choosing between these architectural approaches.
Summary
This post demonstrated how to integrate Amazon Bedrock Agents with Slack, a widely used enterprise collaboration tool. After creating your specialized Amazon Bedrock Agents, this implementation pattern shows how to quickly integrate them into Slack, making them readily accessible to your users. The integration enables AI-powered solutions that enhance user experience through contextual conversations within Slack, improving the quality of support and driving user adoption. You can follow this implementation approach to provide the solution to your Slack users in use cases where quick access to AI-powered insights would benefit team workflows. By integrating custom AI agents, organizations can track improvements in KPIs such as mean time to resolution (MTTR), first-call resolution rates, and overall productivity gains, showcasing the practical benefits of Amazon Bedrock Agents in enterprise collaboration settings.
We provided a sample agent to help you test and deploy the complete solution. Organizations can now quickly implement their Amazon Bedrock agents and integrate them into Slack, allowing teams to access powerful generative AI capabilities through a familiar interface they use daily. Get started today by developing your own agent using Amazon Bedrock Agents.
Additional resources
To learn more about building Amazon Bedrock Agents, refer to the following resources:
- Build a FinOps agent using Amazon Bedrock with multi-agent capability and Amazon Nova as the foundation model
- Building a virtual meteorologist using Amazon Bedrock Agents
- Build a gen AI–powered financial assistant with Amazon Bedrock multi-agent collaboration
About the Authors
 Salman Ahmed is a Senior Technical Account Manager in AWS Enterprise Support. He specializes in guiding customers through the design, implementation, and support of AWS solutions. Combining his networking expertise with a drive to explore new technologies, he helps organizations successfully navigate their cloud journey. Outside of work, he enjoys photography, traveling, and watching his favorite sports teams.
Salman Ahmed is a Senior Technical Account Manager in AWS Enterprise Support. He specializes in guiding customers through the design, implementation, and support of AWS solutions. Combining his networking expertise with a drive to explore new technologies, he helps organizations successfully navigate their cloud journey. Outside of work, he enjoys photography, traveling, and watching his favorite sports teams.
 Sergio Barraza is a Senior Technical Account Manager at AWS, helping customers on designing and optimizing cloud solutions. With more than 25 years in software development, he guides customers through AWS services adoption. Outside work, Sergio is a multi-instrument musician playing guitar, piano, and drums, and he also practices Wing Chun Kung Fu.
Sergio Barraza is a Senior Technical Account Manager at AWS, helping customers on designing and optimizing cloud solutions. With more than 25 years in software development, he guides customers through AWS services adoption. Outside work, Sergio is a multi-instrument musician playing guitar, piano, and drums, and he also practices Wing Chun Kung Fu.
 Ravi Kumar is a Senior Technical Account Manager in AWS Enterprise Support who helps customers in the travel and hospitality industry to streamline their cloud operations on AWS. He is a results-driven IT professional with over 20 years of experience. In his free time, Ravi enjoys creative activities like painting. He also likes playing cricket and traveling to new places.
Ravi Kumar is a Senior Technical Account Manager in AWS Enterprise Support who helps customers in the travel and hospitality industry to streamline their cloud operations on AWS. He is a results-driven IT professional with over 20 years of experience. In his free time, Ravi enjoys creative activities like painting. He also likes playing cricket and traveling to new places.
 Ankush Goyal is a Enterprise Support Lead in AWS Enterprise Support who helps customers streamline their cloud operations on AWS. He is a results-driven IT professional with over 20 years of experience.
Ankush Goyal is a Enterprise Support Lead in AWS Enterprise Support who helps customers streamline their cloud operations on AWS. He is a results-driven IT professional with over 20 years of experience.
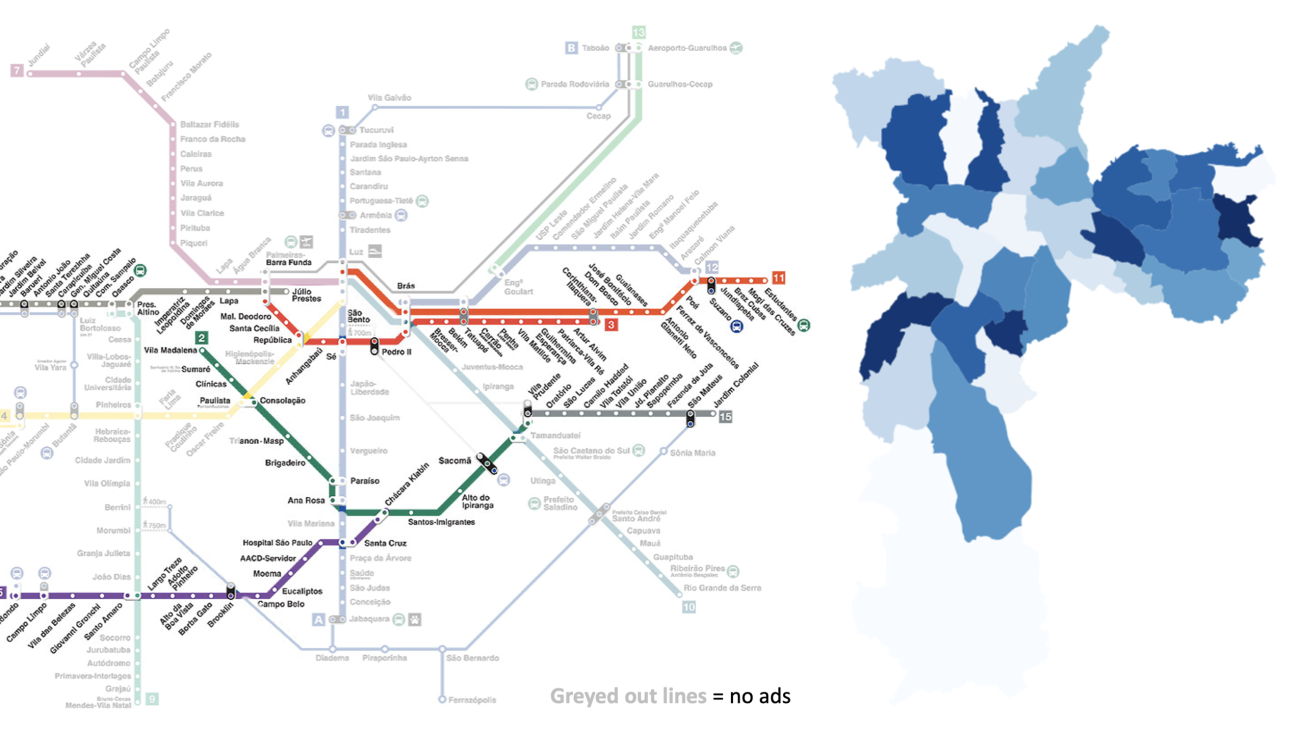
A first-of-its-kind experiment to measure the impact of out-of-home advertising
A first-of-its-kind experiment to measure the impact of out-of-home advertising
By combining surveys with ads targeted to metro and commuter rail lines, Amazon researchers identify the fraction of residents of different neighborhoods exposed to the ads and measure ad effectiveness.
Economics
Egor AbramovMay 21, 02:47 PMMay 21, 02:47 PM
Amazon promotes its products and services through many advertising channels, and we naturally want to know how much bang we get for our buck. We thus try to measure the effectiveness of our ads through a combination of data modeling and, most importantly, experimentation.
In online environments, where the majority of ads live today, researchers can randomize ads and make use of tracking technologies like cookies to measure behavior. This approach provides high-quality data and statistically significant results. In contrast, more-conventional ads found outdoors, in malls and airports, and on transport, referred to as out-of-home (OOH) ads, dont offer the same opportunity for personalized behavior measurements and therefore havent lent themselves well to experiments.
To close this gap, our team at Amazon has developed and successfully implemented an experimental design that focuses on metro and commuter lines. Based on the knowledge of Amazon marketing teams and marketing agencies engaged by Amazon including several that specialize in OOH advertising this is the first experiment of its kind.
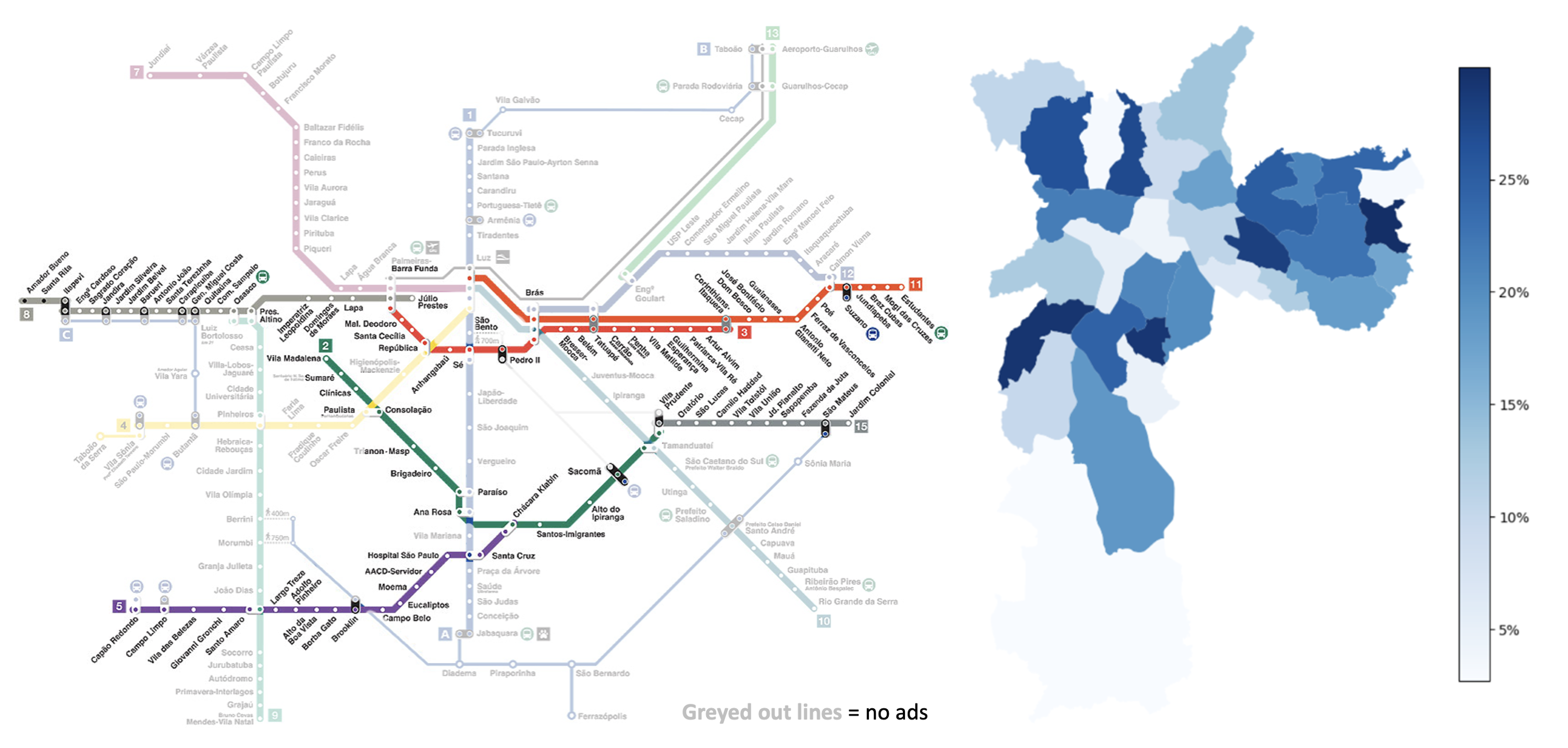
First, we randomized ads across commuter lines in a particular city (not So Paulo: the figure below is a hypothetical example). Second, we sent out an e-mail survey to residents, asking which lines they regularly use. From the survey, we calculated the fraction of residents who had the opportunity to see ads in various neighborhoods. We then used this data to directly measure the effectiveness of an ad campaign.
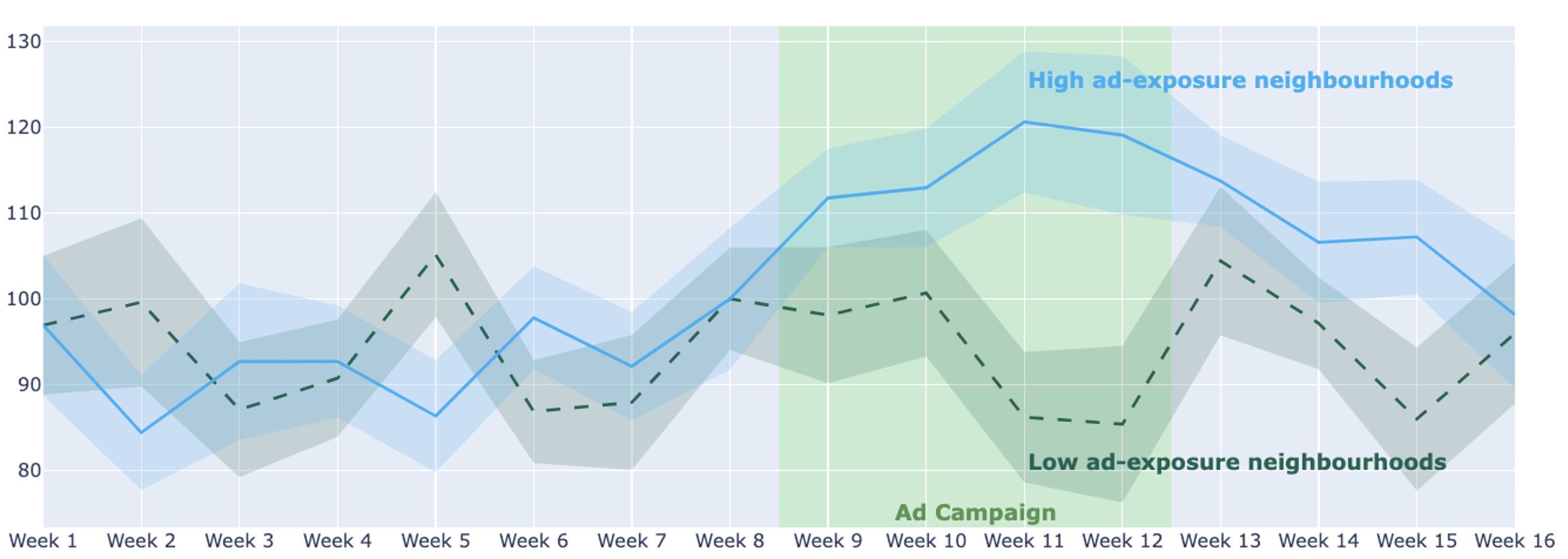
This radically simple approach produces strikingly clear results: over the course of a four-week ad campaign, the high-ad-exposure neighborhoods saw a measurable increase in sales versus neighborhoods with low exposure.
Our experimental design borrows concepts from a technique called geoexperimentation, an approach commonly used for online ads when individual user tracking or personalized ads arent available. Researchers deploying geoexperimentation take a given country and isolate geographical units states, regions, or metropolitan areas in which they randomly apply an ad campaign or not.
Geographic units are typically selected to be large enough that advertisements within a given unit are seen almost exclusively by people living there; that way, the campaigns impact is concentrated within the unit. To estimate the campaigns impact, researchers then compare sales numbers from different geographical units over time, with and without ads. Geoexperiments are effective because within any given country, there is usually a large enough number of relevant geographical units for the experiment to have sufficient statistical power.
There was a working assumption that OOH advertising wouldnt be a good candidate for a real-world implementation of geo experimentation, given how geographically concentrated OOH ad campaigns are. The typical geoexperiment requires dozens of geographic units to ensure sufficient statistical power, but OOH ads are generally deployed in only a handful of bigger cities or, in some cases, a single city within a country.
Using more-granular geographic units for example, city neighborhoods or districts is not an option either, as thered be no way to isolate or identify users who might see the ads. This, for instance, is the challenge posed by a billboard in one district that residents of other districts may drive past.
We realized, however, that these challenges can be met if you choose your OOH ad environments wisely. Targeting ads to metro and commuter rail lines lets us isolate and identify the users who have the opportunity to see them. Our survey asks which metro and commuter rail lines respondents use for commute and occasional travel, how often they so use them, and which part of the city they live in; this gives the fraction of residents exposed to our ads in each neighborhood. At the same time, the random ad placement creates random variation in ad exposure across the citys neighborhoods, giving us the number of geographic units we need for statistical power.
The idea, then, is to compare changes in sales in the treated and control regions, adjusted for historical sales trends. Many techniques used for analyzing geoexperiments apply here, too, including synthetic-control and difference-in-difference methods.
With this first-ever experimental design for OOH advertising, we believe weve opened the door for causal measurement of OOH ad effectiveness. To be sure, this implementation is specific to metro and commuter rail ads, which limits it to cities that support that kind of public transportation. However, we believe lessons learned from such experiments can be extrapolated to other types of OOH ad environments and can be combined with other, non-experiment-based measures of ad performance such as awareness surveys or multimedia models.
Research areas: Economics
Tags: Experimental design

Secure distributed logging in scalable multi-account deployments using Amazon Bedrock and LangChain
Data privacy is a critical issue for software companies that provide services in the data management space. If they want customers to trust them with their data, software companies need to show and prove that their customers’ data will remain confidential and within controlled environments. Some companies go to great lengths to maintain confidentiality, sometimes adopting multi-account architectures, where each customer has their data in a separate AWS account. By isolating data at the account level, software companies can enforce strict security boundaries, help prevent cross-customer data leaks, and support adherence with industry regulations such as HIPAA or GDPR with minimal risk.
Multi-account deployment represents the gold standard for cloud data privacy, allowing software companies to make sure customer data remains segregated even at massive scale, with AWS accounts providing security isolation boundaries as highlighted in the AWS Well-Architected Framework. Software companies increasingly adopt generative AI capabilities like Amazon Bedrock, which provides fully managed foundation models with comprehensive security features. However, managing a multi-account deployment powered by Amazon Bedrock introduces unique challenges around access control, quota management, and operational visibility that could complicate its implementation at scale. Constantly requesting and monitoring quota for invoking foundation models on Amazon Bedrock becomes a challenge when the number of AWS accounts reaches double digits. One approach to simplify operations is to configure a dedicated operations account to centralize management while data from customers transits through managed services and is stored at rest only in their respective customer accounts. By centralizing operations in a single account while keeping data in different accounts, software companies can simplify the management of model access and quotas while maintaining strict data boundaries and security isolation.
In this post, we present a solution for securing distributed logging multi-account deployments using Amazon Bedrock and LangChain.
Challenges in logging with Amazon Bedrock
Observability is crucial for effective AI implementations—organizations can’t optimize what they don’t measure. Observability can help with performance optimization, cost management, and model quality assurance. Amazon Bedrock offers built-in invocation logging to Amazon CloudWatch or Amazon Simple Storage Service (Amazon S3) through a configuration on the AWS Management Console, and individual logs can be routed to different CloudWatch accounts with cross-account sharing, as illustrated in the following diagram.

Routing logs to each customer account presents two challenges: logs containing customer data would be stored in the operations account for the user-defined retention period (at least 1 day), which might not comply with strict privacy requirements, and CloudWatch has a limit of five monitoring accounts (customer accounts). With these limitations, how can organizations build a secure logging solution that scales across multiple tenants and customers?
In this post, we present a solution for enabling distributed logging for Amazon Bedrock in multi-account deployments. The objective of this design is to provide robust AI observability while maintaining strict privacy boundaries for data at rest by keeping logs exclusively within the customer accounts. This is achieved by moving logging to the customer accounts rather than invoking it from the operations account. By configuring the logging instructions in each customer’s account, software companies can centralize AI operations while enforcing data privacy, by keeping customer data and logs within strict data boundaries in each customer’s account. This architecture uses AWS Security Token Service (AWS STS) to allow customer accounts to assume dedicated roles in AWS Identity and Access Management (IAM) in the operations account while invoking Amazon Bedrock. For logging, this solution uses LangChain callbacks to capture invocation metadata directly in each customer’s account, making the entire process in the operations account memoryless. Callbacks can be used to log token usage, performance metrics, and the overall quality of the model in response to customer queries. The proposed solution balances centralized AI service management with strong data privacy, making sure customer interactions remain within their dedicated environments.
Solution overview
The complete flow of model invocations on Amazon Bedrock is illustrated in the following figure. The operations account is the account where the Amazon Bedrock permissions will be managed using an identity-based policy, where the Amazon Bedrock client will be created, and where the IAM role with the correct permissions will exist. Every customer account will assume a different IAM role in the operations account. The customer accounts are where customers will access the software or application. This account will contain an IAM role that will assume the corresponding role in the operations account, to allow Amazon Bedrock invocations. It is important to note that it is not necessary for these two accounts to exist in the same AWS organization. In this solution, we use an AWS Lambda function to invoke models from Amazon Bedrock, and use LangChain callbacks to write invocation data to CloudWatch. Without loss of generality, the same principle can be applied to other forms of compute such as servers in Amazon Elastic Compute Cloud (Amazon EC2) instances or managed containers on Amazon Elastic Container Service (Amazon ECS).

The sequence of steps in a model invocation are:
- The process begins when the IAM role in the customer account assumes the role in the operations account, allowing it to access the Amazon Bedrock service. This is accomplished through the AWS STS AssumeRole API operation, which establishes the necessary cross-account relationship.
- The operations account verifies that the requesting principal (IAM role) from the customer account is authorized to assume the role it is targeting. This verification is based on the trust policy attached to the IAM role in the operations account. This step makes sure that only authorized customer accounts and roles can access the centralized Amazon Bedrock resources.
- After trust relationship verification, temporary credentials (access key ID, secret access key, and session token) with specified permissions are returned to the customer account’s IAM execution role.
- The Lambda function in the customer account invokes the Amazon Bedrock client in the operations account. Using temporary credentials, the customer account’s IAM role sends prompts to Amazon Bedrock through the operations account, consuming the operations account’s model quota.
- After the Amazon Bedrock client response returns to the customer account, LangChain callbacks log the response metrics directly into CloudWatch in the customer account.
Enabling cross-account access with IAM roles
The key idea in this solution is that there will be an IAM role per customer in the operations account. The software company will manage this role and assign permissions to define aspects such as which models can be invoked, in which AWS Regions, and what quotas they’re subject to. This centralized approach significantly simplifies the management of model access and permissions, especially when scaling to hundreds or thousands of customers. For enterprise customers with multiple AWS accounts, this pattern is particularly valuable because it allows the software company to configure a single role that can be assumed by a number of the customer’s accounts, providing consistent access policies and simplifying both permission management and cost tracking. Through carefully crafted trust relationships, the operations account maintains control over who can access what, while still enabling the flexibility needed in complex multi-account environments.
The IAM role can have assigned one or more policies. For example, the following policy allows a certain customer to invoke some models:
The control would be implemented at the trust relationship level, where we would only allow some accounts to assume that role. For example, in the following script, the trust relationship allows the role for customer 1 to only be assumed by the allowed AWS account when the ExternalId matches a specified value, with the purpose of preventing the confused deputy problem:
AWS STS AssumeRole operations constitute the cornerstone of secure cross-account access within multi-tenant AWS environments. By implementing this authentication mechanism, organizations establish a robust security framework that enables controlled interactions between the operations account and individual customer accounts. The operations team grants precisely scoped access to resources across the customer accounts, with permissions strictly governed by the assumed role’s trust policy and attached IAM permissions. This granular control makes sure that the operational team and customers can perform only authorized actions on specific resources, maintaining strong security boundaries between tenants.
As organizations scale their multi-tenant architectures to encompass thousands of accounts, the performance characteristics and reliability of these cross-account authentication operations become increasingly critical considerations. Engineering teams must carefully design their cross-account access patterns to optimize for both security and operational efficiency, making sure that authentication processes remain responsive and dependable even as the environment grows in complexity and scale.
When considering the service quotas that govern these operations, it’s important to note that AWS STS requests made using AWS credentials are subject to a default quota of 600 requests per second, per account, per Region—including AssumeRole operations. A key architectural advantage emerges in cross-account scenarios: only the account initiating the AssumeRole request (customer account) counts against its AWS STS quota; the target account’s (operations account) quota remains unaffected. This asymmetric quota consumption means that the operations account doesn’t deplete their AWS STS service quotas when responding to API requests from customer accounts. For most multi-tenant implementations, the standard quota of 600 requests per second provides ample capacity, though AWS offers quota adjustment options for environments with exceptional requirements. This quota design enables scalable operational models where a single operations account can efficiently service thousands of tenant accounts without encountering service limits.
Writing private logs using LangChain callbacks
LangChain is a popular open source orchestration framework that enables developers to build powerful applications by connecting various components through chains, which are sequential series of operations that process and transform data. At the core of LangChain’s extensibility is the BaseCallbackHandler class, a fundamental abstraction that provides hooks into the execution lifecycle of chains, allowing developers to implement custom logic at different stages of processing. This class can be extended to precisely define behaviors that should occur upon completion of a chain’s invocation, enabling sophisticated monitoring, logging, or triggering of downstream processes. By implementing custom callback handlers, developers can capture metrics, persist results to external systems, or dynamically alter the execution flow based on intermediate outputs, making LangChain both flexible and powerful for production-grade language model applications.
Implementing a custom CloudWatch logging callback in LangChain provides a robust solution for maintaining data privacy in multi-account deployments. By extending the BaseCallbackHandler class, we can create a specialized handler that establishes a direct connection to the customer account’s CloudWatch logs, making sure model interaction data remains within the account boundaries. The implementation begins by initializing a Boto3 CloudWatch Logs client using the customer account’s credentials, rather than the operations account’s credentials. This client is configured with the appropriate log group and stream names, which can be dynamically generated based on customer identifiers or application contexts. During model invocations, the callback captures critical metrics such as token usage, latency, prompt details, and response characteristics. The following Python script serves as an example of this implementation:
The on_llm_start, on_llm_end, and on_llm_error methods are overridden to intercept these lifecycle events and persist the relevant data. For example, the on_llm_end method can extract token counts, execution time, and model-specific metadata, formatting this information into structured log entries before writing them to CloudWatch. By implementing proper error handling and retry logic within the callback, we provide reliable logging even during intermittent connectivity issues. This approach creates a comprehensive audit trail of AI interactions while maintaining strict data isolation in the customer account, because the logs do not transit through or rest in the operations account.
The AWS Shared Responsibility Model in multi-account logging
When implementing distributed logging for Amazon Bedrock in multi-account architectures, understanding the AWS Shared Responsibility Model becomes paramount. Although AWS secures the underlying infrastructure and services like Amazon Bedrock and CloudWatch, customers remain responsible for securing their data, configuring access controls, and implementing appropriate logging strategies. As demonstrated in our IAM role configurations, customers must carefully craft trust relationships and permission boundaries to help prevent unauthorized cross-account access. The LangChain callback implementation outlined places the responsibility on customers to enforce proper encryption of logs at rest, define appropriate retention periods that align with compliance requirements, and implement access controls for who can view sensitive AI interaction data. This aligns with the multi-account design principle where customer data remains isolated within their respective accounts. By respecting these security boundaries while maintaining operational efficiency, software companies can uphold their responsibilities within the shared security model while delivering scalable AI capabilities across their customer base.
Conclusion
Implementing a secure, scalable multi-tenant architecture with Amazon Bedrock requires careful planning around account structure, access patterns, and operational management. The distributed logging approach we’ve outlined demonstrates how organizations can maintain strict data isolation while still benefiting from centralized AI operations. By using IAM roles with precise trust relationships, AWS STS for secure cross-account authentication, and LangChain callbacks for private logging, companies can create a robust foundation that scales to thousands of customers without compromising on security or operational efficiency.
This architecture addresses the critical challenge of maintaining data privacy in multi-account deployments while still enabling comprehensive observability. Organizations should prioritize automation, monitoring, and governance from the beginning to avoid technical debt as their system scales. Implementing infrastructure as code for role management, automated monitoring of cross-account access patterns, and regular security reviews will make sure the architecture remains resilient and will help maintain adherence with compliance standards as business requirements evolve. As generative AI becomes increasingly central to software provider offerings, these architectural patterns provide a blueprint for maintaining the highest standards of data privacy while delivering innovative AI capabilities to customers across diverse regulatory environments and security requirements.
To learn more, explore the comprehensive Generative AI Security Scoping Matrix through Securing generative AI: An introduction to the Generative AI Security Scoping Matrix, which provides essential frameworks for securing AI implementations. Building on these security foundations, strengthen Amazon Bedrock deployments by getting familiar with IAM authentication and authorization mechanisms that establish proper access controls. As organizations grow to require multi-account structures, these IAM practices connect seamlessly with AWS STS, which delivers temporary security credentials enabling secure cross-account access patterns. To complete this integrated security approach, delve into LangChain and LangChain on AWS capabilities, offering powerful tools that build upon these foundational security services to create secure, context-aware AI applications, while maintaining appropriate security boundaries across your entire generative AI workflow.
About the Authors
 Mohammad Tahsin is an AI/ML Specialist Solutions Architect at AWS. He lives for staying up-to-date with the latest technologies in AI/ML and helping customers deploy bespoke solutions on AWS. Outside of work, he loves all things gaming, digital art, and cooking.
Mohammad Tahsin is an AI/ML Specialist Solutions Architect at AWS. He lives for staying up-to-date with the latest technologies in AI/ML and helping customers deploy bespoke solutions on AWS. Outside of work, he loves all things gaming, digital art, and cooking.
 Felipe Lopez is a Senior AI/ML Specialist Solutions Architect at AWS. Prior to joining AWS, Felipe worked with GE Digital and SLB, where he focused on modeling and optimization products for industrial applications.
Felipe Lopez is a Senior AI/ML Specialist Solutions Architect at AWS. Prior to joining AWS, Felipe worked with GE Digital and SLB, where he focused on modeling and optimization products for industrial applications.
 Aswin Vasudevan is a Senior Solutions Architect for Security, ISV at AWS. He is a big fan of generative AI and serverless architecture and enjoys collaborating and working with customers to build solutions that drive business value.
Aswin Vasudevan is a Senior Solutions Architect for Security, ISV at AWS. He is a big fan of generative AI and serverless architecture and enjoys collaborating and working with customers to build solutions that drive business value.

Abstracts: Aurora with Megan Stanley and Wessel Bruinsma

Members of the research community at Microsoft work continuously to advance their respective fields. Abstracts brings its audience to the cutting edge with them through short, compelling conversations about new and noteworthy achievements.
In this episode of Abstracts, Microsoft senior researchers Megan Stanley and Wessel Bruinsma join host Amber Tingle to discuss their groundbreaking work on environmental forecasting. Their new Nature publication, “A Foundation Model for the Earth System,” (opens in new tab) features Aurora, an AI model that redefines weather prediction and extends its capabilities to other environmental domains such as tropical cyclones and ocean wave forecasting.
Learn more
A foundation model for the Earth system (opens in new tab)
Nature | May 2025
Introducing Aurora: The first large-scale foundation model of the atmosphere
Microsoft Research Blog | June 2024
Project Aurora: The first large-scale foundation model of the atmosphere
Video | September 2024
A Foundation Model for the Earth System
Paper | November 2024
Aurora (opens in new tab)
Azure AI Foundry Labs
Subscribe to the Microsoft Research Podcast:
Transcript
[MUSIC]AMBER TINGLE: Welcome to Abstracts, a Microsoft Research Podcast that puts the spotlight on world-class research in brief. I’m Amber Tingle. In this series, members of the research community at Microsoft give us a quick snapshot—or a podcast abstract—of their new and noteworthy papers.
[MUSIC FADES]Our guests today are Megan Stanley and Wessel Bruinsma. They are both senior researchers within the Microsoft Research AI for Science initiative. They are also two of the coauthors on a new Nature publication called “A Foundation Model for the Earth System.”
This is such exciting work about environmental forecasting, so we’re happy to have the two of you join us today.
Megan and Wessel, welcome.
MEGAN STANLEY: Thank you. Thanks. Great to be here.
WESSEL BRUINSMA: Thanks.
TINGLE: Let’s jump right in. Wessel, share a bit about the problem your research addresses and why this work is so important.
BRUINSMA: I think we’re all very much aware of the revolution that’s happening in the space of large language models, which have just become so strong. What’s perhaps lesser well-known is that machine learning models have also started to revolutionize this field of weather prediction. Whereas traditional weather prediction models, based on physical laws, used to be the state of the art, these traditional models are now challenged and often even outperformed by AI models.
This advancement is super impressive and really a big deal. Mostly because AI weather forecasting models are computationally much more efficient and can even be more accurate. What’s unfortunate though, about this big step forward, is that these developments are mostly limited to the setting of weather forecasting.
Weather forecasting is very important, obviously, but there are many other important environmental forecasting problems out there, such as air pollution forecasting or ocean wave forecasting. We have developed a model, named Aurora, which really kicks the AI revolution in weather forecasting into the next gear by extending these advancements to other environmental forecasting fields, too. With Aurora, we’re now able to produce state-of-the-art air pollution forecasts using an AI approach. And that wasn’t possible before!
TINGLE: Megan, how does this approach differ from or build on work that’s already been done in the atmospheric sciences?
STANLEY: Current approaches have really focused training very specifically on weather forecasting models. And in contrast, with Aurora, what we’ve attempted to do is train a so-called foundation model for the Earth system. In the first step, we train Aurora on a vast body of Earth system data. This is our pretraining step.
And when I say a vast body of data, I really do mean a lot. And the purpose of this pretraining is to let Aurora, kind of, learn some general-purpose representation of the dynamics that govern the Earth system. But then once we’ve pretrained Aurora, and this really is the crux of this, the reason why we’re doing this project, is after the model has been pretrained, it can leverage this learned general-purpose representation and efficiently adapt to new tasks, new domains, new variables. And this is called fine-tuning.
The idea is that the model really uses the learned representation to perform this adaptation very efficiently, which basically means Aurora is a powerful, flexible model that can relatively cheaply be adapted to any environmental forecasting task.
TINGLE: Wessel, can you tell us about your methodology? How did you all conduct this research?
BRUINSMA: While approaches so far have trained models on primarily one particular data set, this one dataset is very large, which makes it possible to train very good models. But it does remain only one dataset, and that’s not very diverse. In the domain of environmental forecasting, we have really tried to push the limits of scaling to large data by training Aurora on not just this one large dataset, but on as many very large datasets as we could find.
These datasets are a combination of estimates of the historical state of the world, forecasts by other models, climate simulations, and more. We’ve been able to show that training on not just more data but more diverse data helps the model achieve even better performance. Showing this is difficult because there is just so much data.
In addition to scaling to more and more diverse data, we also increased the size of the model as much as we could. Here we found that bigger models, despite being slower to run, make more efficient use of computational resources. It’s cheaper to train a good big model than a good small model. The mantra of this project was to really keep it simple and to scale to simultaneously very large and, more importantly, diverse data and large model size.
TINGLE: So, Megan, what were your major findings? And we know they’re major because they’re in Nature. [LAUGHS]
STANLEY: Yeah, [LAUGHS] I guess they really are. So the main outcome of this project is we were actually able to train a single foundation model that achieves state-of-the-art performance in four different domains. Air pollution forecasting. For example, predicting particulate matter near the surface or ozone in the atmosphere. Ocean wave forecasting, which is critical for planning shipping routes.
Tropical cyclone track forecasting, so that means being able to predict where a hurricane or a typhoon is expected to go, which is obviously incredibly important, and very high-resolution weather forecasting.
And I’ve, kind of, named these forecasting domains as if they’re just items in a list, but in every single one, Aurora really pushed the limits of what is possible with AI models. And we’re really proud of that.
But perhaps, kind of, you know, to my mind, the key takeaway here is that the foundation model approach actually works. So what we have shown is it’s possible to actually train some kind of general model, a foundation model, and then adapt it to a wide variety of environmental tasks. Now we definitely do not claim that Aurora is some kind of ultimate environmental forecasting model. We are sure that the model and the pretraining procedure can actually be improved. But, nevertheless, we’ve shown that this approach works for environmental forecasting. It really holds massive promise, and that’s incredibly cool.
TINGLE: Wessel, what do you think will be the real-world impact of this work?
BRUINSMA: Well, for applications that we mentioned, which are air pollution forecasting, ocean wave forecasting, tropical cyclone track forecasting, and very high-resolution weather forecasting, Aurora could today be deployed in real-time systems to produce near real-time forecasts. And, you know, in fact, it already is. You can view real-time weather forecasts by the high-resolution version of the model on the website of ECMWF (European Centre for Medium-Range Weather Forecasts).
But what’s remarkable is that every of these applications took a small team of engineers about four to eight weeks to fully execute. You should compare this to a typical development timeline for more traditional models, which can be on the order of multiple years. Using the pretraining fine-tuning approach that we used for Aurora, we might see significantly accelerated development cycles for environmental forecasting problems. And that’s exciting.
TINGLE: Megan, if our listeners only walk away from this conversation with one key talking point, what would you like that to be? What should we remember about this paper?
STANLEY: The biggest takeaway is that the pretraining fine-tuning paradigm, it really works for environmental forecasting, right? So you can train a foundational model, it learns some kind of general-purpose representation of the Earth system dynamics, and this representation boosts performance in a wide variety of forecasting tasks. But we really want to emphasize that Aurora only scratches the surface of what’s actually possible.
So there are many more applications to explore than the four we’ve mentioned. And undoubtedly, the model and pretraining procedure can actually be improved. So we’re really excited to see what the next few years will bring.
TINGLE: Wessel, tell us more about those opportunities and unanswered questions. What’s next on the research agenda in environmental prediction?
BRUINSMA: Well, Aurora has two main limitations. The first is that the model produces only deterministic predictions, by which I mean a single predicted value. For variables like temperature, this is mostly fine. But other variables like precipitation, they are inherently some kind of stochastic. For these variables, we really want to assign probabilities to different levels of precipitation rather than predicting only a single value.
An extension of Aurora to allow this sort of prediction would be a great next step.
The second limitation is that Aurora depends on a procedure called assimilation. Assimilation attempts to create a starting point for the model from real-world observations, such as from weather stations and satellites. The model then takes the starting point and uses it to make predictions. Unfortunately, assimilation is super expensive, so it would be great if we could somehow circumvent the need for it.
Finally, what we find really important is to make our advancements available to the community.
[MUSIC]TINGLE: Great. Megan and Wessel, thanks for joining us today on the Microsoft Research Podcast.
BRUINSMA: Thanks for having us.
STANLEY: Yeah, thank you. It’s been great.
TINGLE: You can check out the Aurora model on Azure AI Foundry. You can read the entire paper, “A Foundation Model for the Earth System,” at aka.ms/abstracts. And you’ll certainly find it on the Nature website, too.
Thank you so much for tuning in to Abstracts today. Until next time.
[MUSIC FADES]
The post Abstracts: Aurora with Megan Stanley and Wessel Bruinsma appeared first on Microsoft Research.

NVIDIA and SAP Bring AI Agents to the Physical World
As robots increasingly make their way to the largest enterprises’ manufacturing plants and warehouses, the need for access to critical business and operational data has never been more crucial.
At its Sapphire conference, SAP announced it is collaborating with NEURA Robotics and NVIDIA to enable its SAP Joule agents to connect enterprise data and processes with NEURA’s advanced cognitive robots.
The integration will enable robots to support tasks including adaptive manufacturing, autonomous replenishment, compliance monitoring and predictive maintenance. Using the Mega NVIDIA Omniverse Blueprint, SAP customers will be able to simulate and validate large robotic fleets in digital twins before deploying them in real-world facilities.
Virtual Assistants Become Physical Helpers
AI agents are traditionally confined to the digital world, which means they’re unable to take actionable steps for physical tasks and do real-world work in warehouses, factories and other industrial workplaces.
SAP’s collaboration with NVIDIA and NEURA Robotics shows how enterprises will be able to use Joule to plan and simulate complex and dynamic scenarios that include physical AI and autonomous humanoid robots to address critical planning, safety and project requirements, streamline operations and embody business intelligence in the physical world.
Revolutionizing Supply Chain Management: NVIDIA, SAP Tackle Complex Challenges
Today’s supply chains have become more fragile and complex with ever-evolving constraints around consumer, economic, political and environmental dimensions. The partnership between NVIDIA and SAP aims to enhance supply chain planning capabilities by integrating NVIDIA cuOpt technology — for real-time route optimization — with SAP Integrated Business Planning (IBP) to enable customers to plan and simulate the most complex and dynamic scenarios for more rapid and confident decision making.
By extending SAP IBP with NVIDIA’s highly scalable, GPU-powered platform, customers can accelerate time-to-value by facilitating the management of larger and more intricate models without sacrificing runtime. This groundbreaking collaboration will empower businesses to address unique planning requirements, streamline operations and drive better business outcomes.
Supporting Supply Chains With AI and Humanoid Robots
SAP Chief Technology Officer Philipp Herzig offered a preview of the technology integration in a keynote demonstration at SAP Sapphire in Orlando, showing the transformative potential for physical AI in businesses in how Joule — SAP’s generative AI co-pilot — works with data from the real world in combination with humanoid robots.
“Robots and autonomous agents are at the heart of the next wave of industrial AI, seamlessly connecting people, data, and processes to unlock new levels of efficiency and innovation,” said Herzig. “SAP, NVIDIA and NEURA Robotics share a vision for uniting AI and robotics to improve safety, efficiency and productivity across industries.”
With the integration of the Mega NVIDIA Omniverse Blueprint, enterprises can harness physical AI and digital twins to enable new AI agents that can deliver real-time, contextual insights and automate routine tasks.
The collaboration between the three companies allows NEURA robots to see, learn and adapt in real time — whether restocking shelves, inspecting infrastructure or resolving supply chain disruptions.
SAP Joule AI Agents are deployed directly onto NEURA’s cognitive robots, enabling real-time decision-making and the execution of physical tasks such as inventory audits or equipment repairs. The robots learn continuously in physically accurate digital twins, powered by NVIDIA Omniverse libraries and technologies, and using business-critical data from SAP applications, while the Mega NVIDIA Omniverse Blueprint helps evaluate and validate deployment options and large-scale task interactions.
Showcasing Joule’s Data-Driven Insights on NEURA Robots
The technology demonstration showcases the abilities of NEURA robots to handle tasks guided by Joule’s data-driven insights.
Businesses bridging simulation-to-reality deployments can use the integrated technology stack to provide zero-shot navigation and inference to address defect rates and production line inefficiencies without interrupting operations.
Herzig showed how Joule can direct a NEURA 4NE1 robot to inspect a machine in the showroom, powered by AI agents, scanning equipment and triggering an SAP Asset Performance management alert before a failure disrupts operations.
It’s but a glimpse into the future of what’s possible with AI agents and robotics.
Humanoid Policy ~ Human Policy
Training manipulation policies for humanoid robots with
diverse data enhances their robustness and generalization across tasks and platforms. However, learning solely from robot demonstrations is labor-intensive, requiring expensive tele-operated data
collection which is difficult to scale. This paper investigates a more scalable data source, egocentric human demonstrations, to serve as cross-embodiment training data for robot learning. We mitigate the embodiment gap between humanoids and humans
from both the data and modeling perspectives. We collect an egocentric task-oriented dataset (PH2D)…Apple Machine Learning Research
Cubify Anything: Scaling Indoor 3D Object Detection
We consider indoor 3D object detection with respect to a single RGB(-D) frame acquired from a commodity handheld device. We seek to significantly advance the status quo with respect to both data and modeling. First, we establish that existing datasets have significant limitations to scale, accuracy, and diversity of objects. As a result, we introduce the Cubify-Anything 1M (CA-1M) dataset, which exhaustively labels over 400K 3D objects on over 1K highly accurate laser-scanned scenes with near-perfect registration to over 3.5K handheld, egocentric captures. Next, we establish Cubify Transformer…Apple Machine Learning Research
Understand all the I/O news with NotebookLM.
 Google I/O 2025 was full of tons of announcements, lots of launches and plenty of demos! And if you just can’t get enough of all things I/O, you can dive deeper into the…Read More
Google I/O 2025 was full of tons of announcements, lots of launches and plenty of demos! And if you just can’t get enough of all things I/O, you can dive deeper into the…Read More