This post was co-written with Federico Thibaud, Neil Holloway, Fraser Price, Christian Dunn, and Frederica Schrager from Gardenia Technologies
“What gets measured gets managed” has become a guiding principle for organizations worldwide as they begin their sustainability and environmental, social, and governance (ESG) journeys. Companies are establishing baselines to track their progress, supported by an expanding framework of reporting standards, some mandatory and some voluntary. However, ESG reporting has evolved into a significant operational burden. A recent survey shows that 55% of sustainability leaders cite excessive administrative work in report preparation, while 70% indicate that reporting demands inhibit their ability to execute strategic initiatives. This environment presents a clear opportunity for generative AI to automate routine reporting tasks, allowing organizations to redirect resources toward more impactful ESG programs.
Gardenia Technologies, a data analytics company, partnered with the AWS Prototyping and Cloud Engineering (PACE) team to develop Report GenAI, a fully automated ESG reporting solution powered by the latest generative AI models on Amazon Bedrock. This post dives deep into the technology behind an agentic search solution using tooling with Retrieval Augmented Generation (RAG) and text-to-SQL capabilities to help customers reduce ESG reporting time by up to 75%.
In this post, we demonstrate how AWS serverless technology, combined with agents in Amazon Bedrock, are used to build scalable and highly flexible agent-based document assistant applications.
Scoping the challenge: Growing ESG reporting requirements and complexity
Sustainability disclosures are now a standard part of corporate reporting, with 96% of the 250 largest companies reporting on their sustainability progress based on government and regulatory frameworks. To meet reporting mandates, organizations must overcome many data collection and process-based barriers. Data for a single report includes thousands of data points from a multitude of sources including official documentation, databases, unstructured document stores, utility bills, and emails. The EU Corporate Sustainability Reporting Directive (CSRD) framework, for example, comprises of 1,200 individual data points that need to be collected across an enterprise. Even voluntary disclosures like the CDP, which is approximately 150 questions, cover a wide range of questions related to climate risk and impact, water stewardship, land use, and energy consumption. Collecting this information across an organization is time consuming.
A secondary challenge is that many organizations with established ESG programs need to report to multiple disclosure frameworks, such as SASB, GRI, TCFD, each using different reporting and disclosure standards. To complicate matters, reporting requirements are continually evolving, leaving organizations struggling just to keep up with the latest changes. Today, much of this work is highly manual and leaves sustainability teams spending more time on managing data collection and answering questionnaires rather than developing impactful sustainability strategies.
Solution overview: Automating undifferentiated heavy lifting with AI agents
Gardenia’s approach to strengthen ESG data collection for enterprises is Report GenAI, an agentic framework using generative AI models on Amazon Bedrock to automate large chunks of the ESG reporting process. Report GenAI pre-fills reports by drawing on existing databases, document stores and web searches. The agent then works collaboratively with ESG professionals to review and fine-tune responses. This workflow has five steps to help automate ESG data collection and assist in curating responses. These steps include setup, batch-fill, review, edit, and repeat. Let’s explore each step in more detail.
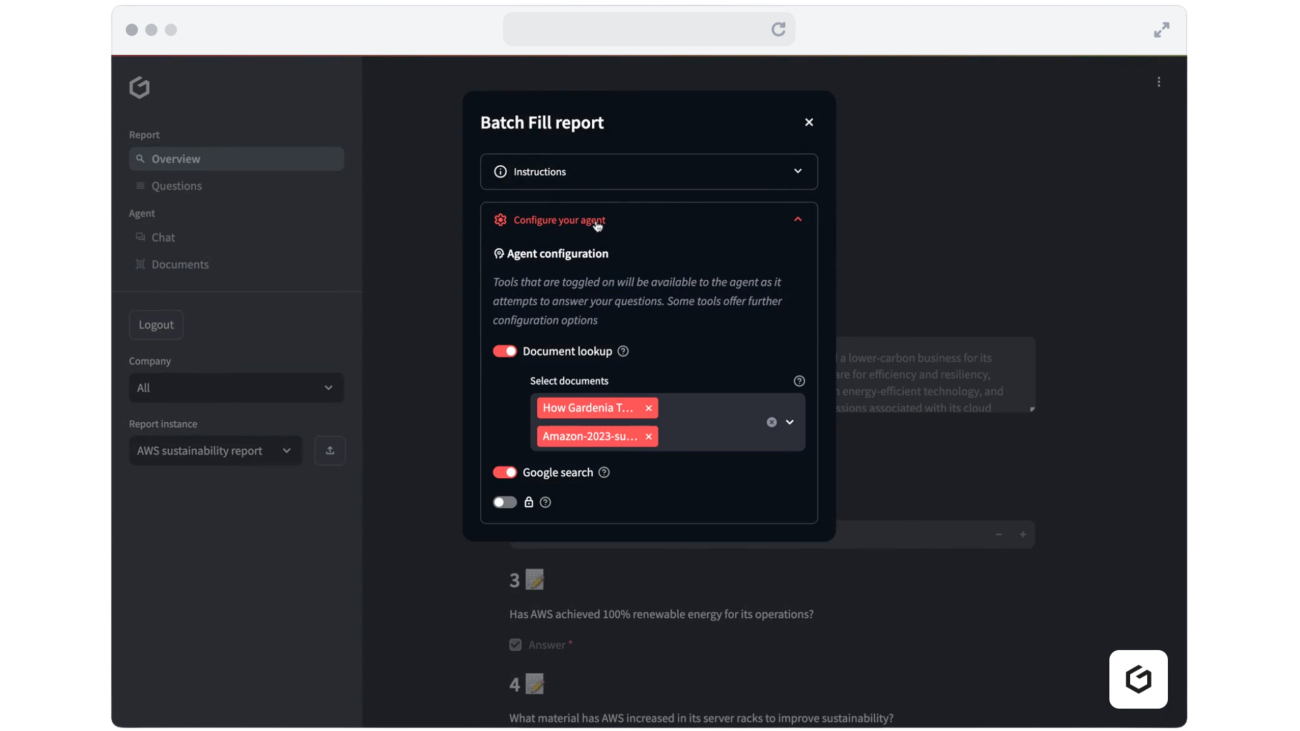
- Setup: The Report GenAI agent is configured and authorized to access an ESG and emissions database, client document stores (emails, previous reports, data sheets), and document searches over the public internet. Client data is stored within specified AWS Regions using encrypted Amazon Simple Storage Service (Amazon S3) buckets with VPC endpoints for secure access, while relational data is hosted in Amazon Relational Database Service (Amazon RDS) instances deployed within Gardenia’s virtual private cloud (VPC). This architecture helps make sure data residency requirements can be fulfilled, while maintaining strict access controls through private network connectivity. The agent also has access to the relevant ESG disclosure questionnaire including questions and expected response format (we refer to this as a report specification). The following figure is an example of the Report GenAI user interface at the agent configuration step. As shown in the figure, the user can choose which databases, documents, or other tools the agent will use to answer a given question.

- Batch-fill: The agent then iterates through each question and data point to be disclosed and then retrieves relevant data from the client document stores and document searches. This information is processed to produce a response in the expected format depending on the disclosure report requirements.
- Review: Each response includes cited sources and—if the response is quantitative—calculation methodology. This enables users to maintain a clear audit trail and verify the accuracy of batch-filled responses quickly.
- Edit: While the agentic workflow is automated, our approach allows for a human-in-the-loop to review, validate, and iterate on batch-filled facts and figures. In the following figure, we show how users can chat with the AI assistant to request updates or manually refine responses. When the user is satisfied, the final answer is recorded. The agent will show references from which responses were sourced and allow the user to modify answers either directly or by providing an additional prompt.

- Repeat: Users can batch-fill multiple reporting frameworks to simplify and expand their ESG disclosure scope while avoiding extra effort to manually complete multiple questionnaires. After a report has been completed, it can then be added to the client document store so future reports can draw on it for knowledge. Report GenAI also supports bring your own report, which allows users to develop their own reporting specification (question and response model), which can then be imported into the application, as shown in the following figure.

Now that you have a description of the Report GenAI workflow, let’s explore how the architecture is built.
Architecture deep-dive: A serverless generative AI agent
The Report GenAI architecture consists of six components as illustrated in the following figure: A user interface (UI), the generative AI executor, the web search endpoint, a text-to-SQL tool, the RAG tool, and an embedding generation pipeline. The UI, generative AI executor, and generation pipeline components help orchestrate the workflow. The remaining three components function together to generate responses to perform the following actions:
- Web search tool: Uses an internet search engine to retrieve content from public web pages.
- Text-to-SQL tool: Generates and executes SQL queries to the company’s emissions database hosted by Gardenia Technologies. The tool uses natural language requests, such as “What were our Scope 2 emissions in 2024,” as input and returns the results from the emissions database.
- Retrieval Augmented Generation (RAG) tool: Accesses information from the corporate document store (such as procedures, emails, and internal reports) and uses it as a knowledge base. This component acts as a retriever to return relevant text from the document store as a plain text query.

Let’s take a look at each of the components.
1: Lightweight UI hosted on auto-scaled Amazon ECS Fargate
Users access Report GenAI by using the containerized Streamlit frontend. Streamlit offers an appealing UI for data and chat apps allowing data scientists and ML to build convincing user experiences with relatively limited effort. While not typically used for large-scale deployments, Streamlit proved to be a suitable choice for the initial iteration of Report GenAI.
The frontend is hosted on a load-balanced and auto-scaled Amazon Elastic Container Service (Amazon ECS) with Fargate launch type. This implementation of the frontend not only reduces the management overhead but also suits the expected intermittent usage pattern of Report GenAI, which is anticipated to be spikey with high-usage periods around the times when new reports must be generated (typically quarterly or yearly) and lower usage outside these windows. User authentication and authorization is handled by Amazon Cognito.
2: Central agent executor
The executor is an agent that uses reasoning capabilities of leading text-based foundation models (FMs) (for example, Anthropic’s Claude Sonnet 3.5 and Haiku 3.5) to break down user requests, gather information from document stores, and efficiently orchestrate tasks. The agent uses Reason and Act (ReAct), a prompt-based technique that enables large language models (LLMs) to generate both reasoning traces and task-specific actions in an interleaved manner. Reasoning traces help the model develop, track, and update action plans, while actions allow it to interface with a set of tools and information sources (also known as knowledge bases) that it can use to fulfil the task. The agent is prompted to think about an optimal sequence of actions to complete a given task with the tools at its disposal, observe the outcome, and iterate and improve until satisfied with the answer.
In combination, these tools provide the agent with capabilities to iteratively complete complex ESG reporting templates. The expected questions and response format for each questionnaire is captured by a report specification (ReportSpec) using Pydantic to enforce the desired output format for each reporting standard (for example, CDP, or TCFD). This ReportSpec definition is inserted into the task prompt. The first iteration of Report GenAI used Claude Sonnet 3.5 on Amazon Bedrock. As more capable and more cost effective LLMs become available on Amazon Bedrock (such as the recent release of Amazon Nova models), foundation models in Report GenAI can be swapped to remain up to date with the latest models.
The agent-executor is hosted on AWS Lambda and uses the open-source LangChain framework to implement the ReAct orchestration logic and implement the needed integration with memory, LLMs, tools and knowledge bases. LangChain offers deep integration with AWS using the first-party langchain-aws module. The module langchain-aws provides useful one-line wrappers to call tools using AWS Lambda, draw from a chat memory backed by Dynamo DB and call LLM models on Amazon Bedrock. LangChain also provides fine-grained visibility into each step of the ReAct decision making process to provide decision transparency.

3: Web-search tool
The web search tool is hosted on Lambda and calls an internet search engine through an API. The agent executor retrieves the information returned from the search engine to formulate a response. Web searches can be used in combination with the RAG tool to retrieve public context needed to formulate responses for certain generic questions, such as providing a short description of the reporting company or entity.
4: Text-to-SQL tool
A large portion of ESG reporting requirements is analytical in nature and requires processing of large amounts of numerical or tabular data. For example, a reporting standard might ask for total emissions in a certain year or quarter. LLMs are ill-equipped for questions of this nature. The Lambda-hosted text-to-SQL tool provides the agent with the required analytical capabilities. The tool uses a separate LLM to generate a valid SQL query given a natural language question along with the schema of an emissions database hosted on Gardenia. The generated query is then executed against this database and the results are passed back to the agent executor. SQL linters and error-correction loops are used for added robustness.
5: Retrieval Augmented Generation (RAG) tool
Much of the information required to complete ESG reporting resides in internal, unstructured document stores and can consist of PDF or Word documents, Excel spreadsheets, and even emails. Given the size of these document stores, a common approach is to use knowledge bases with vector embeddings for semantic search. The RAG tool enables the agent executor to retrieve only the relevant parts to answer questions from the document store. The RAG tool is hosted on Lambda and uses an in-memory Faiss index as a vector store. The index is persisted on Amazon S3 and loaded on demand whenever required. This workflow is advantageous for the given workload because of the intermittent usage of Report GenAI. The RAG tool accepts a plain text query from the agent executor as input, uses an embedding model on Amazon Bedrock to perform a vector search against the vector data base. The retrieved text is returned to the agent executor.
6: Embedding the generation asynchronous pipeline
To make text searchable, it must be indexed in a vector database. Amazon Step Functions provides a straightforward orchestration framework to manage this process: extracting plain text from the various document types, chunking it into manageable pieces, embedding the text, and then loading embeddings into a vector DB. Amazon Textract can be used as the first step for extracting text from visual-heavy documents like presentations or PDFs. An embedding model such as Amazon Titan Text Embeddings can then be used to embed the text and store it into a vector DB such as Lance DB. Note that Amazon Bedrock Knowledge Bases provides an end-to-end retrieval service automating most of the steps that were just described. However, for this application, Gardenia Technologies opted for a fully flexible implementation to retain full control over each design choice of the RAG pipeline (text extraction approach, embedding model choice, and vector database choice) at the expense of higher management and development overhead.
Evaluating agent performance
Making sure of accuracy and reliability in ESG reporting is paramount, given the regulatory and business implications of these disclosures. Report GenAI implements a sophisticated dual-layer evaluation framework that combines human expertise with advanced AI validation capabilities.
Validation is done both at a high level (such as evaluating full question responses) and sub-component level (such as breaking down to RAG, SQL search, and agent trajectory modules). Each of these has separate evaluation sets in addition to specific metrics of interest.
Human expert validation
The solution’s human-in-the-loop approach allows ESG experts to review and validate the AI-generated responses. This expert oversight serves as the primary quality control mechanism, making sure that generated reports align with both regulatory requirements and organization-specific context. The interactive chat interface enables experts to:
- Verify factual accuracy of automated responses
- Validate calculation methodologies
- Verify proper context interpretation
- Confirm regulatory compliance
- Flag potential discrepancies or areas requiring additional review
A key feature in this process is the AI reasoning module, which displays the agent’s decision-making process, providing transparency into not only what answers were generated but how the agent arrived at those conclusions.

These expert reviews provide valuable training data that can be used to enhance system performance through refinements to RAG implementations, agent prompts, or underlying language models.
AI-powered quality assessment
Complementing human oversight, Report GenAI uses state-of-the-art LLMs on Amazon Bedrock as LLM judges. These models are prompted to evaluate:
- Response accuracy relative to source documentation
- Completeness of answers against question requirements
- Consistency with provided context
- Alignment with reporting framework guidelines
- Mathematical accuracy of calculations
The LLM judge operates by:
- Analyzing the original question and context
- Reviewing the generated response and its supporting evidence
- Comparing the response against retrieved data from structured and unstructured sources
- Providing a confidence score and detailed assessment of the response quality
- Flagging potential issues or areas requiring human review
This dual-validation approach creates a robust quality assurance framework that combines the pattern recognition capabilities of AI with human domain expertise. The system continuously improves through feedback loops, where human corrections and validations help refine the AI’s understanding and response generation capabilities.
How Omni Helicopters International cuts its reporting time by 75%
Omni Helicopters International cut their CDP reporting time by 75% using Gardenia’s Report GenAI solution. In previous years, OHI’s CDP reporting required one month of dedicated effort from their sustainability team. Using Report GenAI, OHI tracked their GHG inventory and relevant KPIs in real time and then prepared their 2024 CDP submission in just one week. Read the full story in Preparing Annual CDP Reports 75% Faster.
“In previous years we needed one month to complete the report, this year it took just one week,” said Renato Souza, Executive Manager QSEU at OTA. “The ‘Ask the Agent’ feature made it easy to draft our own answers. The tool was a great support and made things much easier compared to previous years.”
Conclusion
In this post, we stepped through how AWS and Gardenia collaborated to build Report GenAI, an automated ESG reporting solution that relieves ESG experts of the undifferentiated heavy lifting of data gathering and analysis associated with a growing ESG reporting burden. This frees up time for more impactful, strategic sustainability initiatives. Report GenAI is available on the AWS Marketplace today. To dive deeper and start developing your own generative AI app to fit your use case, explore this workshop on building an Agentic LLM assistant on AWS.
About the Authors
 Federico Thibaud is the CTO and Co-Founder of Gardenia Technologies, where he leads the data and engineering teams, working on everything from data acquisition and transformation to algorithm design and product development. Before co-founding Gardenia, Federico worked at the intersection of finance and tech — building a trade finance platform as lead developer and developing quantitative strategies at a hedge fund.
Federico Thibaud is the CTO and Co-Founder of Gardenia Technologies, where he leads the data and engineering teams, working on everything from data acquisition and transformation to algorithm design and product development. Before co-founding Gardenia, Federico worked at the intersection of finance and tech — building a trade finance platform as lead developer and developing quantitative strategies at a hedge fund.
 Neil Holloway is Head of Data Science at Gardenia Technologies where he is focused on leveraging AI and machine learning to build and enhance software products. Neil holds a masters degree in Theoretical Physics, where he designed and built programs to simulate high energy collisions in particle physics.
Neil Holloway is Head of Data Science at Gardenia Technologies where he is focused on leveraging AI and machine learning to build and enhance software products. Neil holds a masters degree in Theoretical Physics, where he designed and built programs to simulate high energy collisions in particle physics.
 Fraser Price is a GenAI-focused Software Engineer at Gardenia Technologies in London, where he focuses on researching, prototyping and developing novel approaches to automation in the carbon accounting space using GenAI and machine learning. He received his MEng in Computing: AI from Imperial College London.
Fraser Price is a GenAI-focused Software Engineer at Gardenia Technologies in London, where he focuses on researching, prototyping and developing novel approaches to automation in the carbon accounting space using GenAI and machine learning. He received his MEng in Computing: AI from Imperial College London.
 Christian Dunn is a Software Engineer based in London building ETL pipelines, web-apps, and other business solutions at Gardenia Technologies.
Christian Dunn is a Software Engineer based in London building ETL pipelines, web-apps, and other business solutions at Gardenia Technologies.
 Frederica Schrager is a Marketing Analyst at Gardenia Technologies.
Frederica Schrager is a Marketing Analyst at Gardenia Technologies.
 Karsten Schroer is a Senior ML Prototyping Architect at AWS. He supports customers in leveraging data and technology to drive sustainability of their IT infrastructure and build cloud-native data-driven solutions that enable sustainable operations in their respective verticals. Karsten joined AWS following his PhD studies in applied machine learning & operations management. He is truly passionate about technology-enabled solutions to societal challenges and loves to dive deep into the methods and application architectures that underlie these solutions.
Karsten Schroer is a Senior ML Prototyping Architect at AWS. He supports customers in leveraging data and technology to drive sustainability of their IT infrastructure and build cloud-native data-driven solutions that enable sustainable operations in their respective verticals. Karsten joined AWS following his PhD studies in applied machine learning & operations management. He is truly passionate about technology-enabled solutions to societal challenges and loves to dive deep into the methods and application architectures that underlie these solutions.
 Mohamed Ali Jamaoui is a Senior ML Prototyping Architect with over 10 years of experience in production machine learning. He enjoys solving business problems with machine learning and software engineering, and helping customers extract business value with ML. As part of AWS EMEA Prototyping and Cloud Engineering, he helps customers build business solutions that leverage innovations in MLOPs, NLP, CV and LLMs.
Mohamed Ali Jamaoui is a Senior ML Prototyping Architect with over 10 years of experience in production machine learning. He enjoys solving business problems with machine learning and software engineering, and helping customers extract business value with ML. As part of AWS EMEA Prototyping and Cloud Engineering, he helps customers build business solutions that leverage innovations in MLOPs, NLP, CV and LLMs.
 Marco Masciola is a Senior Sustainability Scientist at AWS. In his role, Marco leads the development of IT tools and technical products to support AWS’s sustainability mission. He’s held various roles in the renewable energy industry, and leans on this experience to build tooling to support sustainable data center operations.
Marco Masciola is a Senior Sustainability Scientist at AWS. In his role, Marco leads the development of IT tools and technical products to support AWS’s sustainability mission. He’s held various roles in the renewable energy industry, and leans on this experience to build tooling to support sustainable data center operations.
 Hin Yee Liu is a Senior Prototyping Engagement Manager at Amazon Web Services. She helps AWS customers to bring their big ideas to life and accelerate the adoption of emerging technologies. Hin Yee works closely with customer stakeholders to identify, shape and deliver impactful use cases leveraging Generative AI, AI/ML, Big Data, and Serverless technologies using agile methodologies.
Hin Yee Liu is a Senior Prototyping Engagement Manager at Amazon Web Services. She helps AWS customers to bring their big ideas to life and accelerate the adoption of emerging technologies. Hin Yee works closely with customer stakeholders to identify, shape and deliver impactful use cases leveraging Generative AI, AI/ML, Big Data, and Serverless technologies using agile methodologies.

 Google for Nonprofits is expanding to 100 more countries, and introducing new Workspace for Nonprofits and Ad Grants AI features.
Google for Nonprofits is expanding to 100 more countries, and introducing new Workspace for Nonprofits and Ad Grants AI features.
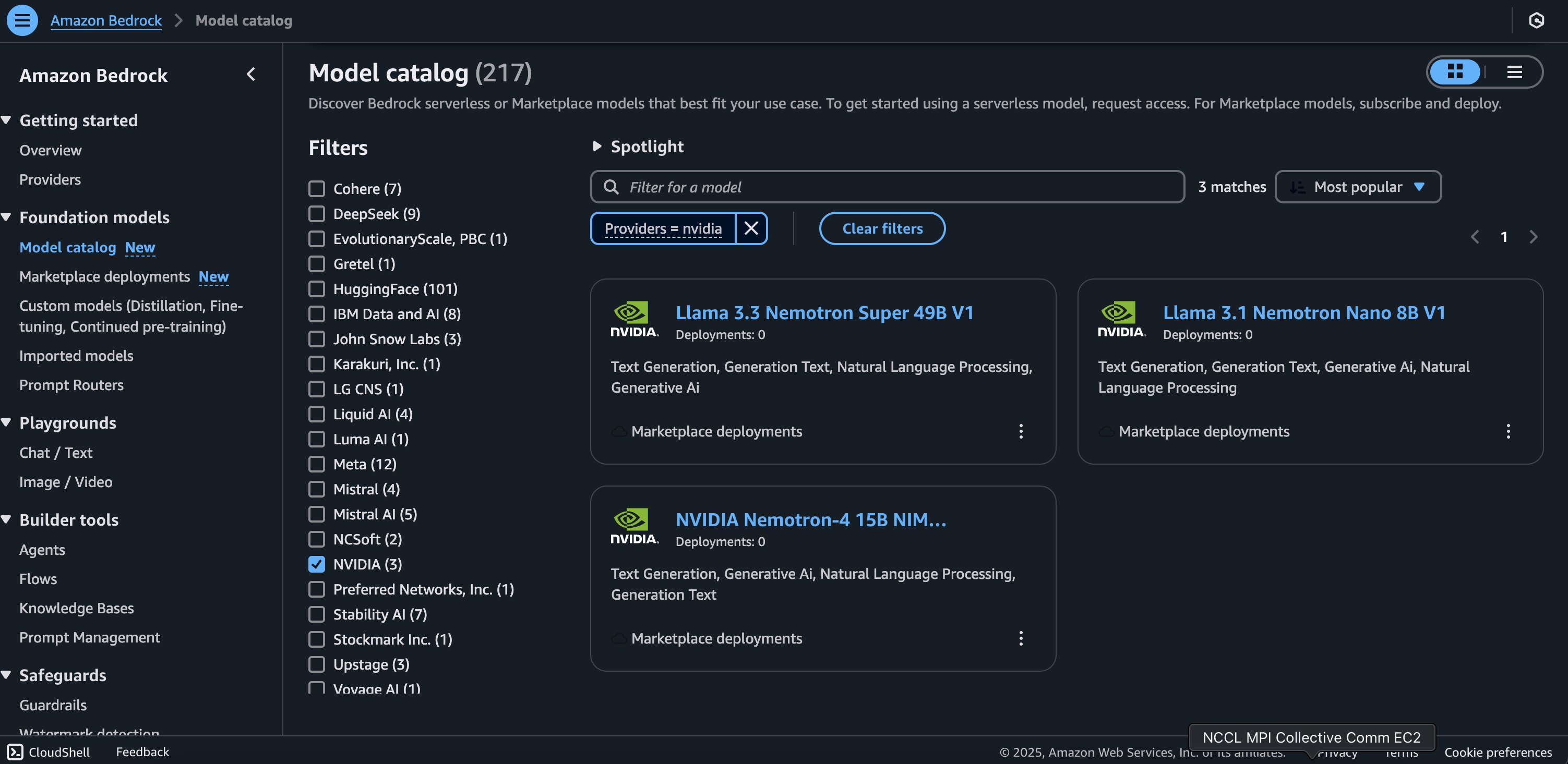
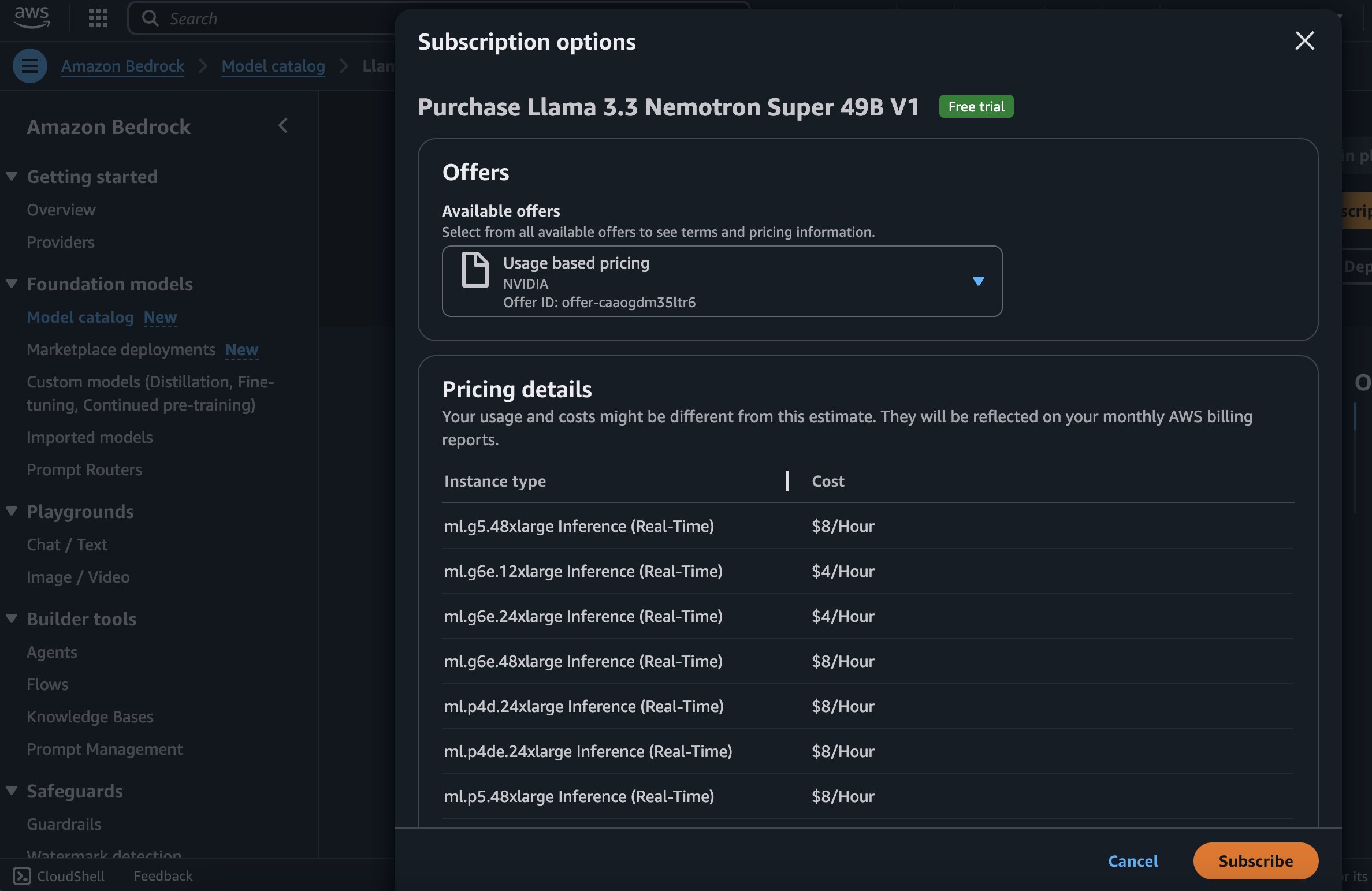
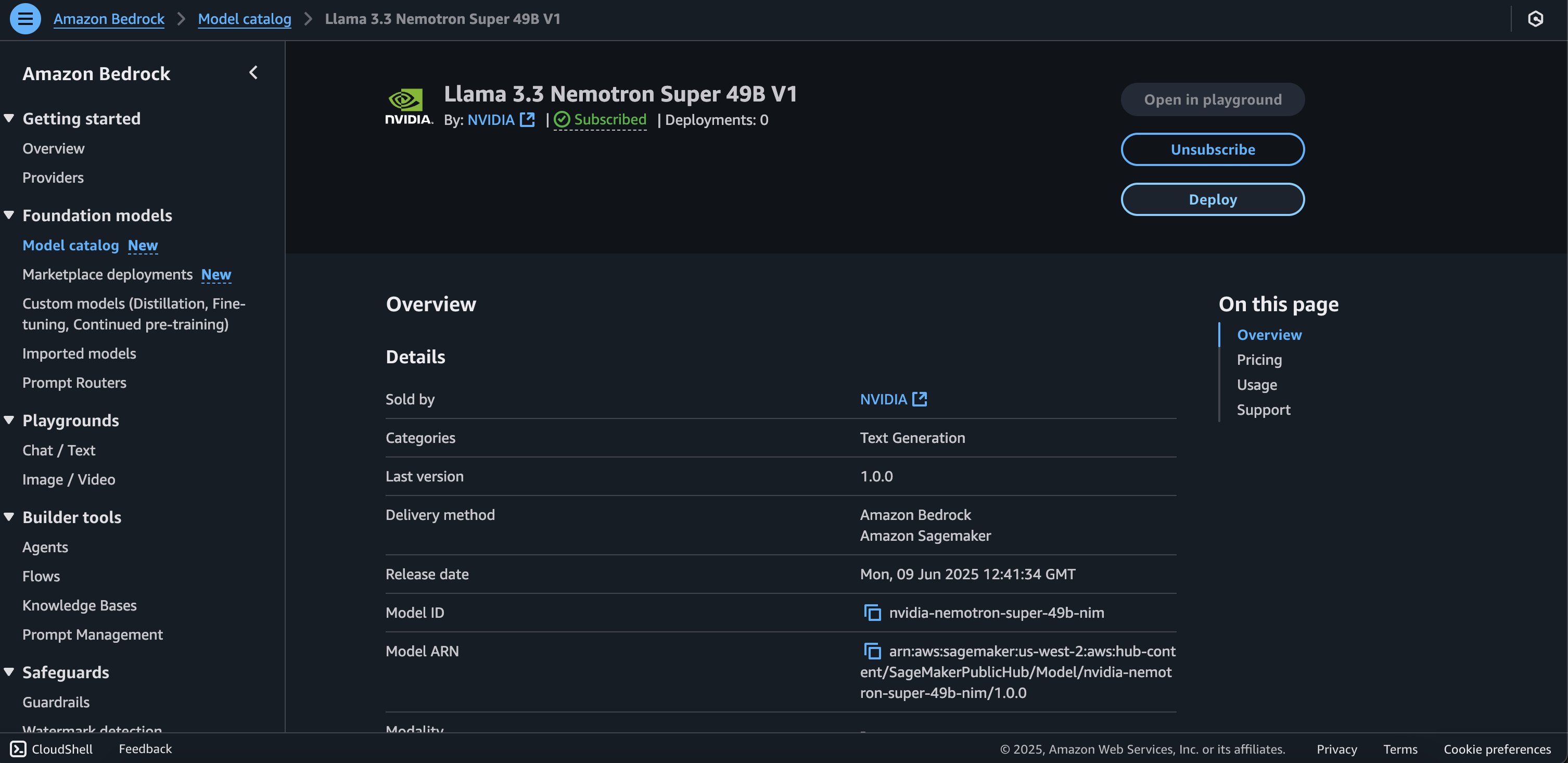
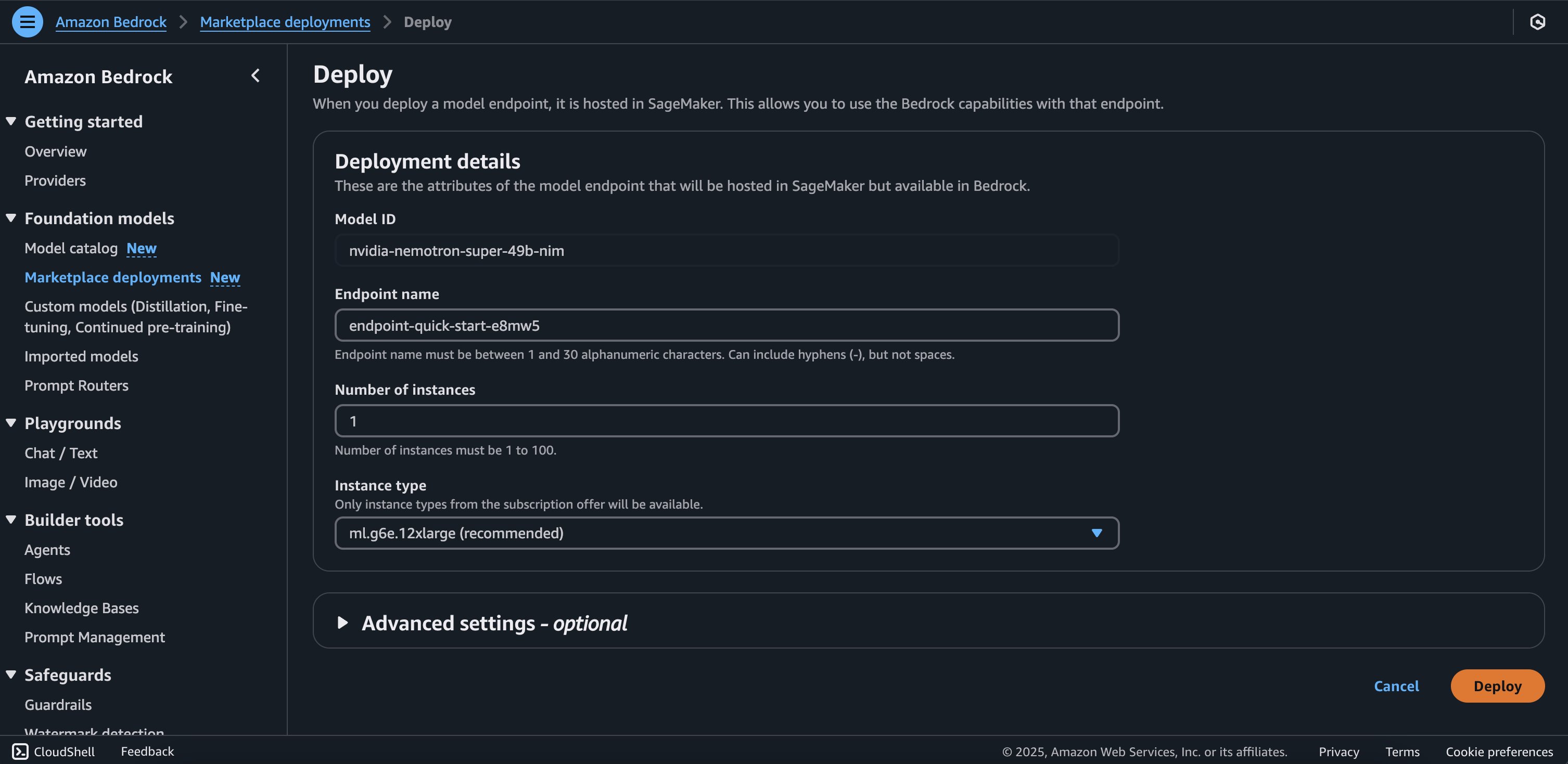
 Deployment starts when you choose the Deploy option, you may be prompted to subscribe to this model on the Marketplace. If you are already subscribed, then you can move forward with selecting the second Deploy button. After deployment finishes, you will see that an endpoint is created. You can test the endpoint by passing a sample inference request payload or by selecting the testing option using the SDK.
Deployment starts when you choose the Deploy option, you may be prompted to subscribe to this model on the Marketplace. If you are already subscribed, then you can move forward with selecting the second Deploy button. After deployment finishes, you will see that an endpoint is created. You can test the endpoint by passing a sample inference request payload or by selecting the testing option using the SDK. 
 Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s in Computer Science and Bioinformatics.
Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s in Computer Science and Bioinformatics. Chase Pinkerton is a Startups Solutions Architect at Amazon Web Services. He holds a Bachelor’s in Computer Science with a minor in Economics from Tufts University. He’s passionate about helping startups grow and scale their businesses. When not working, he enjoys road cycling, hiking, playing volleyball, and photography.
Chase Pinkerton is a Startups Solutions Architect at Amazon Web Services. He holds a Bachelor’s in Computer Science with a minor in Economics from Tufts University. He’s passionate about helping startups grow and scale their businesses. When not working, he enjoys road cycling, hiking, playing volleyball, and photography. Varun Morishetty is a Software Engineer with Amazon SageMaker JumpStart and Bedrock Marketplace. Varun received his Bachelor’s degree in Computer Science from Northeastern University. In his free time, he enjoys cooking, baking and exploring New York City.
Varun Morishetty is a Software Engineer with Amazon SageMaker JumpStart and Bedrock Marketplace. Varun received his Bachelor’s degree in Computer Science from Northeastern University. In his free time, he enjoys cooking, baking and exploring New York City. Brian Kreitzer is a Partner Solutions Architect at Amazon Web Services (AWS). He works with partners to define business requirements, provide architectural guidance, and design solutions for the Amazon Marketplace.
Brian Kreitzer is a Partner Solutions Architect at Amazon Web Services (AWS). He works with partners to define business requirements, provide architectural guidance, and design solutions for the Amazon Marketplace. Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA, empowering Amazon’s AI MLOps, DevOps, scientists, and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing generative AI foundation models spanning from data curation, GPU training, model inference, and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, and tennis and poker player.
Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA, empowering Amazon’s AI MLOps, DevOps, scientists, and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing generative AI foundation models spanning from data curation, GPU training, model inference, and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, and tennis and poker player. Abhishek Sawarkar is a product manager in the NVIDIA AI Enterprise team working on integrating NVIDIA AI Software in Cloud MLOps platforms. He focuses on integrating the NVIDIA AI end-to-end stack within cloud platforms and enhancing user experience on accelerated computing.
Abhishek Sawarkar is a product manager in the NVIDIA AI Enterprise team working on integrating NVIDIA AI Software in Cloud MLOps platforms. He focuses on integrating the NVIDIA AI end-to-end stack within cloud platforms and enhancing user experience on accelerated computing. Abdullahi Olaoye is a Senior AI Solutions Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and products with cloud AI services and open source tools to optimize AI model deployment, inference, and generative AI workflows. He collaborates with AWS to enhance AI workload performance and drive adoption of NVIDIA-powered AI and generative AI solutions.
Abdullahi Olaoye is a Senior AI Solutions Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and products with cloud AI services and open source tools to optimize AI model deployment, inference, and generative AI workflows. He collaborates with AWS to enhance AI workload performance and drive adoption of NVIDIA-powered AI and generative AI solutions.