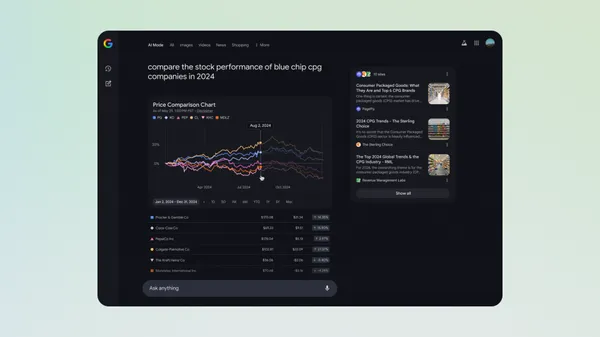
 Today, we’re starting to roll out interactive chart visualizations in AI Mode in Labs to help bring financial data to life for questions on stocks and mutual funds.Now, …Read More
Today, we’re starting to roll out interactive chart visualizations in AI Mode in Labs to help bring financial data to life for questions on stocks and mutual funds.Now, …Read More
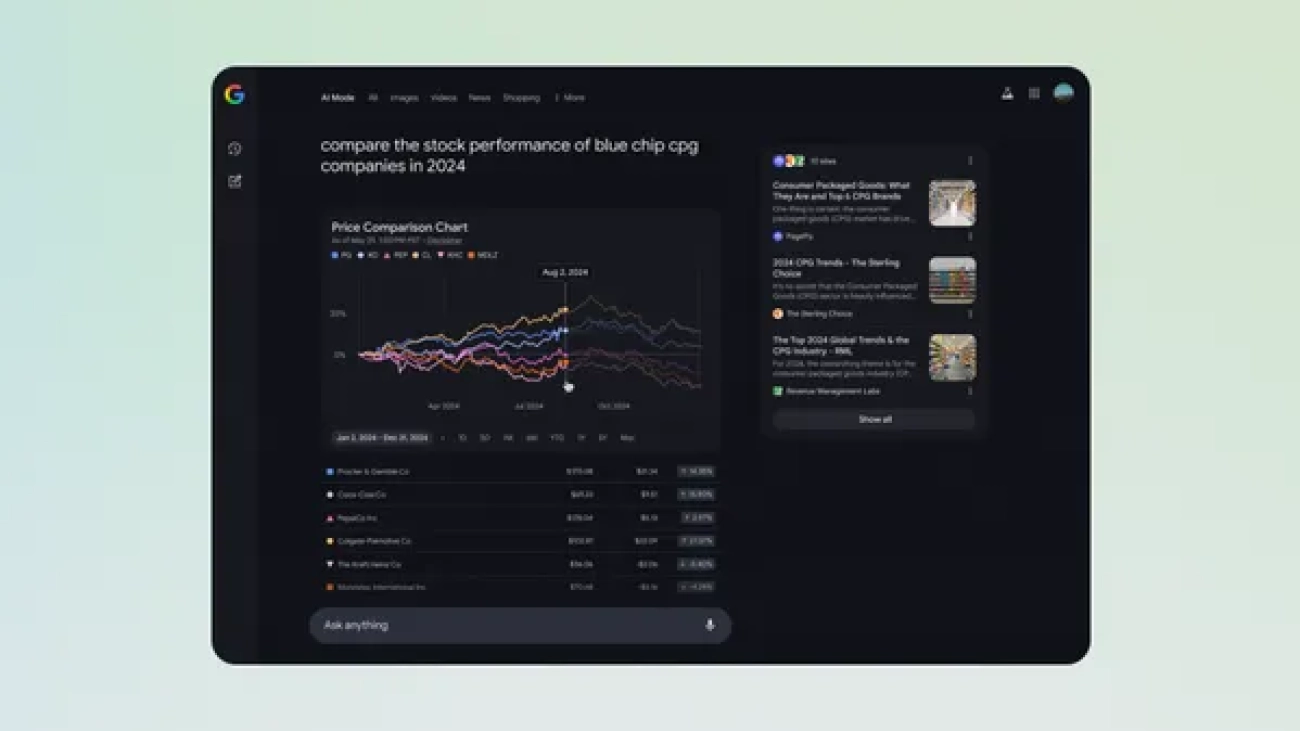
Today, we’re starting to roll out interactive chart visualizations in AI Mode in Labs to help bring financial data to life for questions on stocks and mutual funds.Now, …Read More

 Here are Google’s latest AI updates from May 2025Read More
Here are Google’s latest AI updates from May 2025Read More
 AI Mode is our most powerful AI search, which we’re rolling out to everyone in the U.S. Here’s how we brought it to life (and to your fingertips).Read More
AI Mode is our most powerful AI search, which we’re rolling out to everyone in the U.S. Here’s how we brought it to life (and to your fingertips).Read More
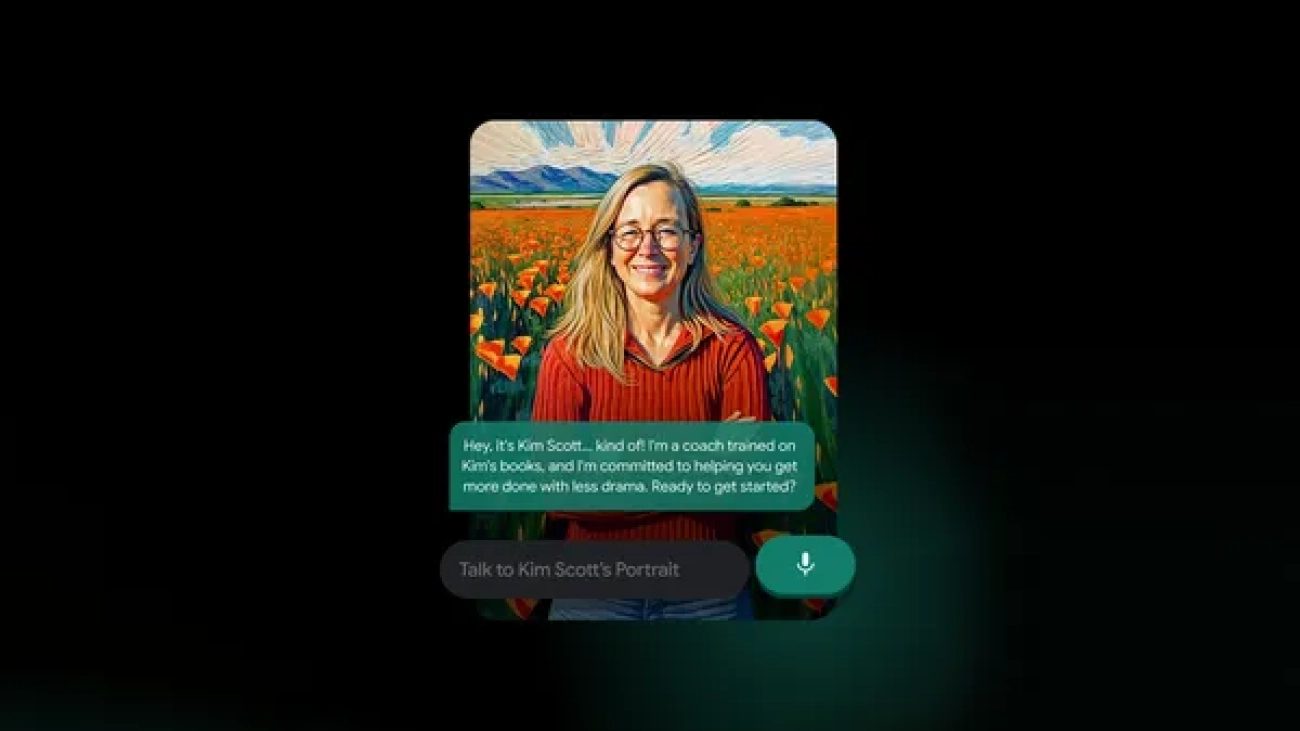
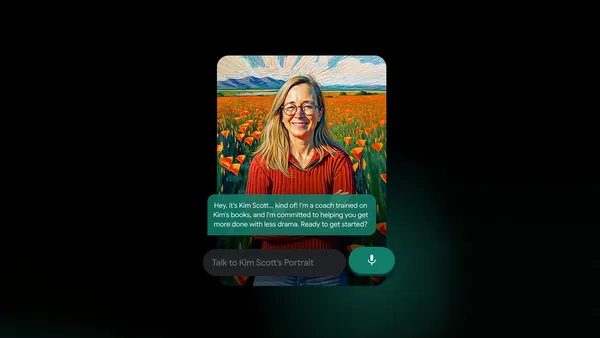 Our first Portrait features Kim Scott, bestselling author of “Radical Candor.”Read More
Our first Portrait features Kim Scott, bestselling author of “Radical Candor.”Read More
This post is co-written with Qing Chen and Mark Sinclair from Radial.
Radial is the largest 3PL fulfillment provider, also offering integrated payment, fraud detection, and omnichannel solutions to mid-market and enterprise brands. With over 30 years of industry expertise, Radial tailors its services and solutions to align strategically with each brand’s unique needs.
Radial supports brands in tackling common ecommerce challenges, from scalable, flexible fulfillment enabling delivery consistency to providing secure transactions. With a commitment to fulfilling promises from click to delivery, Radial empowers brands to navigate the dynamic digital landscape with the confidence and capability to deliver a seamless, secure, and superior ecommerce experience.
In this post, we share how Radial optimized the cost and performance of their fraud detection machine learning (ML) applications by modernizing their ML workflow using Amazon SageMaker.
ML has proven to be an effective approach in fraud detection compared to traditional approaches. ML models can analyze vast amounts of transactional data, learn from historical fraud patterns, and detect anomalies that signal potential fraud in real time. By continuously learning and adapting to new fraud patterns, ML can make sure fraud detection systems stay resilient and robust against evolving threats, enhancing detection accuracy and reducing false positives over time. This post showcases how companies like Radial can modernize and migrate their on-premises fraud detection ML workflows to SageMaker. By using the AWS Experience-Based Acceleration (EBA) program, they can enhance efficiency, scalability, and maintainability through close collaboration.
Although ML models are highly effective at combating evolving fraud trends, managing these models on premises presents significant scalability and maintenance challenges.
On-premises systems are inherently limited by the physical hardware available. During peak shopping seasons, when transaction volumes surge, the infrastructure might struggle to keep up without substantial upfront investment. This can result in slower processing times or a reduced capacity to run multiple ML applications concurrently, potentially leading to missed fraud detections. Scaling an on-premises infrastructure is typically a slow and resource-intensive process, hindering a business’s ability to adapt quickly to increased demand. On the model training side, data scientists often face bottlenecks due to limited resources, forcing them to wait for infrastructure availability or reduce the scope of their experiments. This delays innovation and can lead to suboptimal model performance, putting businesses at a disadvantage in a rapidly changing fraud landscape.
Maintaining an on-premises infrastructure for fraud detection requires a dedicated IT team to manage servers, storage, networking, and backups. Maintaining uptime often involves implementing and maintaining redundant systems, because a failure could result in critical downtime and an increased risk of undetected fraud. Moreover, fraud detection models naturally degrade over time and require regular retraining, deployment, and monitoring. On-premises systems typically lack the built-in automation tools needed to manage the full ML lifecycle. As a result, IT teams must manually handle tasks such as updating models, monitoring for drift, and deploying new versions. This adds operational complexity, increases the likelihood of errors, and diverts valuable resources from other business-critical activities.
Organizations face several significant challenges when modernizing their ML workloads through cloud migration. One major hurdle is the skill gap, where developers and data scientists might lack expertise in microservices architecture, advanced ML tools, and DevOps practices for cloud environments. This can lead to development delays, complex and costly architectures, and increased security vulnerabilities. Cross-functional barriers, characterized by limited communication and collaboration between teams, can also impede modernization efforts by hindering information sharing. Slow decision-making is another critical challenge. Many organizations take too long to make choices about their cloud move. They spend too much time thinking about options instead of taking action. This delay can cause them to miss chances to speed up their modernization. It also stops them from using the cloud’s ability to quickly try new things and make changes. In the fast-moving world of ML and cloud technology, being slow to decide can put companies behind their competitors. Another significant obstacle is complex project management, because modernization initiatives often require coordinating work across multiple teams with conflicting priorities. This challenge is compounded by difficulties in aligning stakeholders on business outcomes, quantifying and tracking benefits to demonstrate value, and balancing long-term benefits with short-term goals. To address these challenges and streamline modernization efforts, AWS offers the EBA program. This methodology is designed to assist customers in aligning executives’ vision and resolving roadblocks, accelerating their cloud journey, and achieving a successful migration and modernization of their ML workloads to the cloud.
EBA is a 3-day interactive workshop that uses SageMaker to accelerate business outcomes. It guides participants through a prescriptive ML lifecycle, starting with identifying business goals and ML problem framing, and progressing through data processing, model development, production deployment, and monitoring.
We recognize that customers have different starting points. For those beginning from scratch, it’s often simpler to start with low code or no code solutions like Amazon SageMaker Canvas and Amazon SageMaker JumpStart, gradually transitioning to developing custom models on Amazon SageMaker Studio. However, because Radial has an existing on-premises ML infrastructure, we can begin directly by using SageMaker to address challenges in their current solution.
During the EBA, experienced AWS ML subject matter experts and the AWS Account Team worked closely with Radial’s cross-functional team. The AWS team offered tailored advice, tackled obstacles, and enhanced the organization’s capacity for ongoing ML integration. Instead of concentrating solely on data and ML technology, the emphasis is on addressing critical business challenges. This strategy helps organizations extract significant value from previously underutilized resources.
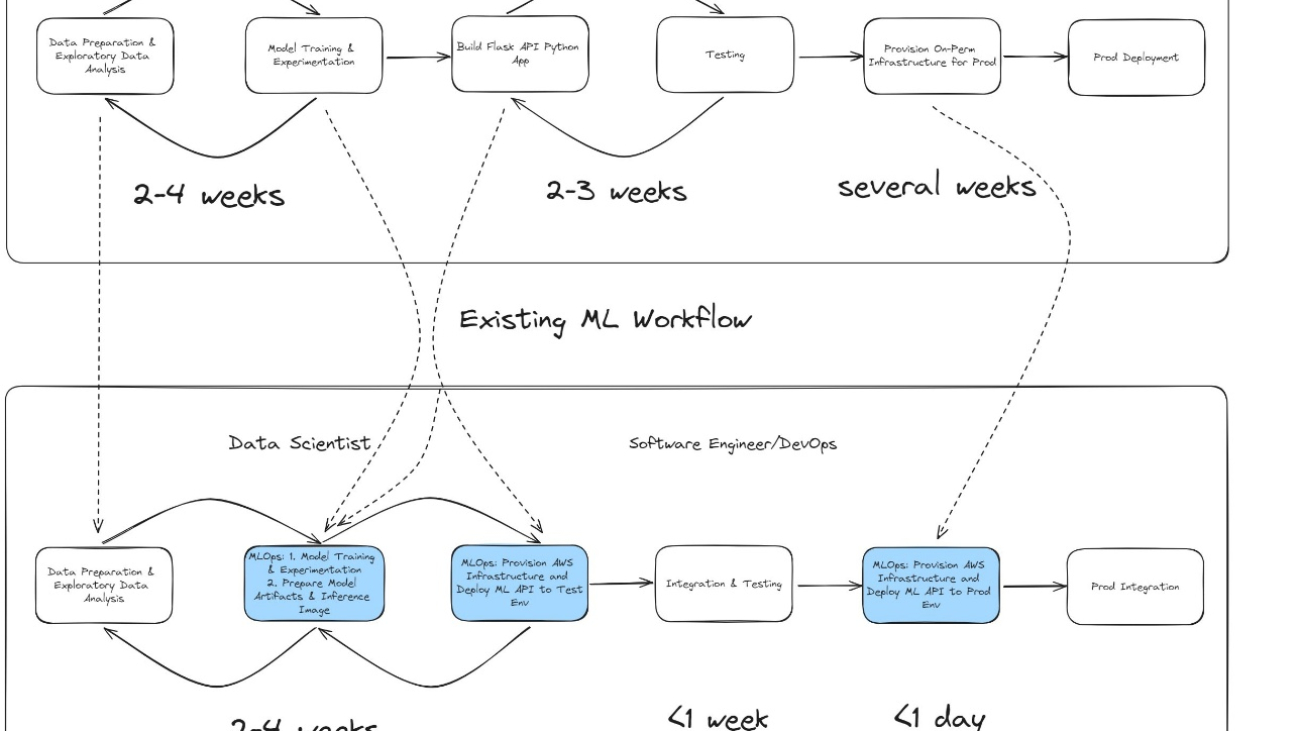
Before modernization, Radial hosted its ML applications on premises within its data center. The legacy ML workflow presented several challenges, particularly in the time-intensive model development and deployment processes.
When the data science team needed to build a new fraud detection model, the development process typically took 2–4 weeks. During this phase, data scientists performed tasks such as the following:
These steps were carried out using on-premises servers, which limited the number of experiments that could be run concurrently due to hardware constraints. After the model was finalized, the data science team handed over the model artifacts and implementation code—along with detailed instructions—to the software developers and DevOps teams. This transition initiated the model deployment process, which involved:
Overall, the legacy workflow was prone to delays and inefficiencies, with significant communication overhead and a reliance on manual provisioning.
With the migration to SageMaker and the adoption of a machine learning operations (MLOps) architecture, Radial streamlined its entire ML lifecycle—from development to deployment. The new workflow consists of the following stages:
The MLOps pipeline not only automates the provisioning of cloud resources, but also provides consistency between pre-production and production environments, minimizing deployment risks.
The new workflow significantly reduces time and complexity:
This transformation enables Radial to respond more quickly to evolving fraud trends while maintaining high standards of efficiency and reliability. The following figure provides a visual comparison of the legacy and modern ML workflows.
 Solution overview
Solution overviewWhen Radial migrated their fraud detection systems to the cloud, they collaborated with AWS Machine Learning Specialists and Solutions Architects to redesign how Radial manage the lifecycle of ML models. By using AWS and integrating continuous integration and delivery (CI/CD) pipelines with GitLab, Terraform, and AWS CloudFormation, Radial developed a scalable, efficient, and secure MLOps architecture. This new design accelerates model development and deployment, so Radial can respond faster to evolving fraud detection challenges.
The architecture incorporates best practices in MLOps, making sure that the different stages of the ML lifecycle—from data preparation to production deployment—are optimized for performance and reliability. Key components of the solution include:
The overall solution architecture is illustrated in the following figure, showcasing how each component integrates seamlessly to support Radial’s fraud detection initiatives.

To streamline operations and enforce security, the MLOps architecture is built on a multi-account strategy that isolates environments based on their purpose. This design enforces strict security boundaries, reduces risks, and promotes efficient collaboration across teams. The accounts are as follows:
With this multi-account architecture, data scientists can work independently while providing seamless transitions between development and production. The automation of CI/CD pipelines reduces deployment cycles, enhances scalability, and provides the security and performance necessary to maintain effective fraud detection systems.
Radial prioritizes the protection and security of their customers’ data. As a leader in ecommerce solutions, they are committed to meeting the high standards of data privacy and regulatory compliance such as CPPA and PCI. Radial fraud detection ML APIs process sensitive information such as transaction details and behavioral analytics. To meet strict compliance requirements, they use AWS Direct Connect, Amazon Virtual Private Cloud (Amazon VPC), and Amazon S3 with AWS Key Management Service (AWS KMS) encryption to build a secure and compliant architecture.
Data is never exposed to the public internet at any stage. To maintain the secure transfer of sensitive data between on-premises systems and AWS environments, Radial uses Direct Connect, which offers the following capabilities:
When data reaches AWS, it’s processed in a VPC for maximum security. This offers the following benefits:
Data involved in the fraud detection workflows (for both model development and real-time inference) is securely stored in Amazon S3, with encryption powered by AWS KMS. This offers the following benefits:
Data privacy is integrated into every step of the ML API workflow:
To summarize, the implementation of the new ML workflow on AWS offers several key benefits:
To help modernize your MLOps workflow on AWS, the following are a few key takeaways and lessons learned from Radial’s experience:
This post demonstrated the high-level approach taken by Radial’s fraud team to successfully modernize their ML workflow by implementing an MLOps pipeline and migrating from on premises to the AWS Cloud. This was achieved through close collaboration with AWS during the EBA process. The EBA process begins with 4–6 weeks of preparation, culminating in a 3-day intensive workshop where a minimum viable MLOps pipeline is created using SageMaker, Amazon S3, GitLab, Terraform, and AWS CloudFormation. Following the EBA, teams typically spend an additional 2–6 weeks to refine the pipeline and fine-tune the models through feature engineering and hyperparameter optimization before production deployment. This approach enabled Radial to effectively select relevant AWS services and features, accelerating the training, deployment, and testing of ML models in a pre-production SageMaker environment. As a result, Radial successfully deployed multiple new ML models on AWS in their production environment around Q3 2024, achieving a more than 75% reduction in ML model deployment cycle and a 9% improvement in overall model performance.
“In the ecommerce retail space, mitigating fraudulent transactions and enhancing consumer experiences are top priorities for merchants. High-performing machine learning models have become invaluable tools in achieving these goals. By leveraging AWS services, we have successfully built a modernized machine learning workflow that enables rapid iterations in a stable and secure environment.”
– Lan Zhang, Head of Data Science and Advanced Analytics
To learn more about EBAs and how this approach can benefit your organization, reach out to your AWS Account Manager or Customer Solutions Manager. For additional information, refer to Using experience-based acceleration to achieve your transformation and Get to Know EBA.
 Jake Wen is a Solutions Architect at AWS, driven by a passion for Machine Learning, Natural Language Processing, and Deep Learning. He assists Enterprise customers in achieving modernization and scalable deployment in the Cloud. Beyond the tech world, Jake finds delight in skateboarding, hiking, and piloting air drones.
Jake Wen is a Solutions Architect at AWS, driven by a passion for Machine Learning, Natural Language Processing, and Deep Learning. He assists Enterprise customers in achieving modernization and scalable deployment in the Cloud. Beyond the tech world, Jake finds delight in skateboarding, hiking, and piloting air drones.
 Qing Chen is a senior data scientist at Radial, a full-stack solution provider for ecommerce merchants. In his role, he modernizes and manages the machine learning framework in the payment & fraud organization, driving a solid data-driven fraud decisioning flow to balance risk & customer friction for merchants.
Qing Chen is a senior data scientist at Radial, a full-stack solution provider for ecommerce merchants. In his role, he modernizes and manages the machine learning framework in the payment & fraud organization, driving a solid data-driven fraud decisioning flow to balance risk & customer friction for merchants.
 Mark Sinclair is a senior cloud architect at Radial, a full-stack solution provider for ecommerce merchants. In his role, he designs, implements and manages the cloud infrastructure and DevOps for Radial engineering systems, driving a solid engineering architecture and workflow to provide highly scalable transactional services for Radial clients.
Mark Sinclair is a senior cloud architect at Radial, a full-stack solution provider for ecommerce merchants. In his role, he designs, implements and manages the cloud infrastructure and DevOps for Radial engineering systems, driving a solid engineering architecture and workflow to provide highly scalable transactional services for Radial clients.
For an AI model to perform effectively in specialized domains, it requires access to relevant background knowledge. A customer support chat assistant, for instance, needs detailed information about the business it serves, and a legal analysis tool must draw upon a comprehensive database of past cases.
To equip large language models (LLMs) with this knowledge, developers often use Retrieval Augmented Generation (RAG). This technique retrieves pertinent information from a knowledge base and incorporates it into the user’s prompt, significantly improving the model’s responses. However, a key limitation of traditional RAG systems is that they often lose contextual nuances when encoding data, leading to irrelevant or incomplete retrievals from the knowledge base.
In traditional RAG, documents are often divided into smaller chunks to optimize retrieval efficiency. Although this method performs well in many cases, it can introduce challenges when individual chunks lack the necessary context. For example, if a policy states that remote work requires “6 months of tenure” (chunk 1) and “HR approval for exceptions” (chunk 3), but omits the middle chunk linking exceptions to manager approval, a user asking about eligibility for a 3-month tenure employee might receive a misleading “No” instead of the correct “Only with HR approval.” This occurs because isolated chunks fail to preserve dependencies between clauses, highlighting a key limitation of basic chunking strategies in RAG systems.
Contextual retrieval enhances traditional RAG by adding chunk-specific explanatory context to each chunk before generating embeddings. This approach enriches the vector representation with relevant contextual information, enabling more accurate retrieval of semantically related content when responding to user queries. For instance, when asked about remote work eligibility, it fetches both the tenure requirement and the HR exception clause, enabling the LLM to provide an accurate response such as “Normally no, but HR may approve exceptions.” By intelligently stitching fragmented information, contextual retrieval mitigates the pitfalls of rigid chunking, delivering more reliable and nuanced answers.
In this post, we demonstrate how to use contextual retrieval with Anthropic and Amazon Bedrock Knowledge Bases.
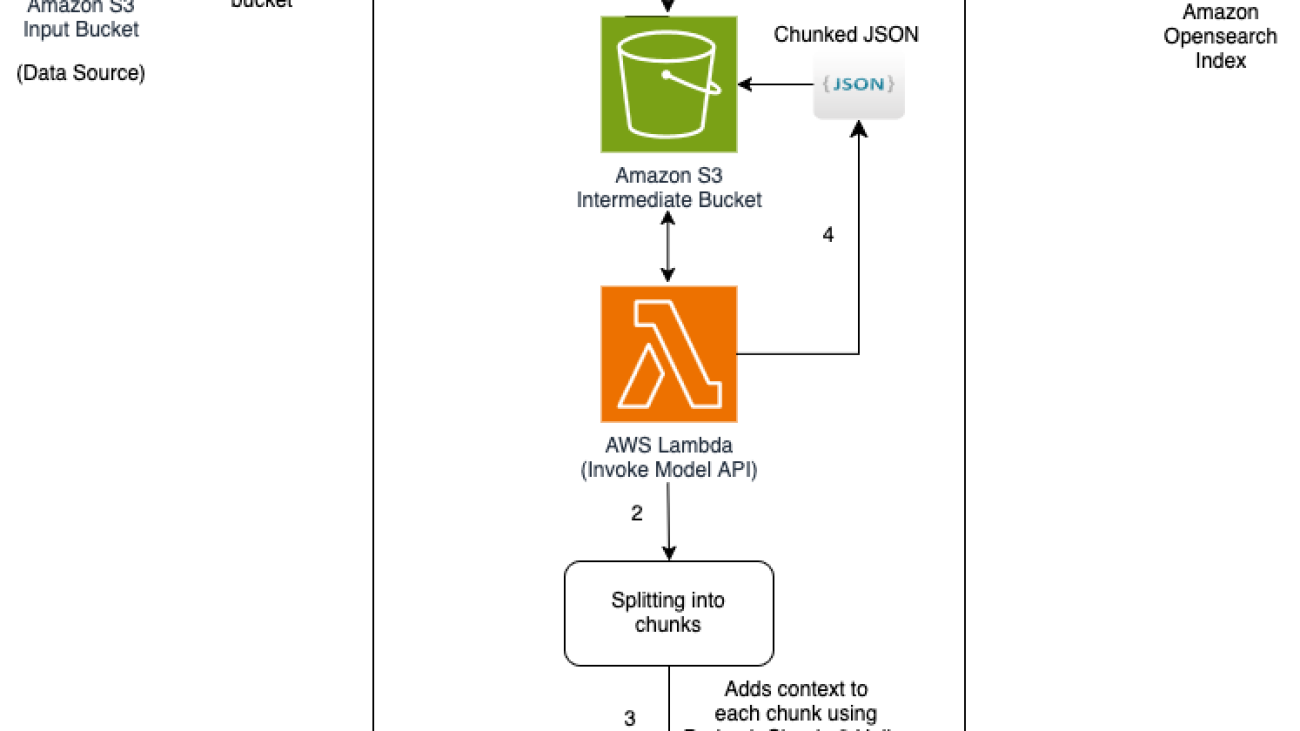
This solution uses Amazon Bedrock Knowledge Bases, incorporating a custom Lambda function to transform data during the knowledge base ingestion process. This Lambda function processes documents from Amazon Simple Storage Service (Amazon S3), chunks them into smaller pieces, enriches each chunk with contextual information using Anthropic’s Claude in Amazon Bedrock, and then saves the results back to an intermediate S3 bucket. Here’s a step-by-step explanation:
The following diagram is the solution architecture.

To implement the solution, complete the following prerequisite steps:
Before you begin, you can deploy this solution by downloading the required files and following the instructions in its corresponding GitHub repository. This architecture is built around using the proposed chunking solution to implement contextual retrieval using Amazon Bedrock Knowledge Bases.
In this section, we demonstrate how to use the proposed custom chunking solution to implement contextual retrieval using Amazon Bedrock Knowledge Bases. Developers can use custom chunking strategies in Amazon Bedrock to optimize how large documents or datasets are divided into smaller, more manageable pieces for processing by foundation models (FMs). This approach enables more efficient and effective handling of long-form content, improving the quality of responses. By tailoring the chunking method to the specific characteristics of the data and the requirements of the task at hand, developers can enhance the performance of natural language processing applications built on Amazon Bedrock. Custom chunking can involve techniques such as semantic segmentation, sliding windows with overlap, or using document structure to create logical divisions in the text.
To implement contextual retrieval in Amazon Bedrock, complete the following steps, which can be found in the notebook in the GitHub repository.
To set up the environment, follow these steps:
To create knowledge bases with different chunking strategies, use the following code.
To evaluate performance using the RAGAS framework, follow these steps:
To evaluate the performance of the proposed contextual retrieval approach, we used the AWS Decision Guide: Choosing a generative AI service as the document for RAG testing. We set up two Amazon Bedrock knowledge bases for the evaluation:
We used the RAGAS framework to assess the performance of these two approaches using small datasets. Specifically, we looked at the following metrics:
context_recall – Context recall measures how many of the relevant documents (or pieces of information) were successfully retrievedcontext_precision – Context precision is a metric that measures the proportion of relevant chunks in the retrieved_contextsanswer_correctness – The assessment of answer correctness involves gauging the accuracy of the generated answer when compared to the ground truthThe results obtained using the default chunking strategy are presented in the following table.

The results obtained using the contextual retrieval chunking strategy are presented in the following table. It demonstrates improved performance across the key metrics evaluated, including context recall, context precision, and answer correctness.

By aggregating the results, we can observe that the contextual chunking approach outperformed the default chunking strategy across the context_recall, context_precision, and answer_correctness metrics. This indicates the benefits of the more sophisticated contextual retrieval techniques implemented.

When implementing contextual retrieval using Amazon Bedrock, several factors need careful consideration. First, the custom chunking strategy must be optimized for both performance and accuracy, requiring thorough testing across different document types and sizes. The Lambda function’s memory allocation and timeout settings should be calibrated based on the expected document complexity and processing requirements, with initial recommendations of 1024 MB memory and 900-second timeout serving as baseline configurations. Organizations must also configure IAM roles with the principle of least privilege while maintaining sufficient permissions for Lambda to interact with Amazon S3 and Amazon Bedrock services. Additionally, the vectorization process and knowledge base configuration should be fine-tuned to balance between retrieval accuracy and computational efficiency, particularly when scaling to larger datasets.
Infrastructure scalability and monitoring considerations are equally crucial for successful implementation. Organizations should implement robust error-handling mechanisms within the Lambda function to manage various document formats and potential processing failures gracefully. Monitoring systems should be established to track key metrics such as chunking performance, retrieval accuracy, and system latency, enabling proactive optimization and maintenance.
Using Langfuse with Amazon Bedrock is a good option to introduce observability to this solution. The S3 bucket structure for both source and intermediate storage should be designed with clear lifecycle policies and access controls and consider Regional availability and data residency requirements. Furthermore, implementing a staged deployment approach, starting with a subset of data before scaling to full production workloads, can help identify and address potential bottlenecks or optimization opportunities early in the implementation process.
When you’re done experimenting with the solution, clean up the resources you created to avoid incurring future charges.
By combining Anthropic’s sophisticated language models with the robust infrastructure of Amazon Bedrock, organizations can now implement intelligent systems for information retrieval that deliver deeply contextualized, nuanced responses. The implementation steps outlined in this post provide a clear pathway for organizations to use contextual retrieval capabilities through Amazon Bedrock. By following the detailed configuration process, from setting up IAM permissions to deploying custom chunking strategies, developers and organizations can unlock the full potential of context-aware AI systems.
By leveraging Anthropic’s language models, organizations can deliver more accurate and meaningful results to their users while staying at the forefront of AI innovation. You can get started today with contextual retrieval using Anthropic’s language models through Amazon Bedrock and transform how your AI processes information with a small-scale proof of concept using your existing data. For personalized guidance on implementation, contact your AWS account team.
 Suheel Farooq is a Principal Engineer in AWS Support Engineering, specializing in Generative AI, Artificial Intelligence, and Machine Learning. As a Subject Matter Expert in Amazon Bedrock and SageMaker, he helps enterprise customers design, build, modernize, and scale their AI/ML and Generative AI workloads on AWS. In his free time, Suheel enjoys working out and hiking.
Suheel Farooq is a Principal Engineer in AWS Support Engineering, specializing in Generative AI, Artificial Intelligence, and Machine Learning. As a Subject Matter Expert in Amazon Bedrock and SageMaker, he helps enterprise customers design, build, modernize, and scale their AI/ML and Generative AI workloads on AWS. In his free time, Suheel enjoys working out and hiking.
 Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
 Vinita is a Senior Serverless Specialist Solutions Architect at AWS. She combines AWS knowledge with strong business acumen to architect innovative solutions that drive quantifiable value for customers and has been exceptional at navigating complex challenges. Vinita’s technical expertise on application modernization, GenAI, cloud computing and ability to drive measurable business impact make her show great impact in customer’s journey with AWS.
Vinita is a Senior Serverless Specialist Solutions Architect at AWS. She combines AWS knowledge with strong business acumen to architect innovative solutions that drive quantifiable value for customers and has been exceptional at navigating complex challenges. Vinita’s technical expertise on application modernization, GenAI, cloud computing and ability to drive measurable business impact make her show great impact in customer’s journey with AWS.
 Sharon Li is an AI/ML Specialist Solutions Architect at Amazon Web Services (AWS) based in Boston, Massachusetts. With a passion for leveraging cutting-edge technology, Sharon is at the forefront of developing and deploying innovative generative AI solutions on the AWS cloud platform.
Sharon Li is an AI/ML Specialist Solutions Architect at Amazon Web Services (AWS) based in Boston, Massachusetts. With a passion for leveraging cutting-edge technology, Sharon is at the forefront of developing and deploying innovative generative AI solutions on the AWS cloud platform.
 Venkata Moparthi is a Senior Solutions Architect, specializes in cloud migrations, generative AI, and secure architecture for financial services and other industries. He combines technical expertise with customer-focused strategies to accelerate digital transformation and drive business outcomes through optimized cloud solutions.
Venkata Moparthi is a Senior Solutions Architect, specializes in cloud migrations, generative AI, and secure architecture for financial services and other industries. He combines technical expertise with customer-focused strategies to accelerate digital transformation and drive business outcomes through optimized cloud solutions.
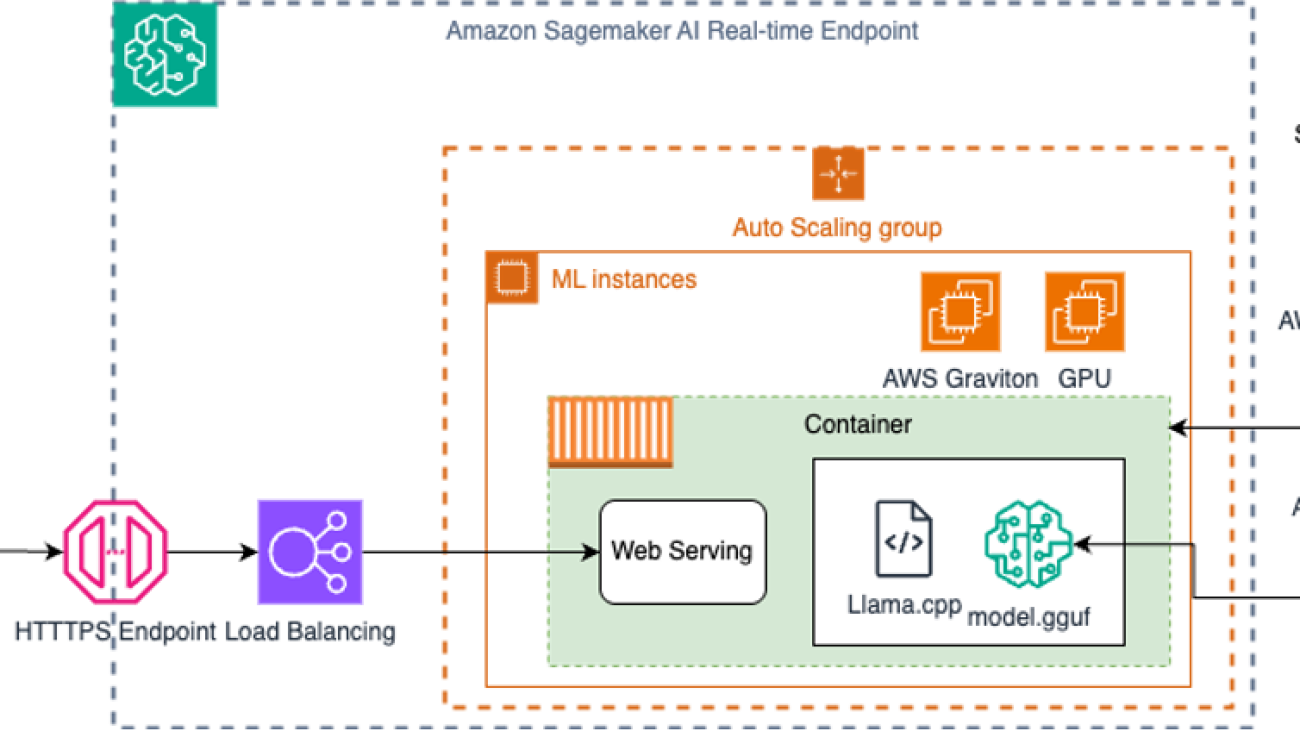
As organizations look to incorporate AI capabilities into their applications, large language models (LLMs) have emerged as powerful tools for natural language processing tasks. Amazon SageMaker AI provides a fully managed service for deploying these machine learning (ML) models with multiple inference options, allowing organizations to optimize for cost, latency, and throughput. AWS has always provided customers with choice. That includes model choice, hardware choice, and tooling choice. In terms of hardware choice, in addition to NVIDIA GPUs and AWS custom AI chips, CPU-based instances represent (thanks to the latest innovations in CPU hardware) an additional choice for customers who want to run generative AI inference, like hosting small language models and asynchronous agents.
Traditional LLMs with billions of parameters require significant computational resources. For example, a 7-billion-parameter model like Meta Llama 7B at BFloat16 (2 bytes per parameter) typically needs around 14 GB of GPU memory to store the model weights—the total GPU memory requirement is usually 3–4 times bigger at long sequence lengths. However, recent developments in model quantization and knowledge distillation have made it possible to run smaller, efficient language models on CPU infrastructure. Although these models might not match the capabilities of the largest LLMs, they offer a practical alternative for many real-world applications where cost optimization is crucial.
In this post, we demonstrate how to deploy a small language model on SageMaker AI by extending our pre-built containers to be compatible with AWS Graviton instances. We first provide an overview of the solution, and then provide detailed implementation steps to help you get started. You can find the example notebook in the GitHub repo.
Our solution uses SageMaker AI with Graviton3 processors to run small language models cost-efficiently. The key components include:
Graviton processors, which are specifically designed for cloud workloads, provide an optimal platform for running these quantized models. Graviton3 based instances can deliver up to 50% better price-performance compared to traditional x86-based CPU instances for ML inference workloads.
We have used Llama.cpp as the inference framework. It supports quantized general matrix multiply-add (GEMM) kernels for faster inference and reduced memory use. The quantized GEMM kernels are optimized for Graviton processors using Arm Neon and SVE-based matrix multiply-accumulate (MMLA) instructions.
Llama.cpp uses GGUF, a special binary format for storing the model and metadata. GGUF format is optimized for quick loading and saving of models, making it highly efficient for inference purposes. Existing models need to be converted to GGUF format before they can be used for the inference. You can find most of popular GGUF format models from the following Hugging Face repo, or you can also convert your model to GGUF format using the following tool.
The following diagram illustrates the solution architecture.

To deploy your model on SageMaker with Graviton, you will need to complete the following steps:
We walk through these steps in the following sections.
To implement this solution, you need an AWS account with the necessary permissions.
Let’s first review how SageMaker AI works with Docker containers. Basically, by packaging an algorithm in a container, you can bring almost any code to the SageMaker environment, regardless of programming language, environment, framework, or dependencies. For more information and an example of how to build your own Docker container for training and inference with SageMaker AI, see Build your own algorithm container.
You can also extend a pre-built container to accommodate your needs. By extending a pre-built image, you can use the included deep learning libraries and settings without having to create an image from scratch. You can extend the container to add libraries, modify settings, and install additional dependencies. For a list of available pre-built containers, refer to the following GitHub repo. In this example, we show how to package a pre-built PyTorch container that supports Graviton instances, extending the SageMaker PyTorch container, with a Python example that works with the DeepSeek distilled model.
Firstly, let’s review how SageMaker AI runs your Docker container. Typically, you specify a program (such as a script) as an ENTRYPOINT in the Dockerfile; that program will run at startup and decide what to do. The original ENTRYPOINT specified within the SageMaker PyTorch is listed in the GitHub repo. To learn how to extend our pre-built container for model training, refer to Extend a Pre-built Container. In this example, we only use the inference container.
Hosting has a very different model than training because hosting is responding to inference requests that come in through HTTP. At the time of writing, the SageMaker PyTorch containers use our TorchServe to provide robust and scalable serving of inference requests, as illustrated in the following diagram.

SageMaker uses two URLs in the container:
/ping receives GET requests from the infrastructure. Your program returns 200 if the container is up and accepting requests./invocations is the endpoint that receives client inference POST The format of the request and the response is up to the algorithm. If the client supplied ContentType and Accept headers, these are passed in as well.The container has the model files in the same place that they were written to during training:
/opt/ml`-- model `-- <model files>
The container directory has all the components you need to extend the SageMaker PyTorch container to use as a sample algorithm:
.|-- Dockerfile|-- build_and_push.sh`-- code `-- inference.py `-- requirements.txt
Let’s discuss each of these in turn:
In this application, we install or update a few libraries for running Llama.cpp in Python. We put the following files in the container:
The Dockerfile describes the image that we want to build. We start from the SageMaker PyTorch image as the base inference one. The SageMaker PyTorch ECR image that supports Graviton in this case would be:
FROM 763104351884.dkr.ecr.{region}.amazonaws.com/pytorch-inference-arm64:2.5.1-cpu-py311-ubuntu22.04-sagemaker
Next, we install the required additional libraries and add the code that implements our specific algorithm to the container, and set up the right environment for it to run under. We recommend configuring the following optimizations for Graviton in the Dockerfile and the inference code for better performance:
-mcpu=native -fopenmp when installing the llama.cpp Python package. The combination of these flags can lead to code optimized for the specific ARM architecture of Graviton and parallel execution that takes full advantage of the multi-core nature of Graviton processors.n_threads to the number of vCPUs explicitly in the inference code to use all cores (vCPUs) on Graviton.q4_0 models, which minimizes accuracy loss while aligning well with CPU architectures, improving CPU inference performance by reducing memory footprint and enhancing cache utilization. For information on how to quantize models, refer to the llama.cpp README.The build_and_push.sh script describes how to automate the setup of a CodeBuild project specifically designed for building Docker images on ARM64 architecture. It sets up essential configuration variables; creates necessary AWS Identity and Access Management (IAM) roles with appropriate permissions for Amazon CloudWatch Logs, Amazon Simple Storage Service (Amazon S3), and Amazon ECR access; and establishes a CodeBuild project using an ARM-based container environment. The script includes functions to check for project existence and wait for project readiness, while configuring the build environment with required variables and permissions for building and pushing Docker images, particularly for the llama.cpp inference code.
Given the use of a pre-built SageMaker PyTorch container, we can simply write an inference script that defines the following functions to handle input data deserialization, model loading, and prediction:
model_fn() reads the content of an existing model weights directory from the `/opt/ml/model` or uses the model_dir parameter passed to the function, which is a directory where the model is savedinput_fn() is used to format the data received from a request made to the endpointpredict_fn() calls the output of model_fn() to run inference on the output of input_fn()output_fn() optionally serializes predictions from predict_fn to the format that can be transferred back through HTTP packages, such as JSONNormally, you would compress model files into a TAR file; however, this can cause startup time to take longer due to having to download and untar large files. To improve startup times, SageMaker AI supports use of uncompressed files. This removes the need to untar large files. In this example, we upload all the files to an S3 prefix and then pass the location into the model with “CompressionType”: “None”.
Now we can use the PyTorchModel class provided by SageMaker Python SDK to create a PyTorch SageMaker model that can be deployed to a SageMaker endpoint:
TorchServe runs multiple workers on the container for inference, where each worker hosts a copy of the model. model_server_workers controls the number of workers that TorchServe will run by configuring the ‘SAGEMAKER_MODEL_SERVER_WORKERS‘ environment variable. Therefore, we recommend using a small number for the model server workers.
Then we can invoke the endpoint with either the predictor object returned by the deploy function or use a low-level Boto3 API as follows:
When you’re happy with a specific model, or a quantized version of it, for your use case, you can start tuning your compute capacity to serve your users at scale. When running LLM inference, we look at two main metrics to evaluate performance: latency and throughput. Tools like LLMPerf enable measuring these metrics on SageMaker AI endpoints.
When serving users in parallel, batching those parallel requests together can improve throughput and increase compute utilization by moving the multiple inputs together with the model weights from the host memory to the CPU in order to generate the output tokens. Model serving backends like vLLM and Llama.cpp support continuous batching, which automatically adds new requests to the existing batch, replacing old requests that finished their token generation phases. However, configuring higher batch sizes comes at the expense of per-user latency, so you should tune the batch size for the best latency-throughput combination on the ML instance you’re using on SageMaker AI. In addition to batching, using prompt or prefix caching to reuse the precomputed attention matrices in similar subsequent requests can further boost latency.
When you find the optimal batch size for your use case, you can tune your endpoint’s auto scaling policy to serve your users at scale using an endpoint exposing multiple CPU-based ML instances, which scales according the application load. Let’s say you are able to successfully serve 10 requests users in parallel with one ML instance. You can scale out by increasing the number of instances to reach the number of instances needed to serve your target number of users—for example, you would need 10 instances to serve 100 users in parallel.
To avoid unwanted charges, clean up the resources you created as part of this solution if you no longer need it.
SageMaker AI with Graviton processors offers a compelling solution for organizations looking to deploy AI capabilities cost-effectively. By using CPU-based inference with quantized models, this approach delivers up to 50% cost savings compared to traditional deployments while maintaining robust performance for many real-world applications. The combination of simplified operations through the fully managed SageMaker infrastructure, flexible auto scaling with zero-cost downtime, and enhanced deployment speed with container caching technology makes it an ideal platform for production AI workloads.
To get started, explore our sample notebooks on GitHub and reference documentation to evaluate whether CPU-based inference suits your use case. You can also refer to the AWS Graviton Technical Guide, which provides the list of optimized libraries and best practices that can help you achieve cost benefits with Graviton instances across different workloads.
 Vincent Wang is an Efficient Compute Specialist Solutions Architect at AWS based in Sydney, Australia. He helps customers optimize their cloud infrastructure by leveraging AWS’s silicon innovations, including AWS Graviton processors and AWS Neuron technology. Vincent’s expertise lies in developing AI/ML applications that harness the power of open-source software combined with AWS’s specialized AI chips, enabling organizations to achieve better performance and cost-efficiency in their cloud deployments.
Vincent Wang is an Efficient Compute Specialist Solutions Architect at AWS based in Sydney, Australia. He helps customers optimize their cloud infrastructure by leveraging AWS’s silicon innovations, including AWS Graviton processors and AWS Neuron technology. Vincent’s expertise lies in developing AI/ML applications that harness the power of open-source software combined with AWS’s specialized AI chips, enabling organizations to achieve better performance and cost-efficiency in their cloud deployments.
 Andrew Smith is a Cloud Support Engineer in the SageMaker, Vision & Other team at AWS, based in Sydney, Australia. He supports customers using many AI/ML services on AWS with expertise in working with Amazon SageMaker. Outside of work, he enjoys spending time with friends and family as well as learning about different technologies.
Andrew Smith is a Cloud Support Engineer in the SageMaker, Vision & Other team at AWS, based in Sydney, Australia. He supports customers using many AI/ML services on AWS with expertise in working with Amazon SageMaker. Outside of work, he enjoys spending time with friends and family as well as learning about different technologies.
 Melanie Li, PhD, is a Senior Generative AI Specialist Solutions Architect at AWS based in Sydney, Australia, where her focus is on working with customers to build solutions leveraging state-of-the-art AI and machine learning tools. She has been actively involved in multiple Generative AI initiatives across APJ, harnessing the power of Large Language Models (LLMs). Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries.
Melanie Li, PhD, is a Senior Generative AI Specialist Solutions Architect at AWS based in Sydney, Australia, where her focus is on working with customers to build solutions leveraging state-of-the-art AI and machine learning tools. She has been actively involved in multiple Generative AI initiatives across APJ, harnessing the power of Large Language Models (LLMs). Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries.
 Oussama Maxime Kandakji is a Senior AI/ML Solutions Architect at AWS focusing on AI Inference and Agents. He works with companies of all sizes on solving business and performance challenges in AI and Machine Learning workloads. He enjoys contributing to open source and working with data.
Oussama Maxime Kandakji is a Senior AI/ML Solutions Architect at AWS focusing on AI Inference and Agents. He works with companies of all sizes on solving business and performance challenges in AI and Machine Learning workloads. He enjoys contributing to open source and working with data.
 Romain Legret is a Senior Efficient Compute Specialist Solutions Architect at AWS. Romain promotes the benefits of AWS Graviton, EC2 Spot, Karpenter, or Auto-Scaling while helping French customers in their adoption journey. “Always try to achieve more with less” is his motto !
Romain Legret is a Senior Efficient Compute Specialist Solutions Architect at AWS. Romain promotes the benefits of AWS Graviton, EC2 Spot, Karpenter, or Auto-Scaling while helping French customers in their adoption journey. “Always try to achieve more with less” is his motto !

 We’re introducing an upgraded preview of Gemini 2.5 Pro, our most intelligent model yet. Building on the version we released in May and showed at I/O, this model will be…Read More
We’re introducing an upgraded preview of Gemini 2.5 Pro, our most intelligent model yet. Building on the version we released in May and showed at I/O, this model will be…Read More

One of the key use cases for generative AI involves answering questions over private datasets, with retrieval-augmented generation (RAG) as the go-to framework. As new RAG techniques emerge, there’s a growing need to benchmark their performance across diverse datasets and metrics.
To meet this need, we’re introducing BenchmarkQED, a new suite of tools that automates RAG benchmarking at scale, available on GitHub (opens in new tab). It includes components for query generation, evaluation, and dataset preparation, each designed to support rigorous, reproducible testing.
BenchmarkQED complements the RAG methods in our open-source GraphRAG library, enabling users to run a GraphRAG-style evaluation across models, metrics, and datasets. GraphRAG uses a large language model (LLM) to generate and summarize entity-based knowledge graphs, producing more comprehensive and diverse answers than standard RAG for large-scale tasks.
In this post, we walk through the core components of BenchmarkQED that contribute to the overall benchmarking process. We also share some of the latest benchmark results comparing our LazyGraphRAG system to competing methods, including a vector-based RAG with a 1M-token context window, where the leading LazyGraphRAG configuration showed significant win rates across all combinations of quality metrics and query classes.
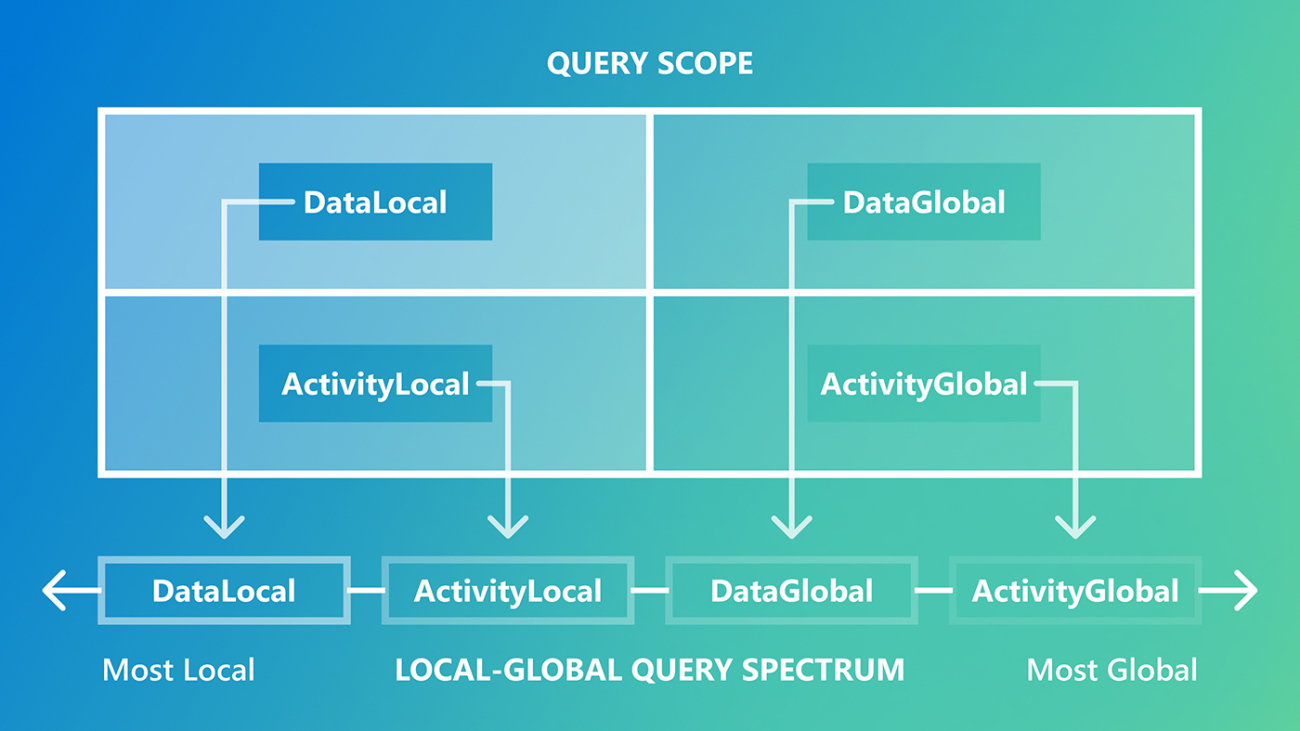
In the paper, we distinguish between local queries, where answers are found in a small number of text regions, and sometimes even a single region, and global queries, which require reasoning over large portions of or even the entire dataset.
Conventional vector-based RAG excels at local queries because the regions containing the answer to the query resemble the query itself and can be retrieved as the nearest neighbor in the vector space of text embeddings. However, it struggles with global questions, such as, “What are the main themes of the dataset?” which require understanding dataset qualities not explicitly stated in the text.
This limitation motivated the development of GraphRAG a system designed to answer global queries. GraphRAG’s evaluation requirements subsequently led to the creation of AutoQ, a method for synthesizing these global queries for any dataset.
AutoQ extends this approach by generating synthetic queries across the spectrum of queries, from local to global. It defines four distinct classes based on the source and scope of the query (Figure 1, top) forming a logical progression along the spectrum (Figure 1, bottom).

AutoQ can be configured to generate any number and distribution of synthetic queries along these classes, enabling consistent benchmarking across datasets without requiring user customization. Figure 2 shows the synthesis process and sample queries from each class, using an AP News dataset.

Microsoft research podcast

Model maker and fabricator Lex Story helps bring research to life through prototyping. He discusses his take on failure; the encouragement and advice that has supported his pursuit of art and science; and the sabbatical that might inspire his next career move.
Our evaluation of GraphRAG focused on analyzing key qualities of answers to global questions. The following qualities were used for the current evaluation:
The AutoE component scales evaluation of these qualities using the LLM-as-a-Judge method. It presents pairs of answers to an LLM, along with the query and target metric, in counterbalanced order. The model determines whether the first answer wins, loses, or ties with the second. Over a set of queries, whether from AutoQ or elsewhere, this produces win rates between competing methods. When ground truth is available, AutoE can also score answers on correctness, completeness, and related metrics.
An illustrative evaluation is shown in Figure 3. Using a dataset of 1,397 AP News articles on health and healthcare, AutoQ generated 50 queries per class (200 total). AutoE then compared LazyGraphRAG to a competing RAG method, running six trials per query across four metrics, using GPT-4.1 as a judge.
These trial-level results were aggregated using metric-based win rates, where each trial is scored 1 for a win, 0.5 for a tie, and 0 for a loss, and then averaged to calculate the overall win rate for each RAG method.

The four LazyGraphRAG conditions (LGR_b200_c200, LGR_b50_c200, LGR_b50_c600, LGR_b200_c200_mini) differ by query budget (b50, b200) and chunk size (c200, c600). All used GPT-4o mini for relevance tests and GPT-4o for query expansion (to five subqueries) and answer generation, except for LGR_b200_c200_mini, which used GPT-4o mini throughout.
Comparison systems were GraphRAG (Local, Global, and Drift Search), Vector RAG with 8k- and 120k-token windows, and three published methods: LightRAG (opens in new tab), RAPTOR (opens in new tab), and TREX (opens in new tab). All methods were limited to the same 8k tokens for answer generation. GraphRAG Global Search used level 2 of the community hierarchy.
LazyGraphRAG outperformed every comparison condition using the same generative model (GPT-4o), winning all 96 comparisons, with all but one reaching statistical significance. The best overall performance came from the larger budget, smaller chunk size configuration (LGR_b200_c200). For DataLocal queries, the smaller budget (LGR_b50_c200) performed slightly better, likely because fewer chunks were relevant. For ActivityLocal queries, the larger chunk size (LGR_b50_c600) had a slight edge, likely because longer chunks provide a more coherent context.
Competing methods performed relatively better on the query classes for which they were designed: GraphRAG Global for global queries, Vector RAG for local queries, and GraphRAG Drift Search, which combines both strategies, posed the strongest challenge overall.
Increasing Vector RAG’s context window from 8k to 120k tokens did not improve its performance compared to LazyGraphRAG. This raised the question of how LazyGraphRAG would perform against Vector RAG with 1-million token context window containing most of the dataset.
Figure 4 shows the follow-up experiment comparing LazyGraphRAG to Vector RAG using GPT-4.1 that enabled this comparison. Even against the 1M-token window, LazyGraphRAG achieved higher win rates across all comparisons, failing to reach significance only for the relevance of answers to DataLocal queries. These queries tend to benefit most from Vector RAG’s ranking of directly relevant chunks, making it hard for LazyGraphRAG to generate answers that have greater relevance to the query, even though these answers may be dramatically more comprehensive, diverse, and empowering overall.

Text datasets have an underlying topical structure, but the depth, breadth, and connectivity of that structure can vary widely. This variability makes it difficult to evaluate RAG systems consistently, as results may reflect the idiosyncrasies of the dataset rather than the system’s general capabilities.
The AutoD component addresses this by sampling datasets to meet a target specification, defined by the number of topic clusters (breadth) and the number of samples per cluster (depth). This creates consistency across datasets, enabling more meaningful comparisons, as structurally aligned datasets lead to comparable AutoQ queries, which in turn support consistent AutoE evaluations.
AutoD also includes tools for summarizing input or output datasets in a way that reflects their topical coverage. These summaries play an important role in the AutoQ query synthesis process, but they can also be used more broadly, such as in prompts where context space is limited.
Since the release of the GraphRAG paper, we’ve received many requests to share the dataset of the Behind the Tech (opens in new tab) podcast transcripts we used in our evaluation. An updated version of this dataset is now available in the BenchmarkQED repository (opens in new tab), alongside the AP News dataset containing 1,397 health-related articles, licensed for open release.
We hope these datasets, together with the BenchmarkQED tools (opens in new tab), help accelerate benchmark-driven development of RAG systems and AI question-answering. We invite the community to try them on GitHub (opens in new tab).
The post BenchmarkQED: Automated benchmarking of RAG systems appeared first on Microsoft Research.
GeForce NOW is a gamer’s ticket to an unforgettable summer of gaming. With 25 titles coming this month and endless ways to play, the summer is going to be epic.
Dive in, level up and make it a summer to remember, one game at a time. Start with the ten games available this week, including advanced access for those who’ve preordered the Deluxe or Ultimate versions of Funcom’s highly anticipated Dune: Awakening.
Plus, check out the latest update for miHoYo’s Zenless Zone Zero, bringing fresh content and even more action for summer.
And to keep the good times rolling, take advantage of the GeForce NOW Summer Sale to enjoy a sizzling 40% off a six-month Performance membership. It’s the perfect way to extend a summer of fun in the cloud.

Get ready for a new leap in Zenless Zone Zero. Version 2.0 “Where Clouds Embrace the Dawn” launches tomorrow, June 6, marking the start of the game’s second season. Explore the new Waifei Peninsula, team up with Grandmaster Yixuan and manage the Suibian Temple, all with enhanced maps and navigation.
Celebrate the game’s first anniversary with free rewards — including an S-Rank Agent, S-Rank W-Engine, and 1,600 Polychromes. With new agents, expanded content and major improvements, now’s the perfect time to jump into New Eridu.
Stream it on GeForce NOW for instant access and top-tier performance — no downloads or high-end hardware needed. Stream the latest content with smooth graphics and low latency on any device, and jump straight into the action to enjoy all the new features and anniversary rewards.
Level up summer gaming with the Summer Sale. Get 40% off six-month GeForce NOW Performance memberships — perfect for playing on handheld devices, including the new GeForce NOW app on Steam Deck, which lets gamers stream over 2,200 games at up to 4K 60 frames per second or 1440p 120 fps. Experience AAA gaming at max settings with longer battery life, and access supported games from Steam, Epic Games Store, PC Game Pass and more.
Put that upgraded membership to the test with what’s coming to the cloud this week on GeForce NOW:
Here’s what to expect for the rest of June:
May I Have More Games?
In addition to the 21 games announced last month, 16 more joined the GeForce NOW library:
War Robots: Frontiers is no longer coming to GeForce NOW. Stay tuned for more game announcements and updates every GFN Thursday.
What are you planning to play this weekend? Let us know on X or in the comments below.
What’s your game of the summer?
—
NVIDIA GeForce NOW (@NVIDIAGFN) June 4, 2025
