Perceptual voice quality dimensions describe key characteristics of atypical speech and other speech modulations. Here we develop and evaluate voice quality models for seven voice and speech dimensions (intelligibility, imprecise consonants, harsh voice, naturalness, monoloudness, monopitch, and breathiness). Probes were trained on the public Speech Accessibility (SAP) project dataset with 11,184 samples from 434 speakers, using embeddings from frozen pre-trained models as features. We found that our probes had both strong performance and strong generalization across speech elicitation…Apple Machine Learning Research
Improve Vision Language Model Chain-of-thought Reasoning
Chain-of-thought (CoT) reasoning in vision language
models (VLMs) is crucial for improving
interpretability and trustworthiness. However,
current training recipes often relying on
datasets dominated by short annotations with
minimal rationales. In this work, we show that
training VLM on short answers leads to poor
generalization on reasoning tasks that require
more detailed explanations. To address this limitation,
we propose a two-stage post-training
strategy that extends the usage of short answer
data for enhanced CoT reasoning. First, we
augment short answers with CoT reasoning
generated by…Apple Machine Learning Research
The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
Recent generations of frontier language models have introduced Large Reasoning Models
(LRMs) that generate detailed thinking processes before providing answers. While these models
demonstrate improved performance on reasoning benchmarks, their fundamental capabilities, scal-
ing properties, and limitations remain insufficiently understood. Current evaluations primarily fo-
cus on established mathematical and coding benchmarks, emphasizing final answer accuracy. How-
ever, this evaluation paradigm often suffers from data contamination and does not provide insights
into the reasoning traces’…Apple Machine Learning Research
Proxy-FDA: Proxy-Based Feature Distribution Alignment for Fine-Tuning Vision Foundation Models Without Forgetting
Vision foundation models pre-trained on massive data encode rich representations of real-world concepts, which can be adapted to downstream tasks by fine-tuning. However, fine-tuning foundation models on one task often leads to the issue of concept forgetting on other tasks. Recent methods of robust fine-tuning aim to mitigate forgetting of prior knowledge without affecting the fine-tuning performance. Knowledge is often preserved by matching the original and fine-tuned model weights or feature pairs. However, such point-wise matching can be too strong, without explicit awareness of the…Apple Machine Learning Research
Beyond Text Compression: Evaluating Tokenizers Across Scales
Tokenizer design significantly impacts language model performance,
yet evaluating tokenizer quality remains challenging. While text compression has emerged as a common intrinsic metric, recent work questions its reliability as a quality indicator. We investigate whether evaluating tokenizers on smaller models (350M parameters) reliably predicts their impact at larger scales (2.7B parameters).
Through experiments with established tokenizers from widely-adopted language models, we find that tokenizer choice minimally affects English tasks but yields significant, scale-consistent differences in…Apple Machine Learning Research
Impel enhances automotive dealership customer experience with fine-tuned LLMs on Amazon SageMaker
This post is co-written with Tatia Tsmindashvili, Ana Kolkhidashvili, Guram Dentoshvili, Dachi Choladze from Impel.
Impel transforms automotive retail through an AI-powered customer lifecycle management solution that drives dealership operations and customer interactions. Their core product, Sales AI, provides all-day personalized customer engagement, handling vehicle-specific questions and automotive trade-in and financing inquiries. By replacing their existing third-party large language model (LLM) with a fine-tuned Meta Llama model deployed on Amazon SageMaker AI, Impel achieved 20% improved accuracy and greater cost controls. The implementation using the comprehensive feature set of Amazon SageMaker, including model training, Activation-Aware Weight Quantization (AWQ), and Large Model Inference (LMI) containers. This domain-specific approach not only improved output quality but also enhanced security and operational overhead compared to general-purpose LLMs.
In this post, we share how Impel enhances the automotive dealership customer experience with fine-tuned LLMs on SageMaker.
Impel’s Sales AI
Impel optimizes how automotive retailers connect with customers by delivering personalized experiences at every touchpoint—from initial research to purchase, service, and repeat business, acting as a digital concierge for vehicle owners, while giving retailers personalization capabilities for customer interactions. Sales AI uses generative AI to provide instant responses around the clock to prospective customers through email and text. This maintained engagement during the early stages of a customer’s car buying journey leads to showroom appointments or direct connections with sales teams. Sales AI has three core features to provide this consistent customer engagement:
- Summarization – Summarizes past customer engagements to derive customer intent
- Follow-up generation – Provides consistent follow-up to engaged customers to help prevent stalled customer purchasing journeys
- Response personalization – Personalizes responses to align with retailer messaging and customer’s purchasing specifications
Two key factors drove Impel to transition from their existing LLM provider: the need for model customization and cost optimization at scale. Their previous solution’s per-token pricing model became cost-prohibitive as transaction volumes grew, and limitations on fine-tuning prevented them from fully using their proprietary data for model improvement. By deploying a fine-tuned Meta Llama model on SageMaker, Impel achieved the following:
- Cost predictability through hosted pricing, mitigating per-token charges
- Greater control of model training and customization, leading to 20% improvement across core features
- Secure processing of proprietary data within their AWS account
- Automatic scaling to meet the spike in inference demand
Solution overview
Impel chose SageMaker AI, a fully managed cloud service that builds, trains, and deploys machine learning (ML) models using AWS infrastructure, tools, and workflows to fine-tune a Meta Llama model for Sales AI. Meta Llama is a powerful model, well-suited for industry-specific tasks due to its strong instruction-following capabilities, support for extended context windows, and efficient handling of domain knowledge.
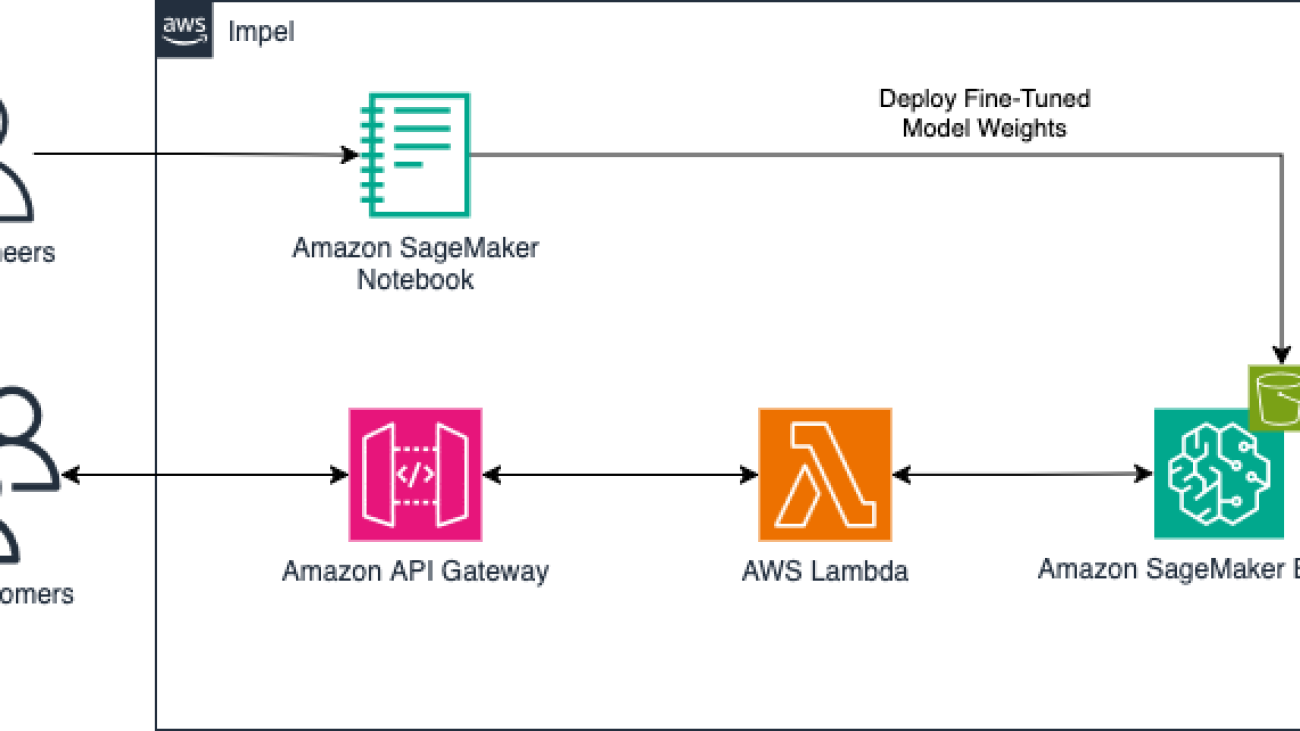
Impel used SageMaker LMI containers to deploy LLM inference on SageMaker endpoints. These purpose-built Docker containers offer optimized performance for models like Meta Llama with support for LoRA fine-tuned models and AWQ. Impel used LoRA fine-tuning, an efficient and cost-effective technique to adapt LLMs for specialized applications, through Amazon SageMaker Studio notebooks running on ml.p4de.24xlarge instances. This managed environment simplified the development process, enabling Impel’s team to seamlessly integrate popular open source tools like PyTorch and torchtune for model training. For model optimization, Impel applied AWQ techniques to reduce model size and improve inference performance.
In production, Impel deployed inference endpoints on ml.g6e.12xlarge instances, powered by four NVIDIA GPUs and high memory capacity, suitable for serving large models like Meta Llama efficiently. Impel used the SageMaker built-in automatic scaling feature to automatically scale serving containers based on concurrent requests, which helped meet variable production traffic demands while optimizing for cost.
The following diagram illustrates the solution architecture, showcasing model fine-tuning and customer inference.

Impel’s Sales AI reference architecture.
Impel’s R&D team partnered closely with various AWS teams, including its Account team, GenAI strategy team, and SageMaker service team. This virtual team collaborated over multiple sprints leading up to the fine-tuned Sales AI launch date to review model evaluations, benchmark SageMaker performance, optimize scaling strategies, and identify the optimal SageMaker instances. This partnership encompassed technical sessions, strategic alignment meetings, and cost and operational discussions for post-implementation. The tight collaboration between Impel and AWS was instrumental in realizing the full potential of Impel’s fine-tuned model hosted on SageMaker AI.
Fine-tuned model evaluation process
Impel’s transition to its fine-tuned Meta Llama model delivered improvements across key performance metrics with noticeable improvements in understanding automotive-specific terminology and generating personalized responses. Structured human evaluations revealed enhancements in critical customer interaction areas: personalized replies improved from 73% to 86% accuracy, conversation summarization increased from 70% to 83%, and follow-up message generation showed the most significant gain, jumping from 59% to 92% accuracy. The following screenshot shows how customers interact with Sales AI. The model evaluation process included Impel’s R&D team grading various use cases served by the incumbent LLM provider and Impel’s fine-tuned models.

Example of a customer interaction with Sales AI.
In addition to output quality, Impel measured latency and throughput to validate the model’s production readiness. Using awscurl for SigV4-signed HTTP requests, the team confirmed these improvements in real-world performance metrics, ensuring optimal customer experience in production environments.
Using domain-specific models for better performance
Impel’s evolution of Sales AI progressed from a general-purpose LLM to a domain-specific, fine-tuned model. Using anonymized customer interaction data, Impel fine-tuned a publicly available foundation model, resulting in several key improvements. The new model exhibited a 20% increase in accuracy across core features, showcasing enhanced automotive industry comprehension and more efficient context window utilization. By transitioning to this approach, Impel achieved three primary benefits:
- Enhanced data security through in-house processing within their AWS accounts
- Reduced reliance on external APIs and third-party providers
- Greater operational control for scaling and customization
These advancements, coupled with the significant output quality improvement, validated Impel’s strategic shift towards a domain-specific AI model for Sales AI.
Expanding AI innovation in automotive retail
Impel’s success deploying fine-tuned models on SageMaker has established a foundation for extending its AI capabilities to support a broader range of use cases tailored to the automotive industry. Impel is planning to transition to in-house, domain-specific models to extend the benefits of improved accuracy and performance throughout their Customer Engagement Product suite.Looking ahead, Impel’s R&D team is advancing their AI capabilities by incorporating Retrieval Augmented Generation (RAG) workflows, advanced function calling, and agentic workflows. These innovations can help deliver adaptive, context-aware systems designed to interact, reason, and act across complex automotive retail tasks.
Conclusion
In this post, we discussed how Impel has enhanced the automotive dealership customer experience with fine-tuned LLMs on SageMaker.
For organizations considering similar transitions to fine-tuned models, Impel’s experience demonstrates how working with AWS can help achieve both accuracy improvements and model customization opportunities while building long-term AI capabilities tailored to specific industry needs. Connect with your account team or visit Amazon SageMaker AI to learn how SageMaker can help you deploy and manage fine-tuned models.
About the Authors
 Nicholas Scozzafava is a Senior Solutions Architect at AWS, focused on startup customers. Prior to his current role, he helped enterprise customers navigate their cloud journeys. He is passionate about cloud infrastructure, automation, DevOps, and helping customers build and scale on AWS.
Nicholas Scozzafava is a Senior Solutions Architect at AWS, focused on startup customers. Prior to his current role, he helped enterprise customers navigate their cloud journeys. He is passionate about cloud infrastructure, automation, DevOps, and helping customers build and scale on AWS.
 Sam Sudakoff is a Senior Account Manager at AWS, focused on strategic startup ISVs. Sam specializes in technology landscapes, AI/ML, and AWS solutions. Sam’s passion lies in scaling startups and driving SaaS and AI transformations. Notably, his work with AWS’s top startup ISVs has focused on building strategic partnerships and implementing go-to-market initiatives that bridge enterprise technology with innovative startup solutions, while maintaining strict adherence with data security and privacy requirements.
Sam Sudakoff is a Senior Account Manager at AWS, focused on strategic startup ISVs. Sam specializes in technology landscapes, AI/ML, and AWS solutions. Sam’s passion lies in scaling startups and driving SaaS and AI transformations. Notably, his work with AWS’s top startup ISVs has focused on building strategic partnerships and implementing go-to-market initiatives that bridge enterprise technology with innovative startup solutions, while maintaining strict adherence with data security and privacy requirements.
 Vivek Gangasani is a Lead Specialist Solutions Architect for Inference at AWS. He helps emerging generative AI companies build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of large language models. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines.
Vivek Gangasani is a Lead Specialist Solutions Architect for Inference at AWS. He helps emerging generative AI companies build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of large language models. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines.
 Dmitry Soldatkin is a Senior AI/ML Solutions Architect at AWS, helping customers design and build AI/ML solutions. Dmitry’s work covers a wide range of ML use cases, with a primary interest in generative AI, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, utilities, and telecommunications. Prior to joining AWS, Dmitry was an architect, developer, and technology leader in data analytics and machine learning fields in the financial services industry.
Dmitry Soldatkin is a Senior AI/ML Solutions Architect at AWS, helping customers design and build AI/ML solutions. Dmitry’s work covers a wide range of ML use cases, with a primary interest in generative AI, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, utilities, and telecommunications. Prior to joining AWS, Dmitry was an architect, developer, and technology leader in data analytics and machine learning fields in the financial services industry.
 Tatia Tsmindashvili is a Senior Deep Learning Researcher at Impel with an MSc in Biomedical Engineering and Medical Informatics. She has over 5 years of experience in AI, with interests spanning LLM agents, simulations, and neuroscience. You can find her on LinkedIn.
Tatia Tsmindashvili is a Senior Deep Learning Researcher at Impel with an MSc in Biomedical Engineering and Medical Informatics. She has over 5 years of experience in AI, with interests spanning LLM agents, simulations, and neuroscience. You can find her on LinkedIn.
 Ana Kolkhidashvili is the Director of R&D at Impel, where she leads AI initiatives focused on large language models and automated conversation systems. She has over 8 years of experience in AI, specializing in large language models, automated conversation systems, and NLP. You can find her on LinkedIn.
Ana Kolkhidashvili is the Director of R&D at Impel, where she leads AI initiatives focused on large language models and automated conversation systems. She has over 8 years of experience in AI, specializing in large language models, automated conversation systems, and NLP. You can find her on LinkedIn.
 Guram Dentoshvili is the Director of Engineering and R&D at Impel, where he leads the development of scalable AI solutions and drives innovation across the company’s conversational AI products. He began his career at Pulsar AI as a Machine Learning Engineer and played a key role in building AI technologies tailored to the automotive industry. You can find him on LinkedIn.
Guram Dentoshvili is the Director of Engineering and R&D at Impel, where he leads the development of scalable AI solutions and drives innovation across the company’s conversational AI products. He began his career at Pulsar AI as a Machine Learning Engineer and played a key role in building AI technologies tailored to the automotive industry. You can find him on LinkedIn.
 Dachi Choladze is the Chief Innovation Officer at Impel, where he leads initiatives in AI strategy, innovation, and product development. He has over 10 years of experience in technology entrepreneurship and artificial intelligence. Dachi is the co-founder of Pulsar AI, Georgia’s first globally successful AI startup, which later merged with Impel. You can find him on LinkedIn.
Dachi Choladze is the Chief Innovation Officer at Impel, where he leads initiatives in AI strategy, innovation, and product development. He has over 10 years of experience in technology entrepreneurship and artificial intelligence. Dachi is the co-founder of Pulsar AI, Georgia’s first globally successful AI startup, which later merged with Impel. You can find him on LinkedIn.
 Deepam Mishra is a Sr Advisor to Startups at AWS and advises startups on ML, Generative AI, and AI Safety and Responsibility. Before joining AWS, Deepam co-founded and led an AI business at Microsoft Corporation and Wipro Technologies. Deepam has been a serial entrepreneur and investor, having founded 4 AI/ML startups. Deepam is based in the NYC metro area and enjoys meeting AI founders.
Deepam Mishra is a Sr Advisor to Startups at AWS and advises startups on ML, Generative AI, and AI Safety and Responsibility. Before joining AWS, Deepam co-founded and led an AI business at Microsoft Corporation and Wipro Technologies. Deepam has been a serial entrepreneur and investor, having founded 4 AI/ML startups. Deepam is based in the NYC metro area and enjoys meeting AI founders.

Open Source AI is Transforming the Economy—Here’s What the Data Shows

Blog cross-posted on the Linux Foundation blog.
As we approach the midpoint of 2025, the potential of AI to transform businesses, economies, and industries is not only widely anticipated and nearly universal but also well documented. In a commissioned project by Meta, LF Research set out to capture existing evidence on this topic, with the specific aim of understanding how open source is playing a role in this transformation.
In its latest publication, The Economic and Workforce Impacts of Open Source AI, LF Research describes the nuances of how and to what extent open source AI (OSAI) is impacting the global economy and workforce. By examining existing evidence from industry, academic, and open source research, the authors found important insights on OSAI’s adoption rates, cost effectiveness, innovation-boosting potential, and more. Here are the big takeaways.
First, the adoption of open source AI is already widespread. Nearly all software developers have experimented with open models, and about 63% of companies are actively using them. In fact, among organizations that have embraced AI in any form, a striking 89% incorporate open source AI somewhere in their infrastructure. It’s no longer a fringe approach—it’s becoming the standard.

Why? Cost is a huge factor. Open source tools often come with significantly lower price tags than their proprietary counterparts. My prior research with Manuel Hoffmann and Yanuo Zhou has shown that if open source didn’t exist, companies would spend 3.5 times more on software than they currently do. The new LF report shows that two-thirds of organizations say OSAI is cheaper to deploy, and nearly half cite cost savings as a primary reason for choosing open source. Combine that with studies showing AI’s ability to cut business unit costs by over 50%, while still being user friendly and maintaining high performance, and it’s clear that OSAI represents a strategic advantage for boosting margins and scaling innovation.

Innovation and entrepreneurship are other major benefits of open source. In research with Nataliya Langburd Wright and Shane Greenstein, we found that when open source contributions increase at the country level, so do new startups; at the company level, there is a positive relationship between contributing to open source and startup growth. Open source encourages collaboration, inviting contributions from a global pool of developers and researchers. This external input helps accelerate the development of high-quality models. As Daniel Yue and I found when Meta donated the machine learning library PyTorch to the Linux Foundation, there was a notable increase in corporate contributions, especially from chip manufacturers.

AI’s cost-cutting capabilities are not only linked to the increased productivity that comes from freed-up resources, but also from a re-orienting of the way people work—similar to how the full impact of the steam engine led to the industrial revolution, but only after factories re-oriented their entire work flow around it. Manuel Hoffmann, Sam Boysel, Kevin Xu, Sida Peng, and I found this to be the case with software developers. When GitHub rolled out their GenAI coding tool Copilot, developers changed the way that they worked by spending more time writing code and substantially less time doing project management. However, according to existing research identified in the LF study, this has not translated to substantial layoffs: 95% of surveyed hiring managers over the past two years said they do not plan to reduce headcount due to AI. What’s more, being able to use AI tools effectively may actually increase wages by over 20%.
Looking ahead, open source AI is likely to become foundational in areas like edge computing, where smaller, privacy-preserving models need to run efficiently on local devices. OSAI is also making big inroads in industry-specific applications. In manufacturing, for instance, open models offer the flexibility required to integrate AI into complex operational workflows. And in healthcare—a traditionally conservative and risk-averse field—open models are already matching proprietary ones in performance, giving institutions confidence to adopt without compromising on quality. OSAI is an important avenue to level the playing field, no matter your organization’s size or financial resources—as the report found, small businesses are adopting OSAI at higher rates than their larger counterparts.

OSAI is an economic force. It’s reducing costs, accelerating innovation, and empowering a wider range of players to shape the future of technology.
What’s Next for OSAI? Five Areas Ripe for Research
While the impact of OSAI is starting to take shape, the full scope of its influence is just beginning to unfold. To better understand and harness the potential of OSAI, the report outlines five key areas for future research, each crucial to shaping smart policy, business strategy, and innovation ecosystems.
- Tracking the Bigger Picture: OSAI’s Role in Market Growth
One pressing question is how open models are influencing the overall AI market. Beyond the tools themselves, OSAI may be driving complementary innovation, spurring growth in services, applications, and platforms built on top of open infrastructure. Understanding this broader ripple effect is essential for grasping the true economic footprint of open AI. - Making the Case for Investment
To help make informed decisions, researchers are encouraged to analyze the return on investment in OSAI infrastructure at both country and company levels. Quantifying the long-term value of these open components, from datasets and compute to developer tooling, can guide resource allocation and policy decisions in a fast-moving field. - Connecting Openness to Innovation
Does OSAI directly foster more startups, patents, or efficient R&D? Future studies should explore how open access to models and tools correlates with concrete innovation metrics. This could provide evidence for how openness accelerates not just adoption, but invention. - Crunching the Cost Numbers
A detailed comparison of costs between open and proprietary AI solutions across sectors, company sizes, and global regions would shed light on who benefits most from going open. These insights would be invaluable for organizations navigating tight budgets and evaluating technology strategies. - Understanding Workforce Impacts
Finally, the human side matters. As AI tools reshape work, it’s vital to measure how open models affect worker productivity, satisfaction, and work patterns. Do open tools empower workers in certain tasks or industries more than others? Do they lead to more flexible, fulfilling roles? Answers to these questions will help ensure that AI benefits not just business, but people.
By exploring these future research areas, we can unlock a deeper understanding of how open source AI is transforming the global economy and workforce. The era of open source AI is here—and it’s time to study its impact with depth and rigor.

AI breakthroughs are bringing hope to cancer research and treatment
 Read Ruth Porat’s remarks on AI and cancer research at the American Society of Clinical Oncology.Read More
Read Ruth Porat’s remarks on AI and cancer research at the American Society of Clinical Oncology.Read More
How climate tech startups are building foundation models with Amazon SageMaker HyperPod
Climate tech startups are companies that use technology and innovation to address the climate crisis, with a primary focus on either reducing greenhouse gas emissions or helping society adapt to climate change impacts. Their unifying mission is to create scalable solutions that accelerate the transition to a sustainable, low-carbon future. Solutions to the climate crisis are ever more important as climate-driven extreme weather disasters increase globally. In 2024, climate disasters caused more than $417B in damages globally, and there’s no slowing down in 2025 with LA wildfires that destroyed more than $135B in the first month of the year alone. Climate tech startups are at the forefront of building impactful solutions to the climate crisis, and they’re using generative AI to build as quickly as possible.
In this post, we show how climate tech startups are developing foundation models (FMs) that use extensive environmental datasets to tackle issues such as carbon capture, carbon-negative fuels, new materials design for microplastics destruction, and ecosystem preservation. These specialized models require advanced computational capabilities to process and analyze vast amounts of data effectively.
Amazon Web Services (AWS) provides the essential compute infrastructure to support these endeavors, offering scalable and powerful resources through Amazon SageMaker HyperPod. SageMaker HyperPod is a purpose-built infrastructure service that automates the management of large-scale AI training clusters so developers can efficiently build and train complex models such as large language models (LLMs) by automatically handling cluster provisioning, monitoring, and fault tolerance across thousands of GPUs. With SageMaker HyperPod, startups can train complex AI models on diverse environmental datasets, including satellite imagery and atmospheric measurements, with enhanced speed and efficiency. This computational backbone is vital for startups striving to create solutions that are not only innovative but also scalable and impactful.
The increasing complexity of environmental data demands robust data infrastructure and sophisticated model architectures. Integrating multimodal data, employing specialized attention mechanisms for spatial-temporal data, and using reinforcement learning are crucial for building effective climate-focused models. SageMaker HyperPod optimized GPU clustering and scalable resources help startups save time and money while meeting advanced technical requirements, which means they can focus on innovation. As climate technology demands grow, these capabilities allow startups to develop transformative environmental solutions using Amazon SageMaker HyperPod.
Trends among climate tech startups building with generative AI
Climate tech startups’ adoption of generative AI is evolving rapidly. Starting in early 2023, we saw the first wave of climate tech startups adopting generative AI to optimize operations. For example, startups such as BrainBox AI and Pendulum used Amazon Bedrock and fine-tuned existing LLMs on AWS Trainium using Amazon SageMaker to more rapidly onboard new customers through automated document ingestion and data extraction. Midway through 2023, we saw the next wave of climate tech startups building sophisticated intelligent assistants by fine-tuning existing LLMs for specific use cases. For example, NET2GRID used Amazon SageMaker for fine-tuning and deploying scale-based LLMs based on Llama 7B to build EnergyAI, an assistant that provides quick, personalized responses to utility customers’ energy-related questions.
Over the last 6 months, we’ve seen a flurry of climate tech startups building FMs that address specific climate and environmental challenges. Unlike language-based models, these startups are building models based on real-world data, like weather or geospatial earth data. Whereas LLMs such as Anthropic’s Claude or Amazon Nova have hundreds of billions of parameters, climate tech startups are building smaller models with just a few billion parameters. This means these models are faster and less expensive to train. We’re seeing some emerging trends in use cases or climate challenges that startups are addressing by building FMs. Here are the top use cases, in order of popularity:
- Weather – Trained on historic weather data, these models offer short-term and long-term, hyperaccurate, hyperlocal weather and climate predictions, some focusing on specific weather elements like wind, heat, or sun.
- Sustainable material discovery – Trained on scientific data, these models invent new sustainable material that solve specific problems, like more efficient direct air capture sorbents to reduce the cost of carbon removal or molecules to destroy microplastics from the environment.
- Natural ecosystems – Trained on a mix of data from satellites, lidar, and on-the ground sensors, these models offer insights into natural ecosystems, biodiversity, and wildfire predictions.
- Geological modeling – Trained on geological data, these models help determine the best locations for geothermal or mining operations to reduce waste and save money.
To offer a more concrete look at these trends, the following is a deep dive into how climate tech startups are building FMs on AWS.
Orbital Materials: Foundation models for sustainable material discovery
Orbital Materials has built a proprietary AI platform to design, synthesize, and test new sustainable materials. Developing new advanced materials has traditionally been a slow process of trial and error in the lab. Orbital replaces this with generative AI design, radically speeding up materials discovery and new technology commercialization. They’ve released a generative AI model called “Orb” that suggests new material design, which the team then tests and perfects in the lab.
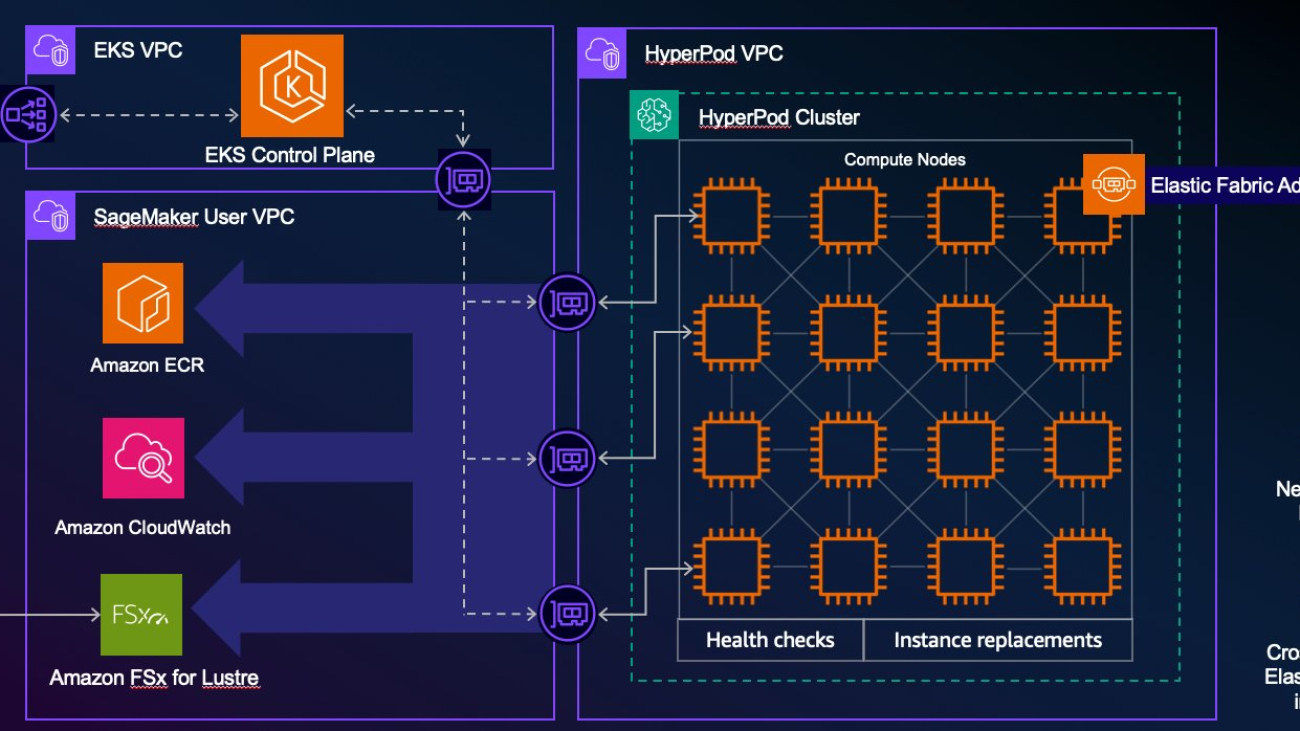
Orb is a diffusion model that Orbital Materials trained from scratch using SageMaker HyperPod. The first product the startup designed with Orb is a sorbent for carbon capture in direct air capture facilities. Since establishing its lab in the first quarter of 2024, Orbital has achieved a tenfold improvement in its material’s performance using its AI platform—an order of magnitude faster than traditional development and breaking new ground in carbon removal efficacy. By improving the performance of the materials, the company can help drive down the costs of carbon removal, which can enable rapid scale-up. They chose to use SageMaker HyperPod because they “like the one-stop shop for control and monitoring,” explained Jonathan Godwin, CEO of Orbital Material. Orbital was able to reduce their total cost of ownership (TCO) for their GPU cluster with Amazon SageMaker HyperPod deep health checks for stress testing their GPU instances to swap out faulty nodes. Moreover, Orbital can use SageMaker HyperPod to automatically swap out failing nodes and restart model training from the last saved checkpoint, freeing up time for the Orbital Materials team. The SageMaker HyperPod monitoring agent continually monitors and detects potential issues, including memory exhaustion, disk failures, GPU anomalies, kernel deadlocks, container runtime issues, and out-of-memory (OOM) crashes. Based on the underlying issue the monitoring agent either replaces or reboots the node.
With the launch of SageMaker HyperPod on Amazon Elastic Kubernetes Service (Amazon EKS), Orbital can set up a unified control plane consisting of both CPU-based workloads and GPU-accelerated tasks within the same Kubernetes cluster. This architectural approach eliminates the traditional complexity of managing separate clusters for different compute resources, significantly reducing operational overhead. Orbital can also monitor the health status of SageMaker HyperPod nodes through Amazon CloudWatch Container Insights with enhanced observability for Amazon EKS. Amazon CloudWatch Container Insights collects, aggregates, and summarizes metrics and logs from containerized applications and microservices, providing detailed insights into performance, health, and status metrics for CPU, GPU, Trainium, or Elastic Fabric Adapter (EFA) and file system up to the container level.
AWS and Orbital Materials have established a deep partnership that enables fly-wheel growth. The companies have entered a multiyear partnership, in which Orbital Material builds its FMs with SageMaker HyperPod and other AWS services. In return, Orbital Materials is using AI to develop new data center decarbonization and efficiency technologies. To further spin the fly-wheel, Orbital will be making its market-leading open source AI model for simulating advanced materials, Orb, generally available for AWS customers by using Amazon SageMaker JumpStart and AWS Marketplace. This marks the first AI-for-materials model to be on AWS platforms. With Orb, AWS customers working on advanced materials and technologies such as semiconductors, batteries, and electronics can access market-leading accelerated research and development (R&D) within a secure and unified cloud environment.
The architectural advantages of SageMaker HyperPod on Amazon EKS are demonstrated in the following diagram. The diagram illustrates how Orbital can establish a unified control plane that manages both CPU-based workloads and GPU-accelerated tasks within a single Kubernetes cluster. This streamlined architecture eliminates the traditional complexity of managing separate clusters for different compute resources, providing a more efficient and integrated approach to resource management. The visualization shows how this consolidated infrastructure enables Orbital to seamlessly orchestrate their diverse computational needs through a single control interface.

Hum.AI: Foundation models for earth observation
Hum.AI is building generative AI FMs that provide general intelligence of the natural world. Customers can use the platform to track and predict ecosystems and biodiversity to understand business impact and better protect the environment. For example, they work with coastal communities who use the platform and insights to restore coastal ecosystems and improve biodiversity.
Hum.AI’s foundation model looks at natural world data and learns to represent it visually. They’re training on 50 years of historic data collected by satellites, which amounts to thousands of petabytes of data. To accommodate processing this massive dataset, they chose SageMaker HyperPod for its scalable infrastructure. Through their innovative model architecture, the company achieved the ability to see underwater from space for the very first time, overcoming the historical challenges posed by water reflections
Hum.AI’s FM architecture employs a variational autoencoder (VAE) and generative adversarial network (GAN) hybrid design, specifically optimized for satellite imagery analysis. It’s an encoder-decoder model, where the encoder transforms satellite data into a learned latent space, while the decoder reconstructs the imagery (after being processed in the latent space), maintaining consistency across different satellite sources. The discriminator network provides both adversarial training signals and learned feature-wise reconstruction metrics. This approach helps preserve important ecosystem details that would otherwise be lost with traditional pixel-based comparisons, particularly for underwater environments, where water reflections typically interfere with visibility.
Using SageMaker HyperPod to train such a complex model enables Hum.AI to efficiently process their personally curated SeeFar dataset through distributed training across multiple GPU-based instances. The model simultaneously optimizes both VAE and GAN objectives across GPUs. This, paired with the SageMaker HyperPod auto-resume feature that automatically resumes a training run from the latest checkpoint, provides training continuity, even through node failures.
Hum.AI also used the SageMaker HyperPod out-of-the-box comprehensive observability features through Amazon Managed Service for Prometheus and Amazon Managed Service for Grafana for metric tracking. For their distributed training needs, they used dashboards to monitor cluster performance, GPU metrics, network traffic, and storage operations. This extensive monitoring infrastructure enabled Hum.AI to optimize their training process and maintain high resource utilization throughout their model development.
“Our decision to use SageMaker HyperPod was simple; it was the only service out there where you can continue training through failure. We were able to train larger models faster by taking advantage of the large-scale clusters and redundancy offered by SageMaker HyperPod. We were able to execute experiments faster and iterate models at speeds that were impossible prior to SageMaker HyperPod. SageMaker HyperPod took all of the worry out of large-scale training failures. They’ve built the infrastructure to hot swap GPUs if anything goes wrong, and it saves thousands in lost progress between checkpoints. The SageMaker HyperPod team personally helped us set up and execute large training rapidly and easily.”
– Kelly Zheng, CEO of Hum.AI.
Hum.AI’s innovative approach to model training is illustrated in the following figure. The diagram showcases how their model simultaneously optimizes both VAE and GAN objectives across multiple GPUs. This distributed training strategy is complemented by the SageMaker HyperPod auto-resume feature, which automatically restarts training runs from the latest checkpoint. Together, these capabilities provide continual and efficient training, even in the face of potential node failures. The image provides a visual representation of this robust training process, highlighting the seamless integration between Hum.AI’s model architecture and SageMaker HyperPod infrastructure support.

How to save time and money building with Amazon SageMaker HyperPod
Amazon SageMaker HyperPod removes the undifferentiated heavy lifting for climate tech startups building FMs, saving them time and money. For more information on how SageMaker HyperPod’s resiliency helps save costs while training, check out Reduce ML training costs with Amazon SageMaker HyperPod.
At its core is deep infrastructure control optimized for processing complex environmental data, featuring secure access to Amazon Elastic Compute Cloud (Amazon EC2) instances and seamless integration with orchestration tools such as Slurm and Amazon EKS. This infrastructure excels at handling multimodal environmental inputs, from satellite imagery to sensor network data, through distributed training across thousands of accelerators.
The intelligent resource management available in SageMaker HyperPod is particularly valuable for climate modeling, automatically governing task priorities and resource allocation while reducing operational overhead by up to 40%. This efficiency is crucial for climate tech startups processing vast environmental datasets because the system maintains progress through checkpointing while making sure that critical climate modeling workloads receive necessary resources.
For climate tech innovators, the SageMaker HyperPod library of over 30 curated model training recipes accelerates development, allowing teams to begin training environmental models in minutes rather than weeks. The platform’s integration with Amazon EKS provides robust fault tolerance and high availability, essential for maintaining continual environmental monitoring and analysis.
SageMaker HyperPod flexible training plans are particularly beneficial for climate tech projects, allowing organizations to specify completion dates and resource requirements while automatically optimizing capacity for complex environmental data processing. The system’s ability to suggest alternative plans provides optimal resource utilization for computationally intensive climate modeling tasks.With support for next-generation AI accelerators such as the AWS Trainium chips and comprehensive monitoring tools, SageMaker HyperPod provides climate tech startups with a sustainable and efficient foundation for developing sophisticated environmental solutions. This infrastructure enables organizations to focus on their core mission of addressing climate challenges while maintaining operational efficiency and environmental responsibility.
Practices for sustainable computing
Climate tech companies are especially aware of the importance of sustainable computing practices. One key approach is the meticulous monitoring and optimization of energy consumption during computational processes. By adopting efficient training strategies, such as reducing the number of unnecessary training iterations and employing energy-efficient algorithms, startups can significantly lower their carbon footprint.
Additionally, the integration of renewable energy sources to power data centers plays a crucial role in minimizing environmental impact. AWS is determined to make the cloud the cleanest and the most energy-efficient way to run all our customers’ infrastructure and business. We have made significant progress over the years. For example, Amazon is the largest corporate purchaser of renewable energy in the world, every year since 2020. We’ve achieved our renewable energy goal to match all the electricity consumed across our operations—including our data centers—with 100% renewable energy, and we did this 7 years ahead of our original 2030 timeline.
Companies are also turning to carbon-aware computing principles, which involve scheduling computational tasks to coincide with periods of low carbon intensity on the grid. This practice means that the energy used for computing has a lower environmental impact. Implementing these strategies not only aligns with broader sustainability goals but also promotes cost efficiency and resource conservation. As the demand for advanced computational capabilities grows, climate tech startups are becoming vigilant in their commitment to sustainable practices so that their innovations contribute positively to both technological progress and environmental stewardship.
Conclusion
Amazon SageMaker HyperPod is emerging as a crucial tool for climate tech startups in their quest to develop innovative solutions to pressing environmental challenges. By providing scalable, efficient, and cost-effective infrastructure for training complex multimodal and multi- model architectures, SageMaker HyperPod enables these companies to process vast amounts of environmental data and create sophisticated predictive models. From Orbital Materials’ sustainable material discovery to Hum.AI’s advanced earth observation capabilities, SageMaker HyperPod is powering breakthroughs that were previously out of reach. As climate change continues to pose urgent global challenges, SageMaker HyperPod automated management of large-scale AI training clusters, coupled with its fault-tolerance and cost-optimization features, allows climate tech innovators to focus on their core mission rather than infrastructure management. By using SageMaker HyperPod, climate tech startups are not only building more efficient models—they’re accelerating the development of powerful new tools in our collective effort to address the global climate crisis.
About the authors
 Ilan Gleiser is a Principal GenAI Specialist at Amazon Web Services (AWS) on the WWSO Frameworks team, focusing on developing scalable artificial general intelligence architectures and optimizing foundation model training and inference. With a rich background in AI and machine learning, Ilan has published over 30 blog posts and delivered more than 100 prototypes globally over the last 5 years. Ilan holds a master’s degree in mathematical economics.
Ilan Gleiser is a Principal GenAI Specialist at Amazon Web Services (AWS) on the WWSO Frameworks team, focusing on developing scalable artificial general intelligence architectures and optimizing foundation model training and inference. With a rich background in AI and machine learning, Ilan has published over 30 blog posts and delivered more than 100 prototypes globally over the last 5 years. Ilan holds a master’s degree in mathematical economics.
 Lisbeth Kaufman is the Head of Climate Tech BD, Startups and Venture Capital at Amazon Web Services (AWS). Her mission is to help the best climate tech startups succeed and reverse the global climate crisis. Her team has technical resources, go-to-market support, and connections to help climate tech startups overcome obstacles and scale. Lisbeth worked on climate policy as an energy/environment/agriculture policy advisor in the U.S. Senate. She has a BA from Yale and an MBA from NYU Stern, where she was a Dean’s Scholar. Lisbeth helps climate tech founders with product, growth, fundraising, and making strategic connections to teams at AWS and Amazon.
Lisbeth Kaufman is the Head of Climate Tech BD, Startups and Venture Capital at Amazon Web Services (AWS). Her mission is to help the best climate tech startups succeed and reverse the global climate crisis. Her team has technical resources, go-to-market support, and connections to help climate tech startups overcome obstacles and scale. Lisbeth worked on climate policy as an energy/environment/agriculture policy advisor in the U.S. Senate. She has a BA from Yale and an MBA from NYU Stern, where she was a Dean’s Scholar. Lisbeth helps climate tech founders with product, growth, fundraising, and making strategic connections to teams at AWS and Amazon.
 Aman Shanbhag is an Associate Specialist Solutions Architect on the ML Frameworks team at Amazon Web Services (AWS), where he helps customers and partners with deploying ML training and inference solutions at scale. Before joining AWS, Aman graduated from Rice University with degrees in computer science, mathematics, and entrepreneurship.
Aman Shanbhag is an Associate Specialist Solutions Architect on the ML Frameworks team at Amazon Web Services (AWS), where he helps customers and partners with deploying ML training and inference solutions at scale. Before joining AWS, Aman graduated from Rice University with degrees in computer science, mathematics, and entrepreneurship.
 Rohit Talluri is a Generative AI GTM Specialist at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory.
Rohit Talluri is a Generative AI GTM Specialist at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory.
 Ankit Anand is a Senior Foundation Models Go-To-Market (GTM) Specialist at AWS. He partners with top generative AI model builders, strategic customers, and AWS Service Teams to enable the next generation of AI/ML workloads on AWS. Ankit’s experience includes product management expertise within the financial services industry for high-frequency/low-latency trading and business development for Amazon Alexa.
Ankit Anand is a Senior Foundation Models Go-To-Market (GTM) Specialist at AWS. He partners with top generative AI model builders, strategic customers, and AWS Service Teams to enable the next generation of AI/ML workloads on AWS. Ankit’s experience includes product management expertise within the financial services industry for high-frequency/low-latency trading and business development for Amazon Alexa.
Supercharge your development with Claude Code and Amazon Bedrock prompt caching
Prompt caching in Amazon Bedrock is now generally available, delivering performance and cost benefits for agentic AI applications. Coding assistants that process large codebases represent an ideal use case for prompt caching.
In this post, we’ll explore how to combine Amazon Bedrock prompt caching with Claude Code—a coding agent released by Anthropic that is now generally available. This powerful combination transforms your development workflow by delivering lightning-fast responses from reducing inference response latency, as well as lowering input token costs. You’ll discover how this makes AI-assisted coding not just more efficient, but also more economically viable for everyday development tasks.
What is Claude Code?

Claude Code is Anthropic’s AI coding assistant powered by Claude Sonnet 4. It operates directly in your terminal, your favorite IDEs such as VS Code and Jetbrains, and in the background with Claude Code SDK, understanding your project context and taking actions without requiring you to manually manipulate and add generated code to a project. Unlike traditional coding assistants, Claude Code can:
- Write code and fix bugs spanning multiple files across your codebase
- Answer questions about your code’s architecture and logic
- Execute and fix tests, linting, and other commands
- Search through git history, resolve merge conflicts, and create commits and PRs
- Operate all of your other command line tools, like AWS CLI, Terraform, and k8s
The most compelling aspect of Claude Code is how it integrates into your existing workflow. You simply point it to your project directory and interact with it using natural language commands. Claude Code also supports Model Context Protocol (MCP), allowing you to connect external tools and data sources directly to your terminal and customize its AI capabilities with your context.
To learn more, see Claude Code tutorials and Claude Code: Best practices for agentic coding.
Amazon Bedrock prompt caching for AI-assisted development
The prompt caching feature of Amazon Bedrock dramatically reduces both response times and costs when working with large context. Here’s how it works: When prompt caching is enabled, your agentic AI application (such as Claude Code) inserts cache checkpoint markers at specific points in your prompts. Amazon Bedrock then interprets these application-defined markers and creates cache checkpoints that save the entire model state after processing the preceding text. On subsequent requests, if your prompt reuses that same prefix, the model loads the cached state instead of recomputing.
In the context of Claude Code specifically, this means the application intelligently manages these cache points when processing your codebase, allowing Claude to “remember” previously analyzed code without incurring the full computational and financial cost of reprocessing it. When you ask multiple questions about the same code or iteratively refine solutions, Claude Code leverages these cache checkpoints to deliver faster responses while dramatically reducing token consumption and associated costs.
To learn more, see documentation for Amazon Bedrock prompt caching.
Solution overview: Try Claude Code with Amazon Bedrock prompt caching
Prerequisites
- An AWS account with access to Amazon Bedrock.
- Appropriate AWS Identity and Access Management (IAM) roles and permissions for Amazon Bedrock.
- Amazon Bedrock model access to Anthropic Claude Sonnet 4 on AWS Regions where prompt caching is currently supported such as us-east-1 and us-west-2.
- AWS command line interface (AWS CLI) configured with your AWS credentials.
Prompt caching is automatically turned on for supported models and AWS Regions.
Setting up Claude Code with Claude Sonnet 4 on Amazon Bedrock
After configuring AWS CLI with your credentials, follow these steps:
- In your terminal, execute the following commands:
# Install Claude Code npm install -g @anthropic-ai/claude-code # Configure for Amazon Bedrock export CLAUDE_CODE_USE_BEDROCK=1 export ANTHROPIC_MODEL='us.anthropic.claude-sonnet-4-20250514-v1:0' export ANTHROPIC_SMALL_FAST_MODEL='us.anthropic.claude-3-5-haiku-20241022-v1:0' # Launch Claude Code claude - Verify that Claude Code is running by checking for the Welcome to Claude Code! message in your terminal.

To learn more about how to configure Claude Code for Amazon Bedrock, see Connect to Amazon Bedrock.
Getting started with prompt caching
To get started, let’s experiment with a simple prompt.
- In Claude Code, execute the prompt:
build a basic text-based calculator - Review and respond to Claude Code’s requests:
- When prompted with questions like
Do you want to create calculator.py?select1. Yesto continue.
Example question:Do you want to create calculator.py? 1. Yes 2. Yes, and don't ask again for this session (shift+tab) 3. No, and tell Claude what to do differently (esc) - Carefully review each request before approving to maintain security.
- When prompted with questions like
- After Claude Code generates the calculator application, it will display execution instructions such as:
Run the calculator with: python3 calculator.py - Test the application by executing the instructed command above. Then, follow the on-screen prompts to perform calculations.
Claude Code automatically enables prompt caching to optimize performance and costs. To monitor token usage and costs, use the /cost command. You will receive a detailed breakdown similar to this:
/cost
⎿ Total cost: $0.0827
⎿ Total duration (API): 26.3s
⎿ Total duration (wall): 42.3s
⎿ Total code changes: 62 lines added, 0 lines removedThis output provides valuable insights into your session’s resource consumption, including total cost, API processing time, wall clock time, and code modifications.
Getting started with prompt caching
To understand the benefits of prompt caching, let’s try the same prompt without prompt caching for comparison:
- In the terminal, exit Claude Code by pressing
Ctrl+C. - To create a new project directory, run the command:
mkdir test-disable-prompt-caching; cd test-disable-prompt-caching - Disable prompt caching by setting an environment variable:
export DISABLE_PROMPT_CACHING=1 - Execute
claudeto run Claude Code. - Verify prompt caching is disabled by checking the terminal output. You should see
Prompt caching: offunder the Overrides (via env) section.
- Execute the prompt:
build a basic text-based calculator - After completion, execute
/costto view resource usage.
You will see a higher resource consumption compared to when prompt caching is enabled, even with a simple prompt:
/cost
⎿ Total cost: $0.1029
⎿ Total duration (API): 32s
⎿ Total duration (wall): 1m 17.5s
⎿ Total code changes: 57 lines added, 0 lines removedWithout prompt caching, each interaction incurs the full cost of processing your context.
Cleanup
To re-enable prompt caching, exit Claude Code and run unset DISABLE_PROMPT_CACHING before restarting Claude. Claude Code does not incur cost when you are not using it.
Prompt caching for complex codebases and efficient iteration
When working with complex codebases, prompt caching delivers significantly greater benefits than with simple prompts. For an illustrative example, consider the initial prompt: Develop a game similar to Pac-Man. This initial prompt generates the foundational project structure and files. As you refine the application with prompts such as Implement unique chase patterns for different ghosts, the coding agent must comprehend your entire codebase to be able to make targeted changes.
Without prompt caching, you force the model to reprocess thousands of tokens representing your code structure, class relationships, and existing implementations, with each iteration.
Prompt caching alleviates this redundancy by preserving your complex context, transforming your software development workflow with:
- Dramatically reduced token costs for repeated interactions with the same files
- Faster response times as Claude Code doesn’t need to reprocess your entire codebase
- Efficient development cycles as you iterate without incurring full costs each time
Prompt caching with Model Context Protocol (MCP)
Model Context Protocol (MCP) transforms your coding experience by connecting coding agents to your specific tools and information sources. You can connect Claude Code to MCP servers that integrate to your file systems, databases, development tools and other productivity tools. This transforms a generic coding assistant into a personalized assistant that can interact with your data and tools beyond your codebase, follow your organization’s best practices, accelerating your unique development processes and workflows.
When you build on AWS, you gain additional advantages by leveraging AWS open source MCP servers for code assistants that provide intelligent AWS documentation search, best-practice recommendations, and real-time cost visibility, analysis and insights – without leaving your software development workflow.
Amazon Bedrock prompt caching becomes essential when working with MCP, as it preserves complex context across multiple interactions. With MCP continuously enriching your prompts with external knowledge and tools, prompt caching alleviates the need to repeatedly process this expanded context, slashing costs by up to 90% and reducing latency by up to 85%. This optimization proves particularly valuable as your MCP servers deliver increasingly sophisticated context about your unique development environment, so you can rapidly iterate through complex coding challenges while maintaining relevant context for up to 5 minutes without performance penalties or additional costs.
Considerations when deploying Claude Code to your organization
With Claude Code now generally available, many customers are considering deployment options on AWS to take advantage of its coding capabilities. For deployments, consider your foundational architecture for security and governance:
Consider leveraging AWS IAM Identity Center, formerly AWS Single Sign On (SSO) to centrally govern identity and access to Claude Code. This verifies that only authorized developers have access. Additionally, it allows developers to access resources with temporary, role-based credentials, alleviating the need for static access keys and enhancing security. Prior to opening Claude Code, make sure that you configure AWS CLI to use an IAM Identity Center profile by using aws configure sso --profile <PROFILE_NAME>. Then, you login using the profile created aws sso login --profile <PROFILE_NAME>.
Consider implementing a generative AI gateway on AWS to track and attribute costs effectively across different teams or projects using inference profiles. For Claude Code to use a custom endpoint, configure the ANTHROPIC_BEDROCK_BASE_URL environment variable with the gateway endpoint. Note that the gateway should be a pass-through proxy, see example implementation with LiteLLM. To learn more about AI gateway solutions, contact your AWS account team.
Consider automated configuration of default environment variables. This includes the environment variables outlined in this post, such as CLAUDE_CODE_USE_BEDROCK, ANTHROPIC_MODEL, and ANTHROPIC_FAST_MODEL. This will configure Claude Code to automatically connect Bedrock, providing a consistent baseline for development across teams. To begin with, organizations can start by providing developers with self-service instructions.
Consider permissions, memory and MCP servers for your organization. Security teams can configure managed permissions for what Claude Code is and is not allowed to do, which cannot be overwritten by local configuration. In addition, you can configure memory across all projects which allows you to auto-add common bash commands files workflows, and style conventions to align with your organization’s preference. This can be done by deploying your CLAUDE.md file into an enterprise directory /<enterprise root>/CLAUDE.md or the user’s home directory ~/.claude/CLAUDE.md. Finally, we recommend that one central team configures MCP servers and checks a .mcp.json configuration into the codebase so that all users benefit.
To learn more, see Claude Code team setup documentation or contact your AWS account team.
Conclusion
In this post, you learned how Amazon Bedrock prompt caching can significantly enhance AI applications, with Claude Code’s agentic AI assistant serving as a powerful demonstration. By leveraging prompt caching, you can process large codebases more efficiently, helping to dramatically reduce costs and response times. With this technology you can have faster, more natural interactions with your code, allowing you to iterate rapidly with generative AI. You also learned about Model Context Protocol (MCP), and how the seamless integration of external tools lets you customize your AI assistant with specific context like documentation and web resources. Whether you’re tackling complex debugging, refactoring legacy systems, or developing new features, the combination of Amazon Bedrock’s prompt caching and AI coding agents like Claude Code offers a more responsive, cost-effective, and intelligent approach to software development.
Amazon Bedrock prompt caching is generally available with Claude 4 Sonnet and Claude 3.5 Haiku. To learn more, see prompt caching and Amazon Bedrock.
Anthropic Claude Code is now generally available. To learn more, see Claude Code overview and contact your AWS account team for guidance on deployment.
About the Authors
 Jonathan Evans is a Worldwide Solutions Architect for Generative AI at AWS, where he helps customers leverage cutting-edge AI technologies with Anthropic’s Claude models on Amazon Bedrock, to solve complex business challenges. With a background in AI/ML engineering and hands-on experience supporting machine learning workflows in the cloud, Jonathan is passionate about making advanced AI accessible and impactful for organizations of all sizes.
Jonathan Evans is a Worldwide Solutions Architect for Generative AI at AWS, where he helps customers leverage cutting-edge AI technologies with Anthropic’s Claude models on Amazon Bedrock, to solve complex business challenges. With a background in AI/ML engineering and hands-on experience supporting machine learning workflows in the cloud, Jonathan is passionate about making advanced AI accessible and impactful for organizations of all sizes.
 Daniel Wirjo is a Solutions Architect at AWS, focused on SaaS and AI startups. As a former startup CTO, he enjoys collaborating with founders and engineering leaders to drive growth and innovation on AWS. Outside of work, Daniel enjoys taking walks with a coffee in hand, appreciating nature, and learning new ideas.
Daniel Wirjo is a Solutions Architect at AWS, focused on SaaS and AI startups. As a former startup CTO, he enjoys collaborating with founders and engineering leaders to drive growth and innovation on AWS. Outside of work, Daniel enjoys taking walks with a coffee in hand, appreciating nature, and learning new ideas.
 Omar Elkharbotly is a Senior Cloud Support Engineer at AWS, specializing in Data, Machine Learning, and Generative AI solutions. With extensive experience in helping customers architect and optimize their cloud-based AI/ML/GenAI workloads, Omar works closely with AWS customers to solve complex technical challenges and implement best practices across the AWS AI/ML/GenAI service portfolio. He is passionate about helping organizations leverage the full potential of cloud computing to drive innovation in generative AI and machine learning.
Omar Elkharbotly is a Senior Cloud Support Engineer at AWS, specializing in Data, Machine Learning, and Generative AI solutions. With extensive experience in helping customers architect and optimize their cloud-based AI/ML/GenAI workloads, Omar works closely with AWS customers to solve complex technical challenges and implement best practices across the AWS AI/ML/GenAI service portfolio. He is passionate about helping organizations leverage the full potential of cloud computing to drive innovation in generative AI and machine learning.
 Gideon Teo is a FSI Solution Architect at AWS in Melbourne, where he brings specialised expertise in Amazon SageMaker and Amazon Bedrock. With a deep passion for both traditional AI/ML methodologies and the emerging field of Generative AI, he helps financial institutions leverage cutting-edge technologies to solve complex business challenges. Outside of work, he cherishes quality time with friends and family, and continuously expands his knowledge across diverse technology domains.
Gideon Teo is a FSI Solution Architect at AWS in Melbourne, where he brings specialised expertise in Amazon SageMaker and Amazon Bedrock. With a deep passion for both traditional AI/ML methodologies and the emerging field of Generative AI, he helps financial institutions leverage cutting-edge technologies to solve complex business challenges. Outside of work, he cherishes quality time with friends and family, and continuously expands his knowledge across diverse technology domains.