Recent research demonstrated that training large language models involves memorization of a significant fraction of training data. Such memorization can lead to privacy violations when training on sensitive user data and thus motivates the study of data memorization’s role in learning.
In this work, we develop a general approach for proving lower bounds on excess data memorization, that relies on a new connection between strong data processing inequalities and data memorization. We then demonstrate that several simple and natural binary classification problems exhibit a trade-off between the…Apple Machine Learning Research
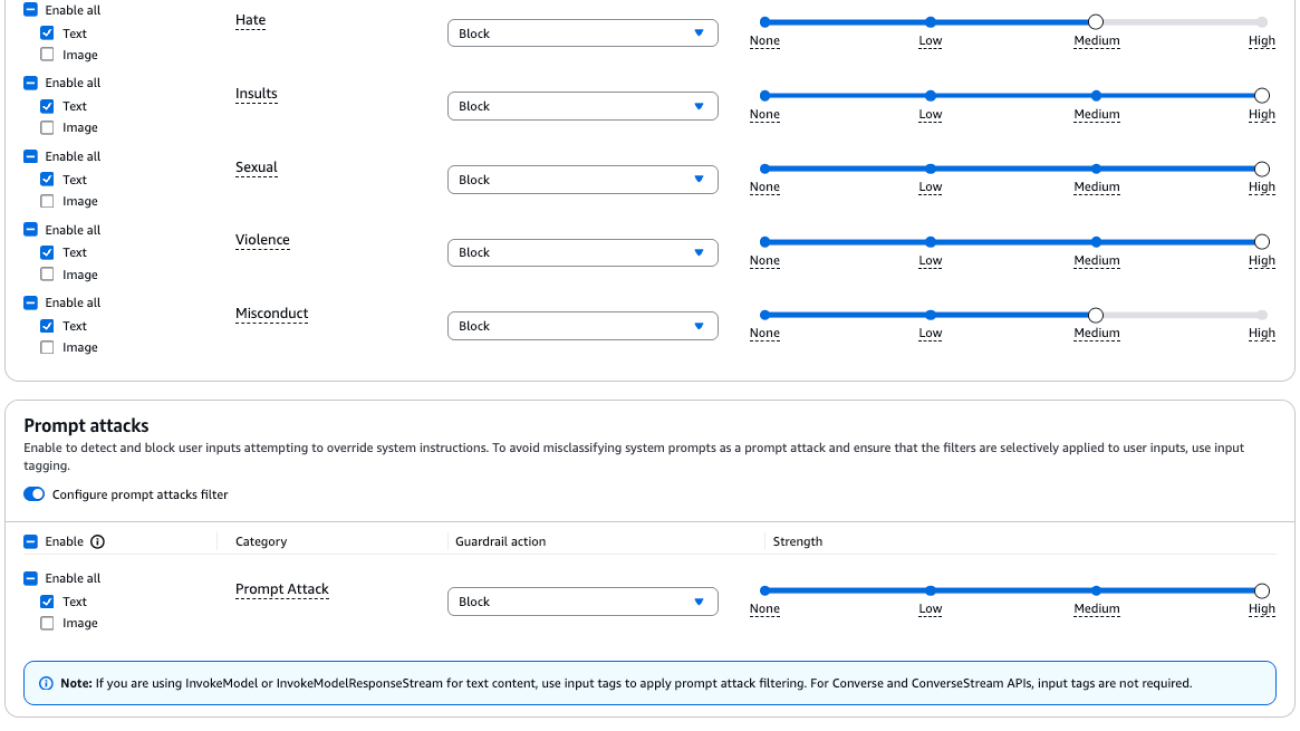
Tailor responsible AI with new safeguard tiers in Amazon Bedrock Guardrails
Amazon Bedrock Guardrails provides configurable safeguards to help build trusted generative AI applications at scale. It provides organizations with integrated safety and privacy safeguards that work across multiple foundation models (FMs), including models available in Amazon Bedrock, as well as models hosted outside Amazon Bedrock from other model providers and cloud providers. With the standalone ApplyGuardrail API, Amazon Bedrock Guardrails offers a model-agnostic and scalable approach to implementing responsible AI policies for your generative AI applications. Guardrails currently offers six key safeguards: content filters, denied topics, word filters, sensitive information filters, contextual grounding checks, and Automated Reasoning checks (preview), to help prevent unwanted content and align AI interactions with your organization’s responsible AI policies.
As organizations strive to implement responsible AI practices across diverse use cases, they face the challenge of balancing safety controls with varying performance and language requirements across different applications, making a one-size-fits-all approach ineffective. To address this, we’ve introduced safeguard tiers for Amazon Bedrock Guardrails, so you can choose appropriate safeguards based on your specific needs. For instance, a financial services company can implement comprehensive, multi-language protection for customer-facing AI assistants while using more focused, lower-latency safeguards for internal analytics tools, making sure each application upholds responsible AI principles with the right level of protection without compromising performance or functionality.
In this post, we introduce the new safeguard tiers available in Amazon Bedrock Guardrails, explain their benefits and use cases, and provide guidance on how to implement and evaluate them in your AI applications.
Solution overview
Until now, when using Amazon Bedrock Guardrails, you were provided with a single set of the safeguards associated to specific AWS Regions and a limited set of languages supported. The introduction of safeguard tiers in Amazon Bedrock Guardrails provides three key advantages for implementing AI safety controls:
- A tier-based approach that gives you control over which guardrail implementations you want to use for content filters and denied topics, so you can select the appropriate protection level for each use case. We provide more details about this in the following sections.
- Cross-Region Inference Support (CRIS) for Amazon Bedrock Guardrails, so you can use compute capacity across multiple Regions, achieving better scaling and availability for your guardrails. With this, your requests get automatically routed during guardrail policy evaluation to the optimal Region within your geography, maximizing available compute resources and model availability. This helps maintain guardrail performance and reliability when demand increases. There’s no additional cost for using CRIS with Amazon Bedrock Guardrails, and you can select from specific guardrail profiles for controlling model versioning and future upgrades.
- Advanced capabilities as a configurable tier option for use cases where more robust protection or broader language support are critical priorities, and where you can accommodate a modest latency increase.
Safeguard tiers are applied at the guardrail policy level, specifically for content filters and denied topics. You can tailor your protection strategy for different aspects of your AI application. Let’s explore the two available tiers:
- Classic tier (default):
- Maintains the existing behavior of Amazon Bedrock Guardrails
- Limited language support: English, French, and Spanish
- Does not require CRIS for Amazon Bedrock Guardrails
- Optimized for lower-latency applications
- Standard tier:
- Provided as a new capability that you can enable for existing or new guardrails
- Multilingual support for more than 60 languages
- Enhanced robustness against prompt typos and manipulated inputs
- Enhanced prompt attack protection covering modern jailbreak and prompt injection techniques, including token smuggling, AutoDAN, and many-shot, among others
- Enhanced topic detection with improved understanding and handling of complex topics
- Requires the use of CRIS for Amazon Bedrock Guardrails and might have a modest increase in latency profile compared to the Classic tier option
You can select each tier independently for content filters and denied topics policies, allowing for mixed configurations within the same guardrail, as illustrated in the following hierarchy. With this flexibility, companies can implement the right level of protection for each specific application.
- Policy: Content filters
- Tier: Classic or Standard
- Policy: Denied topics
- Tier: Classic or Standard
- Other policies: Word filters, sensitive information filters, contextual grounding checks, and Automated Reasoning checks (preview)
To illustrate how these tiers can be applied, consider a global financial services company deploying AI in both customer-facing and internal applications:
- For their customer service AI assistant, they might choose the Standard tier for both content filters and denied topics, to provide comprehensive protection across many languages.
- For internal analytics tools, they could use the Classic tier for content filters prioritizing low latency, while implementing the Standard tier for denied topics to provide robust protection against sensitive financial information disclosure.
You can configure the safeguard tiers for content filters and denied topics in each guardrail through the AWS Management Console, or programmatically through the Amazon Bedrock SDK and APIs. You can use a new or existing guardrail. For information on how to create or modify a guardrail, see Create your guardrail.
Your existing guardrails are automatically set to the Classic tier by default to make sure you have no impact on your guardrails’ behavior.
Quality enhancements with the Standard tier
According to our tests, the new Standard tier improves harmful content filtering recall by more than 15% with a more than 7% gain in balanced accuracy compared to the Classic tier. A key differentiating feature of the new Standard tier is its multilingual support, maintaining strong performance with over 78% recall and over 88% balanced accuracy for the most common 14 languages.The enhancements in protective capabilities extend across several other aspects. For example, content filters for prompt attacks in the Standard tier show a 30% improvement in recall and 16% gain in balanced accuracy compared to the Classic tier, while maintaining a lower false positive rate. For denied topic detection, the new Standard tier delivers a 32% increase in recall, resulting in an 18% improvement in balanced accuracy.These substantial evolutions in detection capabilities for Amazon Bedrock Guardrails, combined with consistently low false positive rates and robust multilingual performance, also represent a significant advancement in content protection technology compared to other commonly available solutions. The multilingual improvements are particularly noteworthy, with the new Standard tier in Amazon Bedrock Guardrails showing consistent performance gains of 33–49% in recall across different language evaluations compared to other competitors’ options.
Benefits of safeguard tiers
Different AI applications have distinct safety requirements based on their audience, content domain, and geographic reach. For example:
- Customer-facing applications often require stronger protection against potential misuse compared to internal applications
- Applications serving global customers need guardrails that work effectively across many languages
- Internal enterprise tools might prioritize controlling specific topics in just a few primary languages
The combination of the safeguard tiers with CRIS for Amazon Bedrock Guardrails also addresses various operational needs with practical benefits that go beyond feature differences:
- Independent policy evolution – Each policy (content filters or denied topics) can evolve at its own pace without disrupting the entire guardrail system. You can configure these with specific guardrail profiles in CRIS for controlling model versioning in the models powering your guardrail policies.
- Controlled adoption – You decide when and how to adopt new capabilities, maintaining stability for production applications. You can continue to use Amazon Bedrock Guardrails with your previous configurations without changes and only move to the new tiers and CRIS configurations when you consider it appropriate.
- Resource efficiency – You can implement enhanced protections only where needed, balancing security requirements with performance considerations.
- Simplified migration path – When new capabilities become available, you can evaluate and integrate them gradually by policy area rather than facing all-or-nothing choices. This also simplifies testing and comparison mechanisms such as A/B testing or blue/green deployments for your guardrails.
This approach helps organizations balance their specific protection requirements with operational considerations in a more nuanced way than a single-option system could provide.
Configure safeguard tiers on the Amazon Bedrock console
On the Amazon Bedrock console, you can configure the safeguard tiers for your guardrail in the Content filters tier or Denied topics tier sections by selecting your preferred tier.


Use of the new Standard tier requires setting up cross-Region inference for Amazon Bedrock Guardrails, choosing the guardrail profile of your choice.

Configure safeguard tiers using the AWS SDK
You can also configure the guardrail’s tiers using the AWS SDK. The following is an example to get started with the Python SDK:
Within a given guardrail, the content filter and denied topic policies can be configured with its own tier independently, giving you granular control over how guardrails behave. For example, you might choose the Standard tier for content filtering while keeping denied topics in the Classic tier, based on your specific requirements.
For migrating existing guardrails’ configurations to use the Standard tier, add the sections highlighted in the preceding example for crossRegionConfig and tierConfig to your current guardrail definition. You can do this using the UpdateGuardrail API, or create a new guardrail with the CreateGuardrail API.
Evaluating your guardrails
To thoroughly evaluate your guardrails’ performance, consider creating a test dataset that includes the following:
- Safe examples – Content that should pass through guardrails
- Harmful examples – Content that should be blocked
- Edge cases – Content that tests the boundaries of your policies
- Examples in multiple languages – Especially important when using the Standard tier
You can also rely on openly available datasets for this purpose. Ideally, your dataset should be labeled with the expected response for each case for assessing accuracy and recall of your guardrails.
With your dataset ready, you can use the Amazon Bedrock ApplyGuardrail API as shown in the following example to efficiently test your guardrail’s behavior for user inputs without invoking FMs. This way, you can save the costs associated with the large language model (LLM) response generation.
Later, you can repeat the process for the outputs of the LLMs if needed. For this, you can use the ApplyGuardrail API if you want an independent evaluation for models in AWS or outside in another provider, or you can directly use the Converse API if you intend to use models in Amazon Bedrock. When using the Converse API, the inputs and outputs are evaluated with the same invocation request, optimizing latency and reducing coding overheads.
Because your dataset is labeled, you can directly implement a mechanism for assessing the accuracy, recall, and potential false negatives or false positives through the use of libraries like SKLearn Metrics:
Alternatively, if you don’t have labeled data or your use cases have subjective responses, you can also rely on mechanisms such as LLM-as-a-judge, where you pass the inputs and guardrails’ evaluation outputs to an LLM for assessing a score based on your own predefined criteria. For more information, see Automate building guardrails for Amazon Bedrock using test-drive development.
Best practices for implementing tiers
We recommend considering the following aspects when configuring your tiers for Amazon Bedrock Guardrails:
- Start with staged testing – Test both tiers with a representative sample of your expected inputs and responses before making broad deployment decisions.
- Consider your language requirements – If your application serves users in multiple languages, the Standard tier’s expanded language support might be essential.
- Balance safety and performance – Evaluate both the accuracy improvements and latency differences to make informed decisions. Consider if you can afford a few additional milliseconds of latency for improved robustness with the Standard tier or prefer a latency-optimized option for more straight forward evaluations with the Classic tier.
- Use policy-level tier selection – Take advantage of the ability to select different tiers for different policies to optimize your guardrails. You can choose separate tiers for content filters and denied topics, while combining with the rest of the policies and features available in Amazon Bedrock Guardrails.
- Remember cross-Region requirements – The Standard tier requires cross-Region inference, so make sure your architecture and compliance requirements can accommodate this. With CRIS, your request originates from the Region where your guardrail is deployed, but it might be served from a different Region from the ones included in the guardrail inference profile for optimizing latency and availability.
Conclusion
The introduction of safeguard tiers in Amazon Bedrock Guardrails represents a significant step forward in our commitment to responsible AI. By providing flexible, powerful, and evolving safety tools for generative AI applications, we’re empowering organizations to implement AI solutions that are not only innovative but also ethical and trustworthy. This capabilities-based approach enables you to tailor your responsible AI practices to each specific use case. You can now implement the right level of protection for different applications while creating a path for continuous improvement in AI safety and ethics.The new Standard tier delivers significant improvements in multilingual support and detection accuracy, making it an ideal choice for many applications, especially those serving diverse global audiences or requiring enhanced protection. This aligns with responsible AI principles by making sure AI systems are fair and inclusive across different languages and cultures. Meanwhile, the Classic tier remains available for use cases prioritizing low latency or those with simpler language requirements, allowing organizations to balance performance with protection as needed.
By offering these customizable protection levels, we’re supporting organizations in their journey to develop and deploy AI responsibly. This approach helps make sure that AI applications are not only powerful and efficient but also align with organizational values, comply with regulations, and maintain user trust.
To learn more about safeguard tiers in Amazon Bedrock Guardrails, refer to Detect and filter harmful content by using Amazon Bedrock Guardrails, or visit the Amazon Bedrock console to create your first tiered guardrail.
About the Authors
 Koushik Kethamakka is a Senior Software Engineer at AWS, focusing on AI/ML initiatives. At Amazon, he led real-time ML fraud prevention systems for Amazon.com before moving to AWS to lead development of AI/ML services like Amazon Lex and Amazon Bedrock. His expertise spans product and system design, LLM hosting, evaluations, and fine-tuning. Recently, Koushik’s focus has been on LLM evaluations and safety, leading to the development of products like Amazon Bedrock Evaluations and Amazon Bedrock Guardrails. Prior to joining Amazon, Koushik earned his MS from the University of Houston.
Koushik Kethamakka is a Senior Software Engineer at AWS, focusing on AI/ML initiatives. At Amazon, he led real-time ML fraud prevention systems for Amazon.com before moving to AWS to lead development of AI/ML services like Amazon Lex and Amazon Bedrock. His expertise spans product and system design, LLM hosting, evaluations, and fine-tuning. Recently, Koushik’s focus has been on LLM evaluations and safety, leading to the development of products like Amazon Bedrock Evaluations and Amazon Bedrock Guardrails. Prior to joining Amazon, Koushik earned his MS from the University of Houston.
 Hang Su is a Senior Applied Scientist at AWS AI. He has been leading the Amazon Bedrock Guardrails Science team. His interest lies in AI safety topics, including harmful content detection, red-teaming, sensitive information detection, among others.
Hang Su is a Senior Applied Scientist at AWS AI. He has been leading the Amazon Bedrock Guardrails Science team. His interest lies in AI safety topics, including harmful content detection, red-teaming, sensitive information detection, among others.
 Shyam Srinivasan is on the Amazon Bedrock product team. He cares about making the world a better place through technology and loves being part of this journey. In his spare time, Shyam likes to run long distances, travel around the world, and experience new cultures with family and friends.
Shyam Srinivasan is on the Amazon Bedrock product team. He cares about making the world a better place through technology and loves being part of this journey. In his spare time, Shyam likes to run long distances, travel around the world, and experience new cultures with family and friends.
 Aartika Sardana Chandras is a Senior Product Marketing Manager for AWS Generative AI solutions, with a focus on Amazon Bedrock. She brings over 15 years of experience in product marketing, and is dedicated to empowering customers to navigate the complexities of the AI lifecycle. Aartika is passionate about helping customers leverage powerful AI technologies in an ethical and impactful manner.
Aartika Sardana Chandras is a Senior Product Marketing Manager for AWS Generative AI solutions, with a focus on Amazon Bedrock. She brings over 15 years of experience in product marketing, and is dedicated to empowering customers to navigate the complexities of the AI lifecycle. Aartika is passionate about helping customers leverage powerful AI technologies in an ethical and impactful manner.
 Satveer Khurpa is a Sr. WW Specialist Solutions Architect, Amazon Bedrock at Amazon Web Services, specializing in Amazon Bedrock security. In this role, he uses his expertise in cloud-based architectures to develop innovative generative AI solutions for clients across diverse industries. Satveer’s deep understanding of generative AI technologies and security principles allows him to design scalable, secure, and responsible applications that unlock new business opportunities and drive tangible value while maintaining robust security postures.
Satveer Khurpa is a Sr. WW Specialist Solutions Architect, Amazon Bedrock at Amazon Web Services, specializing in Amazon Bedrock security. In this role, he uses his expertise in cloud-based architectures to develop innovative generative AI solutions for clients across diverse industries. Satveer’s deep understanding of generative AI technologies and security principles allows him to design scalable, secure, and responsible applications that unlock new business opportunities and drive tangible value while maintaining robust security postures.
 Antonio Rodriguez is a Principal Generative AI Specialist Solutions Architect at Amazon Web Services. He helps companies of all sizes solve their challenges, embrace innovation, and create new business opportunities with Amazon Bedrock. Apart from work, he loves to spend time with his family and play sports with his friends.
Antonio Rodriguez is a Principal Generative AI Specialist Solutions Architect at Amazon Web Services. He helps companies of all sizes solve their challenges, embrace innovation, and create new business opportunities with Amazon Bedrock. Apart from work, he loves to spend time with his family and play sports with his friends.
We’re improving Ask Photos and bringing it to more Google Photos users.
 We love seeing how you’re using Ask Photos in early access, like asking “suggest photos that’d make great phone backgrounds” or “what did I eat on my trip to Barcelona?”…Read More
We love seeing how you’re using Ask Photos in early access, like asking “suggest photos that’d make great phone backgrounds” or “what did I eat on my trip to Barcelona?”…Read More

PadChest-GR: A bilingual grounded radiology reporting benchmark for chest X-rays

In our ever-evolving journey to enhance healthcare through technology, we’re announcing a unique new benchmark for grounded radiology report generation—PadChest-GR (opens in new tab). The world’s first multimodal, bilingual sentence-level radiology report dataset, developed by the University of Alicante with Microsoft Research, University Hospital Sant Joan d’Alacant and MedBravo, is set to redefine how AI and radiologists interpret radiological images. Our work demonstrates how collaboration between humans and AI can create powerful feedback loops—where new datasets drive better AI models, and those models, in turn, inspire richer datasets. We’re excited to share this progress in NEJM AI, highlighting both the clinical relevance and research excellence of this initiative.
A new frontier in radiology report generation
It is estimated that over half of people visiting hospitals have radiology scans that must be interpreted by a clinical professional. Traditional radiology reports often condense multiple findings into unstructured narratives. In contrast, grounded radiology reporting demands that each finding be described and localized individually.
This can mitigate the risk of AI fabrications and enable new interactive capabilities that enhance clinical and patient interpretability. PadChest-GR is the first bilingual dataset to address this need with 4,555 chest X-ray studies complete with Spanish and English sentence-level descriptions and precise spatial (bounding box) annotations for both positive and negative findings. It is the first public benchmark that enables us to evaluate generation of fully grounded radiology reports in chest X-rays.

This benchmark isn’t standing alone—it plays a critical role in powering our state-of-the-art multimodal report generation model, MAIRA-2. Leveraging the detailed annotations of PadChest-GR, MAIRA-2 represents our commitment to building more interpretable and clinically useful AI systems. You can explore our work on MAIRA-2 on our project web page, including recent user research conducted with clinicians in healthcare settings.
PadChest-GR is a testament to the power of collaboration. Aurelia Bustos at MedBravo and Antonio Pertusa at the University of Alicante published the original PadChest dataset (opens in new tab) in 2020, with the help of Jose María Salinas from Hospital San Juan de Alicante and María de la Iglesia Vayá from the Center of Excellence in Biomedical Imaging at the Ministry of Health in Valencia, Spain. We started to look at PadChest and were deeply impressed by the scale, depth, and diversity of the data.
As we worked more closely with the dataset, we realized the opportunity to develop this for grounded radiology reporting research and worked with the team at the University of Alicante to determine how to approach this together. Our complementary expertise was a nice fit. At Microsoft Research, our mission is to push the boundaries of medical AI through innovative, data-driven solutions. The University of Alicante, with its deep clinical expertise, provided critical insights that greatly enriched the dataset’s relevance and utility. The result of this collaboration is the PadChest-GR dataset.
A significant enabler of our annotation process was Centaur Labs. The team of senior and junior radiologists from the University Hospital Sant Joan d’Alacant, coordinated by Joaquin Galant, used this HIPAA-compliant labeling platform to perform rigorous study-level quality control and bounding box annotations. The annotation protocol implemented ensured that each annotation was accurate and consistent, forming the backbone of a dataset designed for the next generation of grounded radiology report generation models.
Accelerating PadChest-GR dataset annotation with AI
Our approach integrates advanced large language models with comprehensive manual annotation:
Data Selection & Processing: Leveraging Microsoft Azure OpenAI Service (opens in new tab) with GPT-4, we extracted sentences describing individual positive and negative findings from raw radiology reports, translated them from Spanish to English, and linked each sentence to the existing expert labels from PadChest. This was done for a selected subset of the full PadChest dataset, carefully curated to reflect a realistic distribution of clinically relevant findings.
Manual Quality Control & Annotation: The processed studies underwent meticulous quality checks on the Centaur Labs platform by radiologist from Hospital San Juan de Alicante. Each positive finding was then annotated with bounding boxes to capture critical spatial information.
Standardization & Integration: All annotations were harmonized into coherent grounded reports, preserving the structure and context of the original findings while enhancing interpretability.

Impact and future directions
PadChest-GR not only sets a new benchmark for grounded radiology reporting, but also serves as the foundation for our MAIRA-2 model, which already showcases the potential of highly interpretable AI in clinical settings. While we developed PadChest-GR to help train and validate our own models, we believe the research community will greatly benefit from this dataset for many years to come. We look forward to seeing the broader research community build on this—improving grounded reporting AI models and using PadChest-GR as a standard for evaluation. We believe that by fostering open collaboration and sharing our resources, we can accelerate progress in medical imaging AI and ultimately improve patient care together with the community.
The collaboration between Microsoft Research and the University of Alicante highlights the transformative power of working together across disciplines. With our publication in NEJM-AI and the integral role of PadChest-GR in the development of MAIRA-2 (opens in new tab) and RadFact (opens in new tab), we are excited about the future of AI-empowered radiology. We invite researchers and industry experts to explore PadChest-GR and MAIRA-2, contribute innovative ideas, and join us in advancing the field of grounded radiology reporting.
Papers already using PadChest-GR:
- [2406.04449] MAIRA-2: Grounded Radiology Report Generation (opens in new tab)
- RadVLM: A Multitask Conversational Vision-Language Model for Radiology (opens in new tab)
- Enhancing Abnormality Grounding for Vision Language Models with Knowledge Descriptions (opens in new tab)
- Visual Prompt Engineering for Vision Language Models in Radiology (opens in new tab)
For further details or to download PadChest-GR, please visit the BIMCV PadChest-GR Project (opens in new tab).
Models in the Azure Foundry that can do Grounded Reporting:
- How to deploy and use CXRReportGen healthcare AI model with Azure AI Foundry – Azure AI Foundry | Microsoft Learn (opens in new tab)
- Healthcare Orchestrator – Healthcare agent service | Microsoft Learn (opens in new tab)
Acknowledgement
- Authors: Daniel C. Castro (opens in new tab), Aurelia Bustos (opens in new tab), Shruthi Bannur (opens in new tab), Stephanie L. Hyland (opens in new tab), Kenza Bouzid (opens in new tab), Maria Teodora Wetscherek (opens in new tab), Maria Dolores Sánchez-Valverde (opens in new tab), Lara Jaques-Pérez (opens in new tab), Lourdes Pérez-Rodríguez (opens in new tab), Kenji Takeda (opens in new tab), José María Salinas (opens in new tab), Javier Alvarez-Valle (opens in new tab), Joaquín Galant Herrero (opens in new tab), Antonio Pertusa (opens in new tab)
- MSR Health Futures UK: Hannah Richardson, Valentina Salvatelli, Harshita Sharma, Sam Bond-Taylor, Max Ilse, Fernando Perez-Garcia, Anton Schwaighofer, Jonathan Carlson
- MSR Flow: Kenji Takeda, Evelyn Viegas, Ashley Llorens
- HLS: Matthew Lungren, Naiteek Sangani, Shrey Jain, Ivan Tarapov, Will Guyman, Mert Oez, Chris Burt, David Ardman
The post PadChest-GR: A bilingual grounded radiology reporting benchmark for chest X-rays appeared first on Microsoft Research.

Structured data response with Amazon Bedrock: Prompt Engineering and Tool Use
Generative AI is revolutionizing industries by streamlining operations and enabling innovation. While textual chat interactions with GenAI remain popular, real-world applications often depend on structured data for APIs, databases, data-driven workloads, and rich user interfaces. Structured data can also enhance conversational AI, enabling more reliable and actionable outputs. A key challenge is that LLMs (Large Language Models) are inherently unpredictable, which makes it difficult for them to produce consistently structured outputs like JSON. This challenge arises because their training data mainly includes unstructured text, such as articles, books, and websites, with relatively few examples of structured formats. As a result, LLMs can struggle with precision when generating JSON outputs, which is crucial for seamless integration into existing APIs and databases. Models vary in their ability to support structured responses, including recognizing data types and managing complex hierarchies effectively. These capabilities can make a difference when choosing the right model.
This blog demonstrates how Amazon Bedrock, a managed service for securely accessing top AI models, can help address these challenges by showcasing two alternative options:
- Prompt Engineering: A straightforward approach to shaping structured outputs using well-crafted prompts.
- Tool Use with the Bedrock Converse API: An advanced method that enables better control, consistency, and native JSON schema integration.
We will use a customer review analysis example to demonstrate how Bedrock generates structured outputs, such as sentiment scores, with simplified Python code.
Building a prompt engineering solution
This section will demonstrate how to use prompt engineering effectively to generate structured outputs using Amazon Bedrock. Prompt engineering involves crafting precise input prompts to guide large language models (LLMs) in producing consistent and structured responses. It is a fundamental technique for developing Generative AI applications, particularly when structured outputs are required.Here are the five key steps we will follow:
- Configure the Bedrock client and runtime parameters.
- Create a JSON schema for structured outputs.
- Craft a prompt and guide the model with clear instructions and examples.
- Add a customer review as input data to analyse.
- Invoke Bedrock, call the model, and process the response.
While we demonstrate customer review analysis to generate a JSON output, these methods can also be used with other formats like XML or CSV.
Step 1: Configure Bedrock
To begin, we’ll set up some constants and initialize a Python Bedrock client connection object using the Python Boto3 SDK for Bedrock runtime, which facilitates interaction with Bedrock:

The REGION specifies the AWS region for model execution, while the MODEL_ID identifies the specific Bedrock model. The TEMPERATURE constant controls the output randomness, where higher values increase creativity, and lower values maintain precision, such as when generating structured output. MAX_TOKENS determines the output length, balancing cost-efficiency and data completeness.
Step 2: Define the Schema
Defining a schema is essential for facilitating structured and predictable model outputs, maintaining data integrity, and enabling seamless API integration. Without a well-defined schema, models may generate inconsistent or incomplete responses, leading to errors in downstream applications. The JSON standard schema used in the code below serves as a blueprint for structured data generation, guiding the model on how to format its output with explicit instructions.
Let’s create a JSON schema for customer reviews with three required fields: reviewId (string, max 50 chars), sentiment (number, -1 to 1), and summary (string, max 200 chars).

Step 3: Craft the Prompt text
To generate consistent, structured, and accurate responses, prompts must be clear and well-structured, as LLMs rely on precise input to produce reliable outputs. Poorly designed prompts can lead to ambiguity, errors, or formatting issues, disrupting structured workflows, so we follow these best practices:
- Clearly outline the AI’s role and objectives to avoid ambiguity.
- Divide tasks into smaller, manageable numbered steps for clarity.
- Indicate that a JSON schema will be provided (see Step 5 below) to maintain a consistent and valid structure.
- Use one-shot prompting with a sample output to guide the model; add more examples if needed for consistency, but avoid too many, as they may limit the model’s ability to handle new inputs.
- Define how to handle missing or invalid data.

Step 4: Integrate Input Data
For demonstration purposes, we’ll include a review text in the prompt as a Python variable:

Separating the input data with <input> tags improve readability and clarity, making it straightforward to identify and reference. This hardcoded input simulates real-world data integration. For production use, you might dynamically populate input data from APIs or user submissions.
Step 5: Call Bedrock
In this section, we construct a Bedrock request by defining a body object that includes the JSON schema, prompt, and input review data from previous steps. This structured request makes sure the model receives clear instructions, adheres to a predefined schema, and processes sample input data correctly. Once the request is prepared, we invoke Amazon Bedrock to generate a structured JSON response.

We reuse the MAX_TOKENS, TEMPERATURE, and MODEL_ID constants defined in Step 1. The body object has essential inference configurations like anthropic_version for model compatibility and the messages array, which includes a single message to provide the model with task instructions, the schema, and the input data. The role defines the “speaker” in the interaction context, with user value representing the program sending the request. Alternatively, we could simplify the input by combining instructions, schema, and data into one text prompt, which is straightforward to manage but less modular.
Finally, we use the client.invoke_model method to send the request. After invoking, the model processes the request, and the JSON data must be properly (not explained here) extracted from the Bedrock response. For example:

Tool Use with the Amazon Bedrock Converse API
In the previous chapter, we explored a solution using Bedrock Prompt Engineering. Now, let’s look at an alternative approach for generating structured responses with Bedrock.
We will extend the previous solution by using the Amazon Bedrock Converse API, a consistent interface designed to facilitate multi-turn conversations with Generative AI models. The API abstracts model-specific configurations, including inference parameters, simplifying integration.
A key feature of the Converse API is Tool Use (also known as Function Calling), which enables the model to execute external tools, such as calling an external API. This method supports standard JSON schema integration directly into tool definitions, facilitating output alignment with predefined formats. Not all Bedrock models support Tool Use, so make sure you check which models are compatible with these feature.
Building on the previously defined data, the following code provides a straightforward example of Tool Use tailored to our curstomer review use case:

In this code the tool_list defines a custom customer review analysis tool with its input schema and purpose, while the messages provide the earlier defined instructions and input data. Unlike in the previous prompt engineering example we used the earlier defined JSON schema in the definition of a tool. Finally, the client.converse call combines these components, specifying the tool to use and inference configurations, resulting in outputs tailored to the given schema and task. After exploring Prompt Engineering and Tool Use in Bedrock solutions for structured response generation, let’s now evaluate how different foundation models perform across these approaches.
Test Results: Claude Models on Amazon Bedrock
Understanding the capabilities of foundation models in structured response generation is essential for maintaining reliability, optimizing performance, and building scalable, future-proof Generative AI applications with Amazon Bedrock. To evaluate how well models handle structured outputs, we conducted extensive testing of Anthropic’s Claude models, comparing prompt-based and tool-based approaches across 1,000 iterations per model. Each iteration processed 100 randomly generated items, providing broad test coverage across different input variations.The examples shown earlier in this blog are intentionally simplified for demonstration purposes, where Bedrock performed seamlessly with no issues. To better assess the models under real-world challenges, we used a more complex schema that featured nested structures, arrays, and diverse data types to identify edge cases and potential issues. The outputs were validated for adherence to the JSON format and schema, maintaining consistency and accuracy. The following diagram summarizes the results, showing the number of successful, valid JSON responses for each model across the two demonstrated approaches: Prompt Engineering and Tool Use.

The results demonstrated that all models achieved over 93% success across both approaches, with Tool Use methods consistently outperforming prompt-based ones. While the evaluation was conducted using a highly complex JSON schema, simpler schemas result in significantly fewer issues, often nearly none. Future updates to the models are expected to further enhance performance.
Final Thoughts
In conclusion, we demonstrated two methods for generating structured responses with Amazon Bedrock: Prompt Engineering and Tool Use with the Converse API. Prompt Engineering is flexible, works with Bedrock models (including those without Tool Use support), and handles various schema types (e.g., Open API schemas), making it a great starting point. However, it can be fragile, requiring exact prompts and struggling with complex needs. On the other hand, Tool Use offers greater reliability, consistent results, seamless API integration, and runtime validation of JSON schema for enhanced control.
For simplicity, we did not demonstrate a few areas in this blog. Other techniques for generating structured responses include using models with built-in support for configurable response formats, such as JSON, when invoking models, or leveraging constraint decoding techniques with third-party libraries like LMQL. Additionally, generating structured data with GenAI can be challenging due to issues like invalid JSON, missing fields, or formatting errors. To maintain data integrity and handle unexpected outputs or API failures, effective error handling, thorough testing, and validation are essential.
To try the Bedrock techniques demonstrated in this blog, follow the steps to Run example Amazon Bedrock API requests through the AWS SDK for Python (Boto3). With pay-as-you-go pricing, you’re only charged for API calls, so little to no cleanup is required after testing. For more details on best practices, refer to the Bedrock prompt engineering guidelines and model-specific documentation, such as Anthropic’s best practices.
Structured data is key to leveraging Generative AI in real-world scenarios like APIs, data-driven workloads, and rich user interfaces beyond text-based chat. Start using Amazon Bedrock today to unlock its potential for reliable structured responses.
About the authors
 Adam Nemeth is a Senior Solutions Architect at AWS, where he helps global financial customers embrace cloud computing through architectural guidance and technical support. With over 24 years of IT expertise, Adam previously worked at UBS before joining AWS. He lives in Switzerland with his wife and their three children.
Adam Nemeth is a Senior Solutions Architect at AWS, where he helps global financial customers embrace cloud computing through architectural guidance and technical support. With over 24 years of IT expertise, Adam previously worked at UBS before joining AWS. He lives in Switzerland with his wife and their three children.
 Dominic Searle is a Senior Solutions Architect at Amazon Web Services, where he has had the pleasure of working with Global Financial Services customers as they explore how Generative AI can be integrated into their technology strategies. Providing technical guidance, he enjoys helping customers effectively leverage AWS Services to solve real business problems.
Dominic Searle is a Senior Solutions Architect at Amazon Web Services, where he has had the pleasure of working with Global Financial Services customers as they explore how Generative AI can be integrated into their technology strategies. Providing technical guidance, he enjoys helping customers effectively leverage AWS Services to solve real business problems.
Using Amazon SageMaker AI Random Cut Forest for NASA’s Blue Origin spacecraft sensor data
The successful deorbit, descent, and landing of spacecraft on the Moon requires precise control and monitoring of vehicle dynamics. Anomaly detection provides a unique utility for identifying important states that might represent vehicle behaviors of interest. By producing unique vehicle behavior points, critical spacecraft system states can be identified to be more appropriately addressed and potentially better understood. These identified states can be invaluable for efforts such as system failure mitigation, engineering design improvements, and mission planning. Today, space missions have become more frequent and complex, and the volume of telemetry data generated has grown exponentially. With this growth, methods of analyzing this data for anomalies need to effectively scale and without risking missing subtle, but important deviations in spacecraft behavior. Fortunately, AWS uses powerful AI/ML applications within Amazon SageMaker AI that can address these needs.
In this post, we demonstrate how to use SageMaker AI to apply the Random Cut Forest (RCF) algorithm to detect anomalies in spacecraft position, velocity, and quaternion orientation data from NASA and Blue Origin’s demonstration of lunar Deorbit, Descent, and Landing Sensors (BODDL-TP). The presented analysis focuses on detecting anomalies in spacecraft dynamics data, including positions, velocities, and quaternion orientations.
Solution overview
This solution provides an effective approach to anomaly detection in spacecraft data. We begin with data preprocessing and cleaning to produce quality input for our analysis. Using SageMaker AI, we train an RCF model specifically for detecting anomalies in complex spacecraft dynamics data. To handle the substantial volume of telemetry data efficiently, we implement batch processing for anomaly detection across large datasets.
After the model is trained and anomalies are detected, this solution produces robust visualization capabilities, presenting results with highlighted anomalies for clear interpretation of the findings. We use Amazon Simple Storage Service (Amazon S3) for seamless data storage and retrieval, including both raw data and generated plots. Throughout the implementation, we maintain careful cost management of SageMaker AI instances by deleting resources after they’re used to achieve efficient utilization while maintaining performance.
This combination of features creates a scalable, efficient pipeline for processing and analyzing spacecraft dynamics data, making it particularly suitable for space mission applications where reliability and precision are crucial.
Key concepts
In this section, we discuss some key concepts of spacecraft dynamics and machine learning (ML) in this solution.
Position and velocity in spacecraft dynamics
Position and velocity vectors in our NASA Blue Origin DDL data are represented in the Earth-Centered Earth-Fixed (ECEF) coordinate system. This reference frame rotates with the Earth, making it ideal for tracking spacecraft relative to landing sites on the lunar surface. The position vector [x, y, z] in ECEF pinpoints the spacecraft’s location in three-dimensional space. Its origin is at Earth’s center, with the X-axis intersecting the prime meridian at the equator, the Y-axis 90 degrees east in the equatorial plane, and the Z-axis aligned with Earth’s rotational axis. Measured in meters, this position data can reveal crucial information about orbital descent trajectories, landing approach paths, terminal descent profiles, and final touchdown positioning. Complementing position data, the velocity vector [vx, vy, vz] represents the spacecraft’s rate of position change in each direction. Measured in meters per second, this velocity data is vital for monitoring descent rates, maintaining safe approach speeds, controlling deceleration profiles, and verifying landing constraints. Our RCF algorithm scrutinizes both position and velocity data for anomalies. In position data, it looks for anomalies that might be caused by unexpected trajectory deviations, unrealistic position jumps, sensor glitches, or data recording errors. For velocity, its detected anomalies might be due to sudden speed changes, unusual acceleration patterns, potential thruster misfires, or navigation system issues. The fusion of position and velocity data offers a comprehensive view of the spacecraft’s translational motion. When combined with quaternion data describing rotational state, we obtain a complete picture of the spacecraft’s dynamic state during critical mission phases. These metrics play essential roles in mission planning, real-time monitoring, post-flight analysis, safety verification, C2 (command and control), and overall system performance evaluation. By using these rich datasets and advanced anomaly detection techniques, we enhance our ability to achieve mission success and spacecraft safety throughout the dynamic phases of lunar deorbit, descent, and landing.
Quaternions in spacecraft dynamics
Quaternions play a crucial role in spacecraft attitude (orientation) representation. Although Euler angles (roll, pitch, and yaw) are more intuitive, they can suffer from gimbal lock—a loss of one degree of freedom in certain orientations. Quaternions solve this problem by using a four-parameter representation that avoids such singularities. This representation consists of one scalar component (q0) and three vector components (q1, q2, q3), providing a robust mathematical framework for describing spacecraft orientation. In our NASA Blue Origin DDL data, quaternions serve a vital purpose: they represent the rotation from the spacecraft’s body-fixed coordinate system (CON) to the ECEF frame. This transformation is fundamental to several critical aspects of spacecraft operation, including maintaining precise attitude control during descent, preserving correct thrust vector orientation, facilitating accurate sensor measurements, and computing landing trajectories. For reliable anomaly detection, quaternion values must satisfy two essential mathematical properties. First, they must maintain unit magnitude, meaning the sum of their squared components (q0² + q1² + q2² + q3² = 1) equals one. Second, they must demonstrate continuity, avoiding sudden jumps that would indicate physically impossible rotations. These properties help confirm the validity of our orientation measurements and the effectiveness of our anomaly detection system. When our RCF algorithm identifies anomalies in quaternion data, these could signal various issues requiring attention. Such anomalies might indicate sensor malfunctions, attitude control system issues, data transmission errors, or actual problems with spacecraft orientation. By carefully monitoring these quaternion components alongside position and velocity data, we develop a comprehensive understanding of the spacecraft’s dynamic state during the critical phases of deorbit, descent, and landing.
The Random Cut Forest algorithm
Random Cut Forest is an unsupervised algorithm for detecting anomalies in high-dimensional data. The algorithm’s construction begins by creating multiple decision trees, each built through a process of repeatedly cutting the data space with random hyperplanes. This partitioning continues until each data point is isolated, creating a forest of trees that captures the underlying structure of the data. The novelty of RCF lies in the scoring mechanism. Points located in sparse regions of the data space that require fewer cuts to isolate score higher, while points in dense regions that need more cuts score lower. This fundamental principle allows the algorithm to assign anomaly scores inversely proportional to the number of cuts needed to isolate each point. Higher scores, therefore, indicate potential anomalies, making it straightforward to identify unusual patterns in the data.
In our spacecraft dynamics context, we apply RCF to 10-dimensional vectors that combine position (three dimensions), velocity (three dimensions), and quaternion orientation (four dimensions). Each vector represents a specific moment in time during the spacecraft’s mission states. The flight patterns create dense regions in this high-dimensional space, while anomalies appear as isolated points in sparse regions. This data is high-dimensional, multivariate time series, and has no labels, which RCF handles fairly well while maintaining computational efficiency and handling sensor noise. For this use case, RCF is able to detect subtle deviations between data points of spacecraft dynamics while handling the complex relationships between position, velocity, and orientation parameters. These features of RCF make it an effective tool for spacecraft dynamics monitoring analysis and anomaly detection.
Solution architecture
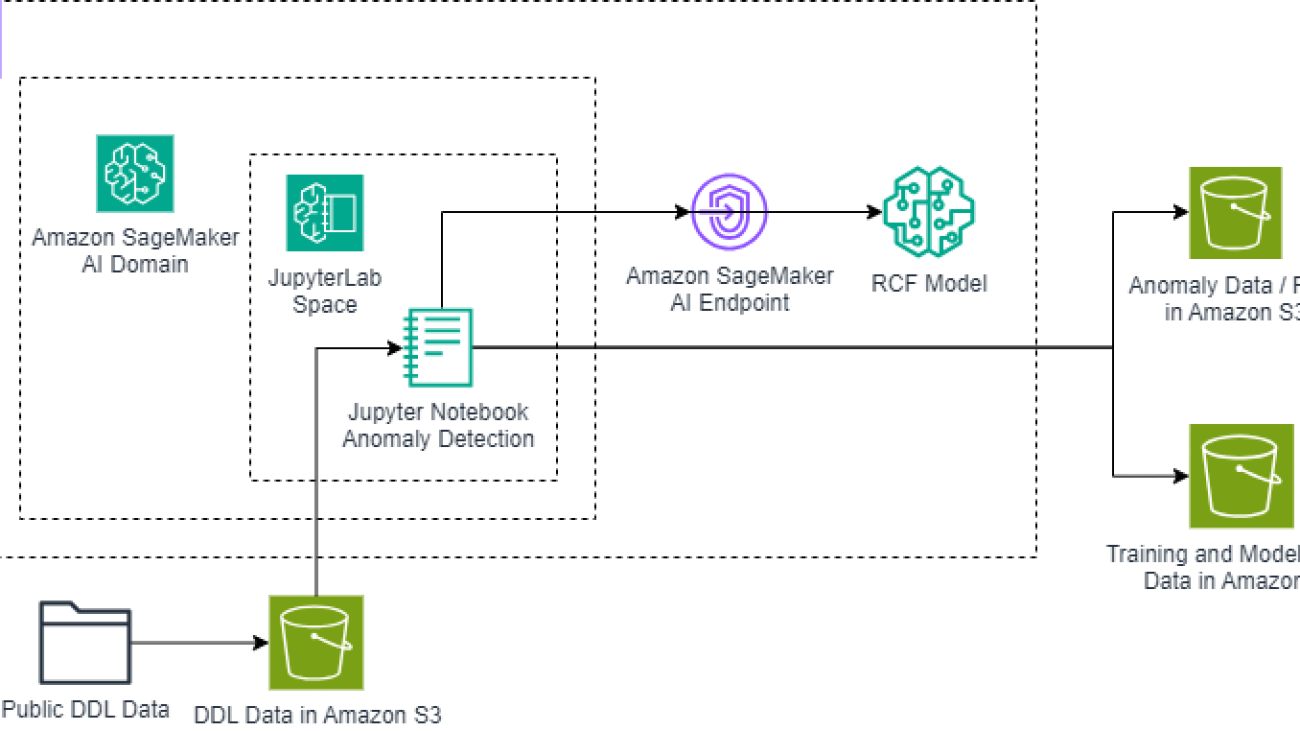
The solution architecture implements anomaly detection for NASA-Blue Origin Lunar DDL data using the RCF algorithm, as illustrated in the following diagram.

Our solution’s data flow begins with public DDL (Deorbit, Descent, and Landing) data securely stored in an S3 bucket. This data is then accessed through a SageMaker AI domain using JupyterLab, providing a powerful and flexible environment for data scientists and engineers. Within JupyterLab, we use a custom notebook to process the raw data and implement our anomaly detection algorithms.
The core of our solution lies in the processing pipeline. It starts in the JupyterLab notebook, where we train an RCF model using SageMaker AI. After it’s trained, this model is deployed to a SageMaker AI endpoint, creating a scalable and responsive anomaly detection service. We then feed our spacecraft dynamics data through this model to identify potential anomalies. The pipeline concludes by generating detailed visualizations of these anomalies, providing clear and actionable insights.
For output, our system saves both the detected anomaly data and the generated plots back to Amazon S3. This makes sure the results are securely stored and accessible for further analysis or reporting. Additionally, we preserve all training data and model outputs in Amazon S3, enabling reproducibility and facilitating iterative improvements to our anomaly detection process. Throughout these operations, we maintain robust security measures, using Amazon Virtual Private Cloud (Amazon VPC) to enforce data privacy and integrity at every step of the process.
Prerequisites
Before standing up the project, you must set up the necessary tools and access rights:
- The AWS environment should include an active AWS account with appropriate permissions for running ML workloads, along with the AWS Command Line Interface (AWS CLI) for command line operations installed
- Access to SageMaker AI is essential for the ML implementation
- On the development side, Python 3.7 or later needs to be installed, along with several key Python packages:
- Boto3 for AWS service integration
- Pandas for data manipulation
- Matplotlib for visualization
- NumPy for numerical operations
- The SageMaker AI Python SDK for interacting with the SageMaker services
Set up the solution
The setup process includes accessing the SageMaker AI environment, where all the data analysis and model training is executed.
- On the SageMaker AI console, open the SageMaker domain details page.
- Open JupyterLab, then create a new Python notebook instance for this project.
- When the environment is ready, open a terminal in SageMaker AI JupyterLab to clone the project repository using the following commands:
- Install the required Python libraries:
pip install -r requirements.txt
This process will set up the necessary dependencies for running anomaly detection analysis on the spacecraft data.
Execute anomaly detection
Update the bucket_name and file_name variables in the script with your S3 bucket and data file names.
Run the script in JupyterLab as a Jupyter notebook or run as a Python script: python Lunar_DDL_AD.py
Upon execution, the notebook or script performs a series of automated tasks to analyze the spacecraft data. It begins by loading and preprocessing the raw data, making sure it’s in the correct format for analysis. Next, it trains and deploys an RCF model using SageMaker AI, establishing the foundation for our anomaly detection system. When the model is operational, it processes the spacecraft dynamics data to identify potential anomalies in position, velocity, and quaternion measurements. Finally, the script generates detailed visualizations of these findings and automatically uploads both the plots and analysis results to Amazon S3 for secure storage and straightforward access.
Code structure
The Python implementation centers around an anomaly detection pipeline, structured in the main script. At its core is the AnomalyDetector class, which orchestrates the entire workflow from data ingestion to visualization. This class contains several methods that together process spacecraft telemetry data and identify anomalies.
The load_and_prepare_data method handles the initial data ingestion and preprocessing, making sure spacecraft measurements are properly formatted for analysis. After the data is prepared, train_and_deploy_model trains the RCF model and deploys it as a SageMaker endpoint. The predict_anomalies method then uses this trained model to identify unusual patterns in the spacecraft’s position, velocity, and quaternion data.
For visualization and storage, the plot_results method creates detailed graphs highlighting detected anomalies, and upload_plot_to_s3 makes sure these visualizations are securely stored in Amazon S3 for future reference and centralized access.
Together, these components create a comprehensive pipeline for processing spacecraft telemetry data and identifying potential anomalies that might warrant further investigation.
Configuration
Adjust the following parameters in the script as needed:
threshold_percentilefor the threshold for anomaly classification- RCF hyperparameters in
train_and_deploy_model:feature_dim: Number of input featuresnum_samples_per_tree: Random data points per treenum_trees: Number of trees in the algorithmic forest
batch_sizeinpredict_anomaliesfor large datasets
For RCF applications, the hyperparameters and threshold configuration significantly influence anomaly detections. We use the following configuration values for this example:
threshold_percentile=0.9- RCF hyperparameters in
train_and_deploy_model():feature_dim=10num_samples_per_tree=512num_trees=100
batch_size=1000inpredict_anomalies()
SageMaker AI instance type size for training and inference can affect anomaly results, processing time, and cost. In this example, we used an ml.m5.4xlarge instance for both training and inference.
In addition, SageMaker AI can be integrated with various security features for protecting sensitive data and models. It’s possible to operate in no internet or VPC only modes so SageMaker AI instances remain isolated within your Amazon VPC. Secure data access can also be achieved through AWS PrivateLink, enabling private connections to Amazon S3 without internet exposure. Also, integration with AWS Identity and Access Management (IAM) provides fine-grained access control through custom user profiles, enforcing data privacy and adhering to the principle of least privilege, such as when using sensitive spacecraft telemetry data. These are some of the security enhancement services that can be applied according to your appropriate use case with SageMaker AI.
Data
The script uses public NASA-Blue Origin Demo of Lunar Deorbit, Descent, and Landing Sensors (BODDL-TP) data, which you can download. Make sure your data is in the correct format with columns for timestamps, positions, velocities, and quaternions.
Results
The script generates plots for positions, velocities, and quaternions. The respective data is plotted and the anomalies are plotted as an overlay in red. The plots are saved to the specified S3 bucket. Due to the small scale, the positions plot is difficult to observe anomalies. However, the SageMaker AI RCF algorithm can detect them and are highlighted in red. In the following plots, the sharp changes in velocities and quaternions correspond with the anomalies shown.

Unlike the positions plot, the velocities plot shows discontinuities, which are detected as anomalies. This is likely due to rate changes for vehicle maneuvers during the deorbit, descent, and landing demonstration stages.

Similarly to the velocities plot, the quaternions plot shows sharp changes, which are also detected as anomalies. This is likely due to rotational accelerations during vehicle maneuvers of the deorbit, descent, and landing demonstration stages.

These anomalies most likely represent the lunar spacecraft vehicle dynamics at key maneuver stages of the deorbit, descent, and landing demonstration. Momentum wheels, thrusters, and various other C2 applications could be the cause of the observed abrupt positional, velocity, and quaternion changes being detected as anomalous. By having these results, data points of interest are indicated for more precise and potentially valuable analysis for improved vehicle health and status awareness.
Clean up
The provided script includes SageMaker AI endpoint deletion after training and inference to avoid any unnecessary charges. If you’re using JupyterLab and want to further avoid charges, stop the SageMaker AI instance running the RCF JupyterLab Python notebook.
Conclusion
In this post, we demonstrated how the SageMaker AI RCF algorithm can effectively detect anomalies in spacecraft dynamics data from NASA and Blue Origin’s lunar Deorbit, Descent, and Landing demonstration. By detecting anomalies for position, velocity, and quaternion orientation data, we’ve shown how ML can enhance space mission analysis, situational awareness, and autonomy. The built-in algorithm processes complex, multi-dimensional spacecraft telemetry data. Through efficient batch processing, we can analyze large-scale mission data effectively, and our visualization approach enables quick identification of potential issues in spacecraft dynamics. From there, the solution’s scalability shows the ability adapt to handle varying data volumes and mission durations, making it potentially suitable for a wide range of space applications. Although this solution applies to a lunar mission demonstration, the approach could have broad applications throughout the space industry. You can adapt the same architecture for various space operations, such as landing missions on other celestial bodies, orbital rendezvous, space station docking, and satellite constellations. This integration of AWS services with aerospace applications creates a robust, secure, and scalable platform for space mission analytics, which is becoming increasingly valuable as we continue to execute missions in the space environment. Looking forward, this solution opens many possibilities for enhancement and expansion. Real-time anomaly detection could be implemented for live mission data, providing immediate insights during critical operations. Also, the system could be enhanced by incorporating additional spacecraft parameters and sensor data, and automated alert services could be developed to provide immediate notification of detected anomalies. In addition, further developments might include extending the analysis to incorporate predictive ML models and creating custom metrics tailored to specific mission requirements. These potential advancements would continue to build upon the foundation we’ve established, creating even more powerful tools for spacecraft mission analysis.
The code and implementation details are available in our GitHub repository, enabling you to adapt and enhance the solution for your specific needs.
For space operations, the combination of cloud computing and ML have strong potential to play an increasingly crucial role in ensuring mission success. This solution demonstrates just one of many possible applications of AWS services for improving spacecraft mission compute and data analysis.
To learn more about the AWS services used in this solution, refer to Guide to getting set up with Amazon SageMaker AI, Train a Model with Amazon SageMaker, and the JupyterLab user guide.
About the authors
 Dr. Ian Lunsford is an Aerospace AI Engineer at AWS Professional Services. He integrates cloud services into aerospace applications. Additionally, Ian focuses on building AI/ML solutions using AWS services.
Dr. Ian Lunsford is an Aerospace AI Engineer at AWS Professional Services. He integrates cloud services into aerospace applications. Additionally, Ian focuses on building AI/ML solutions using AWS services.
 Nick Biso is a Machine Learning Engineer at AWS Professional Services. He solves complex organizational and technical challenges using data science and engineering. In addition, he builds and deploys AI/ML models on the AWS Cloud. His passion extends to his proclivity for travel and diverse cultural experiences.
Nick Biso is a Machine Learning Engineer at AWS Professional Services. He solves complex organizational and technical challenges using data science and engineering. In addition, he builds and deploys AI/ML models on the AWS Cloud. His passion extends to his proclivity for travel and diverse cultural experiences.
Game On With GeForce NOW, the Membership That Keeps on Delivering
This GFN Thursday rolls out a new reward and games for GeForce NOW members. Whether hunting for hot new releases or rediscovering timeless classics, members can always find more ways to play, games to stream and perks to enjoy.
Gamers can score major discounts on the titles they’ve been eyeing — perfect for streaming in the cloud — during the Steam Summer Sale, running until Thursday, July 10, at 10 a.m. PT.
This week also brings unforgettable adventures to the cloud: We Happy Few and Broken Age are part of the five additions to the GeForce NOW library this week.
The fun doesn’t stop there. A new in-game reward for Elder Scrolls Online is now available for members to claim.
And SteelSeries has launched a new mobile controller that transforms phones into cloud gaming devices with GeForce NOW. Add it to the roster of on-the-go gaming devices — including the recently launched GeForce NOW app on Steam Deck for seamless 4K streaming.
Scroll Into Power
GeForce NOW Premium members receive exclusive 24-hour early access to a new mythical reward in The Elder Scrolls Online — Bethesda’s award-winning role-playing game — before it opens to all members. Sharpen the sword, ready the staff and chase glory across the vast, immersive world of Tamriel.

Claim the mythical Grand Gold Coast Experience Scrolls reward, a rare item that grants a bonus of 150% Experience Points from all sources for one hour. The scroll’s effect pauses while players are offline and resumes upon return, ensuring every minute counts. Whether tackling dungeon runs, completing epic quests or leveling a new character, the scrolls provide a powerful edge. Claim the reward, harness its power and scroll into the next adventure.
Members who’ve opted into the GeForce NOW Rewards program can check their emails for redemption instructions. The offer runs through Saturday, July 26, while supplies last. Don’t miss this opportunity to become a legend in Tamriel.
Steam Up Summer
The Steam Summer Sale is in full swing. Snag games at discounted prices and stream them instantly from the cloud — no downloads, no waiting, just pure gaming bliss.
Check out the “Steam Summer Sale” row in the GeForce NOW app to find deals on the next adventure. With GeForce NOW, gaming favorites are always just a click away.
While picking up discounted games, don’t miss the chance to get a GeForce NOW six-month Performance membership at 40% off. This is also the last opportunity to take advantage of the Performance Day Pass sale, ending Friday, June 27 — which lets gamers access cloud gaming for 24 hours — before diving into the 6-month Performance membership.
Find Adventure
Two distinct worlds — where secrets simmer and imagination runs wild — are streaming onto the cloud this week.

Step into the surreal, retro-futuristic streets of We Happy Few, where a society obsessed with happiness hides its secrets behind a mask of forced cheer and a haze of “Joy.” This darkly whimsical adventure invites players to blend in, break out and uncover the truth lurking beneath the surface of Wellington Wells.

Broken Age spins a charming, hand-painted tale of two teenagers leading parallel lives in worlds at once strange and familiar. One of the teens yearns to escape a stifling spaceship, and the other is destined to challenge ancient traditions. With witty dialogue and heartfelt moments, Broken Age is a storybook come to life, brimming with quirky characters and clever puzzles.
Each of these unforgettable adventures brings its own flavor — be it dark satire, whimsical wonder or pulse-pounding suspense — offering a taste of gaming at its imaginative peaks. Stream these captivating worlds straight from the cloud and enjoy seamless gameplay, no downloads or high-end hardware required.
An Ultimate Controller

Get ready for the SteelSeries Nimbus Cloud, a new dual-mode cloud controller. When paired with GeForce NOW, this new controller reaches new heights.
Designed for versatility and comfort, and crafted specifically for cloud gaming, the SteelSeries Nimbus Cloud effortlessly shifts from a mobile device controller to a full-sized wireless controller, delivering top-notch performance and broad compatibility across devices.
The Nimbus Cloud enables gamers to play wherever they are, as it easily adapts to fit iPhones and Android phones. Or collapse and connect the controller via Bluetooth to a gaming rig or smart TV. Transform any space into a personal gaming station with GeForce NOW and the Nimbus Cloud, part of the list of recommended products for an elevated cloud gaming experience.
Gaming Never Sleeps

System Shock 2: 25th Anniversary Remaster is an overhaul of the acclaimed sci-fi horror classic, rebuilt by Nightdive Studios with enhanced visuals, refined gameplay and features such as cross-play co-op multiplayer. Face the sinister AI SHODAN and her mutant army aboard the starship Von Braun as a cybernetically enhanced soldier with upgradable skills, powerful weapons and psionic abilities. Stream the title from the cloud with GeForce NOW for ultimate flexibility and performance.
Look for the following games available to stream in the cloud this week:
- System Shock 2: 25th Anniversary Remaster (New release on Steam, June 26)
- Broken Age (Steam)
- Easy Red 2 (Steam)
- Sandwich Simulator (Steam)
- We Happy Few (Steam)
What are you planning to play this weekend? Let us know on X or in the comments below.
The official GFN summer bucket list
Play anywhere
Stream on every screen you own
Finally crush that backlog
Skip every single download bar
Drop the emoji for the one you’re tackling right now
—
NVIDIA GeForce NOW (@NVIDIAGFN) June 25, 2025


Startup Uses NVIDIA RTX-Powered Generative AI to Make Coolers, Cooler
Mark Theriault founded the startup FITY envisioning a line of clever cooling products: cold drink holders that come with freezable pucks to keep beverages cold for longer without the mess of ice. The entrepreneur started with 3D prints of products in his basement, building one unit at a time, before eventually scaling to mass production.
Founding a consumer product company from scratch was a tall order for a single person. Going from preliminary sketches to production-ready designs was a major challenge. To bring his creative vision to life, Theriault relied on AI and his NVIDIA GeForce RTX-equipped system. For him, AI isn’t just a tool — it’s an entire pipeline to help him accomplish his goals. Read more about his workflow below.
Plus, GeForce RTX 5050 laptops start arriving today at retailers worldwide, from $999. GeForce RTX 5050 Laptop GPUs feature 2,560 NVIDIA Blackwell CUDA cores, fifth-generation AI Tensor Cores, fourth-generation RT Cores, a ninth-generation NVENC encoder and a sixth-generation NVDEC decoder.
In addition, NVIDIA’s Plug and Play: Project G-Assist Plug-In Hackathon — running virtually through Wednesday, July 16 — invites developers to explore AI and build custom G-Assist plug-ins for a chance to win prizes. Save the date for the G-Assist Plug-In webinar on Wednesday, July 9, from 10-11 a.m. PT, to learn more about Project G-Assist capabilities and fundamentals, and to participate in a live Q&A session.
From Concept to Completion
To create his standout products, Theriault tinkers with potential FITY Flex cooler designs with traditional methods, from sketch to computer-aided design to rapid prototyping, until he finds the right vision. A unique aspect of the FITY Flex design is that it can be customized with fun, popular shoe charms.
For packaging design inspiration, Theriault uses his preferred text-to-image generative AI model for prototyping, Stable Diffusion XL — which runs 60% faster with the NVIDIA TensorRT software development kit — using the modular, node-based interface ComfyUI.
ComfyUI gives users granular control over every step of the generation process — prompting, sampling, model loading, image conditioning and post-processing. It’s ideal for advanced users like Theriault who want to customize how images are generated.

NVIDIA and GeForce RTX GPUs based on the NVIDIA Blackwell architecture include fifth-generation Tensor Cores designed to accelerate AI and deep learning workloads. These GPUs work with CUDA optimizations in PyTorch to seamlessly accelerate ComfyUI, reducing generation time on FLUX.1-dev, an image generation model from Black Forest Labs, from two minutes per image on the Mac M3 Ultra to about four seconds on the GeForce RTX 5090 desktop GPU.
ComfyUI can also add ControlNets — AI models that help control image generation — that Theriault uses for tasks like guiding human poses, setting compositions via depth mapping and converting scribbles to images.
Theriault even creates his own fine-tuned models to keep his style consistent. He used low-rank adaptation (LoRA) models — small, efficient adapters into specific layers of the network — enabling hyper-customized generation with minimal compute cost.
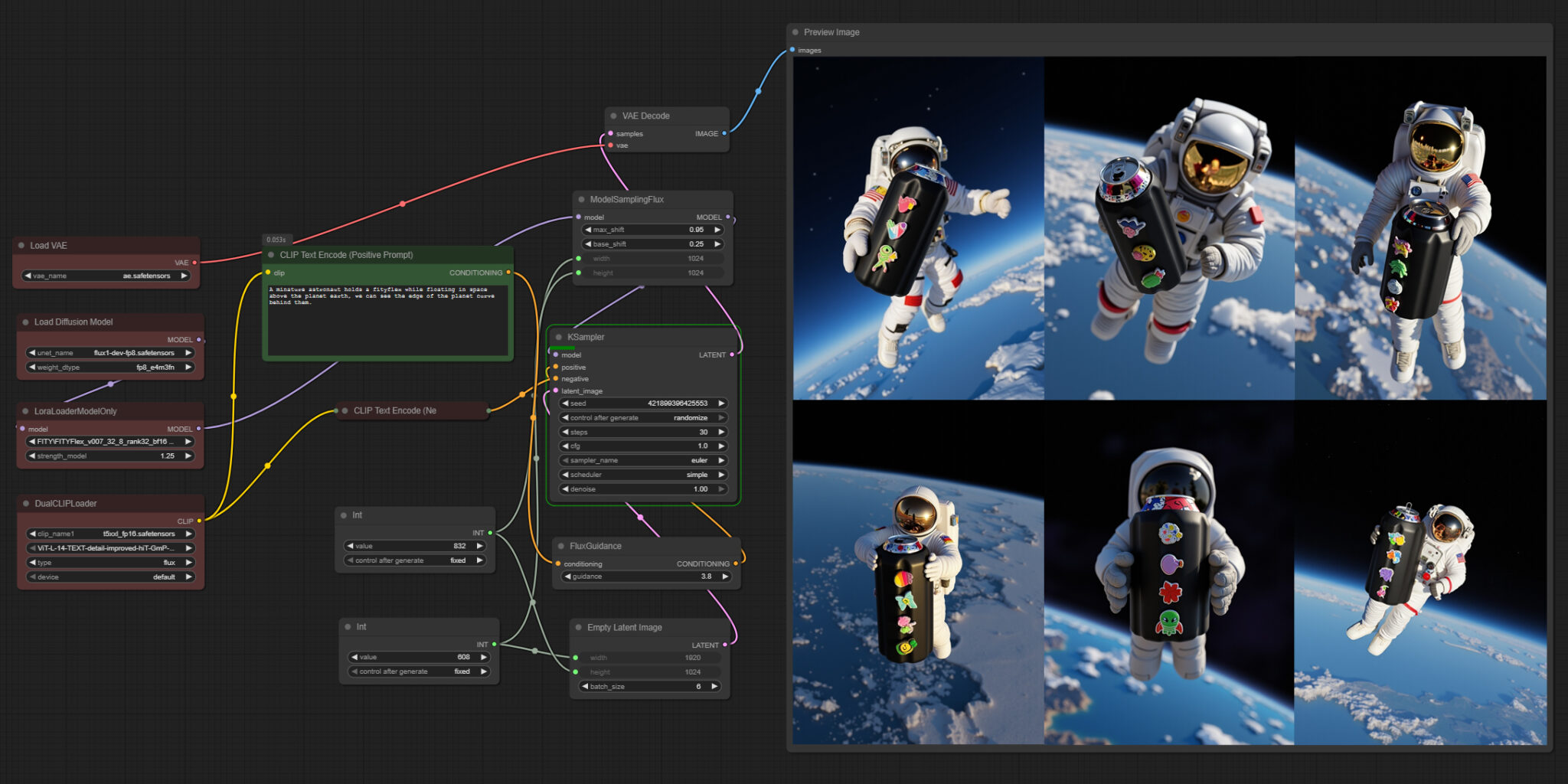
“Over the last few months, I’ve been shifting from AI-assisted computer graphics renders to fully AI-generated product imagery using a custom Flux LoRA I trained in house. My RTX 4080 SUPER GPU has been essential for getting the performance I need to train and iterate quickly.” – Mark Theriault, founder of FITY
Theriault also taps into generative AI to create marketing assets like FITY Flex product packaging. He uses FLUX.1, which excels at generating legible text within images, addressing a common challenge in text-to-image models.
Though FLUX.1 models can typically consume over 23GB of VRAM, NVIDIA has collaborated with Black Forest Labs to help reduce the size of these models using quantization — a technique that reduces model size while maintaining quality. The models were then accelerated with TensorRT, which provides an up to 2x speedup over PyTorch.
To simplify using these models in ComfyUI, NVIDIA created the FLUX.1 NIM microservice, a containerized version of FLUX.1 that can be loaded in ComfyUI and enables FP4 quantization and TensorRT support. Combined, the models come down to just over 11GB of VRAM, and performance improves by 2.5x.
Theriault uses the Blender Cycles app to render out final files. For 3D workflows, NVIDIA offers the AI Blueprint for 3D-guided generative AI to ease the positioning and composition of 3D images, so anyone interested in this method can quickly get started.

Finally, Theriault uses large language models to generate marketing copy — tailored for search engine optimization, tone and storytelling — as well as to complete his patent and provisional applications, work that usually costs thousands of dollars in legal fees and considerable time.

“As a one-man band with a ton of content to generate, having on-the-fly generation capabilities for my product designs really helps speed things up.” – Mark Theriault, founder of FITY
Every texture, every word, every photo, every accessory was a micro-decision, Theriault said. AI helped him survive the “death by a thousand cuts” that can stall solo startup founders, he added.
Each week, the RTX AI Garage blog series features community-driven AI innovations and content for those looking to learn more about NVIDIA NIM microservices and AI Blueprints, as well as building AI agents, creative workflows, digital humans, productivity apps and more on AI PCs and workstations.
Plug in to NVIDIA AI PC on Facebook, Instagram, TikTok and X — and stay informed by subscribing to the RTX AI PC newsletter.
Follow NVIDIA Workstation on LinkedIn and X.
See notice regarding software product information.

Into the Omniverse: World Foundation Models Advance Autonomous Vehicle Simulation and Safety
Editor’s note: This blog is a part of Into the Omniverse, a series focused on how developers, 3D practitioners and enterprises can transform their workflows using the latest advances in OpenUSD and NVIDIA Omniverse.
Simulated driving environments enable engineers to safely and efficiently train, test and validate autonomous vehicles (AVs) across countless real-world and edge-case scenarios without the risks and costs of physical testing.
These simulated environments can be created through neural reconstruction of real-world data from AV fleets or generated with world foundation models (WFMs) — neural networks that understand physics and real-world properties. WFMs can be used to generate synthetic datasets for enhanced AV simulation.
To help physical AI developers build such simulated environments, NVIDIA unveiled major advances in WFMs at the GTC Paris and CVPR conferences earlier this month. These new capabilities enhance NVIDIA Cosmos — a platform of generative WFMs, advanced tokenizers, guardrails and accelerated data processing tools.
Key innovations like Cosmos Predict-2, the Cosmos Transfer-1 NVIDIA preview NIM microservice and Cosmos Reason are improving how AV developers generate synthetic data, build realistic simulated environments and validate safety systems at unprecedented scale.
Universal Scene Description (OpenUSD), a unified data framework and standard for physical AI applications, enables seamless integration and interoperability of simulation assets across the development pipeline. OpenUSD standardization plays a critical role in ensuring 3D pipelines are built to scale.
NVIDIA Omniverse, a platform of application programming interfaces, software development kits and services for building OpenUSD-based physical AI applications, enables simulations from WFMs and neural reconstruction at world scale.
Leading AV organizations — including Foretellix, Mcity, Oxa, Parallel Domain, Plus AI and Uber — are among the first to adopt Cosmos models.
Foundations for Scalable, Realistic Simulation
Cosmos Predict-2, NVIDIA’s latest WFM, generates high-quality synthetic data by predicting future world states from multimodal inputs like text, images and video. This capability is critical for creating temporally consistent, realistic scenarios that accelerate training and validation of AVs and robots.

In addition, Cosmos Transfer, a control model that adds variations in weather, lighting and terrain to existing scenarios, will soon be available to 150,000 developers on CARLA, a leading open-source AV simulator. This greatly expands the broad AV developer community’s access to advanced AI-powered simulation tools.
Developers can start integrating synthetic data into their own pipelines using the NVIDIA Physical AI Dataset. The latest release includes 40,000 clips generated using Cosmos.
Building on these foundations, the Omniverse Blueprint for AV simulation provides a standardized, API-driven workflow for constructing rich digital twins, replaying real-world sensor data and generating new ground-truth data for closed-loop testing.
The blueprint taps into OpenUSD’s layer-stacking and composition arcs, which enable developers to collaborate asynchronously and modify scenes nondestructively. This helps create modular, reusable scenario variants to efficiently generate different weather conditions, traffic patterns and edge cases.
Driving the Future of AV Safety
To bolster the operational safety of AV systems, NVIDIA earlier this year introduced NVIDIA Halos — a comprehensive safety platform that integrates the company’s full automotive hardware and software stack with AI research focused on AV safety.
The new Cosmos models — Cosmos Predict- 2, Cosmos Transfer- 1 NIM and Cosmos Reason — deliver further safety enhancements to the Halos platform, enabling developers to create diverse, controllable and realistic scenarios for training and validating AV systems.
These models, trained on massive multimodal datasets including driving data, amplify the breadth and depth of simulation, allowing for robust scenario coverage — including rare and safety-critical events — while supporting post-training customization for specialized AV tasks.
At CVPR, NVIDIA was recognized as an Autonomous Grand Challenge winner, highlighting its leadership in advancing end-to-end AV workflows. The challenge used OpenUSD’s robust metadata and interoperability to simulate sensor inputs and vehicle trajectories in semi-reactive environments, achieving state-of-the-art results in safety and compliance.
Learn more about how developers are leveraging tools like CARLA, Cosmos, and Omniverse to advance AV simulation in this livestream replay:
Hear NVIDIA Director of Autonomous Vehicle Research Marco Pavone on the NVIDIA AI Podcast share how digital twins and high-fidelity simulation are improving vehicle testing, accelerating development and reducing real-world risks.
Get Plugged Into the World of OpenUSD
Learn more about what’s next for AV simulation with OpenUSD by watching the replay of NVIDIA founder and CEO Jensen Huang’s GTC Paris keynote.
Looking for more live opportunities to learn more about OpenUSD? Don’t miss sessions and labs happening at SIGGRAPH 2025, August 10–14.
Discover why developers and 3D practitioners are using OpenUSD and learn how to optimize 3D workflows with the self-paced “Learn OpenUSD” curriculum for 3D developers and practitioners, available for free through the NVIDIA Deep Learning Institute.
Explore the Alliance for OpenUSD forum and the AOUSD website.
Stay up to date by subscribing to NVIDIA Omniverse news, joining the community and following NVIDIA Omniverse on Instagram, LinkedIn, Medium and X.

The Google for Startups Gemini kit is here
 Learn more about how startups can use Gemini models and other AI resources from Google.Read More
Learn more about how startups can use Gemini models and other AI resources from Google.Read More