 Here are five tips for making videos with Flow, Google’s new AI filmmaking tool.Read More
Here are five tips for making videos with Flow, Google’s new AI filmmaking tool.Read More

Here are five tips for making videos with Flow, Google’s new AI filmmaking tool.Read More
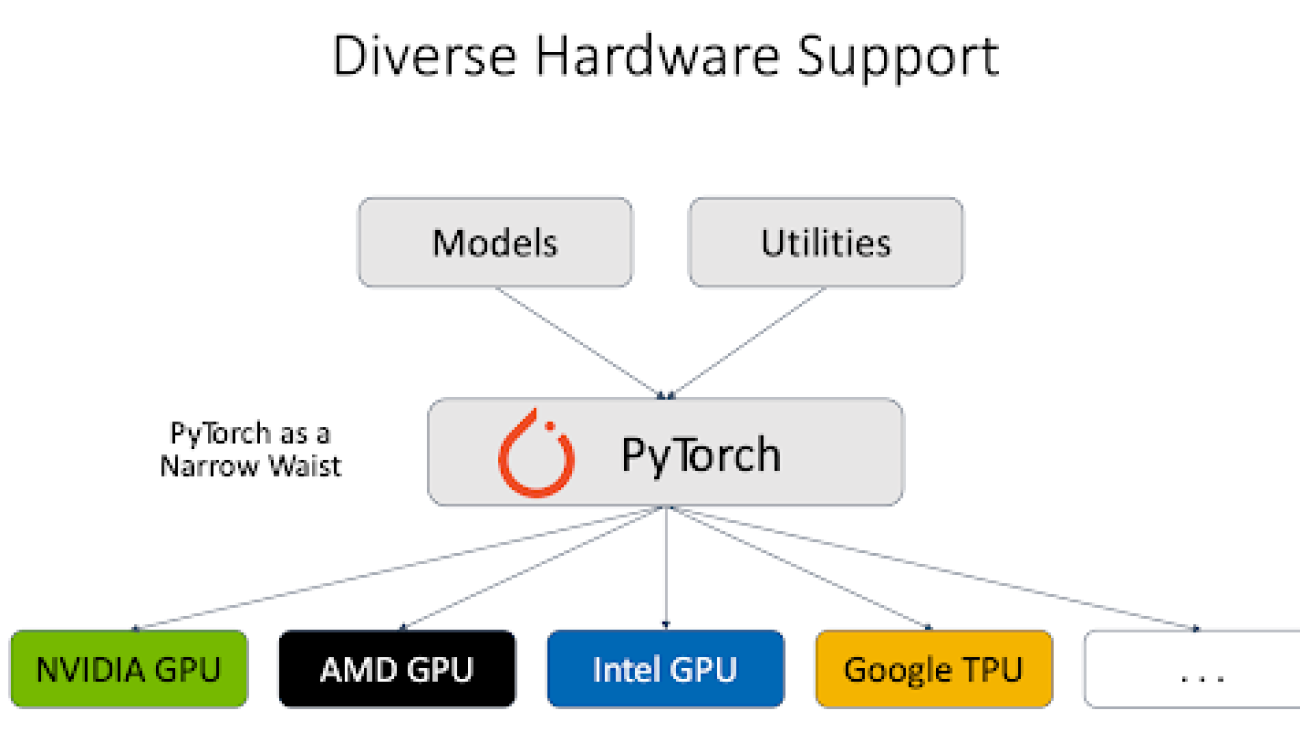
Key takeaways:
Even prior to vLLM joining the PyTorch Foundation, we’ve seen organic and widespread adoption of PyTorch and vLLM together in some of the top companies deploying LLMs at scale in the world. Interestingly, the projects share many commonalities, including: strong visionary leaders; a broad organically-attained multilateral governance structure with committers from several entities, including both industry and academia; and an overwhelming focus on the developer experience.
Additionally, over the last year plus, we’ve seen the two projects underpin many of the most popular open source LLMs, including the various Llama and DeepSeek models. With such similarities and how complementary the projects are, it’s really exciting to see all of the different integration points.
The overall goal for integrating at various points is to unlock performance and bring new capabilities to users. This includes optimization and support for Llama models, but also broader open models.
torch.compile: torch.compile is a compiler that optimizes PyTorch code, delivering fast performance with minimal user effort. While manually tuning a model’s performance can take days, weeks, or even months, this approach becomes impractical for a large number of models. Instead, torch.compile provides a convenient solution for optimizing model performance. vLLM uses torch.compile by default to generate optimized kernels for the majority of its models. Recent benchmarks show significant speedups with torch.compile, ranging from 1.05x to 1.9x speedups on CUDA for popular models like Llama4, Qwen3, and Gemma3.
TorchAO: We’re excited to announce that TorchAO is now officially supported as a quantization solution in vLLM. This integration brings high-performance inference capabilities using Int4, Int8, and FP8 data types, with upcoming support for MXFP8, MXFP4, and NVFP4 optimizations specifically designed for B200 GPUs. Additionally, we’re working on planned FP8 inference support for AMD GPUs, expanding hardware compatibility for high-performance quantized inference.
TorchAO’s quantization APIs are powered by a robust collection of high-performance kernels, including those from PyTorch Core, FBGEMM, and gemlite. TorchAO techniques are designed to compose torch.compile. This means simpler implementations and automatic performance gains from PT2. Write less code, get better performance
One of the most exciting aspects of this integration is the seamless workflow it enables: vLLM users can now perform float8 training using TorchTitan, Quantization-Aware Training (QAT) using TorchTune, then directly load and deploy their quantized models through vLLM for production inference. This end-to-end pipeline significantly streamlines the path from model training and fine-tuning to deployment, making advanced quantization techniques more accessible to developers.
FlexAttention: vLLM now includes FlexAttention – a new attention backend designed for flexibility. FlexAttention provides a programmable attention framework that allows developers to define custom attention patterns, making it easier to support novel model designs without extensive backend modifications.
This backend, enabled by torch.compile, produces JIT fused kernels. This allows for flexibility while maintaining performance for non-standard attention patterns. FlexAttention is currently in early development within vLLM and not yet ready for production use. We’re continuing to invest in this integration and plan to make it a robust part of vLLM’s modeling toolkit. The goal is to simplify support for emerging attention patterns and model architectures, making it easier to bridge the gap between research innovations and deployment-ready inference.
Heterogeneous hardware: The PyTorch team worked with different hardware vendors and provided solid support for different types of hardware backends, including NVIDIA GPU, AMD GPU, Intel GPU, Google TPU, etc. vLLM inference engine leverages PyTorch as a proxy talking to different hardware, and this significantly simplified the support for heterogeneous hardware.
In addition, PyTorch engineers work closely with other vLLM contributors to support the next generation of NVIDIA GPUs. For example, we have thoroughly tested FlashInfer support in vLLM on Blackwell, conducted performance comparison, and debugged accuracy issues.
The PyTorch team also worked with AMD to enhance the support for vLLM + Llama4, such as day 0 llama 4 support on AMD as well as Llama4 perf optimization on MI300x.
Parallelism: At Meta, we leverage different types of parallelism and their combination in production. Pipeline parallelism (PP) is one important type. The original PP in vLLM has hard dependencies on Ray. However, not all the users leverage Ray to manage their service and coordinate different hosts. The PyTorch team developed the PP with plain torchrun support, and further optimized its approach to overlap the computation between microbatches. In addition, PyTorch engineers also developed the Data Parallelism for vision encoder, which is critical to the multi-modal models’ performance.
Continuous integration (CI): With vLLM critical for the PyTorch ecosystem, we are collaborating to ensure that CI between the projects has good test coverage, is well funded and overall the community can rely on all of these integrations. Just integrating APIs isn’t enough; it’s also important that CI is in place to ensure that nothing breaks over time as vLLM and PyTorch both release new versions and features. More concretely, we are testing the combination of vLLM main and PyTorch nightlies, which we believe will give us and the community the signal needed to monitor the state of the integration between the two projects. At Meta, we started moving some of our development effort on top of vLLM main to stress test various correctness and performance aspects of vLLM. As well, performance dashboards for vLLM v1 are now available on hud.pytorch.org.
This is just the beginning. We are working together to build out the following advanced capabilities:
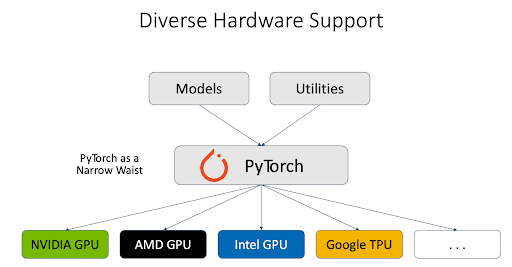
1. Large Scale Model Inference: The primary goal is to ensure vLLM runs efficiently at scale on cloud offerings, demonstrates key capabilities (prefill-decode disagg, multi-node parallelism, performant kernels and comms, context-aware routing and fault-tolerance) to scale to thousands of nodes, and becomes a stable foundation for enterprises to build on. In Q2, Meta engineers have prototyped disagg integration on top of the vLLM engine and KV connector APIs. The team is working with the community to try out new strategies and will plan to upstream the most successful ones to push further what can be done with vLLM.
Hardware: H100 GPUs, 96 GB HBM2e, AMD Genoa CPUs, CUDA 12.4
2. Post-training with reinforcement learning: Inference time compute is quickly becoming critical for LLMs and agentic systems. We are working on end-to-end native post-training that incorporates RL at large scale with vLLM as the inference backbone of the system.
Cheers!
-Team PyTorch (at Meta) & Team vLLM

In this post, we demonstrate how to build a multi-agent system using multi-agent collaboration in Amazon Bedrock Agents to solve complex business questions in the biopharmaceutical industry. We show how specialized agents in research and development (R&D), legal, and finance domains can work together to provide comprehensive business insights by analyzing data from multiple sources.
Business intelligence and market research enable large and small businesses to capture the trends of the industry, competitive landscape through data, and influences key business strategies. For example, biopharmaceutical companies use data to understand drug market size, clinical trials, prevalence of side effects, and innovation and pitfalls through analyzing patent and legal briefs to form investment strategies. In doing so, organizations face the challenges of accessing and analyzing information scattered across multiple data sources. Consolidating and querying these disparate datasets can be a complex and time-consuming task, requiring developers to navigate different data formats, query languages, and access mechanisms. Additionally, gaining a comprehensive understanding of an organization’s operations often requires combining data insights from various segments, such as legal, finance, and R&D.
Generative AI agentic systems have emerged as a promising solution, enabling organizations to use generative AI for autonomous reasoning and action-based tasks. However, many agentic systems to-date are built with a single-agent setup, which poses challenges in a complex business environment. Besides the challenge of managing multiple data sources, encoding information and guidance for multiple business domains might cause the prompt for an agent’s large language model (LLM) to grow to such an extent that is suffers from “forgetting the middle” of a long context. Therefore, there is a trade-off between the breadth vs. depth of knowledge for each domain that can be encoded in an agent effectively. Additionally, the use of a single LLM with an agent limits cost, latency, and accuracy optimizations for the selected model.
Amazon Bedrock Agents and its multi-agent collaboration feature provides powerful, enterprise-ready solutions for addressing these challenges and building intelligent and automated agentic systems. As a managed service within the AWS ecosystem, Amazon Bedrock Agents offers seamless integration with AWS data sources, built-in security controls, and enterprise-grade scalability. It contains built-in support for additional Amazon Bedrock features such as Amazon Bedrock Guardrails and Amazon Bedrock Knowledge Bases. The service significantly reduces deployment overhead, empowering developers to focus on agent logic through an API-driven, familiar AWS Cloud environment and console. The supervisor agent model with specialized sub-agents enables efficient distributed problem-solving, breaking down complex tasks with intelligent routing.
In this post, we discuss how to build a multi-agent system using multi-agent collaboration to solve complex business questions faced in a fictional biopharmaceutical company that requires expertise and data from three specialized domains: R&D, legal, and finance. We demonstrate how data in disparate sources can be combined intelligently to support complex reasoning, and how agent collaboration facilitates open-ended question answering, such as “What are the potential legal and financial risks associated with the side effects of therapeutic product X, and how might they affect the company’s long-term stock performance?”
(Below image depicts the roles of supervisor agent and the 3 subagents being used in our pharmaceutical example along with the benefits of using Multi Agent Collaboration. )

Our use case centers around PharmaCorp, a fictional pharmaceutical company, which faces the challenge of managing vast amounts of data across its Pharma R&D, Legal, and Finance divisions. Each division works with structured data, such as stock prices, and unstructured data, such as clinical trial reports. The data for each division is located in different data stores, which makes it difficult for teams to access cross-functional insights and slows down decision-making processes.
To address this, we build a multi-agent system with domain-specific sub-agents for each division using multi-agent collaboration within Amazon Bedrock Agents. These sub-agents efficiently handle data queries and information retrieval, and the main agent passes necessary context between sub-agents and synthesizes insights across divisions. The multi-agent setup empowers PharmaCorp to access expertise and information within minutes that would otherwise take hours of human effort to compile. This approach breaks down data silos and strengthens organizational collaboration.
The following architecture diagram illustrates the solution setup.

The main agent acts as an orchestrator, asking questions to multiple sub-agents and synthesizing retrieved data:
Each sub-agent has granular permissions to only access the data in its domain. Detailed information about the data and models used and main agent interactions are described in the following sections.
We generated synthetic data using Anthropic’s Claude 3.5 Sonnet model, comprised of three domains: Pharma R&D, Legal, and Finance. The domains contain structured data stored in SQL tables and unstructured data that is used in domain knowledge bases. The data can be accessed through the following files: R&D, Legal, Finance.
Efforts have been made to align synthetic data within and across domains. For example, clinical trial reports map to each trial and side effects in related tables. Rises and dips in stock prices tend to correlate with patents and lawsuits. However, there might still be minor inconsistencies between data.
The Pharma R&D domain has three tables: Drugs, Drug Trials, and Side Effects. Each table is queried from Amazon Simple Storage Service (Amazon S3) through Athena. The Drugs table contains information on the company’s available products, therapeutic areas, target conditions, mechanisms of action, development phase, discovery year, and lead scientist. The Drug Trials table contains information on specific trials for each drug such as phase, dates, number of participations, and outcomes. The Side Effects table contains side effects, frequency, and severity reported from each trial.
The unstructured data for the Pharma R&D domain consists of synthetic clinical trial reports for each trial, which contain more detailed information about the trial design, outcomes, and recommendations.
The Legal domain has unstructured data consisting of patents and lawsuit legal briefs. The patents contain information about invention background, description, and experimental results. The legal briefs contain information about lawsuit court proceedings, outcomes, and analysis.
The Finance domain has two tables: Stock Price and Research Budgets. The Stock Price table is stored in Amazon Redshift and contains PharmaCorp’s historical monthly stock prices and volume. Amazon Redshift is a database optimized for online analytical processing (OLAP), which generally entails analyzing large amounts of data and performing complex analysis, as might be done by analysts looking at historical stock prices. The Research Budgets table is accessed from Amazon S3 through Athena and contains annual budgets for each department.
The data setup showcases how a multi-agent framework can synthesize data from multiple data sources and databases. In practice, data could also be stored in other databases such as Amazon Relational Database Service (Amazon RDS).
Anthropic’s Claude 3 Sonnet, which has a good balance of intelligence and speed, is used in this multi-agent demonstration. With the multi-agent setup, you can also employ a more intelligent or a smaller, faster model depending on the use case and requirements such as accuracy and latency.
To deploy this solution, you need the following prerequisites:
To deploy the solution resources, we use AWS CloudFormation. The CloudFormation template creates two S3 buckets, two AWS Lambda functions, an Amazon Bedrock agent, an Amazon Bedrock knowledge base, and an Amazon Elastic Compute Cloud (Amazon EC2) instance.
Download the provided CloudFormation template, then complete the following steps to deploy the stack:
us-west-2 or us-east-1 for the solution).After the stack is complete, you can view the new supervisor agent on the Amazon Bedrock console.
After you deploy the solution, you can test the communication among agents that help answer complex questions across PharmaCorp’s three divisions. For example, we ask the main agent “How did the results of NeuroClear’s Phase 2 trials affect PharmaCorp’s stock price, patent filings, and potential legal risks?”
This question requires a comprehensive understanding of the relationships between NeuroClear’s clinical trial results, financial impacts, and legal outcomes for PharmaCorp. Let’s see how the multi-agent system addresses this complex query.
The main agent identifies that it needs input from three specialized sub-agents to fully assess how NeuroClear’s clinical trial results might impact PharmaCorp’s legal and financial performance. It breaks down the user’s question into key components and develops a plan to gather detailed insights from each expert. The following is its chain-of-thought reasoning, task breakdown, and sub-agent routing:
Then, the main agent asks a question to the R&D sub-agent:
The R&D sub-agent correctly plans and executes its own sequence of steps, which include performing queries and searching its own knowledge base. It responds with the following:
The main agent takes this information and determines its next step:
It asks the finance sub-agent the following:
Through this example, we can see how multi-agent collaboration enables a comprehensive analysis of complex business questions by using specialized knowledge from different domains. The main agent effectively orchestrates the interaction between sub-agents, synthesizing their insights to provide a holistic answer that considers R&D, financial, and legal aspects of the NeuroClear clinical trials and their potential impacts on PharmaCorp.
When you’re done testing the agent, complete the following steps to clean up your AWS environment and avoid unnecessary charges:
structured-data-${AWS::AccountId}-${AWS::Region} and unstructured-data-${AWS::AccountId}-${AWS::Region}. Make sure that both of these buckets are empty by deleting the files.CopyDataLambda function.CopyUnstructuredDataLambda function.Implementing this multi-agent system using Amazon Bedrock Agents can provide significant benefits for pharmaceutical companies. By automating data retrieval and analysis across domains, companies can reduce research time and enable faster, data-driven decision-making, especially when domain experts are distributed across different organizational units with limited direct interaction. The system’s ability to provide comprehensive, cross-functional insights in minutes can lead to improved risk mitigation, because potential legal and financial issues can be identified earlier by connecting disparate data points. This automation also allows for more effective allocation of human resources, freeing up experts to focus on high-value tasks rather than routine data analysis.
Our example demonstrates the power of multi-agent systems in pharmaceutical research and development, but the applications of this technology extend far beyond a single use case. For example, biotech companies can accelerate the discovery of cancer biomarkers by having specialist agents extract genomic signals from Amazon Redshift, perform Kaplan-Meier survival analyses, and interpret CT scans in parallel. Large health systems could automatically aggregate patient records, lab results, and trial data to streamline care coordination and flag urgent cases. Travel agencies can orchestrate end‑to‑end itineraries, and firms can manage personalized client communications. For more information on potential applications, see the following posts:
Although the potential of multi-agent systems is compelling across these diverse applications, it’s important to understand the practical considerations in implementing such systems. Complex orchestration workflows can drive up inference costs through multiple model calls, increase end‑to‑end latency, amplify testing and maintenance requirements, and introduce operational overhead around rate limits, retries, and inter‑agent or data connection protocols. However, the state of the art is rapidly advancing. New generations of faster, cheaper models can help keep per‑call expenses and latency low, and more powerful models can accomplish tasks in fewer turns. Observability tools offer end‑to‑end tracing and dashboarding for multi‑agent pipelines. Finally, protocols like Anthropic’s Model Context Protocol are beginning to standardize the way agents access data, paving the way for robust multi‑agent ecosystems.
In this post, we explored how a multi-agent generative AI system, implemented with Amazon Bedrock Agents using multi-agent collaboration, addresses data access and analysis challenges across multiple business domains. Through a demo use case with a fictional pharmaceutical company managing data across its different divisions, we showcased how specialized sub-agents tailored to each domain streamline information retrieval and synthesis. Each sub-agent uses domain-optimized models and securely accesses relevant data sources, enabling the organization to generate cross-functional insights.
With this multi-agent architecture, organizations can overcome data silos, enhance collaboration, and achieve efficient, data-driven decision-making while optimizing for cost, latency, and security. Amazon Bedrock Agents with multi-agent collaboration facilitates this setup by providing a secure, scalable framework that manages the collaboration, communication, and task delegation between agents. Explore other demos and workshops about multi-agent collaboration in Amazon Bedrock in the following resources:
 Justin Ossai is a GenAI Labs Specialist Solutions Architect based in Dallas, TX. He is a highly passionate IT professional with over 15 years of technology experience. He has designed and implemented solutions with on-premises and cloud-based infrastructure for small and enterprise companies.
Justin Ossai is a GenAI Labs Specialist Solutions Architect based in Dallas, TX. He is a highly passionate IT professional with over 15 years of technology experience. He has designed and implemented solutions with on-premises and cloud-based infrastructure for small and enterprise companies.
 Michael Hsieh is a Principal AI/ML Specialist Solutions Architect. He works with HCLS customers to advance their ML journey with AWS technologies and his expertise in medical imaging. As a Seattle transplant, he loves exploring the great mother nature the city has to offer, such as the hiking trails, scenery kayaking in the SLU, and the sunset at Shilshole Bay.
Michael Hsieh is a Principal AI/ML Specialist Solutions Architect. He works with HCLS customers to advance their ML journey with AWS technologies and his expertise in medical imaging. As a Seattle transplant, he loves exploring the great mother nature the city has to offer, such as the hiking trails, scenery kayaking in the SLU, and the sunset at Shilshole Bay.
 Shreya Mohanty is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she partners with customers across industries to design and implement high-impact GenAI-powered solutions. She specializes in translating customer goals into tangible outcomes that drive measurable impact.
Shreya Mohanty is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she partners with customers across industries to design and implement high-impact GenAI-powered solutions. She specializes in translating customer goals into tangible outcomes that drive measurable impact.
 Rachel Hanspal is a Deep Learning Architect at AWS Generative AI Innovation Center, specializing in end-to-end GenAI solutions with a focus on frontend architecture and LLM integration. She excels in translating complex business requirements into innovative applications, leveraging expertise in natural language processing, automated visualization, and secure cloud architectures.
Rachel Hanspal is a Deep Learning Architect at AWS Generative AI Innovation Center, specializing in end-to-end GenAI solutions with a focus on frontend architecture and LLM integration. She excels in translating complex business requirements into innovative applications, leveraging expertise in natural language processing, automated visualization, and secure cloud architectures.


In the race to accelerate large language models across diverse AI hardware, FlagGems delivers a high-performance, flexible, and scalable solution. Built on Triton language, FlagGems is a plugin-based PyTorch operator and kernel library designed to democratize AI compute. Its mission: to enable a write-once, JIT-everywhere experience, so developers can deploy optimized kernels effortlessly across a wide spectrum of hardware backends. FlagGems recently joined the PyTorch Ecosystem upon acceptance by the PyTorch Ecosystem Working Group.
With over 180 operators already implemented—spanning native PyTorch ops and widely used custom ops for large models—FlagGems is evolving fast to keep pace with the generative AI frontier.
To view the PyTorch Ecosystem, see the PyTorch Landscape and learn more about how projects can join the PyTorch Ecosystem.
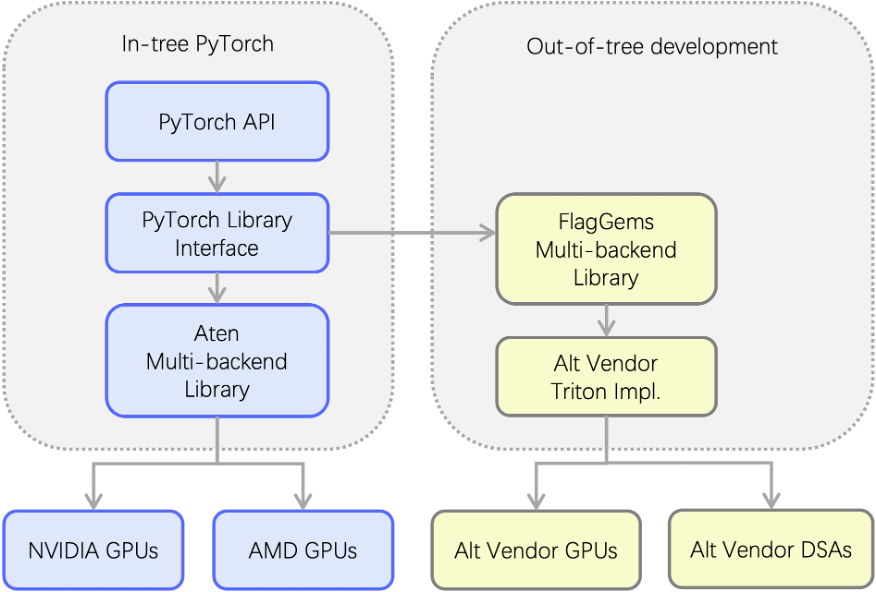
FlagGems extends the PyTorch dispatch system out-of-tree through a multi-backend library powered by Triton. It intercepts ATen operator calls and provides backend-specific Triton implementations, making it easy to support alternative GPUs and domain-specific accelerators (DSAs).
Plug-and-Play
Write Once, Compile Anywhere
pip install torch>=2.2.0 # 2.6.0 preferred pip install triton>=2.2.0 # 3.2.0 preferred
git clone https://github.com/FlagOpen/FlagGems.git cd FlagGems pip install --no-build-isolation . or editable install: pip install --no-build-isolation -e .
import flag_gems flag_gems.enable() # Replaces supported PyTorch ops globally
Prefer finer control? Use a managed context:
with flag_gems.use_gems(): output = model.generate(**inputs)
Need explicit ops?
out = flag_gems.ops.slice_scatter(inp, dim=0, src=src, start=0, end=10, step=1)
With the @pointwise_dynamic decorator, FlagGems can auto-generate efficient kernels with broadcast, fusion, and memory layout support. Here’s an example implementing fused GeLU and element-wise multiplication:
@pointwise_dynamic(promotion_methods=[(0, 1, “DEFAULT”)]) @triton.jit
def gelu_tanh_and_mul_kernel(x, y): x_fp32 = x.to(tl.float32) x_gelu = 0.5 * x_fp32 * (1 + tanh(x_fp32 * 0.79788456 * (1 + 0.044715 * pow(x_fp32, 2)))) return x_gelu * y
FlagGems includes built-in testing and benchmarking:
cd tests pytest test_<op_name>_ops.py --ref cpu
cd benchmark pytest test_<op_name>_perf.py -s # CUDA microbenchmarks pytest test_<op_name>_perf.py -s --mode cpu # End-to-end comparison
Benchmark Results
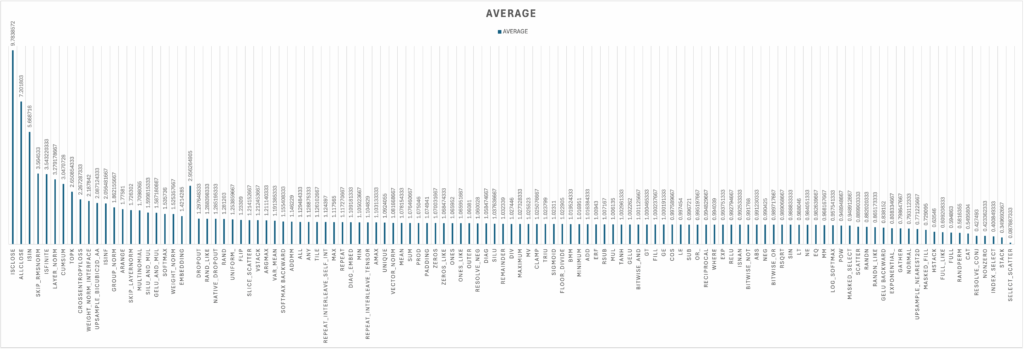
Initial benchmark results of FlagGems showcase its performance against PyTorch’s native operator implementations. The results represent the average measured speedups, a value greater than 1 indicating that FlagGems is faster than the native PyTorch operator. For a vast majority of operators, FlagGems either matches or significantly surpasses the performance of PyTorch’s native implementations.
For a significant portion of the 180+ operators, FlagGems achieves a speedup close to 1.0, indicating performance on par with the native PyTorch implementations.
Some of the core operations like LAYERNORM, CROSS_ENTROPY_LOSS, ADDMM and SOFTMAX also show impressive speedups.
FlagGems is vendor-flexible and backend-aware:
Set the desired backend with:
export GEMS_VENDOR=<vendor>
Check active backend in Python:
import flag_gems print(flag_gems.vendor_name)

FlagGems delivers a unified kernel library for large models acceleration that bridges software portability and hardware performance. With broad backend support, a growing op set, and advanced codegen features, it’s your go-to Triton playground for pushing the limits of AI compute.
Amazon operations span the globe, touching the lives of millions of customers, employees, and vendors every day. From the vast logistics network to the cutting-edge technology infrastructure, this scale is a testament to the company’s ability to innovate and serve its customers. With this scale comes a responsibility to manage risks and address claims—whether they involve worker’s compensation, transportation incidents, or other insurance-related matters. Risk managers oversee claims against Amazon throughout their lifecycle. Claim documents from various sources grow as the claims mature, with a single claim consisting of 75 documents on average. Risk managers are required to strictly follow the relevant standard operating procedure (SOP) and review the evolution of dozens of claim aspects to assess severity and to take proper actions, reviewing and addressing each claim fairly and efficiently. But as Amazon continues to grow, how are risk managers empowered to keep up with the growing number of claims?
In December 2024, an internal technology team at Amazon built and implemented an AI-powered solution as applied to data related to claims against the company. This solution generates structured summaries of claims under 500 words across various categories, improving efficiency while maintaining accuracy of the claims review process. However, the team faced challenges with high inference costs and processing times (3–5 minutes per claim), particularly as new documents are added. Because the team plans to expand this technology to other business lines, they explored Amazon Nova Foundation Models as potential alternatives to address cost and latency concerns.
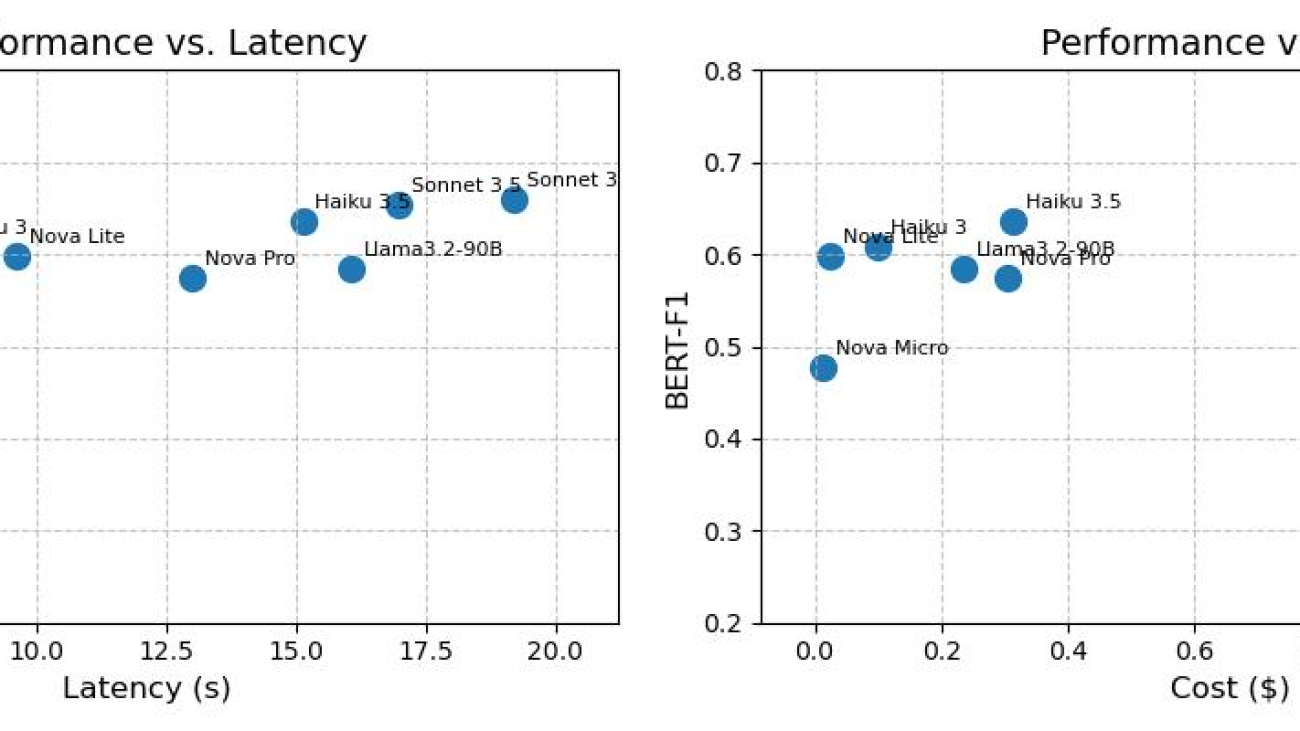
The following graphs show performance compared with latency and performance compared with cost for various foundation models on the claim dataset.

The evaluation of the claims summarization use case proved that Amazon Nova foundation models (FMs) are a strong alternative to other frontier large language models (LLMs), achieving comparable performance with significantly lower cost and higher overall speed. The Amazon Nova Lite model demonstrates strong summarization capabilities in the context of long, diverse, and messy documents.
The summarization pipeline begins by processing raw claim data using AWS Glue jobs. It stores data into intermediate Amazon Simple Storage Service (Amazon S3) buckets, and uses Amazon Simple Queue Service (Amazon SQS) to manage summarization jobs. Claim summaries are generated by AWS Lambda using foundation models hosted in Amazon Bedrock. We first filter the irrelevant claim data using an LLM-based classification model based on Nova Lite and summarize only the relevant claim data to reduce the context window. Considering relevance and summarization requires different levels of intelligence, we select the appropriate models to optimize cost while maintaining performance. Because claims are summarized upon arrival of new information, we also cache the intermediate results and summaries using Amazon DynamoDB to reduce duplicate inference and reduce cost. The following image shows a high-level architecture of the claim summarization use case solution.

Although the Amazon Nova team has published performance benchmarks across several different categories, claims summarization is a unique use case given its diversity of inputs and long context windows. This prompted the technology team owning the claims solution to investigate further with their own benchmarking study. To assess the performance, speed, and cost of Amazon Nova models for their specific use case, the team curated a benchmark dataset consisting of 95 pairs of claim documents and verified aspect summaries. Claim documents range from 1,000 to 60,000 words, with most being around 13,000 words (median 10,100). The verified summaries of these documents are usually brief, containing fewer than 100 words. Inputs to the models include diverse types of documents and summaries that cover a variety of aspects in production.
According to benchmark tests, the team observed that Amazon Nova Lite is twice as fast and costs 98% less than their current model. Amazon Nova Micro is even more efficient, running four times faster and costing 99% less. The substantial cost-effectiveness and latency improvements offer more flexibility for designing a sophisticated model and scaling up test compute to improve summary quality. Moreover, the team also observed that the latency gap between Amazon Nova models and the next best model widened for long context windows and long output, making Amazon Nova a stronger alternative in the case of long documents while optimizing for latency. Additionally, the team performed this benchmarking study using the same prompt as the current in-production solution with seamless prompt portability. Despite this, Amazon Nova models successfully followed instructions and generated the desired format for post-processing. Based on the benchmarking and evaluation results, the team used Amazon Nova Lite for classification and summarization use cases.
In this post, we shared how an internal technology team at Amazon evaluated Amazon Nova models, resulting in notable improvements in inference speed and cost-efficiency. Looking back on the initiative, the team identified several critical factors that offer key advantages:
If your organization has a similar use case of large document processing that is costly and time-consuming, the above evaluation exercise shows that Amazon Nova Lite and Amazon Nova Micro can be game-changing. These models excel at handling large volumes of diverse documents and long context windows—perfect for complex data processing environments. What makes this particularly compelling is the models’ ability to maintain high performance while significantly reducing operational costs. It’s important to iterate over new models for all three pillars—quality, cost, and speed. Benchmark these models with your own use case and datasets.
You can get started with Amazon Nova on the Amazon Bedrock console. Learn more at the Amazon Nova product page.
 Aitzaz Ahmad is an Applied Science Manager at Amazon, where he leads a team of scientists building various applications of machine learning and generative AI in finance. His research interests are in natural language processing (NLP), generative AI, and LLM agents. He received his PhD in electrical engineering from Texas A&M University.
Aitzaz Ahmad is an Applied Science Manager at Amazon, where he leads a team of scientists building various applications of machine learning and generative AI in finance. His research interests are in natural language processing (NLP), generative AI, and LLM agents. He received his PhD in electrical engineering from Texas A&M University.
 Stephen Lau is a Senior Manager of Software Development at Amazon, leads teams of scientists and engineers. His team develops powerful fraud detection and prevention applications, saving Amazon billions annually. They also build Treasury applications that optimize Amazon global liquidity while managing risks, significantly impacting the financial security and efficiency of Amazon.
Stephen Lau is a Senior Manager of Software Development at Amazon, leads teams of scientists and engineers. His team develops powerful fraud detection and prevention applications, saving Amazon billions annually. They also build Treasury applications that optimize Amazon global liquidity while managing risks, significantly impacting the financial security and efficiency of Amazon.
 Yong Xie is an applied scientist in Amazon FinTech. He focuses on developing large language models and generative AI applications for finance.
Yong Xie is an applied scientist in Amazon FinTech. He focuses on developing large language models and generative AI applications for finance.
 Kristen Henkels is a Sr. Product Manager – Technical in Amazon FinTech, where she focuses on helping internal teams improve their productivity by leveraging ML and AI solutions. She holds an MBA from Columbia Business School and is passionate about empowering teams with the right technology to enable strategic, high-value work.
Kristen Henkels is a Sr. Product Manager – Technical in Amazon FinTech, where she focuses on helping internal teams improve their productivity by leveraging ML and AI solutions. She holds an MBA from Columbia Business School and is passionate about empowering teams with the right technology to enable strategic, high-value work.
 Shivansh Singh is a Principal Solutions Architect at Amazon. He is passionate about driving business outcomes through innovative, cost-effective and resilient solutions, with a focus on machine learning, generative AI, and serverless technologies. He is a technical leader and strategic advisor to large-scale games, media, and entertainment customers. He has over 16 years of experience transforming businesses through technological innovations and building large-scale enterprise solutions.
Shivansh Singh is a Principal Solutions Architect at Amazon. He is passionate about driving business outcomes through innovative, cost-effective and resilient solutions, with a focus on machine learning, generative AI, and serverless technologies. He is a technical leader and strategic advisor to large-scale games, media, and entertainment customers. He has over 16 years of experience transforming businesses through technological innovations and building large-scale enterprise solutions.
 Dushan Tharmal is a Principal Product Manager – Technical on the Amazons Artificial General Intelligence team, responsible for the Amazon Nova Foundation Models. He earned his bachelor’s in mathematics at the University of Waterloo and has over 10 years of technical product leadership experience across financial services and loyalty. In his spare time, he enjoys wine, hikes, and philosophy.
Dushan Tharmal is a Principal Product Manager – Technical on the Amazons Artificial General Intelligence team, responsible for the Amazon Nova Foundation Models. He earned his bachelor’s in mathematics at the University of Waterloo and has over 10 years of technical product leadership experience across financial services and loyalty. In his spare time, he enjoys wine, hikes, and philosophy.
 Anupam Dewan is a Senior Solutions Architect with a passion for generative AI and its applications in real life. He and his team enable Amazon builders who build customer-facing applications using generative AI. He lives in the Seattle area, and outside of work, he loves to go hiking and enjoy nature.
Anupam Dewan is a Senior Solutions Architect with a passion for generative AI and its applications in real life. He and his team enable Amazon builders who build customer-facing applications using generative AI. He lives in the Seattle area, and outside of work, he loves to go hiking and enjoy nature.
In our earlier post, diffusion-fast, we showed how the Stable Diffusion XL (SDXL) pipeline can be optimized up to 3x using native PyTorch code. Back then, SDXL was an open SoTA pipeline for image generation. Quite unsurprisingly, a lot has changed since then, and it’s safe to say that Flux is now one of the most capable open-weight models in the space.
In this post, we’re excited to show how we enabled ~2.5x speedup on Flux.1-Schnell and Flux.1-Dev using (mainly) pure PyTorch code and a beefy GPU like H100.
If you cannot wait to get started with the code, you can find the repository here.
The pipelines shipped in the Diffusers library try to be as `torch.compile`-friendly as possible. This means:
Therefore, it already gives us a reasonable starting point. For this project, we took the same underlying principles used in the diffusion-fast project and applied them to the FluxPipeline. Below, we share an overview of the optimizations we applied (details in the repository):
Most of these optimizations are self-explanatory, barring these two:
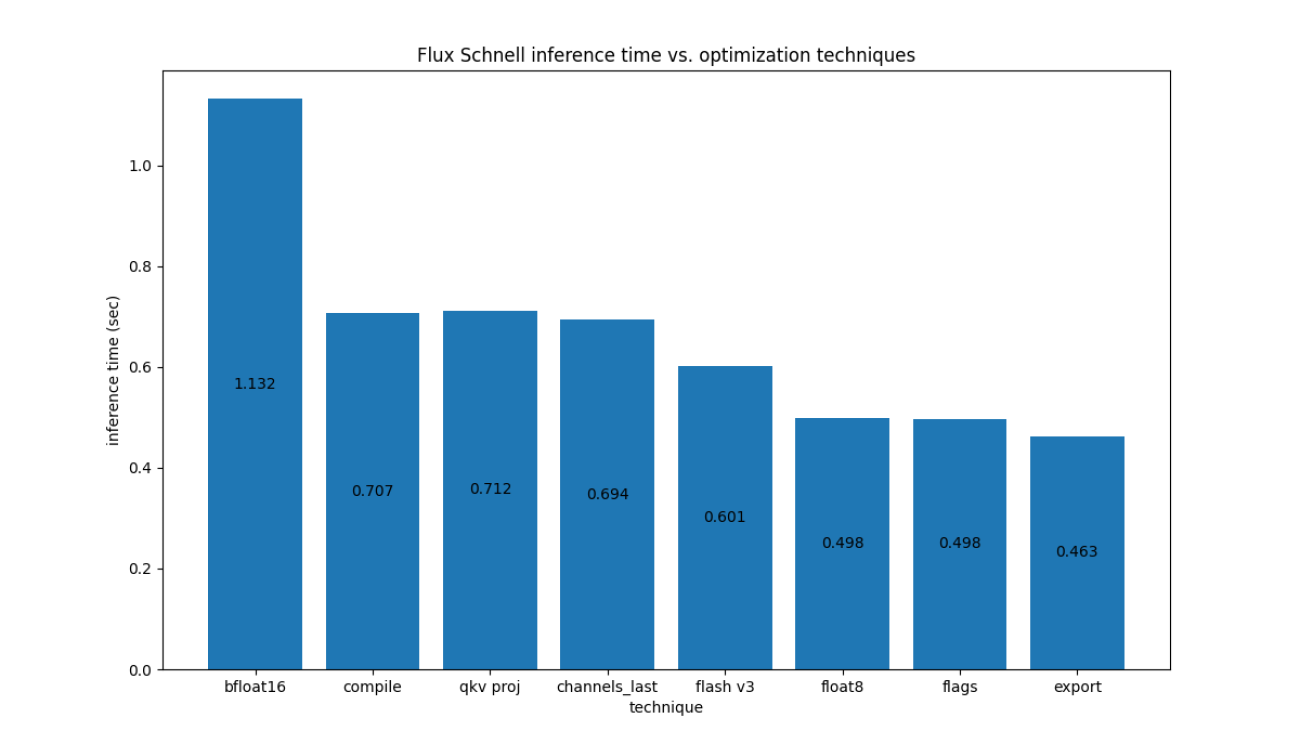
Unlike LLMs, diffusion models are heavily compute-bound, so optimizations from gpt-fast don’t exactly carry over here. The figure below shows the impact of each of the optimizations (applied incrementally from left-right) to Flux.1-Schnell on an H100 700W GPU:
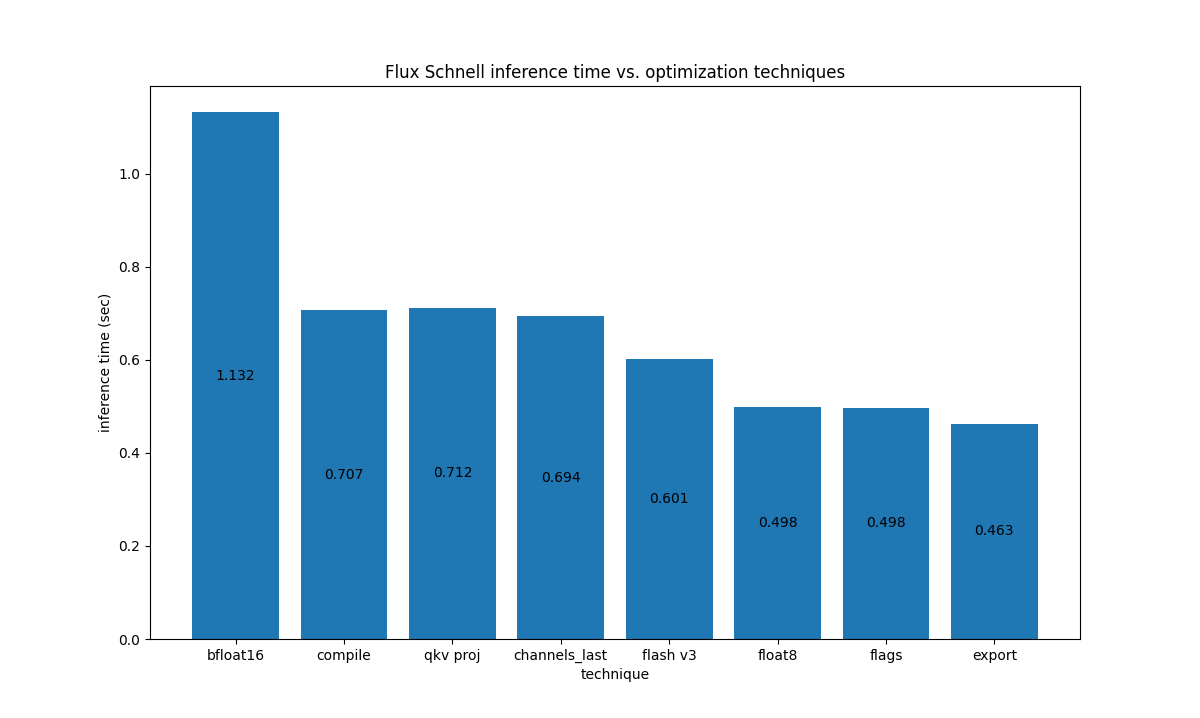 For Flux.1-Dev on H100, we have the following
For Flux.1-Dev on H100, we have the following
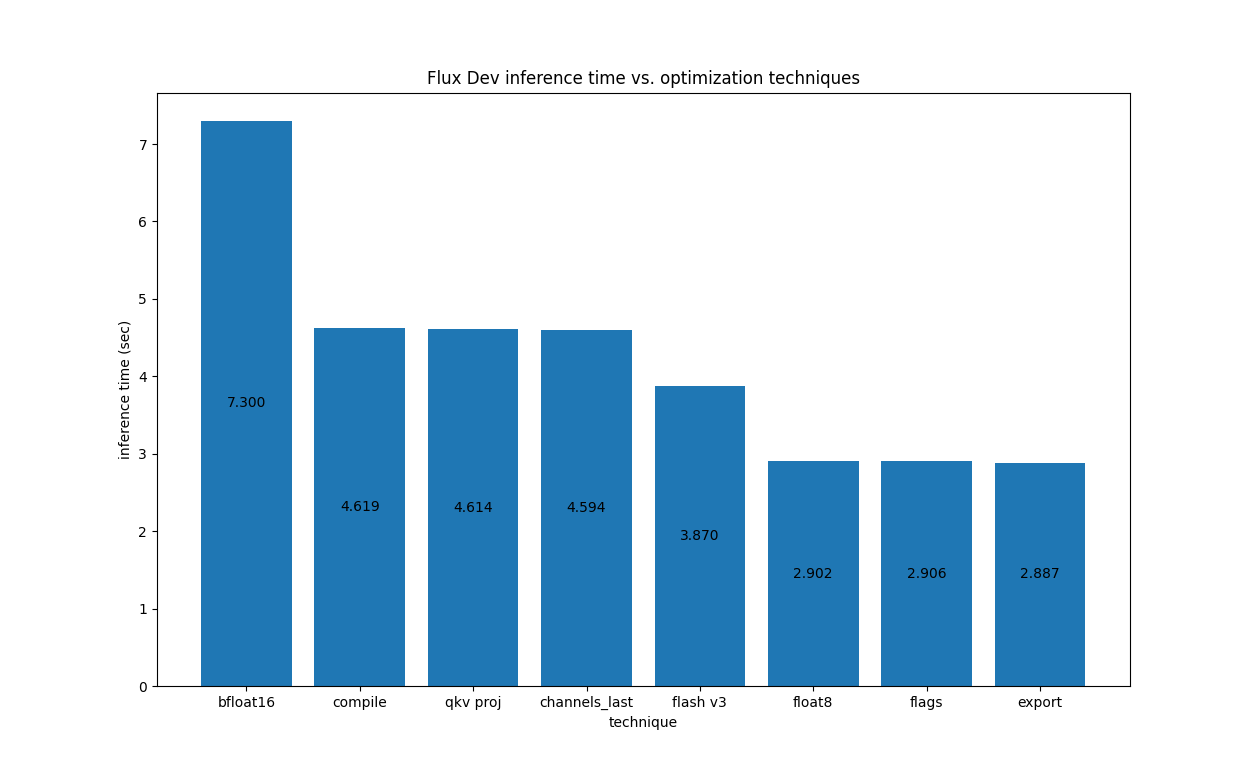 Below is a visual comparison of the images obtained with different optimizations applied to Flux.1-Dev:
Below is a visual comparison of the images obtained with different optimizations applied to Flux.1-Dev:

It should be noted that only FP8 quantization is lossy in nature so, for most of these optimizations, the image quality should stay identical. However, in this case, we see very negligible differences in the case of FP8.
During our investigations, we found out that at the first step of the denoising loop, there’s a CPU<->GPU sync point caused by this step in the scheduler. We could get rid of it by adding `self.scheduler.set_begin_index(0)` at the beginning of the denoising loop (PR).
It actually makes a bigger deal when torch.compile is used, since the CPU has to wait for the sync before it can do a Dynamo cache lookup and then launch instructions on the GPU, and this cache lookup is a bit slow. Hence, the takeaway message is that it’s always wise to profile your pipeline implementation and to try to eliminate these syncs as much as possible to benefit compilation.
The post went over a recipe to optimize Flux for Hopper architectures using native PyTorch code. The recipe tries to balance between simplicity and performance. Other kinds of optimizations are also likely possible (such as using fused MLP kernels and fused adaptive LayerNorm kernels), but for the purpose of simplicity, we didn’t go over them.
Another crucial point is that GPUs with the Hopper architecture are generally costly. So, to provide reasonable speed-memory trade-offs on consumer GPUs, there are other (often `torch.compile`-compatible) options available in the Diffusers library, too. We invite you to check them here and here.
We invite you to try these techniques out on other models and share the results. Happy optimizing!

Introducing a new, unifying DNA sequence model that advances regulatory variant-effect prediction and promises to shed new light on genome function — now available via API.Read More

 Free and open source, Gemini CLI brings Gemini directly into developers’ terminals — with unmatched access for individuals.Read More
Free and open source, Gemini CLI brings Gemini directly into developers’ terminals — with unmatched access for individuals.Read More
June 25, 09:00 AMJune 25, 09:00 AM
For most of the past 10 years, machine learning (ML) relied heavily on the concept of embedding: an ML model would learn to convert input data into vectors (embeddings) such that geometric relationships within the vector space had semantic implications. For instance, words whose embeddings were near each other in the representational space might have similar meanings.
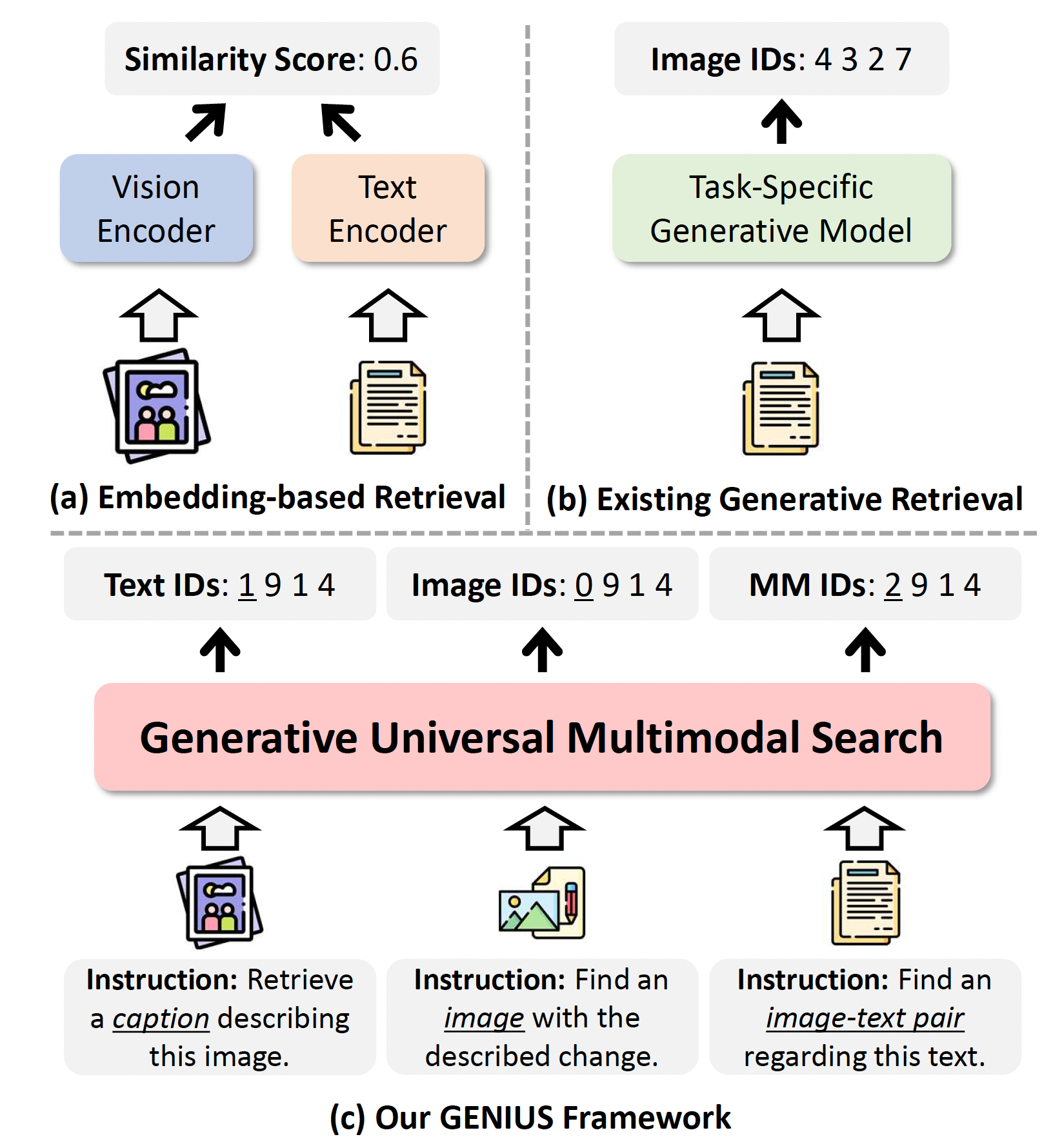
The concept of embedding implied an obvious information retrieval paradigm: a query would be embedded in the representational space, and the model would select the response whose embedding was closest to it. This worked with multimodal information retrieval, too, as text and images (or other modalities) could be embedded in the same space.
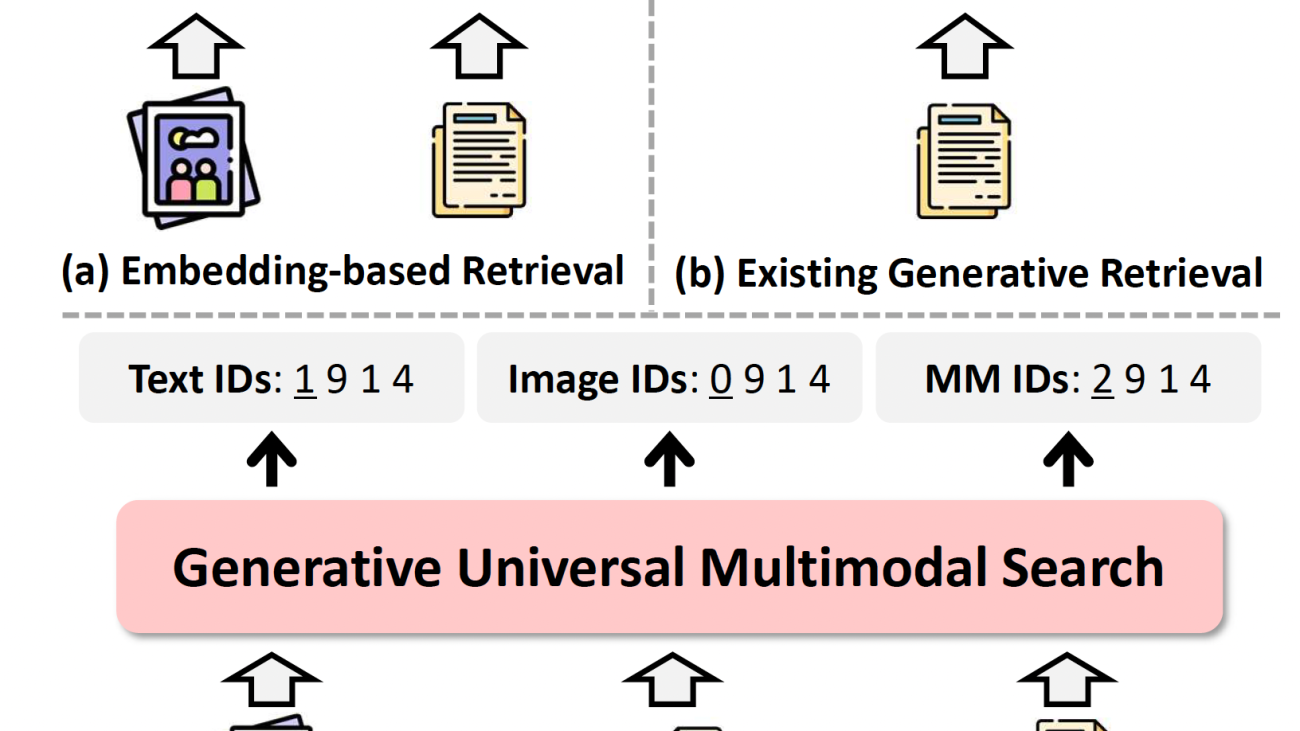
More recently, however, generative AI has come to dominate ML research, and at the 2025 Conference on Computer Vision and Pattern Recognition (CVPR), we presented a paper that updates ML-based information retrieval for the generative-AI era. Our model, dubbed GENIUS (for generative universal multimodal search), is a multimodal model whose inputs and outputs can be any combination of images, texts, or image-text pairs.
Instead of comparing a query vector to every possible response vector a time-consuming task, if the image catalogue or text corpus is large enough our model takes a query as input and generates a single ID code as output. This approach has been tried before, but GENIUS dramatically improves on previous generation-based information retrieval methods. In tests on two different datasets using three different metrics retrieval accuracy when one, five, or ten candidate responses are retrieved GENIUS improves on the best-performing prior generative retrieval model by 22% to 36%.
When we then use conventional embedding-based methods to rerank the top generated response candidates, we improve performance still further, by 31% to 56%, significantly narrowing the gap between generation-based methods and embedding-based methods.
Information retrieval (IR) is the process of finding relevant information from a large database. With traditional embedding-based retrieval, queries and database items are both mapped into a high-dimensional space, and similarity is measured using metrics like cosine similarity. While effective, these methods face scalability issues as the database grows, due to the increasing cost of index building, maintenance, and nearest-neighbor search.
Generative retrieval has emerged as a promising alternative. Instead of embedding items, generative models directly generate identifiers (IDs) of target data based on a query. This approach enables constant-time retrieval, regardless of database size. However, existing generative methods are often task specific, falling short in performance compared to embedding-based methods, and they struggle with multimodal data.
Unlike prior approaches that are limited to single-modality tasks or specific benchmarks, GENIUS generalizes across retrieval of texts, images, and image-text pairs, maintaining high speed and competitive accuracy. Its advantages over prior generation-based models are based on two key innovations:
Semantic quantization: During training, the models target output IDs are generated through residual quantization. Each ID is actually a sequence of codes, the first of which defines the data items modality image, text, or image-text pair. The successive codes define the data items region of the representational space with greater specificity: items that share the first code are in the same general area; items that share the first two codes are clustered more tightly in that area; items that share the first three codes are clustered more tightly still, and so on. The model tries to learn to reproduce the sequence of codes from the input encodings.
Query augmentation: This approach results in a model that can generate accurate ID codes for familiar types of objects and texts, but it can struggle to generalize to new data types. To address this limitation, we use query augmentation. For a representative sampling of query-ID pairs, we generate new queries by interpolating between the initial query and the target ID in the representational space. This way, the model learns that a variety of queries can map to the same target, which helps it generalize.

In experiments using the M-BEIR benchmark, GENIUS surpassed the best generative retrieval method by 28.6 points in Recall@5 on the COCO dataset for text-to-image retrieval. With embedding-based re-ranking, GENIUS often achieved results close to those of embedding-based baselines on the M-BEIR benchmark while preserving the efficiency benefits of generative retrieval.
GENIUS achieves state-of-the-art performance among generative methods and narrows the performance gap between generative and embedding-based methods. Its efficiency advantage becomes more significant as the dataset grows, maintaining high retrieval speed without the expensive index building typical of embedding-based methods. It thus represents a significant step forward in generative multimodal retrieval.
Research areas: Search and information retrieval
Tags: Generative AI

Today we are excited to introduce the Text Ranking and Question and Answer UI templates to SageMaker AI customers. The Text Ranking template enables human annotators to rank multiple responses from a large language model (LLM) based on custom criteria, such as relevance, clarity, or factual accuracy. This ranked feedback provides critical insights that help refine models through Reinforcement Learning from Human Feedback (RLHF), generating responses that better align with human preferences. The Question and Answer template facilitates the creation of high-quality Q&A pairs based on provided text passages. These pairs act as demonstration data for Supervised Fine-Tuning (SFT), teaching models how to respond to similar inputs accurately.
In this blog post, we’ll walk you through how to set up these templates in SageMaker to create high-quality datasets for training your large language models. Let’s explore how you can leverage these new tools.
The Text Ranking template allows annotators to rank multiple text responses generated by a large language model based on customizable criteria such as relevance, clarity, or correctness. Annotators are presented with a prompt and several model-generated responses, which they rank according to guidelines specific to your use case. The ranked data is captured in a structured format, detailing the re-ranked indices for each criterion, such as “clarity” or “inclusivity.” This information is invaluable for fine-tuning models using RLHF, aligning the model outputs more closely with human preferences. In addition, this template is also highly effective for evaluating the quality of LLM outputs by allowing you to see how well responses match the intended criteria.
A new Generative AI category has been added under Task Type in the SageMaker AI console, allowing you to select these templates. To configure the labeling job using the AWS Management Console, complete the following steps:
Here is an example of our input manifest file:

Upload this input manifest file into your S3 location and provide the S3 path to this file under Input dataset location:





When the annotators submit their evaluations, their responses are saved directly to your specified S3 bucket. The output manifest file includes the original data fields and a worker-response-ref that points to a worker response file in S3. This worker response file contains the ranked responses for each specified dimension, which can be used to fine-tune or evaluate your model’s outputs. If multiple annotators have worked on the same data object, their individual annotations are included within this file under an answers key, which is an array of responses. Each response includes the annotator’s input and metadata such as acceptance time, submission time, and worker ID. Here is an example of the output json file containing the annotations:

The Question and Answer template allows you to create datasets for Supervised Fine-Tuning (SFT) by generating question-and-answer pairs from text passages. Annotators read the provided text and create relevant questions and corresponding answers. This process acts as a source of demonstration data, guiding the model on how to handle similar tasks. The template supports flexible input, letting annotators reference entire passages or specific sections of text for more targeted Q&A. A color-coded matching feature visually links questions to the relevant sections, helping streamline the annotation process. By using these Q&A pairs, you enhance the model’s ability to follow instructions and respond accurately to real-world inputs.
The process for setting up a labeling job with the Question and Answer template follows similar steps as the Text Ranking template. However, there are differences in how you configure the input file and select the appropriate UI template to suit the Q&A task.
Here is an example of an input manifest file:

Upload this input manifest file into your S3 location and provide the S3 path to this file under Input dataset location


When annotators submit their work, their responses are saved directly to your specified S3 bucket. The output manifest file contains the original data fields along with a worker-response-ref that points to the worker response file in S3. This worker response file includes the detailed annotations provided by the workers, such as the ranked responses or question-and-answer pairs generated for each task.
Here’s an example of what the output might look like:

CreateLabelingJob API
In addition to creating these labeling jobs through the Amazon SageMaker AI console, customers can also use the Create Labeling Job API to set up Text Ranking and Question and Answer jobs programmatically. This method provides more flexibility for automation and integration into existing workflows. Using the API, you can define job configurations, input manifests, and worker task templates, and monitor the job’s progress directly from your application or system.
For a step-by-step guide on how to implement this, you can refer to the following notebooks, which walk through the entire process of setting up Human-in-the-Loop (HITL) workflows for Reinforcement Learning from Human Feedback (RLHF) using both the Text Ranking and Question and Answer templates. These notebooks will guide you through setting up the required Ground Truth pre-requisites, downloading sample JSON files with prompts and responses, converting them to Ground Truth input manifests, creating worker task templates, and monitoring the labeling jobs. They also cover post-processing the results to create a consolidated dataset with ranked responses.
With the introduction of the Text Ranking and Question and Answer templates, Amazon SageMaker AI empowers customers to generate high-quality datasets for training large language models more efficiently. These built-in capabilities simplify the process of fine-tuning models for specific tasks and aligning their outputs with human preferences, whether through supervised fine-tuning or reinforcement learning from human feedback. By leveraging these templates, you can better evaluate and refine your models to meet the needs of your specific application, helping achieve more accurate, reliable, and user-aligned outputs. Whether you’re creating datasets for training or evaluating your models’ outputs, SageMaker AI provides the tools you need to succeed in building state-of-the-art generative AI solutions.To begin creating fine-tuning datasets with the new templates:
 Sundar Raghavan is a Generative AI Specialist Solutions Architect at AWS, helping customers use Amazon Bedrock and next-generation AWS services to design, build and deploy AI agents and scalable generative AI applications. In his free time, Sundar loves exploring new places, sampling local eateries and embracing the great outdoors.
Sundar Raghavan is a Generative AI Specialist Solutions Architect at AWS, helping customers use Amazon Bedrock and next-generation AWS services to design, build and deploy AI agents and scalable generative AI applications. In his free time, Sundar loves exploring new places, sampling local eateries and embracing the great outdoors.
 Jesse Manders is a Senior Product Manager on Amazon Bedrock, the AWS Generative AI developer service. He works at the intersection of AI and human interaction with the goal of creating and improving generative AI products and services to meet our needs. Previously, Jesse held engineering team leadership roles at Apple and Lumileds, and was a senior scientist in a Silicon Valley startup. He has an M.S. and Ph.D. from the University of Florida, and an MBA from the University of California, Berkeley, Haas School of Business.
Jesse Manders is a Senior Product Manager on Amazon Bedrock, the AWS Generative AI developer service. He works at the intersection of AI and human interaction with the goal of creating and improving generative AI products and services to meet our needs. Previously, Jesse held engineering team leadership roles at Apple and Lumileds, and was a senior scientist in a Silicon Valley startup. He has an M.S. and Ph.D. from the University of Florida, and an MBA from the University of California, Berkeley, Haas School of Business.
 Niharika Jayanti is a Front-End Engineer at Amazon, where she designs and develops user interfaces to delight customers. She contributed to the successful launch of LLM evaluation tools on Amazon Bedrock and Amazon SageMaker Unified Studio. Outside of work, Niharika enjoys swimming, hitting the gym and crocheting.
Niharika Jayanti is a Front-End Engineer at Amazon, where she designs and develops user interfaces to delight customers. She contributed to the successful launch of LLM evaluation tools on Amazon Bedrock and Amazon SageMaker Unified Studio. Outside of work, Niharika enjoys swimming, hitting the gym and crocheting.
 Muyun Yan is a Senior Software Engineer at Amazon Web Services (AWS) SageMaker AI team. With over 6 years at AWS, she specializes in developing machine learning-based labeling platforms. Her work focuses on building and deploying innovative software applications for labeling solutions, enabling customers to access cutting-edge labeling capabilities. Muyun holds a M.S. in Computer Engineering from Boston University.
Muyun Yan is a Senior Software Engineer at Amazon Web Services (AWS) SageMaker AI team. With over 6 years at AWS, she specializes in developing machine learning-based labeling platforms. Her work focuses on building and deploying innovative software applications for labeling solutions, enabling customers to access cutting-edge labeling capabilities. Muyun holds a M.S. in Computer Engineering from Boston University.
 Kavya Kotra is a Software Engineer on the Amazon SageMaker Ground Truth team, helping build scalable and reliable software applications. Kavya played a key role in the development and launch of the Generative AI Tools on SageMaker. Previously, Kavya held engineering roles within AWS EC2 Networking, and Amazon Audible. In her free time, she enjoys painting, and exploring Seattle’s nature scene.
Kavya Kotra is a Software Engineer on the Amazon SageMaker Ground Truth team, helping build scalable and reliable software applications. Kavya played a key role in the development and launch of the Generative AI Tools on SageMaker. Previously, Kavya held engineering roles within AWS EC2 Networking, and Amazon Audible. In her free time, she enjoys painting, and exploring Seattle’s nature scene.
 Alan Ismaiel is a software engineer at AWS based in New York City. He focuses on building and maintaining scalable AI/ML products, like Amazon SageMaker Ground Truth and Amazon Bedrock. Outside of work, Alan is learning how to play pickleball, with mixed results.
Alan Ismaiel is a software engineer at AWS based in New York City. He focuses on building and maintaining scalable AI/ML products, like Amazon SageMaker Ground Truth and Amazon Bedrock. Outside of work, Alan is learning how to play pickleball, with mixed results.