
Artificial intelligence is advancing across a wide range of fields, with one of the most important developments being its growing capacity for reasoning. This capability could help AI becomes a reliable partner in critical domains like scientific research and healthcare.
To support this progress, we’ve identified three primary strategies to strengthen reasoning capabilities in both small and large language models: improve architectural design to boost performance in smaller models; incorporate mathematical reasoning techniques to increase reliability; and build stronger generalization capabilities to enable reasoning across a variety of fields.
Smarter reasoning in smaller models
While language models trained on broad world knowledge hold great potential, they lack the ability to learn continuously and refine their understanding. This limitation becomes especially pronounced in smaller models, where limited capacity makes strong reasoning even harder.
The problem stems from how current language models operate. They rely on fast, pattern recognition-based responses that break down in complex scenarios. In contrast, people use deliberate, step-by-step reasoning, test different approaches, and evaluate outcomes. To address this gap, we’re building methods to enable stronger reasoning in smaller systems.
rStar-Math is a method that uses Monte Carlo Tree Search (MCTS) to simulate deeper, more methodical reasoning in smaller models. It uses a three-step, self-improving cycle:
- Problem decomposition breaks down complex mathematical problems into manageable steps, creating a thorough and accurate course of reasoning.
- Process preference model (PPM) trains small models to predict reward labels for each step, improving process-level supervision.
- Iterative refinement applies a four-round, self-improvement cycle in which updated strategy models and PPMs guide MCTS to improve performance.
When tested on four small language models ranging from 1.5 billion to 7 billion parameters, rStar-Math achieved an average accuracy of 53% on the American Invitational Mathematics Examination (AIME)—performance that places it among the top 20% of high school competitors in the US.

Logic-RL is a reinforcement learning framework that strengthens logical reasoning through a practical system prompt and a structured reward function. By training models on logic puzzles, Logic-RL grants rewards only when both the reasoning process and the final answer meet strict formatting requirements. This prevents shortcuts and promotes analytical rigor.
Language models trained with Logic-RL demonstrate strong performance beyond logic puzzles, generalizing effectively to mathematical competition problems. On the AIME and AMC (American Mathematics Competitions) datasets, 7-billion-parameter models improved accuracy by 125% and 38%, respectively, compared with baseline models.
Building reliable mathematical reasoning
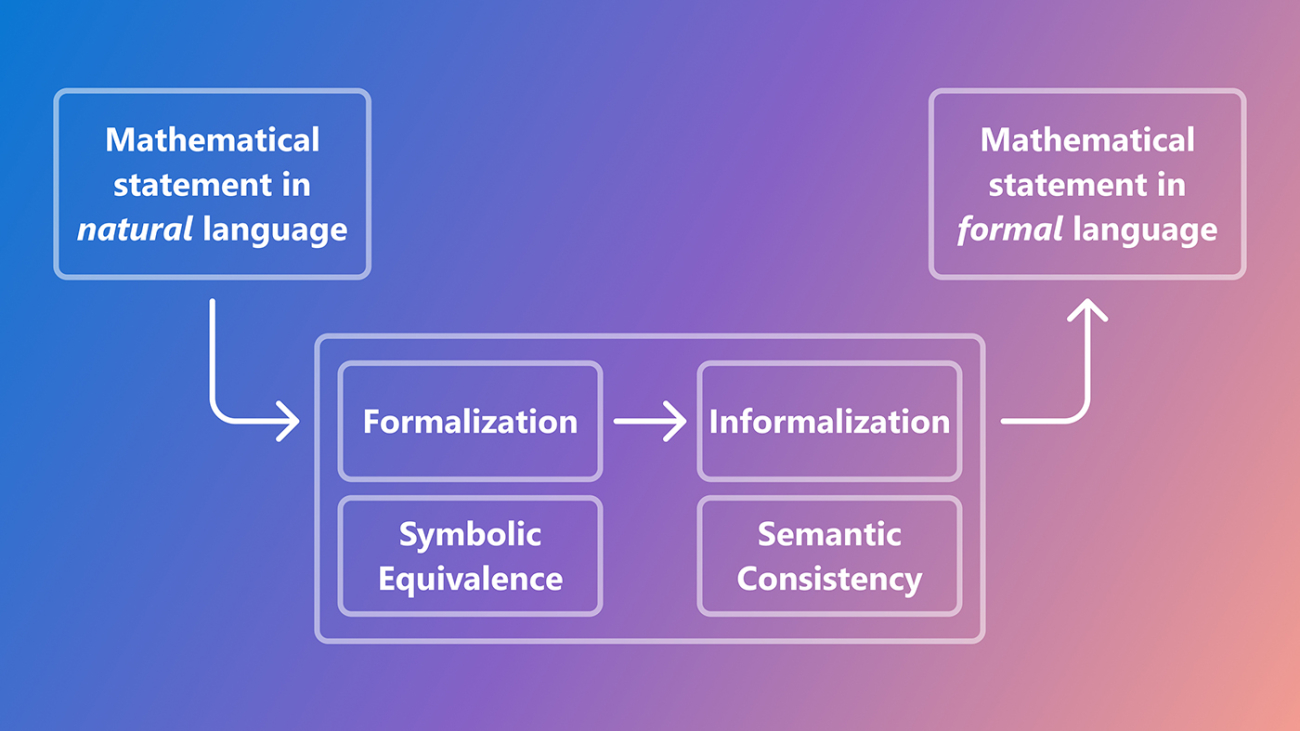
Mathematics poses a unique challenge for language models, which often struggle to meet its precision and rigor using natural language. To address this, we’re creating formal and symbolic methods to enable language models to adopt structured mathematical tools. The goal is to convert language model outputs into code based on the fundamental rules of arithmetic, like 1 + 1 = 2, allowing us to systematically verify accuracy.
LIPS (LLM-based Inequality Prover with Symbolic Reasoning) is a system that combines LLMs’ pattern recognition capabilities with symbolic reasoning. LIPS draws on the strategies participants in math competitions use in order to distinguish between tasks best suited to symbolic solvers (e.g., scaling) and those better handled by language models (e.g., rewriting). On 161 Olympiad-level problems, LIPS achieved state-of-the-art results without additional training data.

However, translating natural-language math problems into precise, machine-readable formats is a challenge. Our goal is to bridge the gap between the one-pass success rate, where the top-ranked generated result is correct, and the k-pass success rate, where at least one of the top k generated results is correct.
We developed a new framework using two evaluation methods. Symbolic equivalence checks whether outputs are logically identical, while semantic consistency uses embedding similarity to detect subtle differences missed by symbolic checks.
When we evaluated this approach on the MATH and miniF2F datasets, which include problems from various math competitions, it improved accuracy by up to 1.35 times over baseline methods.

To address the shortage of high-quality training data, we developed a neuro-symbolic framework that automatically generates diverse, well-structured math problems. Symbolic solvers create the problems, while language models translate them into natural language. This approach not only broadens training resources but also supports more effective instruction and evaluation of mathematical reasoning in language models.

Boosting generalization across domains
A key indicator of advanced AI is its ability to generalize—the ability to transfer reasoning skills across different domains. We found that training language models on math data significantly improved performance in coding, science, and other areas, revealing unexpected cross-domain benefits.
This discovery motivated us to develop Chain-of-Reasoning (CoR), an approach that unifies reasoning across natural language, code, and symbolic forms. CoR lets models blend these formats using natural language to frame context, code for precise calculations, and symbolic representations for abstraction. By adjusting prompts, CoR adapts both reasoning depth and paradigm diversity to match specific problem requirements.
Tests of CoR across five math datasets showed its ability to tackle both computational and proof-based problems, demonstrating strong general mathematical problem-solving skills.

Current language models often rely on domain-specific solutions, limiting their flexibility across different types of problems. To move beyond this constraint, we developed Critical Plan Step Learning (CPL), an approach focused on high-level abstract planning that teaches models to identify key knowledge, break down problems, and make strategic decisions.
The technique draws on how people solve problems, by breaking them down, identifying key information, and recalling relevant knowledge—strategies we want language models to learn.
CPL combines two key components: plan-based MCTS, which searches multi-step solution paths and constructs planning trees, and step-APO, which learns preferences for strong intermediate steps while filtering out weak ones. This combination enhances reasoning and improves generalization across tasks, moving AI systems closer to the flexible thinking that characterizes human intelligence.

Looking ahead: Next steps in AI reasoning
From building reliable math solvers to unifying reasoning approaches, researchers are redefining how language models approach complex tasks. Their work sets the stage for more capable and versatile AI systems—applicable to education, science, healthcare, and beyond. Despite these advances, hallucinations and imprecise logic continue to pose risks in critical fields like medicine and scientific research, where accuracy is essential.
These challenges are driving the team’s exploration of additional tools and frameworks to improve language model reasoning. This includes AutoVerus for automated proof generation in Rust code, SAFE for addressing data scarcity in Rust formal verification, and Alchemy, which uses symbolic mutation to improve neural theorem proving.
Together, these technologies represent important progress toward building trustworthy, high-performing reasoning models and signal a broader shift toward addressing some of AI’s current limitations.
The post New methods boost reasoning in small and large language models appeared first on Microsoft Research.





 Vicky Andonova is the GM of Generative AI at Anomalo, the company reinventing enterprise data quality. As a founding team member, Vicky has spent the past six years pioneering Anomalo’s machine learning initiatives, transforming advanced AI models into actionable insights that empower enterprises to trust their data. Currently, she leads a team that not only brings innovative generative AI products to market but is also building a first-in-class data quality monitoring solution specifically designed for unstructured data. Previously, at Instacart, Vicky built the company’s experimentation platform and led company-wide initiatives to grocery delivery quality. She holds a BE from Columbia University.
Vicky Andonova is the GM of Generative AI at Anomalo, the company reinventing enterprise data quality. As a founding team member, Vicky has spent the past six years pioneering Anomalo’s machine learning initiatives, transforming advanced AI models into actionable insights that empower enterprises to trust their data. Currently, she leads a team that not only brings innovative generative AI products to market but is also building a first-in-class data quality monitoring solution specifically designed for unstructured data. Previously, at Instacart, Vicky built the company’s experimentation platform and led company-wide initiatives to grocery delivery quality. She holds a BE from Columbia University. Jonathan Karon leads Partner Innovation at Anomalo. He works closely with companies across the data ecosystem to integrate data quality monitoring in key tools and workflows, helping enterprises achieve high-functioning data practices and leverage novel technologies faster. Prior to Anomalo, Jonathan created Mobile App Observability, Data Intelligence, and DevSecOps products at New Relic, and was Head of Product at a generative AI sales and customer success startup. He holds a BA in Cognitive Science from Hampshire College and has worked with AI and data exploration technology throughout his career.
Jonathan Karon leads Partner Innovation at Anomalo. He works closely with companies across the data ecosystem to integrate data quality monitoring in key tools and workflows, helping enterprises achieve high-functioning data practices and leverage novel technologies faster. Prior to Anomalo, Jonathan created Mobile App Observability, Data Intelligence, and DevSecOps products at New Relic, and was Head of Product at a generative AI sales and customer success startup. He holds a BA in Cognitive Science from Hampshire College and has worked with AI and data exploration technology throughout his career. Mahesh Biradar is a Senior Solutions Architect at AWS with a history in the IT and services industry. He helps SMBs in the US meet their business goals with cloud technology. He holds a Bachelor of Engineering from VJTI and is based in New York City (US)
Mahesh Biradar is a Senior Solutions Architect at AWS with a history in the IT and services industry. He helps SMBs in the US meet their business goals with cloud technology. He holds a Bachelor of Engineering from VJTI and is based in New York City (US) Emad Tawfik is a seasoned Senior Solutions Architect at Amazon Web Services, boasting more than a decade of experience. His specialization lies in the realm of Storage and Cloud solutions, where he excels in crafting cost-effective and scalable architectures for customers.
Emad Tawfik is a seasoned Senior Solutions Architect at Amazon Web Services, boasting more than a decade of experience. His specialization lies in the realm of Storage and Cloud solutions, where he excels in crafting cost-effective and scalable architectures for customers.












 Harsh Vardhan is a distinguished global leader in Business-first AI-first Digital Transformation with over two- decades of industry experience. As the Global Head of the Digital Innovation Hub at Apollo Tyres Limited, he leads industrialisation of AI-led Digital Manufacturing, Industry 4.0/5.0 excellence, and fostering enterprise-wide AI-first innovation culture. He is A+ contributor in field of Advanced AI with Arctic code vault badge, Strategic Intelligence member at World Economic Forum, and executive member of CII National Committee. He is an avid reader and loves to drive.
Harsh Vardhan is a distinguished global leader in Business-first AI-first Digital Transformation with over two- decades of industry experience. As the Global Head of the Digital Innovation Hub at Apollo Tyres Limited, he leads industrialisation of AI-led Digital Manufacturing, Industry 4.0/5.0 excellence, and fostering enterprise-wide AI-first innovation culture. He is A+ contributor in field of Advanced AI with Arctic code vault badge, Strategic Intelligence member at World Economic Forum, and executive member of CII National Committee. He is an avid reader and loves to drive. Gautam Kumar is a Solutions Architect at Amazon Web Services. He helps various Enterprise customers to design and architect innovative solutions on AWS. Outside work, he enjoys travelling and spending time with family.
Gautam Kumar is a Solutions Architect at Amazon Web Services. He helps various Enterprise customers to design and architect innovative solutions on AWS. Outside work, he enjoys travelling and spending time with family. Deepak Dixit is a Solutions Architect at Amazon Web Services, specializing in Generative AI and cloud solutions. He helps enterprises architect scalable AI/ML workloads, implement Large Language Models (LLMs), and optimize cloud-native applications.
Deepak Dixit is a Solutions Architect at Amazon Web Services, specializing in Generative AI and cloud solutions. He helps enterprises architect scalable AI/ML workloads, implement Large Language Models (LLMs), and optimize cloud-native applications.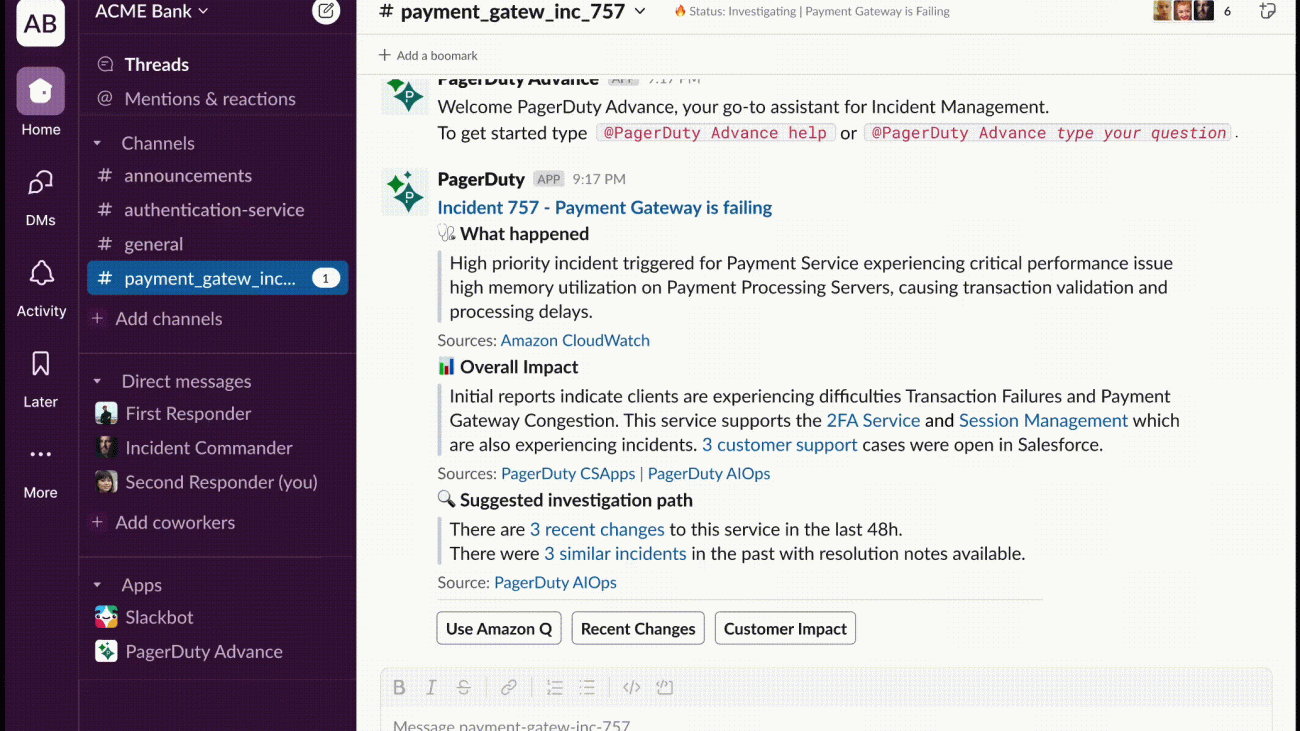









 Jacky Leybman is a Principal Product Manager at PagerDuty, leading the development of PagerDuty Advance and AI Agents. With over 19 years of experience in technology and product management, Jacky specializes in leading Agile cross-functional teams to develop and launch innovative digital products. Based in Miami, Florida, Jacky brings extensive expertise in product strategy, team leadership, and artificial intelligence implementations.
Jacky Leybman is a Principal Product Manager at PagerDuty, leading the development of PagerDuty Advance and AI Agents. With over 19 years of experience in technology and product management, Jacky specializes in leading Agile cross-functional teams to develop and launch innovative digital products. Based in Miami, Florida, Jacky brings extensive expertise in product strategy, team leadership, and artificial intelligence implementations. Takeshi Kobayashi is a Senior AI/ML Solutions Architect within the Amazon Q Business team, responsible for developing advanced AI/ML solutions for enterprise customers. With over 14 years of experience at Amazon in AWS, AI/ML, and technology, Takeshi is dedicated to leveraging generative AI and AWS services to build innovative solutions that address customer needs. Based in Seattle, WA, Takeshi is passionate about pushing the boundaries of artificial intelligence and machine learning technologies.
Takeshi Kobayashi is a Senior AI/ML Solutions Architect within the Amazon Q Business team, responsible for developing advanced AI/ML solutions for enterprise customers. With over 14 years of experience at Amazon in AWS, AI/ML, and technology, Takeshi is dedicated to leveraging generative AI and AWS services to build innovative solutions that address customer needs. Based in Seattle, WA, Takeshi is passionate about pushing the boundaries of artificial intelligence and machine learning technologies. Daniel Lopes is a Solutions Architect at AWS, where he partners with ISVs to architect solutions that align with their strategic objectives. He specializes in leveraging AWS services to help ISVs transform their product vision into reality, with particular expertise in event-driven architectures, serverless computing, and generative AI. Outside work, Daniel mentors his kids in video games and pop culture.
Daniel Lopes is a Solutions Architect at AWS, where he partners with ISVs to architect solutions that align with their strategic objectives. He specializes in leveraging AWS services to help ISVs transform their product vision into reality, with particular expertise in event-driven architectures, serverless computing, and generative AI. Outside work, Daniel mentors his kids in video games and pop culture.



























 Ajit Mahareddy is an experienced Product and Go-To-Market (GTM) leader with over 20 years of experience in Product Management, Engineering, and Go-To-Market. Prior to his current role, Ajit led product management building AI/ML products at leading technology companies, including Uber, Turing, and eHealth. He is passionate about advancing Generative AI technologies and driving real-world impact with Generative AI.
Ajit Mahareddy is an experienced Product and Go-To-Market (GTM) leader with over 20 years of experience in Product Management, Engineering, and Go-To-Market. Prior to his current role, Ajit led product management building AI/ML products at leading technology companies, including Uber, Turing, and eHealth. He is passionate about advancing Generative AI technologies and driving real-world impact with Generative AI. Shreyas Subramanian is a Principal Data Scientist and helps customers by using generative AI and deep learning to solve their business challenges using AWS services. Shreyas has a background in large-scale optimization and ML and in the use of ML and reinforcement learning for accelerating optimization tasks.
Shreyas Subramanian is a Principal Data Scientist and helps customers by using generative AI and deep learning to solve their business challenges using AWS services. Shreyas has a background in large-scale optimization and ML and in the use of ML and reinforcement learning for accelerating optimization tasks. Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things.
Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things. Dharinee Gupta is an Engineering Manager at AWS Bedrock, where she focuses on enabling customers to seamlessly utilize open source models through serverless solutions. Her team specializes in optimizing these models to deliver the best cost-performance balance for customers. Prior to her current role, she gained extensive experience in authentication and authorization systems at Amazon, developing secure access solutions for Amazon offerings. Dharinee is passionate about making advanced AI technologies accessible and efficient for AWS customers.
Dharinee Gupta is an Engineering Manager at AWS Bedrock, where she focuses on enabling customers to seamlessly utilize open source models through serverless solutions. Her team specializes in optimizing these models to deliver the best cost-performance balance for customers. Prior to her current role, she gained extensive experience in authentication and authorization systems at Amazon, developing secure access solutions for Amazon offerings. Dharinee is passionate about making advanced AI technologies accessible and efficient for AWS customers. Lokeshwaran Ravi is a Senior Deep Learning Compiler Engineer at AWS, specializing in ML optimization, model acceleration, and AI security. He focuses on enhancing efficiency, reducing costs, and building secure ecosystems to democratize AI technologies, making cutting-edge ML accessible and impactful across industries.
Lokeshwaran Ravi is a Senior Deep Learning Compiler Engineer at AWS, specializing in ML optimization, model acceleration, and AI security. He focuses on enhancing efficiency, reducing costs, and building secure ecosystems to democratize AI technologies, making cutting-edge ML accessible and impactful across industries.