Amazon Bedrock Knowledge Bases has extended its vector store options by enabling support for Amazon OpenSearch Service managed clusters, further strengthening its capabilities as a fully managed Retrieval Augmented Generation (RAG) solution. This enhancement builds on the core functionality of Amazon Bedrock Knowledge Bases , which is designed to seamlessly connect foundation models (FMs) with internal data sources. Amazon Bedrock Knowledge Bases automates critical processes such as data ingestion, chunking, embedding generation, and vector storage, and the application of advanced indexing algorithms and retrieval techniques, empowering users to develop intelligent applications with minimal effort.
The latest update broadens the vector database options available to users. In addition to the previously supported vector stores such as Amazon OpenSearch Serverless, Amazon Aurora PostgreSQL-Compatible Edition, Amazon Neptune Analytics, Pinecone, MongoDB, and Redis Enterprise Cloud, users can now use OpenSearch Service managed clusters. This integration enables the use of an OpenSearch Service domain as a robust backend for storing and retrieving vector embeddings, offering greater flexibility and choice in vector storage solutions.
To help users take full advantage of this new integration, this post provides a comprehensive, step-by-step guide on integrating an Amazon Bedrock knowledge base with an OpenSearch Service managed cluster as its vector store.
Why use OpenSearch Service Managed Cluster as a vector store?
OpenSearch Service provides two complementary deployment options for vector workloads: managed clusters and serverless collections. Both harness the powerful vector search and retrieval capabilities of OpenSearch Service, though each excels in different scenarios. Managed clusters offer extensive configuration flexibility, performance tuning options, and scalability that make them particularly well-suited for enterprise-grade AI applications.Organizations seeking greater control over cluster configurations, compute instances, the ability to fine-tune performance and cost, and support for a wider range of OpenSearch features and API operations will find managed clusters a natural fit for their use cases. Alternatively, OpenSearch Serverless excels in use cases that require automatic scaling and capacity management, simplified operations without the need to manage clusters or nodes, automatic software updates, and built-in high availability and redundancy. The optimal choice depends entirely on specific use case, operational model, and technical requirements. Here are some key reasons why OpenSearch Service managed clusters offer a compelling choice for organizations:
- Flexible configuration – Managed clusters provide flexible and extensive configuration options that enable fine-tuning for specific workloads. This includes the ability to select instance types, adjust resource allocations, configure cluster topology, and implement specialized performance optimizations. For organizations with specific performance requirements or unique workload characteristics, this level of customization can be invaluable.
- Performance and cost optimizations to meet your design criteria – Vector database performance is a trade-off between three key dimensions: accuracy, latency, and cost. Managed Cluster provides the granular control to optimize along one or a combination of these dimensions and meet the specific design criteria.
- Early access to advanced ML features – OpenSearch Service follows a structured release cycle, with new capabilities typically introduced first in the open source project, then in managed clusters, and later in serverless offerings. Organizations that prioritize early adoption of advanced vector search capabilities might benefit from choosing managed clusters, which often provide earlier exposure to new innovation. However, for customers using Amazon Bedrock Knowledge Bases, these features become beneficial only after they have been fully integrated into the knowledge bases. This means that even if a feature is available in a managed OpenSearch Service cluster, it might not be immediately accessible within Amazon Bedrock Knowledge Bases. Nonetheless, opting for managed clusters positions organizations to take advantage of the latest OpenSearch advancements more promptly after they’re supported within Bedrock Knowledge Bases.
Prerequisites
Before we dive into the setup, make sure you have the following prerequisites in place:
- Data source – An Amazon S3 bucket (or custom source) with documents for knowledge base ingestion. We will assume your bucket contains supported documents types (PDFs, TXTs, etc.) for retrieval.
- OpenSearch Service domain (optional) – For existing domains, make sure it’s in the same Region and account where you’ll create your Amazon Bedrock knowledge base. As of this writing, Bedrock Knowledge Bases requires OpenSearch Service domains with public access; virtual private cloud (VPC)-only domains aren’t supported yet. Make sure you have the necessary permissions to create or configure domains. This guide covers setup for both new and existing domains.
Solution overview
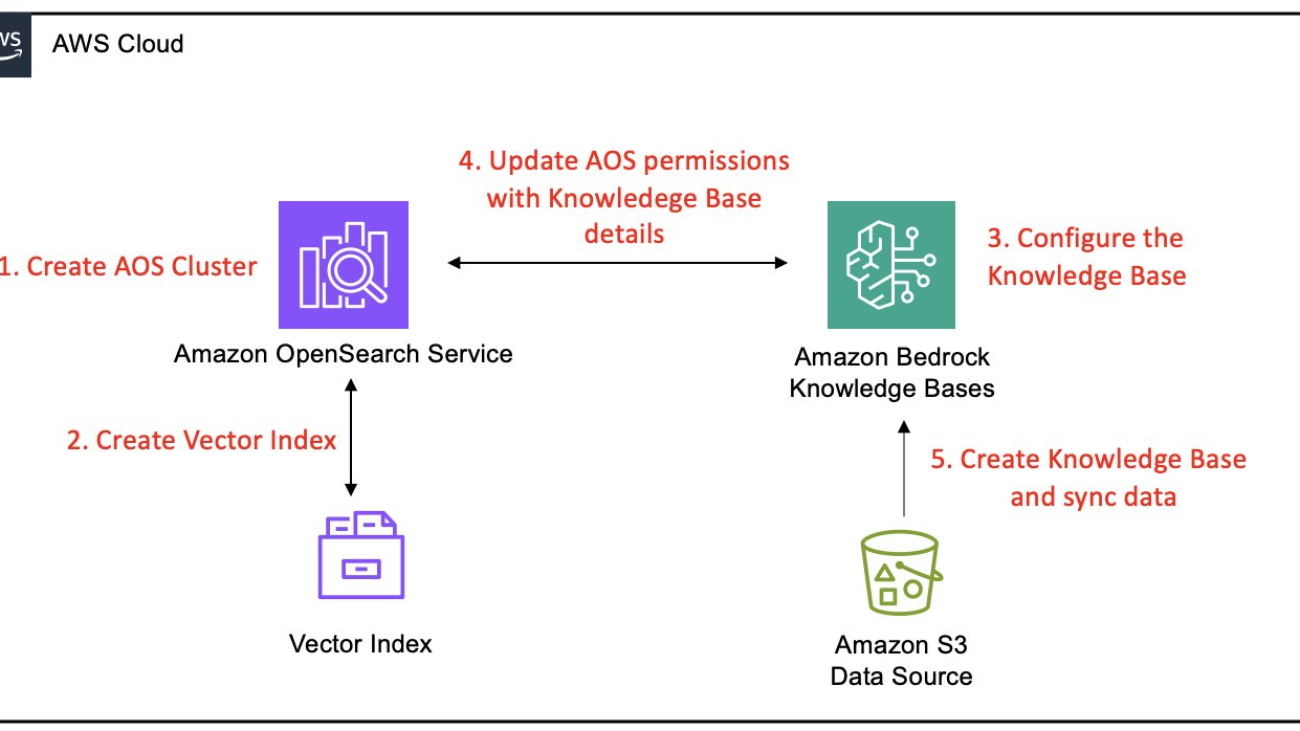
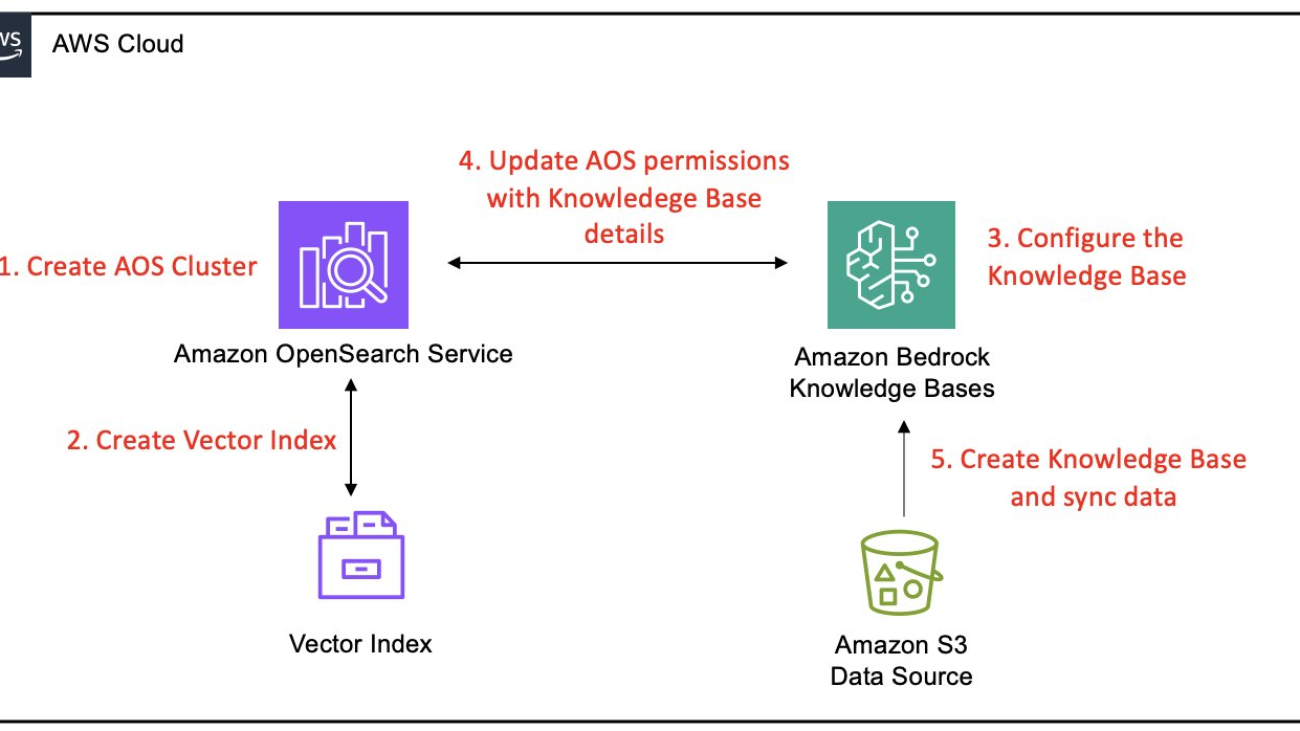
This section covers the following high-level steps to integrate an OpenSearch Service managed cluster with Amazon Bedrock Knowledge Bases:
- Create an OpenSearch Service domain – Set up a new OpenSearch Service managed cluster with public access, appropriate engine version, and security settings, including AWS Identity and Access Management (IAM) master user role and fine-grained access control. This step includes establishing administrative access by creating dedicated IAM resources and configuring Amazon Cognito authentication for secure dashboard access.
- Configure a vector index in OpenSearch Service – Create a k-nearest neighbors (k-NN) enabled index on the domain with the appropriate mappings for vector, text chunk, and metadata fields to be compatible with Amazon Bedrock Knowledge Bases.
- Configure the Amazon Bedrock knowledge base – Initiate the creation of an Amazon Bedrock knowledge base, enable your Amazon Simple Storage Service (Amazon S3) data source, and configure it to use your OpenSearch Service domain as the vector store with all relevant domain details.
- Configure fine-grained access control permissions in OpenSearch Service – Configure fine-grained access control in OpenSearch Service by creating a role with specific permissions and mapping it to the Amazon Bedrock IAM service role, facilitating secure and controlled access for the knowledge base.
- Complete knowledge base creation and ingest data – Initiate a sync operation in the Amazon Bedrock console to process S3 documents, generate embeddings, and store them in your OpenSearch Service index.
The following diagram illustrates these steps:

Solution walkthrough
Here are the steps to follow in the AWS console to integrate Amazon Bedrock Knowledge Bases with OpenSearch Service Managed Cluster.
Establish administrative access with IAM master user and role
Before creating an OpenSearch Service domain, you need to create two key IAM resources: a dedicated IAM admin user and a master role. This approach facilitates proper access management for your OpenSearch Service domain, particularly when implementing fine-grained access control, which is strongly recommended for production environments. This user and role will have the necessary permissions to create, configure, and manage the OpenSearch Service domain and its integration with Amazon Bedrock Knowledge Bases.
Create an IAM admin user
The administrative user serves as the principal account for managing the OpenSearch Service configuration. To create an IAM admin user, follow these steps:
- Open the IAM console in your AWS account
- In the left navigation pane, choose Users and then choose Create user
- Enter a descriptive username like
<opensearch-admin> - On the permissions configuration page, choose Attach policies directly
- Search for and attach the
AmazonOpenSearchServiceFullAccessmanaged policy, which grants comprehensive permissions for OpenSearch Service operations - Review your settings and choose Create user
After creating the user, copy and save the user’s Amazon Resource name (ARN) for later use in domain configuration, replacing <ACCOUNT_ID> with your AWS account ID.
The ARN will look like this:
arn:aws:iam::<ACCOUNT_ID>:user/opensearch-admin
Create an IAM role to act as the OpenSearch Service master user
With OpenSearch Service, you can assign a master user for domains with fine-grained access control. By configuring an IAM role as the master user, you can manage access using trusted principles and avoid static usernames and passwords. To create the IAM role, follow these steps:
- On the IAM console, in the left-hand navigation pane, choose Roles and then choose Create role
- Choose Custom trust policy as the trusted entity type to precisely control which principals can assume this role
- In the JSON editor, paste the following trust policy that allows entities, such as your
opensearch-adminuser, to assume this role
- Proceed to the Add permissions page and attach the same
AmazonOpenSearchServiceFullAccessmanaged policy you used for your admin user - Provide a descriptive name such as
OpenSearchMasterRoleand choose Create role
After the role is created, navigate to its summary page and copy the role’s ARN. You’ll need this ARN when configuring your OpenSearch Service domain’s master user.
arn:aws:iam:: <ACCOUNT_ID>:role/OpenSearchMasterRole
Create an OpenSearch Service domain for vector search
With the administrative IAM role established, the next step is to create the OpenSearch Service domain that will serve as the vector store for your Amazon Bedrock knowledge base. This involves configuring the domain’s engine, network access, and, most importantly, its security settings using fine-grained access control.
- In the OpenSearch Service console, select Managed clusters as your deployment type. Then choose Create domain.
- Configure your domain details:
- Provide a domain name such as
bedrock-kb-domain. - For a quick and straightforward setup, choose Easy create, as shown in the following screenshot. This option automatically selects suitable instance types and default configurations optimized for development or small-scale workloads. This way, you can quickly deploy a functional OpenSearch Service domain without manual configuration. Many of these settings can be modified later as your needs evolve, making this approach ideal for experimentation or nonproduction use cases while still providing a solid foundation.
- Provide a domain name such as

If your workload demands higher input/output operations per second (IOPS) or throughput or involves managing substantial volumes of data, selecting Standard create is recommended. With this option enabled, you can customize instance types, storage configurations, and advanced security settings to optimize the speed and efficiency of data storage and retrieval operations, making it well-suited for production environments. For example, you can scale the baseline GP3 volume performance from 3,000 IOPS and 125 MiB/s throughput up to 16,000 IOPS and 1,000 MiB/s throughput for every 3 TiB of storage provisioned per data node. This flexibility means that you can align your OpenSearch Service domain performance with specific workload demands, facilitating efficient indexing and retrieval operations for high-throughput or large-scale applications. These settings should be fine-tuned based on the size and complexity of your OpenSearch Service workload to optimize both performance and cost.
However, although increasing your domain’s throughput and storage settings can help improve domain performance—and might help mitigate ingestion errors caused by storage or node-level bottlenecks—it doesn’t increase the ingestion speed into Amazon Bedrock Knowledge Bases as of this writing. Knowledge base ingestion operates at a fixed throughput rate for customers and vector databases, regardless of underlying domain configuration. AWS continues to invest in scaling and evolving the ingestion capabilities of Bedrock Knowledge Bases, and future improvements might offer greater flexibility.
- For engine version, choose OpenSearch version 2.13 or higher. If you plan to store binary embeddings, select version 2.16 or above because it’s required for binary vector indexing. It’s recommended to use the latest available version to benefit from performance improvements and feature updates.
- For network configuration, under Network, choose Public access, as shown in the following screenshot. This is crucial because, as of this writing, Amazon Bedrock Knowledge Bases doesn’t support connecting to OpenSearch Service domains that are behind a VPC. To maintain security, we implement IAM policies and fine-grained access controls to manage access at a granular level. Using these controls, you can define who can access your resources and what actions they can perform, adhering to the principle of least privilege. Select Dual-stack mode for network settings if prompted. This enables support for both IPv4 and IPv6, offering greater compatibility and accessibility.

- For security, enable Fine-grained access control to secure your domain by defining detailed, role-based permissions at the index, document, and field levels. This feature offers more precise control compared to resource-based policies, which operate only at the domain level.
In the fine-grained access control implementation section, we guide you through creating a custom OpenSearch Service role with specific index and cluster permissions, then authorizing Amazon Bedrock Knowledge Bases by associating its service role with this custom role. This mapping establishes a trust relationship that restricts Bedrock Knowledge Bases to only the operations you’ve explicitly permitted when accessing your OpenSearch Service domain with its service credentials, facilitating secure and controlled integration.
When enabling fine-grained access control, you must select a master user to manage the domain. You have two options:
-
- Create master user (Username and Password) – This option establishes credentials in OpenSearch Service internal user database, providing quick setup and direct access to OpenSearch Dashboards using basic authentication. Although convenient for initial configuration or development environments, it requires careful management of these credentials as a separate identity from your AWS infrastructure.
- Set IAM ARN as master user – This option integrates with the AWS identity landscape, allowing IAM based authentication. This is strongly recommended for production environments where applications and services already rely on IAM for secure access and where you need auditability and integration with your existing AWS security posture.
For this walkthrough, we choose Set IAM ARN as master user. This is the recommended approach for production environments because it integrates with your existing AWS identity framework, providing better auditability and security management.
In the text box, paste the ARN of the OpenSearchMasterRole that you created in the first step, as shown in the following screenshot. This designates the IAM role as the superuser for your OpenSearch Service domain, granting it full permissions to manage users, roles, and permissions within OpenSearch Dashboards.

Although setting an IAM master user is ideal for programmatic access, it’s not convenient for allowing users to log in to the OpenSearch Dashboards. In a subsequent step, after the domain is created and we’ve configured Cognito resources, we’ll revisit this security configuration to enable Amazon Cognito authentication. Then you’ll be able to create a user-friendly login experience for the OpenSearch Dashboards, where users can sign in through a hosted UI and be automatically mapped to IAM roles (such as the MasterUserRole or more limited roles), combining ease of use with robust, role-based security. For now, proceed with the IAM ARN as the master user to complete the initial domain setup.
- Review your settings and choose Create to launch the domain. The initialization process typically takes around 10–15 minutes. During this time, OpenSearch Service will set up the domain and apply your configurations.
After your domain becomes active, navigate to its detail page to retrieve the following information:
- Domain endpoint – This is the HTTPS URL where your OpenSearch Service is accessible, typically following the format:
https://search-<domain-name>-<unique-identifier>.<region>.es.amazonaws.com - Domain ARN – This uniquely identifies your domain and follows the structure:
arn:aws:es:<region>:<account-id>:domain/<domain-name>
Make sure to copy and securely store both these details because you’ll need them when configuring your Amazon Bedrock knowledge base in subsequent steps. With the OpenSearch Service domain up and running, you now have an empty cluster ready to store your vector embeddings. Next, we move on to configuring a vector index within this domain.
Create an Amazon Cognito user pool
Following the creation of your OpenSearch Service domain, the next step is to configure an Amazon Cognito user pool. This user pool will provide a secure and user-friendly authentication layer for accessing the OpenSearch Dashboards. Follow these steps:
- Navigate to the Amazon Cognito console and choose User pools from the main dashboard. Choose Create user pool to begin the configuration process. The latest developer-focused console experience presents a unified application setup interface rather than the traditional step-by-step wizard.
- For OpenSearch Dashboards integration, choose Traditional web application. This application type supports the authentication flow required for dashboard access and can securely handle the OAuth flows needed for the integration.
- Enter a descriptive name in the Name your application field, such as
opensearch-kb-app. This name will automatically become your app client name. - Configure how users will authenticate with your system. For OpenSearch integration, select Email as the primary sign-in option. This allows users to sign up and sign in using their email addresses, providing a familiar authentication method. Additional options include Phone number and Username if your use case requires alternative sign-in methods.
- Specify the user information that must be collected during registration. At minimum, make sure Email is selected as a required attribute. This is essential for account verification and recovery processes.
- This step is a critical security configuration that specifies where Cognito can redirect users after successful authentication. In the Add a return URL field, enter your OpenSearch Dashboards URL in the following format:
https://search-<domain-name>-<unique-identifier>.aos.<region>.on.aws/_dashboards. - Choose Create user directory to provision your user pool and its associated app client.
The simplified interface automatically configures optimal settings for your selected application type, including appropriate security policies, OAuth flows, and hosted UI domain generation. Copy and save the User pool ID and App client ID values. You’ll need them to configure the Cognito identity pool and update the OpenSearch Service domain’s security settings.
Add an admin user to the user pool
After creating your Amazon Cognito user pool, you need to add an administrator user who will have access to OpenSearch Dashboards. Follow these steps:
- In the Amazon Cognito console, select your newly created user pool
- In the left navigation pane, choose Users
- Choose Create user
- Select Send an email invitation
- Enter an Email address for the administrator, for example,
admin@example.com - Choose whether to set a Temporary password or have Cognito generate one
- Choose Create user

Upon the administrator’s first login, they’ll be prompted to create a permanent password. When all the subsequent setup steps are complete, this admin user will be able to authenticate to OpenSearch Dashboards.
Configure app client settings
With your Amazon Cognito user pool created, the next step is to configure app client parameters that will enable seamless integration with your OpenSearch dashboard. The app client configuration defines how OpenSearch Dashboards will interact with the Cognito authentication system, including callback URLs, OAuth flows, and scope permissions. Follow these steps:
- Navigate to your created user pool on the Amazon Cognito console and locate your app client in the applications list. Select your app client to access its configuration dashboard.
- Choose the Login tab from the app client interface. This section displays your current managed login pages configuration, including callback URLs, identity providers, and OAuth settings.
- To open the OAuth configuration interface, in the Managed login pages configuration section, choose Edit.
- Add your OpenSearch Dashboards URL in the Allowed callback URLs section from the Create an Amazon Cognito user pool section.
- To allow authentication using your user pool credentials, in the Identity providers dropdown list, select Cognito user pool.
- Select Authorization code grant from the OAuth 2.0 grant types dropdown list. This provides the most secure OAuth flow for web applications by exchanging authorization codes for access tokens server-side.
- Configure OpenID Connect scopes by selecting the appropriate scopes from the available options:
- Email: Enables access to user email addresses for identification.
- OpenID: Provides basic OpenID Connect (OIDC) functionality.
- Profile: Allows access to user profile information.
Save the configuration by choosing Save changes at the bottom of the page to apply the OAuth settings to your app client. The system will validate your configuration and confirm the updates have been successfully applied.
Update master role trust policy for Cognito integration
Before creating the Cognito identity pool, you must first update your existing OpenSearchMasterRoleto trust the Cognito identity service. This is required because only IAM roles with the proper trust policy for cognito-identity.amazonaws.com will appear in the Identity pool role selection dropdown list. Follow these steps:
- Navigate to IAM on the console.
- In the left navigation menu, choose Roles.
- Find and select OpenSearchMasterRole from the list of roles.
- Choose the Trust relationships tab.
- Choose Edit trust policy.
- Replace the existing trust policy with the following configuration that includes both your IAM user access and Cognito federated access. Replace
YOUR_ACCOUNT_IDwith your AWS account number. LeavePLACEHOLDER_IDENTITY_POOL_IDas is for now. You’ll update this in Step 6 after creating the identity pool:
- Choose Update policy to save the trust relationship configuration.
Create and configure Amazon Cognito identity pool
The identity pool serves as a bridge between your Cognito user pool authentication and AWS IAM roles so that authenticated users can assume specific IAM permissions when accessing your OpenSearch Service domain. This configuration is essential for mapping Cognito authenticated users to the appropriate OpenSearch Service access permissions. This step primarily configures administrative access to the OpenSearch Dashboards, allowing domain administrators to manage users, roles, and domain settings through a secure web interface. Follow these steps:
- Navigate to Identity pools on the Amazon Cognito console and choose Create identity pool to begin the configuration process.
- In the Authentication section, configure the types of access your identity pool will support:
- Select Authenticated access to enable your identity pool to issue credentials to users who have successfully authenticated through your configured identity providers. This is essential for Cognito authenticated users to be able to access AWS resources.
- In the Authenticated identity sources section, choose Amazon Cognito user pool as the authentication source for your identity pool.
- Choose Next to proceed to the permissions configuration.
- For the Authenticated role, select Use an existing role and choose the
OpenSearchMasterRolethat you created in Establish administrative access with IAM master user and role. This assignment grants authenticated users the comprehensive permissions defined in your master role so that they can:- Access and manage your OpenSearch Service domain through the dashboards interface.
- Configure security settings and user permissions.
- Manage indices and perform administrative operations.
- Create and modify OpenSearch Service roles and role mappings.

This configuration provides full administrative access to your OpenSearch Service domain. Users who authenticate through this Cognito setup will have master-level permissions, making this suitable for domain administrators who need to configure security settings, manage users, and perform maintenance tasks.
- Choose Next to continue with identity provider configuration.
- From the dropdown list, choose the User pool you created in Create an Amazon Cognito user pool.
- Choose the app client you configured in the previous step from the available options in the App client dropdown list.
- Keep the default role setting, which will assign the
OpenSearchMasterRoleto authenticated users from this user pool. - Choose Next.
- Provide a descriptive name such as
OpenSearchIdentityPool. - Review all configuration settings and choose Create identity pool. Amazon Cognito will provision the identity pool and establish the necessary trust relationships. After creation, copy the identity pool ID.
To update your master role’s trust policy with the identity pool ID, follow these steps:
- On the IAM console in the left navigation menu, choose Roles
- From the list of roles, find and select OpenSearchMasterRole
- Choose the Trust relationships tab and choose Edit trust policy
- Replace
PLACEHOLDER_IDENTITY_POOL_IDwith your identity pool ID from the previous step - To finalize the configuration, choose Update policy
Your authentication infrastructure is now configured to provide secure, administrative access to OpenSearch Dashboards through Amazon Cognito authentication. Users who authenticate through the Cognito user pool will assume the master role and gain full administrative capabilities for your OpenSearch Service domain.
Enable Amazon Cognito authentication for OpenSearch Dashboards
After setting up your Cognito user pool, app client, and identity pool, the next step is to configure your OpenSearch Service domain to use Cognito authentication for OpenSearch Dashboards. Follow these steps:
- Navigate to the Amazon OpenSearch Service console
- Select the name of the domain that you previously created
- Choose the Security configuration tab and choose Edit
- Scroll to the Amazon Cognito authentication section and select Enable Amazon Cognito authentication, as shown in the following screenshot
- You’ll be prompted to provide the following:
- Cognito user pool ID: Enter the user pool ID you created in a previous step
- Cognito identity pool ID: Enter the identity pool ID you created
- Review your settings and choose Save changes

The domain will update its configuration, which might take several minutes. You’ll receive a progress pop-up, as shown in the following screenshot.

Create a k-NN vector index in OpenSearch Service
This step involves creating a vector search–enabled index in your OpenSearch Service domain for Amazon Bedrock to store document embedding vectors, text chunks, and metadata. The index must contain three essential fields: an embedding vector field that stores numerical representations of your content (in floating-point or binary format), a text field that holds the raw text chunks, and a field for Amazon Bedrock managed metadata where Amazon Bedrock tracks critical information such as document IDs and source attributions. With proper index mapping, Amazon Bedrock Knowledge Bases can efficiently store and retrieve the components of your document data.
You create this index using the Dev Tools feature in OpenSearch Dashboards. To access Dev Tools in OpenSearch Dashboards, follow these steps:
- Sign in to your OpenSearch Dashboards account
- Navigate to your OpenSearch Dashboards URL
- You’ll be redirected to the Cognito sign-in page
- Sign in using the admin user credentials you created in the Add an admin user to the user pool section
- Enter the email address you provided (
admin@example.com) - Enter your password (if this is your first sign-in, you’ll be prompted to create a permanent password)
- After successful authentication, you’ll be directed to the OpenSearch Dashboards home page
- In the left navigation pane under the Management group, choose Dev Tools
- Confirm you’re on the Console page, as shown in the following screenshot, where you’ll enter API commands

To define and create the index copy the following command into the Dev Tools console and replace bedrock-kb-index with your preferred index name if needed. If you’re setting up a binary vector index (for example, to use binary embeddings with Amazon Titan Text Embeddings V2), include the additional required fields in your index mapping:
- Set “
data_type“: “binary” for the vector field - Set “
space_type“: “hamming” (instead of “l2”, which is used for float embeddings)
For more details, refer to the Amazon Bedrock Knowledge Bases setup documentation.
The key components of this index mapping are:
- k-NN enablement – Activates k-NN functionality in the index settings, allowing the use of
knn_vectorfield type. - Vector field configuration – Defines the
embeddingsfield for storing vector data, specifying dimension, space type, and data type based on the chosen embedding model. It’s critical to match the dimension with the embedding model’s output. Amazon Bedrock Knowledge Bases offers models such as Amazon Titan Embeddings V2 (with 256, 512, or 1,024 dimensions) and Cohere Embed (1,024 dimensions). For example, using Amazon Titan Embeddings V2 with 1,024 dimensions requires setting dimension: 1024 in the mapping. A mismatch between the model’s vector size and index mapping will cause ingestion failures, so it’s crucial to verify this value. - Vector method setup – Configures the hierarchical navigable small world (HNSW) algorithm with the Faiss engine, setting parameters for balancing index build speed and accuracy. Amazon Bedrock Knowledge Bases integration specifically requires the Faiss engine for OpenSearch Service k-NN index.
- Text chunk storage – Establishes a field for storing raw text chunks from documents, enabling potential full-text queries.
- Metadata field – Creates a field for Amazon Bedrock managed metadata, storing essential information without indexing for direct searches.
After pasting the command into the Dev Tools console, choose Run. If successful, you’ll receive a response similar to the one shown in the following screenshot.

Now, you should have a new index (for example, named bedrock-kb-index) on your domain with the preceding mapping. Make a note of the index name you created, the vector field name (embeddings), the text field name (AMAZON_BEDROCK_TEXT_CHUNK), and the metadata field name (AMAZON_BEDROCK_METADATA). In the next steps, you’ll grant Amazon Bedrock permission to use this index and then plug these details into the Amazon Bedrock Knowledge Bases setup.
With the vector index successfully created, your OpenSearch Service domain is now ready to store and retrieve embedding vectors. Next, you’ll configure IAM roles and access policies to facilitate secure interaction between Amazon Bedrock and your OpenSearch Service domain.
Initiate Amazon Bedrock knowledge base creation
Now that your OpenSearch Service domain and vector index are ready, it’s time to configure an Amazon Bedrock knowledge base to use this vector store. In this step, you will:
- Begin creating a new knowledge base in the Amazon Bedrock console
- Configure it to use your existing OpenSearch Service domain as a vector store
We will pause the knowledge base creation midway to update OpenSearch Service access policies before finalizing the setup.
To create the Amazon Bedrock knowledge base in the console, follow these steps. For detailed instructions, refer to Create a knowledge base by connecting to a data source in Amazon Bedrock Knowledge Bases in the AWS documentation. The following steps provide a streamlined overview of the general process:
- On the Amazon Bedrock Console, go to Knowledge Bases and choose Create with vector store.
- Enter a name and description and choose Create and use a new service role for the runtime role. Choose Amazon S3 as the data source for the knowledge base.
- Provide the details for the data source, including data source name, location, Amazon S3 URI, and keep the parsing and chunking strategies as default.
- Choose Amazon Titan Embeddings v2 as your embeddings model to convert your data. Make sure the embeddings dimensions match what you configured in your index mappings in the Create an OpenSearch Service domain for vector search section because mismatches will cause the integration to fail.
To configure OpenSearch Service Managed Cluster as the vector store, follow these steps:
- Under Vector database, select Use an existing vector store and for Vector store, select OpenSearch Service Managed Cluster, as shown in the following screenshot

- Enter the details from your OpenSearch Service domain setup in the following fields, as shown in the following screenshot:
- Domain ARN: Provide the ARN of your OpenSearch Service domain.
- Domain endpoint: Enter the endpoint URL of your OpenSearch Service domain.
- Vector index name: Specify the name of the vector index created in your OpenSearch Service domain.
- Vector field name
- Text field name
- Bedrock-managed metadata field name

You must not choose Create yet. Amazon Bedrock will be ready to create the knowledge base, but you need to configure OpenSearch Service access permissions first. Copy the ARN of the new IAM service role that Amazon Bedrock will use for this knowledge base (the console will display the role ARN you selected or just created). Keep this ARN handy and leave the Amazon Bedrock console open (pause the creation process here).
Configure fine-grained access control permissions in OpenSearch Service
With the IAM service role ARN copied, configure fine-grained permissions in the OpenSearch dashboard. Fine-grained access control provides role-based permission management at a granular level (indices, documents, and fields), so that your Amazon Bedrock knowledge base has precisely controlled access. Follow these steps:
- On the OpenSearch Service console, navigate to your OpenSearch Service domain.
- Choose the URL for OpenSearch Dashboards. It typically looks like:
https://<your-domain-endpoint>/_dashboards/ - From the OpenSearch Dashboards interface, in the left navigation pane, choose Security, then choose Roles.
- Choose Create role and provide a meaningful name, such as
bedrock-knowledgebase-role. - Under Cluster Permissions, enter the following permissions necessary for Amazon Bedrock operations, as shown in the following screenshot:

- Under Index permissions:
- Specify the exact vector index name you created previously (for example,
bedrock-kb-index). - Choose Create new permission group, then choose Create new action group.
- Add the following specific permissions, essential for Amazon Bedrock Knowledge Bases:
- Confirm by choosing Create.
- Specify the exact vector index name you created previously (for example,
To map the Amazon Bedrock IAM service role (copied earlier) to the newly created OpenSearch Service role, follow these steps:
- In OpenSearch Dashboards, navigate to Security and then Roles.
- Locate and open the role you created in the previous step (
bedrock-knowledgebase-role). - Choose the Mapped users tab and choose Manage mapping, as shown in the following screenshot.
- In the Backend roles section, paste the knowledge base’s service role ARN you copied from Amazon Bedrock (for example,
arn:aws:iam::<accountId>:role/service-role/BedrockKnowledgeBaseRole). When mapping this IAM role to an OpenSearch Service role, the IAM role doesn’t need to exist in your AWS account at the time of mapping. You’re referencing its ARN to establish the association within the OpenSearch backend. This allows OpenSearch Service to recognize and authorize the role when it’s eventually created and used. Make sure that the ARN is correctly specified to facilitate proper permission mapping. - Choose Map to finalize the connection between the IAM role and OpenSearch Service permissions.

Complete knowledge base creation and verify resource-based policy
With fine-grained permissions in place, return to the paused Amazon Bedrock console to finalize your knowledge base setup. Confirm that all OpenSearch Service domain details are correctly entered, including the domain endpoint, domain ARN, index name, vector field name, text field name, and metadata field name. Choose Create knowledge base.
Amazon Bedrock will use the configured IAM service role to securely connect to your OpenSearch Service domain. After the setup is complete, the knowledge base status should change to Available, confirming successful integration.
Understanding access policies
When integrating OpenSearch Service Managed Cluster with Amazon Bedrock Knowledge Bases, it’s important to understand how access control works across different layers.
For same-account configurations (where both the knowledge base and OpenSearch Service domain are in the same AWS account), no updates to the OpenSearch Service domain’s resource-based policy are required as long as fine-grained access control is enabled and your IAM role is correctly mapped. In this case, IAM permissions and fine-grained access control mappings are sufficient to authorize access. However, if the domain’s resource-based policy includes deny statements targeting your knowledge base service role or principals, access will be blocked—regardless of IAM or fine-grained access control settings. To avoid unintended failures, make sure the policy doesn’t explicitly restrict access to the Amazon Bedrock Knowledge Bases service role.
For cross-account access (when the IAM role used by Amazon Bedrock Knowledge Bases belongs to a different AWS account than the OpenSearch Service domain), you must include an explicit allow statement in the domain’s resource-based policy for the external role. Without this, access will be denied even if all other permissions are correctly configured.

To begin using your knowledge base, select your configured data source and initiate the sync process. This action starts the ingestion of your Amazon S3 data. After synchronization is complete, your knowledge base is ready for information retrieval.
Conclusion
Integrating Amazon Bedrock Knowledge Bases with OpenSearch Service Managed Cluster offers a powerful solution for vector storage and retrieval in AI applications. In this post, we walked you through the process of setting up an OpenSearch Service domain, configuring a vector index, and connecting it to an Amazon Bedrock knowledge base. With this setup, you’re now equipped to use the full potential of vector search capabilities in your AI-driven applications, enhancing your ability to process and retrieve information from large datasets efficiently.
Get started with Amazon Bedrock Knowledge Bases and let us know your thoughts in the comments section.
About the authors
 Manoj Selvakumar is a Generative AI Specialist Solutions Architect at AWS, where he helps startups design, prototype, and scale intelligent, agent-driven applications using Amazon Bedrock. He works closely with founders to turn ambitious ideas into production-ready solutions—bridging startup agility with the advanced capabilities of AWS’s generative AI ecosystem. Before joining AWS, Manoj led the development of data science solutions across healthcare, telecom, and enterprise domains. He has delivered end-to-end machine learning systems backed by solid MLOps practices—enabling scalable model training, real-time inference, continuous evaluation, and robust monitoring in production environments.
Manoj Selvakumar is a Generative AI Specialist Solutions Architect at AWS, where he helps startups design, prototype, and scale intelligent, agent-driven applications using Amazon Bedrock. He works closely with founders to turn ambitious ideas into production-ready solutions—bridging startup agility with the advanced capabilities of AWS’s generative AI ecosystem. Before joining AWS, Manoj led the development of data science solutions across healthcare, telecom, and enterprise domains. He has delivered end-to-end machine learning systems backed by solid MLOps practices—enabling scalable model training, real-time inference, continuous evaluation, and robust monitoring in production environments.
 Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High-Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High-Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
 Dani Mitchell is a Generative AI Specialist Solutions Architect at AWS. He is focused on helping accelerate enterprises across the world on their generative AI journeys with Amazon Bedrock.
Dani Mitchell is a Generative AI Specialist Solutions Architect at AWS. He is focused on helping accelerate enterprises across the world on their generative AI journeys with Amazon Bedrock.
 Juan Camilo Del Rio Cuervo is a Software Developer Engineer at Amazon Bedrock Knowledge Bases team. He is focused on building and improving RAG experiences for AWS customers.
Juan Camilo Del Rio Cuervo is a Software Developer Engineer at Amazon Bedrock Knowledge Bases team. He is focused on building and improving RAG experiences for AWS customers.


 Nina Chen is a Customer Solutions Manager at AWS specializing in leading software companies to leverage the power of the AWS cloud to accelerate their product innovation and growth. With over 4 years of experience working in the strategic Independent Software Vendor (ISV) vertical, Nina enjoys guiding ISV partners through their cloud transformation journeys, helping them optimize their cloud infrastructure, driving product innovation, and delivering exceptional customer experiences.
Nina Chen is a Customer Solutions Manager at AWS specializing in leading software companies to leverage the power of the AWS cloud to accelerate their product innovation and growth. With over 4 years of experience working in the strategic Independent Software Vendor (ISV) vertical, Nina enjoys guiding ISV partners through their cloud transformation journeys, helping them optimize their cloud infrastructure, driving product innovation, and delivering exceptional customer experiences. Sujatha Kuppuraju is a Principal Solutions Architect at AWS, specializing in Cloud and, Generative AI Security. She collaborates with software companies’ leadership teams to architect secure, scalable solutions on AWS and guide strategic product development. Leveraging her expertise in cloud architecture and emerging technologies, Sujatha helps organizations optimize offerings, maintain robust security, and bring innovative products to market in an evolving tech landscape.
Sujatha Kuppuraju is a Principal Solutions Architect at AWS, specializing in Cloud and, Generative AI Security. She collaborates with software companies’ leadership teams to architect secure, scalable solutions on AWS and guide strategic product development. Leveraging her expertise in cloud architecture and emerging technologies, Sujatha helps organizations optimize offerings, maintain robust security, and bring innovative products to market in an evolving tech landscape. Jason Mimick is a Partner Solutions Architect at AWS supporting top customers and working closely with product, engineering, marketing, and sales teams daily. Jason focuses on enabling product development and sales success for partners and customers across all industries.
Jason Mimick is a Partner Solutions Architect at AWS supporting top customers and working closely with product, engineering, marketing, and sales teams daily. Jason focuses on enabling product development and sales success for partners and customers across all industries. Mohammad Jama is a Product Marketing Manager at Datadog. He leads go-to-market for Datadog’s AWS integrations, working closely with product, marketing, and sales to help companies observe and secure their hybrid and AWS environments.
Mohammad Jama is a Product Marketing Manager at Datadog. He leads go-to-market for Datadog’s AWS integrations, working closely with product, marketing, and sales to help companies observe and secure their hybrid and AWS environments. Yun Kim is a software engineer on Datadog’s LLM Observability team, where he specializes on developing client-side SDKs and integrations. He is excited about the development of trustworthy, transparent Generative AI models and frameworks.
Yun Kim is a software engineer on Datadog’s LLM Observability team, where he specializes on developing client-side SDKs and integrations. He is excited about the development of trustworthy, transparent Generative AI models and frameworks. Barry Eom is a Product Manager at Datadog, where he has launched and leads the development of AI/ML and LLM Observability solutions. He is passionate about enabling teams to create and productionize ethical and humane technologies.
Barry Eom is a Product Manager at Datadog, where he has launched and leads the development of AI/ML and LLM Observability solutions. He is passionate about enabling teams to create and productionize ethical and humane technologies.




























 Vara Bonthu is a Principal Open Source Specialist SA leading Data on EKS and AI on EKS at AWS, driving open source initiatives and helping AWS customers to diverse organizations. He specializes in open source technologies, data analytics, AI/ML, and Kubernetes, with extensive experience in development, DevOps, and architecture. Vara focuses on building highly scalable data and AI/ML solutions on Kubernetes, enabling customers to maximize cutting-edge technology for their data-driven initiatives.
Vara Bonthu is a Principal Open Source Specialist SA leading Data on EKS and AI on EKS at AWS, driving open source initiatives and helping AWS customers to diverse organizations. He specializes in open source technologies, data analytics, AI/ML, and Kubernetes, with extensive experience in development, DevOps, and architecture. Vara focuses on building highly scalable data and AI/ML solutions on Kubernetes, enabling customers to maximize cutting-edge technology for their data-driven initiatives. Chad Elias is a Senior Solutions Architect for AWS. He’s passionate about helping organizations modernize their infrastructure and applications through AI/ML solutions. When not designing the next generation of cloud architectures, Chad enjoys contributing to open source projects, mentoring junior engineers, and exploring the latest technologies.
Chad Elias is a Senior Solutions Architect for AWS. He’s passionate about helping organizations modernize their infrastructure and applications through AI/ML solutions. When not designing the next generation of cloud architectures, Chad enjoys contributing to open source projects, mentoring junior engineers, and exploring the latest technologies. Brian Kreitzer is a Partner Solutions Architect at Amazon Web Services (AWS). He is responsible for working with partners to create accelerators and solutions for AWS customers, engages in technical co-sell opportunities, and evangelizes accelerator and solution adoption to the technical community.
Brian Kreitzer is a Partner Solutions Architect at Amazon Web Services (AWS). He is responsible for working with partners to create accelerators and solutions for AWS customers, engages in technical co-sell opportunities, and evangelizes accelerator and solution adoption to the technical community. Timothy Ma is a Principal Specialist in generative AI at AWS, where he collaborates with customers to design and deploy cutting-edge machine learning solutions. He also leads go-to-market strategies for generative AI services, helping organizations harness the potential of advanced AI technologies.
Timothy Ma is a Principal Specialist in generative AI at AWS, where he collaborates with customers to design and deploy cutting-edge machine learning solutions. He also leads go-to-market strategies for generative AI services, helping organizations harness the potential of advanced AI technologies. Andrew Liu is the manager of the DGX Cloud Technical Marketing Engineering team, focusing on showcasing the use cases and capabilities of DGX Cloud by creating technical assets and collateral. His goal is to demonstrate how DGX Cloud empowers NVIDIA and the ecosystem to create world-class AI solutions. In his free time, Andrew enjoys being outdoors and going mountain biking and skiing.
Andrew Liu is the manager of the DGX Cloud Technical Marketing Engineering team, focusing on showcasing the use cases and capabilities of DGX Cloud by creating technical assets and collateral. His goal is to demonstrate how DGX Cloud empowers NVIDIA and the ecosystem to create world-class AI solutions. In his free time, Andrew enjoys being outdoors and going mountain biking and skiing. Chelsea Isaac is a Senior Solutions Architect for DGX Cloud at NVIDIA. She’s passionate about helping enterprise customers and partners deploy and scale AI solutions in the cloud. In her free time, she enjoys working out, traveling, and reading.
Chelsea Isaac is a Senior Solutions Architect for DGX Cloud at NVIDIA. She’s passionate about helping enterprise customers and partners deploy and scale AI solutions in the cloud. In her free time, she enjoys working out, traveling, and reading. Zoey Zhang is a Technical Marketing Engineer on DGX Cloud at NVIDIA. She works on integrating machine learning models into large-scale compute clusters on the cloud and uses her technical expertise to bring NVIDIA products to market.
Zoey Zhang is a Technical Marketing Engineer on DGX Cloud at NVIDIA. She works on integrating machine learning models into large-scale compute clusters on the cloud and uses her technical expertise to bring NVIDIA products to market. Charlie Huang is a senior product marketing manager for Cloud AI at NVIDIA. Charlie is responsible for taking NVIDIA DGX Cloud to market with cloud partners. He has vast experience in AI/ML, cloud and data center solutions, virtualization, and security.
Charlie Huang is a senior product marketing manager for Cloud AI at NVIDIA. Charlie is responsible for taking NVIDIA DGX Cloud to market with cloud partners. He has vast experience in AI/ML, cloud and data center solutions, virtualization, and security.