This post is co-written with Kshitiz Gupta, Wenhan Tan, Arun Raman, Jiahong Liu, and Eiluth Triana Isaza from NVIDIA.
As large language models (LLMs) and generative AI applications become increasingly prevalent, the demand for efficient, scalable, and low-latency inference solutions has grown. Traditional inference systems often struggle to meet these demands, especially in distributed, multi-node environments. NVIDIA Dynamo (no relation to Amazon DynamoDB) is an open source inference framework designed to address these challenges, offering innovative solutions to optimize performance and scalability. It supports AWS services such as Amazon Simple Storage Service (Amazon S3), Elastic Fabric Adapter (EFA), and Amazon Elastic Kubernetes Service (Amazon EKS), and can be deployed on NVIDIA GPU-accelerated Amazon Elastic Compute Cloud (Amazon EC2) instances, including P6 instances accelerated by NVIDIA Blackwell.
This post introduces NVIDIA Dynamo and explains how to set it up on Amazon EKS for automated scaling and streamlined Kubernetes operations. We provide a hands-on walkthrough, which uses the NVIDIA Dynamo blueprint on the AI on EKS GitHub repo by AWS Labs to provision the infrastructure, configure monitoring, and install the NVIDIA Dynamo operator.
NVIDIA Dynamo: A low-latency distributed inference framework
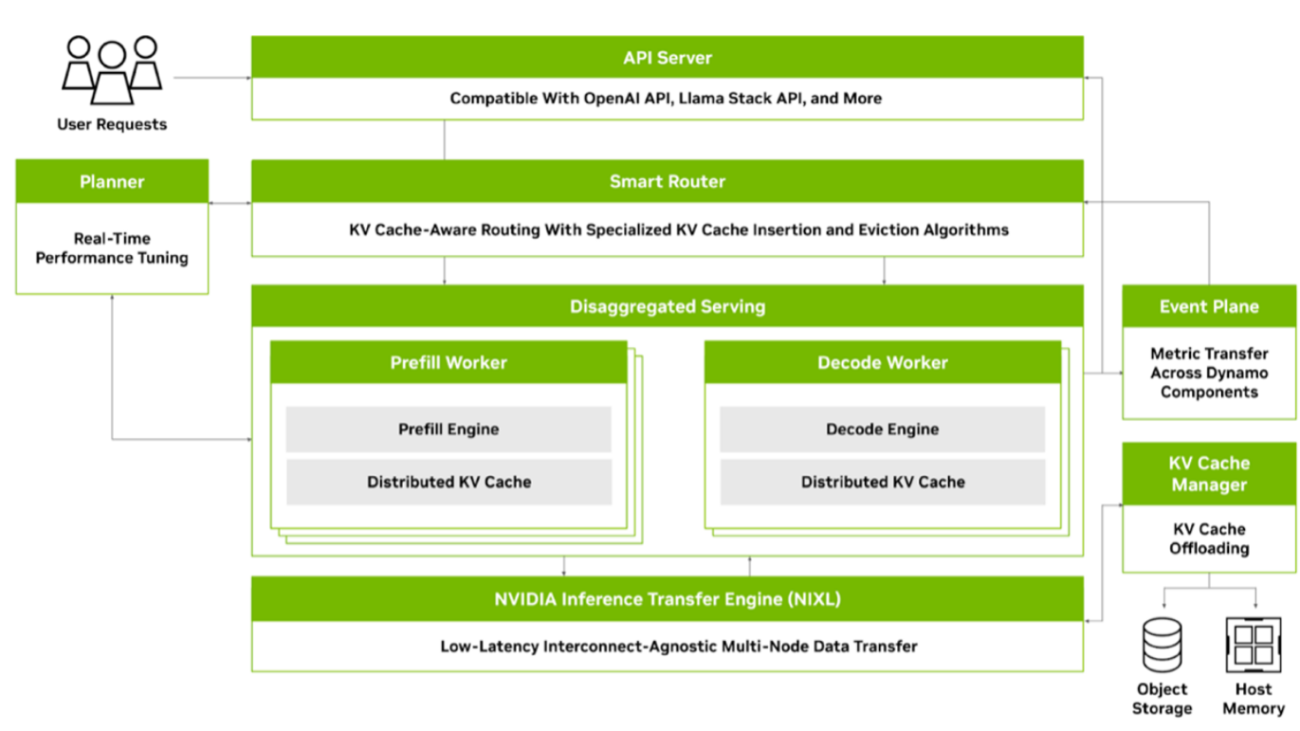
Designed to be inference-engine agnostic, NVIDIA Dynamo supports TRT-LLM, vLLM, SGLang, and other runtimes. It boosts LLM performance by splitting prefill and decode phases to maximize GPU throughput, dynamically scheduling GPU resources, routing requests to avoid KV cache recomputation, accelerating data transfer with the low-latency NIXL library, and efficiently offloading KV cache across memory hierarchies for higher overall system throughput.NVIDIA Dynamo is fully open source and has a modular design so developers can pick and choose the inference serving components, frontend API servers, and inference data transfer libraries that suit their unique needs, facilitating compatibility with your existing AI stack and avoiding costly migration efforts.To enable large-scale distributed and disaggregated inference serving, Dynamo includes five key features, as illustrated in the following figure:
- NVIDIA Dynamo Disaggregated Serving
- NVIDIA Dynamo Planner
- NVIDIA Dynamo Smart Router
- NVIDIA Dynamo KV Cache Block Manager
- NVIDIA Inference Transfer Library (NIXL)

Figure 1: Dynamo’s high-level architecture shows the main features. In the following sections, we explore the main features of the architecture in more detail.
Disaggregated prefill and decode phases
LLM inference involves two distinct phases: the token-parallel prefill phase (processing input to generate the first token) and the autoregressive decode phase (generating subsequent tokens). Workloads like Retrieval Augmented Generation (RAG) that contain long inputs and short outputs, and reasoning workloads with shorter inputs and long outputs have varying demands for these phases. Traditional LLM systems co-locate these phases on the same GPU, leading to resource contention and imbalances.NVIDIA Dynamo addresses this by disaggregating the prefill and decode phases across different GPUs or nodes, allowing each to be optimized independently. For example, using a higher tensor parallelism for the autoregressive decoding phase while using a lower tensor parallelism for the token-parallel prefill phase allows both phases to be computed efficiently, improving scalability and enhancing performance. In addition, for requests with long inputs, separating their prefill phase into dedicated prefill engines allows the ongoing decoding requests to be efficiently processed without being blocked by these long prefills.The following diagram illustrates how disaggregated serving separates prefill and decode on different GPUs to optimize performance.

Figure 2. Disaggregated serving separates prefill and decode on different GPUs to optimize performance.
NVIDIA Dynamo Planner
The NVIDIA Dynamo Planner tackles the challenge of managing GPU resources in dynamic LLM inference environments, where static allocation falters against fluctuating demand and diverse request types (like varying input/output sequence lengths). The NVIDIA Dynamo Planner continuously monitors real-time signals such as request rates, sequence lengths, GPU capacity, and queue wait times. Based on this, it intelligently decides how to best utilize resources—determining whether to serve requests using disaggregated prefill and decode phases or a traditional aggregated approach—and dynamically adjusts the number and type of workers assigned to each phase. For instance, if the NVIDIA Dynamo Planner detects an increase in requests with long input sequences, it can automatically scale up prefill workers to meet heightened demand.The following diagram illustrates this configuration.

Figure 3: The Dynamo Planner combines prefill and decode specific metrics with SLAs to scale GPUs up and down in disaggregated setups, which ensures optimal GPU utilization.
This dynamic optimization makes sure GPU resources are allocated efficiently across prefill and decode tasks without requiring system downtime. By considering application SLOs (like Time To First Token and Inter-Token Latency) and the costs of KV Cache transfer, the NVIDIA Dynamo Planner makes informed decisions to reallocate GPUs or change serving strategy to alleviate bottlenecks and adapt to further workload shifts. This adaptability allows the system to maintain optimal throughput, handle demand spikes effectively, and deliver peak performance across large-scale distributed deployments.
NVIDIA Dynamo Smart Router
Before responding to a user’s prompt, LLMs must build a contextual understanding of the input request known as the KV cache. The NVIDIA Dynamo Smart Router efficiently minimizes KV cache recomputation by tracking KV cache entries across GPUs in large, multi-node, and disaggregated deployments. When new requests arrive, it directs them to workers that already possess relevant cached data. This is particularly advantageous in use cases where the same request is frequently executed, such as system prompts, single-user multi-turn AI assistant interactions, and agentic workflows.The following diagram illustrates this configuration.

Figure 4: Dynamo Smart Router helps reduce unnecessary computationTo achieve this, the NVIDIA Dynamo Smart Router calculates an overlap score between an incoming request, and the KV cache blocks active across the entire distributed GPU cluster. By considering this score along with the current workload distribution, it intelligently routes each request to the most suitable worker. This process not only minimizes unnecessary recomputation and reduces inference time, but also frees up valuable GPU resources and helps maintain a balanced load across the cluster for optimal performance.
NVIDIA Dynamo KV Cache Block Manager
The NVIDIA Dynamo KV Block Manager addresses the significant cost challenge of storing ever-growing volumes of KV cache directly in expensive GPU High-Bandwidth Memory (HBM). Although reusing the KV cache is vital for minimizing recomputation and enhancing inference performance, holding extensive cache history in GPU memory becomes prohibitively costly.To solve this, the NVIDIA Dynamo KV Block Manager implements tiered offloading, intelligently moving older, less frequently accessed, or lower-priority KV cache blocks from fast HBM to more cost-effective storage tiers. These can include shared CPU memory, local SSDs, or networked object storage. This hierarchical strategy helps organizations manage and store significantly larger volumes of KV cache—potentially petabytes—at a fraction of the traditional cost. By freeing up valuable GPU memory while still enabling the reuse of historical KV cache, this feature optimizes resource utilization, supports sustained performance, and improves overall economic efficiency.
Accelerated data transfer with NVIDIA NIXL
High-performance disaggregated serving and efficient KV cache offloading critically depend on ultra-fast, low-latency data transfer between GPUs and across diverse memory or storage tiers. Navigating the complexities of different hardware, network protocols (like EFA), and storage systems to achieve this vital data movement is a major hurdle, often leading to integration challenges and performance bottlenecks in distributed AI deployments.NVIDIA NIXL is NVIDIA Dynamo’s specialized communication library designed to conquer these data transfer challenges. It provides a high-throughput, low-latency communication backbone through a unified, asynchronous API. NIXL intelligently abstracts the underlying complexity, supporting diverse backends like GPUDirect Storage (GDS), UCX, and Amazon S3, and automatically selects the optimal data path over interconnects such as NVLink or EFA. This drastically simplifies development and promotes accelerated, efficient KV cache movement, which is essential for minimizing latency and maximizing the performance of generative AI models.The following diagram illustrates the lifecycle of a request under disaggregated inference in NVIDIA Dynamo.

Figure 5: Lifecycle of a request under disaggregated inference in NVIDIA Dynamo.
This diagram shows the decode to prefill flow, but NVIDIA Dynamo also supports the prefill to decode flow. Refer to the NVIDIA Dynamo documentation to dive deeper into the lifecycle of a request under disaggregated inference.
This architecture enables efficient distributed inference by separating the token parallel prefill phase from the latency-sensitive decode phase, while achieving high throughput through zero-copy GPU transfers and intelligent resource management. Running inference in production isn’t just about performance—you need logging, monitoring, security, and more. Therefore, NVIDIA Dynamo on AWS infrastructure is an attractive option for customers to use self-managed AI/ML services, Amazon Elastic File System (Amazon EFS) or Amazon FSx for Lustre for model storage, Network Load Balancer for access, Amazon CloudWatch or Prometheus for observability, AWS Identity and Access Management IAM and virtual private cloud (VPC) isolation and security groups for security, and EFA for low-latency inter-node communication (critical for prefill and decode disaggregation).
Solution overview
Amazon EKS is a fully managed Kubernetes service that helps you run Kubernetes seamlessly in both the AWS Cloud and on-premises data centers. It manages the availability and scalability of the Kubernetes control plane and provides compute node automatic scaling and lifecycle management support to help you run highly available containerized applications.
Amazon EKS is an ideal platform for running distributed multi-node inference workloads due to its robust integration with AWS services and performance features. It seamlessly integrates with Amazon EFS, a high-throughput file system, enabling fast data access and management among nodes using Kubernetes Persistent Volume Claims (PVCs). Efficient multi-node LLM inference also requires enhanced network performance. AWS Elastic Fabric Adapter (EFA), a network interface that offers low-latency, high-throughput connectivity between Amazon EC2 accelerated instances, is well-suited for this.
In the following sections, we discuss some of the features of Amazon EKS used in this post.
Automatic scaling
Karpenter adds just-in-time provisioning based on actual pod spec, such as GPU count, ENI, and Amazon Elastic Block Store (Amazon EBS) throughput, so NVIDIA Dynamo can burst new g6 instances in less than 60 seconds when the smart router queues fill.
Flexible worker nodes and GPU support
Amazon EKS supports different EC2 instance families. You can mix CPU (M5), accelerated compute (G6, P5, P6), and Arm-based AWS Graviton nodes in one cluster. To enable usage of GPUs in Amazon EKS, you can use Amazon EKS optimized GPU AMIs that ship with the correct NVIDIA driver and container-toolkit versions preinstalled, so pods get /dev/nvidia* devices immediately. The Bottlerocket variant with NVIDIA add-on gives an immutable, minimal operating system to get started quickly with NVIDIA Dynamo.
Storage integrations for large models
Amazon EKS has CSI drivers for the following options:
- Amazon EBS is block storage for high IOPS scratch or local model caching
- Amazon EFS offers an NFS-like read-write-many model repository shared by all pods
- Amazon FSx for Lustre and Amazon FSx for OpenZFS offer sub-millisecond, POSIX‐compatible, bursty throughput
- Amazon S3 with a mountpoint for the S3 Container Storage Interface (CSI) driver offers S3 object access through a file system interface at high throughput
We need a shared file system across all the pods that can store and load the model weights quickly, so we use Amazon EFS in this post. Amazon FSx for Lustre is a high-performance shared file system that is more appropriate for workloads that require sub-millisecond and bursty throughput like ML training jobs. In our case, we don’t need such performance because we are downloading and loading the model weights when we are spinning up or scaling out an NVIDIA Dynamo deployment.
EFA support
Amazon EKS offers VPC networking features, including EFA for low latency. EFA is used to talk between the GPU nodes within a single Availability Zone. EFA is accessed through the Libfabric provider. Refer to Supported interfaces and libraries for supported versions of MPI and NCCL.
Architecture
The example in this post uses the Kubernetes deployment shown in the following AWS deployment architecture diagram. We provision a VPC and associated resources, including subnets (public and private), NAT gateways, and an internet gateway. We create an EKS cluster and with the help of Karpenter, and launch one G6 instance to run the model and a CPU node group using one c7i.16xlarge instance to run NVIDIA Dynamo store pods, frontend pods, and the router pod. We use a single Availability Zone to deploy these nodes.

Figure 6: AWS deployment architecture.
In the following sections, we walk you through the deployment of the DeepSeek-R1-Distill-8b model with disaggregated serving and NVIDIA Dynamo KV Smart Router on Amazon EC2 accelerated GPU instances using Amazon EKS.
For comprehensive step-by-step instructions, detailed configuration options, and troubleshooting guidance, see the complete NVIDIA Dynamo on Amazon EKS documentation.
Prerequisites
To implement this solution, you must have the AWS Command Line Interface (AWS CLI), kubectl, helm, terraform, Docker, earthly, and Python 3.10+ installed. An EC2 instance (t3.xlarge or higher) with Amazon EKS and Amazon Elastic Container Registry (Amazon ECR) permissions is recommended as your setup host.
See the full prerequisites list for installation commands.
Deploy the solution
Complete the following steps to deploy the solution:
- Clone the repository and navigate:
- Deploy the infrastructure and platform:
This single command provisions your complete environment: VPC, EKS cluster with GPU nodes, ECR repositories, monitoring stack, and the NVIDIA Dynamo platform components (Operator, API Store, NATS, PostgreSQL, MinIO).The EKS cluster and node creation process can take 15–30 minutes to complete.
- Build base images:
- Deploy inference graphs:
The deployment of the LLM inference graph takes a few minutes. You can monitor the pod that is building the inference graph (buildkitd or kaniko). When the build is complete, you will see more pods prefixed with the deployment name. You can run the test script to validate the deployment now.
Choose your preferred LLM architecture through the interactive menu (agg, disagg, multinode, and so on). For more information, refer to the LLM architectures in the GitHub repo.
Test and validate the solution
Use the following code to validate the platform health and runs inference tests:
The test.sh script will start a port forward to the frontend service of the deployment, and request the health check, metrics, and /v1/models endpoints to make sure that the deployment is working as intended. After basic functionality is verified, an example LLM inference payload is requested to verify that the inference engine is functional.
Access your deployment
Use the following code to access your deployment:
Monitor and observe
AI-on-EKS can deploy the kube-prometheus-stack add-on, so when NVIDIA Dynamo is installed with this blueprint, you get Grafana and Prometheus out of the box (Grafana on port 3000, Prometheus on 9090):
Clean up
Use the following code to clean up your resources:
This will destroy the NVIDIA Dynamo deployments and start spinning down the infrastructure step by step.
Advanced usage
For custom model deployment, monitoring configuration, troubleshooting, and production considerations, refer to the complete documentation.
This deployment uses the enterprise-grade features of Amazon EKS, including Karpenter automatic scaling, EFA networking, and seamless AWS service integration to provide a production-ready NVIDIA Dynamo environment.
Conclusion
In this post, we discussed the benefits of using NVIDIA Dynamo, a high-throughput, low-latency open source inference serving framework for deploying generative AI and reasoning models in large-scale distributed environments. We demonstrated how to deploy your LLM application on Amazon EKS using the NVIDIA Dynamo Kubernetes Operator. This example showed g6e instances, but it can also work with other NVIDIA GPU instances, such as P6, P5, P4d, P4de, G5, and G6.
Developers can start with NVIDIA Dynamo today. For more Dynamo examples, check out the examples folder in the GitHub repo.
About the authors
 Baladithya Balamurugan is a Solutions Architect at AWS focused on ML deployments for inference and using AWS Neuron to accelerate training and inference. He works with customers to enable and accelerate their ML deployments on services such as Amazon SageMaker and Amazon EC2. Based out of San Francisco, Baladithya enjoys tinkering, developing applications and his homelab in his free time.
Baladithya Balamurugan is a Solutions Architect at AWS focused on ML deployments for inference and using AWS Neuron to accelerate training and inference. He works with customers to enable and accelerate their ML deployments on services such as Amazon SageMaker and Amazon EC2. Based out of San Francisco, Baladithya enjoys tinkering, developing applications and his homelab in his free time.
 Harish Rao is a Senior Solutions Architect at AWS, specializing in large-scale distributed AI training and inference. He empowers customers to harness the power of AI to drive innovation and solve complex challenges. Outside of work, Harish embraces an active lifestyle, enjoying the tranquility of hiking, the intensity of racquetball, and the mental clarity of mindfulness practices.
Harish Rao is a Senior Solutions Architect at AWS, specializing in large-scale distributed AI training and inference. He empowers customers to harness the power of AI to drive innovation and solve complex challenges. Outside of work, Harish embraces an active lifestyle, enjoying the tranquility of hiking, the intensity of racquetball, and the mental clarity of mindfulness practices.
 Brian Kreitzer is a Partner Solutions Architect at Amazon Web Services (AWS). He is responsible for working with partners to create accelerators and solutions for AWS customers, engages in technical co-sell opportunities, and evangelizes accelerator and solution adoption to the technical community.
Brian Kreitzer is a Partner Solutions Architect at Amazon Web Services (AWS). He is responsible for working with partners to create accelerators and solutions for AWS customers, engages in technical co-sell opportunities, and evangelizes accelerator and solution adoption to the technical community.
 Anton Alexander is a Senior Specialist in Generative AI at AWS, focusing on scaling large training and inference workloads with AWS HyperPod. As a veteran CUDA programmer and Kubernetes expert, he helps enterprises integrate NVIDIA technologies for distributed training, specializing in EKS and Slurm implementations. Anton works closely with MENA Region and Government sector clients to optimize GenAI solutions. He holds a patent pending for machine learning edge computing systems. Outside work, Anton is a Brazilian jiu-jitsu and collegiate boxing champion who enjoys flying planes.
Anton Alexander is a Senior Specialist in Generative AI at AWS, focusing on scaling large training and inference workloads with AWS HyperPod. As a veteran CUDA programmer and Kubernetes expert, he helps enterprises integrate NVIDIA technologies for distributed training, specializing in EKS and Slurm implementations. Anton works closely with MENA Region and Government sector clients to optimize GenAI solutions. He holds a patent pending for machine learning edge computing systems. Outside work, Anton is a Brazilian jiu-jitsu and collegiate boxing champion who enjoys flying planes.
 Kshitiz Gupta is a Senior Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running and hiking.
Kshitiz Gupta is a Senior Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running and hiking.
 Wenhan Tan is a Solutions Architect at NVIDIA, assisting customers to adopt NVIDIA AI solutions at large-scale. His work focuses on accelerating deep learning applications and addressing inference and training challenges.
Wenhan Tan is a Solutions Architect at NVIDIA, assisting customers to adopt NVIDIA AI solutions at large-scale. His work focuses on accelerating deep learning applications and addressing inference and training challenges.
 Arun Raman is a Senior Solution Architect at NVIDIA, specializing in AI applications at the edge, in the cloud, and on premises for the consumer Internet industry. In his current role, he works on end-to-end AI pipelines including preprocessing, training, and inference. In addition to his AI work, he has also worked on a wide range of products, including network routers and switches, multi-cloud infrastructure, and services. He holds a master’s degree in electrical engineering from the University of Texas at Dallas.
Arun Raman is a Senior Solution Architect at NVIDIA, specializing in AI applications at the edge, in the cloud, and on premises for the consumer Internet industry. In his current role, he works on end-to-end AI pipelines including preprocessing, training, and inference. In addition to his AI work, he has also worked on a wide range of products, including network routers and switches, multi-cloud infrastructure, and services. He holds a master’s degree in electrical engineering from the University of Texas at Dallas.
 Jiahong Liu is a Senior Solution Architect on the Cloud Service Provider team at NVIDIA. He assists clients build and deploy AI and machine learning solutions using NVIDIA’s accelerated computing to solve complex inference problems. In his leisure time, he enjoys origami, DIY projects, and playing basketball.
Jiahong Liu is a Senior Solution Architect on the Cloud Service Provider team at NVIDIA. He assists clients build and deploy AI and machine learning solutions using NVIDIA’s accelerated computing to solve complex inference problems. In his leisure time, he enjoys origami, DIY projects, and playing basketball.
 Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA, empowering Amazon’s AI MLOps, DevOps, scientists, and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing generative AI foundation models spanning from data curation, GPU training, model inference, and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, and tennis and poker player.
Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA, empowering Amazon’s AI MLOps, DevOps, scientists, and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing generative AI foundation models spanning from data curation, GPU training, model inference, and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, and tennis and poker player.



 Francessca Vasquez is the Vice President of Professional Services and Agentic AI for Amazon Web Services (AWS). She leads global consulting and product services for AWS, overseeing the sales and delivery P&L and customer engagements across public sector, commercial, and partners worldwide. Her team operates in over 48 countries directing programs that accelerate innovation and time-to-value for customers. Francessca drives the co-innovation and service delivery of emerging technologies, such as Agentic AI, Quantum Computing, and Application Modernization, helping customers successfully build and deploy Generative AI solutions. Her team connects AWS AI and ML experts with customers globally to envision, design, and launch cutting-edge generative AI products, services, and processes. As Executive Sponsor for the AWS Global CIO Council, Francessca strengthens strategic partnerships and enhances customer outcomes through collaborative innovation. Under her leadership, AWS Professional Services helps organizations accelerate their digital transformation and unlock the full potential of cloud computing and artificial intelligence technologies.
Francessca Vasquez is the Vice President of Professional Services and Agentic AI for Amazon Web Services (AWS). She leads global consulting and product services for AWS, overseeing the sales and delivery P&L and customer engagements across public sector, commercial, and partners worldwide. Her team operates in over 48 countries directing programs that accelerate innovation and time-to-value for customers. Francessca drives the co-innovation and service delivery of emerging technologies, such as Agentic AI, Quantum Computing, and Application Modernization, helping customers successfully build and deploy Generative AI solutions. Her team connects AWS AI and ML experts with customers globally to envision, design, and launch cutting-edge generative AI products, services, and processes. As Executive Sponsor for the AWS Global CIO Council, Francessca strengthens strategic partnerships and enhances customer outcomes through collaborative innovation. Under her leadership, AWS Professional Services helps organizations accelerate their digital transformation and unlock the full potential of cloud computing and artificial intelligence technologies. Taimur Rashid is an accomplished product and business executive with over two decades of experience encompassing leadership roles in product, market/business development, and cloud solutions architecture and engineering. His expertise spans big tech firms and growth-stage startups, particularly in areas bridging technology, product, business, and Go-To-Market (GTM). He currently leads the Generative AI Innovation and Delivery organization, building end-to-end AI solutions for customers.
Taimur Rashid is an accomplished product and business executive with over two decades of experience encompassing leadership roles in product, market/business development, and cloud solutions architecture and engineering. His expertise spans big tech firms and growth-stage startups, particularly in areas bridging technology, product, business, and Go-To-Market (GTM). He currently leads the Generative AI Innovation and Delivery organization, building end-to-end AI solutions for customers.
 Here’s what we’re announcing at cybersecurity conferences like Black Hat USA and DEF CON 33.
Here’s what we’re announcing at cybersecurity conferences like Black Hat USA and DEF CON 33.



 Giridhar Akila Dhakshinamoorthy is the Senior Staff Engineer and AI/ML Tech Lead in the CTO Office at Sonatus.
Giridhar Akila Dhakshinamoorthy is the Senior Staff Engineer and AI/ML Tech Lead in the CTO Office at Sonatus. Tanay Chowdhury is a Data Scientist at Generative AI Innovation Center at Amazon Web Services who helps customers solve their business problems using generative AI and machine learning. He has done MS with Thesis in Machine Learning from University of Illinois and has extensive experience in solving customer problem in the field of data science.
Tanay Chowdhury is a Data Scientist at Generative AI Innovation Center at Amazon Web Services who helps customers solve their business problems using generative AI and machine learning. He has done MS with Thesis in Machine Learning from University of Illinois and has extensive experience in solving customer problem in the field of data science. Parth Patwa is a Data Scientist in the Generative AI Innovation Center at Amazon Web Services. He has co-authored research papers at top AI/ML venues and has 1000+ citations.
Parth Patwa is a Data Scientist in the Generative AI Innovation Center at Amazon Web Services. He has co-authored research papers at top AI/ML venues and has 1000+ citations. Yingwei Yu is an Applied Science Manager at Generative AI Innovation Center, AWS, where he leverages machine learning and generative AI to drive innovation across industries. With a PhD in Computer Science from Texas A&M University and years of working experience, Yingwei brings extensive expertise in applying cutting-edge technologies to real-world applications.
Yingwei Yu is an Applied Science Manager at Generative AI Innovation Center, AWS, where he leverages machine learning and generative AI to drive innovation across industries. With a PhD in Computer Science from Texas A&M University and years of working experience, Yingwei brings extensive expertise in applying cutting-edge technologies to real-world applications. Hamed Yazdanpanah was a Data Scientist in the Generative AI Innovation Center at Amazon Web Services. He helps customers solve their business problems using generative AI and machine learning.
Hamed Yazdanpanah was a Data Scientist in the Generative AI Innovation Center at Amazon Web Services. He helps customers solve their business problems using generative AI and machine learning.







 Venkata Sistla is a Senior Specialist Solutions Architect in the Worldwide team at Amazon Web Services (AWS), with over 12 years of experience in cloud architecture. He specializes in designing and implementing enterprise-scale AI/ML systems across financial services, healthcare, mining and energy, independent software vendors (ISVs), sports, and retail sectors. His expertise lies in helping organizations transform their data challenges into competitive advantages through innovative cloud solutions while mentoring teams and driving technological excellence. He focuses on architecting highly scalable infrastructures that accelerate machine learning initiatives and deliver measurable business outcomes.
Venkata Sistla is a Senior Specialist Solutions Architect in the Worldwide team at Amazon Web Services (AWS), with over 12 years of experience in cloud architecture. He specializes in designing and implementing enterprise-scale AI/ML systems across financial services, healthcare, mining and energy, independent software vendors (ISVs), sports, and retail sectors. His expertise lies in helping organizations transform their data challenges into competitive advantages through innovative cloud solutions while mentoring teams and driving technological excellence. He focuses on architecting highly scalable infrastructures that accelerate machine learning initiatives and deliver measurable business outcomes. Aamna Najmi is a Senior GenAI and Data Specialist in the Worldwide team at Amazon Web Services (AWS). She assists customers across industries and Regions in operationalizing and governing their generative AI systems at scale, ensuring they meet the highest standards of performance, safety, and ethical considerations, bringing a unique perspective of modern data strategies to complement the field of AI. In her spare time, she pursues her passion of experimenting with food and discovering new places.
Aamna Najmi is a Senior GenAI and Data Specialist in the Worldwide team at Amazon Web Services (AWS). She assists customers across industries and Regions in operationalizing and governing their generative AI systems at scale, ensuring they meet the highest standards of performance, safety, and ethical considerations, bringing a unique perspective of modern data strategies to complement the field of AI. In her spare time, she pursues her passion of experimenting with food and discovering new places.
 NotebookLM is adding featured notebooks, with works selected by partners like The Atlantic and The Economist.
NotebookLM is adding featured notebooks, with works selected by partners like The Atlantic and The Economist.
