Today, we announce the public preview of long-running execution (asynchronous) flow support within Amazon Bedrock Flows. With Amazon Bedrock Flows, you can link foundation models (FMs), Amazon Bedrock Prompt Management, Amazon Bedrock Agents, Amazon Bedrock Knowledge Bases, Amazon Bedrock Guardrails, and other AWS services together to build and scale predefined generative AI workflows.
As customers across industries build increasingly sophisticated applications, they’ve shared feedback about needing to process larger datasets and run complex workflows that take longer than a few minutes to complete. Many customers told us they want to transform entire books, process massive documents, and orchestrate multi-step AI workflows without worrying about runtime limits, highlighting the need for a solution that can handle long-running background tasks. To address those concerns, Amazon Bedrock Flows introduces a new feature in public preview that extends workflow execution time from 5 minutes (synchronous) to 24 hours (asynchronous).
With Amazon Bedrock long-running execution flows (asynchronous), you can chain together multiple prompts, AI services, and Amazon Bedrock components into complex, long-running workflows (up to 24 hours asynchronously). The new capabilities include built-in execution tracing directly using the AWS Management Console and Amazon Bedrock Flow API for observability. These enhancements significantly streamline workflow development and management in Amazon Bedrock Flows, helping you focus on building and deploying your generative AI applications.
By decoupling the workflow execution (asynchronously through long-running flows that can run for up to 24 hours) from the user’s immediate interaction, you can now build applications that can handle large payloads that take longer than 5 minutes to process, perform resource-intensive tasks, apply multiple rules for decision-making, and even run the flow in the background while integrating with multiple systems—while providing your users with a seamless and responsive experience.
Solution overview
Organizations using Amazon Bedrock Flows now can use long-running execution flow capabilities to design and deploy long-running workflows for building more scalable and efficient generative AI applications. This feature offers the following benefits:
- Long-running workflows – You can run long-running workflows (up to 24 hours) as background tasks and decouple workflow execution from the user’s immediate interaction.
- Large payload – The feature enables large payload processing and resource-intensive tasks that can continue for 24 hours instead of the current limit of 5 minutes.
- Complex use cases – It can manage the execution of complex, multi-step decision-making generative AI workflows that integrate multiple external systems.
- Builder-friendly – You can create and manage long-running execution flows through both the Amazon Bedrock API and Amazon Bedrock console.
- Observability – You can enjoy a seamless user experience with the ability to check flow execution status and retrieve results accordingly. The feature also provides traces so you can view the inputs and outputs from each node.
Dentsu, a leading advertising agency and creative powerhouse, needs to handle complex, multi-step generative AI use cases that require longer execution time. One use case is their Easy Reading application, which converts books with many chapters and illustrations into easily readable formats to enable people with intellectual disabilities to access literature. With Amazon Bedrock long-running execution flows, now Dentsu can:
- Process large inputs and perform complex resource-intensive tasks within the workflow. Prior to long-running execution flows, input size was limited due to the 5 minutes execution limit of flows.
- Integrate multiple external systems and services into the generative AI workflow.
- Support both quick, near real-time workflows and longer-running, more complex workflows.
“Amazon Bedrock has been amazing to work with and demonstrate value to our clients,” says Victoria Aiello, Innovation Director, Dentsu Creative Brazil. “Using traces and flows, we are able to show how processing happens behind the scenes of the work AI is performing, giving us better visibility and accuracy on what’s to be produced. For the Easy Reading use case, long-running execution flows will allow for processing of the entire book in one go, taking advantage of the 24-hour flow execution time instead of writing custom code to manage multiple sections of the book separately. This saves us time when producing new books or even integrating with different models; we can test different results according to the needs or content of each book.”
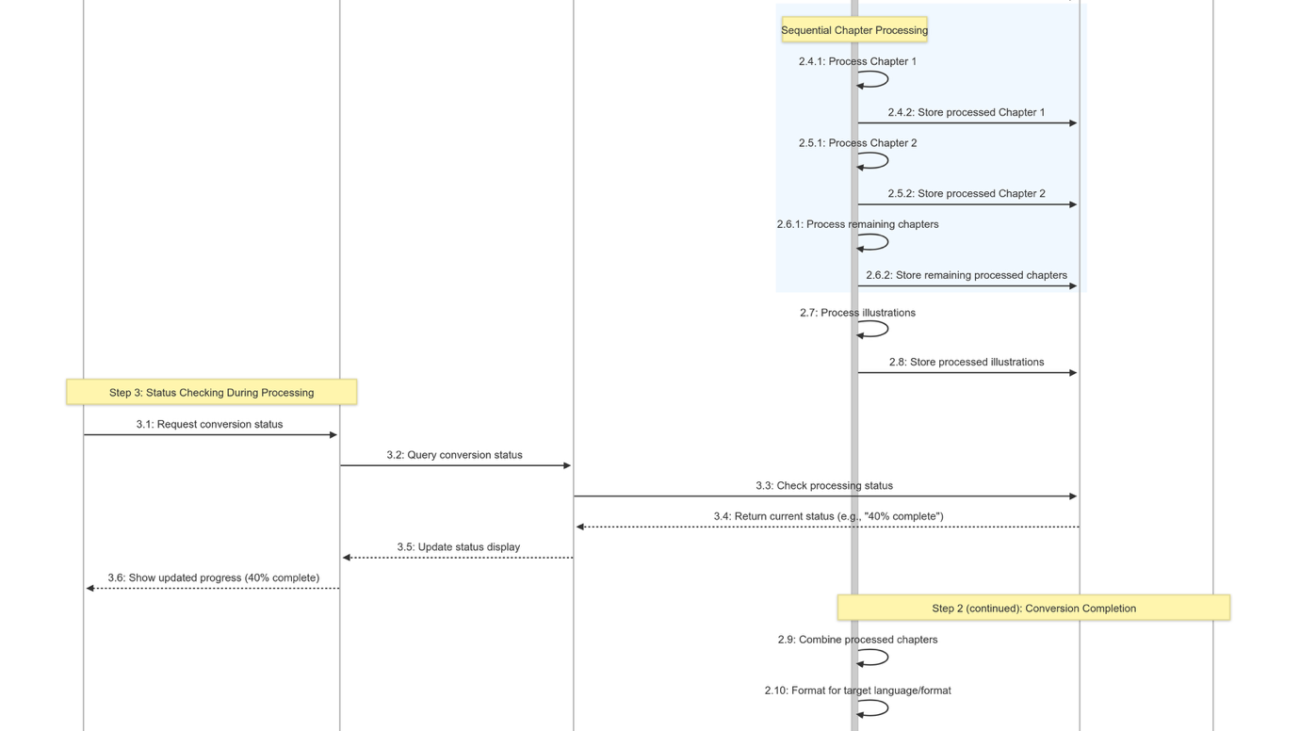
Let’s explore how the new long-running execution flow capability in Amazon Bedrock Flows enables Dentsu to build a more efficient and long-running book processing generative AI application. The following diagram illustrates the end-to-end flow of Dentsu’s book processing application. The process begins when a client uploads a book to Amazon Simple Storage Service (Amazon S3), triggering a flow that processes multiple chapters, where each chapter undergoes accessibility transformations and formatting according to specific user requirements. The transformed chapters are then collected, combined with a table of contents, and stored back in Amazon S3 as a final accessible document. This long-running execution (asynchronous) flow can handle large books efficiently, processing them within the 24-hour execution window while providing status updates and traceability throughout the transformation process.

In the following sections, we demonstrate how to create a long-running execution flow in Amazon Bedrock Flows using Dentsu’s real-world use case of books transformation.
Prerequisites
Before implementing the new capabilities, make sure you have the following:
- An AWS account
- Other Amazon Bedrock features enabled, for example:
- Create and test your base prompts for customer service interactions in Amazon Bedrock Prompt Management
- Set up Amazon Bedrock Guardrails with relevant rules
- Auxiliary AWS services configured as needed for your workflow, such as Amazon DynamoDB, Amazon S3, and Amazon Simple Notification Service (Amazon SNS)
- Required AWS Identity and Access Management (IAM) permissions:
After these components are in place, you can implement Amazon Bedrock long-running execution flow capabilities in your generative AI use case.
Create a long-running execution flow
Complete the following steps to create your long-running execution flow:
- On the Amazon Bedrock console, in the navigation pane under Builder tools, choose Flows.
- Choose Create a flow.
- Provide a name for your a new flow, for example, easy-read-long-running-flow.
For detailed instructions on creating a flow, see Amazon Bedrock Flows is now generally available with enhanced safety and traceability. Amazon Bedrock provides different node types to build your prompt flow.
The following screenshot shows the high-level flow of Dentsu’s book conversion generative AI-powered application. The workflow demonstrates a sequential process from input handling through content transformation to final storage and delivery.

The following table outlines the core components and nodes within the preceding workflow, designed for document processing and accessibility transformation.
| Node | Purpose |
| Flow Input | Entry point accepting an array of S3 prefixes (chapters) and accessibility profile |
| Iterator | Processes each chapter (prefix) individually |
| S3 Retrieval | Downloads chapter content from the specified Amazon S3 location |
| Easifier | Applies accessibility transformation rules to chapter content |
| HTML Formatter | Formats transformed content with appropriate HTML structure |
| Collector | Assembles transformed chapters while maintaining order |
| Lambda Function | Combines chapters into a single document with table of contents |
| S3 Storage | Stores the final transformed document in Amazon S3 |
| Flow Output | Returns Amazon S3 location of the transformed book with metadata |
Test the book processing flow
We are now ready to test the flow through the Amazon Bedrock console or API. We use a fictional book called “Beyond Earth: Humanity’s Journey to the Stars.” This book tells the story of humanity’s greatest adventure beyond our home planet, tracing our journey from the first satellites and moonwalks to space stations and robotic explorers that continue to unveil the mysteries of our solar system.
- On the Amazon Bedrock console, choose Flows in the navigation pane.
- Choose the flow (easy-read-long-running-flow) and choose Create execution.
The flow must be in the Prepared state before creating an execution.
The Execution tab shows the previous executions for the selected flow.

- Provide the following input:
dyslexia test input
These are the different chapters of our book that need to be transformed.
- Choose Create.

Amazon Bedrock Flows initiates the long-running execution (asynchronous) flow of our workflow. The dashboard displays the executions of our flow with their respective statuses (Running, Succeeded, Failed, TimedOut, Aborted). When an execution is marked as Completed, the results become available in our designated S3 bucket.

Choosing an execution takes you to the summary page containing its details. The Overview section displays start and end times, plus the execution Amazon Resource Name (ARN)—a unique identifier that’s essential for troubleshooting specific executions later.

When you select a node in the flow builder, its configuration details appear. For instance, choosing the Easifier node reveals the prompt used, the selected model (here it’s Amazon Nova Lite), and additional configuration parameters. This is essential information for understanding how that specific component is set up.

The system also provides access to execution traces, offering detailed insights into each processing step, tracking real-time performance metrics, and highlighting issues that occurred during the flow’s execution. Traces can be enabled using the API and sent to an Amazon CloudWatch log. In the API, set the enableTrace field to true in an InvokeFlow request. Each flowOutputEvent in the response is returned alongside a flowTraceEvent.

We have now successfully created and executed a long-running execution flow. You can also use Amazon Bedrock APIs to programmatically start, stop, list, and get flow executions. For more details on how to configure flows with enhanced safety and traceability, refer to Amazon Bedrock Flows is now generally available with enhanced safety and traceability.
Conclusion
The integration of long-running execution flows in Amazon Bedrock Flows represents a significant advancement in generative AI development. With these capabilities, you can create more efficient AI-powered solutions to automate long-running operations, addressing critical challenges in the rapidly evolving field of AI application development.
Long-running execution flow support in Amazon Bedrock Flows is now available in public preview in AWS Regions where Amazon Bedrock Flows is available, except for the AWS GovCloud (US) Regions. To get started, open the Amazon Bedrock console or APIs to begin building flows with long-running execution flow with Amazon Bedrock Flows. To learn more, see Create your first flow in Amazon Bedrock and Track each step in your flow by viewing its trace in Amazon Bedrock.
We’re excited to see the innovative applications you will build with these new capabilities. As always, we welcome your feedback through AWS re:Post for Amazon Bedrock or your usual AWS contacts. Join the generative AI builder community at community.aws to share your experiences and learn from others.
About the authors
 Shubhankar Sumar is a Senior Solutions Architect at AWS, where he specializes in architecting generative AI-powered solutions for enterprise software and SaaS companies across the UK. With a strong background in software engineering, Shubhankar excels at designing secure, scalable, and cost-effective multi-tenant systems on the cloud. His expertise lies in seamlessly integrating cutting-edge generative AI capabilities into existing SaaS applications, helping customers stay at the forefront of technological innovation.
Shubhankar Sumar is a Senior Solutions Architect at AWS, where he specializes in architecting generative AI-powered solutions for enterprise software and SaaS companies across the UK. With a strong background in software engineering, Shubhankar excels at designing secure, scalable, and cost-effective multi-tenant systems on the cloud. His expertise lies in seamlessly integrating cutting-edge generative AI capabilities into existing SaaS applications, helping customers stay at the forefront of technological innovation.
 Amit Lulla is a Principal Solutions Architect at AWS, where he architects enterprise-scale generative AI and machine learning solutions for software companies. With over 15 years in software development and architecture, he’s passionate about turning complex AI challenges into bespoke solutions that deliver real business value. When he’s not architecting cutting-edge systems or mentoring fellow architects, you’ll find Amit on the squash court, practicing yoga, or planning his next travel adventure. He also maintains a daily meditation practice, which he credits for keeping him centered in the fast-paced world of AI innovation.
Amit Lulla is a Principal Solutions Architect at AWS, where he architects enterprise-scale generative AI and machine learning solutions for software companies. With over 15 years in software development and architecture, he’s passionate about turning complex AI challenges into bespoke solutions that deliver real business value. When he’s not architecting cutting-edge systems or mentoring fellow architects, you’ll find Amit on the squash court, practicing yoga, or planning his next travel adventure. He also maintains a daily meditation practice, which he credits for keeping him centered in the fast-paced world of AI innovation.
 Huong Nguyen is a Principal Product Manager at AWS. She is leading the Amazon Bedrock Flows, with 18 years of experience building customer-centric and data-driven products. She is passionate about democratizing responsible machine learning and generative AI to enable customer experience and business innovation. Outside of work, she enjoys spending time with family and friends, listening to audiobooks, traveling, and gardening.
Huong Nguyen is a Principal Product Manager at AWS. She is leading the Amazon Bedrock Flows, with 18 years of experience building customer-centric and data-driven products. She is passionate about democratizing responsible machine learning and generative AI to enable customer experience and business innovation. Outside of work, she enjoys spending time with family and friends, listening to audiobooks, traveling, and gardening.
 Christian Kamwangala is an AI/ML and Generative AI Specialist Solutions Architect at AWS, based in Paris, France. He partners with enterprise customers to architect, optimize, and deploy production-grade AI solutions leveraging AWS’s comprehensive machine learning stack. Christian specializes in inference optimization techniques that balance performance, cost, and latency requirements for large-scale deployments. In his spare time, Christian enjoys exploring nature and spending time with family and friends.
Christian Kamwangala is an AI/ML and Generative AI Specialist Solutions Architect at AWS, based in Paris, France. He partners with enterprise customers to architect, optimize, and deploy production-grade AI solutions leveraging AWS’s comprehensive machine learning stack. Christian specializes in inference optimization techniques that balance performance, cost, and latency requirements for large-scale deployments. In his spare time, Christian enjoys exploring nature and spending time with family and friends.
 Jeremy Bartosiewicz is a Senior Solutions Architect at AWS, with over 15 years of experience working in technology in multiple roles. Coming from a consulting background, Jeremy enjoys working on a multitude of projects that help organizations grow using cloud solutions. He helps support large enterprise customers at AWS and is part of the Advertising and Machine Learning TFCs.
Jeremy Bartosiewicz is a Senior Solutions Architect at AWS, with over 15 years of experience working in technology in multiple roles. Coming from a consulting background, Jeremy enjoys working on a multitude of projects that help organizations grow using cloud solutions. He helps support large enterprise customers at AWS and is part of the Advertising and Machine Learning TFCs.


 Ray Wang is a Senior Solutions Architect at AWS. With 12 years of experience in the backend and consultant, Ray is dedicated to building modern solutions in the cloud, especially in especially in NoSQL, big data, machine learning, and Generative AI. As a hungry go-getter, he passed all 12 AWS certificates to increase the breadth and depth of his technical knowledge. He loves to read and watch sci-fi movies in his spare time.
Ray Wang is a Senior Solutions Architect at AWS. With 12 years of experience in the backend and consultant, Ray is dedicated to building modern solutions in the cloud, especially in especially in NoSQL, big data, machine learning, and Generative AI. As a hungry go-getter, he passed all 12 AWS certificates to increase the breadth and depth of his technical knowledge. He loves to read and watch sci-fi movies in his spare time. Kanwaljit Khurmi is a Principal Solutions Architect at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance, helping them improve the value of their solutions when using AWS. Kanwaljit specializes in helping customers with containerized and machine learning applications.
Kanwaljit Khurmi is a Principal Solutions Architect at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance, helping them improve the value of their solutions when using AWS. Kanwaljit specializes in helping customers with containerized and machine learning applications. James Chan is a Solutions Architect at AWS specializing in the Financial Services Industry (FSI). With extensive experience in financial services, Fintech, and manufacturing sectors, James help FSI customers at AWS innovate and build scalable cloud solutions and financial system architectures. James specialize in AWS container, network architecture, and generative AI solutions that combine cloud-native technologies with strict financial compliance requirements.
James Chan is a Solutions Architect at AWS specializing in the Financial Services Industry (FSI). With extensive experience in financial services, Fintech, and manufacturing sectors, James help FSI customers at AWS innovate and build scalable cloud solutions and financial system architectures. James specialize in AWS container, network architecture, and generative AI solutions that combine cloud-native technologies with strict financial compliance requirements. Mike Xu is an Associate Solutions Architect specializing in AI/ML at Amazon Web Services. He works with customers to design machine learning solutions using services like Amazon SageMaker and Amazon Bedrock. With a background in computer engineering and a passion for generative AI, Mike focuses on helping organizations accelerate their AI/ML journey in the cloud. Outside of work, he enjoys producing electronic music and exploring emerging tech.
Mike Xu is an Associate Solutions Architect specializing in AI/ML at Amazon Web Services. He works with customers to design machine learning solutions using services like Amazon SageMaker and Amazon Bedrock. With a background in computer engineering and a passion for generative AI, Mike focuses on helping organizations accelerate their AI/ML journey in the cloud. Outside of work, he enjoys producing electronic music and exploring emerging tech.













 Jordan Jones is a Solutions Architect at AWS within the Cloud Sales Center organization. He uses cloud technologies to solve complex problems, bringing defense industry experience and expertise in various operating systems, cybersecurity, and cloud architecture. He enjoys mentoring aspiring professionals and speaking on various career panels. Outside of work, he volunteers within the community and can be found watching Golden State Warriors games, solving Sudoku puzzles, or exploring new cultures through world travel.
Jordan Jones is a Solutions Architect at AWS within the Cloud Sales Center organization. He uses cloud technologies to solve complex problems, bringing defense industry experience and expertise in various operating systems, cybersecurity, and cloud architecture. He enjoys mentoring aspiring professionals and speaking on various career panels. Outside of work, he volunteers within the community and can be found watching Golden State Warriors games, solving Sudoku puzzles, or exploring new cultures through world travel. Jean Jacques Mikem is a Solutions Architect at AWS with a passion for designing secure and scalable technology solutions. He uses his expertise in cybersecurity and technological hardware to architect robust systems that meet complex business needs. With a strong foundation in security principles and computing infrastructure, he excels at creating solutions that bridge business requirements with technical implementation.
Jean Jacques Mikem is a Solutions Architect at AWS with a passion for designing secure and scalable technology solutions. He uses his expertise in cybersecurity and technological hardware to architect robust systems that meet complex business needs. With a strong foundation in security principles and computing infrastructure, he excels at creating solutions that bridge business requirements with technical implementation.