Organizations deploying video monitoring systems face a critical challenge: processing continuous video streams while maintaining accurate situational awareness. Traditional monitoring approaches that use rule-based detection or basic computer vision frequently miss important events or generate excessive false positives, leading to operational inefficiencies and alert fatigue.
In this post, we show how to build a fully deployable solution that processes video streams using OpenCV, Amazon Bedrock for contextual scene understanding and automated responses through Amazon Bedrock Agents. This solution extends the capabilities demonstrated in Automate chatbot for document and data retrieval using Amazon Bedrock Agents and Knowledge Bases, which discussed using Amazon Bedrock Agents for document and data retrieval. In this post, we apply Amazon Bedrock Agents to real-time video analysis and event monitoring.
Benefits of using Amazon Bedrock Agents for video monitoring
The following figure shows example video stream inputs from different monitoring scenarios. With contextual scene understanding, users can search for specific events.

A front door camera will capture many events throughout the day, but some are more interesting than others—having context if a package is being delivered or removed (as in the following package example) limits alerts to urgent events.

Amazon Bedrock is a fully managed service that provides access to high-performing foundation models (FMs) from leading AI companies through a single API. Using Amazon Bedrock, you can build secure, responsible generative AI applications. Amazon Bedrock Agents extends these capabilities by enabling applications to execute multi-step tasks across systems and data sources, making it ideal for complex monitoring scenarios. The solution processes video streams through these key steps:
- Extract frames when motion is detected from live video streams or local files.
- Analyze context using multimodal FMs.
- Make decisions using agent-based logic with configurable responses.
- Maintain searchable semantic memory of events.
You can build this intelligent video monitoring system using Amazon Bedrock Agents and Amazon Bedrock Knowledge Bases in an automated solution. The complete code is available in the GitHub repo.
Limitations of current video monitoring systems
Organizations deploying video monitoring systems face a fundamental dilemma. Despite advances in camera technology and storage capabilities, the intelligence layer interpreting video feeds often remains rudimentary. This creates a challenging situation where security teams must make significant trade-offs in their monitoring approach. Current video monitoring solutions typically force organizations to choose between the following:
- Simple rules that scale but generate excessive false positives
- Complex rules that require ongoing maintenance and customization
- Manual monitoring that relies on human attention and doesn’t scale
- Point solutions that only handle specific scenarios but lack flexibility
These trade-offs create fundamental barriers to effective video monitoring that impact security, safety, and operational efficiency across industries. Based on our work with customers, we’ve identified three critical challenges that emerge from these limitations:
- Alert fatigue – Traditional motion detection and object recognition systems generate alerts for any detected change or recognized object. Security teams quickly become overwhelmed by the volume of notifications for normal activities. This leads to reduced attention when genuinely critical events occur, diminishing security effectiveness and increasing operational costs from constant human verification of false alarms.
- Limited contextual understanding – Rule-based systems fundamentally struggle with nuanced scene interpretation. Even sophisticated traditional systems operate with limited understanding of the environments they monitor due to a lack of contextual awareness, because they can’t easily do the following:
- Distinguish normal from suspicious behavior
- Understand temporal patterns like recurring weekly events
- Consider environmental context such as time of day or location
- Correlate multiple events that might indicate a pattern
- Lack of semantic memory – Conventional systems lack the ability to build and use knowledge over time. They can’t do the following:
- Establish baselines of routine versus unusual events
- Offer natural language search capabilities across historical data
- Support reasoning about emerging patterns
Without these capabilities, you can’t gain cumulative benefits from your monitoring infrastructure or perform sophisticated retrospective analysis. To address these challenges effectively, you need a fundamentally different approach. By combining the contextual understanding capabilities of FMs with a structured framework for event classification and response, you can build more intelligent monitoring systems. Amazon Bedrock Agents provides the ideal platform for this next-generation approach.
Solution overview
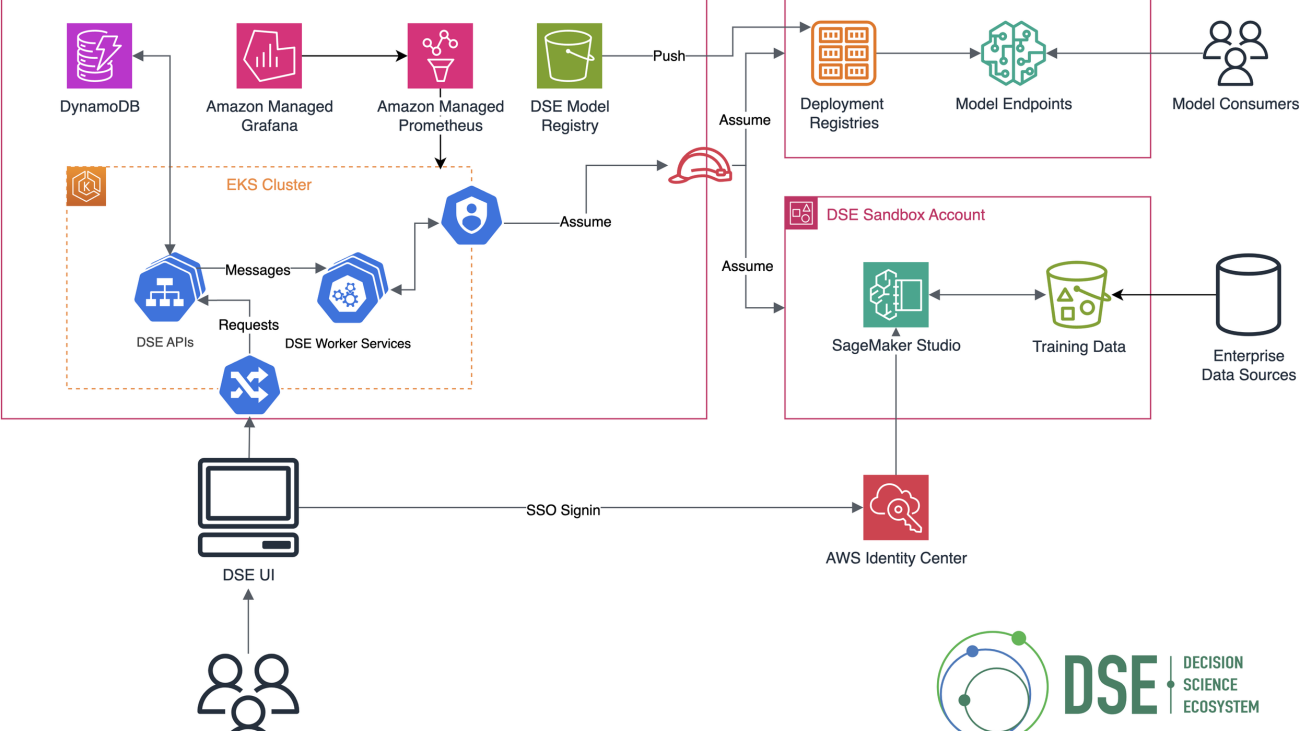
You can address these monitoring challenges by building a video monitoring solution with Amazon Bedrock Agents. The system intelligently screens events, filters routine activity, and escalates situations requiring human attention, helping reduce alert fatigue while improving detection accuracy. The solution uses Amazon Bedrock Agents to analyze detected motion from video, and alerts users when an event of interest happens according to the provided instructions. This allows the system to intelligently filter out trivial events that can trigger motion detection, such as wind or birds, and direct the user’s attention only to events of interest. The following diagram illustrates the solution architecture.

The solution uses three primary components to address the core challenges: agents as escalators, a video processing pipeline, and Amazon Bedrock Agents. We discuss these components in more detail in the following sections.
The solution uses the AWS Cloud Development Kit (AWS CDK) to deploy the solution components. The AWS CDK is an open source software development framework for defining cloud infrastructure as code and provisioning it through AWS CloudFormation.
Agent as escalators
The first component uses Amazon Bedrock Agents to examine detected motion events with the following capabilities:
- Provides natural language understanding of scenes and activities for contextual interpretation
- Maintains temporal awareness across frame sequences to understand event progression
- References historical patterns to distinguish unusual from routine events
- Applies contextual reasoning about behaviors, considering factors like time of day, location, and action sequences
We implement a graduated response framework that categorizes events by severity and required action:
- Level 0: Log only – The system logs normal or expected activities. For example, when a delivery person arrives during business hours or a recognized vehicle enters the driveway, these events are documented for pattern analysis and future reference but require no immediate action. They remain searchable in the event history.
- Level 1: Human notification – This level handles unusual but non-critical events that warrant human attention. An unrecognized vehicle parked nearby, an unexpected visitor, or unusual movement patterns trigger a notification to security personnel. These events require human verification and assessment.
- Level 2: Immediate response – Reserved for critical security events. Unauthorized access attempts, detection of smoke or fire, or suspicious behavior trigger automatic response actions through API calls. The system notifies personnel through SMS or email alerts with event information and context.
The solution provides an interactive processing and monitoring interface through a Streamlit application. With the Streamlit UI, users can provide instructions and interact with the agent.

The application consists of the following key features:
- Live stream or video file input – The application accepts M3U8 stream URLs from webcams or security feeds, or local video files in common formats (MP4, AVI). Both are processed using the same motion detection pipeline that saves triggered events to Amazon Simple Storage Service (Amazon S3) for agent analysis.
- Custom instructions – Users can provide specific monitoring guidance, such as “Alert me about unknown individuals near the loading dock after hours” or “Focus on vehicle activity in the parking area.” These instructions adjust how the agent interprets detected motion events.
- Notification configuration – Users can specify contact information for different alert levels. The system uses Amazon Simple Notification Service (Amazon SNS) to send emails or text messages based on event severity, so different personnel can be notified for potential issues vs. critical situations.
- Natural language queries about past events – The interface includes a chat component for historical event retrieval. Users can ask “What vehicles have been in the driveway this week?” or “Show me any suspicious activity from last night,” receiving responses based on the system’s event memory.
Video processing pipeline
The solution uses several AWS services to capture and prepare video data for analysis through a modular processing pipeline. The solution supports multiple types of video sources:
When using streams, OpenCV’s VideoCapture component handles the connection and frame extraction. For testing, we’ve included sample event videos demonstrating different scenarios. The core of the video processing is a modular pipeline implemented in Python. Key components include:
- SimpleMotionDetection – Identifies movement in the video feed
- FrameSampling – Captures sequences of frames over time when motion is detected
- GridAggregator – Organizes multiple frames into a visual grid for context
- S3Storage – Stores captured frame sequences in Amazon S3
This multi-process framework optimizes performance by running components concurrently and maintaining a queue of frames to process. The video processing pipeline organizes captured frame data in a structured way before passing it to the Amazon Bedrock agent for analysis:
- Frame sequence storage – When motion is detected, the system captures a sequence of frames over 10 seconds. These frames are stored in Amazon S3 using a timestamp-based path structure (YYYYMMDD-HHMMSS) that allows for efficient retrieval by date and time. In the case where motions exceed 10 seconds, multiple events are created.
- Image grid format – Rather than processing individual frames separately, the system arranges multiple sequential frames into a grid format (typically 3×4 or 4×5). This presentation provides temporal context and is sent to the Amazon Bedrock agent for analysis. The grid format enables understanding of how motion progresses over time, which is critical for accurate scene interpretation.
The following figure is an example of an image grid sent to the agent. Package theft is difficult to identify with classic image models. The large language model’s (LLM’s) ability to reason over a sequence of image allows it to make observations about intent.

The video processing pipeline’s output—timestamped frame grids stored in Amazon S3—serves as the input for the Amazon Bedrock agent components, which we discuss in the next section.
Amazon Bedrock agent components
The solution integrates multiple Amazon Bedrock services to create an intelligent analysis system:
- Core agent architecture – The agent orchestrates these key workflows:
- Receives frame grids from Amazon S3 on motion detection
- Coordinates multi-step analysis processes
- Makes classification decisions
- Triggers appropriate response actions
- Maintains event context and state
- Knowledge management – The solution uses Amazon Bedrock Knowledge Bases with Amazon OpenSearch Serverless to:
- Store and index historical events
- Build baseline activity patterns
- Enable natural language querying
- Track temporal patterns
- Support contextual analysis
- Action groups – The agent has access to several actions defined through API schemas:
- Analyze grid – Process incoming frame grids from Amazon S3
- Alert – Send notifications through Amazon SNS based on severity
- Log – Record event details for future reference
- Search events by date – Retrieve past events based on a date range
- Look up vehicle (Text-to-SQL) – Query the vehicle database for information
For structured data queries, the system uses the FM’s ability to convert natural language to SQL. This enables the following:
- Querying Amazon Athena tables containing event records
- Retrieving information about registered vehicles
- Generating reports from structured event data
These components work together to create a comprehensive system that can analyze video content, maintain event history, and support both real-time alerting and retrospective analysis through natural language interaction.
Video processing framework
The video processing framework implements a multi-process architecture for handling video streams through composable processing chains.
Modular pipeline architecture
The framework uses a composition-based approach built around the FrameProcessor abstract base class.
Processing components implement a consistent interface with a process(frame) method that takes a Frame and returns a potentially modified Frame:
```
class FrameProcessor(ABC):
@abstractmethod
def process(self, frame: Frame) -> Optional[Frame]: ...
```
The Frame class encapsulates the image data along with timestamps, indexes, and extensible metadata:
```
@dataclass
class Frame:
buffer: ndarray # OpenCV image array
timestamp: float
index: float
fps: float
metadata: dict = field(default_factory=dict)
```
Customizable processing chains
The architecture supports configuring multiple processing chains that can be connected in sequence. The solution uses two primary chains. The detection and analysis chain processes incoming video frames to identify events of interest:
```
chain = FrameProcessorChain([
SimpleMotionDetection(motion_threshold=10_000, frame_skip_size=1),
FrameSampling(timedelta(milliseconds=250), threshold_time=timedelta(seconds=2)),
GridAggregator(shape=(13, 3))
])
```
The storage and notification chain handles the storage of identified events and invocation of the agent:
```
storage_chain = FrameProcessorChain([
S3Storage(bucket_name=TARGET_S3_BUCKET, prefix=S3_PREFIX, s3_client_provider=s3_client_provider),
LambdaProcessor(get_response=get_response, monitoring_instructions=config.monitoring_instructions)
])
```
You can modify these changes independently to add or replace components based on specific monitoring requirements.
Component implementation
The solution includes several processing components that demonstrate the framework’s capabilities. You can modify each processing step or add new ones. For example, for simple motion detection, we use a simple pixel difference, but you can refine the motion detection functionality as needed, or follow the format to implement other detection algorithms, such as object detection or scene segmentation.
Additional components include the FrameSampling processor to control capture timing, GridAggregator to create visual frame grids, and storage processors that save event data and trigger agent analysis, and these can be customized and replaced as needed. For example:
- Modify existing components – Adjust thresholds or parameters to tune for specific environments
- Create alternative storage backends – Direct output to different storage services or databases
- Implement preprocessing and postprocessing steps – Add image enhancement, data filtering, or additional context generation
Finally, the LambdaProcessor serves as the bridge to the Amazon Bedrock agent by invoking an AWS Lambda function that sends the information in a request to the deployed agent. From there, the Amazon Bedrock agent takes over and analyzes the event and takes action accordingly.
Agent implementation
After you deploy the solution, an Amazon Bedrock agent alias becomes available. This agent functions as an intelligent analysis layer, processing captured video events and executing appropriate actions based on its analysis. You can test the agent and view its reasoning trace directly on the Amazon Bedrock console, as shown in the following screenshot.

This agent will lack some of the metadata supplied by the Streamlit application (such as current time) and might not give the same answers as the full application.
Invocation flow
The agent is invoked through a Lambda function that handles the request-response cycle and manages session state. It finds the highest published version ID and uses it to invoke the agent and parses the response.
Action groups
The agent’s capabilities are defined through action groups implemented using the BedrockAgentResolver framework. This approach automatically generates the OpenAPI schema required by the agent.
When the agent is invoked, it receives an event object that includes the API path and other parameters that inform the agent framework how to route the request to the appropriate handler based. You can add new actions by defining additional endpoint handlers following the same pattern and generating a new OpenAPI schema:
```
if __name__ == "__main__":
print(app.get_openapi_json_schema())
```
Text-to-SQL integration
Through its action group, the agent is able to translate natural language queries into SQL for structured data analysis. The system reads data from assets/data_query_data_source, which can include various formats like CSV, JSON, ORC, or Parquet.
This capability enables users to query structured data using natural language. As demonstrated in the following example, the system translates natural language queries about vehicles into SQL, returning structured information from the database.

The database connection is configured through a SQL Alchemy engine. Users can connect to existing databases by updating the create_sql_engine() function to use their connection parameters.
Event memory and semantic search
The agent maintains a detailed memory of past events, storing event logs with rich descriptions in Amazon S3. These events become searchable through both vector-based semantic search and date-based filtering. As shown in the following example, temporal queries make it possible to retrieve information about events within specific time periods, such as vehicles observed in the past 72 hours.

The system’s semantic memory capabilities enable queries based on abstract concepts and natural language descriptions. As shown in the following example, the agent can understand abstract concepts like “funny” and retrieve relevant events, such as a person dropping a birthday cake.

Events can be linked together by the agent to identify patterns or related incidents. For example, the system can correlate separate sightings of individuals with similar characteristics. In the following screenshots, the agent connects related incidents by identifying common attributes like clothing items across different events.


This event memory store allows the system to build knowledge over time, providing increasingly valuable insights as it accumulates data. The combination of structured database querying and semantic search across event descriptions creates an agent with a searchable memory of all past events.
Prerequisites
Before you deploy the solution, complete the following prerequisites:
- Configure AWS credentials using
aws configure. Use either the us-west-2 or us-east-1 AWS Region.
- Enable access to Anthropic’s Claude 3.x models, or another supported Amazon Bedrock Agents model you want to use.
- Make sure you have the following dependencies:
Deploy the solution
The AWS CDK deployment creates the following resources:
- Storage – S3 buckets for assets and query results
- Amazon Bedrock resources – Agent and knowledge base
- Compute – Lambda functions for actions, invocation, and updates
- Database – Athena database for structured queries, and an AWS Glue crawler for data discovery
Deploy the solution with the following commands:
```
#1. Clone the repository and navigate to folder
git clone https://github.com/aws-samples/sample-video-monitoring-agent.git && cd sample-video-monitoring-agent
#2. Set up environment and install dependencies
python3 -m venv .venv && source .venv/bin/activate && pip install -r requirements.txt
#3. Deploy AWS resources
cdk bootstrap && cdk deploy
#4. Run the streamlit app
cd code/streamlit_app && streamlit run app.py
```
On Windows, replace the second line with the following code:
```
python3 -m venv .venv && % .venvScriptsactivate.bat && pip install -r requirements.txt
```
Clean up
To destroy the resources you created and stop incurring charges, run the following command:
Future enhancements
The current implementation demonstrates the potential of agent-based video monitoring in a home security setting, but there are many potential applications.
Sample Use Cases
The following showcases the application of the solution to various scenarios.
Small business

{ “alert_level”: 0, “timestamp”: “2024-11-20T15:24:15Z”, “reason”: “Vehicle arrival in driveway”, “description”: ”Standard vehicle arrival and parking sequence. Vehicles present: Black Nissan Frontier pickup (parked), silver Honda CR-V (arriving), and partial view of blue vehicle in foreground. Area features: Gravel driveway surface, two waste bins (County Waste and recycling), evergreen trees in background. Sequence shows Honda CR-V executing normal parking maneuver: approaches from east, performs standard three-point turn, achieves final position next to pickup truck. Daytime conditions, clear visibility. Vehicle condition: Clean, well-maintained CR-V appears to be 2012-2016 model year, no visible damage or unusual modifications. Movement pattern indicates familiar driver performing routine parking. No suspicious behavior or safety concerns observed. Timestamp indicates standard afternoon arrival time. Waste bins properly positioned and undisturbed during parking maneuver.” }
Industrial

{ “alert_level”: 2, “timestamp”: “2024-11-20T15:24:15Z”, “reason”: “Warehouse product spill/safety hazard”,”description”: ”Significant product spill incident in warehouse storage aisle. Location: Main warehouse aisle between high-bay racking systems containing boxed inventory. Sequence shows what appears to be liquid or container spill, likely water/beverage products based on blue colored containers visible. Infrastructure: Professional warehouse setup with multi-level blue metal racking, concrete flooring, overhead lighting. Incident progression: Initial frames show clean aisle, followed by product falling/tumbling, resulting in widespread dispersal of items across aisle floor. Hazard assessment: Creates immediate slip/trip hazard, blocks emergency egress path, potential damage to inventory. Area impact: Approximately 15-20 feet of aisle space affected. Facility type appears to be distribution center or storage warehouse. Multiple cardboard boxes visible on surrounding shelves potentially at risk from liquid damage.” }
Backyard

{ “alert_level”: 1, “timestamp”: “2024-11-20T15:24:15Z”, “reason”: “Wildlife detected on property”, “description”: ”Adult raccoon observed investigating porch/deck area with white railings. Night vision/IR camera provides clear footage of animal. Subject animal characteristics: medium-sized adult raccoon, distinctive facial markings clearly visible, healthy coat condition, normal movement patterns. Sequence shows animal approaching camera (15:42PM), investigating area near railing (15:43-15:44PM), with close facial examination (15:45PM). Final frame shows partial view as animal moves away. Environment: Location appears to be elevated deck/porch with white painted wooden railings and balusters. Lighting conditions: Nighttime, camera operating in infrared/night vision mode providing clear black and white footage. Animal behavior appears to be normal nocturnal exploration, no signs of aggression or disease.” }
Home safety

{ “alert_level”: 2, “timestamp”: “2024-11-20T15:24:15Z”, “reason”: “Smoke/possible fire detected”, “description”: ”Rapid development of white/grey smoke visible in living room area. Smoke appears to be originating from left side of frame, possibly near electronics/TV area. Room features: red/salmon colored walls, grey couch, illuminated aquarium, table lamps, framed artwork. Sequence shows progressive smoke accumulation over 4-second span (15:42PM – 15:46PM).Notable smoke density increase in upper left corner of frame with potential light diffusion indicating particulate matter in air. Smoke pattern suggests active fire development rather than residual smoke. Blue light from aquarium remains visible throughout sequence providing contrast reference for smoke density.”
Further extensions
In addition, you can extend the FM capabilities using the following methods:
- Fine-tuning for specific monitoring contexts – Adapting the models to recognize domain-specific objects, behaviors, and scenarios
- Refined prompts for specific use cases – Creating specialized instructions that optimize the agent’s performance for particular environments like industrial facilities, retail spaces, or residential settings
You can expand the agent’s ability to take action, for example:
- Direct control of smart home and smart building systems – Integrating with Internet of Things (IoT) device APIs to control lights, locks, or alarm systems
- Integration with security and safety protocols – Connecting to existing security infrastructure to follow established procedures
- Automated response workflows – Creating multi-step action sequences that can be triggered by specific events
You can also consider enhancing the event memory system:
- Long-term pattern recognition – Identifying recurring patterns over extended time periods
- Cross-camera correlation – Linking observations from multiple cameras to track movement through a space
- Anomaly detection based on historical patterns – Automatically identifying deviations from established baselines
Lastly, consider extending the monitoring capabilities beyond fixed cameras:
- Monitoring for robotic vision systems – Applying the same intelligence to mobile robots that patrol or inspect areas
- Drone-based surveillance – Processing aerial footage for comprehensive site monitoring
- Mobile security applications – Extending the platform to process feeds from security personnel body cameras or mobile devices
These enhancements can transform the system from a passive monitoring tool into an active participant in security operations, with increasingly sophisticated understanding of normal patterns and anomalous events.
Conclusion
The approach of using agents as escalators represents a significant advancement in video monitoring, using the contextual understanding capabilities of FMs with the action-oriented framework of Amazon Bedrock Agents. By filtering the signal from the noise, this solution addresses the critical problem of alert fatigue while enhancing security and safety monitoring capabilities.With this solution, you can:
- Reduce false positives while maintaining high detection sensitivity
- Provide human-readable descriptions and classifications of events
- Maintain searchable records of all activity
- Scale monitoring capabilities without proportional human resources
The combination of intelligent screening, graduated responses, and semantic memory enables a more effective and efficient monitoring system that enhances human capabilities rather than replacing them. Try the solution today and experience how Amazon Bedrock Agents can transform your video monitoring capabilities from simple motion detection to intelligent scene understanding.
About the authors
 Kiowa Jackson is a Senior Machine Learning Engineer at AWS ProServe, specializing in computer vision and agentic systems for industrial applications. His work bridges classical machine learning approaches with generative AI to enhance industrial automation capabilities. His past work includes collaborations with Amazon Robotics, NFL, and Koch Georgia Pacific.
Kiowa Jackson is a Senior Machine Learning Engineer at AWS ProServe, specializing in computer vision and agentic systems for industrial applications. His work bridges classical machine learning approaches with generative AI to enhance industrial automation capabilities. His past work includes collaborations with Amazon Robotics, NFL, and Koch Georgia Pacific.
 Piotr Chotkowski is a Senior Cloud Application Architect at AWS Generative AI Innovation Center. He has experience in hands-on software engineering as well as software architecture design. In his role at AWS, he helps customers design and build production grade generative AI applications in the cloud.
Piotr Chotkowski is a Senior Cloud Application Architect at AWS Generative AI Innovation Center. He has experience in hands-on software engineering as well as software architecture design. In his role at AWS, he helps customers design and build production grade generative AI applications in the cloud.
Read More

 Lance Smith is a Senior Solutions Architect and part of the Global Healthcare and Life Sciences industry division at AWS. He has spent the last 2 decades helping life sciences companies apply technology in pursuit of their missions to help patients. Outside of work, he loves traveling, backpacking, and spending time with his family.
Lance Smith is a Senior Solutions Architect and part of the Global Healthcare and Life Sciences industry division at AWS. He has spent the last 2 decades helping life sciences companies apply technology in pursuit of their missions to help patients. Outside of work, he loves traveling, backpacking, and spending time with his family. Kenton Blacutt is an AI Consultant within the Amazon Q Customer Success team. He works hands-on with customers, helping them solve real-world business problems with cutting-edge AWS technologies. In his free time, he likes to travel and run an occasional marathon.
Kenton Blacutt is an AI Consultant within the Amazon Q Customer Success team. He works hands-on with customers, helping them solve real-world business problems with cutting-edge AWS technologies. In his free time, he likes to travel and run an occasional marathon. Karthik Prabhakar is a Senior Applications Architect within the AWS Professional Services team. In this role, he collaborates with customers to design and implement cutting-edge solutions for their mission-critical business systems, focusing on areas such as scalability, reliability, and cost optimization in digital transformation and modernization projects.
Karthik Prabhakar is a Senior Applications Architect within the AWS Professional Services team. In this role, he collaborates with customers to design and implement cutting-edge solutions for their mission-critical business systems, focusing on areas such as scalability, reliability, and cost optimization in digital transformation and modernization projects. Jake Malmad is a Senior DevOps Consultant within the AWS Professional Services team, specializing in infrastructure as code, security, containers, and orchestration. As a DevOps consultant, he uses this expertise to collaboratively works with customers, architecting and implementing solutions for automation, scalability, reliability, and security across a wide variety of cloud adoption and transformation engagements.
Jake Malmad is a Senior DevOps Consultant within the AWS Professional Services team, specializing in infrastructure as code, security, containers, and orchestration. As a DevOps consultant, he uses this expertise to collaboratively works with customers, architecting and implementing solutions for automation, scalability, reliability, and security across a wide variety of cloud adoption and transformation engagements. Nicole Brown is a Senior Engagement Manager within the AWS Professional Services team based in Minneapolis, MN. With over 10 years of professional experience, she has led multidisciplinary, global teams across the healthcare and life sciences industries. She is also a supporter of women in tech and currently holds a board position within the Women at Global Services affinity group.
Nicole Brown is a Senior Engagement Manager within the AWS Professional Services team based in Minneapolis, MN. With over 10 years of professional experience, she has led multidisciplinary, global teams across the healthcare and life sciences industries. She is also a supporter of women in tech and currently holds a board position within the Women at Global Services affinity group.





















 Senaka Ariyasinghe is a Senior Partner Solutions Architect at AWS. He collaborates with Global Systems Integrators to drive cloud innovation across the Asia-Pacific and Japan region. He specializes in helping AWS partners develop and implement scalable, well-architected solutions, with particular emphasis on generative AI, machine learning, cloud migration strategies, and the modernization of enterprise applications.
Senaka Ariyasinghe is a Senior Partner Solutions Architect at AWS. He collaborates with Global Systems Integrators to drive cloud innovation across the Asia-Pacific and Japan region. He specializes in helping AWS partners develop and implement scalable, well-architected solutions, with particular emphasis on generative AI, machine learning, cloud migration strategies, and the modernization of enterprise applications. Senthil Nathan is a Senior Partner Solutions Architect working with Global Systems Integrators at AWS. In his role, Senthil works closely with global partners to help them maximize the value and potential of the AWS Cloud landscape. He is passionate about using the transformative power of cloud computing and emerging technologies to drive innovation and business impact.
Senthil Nathan is a Senior Partner Solutions Architect working with Global Systems Integrators at AWS. In his role, Senthil works closely with global partners to help them maximize the value and potential of the AWS Cloud landscape. He is passionate about using the transformative power of cloud computing and emerging technologies to drive innovation and business impact. Deependra Shekhawat is a Senior Energy and Utilities Industry Specialist Solutions Architect based in Sydney, Australia. In his role, Deependra helps energy companies across the Asia-Pacific and Japan region use cloud technologies to drive sustainability and operational efficiency. He specializes in creating robust data foundations and advanced workflows that enable organizations to harness the power of big data, analytics, and machine learning for solving critical industry challenges.
Deependra Shekhawat is a Senior Energy and Utilities Industry Specialist Solutions Architect based in Sydney, Australia. In his role, Deependra helps energy companies across the Asia-Pacific and Japan region use cloud technologies to drive sustainability and operational efficiency. He specializes in creating robust data foundations and advanced workflows that enable organizations to harness the power of big data, analytics, and machine learning for solving critical industry challenges. Aaron Sempf is Next Gen Tech Lead for the AWS Partner Organization in Asia-Pacific and Japan. With over 20 years in distributed system engineering design and development, he focuses on solving for large-scale complex integration and event-driven systems. In his spare time, he can be found coding prototypes for autonomous robots, IoT devices, distributed solutions, and designing agentic architecture patterns for generative AI-assisted business automation.
Aaron Sempf is Next Gen Tech Lead for the AWS Partner Organization in Asia-Pacific and Japan. With over 20 years in distributed system engineering design and development, he focuses on solving for large-scale complex integration and event-driven systems. In his spare time, he can be found coding prototypes for autonomous robots, IoT devices, distributed solutions, and designing agentic architecture patterns for generative AI-assisted business automation. Ozan Eken is a Product Manager at AWS, passionate about building cutting-edge generative AI and graph analytics products. With a focus on simplifying complex data challenges, Ozan helps customers unlock deeper insights and accelerate innovation. Outside of work, he enjoys trying new foods, exploring different countries, and watching soccer.
Ozan Eken is a Product Manager at AWS, passionate about building cutting-edge generative AI and graph analytics products. With a focus on simplifying complex data challenges, Ozan helps customers unlock deeper insights and accelerate innovation. Outside of work, he enjoys trying new foods, exploring different countries, and watching soccer. JaiPrakash Dave is a Partner Solutions Architect working with Global Systems Integrators at AWS based in India. In his role, JaiPrakash guides AWS partners in the India region to design and scale well-architected solutions, focusing on generative AI, machine learning, DevOps, and application and data modernization initiatives.
JaiPrakash Dave is a Partner Solutions Architect working with Global Systems Integrators at AWS based in India. In his role, JaiPrakash guides AWS partners in the India region to design and scale well-architected solutions, focusing on generative AI, machine learning, DevOps, and application and data modernization initiatives.








 Riza Saputra is a Senior Solutions Architect at AWS, working with startups of all stages to help them grow securely, scale efficiently, and innovate faster. His current focus is on generative AI, guiding organizations in building and scaling AI solutions securely and efficiently. With experience across roles, industries, and company sizes, he brings a versatile perspective to solving technical and business challenges. Riza also shares his knowledge through public speaking and content to support the broader tech community.
Riza Saputra is a Senior Solutions Architect at AWS, working with startups of all stages to help them grow securely, scale efficiently, and innovate faster. His current focus is on generative AI, guiding organizations in building and scaling AI solutions securely and efficiently. With experience across roles, industries, and company sizes, he brings a versatile perspective to solving technical and business challenges. Riza also shares his knowledge through public speaking and content to support the broader tech community.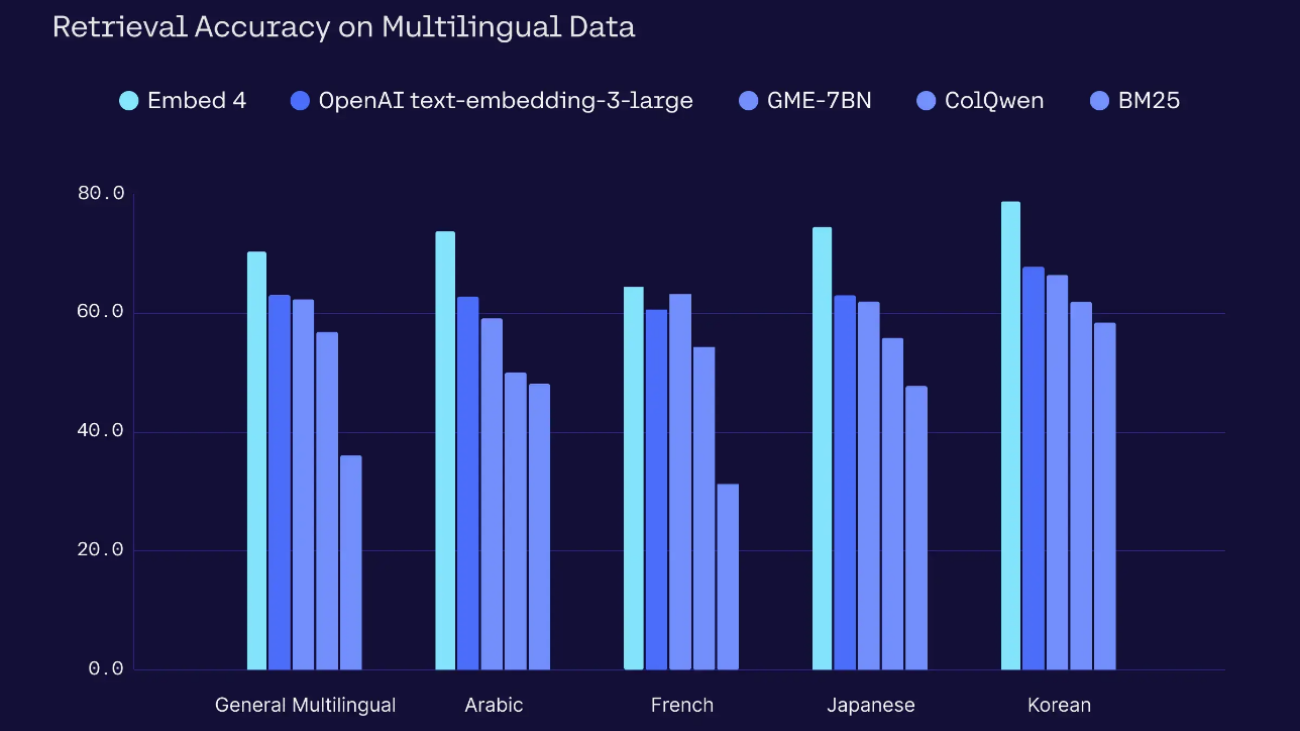







 James Yi is a Senior AI/ML Partner Solutions Architect at AWS. He spearheads AWS’s strategic partnerships in Emerging Technologies, guiding engineering teams to design and develop cutting-edge joint solutions in generative AI. He enables field and technical teams to seamlessly deploy, operate, secure, and integrate partner solutions on AWS. James collaborates closely with business leaders to define and execute joint Go-To-Market strategies, driving cloud-based business growth. Outside of work, he enjoys playing soccer, traveling, and spending time with his family.
James Yi is a Senior AI/ML Partner Solutions Architect at AWS. He spearheads AWS’s strategic partnerships in Emerging Technologies, guiding engineering teams to design and develop cutting-edge joint solutions in generative AI. He enables field and technical teams to seamlessly deploy, operate, secure, and integrate partner solutions on AWS. James collaborates closely with business leaders to define and execute joint Go-To-Market strategies, driving cloud-based business growth. Outside of work, he enjoys playing soccer, traveling, and spending time with his family. Karan Singh is a Generative AI Specialist at AWS, where he works with top-tier third-party foundation model and agentic frameworks providers to develop and execute joint go-to-market strategies, enabling customers to effectively deploy and scale solutions to solve enterprise generative AI challenges.
Karan Singh is a Generative AI Specialist at AWS, where he works with top-tier third-party foundation model and agentic frameworks providers to develop and execute joint go-to-market strategies, enabling customers to effectively deploy and scale solutions to solve enterprise generative AI challenges. Mehran Najafi, PhD, serves as AWS Principal Solutions Architect and leads the Generative AI Solution Architects team for AWS Canada. His expertise lies in ensuring the scalability, optimization, and production deployment of multi-tenant generative AI solutions for enterprise customers.
Mehran Najafi, PhD, serves as AWS Principal Solutions Architect and leads the Generative AI Solution Architects team for AWS Canada. His expertise lies in ensuring the scalability, optimization, and production deployment of multi-tenant generative AI solutions for enterprise customers. John Liu has 15 years of experience as a product executive and 9 years of experience as a portfolio manager. At AWS, John is a Principal Product Manager for Amazon Bedrock. Previously, he was the Head of Product for AWS Web3 / Blockchain. Prior to AWS, John held various product leadership roles at public blockchain protocols, fintech companies and also spent 9 years as a portfolio manager at various hedge funds.
John Liu has 15 years of experience as a product executive and 9 years of experience as a portfolio manager. At AWS, John is a Principal Product Manager for Amazon Bedrock. Previously, he was the Head of Product for AWS Web3 / Blockchain. Prior to AWS, John held various product leadership roles at public blockchain protocols, fintech companies and also spent 9 years as a portfolio manager at various hedge funds. Hugo Tse is a Solutions Architect at AWS, with a focus on Generative AI and Storage solutions. He is dedicated to empowering customers to overcome challenges and unlock new business opportunities using technology. He holds a Bachelor of Arts in Economics from the University of Chicago and a Master of Science in Information Technology from Arizona State University.
Hugo Tse is a Solutions Architect at AWS, with a focus on Generative AI and Storage solutions. He is dedicated to empowering customers to overcome challenges and unlock new business opportunities using technology. He holds a Bachelor of Arts in Economics from the University of Chicago and a Master of Science in Information Technology from Arizona State University. Payal Singh is a Solutions Architect at Cohere with over 15 years of cross-domain expertise in DevOps, Cloud, Security, SDN, Data Center Architecture, and Virtualization. She drives partnerships at Cohere and helps customers with complex GenAI solution integrations.
Payal Singh is a Solutions Architect at Cohere with over 15 years of cross-domain expertise in DevOps, Cloud, Security, SDN, Data Center Architecture, and Virtualization. She drives partnerships at Cohere and helps customers with complex GenAI solution integrations.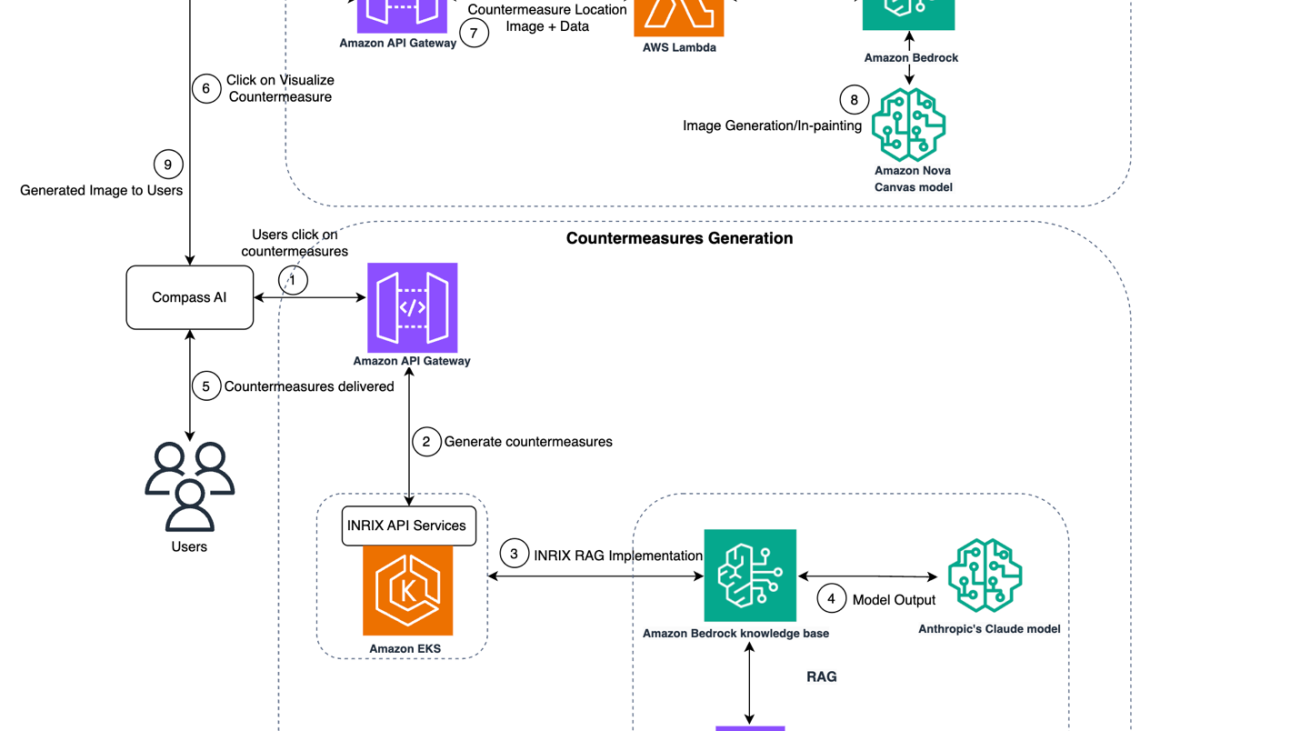







 Arun is a Senior Solutions Architect at AWS, supporting enterprise customers in the Pacific Northwest. He’s passionate about solving business and technology challenges as an AWS customer advocate, with his recent interest being AI strategy. When not at work, Arun enjoys listening to podcasts, going for short trail runs, and spending quality time with his family.
Arun is a Senior Solutions Architect at AWS, supporting enterprise customers in the Pacific Northwest. He’s passionate about solving business and technology challenges as an AWS customer advocate, with his recent interest being AI strategy. When not at work, Arun enjoys listening to podcasts, going for short trail runs, and spending quality time with his family. Alicja Kwasniewska, PhD, is an AI leader driving generative AI innovations in enterprise solutions and decision intelligence for customer engagements in North America, advertisement and marketing verticals at AWS. She is recognized among the top 10 women in AI and 100 women in data science. Alicja published in more than 40 peer-reviewed publications. She also serves as a reviewer for top-tier conferences, including ICML,NeurIPS,and ICCV. She advises organizations on AI adoption, bridging research and industry to accelerate real-world AI applications.
Alicja Kwasniewska, PhD, is an AI leader driving generative AI innovations in enterprise solutions and decision intelligence for customer engagements in North America, advertisement and marketing verticals at AWS. She is recognized among the top 10 women in AI and 100 women in data science. Alicja published in more than 40 peer-reviewed publications. She also serves as a reviewer for top-tier conferences, including ICML,NeurIPS,and ICCV. She advises organizations on AI adoption, bridging research and industry to accelerate real-world AI applications. Shashank is the VP of Engineering at INRIX, where he leads multiple verticals, including generative AI and traffic. He is passionate about using technology to make roads safer for drivers, bikers, and pedestrians every day. Prior to working at INRIX, he held engineering leadership roles at Amazon and Lyft. Shashank brings deep experience in building impactful products and high-performing teams at scale. Outside of work, he enjoys traveling, listening to music, and spending time with his family.
Shashank is the VP of Engineering at INRIX, where he leads multiple verticals, including generative AI and traffic. He is passionate about using technology to make roads safer for drivers, bikers, and pedestrians every day. Prior to working at INRIX, he held engineering leadership roles at Amazon and Lyft. Shashank brings deep experience in building impactful products and high-performing teams at scale. Outside of work, he enjoys traveling, listening to music, and spending time with his family. Nat Gale is the Head of Product at INRIX, where he manages the Safety and Traffic product verticals. Nat leads the development of data products and software that help transportation professionals make smart, more informed decisions. He previously ran the City of Los Angeles’ Vision Zero program and was the Director of Capital Projects and Operations for the City of Hartford, CT.
Nat Gale is the Head of Product at INRIX, where he manages the Safety and Traffic product verticals. Nat leads the development of data products and software that help transportation professionals make smart, more informed decisions. He previously ran the City of Los Angeles’ Vision Zero program and was the Director of Capital Projects and Operations for the City of Hartford, CT. Durran is a Lead Software Engineer at INRIX, where he designs scalable backend systems and mentors engineers across multiple product lines. With over a decade of experience in software development, he specializes in distributed systems, generative AI, and cloud infrastructure. Durran is passionate about writing clean, maintainable code and sharing best practices with the developer community. Outside of work, he enjoys spending quality time with his family and deepening his Japanese language skills.
Durran is a Lead Software Engineer at INRIX, where he designs scalable backend systems and mentors engineers across multiple product lines. With over a decade of experience in software development, he specializes in distributed systems, generative AI, and cloud infrastructure. Durran is passionate about writing clean, maintainable code and sharing best practices with the developer community. Outside of work, he enjoys spending quality time with his family and deepening his Japanese language skills.







 Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s degree in Computer Science and Bioinformatics.
Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s degree in Computer Science and Bioinformatics. Avan Bala is a Solutions Architect at AWS. His area of focus is AI for DevOps and machine learning. He holds a bachelor’s degree in Computer Science with a minor in Mathematics and Statistics from the University of Maryland. Avan is currently working with the Enterprise Engaged East Team and likes to specialize in projects about emerging AI technologies.
Avan Bala is a Solutions Architect at AWS. His area of focus is AI for DevOps and machine learning. He holds a bachelor’s degree in Computer Science with a minor in Mathematics and Statistics from the University of Maryland. Avan is currently working with the Enterprise Engaged East Team and likes to specialize in projects about emerging AI technologies. Mohhid Kidwai is a Solutions Architect at AWS. His area of focus is generative AI and machine learning solutions for small-medium businesses. He holds a bachelor’s degree in Computer Science with a minor in Biological Science from North Carolina State University. Mohhid is currently working with the SMB Engaged East Team at AWS.
Mohhid Kidwai is a Solutions Architect at AWS. His area of focus is generative AI and machine learning solutions for small-medium businesses. He holds a bachelor’s degree in Computer Science with a minor in Biological Science from North Carolina State University. Mohhid is currently working with the SMB Engaged East Team at AWS. Yousuf Athar is a Solutions Architect at AWS specializing in generative AI and AI/ML. With a Bachelor’s degree in Information Technology and a concentration in Cloud Computing, he helps customers integrate advanced generative AI capabilities into their systems, driving innovation and competitive edge. Outside of work, Yousuf loves to travel, watch sports, and play football.
Yousuf Athar is a Solutions Architect at AWS specializing in generative AI and AI/ML. With a Bachelor’s degree in Information Technology and a concentration in Cloud Computing, he helps customers integrate advanced generative AI capabilities into their systems, driving innovation and competitive edge. Outside of work, Yousuf loves to travel, watch sports, and play football. Rohit Talluri is a Generative AI GTM Specialist at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory.
Rohit Talluri is a Generative AI GTM Specialist at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory. Varun Morishetty is a Software Engineer with Amazon SageMaker JumpStart and Bedrock Marketplace. Varun received his Bachelor’s degree in Computer Science from Northeastern University. In his free time, he enjoys cooking, baking and exploring New York City.
Varun Morishetty is a Software Engineer with Amazon SageMaker JumpStart and Bedrock Marketplace. Varun received his Bachelor’s degree in Computer Science from Northeastern University. In his free time, he enjoys cooking, baking and exploring New York City.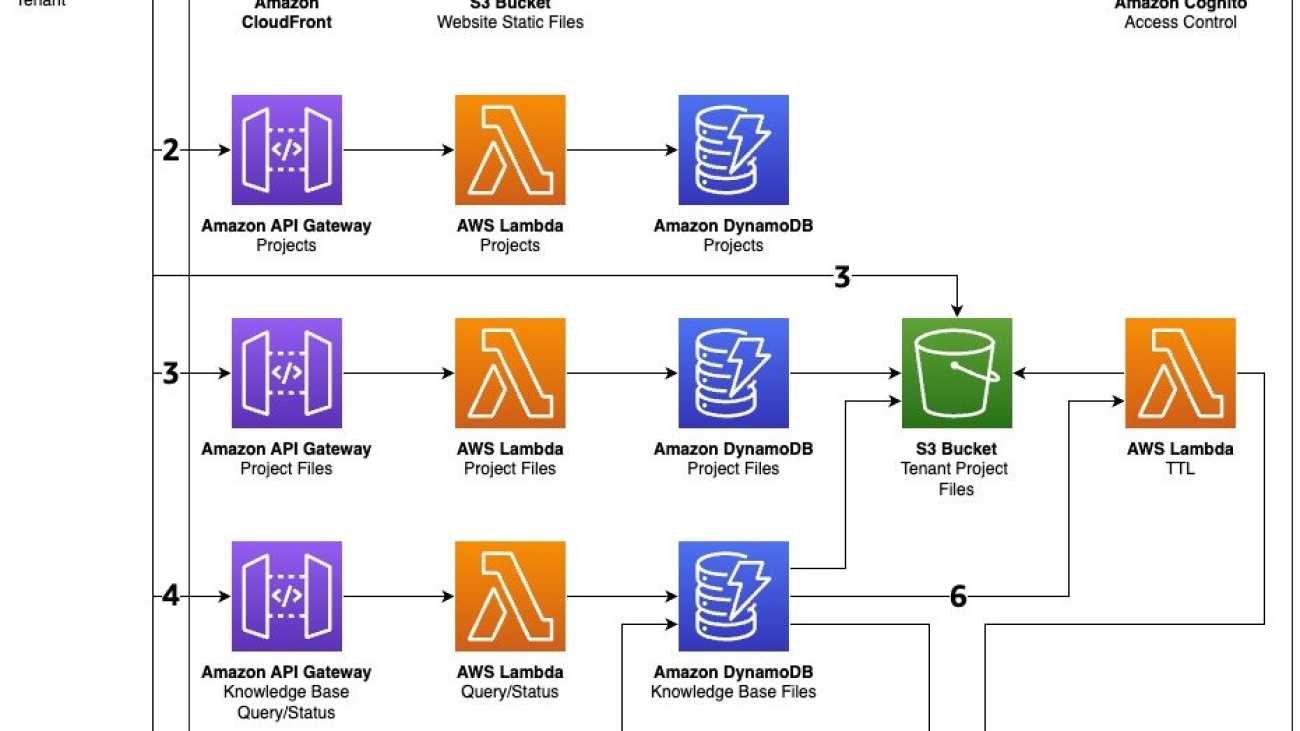


 Steven Warwick is a Senior Solutions Architect at AWS, where he leads customer engagements to drive successful cloud adoption and specializes in SaaS architectures and Generative AI solutions. He produces educational content including blog posts and sample code to help customers implement best practices, and has led programs on GenAI topics for solution architects. Steven brings decades of technology experience to his role, helping customers with architectural reviews, cost optimization, and proof-of-concept development.
Steven Warwick is a Senior Solutions Architect at AWS, where he leads customer engagements to drive successful cloud adoption and specializes in SaaS architectures and Generative AI solutions. He produces educational content including blog posts and sample code to help customers implement best practices, and has led programs on GenAI topics for solution architects. Steven brings decades of technology experience to his role, helping customers with architectural reviews, cost optimization, and proof-of-concept development.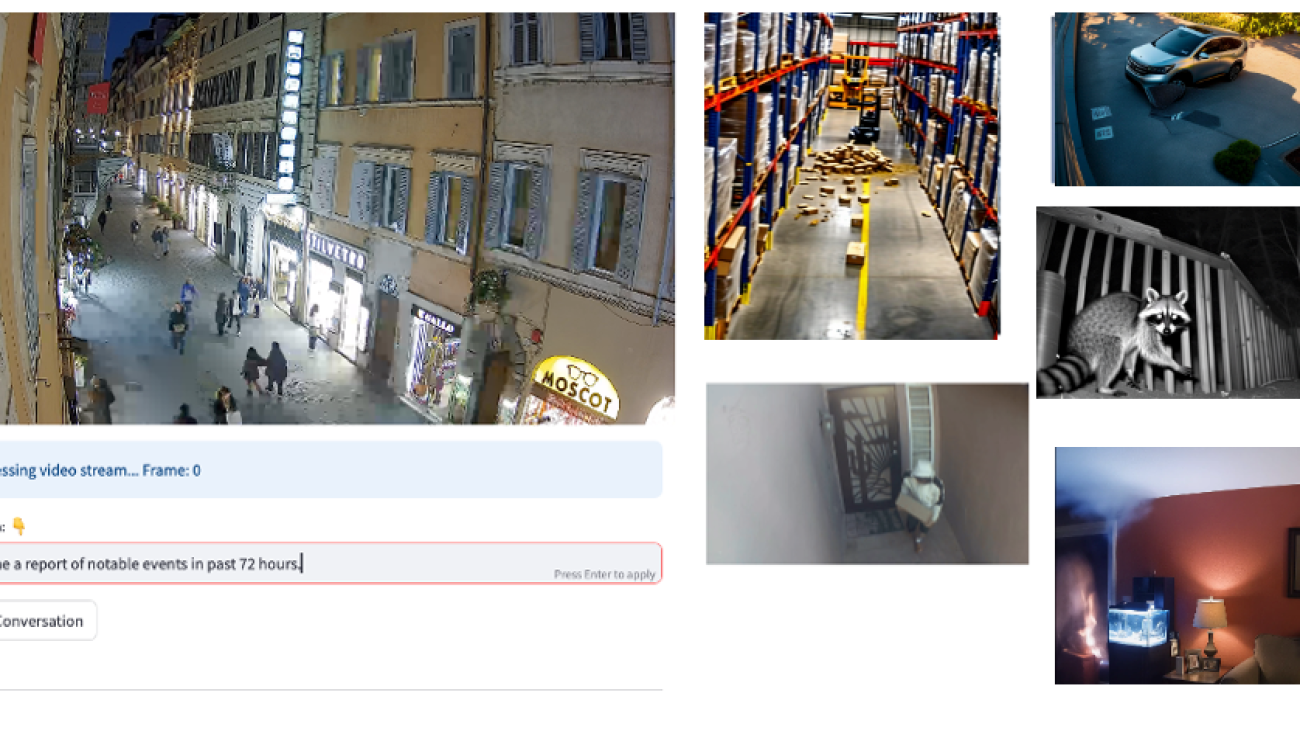

 This field guide and investment support AI’s potential in evidence-based mental health interventions and research.
This field guide and investment support AI’s potential in evidence-based mental health interventions and research.