DANIEL CARPENTER: Thanks for having me.
SULLIVAN: Dan, before we dissect policy, let’s rewind the tape to your origin story. Can you take us to the moment that you first became fascinated with regulators rather than, say, politicians? Was there a spark that pulled you toward the FDA story?
CARPENTER: At one point during graduate school, I was studying a combination of American politics and political theory, and I did a summer interning at the Department of Housing and Urban Development. And I began to think, why don’t people study these administrators more and the rules they make, the, you know, inefficiencies, the efficiencies? Really more from, kind of, a descriptive standpoint, less from a normative standpoint. And I was reading a lot that summer about the Food and Drug Administration and some of the decisions it was making on AIDS drugs. That was a, sort of, a major, …
SULLIVAN: Right.
CARPENTER: … sort of, you know, moment in the news, in the global news as well as the national news during, I would say, what? The late ’80s, early ’90s? And so I began to look into that.
SULLIVAN: So now that we know what pulled you in, let’s zoom out for our listeners. Give us the whirlwind tour. I think most of us know pharma involves years of trials, but what’s the part we don’t know?
CARPENTER: So I think when most businesses develop a product, they all go through some phases of research and development and testing. And I think what’s different about the FDA is, sort of, two- or three-fold.
First, a lot of those tests are much more stringently specified and regulated by the government, and second, one of the reasons for that is that the FDA imposes not simply safety requirements upon drugs in particular but also efficacy requirements. The FDA wants you to prove not simply that it’s safe and non-toxic but also that it’s effective. And the final thing, I think, that makes the FDA different is that it stands as what I would call the “veto player” over R&D [research and development] to the marketplace. The FDA basically has, sort of, this control over entry to the marketplace.
And so what that involves is usually first, a set of human trials where people who have no disease take it. And you’re only looking for toxicity generally. Then there’s a set of Phase 2 trials, where they look more at safety and a little bit at efficacy, and you’re now examining people who have the disease that the drug claims to treat. And you’re also basically comparing people who get the drug, often with those who do not.
And then finally, Phase 3 involves a much more direct and large-scale attack, if you will, or assessment of efficacy, and that’s where you get the sort of large randomized clinical trials that are very expensive for pharmaceutical companies, biomedical companies to launch, to execute, to analyze. And those are often the sort of core evidence base for the decisions that the FDA makes about whether or not to approve a new drug for marketing in the United States.
SULLIVAN: Are there differences in how that process has, you know, changed through other countries and maybe just how that’s evolved as you’ve seen it play out?
CARPENTER: Yeah, for a long time, I would say that the United States had probably the most stringent regime of regulation for biopharmaceutical products until, I would say, about the 1990s and early 2000s. It used to be the case that a number of other countries, especially in Europe but around the world, basically waited for the FDA to mandate tests on a drug and only after the drug was approved in the United States would they deem it approvable and marketable in their own countries. And then after the formation of the European Union and the creation of the European Medicines Agency, gradually the European Medicines Agency began to get a bit more stringent.
But, you know, over the long run, there’s been a lot of, sort of, heterogeneity, a lot of variation over time and space, in the way that the FDA has approached these problems. And I’d say in the last 20 years, it’s begun to partially deregulate, namely, you know, trying to find all sorts of mechanisms or pathways for really innovative drugs for deadly diseases without a lot of treatments to basically get through the process at lower cost. For many people, that has not been sufficient. They’re concerned about the cost of the system. Of course, then the agency also gets criticized by those who believe it’s too lax. It is potentially letting ineffective and unsafe therapies on the market.
SULLIVAN: In your view, when does the structured model genuinely safeguard patients and where do you think it maybe slows or limits innovation?
CARPENTER: So I think the worry is that if you approach pharmaceutical approval as a world where only things can go wrong, then you’re really at a risk of limiting innovation. And even if you end up letting a lot of things through, if by your regulations you end up basically slowing down the development process or making it very, very costly, then there’s just a whole bunch of drugs that either come to market too slowly or they come to market not at all because they just aren’t worth the kind of cost-benefit or, sort of, profit analysis of the firm. You know, so that’s been a concern. And I think it’s been one of the reasons that the Food and Drug Administration as well as other world regulators have begun to basically try to smooth the process and accelerate the process at the margins.
The other thing is that they’ve started to basically make approvals on the basis of what are called surrogate endpoints. So the idea is that a cancer drug, we really want to know whether that drug saves lives, but if we wait to see whose lives are saved or prolonged by that drug, we might miss the opportunity to make judgments on the basis of, well, are we detecting tumors in the bloodstream? Or can we measure the size of those tumors in, say, a solid cancer? And then the further question is, is the size of the tumor basically a really good correlate or predictor of whether people will die or not, right? Generally, the FDA tends to be less stringent when you’ve got, you know, a remarkably innovative new therapy and the disease being treated is one that just doesn’t have a lot of available treatments, right.
The one thing that people often think about when they’re thinking about pharmaceutical regulation is they often contrast, kind of, speed versus safety …
SULLIVAN: Right.
CARPENTER: … right. And that’s useful as a tradeoff, but I often try to remind people that it’s not simply about whether the drug gets out there and it’s unsafe. You know, you and I as patients and even doctors have a hard time knowing whether something works and whether it should be prescribed. And the evidence for knowing whether something works isn’t just, well, you know, Sally took it or Dan took it or Kathleen took it, and they seem to get better or they didn’t seem to get better.
The really rigorous evidence comes from randomized clinical trials. And I think it’s fair to say that if you didn’t have the FDA there as a veto player, you wouldn’t get as many randomized clinical trials and the evidence probably wouldn’t be as rigorous for whether these things work. And as I like to put it, basically there’s a whole ecology of expectations and beliefs around the biopharmaceutical industry in the United States and globally, and to some extent, it’s undergirded by all of these tests that happen.
SULLIVAN: Right.
CARPENTER: And in part, that means it’s undergirded by regulation. Would there still be a market without regulation? Yes. But it would be a market in which people had far less information in and confidence about the drugs that are being taken. And so I think it’s important to recognize that kind of confidence-boosting potential of, kind of, a scientific regulation base.
SULLIVAN: Actually, if we could double-click on that for a minute, I’d love to hear your perspective on, testing has been completed; there’s results. Can you walk us through how those results actually shape the next steps and decisions of a particular drug and just, like, how regulators actually think about using that data to influence really what happens next with it?
CARPENTER: Right. So it’s important to understand that every drug is approved for what’s called an indication. It can have a first primary indication, which is the main disease that it treats, and then others can be added as more evidence is shown. But a drug is not something that just kind of exists out there in the ether. It has to have the right form of administration. Maybe it should be injected. Maybe it should be ingested. Maybe it should be administered only at a clinic because it needs to be kind of administered in just the right way. As doctors will tell you, dosage is everything, right.
And so one of the reasons that you want those trials is not simply a, you know, yes or no answer about whether the drug works, right. It’s not simply if-then. It’s literally what goes into what you might call the dose response curve. You know, how much of this drug do we need to basically, you know, get the benefit? At what point does that fall off significantly that we can basically say, we can stop there? All that evidence comes from trials. And that’s the kind of evidence that is required on the basis of regulation.
Because it’s not simply a drug that’s approved. It’s a drug and a frequency of administration. It’s a method of administration. And so the drug isn’t just, there’s something to be taken off the shelf and popped into your mouth. I mean, sometimes that’s what happens, but even then, we want to know what the dosage is, right. We want to know what to look for in terms of side effects, things like that.
SULLIVAN: Going back to that point, I mean, it sounds like we’re making a lot of progress from a regulation perspective in, you know, sort of speed and getting things approved but doing it in a really balanced way. I mean, any other kind of closing thoughts on the tradeoffs there or where you’re seeing that going?
CARPENTER: I think you’re going to see some move in the coming years—there’s already been some of it—to say, do we always need a really large Phase 3 clinical trial? And to what degree do we need the, like, you know, all the i’s dotted and the t’s crossed or a really, really large sample size? And I’m open to innovation there. I’m also open to the idea that we consider, again, things like accelerated approvals or pathways for looking at different kinds of surrogate endpoints. I do think, once we do that, then we also have to have some degree of follow-up.
SULLIVAN: So I know we’re getting close to out of time, but maybe just a quick rapid fire if you’re open to it. Biggest myth about clinical trials?
CARPENTER: Well, some people tend to think that the FDA performs them. You know, it’s companies that do it. And the only other thing I would say is the company that does a lot of the testing and even the innovating is not always the company that takes the drug to market, and it tells you something about how powerful regulation is in our system, in our world, that you often need a company that has dealt with the FDA quite a bit and knows all the regulations and knows how to dot the i’s and cross the t’s in order to get a drug across the finish line.
SULLIVAN: If you had a magic wand, what’s the one thing you’d change in regulation today?
CARPENTER: I would like people to think a little bit less about just speed versus safety and, again, more about this basic issue of confidence. I think it’s fundamental to everything that happens in markets but especially in biopharmaceuticals.
SULLIVAN: Such a great point. This has been really fun. Just thanks so much for being here today. We’re really excited to share your thoughts out to our listeners. Thanks.
[TRANSITION MUSIC]
CARPENTER: Likewise.
SULLIVAN: Now to the world of medical devices, I’m joined by Professor Timo Minssen. Professor Minssen, it’s great to have you here. Thank you for joining us today.
TIMO MINSSEN: Yeah, thank you very much, it’s a pleasure.
SULLIVAN: Before getting into the regulatory world of medical devices, tell our audience a bit about your personal journey or your origin story, as we’re asking our guests. How did you land in regulation, and what’s kept you hooked in this space?
MINSSEN: So I started out as a patent expert in the biomedical area, starting with my PhD thesis on patenting biologics in Europe and in the US. So during that time, I was mostly interested in patent and trade secret questions. But at the same time, I also developed and taught courses in regulatory law and held talks on regulating advanced medical therapy medicinal products. I then started to lead large research projects on legal challenges in a wide variety of health and life science innovation frontiers. I also started to focus increasingly on AI-enabled medical devices and software as a medical device, resulting in several academic articles in this area and also in the regulatory area and a book on the future of medical device regulation.
SULLIVAN: Yeah, what’s kept you hooked in the space?
MINSSEN: It’s just incredibly exciting, in particular right now with everything that is going on, you know, in the software arena, in the marriage between AI and medical devices. And this is really challenging not only societies but also regulators and authorities in Europe and in the US.
SULLIVAN: Yeah, it’s a super exciting time to be in this space. You know, we talked to Daniel a little earlier and, you know, I think similar to pharmaceuticals, people have a general sense of what we mean when we say medical devices, but most listeners may picture like a stethoscope or a hip implant. The word “medical device” reaches much wider. Can you give us a quick, kind of, range from perhaps very simple to even, I don’t know, sci-fi and then your 90-second tour of how risk assessment works and why a framework is essential?
MINSSEN: Let me start out by saying that the WHO [World Health Organization] estimates that today there are approximately 2 million different kinds of medical devices on the world market, and as of the FDA’s latest update that I’m aware of, the FDA has authorized more than 1,000 AI-, machine learning-enabled medical devices, and that number is rising rapidly.
So in that context, I think it is important to understand that medical devices can be any instrument, apparatus, implement, machine, appliance, implant, reagent for in vitro use, software, material, or other similar or related articles that are intended by the manufacturer to be used alone or in combination for a medical purpose. And the spectrum of what constitutes a medical device can thus range from very simple devices such as tongue depressors, contact lenses, and thermometers to more complex devices such as blood pressure monitors, insulin pumps, MRI machines, implantable pacemakers, and even software as a medical device or AI-enabled monitors or drug device combinations, as well.
So talking about regulation, I think it is also very important to stress that medical devices are used in many diverse situations by very different stakeholders. And testing has to take this variety into consideration, and it is intrinsically tied to regulatory requirements across various jurisdictions.
During the pre-market phase, medical testing establishes baseline safety and effectiveness metrics through bench testing, performance standards, and clinical studies. And post-market testing ensures that real-world data informs ongoing compliance and safety improvements. So testing is indispensable in translating technological innovation into safe and effective medical devices. And while particular details of pre-market and post-market review procedures may slightly differ among countries, most developed jurisdictions regulate medical devices similarly to the US or European models.
So most jurisdictions with medical device regulation classify devices based on their risk profile, intended use, indications for use, technological characteristics, and the regulatory controls necessary to provide a reasonable assurance of safety and effectiveness.
SULLIVAN: So medical devices face a pretty prescriptive multi-level testing path before they hit the market. From your vantage point, what are some of the downsides of that system and when does it make the most sense?
MINSSEN: One primary drawback is, of course, the lengthy and expensive approval process. High-risk devices, for example, often undergo years of clinical trials, which can cost millions of dollars, and this can create a significant barrier for startups and small companies with limited resources. And even for moderate-risk devices, the regulatory burden can slow product development and time to the market.
And the approach can also limit flexibility. Prescriptive requirements may not accommodate emerging innovations like digital therapeutics or AI-based diagnostics in a feasible way. And in such cases, the framework can unintentionally [stiffen] innovation by discouraging creative solutions or iterative improvements, which as matter of fact can also put patients at risk when you don’t use new technologies and AI. And additionally, the same level of scrutiny may be applied to low-risk devices, where the extensive testing and documentation may also be disproportionate to the actual patient risk.
However, the prescriptive model is highly appropriate where we have high testing standards for high-risk medical devices, in my view, particularly those that are life-sustaining, implanted, or involve new materials or mechanisms.
I also wanted to say that I think that these higher compliance thresholds can be OK and necessary if you have a system where authorities and stakeholders also have the capacity and funding to enforce, monitor, and achieve compliance with such rules in a feasible, time-effective, and straightforward manner. And this, of course, requires resources, novel solutions, and investments.
SULLIVAN: A range of tests are undertaken across the life cycle of medical devices. How do these testing requirements vary across different stages of development and across various applications?
MINSSEN: Yes, that’s a good question. So I think first it is important to realize that testing is conducted by various entities, including manufacturers, independent third-party laboratories, and regulatory agencies. And it occurs throughout the device life cycle, beginning with iterative testing during the research and development stage, advancing to pre-market evaluations, and continuing into post-market monitoring. And the outcomes of these tests directly impact regulatory approvals, market access, and device design refinements, as well. So the testing results are typically shared with regulatory authorities and in some cases with healthcare providers and the broader public to enhance transparency and trust.
So if you talk about the different phases that play a role here … so let’s turn to the pre-market phase, where manufacturers must demonstrate that the device is conformed to safety and performance benchmarks defined by regulatory authorities. Pre-market evaluations include functional bench testing, biocompatibility, for example, assessments and software validation, all of which are integral components of a manufacturer’s submission.
But, yes, but, testing also, and we touched already up on that, extends into the post-market phase, where it continues to ensure device safety and efficacy, and post-market surveillance relies on testing to monitor real-world performance and identify emerging risks on the post-market phase. By integrating real-world evidence into ongoing assessments, manufacturers can address unforeseen issues, update devices as needed, and maintain compliance with evolving regulatory expectations. And I think this is particularly important in this new generation of medical devices that are AI-enabled or machine-learning enabled.
I think we have to understand that in this AI-enabled medical devices field, you know, the devices and the algorithms that are working with them, they can improve in the lifetime of a product. So actually, not only you could assess them and make sure that they maintain safe, you could also sometimes lower the risk category by finding evidence that these devices are actually becoming more precise and safer. So it can both, you know, heighten the risk category or lower the risk category, and that’s why this continuous testing is so important.
SULLIVAN: Given what you just said, how should regulators handle a device whose algorithm keeps updating itself after approval?
MINSSEN: Well, it has to be an iterative process that is feasible and straightforward and that is based on a very efficient, both time efficient and performance efficient, communication between the regulatory authorities and the medical device developers, right. We need to have the sensors in place that spot potential changes, and we need to have the mechanisms in place that allow us to quickly react to these changes both regulatory wise and also in the technological way.
So I think communication is important, and we need to have the pathways and the feedback loops in the regulation that quickly allow us to monitor these self-learning algorithms and devices.
SULLIVAN: It sounds like it’s just … there’s such a delicate balance between advancing technology and really ensuring public safety. You know, if we clamp down too hard, we stifle that innovation. You already touched upon this a bit. But if we’re too lax, we risk unintended consequences. And I’d just love to hear how you think the field is balancing that and any learnings you can share.
MINSSEN: So this is very true, and you just touched upon a very central question also in our research and our writing. And this is also the reason why medical device regulation is so fascinating and continues to evolve in response to rapid advancements in technologies, particularly dual technologies regarding digital health, artificial intelligence, for example, and personalized medicine.
And finding the balance is tricky because also [a] related major future challenge relates to the increasing regulatory jungle and the complex interplay between evolving regulatory landscapes that regulate AI more generally.
We really need to make sure that the regulatory authorities that deal with this, that need to find the right balance to promote innovation and mitigate and prevent risks, need to have the capacity to do this. So this requires investments, and it also requires new ways to regulate this technology more flexibly, for example through regulatory sandboxes and so on.
SULLIVAN: Could you just expand upon that a bit and double-click on what it is you’re seeing there? What excites you about what’s happening in that space?
MINSSEN: Yes, well, the research of my group at the Center for Advanced Studies in Bioscience Innovation Law is very broad. I mean, we are looking into gene editing technologies. We are looking into new biologics. We are looking into medical devices, as well, obviously, but also other technologies in advanced medical computing.
And what we see across the line here is that there is an increasing demand for having more adaptive and flexible regulatory frameworks in these new technologies, in particular when they have new uses, regulations that are focusing more on the product rather than the process. And I have recently written a report, for example, for emerging biotechnologies and bio-solutions for the EU commission. And even in that area, regulatory sandboxes are increasingly important, increasingly considered.
So this idea of regulatory sandboxes has been developing originally in the financial sector, and it is now penetrating into other sectors, including synthetic biology, emerging biotechnologies, gene editing, AI, quantum technology, as well. This is basically creating an environment where actors can test new ideas in close collaboration and under the oversight of regulatory authorities.
But to implement this in the AI sector now also leads us to a lot of questions and challenges. For example, you need to have the capacities of authorities that are governing and monitoring and deciding on these regulatory sandboxes. There are issues relating to competition law, for example, which you call antitrust law in the US, because the question is, who can enter the sandbox and how may they compete after they exit the sandbox? And there are many questions relating to, how should we work with these sandboxes and how should we implement these sandboxes?
[TRANSITION MUSIC]
SULLIVAN: Well, Timo, it has just been such a pleasure to speak with you today.
MINSSEN: Yes, thank you very much.
And now I’m happy to introduce Chad Atalla.
Chad is senior applied scientist in Microsoft Research New York City’s Sociotechnical Alignment Center, where they contribute to foundational responsible AI research and practical responsible AI solutions for teams across Microsoft.
Chad, welcome!
CHAD ATALLA: Thank you.
SULLIVAN: So we’ll kick off with a couple questions just to dive right in. So tell me a little bit more about the Sociotechnical Alignment Center, or STAC? I know it was founded in 2022. I’d love to just learn a little bit more about what the group does, how you’re thinking about evaluating AI, and maybe just give us a sense of some of the projects you’re working on.
ATALLA: Yeah, absolutely. The name is quite a mouthful.
SULLIVAN: It is! [LAUGHS]
ATALLA: So let’s start by breaking that down and seeing what that means.
SULLIVAN: Great.
ATALLA: So modern AI systems are sociotechnical systems, meaning that the social and technical aspects are deeply intertwined. And we’re interested in aligning the behaviors of these sociotechnical systems with some values. Those could be societal values; they could be regulatory values, organizational values, etc. And to make this alignment happen, we need the ability to evaluate the systems.
So my team is broadly working on an evaluation framework that acknowledges the sociotechnical nature of the technology and the often-abstract nature of the concepts we’re actually interested in evaluating. As you noted, it’s an applied science team, so we split our time between some fundamental research and time to bridge the work into real products across the company. And I also want to note that to power this sort of work, we have an interdisciplinary team drawing upon the social sciences, linguistics, statistics, and, of course, computer science.
SULLIVAN: Well, I’m eager to get into our takeaways from the conversation with both Daniel and Timo. But maybe just to double-click on this for a minute, can you talk a bit about some of the overarching goals of the AI evaluations that you noted?
ATALLA: So evaluation is really the act of making valuative judgments based on some evidence, and in the case of AI evaluation, that evidence might be from tests or measurements, right. And the goal of why we’re doing this in the first place is to make decisions and claims most often.
So perhaps I am going to make a claim about a model that I’m producing, and I want to say that it’s better than this other model. Or we are asking whether a certain product is safe to ship. All of these decisions need to be informed by good evaluation and therefore good measurement or testing. And I’ll also note that in the regulatory conversation, risk is often what we want to evaluate. So that is a goal in and of itself. And I’ll touch more on that later.
SULLIVAN: I read a recent paper that you had put out with some of our colleagues from Microsoft Research, from the University of Michigan, and Stanford, and you were arguing that evaluating generative AI is the social-science measurement challenge. Maybe for those who haven’t read the paper, what does this mean? And can you tell us a little bit more about what motivated you and your coauthors?
ATALLA: So the measurement tasks involved in evaluating generative AI systems are often abstract and contested. So that means they cannot be directly measured and must instead [be] indirectly measured via other observable phenomena. So this is very different than the older machine learning paradigm, where, let’s say, for example, I had a system that took a picture of a traffic light and told you whether it was green, yellow, or red at a given time.
If we wanted to evaluate that system, the task is much simpler. But with the modern generative AI systems that are also general purpose, they have open-ended output, and language in a whole chat or multiple paragraphs being outputted can have a lot of different properties. And as I noted, these are general-purpose systems, so we don’t know exactly what task they’re supposed to be carrying out.
So then the question becomes, if I want to make some decision or claim—maybe I want to make a claim that this system has human-level reasoning capabilities—well, what does that mean? Do I have the same impression of what that means as you do? And how do we know whether the downstream, you know, measurements and tests that I’m conducting actually will support my notion of what it means to have human-level reasoning, right? Difficult questions. But luckily, social scientists have been dealing with these exact sorts of challenges for multiple decades in fields like education, political science, and psychometrics. So we’re really attempting to avoid reinventing the wheel here and trying to learn from their past methodologies.
And so the rest of the paper goes on to delve into a four-level framework, a measurement framework, that’s grounded in the measurement theory from the quantitative social sciences that takes us all the way from these abstract and contested concepts through processes to get much clearer and eventually reach reliable and valid measurements that can power our evaluations.
SULLIVAN: I love that. I mean, that’s the whole point of this podcast, too, right. Is to really build on those other learnings and frameworks that we’re taking from industries that have been thinking about this for much longer. Maybe from your vantage point, what are some of the biggest day-to-day hurdles in building solid AI evaluations and, I don’t know, do we need more shared standards? Are there bespoke methods? Are those the way to go? I would love to just hear your thoughts on that.
ATALLA: So let’s talk about some of those practical challenges. And I want to briefly go back to what I mentioned about risk before, all right. Oftentimes, some of the regulatory environment is requiring practitioners to measure the risk involved in deploying one of their models or AI systems. Now, risk is importantly a concept that includes both event and impact, right. So there’s the probability of some event occurring. For the case of AI evaluation, perhaps this is us seeing a certain AI behavior exhibited. Then there’s also the severity of the impacts, and this is a complex chain of effects in the real world that happen to people, organizations, systems, etc., and it’s a lot more challenging to observe the impacts, right.
So if we’re saying that we need to measure risk, we have to measure both the event and the impacts. But realistically, right now, the field is not doing a very good job of actually measuring the impacts. This requires vastly different techniques and methodologies where if I just wanted to measure something about the event itself, I can, you know, do that in a technical sandbox environment and perhaps have some automated methods to detect whether a certain AI behavior is being exhibited. But if I want to measure the impacts? Now, we’re in the realm of needing to have real people involved, and perhaps a longitudinal study where you have interviews, questionnaires, and more qualitative evidence-gathering techniques to truly understand the long-term impacts. So that’s a significant challenge.
Another is that, you know, let’s say we forget about the impacts for now and we focus on the event side of things. Still, we need datasets, we need annotations, and we need metrics to make this whole thing work. When I say we need datasets, if I want to test whether my system has good mathematical reasoning, what questions should I ask? What are my set of inputs that are relevant? And then when I get the response from the system, how do I annotate them? How do I know if it was a good response that did demonstrate mathematical reasoning or if it was a mediocre response? And then once I have an annotation of all of these outputs from the AI system, how do I aggregate those all up into a single informative number?
SULLIVAN: Earlier in this episode, we heard Daniel and Timo walk through the regulatory frameworks in pharma and medical devices. I’d be curious what pieces of those mature systems are already showing up or at least may be bubbling up in AI governance.
ATALLA: Great question. You know, Timo was talking about the pre-market and post-market testing difference. Of course, this is similarly important in the AI evaluation space. But again, these have different methodologies and serve different purposes.
So within the pre-deployment phase, we don’t have evidence of how people are going to use the system. And when we have these general-purpose AI systems, to understand what the risks are, we really need to have a sense of what might happen and how they might be used. So there are significant challenges there where I think we can learn from other fields and how they do pre-market testing. And the difference in that pre- versus post-market testing also ties to testing at different stages in the life cycle.
For AI systems, we already see some regulations saying you need to start with the base model and do some evaluation of the base model, some basic attributes, some core attributes, of that base model before you start putting it into any real products. But once we have a product in mind, we have a user base in mind, we have a specific task—like maybe we’re going to integrate this model into Outlook and it’s going to help you write emails—now we suddenly have a much crisper picture of how the system will interact with the world around it. And again, at that stage, we need to think about another round of evaluation.
Another part that jumped out to me in what they were saying about pharmaceuticals is that sometimes approvals can be based on surrogate endpoints. So this is like we’re choosing some heuristic. Instead of measuring the long-term impact, which is what we actually care about, perhaps we have a proxy that we feel like is a good enough indicator of what that long-term impact might look like.
This is occurring in the AI evaluation space right now and is often perhaps even the default here since we’re not seeing that many studies of the long-term impact itself. We are seeing, instead, folks constructing these heuristics or proxies and saying if I see this behavior happen, I’m going to assume that it indicates this sort of impact will happen downstream. And that’s great. It’s one of the techniques that was used to speed up and reduce the barrier to innovation in the other fields. And I think it’s great that we are applying that in the AI evaluation space. But special care is, of course, needed to ensure that those heuristics and proxies you’re using are reasonable indicators of the greater outcome you’re looking for.
SULLIVAN: What are some of the promising ideas from maybe pharma or med device regulation that maybe haven’t made it to AI testing yet and maybe should? And where would you urge technologists, policymakers, and researchers to focus their energy next?
ATALLA: Well, one of the key things that jumped out to me in the discussion about pharmaceuticals was driving home the emphasis that there is a holistic focus on safety and efficacy. These go hand in hand and decisions must be made while considering both pieces of the picture. I would like to see that further emphasized in the AI evaluation space.
Often, we are seeing evaluations of risk being separated from evaluations of performance or quality or efficacy, but these two pieces of the puzzle really are not enough for us to make informed decisions independently. And that ties back into my desire to really also see us measuring the impacts.
So we see Phase 3 trials as something that occurs in the medical devices and pharmaceuticals field. That’s not something that we are doing an equivalent of in the AI evaluation space at this time. These are really cost intensive. They can last years and really involve careful monitoring of that holistic picture of safety and efficacy. And realistically, we are not going to be able to put that on the critical path to getting specific individual AI models or AI systems vetted before they go out into the world. However, I would love to see a world in which this sort of work is prioritized and funded or required. Think of how, with social media, it took quite a long time for us to understand that there are some long-term negative impacts on mental health, and we have the opportunity now, while the AI wave is still building, to start prioritizing and funding this sort of work. Let it run in the background and as soon as possible develop a good understanding of the subtle, long-term effects.
More broadly, I would love to see us focus on reliability and validity of the evaluations we’re conducting because trust in these decisions and claims is important. If we don’t focus on building reliable, valid, and trustworthy evaluations, we’re just going to continue to be flooded by a bunch of competing, conflicting, and largely meaningless AI evaluations.
SULLIVAN: In a number of the discussions we’ve had on this podcast, we talked about how it’s not just one entity that really needs to ensure safety across the board, and I’d just love to hear from you how you think about some of those ecosystem collaborations, and you know, from across … where we think about ourselves as more of a platform company or places that these AI models are being deployed more at the application level. Tell me a little bit about how you think about, sort of, stakeholders in that mix and where responsibility lies across the board.
ATALLA: It’s interesting. In this age of general-purpose AI technologies, we’re often seeing one company or organization being responsible for building the foundational model. And then many, many other people will take that model and build it into specific products that are designed for specific tasks and contexts.
Of course, in that, we already see that there is a responsibility of the owners of that foundational model to do some testing of the central model before they distribute it broadly. And then again, there is responsibility of all of the downstream individuals digesting that and turning it into products to consider the specific contexts that they are deploying into and how that may affect the risks we’re concerned with or the types of quality and safety and performance we need to evaluate.
Again, because that field of risks we may be concerned with is so broad, some of them also require an immense amount of expertise. Let’s think about whether AI systems can enable people to create dangerous chemicals or dangerous weapons at home. It’s not that every AI practitioner is going to have the knowledge to evaluate this, so in some of those cases, we really need third-party experts, people who are experts in chemistry, biology, etc., to come in and evaluate certain systems and models for those specific risks, as well.
So I think there are many reasons why multiple stakeholders need to be involved, partly from who owns what and is responsible for what and partly from the perspective of who has the expertise to meaningfully construct the evaluations that we need.
SULLIVAN: Well, Chad, this has just been great to connect, and in a few of our discussions, we’ve done a bit of a lightning round, so I’d love to just hear your 30-second responses to a few of these questions. Perhaps favorite evaluation you’ve run so far this year?
ATALLA: So I’ve been involved in trying to evaluate some language models for whether they infer sensitive attributes about people. So perhaps you’re chatting with a chatbot, and it infers your religion or sexuality based on things you’re saying or how you sound, right. And in working to evaluate this, we encounter a lot of interesting questions. Or, like, what is a sensitive attribute? What makes these attributes sensitive, and what are the differences that make it inappropriate for an AI system to infer these things about a person? Whereas realistically, whenever I meet a person on the street, my brain is immediately forming first impressions and some assumptions about these people. So it’s a very interesting and thought-provoking evaluation to conduct and think about the norms that we place upon people interacting with other people and the norms we place upon AI systems interacting with other people.
SULLIVAN: That’s fascinating! I’d love to hear the AI buzzword you’d retire tomorrow. [LAUGHTER]
ATALLA: I would love to see the term “bias” being used less when referring to fairness-related issues and systems. Bias happens to be a highly overloaded term in statistics and machine learning and has a lot of technical meanings and just fails to perfectly capture what we mean in the AI risk sense.
SULLIVAN: And last one. One metric we’re not tracking enough.
ATALLA: I would say over-blocking, and this comes into that connection between the holistic picture of safety and efficacy. It’s too easy to produce systems that throw safety to the wind and focus purely on utility or achieving some goal, but simultaneously, the other side of the picture is possible, where we can clamp down too hard and reduce the utility of our systems and block even benign and useful outputs just because they border on something sensitive. So it’s important for us to track that over-blocking and actively track that tradeoff between safety and efficacy.
SULLIVAN: Yeah, we talk a lot about this on the podcast, too, of how do you both make things safe but also ensure innovation can thrive, and I think you hit the nail on the head with that last piece.
[MUSIC]
Well, Chad, this was really terrific. Thanks for joining us and thanks for your work and your perspectives. And another big thanks to Daniel and Timo for setting the stage earlier in the podcast.
And to our listeners, thanks for tuning in. You can find resources related to this podcast in the show notes. And if you want to learn more about how Microsoft approaches AI governance, you can visit microsoft.com/RAI.
See you next time!
[MUSIC FADES]
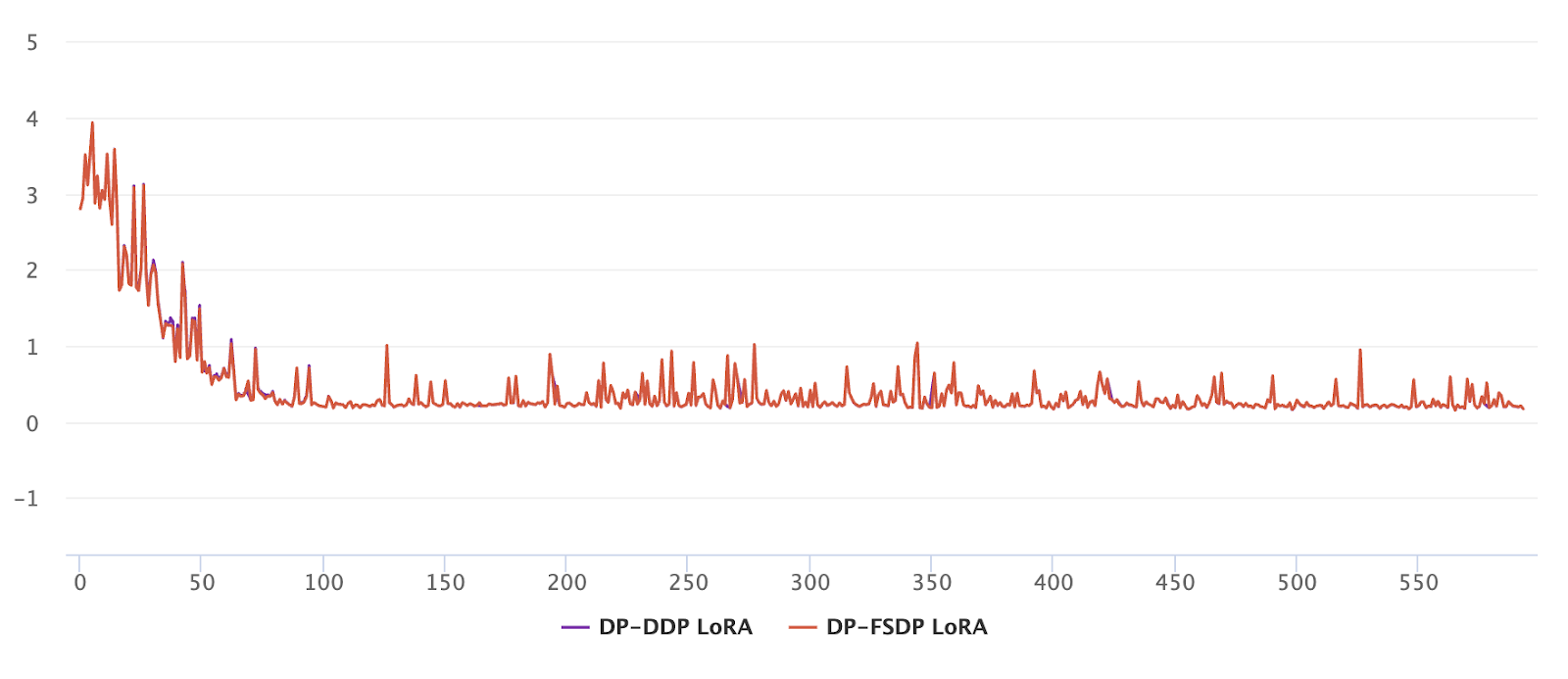
 Figure 1: Workflow of FSDP based Fast Gradient Clipping or Ghost Clipping in Opacus. Note that there is an overlap between compute and communication – 1) In the forward pass: computation of the current layer (l) is overlapped with the all_gather of next layer’s (l+1) parameter. 2) In the backward pass: gradient computation of the current layer (l) is overlapped with the reduce_scatter of the previous layer’s (l+1) gradients and all_gather of the next layer’s (l-1) parameter.
Figure 1: Workflow of FSDP based Fast Gradient Clipping or Ghost Clipping in Opacus. Note that there is an overlap between compute and communication – 1) In the forward pass: computation of the current layer (l) is overlapped with the all_gather of next layer’s (l+1) parameter. 2) In the backward pass: gradient computation of the current layer (l) is overlapped with the reduce_scatter of the previous layer’s (l+1) gradients and all_gather of the next layer’s (l-1) parameter.




 Pablo García Benedicto is an experienced Data & AI Cloud Engineer with strong expertise in cloud hyperscalers and data engineering. With a background in telecommunications, he currently works at Swisscom, where he leads and contributes to projects involving Generative AI applications and agents using Amazon Bedrock. Aiming for AI and data specialization, his latest projects focus on building intelligent assistants and autonomous agents that streamline business information retrieval, leveraging cloud-native architectures and scalable data pipelines to reduce toil and drive operational efficiency.
Pablo García Benedicto is an experienced Data & AI Cloud Engineer with strong expertise in cloud hyperscalers and data engineering. With a background in telecommunications, he currently works at Swisscom, where he leads and contributes to projects involving Generative AI applications and agents using Amazon Bedrock. Aiming for AI and data specialization, his latest projects focus on building intelligent assistants and autonomous agents that streamline business information retrieval, leveraging cloud-native architectures and scalable data pipelines to reduce toil and drive operational efficiency. Ruben Merz Ruben Merz is a Principal Solutions Architect at AWS. With a background in distributed systems and networking, his work with customers at AWS focuses on digital sovereignty, AI, and networking.
Ruben Merz Ruben Merz is a Principal Solutions Architect at AWS. With a background in distributed systems and networking, his work with customers at AWS focuses on digital sovereignty, AI, and networking. Jordi Montoliu Nerin is a Data & AI Leader currently serving as Senior AI/ML Specialist at AWS, where he helps worldwide telecommunications customers implement AI strategies after previously driving Data & Analytics business across EMEA regions. He has over 10 years of experience, where he has led multiple Data & AI implementations at scale, led executions of data strategy and data governance frameworks, and has driven strategic technical and business development programs across multiple industries and continents. Outside of work, he enjoys sports, cooking and traveling.
Jordi Montoliu Nerin is a Data & AI Leader currently serving as Senior AI/ML Specialist at AWS, where he helps worldwide telecommunications customers implement AI strategies after previously driving Data & Analytics business across EMEA regions. He has over 10 years of experience, where he has led multiple Data & AI implementations at scale, led executions of data strategy and data governance frameworks, and has driven strategic technical and business development programs across multiple industries and continents. Outside of work, he enjoys sports, cooking and traveling.