Although rapid generative AI advancements are revolutionizing organizational natural language processing tasks, developers and data scientists face significant challenges customizing these large models. These hurdles include managing complex workflows, efficiently preparing large datasets for fine-tuning, implementing sophisticated fine-tuning techniques while optimizing computational resources, consistently tracking model performance, and achieving reliable, scalable deployment.The fragmented nature of these tasks often leads to reduced productivity, increased development time, and potential inconsistencies in the model development pipeline. Organizations need a unified, streamlined approach that simplifies the entire process from data preparation to model deployment.
To address these challenges, AWS has expanded Amazon SageMaker with a comprehensive set of data, analytics, and generative AI capabilities. At the heart of this expansion is Amazon SageMaker Unified Studio, a centralized service that serves as a single integrated development environment (IDE). SageMaker Unified Studio streamlines access to familiar tools and functionality from purpose-built AWS analytics and artificial intelligence and machine learning (AI/ML) services, including Amazon EMR, AWS Glue, Amazon Athena, Amazon Redshift, Amazon Bedrock, and Amazon SageMaker AI. With SageMaker Unified Studio, you can discover data through Amazon SageMaker Catalog, access it from Amazon SageMaker Lakehouse, select foundation models (FMs) from Amazon SageMaker JumpStart or build them through JupyterLab, train and fine-tune them with SageMaker AI training infrastructure, and deploy and test models directly within the same environment. SageMaker AI is a fully managed service to build, train, and deploy ML models—including FMs—for different use cases by bringing together a broad set of tools to enable high-performance, low-cost ML. It’s available as a standalone service on the AWS Management Console, or through APIs. Model development capabilities from SageMaker AI are available within SageMaker Unified Studio.
In this post, we guide you through the stages of customizing large language models (LLMs) with SageMaker Unified Studio and SageMaker AI, covering the end-to-end process starting from data discovery to fine-tuning FMs with SageMaker AI distributed training, tracking metrics using MLflow, and then deploying models using SageMaker AI inference for real-time inference. We also discuss best practices to choose the right instance size and share some debugging best practices while working with JupyterLab notebooks in SageMaker Unified Studio.
Solution overview
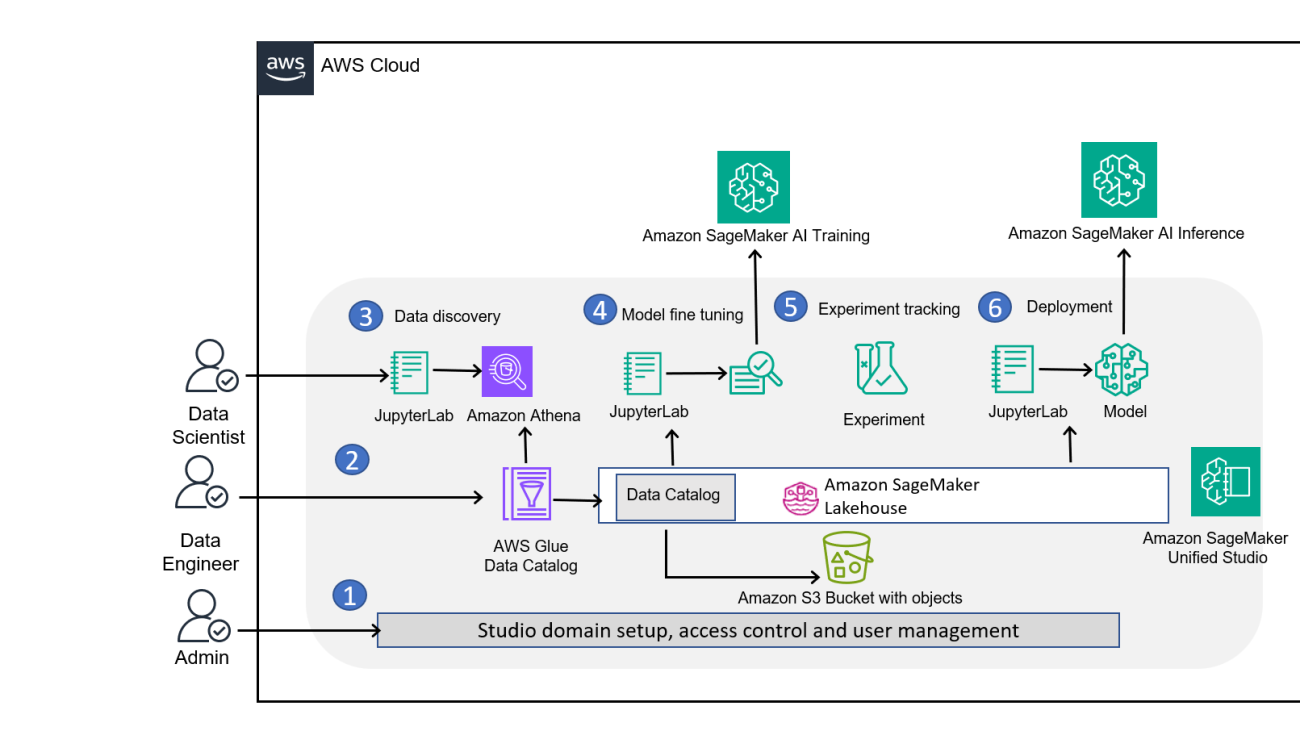
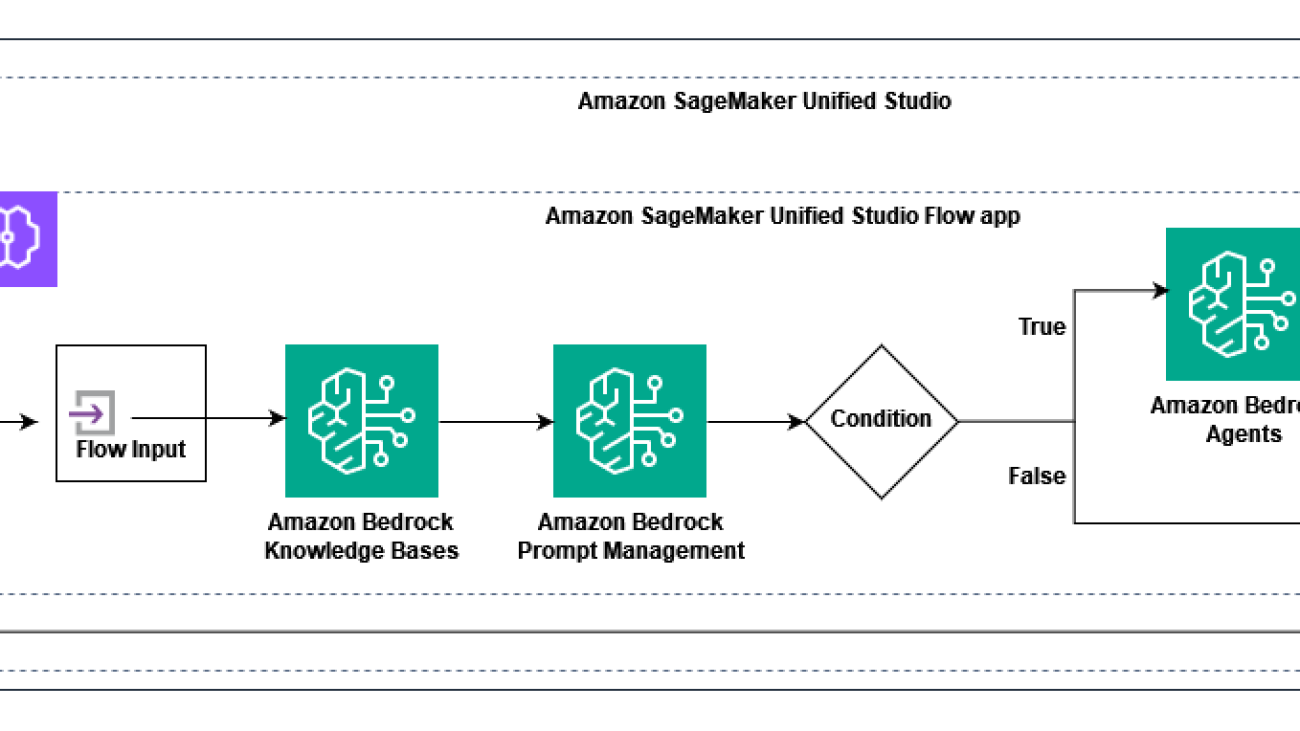
The following diagram illustrates the solution architecture. There are three personas: admin, data engineer, and user, which can be a data scientist or an ML engineer.

AWS SageMaker Unified Studio ML workflow showing data processing, model training, and deployment stages
Setting up the solution consists of the following steps:
- The admin sets up the SageMaker Unified Studio domain for the user and sets the access controls. The admin also publishes the data to SageMaker Catalog in SageMaker Lakehouse.
- Data engineers can create and manage extract, transform, and load (ETL) pipelines directly within Unified Studio using Visual ETL. They can transform raw data sources into datasets ready for exploratory data analysis. The admin can then manage the publication of these assets to the SageMaker Catalog, making them discoverable and accessible to other team members or users such as data engineers in the organization.
- Users or data engineers can log in to the Unified Studio web-based IDE using the login provided by the admin to create a project and create a managed MLflow server for tracking experiments. Users can discover available data assets in the SageMaker Catalog and request a subscription to an asset published by the data engineer. After the data engineer approves the subscription request, the user performs an exploratory data analysis of the content of the table with the query editor or with a JupyterLab notebook, then prepares the dataset by connecting with SageMaker Catalog through an AWS Glue or Athena connection.
- You can explore models from SageMaker JumpStart, which hosts over 200 models for various tasks, and fine-tune directly with the UI, or develop a training script for fine-tuning the LLM in the JupyterLab IDE. SageMaker AI provides distributed training libraries and supports various distributed training options for deep learning tasks. For this post, we use the PyTorch framework and use Hugging Face open source FMs for fine-tuning. We will show you how you can use parameter efficient fine-tuning (PEFT) with Low-Rank Adaptation (LoRa), where you freeze the model weights, train the model with modifying weight metrics, and then merge these LoRa adapters back to the base model after distributed training.
- You can track and monitor fine-tuning metrics directly in SageMaker Unified Studio using MLflow, by analyzing metrics such as loss to make sure the model is correctly fine-tuned.
- You can deploy the model to a SageMaker AI endpoint after the fine-tuning job is complete and test it directly from SageMaker Unified Studio.
Prerequisites
Before starting this tutorial, make sure you have the following:
- An AWS account with permissions to create SageMaker resources. For setup instructions, see Set up an AWS account and create an administrator user.
- Familiarity with Python and PyTorch for distributed training and model customization.
Set up SageMaker Unified Studio and configure user access
SageMaker Unified Studio is built on top of Amazon DataZone capabilities such as domains to organize your assets and users, and projects to collaborate with others users, securely share artifacts, and seamlessly work across compute services.
To set up Unified Studio, complete the following steps:
- As an admin, create a SageMaker Unified Studio domain, and note the URL.
- On the domain’s details page, on the User management tab, choose Configure SSO user access. For this post, we recommend setting up using single sign-on (SSO) access using the URL.
For more information about setting up user access, see Managing users in Amazon SageMaker Unified Studio.
Log in to SageMaker Unified Studio
Now that you have created your new SageMaker Unified Studio domain, complete the following steps to access SageMaker Unified Studio:
- On the SageMaker console, open the details page of your domain.
- Choose the link for the SageMaker Unified Studio URL.
- Log in with your SSO credentials.
Now you’re signed in to SageMaker Unified Studio.
Create a project
The next step is to create a project. Complete the following steps:
- In SageMaker Unified Studio, choose Select a project on the top menu, and choose Create project.
- For Project name, enter a name (for example,
demo). - For Project profile, choose your profile capabilities. A project profile is a collection of blueprints, which are configurations used to create projects. For this post, we choose All capabilities, then choose Continue.

Creating a project in Amazon SageMaker Unified Studio
Create a compute space
SageMaker Unified Studio provides compute spaces for IDEs that you can use to code and develop your resources. By default, it creates a space for you to get started with you project. You can find the default space by choosing Compute in the navigation pane and choosing the Spaces tab. You can then choose Open to go to the JuypterLab environment and add members to this space. You can also create a new space by choosing Create space on the Spaces tab.

To use SageMaker Studio notebooks cost-effectively, use smaller, general-purpose instances (like the T or M families) for interactive data exploration and prototyping. For heavy lifting like training or large-scale processing or deployment, use SageMaker AI training jobs and SageMaker AI prediction to offload the work to separate and more powerful instances such as the P5 family. We will show you in the notebook how you can run training jobs and deploy LLMs in the notebook with APIs. It is not recommended to run distributed workloads in notebook instances. The chances of kernel failures is high because JupyterLab notebooks should not be used for large distributed workloads (both for data and ML training).
The following screenshot shows the configuration options for your space. You can change your instance size from default (ml.t3.medium) to (ml.m5.xlarge) for the JupyterLab IDE. You can also increase the Amazon Elastic Block Store (Amazon EBS) volume capacity from 16 GB to 50 GB for training LLMs.

Canfigure space in Amazon SageMaker Unified Studio
Set up MLflow to track ML experiments
You can use MLflow in SageMaker Unified Studio to create, manage, analyze, and compare ML experiments. Complete the following steps to set up MLflow:
- In SageMaker Unified Studio, choose Compute in the navigation pane.
- On the MLflow Tracking Servers tab, choose Create MLflow Tracking Server.
- Provide a name and create your tracking server.
- Choose Copy ARN to copy the Amazon Resource Name (ARN) of the tracking server.

You will need this MLflow ARN in your notebook to set up distributed training experiment tracking.
Set up the data catalog
For model fine-tuning, you need access to a dataset. After you set up the environment, the next step is to find the relevant data from the SageMaker Unified Studio data catalog and prepare the data for model tuning. For this post, we use the Stanford Question Answering Dataset (SQuAD) dataset. This dataset is a reading comprehension dataset, consisting of questions posed by crowd workers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
Download the SQuaD dataset and upload it to SageMaker Lakehouse by following the steps in Uploading data.

Adding data to Catalog in Amazon SageMaker Unified Studio
To make this data discoverable by the users or ML engineers, the admin needs to publish this data to the Data Catalog. For this post, you can directly download the SQuaD dataset and upload it to the catalog. To learn how to publish the dataset to SageMaker Catalog, see Publish assets to the Amazon SageMaker Unified Studio catalog from the project inventory.
Query data with the query editor and JupyterLab
In many organizations, data preparation is a collaborative effort. A data engineer might prepare an initial raw dataset, which a data scientist then refines and augments with feature engineering before using it for model training. In the SageMaker Lakehouse data and model catalog, publishers set subscriptions for automatic or manual approval (wait for admin approval). Because you already set up the data in the previous section, you can skip this section showing how to subscribe to the dataset.
To subscribe to another dataset like SQuAD, open the data and model catalog in Amazon SageMaker Lakehouse, choose SQuAD, and subscribe.

Subscribing to any asset or dataset published by Admin
Next, let’s use the data explorer to explore the dataset you subscribed to. Complete the following steps:
- On the project page, choose Data.
- Under Lakehouse, expand
AwsDataCatalog. - Expand your database starting from
glue_db_. - Choose the dataset you created (starting with
squad) and choose Query with Athena.

Querying the data using Query Editor in Amazon SageMaker Unfied Studio
Process your data through a multi-compute JupyterLab IDE notebook
SageMaker Unified Studio provides a unified JupyterLab experience across different languages, including SQL, PySpark, Python, and Scala Spark. It also supports unified access across different compute runtimes such as Amazon Redshift and Athena for SQL, Amazon EMR Serverless, Amazon EMR on EC2, and AWS Glue for Spark.
Complete the following steps to get started with the unified JupyterLab experience:
- Open your SageMaker Unified Studio project page.
- On the top menu, choose Build, and under IDE & APPLICATIONS, choose JupyterLab.
- Wait for the space to be ready.
- Choose the plus sign and for Notebook, choose Python 3.
- Open a new terminal and enter
git clonehttps://github.com/aws-samples/amazon-sagemaker-generativeai. - Go to the folder
amazon-sagemaker-generativeai/3_distributed_training/distributed_training_sm_unified_studio/and open thedistributed training in unified studio.ipynbnotebook to get started. - Enter the MLflow server ARN you created in the following code:
Now you an visualize the data through the notebook.
- On the project page, choose Data.
- Under Lakehouse, expand
AwsDataCatalog. - Expand your database starting from
glue_db, copy the name of the database, and enter it in the following code:
- You can now access the entire dataset directly by using the in-line SQL query capabilities of JupyterLab notebooks in SageMaker Unified Studio. You can follow the data preprocessing steps in the notebook.
The following screenshot shows the output.

We are going to split the dataset into a test set and training set for model training. When the data processing in done and we have split the data into test and training sets, the next step is to perform fine-tuning of the model using SageMaker Distributed Training.
Fine-tune the model with SageMaker Distributed training
You’re now ready to fine-tune your model by using SageMaker AI capabilities for training. Amazon SageMaker Training is a fully managed ML service offered by SageMaker that helps you efficiently train a wide range of ML models at scale. The core of SageMaker AI jobs is the containerization of ML workloads and the capability of managing AWS compute resources. SageMaker Training takes care of the heavy lifting associated with setting up and managing infrastructure for ML training workloads
We select one model directly from the Hugging Face Hub, DeepSeek-R1-Distill-Llama-8B, and develop our training script in the JupyterLab space. Because we want to distribute the training across all the available GPUs in our instance, by using PyTorch Fully Sharded Data Parallel (FSDP), we use the Hugging Face Accelerate library to run the same PyTorch code across distributed configurations. You can start the fine-tuning job directly in your JupyterLab notebook or use the SageMaker Python SDK to start the training job. We use the Trainer from transfomers to fine-tune our model. We prepared the script train.py, which loads the dataset from disk, prepares the model and tokenizer, and starts the training.
For configuration, we use TrlParser, and provide hyperparameters in a YAML file. You can upload this file and provide it to SageMaker similar to your datasets. The following is the config file for fine-tuning the model on ml.g5.12xlarge. Save the config file as args.yaml and upload it to Amazon Simple Storage Service (Amazon S3).
Use the following code to use the native PyTorch container image, pre-built for SageMaker:
Define the trainer as follows:
Run the trainer with the following:
You can follow the steps in the notebook.
You can explore the job execution in SageMaker Unified Studio. The training job runs on the SageMaker training cluster by distributing the computation across the four available GPUs on the selected instance type ml.g5.12xlarge. We choose to merge the LoRA adapter with the base model. This decision was made during the training process by setting the merge_weights parameter to True in our train_fn() function. Merging the weights provides a single, cohesive model that incorporates both the base knowledge and the domain-specific adaptations we’ve made through fine-tuning.
Track training metrics and model registration using MLflow
You created an MLflow server in an earlier step to track experiments and registered models, and provided the server ARN in the notebook.
You can log MLflow models and automatically register them with Amazon SageMaker Model Registry using either the Python SDK or directly through the MLflow UI. Use mlflow.register_model() to automatically register a model with SageMaker Model Registry during model training. You can explore the MLflow tracking code in train.py and the notebook. The training code tracks MLflow experiments and registers the model to the MLflow model registry. To learn more, see Automatically register SageMaker AI models with SageMaker Model Registry.
To see the logs, complete the following steps:
- Choose Build, then choose Spaces.
- Choose Compute in the navigation pane.
- On the MLflow Tracking Servers tab, choose Open to open the tracking server.
You can see both the experiments and registered models.

Deploy and test the model using SageMaker AI Inference
When deploying a fine-tuned model on AWS, SageMaker AI Inference offers multiple deployment strategies. In this post, we use SageMaker real-time inference. The real-time inference endpoint is designed for having full control over the inference resources. You can use a set of available instances and deployment options for hosting your model. By using the SageMaker built-in container DJL Serving, you can take advantage of the inference script and optimization options available directly in the container. In this post, we deploy the fine-tuned model to a SageMaker endpoint for running inference, which will be used for testing the model.
In SageMaker Unified Studio, in JupyterLab, we create the Model object, which is a high-level SageMaker model class for working with multiple container options. The image_uri parameter specifies the container image URI for the model, and model_data points to the Amazon S3 location containing the model artifact (automatically uploaded by the SageMaker training job). We also specify a set of environment variables to configure the specific inference backend option (OPTION_ROLLING_BATCH), the degree of tensor parallelism based on the number of available GPUs (OPTION_TENSOR_PARALLEL_DEGREE), and the maximum allowable length of input sequences (in tokens) for models during inference (OPTION_MAX_MODEL_LEN).
After you create the model object, you can deploy it to an endpoint using the deploy method. The initial_instance_count and instance_type parameters specify the number and type of instances to use for the endpoint. We selected the ml.g5.4xlarge instance for the endpoint. The container_startup_health_check_timeout and model_data_download_timeout parameters set the timeout values for the container startup health check and model data download, respectively.
It takes a few minutes to deploy the model before it becomes available for inference and evaluation. You can test the endpoint invocation in JupyterLab, by using the AWS SDK with the boto3 client for sagemaker-runtime, or by using the SageMaker Python SDK and the predictor previously created, by using the predict API.
You can also test the model invocation in SageMaker Unified Studio, on the Inference endpoint page and Text inference tab.
Troubleshooting
You might encounter some of the following errors while running your model training and deployment:
- Training job fails to start – If a training job fails to start, make sure your IAM role AmazonSageMakerDomainExecution has the necessary permissions, verify the instance type is available in your AWS Region, and check your S3 bucket permissions. This role is created when an admin creates the domain, and you can ask the admin to check your IAM access permissions associated with this role.
- Out-of-memory errors during training – If you encounter out-of-memory errors during training, try reducing the batch size, use gradient accumulation to simulate larger batches, or consider using a larger instance.
- Slow model deployment – For slow model deployment, make sure model artifacts aren’t excessively large, and use appropriate instance types for inference and capacity available for that instance in your Region.
For more troubleshooting tips, refer to Troubleshooting guide.
Clean up
SageMaker Unified Studio by default shuts down idle resources such as JupyterLab spaces after 1 hour. However, you must delete the S3 bucket and the hosted model endpoint to stop incurring costs. You can delete the real-time endpoints you created using the SageMaker console. For instructions, see Delete Endpoints and Resources.
Conclusion
This post demonstrated how SageMaker Unified Studio serves as a powerful centralized service for data and AI workflows, showcasing its seamless integration capabilities throughout the fine-tuning process. With SageMaker Unified Studio, data engineers and ML practitioners can efficiently discover and access data through SageMaker Catalog, prepare datasets, fine-tune models, and deploy them—all within a single, unified environment. The service’s direct integration with SageMaker AI and various AWS analytics services streamlines the development process, alleviating the need to switch between multiple tools and environments. The solution highlights the service’s versatility in handling complex ML workflows, from data discovery and preparation to model deployment, while maintaining a cohesive and intuitive user experience. Through features like integrated MLflow tracking, built-in model monitoring, and flexible deployment options, SageMaker Unified Studio demonstrates its capability to support sophisticated AI/ML projects at scale.
To learn more about SageMaker Unified Studio, see An integrated experience for all your data and AI with Amazon SageMaker Unified Studio.
If this post helps you or inspires you to solve a problem, we would love to hear about it! The code for this solution is available on the GitHub repo for you to use and extend. Contributions are always welcome!
About the authors
 Mona Mona currently works as a Sr World Wide Gen AI Specialist Solutions Architect at Amazon focusing on Gen AI Solutions. She was a Lead Generative AI specialist in Google Public Sector at Google before joining Amazon. She is a published author of two books – Natural Language Processing with AWS AI Services and Google Cloud Certified Professional Machine Learning Study Guide. She has authored 19 blogs on AI/ML and cloud technology and a co-author on a research paper on CORD19 Neural Search which won an award for Best Research Paper at the prestigious AAAI (Association for the Advancement of Artificial Intelligence) conference.
Mona Mona currently works as a Sr World Wide Gen AI Specialist Solutions Architect at Amazon focusing on Gen AI Solutions. She was a Lead Generative AI specialist in Google Public Sector at Google before joining Amazon. She is a published author of two books – Natural Language Processing with AWS AI Services and Google Cloud Certified Professional Machine Learning Study Guide. She has authored 19 blogs on AI/ML and cloud technology and a co-author on a research paper on CORD19 Neural Search which won an award for Best Research Paper at the prestigious AAAI (Association for the Advancement of Artificial Intelligence) conference.
 Bruno Pistone is a Senior Generative AI and ML Specialist Solutions Architect for AWS based in Milan. He works with large customers helping them to deeply understand their technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His expertise include: Machine Learning end to end, Machine Learning Industrialization, and Generative AI. He enjoys spending time with his friends and exploring new places, as well as travelling to new destinations.
Bruno Pistone is a Senior Generative AI and ML Specialist Solutions Architect for AWS based in Milan. He works with large customers helping them to deeply understand their technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His expertise include: Machine Learning end to end, Machine Learning Industrialization, and Generative AI. He enjoys spending time with his friends and exploring new places, as well as travelling to new destinations.
 Lauren Mullennex is a Senior GenAI/ML Specialist Solutions Architect at AWS. She has a decade of experience in DevOps, infrastructure, and ML. Her areas of focus include MLOps/LLMOps, generative AI, and computer vision.
Lauren Mullennex is a Senior GenAI/ML Specialist Solutions Architect at AWS. She has a decade of experience in DevOps, infrastructure, and ML. Her areas of focus include MLOps/LLMOps, generative AI, and computer vision.

 New month, new energy.
New month, new energy.

 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN) 









 Vivek Gangasani is a Lead Specialist Solutions Architect for Inference at AWS. He helps emerging generative AI companies build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of large language models. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines.
Vivek Gangasani is a Lead Specialist Solutions Architect for Inference at AWS. He helps emerging generative AI companies build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of large language models. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines.

 Sohaib Katariwala is a Sr. Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. His interests are in all things data and analytics. More specifically he loves to help customers use AI in their data strategy to solve modern day challenges.
Sohaib Katariwala is a Sr. Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. His interests are in all things data and analytics. More specifically he loves to help customers use AI in their data strategy to solve modern day challenges. Karan Jain is a Senior Machine Learning Specialist at AWS, where he leads the worldwide Go-To-Market strategy for Amazon SageMaker Inference. He helps customers accelerate their generative AI and ML journey on AWS by providing guidance on deployment, cost-optimization, and GTM strategy. He has led product, marketing, and business development efforts across industries for over 10 years, and is passionate about mapping complex service features to customer solutions.
Karan Jain is a Senior Machine Learning Specialist at AWS, where he leads the worldwide Go-To-Market strategy for Amazon SageMaker Inference. He helps customers accelerate their generative AI and ML journey on AWS by providing guidance on deployment, cost-optimization, and GTM strategy. He has led product, marketing, and business development efforts across industries for over 10 years, and is passionate about mapping complex service features to customer solutions.






 Deepak Chandrasekar is the VP of Software Engineering & User Experience and leads multidisciplinary teams at Boomi. He oversees flagship initiatives like Boomi’s Agent Control Tower, Task Automation, and Market Reach, while driving a cohesive and intelligent experience layer across products. Previously, Deepak held a key leadership role at Unifi Software, which was acquired by Boomi. With a passion for building scalable, and intuitive AI-powered solutions, he brings a commitment to engineering excellence and responsible innovation.
Deepak Chandrasekar is the VP of Software Engineering & User Experience and leads multidisciplinary teams at Boomi. He oversees flagship initiatives like Boomi’s Agent Control Tower, Task Automation, and Market Reach, while driving a cohesive and intelligent experience layer across products. Previously, Deepak held a key leadership role at Unifi Software, which was acquired by Boomi. With a passion for building scalable, and intuitive AI-powered solutions, he brings a commitment to engineering excellence and responsible innovation. Sandeep Singh is Director of Engineering at Boomi, where he leads global teams building solutions that enable enterprise integration and automation at scale. He drives initiatives like Boomi Agent Control Tower, Marketplace, and Labs, empowering partners and customers with intelligent, trusted solutions. With leadership experience at GE and Fujitsu, Sandeep brings expertise in API strategy, product engineering, and AI/ML solutions. A former solution architect, he is passionate about designing mission-critical systems and driving innovation through scalable, intelligent solutions.
Sandeep Singh is Director of Engineering at Boomi, where he leads global teams building solutions that enable enterprise integration and automation at scale. He drives initiatives like Boomi Agent Control Tower, Marketplace, and Labs, empowering partners and customers with intelligent, trusted solutions. With leadership experience at GE and Fujitsu, Sandeep brings expertise in API strategy, product engineering, and AI/ML solutions. A former solution architect, he is passionate about designing mission-critical systems and driving innovation through scalable, intelligent solutions. Santosh Ameti is a seasoned Engineering leader in the Amazon Bedrock team and has built Agents, Evaluation, Guardrails, and Prompt Management solutions. His team continuously innovates in the agentic space, delivering one of the most secure and managed agentic solutions for enterprises.
Santosh Ameti is a seasoned Engineering leader in the Amazon Bedrock team and has built Agents, Evaluation, Guardrails, and Prompt Management solutions. His team continuously innovates in the agentic space, delivering one of the most secure and managed agentic solutions for enterprises. Greg Sligh is a Senior Solutions Architect at AWS with more than 25 years of experience in software engineering, software architecture, consulting, and IT and Engineering leadership roles across multiple industries. For the majority of his career, he has focused on creating and delivering distributed, data-driven applications with particular focus on scale, performance, and resiliency. Now he helps ISVs meet their objectives across technologies, with particular focus on AI/ML.
Greg Sligh is a Senior Solutions Architect at AWS with more than 25 years of experience in software engineering, software architecture, consulting, and IT and Engineering leadership roles across multiple industries. For the majority of his career, he has focused on creating and delivering distributed, data-driven applications with particular focus on scale, performance, and resiliency. Now he helps ISVs meet their objectives across technologies, with particular focus on AI/ML. Padma Iyer is a Senior Customer Solutions Manager at Amazon Web Services, where she specializes in supporting ISVs. With a passion for cloud transformation and financial technology, Padma works closely with ISVs to guide them through successful cloud transformations, using best practices to optimize their operations and drive business growth. Padma has over 20 years of industry experience spanning banking, tech, and consulting.
Padma Iyer is a Senior Customer Solutions Manager at Amazon Web Services, where she specializes in supporting ISVs. With a passion for cloud transformation and financial technology, Padma works closely with ISVs to guide them through successful cloud transformations, using best practices to optimize their operations and drive business growth. Padma has over 20 years of industry experience spanning banking, tech, and consulting.
 Here are Google’s latest AI updates from June 2025
Here are Google’s latest AI updates from June 2025

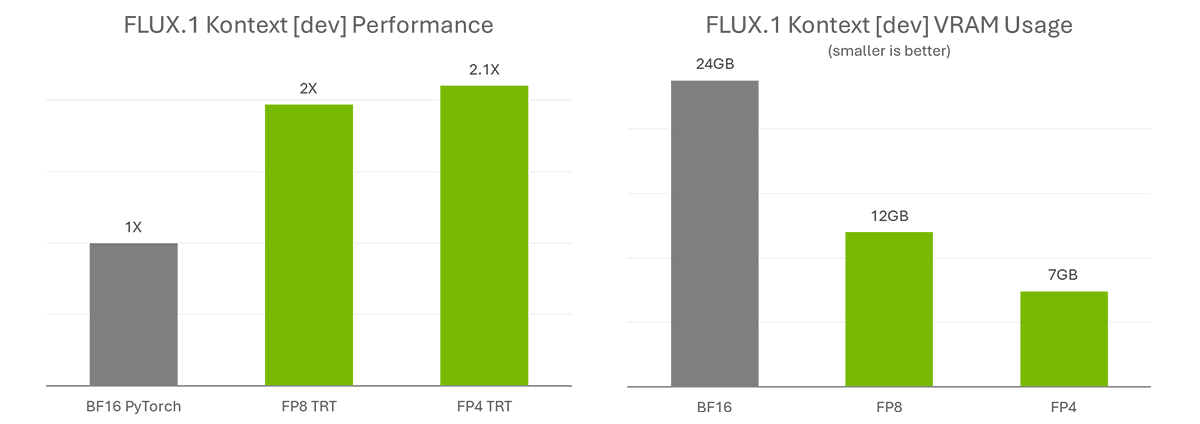
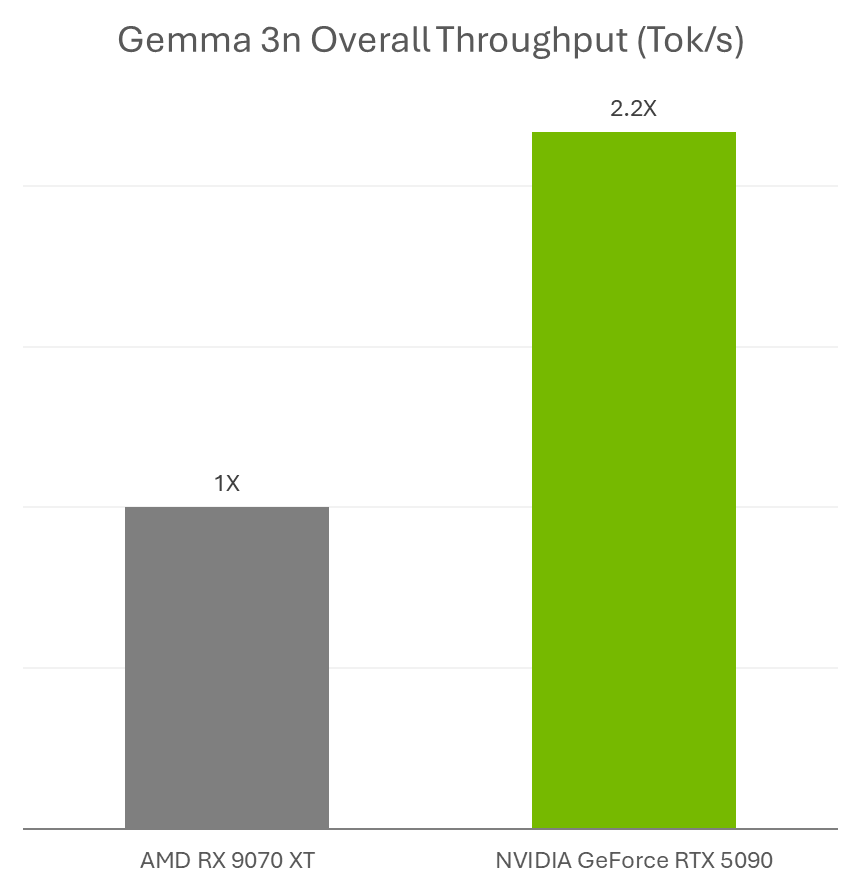















 Sumeet Tripathi is an Enterprise Support Lead (TAM) at AWS in North Carolina. He has over 17 years of experience in technology across various roles. He is passionate about helping customers to reduce operational challenges and friction. His focus area is AI/ML and Energy & Utilities Segment. Outside work, He enjoys traveling with family, watching cricket and movies.
Sumeet Tripathi is an Enterprise Support Lead (TAM) at AWS in North Carolina. He has over 17 years of experience in technology across various roles. He is passionate about helping customers to reduce operational challenges and friction. His focus area is AI/ML and Energy & Utilities Segment. Outside work, He enjoys traveling with family, watching cricket and movies. Vishal Naik is a Sr. Solutions Architect at Amazon Web Services (AWS). He is a builder who enjoys helping customers accomplish their business needs and solve complex challenges with AWS solutions and best practices. His core area of focus includes Generative AI and Machine Learning. In his spare time, Vishal loves making short films on time travel and alternate universe themes.
Vishal Naik is a Sr. Solutions Architect at Amazon Web Services (AWS). He is a builder who enjoys helping customers accomplish their business needs and solve complex challenges with AWS solutions and best practices. His core area of focus includes Generative AI and Machine Learning. In his spare time, Vishal loves making short films on time travel and alternate universe themes.









 Xan Huang is a Senior Solutions Architect with AWS and is based in Singapore. He works with major financial institutions to design and build secure, scalable, and highly available solutions in the cloud. Outside of work, Xan dedicates most of his free time to his family, where he lovingly takes direction from his two young daughters, aged one and four. You can find Xan on LinkedIn:
Xan Huang is a Senior Solutions Architect with AWS and is based in Singapore. He works with major financial institutions to design and build secure, scalable, and highly available solutions in the cloud. Outside of work, Xan dedicates most of his free time to his family, where he lovingly takes direction from his two young daughters, aged one and four. You can find Xan on LinkedIn:  Vikesh Pandey is a Principal GenAI/ML Specialist Solutions Architect at AWS helping large financial institutions adopt and scale generative AI and ML workloads. He is the author of book “Generative AI for financial services.” He carries more than decade of experience building enterprise-grade applications on generative AI/ML and related technologies. In his spare time, he plays an unnamed sport with his son that lies somewhere between football and rugby.
Vikesh Pandey is a Principal GenAI/ML Specialist Solutions Architect at AWS helping large financial institutions adopt and scale generative AI and ML workloads. He is the author of book “Generative AI for financial services.” He carries more than decade of experience building enterprise-grade applications on generative AI/ML and related technologies. In his spare time, he plays an unnamed sport with his son that lies somewhere between football and rugby.