Customers are increasingly looking to use the power of large language models (LLMs) to solve real-world problems. However, bridging the gap between these LLMs and practical applications has been a challenge. AI agents have appeared as an innovative technology that bridges this gap.
The foundation models (FMs) available through Amazon Bedrock serve as the cognitive engine for AI agents, providing the reasoning and natural language understanding capabilities essential for interpreting user requests and generating appropriate responses. You can integrate these models with various agent frameworks and orchestration layers to create AI applications that can understand context, make decisions, and take actions. You can build with Amazon Bedrock Agents or other frameworks like LangGraph and the recently launched Strands Agent SDK.
This blog post explores how to create powerful agentic applications using the Amazon Bedrock FMs, LangGraph, and the Model Context Protocol (MCP), with a practical scenario of handling a GitHub workflow of issue analysis, code fixes, and pull request generation.
For teams seeking a managed solution to streamline GitHub workflows, Amazon Q Developer in GitHub offers native integration with GitHub repositories. It provides built-in capabilities for code generation, review, and code transformation without requiring custom agent development. While Amazon Q Developer provides out-of-the-box functionality for common development workflows, organizations with specific requirements or unique use cases may benefit from building custom solutions using Amazon Bedrock and agent frameworks. This flexibility allows teams to choose between a ready-to-use solution with Amazon Q Developer or a customized approach using Amazon Bedrock, depending on their specific needs, technical requirements, and desired level of control over the implementation.
Challenges with the current state of AI agents
Despite the remarkable advancements in AI agent technology, the current state of agent development and deployment faces significant challenges that limit their effectiveness, reliability, and broader adoption. These challenges span technical, operational, and conceptual domains, creating barriers that developers and organizations must navigate when implementing agentic solutions.
One of the significant challenges is tool integration. Although frameworks like Amazon Bedrock Agents, LangGraph, and the Strands Agent SDK provide mechanisms for agents to interact with external tools and services, the current approaches often lack standardization and flexibility. Developers must create custom integrations for each tool, define precise schemas, and handle a multitude of edge cases in tool invocation and response processing. Furthermore, the rigid nature of many tool integration frameworks means that agents struggle to adapt to changes in tool interfaces or to discover and use new capabilities dynamically.
How MCP helps in creating agents
Appearing as a response to the limitations and challenges of current agent architectures, MCP provides a standardized framework that fundamentally redefines the relationship between FMs, context management, and tool integration. This protocol addresses many of the core challenges that have hindered the broader adoption and effectiveness of AI agents, particularly in enterprise environments and complex use cases.
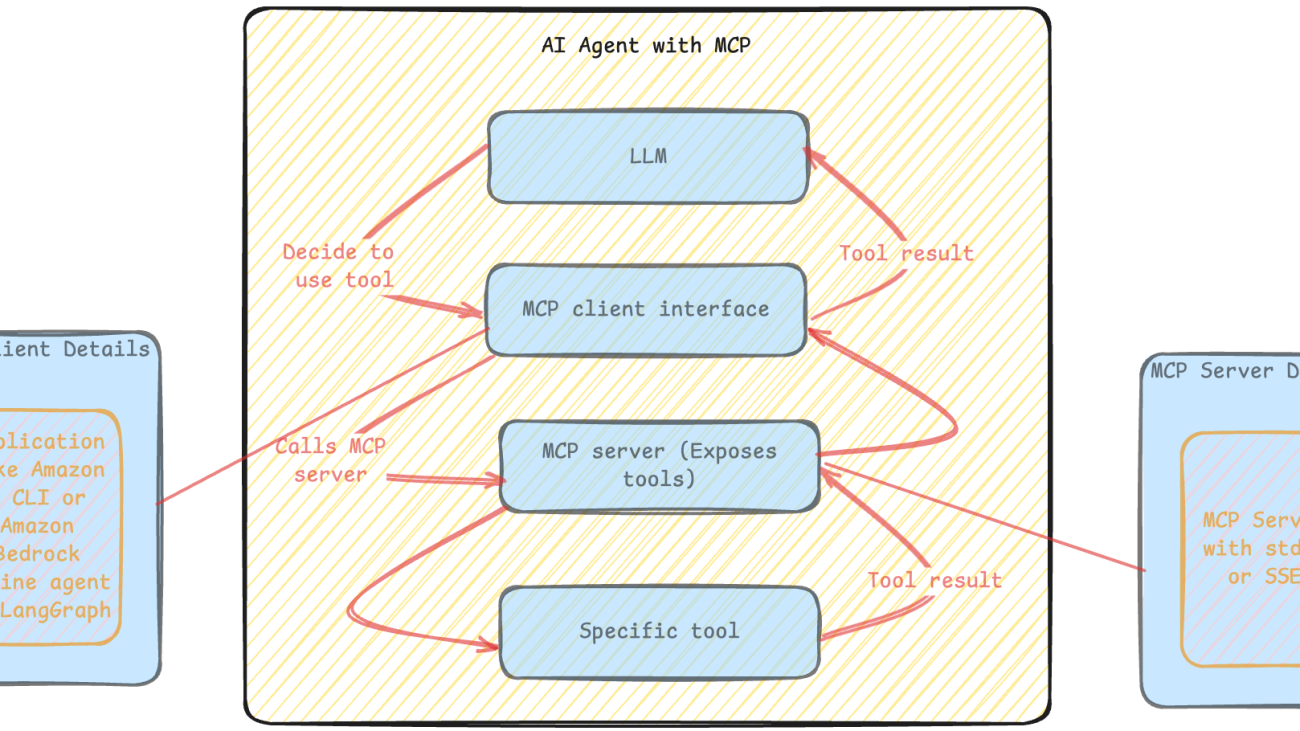
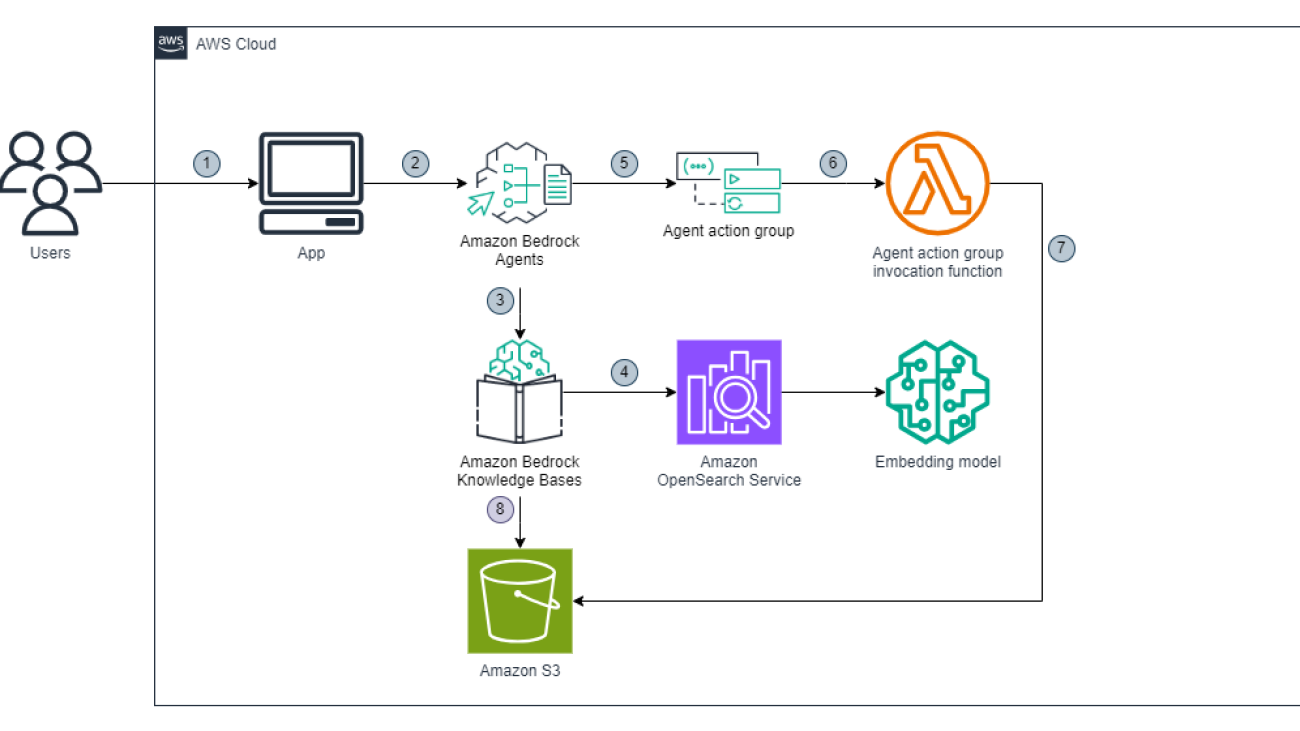
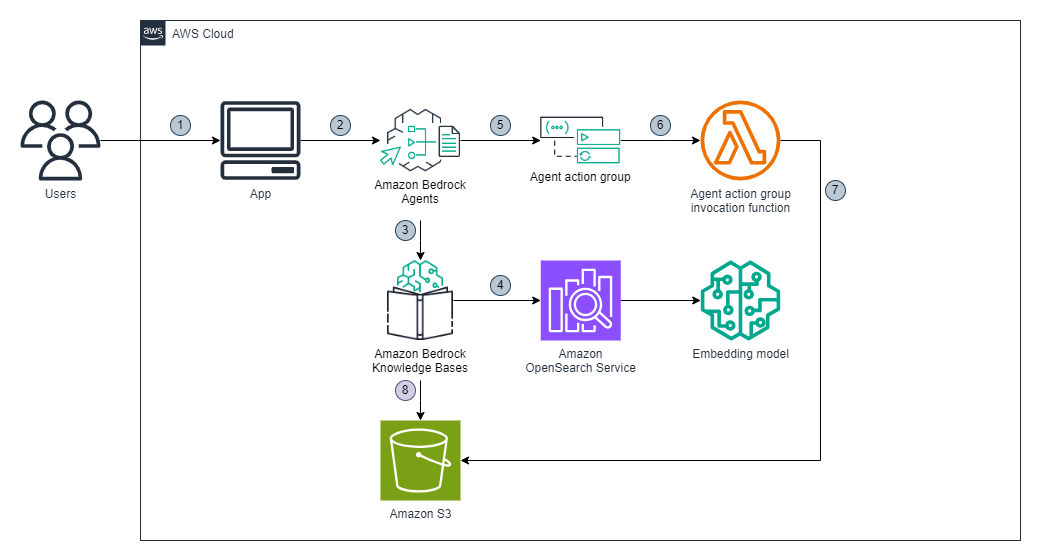
The following diagram illustrates an example architecture.
Tool integration is dramatically simplified through MCP’s Tool Registry and standardized invocation patterns. Developers can register tools with the registry using a consistent format, and the protocol manages the complexities of tool selection, parameter preparation, and response processing. This not only reduces the development effort required to integrate new tools but also enables more sophisticated tool usage patterns, such as tool chaining and parallel tool invocation, that are challenging to implement in current frameworks.
This combination takes advantage of the strengths of each technology—high-quality FMs in Amazon Bedrock, MCP’s context management capabilities, and LangGraph’s orchestration framework—to create agents that can tackle increasingly complex tasks with greater reliability and effectiveness.
Imagine your development team wakes up to find yesterday’s GitHub issues already analyzed, fixed, and waiting as pull requests — all handled autonomously overnight.
Recent advances in AI, particularly LLMs with code generation capabilities, have resulted in an impactful approach to development workflows. By using agents, development teams can automate simple changes—such as dependency updates or straightforward bug fixes.
Solution Overview
Amazon Bedrock is a fully managed service that makes high-performing FMs from leading AI companies and Amazon available through a unified API. Amazon Bedrock also offers a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
LangGraph orchestrates agentic workflows through a graph-based architecture that handles complex processes and maintains context across agent interactions. It uses supervisory control patterns and memory systems for coordination. For more details, refer to Build multi-agent systems with LangGraph and Amazon Bedrock.
The Model Context Protocol (MCP) is an open standard that empowers developers to build secure, two-way connections between their data sources and AI-powered tools. The GitHub MCP Server is an MCP server that provides seamless integration with GitHub APIs. It offers a standard way for AI tools to work with GitHub’s repositories. Developers can use it to automate tasks, analyze code, and improve workflows without handling complex API calls.
This post uses these three technologies in a complementary fashion. Amazon Bedrock offers the AI capabilities for understanding issues and generating code fixes. LangGraph orchestrates the end-to-end workflow, managing the state and decision-making throughout the process. The GitHub MCP Server interfaces with GitHub repositories, providing context to the FM and implementing the generated changes. Together, these technologies enable an automation system that can understand and analyze GitHub issues, extract relevant code context, generate code fixes, create well-documented pull requests, and integrate seamlessly with existing GitHub workflows.
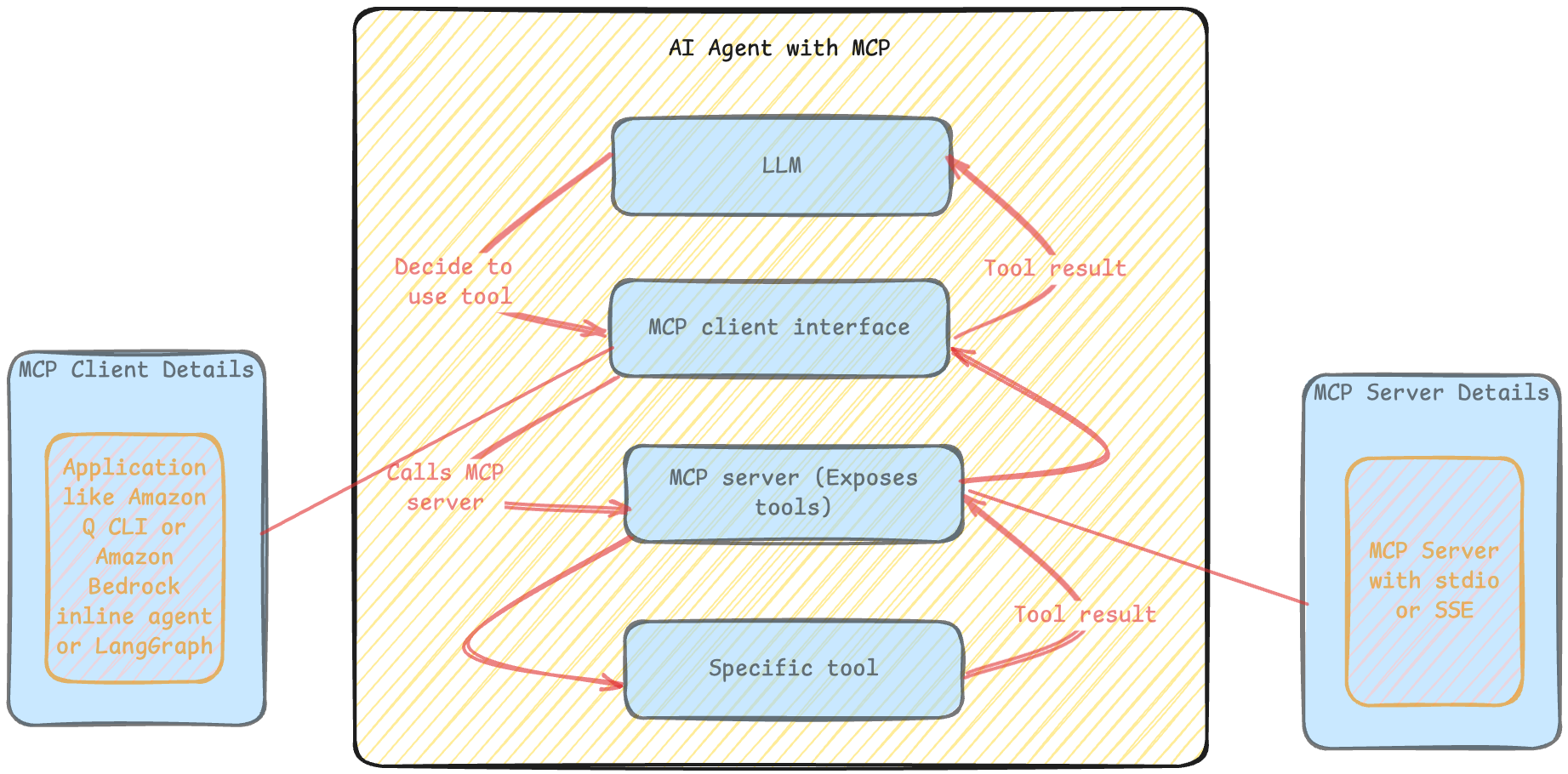
The figure below shows high-level view of how LangGraph integrates with GitHub through MCP while leveraging LLMs from Amazon Bedrock.

In the following sections, we explore the technical approach for building an AI-powered automation system, using Amazon Bedrock, LangGraph, and the GitHub MCP Server. We discuss the core concepts of building the solution; we don’t focus on deploying the agent or running the MCP server in the AWS environment. For a detailed explanation, refer to the GitHub repository.
Prerequisites
You must have the following prerequisites before you can deploy this solution. For this post, we use the us-west-2 AWS Region. For details on available Regions, see Amazon Bedrock endpoints and quotas.
- A valid AWS account.
- An AWS Identity and Access Management (IAM) role in the account that has sufficient permissions to invoke Amazon Bedrock models. If you’re planning to run your code on a Amazon SageMaker Jupyter notebook instance (rather than locally), you will also need permissions to set up and manage SageMaker resources. If you have administrator access, no action is needed for this step.
- Access to Anthropic’s Claude 3.5 Haiku on Amazon Bedrock. For instructions, see Access Amazon Bedrock foundation models.
- Docker or Finch to run GitHub MCP server as a container.
- A fine-grained personal access token. The GitHub MCP server can use supported GitHub APIs, so enable the least permission needed for this post. Assign repository permissions for contents, issues, and pull requests.
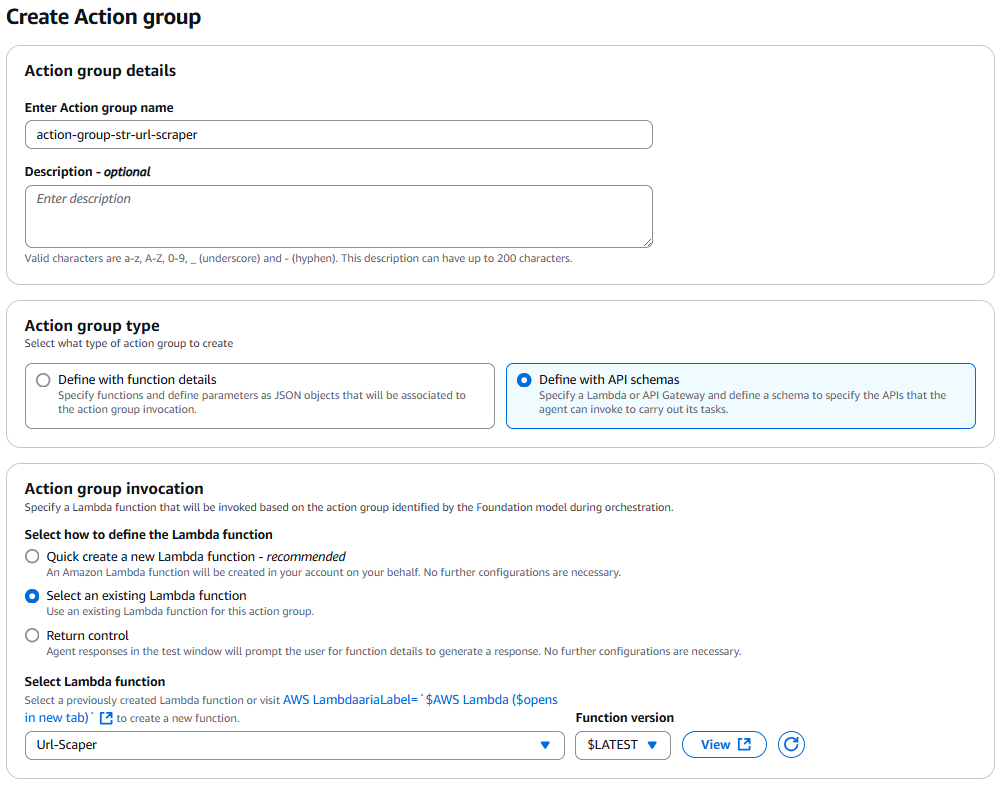
Environment configuration and setup
The MCP server acts as a bridge between our LangGraph agent and GitHub’s API. Instead of directly calling GitHub APIs, we use the containerized the GitHub MCP Server, which provides standardized tool interfaces.
You need to define the MCP configuration using the personal access token that you defined in the prerequisites. This configuration will start the GitHub MCP Server using Docker or Finch.
Agent state
LangGraph needs a shared state object that flows between the nodes in the workflow. This state acts as memory, allowing each step to access data from earlier steps and pass results to later ones.
Structured output
Instead of parsing free-form LLM responses, we use Pydantic models to enforce consistent, machine-readable outputs. This reduces parsing errors and make sure downstream nodes receive data in expected formats. The Field descriptions guide the LLM to provide exactly what we need.
MCP tools integration
The load_mcp_tools function from the LangChain’s MCP adapter automatically converts the MCP server capabilities into LangChain-compatible tools. This abstraction makes it possible to use the GitHub operations (list issues, create branches, update files) as if they were built-in LangChain tools.
Workflow structure
Each node is stateless — it takes the current state, performs one specific task, and returns state updates. This makes the workflow predictable, testable, and straightforward to debug. These nodes are connected using edges or conditional edges. Not every GitHub issue requires code changes. Some might be documentation requests, duplicates, or need clarification. The routing functions use the structured LLM output to dynamically decide the next step, making the workflow adaptive rather than rigid.
Finally, we start the agent by invoking the compiled graph with an initial state. The agent then follows the steps and decisions defined in the graph. The following diagram illustrates the workflow.
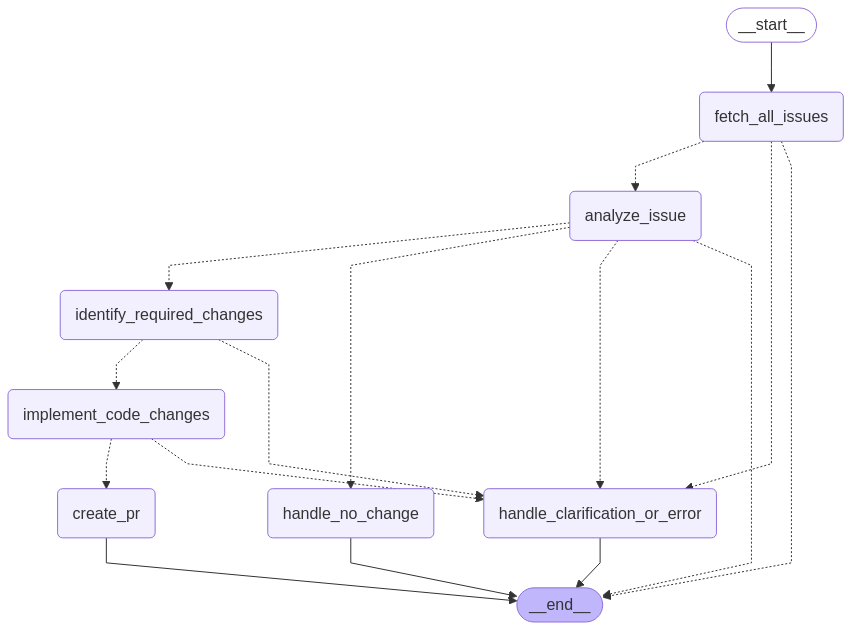
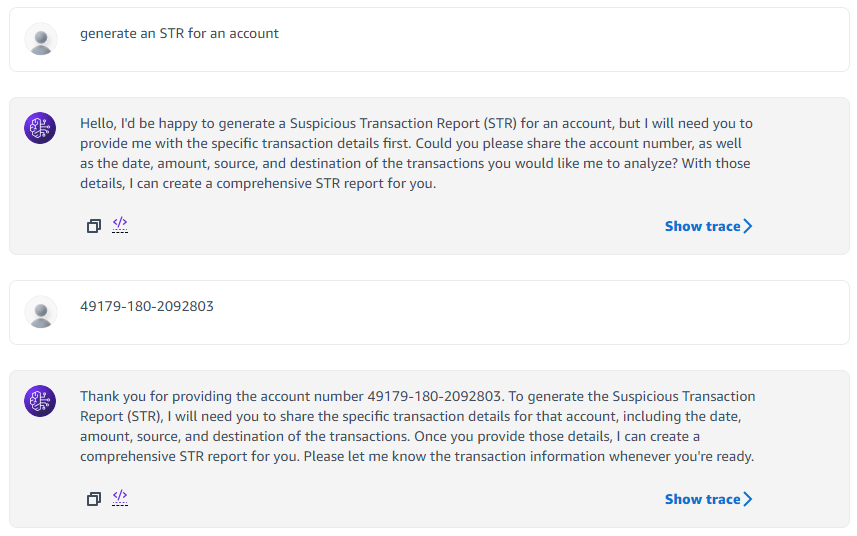
Agent Execution and Result
We can invoke the compiled graph with the initial_state and recursion_limit. It will fetch open issues from the given GitHub repository, analyze them one at a time, make the code changes if needed and then create the pull request in GitHub.
Considerations
To enable automated workflows, Amazon EventBridge offers an integration with GitHub through its SaaS partner event sources. After it’s configured, EventBridge receives these GitHub events in near real-time. You can create rules that match specific issue patterns and route them to various AWS services like AWS Lambda functions, AWS Step Functions state machines, or Amazon Simple Notification Service (Amazon SNS) topics for further processing. This integration enables automated workflows that can trigger your analysis pipelines or code generation processes when relevant GitHub issue activities occur.
When deploying the system, consider a phased rollout strategy. Start with a pilot phase in two or three non-critical repositories to confirm effectiveness and find issues. During this pilot phase, it’s crucial to thoroughly evaluate the solution across a diverse set of code files. This test should cover different programming languages, frameworks, formats (such as – Jupyter notebook), and varying levels of complexity in number and size of code files. Gradually expand to more repositories, prioritizing those with high maintenance burdens or standardized code patterns.
Infrastructure best practices include containerization, designing for scalability, providing high availability, and implementing comprehensive monitoring for application, system, and business metrics. Security considerations are paramount, including operating with least privilege access, proper secrets management, input validation, and vulnerability management through regular updates and security scanning.
It is crucial to align with your company’s generative AI operations and governance frameworks. Prior to deployment, verify alignment with your organization’s AI safety protocols, data handling policies, and model deployment guidelines. Although this architectural pattern offers significant benefits, you should adapt implementation to fit within your organization’s specific AI governance structure and risk management frameworks.
Clean up
Clean up your environment by completing the following steps:
- Delete IAM roles and policies created specifically for this post.
- Delete the local copy of this post’s code.
- If you no longer need access to an Amazon Bedrock FM, you can remove access to it. For instructions, see Add or remove access to Amazon Bedrock foundation models.
- Delete the personal access token. For instructions, see Deleting a personal access token.
Conclusion
The integration of Amazon Bedrock FMs with the MCP and LangGraph is a significant advancement in the field of AI agents. By addressing the fundamental challenges of context management and tool integration, this combination enables the development of more sophisticated, reliable, and powerful agentic applications.
The GitHub issues workflow scenario demonstrates benefits that include productivity enhancement, consistency improvement, faster response times, scalable maintenance, and knowledge amplification. Important insights include the role of FMs as development partners, the necessity of workflow orchestration, the importance of repository context, the need for confidence assessment, and the value of feedback loops for continuous improvement.
The future of AI-powered development automation will see trends like multi-agent collaboration systems, proactive code maintenance, context-aware code generation, enhanced developer collaboration, and ethical AI development. Challenges include skill evolution, governance complexity, quality assurance, and integration complexity, whereas opportunities include developer experience transformation, accelerated innovation, knowledge democratization, and accessibility improvements. Organizations can prepare by starting small, investing in knowledge capture, building feedback loops, developing AI literacy, and experimenting with new capabilities. The goal is to enhance developer capabilities, not replace them, fostering a collaborative future where AI and human developers work together to build better software.
For the example code and demonstration discussed in this post, refer to the accompanying GitHub repository.
Refer to the following resources for additional guidance to get started:
About the authors
 Jagdeep Singh Soni is a Senior Partner Solutions Architect at AWS based in the Netherlands. He uses his passion for generative AI to help customers and partners build generative AI applications using AWS services. Jagdeep has 15 years of experience in innovation, experience engineering, digital transformation, cloud architecture, and ML applications.
Jagdeep Singh Soni is a Senior Partner Solutions Architect at AWS based in the Netherlands. He uses his passion for generative AI to help customers and partners build generative AI applications using AWS services. Jagdeep has 15 years of experience in innovation, experience engineering, digital transformation, cloud architecture, and ML applications.
 Ajeet Tewari is a Senior Solutions Architect for Amazon Web Services. He works with enterprise customers to help them navigate their journey to AWS. His specialties include architecting and implementing scalable OLTP systems and leading strategic AWS initiatives.
Ajeet Tewari is a Senior Solutions Architect for Amazon Web Services. He works with enterprise customers to help them navigate their journey to AWS. His specialties include architecting and implementing scalable OLTP systems and leading strategic AWS initiatives.
 Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High-Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High-Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.

 Google Earth AI is our collection of geospatial models and datasets to help tackle the planet’s most critical needs.
Google Earth AI is our collection of geospatial models and datasets to help tackle the planet’s most critical needs.








 Parag Srivastava is a Senior Solutions Architect at AWS, where he has been helping customers successfully apply generative AI to real-life business scenarios. During his professional career, he has been extensively involved in complex digital transformation projects. He is also passionate about building innovative solutions around geospatial aspects of addresses.
Parag Srivastava is a Senior Solutions Architect at AWS, where he has been helping customers successfully apply generative AI to real-life business scenarios. During his professional career, he has been extensively involved in complex digital transformation projects. He is also passionate about building innovative solutions around geospatial aspects of addresses.
 Vineet Kachhawaha is a Senior Solutions Architect at AWS focusing on AI/ML and generative AI. He co-leads the AWS for Legal Tech team within AWS. He is passionate about working with enterprise customers and partners to design, deploy, and scale AI/ML applications to derive business value.
Vineet Kachhawaha is a Senior Solutions Architect at AWS focusing on AI/ML and generative AI. He co-leads the AWS for Legal Tech team within AWS. He is passionate about working with enterprise customers and partners to design, deploy, and scale AI/ML applications to derive business value.

 Shantanu Tripathi is a Software Development Engineer at AWS with over 4 years of experience in building and optimizing large-scale AI/ML solutions. His experience spans developing distributed AI training libraries, creating and launching DLCs and Deep Learning AMIs, designing scalable infrastructure for high-performance AI workloads, and working on generative AI solutions. He has contributed to AWS services like Amazon SageMaker HyperPod, AWS DLCs, and DLAMIs, along with driving innovations in AI security. Outside of work, he enjoys theater and swimming.
Shantanu Tripathi is a Software Development Engineer at AWS with over 4 years of experience in building and optimizing large-scale AI/ML solutions. His experience spans developing distributed AI training libraries, creating and launching DLCs and Deep Learning AMIs, designing scalable infrastructure for high-performance AI workloads, and working on generative AI solutions. He has contributed to AWS services like Amazon SageMaker HyperPod, AWS DLCs, and DLAMIs, along with driving innovations in AI security. Outside of work, he enjoys theater and swimming. Junpu Fan is a Senior Software Development Engineer at Amazon Web Services, specializing in AI/ML Infrastructure. With over 5 years of experience in the field, Junpu has developed extensive expertise across the full cycle of AI/ML workflows. His work focuses on building robust systems that power ML applications at scale, helping organizations transform their data into actionable insights.
Junpu Fan is a Senior Software Development Engineer at Amazon Web Services, specializing in AI/ML Infrastructure. With over 5 years of experience in the field, Junpu has developed extensive expertise across the full cycle of AI/ML workflows. His work focuses on building robust systems that power ML applications at scale, helping organizations transform their data into actionable insights. Harish Rao is a Senior Solutions Architect at AWS, specializing in large-scale distributed AI training and inference. He helps customers harness the power of AI to drive innovation and solve complex challenges. Outside of work, Harish embraces an active lifestyle, enjoying the tranquility of hiking, the intensity of racquetball, and the mental clarity of mindfulness practices.
Harish Rao is a Senior Solutions Architect at AWS, specializing in large-scale distributed AI training and inference. He helps customers harness the power of AI to drive innovation and solve complex challenges. Outside of work, Harish embraces an active lifestyle, enjoying the tranquility of hiking, the intensity of racquetball, and the mental clarity of mindfulness practices. Arindam Paul is a Sr. Product Manager in SageMaker AI team at AWS responsible for Deep Learning workloads on SageMaker, EC2, EKS, and ECS. He is passionate about using AI to solve customer problems. In his spare time, he enjoys working out and gardening.
Arindam Paul is a Sr. Product Manager in SageMaker AI team at AWS responsible for Deep Learning workloads on SageMaker, EC2, EKS, and ECS. He is passionate about using AI to solve customer problems. In his spare time, he enjoys working out and gardening.

 AI Mode in Search has several new features to help learners, educators and anyone who’s curious about the world.
AI Mode in Search has several new features to help learners, educators and anyone who’s curious about the world.
 Hear how Googlers developed and tested NotebookLM, your virtual research assistant — straight from the source.
Hear how Googlers developed and tested NotebookLM, your virtual research assistant — straight from the source.
 Google Cloud is working with HCA Healthcare on an AI app to help nurses save time on daily patient handoffs.
Google Cloud is working with HCA Healthcare on an AI app to help nurses save time on daily patient handoffs.