Pairwise preferences over model responses are widely collected to evaluate and provide feedback to large language models (LLMs). Given two alternative model responses to the same input, a human or AI annotator selects the “better” response. Such data can provide a feedback signal in domains where traditional hard-coded metrics are difficult to obtain (e.g. quality of a chat interactions), thereby helping measure model progress or model fine-tuning (e.g., via reinforcement learning from human feedback, RLHF). However, for some domains it can be tricky to obtain such pairwise comparisons in…Apple Machine Learning Research
mRAKL: Multilingual Retrieval-Augmented Knowledge Graph Construction for Low-Resourced Languages
Knowledge Graphs represent real-world entities and the relationships between them. Multilingual Knowledge Graph Construction (mKGC) refers to the task of automatically constructing or predicting missing entities and links for knowledge graphs in a multilingual setting. In this work, we reformulate the mKGC task as a Question Answering (QA) task and introduce mRAKL: a Retrieval-Augmented Generation (RAG) based system to perform mKGC. We achieve this by using the head entity and linking relation in a question, and having our model predict the tail entity as an answer. Our experiments focus…Apple Machine Learning Research
ASPERA: A Simulated Environment to Evaluate Planning for Complex Action Execution
This work evaluates the potential of large language models (LLMs) to power digital assistants capable of complex action execution. These assistants rely on pre-trained programming knowledge to execute multi-step goals by composing objects and functions defined in assistant libraries into action execution programs. To achieve this, we develop ASPERA, a framework comprising an assistant library simulation and a human-assisted LLM data generation engine. Our engine allows developers to guide LLM generation of high-quality tasks consisting of complex user queries, simulation state and…Apple Machine Learning Research
On the Way to LLM Personalization: Learning to Remember User Conversations
This paper was accepted at the Workshop on Large Language Model Memorization (L2M2) 2025.
Large Language Models (LLMs) have quickly become an invaluable assistant for a variety of tasks. However, their effectiveness is constrained by their ability to tailor responses to human preferences and behaviors via personalization. Prior work in LLM personalization has largely focused on style transfer or incorporating small factoids about the user, as knowledge injection remains an open challenge. In this paper, we explore injecting knowledge of prior conversations into LLMs to enable future work on…Apple Machine Learning Research
On Information Geometry and Iterative Optimization in Model Compression: Operator Factorization
The ever-increasing parameter counts of deep learning models necessitate effective compression techniques for deployment on resource-constrained devices. This paper explores the application of information geometry, the study of density-induced metrics on parameter spaces, to analyze existing methods within the space of model compression, primarily focusing on operator factorization. Adopting this perspective highlights the core challenge: defining an optimal low-compute submanifold (or subset) and projecting onto it. We argue that many successful model compression approaches can be understood…Apple Machine Learning Research
Steering into New Embedding Spaces: Analyzing Cross-Lingual Alignment Induced by Model Interventions in Multilingual Language Models
Aligned representations across languages is a desired property in multilingual large language models (mLLMs), as alignment can improve performance in cross-lingual tasks. Typically alignment requires fine-tuning a model, which is computationally expensive, and sizable language data, which often may not be available. A data-efficient alternative to fine-tuning is model interventions — a method for manipulating model activations to steer generation into the desired direction. We analyze the effect of a popular intervention (finding experts) on the alignment of cross-lingual representations in…Apple Machine Learning Research
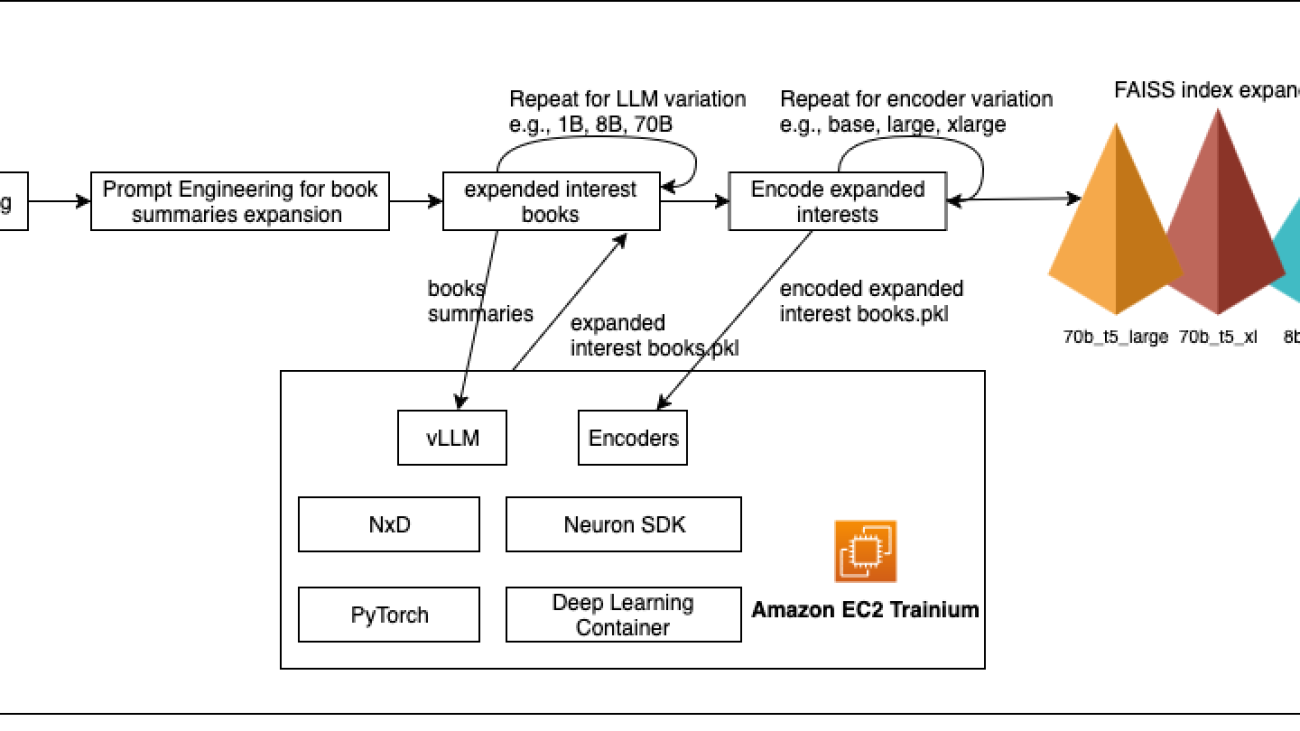
Boost cold-start recommendations with vLLM on AWS Trainium
Cold start in recommendation systems goes beyond just new user or new item problems—it’s the complete absence of personalized signals at launch. When someone first arrives, or when fresh content appears, there’s no behavioral history to tell the engine what they care about, so everyone ends up in broad generic segments. That not only dampens click-through and conversion rates, it can drive users away before a system ever gets a chance to learn their tastes. Standard remedies—collaborative filtering, matrix factorization, or popularity lists—lack the nuance to bridge that signal gap, and their one-size-fits-all suggestions quickly feel stale. Imagine, instead, if you could generate detailed interest profiles from day one. By tapping into large language models (LLMs) for zero-shot reasoning, you can synthesize rich, context-aware user and item embeddings without waiting for weeks of interaction data—turning a cold start into a warm welcome.
In this post, we demonstrate how to use vLLM for scalable inference and use AWS Deep Learning Containers (DLC) to streamline model packaging and deployment. We’ll generate interest expansions through structured prompts, encode them into embeddings, retrieve candidates with FAISS, apply validation to keep results grounded, and frame the cold-start challenge as a scientific experiment—benchmarking LLM and encoder pairings, iterating rapidly on recommendation metrics, and showing clear ROI for each configuration.
Solution overview
We build our cold-start solution on Amazon EC2 Trainium chips. To streamline model deployment, we use DLCs with the AWS Neuron SDK, which installs Neuron-optimized PyTorch modules and includes the latest AWS Trainium drivers and runtime pre-installed.
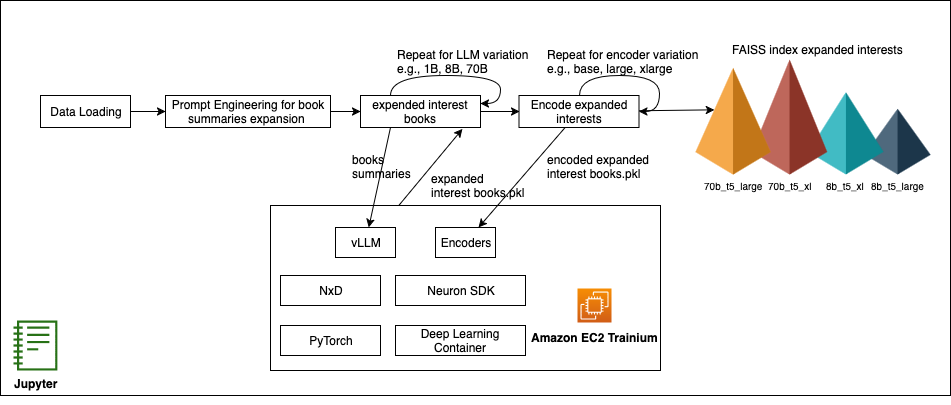
Figure : Cold-start recommendation pipeline on AWS Trainium with vLLM & NxD
Sharding large models across multiple Trainium chips is handled by the distributed library used by Neuron, NeuronX Distributed (NxD), which integrates seamlessly with vLLM. NxD manages model partitions across multiple instances with minimal code changes, enabling parallel inference of even 70B parameter LLMs. This combination—Trainium chips, Neuron Tools, and vLLM—gives machine learning (ML) engineers a flexible, cost-efficient, production-ready solution for experimenting with different LLM and encoder configurations and delivers rapid iteration on recommendation quality metrics without modifying core model code.
In the next section, we orchestrate our experiments in a Jupyter notebook—providing a reproducible, end-to-end workflow from loading data and engineering structured prompts to generating embeddings and retrieving candidates with FAISS—complete with interactive charts to visualize recommendation performance. Then, in the production deep-dive, we walk through a reference implementation that packages your Neuron-optimized LLM and encoder as DLC images and deploys them on Amazon Elastic Kubernetes Service (Amazon EKS) with autoscaling, so your inference layer automatically adapts to demand while optimizing cost and performance.
Expanding user interest profiles with LLMs
In this post, we use the Amazon Book Reviews dataset (mohamedbakhet/amazon-books-reviews) from Kaggle, which provides real-world user reviews and metadata for tens of thousands of books. This rich collection lets us simulate cold-start scenarios—where a brand-new user has only a single review or like—and evaluate how well our interest expansions, powered by distilled versions of Meta’s Llama 8B and 70B models, generate rich user profiles. We use an LLM to enrich a new user’s profile from minimal initial data. For example, if a user has only reviewed one science fiction novel, the LLM infers related subtopics—such as galactic empires, cyberpunk dystopias, or space exploration—that the user is likely to enjoy. We use structured prompts that embed the user’s existing activity into a concise instruction to verify consistency and relevance, as demonstrated in the following example:
By constraining the LLM’s output format—asking it to return a JSON array of topic keywords—we avoid free‑form tangents and obtain a predictable list of interest expansions. Modern generative models, such as Meta’s Llama, possess broad domain knowledge and human‑like reasoning, enabling them to connect related concepts and serve as powerful cold‑start boosters by inferring deep user preferences from a single review. These synthetic interests become new signals for our recommendation pipeline, allowing us to retrieve and rank books from the Amazon Reviews collection even with minimal user history. You can experiment with Llama variants ranging from one‑billion to seventy‑billion parameters to identify which model yields the most discriminative and relevant expansions. Those findings will guide our choice of model for production and determine the size and scale of the Amazon EC2 Trainium and Inferentia instances we provision, setting us up for live user A/B tests to validate performance in real‑world settings.
Encoding user interests and retrieving relevant content
After we have our expanded interests, the next step is to turn both those interests and our catalog of books into vectors that we can compare. We explore three sizes of the Google T5 encoder—base, large and XL—to see how embedding dimensionality affects matching quality. The following are the steps:
- Load the encoder for each size
- Encode book summaries into a single NumPy matrix and normalize it
- Build a FAISS index on those normalized vectors for fast nearest‑neighbor search
- Encode the expanded interest text the same way and query FAISS to retrieve the top k most similar books
You can compare how each encoder scale affects both the average FAISS distance (that is, how far apart your interest is from the content) and the actual recommended titles. Swapping in a different encoder family—such as SentenceTransformers—is as straightforward as replacing the model and tokenizer imports.
Measuring and improving recommendation quality
Now that we’ve generated FAISS indexes for every LLM‑encoder pairing and computed the mean distance between each expanded interest query and its top 10 neighbors, we know exactly how tightly or loosely each model’s embeddings cluster. The following chart shows those average distances for each combination—revealing that 1B and 3B models collapse to almost zero, while 8B and 70B models (especially with larger encoders) produce progressively higher distances, signifying richer, more discriminative signals for recommendation.
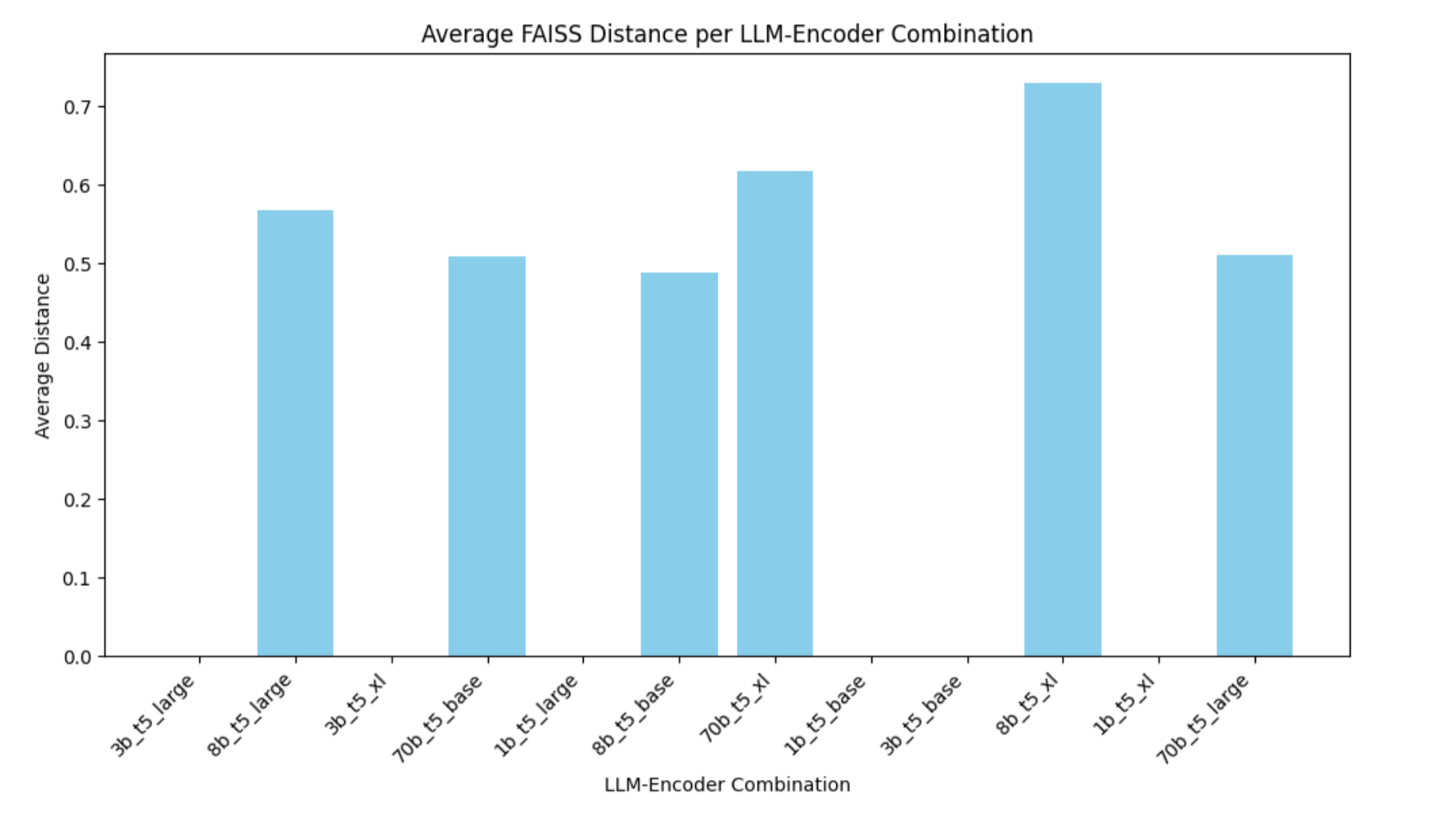
Figure : Average FAISS distance by model and encoder
The chart shows that the 1B and 3B models yield an average FAISS distance of zero, meaning their expanded‑interest embeddings are essentially identical and offer no differentiation. By contrast, the 8B model produces a distance of about 0.5 with t5‑base, rising further with t5‑large and t5‑xl, which demonstrates that larger encoders capture more of the model’s nuance. The 70B model only adds a small boost—and only with the XL encoder—so its extra cost yields limited benefit.
In practical terms, a Llama 8B LLM paired with a base or large T5 encoder delivers clear separation in embedding space without the higher inference time and resource usage of a 70B model.
Comparing model and encoder impact on embedding spread
To see how LLM size and encoder scale shape our embedding space, you can measure—for each LLM and encoder pair—the mean FAISS distance from a representative expanded interest vector to its top 10 neighbors. The following bar chart plots those averages side by side. You can instantly spot that 1B and 3B collapse to zero, 8B jumps to around 0.5 and rises with larger encoders, and 70B only adds a small extra spread at the XL scale. This helps you choose the smallest combination that still gives you the embedding diversity needed for effective cold‑start recommendations.
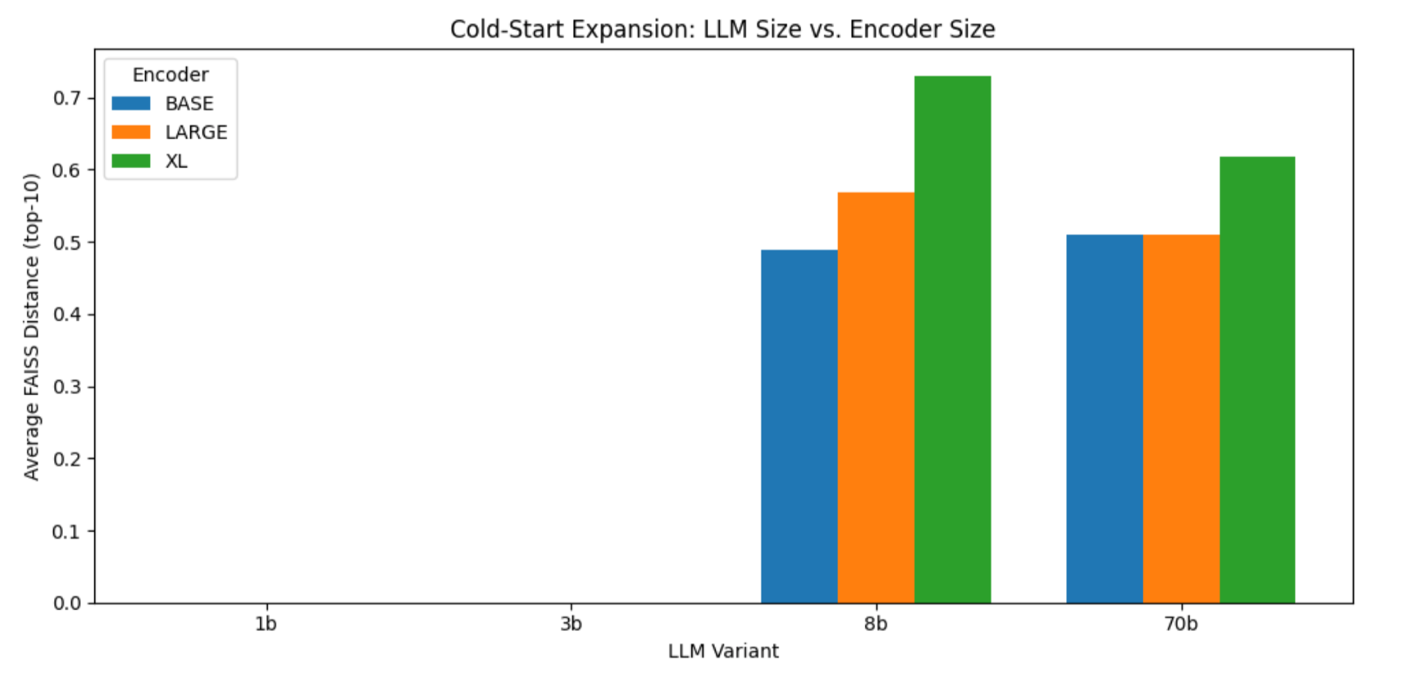
Figure : FAISS distance by LLM and encoder size
Evaluating recommendation overlap across Llama variations and encoders to balance consistency and novelty
In the next analysis, you build a basic recommend_books helper that, for various LLM sizes and encoder choices, loads the corresponding expanded‑interest DataFrame, reads its FAISS index, reconstructs the first embedding as a stand‑in query, and returns the top-k book titles. Using this helper, we first measure how much each pair of encoders agrees on recommendations for a single LLM—comparing base compared to large, base compared to XL, and large compared XL—and then, separately, how each pair of LLM sizes aligns for a fixed encoder. Finally, we focus on the 8B model (shown in the following figure) and plot a heatmap of its encoder overlaps, which shows that base and large share about 40% of their top 5 picks while XL diverges more—illustrating how changing the encoder shifts the balance between consistency and novelty in the recommendations.
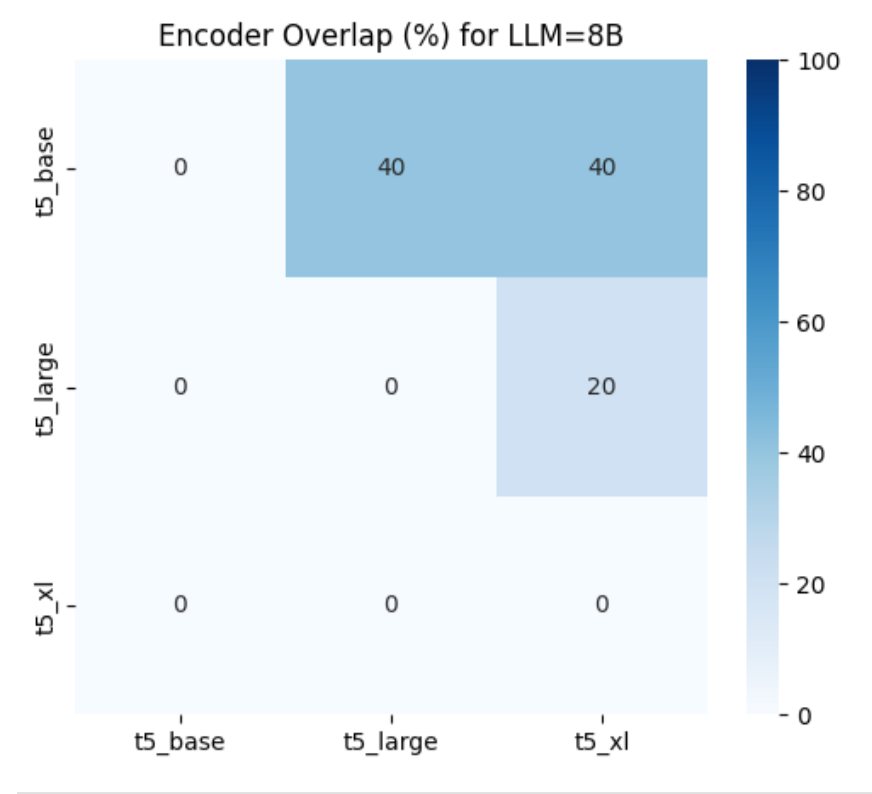
Figure : 8B model: encoder overlap heatmap
For the 8B model, the heatmap shows that t5_base and t5_large share 40% of their top 5 recommendations, t5_base and t5_xl also overlap 40%, while t5_large vs t5_xl overlap only 20%, indicating that the XL encoder introduces the greatest amount of novel titles compared to the other pairs.
Tweaking tensor_parallel_size for optimal cost performance
To balance inference speed against resource cost, we measured how increasing Neuron tensor parallelism affects latency when expanding user interests with the Llama 3.1 8B model on a trn1.32xlarge instance. We ran the same zero‑shot expansion workload at tensor_parallel_size values of 2, 8, 16, and 32. As shown in the first chart, P50 Latency falls by 74 %—from 2,480 ms at TP = 2 to 650 ms at TP = 16—then inches lower to 532 ms at TP = 32 (an additional 18 % drop). The following cost-to-performance chart shows that beyond TP = 16, doubling parallelism roughly doubles cost for only a 17 % further latency gain.
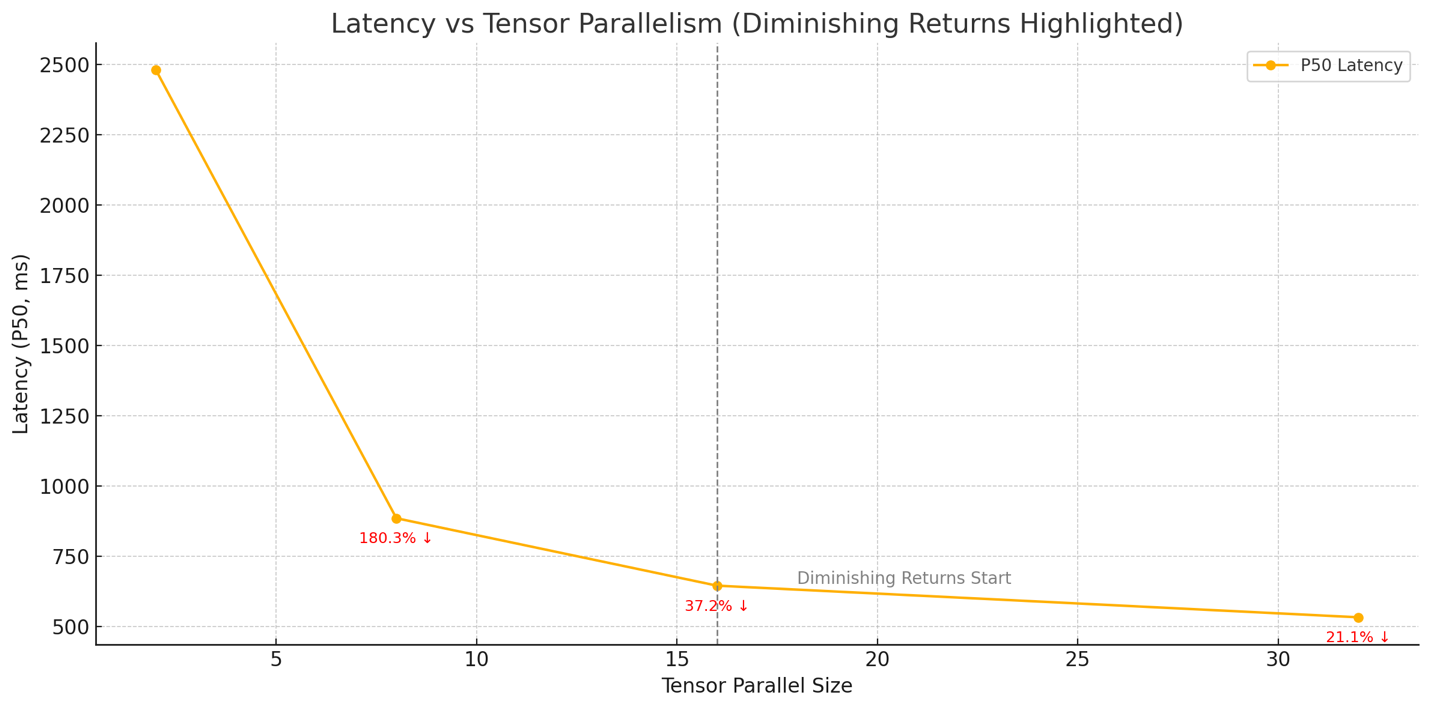
Figure : Latency compared to tensor parallel size
In practice, setting tensor_parallel_size to 16 delivers the best trade‑off: you capture most of the speed‑up from model sharding while avoiding the sharply diminishing returns and higher core‑hour costs that come with maximal parallelism, as shown in the following figure.
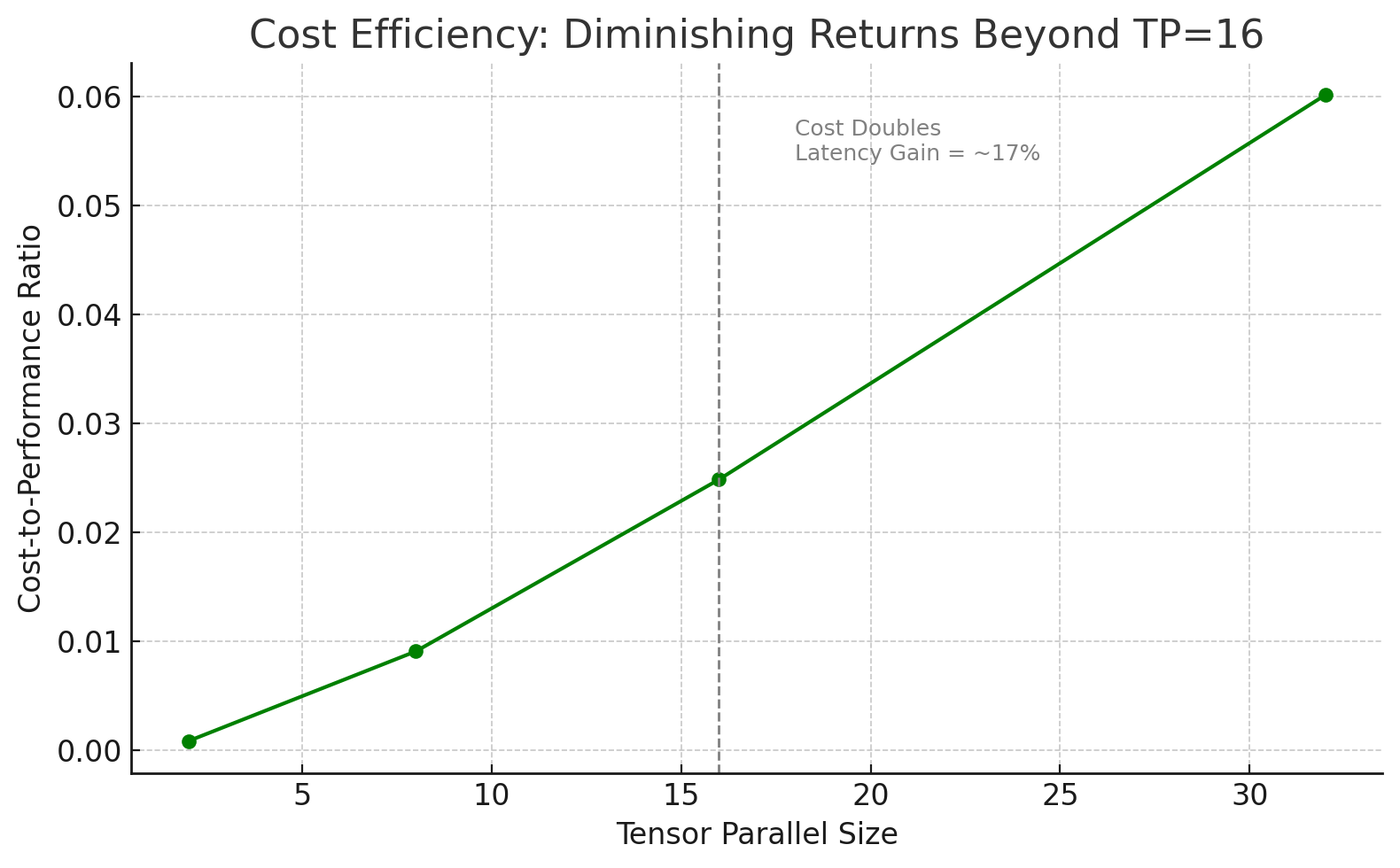
Figure : Cost-performance compared to tensor parallel size
The preceding figure visualizes the cost-to-performance ratio of the Llama 8B tests, emphasizing that TP=16 offers the most balanced efficiency before the benefits plateau.
What’s next?
Now that we have determined the models and encoders to use, as well as the optimal configuration to use with our dataset, such as sequence size and batch size, the next step is to deploy the models and define a production workflow that generates expanded interest that is encoded and ready for match with more content.
Conclusion
This post showed how AWS Trainium, the Neuron SDK, and scalable LLM inference can tackle cold-start challenges by enriching sparse user profiles for better recommendations from day one.
Importantly, our experiments highlight that larger models and encoders don’t always mean better outcomes. While they can produce richer signals, the gains often don’t justify the added cost. You might find that an 8B LLM with a T5-large encoder strikes the best balance between performance and efficiency.
Rather than assuming bigger is better, this approach helps teams identify the optimal model-encoder pair—delivering high-quality recommendations with cost-effective infrastructure.
About the authors
 Yahav Biran is a Principal Architect at AWS, focusing on large-scale AI workloads. He contributes to open-source projects and publishes in AWS blogs and academic journals, including the AWS compute and AI blogs and the Journal of Systems Engineering. He frequently delivers technical presentations and collaborates with customers to design Cloud applications. Yahav holds a Ph.D. in Systems Engineering from Colorado State University.
Yahav Biran is a Principal Architect at AWS, focusing on large-scale AI workloads. He contributes to open-source projects and publishes in AWS blogs and academic journals, including the AWS compute and AI blogs and the Journal of Systems Engineering. He frequently delivers technical presentations and collaborates with customers to design Cloud applications. Yahav holds a Ph.D. in Systems Engineering from Colorado State University.
 Nir Ozeri Nir is a Sr. Solutions Architect Manager with Amazon Web Services, based out of New York City. Nir leads a team of Solution Architects focused on ISV customers. Nir specializes in application modernization, application and product delivery, and scalable application architecture.
Nir Ozeri Nir is a Sr. Solutions Architect Manager with Amazon Web Services, based out of New York City. Nir leads a team of Solution Architects focused on ISV customers. Nir specializes in application modernization, application and product delivery, and scalable application architecture.
Navigating medical education in the era of generative AI

In November 2022, OpenAI’s ChatGPT kick-started a new era in AI. This was followed less than a half year later by the release of GPT-4. In the months leading up to GPT-4’s public release, Peter Lee, president of Microsoft Research, cowrote a book full of optimism for the potential of advanced AI models to transform the world of healthcare. What has happened since? In this special podcast series, The AI Revolution in Medicine, Revisited, Lee revisits the book, exploring how patients, providers, and other medical professionals are experiencing and using generative AI today while examining what he and his coauthors got right—and what they didn’t foresee.
In this episode, Dr. Morgan Cheatham (opens in new tab) and Daniel Chen (opens in new tab), two rising physicians and experts in both medicine and technology, join Lee to explore how generative AI is reshaping medical education. Cheatham, a partner and head of healthcare and life sciences at Breyer Capital and a resident physician at Boston Children’s Hospital, discusses how AI is changing how clinicians acquire and apply medical knowledge at the point of care, emphasizing the need for training and curriculum changes to help ensure AI is used responsibly and that clinicians are equipped to maximize its potential. Chen, a medical student at the Kaiser Permanente Bernard J. Tyson School of Medicine, shares how he and his peers use AI tools as study aids, clinical tutors, and second opinions and reflects on the risks of overreliance and the importance of preserving critical thinking.
Learn more:
Perspectives on the Current and Future State of Artificial Intelligence in Medical Genetics (opens in new tab) (Cheatham)
Publication | May 2025
Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models (opens in new tab) (Cheatham)
Publication | February 2023
The AI Revolution in Medicine: GPT-4 and Beyond
Book | Peter Lee, Carey Goldberg, Isaac Kohane | April 2023
Subscribe to the Microsoft Research Podcast:
Transcript
[MUSIC] [BOOK PASSAGE]PETER LEE: “Medicine often uses the training approach when trying to assess multipurpose talent. To ensure students can safely and effectively take care of patients, we have them jump through quite a few hoops, … [and] they need good evaluations once they reach the clinic, passing grades on more exams like the USMLE [United States Medical Licensing Examination]. … [But] GPT-4 gets more than 90 percent of questions on licensing exams correct. … Does that provide any level of comfort in using GPT-4 in medicine?”
[END OF BOOK PASSAGE] [THEME MUSIC]This is The AI Revolution in Medicine, Revisited. I’m your host, Peter Lee.
Shortly after OpenAI’s GPT-4 was publicly released, Carey Goldberg, Dr. Zak Kohane, and I published The AI Revolution in Medicine to help educate the world of healthcare and medical research about the transformative impact this new generative AI technology could have. But because we wrote the book when GPT-4 was still a secret, we had to speculate. Now, two years later, what did we get right, and what did we get wrong?
In this series, we’ll talk to clinicians, patients, hospital administrators, and others to understand the reality of AI in the field and where we go from here.
[THEME MUSIC FADES]
The book passage I read at the top is from Chapter 4, “Trust but Verify.” In it, we explore how AI systems like GPT-4 should be evaluated for performance, safety, and reliability and compare this to how humans are both trained and assessed for readiness to deliver healthcare.
In previous conversations with guests, we’ve spoken a lot about AI in the clinic as well as in labs and companies developing AI-driven tools. We’ve also talked about AI in the hands of patients and consumers. But there has been some discussion also about AI’s role in medical training. And, as a founding board member of a new medical school at Kaiser Permanente, I definitely have my own thoughts about this. But today, I’m excited to welcome two guests who represent the next generation of medical professionals for their insights, Morgan Cheatham and Daniel Chen.
Morgan Cheatham is a graduate of Brown University’s Warren Alpert Medical School with clinical training in genetics at Harvard and is a clinical fellow at Boston Children’s Hospital. While Morgan is a bona fide doctor in training, he’s also amazingly an influential health technology strategist. He was recently named partner and head of healthcare and life sciences at Breyer Capital and has led investments in several healthcare AI companies that have eclipsed multibillion-dollar valuations.
Daniel Chen is finishing his second year as a medical student at the Kaiser Permanente Bernard J. Tyson School of Medicine. He holds a neuroscience degree from the University of Washington and was a research assistant in the Raskind Lab at the UW School of Medicine, working with imaging and genetic data analyses for biomedical research. Prior to med school, Daniel pursued experiences that cultivated his interest in the application of AI in medical practice and education.
Daniel and Morgan exemplify the real-world future of healthcare, a student entering his third year of medical school and a fresh medical-school graduate who is starting a residency while at the same time continuing his work on investing in healthcare startups.
[TRANSITION MUSIC]Here is my interview with Morgan Cheatham:
LEE: Morgan, thanks for joining. Really, really looking forward to this chat.
MORGAN CHEATHAM: Peter, it’s a privilege to be here with you. Thank you.
LEE: So are there any other human beings who are partners at big-league venture firms, residents at, you know, a Harvard-affiliated medical center, author, editor for a leading medical journal? I mean, who are your … who’s your cohort? Who are your peers?
CHEATHAM: I love this question. There are so many people who I consider peers that I look up to who have paved this path. And I think what is distinct about each of them is they have this physician-plus orientation. They are multilingual in terms of knowing the language of medicine but having learned other disciplines. And we share a common friend, Dr. Zak Kohane, who was among the first to really show how you can meld two worlds as a physician and make significant contributions to the intersections thereof.
I also deeply, in the world of business, respect physicians like Dr. Krishna Yeshwant at Google Ventures, who simultaneously pursued residency training and built what is now, you know, a large and enduring venture firm.
So there are plenty of people out there who’ve carved their own path and become these multilingual beings, and I aspire to be one.
LEE: So, you know, one thing I’ve been trying to explore with people are their origins with respect to the technology of AI. And there’s two eras for that. There’s AI before ChatGPT and before, you know, generative AI really became a big thing, and then afterwards.
So let’s start first before ChatGPT. You know, what was your contact? What was, you know, your knowledge of AI and machine learning?
CHEATHAM: Sure, so my experiences in computer science date back to high school. I went to Thomas Jefferson, which is a high school in Alexandria, Virginia, that prides itself on requiring students to take computer science in their first year of high school as kind of a required torturous experience. [LAUGHTER] And I remember that fondly. Our final project was Brick Breaker. It was actually, I joke, all hard coded. So there was nothing intelligent about the Brick Breaker that we built. But that was my first exposure.
I was a classics nerd, and I was really interested in biology and chemistry as a pre-medical student. So I really wouldn’t intersect with this field again until I was shadowing at Inova Hospital, which was a local hospital near me. And it was interesting because, at the time—I was shadowing in the anesthesia department—they were actually implementing their first instance of Epic.
LEE: Mmm. Wow.
CHEATHAM: And I remember that experience fondly because the entire hospital was going from analog—they were going from paper-based charts—to this new digital system. And I didn’t quite know in that moment what it would mean for the field or for my career, but I knew it was a big deal because a lot of people had a lot of emotion around what was going on, and it was in that experience that I kind of decided to attach myself to the intersection of computation and medicine. So when I got to undergrad, I was a pre-medical student. I was very passionate about studying the sacred physician-patient relationship and everything that had to go on in that exam room to provide excellent care.
But there were a few formative experiences: one, working at a physician-founded startup that was using at the time we called it big data, if you remember, …
LEE: Yup.
CHEATHAM: … to match the right patient to the right provider at the right time. And it was in that moment that I realized that as a physician, I could utilize technology to scale that sacred one-to-one patient-provider interaction in nonlinear ways. So that was, kind of, the first experience where I saw deployed systems that were using patient data and clinical information in an intelligent format.
LEE: Yeah. And so you’re a pre-medical student, but you have this computer science understanding. You have an intuition, I guess is the right way to say it, that the clinical data becoming digital is going to be important. So then what happens from there to your path to medical school?
CHEATHAM: Yeah, so I had a few formative research experiences in my undergraduate years. You know, nothing that ever amounted to a significant publication, but I was toying around with SVMs [support vector machines] for sepsis and working with the MIMIC [Medical Information Mart for Intensive Care] database early days and really just trying to understand what it meant that medical data was becoming digitized.
And at the same time, again, I was rather unsatisfied doing that purely in an academic context. And I so early craved seeing how this would roll out in the wild, roll out in a clinical setting that I would soon occupy. And that was really what drove me to work at this company called Kyruus [Health] and understand how these systems, you know, scaled. Obviously, that’s something with AI that we’re now grappling with in a real way because it looks much different.
LEE: Right. Yep.
CHEATHAM: So the other experience I had, which is less relevant to AI, but I did do a summer in banking. And I mention this because what I learned in the experience was … it was a master class in business. And I learned that there was another scaling factor that I should appreciate as we think about medicine, and that was capital and business formation. And that was also something that could scale nonlinearly.
So when you married that with technology, it was, kind of, a natural segue for me before going to med school to think about venture capital and partnering with founders who were going to be building these technologies for the long term. And so that’s how I landed on the venture side.
LEE: And then how long of a break before you started your medical studies?
CHEATHAM: It was about four years. Originally, it was going to be a two-year deferral, and the pandemic happened. Our space became quite active in terms of new companies and investment. So it was about four years before I went back.
LEE: I see. And so you’re in medical school. ChatGPT happened while you were in medical school, is that right?
CHEATHAM: That’s right. That’s right. Right before I was studying for Step 1. So the funny story, Peter, that I like to share with folks is …
LEE: Yeah.
CHEATHAM: … I was just embarking on designing my Step 1 study plan with my mentor. And I went to NeurIPS [Conference] for the first time. And that was in 2022, when, of course, ChatGPT was released.
And for the remainder of that fall period, you know, I should have been studying for these shelf exams and, you know, getting ready …
LEE: Yeah.
CHEATHAM: … for this large board exam. And I was fortunate to partner, actually, with one of our portfolio company CEOs who is a physician—he is an MD/PhD—to work on the first paper that showed that ChatGPT could pass the US Medical Licensing Exam (opens in new tab).
LEE: Yes.
CHEATHAM: And that was a riveting experience for a number of reasons. I joke with folks that it was both the best paper I was ever, you know, a part of and proud to be a coauthor of, but also the worst for a lot of reasons that we could talk about.
It was the best in terms of canonical metrics like citations, but the worst in terms of, wow, did we spend six months as a field thinking this was the right benchmark … [LAUGHTER]
LEE: Right.
CHEATHAM: … for how to assess the performance of these models. And I’m so encouraged …
LEE: You shouldn’t feel bad that way because, you know, at that time, I was secretly, you know, assessing what we now know of as GPT-4 in that period. And what was the first thing I tried to do? Step 1 medical exam.
By the way, just for our listeners who don’t understand about medical education—in the US, there’s a three-part exam that extends over a couple of years of medical school. Step 1, Step 2, Step 3. And Step 1 and Step 2 in particular are multiple-choice exams.
And they are very high stakes when you’re in medical school. And you really have to have a command of quite a lot of clinical knowledge to pass these. And it’s funny to hear you say what you were just sharing there because it was also the first impulse I had with GPT-4. And in retrospect, I feel silly about that.
CHEATHAM: I think many of us do, but I’ve been encouraged over the last two years, to your point, that we really have moved our discourse beyond these exams to thinking about more robust systems for the evaluation of performance, which becomes even more interesting as you and I have spoken about these multi-agent frameworks that we are now, you know, compelled to explore further.
LEE: Yeah. Well, and even though I know you’re a little sheepish about it now, I think in the show notes, we’ll link to that paper because it really was one of the seminal moments when we think about AI, AI in medicine.
And so you’re seeing this new technology, and it’s happening at a moment when you yourself have to confront taking the Step 1 exam. So how did that feel?
CHEATHAM: It was humbling. It was shocking. What I had worked two years for, grueling over textbooks and, you know, flashcards and all of the things we do as medical students, to see a system emerge out of thin air that was arguably going to perform far better than I ever would, no matter how much …
LEE: Yeah.
CHEATHAM: … I was going to study for that exam, it set me back. It forced me to interrogate what my role in medicine would be. And it dramatically changed the specialties that I considered for myself long term.
And I hope we talk about, you know, how I stumbled upon genetics and why I’m so excited about that field and its evolution in this computational landscape. I had to do a lot of soul searching to relinquish what I thought it meant to be a physician and how I would adapt in this new environment.
LEE: You know, one of the things that we wrote in our book, I think it was in a chapter that I contributed, I was imagining that students studying for Step 1 would be able to do it more actively.
Or you could even do sort of a pseudo-Step 3 exam by having a conversation. You provide the presentation of a patient and then have an encounter, you know, where the ChatGPT is the patient, and then you pretend to be the doctor. And then in the example that we published, then you say, “End of encounter.” And then you ask ChatGPT for an assessment of things.
So, you know, maybe it all came too late for Step 1 for you because you were already very focused and, you know, had your own kind of study framework. But did you have an influence or use of this kind of technology for Step 2 and Step 3?
CHEATHAM: So even for Step 1, I would say, it [ChatGPT], you know, dropped in November. I took it [Step 1 exam] in the spring, so I was able to use it to study. But the lesson I learned in that moment, Peter, was really about the importance of trust with AI and clinicians or clinicians in training, because we all have the same resources that we use for these board exams, right. UWorld is this question bank. It’s been around forever. If you’re not using UWorld, like, good luck. And so why would you deviate off of a well-trodden path to study for this really important exam?
And so I kind of adjunctively used GPT alongside UWorld to come up with more personalized explanations for concepts that I wasn’t understanding, and I found that it was pretty good and it was certainly helpful for me.
Fortunately, I was, you know, able to pass, but I was very intentional about dogfooding AI when I was a medical student, and part of that was because I had been a venture capitalist, and I’d made investments in companies whose products I could actually use.
And so, you know, Abridge is a company in the scribing space that you and I have talked about.
LEE: Yeah.
CHEATHAM: I was so fortunate in the early days of their product to not just be a user but to get to bring their product across the hospital. I could bring the product to the emergency department one week, to neurology another week, to the PICU [pediatric intensive care unit], you know, the next week, and assess the relative performance of, you know, how it handled really complex genetics cases …
LEE: Yeah.
CHEATHAM: … versus these very challenging social situations that you often find yourself navigating in primary care. So not only was I emotional about this technology, but I was a voracious adopter in the moment.
LEE: Yeah, right. And you had a financial interest then on top of that, right?
CHEATHAM: I was not paid by Abridge to use the product, but, you know, I joke that the team was probably sick of me. [LAUGHTER]
LEE: No, no, but you were working for a venture firm that was invested in these, right? So all of these things are wrapped up together. You know, you’re having to get licensed as a doctor while doing all of this.
So I want to get into that investment and new venture stuff there, but let’s stick just for a few more minutes on medical education. So I mentioned, you know, what we wrote in the book, and I remember writing the example, you know, of an encounter. Is that at all realistic? Is anything like that … that was pure speculation on our part. What’s really happening?
And then after we talk about what’s really happening, what do you think should happen in medical education given the reality of generative AI?
CHEATHAM: I’ve been pleasantly surprised talking with my colleagues about AI in clinical settings, how curious people are and how curious they’ve been over the last two years. I think, oftentimes, we say, oh, you know, this technology really is stratified by age and the younger clinicians are using it more and the older physicians are ignoring it. And, you know, maybe that’s true in some regards, but I’ve seen, you know, many, you know, senior attendings pulling up Perplexity, GPT, more recently OpenEvidence (opens in new tab), which has been a really essential tool for me personally at the point of care, to come up with the best decisions for our patients.
The general skepticism arises when people reflect on their own experience in training and they think, “Well, I had to learn how to do it this way.”
LEE: Yeah.
CHEATHAM: “And therefore, you using an AI scribe to document this encounter doesn’t feel right to me because I didn’t get to do that.” And I did face some of those critiques or criticisms, where you need to learn how to do it the old-school way first and then you can use an AI scribe.
And I haven’t yet seen—maybe even taking a step back—I haven’t seen a lot of integration of AI into the core medical curriculum, period.
LEE: Yeah.
CHEATHAM: And, as you know, if you want to add something to medical school curriculum, you can get in a long line of people who also want to do that.
LEE: Yes. Yeah.
CHEATHAM: But it is urgent that our medical schools do create formalized required trainings for this technology because people are already using it.
LEE: Yes.
CHEATHAM: I think what we will need to determine is how much of the old way do people need to learn in order to earn the right to use AI at the point of care and how much of that old understanding, that prior experience, is essential to be able to assess the performance of these tools and whether or not they are having the intended outcome.
I kind of joke it’s like learning cursive, right?
LEE: Yes.
CHEATHAM: I’m old enough to have had to learn cursive. I don’t think people really have to learn it these days. When do I use it? Well, when I’m signing something. I don’t even really sign checks anymore, but …
LEE: Well … the example I’ve used, which you’ve heard, is, I’m sure you were still taught the technique of manual palpation, even though …
CHEATHAM: Of course.
LEE: … you have access to technologies like ultrasound. And in fact, you would use ultrasound in many cases.
And so I need to pin you down. What is your opinion on these things? Do you need to be trained in the old ways?
CHEATHAM: When it comes to understanding the architecture of the medical note, I believe it is important for clinicians in training to know how that information is generated, how it’s characterized, and how to go from a very broad-reaching conversation to a distilled clinical document that serves many functions.
Does that mean that you should be forced to practice without an AI scribe for the entirety of your medical education? No. And I think that as you are learning the architecture of that document, you should be handed an AI scribe and you should be empowered to have visits with patients both in an analog setting—where you are transcribing and generating that note—and soon thereafter, I’m talking in a matter of weeks, working with an AI scribe. That’s my personal belief.
LEE: Yeah, yeah. So you’re going to … well, first off, congratulations on landing a residency at Boston Children’s [Hospital].
CHEATHAM: Thank you, Peter.
LEE: I understand there were only two people selected for this and super competitive. You know, with that perspective, you know, how do you see your future in medicine, just given everything that’s happening with AI right now?
And are there things that you would urge, let’s say, the dean of the Brown Medical School to consider or to change? Or maybe not the dean of Brown but the head of the LCME [Liaison Committee on Medical Education], the accrediting body for US medical schools. What in your mind needs to change?
CHEATHAM: Sure. I’ll answer your first question first and then talk about the future.
LEE: Yeah.
CHEATHAM: For me personally, I fell into the field of genomics. And so my training program will cover both pediatrics as well as clinical genetics and genomics.
And I alluded to this earlier, but one of the reasons I’m so excited to join the field is because I really feel like the field of genetics not only is focused on a very underserved patient population, but not in how we typically think of underserved. I’m talking about underserved as in patients who don’t always have answers. Patients for whom the current guidelines don’t offer information or comfort or support.
Those are patients that are extremely underserved. And I think in this moment of AI, there’s a unique opportunity to utilize the computational systems that we now have access to, to provide these answers more precisely, more quickly.
And so I’m excited to marry those two fields. And genetics has long been a field that has adopted technology. We just think about the foundational technology of genomic sequencing and variant interpretation. And so it’s a kind of natural evolution of the field, I believe, to integrate AI and specifically generative AI.
If I were speaking directly to the LCME, I mean, I would just have to encourage the organization, as well as medical societies who partner with attending physicians across specialties, to lean in here.
When I think about prior revolutions in technology and medicine, physicians were not always at the helm. We have a unique opportunity now, and you talk about companies like Abridge in the AI space, companies like Viz.ai, Cleerly—I mean, I could go on: Iterative Health … I could list 20 organizations that are bringing AI to the point of care that are founded by physicians.
This is our moment to have a seat at the table and to shape not only the discourse but the deployment. And the unique lens, of course, that a physician brings is that of prioritizing the patient, and with AI and this time around, we have to do that.
LEE: So LCME for our listeners is, I think it stands for the Liaison Committee on Medical Education (opens in new tab). It’s basically the accrediting body for US medical schools, and it’s very high stakes. It’s very, very rigorous, which I think is a good thing, but it’s also a bit of a straitjacket.
So if you are on the LCME, are there specific new curricular elements that you would demand that LCME, you know, add to its accreditation standards?
CHEATHAM: We need to unbundle the different components of the medical appointment and think about the different functions of a human clinician to answer that question.
There are a couple of areas that are top of mind for me, the first being medical search. There are large organizations and healthcare incumbents that have been around for many decades, companies like UpToDate or even, you know, the guidelines that are housed by our medical societies, that need to respond to the information demands of clinicians at the point of care in a new way with AI.
And so I would love to see our medical institutions teaching more students how to use AI for medical search problems at the point of care. How to not only, you know, from a prompt perspective, ask questions about patients in a high-efficacy way, but also to interpret the outputs of these systems to inform downstream clinical decision-making.
People are already adopting, as you know, GPT, OpenEvidence, Perplexity, all of these tools to make these decisions now.
And so by not—again, it’s a moral imperative of the LCME—by not having curriculum and support for clinicians doing that, we run the risk of folks not utilizing these tools properly but also to their greatest potential.
LEE: Yeah, then, but zooming forward then, what about board certification?
CHEATHAM: Board certification today is already transitioning to an open-book format for many specialties, is my understanding. And in talking to some of my fellow geneticists, who, you know, that’s a pretty challenging board exam in clinical genetics or biochemical genetics. They are using OpenEvidence during those open-book exams.
So what I would like to see us do is move from a system of rote memorization and regurgitation of fact to an assessment framework that is adaptive, is responsive, and assesses for your ability to use the tools that we now have at our disposal to make sound clinical decisions.
LEE: Yeah. We’ve heard from Sara Murray, you know, that when she’s doing her rounds, she consults routinely with ChatGPT. And that was something we also predicted, especially Carey Goldberg in our book, you know, wrote this fictional account.
Is that the primary real-world use of AI? Not only by clinicians, but also by medical students … are medical students, you know, engaged with ChatGPT or, you know, similar?
CHEATHAM: Absolutely. I’ve listed some of the tools. I think there, in general, Peter, there is this new clinician stack that is emerging of these tools that people are trying, and I think the cycles of iteration are quick, right. Some folks are using Claude [Claude.ai] one week, and they’re trying Perplexity, or they’re trying OpenEvidence, they’re trying GPT for a different task.
There’s this kind of moment in medicine that every clinician experiences where you’re on rounds, and there’s that very senior attending. And you’ve just presented a patient to them, and you think you did an elegant job, and you’ve summarized all the information, and you really feel good about your differential, and they ask you, like, the one question you didn’t think to address. [LAUGHTER]
And I’ll tell you, some of the funniest moments I’ve had using AI in the hospital has been, and let me take a step back, that process of an attending physician interrogating a medical student is called “pimping,” for lack of a better phrase.
And some of the funniest use cases I’ve had for AI in that setting is actually using OpenEvidence or GPT as defense against pimping. [LAUGHTER] So quickly while they’re asking me the question, I put it in, and I’m actually able to answer it right away. So it’s been effective for that. But I would say, you know, [in] the halls of most of the hospitals where I’ve trained, I’m seeing this technology in the wild.
LEE: So now you’re so tech-forward, but that off-label use of AI, we also, when we wrote our book, we weren’t sure that at least top health systems would tolerate this. Do you have an opinion about this? Should these things be better regulated or controlled by the CIOs of Boston Children’s?
CHEATHAM: I’m a big believer that transparency encourages good behaviors.
And so the first time I actually tried to use ChatGPT in a clinical setting, it was at a hospital in Rhode Island. I will not name which hospital. But the site was actually blocked. I wasn’t able to access it from a desktop. That was the hospital’s first response to this technology was, let’s make sure none of our clinicians can access it. It has so much potential for medicine. The irony of that today.
And it’s since, you know, become unblocked. But I was able to use it on my phone. So, to your point, if there’s a will, there’s a way. And we will utilize this technology if we are seeing perceived value.
LEE: So, yeah, no, absolutely. So now, you know, in some discussions, one superpower that seems to be common across people who are really leading the charge here is they seem to be very good readers and students.
And I understand you also as a voracious reader. In fact, you’re even on an editorial team for a major medical journal. To what extent does that help?
And then from your vantage point at New England Journal of Medicine AI—and I’ll have a chance to ask Zak Kohane as the editor in chief the same question—you know, what’s your assessment as you reflect over the last two years for the submitted manuscripts? Are you overall surprised at what you’re seeing? Disappointed? Any kind of notable hits or misses, just in the steady stream of research papers that are getting submitted to that leading journal?
CHEATHAM: I would say overall, the field is becoming more expansive in the kinds of questions that people are asking.
Again, when we started, it was this very myopic approach of: “Can we pass these medical licensing exams? Can we benchmark this technology to how we benchmark our human clinicians?” I think that’s a trap. Some folks call this the Turing Trap, right, of let’s just compare everything to what a human is capable of.
Instead of interrogating what is the unique, as you all talk about in the book, what are the unique attributes of this new substrate for computation and what new behaviors emerge from it, whether that’s from a workflow perspective in the back office, or—as I’m personally more passionate and as we’re seeing more people focus on in the literature—what are the diagnostic capabilities, right.
I love Eric Topol’s framework for “machine eyes,” right, as this notion of like, yes, we as humans have eyes, and we have looked at medical images for many, many decades, but these machines can take a different approach to a retinal image, right.
It’s not just what you can diagnose in terms of an ophthalmological disease but maybe a neurologic disease or, you know, maybe liver disease, right.
So I think the literature is, in general, moving to this place of expansion, and I’m excited by that.
LEE: Yeah, I kind of have referred to that as triangulation. You know, one of the things I think a trap that specialists in medicine can fall into, like a cardiologist will see everything in terms of the cardiac system. And … whereas a nephrologist will see things in a certain lens.
And one of the things that you oftentimes see in the responses from a large language model is that more expansive view. At the same time, you know, I wonder … we have medical specialties for good reason. And, you know, at times I do wonder, you know, if there can be confusion that builds up.
CHEATHAM: This is an under-discussed area of AI—AI collapses medical specialties onto themselves, right.
You have the canonical example of the cardiologist, you know, arguing that, you know, we should diuresis and maybe the nephrologist arguing that we should, you know, protect the kidneys. And how do two disciplines disagree on what is right for the patient when in theory, there is an objective best answer given that patient’s clinical status?
My understanding is that the emergence of medical specialties was a function of the cognitive overload of medicine in general and how difficult it was to keep all of the specifics of a given specialty in the mind. Of course, general practitioners are tasked with doing this at some level, but they’re also tasked with knowing when they’ve reached their limit and when they need to refer to a specialist.
So I’m interested in this question of whether medical specialties themselves need to evolve.
And if we look back in the history of medical technology, there are many times where a new technology forced a medical specialty to evolve, whether it was certain diagnostic tools that have been introduced or, as we’re seeing now with GLP-1s, the entire cardiometabolic field …
LEE: Right.
CHEATHAM: … is having to really reimagine itself with these new tools. So I think AI will look very similar, and we should not hold on to this notion of classical medical specialties simply out of convention.
LEE: Right. All right. So now you’re starting your residency. You’re, you know, basically leading a charge in health and life sciences for a leading venture firm. I’d like you to predict what the world of healthcare is going to look like, you know, two years from now, five years from now, 10 years from now. And to frame that, to make it a little more specific, you know, what do you think will be possible that you, as a doctor and an investor, will be able to do two years from now, five years from now, 10 years from now that you can’t do today?
CHEATHAM: Two years from now, I’m optimistic we’ll have greater adoption of AI by clinicians, both for back-office use cases. So whether that’s the scribe and the generation of the note for billing purposes, but also now thinking about that for patient-facing applications.
We’re already doing this with drafting of notes. I think we’ll see greater proliferation of those more obvious use cases over the next two years. And hopefully we’re seeing that across hospital systems, not just large well-funded academics, but really reaching our community hospitals, our rural hospitals, our under-resourced settings.
I think hopefully we’ll see greater conversion. Right now, we have this challenge of “pilotitis,” right. A lot of people are trying things, but the data shows that only one in three pilots are really converting to production use. So hopefully we’ll kind of move things forward that are working and pare back on those that are not.
We will not solve the problem of payment models in the next two years. That is a prediction I have.
Over the next five years, I suspect that, with the help of regulators, we will identify better payment mechanisms to support the adoption of AI because it cannot and will not sustain itself simply by asking health systems and hospitals to pay for it. That is not a scalable solution.
LEE: Yes. Right. Yep. In fact, I think there have to be new revenue-positive incentives if providers are asked to do more in the adoption of technology.
CHEATHAM: Absolutely. But as we appreciate, some of the most promising applications of AI have nothing to do with revenue. It might simply be providing a diagnosis to somebody, you know, for whom that might drive additional intervention, but may also not.
And we have to be OK with that because that’s the right thing to do. It’s our moral imperative as clinicians to implement this where it provides value to the patient.
Over the next 10 years, what I—again, being a techno-optimist—am hopeful we start to see is a dissolving of the barrier that exists between care delivery and biomedical discovery.
This is the vision of the learning health system that was written over 10 years ago, and we have not realized it in practice. I’m a big proponent of ensuring that every single patient that enters our healthcare system not only receives the best care, but that we learn from the experiences of that individual to help the next.
And in our current system, that is not how it works. But, with AI, that now becomes possible.
LEE: Well, I think connecting healthcare experiences to medical discovery—I think that that is really such a great vision for the future. And I do agree [that] AI really gives us real hope that we can make it true.
Morgan, I think we could talk for a few hours more. It’s just incredible what you’re up to nowadays. Thank you so much for this conversation. I’ve learned a lot talking to you.
CHEATHAM: Peter, thank you so much for your time. I will be clutching my signed copy of The AI Revolution in Medicine for many years to come.
[TRANSITION MUSIC]LEE: Morgan obviously is not an ordinary med school graduate. In previous episodes, one of the things we’ve seen is that people on the leading edge of real-world AI in medicine oftentimes are both practicing doctors as well as technology developers. Morgan is another example of this type of polymath, being both a med student and a venture capitalist.
One thing that struck me about Morgan is he’s just incredibly hands-on. He goes out, finds leading-edge tools and technologies, and often these things, even though they’re experimental, he takes them into his education and into his clinical experiences. I think this highlights a potentially important point for medical schools, and that is, it might be incredibly important to provide the support—and, let’s be serious, the permission—to students to access and use new tools and technologies. Indeed, the insight for me when I interact with Morgan is that in these early days of AI in medicine, there is no substitute for hands-on experimentation, and that is likely best done while in medical school.
Here’s my interview with Daniel Chen:
LEE: Daniel, it’s great to have you here.
DANIEL CHEN: Yeah, it’s a pleasure being here.
LEE: Well, you know, I normally get started in these conversations by asking, you know, how do you explain to your mother what you do all day? And the reason that that’s a good question is a lot of the people we have on this podcast have fancy titles and unusual jobs, but I’m guessing that your mother would have already a preconceived notion of what a medical student does. So I’d like to twist the question around a little bit for you and ask, what does your mother not realize about how you spend your days at school?
Or does she get it all right? [LAUGHS]
CHEN: Oh, no, she is very observant. I’ll say that off the bat. But I think something that she might not realize, is the amount of efforts spent, kind of, outside the classroom or outside the hospital. You know, she’s always, like, saying you have such long days in the hospital. You’re there so early in the morning.
But what she doesn’t realize is that maybe when I come back from the hospital, it’s not just like, oh, I’m done for the day. Let’s wind down, go to bed. But it’s more like, OK, I have some more practice questions I need to get through; I didn’t get through my studying. Let me write on, like wrap up this research project I’m working on, get that back to the PI [principal investigator]. It’s never ending to a certain extent. Those are some things she doesn’t realize.
LEE: Yeah, I think, you know, all the time studying, I think, is something that people expect of second-year medical students. And even nowadays at the top medical schools like this one, being involved in research is also expected.
I think one thing that is a little unusual is that you are actually in clinic, as well, as a second-year student. How has that gone for you?
CHEN: Yeah, I mean, it’s definitely interesting. I would say I spend my time, especially this year, it’s kind of three things. There’s the preclinical stuff I’m doing. So that’s your classic, you know, you’re learning from the books, though I don’t feel like many of us do have textbooks anymore. [LAUGHTER]
There’s the clinical aspect, which you mentioned, which is we have an interesting model, longitudinal integrated clerkships. We can talk about that. And the last component is the research aspect, right. The extracurriculars.
But I think starting out as a second year and doing your rotations, probably early on in, kind of, the clinical medical education, has been really interesting, especially with our format, because typically med students have two years to read up on all the material and, like, get some foundational knowledge. With us, it’s a bit more, we have maybe one year under our belt before we’re thrown into like, OK, go talk to this patient; they have ankle pain, right. But we might have not even started talking about ankle pain in class, right. Well, where do I begin?
So I think starting out, it’s kind of, like, you know, the classic drinking from a fire hydrant. But you also, kind of, have that embarrassment of you’re talking to the patient like, I have no clue what’s happening [LAUGHTER] or you might have … my differentials all over the place, right.
But I think the beauty of the longitudinal aspect is that now that we’re, like, in our last trimester, everything’s kind of coming together. Like, OK, I can start to see, you know, here’s what you’re telling me. Here’s what the physical exam findings are. I’m starting to form a differential. Like, OK, I think these are the top three things.
But in addition to that, I think these are the next steps you should take so we can really focus and hone in on what exact diagnosis this might be.
LEE: All right. So, of course, what we’re trying to get into is about AI.
And, you know, the funny thing about AI and the book that Carey, Zak, and I wrote is we actually didn’t think too much about medical education, although we did have some parts of our book where we, well, first off, we made the guess that medical students would find AI to be useful. And we even had some examples, you know, where, you know, you would have a vignette of a mythical patient, and you would ask the AI to pretend to be that patient.
And then you would have an interaction and have to have an encounter. And so I want to delve into whether any of that is happening. How real it is. But before we do that, let’s get into first off, your own personal contact with AI. So let me start with a very simple question. Do you ever use generative AI systems like ChatGPT or similar?
CHEN: All the time, if not every day.
LEE: [LAUGHS] Every day, OK. And when did that start?
CHEN: I think when it first launched with GPT-3.5, I was, you know, curious. All my friends work in tech. You know, they’re either software engineers, PMs. They’re like, “Hey, Daniel, take a look at this,” and at first, I thought it was just more of a glorified search engine. You know, I was actually looking back.
My first question to ChatGPT was, what was the weather going to be like the next week, you know? Something very, like, something easily you could have looked up on Google or your phone app, right.
I was like, oh, this is pretty cool. But then, kind of, fast-forwarding to, I think, the first instance I was using it in med school. I think the first, like, thing that really helped me was actually a coding problem. It was for a research project. I was trying to use SQL.
Obviously, I’ve never taken a SQL class in my life. So I asked Chat like, “Hey, can you write me this code to maybe morph two columns together,” right? Something that might have taken me hours to maybe Google on YouTube or like try to read some documentation which just goes through my head.
But ChatGPT was able to, you know, not only produce the code, but, like, walk me through like, OK, you’re going to launch SQL. You’re going to click on this menu, [LAUGHTER] put the code in here, make sure your file names are correct. And it worked.
So it’s been a very powerful tool in that way in terms of, like, giving me expertise in something that maybe I traditionally had no training in.
LEE: And so while you’re doing this, I assume you had fellow students, friends, and others. And so what were you observing about their contact with AI? I assume you weren’t alone in this.
CHEN: Yeah, yeah, I think, … I’m not too sure in terms of what they were doing when it first came out, but I think if we were talking about present day, um, a lot of it’s kind of really spot on to what you guys talked about in the book.
Um, I think the idea around this personal tutor, personal mentor, is something that we’re seeing a lot. Even if we’re having in-class discussions, the lecturer might be saying something, right. And then I might be or I see a friend in ChatGPT or some other model looking up a question.
And you guys talked about, you know, how it can, like, explain a concept at different levels, right. But honestly, sometimes if there’s a complex topic, I ask ChatGPT, like, can you explain this to me as if I was a 6-year-old?
LEE: Yeah. [LAUGHS]
CHEN: Breaking down complex topics. Yeah. So I think it’s something that we see in the pre-clinical space, in lecture, but also even in the clinical space, there’s a lot of teaching, as well.
Sometimes if my preceptor is busy with patients, but I had maybe a question, I would maybe converse with ChatGPT, like, “Hey, what are your thoughts about this?” Or, like, a common one is, like, medical doctors love to use abbreviations, …
LEE: Yes.
CHEN: … and these abbreviations are sometimes only very niche and unique to their specialty, right. [LAUGHTER]
And I was reading this note from a urogynecologist. [In] the entire first sentence, I think there were, like, 10 abbreviations. Obviously, I compile lists and ask ChatGPT, like, “Hey, in the context of urogynecology, can you define what these could possibly mean,” right? Instead of hopelessly searching in a Google or maybe, embarrassing, asking the preceptor. So in these instances, it’s played a huge role.
LEE: Yeah. And when you’re doing things like that, it can make mistakes. And so what are your views of the reliability of generative AI, at least in the form of ChatGPT?
CHEN: Yeah, I think into the context of medicine, right, we fear a lot about the hallucinations that these models might have. And it’s something I’m always checking for. When I talk with peers about this, we find it most helpful when the model gives us a source linking it back. I think the gold standard nowadays in medicine is using something called UpToDate (opens in new tab) that’s written by clinicians, for clinicians.
But sometimes searching on UpToDate can be a lot of time as well because it’s a lot of information to, like, sort through. But nowadays a lot of us are using something called OpenEvidence, which is also an LLM. But they always cite their citations with, like, published literature, right.
So I think being able to be conscious of the downfalls of these models and also being able to have the critical understanding of, like, analyzing the actual literature. I think double checking is just something that we’ve been also getting really good at.
LEE: How would you assess student attitudes—med student attitudes—about AI? Is it … the way you’re coming across is it’s just a natural part of life. But do people have firm opinions, you know, pro or con, when it comes to AI, and especially AI in medicine?
CHEN: I think it’s pretty split right now. I think there’s the half, kind of, like us, where we’re very optimistic—cautiously optimistic about, you know, the potential of this, right. It’s able to, you know, give us that extra information, of being that extra tutor, right. It’s also able to give us information very quickly, as well.
But I think the other flip side of what a lot of students hesitate to, which I agree, is this loss of the ability to critically think. Something that you can easily do is, you know, give these models, like, relevant information about the patient history and be like, “Give me a 10-list differential,” right.
LEE: Yes.
CHEN: And I think it’s very easy as a student to, you know, [say], “This is difficult. Let me just use what the model says, and we’ll go with that,” right.
So I think being able to separate that, you know, medical school is a time where, you know, you’re learning to become a good doctor. And part of that requires the ability to be observant and critically think. Having these models simultaneously might hinder the ability to do that.
LEE: Yeah.
CHEN: So I think, you know, the next step is, like, these models can be great—a great tool, absolutely wonderful. But how do you make sure that it’s not hindering these abilities to critically think?
LEE: Right. And so when you’re doing your LIC [longitudinal integrated clerkship] work, these longitudinal experiences, and you’re in clinic, are you pulling the phone out of your pocket and consulting with AI?
CHEN: Definitely. And I think my own policy for this, to kind of counter this, is that the night before when I’m looking over the patient list, the clinic [schedule] of who’s coming, I’m always giving it my best effort first.
Like, OK, the chief complaint is maybe just a runny nose for a kid in a pediatric clinic. What could this possibly be? Right? At this point, we’ve seen a lot. Like, OK, it could be URI [upper respiratory infection], it could be viral, it could be bacterial, you know, and then I go through the—you know, I try to do my due diligence of, like, going through the history and everything like that, right.
But sometimes if it’s a more complex case, something maybe a presentation I’ve never seen before, I’ll still kind of do my best coming up with maybe a differential that might not be amazing. But then I’ll ask, you know, ChatGPT like, OK, in addition to these ideas, what do you think?
LEE: Yeah.
CHEN: Am I missing something? You know, and usually, it gives a pretty good response.
LEE: You know, that particular idea is something that I think Carey, Zak, and I thought would be happening a lot more today than we’re observing. And it’s the idea of a second set of eyes on your work. And somehow, at least our observation is that that isn’t happening quite as much by today as we thought it might.
And it just seems like one of the really safest and most effective use cases. When you go and you’re looking at yourself and other fellow medical students, other second-year students, what do you see when it comes to the “second set of eyes” idea?
CHEN: I think, like, a lot of students are definitely consulting ChatGPT in that regard because, you know, even in the very beginning, we’re taught to be, like, never miss these red flags, right. So these red flags are always on our differential, but sometimes, it can be difficult to figure out where to place them on that, right.
So I think in addition to, you know, coming up with these differentials, something I’ve been finding a lot of value [in] is just chatting with these tools to get their rationale behind their thinking, you know.
Something I find really helpful—I think this is also a part of the, kind of, art of medicine—is figuring out what to order, right, what labs to order.
LEE: Right.
CHEN: Obviously, you have your order sets that automate some of the things, like in the ED [emergency department], or, like, there are some gold standard imaging things you should do for certain presentations.
But then you chat to, like, 10 different physicians on maybe the next steps after that, and they give you 10 different answers.
LEE: Yes.
CHEN: But there’s never … I never understand exactly why. It’s always like, I’ve just been doing this for all my training, or that’s how I was taught.
So asking ChatGPT, like, “Why would you do this next?” Or, like, “Is this a good idea?” And seeing the pros and cons has also been really helpful in my learning.
LEE: Yeah, wow, that’s super interesting. So now, you know, I’d like to get into the education you’re receiving. And, you know, I think it’s fair to say Kaiser Permanente is very progressive in really trying to be very cutting-edge in how the whole curriculum is set up.
And for the listeners who don’t know this, I’m actually on the board of directors of the school and have been since the founding of the school. And I think one of the reasons why I was invited to be on the board is the school really wanted to think ahead and be cutting edge when it comes to technology.
So from where I’ve sat, I’ve never been completely satisfied with the amount of tech that has made it into the curriculum. But at the same time, I’ve also made myself feel better about that just understanding that it’s sort of unstoppable, that students are so tech-forward already.
But I wanted to delve into a little bit here into what your honest opinions are and your fellow students’ opinions are about whether you feel like you’re getting adequate training and background formally as part of your medical education when it comes to things like artificial intelligence or other technologies.
What do you think? Are you … would you wish the curriculum would change?
CHEN: Yeah, I think that’s a great question.
I think from a tech perspective, the school is very good about implementing, you know, opportunities for us to learn. Like, for example, learning how to use Epic, right, or at Kaiser Permanente, what we call HealthConnect, right. These electronic health records. That, my understanding is, a lot of schools maybe don’t teach that.
That’s something where we get training sessions maybe once or twice a year, like, “Hey, here’s how to make a shortcut in the environment,” right.
So I think from that perspective, the school is really proactive in providing those opportunities, and they make it very easy to find resources for that, too. I think it …
LEE: Yeah, I think you’re pretty much guaranteed to be an Epic black belt by the time you [LAUGHS] finish your degree.
CHEN: Yes, yes.
But then I think in terms of the aspects of artificial intelligence, I think the school’s taken a more cautiously optimistic viewpoint. They’re just kind of looking around right now.
Formally in the curriculum, there hasn’t been anything around this topic. I believe the fourth-year students last year got a student-led lecture around this topic.
But talking to other peers at other institutions, it looks like it’s something that’s very slowly being built into the curriculum, and it seems like a lot of it is actually student-led, you know.
You know, my friend at Feinberg [School of Medicine] was like we just got a session before clerkship about best practices on how to use these tools.
I have another friend at Pitt talking about how they’re leading efforts of maybe incorporating some sort of LLM into their in-house curriculum where students can, instead of clicking around the website trying to find the exact slide, they can just ask this tool, like, “OK. We had class this day. They talked about this … but can you provide more information?” and it can pull from that.
So I think a lot of this, a lot of it is student-driven. Which I think is really exciting because it begs the question, I think, you know current physicians may not be very well equipped with these tools as well, right?
So maybe they don’t have a good idea of what exactly is the next steps or what does the curriculum look like. So I think the future in terms of this AI curriculum is really student-led, as well.
LEE: Yeah, yeah, it’s really interesting.
I think one of the reasons I think also that that happens is [that] it’s not just necessarily the curriculum that lags but the accreditation standards. You know, accreditation is really important for medical schools because you want to make sure that anyone who holds an MD, you know, is a bona fide doctor, and so accreditation standards are pretty strictly monitored in most countries, including the United States.
And I think accreditation standards are also—my observation—are slow to understand how to adopt or integrate AI. And it’s not meant as a criticism. It’s a big unknown. No one knows exactly what to do and how to do. And so it’s really interesting to see that, as far as I can tell, I’ve observed the same thing that you just have seen, that most of the innovation in this area about how AI should be integrated into medical education is coming from the students themselves.
It seems, I think, I’d like to think it’s a healthy development. [LAUGHS]
CHEN: Something tells me maybe the students are a bit better at using these tools, as well.
You know, I talk to my preceptors because KP [Kaiser Permanente] also has their own version …
LEE: Preceptor, maybe we should explain what that is.
CHEN: Yeah, sorry. So a preceptor is an attending physician, fully licensed, finished residency, and they are essentially your kind of teacher in the clinical environment.
So KP has their own version of some ambient documentation device, as well. And something I always like to ask, you know, like, “Hey, what are your thoughts on these tools,” right?
And it’s always so polarizing, as well, even among the same specialty. Like, if you ask psychiatrists, which I think is a great use case of these tools, right. My preceptor hates it. Another preceptor next door loves it. [LAUGHTER]
So I think a lot of it’s, like, it’s still, like, a lot of unknowns, like you were mentioning.
LEE: Right. Well, in fact, I’m glad you brought that up because one thing that we’ve been hearing from previous guests a lot when it comes to AI in clinic is about ambient listening by AI, for example, to help set up a clinical note or even write a clinical note.
And another big use case that we heard a lot about that seems to be pretty popular is the use of generative AI to respond to patient messages.
So let’s start with the clinical note thing. First off, do you have opinions about that technology?
CHEN: I think it’s definitely good.
I think especially where, you know, if you’re in the family medicine environment or pediatric environment where you’re spending so much time with patients, a note like that is great, right.
I think coming from a strictly medical student standpoint, I think it’s—honestly, it’d be great to have—but I think there’s a lot of learning when you write the note, you know. There’s a lot of, you know, all of my preceptors talk about, like, when I read your note, you should present it in a way where I can see your thoughts and then once I get to the assessment and plan, it’s kind of funneling down towards a single diagnosis or a handful of diagnoses. And that’s, I think, a skill that requires you to practice over time, right.
So a part of me thinks, like, if I had this tool where [it] can just automatically give me a note as a first year, then it takes away from that learning experience, you know.
Even during our first year throughout school, we frequently get feedback from professors and doctors about these notes. And it’s a lot of feedback. [LAUGHTER] It’s like, “I don’t think you should have written that,” “That should be in this section ” … you know, like a medical note or a SOAP note [Subjective, Objective, Assessment, and Plan], where, you know, the subjective is, like, what the patient tells you. Objective is what the physical findings are, and then your assessment of what’s happening, and then your plan. Like, it’s very particular, and then I think medicine is so structured in a way, that’s kind of, like, how everyone does it, right. So kind of going back to the question, I think it’s a great tool, but I don’t think it’s appropriate for a medical student.
LEE: Yeah, it’s so interesting to hear you say that. I was … one of our previous guests is the head of R&D at Epic, Seth Hain. He said, “You know, Peter, doctors do a lot of their thinking when they write the note.”
And, of course, Epic is providing ambient, you know, clinical notetaking automation. But he was urging caution because, you know, you’re saying, well, this is where you’re learning a lot. But actually, it’s also a point where, as a doctor, you’re thinking about the patient. And we do probably have to be careful with how we automate parts of that.
All right. So you’re gearing up for Step 1 of the USMLE [United States Medical Licensing Examination]. That’ll be a big multiple-choice exam. Then Step 2 is similar: very, very focused on advanced clinical knowledge. And then Step 3, you know, is a little more interactive.
And so one question that people have had about AI is, you know, how do we regulate the use of AI in medicine? And one of the famous papers that came out of both academia and industry was the concept that you might be able to treat AI like a person and have it go through the same licensing. And this is something that Carey, Zak, and I contemplated in our book.
In the end, at the time we wrote the book, I personally rejected the idea, but I think it’s still alive. And so I’ve wondered if you have any … you know, first off, are you opinionated at all about, what should the requirements be for the allowable use of AI in the kind of work that you’re going to be doing?
CHEN: Yeah, I think it’s a tough question because, like, where do you draw that line, right? If you apply the human standards of it’s passing exams, then yes, in theory, it could be maybe a medical doctor, as well, right? It’s more empathetic than medical doctors, right? So where do you draw that line?
I think, you know, part of me thinks it’s maybe it is that human aspect that patients like to connect with, right. And maybe this really is just, like, these tools are just aids in helping, you know, maybe load off some cognitive load, right.
But I think the other part of me, I’m thinking about this is the next generation who are growing up with this technology, right. They’re interacting with applications all day. Maybe they’re on their iPads. They’re talking to chatbots. They’re using ChatGPT. This is, kind of, the environment they grew up with. Does that mean they also have increased, like, trust in these tools that maybe our generation or the generations above us don’t have that value that human connection? Would they value human connection less?
You know, I think those are some troubling thoughts that, you know, yes, at end of the day, maybe I’m not as smart as these tools, but I can still provide that human comfort. But if, at the end of the day, the future generation doesn’t really care about that or they perfectly trust these tools because that’s all they’ve kind of known, then where do human doctors stand?
I think part of that is, there would be certain specialties where maybe the human connection is more important. The longitudinal aspect of building that trust, I think is important. Family medicine is a great example. I think hematology oncology with cancer treatment.
Obviously, I think anyone’s not going to be thrilled to hear cancer diagnosis, but something tells me that seeing that on a screen versus maybe a physician prompting you and telling you about that tells me that maybe in those aspects, you know, the human nature, the human touch plays an important role there, too.
LEE: Yeah, you know, I think it strikes me that it’s going to be your generation that really is going to set the pattern probably for the next 50 years about how this goes. And it’s just so interesting because I think a lot will depend on your reactions to things.
So, for example, you know, one thing that is already starting to happen are patients who are coming in armed, you know, with a differential [LAUGHS], you know, that they’ve developed themselves with the help of ChatGPT. So let me … you must have thought about these things. So, in fact, has it happened in your clinical work already?
CHEN: Yeah, I’ve seen people come into the ED during my ED shift, like emergency department, and they’ll be like, “Oh, I have neck pain and here are all the things that, you know, Chat told me, ChatGPT told me. What do you think … do I need? I want this lab ordered, that lab ordered.”
LEE: Right.
CHEN: And I think my initial reaction is, “Great. Maybe we should do that.” But I think the other reaction is understanding that not everyone has the clinical background of understanding what’s most important, what do we need to absolutely rule out, right?
So, I think in some regards, I would think that maybe ChatGPT errs on the side of caution, …
LEE: Yes.
CHEN: … giving maybe patients more extreme examples of what this could be just to make sure that it’s, in a way, is not missing any red flags as well, right.
LEE: Right. Yeah.
CHEN: But I think a lot of this is … what we’ve been learning is it’s all about shared decision making with the patient, right. Being able to acknowledge like, “Yeah, [in] that list, most of the stuff is very plausible, but maybe you didn’t think about this one symptom you have.”
So I think part of it, maybe it’s a sidebar here, is the idea of prompting, right. You know, they’ve always talked about all these, you know, prompt engineers, you know, how well can you, like, give it context to answer your question?
LEE: Yeah.
CHEN: So I think being able to give these models the correct information and the relevant information and keyword relevant, because relevant is, I guess, where your clinical expertise comes in. Like, what do you give the model, what do you not give? So I think that difference between a medical provider versus maybe your patients is ultimately the difference.
LEE: Let me press on that a little bit more because you brought up the issue of trust, and trust is so essential for patients to feel good about their medical care.
And I can imagine you’re a medical student seeing a patient for the first time. So you don’t have a trust relationship with that patient. And the patient comes in maybe trusting ChatGPT more than you.
CHEN: Very valid. No. I mean, I get that a lot, surprisingly, you know. [LAUGHTER] Sometimes [they’re] like, “Oh, I don’t want to see the medical student,” because we always give the patient an option, right. Like, it’s their time, whether it’s a clinic visit.
But yeah, those patients, I think it’s perfectly reasonable. If I heard a second-year medical student was going to be part of my care team, taking that history, I’d be maybe a little bit concerned, too. Like, are they asking all the right questions? Are they relaying that information back to their attending physician correctly?
So I think a lot of it is, at least from a medical student perspective, is framing it so the patient understands that this is a learning opportunity for the students. And something I do a lot is tell them like, “Hey, like, you know, at the end of the day, there is someone double-checking all my work.”
LEE: Yeah.
CHEN: But for those that come in with a list, I sometimes sit down with them, and we’ll have a discussion, honestly.
I’ll be like, “I don’t think you have meningitis because you’re not having a fever. Some of the physical exam maneuvers we did were also negative. So I don’t think you have anything to worry about that,” you know.
So I think it’s having that very candid conversation with the patient that helps build that initial trust. Telling them like, “Hey … ”
LEE: It’s impressive to hear how even keeled you are about this. You know, I think, of course, and you’re being very humble saying, well, you know, as a second-year medical student, of course, someone might not, you know, have complete trust. But I think that we will be entering into a world where no doctor is going to be, no matter how experienced or how skilled, is going to be immune from this issue.
So we’re starting to run toward the end of our time together. And I like to end with one or two more provocative questions.
And so let me start with this one. Undoubtedly, I mean, you’re close enough to tech and digital stuff, digital health, that you’re undoubtedly familiar with famous predictions, you know, by Turing and Nobel laureates that someday certain medical specialties, most notably radiology, would be completely supplanted by machines. And more recently, there have been predictions by others, like, you know, Elon Musk, that maybe even some types of surgery would be replaced by machines.
What do you think? Do you have an opinion?
CHEN: I think replace is a strong term, right. To say that doctors are completely obsolete, I think, is unlikely.
If anything, I think there might be a shift maybe in what it means to be a doctor, right. Undoubtedly, maybe the demands of radiologists are going to go down because maybe more of the simple things can truly be automated, right. And you just have a supervising radiologist whose output is maybe 10 times as maybe 10 single radiologists, right.
So I definitely see a future where the demand of certain specialties might go down.
And I think when I talk about a shift of what it means to be a physician, maybe it’s not so much diagnostic anymore, right, if these models get so good at, like, just taking in large amounts of information, but maybe it pivots to being really good at understanding the limitations of these models and knowing when to intervene is what it means to be the kind of the next generation of physicians.
I think in terms of surgery, yeah, I think it’s a concern, but maybe not in the next 50 years. Like those Da Vinci robots are great. I think out of Mayo Clinic, they were demoing some videos of these robots leveraging computer vision to, like, close portholes, like laparoscopic scars. And that’s something I do in the OR [operating room], right. And we’re at the same level at this point. [LAUGHTER] So at that point, maybe.
But I think robotics still has to address the understanding of like, what if something goes wrong, right? Who’s responsible? And I don’t see a future where a robot is able to react to these, you know, dangerous situations when maybe something goes wrong. You still have to have a surgeon on board to, kind of, take over. So in that regard, that’s kind of where I see maybe the future going.
LEE: So last question. You know, when you are thinking about the division of time, one of the themes that we’ve seen in the previous guests is more and more doctors are doing more technology work, like writing code and so on. And more and more technologists are thinking deeply and getting educated in clinical and preclinical work.
So for you, let’s look ahead 10 years. What do you see your division of labor to be? Or, you know, how would you … what would you tell your mom then about how you spend a typical day?
CHEN: Yeah, I mean, I think for me, technology is something I definitely want to be involved in in my line of work, whether it’s, you know, AI work, whether it’s improving quality of healthcare through technology.
My perfect division would be maybe still being able to see patients but also balancing some maybe more of these higher-level kind of larger projects. But I think having that division would be something nice.
LEE: Yeah, well, I think you would be great just from the little bit I know about you. And, Daniel, it’s been really great chatting with you. I wish you the best of luck, you know, with your upcoming exams and getting past this year two of your medical studies. And perhaps someday I’ll be your patient.
[TRANSITION MUSIC]CHEN: Thank you so much.
LEE: You know, one of the lucky things about my job is that I pretty regularly get to talk to students at all levels, spanning high school to graduate school. And when I get to talk especially to med students, I’m always impressed with their intelligence, just how serious they are, and their high energy levels. Daniel is absolutely a perfect example of all that.
Now, it comes across as trite to say that the older generation is less adept at technology adoption than younger people. But actually, there probably is a lot of truth to that. And in the conversation with Daniel, I think he was actually being pretty diplomatic but also clear that he and his fellow med students don’t necessarily expect the professors in their med school to understand AI as well as they do.
There’s no doubt in my mind that medical education will have to evolve a lot to help prepare doctors and nurses for an AI future. But where will this evolution come from?
As I reflect on my conversations with Morgan and Daniel, I start to think that it’s most likely to come from the students themselves. And when you meet people like Morgan and Daniel, it’s impossible to not be incredibly optimistic about the next generation of clinicians.
[THEME MUSIC]Another big thank-you to Morgan and Daniel for taking time to share their experiences with us. And to our listeners, thank you for joining us. We have just a couple of episodes left, one on AI’s impact on the operation of public health departments and healthcare systems and another coauthor roundtable. We hope you’ll continue to tune in.
Until next time.
[MUSIC FADES]
The post Navigating medical education in the era of generative AI appeared first on Microsoft Research.
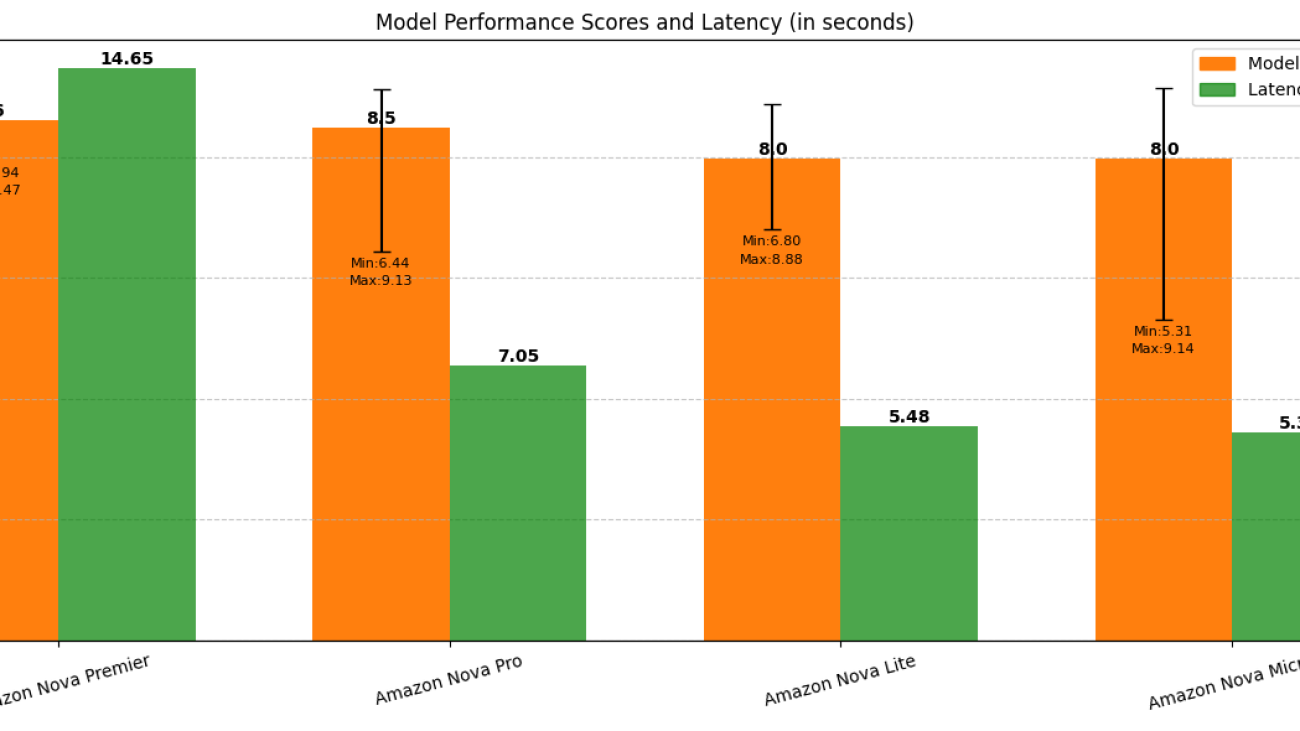
Benchmarking Amazon Nova: A comprehensive analysis through MT-Bench and Arena-Hard-Auto
Large language models (LLMs) have rapidly evolved, becoming integral to applications ranging from conversational AI to complex reasoning tasks. However, as models grow in size and capability, effectively evaluating their performance has become increasingly challenging. Traditional benchmarking metrics like perplexity and BLEU scores often fail to capture the nuances of real-world interactions, making human-aligned evaluation frameworks crucial. Understanding how LLMs are assessed can lead to more reliable deployments and fair comparisons across different models.
In this post, we explore automated and human-aligned judging methods based on LLM-as-a-judge. LLM-as-a-judge refers to using a more powerful LLM to evaluate and rank responses generated by other LLMs based on predefined criteria such as correctness, coherence, helpfulness, or reasoning depth. This approach has become increasingly popular due to the scalability, consistency, faster iteration, and cost-efficiency compared to solely relying on human judges. We discuss different LLM-as-a-judge evaluation scenarios, including pairwise comparisons, where two models or responses are judged against each other, and single-response scoring, where individual outputs are rated based on predefined criteria. To provide concrete insights, we use MT-Bench and Arena-Hard, two widely used evaluation frameworks. MT-Bench offers a structured, multi-turn evaluation approach tailored for chatbot-like interactions, whereas Arena-Hard focuses on ranking LLMs through head-to-head response battles in challenging reasoning and instruction-following tasks. These frameworks aim to bridge the gap between automated and human judgment, making sure that LLMs aren’t evaluated solely based on synthetic benchmarks but also on practical use cases.
The repositories for MT-Bench and Arena-Hard were originally developed using OpenAI’s GPT API, primarily employing GPT-4 as the judge. Our team has expanded its functionality by integrating it with the Amazon Bedrock API to enable using Anthropic’s Claude Sonnet on Amazon as judge. In this post, we use both MT-Bench and Arena-Hard to benchmark Amazon Nova models by comparing them to other leading LLMs available through Amazon Bedrock.
Amazon Nova models and Amazon Bedrock
Our study evaluated all four models from the Amazon Nova family, including Amazon Nova Premier, which is the most recent addition to the family. Introduced at AWS re:Invent in December 2024, Amazon Nova models are designed to provide frontier-level intelligence with leading price-performance ratios. These models rank among the fastest and most economical options in their respective intelligence categories and are specifically optimized for powering enterprise generative AI applications in a cost-effective, secure, and reliable manner.
The understanding model family comprises four distinct tiers: Amazon Nova Micro (text-only, designed for ultra-efficient edge deployment), Amazon Nova Lite (multimodal, optimized for versatility), Amazon Nova Pro (multimodal, offering an ideal balance between intelligence and speed for most enterprise applications), and Amazon Nova Premier (multimodal, representing the most advanced Nova model for complex tasks and serving as a teacher for model distillation). Amazon Nova models support a wide range of applications, including coding, reasoning, and structured text generation.
Additionally, through Amazon Bedrock Model Distillation, customers can transfer the intelligence capabilities of Nova Premier to faster, more cost-effective models such as Nova Pro or Nova Lite, tailored to specific domains or use cases. This functionality is accessible through both the Amazon Bedrock console and APIs, including the Converse API and Invoke API.
MT-Bench analysis
MT-Bench is a unified framework that uses LLM-as-a-judge, based on a set of predefined questions. The evaluation questions are a set of challenging multi-turn open-ended questions designed to evaluate chat assistants. Users also have the flexibility to define their own question and answer pairs in a way that suits their needs. The framework presents models with challenging multi-turn questions across eight key domains:
- Writing
- Roleplay
- Reasoning
- Mathematics
- Coding
- Data Extraction
- STEM
- Humanities
The LLMs are evaluated using two types of evaluation:
- Single-answer grading – This mode asks the LLM judge to grade and give a score to a model’s answer directly without pairwise comparison. For each turn, the LLM judge gives a score on a scale of 0–10. Then the average score is computed on all turns.
- Win-rate based grading – This mode uses two metrics:
- pairwise-baseline – Run a pairwise comparison against a baseline model.
- pairwise-all – Run a pairwise comparison between all model pairs on all questions.
Evaluation setup
In this study, we employed Anthropic’s Claude 3.7 Sonnet as our LLM judge, given its position as one of the most advanced language models available at the time of our study. We focused exclusively on single-answer grading, wherein the LLM judge directly evaluates and scores model-generated responses without conducting pairwise comparisons.
The eight domains covered in our study can be broadly categorized into two groups: those with definitive ground truth and those without. Specifically, Reasoning, Mathematics, Coding, and Data Extraction fall into the former category because they typically have reference answers against which responses can be objectively evaluated. Conversely, Writing, Roleplay, STEM, and Humanities often lack such clear-cut ground truth. Here we provide an example question from the Writing and Math categories:
To account for this distinction, MT-Bench employs different judging prompts for each category (refer to the following GitHub repo), tailoring the evaluation process to the nature of the task at hand. As shown in the following evaluation prompt, for questions without a reference answer, MT-Bench adopts the single-v1 prompt, only passing the question and model-generated answer. When evaluating questions with a reference answer, it only passes the reference_answer, as shown in the single-math-v1 prompt.
Overall performance analysis across Amazon Nova Models
In our evaluation using Anthropic’s Claude 3.7 Sonnet as an LLM-as-a-judge framework, we observed a clear performance hierarchy among Amazon Nova models. The scores ranged from 8.0 to 8.6, with Amazon Nova Premier achieving the highest median score of 8.6, followed closely by Amazon Nova Pro at 8.5. Both Amazon Nova Lite and Nova Micro achieved respectable median scores of 8.0.
What distinguishes these models beyond their median scores is their performance consistency. Nova Premier demonstrated the most stable performance across evaluation categories with a narrow min-max margin of 1.5 (ranging from 7.94 to 9.47). In comparison, Nova Pro showed greater variability with a min-max margin of 2.7 (from 6.44 to 9.13). Similarly, Nova Lite exhibited more consistent performance than Nova Micro, as evidenced by their respective min-max margins. For enterprise deployments where response time is critical, Nova Lite and Nova Micro excel with less than 6-second average latencies for single question-answer generation. This performance characteristic makes them particularly suitable for edge deployment scenarios and applications with strict latency requirements. When factoring in their lower cost, these models present compelling options for many practical use cases where the slight reduction in performance score is an acceptable trade-off.
Interestingly, our analysis revealed that Amazon Nova Premier, despite being the largest model, demonstrates superior token efficiency. It generates more concise responses that consume up to 190 fewer tokens for single question-answer generation than comparable models. This observation aligns with research indicating that more sophisticated models are generally more effective at filtering irrelevant information and structuring responses efficiently.
The narrow 0.6-point differential between the highest and lowest performing models suggests that all Amazon Nova variants demonstrate strong capabilities. Although larger models such as Nova Premier offer marginally better performance with greater consistency, smaller models provide compelling alternatives when latency and cost are prioritized. This performance profile gives developers flexibility to select the appropriate model based on their specific application requirements.
The following graph summarizes the overall performance scores and latency for all four models.
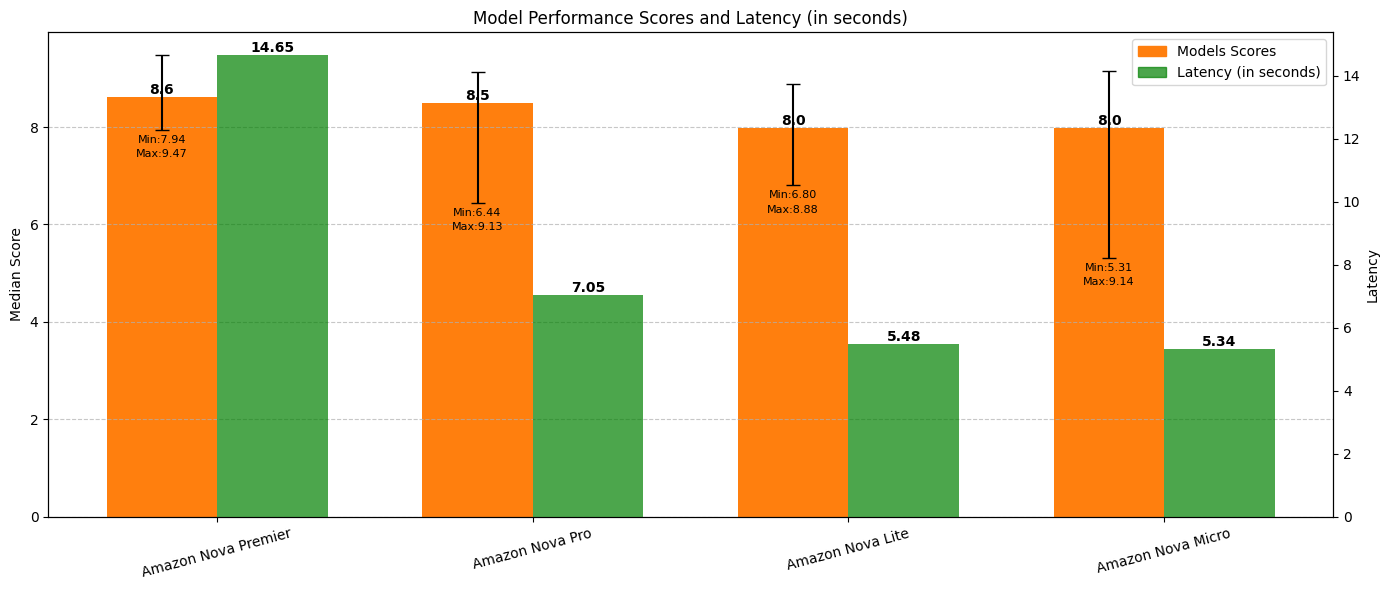
The following table shows token consumption and cost analysis for Amazon Nova Models.
| Model | Avg. total tokens per query | Price per 1k input tokens | Avg. cost per query (cents) |
| Amazon Nova Premier | 2154 | $0.0025 | $5.4 |
| Amazon Nova Pro | 2236 | $0.0008 | $1.8 |
| Amazon Nova Lite | 2343 | $0.00006 | $0.14 |
| Amazon Nova Micro | 2313 | $0.000035 | $0.08 |
Category-specific model comparison
The following radar plot compares the Amazon Nova models across all eight domains.
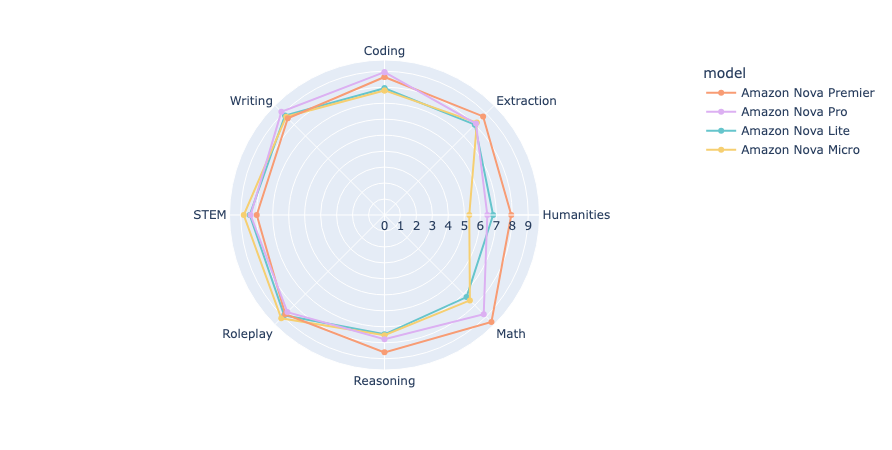
The radar plot reveals distinct performance patterns across the Amazon Nova model family, with a clear stratification across domains. Nova Premier consistently outperforms its counterparts, showing particular strengths in Math, Reasoning, Humanities, and Extraction, where it achieves scores approaching or exceeding 9. Nova Pro follows closely behind Premier in most categories, maintaining competitive performance especially in Writing and Coding, while showing more pronounced gaps in Humanities, Reasoning, and Math. Both Nova Lite and Micro demonstrate similar performance profiles to each other, with their strongest showing in Roleplay, and their most significant limitations in Humanities and Math, where the differential between Premier and the smaller models is most pronounced (approximately 1.5–3 points).
The consistent performance hierarchy across all domains (Premier > Pro > Lite ≈ Micro) aligns with model size and computational resources, though the magnitude of these differences varies significantly by category. Math and reasoning emerge among the most discriminating domains for model capability assessment and suggest substantial benefit from the additional scale of Amazon Nova Premier. However, workloads focused on creative content (Roleplay, Writing) provide the most consistent performance across the Nova family and suggest smaller models as compelling options given their latency and cost benefits. This domain-specific analysis offers practitioners valuable guidance when selecting the appropriate Nova model based on their application’s primary knowledge requirements.
In this study, we adopted Anthropic’s Claude 3.7 Sonnet as the single LLM judge. However, although Anthropic’s Claude 3.7 Sonnet is a popular choice for LLM judging due to its capabilities, studies have shown that it does exhibit certain bias (for example, it prefers longer responses). If permitted by time and resources, consider adopting a multi-LLM judge evaluation framework to effectively reduce biases intrinsic to individual LLM judges and increase evaluation reliability.
Arena-Hard-Auto analysis
Arena-Hard-Auto is a benchmark that uses 500 challenging prompts as a dataset to evaluate different LLMs using LLM-as-a-judge. The dataset is curated through an automated pipeline called BenchBuilder, which uses LLMs to automatically cluster, grade, and filter open-ended prompts from large, crowd-sourced datasets such as Chatbot-Arena to enable continuous benchmarking without a human in the loop. The paper reports that the new evaluation metrics provide three times higher separation of model performances compared to MT-Bench and achieve a 98.6% correlation with human preference rankings.
Test framework and methodology
The Arena-Hard-Auto benchmarking framework evaluates different LLMs using a pairwise comparison. Each model’s performance is quantified by comparing it against a strong baseline model, using a structured, rigorous setup to generate reliable and detailed judgments. We use the following components for the evaluation:
- Pairwise comparison setup – Instead of evaluating models in isolation, they’re compared directly with a strong baseline model. This baseline provides a fixed standard, making it straightforward to understand how the models perform relative to an already high-performing model.
- Judge model with fine-grained categories – A powerful model (Anthropic’s Claude 3.7 Sonnet) is used as a judge. This judge doesn’t merely decide which model is better, it also categorizes the comparison into five detailed preference labels. By using this nuanced scale, large performance gaps are penalized more heavily than small ones, which helps separate models more effectively based on performance differences:
A >> B(A is significantly better than B)A > B(A is better than B)A ~= B(A and B are similar)B > A(B is better than A)B >> A(B is significantly better than A)
- Chain-of-thought (CoT) prompting – CoT prompting encourages the judge model to explain its reasoning before giving a final judgment. This process can lead to more thoughtful and reliable evaluations by helping the model analyze each response in depth rather than making a snap decision.
- Two-game setup to avoid position bias – To minimize bias that might arise from a model consistently being presented first or second, each model pair is evaluated twice, swapping the order of the models. This way, if there’s a preference for models in certain positions, the setup controls for it. The total number of judgments is doubled (for example, 500 queries x 2 positions = 1,000 judgments).
- Bradley-Terry model for scoring – After the comparisons are made, the Bradley-Terry model is applied to calculate each model’s final score. This model uses pairwise comparison data to estimate the relative strength of each model in a way that reflects not only the number of wins but also the strength of wins. This scoring method is more robust than simply calculating win-rate because it accounts for pairwise outcomes across the models.
- Bootstrapping for statistical stability – By repeatedly sampling the comparison results (bootstrapping), the evaluation becomes statistically stable. This stability is beneficial because it makes sure the model rankings are reliable and less sensitive to random variations in the data.
- Style control – Certain style features like response length and markdown formatting are separated from content quality, using style controls, to provide a clearer assessment of each model’s intrinsic capabilities.
The original work focuses on pairwise comparison only. For our benchmarking, we also included our own implementation of single-score judgment, taking inspiration from MT-Bench. We again use Anthropic’s Claude 3.7 Sonnet as the judge and use the following prompt for judging without a reference model:
Performance comparison
We evaluated five models, including Amazon Nova Premier, Amazon Nova Pro, Amazon Nova Lite, Amazon Nova Micro, DeepSeek-R1, and a strong reference model. The Arena-Hard benchmark generates confidence intervals by bootstrapping, as explained before. The 95% confidence interval shows the uncertainty of the models and is indicative of model performance. From the following plot, we can see that all the Amazon Nova models get a high pairwise Bradley-Terry score. It should be noted that the Bradley-Terry score for the reference model is 5; this is because Bradley-Terry scores are computed by pairwise comparisons where the reference model is one of the models in the pair. So, for the reference model, the score will be 50%, and because the total score is normalized between 0 and 10, the reference model has a score of 5.
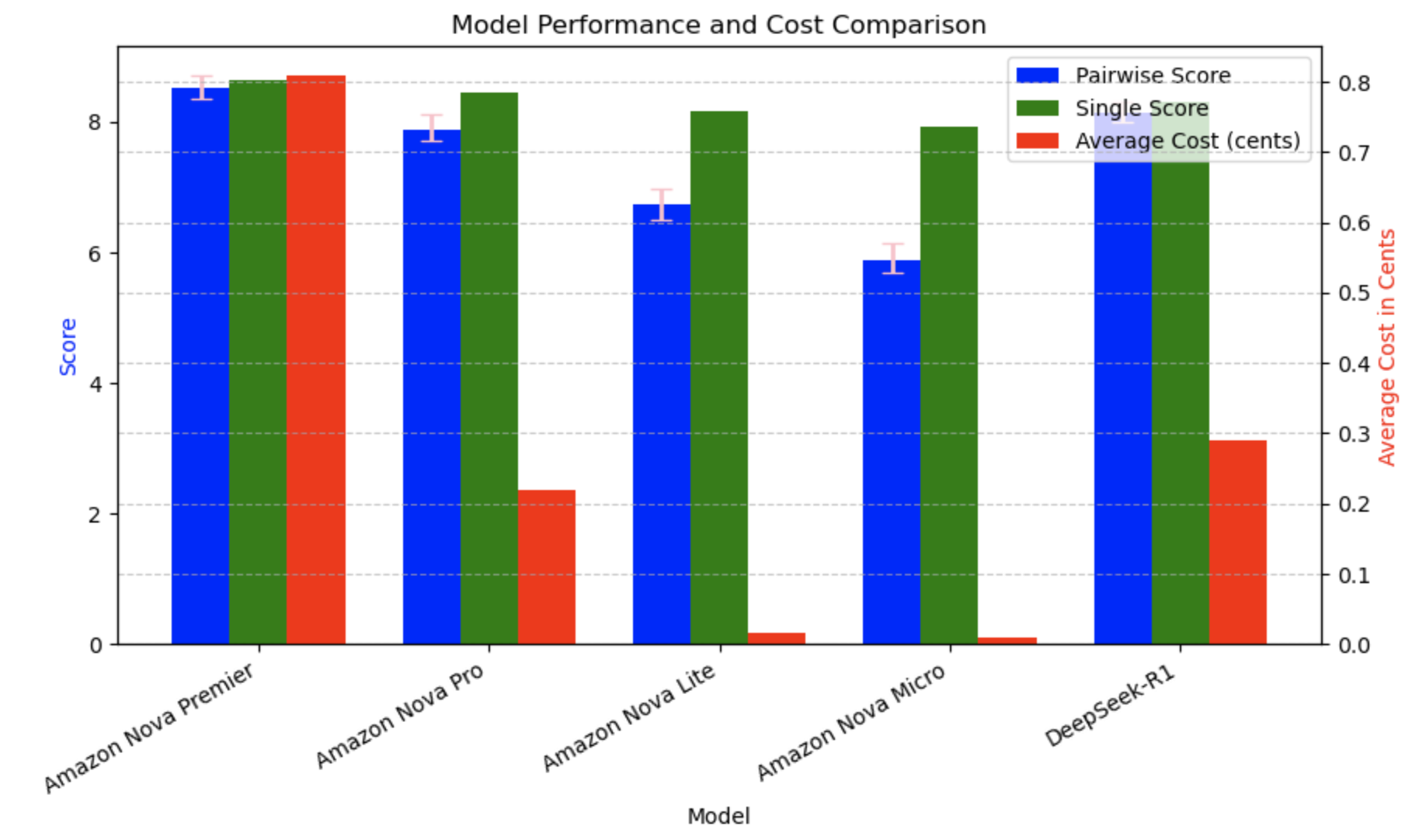
The confidence interval analysis, as shown in the following table, was done to statistically evaluate the Amazon Nova model family alongside DeepSeek-R1, providing deeper insights beyond raw scores. Nova Premier leads the pack (8.36–8.72), with DeepSeek-R1 (7.99–8.30) and Nova Pro (7.72–8.12) following closely. The overlapping confidence intervals among these top performers indicate statistically comparable capabilities. Nova Premier demonstrates strong performance consistency with a tight confidence interval (−0.16, +0.20), while maintaining the highest overall scores. A clear statistical separation exists between these leading models and the purpose-built Nova Lite (6.51–6.98) and Nova Micro (5.68–6.14), which are designed for different use cases. This comprehensive analysis confirms the position of Nova Premier as a top performer, with the entire Nova family offering options across the performance spectrum to meet varied customer requirements and resource constraints.
| Model | Pairwise score 25th quartile | Pairwise score 75th quartile | Confidence interval |
| Amazon Nova Premier | 8.36 | 8.72 | (−0.16, +0.20) |
| Amazon Nova Pro | 7.72 | 8.12 | (−0.18, +0.23) |
| Amazon Nova Lite | 6.51 | 6.98 | (−0.22, +0.25) |
| Amazon Nova Micro | 5.68 | 6.14 | (−0.21, +0.25) |
| DeepSeek-R1 | 7.99 | 8.30 | (−0.15, +0.16) |
Cost per output token is one of the contributors to the overall cost of the LLM model and impacts the usage. The cost was computed based on the average output tokens over the 500 responses. Although Amazon Nova Premier leads in performance (85.22), Nova Light and Nova Micro offer compelling value despite their wider confidence intervals. Nova Micro delivers 69% of the performance of Nova Premier at 89 times cheaper cost, while Nova Light achieves 79% of the capabilities of Nova Premier, at 52 times lower price. These dramatic cost efficiencies make the more affordable Nova models attractive options for many applications where absolute top performance isn’t essential, highlighting the effective performance-cost tradeoffs across the Amazon Nova family.
Conclusion
In this post, we explored the use of LLM-as-a-judge through MT-Bench and Arena-Hard benchmarks to evaluate model performance rigorously. We then compared Amazon Nova models against a leading reasoning model, that is, DeepSeek-R1 hosted on Amazon Bedrock, analyzing their capabilities across various tasks. Our findings indicate that Amazon Nova models deliver strong performance, especially in Extraction, Humanities, STEM, and Roleplay, while maintaining lower operational costs, making them a competitive choice for enterprises looking to optimize efficiency without compromising on quality. These insights highlight the importance of benchmarking methodologies in guiding model selection and deployment decisions in real-world applications.
For more information on Amazon Bedrock and the latest Amazon Nova models, refer to the Amazon Bedrock User Guide and Amazon Nova User Guide. The AWS Generative AI Innovation Center has a group of AWS science and strategy experts with comprehensive expertise spanning the generative AI journey, helping customers prioritize use cases, build a roadmap, and move solutions into production. Check out Generative AI Innovation Center for our latest work and customer success stories.
About the authors
 Mengdie (Flora) Wang is a Data Scientist at AWS Generative AI Innovation Center, where she works with customers to architect and implement scalable Generative AI solutions that address their unique business challenges. She specializes in model customization techniques and agent-based AI systems, helping organizations harness the full potential of generative AI technology. Prior to AWS, Flora earned her Master’s degree in Computer Science from the University of Minnesota, where she developed her expertise in machine learning and artificial intelligence.
Mengdie (Flora) Wang is a Data Scientist at AWS Generative AI Innovation Center, where she works with customers to architect and implement scalable Generative AI solutions that address their unique business challenges. She specializes in model customization techniques and agent-based AI systems, helping organizations harness the full potential of generative AI technology. Prior to AWS, Flora earned her Master’s degree in Computer Science from the University of Minnesota, where she developed her expertise in machine learning and artificial intelligence.
 Baishali Chaudhury is an Applied Scientist at the Generative AI Innovation Center at AWS, where she focuses on advancing Generative AI solutions for real-world applications. She has a strong background in computer vision, machine learning, and AI for healthcare. Baishali holds a PhD in Computer Science from University of South Florida and PostDoc from Moffitt Cancer Centre.
Baishali Chaudhury is an Applied Scientist at the Generative AI Innovation Center at AWS, where she focuses on advancing Generative AI solutions for real-world applications. She has a strong background in computer vision, machine learning, and AI for healthcare. Baishali holds a PhD in Computer Science from University of South Florida and PostDoc from Moffitt Cancer Centre.
 Rahul Ghosh is an Applied Scientist at Amazon’s Generative AI Innovation Center, where he works with AWS customers across different verticals to expedite their use of Generative AI. Rahul holds a Ph.D. in Computer Science from the University of Minnesota.
Rahul Ghosh is an Applied Scientist at Amazon’s Generative AI Innovation Center, where he works with AWS customers across different verticals to expedite their use of Generative AI. Rahul holds a Ph.D. in Computer Science from the University of Minnesota.
 Jae Oh Woo is a Senior Applied Scientist at the AWS Generative AI Innovation Center, where he specializes in developing custom solutions and model customization for a diverse range of use cases. He has a strong passion for interdisciplinary research that connects theoretical foundations with practical applications in the rapidly evolving field of generative AI. Prior to joining Amazon, Jae Oh was a Simons Postdoctoral Fellow at the University of Texas at Austin. He holds a Ph.D. in Applied Mathematics from Yale University.
Jae Oh Woo is a Senior Applied Scientist at the AWS Generative AI Innovation Center, where he specializes in developing custom solutions and model customization for a diverse range of use cases. He has a strong passion for interdisciplinary research that connects theoretical foundations with practical applications in the rapidly evolving field of generative AI. Prior to joining Amazon, Jae Oh was a Simons Postdoctoral Fellow at the University of Texas at Austin. He holds a Ph.D. in Applied Mathematics from Yale University.
 Jamal Saboune is an Applied Science Manager with AWS Generative AI Innovation Center. He is currently leading a team focused on supporting AWS customers build innovative and scalable Generative AI products across several industries. Jamal holds a PhD in AI and Computer Vision from the INRIA Lab in France, and has a long R&D experience designing and building AI solutions that add value to users.
Jamal Saboune is an Applied Science Manager with AWS Generative AI Innovation Center. He is currently leading a team focused on supporting AWS customers build innovative and scalable Generative AI products across several industries. Jamal holds a PhD in AI and Computer Vision from the INRIA Lab in France, and has a long R&D experience designing and building AI solutions that add value to users.
 Wan Chen is an Applied Science Manager at the Generative AI Innovation Center. As a ML/AI veteran in tech industry, she has wide range of expertise on traditional machine learning, recommender system, deep learning and Generative AI. She is a stronger believer of Superintelligence, and is very passionate to push the boundary of AI research and application to enhance human life and drive business growth. She holds Ph.D in Applied Mathematics from University of British Columbia, and had worked as postdoctoral fellow in Oxford University.
Wan Chen is an Applied Science Manager at the Generative AI Innovation Center. As a ML/AI veteran in tech industry, she has wide range of expertise on traditional machine learning, recommender system, deep learning and Generative AI. She is a stronger believer of Superintelligence, and is very passionate to push the boundary of AI research and application to enhance human life and drive business growth. She holds Ph.D in Applied Mathematics from University of British Columbia, and had worked as postdoctoral fellow in Oxford University.
 Anila Joshi has more than a decade of experience building AI solutions. As a AWSI Geo Leader at AWS Generative AI Innovation Center, Anila pioneers innovative applications of AI that push the boundaries of possibility and accelerate the adoption of AWS services with customers by helping customers ideate, identify, and implement secure generative AI solutions.
Anila Joshi has more than a decade of experience building AI solutions. As a AWSI Geo Leader at AWS Generative AI Innovation Center, Anila pioneers innovative applications of AI that push the boundaries of possibility and accelerate the adoption of AWS services with customers by helping customers ideate, identify, and implement secure generative AI solutions.
Web Guide: An experimental AI-organized search results page
 We’re launching Web Guide, a Search Labs experiment that uses AI to intelligently organize the search results page, making it easier to find information and web pages.Read More
We’re launching Web Guide, a Search Labs experiment that uses AI to intelligently organize the search results page, making it easier to find information and web pages.Read More