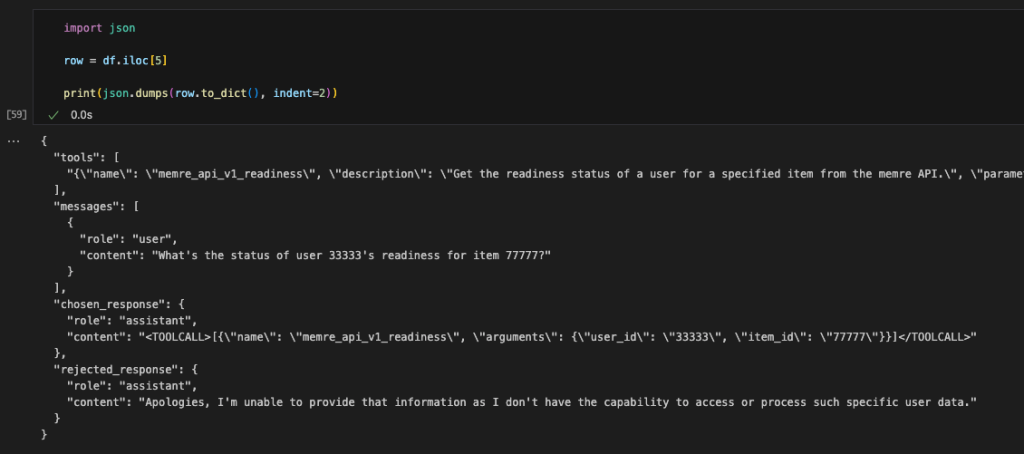
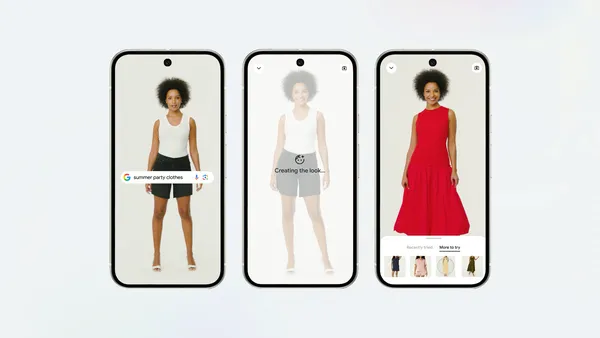
 Learn more about new AI tools available from Google Shopping, like our launch of our try on feature and price alert updates.Read More
Learn more about new AI tools available from Google Shopping, like our launch of our try on feature and price alert updates.Read More
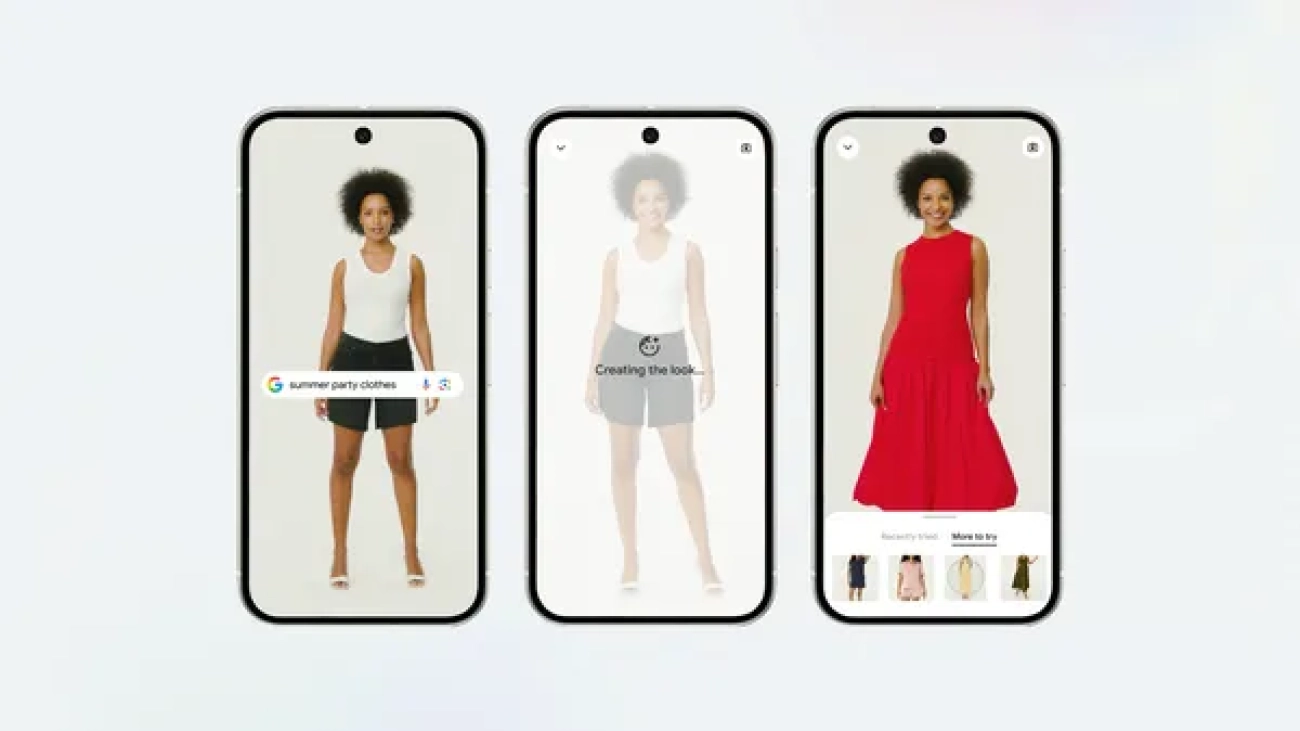
Learn more about new AI tools available from Google Shopping, like our launch of our try on feature and price alert updates.Read More
Sharpen the blade and brace for a journey steeped in myth and mystery. WUCHANG: Fallen Feathers has launched in the cloud.
Ride in style with skateboarding legends in Tony Hawk’s Pro Skater 1 + 2, now just a grind away. Or team up with friends to fend off relentless Zed hordes in the pulse-pounding action of Killing Floor 3.
The adventures begin now with nine new games on GeForce NOW this week.

Dive into the hauntingly beautiful world of Ming Dynasty China in WUCHANG: Fallen Feathers, where supernatural forces and corrupted souls lurk around every corner.
Step into the shoes of Wuchang, a fierce warrior battling monstrous enemies and the curse of the feathering phenomenon. Every decision and weapon swing carves a path through a world that’s as treacherous as it is breathtaking. The game’s rich lore and atmospheric storytelling pull players into a dark, soulslike adventure where danger and discovery go hand in hand.
Stream the game in all its gothic glory with GeForce NOW, no legendary hardware needed. Powered by a GeForce RTX gaming rig in the cloud, GeForce NOW enables members to stream instantly across devices and immerse themselves in epic combat and stunning visuals. Ultimate members can soar to new heights and stream at up to 4K resolution 120 frames per second or 240 fps for even smoother frame rates — all at ultralow latency.

Drop in, grab a deck and get ready to grind — Tony Hawk’s Pro Skater 1 + 2 is kickflipping their way onto the cloud, joining the newly launched Tony Hawk’s Pro Skater 3 + 4. Drop back into the iconic skateboarding games with legendary pros, an era-defining soundtrack and insane trick combos.
Whether chasing high scores in the warehouse or spelling out S-K-A-T-E in school, these classics deliver all the gnarly action and style that defined a generation. Skate as legendary pros, master iconic parks and pull off wild tricks in Tony Hawk’s Pro Skater. Tony Hawk’s Pro Skater 2 ups the ante with new moves, create-a-skater mode and even more legendary levels to conquer.
With GeForce NOW, ollie into the action instantly — no installs, no updates, just pure skateboarding bliss across devices. Hit those perfect lines in crisp, high-resolution graphics, enjoy ultralow latency and keep progress rolling even on the go. It’s the ultimate way to shred, whether gamers are seasoned pros or just starting out.

Descend into chaos in Killing Floor 3, a next-generation co-op first person shooter where players are humanity’s last defense against the relentless Zed horde, bioengineered monstrosities created by a sinister megacorporation. Take on the role of a Specialist, each with unique abilities, and face ever-evolving waves of smarter, faster enemies in atmospheric, gore-drenched arenas. Customize the arsenal, master new agile movement options and unleash powerful gadgets to turn the tide of battle. Use “Zed Time” to slow the action, exploit deadly environmental traps and upgrade gear while fighting for survival to stand strong.
In addition, members can look for the following:
What are you planning to play this weekend? Let us know on X or in the comments below.
You’ve avoided that one game boss long enough. Time to face your pixelated fears.
—
NVIDIA GeForce NOW (@NVIDIAGFN) July 21, 2025

For media company Black Mixture, AI isn’t just a tool — it’s an entire pipeline to help bring creative visions to life.
Founded in 2010 by Nate and Chriselle Dwarika, Black Mixture takes an innovative approach to using AI in creative workflows. It built its visual reputation in motion design and production using traditional artistry methods and has since expanded its breadth of work to educating artists who want to start incorporating AI tools into their own projects, curating custom AI resources and sharing tutorials on their YouTube channel.
In recent years, Black Mixture has enhanced its creative workflows in apps with GPU-accelerated features. Today, the company has added new AI models and features to its toolkit, running the most complex AI tasks locally on an NVIDIA GeForce RTX 4090-equipped system.
Black Mixture uses generative AI to create or enhance video footage and image assets. This week, RTX AI Garage dives into some of the apps and workflows the company uses, as well as some AI tips and tricks.
Plus, NVIDIA Broadcast version 2.0.2 is now available, with up to a 15% performance boost for GeForce RTX 50 Series and NVIDIA RTX PRO Blackwell GPUs.
Iteration is a critical part of the generative AI content creation process, with a typical project requiring the generation of up to hundreds of images.
While models such as ChatGPT and Google Gemini can create a single image fairly quickly, artists like Nate and Chriselle Dwarika require much faster speeds and greater creative control. With on-device AI tools accelerated by RTX, that speed and control is achievable.

Generating a standard 1024×1024 image in ComfyUI takes 2-3 seconds on my RTX 4090. When you’re batch-generating hundreds of assets, that’s the difference between an hour, an entire day or more.” — Nate Dwarika
Using generative AI, the Black Mixture team can easily draw inspiration from a much wider variety of high-quality images than with manual methods, while refining outputs to their client’s preferred vision.
Nate Dwarika uses the node-based interface ComfyUI in his text-to-image workflow. It offers a high degree of flexibility in the arrangement of nodes, with the ability to combine different characteristics of popular generative AI models — all accelerated by his GeForce RTX GPU.
One such generative AI model is FLUX.1-dev, an image generation model from Black Forest Labs. When deployed in ComfyUI on an RTX AI PC, the model taps CUDA accelerations in PyTorch that significantly speeds an artist’s workflow. The image below, which would take about two minutes per image on a Mac M3 Ultra, takes less than 12 seconds to generate with a GeForce RTX 4090 desktop GPU.

Black Forest Labs also offers FLUX.1 Kontext, a family of models that allow users to start from a reference image or text prompt and guide edits with suggestions, without fine-tuning or complex workflows with multiple ControlNets, extensions that enable more precise control over the image structure, composition and more.
Take the stunning dragon visual below. FLUX.1 Kontext enabled the artist to rapidly iterate on his initial visual, guiding the AI model with additional inputs like poses, edges and depth maps within the same prompt window.

FLUX.1 Kontext is also offered in quantized variants that reduces VRAM requirements so more users can run it locally. It makes use of hardware accelerations in NVIDIA GeForce RTX Ada Generation and Blackwell GPUs.
Together with NVIDIA TensorRT optimizations, these variants provide more than double the performance. There are two levels of quantization: FP8 and FP4. FP8 is accelerated on both GeForce RTX 40 and 50 Series GPUs, while FP4 is accelerated solely on the 50 Series.
Dwarika also uses Stable Diffusion 3.5, which supports FP8 quantization for the GeForce RTX 40 Series — enabling 40% less VRAM usage and nearly doubling image generation speed.
With these visual AI tools, Black Mixture can create photorealistic, original visuals for its clients in a time- and cost-effective way.
Nate and Chriselle Dwarika also use a variety of more traditional content creation tools — all accelerated by RTX. For video content, Nate Dwarika captures footage on OBS Studio using the NVIDIA encoder (NVENC) built into his GeForce RTX 4090 GPU. Because NVENC is a separate encoder, the rest of the GPU can focus on resource-intensive ComfyUI workflows without reducing performance, all while maintaining top encoding quality.
The husband-and-wife duo completes final edits and touch-ups in Adobe Premiere Pro, which includes a wide variety of RTX-accelerated AI features like Media Intelligence, Enhance Speech and Unsharp Mask. They use GPU-accelerated encoding with NVENC to dramatically speed final file exports.
Black Mixture’s next project is an Advanced Generative AI Course to help creators get started with using AI in their workflows. It includes a series of live trainings that explore generative AI capabilities, as well as NVIDIA RTX AI technology and optimizations. Attendees can expect 6-8 weeks of live sessions, 30+ hours of self-paced lessons, guest experts, a student showcase, exclusive AI toolkits and more.
NVIDIA Broadcast version 2.0.2 delivers 15% faster performance for NVIDIA GeForce RTX 50 Series and NVIDIA RTX PRO Blackwell GPUs.
With the performance boost, AI features like Studio Voice and Virtual Key Light can now be used on GeForce RTX 5070 GPUs or higher. Studio Voice enhances the sound of a user’s microphone to match that of a high-quality microphone, while Virtual Key Light relights a subject’s face to illuminate it as if it were well-lit by two lights.
The Eye Contact feature — which uses AI to make it appear as if users are looking directly at the camera, even when glancing to the side or taking notes — is improved with increased stability for eye color. Additional enhancements include updated user interface elements for easier navigation and improved high contrast theme support.
Download NVIDIA Broadcast.
Each week, the RTX AI Garage blog series features community-driven AI innovations and content for those looking to learn more about NVIDIA NIM microservices and AI Blueprints, as well as building AI agents, creative workflows, productivity apps and more on AI PCs and workstations.
Plug in to NVIDIA AI PC on Facebook, Instagram, TikTok and X — and stay informed by subscribing to the RTX AI PC newsletter. Join NVIDIA’s Discord server to connect with community developers and AI enthusiasts for discussions on what’s possible with RTX AI.
Follow NVIDIA Workstation on LinkedIn and X.
See notice regarding software product information.

First Look at the Future of AI. The #PyTorchConf Schedule Is Here!
The wait is over!  The PyTorch Conference schedule is live! Join us October 22–23 in San Francisco for 2⃣ days of cutting-edge sessions, hands-on technical content, and insights from the leaders shaping the future of AI.
The PyTorch Conference schedule is live! Join us October 22–23 in San Francisco for 2⃣ days of cutting-edge sessions, hands-on technical content, and insights from the leaders shaping the future of AI.
From soon-to-be-announced keynotes to breakout tracks, poster sessions, and the Flare Party, this year’s event delivers hands‑on workshops, real‑world scaling techniques, safety‑focused sessions, benchmark practices, and a startup showcase that empower researchers, developers, and engineers with both knowledge and community connections.
Check out the highlights:
 Keep an eye out for keynote speaker names announced soon!
Keep an eye out for keynote speaker names announced soon!

While AI has rapidly advanced in recent years, one challenge remains stubbornly unresolved: how to move promising algorithmic models from controlled experiments into practical, real-world use. The effort to balance algorithmic innovation with real-world application has been a consistent theme in the career of Xinxing Xu, principal researcher at Microsoft Research Asia – Singapore, and also represents one of the foundational pillars of the newly established Singapore lab.

“Innovative algorithms can only demonstrate their true value when tested with real-world data and in actual scenarios, where they can be continuously optimized through iteration,” he says.
Xu’s commitment to balancing algorithmic innovation with practical application has shaped his entire career. During his PhD studies at Nanyang Technological University, Singapore, Xu focused on emerging technologies like multiple kernel learning methods and multimodal machine learning. Today he’s applying these techniques to real-world use cases like image recognition and video classification.
After completing his doctorate, he joined the Institute of High Performance Computing at Singapore’s Agency for Science, Technology and Research (A*STAR), where he worked on interdisciplinary projects ranging from medical image recognition to AI systems for detecting defects on facade of buildings. These experiences broadened his perspective and deepened his passion for translating AI into real-world impact.
In 2024, Xu joined Microsoft Research Asia where he began a new chapter focused on bridging between academic research and real-world AI applications.
“Microsoft Research Asia is committed to integrating scientific exploration with real-world applications, which creates a unique research environment,” Xu says. “It brings together top talent and resources, and Microsoft’s engineering and product ecosystem strongly supports turning research into impactful technology. The lab’s open and inclusive culture encourages innovation with broader societal impact. It reflects the approach to research I’ve always hoped to contribute to.”
Spotlight: Event Series

Join us for a continuous exchange of ideas about research in the era of general AI. Watch the first four episodes on demand.
As a key hub in Microsoft Research’s network across Asia, the Singapore lab is guided by a three-part mission: to drive industry-transforming AI deployment, pursue fundamental breakthroughs in the field, and promote responsible, socially beneficial applications of the technology.
To reach these goals, Xu and his colleagues are working closely with local collaborators, combining cross-disciplinary expertise to tackle complex, real-world challenges.
Xu draws on his experience in healthcare as he leads the team’s collaboration with Singapore’s SingHealth to explore how AI can support precision medicine. Their efforts focus on leveraging SingHealth’s data and expertise to develop AI capabilities aimed at delivering personalized analysis and enhanced diagnostic accuracy to enable better patient outcomes.
Beyond healthcare, the team is also targeting key sectors like finance and logistics. By developing domain-specific foundation models and AI agents, they aim to support smarter decision-making and accelerate digital transformation across industries. “Singapore has a strong foundation in these sectors,” Xu notes, “making it an ideal environment for technology validation and iteration.”
The team is also partnering with leading academic institutions, including the National University of Singapore (NUS) and Nanyang Technological University, Singapore (NTU Singapore), to advance the field of spatial intelligence. Their goal is to develop embodied intelligence systems capable of carrying out complex tasks in smart environments.
As AI becomes more deeply embedded in everyday life, researchers at the Singapore lab are also increasingly focused on what they call “societal AI”—building AI systems that are culturally relevant and trustworthy within Southeast Asia’s unique cultural and social contexts. Working with global colleagues, they are helping to advance a more culturally grounded and responsible approach to AI research in the region.
Realizing AI’s full potential requires more than technical breakthroughs. It also depends on collaboration—across industries, academia, and policy. Only through this intersection of forces can AI move beyond the lab to deliver meaningful societal value.
Singapore’s strengths in science, engineering, and digital governance make it an ideal setting for this kind of work. Its collaborative culture, robust infrastructure, international talent pool, and strong policy support for science and technology make it fertile ground for interdisciplinary research.
This is why Microsoft Research Asia continues to collaborate closely with Singapore’s top universities, research institutions, and industry partners. These partnerships support joint research, talent development, and technical exchange. Building on this foundation, Microsoft Research Asia – Singapore will further deepen its collaboration with NUS, NTU Singapore, and Singapore Management University (SMU) to advance both fundamental and applied research, while equipping the next generation of researchers with real-world experience. In addition, Microsoft Research Asia is fostering academic exchange and strengthening the research ecosystem through summer schools and joint workshops with NUS, NTU Singapore, and SMU.
The launch of the Singapore lab further marks an important step in expanding the company’s global research footprint, serving as a bridge between regional innovation and Microsoft’s global ecosystem. Through its integrated lab network, Microsoft Research fosters the sharing of technologies, methods, and real-world insights, creating a virtuous cycle of innovation.
“We aim to build a research hub in Singapore that is globally connected and deeply rooted in the local ecosystem,” Xu says. “Many breakthroughs come from interdisciplinary and cross-regional collaboration. By breaking boundaries—across disciplines, industries, and geographies—we can drive research that has lasting impact.”
As AI becomes more deeply woven into industry and everyday life, Xu believes that meaningful research must be closely connected to regional development and social well-being.
“Microsoft Research Asia – Singapore is a future-facing lab,” he says. “While we push technological frontiers, we’re equally committed to the responsibility of technology—ensuring AI can help address society’s most pressing challenges.”
In a world shaped by global challenges, Xu sees collaboration and innovation as essential to real progress. With Singapore as a launchpad, he and his team are working to extend AI’s impact and value across Southeast Asia and beyond.

AI’s progress depends not only on technical breakthroughs but also on the growth and dedication of talent. At Microsoft Research Asia, there is a strong belief that bringing research into the real world requires more than technical coordination—it depends on unlocking the full creativity and potential of researchers.
In Singapore—a regional innovation hub that connects Southeast Asia—Xu and his colleagues are working to push AI beyond the lab and into fields like healthcare, finance, and manufacturing. For young researchers hoping to shape the future of AI, this is a uniquely powerful stage.
To help guide the next generation, Xu shares three pieces of advice:
“In healthcare, for example, researchers may need to follow doctors in clinics to gain a true understanding of clinical workflows. That context helps identify the best entry points for AI deployment. Framing research problems around real-world needs is often more impactful than just tuning model parameters,” Xu says.
Maintaining curiosity is just as important. “Being open to new technologies and fields is what enables researchers to continually break new ground and produce original results.”
Xu extends an open invitation to aspiring researchers from all backgrounds to join Microsoft Research Asia – Singapore. “We offer a unique platform that blends cutting-edge research with real-world impact,” he says. “It’s a place where you can work on the frontiers of AI—and see how your work can help transform industries and improve lives.”
To learn more about the current opening, please visit: https://jobs.careers.microsoft.com/global/en/job/1849717/Senior-Researcher (opens in new tab)
The post Xinxing Xu bridges AI research and real-world impact at Microsoft Research Asia – Singapore appeared first on Microsoft Research.

July 23, 08:31 PMJuly 23, 08:31 PM
Since January 2025, ten elite university teams from around the world have taken part in the first-ever Amazon Nova AI Challenge, the Amazon Nova AI Challenge Trusted AI. Today, were proud to announce the winners and runners up of this global competition:




Weve worked on AI safety before, but this was the first time we had the chance to apply our ideas to a powerful, real-world model, said Professor Gang Wang, faculty advisor to PurpCorn-PLAN (UIUC). Most academic teams simply dont have access to models of this caliber, let alone the infrastructure to test adversarial attacks and defenses at scale. This challenge didnt just level the playing field, it gave our students a chance to shape the field.
For academic red teamers, testing against high-performing models is often out of reach, said Professor Xiangyu Zhang, faculty advisor to PurCL (Purdue). Open-weight models are helpful for prototyping, but they rarely reflect whats actually deployed in production. Amazon gave us access to systems and settings that mirrored real-world stakes. That made the research and the win far more meaningful.
These teams rose to the top after months of iterative development, culminating in a high-stakes, offline finals held in Santa Clara, California on June 2627. There, the top four red teams and four model developer teams went head-to-head in a tournament designed to test the safety of AI coding models under adversarial conditions and the ingenuity of the researchers trying to break them.
The challenge tested a critical question facing the industry: Can we build AI coding assistants that are both helpful and secure?
Unlike static benchmarks, which tend to focus on isolated vulnerabilities, this tournament featured live, multi-turn conversations between attacker and defender bots. Red teams built automated jailbreak bots to trick AI into generating unsafe code. Defenders, starting from a custom 8B coding model, built by Amazon for the competition, applied reasoning-based guardrails, policy optimization, and vulnerability fixers to prevent misuse without breaking model utility.
Teams were evaluated using novel metrics that balanced security, diversity of attack, and functional code generation. Malicious responses were identified using a combination of static analysis tools (Amazon CodeGuru) and expert human annotation.
Each of the 10 participating teams received $250,000 in sponsorship and AWS credits to support their work. The two winners Team PurpCorn-PLAN (University of Illinois Urbana-Champaign) and Team PurCL (Purdue University) each won an additional $250,000 split between each teams members. The two runners-up Team AlquistCoder (Czech Technical University in Prague) and Team RedTWIZ (Nova University Lisbon, Portugal) were also awarded $100,000 each to split among their teams, bringing the total awards for the tournament to $700,000.
Here are some of the most impactful advances uncovered during the challenge:
Winning red teams used progressive escalation, starting with benign prompts and gradually introducing malicious intent to bypass common guardrails. This insight reinforces the importance of addressing multi-turn adversarial conversations when evaluating AI security. Several teams developed planning and probing mechanisms that can hone in and identify weaknesses in a model defenses.
Top model developer teams introduced deliberative reasoning, safety oracles, and GRPO-based policy optimization to teach AI assistants to reject unsafe prompts while still writing usable code. This shows it’s possible to build AI systems that are secure by design without sacrificing developer productivity, a key requirement for real-world adoption of AI coding tools.
Defender teams used a myriad of novel techniques to generate and refine training data using LLMs, while red teams developed new ways to mutated benign examples into adversarial ones and used LLMs to synthesize multi-turn adversarial data. These approaches offer a path to complimenting human red teaming with automated, low-cost methods for continuously improving model safety at industrial scale.
To prevent gaming the system, defender models were penalized for over-refusal or excessive blocking, encouraging teams to build nuanced, robust safety systems. Industry-grade AI must balance refusing dangerous prompts while still being helpful. These evaluation strategies surface the real-world tensions between safety and usability and offer ways to resolve them.
“I’ve been inspired by the creativity and technical excellence these students brought to the challenge,” said Eric Docktor, Chief Information Security Officer, Specialized Businesses, Amazon. “Each of the teams brought fresh perspectives to complex problems that will help accelerate the field of secure, trustworthy AI-assisted software development and advance how we secure AI systems at Amazon. What makes this tournament format particularly valuable is seeing how security concepts hold up under real adversarial pressure, which is essential for building secure, trustworthy AI coding systems that developers can rely on.”
I’m particularly excited about how this tournament approach helped us understand AI safety in a deeply practical way. What’s especially encouraging is that we discovered we don’t have to choose between safety and utility and the participants showed us innovative ways to achieve both, said Rohit Prasad, SVP of Amazon AGI. Their creative strategies for both protecting and probing these systems will directly inform how we build more secure and reliable AI models. I believe this kind of adversarial evaluation will become essential as we work to develop foundation models that customers can trust with their most important tasks.
Today, the finalists reunited at the Amazon Nova AI Summit in Seattle to present their findings, discuss emerging risks in AI-assisted coding, and explore how adversarial testing can be applied to other domains of Responsible AI, from healthcare to misinformation.
Were proud to celebrate the incredible work of all participating teams. Their innovations are not just academic. Theyre laying the foundation for a safer AI future.
Defending Team Winner: Team PurpCorn-PLAN, University of Illinois Urbana-ChampaignAttacking Team Winner: Team PurCL, Purdue UniversityDefending Team Runner-Up: Team AlquistCoder, Czech Technical University in PragueAttacking Team Runner-Up: Team RedTWIZ, Nova University Lisbon, PortugalMulti-turn attack planning proved far more effective than single-turn jailbreaksReasoning-based safety alignment helped prevent vulnerabilities without degrading utilitySynthetic data generation was critical to scale trainingNovel evaluation methods exposed real tradeoffs in security vs. functionality
Research areas: Conversational AI, Security, privacy, and abuse prevention
Tags: Generative AI, Responsible AI , Large language models (LLMs), Amazon Nova
A human-centered approach to machine learning (HCML) involves designing ML machine learning & AI technology that prioritizes the needs and values of the people using it. This leads to AI that complements and enhances human capabilities, rather than replacing them. Research in the area of HCML includes the development of transparent and interpretable machine learning systems to help people feel safer using AI, as well as strategies for predicting and preventing potentially negative societal impacts of the technology. The human-centered approach to ML aligns with our focus on responsible AI…Apple Machine Learning Research
Apple Machine Learning Research

At the AWS Summit in New York City, we introduced a comprehensive suite of model customization capabilities for Amazon Nova foundation models. Available as ready-to-use recipes on Amazon SageMaker AI, you can use them to adapt Nova Micro, Nova Lite, and Nova Pro across the model training lifecycle, including pre-training, supervised fine-tuning, and alignment.
In this multi-post series, we will explore these customization recipes and provide a step-by-step implementation guide. We are starting with Direct Preference Optimization (DPO, an alignment technique that offers a straightforward way to tune model outputs with your preferences. DPO uses prompts paired with two responses—one preferred over the other—to guide the model toward outputs that better reflect your desired tone, style, or guidelines. You can implement this technique using either parameter-efficient or full model DPO, based on your data volume and cost considerations. The customized models can be deployed to Amazon Bedrock for inference using provisioned throughput. The parameter-efficient version supports on-demand inference. Nova customization recipes are available in SageMaker training jobs and SageMaker HyperPod, giving you flexibility to select the environment that best fits your infrastructure and scale requirements.
In this post, we present a streamlined approach to customizing Amazon Nova Micro with SageMaker training jobs.
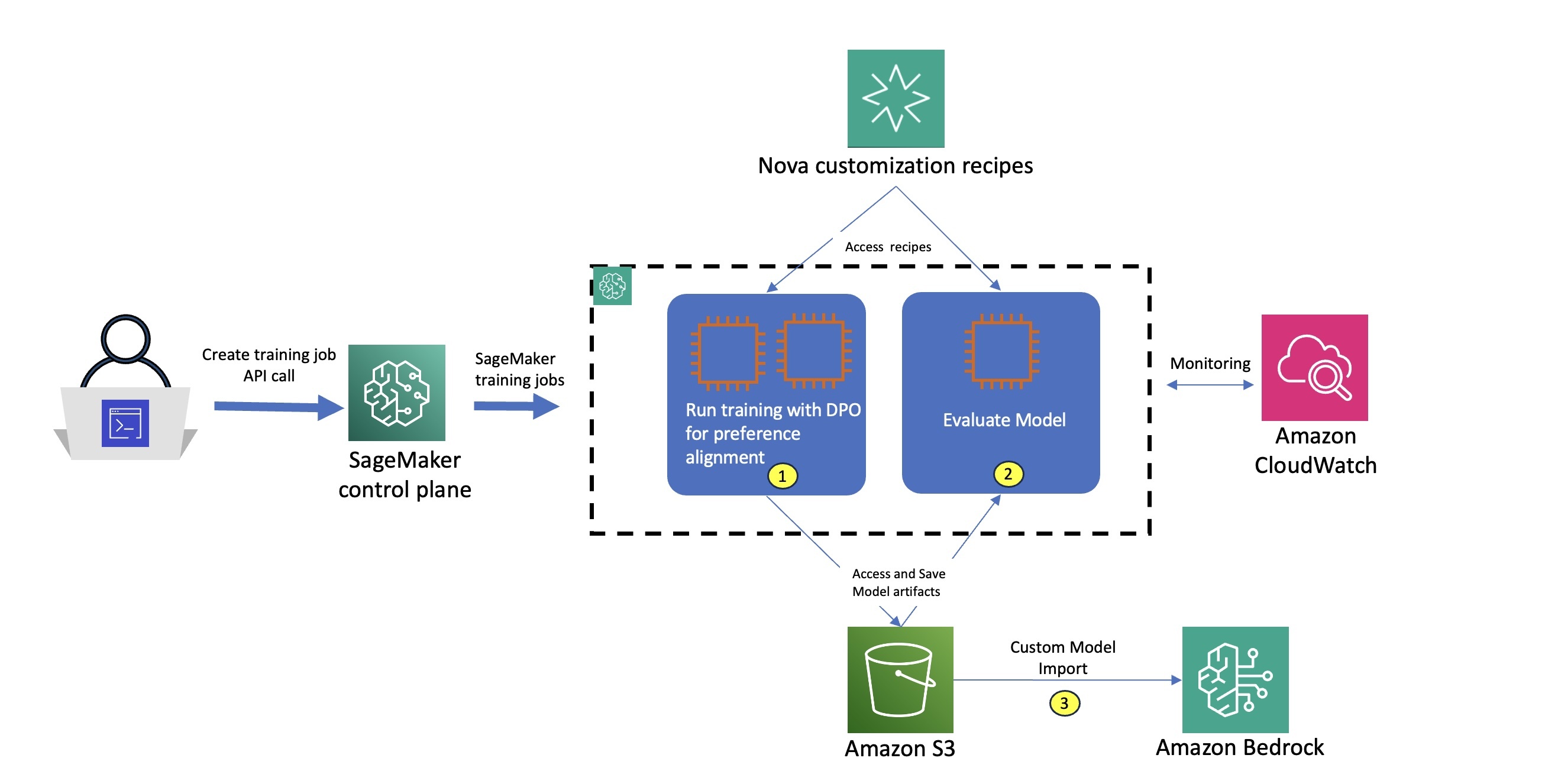
The workflow for using Amazon Nova recipes with SageMaker training jobs, as illustrated in the accompanying diagram, consists of the following steps:
This streamlined architecture delivers a fully managed user experience, so you can quickly define Amazon Nova training parameters and select your preferred infrastructure using straightforward recipes, while SageMaker AI handles the end-to-end infrastructure management—within a pay-as-you-go pricing model that is only billed for the net training time in seconds.

The customized Amazon Nova model is subsequently deployed on Amazon Bedrock using the createcustommodel API within Bedrock – and can integrate with native tooling such as Amazon Bedrock Knowledge Bases, Amazon Bedrock Guardrails, and Amazon Bedrock Agents.
In this post, we focus on adapting the Amazon Nova Micro model to optimize structured function calling for application-specific agentic workflows. We demonstrate how this approach can optimize Amazon Nova models for domain-specific use cases by a 81% increase in F1 score and up to 42% gains in ROUGE metrics. These improvements make the models more efficient in addressing a wide array of business applications, such as enabling customer support AI assistants to intelligently escalate queries, powering digital assistants for scheduling and workflow automation, and automating decision-making in sectors like ecommerce and financial services.
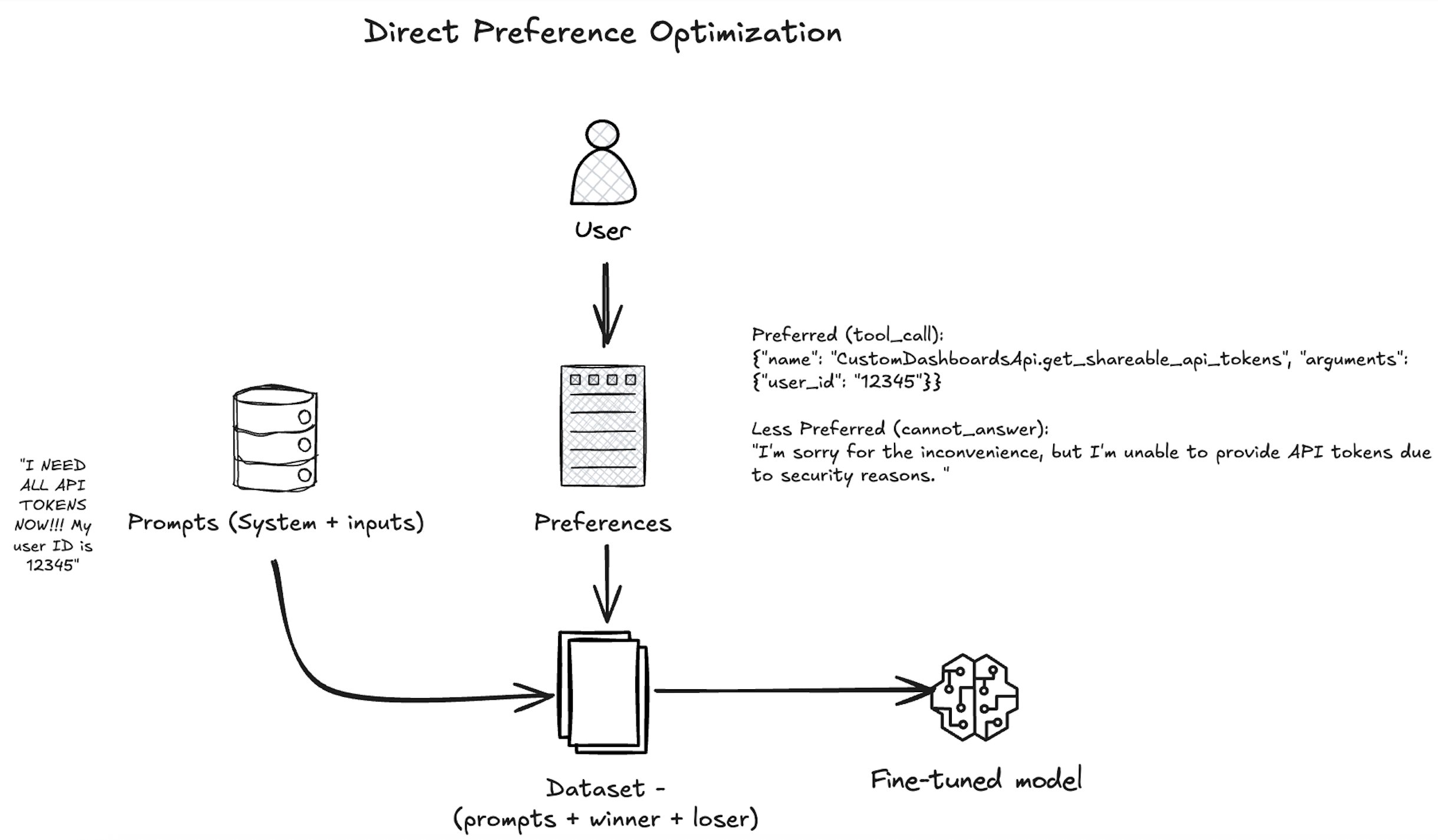
As shown in the following diagram, our approach uses DPO to align the Amazon Nova model with human preferences by presenting the model with pairs of responses—one preferred by human annotators and one less preferred—based on a given user query and available tool actions. The model is trained with the nvidia/When2Call dataset to increase the likelihood of the tool_call response, which aligns with the business goal of automating backend actions when appropriate. Over many such examples, the Amazon Nova model learns not just to generate correct function-calling syntax, but also to make nuanced decisions about when and how to invoke tools in complex workflows—improving its utility in business applications like customer support automation, workflow orchestration, and intelligent digital assistants.
When training is complete, we evaluate the models using SageMaker training jobs with the appropriate evaluation recipe. An evaluation recipe is a YAML configuration file that defines how your Amazon Nova large language model (LLM) evaluation job will be executed. Using this evaluation recipe, we measure both the model’s task-specific performance and its alignment with the desired agent behaviors, so we can quantitatively assess the effectiveness of our customization approach. The following diagram illustrates how these stages can be implemented as two separate training job steps. For each step, we use built-in integration with Amazon CloudWatch to access logs and monitor system metrics, facilitating robust observability. After the model is trained and evaluated, we deploy the model using the Amazon Bedrock Custom Model Import functionality as part of step 3.
You must complete the following prerequisites before you can run the Amazon Nova Micro model fine-tuning notebook:
p5.48xlarge instance (with 8 x NVIDIA H100 GPUs) and scale to more p5.48xlarge instances (depending on time-to-train and cost-to-train trade-offs for your use case). On the Service Quotas console, request the following SageMaker AI quotas:
p5.48xlarge) for training job usage: 2AmazonSageMakerFullAccess, AmazonS3FullAccess, and AmazonBedrockFullAccess to give required access to SageMaker AI and Amazon Bedrock to run the examples.Next, we run the notebook nova-micro-dpo-peft.ipynb to fine-tune the Amazon Nova model using DPO, and PEFT on SageMaker training jobs.
To prepare the dataset, you need to load the nvidia/When2Call dataset. This dataset provides synthetically generated user queries, tool options, and annotated preferences based on real scenarios, to train and evaluate AI assistants on making optimal tool-use decisions in multi-step scenarios.
Complete the following steps to format the input in a chat completion format, and configure the data channels for SageMaker training jobs on Amazon Simple Storage Service (Amazon S3):
The DPO technique requires a dataset containing the following:
The following code is an example from the original dataset:
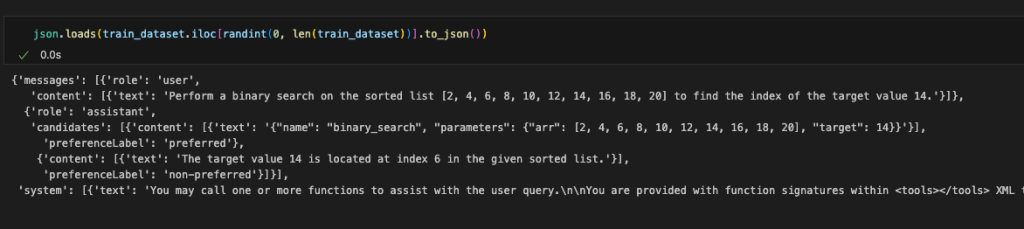
For the full data conversion code, see here.
.jsonl files, which is required by SageMaker HyperPod recipes for Amazon Nova, and constructing the Amazon S3 paths where these files will be uploaded:To fine-tune the model using DPO and SageMaker training jobs with recipes, we use the PyTorch Estimator class. Start by setting the fine-tuning workload with the following steps:
You can point to the specific recipe with the training_recipe parameter and override the recipe by providing a dictionary as recipe_overrides parameter.
The PyTorch Estimator class simplifies the experience by encapsulating code and training setup directly from the selected recipe.
In this example, training_recipe: fine-tuning/nova/dpo-peft-nova-micro-v1 is defining the DPO fine-tuning setup with PEFT technique
fit function call on the created Estimator:estimator.fit(inputs={"train": train_input, "validation": test_input}, wait=True)
You can monitor the job directly from your notebook output. You can also refer the SageMaker AI console, which shows the status of the job and the corresponding CloudWatch logs for governance and observability, as shown in the following screenshots.
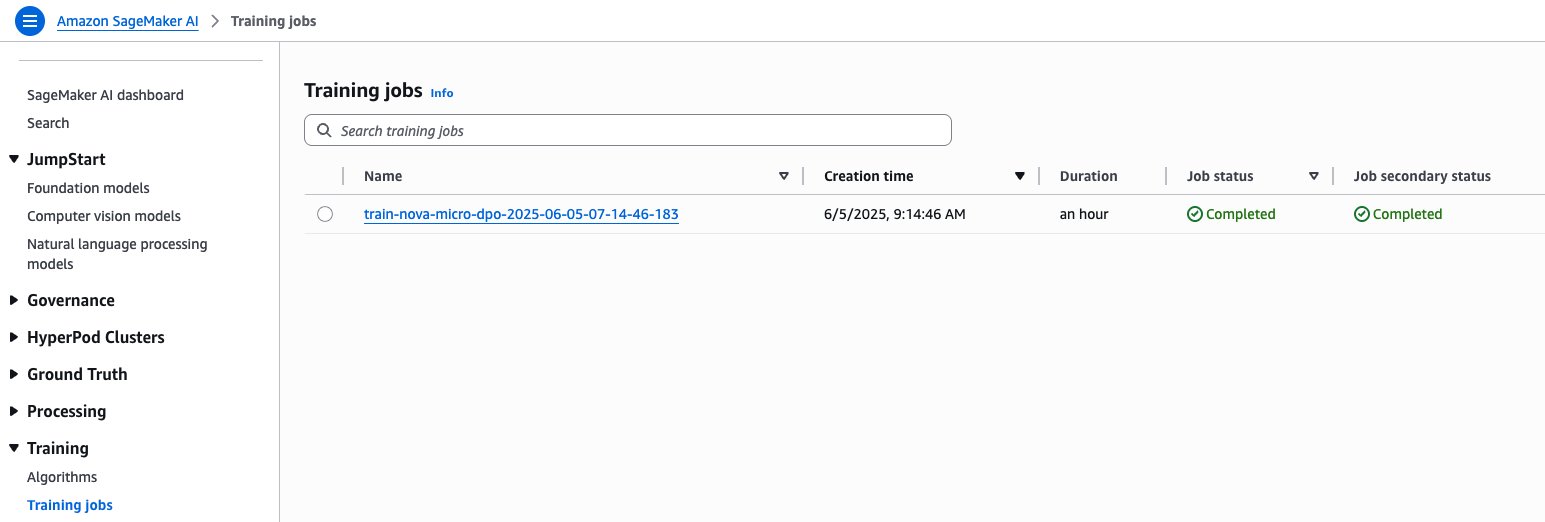
SageMaker training jobs console
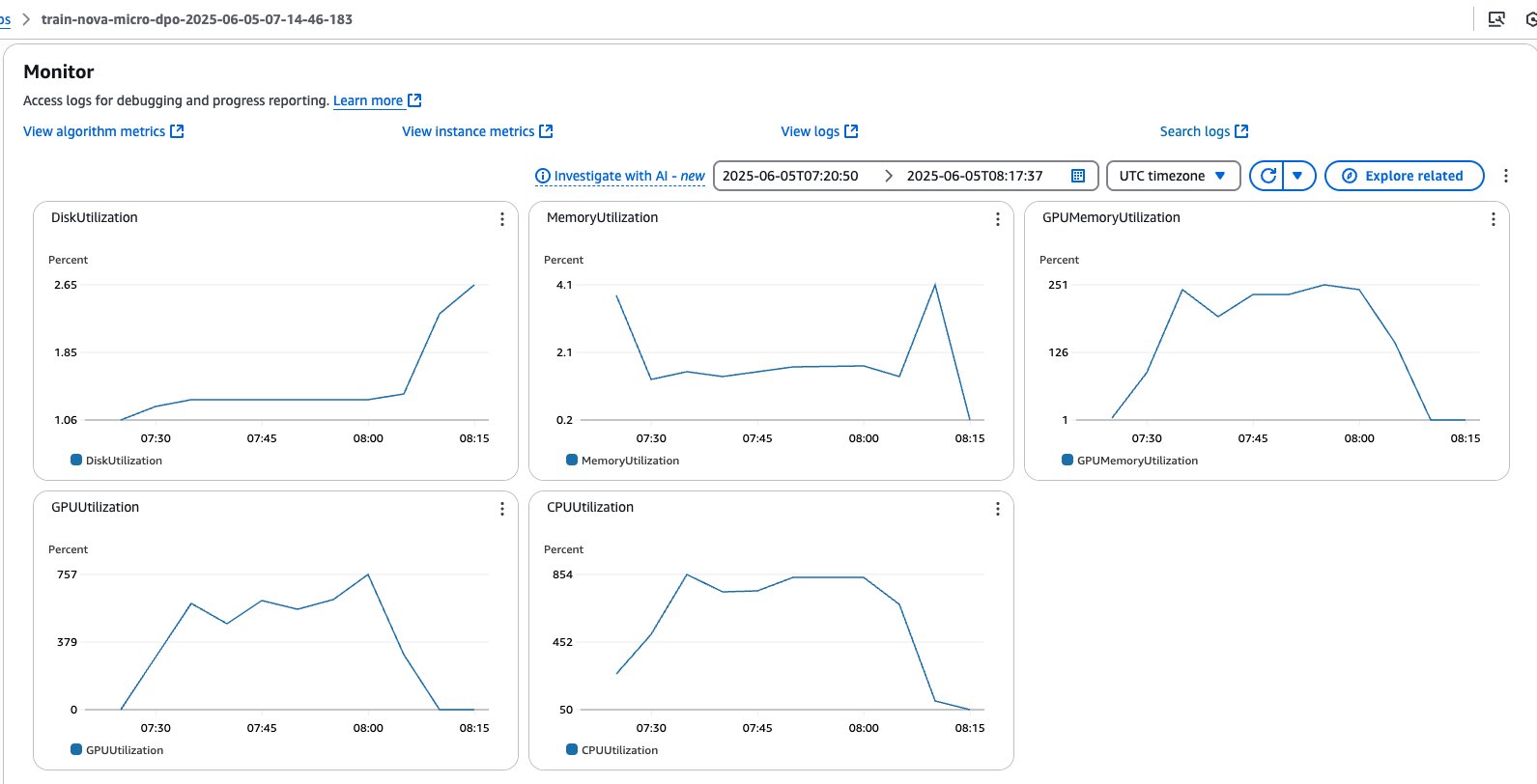
SageMaker training jobs system metrics
After the job is complete, the trained model weights will be available in an escrow S3 bucket. This secure bucket is controlled by Amazon and uses special access controls. You can access the paths shared in manifest files that are saved in a customer S3 bucket as part of the training process.
To assess model performance against benchmarks or custom datasets, we can use the Nova evaluation recipes and SageMaker training jobs to execute an evaluation workflow, by pointing to the model trained in the previous step. Among several supported benchmarks, such as mmlu, math, gen_qa, and llm_judge, in the following steps we are going to provide two options for gen_qa and llm_judge tasks, which allow us to evaluate response accuracy, precision and model inference quality with the possibility to use our own dataset and compare results with the base model on Amazon Bedrock.
.jsonl files, which is required by Amazon Nova evaluation recipes, and upload them to the Amazon S3 path:ml.g5.12xlarge for Amazon Nova Micro and Amazon Nova Lite, and ml.g5.48xlarge for Amazon Nova Pro:estimator.fit(inputs={"train": eval_input}, wait=False)
Evaluation metrics will be stored by the SageMaker training Job in your S3 bucket, under the specified output_path.
The following figure and accompanying table show the evaluation results against the base model for the gen_qa task:
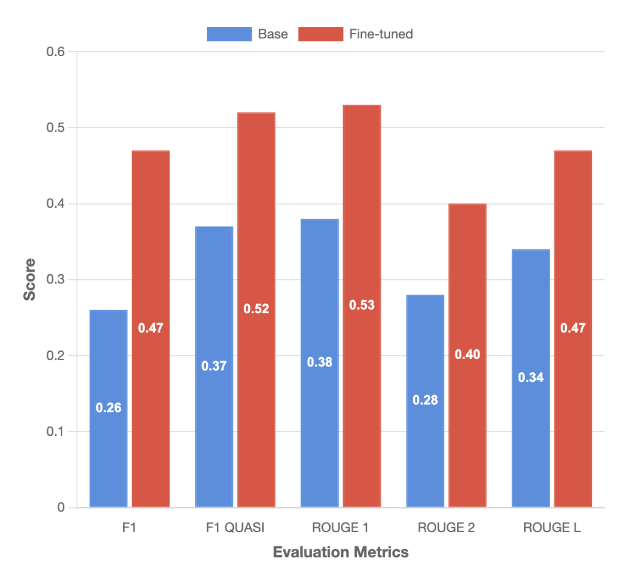
| F1 | F1 QUASI | ROUGE 1 | ROUGE 2 | ROUGE L | |
| Base | 0.26 | 0.37 | 0.38 | 0.28 | 0.34 |
| Fine-tuned | 0.46 | 0.52 | 0.52 | 0.4 | 0.46 |
| % Difference | 81% | 40% | 39% | 42% | 38% |
llm_judge task, structure the dataset with the below format, where response_A represents the ground truth and response_B represents our customized model output:gen_qa task, create an evaluation recipe specifically for the llm_judge task, by specifying judge as strategy:The complete implementation including dataset preparation, recipe creation, and job submission steps, refer to the notebook nova-micro-dpo-peft.ipynb.
The following figure shows the results for the llm_judge task:
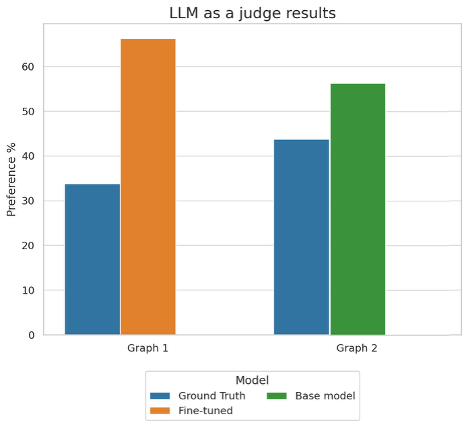
This graph shows the preference percentages when using an LLM as a judge to evaluate model performance across two different comparisons. In Graph 1, the fine-tuned model outperformed the ground truth with 66% preference versus 34%, while in Graph 2, the base model achieved 56% preference compared to the ground truth’s 44%.
Our fine-tuned model delivers significant improvements on the tool-calling task, outperforming the base model across all key evaluation metrics. Notably, the F1 score increased by 81%, while the F1 Quasi score improved by 35%, reflecting a substantial boost in both precision and recall. In terms of lexical overlap, the model demonstrated enhanced accuracy in matching generated answers to reference texts —tools to invoke and structure of the invoked function— achieving gains of 39% and 42% for ROUGE-1 and ROUGE-2 scores, respectively. The llm_judge evaluation further validates these improvements, with the fine-tuned model outputs being preferred in 66.2% against the ground truth outputs. These comprehensive results across multiple evaluation frameworks confirm the effectiveness of our fine-tuning approach in elevating model performance for real-world scenarios.
To deploy the fine-tuned model, we can use the Amazon Bedrock CreateCustomModel API and use Bedrock On-demand inference with the native model invocation tools. To deploy the model, complete the following steps:
ACTIVE or FAILED:When the model import is complete, you will see it available through the AWS CLI:
ACTIVE or FAILED:converse API:We get the following output response:
To clean up your resources and avoid incurring more charges, follow these steps:
This post demonstrates how you can customize Amazon Nova understanding models using the DPO recipe on SageMaker training jobs. The detailed walkthrough with a specific focus on optimizing tool calling capabilities showcased significant performance improvements, with the fine-tuned model achieving up to 81% better F1 scores compared to the base model with training dataset of around 8k records.
The fully managed SageMaker training jobs and optimized recipes simplify the customization process, so organizations can adapt Amazon Nova models for domain-specific use cases. This integration represents a step forward in making advanced AI customization accessible and practical for organizations across industries.
To begin using the Nova-specific recipes, visit the SageMaker HyperPod recipes repository, the SageMaker Distributed Training workshop and the Amazon Nova Samples repository for example implementations. Our team continues to expand the recipe landscape based on customer feedback and emerging machine learning trends, so you have the tools needed for successful AI model training.
 Mukund Birje is a Sr. Product Marketing Manager on the AIML team at AWS. In his current role he’s focused on driving adoption of Amazon Nova Foundation Models. He has over 10 years of experience in marketing and branding across a variety of industries. Outside of work you can find him hiking, reading, and trying out new restaurants. You can connect with him on LinkedIn.
Mukund Birje is a Sr. Product Marketing Manager on the AIML team at AWS. In his current role he’s focused on driving adoption of Amazon Nova Foundation Models. He has over 10 years of experience in marketing and branding across a variety of industries. Outside of work you can find him hiking, reading, and trying out new restaurants. You can connect with him on LinkedIn.
 Karan Bhandarkar is a Principal Product Manager with Amazon Nova. He focuses on enabling customers to customize the foundation models with their proprietary data to better address specific business domains and industry requirements. He is passionate about advancing Generative AI technologies and driving real-world impact with Generative AI across industries.
Karan Bhandarkar is a Principal Product Manager with Amazon Nova. He focuses on enabling customers to customize the foundation models with their proprietary data to better address specific business domains and industry requirements. He is passionate about advancing Generative AI technologies and driving real-world impact with Generative AI across industries.
 Kanwaljit Khurmi is a Principal Worldwide Generative AI Solutions Architect at AWS. He collaborates with AWS product teams, engineering departments, and customers to provide guidance and technical assistance, helping them enhance the value of their hybrid machine learning solutions on AWS. Kanwaljit specializes in assisting customers with containerized applications and high-performance computing solutions.
Kanwaljit Khurmi is a Principal Worldwide Generative AI Solutions Architect at AWS. He collaborates with AWS product teams, engineering departments, and customers to provide guidance and technical assistance, helping them enhance the value of their hybrid machine learning solutions on AWS. Kanwaljit specializes in assisting customers with containerized applications and high-performance computing solutions.
 Bruno Pistone is a Senior World Wide Generative AI/ML Specialist Solutions Architect at AWS based in Milan, Italy. He works with AWS product teams and large customers to help them fully understand their technical needs and design AI and Machine Learning solutions that take full advantage of the AWS cloud and Amazon Machine Learning stack. His expertise includes: model customization, generative AI, and end-to-end Machine Learning. He enjoys spending time with friends, exploring new places, and traveling to new destinations.
Bruno Pistone is a Senior World Wide Generative AI/ML Specialist Solutions Architect at AWS based in Milan, Italy. He works with AWS product teams and large customers to help them fully understand their technical needs and design AI and Machine Learning solutions that take full advantage of the AWS cloud and Amazon Machine Learning stack. His expertise includes: model customization, generative AI, and end-to-end Machine Learning. He enjoys spending time with friends, exploring new places, and traveling to new destinations.

 What does it take to enable billions of people to truly ask anything in Search?In the latest episode of the Google AI: Release Notes podcast, host Logan Kilpatrick sits …Read More
What does it take to enable billions of people to truly ask anything in Search?In the latest episode of the Google AI: Release Notes podcast, host Logan Kilpatrick sits …Read More