Gemini 2.5 Flash-Lite, previously in preview, is now stable and generally available. This cost-efficient model provides high quality in a small size, and includes 2.5 family features like a 1 million-token context window and multimodality.Read More

Gemini 2.5 Flash-Lite, previously in preview, is now stable and generally available. This cost-efficient model provides high quality in a small size, and includes 2.5 family features like a 1 million-token context window and multimodality.Read More

Editor’s note: This post is part of the AI On blog series, which explores the latest techniques and real-world applications of agentic AI, chatbots and copilots. The series also highlights the NVIDIA software and hardware powering advanced AI agents, which form the foundation of AI query engines that gather insights and perform tasks to transform everyday experiences and reshape industries.
With advancements in agentic AI, intelligent AI systems are maturing to now facilitate autonomous decision-making across industries, including financial services.
Over the last year, customer service-related use of generative AI, including chatbots and AI assistants, has more than doubled in financial services, rising from 25% to 60%. Organizations are using AI to automate time-intensive tasks like document processing and report generation, driving significant cost savings and operational efficiency.
According to NVIDIA’s latest State of AI in Financial Services report, more than 90% of respondents reported a positive impact on their organization’s revenue from AI.
AI agents are versatile, capable of adapting to complex tasks that require strict protocols and secure data usage. They can help with an expanding list of use cases, from enabling better investment decisions by automatically identifying portfolio optimization strategies to ensuring regulatory alignment and compliance automation.
To improve market returns and business performance, AI agents are being adopted in various areas that benefit greatly from autonomous decision-making backed by data.
According to the State of AI in Financial Services report, 60% of respondents said customer experience and engagement was the top use case for generative AI. Businesses using AI have already seen customer experiences improve by 26%.
AI agents can help automate repetitive tasks while providing next steps, such as dispute resolution and know-your-customer updates. This reduces operational costs and helps minimize human errors.
By handling customer inquiries and forms, AI chatbots scale support and ensure 24/7 availability, enhancing customer satisfaction. Employees can focus on higher-level, judgment-based cases, rather than performing case intake, data analysis and documentation.
In addition, AI agents are crucial for fraud detection, as they can detect and respond to suspicious transactions automatically. The State of AI report highlighted that out of 20 use cases, cybersecurity experienced the highest growth over the last year, with more than a third of respondents now assessing or investing in AI for cybersecurity.
AI closes the time gap between detection and action, as a lack of action can result in significant financial loss.
To combat fraud, AI agents can monitor transaction patterns in real time, learn from new types of fraud and take immediate action by alerting compliance teams or freezing suspicious accounts — all without the need for human intervention. Plus, teams of AI agents can work with other systems to retrieve additional data, simulate potential fraud scenarios and investigate abnormalities.
AI agents make financial management easier, especially for bill payment and cash flow management. Because agentic AI supports machine-to-machine interactions in digital ecosystems, it can ensure regulatory compliance by automatically maintaining detailed audit trails. This reduces compliance costs and processing time, making it easier for financial institutions to operate in complex regulatory environments.
For capital markets, the most powerful investment insights are often hidden in unstructured text data from everyday document sources such as news articles, blogs and SEC filings. AI agents can accelerate intelligent document processing (IDP) to provide insight and investment recommendations for traders, enabling faster decision-making and reducing the risk of financial losses.
In consumer banking, handling documents like loan records, regulatory filings and transaction records involves a lot of complex data. This amount of data is so large that it can be difficult and time-consuming to process and understand it manually. IDP helps solve this issue, using AI to identify document types, summarize documents, employ retrieval-augmented generation for answers and support, and organize data.
The data-driven insights from multi-agent systems inform strategic business decisions as these systems continuously learn from customer and institutional data using a data flywheel.
Many industry customers and partners have benefited significantly from integrating AI into their workflows.
For example, BlackRock uses Aladdin, a proprietary platform that unifies investment management processes across public and private markets for institutional investors.
With numerous Aladdin applications and thousands of specialized users, the BlackRock team identified an opportunity to use AI to streamline the platform’s user experience while fostering connectivity and operational efficiency. Rapidly and securely, BlackRock has bolstered the Aladdin platform with advanced AI through Aladdin Copilot.
Using a federated development model, where different teams can work on AI agents independently while building on a common foundation, BlackRock’s central AI team established a standardized communication system and plug-in registry. This allows the firm’s developers and data scientists to create and deploy AI agents tailored to their specific areas, improving intelligence and efficiency for clients.
Another example is bunq’s generative AI platform, Finn, which offers users a range of features to help manage finances through an in-app chatbot. It can answer questions about money, provide insight into spending habits and offer tips on using the bunq app. Finn uses advanced AI to improve its responses based on feedback and, beyond the in-app chatbot, now handles over 90% of all users’ support tickets.
Capital One is also assisting customers with Chat Concierge, its multi-agent conversational AI assistant designed to enhance the automotive-buying experience. Consumers have 24/7 access to agents that provide real-time information and take action based on user requests. In a single conversation, Chat Concierge can perform tasks like comparing vehicles to help car buyers find their ideal choice and scheduling test drives or appointments with a sales team.
RBC’s latest platform for global research, Aiden, uses internal agents to automatically perform analysis when companies covered by RBC Capital Markets release SEC filings. Aiden has an orchestration agent working with other agents, such as the SEC filing agent, earnings agent and a real-time news agent.
The building blocks of a powerful financial services agent include:
Learn more about how financial services companies are using AI to enhance services and business operations in the full State of AI in Financial Services report.
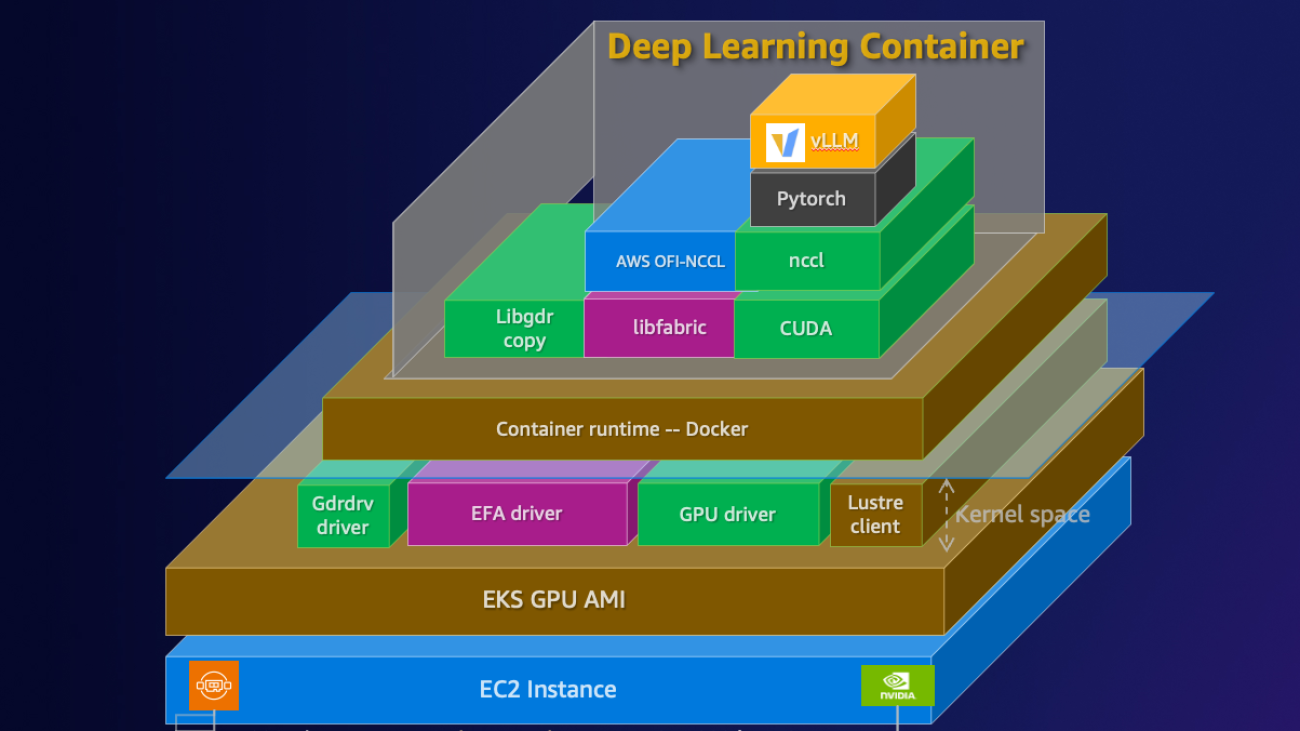
Data science teams working with artificial intelligence and machine learning (AI/ML) face a growing challenge as models become more complex. While Amazon Deep Learning Containers (DLCs) offer robust baseline environments out-of-the-box, customizing them for specific projects often requires significant time and expertise.
In this post, we explore how to use Amazon Q Developer and Model Context Protocol (MCP) servers to streamline DLC workflows to automate creation, execution, and customization of DLC containers.
AWS DLCs provide generative AI practitioners with optimized Docker environments to train and deploy large language models (LLMs) in their pipelines and workflows across Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Kubernetes Service (Amazon EKS), and Amazon Elastic Container Service (Amazon ECS). AWS DLCs are targeted for self-managed machine learning (ML) customers who prefer to build and maintain their AI/ML environments on their own, want instance-level control over their infrastructure, and manage their own training and inference workloads. Provided at no additional cost, the DLCs come pre-packaged with CUDA libraries, popular ML frameworks, and the Elastic Fabric Adapter (EFA) plug-in for distributed training and inference on AWS. They automatically configure a stable connected environment, which eliminates the need for customers to troubleshoot common issues such as version incompatibilities. DLCs are available as Docker images for training and inference with PyTorch and TensorFlow on Amazon Elastic Container Registry (Amazon ECR).
The following figure illustrates the ML software stack on AWS.
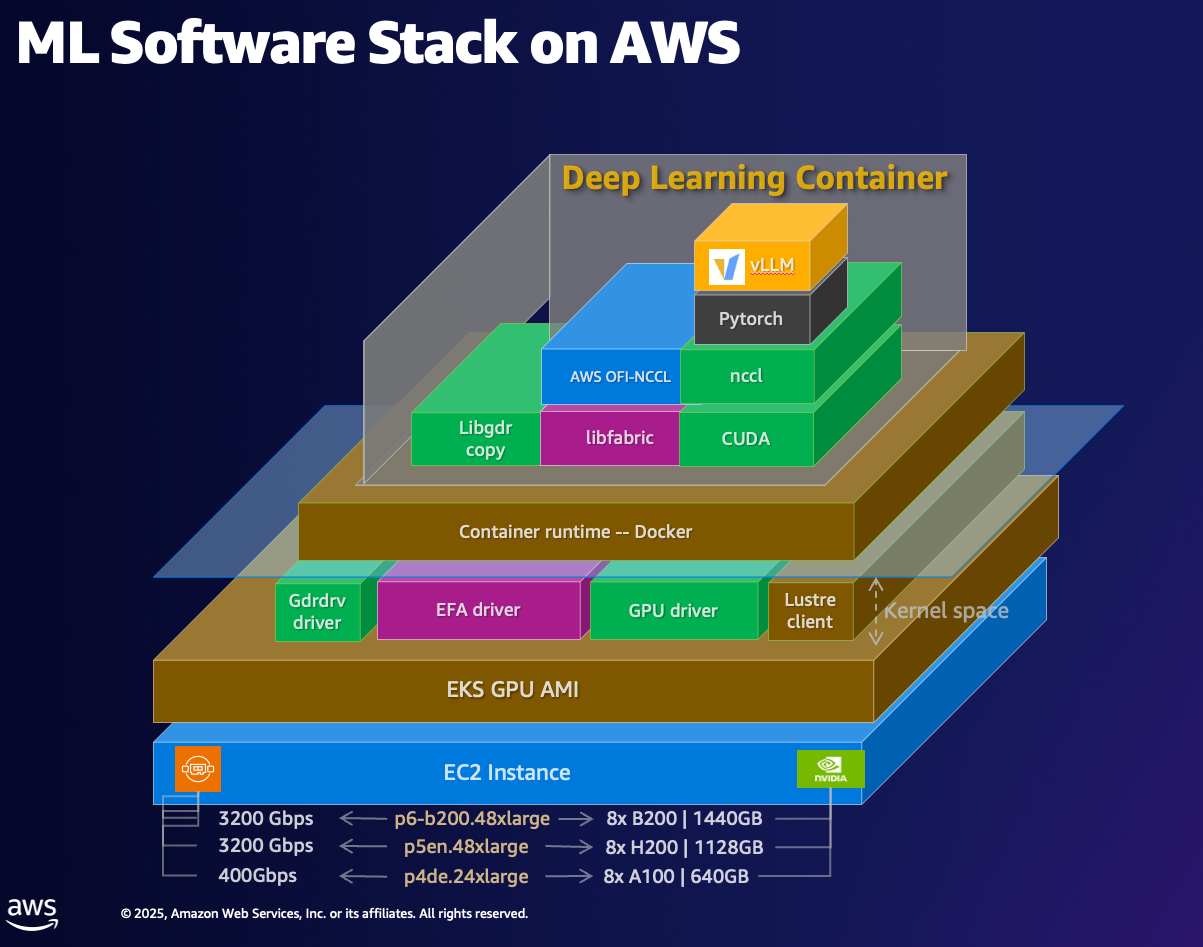
DLCs are kept current with the latest version of frameworks and drivers, tested for compatibility and security, and offered at no additional cost. They are also straightforward to customize by following our recipe guides. Using AWS DLCs as a building block for generative AI environments reduces the burden on operations and infrastructure teams, lowers TCO for AI/ML infrastructure, accelerates the development of generative AI products, and helps generative AI teams focus on the value-added work of deriving generative AI-powered insights from the organization’s data.
Organizations often encounter a common challenge: they have a DLC that serves as an excellent foundation, but it requires customization with specific libraries, patches, or proprietary toolkits. The traditional approach to this customization involves the following steps:
This process often requires days of work from specialized teams, with each iteration introducing potential errors and inconsistencies. For organizations managing multiple AI projects, these challenges compound quickly, leading to significant operational overhead and potential delays in development cycles.
Amazon Q acts as your AI-powered AWS expert, offering real-time assistance to help you build, extend, and operate AWS applications through natural conversations. It combines deep AWS knowledge with contextual understanding to provide actionable guidance when you need it. This tool can help you navigate AWS architecture, manage resources, implement best practices, and access documentation—all through natural language interactions.
The Model Context Protocol (MCP) is an open standard that enables AI assistants to interact with external tools and services. Amazon Q Developer CLI now supports MCP, allowing you to extend Q’s capabilities by connecting it to custom tools and services.
By taking advantage of the benefits of both Amazon Q and MCP, we have implemented a DLC MCP server that transforms container management from complex command line operations into simple conversational instructions. Developers can securely create, customize, and deploy DLCs using natural language prompts. This solution potentially reduces the technical overhead associated with DLC workflows.
The following diagram shows the interaction between users using Amazon Q with a DLC MCP server.
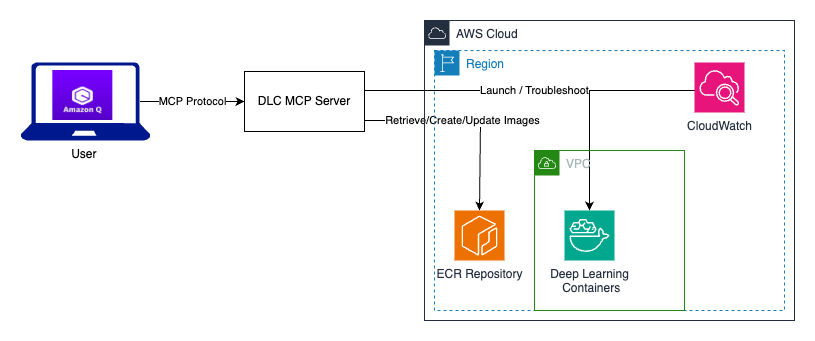
The DLC MCP server provides six core tools:
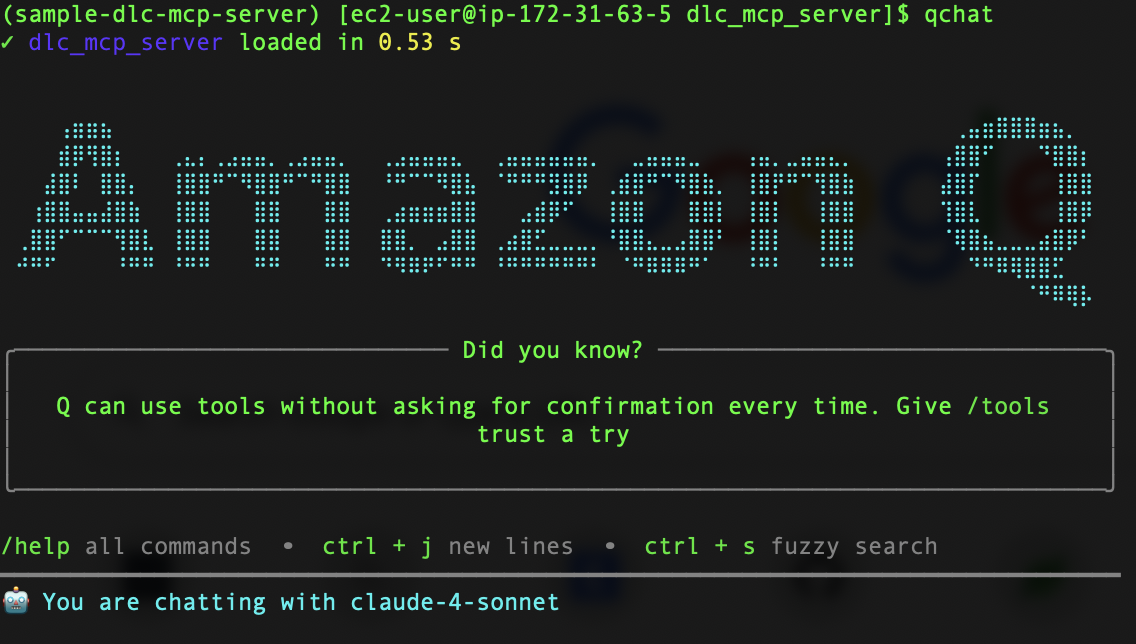
Follow the installation steps in the GitHub repo to set up the DLC MCP server and Amazon Q CLI in your workstation.
You’re now ready to start using the Amazon Q CLI with DLC MCP server. Let’s start with the CLI, as shown in the following screenshot. You can also check the default tools and loaded server tools in the CLI with the /tools command.
In the following sections, we demonstrate three separate use cases using the DLC MPC server.
In this scenario, our goal is to identify a PyTorch base image, launch the image in a local Docker container, and run a simple test script to verify the container.
We start with the prompt “Run Pytorch container for training.”
The MCP server automatically handles the entire workflow: it authenticates with Amazon ECR and pulls the appropriate PyTorch DLC image.
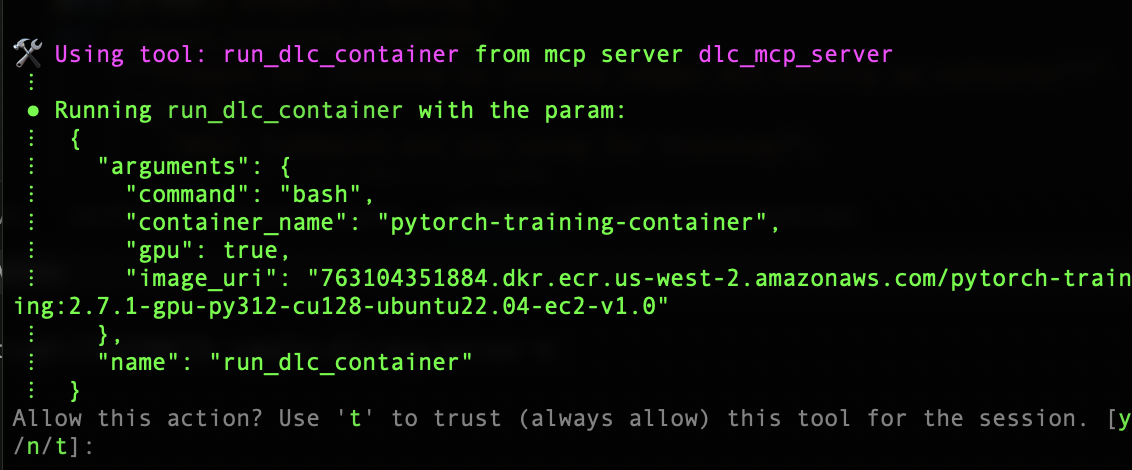
Amazon Q used the GPU image because we didn’t specify the device type. Let’s try asking for a CPU image and see its response. After identifying the image, the server pulls the image from the ECR repository successfully and runs the container in your environment. Amazon Q has built-in tools that handle bash scripting and file operations, and a few other standard tools that speed up the runtime.
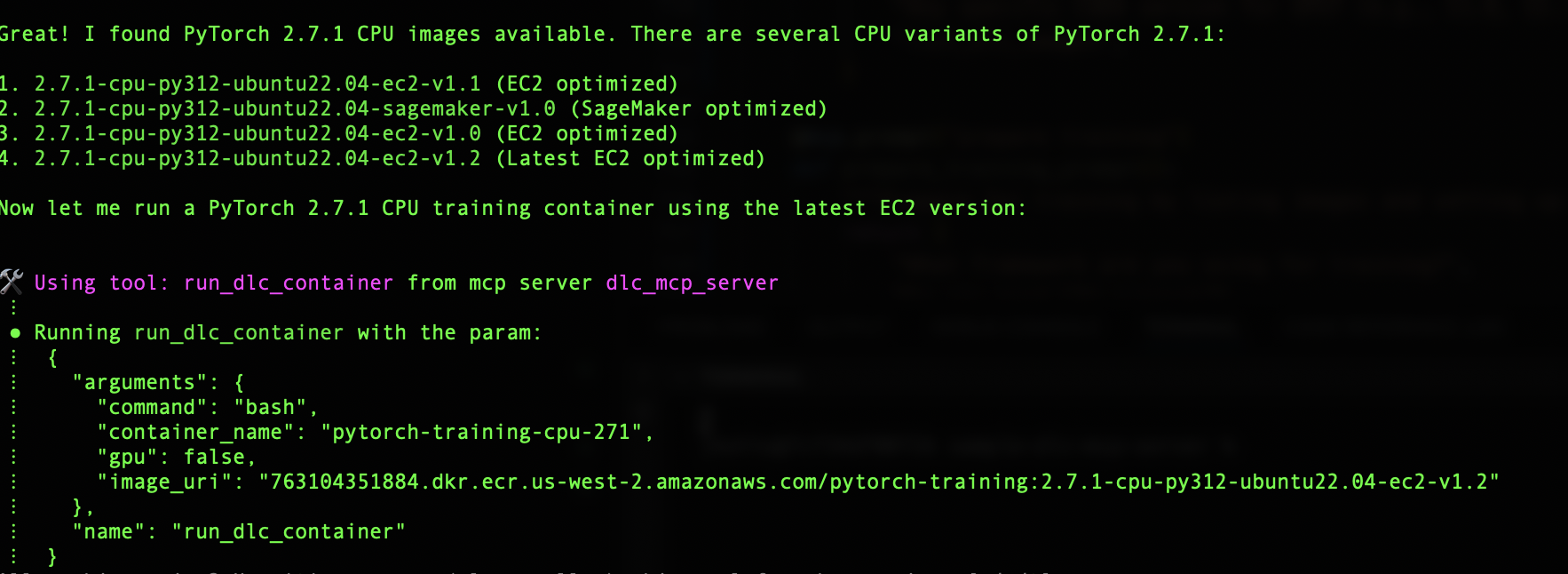
After the image is identified, the run_the_container tool from the DLC MCP server is used to start the container locally, and Amazon Q tests it with simple scripts to make sure the container is loading and running the scripts as expected. In our example, our test script checks the PyTorch version.

We further prompt the server to perform a training task on the PyTorch CPU training container using a popular dataset. Amazon Q autonomously selects the CIFAR-10 dataset for this example. Amazon Q gathers the dataset and model information based on its pretrained knowledge without human intervention. Amazon Q prompts the user about the choices it’s making on your behalf. If needed, you can specify the required model or dataset directly in the prompt.
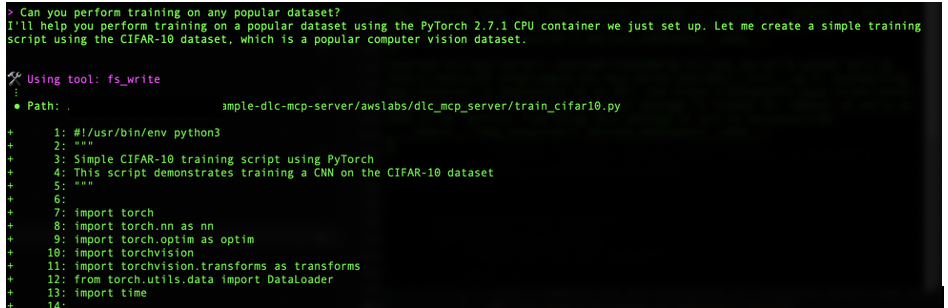
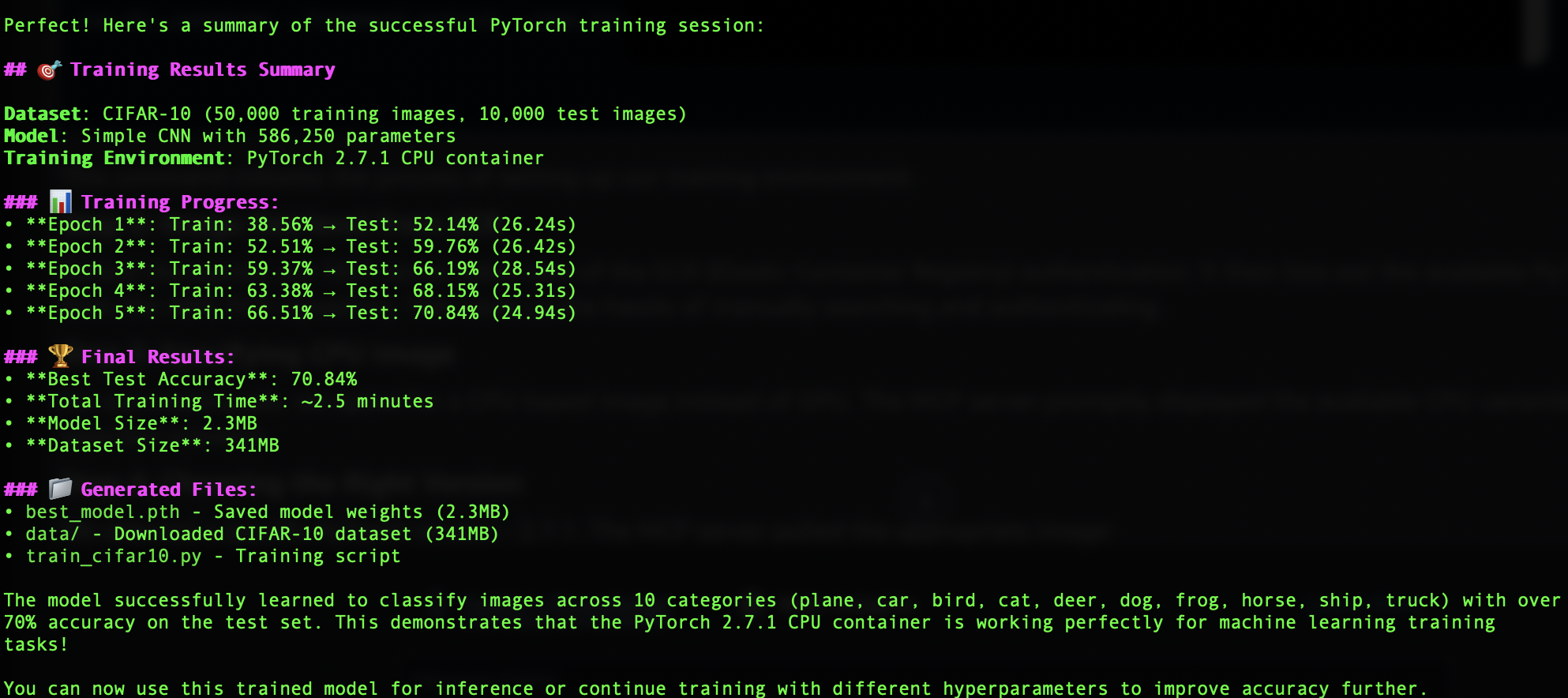
When the scripts are ready for execution, the server runs the training job on the container. After successfully training, it summarizes the training job results along with the model path.
In this scenario, we walk through the process of enhancing an existing DLC with NVIDIA’s NeMo toolkit. NeMo, a powerful framework for conversational AI, is built on PyTorch Lightning and is designed for efficient development of AI models. Our goal is to create a custom Docker image that integrates NeMo into the existing PyTorch GPU training container. This section demonstrates how to create a custom DLC image that combines the PyTorch GPU environment with the advanced capabilities of the NeMo toolkit.
The server invokes the create_custom_dockerfile tool from our MCP server’s image building module. We can use this tool to specify our base image from Amazon ECR and add custom commands to install NeMo.

This Dockerfile serves as a blueprint for our custom DLC image, making sure the necessary components are in place. Refer to the Dockerfile in the GitHub repo.
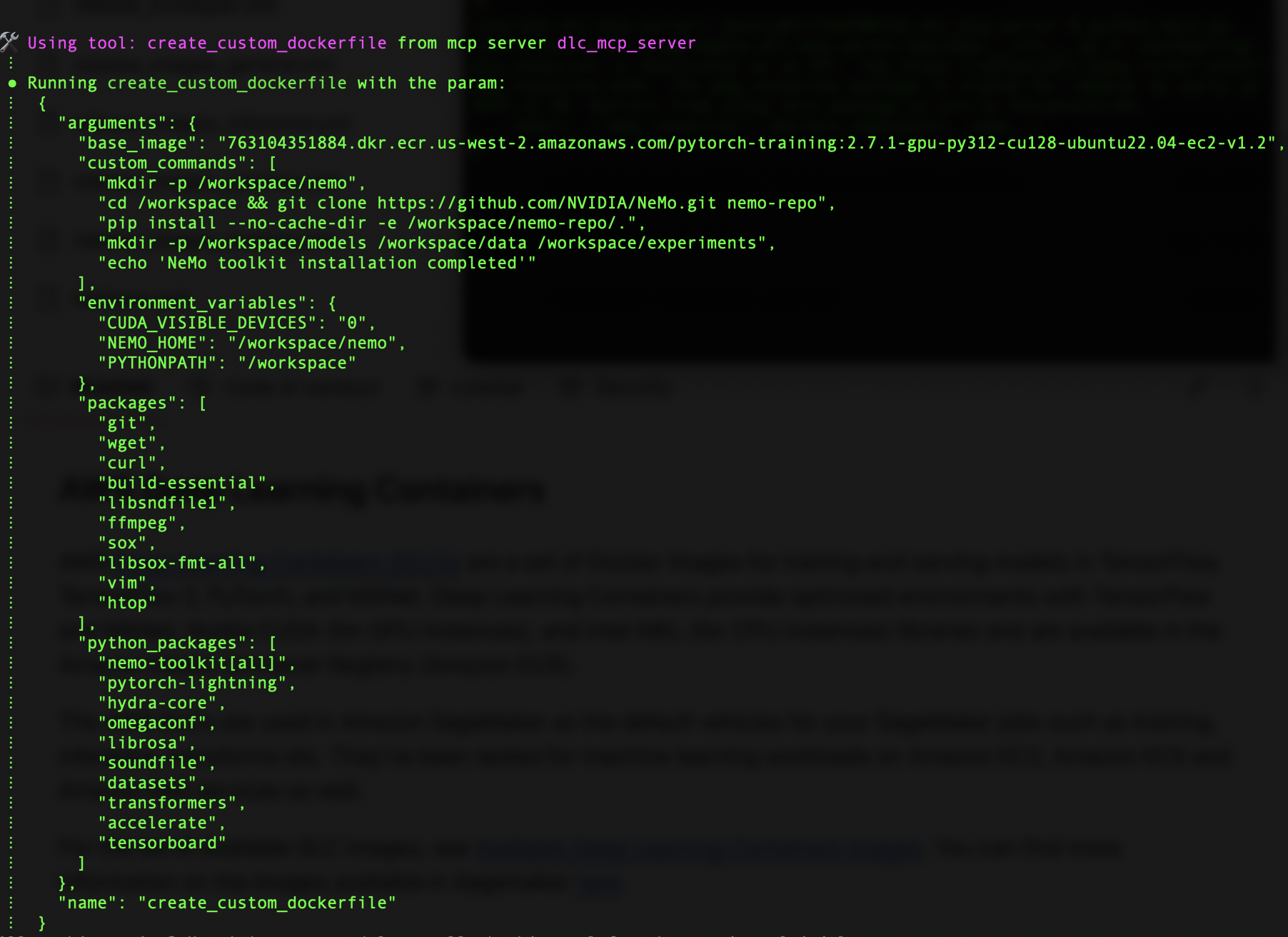
After the custom Dockerfile is created, the server starts building our custom DLC image. To achieve this, Amazon Q uses the build_custom_dlc_image tool in the image building module. This tool streamlines the process by setting up the build environment with specified arguments. This step transforms our base image into a specialized container tailored for NeMo-based AI development.
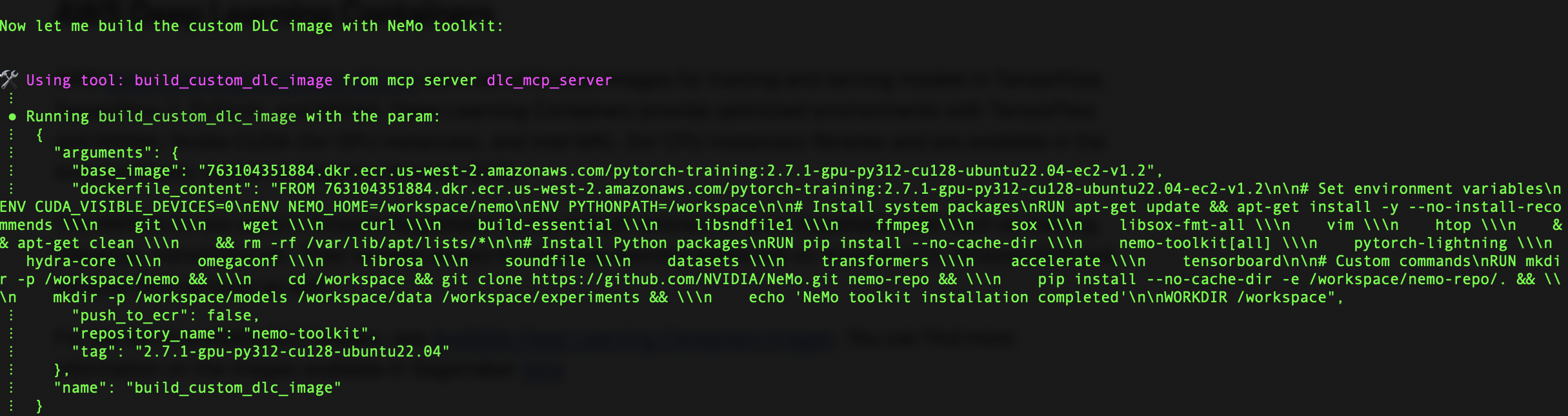
The build command pulls from a specified ECR repository, making sure we’re working with the most up-to-date base image. The image also comes with related packages and libraries to test NeMo; you can specify the requirements in the prompt if required.
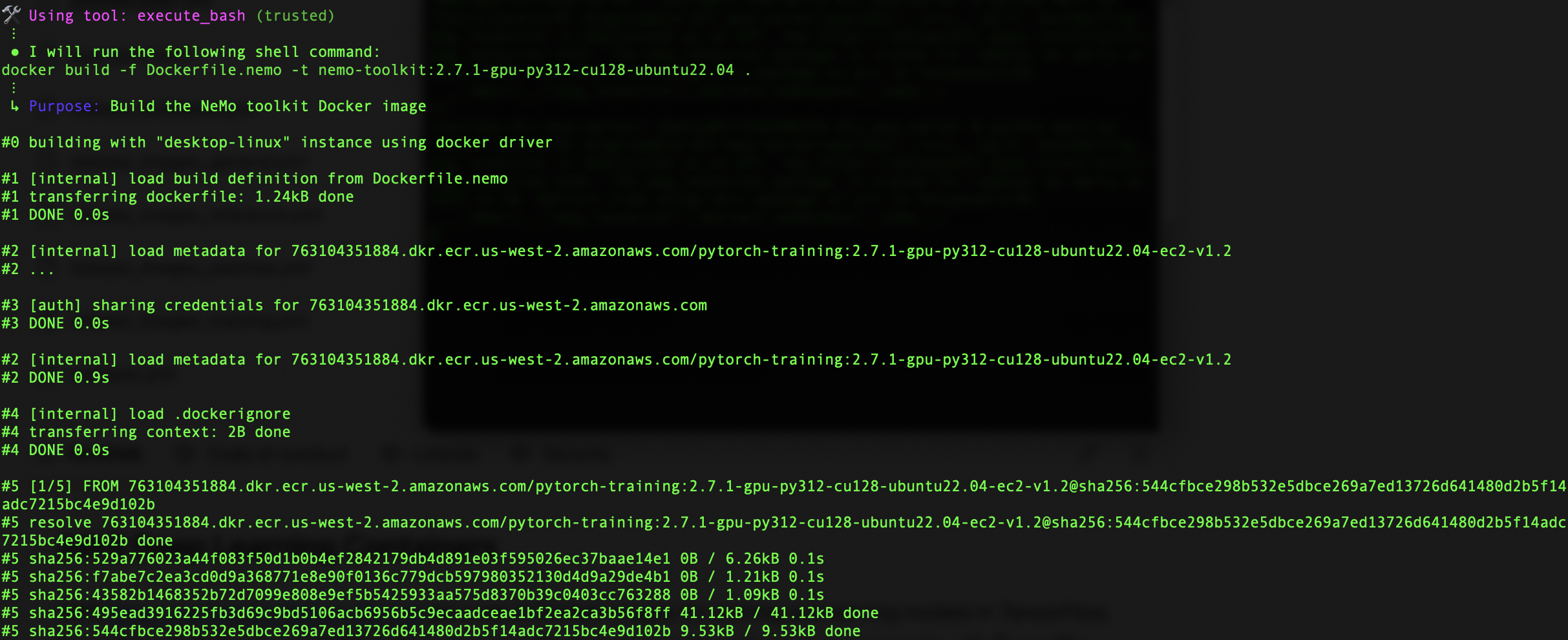
NeMo is now ready to use with a quick environment check to make sure our tools are in the toolbox before we begin. You can run a simple Python script in the Docker container that shows you everything you want to know. In the following screenshot, you can see the PyTorch version 2.7.1+cu128 and PyTorch Lightning version 2.5.2. The NeMo modules are loaded and ready for use.
The DLC MCP server has transformed the way we create custom DLC images. Traditionally, setting up environments, managing dependencies, and writing Dockerfiles for AI development was a time-consuming and error-prone process. It often took hours, if not days, to get everything just right. But now, with Amazon Q along with the DLC MCP server, you can accomplish this in just a few minutes.
For NeMo-based AI applications, you can focus more on model development and less on infrastructure setup. The standardized process makes it straightforward to move from development to production, and you can be confident that your container will work the same way each time it’s built.
In this scenario, we explore how to enhance an existing PyTorch GPU DLC by adding the DeepSeek model. Unlike our previous example where we added the NeMo toolkit, here we integrate a powerful language model using the latest PyTorch GPU container as our base. Let’s start with the prompt shown in the following screenshot.

Amazon Q interacts with DLC MCP server to list the DLC images and check for available PyTorch GPU images. After the base image is picked, multiple tools from the DLC MCP server, such as create_custom_dockerfile and build_custom_dlc_image, are used to create and build the Dockerfile. The key components in Dockerfile for this example are:
This configuration sets up our working directories, handles the PyTorch upgrade to 2.7.1 (latest), and sets essential environment variables for DeepSeek integration. The server also includes important Python packages like transformers, accelerate, and Flask for a production-ready setup.
Before diving into the build process, let’s understand how the MCP server prepares the groundwork. When you initiate the process, the server automatically generates several scripts and configuration files. This includes:
The build process first handles authentication with Amazon ECR, establishing a secure connection to the AWS container registry. Then, it either locates your existing repository or creates a new one if needed. In the image building phase, the base PyTorch 2.6.0 image gets transformed with an upgrade to version 2.7.1, complete with CUDA 12.8 support. The DeepSeek Coder 6.7B Instruct model integration happens seamlessly.
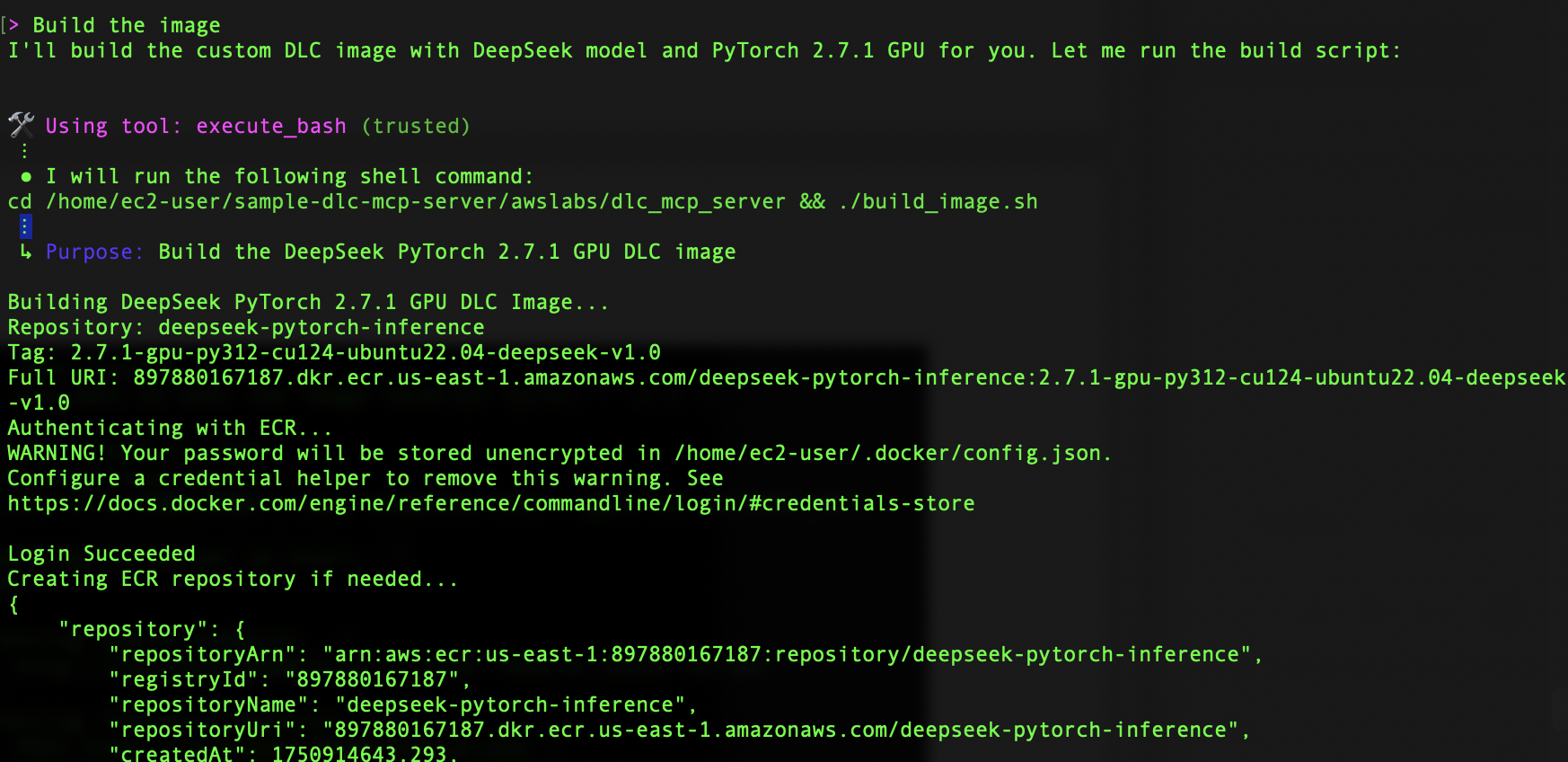
After the build is successful, we move to the testing phase using the automatically generated test scripts. These scripts help verify both the basic functionality and production readiness of the DeepSeek container. To make sure our container is ready for deployment, we spin it up using the code shown in the following screenshot.
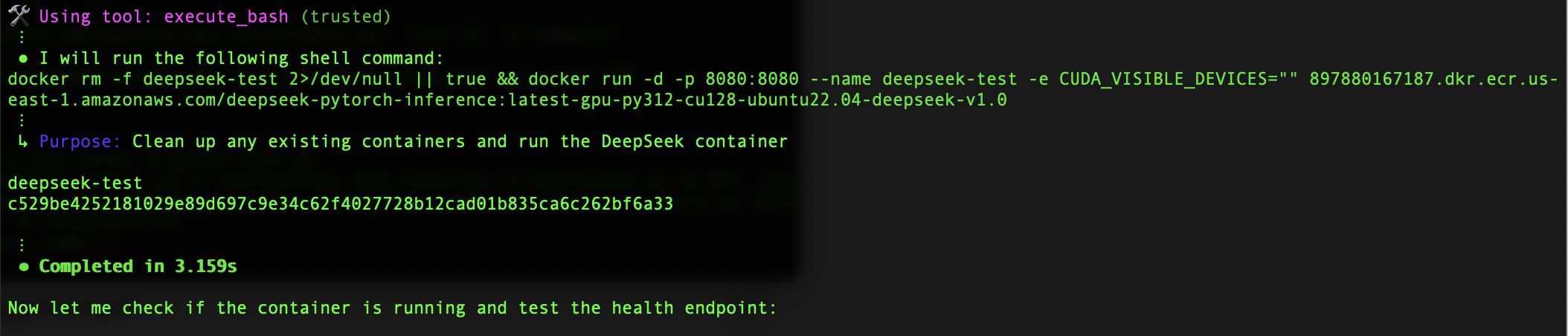
The container initialization takes about 3 seconds—a remarkably quick startup time that’s crucial for production environments. The server performs a simple inference check using a curl command that sends a POST request to our local endpoint. This test is particularly important because it verifies not just the model’s functionality, but also the entire infrastructure we’ve set up.
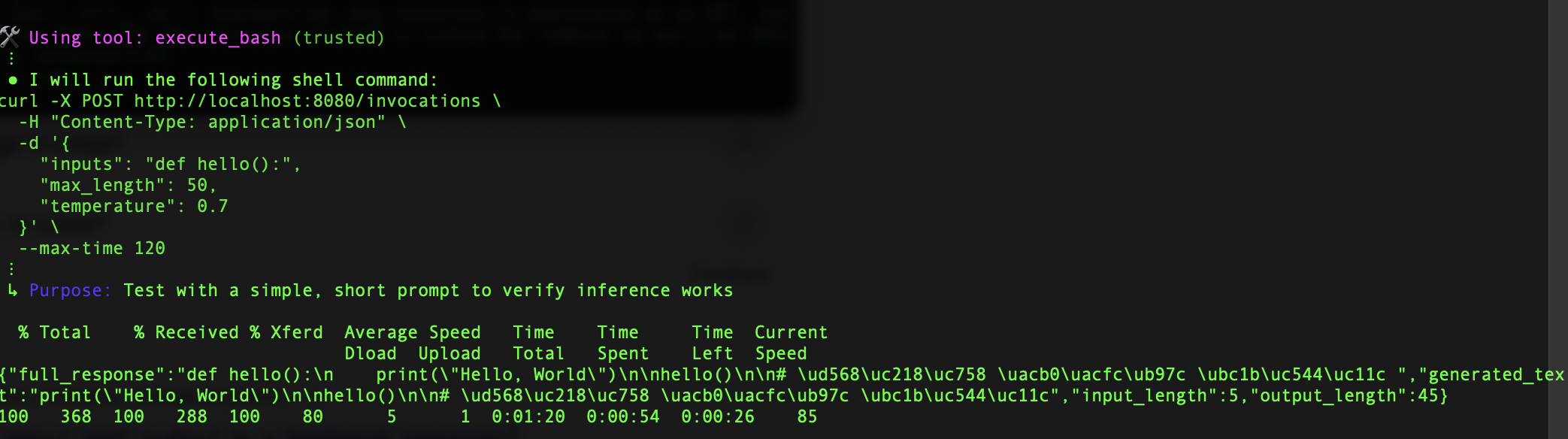
We have successfully created a powerful inference image that uses the DLC PyTorch container’s performance optimizations and GPU acceleration while seamlessly integrating DeepSeek’s advanced language model capabilities. The result is more than just a development tool—it’s a production-ready solution complete with health checks, error handling, and optimized inference performance. This makes it ideal for deployment in environments where reliability and performance are critical. This integration creates new opportunities for developers and organizations looking to implement advanced language models in their applications.
The combination of DLC MCP and Amazon Q transforms what used to be weeks of DevOps work into a conversation with your tools. This not only saves time and reduces errors, but also helps teams focus on their core ML tasks rather than infrastructure management.
For more information about Amazon Q Developer, refer to the Amazon Q Developer product page to find video resources and blog posts. You can share your thoughts with us in the comments section or in the issues section of the project’s GitHub repository.
 Sathya Balakrishnan is a Sr. Cloud Architect in the Professional Services team at AWS, specializing in data and ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
Sathya Balakrishnan is a Sr. Cloud Architect in the Professional Services team at AWS, specializing in data and ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
 Jyothirmai Kottu is a Software Development Engineer in the Deep Learning Containers team at AWS, specializing in building and maintaining robust AI and ML infrastructure. Her work focuses on enhancing the performance, reliability, and usability of DLCs, which are crucial tools for AI/ML practitioners working with AI frameworks. She is passionate about making AI/ML tools more accessible and efficient for developers around the world. Outside of her professional life, she enjoys a good coffee, yoga, and exploring new places with family and friends.
Jyothirmai Kottu is a Software Development Engineer in the Deep Learning Containers team at AWS, specializing in building and maintaining robust AI and ML infrastructure. Her work focuses on enhancing the performance, reliability, and usability of DLCs, which are crucial tools for AI/ML practitioners working with AI frameworks. She is passionate about making AI/ML tools more accessible and efficient for developers around the world. Outside of her professional life, she enjoys a good coffee, yoga, and exploring new places with family and friends.
 Arindam Paul is a Sr. Product Manager in SageMaker AI team at AWS responsible for Deep Learning workloads on SageMaker, EC2, EKS, and ECS. He is passionate about using AI to solve customer problems. In his spare time, he enjoys working out and gardening.
Arindam Paul is a Sr. Product Manager in SageMaker AI team at AWS responsible for Deep Learning workloads on SageMaker, EC2, EKS, and ECS. He is passionate about using AI to solve customer problems. In his spare time, he enjoys working out and gardening.
July 21, 01:52 PMJuly 21, 01:52 PM
Foundation models (FMs) such as large language models and vision-language models are growing in popularity, but their energy inefficiency and computational cost remain an obstacle to broader deployment.
To address those challenges, we propose a new architecture that, in our experiments, reduced an FMs inference time by 30% while maintaining its accuracy. Our architecture overcomes challenges in prior approaches to improving efficiency by maintaining both the models adaptability and its structural integrity.
With the traditional architecture, when an FM is presented with a new task, data passes through all of its processing nodes, or neurons even if theyre irrelevant to the current task. Unfortunately, this all-hands-on-deck approach leads to high computational demands and increased costs.
Our goal was to build a model that can select the appropriate subset of neurons on the fly, depending on the task; this is similar to, for instance, the way the brain relies on clumps of specialized neurons in the visual or auditory cortex to see or hear. Such an FM could adapt to multiple kinds of inputs, such as speech and text, over a range of languages, and produce multiple kinds of outputs.
In a paper we presented at this years International Conference on Learning Representations (ICLR), we propose a novel context-aware FM for multilingual speech recognition, translation, and language identification. Rather than activating the whole network, this model selects bundles of neurons or modules to activate, depending on the input context. The input context includes characteristics such as what language the input is in, speech features of particular languages, and whether the task is speech translation, speech recognition, or language identification.
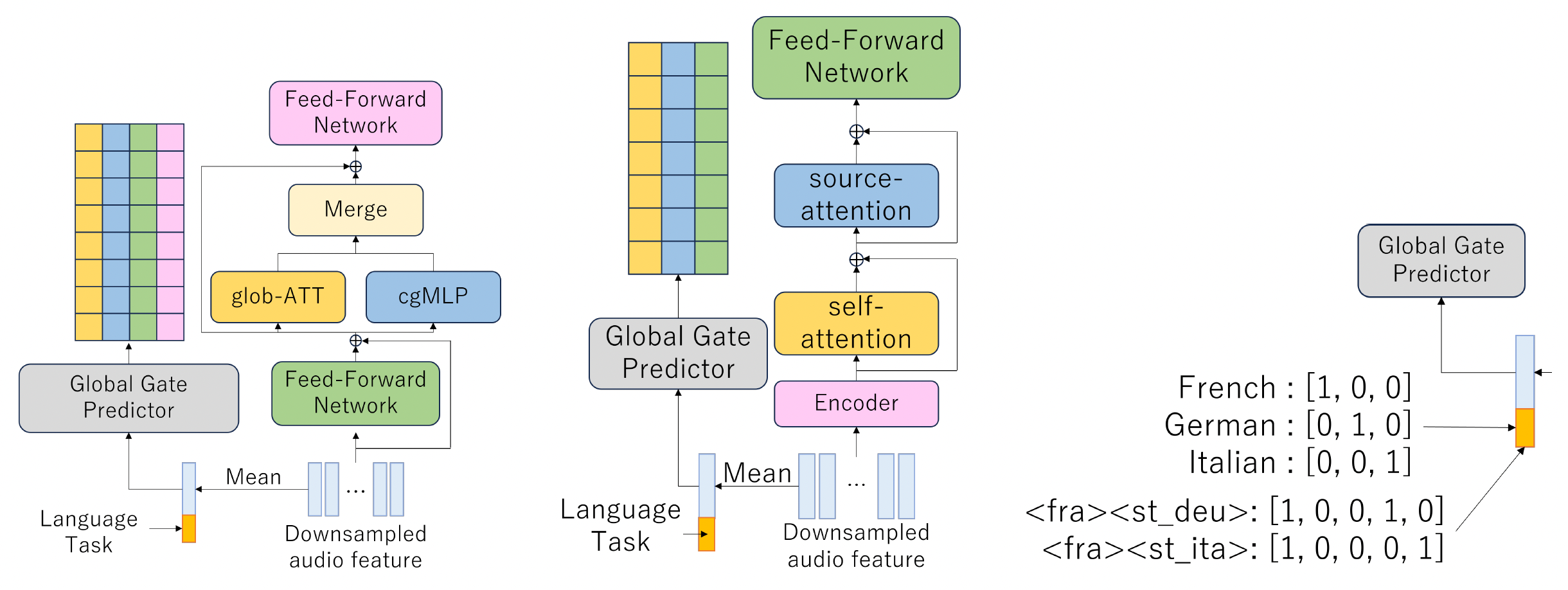
Once the model identifies the context, it predicts the likelihood of activating each of the modules. We call those likelihoods gate probabilities, and each one constitutes a filter that we call a gate predictor. If a gate probability exceeds some threshold, the corresponding module is activated.
For instance, based on a few words of spoken German the model might predict, with a likelihood that crosses the gate threshold, that the context is German audio. That prediction opens up a subset of appropriate pathways, shutting down others.
Prior approaches to pruning have focused on fine-grained pruning of model layers and of convolutional kernels. Layer pruning, however, can impair a models structural integrity, while fine-grained kernel pruning can inhibit a models ability to adapt to different kinds of inputs.
Module-wise pruning lets us balance between structural flexibility and ability to interpret different contexts. The model is trained to dynamically prune irrelevant modules at runtime, which encourages each module to specialize in a different task.
In experiments, our model demonstrated performance comparable to that of a traditional model but with 30% fewer GPUs, reducing costs and increasing speed.
In addition to saving computational resources, our approach also lets us observe how the model processes linguistic information during training. For each component of a task, we can see the probability distributions for the use of various modules. For instance, if we ask the model to transcribe German speech to text, only the modules for German language and spoken language are activated.
This work focused on FMs that specialize in speech tasks. In the future, we aim to explore how this method could generalize to FMs that process even more inputs, including vision, speech, audio, and text.
Acknowledgements: We want thank Shinji Watanabe, Masao Someki, Nathan Susanj, Jimmy Kunzmann, Ariya Rastrow, Ehry MacRostie, Markus Mueller, Yifan Peng, Siddhant Arora, Thanasis Mouchtaris, Rupak Swaminathan, Rajiv Dhawan, Xuandi Fu, Aram Galstyan, Denis Filimonov, and Sravan Bodapati for the helpful discussions.
Research areas: Conversational AI
Tags: Large language models (LLMs), Generative AI, Compression
Extracting meaningful insights from unstructured data presents significant challenges for many organizations. Meeting recordings, customer interactions, and interviews contain invaluable business intelligence that remains largely inaccessible due to the prohibitive time and resource costs of manual review. Organizations frequently struggle to efficiently capture and use key information from these interactions, resulting in not only productivity gaps but also missed opportunities to use critical decision-making information.
This post introduces a serverless meeting summarization system that harnesses the advanced capabilities of Amazon Bedrock and Amazon Transcribe to transform audio recordings into concise, structured, and actionable summaries. By automating this process, organizations can reclaim countless hours while making sure key insights, action items, and decisions are systematically captured and made accessible to stakeholders.
Many enterprises have standardized on infrastructure as code (IaC) practices using Terraform, often as a matter of organizational policy. These practices are typically driven by the need for consistency across environments, seamless integration with existing continuous integration and delivery (CI/CD) pipelines, and alignment with broader DevOps strategies. For these organizations, having AWS solutions implemented with Terraform helps them maintain governance standards while adopting new technologies. Enterprise adoption of IaC continues to grow rapidly as organizations recognize the benefits of automated, version-controlled infrastructure deployment.
This post addresses this need by providing a complete Terraform implementation of a serverless audio summarization system. With this solution, organizations can deploy an AI-powered meeting summarization solution while maintaining their infrastructure governance standards. The business benefits are substantial: reduced meeting follow-up time, improved knowledge sharing, consistent action item tracking, and the ability to search across historical meeting content. Teams can focus on acting upon meeting outcomes rather than struggling to document and distribute them, driving faster decision-making and better organizational alignment.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, DeepSeek, Luma, Meta, Mistral AI, poolside (coming soon), Stability AI, TwelveLabs (coming soon), Writer, and Amazon Nova through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. With Amazon Bedrock, you can experiment with and evaluate top FMs for your use case, customize them with your data using techniques such as fine-tuning and Retrieval Augmented Generation (RAG), and build agents that execute tasks using your enterprise systems and data sources.
Amazon Transcribe is a fully managed, automatic speech recognition (ASR) service that makes it straightforward for developers to add speech to text capabilities to their applications. It is powered by a next-generation, multi-billion parameter speech FM that delivers high-accuracy transcriptions for streaming and recorded speech. Thousands of customers across industries use it to automate manual tasks, unlock rich insights, increase accessibility, and boost discoverability of audio and video content.
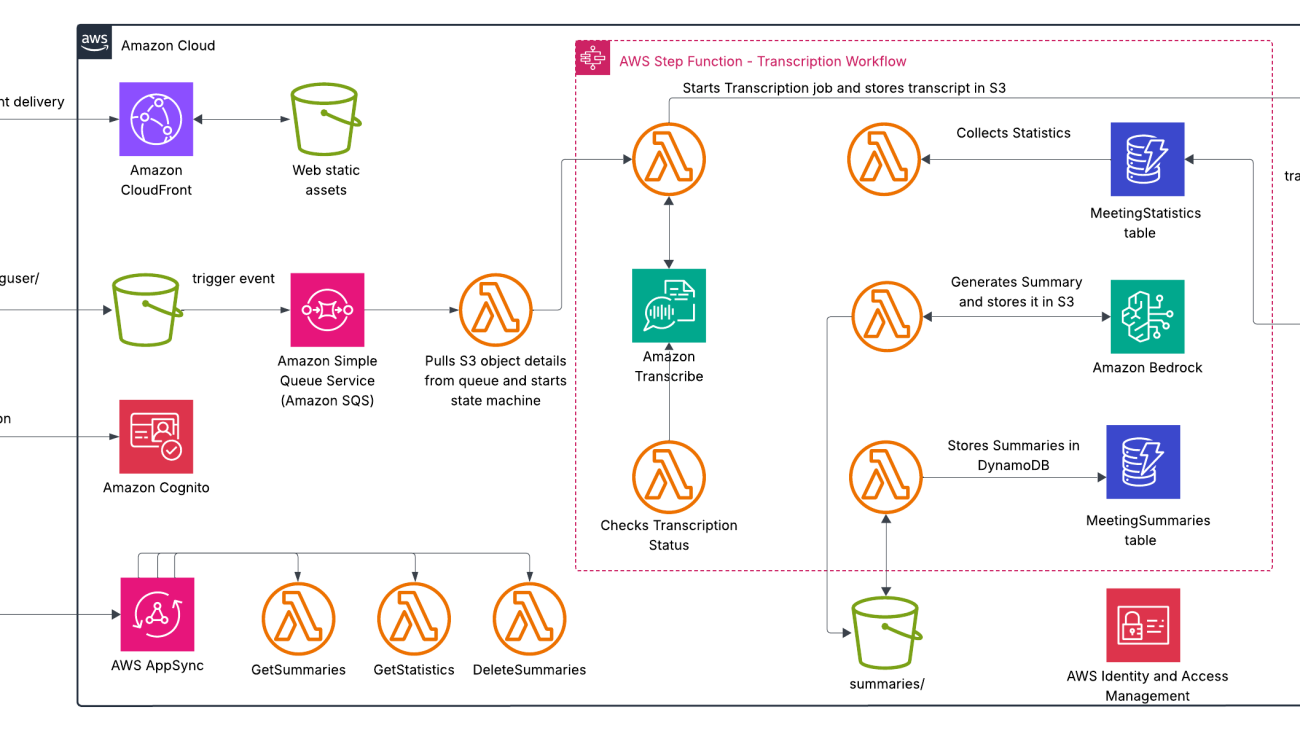
Our comprehensive audio processing system combines powerful AWS services to create a seamless end-to-end solution for extracting insights from audio content. The architecture consists of two main components: a user-friendly frontend interface that handles customer interactions and file uploads, and a backend processing pipeline that transforms raw audio into valuable, structured information. This serverless architecture facilitates scalability, reliability, and cost-effectiveness while delivering insightful AI-driven analysis capabilities without requiring specialized infrastructure management.
The frontend workflow consists of the following steps:
The processing consists of the following steps:
For additional security, AWS Identity and Access Management helps manage identities and access to AWS services and resources.
The following diagram illustrates this architecture.
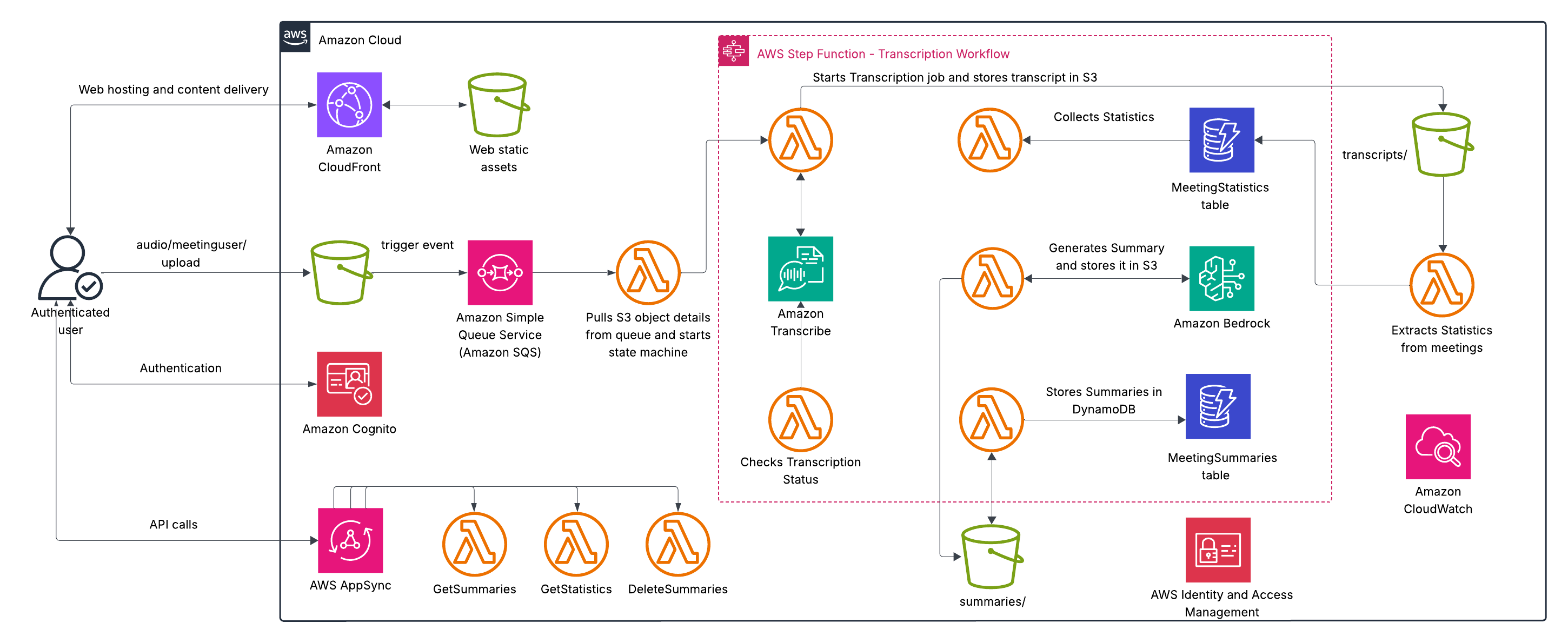
This architecture provides several key benefits:
Let’s walk through the key components of our solution in more detail.
Our meeting audio summarizer project follows a structure with frontend and backend components:
Our solution uses Terraform to define and provision the AWS infrastructure in a consistent and repeatable way. The main Terraform configuration orchestrates the various modules. The following code shows three of them:
The core of our solution is a Step Functions workflow that orchestrates the processing of audio files. The workflow handles language detection, transcription, summarization, and notification in a resilient way with proper error handling.
The summarization component is powered by Amazon Bedrock, which provides access to state-of-the-art FMs. Our solution uses Anthropic’s Claude 3.7 Sonnet version 1 to generate comprehensive meeting summaries:
prompt = f"""Even if it is a raw transcript of a meeting discussion, lacking clear structure and context and containing multiple speakers, incomplete sentences, and tangential topics, PLEASE PROVIDE a clear and thorough analysis as detailed as possible of this conversation. DO NOT miss any information. CAPTURE as much information as possible. Use bullet points instead of dashes in your summary.IMPORTANT: For ALL section headers, use plain text with NO markdown formatting (no #, ##, **, or * symbols). Each section header should be in ALL CAPS followed by a colon. For example: "TITLE:" not "# TITLE" or "## TITLE".
CRITICAL INSTRUCTION: DO NOT use any markdown formatting symbols like #, ##, **, or * in your response, especially for the TITLE section. The TITLE section MUST start with "TITLE:" and not "# TITLE:" or any variation with markdown symbols.
FORMAT YOUR RESPONSE EXACTLY AS FOLLOWS:
TITLE: Give the meeting a short title 2 or 3 words that is related to the overall context of the meeting, find a unique name such a company name or stakeholder and include it in the title
TYPE: Depending on the context of the meeting, the conversation, the topic, and discussion, ALWAYS assign a type of meeting to this summary. Allowed Meeting types are: Client meeting, Team meeting, Technical meeting, Training Session, Status Update, Brainstorming Session, Review Meeting, External Stakeholder Meeting, Decision Making Meeting, and Problem Solving Meeting. This is crucial, don't overlook this.
STAKEHOLDERS:Provide a list of the participants in the meeting, their company, and their corresponding roles. If the name is not provided or not understood, please replace the name with the word 'Not stated'. If a speaker does not introduce themselves, then don't include them in the STAKEHOLDERS section.
CONTEXT:provide a 10-15 summary or context sentences with the following information: Main reason for contact, Resolution provided, Final outcome, considering all the information above
MEETING OBJECTIVES:provide all the objectives or goals of the meeting. Be thorough and detailed.
CONVERSATION DETAILS:Customer's main concerns/requestsSolutions discussedImportant information verifiedDecisions made
KEY POINTS DISCUSSED (Elaborate on each point, if applicable):List all significant topics and issuesImportant details or numbers mentionedAny policies or procedures explainedSpecial requests or exceptions
ACTION ITEMS & NEXT STEPS (Elaborate on each point, if applicable):What the customer needs to do:Immediate actions requiredFuture steps to takeImportant dates or deadlinesWhat the company will do (Elaborate on each point, if applicable):Processing or handling stepsFollow-up actions promisedTimeline for completion
ADDITIONAL NOTES (Elaborate on each point, if applicable):Any notable issues or concernsFollow-up recommendationsImportant reminders
TECHNICAL REQUIREMENTS & RESOURCES (Elaborate on each point, if applicable):Systems or tools discussed/neededTechnical specifications mentionedRequired access or permissionsResource allocation details
The frontend is built with React and provides the following features:
The frontend communicates with the backend through the AWS AppSync GraphQL API, which provides a unified interface for data operations.
Security is a top priority in our solution, which we address with the following measures:
Amazon Bedrock offers several key advantages for our meeting summarization system:
Before implementing this solution, make sure you have:
In the following sections, we walk through the steps to deploy the meeting audio summarizer solution.
First, clone the repository containing the Terraform code:
git clone https://github.com/aws-samples/sample-meeting-audio-summarizer-in-terraform
cd sample-meeting-audio-summarizer-in-terraformMake sure your AWS credentials are properly configured. You can use the AWS CLI to set up your credentials:
aws configure --profile meeting-summarizerYou will be prompted to enter your AWS access key ID, secret access key, default AWS Region, and output format.
To set up the frontend development environment, navigate to the frontend directory and install the required dependencies:
cd frontend
npm installMove to the terraform directory:
cd ../backend/terraform/ Update the terraform.tfvars file in the backend/terraform directory with your specific values. This configuration supplies values for the variables previously defined in the variables.tf file.
You can customize other variables defined in variables.tf according to your needs. In the terraform.tfvars file, you provide actual values for the variables declared in variables.tf, so you can customize the deployment without modifying the core configuration files:
For a-unique-bucket-name, choose a unique name that is meaningful and makes sense to you.
Navigate to the terraform directory and initialize the Terraform environment:
terraform initTo upgrade the previously selected plugins to the newest version that complies with the configuration’s version constraints, use the following command:
terraform init -upgradeThis will cause Terraform to ignore selections recorded in the dependency lock file and take the newest available version matching the configured version constraints.
Review the planned changes:
terraform planApply the Terraform configuration to create the resources:
terraform applyWhen prompted, enter yes to confirm the deployment. You can run terraform apply -auto-approve to skip the approval question.
After the backend deployment is complete, deploy the entire solution using the provided deployment script:
cd ../../scripts
sudo chmod +x deploy.sh
./deploy.shThis script handles the entire deployment process, including:
After the entire solution (both backend and frontend) is deployed, in your terminal you should see something similar to the following text:
The CloudFront URL (*.cloudfront.net/) is unique, so yours will not be the same.
Enter the URL into your browser to open the application. You will see a login page like the following screenshot. You must create an account to access the application.
Start by uploading a file:
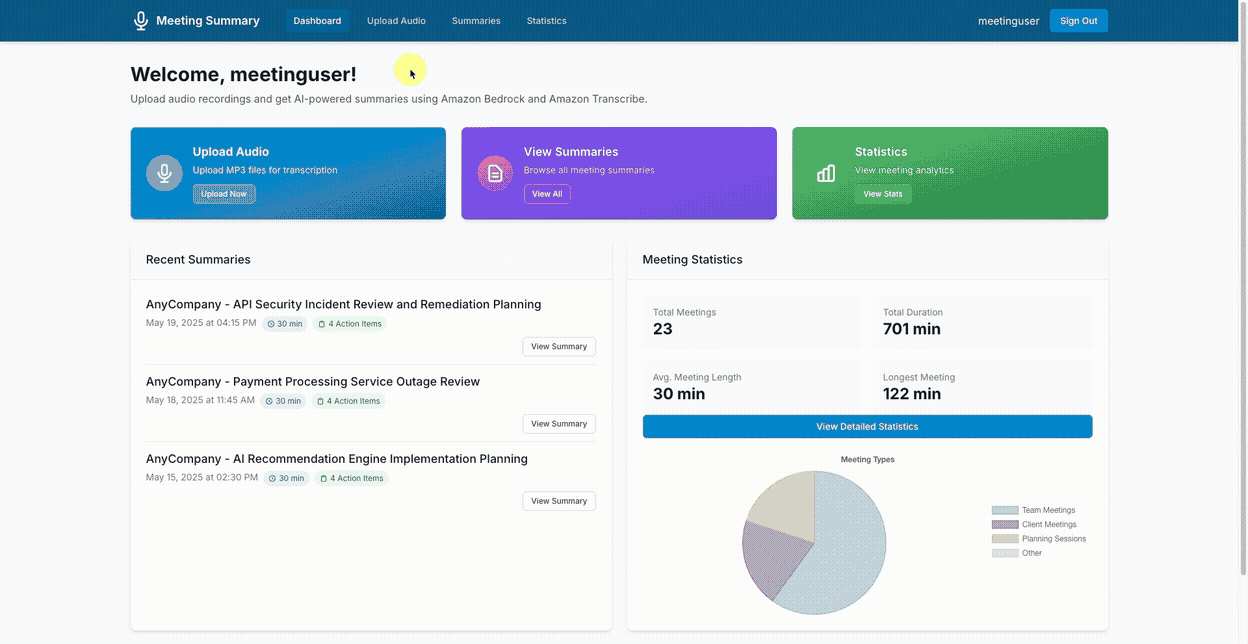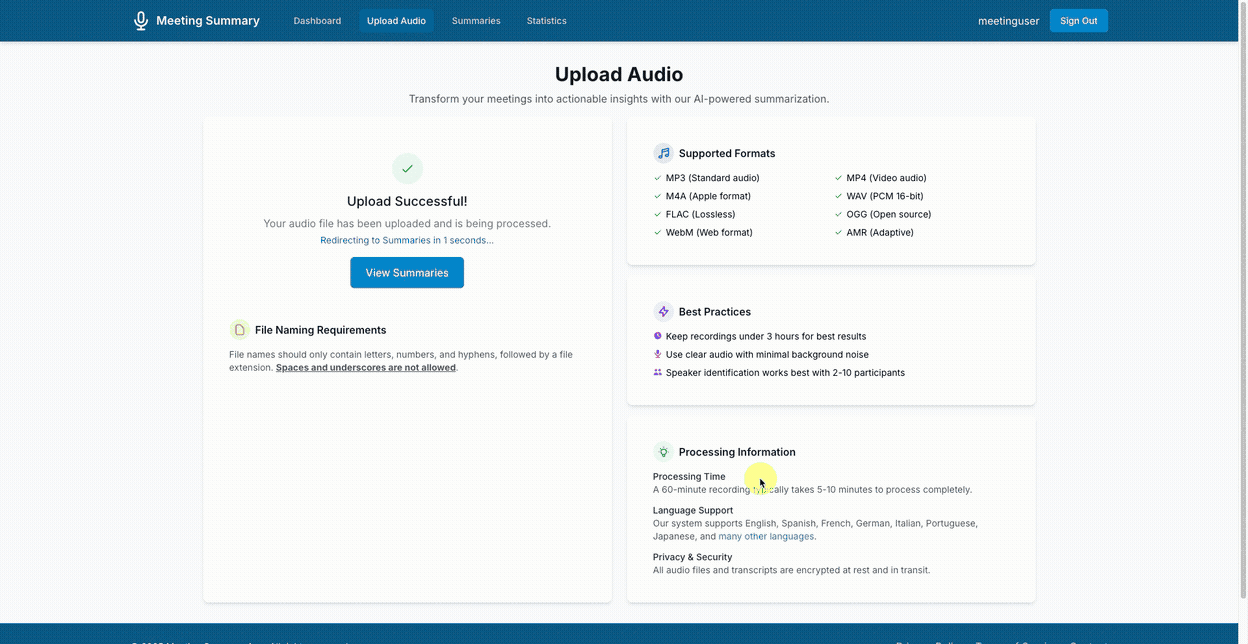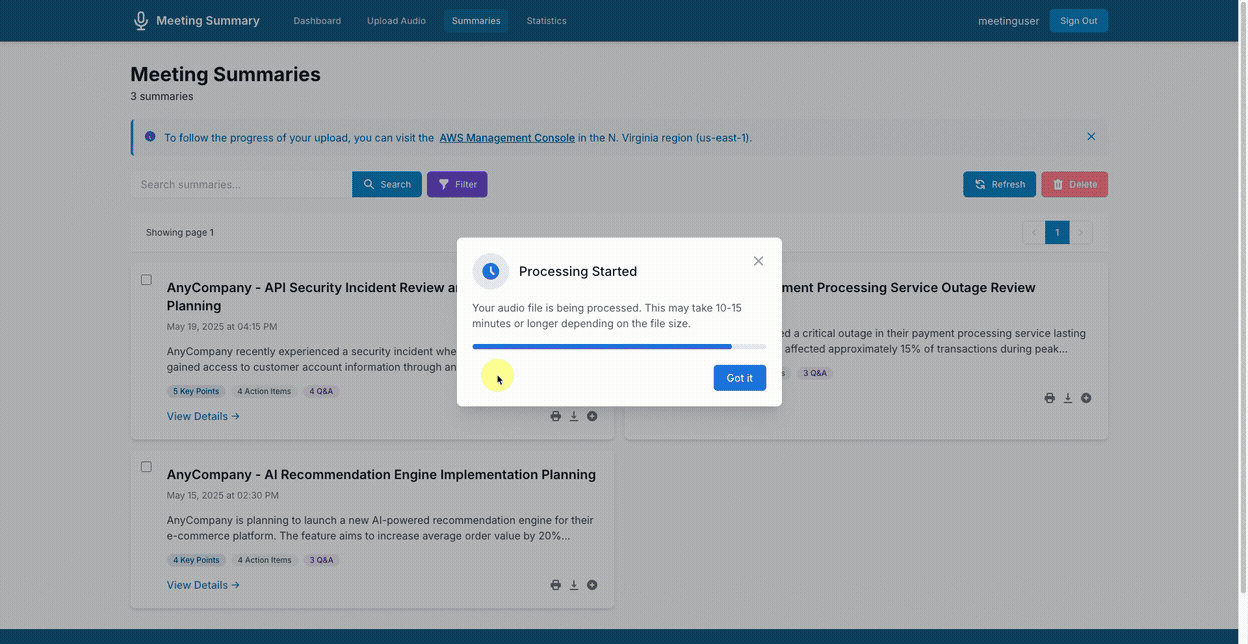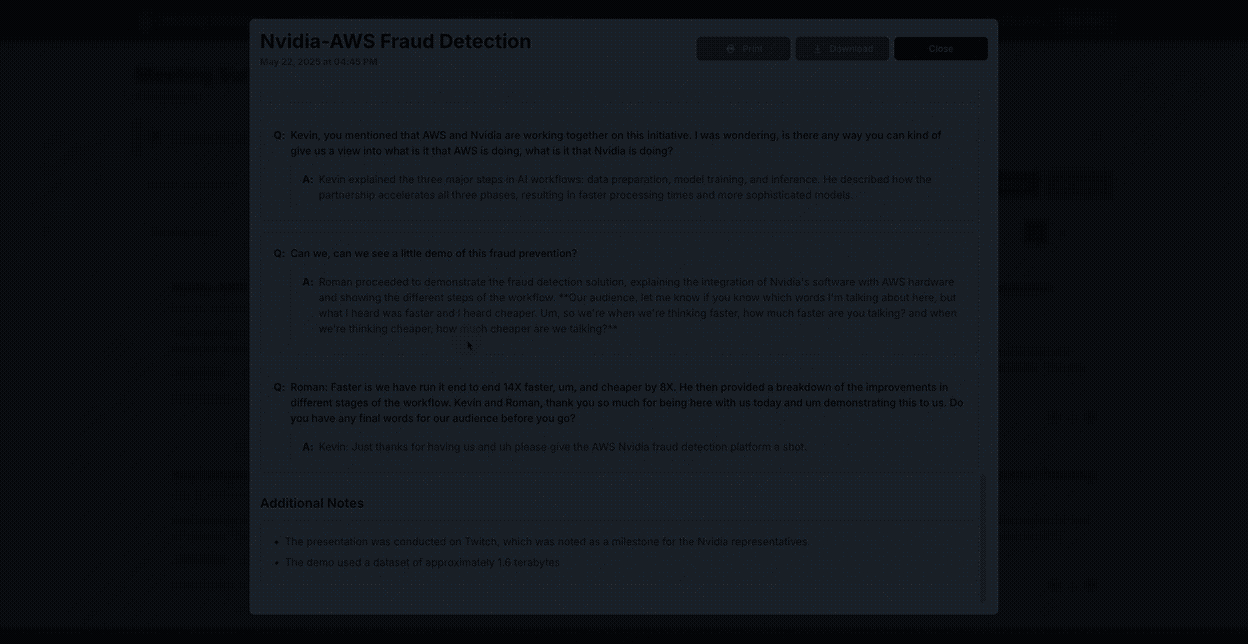
View generated summaries in a structured format:
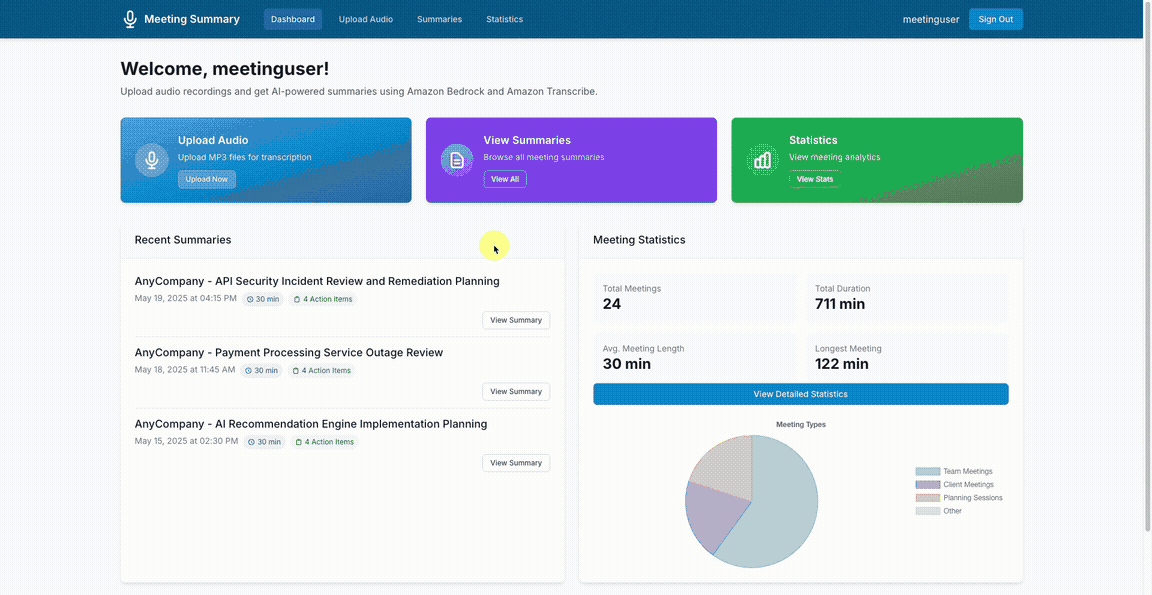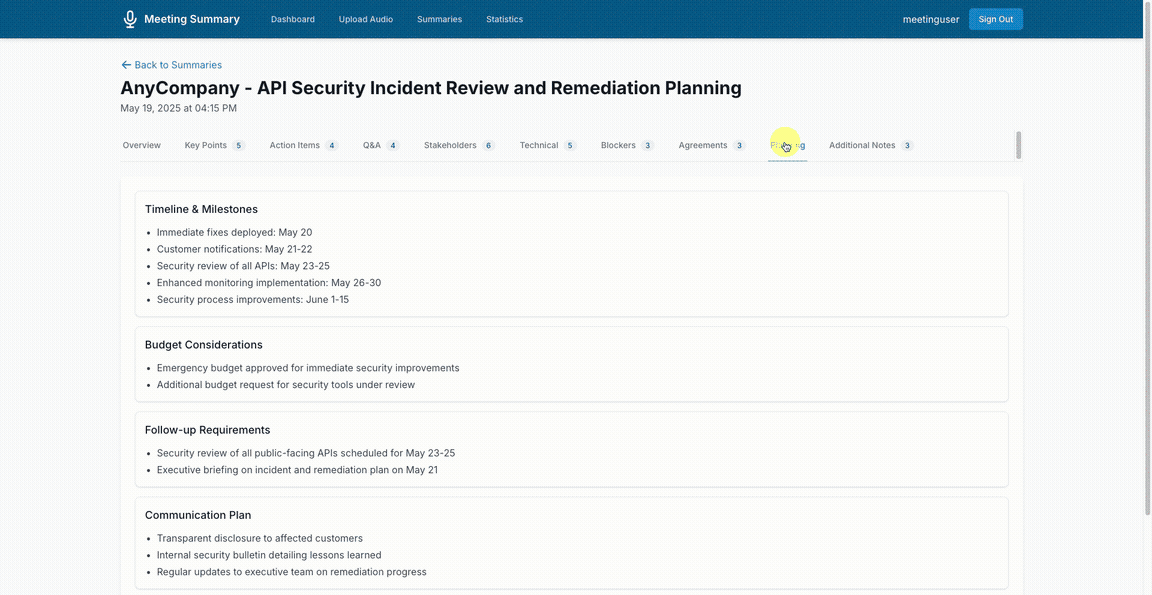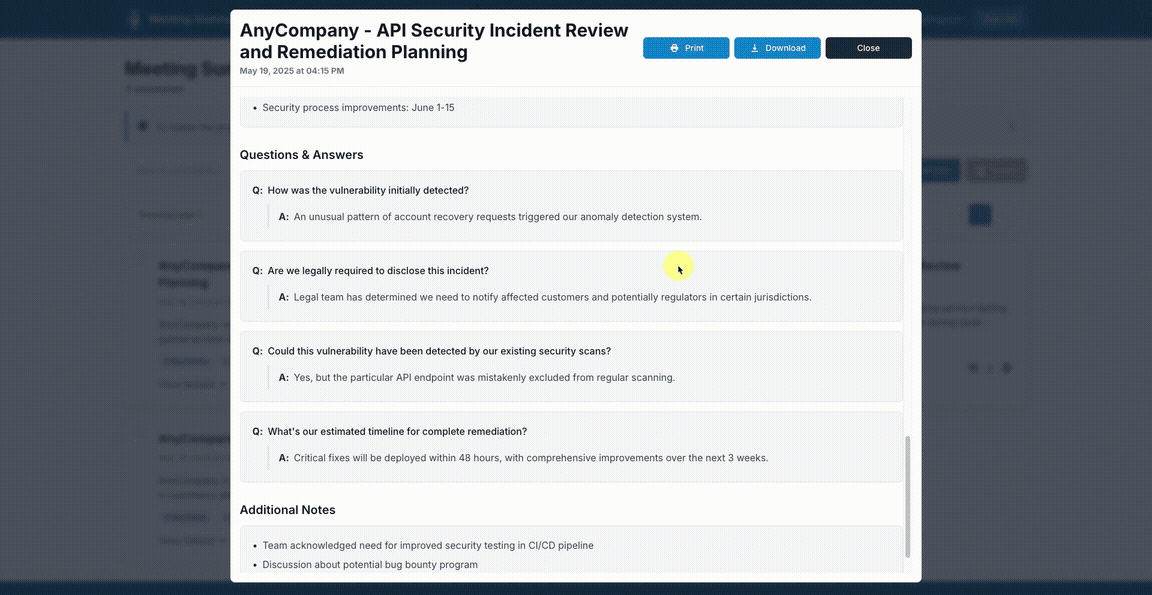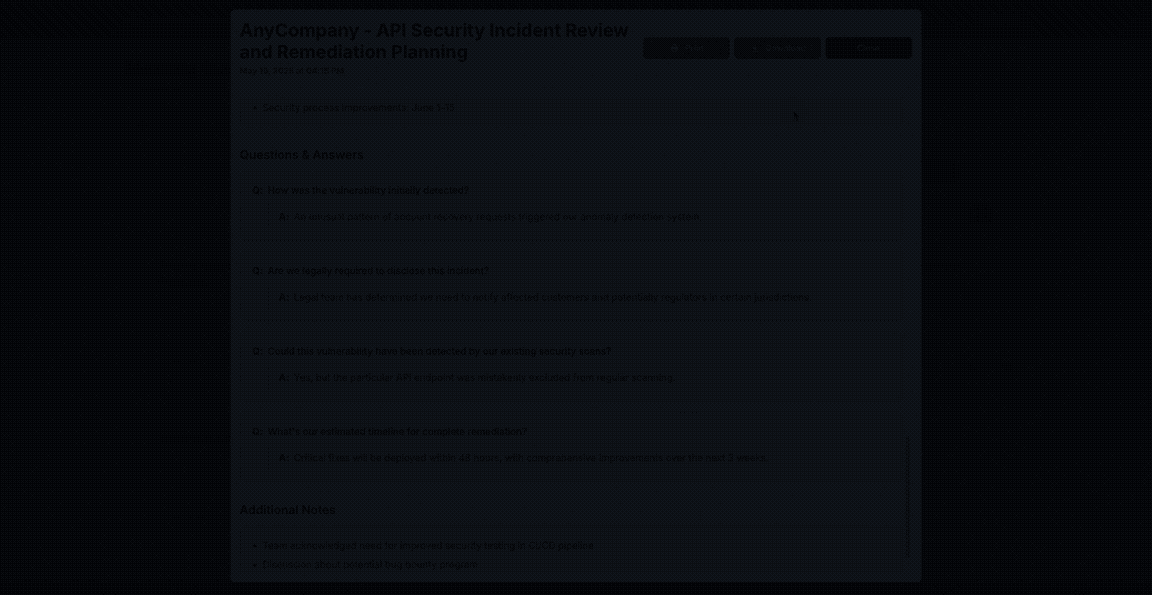
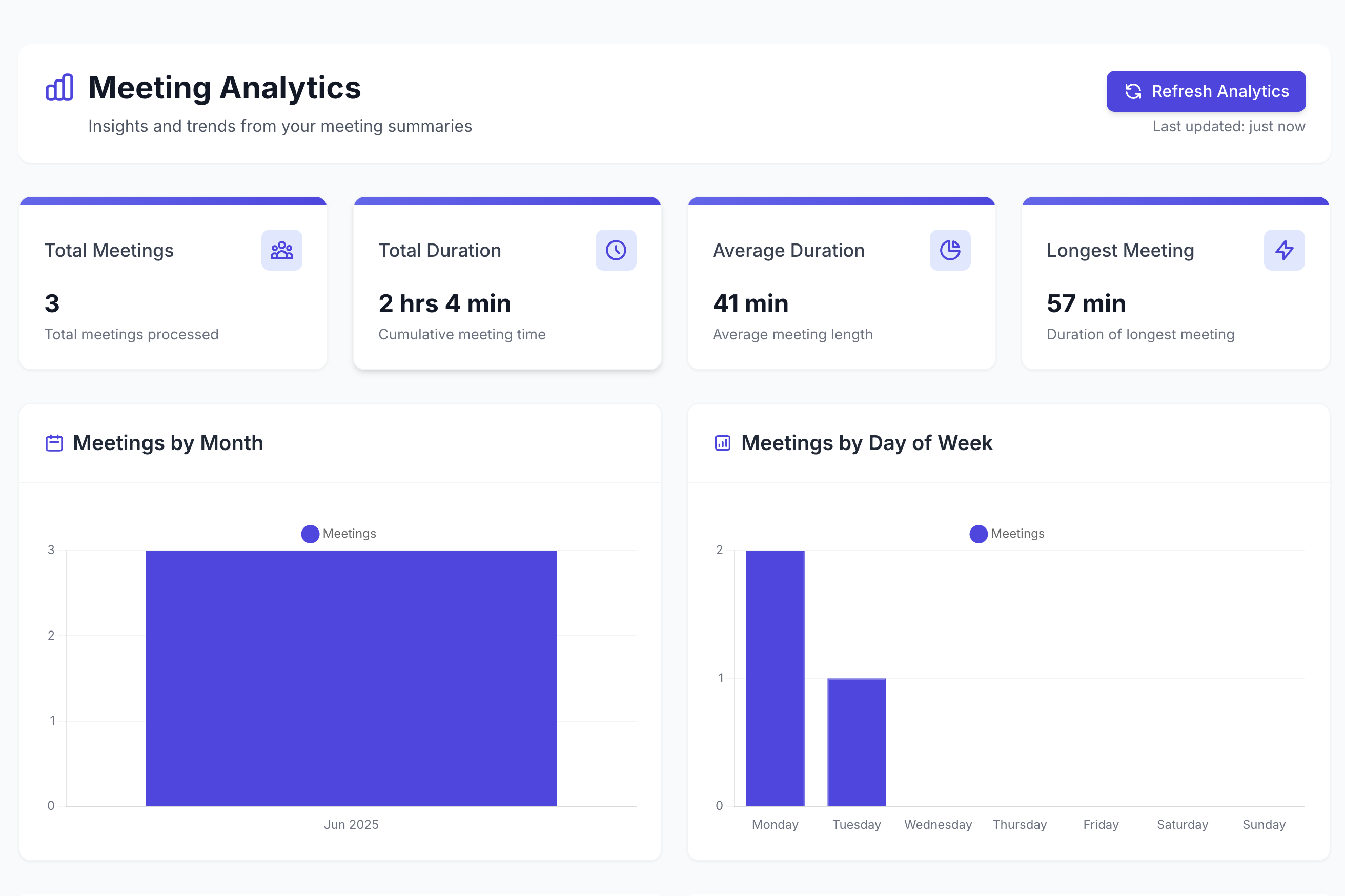
See meeting statistics:
To cleanup the solution you must run this command.
terraform destroyThis command will completely remove the AWS resources provisioned by Terraform in your environment. When executed, it will display a detailed plan showing the resources that will be destroyed, and prompt for confirmation before proceeding. The process may take several minutes as it systematically removes infrastructure components in the correct dependency order.
Remember to verify the destruction is complete by checking your AWS Console to make sure no billable resources remain active.
When implementing this solution, it’s important to understand the cost implications of each component. Let’s analyze the costs based on a realistic usage scenario, based on the following assumptions:
The majority of the cost comes from Amazon Transcribe (approximately 73% of total cost at $72.00), with AWS AppSync being the second largest cost component (approximately 20% at $20.00). Despite providing the core AI functionality, Amazon Bedrock costs approximately 3% of total at $3.00, and DynamoDB, CloudFront, Lambda, Step Functions, Amazon SQS, and Amazon S3 make up the remaining 4%.
We can take advantage of the following cost optimization opportunities:
The following table summarizes these prices. Refer the AWS pricing pages for each service to learn more about the AWS pricing model.
| Service | Usage | Unit Cost | Monthly Cost |
| Amazon Bedrock | 500K input tokens100K output tokens | $3.00 per million tokens$15.00 per million tokens | $3 |
| Amazon CloudFront | 5GB data transfer | $0.085 per GB | $0.43 |
| Amazon Cognito | 100 Monthly Active Users (MAU) | Free tier (first 50K users) | $0 |
| Amazon DynamoDB | 5 RCU/WCU, ~ 1GB storage | $0.25 per RCU/WCU + $0.25/GB | $2.75 |
| Amazon SQS | 1,000 messages | $0.40 per million | $0.01 |
| Amazon S3 Storage | 3GB audio + 12MB transcripts/summaries | $0.023 per GB | $0.07 |
| AWS Step Functions | 1,000 state transitions | $0.025 per 1,000 | $0.03 |
| AWS AppSync | 5M queries | $4.00 per million | $20 |
| AWS Lambda | 300 invocations, 5s avg. runtime, 256MB | Various | $0.10 |
| Amazon Transcribe | 50 hours of audio | $1.44 per hour | $72 |
| TOTAL | 98.39 |
The next phase of our meeting summarization solution will incorporate several advanced AI technologies to deliver greater business value. Amazon Sonic Model can improve transcription accuracy by better handling multiple speakers, accents, and technical terminology—addressing a key pain point for global organizations with diverse teams. Meanwhile, Amazon Bedrock Flows can enhance the system’s analytical capabilities by implementing automated meeting categorization, role-based summary customization, and integration with corporate knowledge bases to provide relevant context. These improvements can help organizations extract actionable insights that would otherwise remain buried in conversation.
The addition of real-time processing capabilities helps teams see key points, action items, and decisions as they emerge during meetings, enabling immediate clarification and reducing follow-up questions. Enhanced analytics functionality track patterns across multiple meetings over time, giving management visibility into communication effectiveness, decision-making processes, and project progress. By integrating with existing productivity tools like calendars, daily agenda, task management systems, and communication services, this solution makes sure that meeting intelligence flows directly into daily workflows, minimizing manual transfer of information and making sure critical insights drive tangible business outcomes across departments.
Our meeting audio summarizer combines AWS serverless technologies with generative AI to solve a critical productivity challenge. It automatically transcribes and summarizes meetings, saving organizations thousands of hours while making sure insights and action items are systematically captured and shared with stakeholders.
The serverless architecture scales effortlessly with fluctuating meeting volumes, costs just $0.98 per meeting on average, and minimizes infrastructure management and maintenance overhead. Amazon Bedrock provides enterprise-grade AI capabilities without requiring specialized machine learning expertise or significant development resources, and the Terraform-based infrastructure as code enables rapid deployment across environments, customization to meet specific organizational requirements, and seamless integration with existing CI/CD pipelines.
As the field of generative AI continues to evolve and new, better-performing models become available, the solution’s ability to perform its tasks will automatically improve on performance and accuracy without additional development effort, enhancing summarization quality, language understanding, and contextual awareness. This makes the meeting audio summarizer an increasingly valuable asset for modern businesses looking to optimize meeting workflows, enhance knowledge sharing, and boost organizational productivity.
Refer to Amazon Bedrock Documentation for more details on model selection, prompt engineering, and API integration for your generative AI applications. Additionally, see Amazon Transcribe Documentation for information about the speech-to-text service’s features, language support, and customization options for achieving accurate audio transcription. For infrastructure deployment needs, see Terraform AWS Provider Documentation for detailed explanations of resource types, attributes, and configuration options for provisioning AWS resources programmatically. To enhance your infrastructure management skills, see Best practices for using the Terraform AWS Provider, where you can find recommended approaches for module organization, state management, security configurations, and resource naming conventions that will help make sure your AWS infrastructure deployments remain scalable and maintainable.
 Dunieski Otano is a Solutions Architect at Amazon Web Services based out of Miami, Florida. He works with World Wide Public Sector MNO (Multi-International Organizations) customers. His passion is Security, Machine Learning and Artificial Intelligence, and Serverless. He works with his customers to help them build and deploy high available, scalable, and secure solutions. Dunieski holds 14 AWS certifications and is an AWS Golden Jacket recipient. In his free time, you will find him spending time with his family and dog, watching a great movie, coding, or flying his drone.
Dunieski Otano is a Solutions Architect at Amazon Web Services based out of Miami, Florida. He works with World Wide Public Sector MNO (Multi-International Organizations) customers. His passion is Security, Machine Learning and Artificial Intelligence, and Serverless. He works with his customers to help them build and deploy high available, scalable, and secure solutions. Dunieski holds 14 AWS certifications and is an AWS Golden Jacket recipient. In his free time, you will find him spending time with his family and dog, watching a great movie, coding, or flying his drone.
 Joel Asante, an Austin-based Solutions Architect at Amazon Web Services (AWS), works with GovTech (Government Technology) customers. With a strong background in data science and application development, he brings deep technical expertise to creating secure and scalable cloud architectures for his customers. Joel is passionate about data analytics, machine learning, and robotics, leveraging his development experience to design innovative solutions that meet complex government requirements. He holds 13 AWS certifications and enjoys family time, fitness, and cheering for the Kansas City Chiefs and Los Angeles Lakers in his spare time.
Joel Asante, an Austin-based Solutions Architect at Amazon Web Services (AWS), works with GovTech (Government Technology) customers. With a strong background in data science and application development, he brings deep technical expertise to creating secure and scalable cloud architectures for his customers. Joel is passionate about data analytics, machine learning, and robotics, leveraging his development experience to design innovative solutions that meet complex government requirements. He holds 13 AWS certifications and enjoys family time, fitness, and cheering for the Kansas City Chiefs and Los Angeles Lakers in his spare time.
 Ezzel Mohammed is a Solutions Architect at Amazon Web Services (AWS) based in Dallas, Texas. He works on the International Organizations team within the World Wide Public Sector, collaborating closely with UN agencies to deliver innovative cloud solutions. With a Computer Science background, Ezzeldien brings deep technical expertise in system design, helping customers architect and deploy highly available and scalable solutions that meet international compliance requirements. He holds 9 AWS certifications and is passionate about applying AI Engineering and Machine Learning to address global challenges. In his free time, he enjoys going on walks, watching soccer with friends and family, playing volleyball, and reading tech articles.
Ezzel Mohammed is a Solutions Architect at Amazon Web Services (AWS) based in Dallas, Texas. He works on the International Organizations team within the World Wide Public Sector, collaborating closely with UN agencies to deliver innovative cloud solutions. With a Computer Science background, Ezzeldien brings deep technical expertise in system design, helping customers architect and deploy highly available and scalable solutions that meet international compliance requirements. He holds 9 AWS certifications and is passionate about applying AI Engineering and Machine Learning to address global challenges. In his free time, he enjoys going on walks, watching soccer with friends and family, playing volleyball, and reading tech articles.
This post was written with Zach Heath of Kyruus Health.
When health plan members need care, they shouldn’t need a dictionary. Yet millions face this exact challenge—describing symptoms in everyday language while healthcare references clinical terminology and complex specialty classifications. This disconnect forces members to become amateur medical translators, attempting to convert phrases like “my knee hurts when I climb stairs” into specialized search criteria such as orthopedics or physical medicine. Traditional provider directories compound this problem with overwhelming filter options and medical jargon, leading to frustrated members, delayed care access, and ultimately higher costs for both individuals and health plans.
Kyruus Health, a leading provider of care access solutions, serves over 1,400 hospitals, 550 medical groups, and 100 health plan brands—connecting more than 500,000 providers with patients seeking care and facilitating over 1 million appointments annually. To address the challenges of healthcare navigation, they developed Guide, an AI-powered solution that understands natural language and connects members with the right providers. With Guide, members can express health concerns in their own words and receive personalized provider matches without requiring clinical knowledge. Health plans implementing this solution have reported enhanced member experience and higher Net Promoter Scores (NPS), along with improved care access conversion and appointment scheduling rates.
In this post, we demonstrate how Kyruus Health uses AWS services to build Guide. We show how Amazon Bedrock, a fully managed service that provides access to foundation models (FMs) from leading AI companies and Amazon through a single API, and Amazon OpenSearch Service, a managed search and analytics service, work together to understand everyday language about health concerns and connect members with the right providers. We explore the solution architecture, share implementation insights, and examine how this approach delivers measurable business value for health plans and their members.
Guide transforms healthcare provider search by translating natural language health concerns into precisely matched provider recommendations. The solution uses Amazon Bedrock with Anthropic’s Claude 3.5 Sonnet to understand everyday descriptions of health concerns and convert them into structured medical parameters. Then it uses OpenSearch Service to match these parameters against comprehensive provider data and deliver targeted recommendations.
This architecture makes it possible for members to express health needs in plain language while making sure provider matches meet clinical requirements. The entire solution maintains HIPAA compliance through end-to-end encryption and fine-grained access controls, so Kyruus Health to focus on improving the member experience instead of managing complex infrastructure.
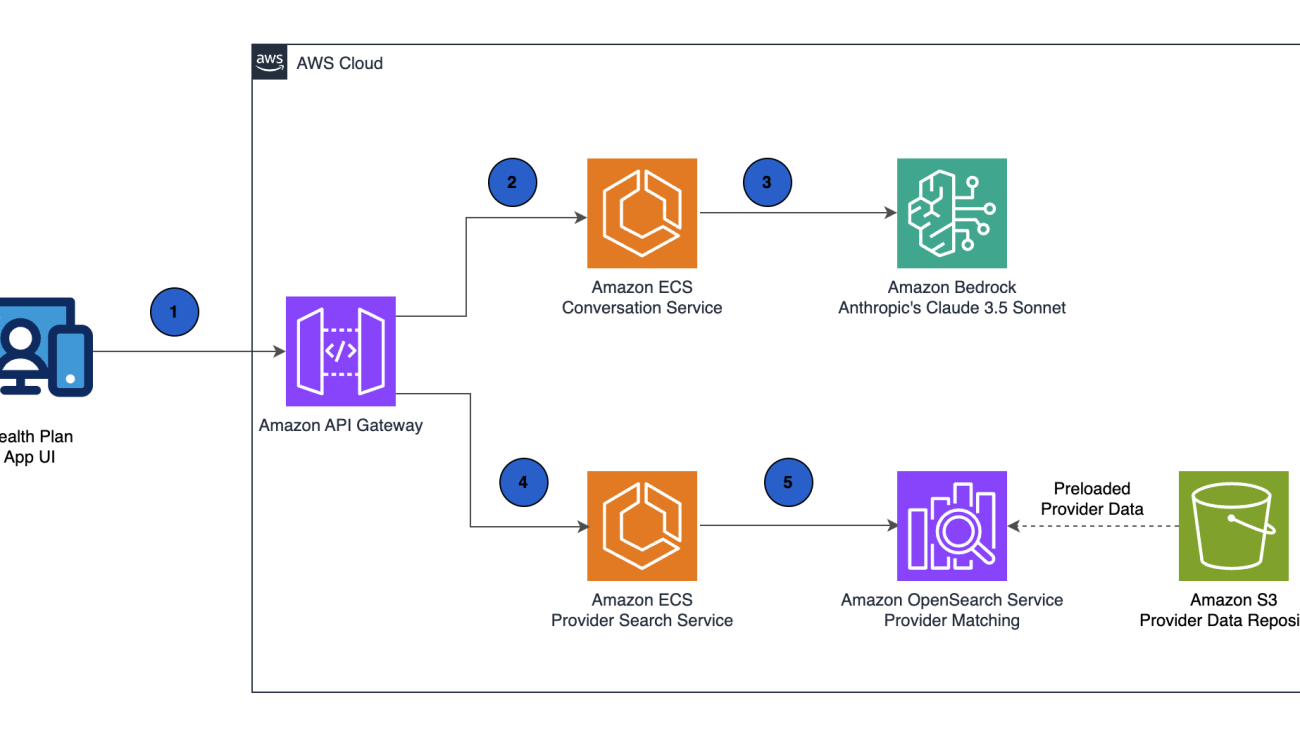
The following diagram illustrates the solution architecture.
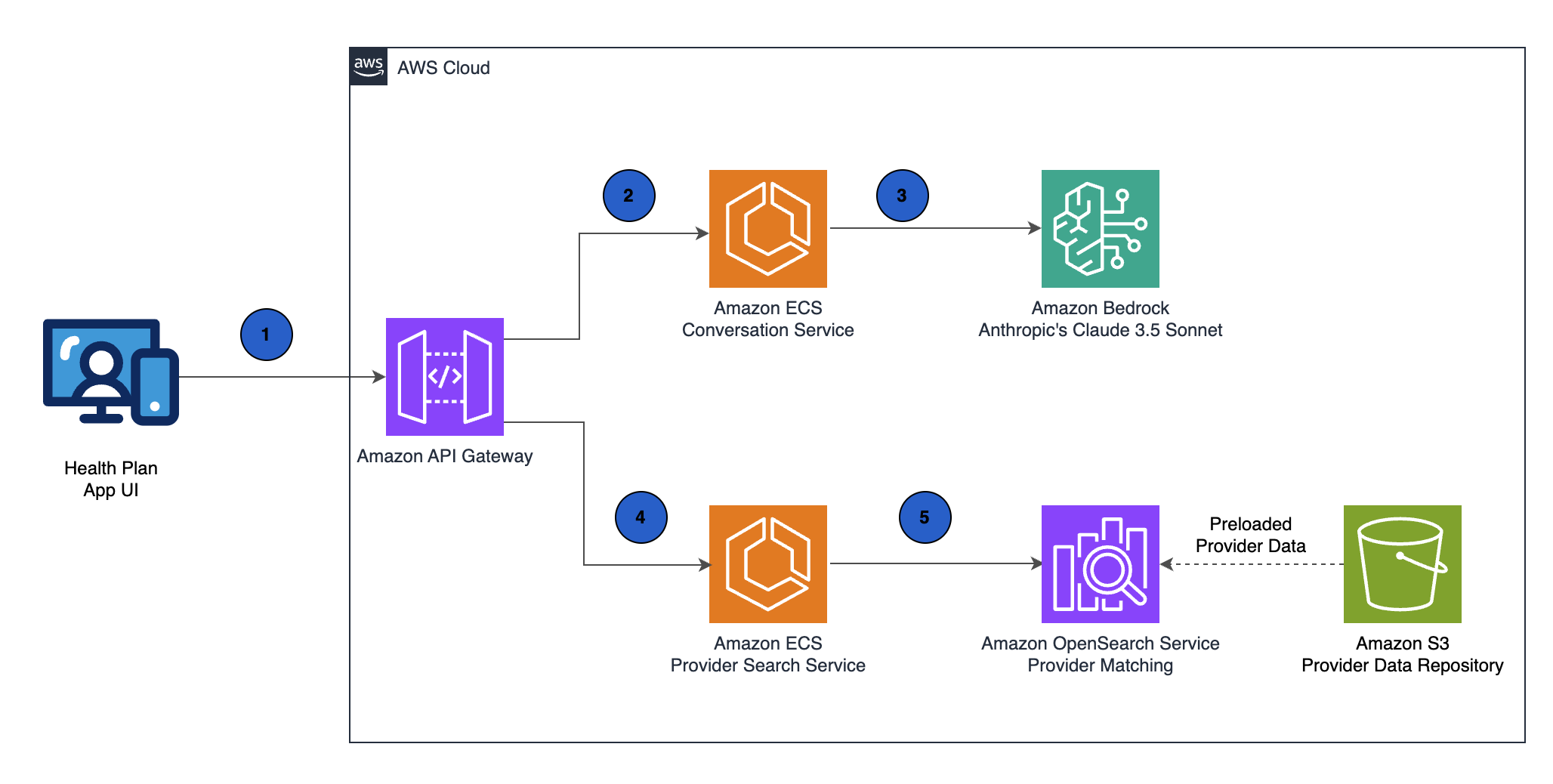
This architecture translates natural language queries into structured healthcare parameters through the following steps:
Matched providers are then returned to the health plan application and presented to the member through an intuitive conversational interface. This architecture demonstrates the powerful combination of Amazon Bedrock FMs with purpose-built AWS services like OpenSearch Service, creating an end-to-end solution that bridges the gap between complex healthcare data and intuitive member experiences.
To accelerate their AI transformation, Kyruus Health partnered with Tribe AI, an AWS Partner with extensive experience in building and implementing enterprise-grade generative AI solutions at scale. Tribe AI’s proven track record in deploying FMs in complex, regulatory environments like healthcare helped de-risk the adoption of generative AI for Kyruus. This partnership allowed Kyruus to focus on their healthcare domain expertise while using Tribe AI’s technical implementation knowledge to bring Guide from concept to production.
Kyruus Health’s successful implementation of Guide yielded key insights that can help organizations building healthcare AI initiatives:
These insights demonstrate how a thoughtful implementation approach can transform complex healthcare navigation challenges into intuitive member experiences that deliver measurable business results.
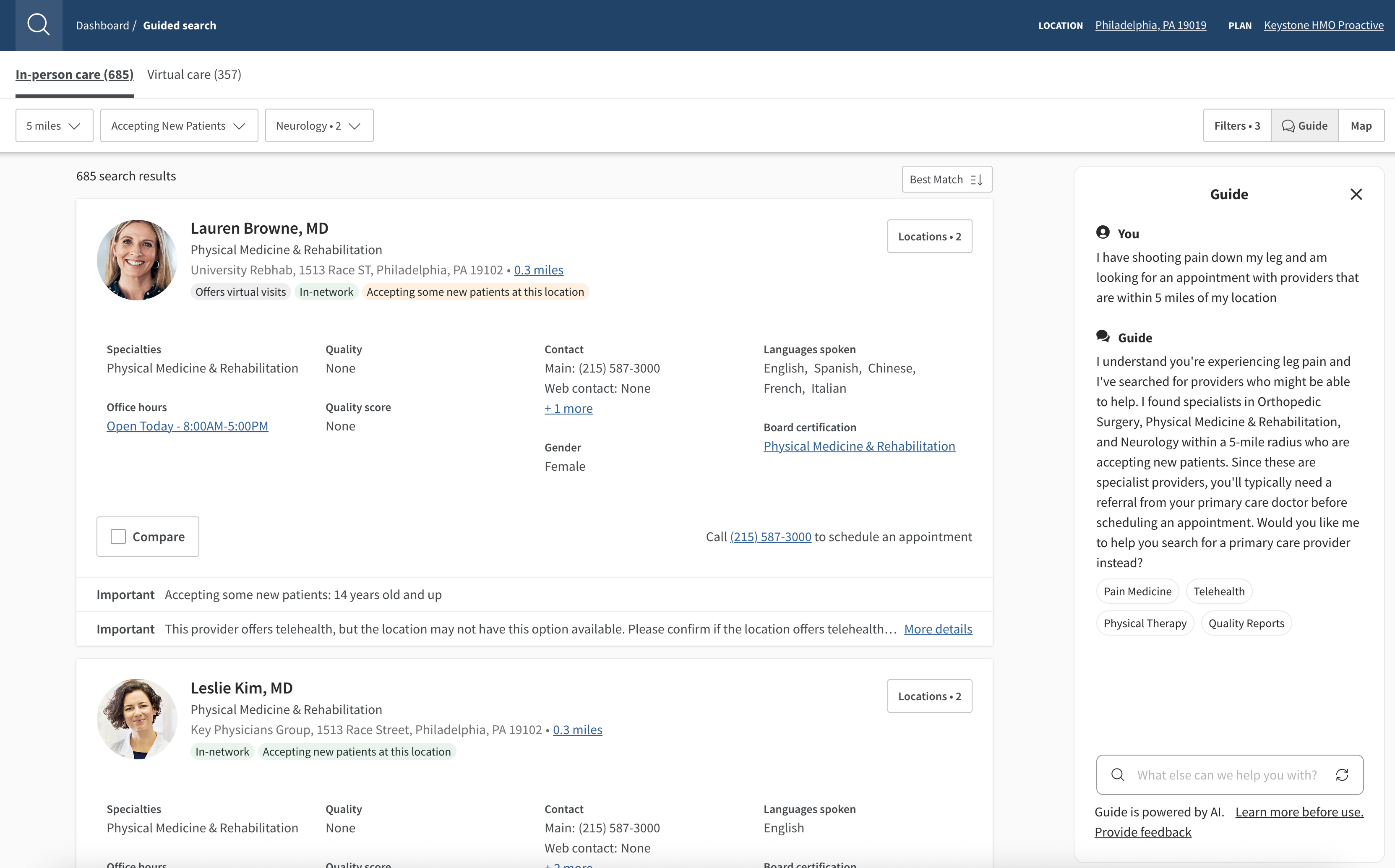
The following screenshot shows how the AWS architecture translates into the real-world member experience. When a member enters their symptom description and location preference, Guide processes this natural language input through Amazon Bedrock and identifies appropriate specialists using OpenSearch Service. The system interprets the medical concern and location requirements, responding with relevant specialists within the requested distance who are accepting new patients. This streamlined experience has delivered higher match rates and increased appointment completion for health plans.
Guide demonstrates how generative AI powered by AWS transforms healthcare navigation by bridging the gap between everyday language and clinical terminology. In this post, we explored how an architecture combining Amazon Bedrock and OpenSearch Service processes natural language queries into personalized provider matches, helping members find appropriate healthcare providers using natural language descriptions of their symptoms.
For health plans evaluating digital initiatives, Guide offers a blueprint for solving complex healthcare challenges while delivering measurable improvements in member satisfaction and appointment conversion rates. To build your own generative AI solutions, explore Amazon Bedrock for managed access to FMs. For healthcare-specific guidance, check out the AWS Healthcare Industry Lens and browse implementation examples, use cases, and technical guidance in the AWS Healthcare and Life Sciences Blog.
 Zach Heath is a Senior Staff Software Engineer at Kyruus Health. A passionate technologist, he specializes in architecting and implementing robust, scalable software solutions that transform healthcare search experiences by connecting patients with the right care through innovative technology.
Zach Heath is a Senior Staff Software Engineer at Kyruus Health. A passionate technologist, he specializes in architecting and implementing robust, scalable software solutions that transform healthcare search experiences by connecting patients with the right care through innovative technology.
 Anil Chinnam is a Solutions Architect at AWS. He is a generative AI enthusiast passionate about translating cutting-edge technologies into tangible business value for healthcare customers. As a trusted technical advisor, he helps customers drive cloud adoption and business transformation outcomes.
Anil Chinnam is a Solutions Architect at AWS. He is a generative AI enthusiast passionate about translating cutting-edge technologies into tangible business value for healthcare customers. As a trusted technical advisor, he helps customers drive cloud adoption and business transformation outcomes.
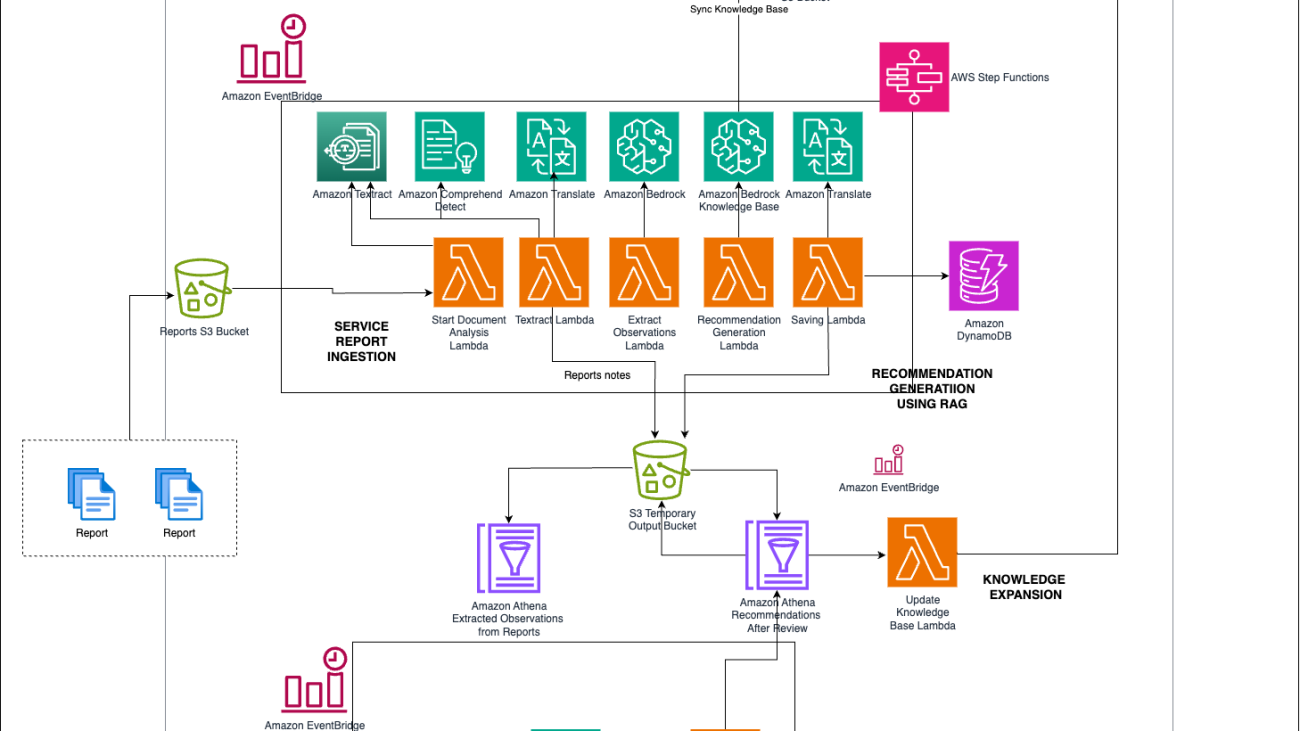
In the manufacturing world, valuable insights from service reports often remain underutilized in document storage systems. This post explores how Amazon Web Services (AWS) customers can build a solution that automates the digitisation and extraction of crucial information from many reports using generative AI.
The solution uses Amazon Nova Pro on Amazon Bedrock and Amazon Bedrock Knowledge Bases to generate recommended actions that are aligned with the observed equipment state, using an existing knowledge base of expert recommendations. The knowledge base expands over time as the solution is used.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Stability AI, Mistral, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Amazon Bedrock Knowledge Base offers fully managed, end-to-end Retrieval-Augmented Generation (RAG) workflows to create highly accurate, low latency, and custom Generative AI applications by incorporating contextual information from your company’s data sources, making it a well-suited service to store engineers’ expert recommendations from past reports and allow FMs to accurately customise their responses.
Traditional service and maintenance cycles rely on manual report submission by engineers with expert knowledge. Time spent referencing past reports can lead to operational delays and business disruption.This solution empowers equipment maintenance teams to:
To help you implement this solution, we provide a GitHub repository containing deployable code and infrastructure as code (IaC) templates. You can quickly set up and customise the solution in your own AWS environment using the GitHub repository.
The following diagram is an architecture representation of the solution presented in this post, showcasing the various AWS services in use. Using this GitHub repository, you can deploy the solution into your AWS account to test it.
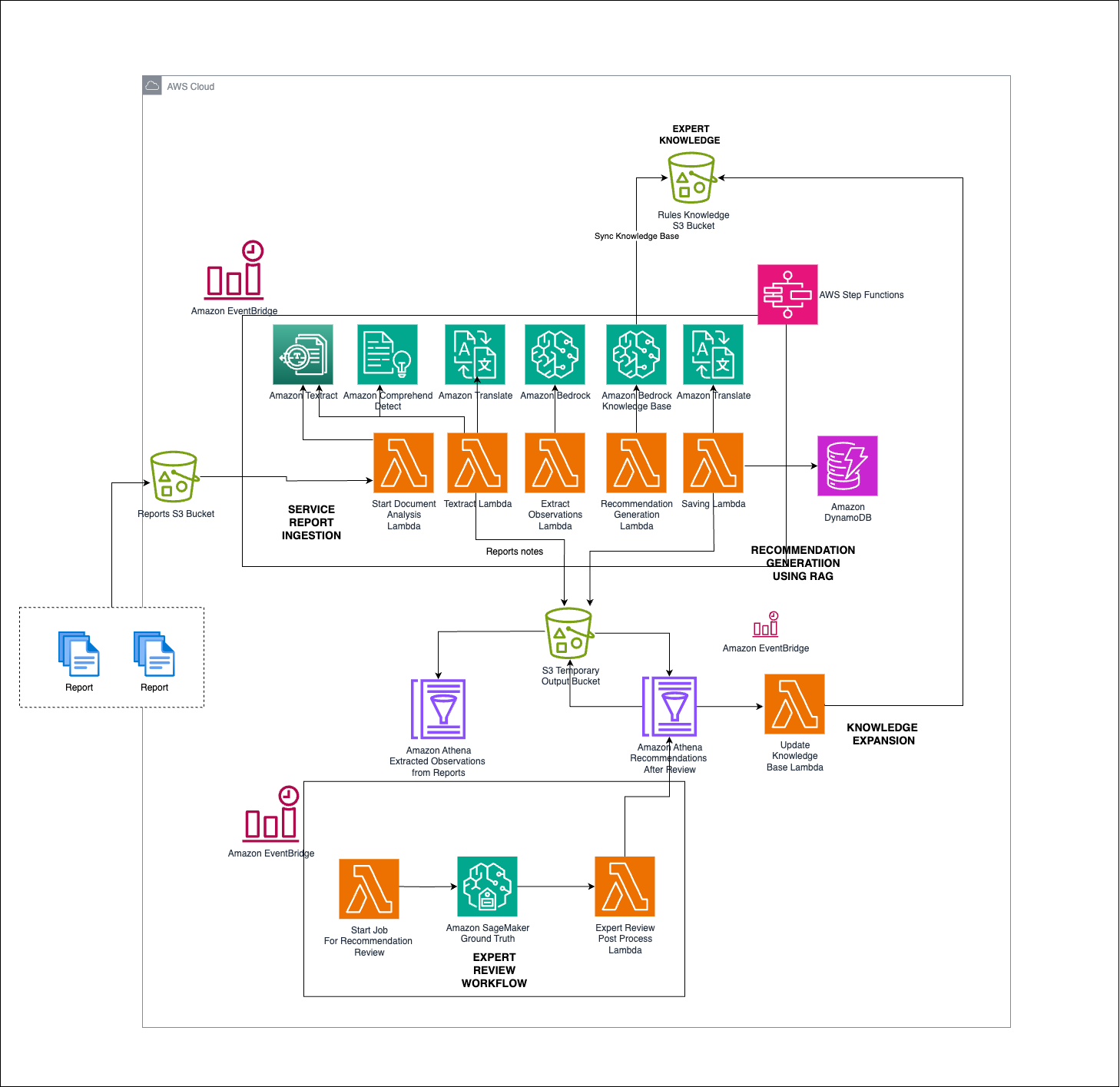
The following are key workflows of the solution:
This compiled set of rules is reviewed by experts, assigned criticality, and then automatically synced into the Amazon Bedrock Knowledge Bases to continually improve the solution’s confidence in generating the next recommended action.Together, these workflows create a seamless and efficient process from report ingestion to actionable recommendations, producing high-quality insights for maintenance operations.This solution is deployable and scalable using IaC with Terraform for ease of implementation and expansion across various environments. Teams have the flexibility to efficiently roll out the solution to customers globally, enhancing maintenance operations and reducing unplanned downtimes.In the following sections, we walk through the steps to customize and deploy the solution.
To deploy the solution, you must have an AWS account with the appropriate permissions and access to Amazon Nova FMs on Amazon Bedrock. This can be enabled from the Amazon Bedrock console page.
Clone the GitHub repository containing the IaC for the solution to your local machine.
To customize the ReportsProcessing AWS Lambda function, follow these steps:
lambdas/python/ReportsProcessing/extract_observations.py file. This file contains the logic for the ReportsProcessing Lambda function.extract_metadata function to handle different report formats or adjust the logic in the standardize_metadata function to comply with your organisation’s standards.To customize the RecommendationGeneration Lambda, follow these steps:
lambdas/python/RecommendationGeneration/generate_recommendations.pyfile. This file contains the logic for the RecommendationGeneration Lambda function, which uses the RAG architecture.query_formulation() function to modify the prompt sent to Anthropic’s Claude 3 Sonnet or update the retrieve_rules function to customize the retrieval process from the knowledge base.If you made changes to the Lambda function names, roles, or other AWS resources, update the corresponding Terraform configuration files in the terraform directory to reflect these changes.
Open a terminal or command prompt and navigate to the terraform directory within the cloned repository. Enter the following command to initialize the Terraform working directory:
Before applying the changes, preview the Terraform run plan by entering the following command:
This command will show you the changes that Terraform plans to make to your AWS infrastructure.
If you’re satisfied with the planned changes, deploy the Terraform stack to your AWS account by entering the following command:
Enter yes and press Enter to proceed with the deployment.
After you deploy the Terraform stack, create an Amazon Bedrock knowledge base to store and retrieve the maintenance rules and recommendations:
Once the knowledge bases are created, do not forget to update the Generate Recommendations lambda function environment variable with the appropriate knowledge base ID.
To test the solution, upload a sample maintenance report to the designated Amazon Simple Storage Service (Amazon S3) bucket:
Once the file is uploaded, navigate to the created AWS Step Functions State machine and validate that a successful execution occurs. The output of a successful execution must contain extracted observations from the input document as well as newly generated recommendations that have been pulled from the knowledge base.
When you’re done with this solution, clean up the resources you created to avoid ongoing charges.
This post provided an overview of implementing a risk-based maintenance solution to preempt potential failures and avoid equipment downtime for maintenance teams. This solution highlights the benefits of Amazon Bedrock. By using Amazon Nova Pro with RAG for your equipment maintenance reports, engineers and scientists can focus their efforts on improving accuracy of recommendations and increasing development velocity. The key capabilities of this solution include:
By using the breadth of AWS services and the flexibility of Amazon Bedrock, equipment maintenance teams can streamline their operations and reduce unplanned downtimes.
AWS Professional Services is ready to help your team develop scalable and production-ready generative AI solutions on AWS. For more information, refer to the AWS Professional Services page or reach out to your account manager to get in touch.
 Jyothsna Puttanna is an AI/ML Consultant at AWS Professional Services. Jyothsna works closely with customers building their machine learning solutions on AWS. She specializes in distributed training, experimentation, and generative AI.
Jyothsna Puttanna is an AI/ML Consultant at AWS Professional Services. Jyothsna works closely with customers building their machine learning solutions on AWS. She specializes in distributed training, experimentation, and generative AI.
 Shantanu Sinha is a Senior Engagement Manager at AWS Professional Services, based out of Berlin, Germany. Shantanu’s focus is on using generative AI to unlock business value and identify strategic business opportunities for his clients.
Shantanu Sinha is a Senior Engagement Manager at AWS Professional Services, based out of Berlin, Germany. Shantanu’s focus is on using generative AI to unlock business value and identify strategic business opportunities for his clients.
 Selena Tabbara is a Data Scientist at AWS Professional Services specializing in AI/ML and Generative AI solutions for enterprise customers in energy, automotive and manufacturing industry.
Selena Tabbara is a Data Scientist at AWS Professional Services specializing in AI/ML and Generative AI solutions for enterprise customers in energy, automotive and manufacturing industry.

Our advanced model officially achieved a gold-medal level performance on problems from the International Mathematical Olympiad (IMO), the world’s most prestigious competition for young mathematicians. It earned a total of 35 points by perfectly solving five out of the six problems.Read More


Generative AI presents a unique challenge and opportunity to reexamine governance practices for the responsible development, deployment, and use of AI. To advance thinking in this space, Microsoft has tapped into the experience and knowledge of experts across domains—from genome editing to cybersecurity—to investigate the role of testing and evaluation as a governance tool. AI Testing and Evaluation: Learnings from Science and Industry, hosted by Microsoft Research’s Kathleen Sullivan, explores what the technology industry and policymakers can learn from these fields and how that might help shape the course of AI development.
In the series finale, Amanda Craig Deckard, senior director of public policy in Microsoft’s Office of Responsible AI, rejoins Sullivan to discuss what Microsoft has learned about testing as a governance tool and what’s next for the company’s work in the AI governance space. The pair explores high-level takeaways (i.e., testing is important and challenging!); the roles of rigor, standardization, and interpretability in making testing a reliable governance tool; and the potential for public-private partnerships to help advance not only model-level evaluation but deployment-level evaluation, too.
Learning from other domains to advance AI evaluation and testing
Microsoft Research Blog | June 2025
Responsible AI: Ethical policies and practices | Microsoft AI
KATHLEEN SULLIVAN: Welcome to AI Testing and Evaluation: Learnings from Science and Industry. I’m your host, Kathleen Sullivan.
As generative AI continues to advance, Microsoft has gathered a range of experts—from genome editing to cybersecurity—to share how their fields approach evaluation and risk assessment. Our goal is to learn from their successes and their stumbles to move the science and practice of AI testing forward. In this series, we’ll explore how these insights might help guide the future of AI development, deployment, and responsible use.
[MUSIC ENDS]For our final episode of the series, I’m thrilled to once again be joined by Amanda Craig Deckard, senior director of public policy in Microsoft’s Office of Responsible AI.
Amanda, welcome back to the podcast!
AMANDA CRAIG DECKARD: Thank you so much.
SULLIVAN: In our intro episode, you really helped set the stage for this series. And it’s been great, because since then, we’ve had the pleasure of speaking with governance experts about genome editing, pharma, medical devices, cybersecurity, and we’ve also gotten to spend some time with our own Microsoft responsible AI leaders and hear reflections from them.
And here’s what stuck with me, and I’d love to hear from you on this, as well: testing builds trust; context is shaping risk; and every field is really thinking about striking its own balance between pre-deployment testing and post-deployment monitoring.
So drawing on what you’ve learned from the workshop and the case studies, what headline insights do you think matter the most for AI governance?
CRAIG DECKARD: It’s been really interesting to learn from all of these different domains, and there are, you know, lots of really interesting takeaways.
I think a starting point for me is actually pretty similar to where you landed, which is just that testing is really important for trust, and it’s also really hard [LAUGHS] to figure out exactly, you know, how to get it right, how to make sure that you’re addressing risks, that you’re not constraining innovation, that you are recognizing that a lot of the industry that’s impacted is really different. You have small organizations, you have large organizations, and you want to enable that opportunity that is enabled by the technology across the board.
And so it’s just difficult to, kind of, get all of these dynamics right, especially when, you know, I think we heard from other domains, testing is not some, sort of, like, oh, simple thing, right. There’s not this linear path from, like, A to B where you just test the one thing and you’re done.
SULLIVAN: Right.
CRAIG DECKARD: It’s complex, right. Testing is multistage. There’s a lot of testing by different actors. There are a lot of different purposes for which you might test. As I think it was Dan Carpenter who talked about it’s not just about testing for safety. It’s also about testing for efficacy and building confidence in the right dosage for pharmaceuticals, for example. And that’s across the board for all of these domains, right. That you’re really thinking about the performance of the technology. You’re thinking about safety. You’re trying to also calibrate for efficiency.
And so those tradeoffs, every expert shared that navigating those is really challenging. And also that there were real impacts to early choices in the, sort of, governance of risk in these different domains and the development of the testing, sort of, expectations, and that in some cases, this had been difficult to reverse, which also just layers on that complexity and that difficulty in a different way. So that’s the super high-level takeaway. But maybe if I could just quickly distill, like, three takeaways that I think really are applicable to AI in a bit more of a granular way.
You know, one is about, how is the testing exactly used? For what purpose? And the second is what emphasis there is on this pre- versus post-deployment testing and monitoring. And then the third is how rigid versus adaptive the, sort of, testing regimes or frameworks are in these different domains.
So on the first—how is testing used?—so is testing something that impacts market entry, for example? Or is it something that might be used more for informing how risk is evolving in the domain and how broader risk management strategies might need to be applied? We have examples, like the pharmaceutical or medical device industry experts with whom you spoke, that’s really, you know, testing … there is a pre-deployment requirement. So that’s one question.
The second is this emphasis on pre- versus post-deployment testing and monitoring, and we really did see across domains that in many cases, there is a desire for both pre- and post-deployment, sort of, testing and monitoring, but also that, sort of, naturally in these different domains, a degree of emphasis on one or the other had evolved and that had a real impact on governance and tradeoffs.
And the third is just how rigid versus adaptive these testing and evaluation regimes or frameworks are in these different domains. We saw, you know, in some domains, the testing requirements were more rigid as you might expect in more of the pharmaceutical or medical devices industries, for example. And in other domains, there was this more, sort of, adaptive approach to how testing might get used. So, for example, in the case of our other general-purpose technologies, you know, you spoke with Alta Charo on genome editing, and in our case studies, we also explored this in the context of nanotechnology. In those general-purpose technology domains, there is more emphasis on downstream or application-context testing that is more, sort of, adaptive to the use scenario of the technology and, you know, having that work in conjunction with testing more at the, kind of, level of the technology itself.
SULLIVAN: I want to double-click on a number of the things we just talked about. But actually, before we go too much deeper, a question on if there’s anything that really surprised you or challenged maybe some of your own assumptions in this space from some of the discussions that we had over the series.
CRAIG DECKARD: Yeah. You know, I know I’ve already just mentioned this pre- versus post-deployment testing and monitoring issue, but it was something that was very interesting to me and in some ways surprised me or made me just realize something that I hadn’t fully connected before, about how these, sort of, regimes might evolve in different contexts and why. And in part, I couldn’t help but bring the context I have from cybersecurity policy into this, kind of, processing of what we learned and reflection because there was a real contrast for me between the pharmaceutical industry and the cybersecurity domain when I think about the emphasis on pre- versus post-deployment monitoring.
And on the one hand, we have in the pharmaceutical domain a real emphasis that has developed around pre-market testing. And there is also an expectation in some circumstances in the pharmaceutical domain for post-deployment testing, as well. But as we learned from our experts in that domain, there has naturally been a real, kind of, emphasis on the pre-market portion of that testing. And in reality, even where post-market monitoring is required and post-market testing is required, it does not always actually happen. And the experts really explained that, you know, part of it is just the incentive structure around the emphasis around, you know, the testing as a pre-market, sort of, entry requirement. And also just the resources that exist among regulators, right. There’s limited resources, right. And so there are just choices and tradeoffs that they need to make in their own, sort of, enforcement work.
And then on the other hand, you know, in cybersecurity, I never thought about the, kind of, emphasis on things like coordinated vulnerability disclosure and bug bounties that have really developed in the cybersecurity domain. But it’s a really important part of how we secure technology and enhance cybersecurity over time, where we have these norms that have developed where, you know, security researchers are doing really important research. They’re finding vulnerabilities in products. And we have norms developed where they report those to the companies that are in a position to address those vulnerabilities. And in some cases, those companies actually pay, through bug bounties, the researchers. And perhaps in some ways, the role of coordinated vulnerability disclosure and bug bounties has evolved the way that it has because there hasn’t been as much emphasis on the pre-market testing across the board at least in the context of software.
And so you look at those two industries and it was interesting to me to study them to some extent in contrast with each other as this way that the incentives and the resources that need to be applied to testing, sort of, evolve to address where there’s, kind of, more or less emphasis.
SULLIVAN: It’s a great point. I mean, I think what we’re hearing—and what you’re saying—is just exactly this choice … like, is there a binary choice between focusing on pre-deployment testing or post-deployment monitoring? And, you know, I think our assumption is that we need to do both. But I’d love to hear from you on that.
CRAIG DECKARD: Absolutely. I think we need to do both. I’m very persuaded by this inclination always that there’s value in trying to really do it all in a risk management context.
And also, we know one of the principles of risk management is you have to prioritize because there are finite resources. And I think that’s where we get to this challenge in really thinking deeply, especially as we’re in the early days of AI governance, and we need to be very thoughtful about, you know, tradeoffs that we may not want to be making but we are because, again, these are finite choices and we, kind of, can’t help but put our finger on the dial in different directions with our choices that, you know, it’s going to be very difficult to have, sort of, equal emphasis on both. And we need to invest in both, but we need to be very deliberate about the roles of each and how they complement each other and who does which and how we use what we learn from pre- versus post-deployment testing and monitoring.
SULLIVAN: Maybe just spending a little bit more time here … you know, a lot of attention goes into testing models upstream, but risk often shows up once they’re wired into real products and workflows. How much does deployment context change the risk picture from your perspective?
CRAIG DECKARD: Yeah, I … such an important question. I really agree that there has been a lot of emphasis to date on, sort of, testing models upstream, the AI model evaluation. And it’s also really important that we bring more attention into evaluation at the system or application level. And I actually see that in governance conversations, this is actually increasingly raised, this need to have system-level evaluation. We see this across regulation. We also see it in the context of just organizations trying to put in governance requirements for how their organization is going to operate in deploying this technology.
And there’s a gap today in terms of best practices around system-level testing, perhaps even more than model-level evaluation. And it’s really important because in a lot of cases, the deployment context really does impact the risk picture, especially with AI, which is a general-purpose technology, and we really saw this in our study of other domains that represented general-purpose technology.
So in the case study that you can find online on nanotechnology, you know, there’s a real distinction between the risk evaluation and the governance of nanotechnology in different deployment contexts. So the chapter that our expert on nanotechnology wrote really goes into incredibly interesting detail around, you know, deployment of nanotechnology in the context of, like, chemical applications versus consumer electronics versus pharmaceuticals versus construction and how the way that nanoparticles are basically delivered in all those different deployment contexts, as well as, like, what the risk of the actual use scenario is just varies so much. And so there’s a real need to do that kind of risk evaluation and testing in the deployment context, and this difference in terms of risks and what we learned in these other domains where, you know, there are these different approaches to trying to really think about and gain efficiencies and address risks at a horizontal level versus, you know, taking a real sector-by-sector approach. And to some extent, it seems like it’s more time intensive to do that sectoral deployment-specific work. And at the same time, perhaps there are efficiencies to be gained by actually doing the work in the context in which, you know, you have a better understanding of the risk that can result from really deploying this technology.
And ultimately, [LAUGHS] really what we also need to think about here is probably, in the end, just like pre- and post-deployment testing, you need both. Not probably; certainly!
So effectively we need to think about evaluation at the model level and the system level as being really important. And it’s really important to get system evaluation right so that we can actually get trust in this technology in deployment context so we enable adoption in low- and in high-risk deployments in a way that means that we’ve done risk evaluation in each of those contexts in a way that really makes sense in terms of the resources that we need to apply and ultimately we are able to unlock more applications of this technology in a risk-informed way.
SULLIVAN: That’s great. I mean, I couldn’t agree more. I think these contexts, the approaches are so important for trust and adoption, and I’d love to hear from you, what do we need to advance AI evaluation and testing in our ecosystem? What are some of the big gaps that you’re seeing, and what role can different stakeholders play in filling them? And maybe an add-on, actually: is there some sort of network effect that could 10x our testing capacity?
CRAIG DECKARD: Absolutely. So there’s a lot of work that needs to be done, and there’s a lot of work in process to really level up our whole evaluation and testing ecosystem. We learned, across domains, that there’s really a need to advance our thinking and our practice in three areas: rigor of testing; standardization of methodologies and processes; and interpretability of test results.
So what we mean by rigor is that we are ensuring that what we are ultimately evaluating in terms of risks is defined in a scientifically valid way and we are able to measure against that risk in a scientifically valid way.
By standardization, what we mean is that there’s really an accepted and well-understood and, again, a scientifically valid methodology for doing that testing and for actually producing artifacts out of that testing that are meeting those standards. And that sets us up for the final portion on interpretability, which is, like, really the process by which you can trust that the testing has been done in this rigorous and standardized way and that then you have artifacts that result from the testing process that can really be used in the risk management context because they can be interpreted, right.
We understand how to, like, apply weight to them for our risk-management decisions. We actually are able to interpret them in a way that perhaps they inform other downstream risk mitigations that address the risks that we see through the testing results and that we actually understand what limitations apply to the test results and why they may or may not be valid in certain, sort of, deployment contexts, for example, and especially in the context of other risk mitigations that we need to apply. So there’s a need to advance all three of those things—rigor, standardization, and interpretability—to level up the whole testing and evaluation ecosystem.
And when we think about what actors should be involved in that work … really everybody, which is both complex to orchestrate but also really important. And so, you know, you need to have the entire value chain involved in really advancing this work. You need the model developers, but you also need the system developers and deployers that are really engaged in advancing the science of evaluation and advancing how we are using these testing artifacts in the risk management process.
When we think about what could actually 10x our testing capacity—that’s the dream, right? We all want to accelerate our progress in this space. You know, I think we need work across all three of those areas of rigor, standardization, and interpretability, but I think one that will really help accelerate our progress across the board is that standardization work, because ultimately, you’re going to need to have these tests be done and applied across so many different contexts, and ultimately, while we want the whole value chain engaged in the development of the thinking and the science and the standards in this space, we also need to realize that not every organization is necessarily going to have the capacity to, kind of, contribute to developing the ways that we create and use these tests. And there are going to be many organizations that are going to benefit from there being standardization of the methodologies and the artifacts that they can pick up and use.
One thing that I know we’ve heard throughout this podcast series from our experts in other domains, including Timo [Minssen] in the medical devices context and Ciaran [Martin] in the cybersecurity context, is that there’s been a recognition, as those domains have evolved, that there’s a need to calibrate our, sort of, expectations for different actors in the ecosystem and really understand that small businesses, for example, just cannot apply the same degree of resources that others may be able to, to do testing and evaluation and risk management. And so the benefit of having standardized approaches is that those organizations are able to, kind of, integrate into the broader supply chain ecosystem and apply their own, kind of, risk management practices in their own context in a way that is more efficient.
And finally, the last stakeholder that I think is really important to think about in terms of partnership across the ecosystem to really advance the whole testing and evaluation work that needs to happen is government partners, right, and thinking beyond the value chain, the AI supply chain, and really thinking about public-private partnership. That’s going to be incredibly important to advancing this ecosystem.
You know, I think there’s been real progress already in the AI evaluation and testing ecosystem in the public-private partnership context. We have been really supportive of the work of the International Network of AI Safety and Security Institutes (opens in new tab)[1] (opens in new tab) and the Center for AI Standards and Innovation (opens in new tab) that all allow for that kind of public-private partnership on actually testing and advancing the science and best practices around standards.
And there are other innovative, kind of, partnerships, as well, in the ecosystem. You know, Singapore has recently launched their Global AI Assurance Pilot (opens in new tab) findings. And that effort really paired application deployers and testers so that consequential impacts at deployment could really be tested. And that’s a really fruitful, sort of, effort that complements the work of these institutes and centers that are more focused on evaluation at the model level, for example.
And in general, you know, I think that there’s just really a lot of benefits for us thinking expansively about what we can accomplish through deep, meaningful public-private partnership in this space. I’m really excited to see where we can go from here with building on, you know, partnerships across AI supply chains and with governments and public-private partnerships.
SULLIVAN: I couldn’t agree more. I mean, this notion of more engagement across the ecosystem and value chain is super important for us and informs how we think about the space completely.
If you could invite any other industry to the next workshop, maybe quantum safety, space tech, even gaming, who’s on your wish list? And maybe what are some of the things you’d want to go deeper on?
CRAIG DECKARD: This is something that we really welcome feedback on if anyone listening has ideas about other domains that would be interesting to study. I will say, I think I shared at the outset of this podcast series, the domains that we added in this round of our efforts in studying other domains actually all came from feedback that we received from, you know, folks we’d engaged with our first study of other domains and multilateral, sort of, governance institutions. And so we’re really keen to think about what other domains could be interesting to study. And we are also keen to go deeper, building on what we learned in this round of effort going forward.
One of the areas that I am particularly really interested in is going deeper on, what, sort of, transparency and information sharing about risk evaluation and testing will be really useful to share in different contexts? So across the AI supply chain, what is the information that’s going to be really meaningful to share between developers and deployers of models and systems and those that are ultimately using this technology in particular deployment contexts? And, you know, I think that we could have much to learn from other general-purpose technologies like genome editing and nanotechnology and cybersecurity, where we could learn a bit more about the kinds of information that they have shared across the development and deployment life cycle and how that has strengthened risk management in general as well as provided a really strong feedback loop around testing and evaluation. What kind of testing is most useful to do at what point in the life cycle, and what artifacts are most useful to share as a result of that testing and evaluation work?
I’ll say, as Microsoft, we have been really investing in how we are sharing information with our various stakeholders. We also have been engaged with others in industry in reporting what we’ve done in the context of the Hiroshima AI Process, or HAIP, Reporting Framework (opens in new tab). This is an effort that is really just in its first round of really exploring how this kind of reporting can be really additive to risk management understanding. And again, I think there’s real opportunity here to look at this kind of reporting and understand, you know, what’s valuable for stakeholders and where is there opportunity to go further in really informing value chains and policymakers and the public about AI risk and opportunity and what can we learn again from other domains that have done this kind of work over decades to really refine that kind of information sharing.
SULLIVAN: It’s really great to hear about all the advances that we’re making on these reports. I’m guessing a lot of the metrics in there are technical, but sociotechnical impacts—jobs, maybe misinformation, well-being—are harder to score. What new measurement ideas are you excited about, and do you have any thoughts on, like, who needs to pilot those?
CRAIG DECKARD: Yeah, it’s an incredibly interesting question that I think also just speaks to, you know, the breadth of, sort of, testing and evaluation that’s needed at different points along that AI life cycle and really not getting lost in one particular kind of testing or another pre- or post-deployment and thinking expansively about the risks that we’re trying to address through this testing.
You know, for example, even with the UK’s AI Security Institute (opens in new tab) that has just recently launched a new program, a new team, that’s focused on societal resilience research. I think it’s going to be a really important area from a sociotechnical impact perspective to bring some focus into as this technology is more widely deployed. Are we understanding the impacts over time as different people and different cultures adopt and use this technology for different purposes?
And I think that’s an area where there really is opportunity for greater public-private partnership in this research. Because we all share this long-term interest in ensuring that this technology is really serving people and we have to understand the impacts so that we understand, you know, what adjustments we can actually pursue sooner upstream to address those impacts and make sure that this technology is really going to work for all of us and in a way that is consistent with the societal values that we want.
SULLIVAN: So, Amanda, looking ahead, I would love to hear just what’s going to be on your radar? What’s top of mind for you in the coming weeks?
CRAIG DECKARD: Well, we are certainly continuing to process all the learnings that we’ve had from studying these domains. It’s really been a rich set of insights that we want to make sure we, kind of, fully take advantage of. And, you know, I think these hard questions and, you know, real opportunities to be thoughtful in these early days of AI governance are not, sort of, going away or being easily resolved soon. And so I think we continue to see value in really learning from others, thinking about what’s distinct in the AI context, but also what we can apply in terms of what other domains have learned.
SULLIVAN: Well, Amanda, it has been such a special experience for me to help illuminate the work of the Office of Responsible AI and our team in Microsoft Research, and [MUSIC] it’s just really special to see all of the work that we’re doing to help set the standard for responsible development and deployment of AI. So thank you for joining us today, and thanks for your reflections and discussion.
And to our listeners, thank you so much for joining us for the series. We really hope you enjoyed it! To check out all of our episodes, visit aka.ms/AITestingandEvaluation (opens in new tab), and if you want to learn more about how Microsoft approaches AI governance, you can visit microsoft.com/RAI (opens in new tab).
See you next time!
[MUSIC FADES]
[1] (opens in new tab) Since the launch of the International Network of AI Safety Institutes, the UK renamed its institute the AI Security Institute (opens in new tab).
The post AI Testing and Evaluation: Reflections appeared first on Microsoft Research.

New experimental AI tool helps people explore the context and origin of images seen online.Read More