
GeForce NOW Delivers Justice With ‘RoboCop: Rogue City — Unfinished Business’
Listen up citizens, the law is back and patrolling the cloud. Nacon’s RoboCop Rogue City — Unfinished Business launches today in the cloud, bringing justice to every device, everywhere.
Log in, lock and load, and take charge with the ten games heading to the cloud this week.
Plus, Cyberpunk 2077’s 2.3 update amps up the chaos in Night City while Zenless Zone Zero’s 2.1 update delivers summer vibes — all instantly playable in the cloud.
Suit Up

Step into the titanium boots of RoboCop, the ultimate cybernetic law enforcer. Whether a veteran of the force or a rookie looking to protect the innocent, players will encounter a fresh case file packed with explosive action, tough choices, and that signature blend of grit and dry wit in RoboCop Rogue City — Unfinished Business.
Tackle a new storyline that puts players’ decision-making skills to the test, and wield the iconic RoboCop weapons while upholding the law.
With GeForce NOW, players won’t need a high-tech lab to experience high visual quality and lightning-fast gameplay. Stream the game instantly on mobile devices, laptops, SHIELD TV, Samsung and LG smart TVs, gaming handhelds or even that old PC that’s seen better days.
Night City, New Tricks

Cyberpunk 2077’s Update 2.3 is rolling out with a turbocharged dose of Night City attitude. Four new quests are dropping, each unlocking a fresh set of wheels — including the ARV-Q340 Semimaru from the “Cyberpunk Kickdown” comic and the Rayfield Caliburn “Mordred,” plucked from the personal collection of Yorinobu Arasaka himself. Getting around just got slicker, too, thanks to the new AutoDrive feature: Players can let their rides do the work while soaking in the neon skyline with cinematic camera angles. Those with eddies to burn can even call a Delamain cab to take them to their destination in style.
Almost every ride in the game is getting an upgrade through the expanded CrystalCoat and TwinTone technologies that let players customize their vehicle’s colors. Plus, Photo Mode is getting a serious glow-up. Add new characters, poses, outfits, stickers and frames to shots, and change the time of day to get the perfect lighting.
Those ready to hit the streets can stream Cyberpunk 2077’s latest update instantly on GeForce NOW and experience Night City’s new thrills from anywhere, on any device — at the highest-quality settings. No upgrades or fancy hardware needed, just pure, cutting-edge gameplay delivered straight from the cloud.
New Games Assemble

Catch Zenless Zone Zero’s 2.1 update, “The Impending Crash of Waves,” in the cloud without having to wait for downloads. The update brings a wave of summer content to the game. Explore two new regions — Sailume Bay and the Fantasy Resort — while diving into a fresh chapter of the main story featuring the Spook Shack faction. The update introduces two new S-Rank agents, Ukinami Yuzuha and Alice Thymefield, plus the S-Rank Bangboo Miss Esme, alongside summer-themed events, mini games — like surfing and fishing — new outfits and quality-of-life improvements.
In addition, members can look for the following:
- Stronghold Crusader: Definitive Edition (New release on Steam, July 15)
- The Drifter (New release on Steam, July 17)
- He Is Coming (New release on Steam, July 17)
- DREADZONE (New release on Steam, July 17)
- RoboCop: Rogue City (New release on Xbox, available on PC Game Pass, July 17)
- RoboCop: Rogue City — Unfinished Business (New release on Steam, July 17)
- Battle Brothers (Steam)
- BitCraft Online (Steam)
- Humanity (Xbox, available on the Microsoft store)
- SteamWorld Dig (Steam)
What are you planning to play this weekend? Let us know on X or in the comments below.
What game soundtrack do you still hear in your head—years later?
—
NVIDIA GeForce NOW (@NVIDIAGFN) July 15, 2025

Building enterprise-scale RAG applications with Amazon S3 Vectors and DeepSeek R1 on Amazon SageMaker AI
Organizations are adopting large language models (LLMs), such as DeepSeek R1, to transform business processes, enhance customer experiences, and drive innovation at unprecedented speed. However, standalone LLMs have key limitations such as hallucinations, outdated knowledge, and no access to proprietary data. Retrieval Augmented Generation (RAG) addresses these gaps by combining semantic search with generative AI, enabling models to retrieve relevant information from enterprise knowledge bases before responding. This approach grounds outputs in accurate, up-to-date context, making applications more reliable, transparent, and capable of using domain expertise without retraining. Yet, as the usage of RAG solutions grows, so do the operational and technical hurdles associated with scaling these solutions in production. Such hurdles include the costs and infrastructure complexities that come with vector databases that enterprises need to seamlessly store, search, and manage high-dimensional embeddings at scale.
Although RAG unlocks remarkable capabilities, organizations building production-grade applications often encounter four major obstacles with existing vector databases:
- Unpredictable costs – Conventional solutions often require over-provisioning, resulting in ballooning expenses as your data grows.
- Operational complexity – Teams are forced to divert valuable engineering resources toward managing and tuning dedicated vector database clusters.
- Scaling limitations – As vector collections expand and diversify, capacity planning becomes increasingly difficult and time-consuming.
- Integration overhead – Connecting vector stores to existing data pipelines, security frameworks, and analytics tools can introduce friction and slow time-to-market.
With the launch of Amazon Simple Storage Service (Amazon S3) Vectors, the first cloud object storage service with native support to store and query vectors, we have a new approach to cost-effectively manage vector data at scale. In this post, we explore how combining S3 Vectors and Amazon SageMaker AI redefines the developer experience for RAG, making it easier than ever to experiment, build, and scale AI-powered applications without the traditional trade-offs.
Amazon SageMaker AI: Streamlining LLM experimentation and governance
Enterprise-scale RAG applications involve high data volumes (often multimillion document knowledge bases, including unstructured data), high query throughput, mission-critical reliability, complex integration, and continuous evaluation and improvement. To realize these enterprise-scale RAG applications, you need more than powerful LLM model deployment. These applications also demand rigorous experimentation, governance, and performance tracking. Amazon SageMaker AI, with its native integration with managed MLflow, offers a unified system for deploying, monitoring, and optimizing LLMs at scale.
Amazon SageMaker JumpStart accelerates embedding and text generation deployment, helping teams rapidly prototype and deliver value. SageMaker JumpStart accelerates the development of RAG solutions with:
- One-click deployment – Quickly deploy models such as GTE-Qwen2-7B for embeddings or DeepSeek R1 Distill Qwen 7B for generation.
- Optimized infrastructure – Get automatic recommendations for the best instance types to balance performance and cost.
- Scalable endpoints – Launch high-performance inference endpoints with built-in monitoring for reliable, low-latency service.
Developing effective RAG systems requires evaluating prompts, chunking strategies, retrieval methods, and model settings. SageMaker managed MLflow supports this in several ways. You can track experiments by logging and comparing chunking, retrieval, and generation configurations. Use built-in LLM-based generative AI metrics such as correctness and relevance to assess output quality. To monitor performance, you can track latency and throughput alongside output quality to verify production-readiness. Improve reproducibility of experiments by capturing parameters for reliable auditing and experiment replication. And by using the governance dashboards, you can visualize results, manage model versions, and control approvals through an intuitive interface.
As enterprises scale their RAG implementations, they face significant challenges for managing their vector stores. Traditional vector databases have unpredictable and rising costs because they incur charges based on compute, storage, and API usage, which scale with data volume. Teams spend significant time on the operational complexity that results from having to manage separate vector database infrastructure instead of focusing on application development. Capacity planning becomes increasingly complex as vector collections grow and diversify, making scaling challenging. Connecting vector stores with existing data infrastructure and security frameworks adds additional complexity.
Introducing Amazon S3 Vectors
Amazon S3 Vectors delivers purpose-built vector storage so you can harness the semantic power of your organization’s unstructured data at scale. Designed for the cost-optimized and durable storage of large vector datasets with sub-second query performance, S3 Vectors is ideal for infrequent query workloads and can help you reduce the overall cost of uploading, storing, and querying vectors by up to 90% compared to alternative solutions. With S3 Vectors, you only pay for what you use without the need for infrastructure provisioning and management. Whether you’re developing semantic search engines, RAG systems, or recommendation services, you can focus on innovation rather than cost constraints and data management complexities.
Amazon S3 Vectors brings the proven economics and simplicity of Amazon S3 to vectors. S3 Vectors is ideal for RAG applications where slightly higher latency than millisecond-level vector databases is acceptable, in exchange for substantial cost savings and simplified operations. You also have elasticity because you can scale vector search applications seamlessly from gigabytes to petabytes, and scale down to zero when these resources are not in use. Moreover, data management becomes more flexible. You can store vectors alongside metadata, minimizing the need for separate databases while enhancing retrieval performance through consolidated data access. S3 Vectors supports up to 40 KB of (filterable and nonfilterable) metadata per vector with schema-less filtering capabilities, using separate vector indexes for streamlined organization.
Solution overview
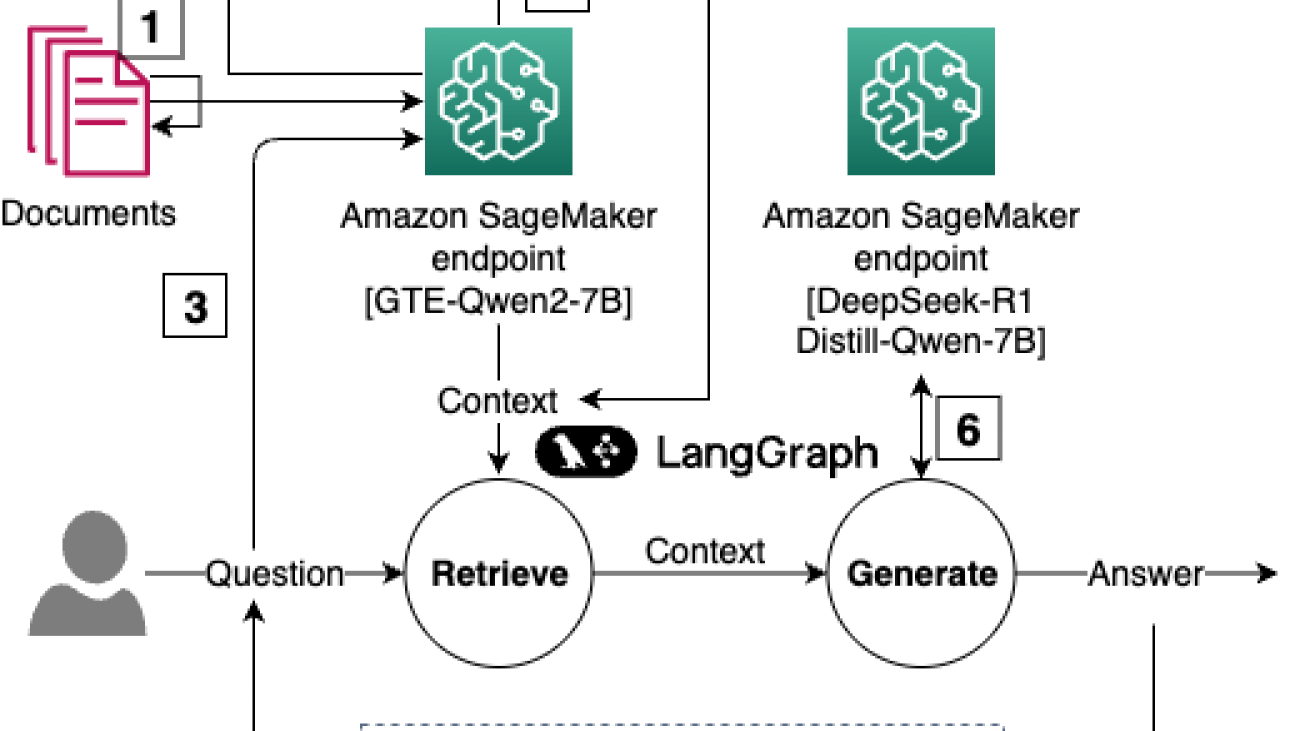
In this post, we show how to build a cost-effective, enterprise-scale RAG application using Amazon S3 Vectors, SageMaker AI for scalable inference, and SageMaker managed MLflow for experiment tracking and evaluation, making sure the responses meet enterprise standards. We demonstrate this by building a RAG system that answers questions about Amazon financials using annual reports, shareholder letters, and 10-K filings as the knowledge base. Our solution consists of the following components:
- Document ingestion – Process PDF documents using LangChain’s document loaders.
- Text chunking – Experiment with different chunking strategies (for example, fixed-size or recursive) and configurations (such as chunk size and overlap).
- Vector embedding – Generate embeddings using SageMaker deployed embedding LLM models.
- Vector storage – Store vectors in Amazon S3 Vectors with associated metadata (such as the type of document). You can also store the entire text chunk in the vector metadata for simple retrieval.
- Retrieval logic – Implement semantic search using vector similarity.
- Response generation – Create responses using retrieved context and a SageMaker deployed LLM.
- Evaluation – Assess performance using ground truth datasets and SageMaker managed MLflow metrics.
The following diagram is the solution architecture.
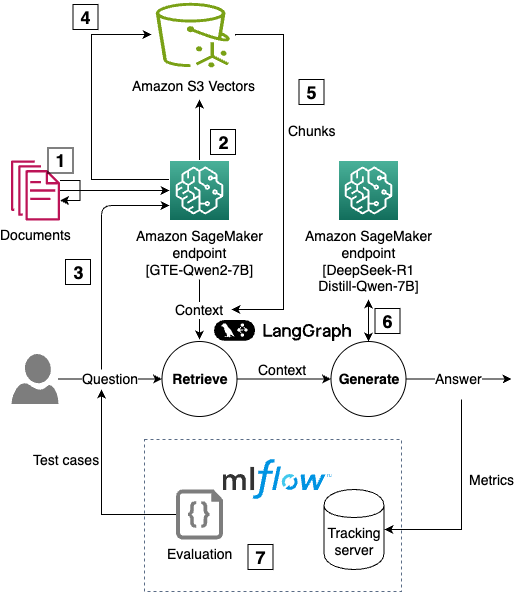
You can follow and execute the full example code from the repository. We use code snippets from this GitHub repository to illustrate RAG solution using S3 Vectors and tracking approaches in the rest of this post.
Prerequisites
To perform the solution, you need to have these prerequisites:
- An AWS account with billing enabled.
- A SageMaker AI Studio domain. For more information, refer to Use quick setup for Amazon SageMaker AI.
- Access to a running SageMaker AI managed MLflow tracking server in Amazon SageMaker Studio. For more information, refer to the instructions for setting up a new MLflow tracking server.
- Enable access to an Amazon Bedrock foundation model (FM) to use in LLM-as-a-judge. In this sample, we use Anthropic’s Claude 3 Sonnet.
Walkthrough
The following steps walk you through this solution:
- Deploy LLMs on SageMaker AI
- Create Amazon S3 Vectors buckets and indexes
- Process documents and generate embeddings
- Implement the RAG pipeline with LangGraph
- Evaluate RAG performance with MLflow
Step 1: Deploy LLMs on SageMaker AI
We use SageMaker JumpStart to deploy state-of-the-art models in minutes using a few lines of code. A RAG application requires:
- An embedding model to convert text into vector representations
- A text generation model to produce responses based on retrieved context
Use the following code:
In this post, we use Qwen2 7B instruct as the embedding model and DeepSeek R1 because they’re highly capable open source models that are among the top models in embedding leaderboards and LLM leaderboards. You can choose an embedding and text generation model from the more than 300 models available on SageMaker JumpStart.
Step 2: Create Amazon S3 Vectors buckets and indexes
Amazon S3 Vectors provide a seamless yet powerful way to store and search vector embeddings. Vectors are stored in vector indexes, which are used for logically grouping. Write and read operations are directed to a single vector index. To start using Amazon S3 Vectors, you need to:
- Create an S3 Vector bucket indicating its name:
- Create vector indexes by giving them a name and defining the number of dimensions and the distance metric to use. Vector indexes can store up to 50,000,000 vectors with a maximum dimension of 4,096 and use either
cosineoreuclideanas their distance metrics. Define your dimensions and distance metric:
Step 3: Process documents and generate embeddings
You can calculate the embedding vectors for each text chunk in the source documents and store them in your S3 vector bucket using the put_vectors API, which supports up to 500 vectors per call. When putting vectors in the vector index, you can include up to 10 fields in the vector metadata to facilitate the retrieval and generation stages of RAG. In the following example, we add the domain (such as a financial document or shareholder letter) and the year for targeted semantic queries, and the text chunk so we can use its content when generating an answer:
Step 4: Implement the RAG pipeline with LangGraph
LangGraph is a framework for building stateful, multi-step applications with LLMs using a graph-based architecture. The first step in the definition of a RAG application with LangGraph is to create Python functions for the retrieval and generation steps.
- The retrieval step runs a semantic query based on an input string and may apply metadata filters to narrow the results to a specific set of documents. The filter syntax in Amazon S3 Vectors supports various types of string and numerical comparison (for example,
$eqfor exact match or$gtfor greater than comparison) and combinations through logical operations (such as$andor$or). - The generation step uses the selected text chunks as context to generate a response.
You can use the query_vectors API in S3 Vectors to run a semantic search on a vector index. In this query, you have to define the query vector (that is, the vector that represents the query or question), search parameters (for example, topK for the number of similar vectors to retrieve), and possibly filter conditions for metadata filtering:
Metadata filters can be used to focus the search on a subset of documents. For example, if you’re asking about business and industry risks from an annual report, you can call the query_vectors function with metadata_filter being equal to “Amazon Annual Report” to only consider those documents: ({"domain": {"$eq": "Amazon Annual Report"}}). For greater specificity, we could add numerical operators to indicate the years of the annual reports to consult ({"year": {"$gt": 2023}}). The choice of operators and filters depends on the use case and on the logic that will allow that only the relevant documents are consulted.
You can automate the retrieval and generation steps of a RAG application using a LangGraph StateGraph. To define a LangGraph graph for RAG, we take the following steps:
- Define functions for retrieval and generation. A snippet of this implementation is shown in the following example. For a complete overview of these functions, visit our GitHub repository.
- Retrieve – Invoke the SageMaker AI embedding model to generate a query vector, then query a vector index to find relevant document chunks.
- Generate – Invoke the SageMaker AI text generation model with the retrieved chunks to generate a response.
- After the LangGraph graph has been built and compiled, it can be invoked with sample questions:
The response from the LangGraph graph is as follows:
The names of the people in Amazon’s board of directors are Jeffrey P. Bezos, Andrew R. Jassy, Keith B. Alexander, Edith W. Cooper, Jamie S. Gorelick, Daniel P. Huttenlocher, and Judith A. McGrath. There are seven members on the board, including Amazon’s CEO.
Step 5: Evaluate RAG performance with MLflow
To validate our RAG system performs well, we use MLflow to track experiments and evaluate performance using a ground truth dataset of questions and answers. You can set up an MLflow evaluation and run it using the following script. Notice that we can complement metrics from the evaluation (for example, latency and answer correctness using LLM as a judge) with parameters from the chunking and embedding stages to provide full visibility of the RAG application:
This evaluation tracks:
- Answer correctness – Using Anthropic’s Claude 3 Sonnet as a judge to provide a measure of answer quality as assessed by an LLM. High scores mean that the model output contains information that is semantically similar to the ground truth and that this information is correct, while low scores mean that outputs disagree with the ground truth or that the information is incorrect.
- Latency – Measuring the end-to-end response time of our RAG system to estimate the fitness for latency-critical applications (for example, chat assistants).
- Chunking parameters – Chunking parameters determine how source documents are split into the chunks that are selectively pulled into the context in a RAG application. Changing the chunking strategy (for example, fixed size chunking or hierarchical chunking), chunk size (the number of characters in the chunk), and the chunk overlap (number of characters repeated between subsequent chunks to aid in contextualization) can affect the performance of the retriever, and the optimal configuration is found through experimentation.
- Embedding parameters – The model ID and version used for embedding, time spent chunking and embedding the source documents. These parameters help with reproducibility and experiment tracking.
The following figure shows the metrics and parameters from one experiment. Using this view, a machine learning (ML) engineer can compare the performance of different RAG applications and pick the combination of retrieval and generation parameters that provide the best user experience. This could be, for example, finding the best combination between high answer correctness and low latency. The ML engineer can then learn the models and chunking parameters that resulted in that performance and implement them in the final application.
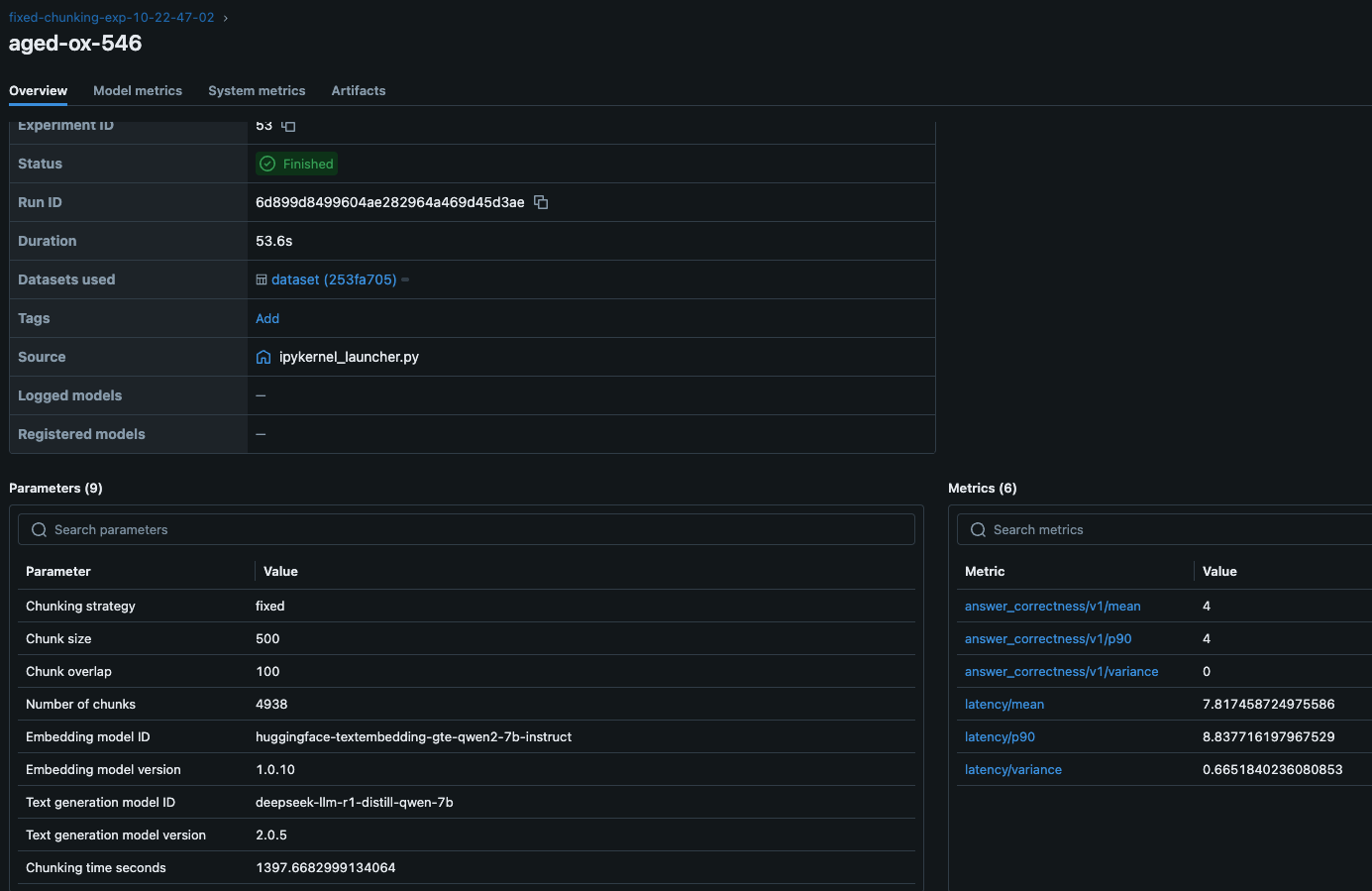
By running multiple experiments with different chunking strategies, embedding models, or retrieval configurations, you can identify the optimal setup for your use case.
Key benefits of Amazon S3 Vectors for RAG
Amazon S3 Vectors bring scalable, cost-effective vector search to your RAG applications with:
- Cost-effective pricing – Pay only for what you use, with no infrastructure to manage.
- Fast similarity search – Supports sub-second retrieval for efficient retrieval.
- Serverless scalability – Automatically scales without provisioning resources.
- Seamless integration – Works with familiar Amazon S3 APIs and AWS services.
- Flexible filtering – Supports metadata queries using a MongoDB-like syntax.
- Unified storage – Store vectors and text metadata together, enabling faster retrieval and reducing the need for separate databases.
Amazon S3 vector store is ideal for use cases where ultra-low latency isn’t required, such as batch processing, periodic reporting, and agent-based workflows. It offers the durability, scalability, and operational simplicity of Amazon S3. A few industry-specific use cases that can benefit from S3 vector store are:
- Healthcare – Searchable medical research databases, mine patterns in historical patient data, and organize diagnostic images for model training
- Financial services – Detect fraud patterns in past transactions, extract insights from financial documents, and manage searchable archives of market research
- Retail – Enrich product catalogs with embeddings, analyze customer reviews for sentiment trends, and study seasonal purchasing patterns
- Manufacturing – Manage technical manuals and documentation, identify trends in quality control data, and optimize supply chains with historical data
- Legal and compliance – Discover relevant legal documents and contracts, organize regulatory and compliance records, and analyze and compare patents
- Media and entertainment – Power non-real-time recommendation engines, organize media archives efficiently, and manage digital content licensing records
- Education – Create searchable academic research repositories, organize and retrieve educational content, and analyze historical student performance trends
Performance Considerations
When building RAG applications with Amazon S3 Vectors, consider these performance optimization strategies:
- Chunking strategy – Experiment with different chunking approaches (such as fixed-size or recursive) to find the optimal balance between context preservation and retrieval precision. Track those experiments using SageMaker managed MLflow.
- Vector dimensions – Higher-dimensional embeddings can capture more semantic information but require more storage.
- Distance metrics – Choose between cosine or Euclidean distance based on your embedding model’s characteristics.
- Metadata filtering – Use metadata filters to narrow down search results and improve relevance.
To summarize, the key advantages demonstrated in using S3 Vectors with SageMaker AI are:
- Cost-efficient scalability – The serverless storage of S3 Vectors adapts dynamically to workload demands, avoiding over-provisioning costs while maintaining low-latency retrieval.
- Integrated evaluation framework – The experiment tracking and generative AI–specific metrics in SageMaker managed MLflow enable systematic optimization of chunking strategies, retrieval parameters, and model configurations.
- Accelerated innovation cycle – Pre-trained models from SageMaker JumpStart and one-click deployments reduce prototyping time from weeks to hours while maintaining enterprise-grade security.
In this post, we’ve shown how to replace traditional vector database complexity with a streamlined AWS based approach that scales with your data and evolves with your generative AI strategy. The SageMaker managed MLflow integration means that every architectural decision is guided by quantifiable metrics, from answer correctness to latency profiles, turning experimentation into actionable insights. As you implement RAG solutions, use these tools to validate retrieval strategies against domain-specific datasets, benchmark embedding models for accuracy and storage tradeoffs, and enforce governance through version-controlled deployments.
Cleanup
To avoid unnecessary costs, delete resources such as the SageMaker-managed MLflow tracking server, S3 Vectors indexes and buckets, and SageMaker endpoints when your RAG experimentation is complete.
Conclusion
In this post, we’ve demonstrated how to build a complete RAG solution using Amazon S3 Vectors and SageMaker AI. The combination of S3 vector buckets, SageMaker AI LLM models, and SageMaker managed MLflow provides a transformative solution for organizations building enterprise-scale RAG applications. In this approach, we illustrate the use of S3 Vectors as a new approach to effectively manage vector data at scale, without the cost and scalability challenges that come with conventional vector databases.
We encourage you to explore Amazon S3 Vectors documentation and experiment with the SageMaker AI LLM models and SageMaker managed MLflow evaluation templates shown in this post. Now it’s your turn to build enterprise-scale AI solutions with serverless, observable, and relentlessly optimized generative AI strategies.
About the Authors
 Sandeep Raveesh is a GenAI Specialist Solutions Architect at AWS. He works with customer through their AIOps journey across model training, Retrieval-Augmented-Generation (RAG), GenAI Agents, and scaling GenAI use-cases. He also focuses on Go-To-Market strategies helping AWS build and align products to solve industry challenges in the Generative AI space. You can find Sandeep on LinkedIn.
Sandeep Raveesh is a GenAI Specialist Solutions Architect at AWS. He works with customer through their AIOps journey across model training, Retrieval-Augmented-Generation (RAG), GenAI Agents, and scaling GenAI use-cases. He also focuses on Go-To-Market strategies helping AWS build and align products to solve industry challenges in the Generative AI space. You can find Sandeep on LinkedIn.
 Felipe Lopez is a Senior AI/ML Specialist Solutions Architect at AWS. Prior to joining AWS, Felipe worked with GE Digital and SLB, where he focused on modeling and optimization products for industrial applications.
Felipe Lopez is a Senior AI/ML Specialist Solutions Architect at AWS. Prior to joining AWS, Felipe worked with GE Digital and SLB, where he focused on modeling and optimization products for industrial applications.
 Indrajit Ghosalkar is a Sr. Solutions Architect at Amazon Web Services based in Singapore. He loves helping customers achieve their business outcomes through cloud adoption and realize their data analytics and ML goals through adoption of DataOps / MLOps practices and solutions. In his spare time, he enjoys playing with his son, traveling and meeting new people.
Indrajit Ghosalkar is a Sr. Solutions Architect at Amazon Web Services based in Singapore. He loves helping customers achieve their business outcomes through cloud adoption and realize their data analytics and ML goals through adoption of DataOps / MLOps practices and solutions. In his spare time, he enjoys playing with his son, traveling and meeting new people.
 Biswanath Hore is a Sr. Solutions Architect at Amazon Web Services. He works with customers early in their AWS journey, helping them adopt cloud solutions to address their business needs. He is passionate about Machine Learning and, outside of work, loves spending time with his family.
Biswanath Hore is a Sr. Solutions Architect at Amazon Web Services. He works with customers early in their AWS journey, helping them adopt cloud solutions to address their business needs. He is passionate about Machine Learning and, outside of work, loves spending time with his family.
Apple Intelligence Foundation Language Models Tech Report 2025
We introduce two multilingual, multimodal foundation language models that power Apple Intelligence features across Apple devices and services: (i) a ∼3B-parameter on-device model optimized for Apple silicon through architectural innovations such as KV-cache sharing and 2-bit quantization-aware training; and (ii) a scalable server model built on a novel Parallel-Track Mixture-of-Experts (PT-MoE) transformer that combines track parallelism, mixture-of-experts sparse computation, and interleaved global–local attention to deliver high quality with competitive cost on Apple’s Private Cloud Compute…Apple Machine Learning Research
Accenture scales video analysis with Amazon Nova and Amazon Bedrock Agents
This post was written with Ilan Geller, Kamal Mannar, Debasmita Ghosh, and Nakul Aggarwal of Accenture.
Video highlights offer a powerful way to boost audience engagement and extend content value for content publishers. These short, high-impact clips capture key moments that drive viewer retention, amplify reach across social media, reinforce brand identity, and open new avenues for monetization. However, traditional highlight creation workflows are slow and labor-intensive. Editors must manually review footage, identify significant moments, cut clips, and add transitions or narration—followed by manual quality checks and formatting for distribution. Although this provides editorial control, it creates bottlenecks that don’t scale efficiently.
This post showcases how Accenture Spotlight delivers a scalable, cost-effective video highlight generation solution using Amazon Nova and Amazon Bedrock Agents. Amazon Nova foundation models (FMs) deliver frontier intelligence and industry-leading price-performance. With Spotlight, content owners can configure AI models and agents to support diverse use cases across the media industry while offering a human-in-the-loop option for quality assurance and collaborative refinement. This maintains accuracy, editorial oversight, and alignment with brand guidelines—without compromising on speed or scalability.
Real-world use cases
Spotlight has been applied across a range of industry scenarios, including:
- Personalized short-form video generation – Spotlight’s specialized agents analyze popular short-form content (such as video reels and other social media) to identify patterns of high-performing content. The agents then apply this understanding to long-form video to generate personalized short clips, with built-in checks for brand alignment and content standards.
- Sports editing and highlights – Spotlight automates creation of video highlights for sports like soccer, Formula 1, and rugby, tailoring them to specific user preferences and interests. It also validates each highlight’s quality and accuracy, streamlining editorial workflows as a result.
- Content matching for stakeholders – Using enriched metadata, Spotlight matches archived or live video content to audience demographics, optimizing distribution strategies and maximizing advertiser value through precise targeting.
- Real-time retail offer generation – In retail environments such as gas stations, Spotlight processes live CCTV footage to infer customer profiles using data (such as vehicle type or transaction history), and then dynamically generates personalized product offers. These offers consider contextual factors such as time of day and weather; and they are delivered with custom visuals in near real time.
Spotlight’s architecture
Spotlight’s architecture addresses the challenge of scalable video processing, efficiently analyzing and generating content while maintaining speed and quality. It incorporates both task-specific models and Amazon Nova FMs that are orchestrated by specialized Amazon Bedrock agents. Key architectural highlights include:
- Task-driven model selection – Spotlight dynamically selects between traditional AI models and Amazon Nova FMs based on a given task’s complexity and latency requirements. This intelligent orchestration enables fast inference for time-sensitive operations while deploying deeper multimodal reasoning where sophisticated analysis is needed—balancing speed and intelligence across applications from real-time retail offers to complex video processing.
- Agent orchestration – Specialized agents, each purpose-built for specific analysis tasks, operate across the end-to-end workflow under the direction of a central orchestrator agent. The orchestrator agent manages task breakdown, data flow, and inter-agent communication.
- Scalable and adaptable – By using AWS capabilities, Spotlight’s architecture is configurable to support different workloads—from high-throughput video highlight generation to low-latency offer personalization at the edge.
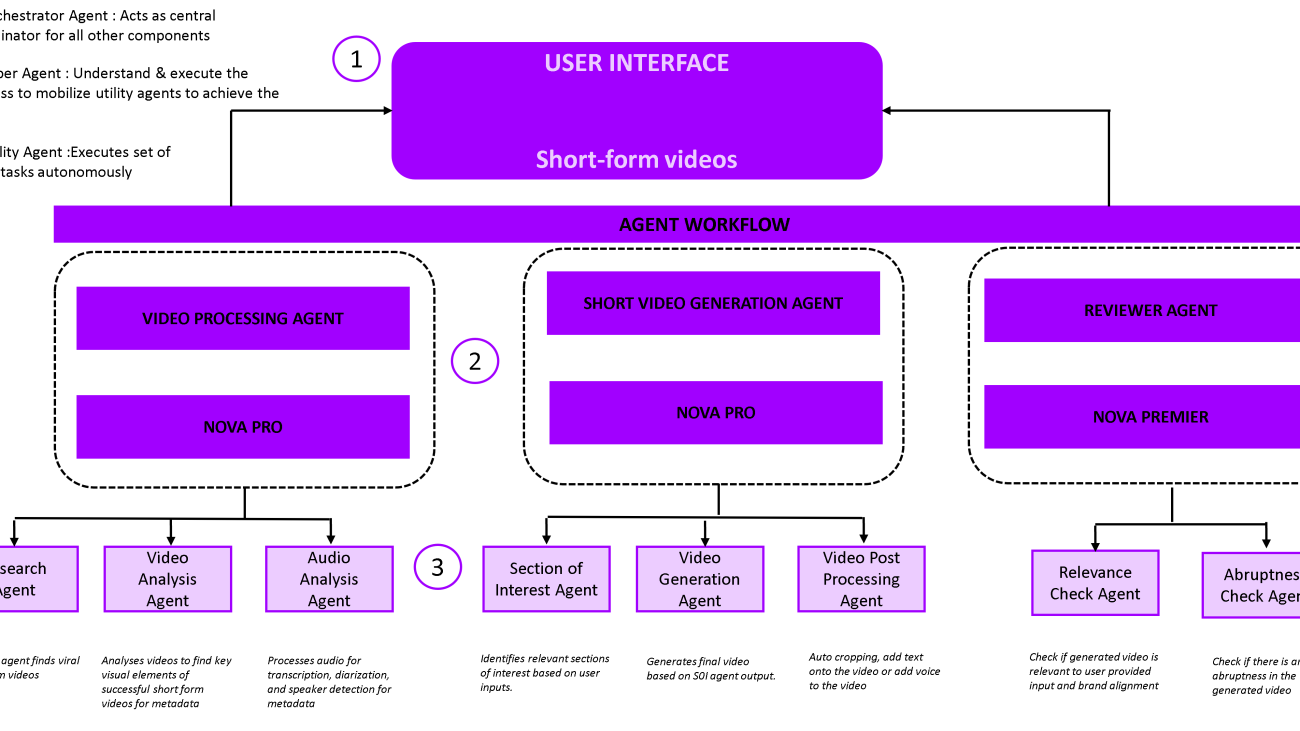
Spotlight uses a multi-layered agent workflow to automate video processing and generation while maintaining quality control. For example, to generate dynamic video highlights, Spotlight uses three specialized “super agents” that work in coordination under a central orchestrator agent’s supervision. Each super agent is powered by Amazon Nova models, and is supported by a collection of utility agents (see the following diagram). These agents work together to understand video content, generate high-quality highlights, and maintain alignment with user requirements and brand standards.
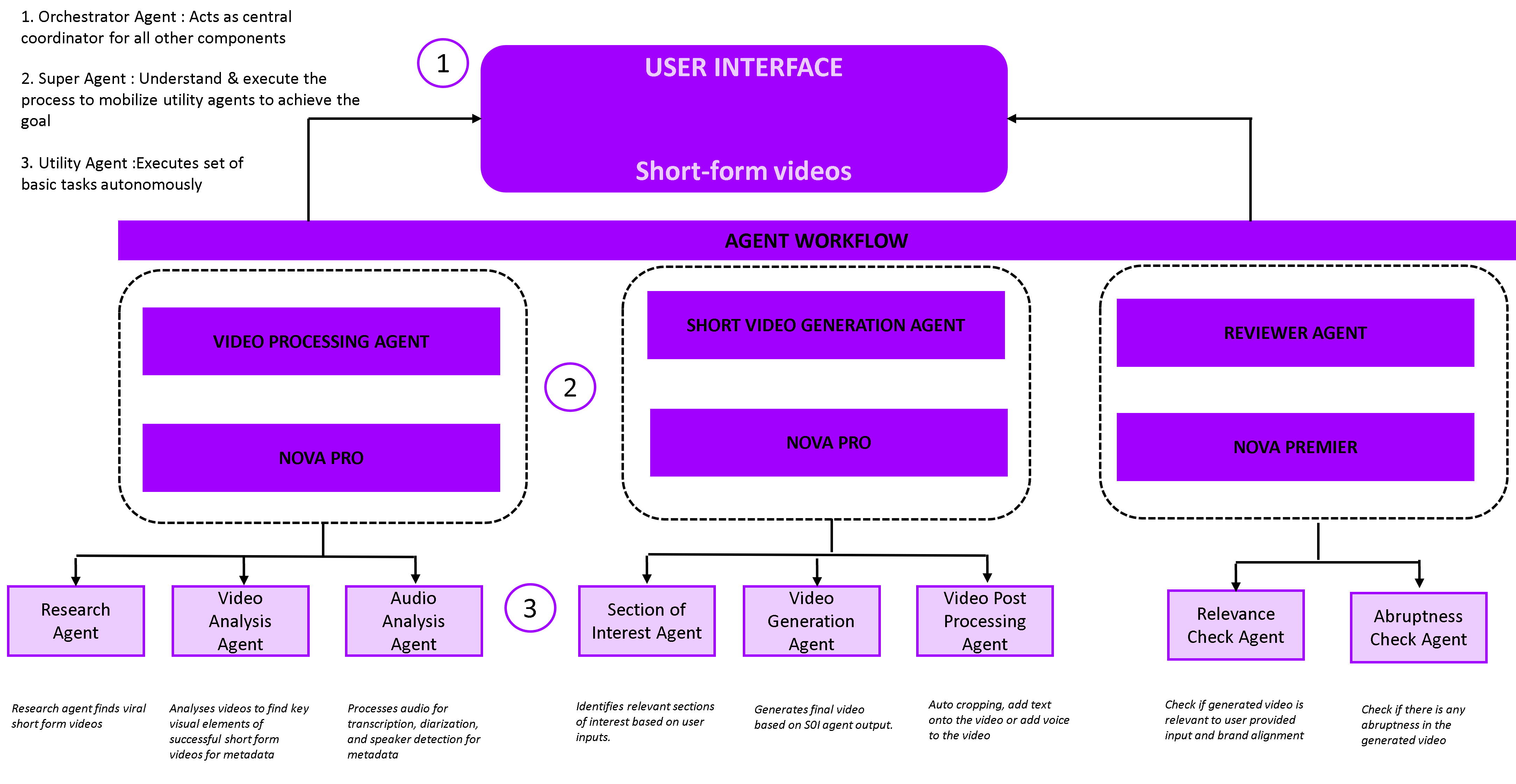
The workflow consists of the following super agents and utility agents:
- Video processing agent – This agent analyzes long-form video and generates detailed metadata to guide short-form video creation. It uses the following utility agents:
- Research agent – Analyzes popular short-form videos to identify key components that create video virality, and creates recipes for successful short-form content. For example, in music videos, it can highlight choreographed dance sequences with the lead performer as essential segments and a recipe based on this insight.
- Visual analysis agent – Applies the research agent’s findings to new long-form content. It identifies matching segments, tags key individuals, and timestamps relevant moments. It uses traditional AI models (such as person recognition and tracking) to capture fine-grained details for segment identification.
- Audio analysis agent – Performs speech diarization and transcription to support both the research and visual analysis agents with deeper context from the video’s audio track.
- Short video generation agent – This agent orchestrates the actual creation of the short-form video by integrating relevant segments and refining the sequence. Its utility agents include:
- Section of interest (SOI) agent – Identifies potential segments based on video genre, target length, featured performers, and JSON metadata from the visual analysis agent. This agent prioritizes logical flow and viewer engagement.
- Video generation agent – Constructs video using segment recommendations and component patterns from the video processing agent. For example, influencer videos might follow a structure of an attention-grabbing hook, key messages, and a call to action. The process will be iteratively improved based on feedback from the reviewer agent.
- Video postprocessing agent – Refines the final output for publishing by performing tasks like cropping to mobile-friendly aspect ratios, or adding subtitles, background music, and brand overlays.
- Reviewer agent – This agent works iteratively with the generation agent to maintain video quality and relevance. Its utility agents include:
- Relevance check agent – Evaluates alignment with user-defined content guidelines, audience expectations, and desired themes.
- Abruptness check agent – Provides smooth transitions between segments to avoid jarring cuts, enhancing viewer experience and professionalism.
See Spotlight in action:
Solution overview
To interact with Spotlight, users access a frontend UI where they provide natural language input to specify their objective. Spotlight then employs its agentic workflow powered by Amazon Nova to achieve its given task. The following diagram illustrates the solution architecture for video highlight generation.
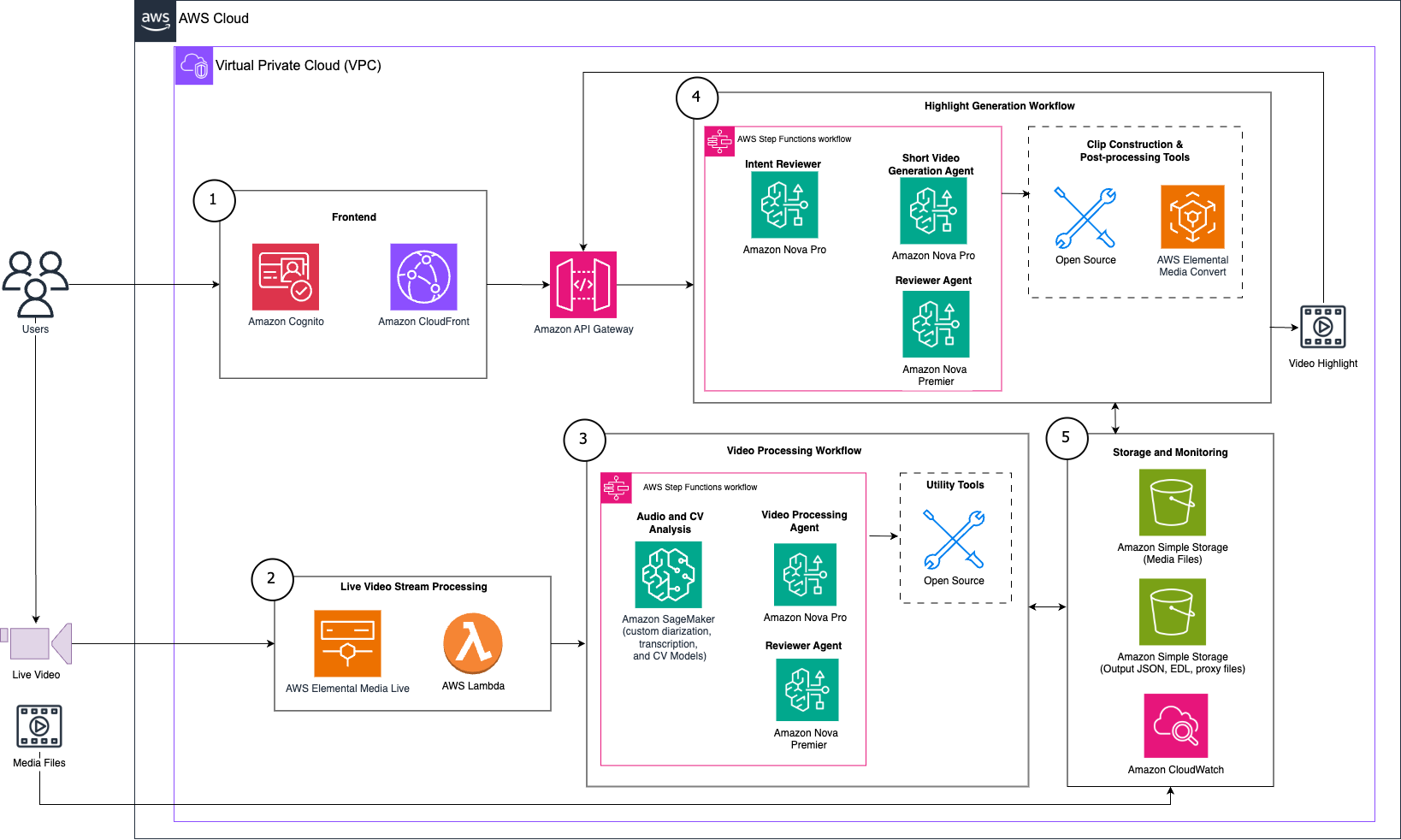
The workflow consists of the following key components (as numbered in the preceding diagram):
- Frontend UI for user interaction:
- Users interact through a web portal secured by Amazon Cognito authentication and delivered using Amazon CloudFront.
- Amazon API Gateway serves a restful endpoint for video processing and highlight generation services.
- Live video stream processing:
- AWS Elemental MediaLive processes incoming video stream and triggers AWS Lambda to initiate workflows. (Spotlight also accepts video archive content as media files for processing and highlight generation.)
- Video processing workflow orchestrated with AWS Step Functions:
- Open source models hosted on Amazon SageMaker enable speech analysis and computer vision for person and object detection.
- The video processing agent powered by Amazon Nova Pro analyzes video and generates fine-grained metadata (for example, identifying patterns from viral videos).
- The reviewer agent powered by Amazon Nova Premier maintains alignment with brand standards.
- Open source utility tooling is used for pre-analysis tasks.
- Highlight generation workflow orchestrated with Step Functions:
- Amazon Nova Pro analyzes the user query for clips of interest to understand intent, and reformulates the query for downstream processing.
- The short video generation agent powered by Amazon Nova Pro constructs a video highlight using segment recommendations.
- The reviewer agent powered by Amazon Nova Premier makes sure the constructed highlight aligns with quality, brand, and contextual expectations.
- AWS Elemental Media Convert and open source tooling enable video highlight construction and postprocessing (such as subtitle layover, aspect ratio change, and transitions).
- Storage and monitoring:
- Amazon Simple Storage Service (Amazon S3) stores metadata extracted from processing workflows, reference content (such as scripts and brand guidelines), and generated outputs.
- Amazon CloudWatch maintains end-to-end system health and monitors performance.
Key benefits
Spotlight’s approach to video processing and generation creates dynamic value. Additionally, its technical design using Amazon Nova and an integrated agentic workflow helps content owners realize gains in their video processing and editorial operations. Key benefits for Spotlight include:
- Cross-industry application – Spotlight’s modular design allows it to be applied seamlessly across industries—from media and entertainment to retail
- Real-time processing – It supports both live stream feeds and pre-recorded video, with custom highlight generation happening in minutes, reducing from hours or days
- Cost-efficient deployment – It is entirely serverless and on-demand, minimizing idle infrastructure costs and maximizing utilization
- Efficiency – Accenture’s review of costs using Amazon Nova models showed that Amazon Nova-powered agents deliver over 10 times better cost savings over traditional highlight creation methods
The following table provides is a comparative analysis of Spotlight’s video processing approach to conventional approaches for video highlight creation.
| Metric | Spotlight Performance | Conventional Approach |
| Video Processing Latency | Minutes for 2–3-hour sessions | Hours to days |
| Highlight Review Cost (3–5 minutes) | 10 times lower with Amazon Nova | High cost using conventional approaches |
| Overall Highlight Generation Cost | 10 times lower using serverless and on-demand LLM deployment | Manual workflows with high operational overhead |
| Deployment Architecture | Fully serverless with scalable LLM invocation | Typically resource-heavy and statically provisioned |
| Use Case Flexibility | Sports, media editing, retail personalization, and more | Often tailored to a single use case |
Conclusion
Spotlight represents a cutting-edge agentic solution designed to tackle complex media processing and customer personalization challenges using generative AI. With modular, multi-agent workflows built on Amazon Nova, Spotlight seamlessly enables dynamic short-form video generation. The solution’s core framework is also extensible to diverse industry use cases that require multimodal content analysis at scale.
As an AWS Premier Tier Services Partner and Managed Services Provider (MSP), Accenture brings deep cloud and industry expertise. Accenture and AWS have worked together for more than a decade to help organizations realize value from their applications and data. Accenture brings its industry understanding and generative AI specialists to build and adapt generative AI solutions to client needs. Together with AWS, through the Accenture AWS Business Group (AABG), we help enterprises unlock business value by rapidly scaling generative AI solutions tailored to their needs—driving innovation and transformation in the cloud.
Try out Spotlight for your own use case, and share your feedback in the comments.
About the authors
 Ilan Geller is a Managing Director in the Data and AI practice at Accenture. He is the Global AWS Partner Lead for Data and AI and the Center for Advanced AI. His roles at Accenture have primarily been focused on the design, development, and delivery of complex data, AI/ML, and most recently Generative AI solutions.
Ilan Geller is a Managing Director in the Data and AI practice at Accenture. He is the Global AWS Partner Lead for Data and AI and the Center for Advanced AI. His roles at Accenture have primarily been focused on the design, development, and delivery of complex data, AI/ML, and most recently Generative AI solutions.
 Dr. Kamal Mannar is a Global Computer Vision Lead at Accenture’s Center for Advanced AI, with over 20 years of experience applying AI across industries like agriculture, healthcare, energy, and telecom. He has led large-scale AI transformations, built scalable GenAI and computer vision solutions, and holds 10+ patents in areas including deep learning, wearable AI, and vision transformers. Previously, he headed AI at Vulcan AI, driving cutting-edge innovation in precision agriculture. Kamal holds a Ph.D. in Industrial & Systems Engineering from the University of Wisconsin–Madison.
Dr. Kamal Mannar is a Global Computer Vision Lead at Accenture’s Center for Advanced AI, with over 20 years of experience applying AI across industries like agriculture, healthcare, energy, and telecom. He has led large-scale AI transformations, built scalable GenAI and computer vision solutions, and holds 10+ patents in areas including deep learning, wearable AI, and vision transformers. Previously, he headed AI at Vulcan AI, driving cutting-edge innovation in precision agriculture. Kamal holds a Ph.D. in Industrial & Systems Engineering from the University of Wisconsin–Madison.
 Debasmita Ghosh is working as Associate Director in Accenture with 21 years of experience in Information Technology (8 years in AI/Gen AI capability), who currently among multiple responsibilities leads Computer Vision practice in India. She has presented her paper on Handwritten Text Recognition in multiple conferences including MCPR 2020, GHCI 2020. She has patent granted on Handwritten Text Recognition solution and received recognition from Accenture under the Accenture Inventor Award Program being named as an inventor on a granted patent. She has multiple papers on Computer Visions solutions like Table Extraction including non-uniform and borderless tables accepted and presented in the ComPE 2021 and CCVPR 2021 international conferences. She has managed projects across multiple technologies (Oracle Apps, SAP). As a programmer, she has worked during various phases of SDLC with experience on Oracle Apps Development across CRM, Procurement, Receivables, SCM, SAP Professional Services, SAP CRM. Debasmita holds M.Sc. in Statistics from Calcutta University.
Debasmita Ghosh is working as Associate Director in Accenture with 21 years of experience in Information Technology (8 years in AI/Gen AI capability), who currently among multiple responsibilities leads Computer Vision practice in India. She has presented her paper on Handwritten Text Recognition in multiple conferences including MCPR 2020, GHCI 2020. She has patent granted on Handwritten Text Recognition solution and received recognition from Accenture under the Accenture Inventor Award Program being named as an inventor on a granted patent. She has multiple papers on Computer Visions solutions like Table Extraction including non-uniform and borderless tables accepted and presented in the ComPE 2021 and CCVPR 2021 international conferences. She has managed projects across multiple technologies (Oracle Apps, SAP). As a programmer, she has worked during various phases of SDLC with experience on Oracle Apps Development across CRM, Procurement, Receivables, SCM, SAP Professional Services, SAP CRM. Debasmita holds M.Sc. in Statistics from Calcutta University.
 Nakul Aggarwal is a Subject Matter Expert in Computer Vision and Generative AI at Accenture, with around 7 years of experience in developing and delivering cutting-edge solutions across computer vision, multimodal AI, and agentic systems. He holds a Master’s degree from the Indian Institute of Technology (IIT) Delhi and has authored several research papers presented at international conferences. He holds two patents in AI and currently leads multiple projects focused on multimodal and agentic AI. Beyond technical delivery, he plays a key role in mentoring teams and driving innovation by bridging advanced research with real-world enterprise applications.
Nakul Aggarwal is a Subject Matter Expert in Computer Vision and Generative AI at Accenture, with around 7 years of experience in developing and delivering cutting-edge solutions across computer vision, multimodal AI, and agentic systems. He holds a Master’s degree from the Indian Institute of Technology (IIT) Delhi and has authored several research papers presented at international conferences. He holds two patents in AI and currently leads multiple projects focused on multimodal and agentic AI. Beyond technical delivery, he plays a key role in mentoring teams and driving innovation by bridging advanced research with real-world enterprise applications.
 Aramide Kehinde is Global Partner Solutions Architect for Amazon Nova at AWS. She works with high growth companies to build and deliver forward thinking technology solutions using AWS Generative AI. Her experience spans multiple industries, including Media & Entertainment, Financial Services, and Healthcare. Aramide enjoys building the intersection of AI and creative arenas and spending time with her family.
Aramide Kehinde is Global Partner Solutions Architect for Amazon Nova at AWS. She works with high growth companies to build and deliver forward thinking technology solutions using AWS Generative AI. Her experience spans multiple industries, including Media & Entertainment, Financial Services, and Healthcare. Aramide enjoys building the intersection of AI and creative arenas and spending time with her family.
 Rajdeep Banerjee is a Senior Partner Solutions Architect at AWS helping strategic partners and clients in the AWS cloud migration and digital transformation journey. Rajdeep focuses on working with partners to provide technical guidance on AWS, collaborate with them to understand their technical requirements, and designing solutions to meet their specific needs. He is a member of Serverless technical field community. Rajdeep is based out of Richmond, Virginia.
Rajdeep Banerjee is a Senior Partner Solutions Architect at AWS helping strategic partners and clients in the AWS cloud migration and digital transformation journey. Rajdeep focuses on working with partners to provide technical guidance on AWS, collaborate with them to understand their technical requirements, and designing solutions to meet their specific needs. He is a member of Serverless technical field community. Rajdeep is based out of Richmond, Virginia.
Deploy conversational agents with Vonage and Amazon Nova Sonic
This post is co-written with Mark Berkeland, Oscar Rodriguez and Marina Gerzon from Vonage.
Voice-based technologies are transforming the way businesses engage with customers across customer support, virtual assistants, and intelligent agents. However, creating real-time, expressive, and highly responsive voice interfaces still requires navigating a complex stack of communication protocols, AI models, and media infrastructure. To simplify this process, Vonage has integrated Amazon Nova Sonic, our speech-to-speech foundation model (FM), with the Vonage Voice API, part of their Communications Platform as a Service (CPaaS) offering.
With this integration, developers can deploy AI voice agents to enable more human-like voice conversations over phone calls, SIP connections, WebRTC, and mobile apps. The solution makes it straightforward to bring intelligent, real-time conversations into workflows for a variety of use cases, such as a small auto repair shop using voice AI to book appointments and track down parts, a global retail brand handling a high volume of customer service calls, or a developer building a scalable voice interface.
In this post, we explore how developers can integrate Amazon Nova Sonic with the Vonage communications service to build responsive, natural-sounding voice experiences in real time. By combining the Vonage Voice API with the low-latency and expressive speech capabilities of Amazon Nova Sonic, businesses can deploy AI voice agents that deliver more human-like interactions than traditional voice interfaces. These agents can be used as customer support, virtual assistants, and more.
Amazon Nova Sonic for real-time conversational AI
Amazon Nova Sonic is a speech-to-speech FM designed to build real-time conversational AI applications in Amazon Bedrock, with industry-leading price-performance and low latency. Its architecture unifies speech understanding and generation into a single model, to enable more human-like voice conversations in AI applications. The model can understand speech in different speaking styles and generate speech in expressive voices, including both masculine-sounding and feminine-sounding voices. Amazon Nova Sonic can adapt the intonation, prosody, and style of the generated speech response to align with the context and content of the speech input and gracefully handle interruptions. Additionally, Amazon Nova Sonic allows for function calling and knowledge grounding with enterprise data using Retrieval Augmented Generation (RAG).
Vonage Voice APIs, powered by AI
Vonage, an AWS partner, provides a developer-friendly platform for building voice, messaging, video, and authentication experiences. With its wide-ranging Voice APIs, Vonage offers WebRTC support, multi-channel communication tools, standard phone call integrations, in-app softphones, front-ending contact centers, and voice-over-browser functionality. The software also offers essential building blocks such as inbound and outbound voice call handling, voicemail support, and programmable logic for call routing and queuing. Vonage’s solution builder and SDKs allow for fast, low-code integration, while its interoperability with business applications and productivity tools enables teams to embed communication directly into their existing workflows.
Solution overview
Vonage collaborated with Amazon Nova Sonic to build low-latency, voice-first applications that can understand and respond like a human agent over standard telephony or WebRTC channels. This new tool can connect inbound and outbound Vonage calls directly to Amazon Nova Sonic for conversational AI processing, using expressive, real-time speech synthesis to deliver fluid, natural interactions. Amazon Nova Sonic’s integration into Vonage Voice API seamlessly manages audio buffering, custom media infrastructure, and protocol translation, so teams can focus on building engaging experiences.
With built-in conversation control logic and noise cancellation, Vonage’s integration with Amazon Nova Sonic makes it straightforward for businesses to rapidly build and deploy responsive AI voice agents. These agents can handle real-time voice conversations and scale voice interactions without relying on traditional contact centers.
Vonage is making this integration available as a GitHub repository for developers to deploy and customize to their needs.
“As an AWS Amazon Partner Network (APN) member, Vonage has a long history of working closely with the AWS innovation team to create new solutions to benefit enterprise customers,” said Christophe Van de Weyer, President and Head of Business Unit API for Vonage. “This latest collaboration with AWS enables organizations to transform how they engage with customers by adopting generative AI solutions that create added value for internal and external communication. By combining Vonage’s communications APIs with AWS’s advanced AI, this new voice AI agent technology enables businesses to streamline the adoption of intelligent agents, accelerate the modernization of legacy voice systems, and provide a robust service to deliver exceptional customer experiences with measurable improvements in satisfaction and operational efficiency.”
The following video showcases a demo of Diana, an AI voice agent built using Vonage’s integration with Amazon Nova Sonic.
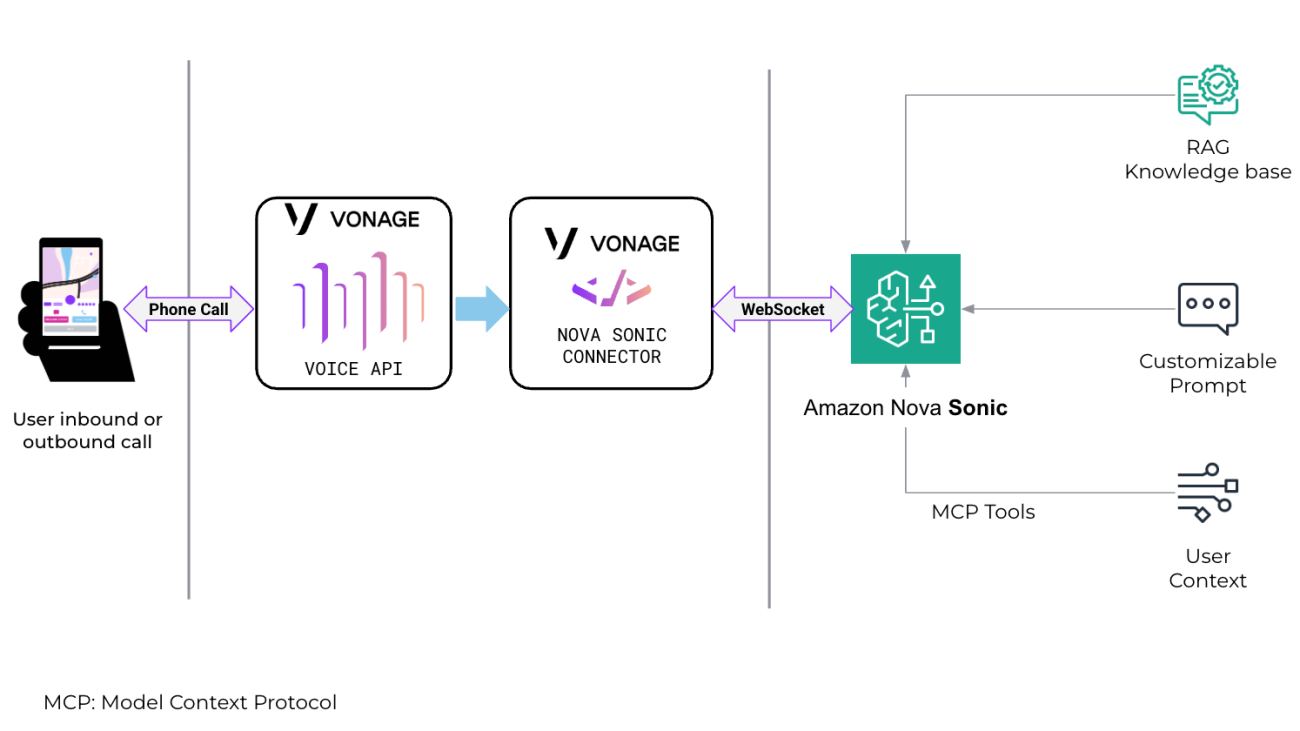
The following architecture diagram provides an overview of Amazon Nova Sonic deployed as a voice agent in the Vonage Voice API framework on AWS.
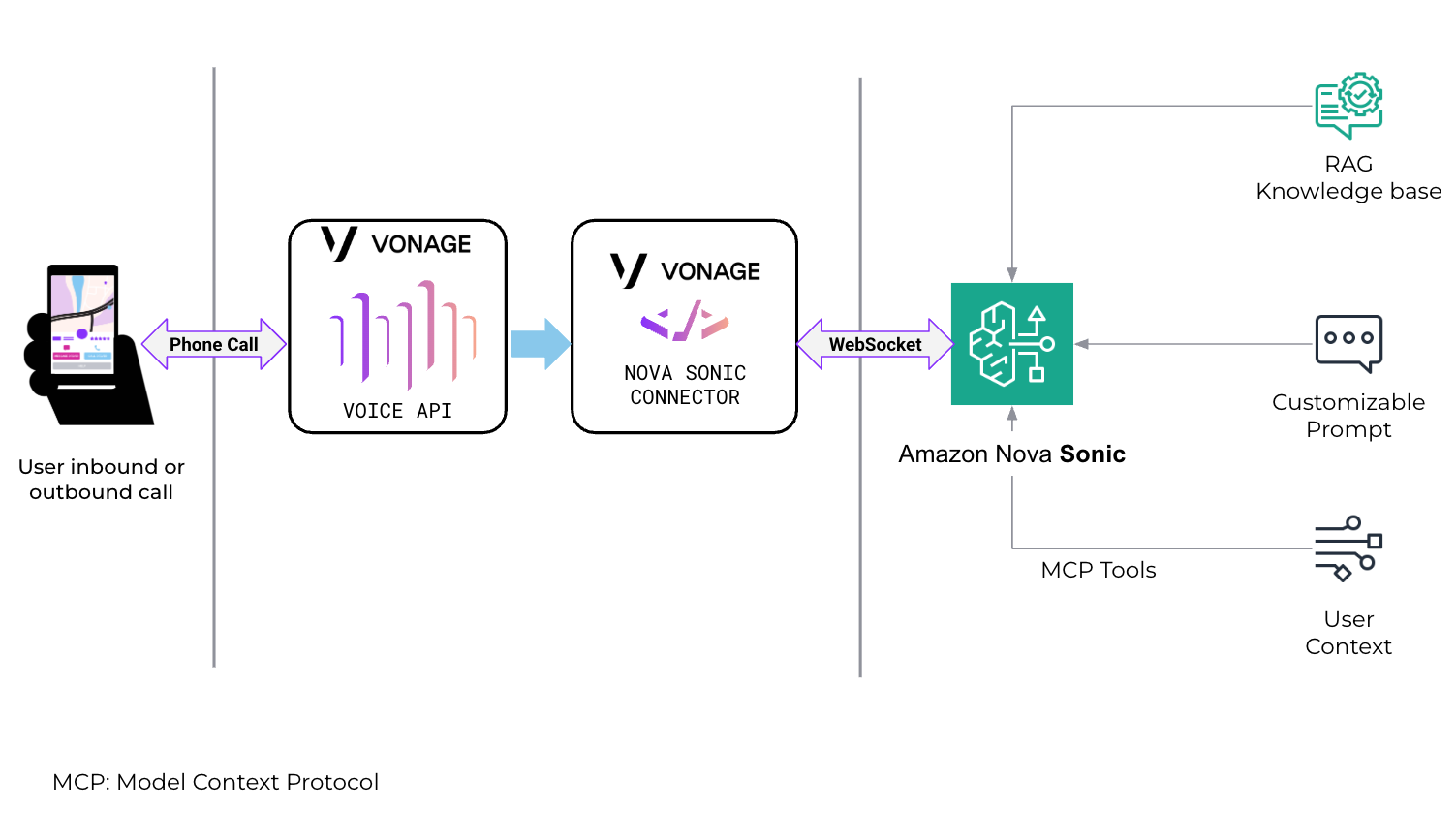
The solution routes different types of incoming calls to Amazon Nova Sonic over a WebSocket connection. The architectural components include (left to right):
- Calls – Incoming voice connections that can come from global phone numbers, SIP connections with contact centers or business systems, or WebRTC connections from web browsers and mobile apps.
- Vonage Voice API – Provides programmatic control over these types of calls and voice connections, allowing them to be integrated with AI systems, routed elsewhere, or given speech and other treatments. Because Amazon Nova Sonic is a full speech-to-speech AI service, the real-time voice streams are connected directly, unlike other AI integrations that might use text-based integration.
- Amazon Nova Sonic connector – A Vonage integration that connects calls to Amazon Nova Sonic over a WebSocket connection, providing low-latency, real-time, bi-directional voice streaming directly with Amazon Nova Sonic. The connector also manages voice isolation to better handle noisy environments, conversational elements like “barge in” where the caller interrupts the conversation, and fallback options if needed.
- Amazon Nova Sonic – Part of the Amazon Nova family of FMs available in Amazon Bedrock. Amazon Nova Sonic unifies speech understanding and generation into a single model, streamlining development and reducing complexity when building conversational applications.
- Retrieval Augmented Generation (RAG) – Tools within Amazon Bedrock that optimize the output of an underlying large language model (LLM). Amazon Nova Sonic can reference enterprise-authorized knowledge sources. Attribution and source visibility can be configured based on customer requirements.
- Customizable prompt – Provided to the AI model and allows the voice agent’s personality and conversational capabilities to be defined and the right knowledge base to be used.
- User context – Maintained by Amazon Nova Sonic throughout interaction sequences to allow a natural continuous conversation. Personally identifiable information (PII) is processed in real time and not retained by Amazon Nova Sonic. AWS safeguards your data through comprehensive security controls, encryption at rest and in transit, and compliance certifications, while also giving you the flexibility to configure additional logging, security, and compliance measures through AWS services.
These components work together to create a flexible, intelligent voice agent service that can dynamically adapt to different communication scenarios and business use cases with different knowledge bases and prompts.
Example use cases
The following are just a few of the high-impact ways businesses are already using this integration to transform voice interactions:
- Customer support automation – Deploy voice agents that answer inbound customer queries, take appointments, and escalate calls only when necessary.
- Proactive outbound calling – Generate dynamic, expressive outbound messages like reminders, confirmations, or follow-ups with voicemail fallback.
- Multilingual voice assistants – Build voice experiences that seamlessly switch between English and Spanish depending on the caller, enabled by Vonage’s language detection and multilingual synthesis with Amazon Nova Sonic.
Conclusion
By combining Amazon Nova Sonic with Vonage’s flexible communication infrastructure, developers can build intelligent, responsive AI voice agents. With this solution, you can provide proactive voice engagement, create multilingual assistants, handle customer support, and more. This integration makes voice-first AI applications more accessible and scalable than ever.
To start building with Amazon Nova Sonic, visit the Amazon Bedrock console. For Vonage integration, explore the Vonage API Developer Portal or use the Vonage Solution Builder to configure your voice agent in minutes.
To learn more about Amazon Nova Sonic, check out the AWS News Blog, Amazon Nova Sonic product page, or Amazon Bedrock User Guide.
About the authors
 Divyesha Malhotra is a Senior Product Manager Technical Intern on the AGI Nova Sonic team. She leads the customer adoption and integrations of cutting-edge speech-to-speech foundation models for next-generation voice-based technologies.
Divyesha Malhotra is a Senior Product Manager Technical Intern on the AGI Nova Sonic team. She leads the customer adoption and integrations of cutting-edge speech-to-speech foundation models for next-generation voice-based technologies.
 Mark Berkeland is a Senior Solutions Engineer in the API Business Unit at Vonage. He designs and implements technical solutions including demos and proofs of concept to help customers bring voice and messaging applications to life. With a professional programming career that began in 1979, his experience ranges from FORTRAN on punched cards to modern cloud-native stacks like React Native, combining deep technical expertise with a passion for making complex ideas accessible.
Mark Berkeland is a Senior Solutions Engineer in the API Business Unit at Vonage. He designs and implements technical solutions including demos and proofs of concept to help customers bring voice and messaging applications to life. With a professional programming career that began in 1979, his experience ranges from FORTRAN on punched cards to modern cloud-native stacks like React Native, combining deep technical expertise with a passion for making complex ideas accessible.
 Oscar Rodriguez is Senior Director of Global Partner Solutions in the API Business Unit at Vonage, where he leads strategic initiatives to empower partners through scalable communications solutions. He brings deep technical expertise and a practical understanding of real-world application development with over 20 years experience in web technologies and the last 10 in CPaaS.
Oscar Rodriguez is Senior Director of Global Partner Solutions in the API Business Unit at Vonage, where he leads strategic initiatives to empower partners through scalable communications solutions. He brings deep technical expertise and a practical understanding of real-world application development with over 20 years experience in web technologies and the last 10 in CPaaS.
 Marina Gerzon is a Partner Solutions Architect at Vonage with over 20 years of experience in real-time communications, specializing in Video and Voice over IP solutions. Known for her ability to bridge technical depth with business impact, her work spans Telecom, Education, Healthcare, Fintech, and Insurance industries, where she has consistently delivered enterprise-grade SaaS and PaaS architectures tailored to complex business needs.
Marina Gerzon is a Partner Solutions Architect at Vonage with over 20 years of experience in real-time communications, specializing in Video and Voice over IP solutions. Known for her ability to bridge technical depth with business impact, her work spans Telecom, Education, Healthcare, Fintech, and Insurance industries, where she has consistently delivered enterprise-grade SaaS and PaaS architectures tailored to complex business needs.

More advanced AI capabilities are coming to Search
 For Google AI Pro and AI Ultra subscribers, AI Mode in Search now features the ability to use Gemini 2.5 Pro and do deeper research for you.Read More
For Google AI Pro and AI Ultra subscribers, AI Mode in Search now features the ability to use Gemini 2.5 Pro and do deeper research for you.Read More

Enabling customers to deliver production-ready AI agents at scale

AI agents will change how we all work and live. Our AWS CEO, Matt Garman, shared a vision of a technological shift as transformative as the advent of the internet. I’m energized by this vision because I’ve witnessed firsthand how these intelligent agent systems are already beginning to solve complex problems, automate workflows, and create new possibilities across industries. With agentic AI, AstraZeneca accelerated healthcare insight discovery, Yahoo Finance transformed financial research for millions of investors, and Syngenta revolutionized agriculture with AI-driven precision farming.
To expand these early successes into widespread adoption, organizations need a practical approach that addresses the inherent complexity of agentic systems. At AWS, we’re committed to being the best place to build the world’s most useful AI agents, empowering organizations to deploy reliable and secure agents at scale.
We’re focused on making our agentic AI vision accessible to every organization by combining rapid innovation with a strong foundation of security, reliability, and operational excellence. Our approach accelerates progress by building on proven principles while embracing new possibilities—creating systems that can adapt as models evolve, new capabilities emerge, and use cases expand across your business.
Today, I’m excited to share how we’re bringing this vision to life with new capabilities that address the fundamental aspects of building and deploying agents at scale. These innovations will help you move beyond experiments to production-ready agent systems that can be trusted with your most critical business processes.
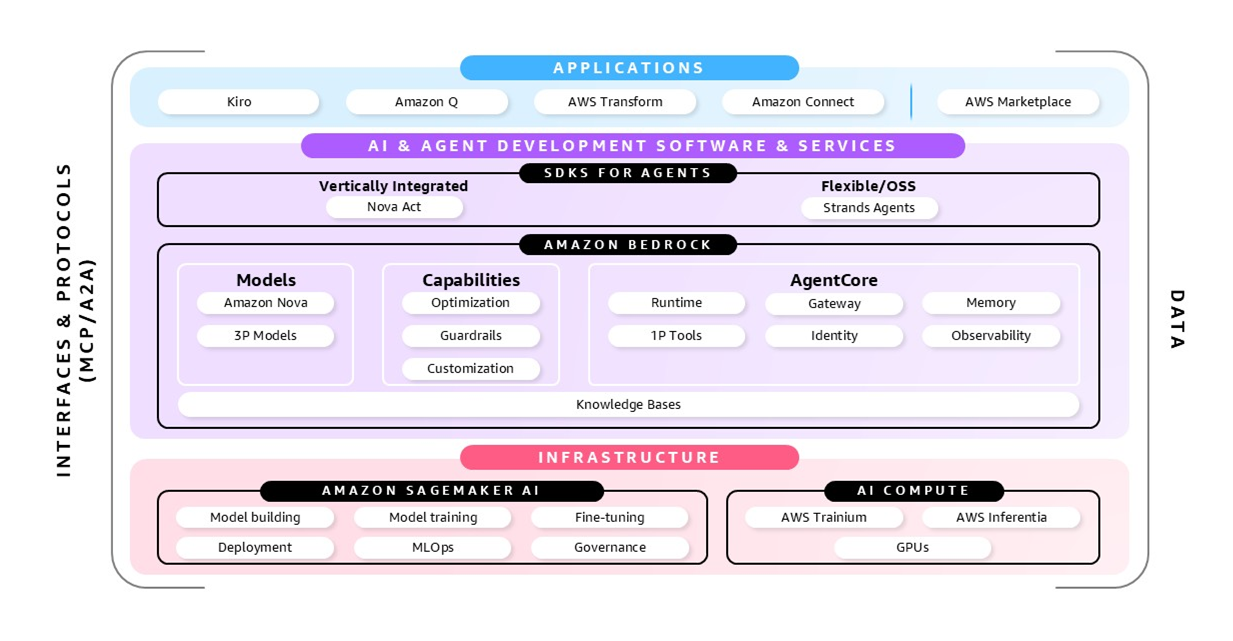
A comprehensive foundation for building and deploying production-ready agentic AI systems at scale.
Guiding principles, evolved for agents
At AWS, our approach to agentic AI is shaped by our experience building agent systems internally and helping hundreds of thousands of customers accelerate their AI journeys. Four core principles guide everything we do in this space:
Principle 1: Embrace agility as a competitive edge
Organizations that thrive won’t be those who perfectly predict the future, but those who adapt quickly as it unfolds. Staying nimble requires an agentic architecture that embraces flexibility and openness rather than rigid frameworks or singular models. It means building systems that can incorporate new models as they emerge, connect to your proprietary data sources, and seamlessly integrate with your existing tools.
The dual need for stability and adaptability led us to create Amazon Bedrock AgentCore, a complete set of services for deploying and operating highly capable agents securely at enterprise scale. AgentCore provides a secure, serverless runtime with complete session isolation and the longest running workload available today, tools and capabilities to help agents execute workflows with the right permissions and context, and controls to operate trustworthy agents. Its capabilities can be used together or independently and work with popular open source frameworks such as CrewAI, LangGraph, LlamaIndex, and Strands Agents and with any model including those in (or outside of) Amazon Bedrock, so developers can stay agile as technology shifts. By reducing the undifferentiated heavy lifting, AgentCore helps organizations move beyond experiments to production-ready agent systems that can be trusted with your most critical business processes.
Customers like Itaú Unibanco, Innovaccer, Boomi, Box, and Epsilon are already experimenting with AgentCore and are excited about how it speeds their deployment of agents to production. These early adopters recognize that AgentCore helps eliminate the trade-off between open source flexibility and enterprise-grade security and reliability, allowing them to focus on creating business value rather than building security and operational foundations from scratch.
Principle 2: Evolve fundamentals for the agentic era
While the core principles of enterprise technology haven’t changed, how we implement them must evolve for the agentic era. These evolved fundamentals create the foundation that makes production-grade agents possible:
- Security and Trust. Agents introduce new security considerations as they cross system boundaries, perform actions on behalf of users or act themselves with pre-authorized user consent. Trust requires transparency, guardrails, and verification. AgentCore Runtime helps address these with dedicated compute environments per session and memory isolation that helps prevent data leaks across agents, building on a decade of AWS Lambda serverless innovation in security and scalability.
- Reliability and Scalability. Traditional approaches to scaling software fall short with agentic systems as they follow unpredictable execution paths and have variable resource requirements across interactions. AgentCore Runtime is highly reliable with checkpointing and recovery capabilities to help ensure graceful recovery in case of unexpected interruptions and failures, and it can automatically handle scaling from zero to thousands of concurrent sessions, eliminating capacity planning and infrastructure maintenance.
- Identity. As agents act on behalf of users and systems, traditional identity models must evolve. Managing permissions of both the agent and the user as agents navigate complex workflows spanning multiple systems becomes critical to securing your data. AgentCore Identity delivers secure agent access across AWS services and third-party applications and tools with temporary, fine-grained permissions, and standards-based authentication. It works with leading identity providers such as Amazon Cognito, Microsoft Entra ID, and Okta, as well as popular OAuth providers such as GitHub, Google, Salesforce, and Slack.
- Observability. Understanding agent decisions requires new approaches to monitoring. Observability becomes essential not just for troubleshooting, but for compliance and continuous improvement, representing a shift from periodic auditing to constant supervision. AgentCore Observability provides real-time visibility through built-in dashboards and standardized telemetry that integrates with your monitoring stack.
- Data. Your proprietary data is more valuable than ever, enabling agents to understand your specific context. The ability to securely access, process, and learn from this data becomes a critical differentiator for agent performance and relevance. For example, with AgentCore Gateway, you can transform your data sources including Amazon Bedrock Knowledge Bases into agent-compatible tools so agents can access recent and relevant information.
- Seamless Integration. Agents must work with everything in your environment: your systems, other clouds, SaaS applications, and other agents. AgentCore Gateway makes it possible by transforming APIs and services into agent-compatible tools with minimal code, eliminating months of integration work while enabling agents to discover and interact with your systems. Our open source Strands Agents SDK complements this with flexible orchestration patterns, and support for MCP and A2A to enable seamless coordination between multiple agents and tools across different environments. AWS API MCP Server gives agents a callable interface to AWS services, enabling foundation models to discover available operations, reason over input and output requirements, and generate plans that invoke AWS APIs to explore, configure, or manage resources with real-time AWS capabilities beyond model training cutoff.
- Tooling and Capabilities. Agents need specialized tools to execute complex tasks and maintain context across interactions. AgentCore Memory makes it easy for developers to build context-aware agents by eliminating complex memory infrastructure management while providing full control over what the AI agent remembers. It provides industry-leading accuracy along with support for both short-term memory for multi-turn conversations and long-term memory that persists across sessions, with the ability to share memory stores across collaborating agents. Built-in tools include AgentCore Browser for web interactions, enabling agents to navigate websites and perform actions on your behalf, and AgentCore Code Interpreter for executing code securely, allowing agents to process data, generate visualizations, and solve complex problems programmatically. These capabilities extend what agents can do while maintaining security and reliability.
Together, these evolved fundamentals help organizations build secure, reliable, and scalable agent architectures that deliver consistent results in production environments. With AgentCore, we’re helping customers focus on creating value rather than reinventing infrastructure.
Principle 3: Deliver superior outcomes with model choice and data
At the heart of every effective agent system lies its foundation model, which powers an agent’s ability to understand, reason, and act. For agents to deliver transformative experiences, carefully selected and potentially tailored models need to interact with rich, context-specific knowledge that determines how effectively the model can make decisions on your behalf. This reality extends to all AI applications, which is why AWS gives customers both the freedom to choose the optimal model for each use case and the tools to enhance those models with their unique data. This approach delivers superior outcomes and the best price-performance for all AI implementations.
Model requirements vary widely—some applications demand sophisticated reasoning, others require fast responses, and many prioritize cost efficiency at scale. No single model excels across all dimensions, which is why we pioneered model choice with Amazon Bedrock in 2023. But the true differentiator is how you combine models with your organization’s proprietary data, transforming generic AI into systems with deep domain expertise.
To help you create models with this high level of expertise, today we’re expanding our model customization capabilities with the launch of Amazon Nova customization in Amazon SageMaker AI. Nova models now offer customers the flexibility to customize the model across the model development life cycle. This includes pre-training and post-training, including both fine-tuning and alignment, with support for parameter efficient fine-tuning (PEFT) and full fine-tuning. With these, Nova now offers the most comprehensive suite of model customization capabilities made available for any proprietary model family. Using techniques including Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), reinforcement learning from human feedback using Proximal Policy Optimization (PPO), Continued Pre-Training (CPT), and Knowledge Distillation, customers can create Nova models optimized for their use-case. Once customized, these models can be deployed directly to Amazon Bedrock, allowing you to seamlessly integrate your custom models into your agent systems and other AI applications.
We are also training our own models optimized for specific agent use cases. Nova Act is an AI model trained to perform actions within a web browser. Customers can get started with building their own browser automation agents with the Nova Act SDK, purpose-built to enable reliable browser agents powered by the Nova Act model. The Nova Act SDK, available in research preview today, uses AgentCore Browser for scalable, cloud-based browser execution.
Once you have the right model, you need to ensure it can interact with your organization’s proprietary and current data. Vectors have emerged as the dominant and fastest way AI models can access your data. Until now, the cost of storing vector embeddings—the key to enabling this intelligence—has forced organizations to limit their AI systems to recent data only, constraining their potential. Today’s launch of Amazon S3 Vectors, the first cloud object store with native vector support, marks a fundamental change. By reducing vector storage costs by 90% while maintaining sub-second query performance, S3 Vectors enables agents that remember more, reason deeper, and maintain comprehensive context from every customer interaction, document, and business insight. S3 Vectors integrates directly with Amazon Bedrock Knowledge Bases for cost-effective RAG applications and Amazon OpenSearch Service for tiered vector strategies.
Principle 4: Deploy solutions that transform experiences
While models and infrastructure change how organizations build, agentic solutions transform how businesses operate. The true power of agentic AI lies in its ability to reshape workflows and human productivity across entire industries. These solutions free people from routine tasks and handle complex information flows, enabling teams to focus on creative thinking and strategic decisions. We’re making this transformation accessible to more organizations through pre-built agentic solutions. By combining foundational building blocks with pre-built solutions you can move beyond experiments to comprehensive AI strategies that deliver tangible business impact.
Today, we’re announcing that you can now buy AI Agents and Tools in AWS Marketplace, with streamlined procurement and multiple deployment options. In today’s fragmented AI landscape, AWS Marketplace offers a centralized catalog of curated agents, tools, and solutions from AWS Partners. Fast-track automation with pre-built agents from AWS Partners. Our new API-based deployment method helps you to streamline integrations with other agents and tools that support MCP and A2A. And these agents can run on trusted AWS services or in your AWS environment, where you maintain control over security and access. You can deploy select pre-built agents and tools on AgentCore.
We’re also continuing to give customers ready-to-deploy agent solutions that enable this transformation. Kiro is an AI IDE that helps developers go from concept to production with spec-driven development. From simple to complex tasks, Kiro works alongside you to turn prompts into detailed specs—then into working code, docs, and tests. So, what you build is exactly what you want and ready to share with your team. Kiro’s agents help you solve challenging problems and automate tasks like generating documentation and unit tests. With Kiro, you can build beyond prototypes while being in the driver’s seat every step of the way. AWS Transform deploys specialized AI agents to automate complex modernization tasks like code analysis, refactoring, and dependency mapping, dramatically reducing project timelines for enterprise workload migrations. Each solution shows our commitment to flexibility and choice, helping you innovate faster and realize business outcomes sooner. And Amazon Connect, a comprehensive customer experience solution, enables organizations to delight their customers with unlimited AI on every customer interaction across all channels.
These four principles guide our product strategy and are embedded in every innovation we’re announcing today: embracing agility, evolving fundamentals, combining model choice with proprietary data, and deploying transformative solutions. Together, they provide a comprehensive framework for successfully implementing agentic AI in your organization.
The path forward
The significant potential for our customers and our own diverse businesses has inspired us to focus on building the most trustworthy agentic AI capabilities on the planet. But the most important advice I can offer is simple: start now.
Don’t get trapped trying to boil the ocean or waiting for all the answers before you begin. Pick a specific business problem that matters and get building. The organizations seeing the greatest success aren’t those with the most ambitious plans, they’re those who have started the learning cycle, gathering real-world feedback that informs each iteration. To help our customers on their AI journey, we’re investing another 100 million dollars, doubling our investment, in the AWS Generative AI Innovation Center which has helped thousands of customers across industries including NFL, Yahoo Finance, BMW, and AstraZeneca achieve millions of dollars in productivity gains and transform customer experiences.
AWS set the standard for security, reliability, and data privacy for cloud computing, and we’re bringing these same principles to agentic AI. No matter your use case or requirements, AWS provides the right foundation to help you succeed. Together, we can reinvent what’s possible for your business through the power of agentic AI.
About the author
 Swami Sivasubramanian is Vice President for Agentic AI at Amazon Web Services (AWS). At AWS, Swami has led the development and growth of leading AI services like Amazon DynamoDB, Amazon SageMaker, Amazon Bedrock, and Amazon Q. His team’s mission is to provide the scale, flexibility, and value that customers and partners require to innovate using agentic AI with confidence and build agents that are not only powerful and efficient, but also trustworthy and responsible. Swami also served from May 2022 through May 2025 as a member of the National Artificial Intelligence Advisory Committee, which was tasked with advising the President of the United States and the National AI Initiative Office on topics related to the National AI Initiative.
Swami Sivasubramanian is Vice President for Agentic AI at Amazon Web Services (AWS). At AWS, Swami has led the development and growth of leading AI services like Amazon DynamoDB, Amazon SageMaker, Amazon Bedrock, and Amazon Q. His team’s mission is to provide the scale, flexibility, and value that customers and partners require to innovate using agentic AI with confidence and build agents that are not only powerful and efficient, but also trustworthy and responsible. Swami also served from May 2022 through May 2025 as a member of the National Artificial Intelligence Advisory Committee, which was tasked with advising the President of the United States and the National AI Initiative Office on topics related to the National AI Initiative.

Google France hosted a hackathon to tackle healthcare’s biggest challenges
 Doctors, developers and researchers gathered in Paris to prototype new medical solutions using Google’s AI models.Read More
Doctors, developers and researchers gathered in Paris to prototype new medical solutions using Google’s AI models.Read More
PREAMBLE: Private and Efficient Aggregation via Block Sparse Vectors
We revisit the problem of secure aggregation of high-dimensional vectors in a two-server system such as Prio. These systems are typically used to aggregate vectors such as gradients in private federated learning, where the aggregate itself is protected via noise addition to ensure differential privacy. Existing approaches require communication scaling with the dimensionality, and thus limit the dimensionality of vectors one can efficiently process in this setup.
We propose PREAMBLE: {bf Pr}ivate {bf E}fficient {bf A}ggregation {bf M}echanism via {bf BL}ock-sparse {bf E}uclidean Vectors…Apple Machine Learning Research