The Uber Eats app serves as a portal to more than 320,000 restaurant-partners in over 500 cities globally across 36 countries. In order to make the user experience more seamless and easy-to-navigate, we show users the dishes, restaurants, and cuisines …
At Uber, we pursue fundamental research to push the frontiers of machine learning, and we endeavor to reduce the latest ML advances to practice, both of which enable us to more effectively ignite opportunity by setting the world in motion.…
We’re releasing Procgen Benchmark, 16 simple-to-use procedurally-generated environments which provide a direct measure of how quickly a reinforcement learning agent learns generalizable skills.
Using the environment is easy whether you’re a human or AI:
$ pip install procgen # install
$ python -m procgen.interactive --env-name starpilot # human
$ python <<EOF # random AI agent
import gym
env = gym.make('procgen:procgen-coinrun-v0')
obs = env.reset()
while True:
obs, rew, done, info = env.step(env.action_space.sample())
env.render()
if done:
break
EOF
We’ve found that all of the Procgen environments require training on 500–1000 different levels before they can generalize to new levels, which suggests that standard RL benchmarks need much more diversity within each environment. Procgen Benchmark has become the standard research platform used by the OpenAI RL team, and we hope that it accelerates the community in creating better RL algorithms.
Environment diversity is key
Inseveralenvironments, it has been observed that agents can overfit to remarkably large training sets. This evidence raises the possibility that overfitting pervades classic benchmarks like the Arcade Learning Environment, which has long served as a gold standard in reinforcement learning (RL). While the diversity between different games in the ALE is one of the benchmark’s greatest strengths, the low emphasis on generalization presents a significant drawback. In each game the question must be asked: are agents robustly learning a relevant skill, or are they approximately memorizing specific trajectories?
CoinRun was designed to address precisely this issue, by using procedural generation to construct distinct sets of training levels and test levels. While CoinRun has helped us better quantify generalization in RL, it is still only a single environment. It’s likely that CoinRun is not fully representative of the many challenges RL agents must face. We want the best of both worlds: a benchmark comprised of many diverse environments, each of which fundamentally requires generalization. To fulfill this need, we have created Procgen Benchmark. CoinRun now serves as the inaugural environment in Procgen Benchmark, contributing its diversity to a greater whole.
Previous work, including the Obstacle Tower Challenge and the General Video Game AI framework, has also encouraged using procedural generation to better evaluate generalization in RL. We’ve designed environments in a similar spirit, with two Procgen environments drawing direct inspiration from GVGAI-based work. Other environments like Dota and StarCraft also provide lots of per-environment complexity, but these environments are hard to rapidly iterate with (and it’s even harder to use more than one such environment at a time). With Procgen Benchmark, we strive for all of the following: experimental convenience, high diversity within environments, and high diversity across environments.
Procgen Benchmark
Procgen Benchmark consists of 16 unique environments designed to measure both sample efficiency and generalization in reinforcement learning. This benchmark is ideal for evaluating generalization since distinct training and test sets can be generated in each environment. This benchmark is also well-suited to evaluate sample efficiency, since all environments pose diverse and compelling challenges for RL agents. The environments’ intrinsic diversity demands that agents learn robust policies; overfitting to narrow regions in state space will not suffice. Put differently, the ability to generalize becomes an integral component of success when agents are faced with ever-changing levels.
Design principles
We’ve designed all Procgen environments to satisfy the following criteria:
High Diversity: Environment generation logic is given maximal freedom, subject to basic design constraints. The diversity in the resulting level distributions presents agents with meaningful generalization challenges.
Fast Evaluation: Environment difficulty is calibrated such that baseline agents make significant progress after training for 200M timesteps. Moreover, the environments are optimized to perform thousands of steps per second on a single CPU core, enabling a fast experimental pipeline.
Tunable Difficulty: All environments support two well-calibrated difficulty settings: easy and hard. While we report results using the hard difficulty setting, we make the easy difficulty setting available for those with limited access to compute power. Easy environments require approximately an eighth of the resources to train.
Emphasis on Visual Recognition and Motor Control: In keeping with precedent, environments mimic the style of many Atari and Gym Retro games. Performing well primarily depends on identifying key assets in the observation space and enacting appropriate low level motor responses.
Evaluating generalization
We came to appreciate how hard RL generalization can be while conducting the Retro Contest, as agents continually failed to generalize from the limited data in the training set. Later, our CoinRun experiments painted an even clearer picture of our agents’ struggle to generalize. We’ve now expanded on those results, conducting our most thorough study of RL generalization to date using all 16 environments in Procgen Benchmark.
We first measured how the size of the training set impacts generalization. In each environment, we generated training sets ranging in size from 100 to 100,000 levels. We trained agents for 200M timesteps on these levels using Proximal Policy Optimization, and we measured performance on unseen test levels.
Generalization performance
Score over 100k levels, log scale
CoinRun
StarPilot
CaveFlyer
Dodgeball
FruitBot
Chaser
Miner
Jumper
Leaper
Maze
BigFish
Heist
Climber
Plunder
Ninja
BossFight
We found that agents strongly overfit to small training sets in almost all environments. In some cases, agents need access to as many as 10,000 levels to close the generalization gap. We also saw a peculiar trend emerge in many environments: past a certain threshold, training performance improves as the training sets grows! This runs counter to trends found in supervised learning, where training performance commonly decreases with the size of the training set. We believe this increase in training performance comes from an implicit curriculum provided by a diverse set of levels. A larger training set can improve training performance if the agent learns to generalize even across levels in the training set. We previously noticed this effect with CoinRun, and have found it often occurs in many Procgen environments as well.
An ablation with deterministic levels
We also conducted a simple ablation study to emphasize the importance of procedural generation. Instead of using a new level at the start of every episode, we trained agents on a fixed sequence of levels. The agent begins each episode on the first level, and when it successfully completes a level, it progresses to the next one. If the agent fails at any point, the episode terminates. The agent can reach arbitrarily many levels, though in practice it rarely progresses beyond the 20th level in any environment.
Train and test performance
Score over 200M timesteps
CoinRun
StarPilot
CaveFlyer
Dodgeball
FruitBot
Chaser
Miner
Jumper
Leaper
Maze
BigFish
Heist
Climber
Plunder
Ninja
BossFight
At test time, we remove the determinism in the sequence of levels, instead choosing level sequences at random. We find that agents become competent over the first several training levels in most games, giving an illusion of meaningful progress. However, test performance demonstrates that the agents have in fact learned almost nothing about the underlying level distribution. We believe this vast gap between training and test performance is worth highlighting. It reveals a crucial hidden flaw in training on environments that follow a fixed sequence of levels. These results show just how essential it is to use diverse environment distributions when training and evaluating RL agents.
Next steps
We expect many insights gleaned from this benchmark to apply in more complex settings, and we’re excited to use these new environments to design more capable and efficient agents.
If you’re interested in helping develop diverse environments, we’re hiring!
Connecting the digital and physical worlds safely and reliably on the Uber platform presents exciting technological challenges and opportunities. For Uber, artificial intelligence (AI) is essential to developing systems that are capable of optimized, automated decision making at scale.
At re:MARS 2019, Brad Porter, Amazon’s vice president of robotics, talked about how a symphony of humans and robots work together to deliver customer orders.Read More
Amazon’s director of forecasting, Jenny Freshwater, speaks about how AI is used to power forecasting decisions, so that items are always in stock for Amazon’s customers.Read More
In the last decade, we’ve seen learning-based systems provide transformative solutions for a wide range of perception and reasoning problems, from recognizing objects in images to recognizing and translating human speech. Recent progress in deep reinforcement learning (i.e. integrating deep neural networks into reinforcement learning systems) suggests that the same kind of success could be realized in automated decision making domains. If fruitful, this line of work could allow learning-based systems to tackle active control tasks, such as robotics and autonomous driving, alongside the passive perception tasks to which they have already been successfully applied.
While deep reinforcement learning methods – like Soft Actor Critic – can learn impressive motor skills, they are challenging to train on large and broad data that is not from the target environment. In contrast, the success of deep networks in fields like computer vision was arguably predicated just as much on large datasets, such as ImageNet, as it was on large neural network architectures. This suggests that applying data-driven methods to robotics will require not just the development of strong reinforcement learning methods, but also access to large and diverse datasets for robotics. Not only can large datasets enable models that generalize effectively, but they can also be used to pre-train models that can then be adapted to more specialized tasks using much more modest datasets. Indeed, “ImageNet pre-training” has become a default approach for tackling diverse tasks with small or medium datasets – like 3D building reconstruction. Can the same kind of approach be adopted to enable broad generalization and transfer in active control domains, such as robotics?
Unfortunately, the design and adoption of large datasets in reinforcement learning and robotics has proven challenging. Since every robotics lab has their own hardware and experimental set-up, it is not apparent how to move towards an “ImageNet-scale” dataset for robotics that is useful for the entire research community. Hence, we propose to collect data across multiple different settings, including from varying camera viewpoints, varying environments, and even varying robot platforms. Motivated by the success of large-scale data-driven learning, we created RoboNet, an extensible and diverse dataset of robot interaction collected across fourdifferentresearchlabs. The collaborative nature of this work allows us to easily capture diverse data in various lab settings across a wide variety of objects, robotic hardware, and camera viewpoints. Finally, we find that pre-training on RoboNet offers substantial performance gains compared to training from scratch in entirely new environments.
Our goal is to pre-train reinforcement learning models on a sufficiently diverse dataset and then transfer knowledge (either zero-shot or with fine-tuning) to a different test environment.
Collecting RoboNet
RoboNet consists of 15 million video frames, collected by different robots interacting with different objects in a table-top setting. Every frame includes the image recorded by the robot’s camera, arm pose, force sensor readings, and gripper state. The collection environment, including the camera view, the appearance of the table or bin, and the objects in front of the robot are varied between trials. Since collection is entirely autonomous, large amounts can be cheaply collected across multiple institutions. A sample of RoboNet along with data statistics is shown below:
A sample of data from RoboNet alongside a summary of the current dataset. Note that any GIF compression artifacts in this animation are not present in the dataset itself.
How can we use RoboNet?
After collecting a diverse dataset, we experimentally investigate how it can be used to enable general skill learning that transfers to new environments. First, we pre-train visual dynamics models on a subset of data from RoboNet, and then fine-tune them to work in an unseen test environment using a small amount of new data. The constructed test environments (one of which is visualized below) all include different lab settings, new cameras and viewpoints, held-out robots, and novel objects purchased after data collection concluded.
Example test environment constructed in a new lab, with a temporary uncalibrated camera, and a new Baxter robot. Note that while Baxters are present in RoboNet that data is not included during model pre-training.
After tuning, we deploy the learned dynamics models in the test environment to perform control tasks – like picking and placing objects – using the visual foresight model based reinforcement learning algorithm. Below are example control tasks executed in various test environments.
Kuka can align shirts next to the others
Baxter can sweep the table with cloth
Franka can grasp and reposition the markers
Kuka can move the plate to the edge of the table
Baxter can pick up and reposition socks
Franka can stack the towel on the pile
Here you can see examples of visual foresight fine-tuned to perform basic control tasks in three entirely different environments. For the experiments, the target robot and environment was subtracted from RoboNet during pre-training. Fine-tuning was accomplished with data collected in one afternoon.
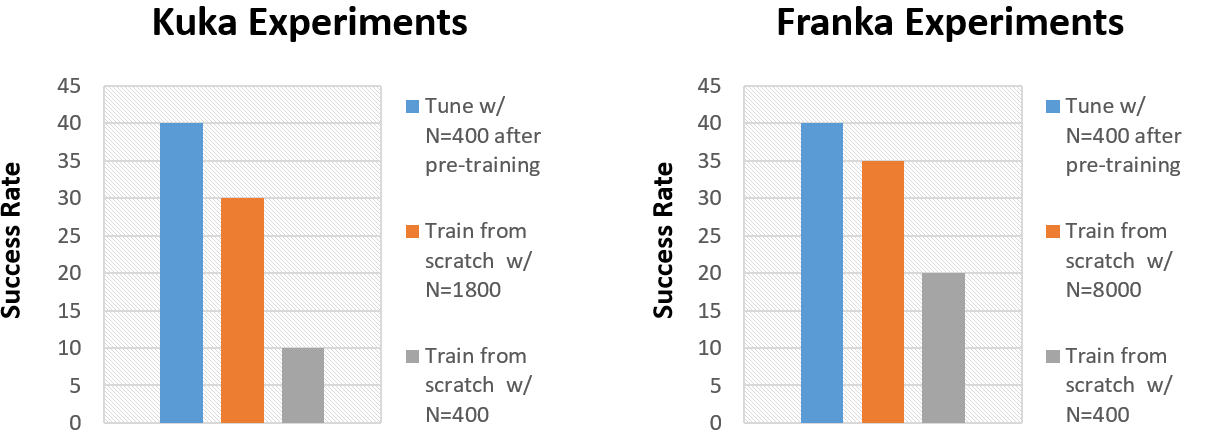
We can now numerically evaluate if our pre-trained controllers can pick up skills in new environments faster than a randomly initialized one. In each environment, we use a standard set of benchmark tasks to compare the performance of our pre-trained controller against the performance of a model trained only on data from the new environment. The results show that the fine-tuned model is ~4x more likely to complete the benchmark task than the one trained without RoboNet. Impressively, the pre-trained models can even slightly outperform models trained from scratch on significantly (5-20x) more data from the test environment. This suggests that transfer from RoboNet does indeed offer large performance gains compared to training from scratch!
We compare the performance of fine-tuned models against their counterparts trained from scratch in two different test environments (with different robot platforms).
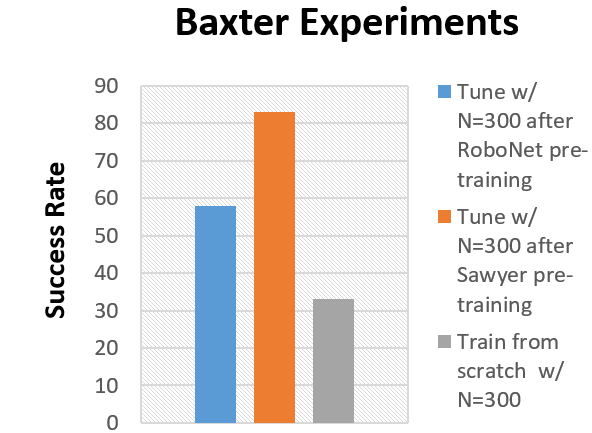
Clearly fine-tuning is better than training from scratch, but is training on all of RoboNet always the best way to go? To test this, we compare pre-training on various subsets of RoboNet versus training from scratch. As seen before, the model pre-trained on all of RoboNet (excluding the Baxter platform) performs substantially better than the random initialization model. However, the “RoboNet pre-trained” model is outperformed by a model trained on a subset of RoboNet data collected on the Sawyer robot – the single-arm variant of Baxter.
Models pre-trained on various subsets of RoboNet are compared to one trained from scratch in an unseen (during pre-training) Baxter control environment
The similarities between the Baxter and Sawyer likely partly explain our results, but why does simply adding data to the training set hurt performance after fine-tuning? We theorize that this effect occurs due to model under-fitting. In other words, RoboNet is an extremely challenging dataset for a visual dynamics model, and imperfections in the model predictions result in bad control performance. However, larger models with more parameters tend to be more powerful, and thus make better predictions on RoboNet (visualized below). Note that increasing the number of parameters greatly improves prediction quality, but even large models with 500M parameters (middle column in the videos below) are still quite blurry. This suggests ample room for improvement, and we hope that the development of newer more powerful models will translate to better control performance in the future.
We compare video prediction models of various size trained on RoboNet. A 75M parameter model (right-most column) generates significantly blurrier predictions than a large model with 500M parameters (center column).
Final Thoughts
This work takes the first step towards creating learned robotic agents that can operate in a wide range of environments and across different hardware. While our experiments primarily explore model-based reinforcement learning, we hope that RoboNet will inspire the broader robotics and reinforcement learning communities to investigate how to scale model-based or model-free RL algorithms to meet the complexity and diversity of the real world.
Since the dataset is extensible, we encourage other researchers to contribute the data generated from their experiments back into RoboNet. After all, any data containing robot telemetry and video could be useful to someone else, so long as it contains the right documentation. In the long term, we believe this process will iteratively strengthen the dataset, and thus allow our algorithms that use it to achieve greater levels of generalization across tasks, environments, robots, and experimental set-ups.
Finally, I would like to thank Sergey Levine, Chelsea Finn, and Frederik Ebert for their helpful feedback on this post, as well as the editors of the BAIR, SAIL, and CMU MLD blogs.
This blog post was based on the following paper:RoboNet: Large-Scale Multi-Robot Learning. S. Dasari, F. Ebert, S. Tian, S. Nair, B. Bucher, K. Schmeckpeper, S. Singh, S. Levine, C. Finn. In Conference on Robot Learning, 2019. (pdf)
Michael I. Jordan, Amazon Scholar and professor at the University of California, Berkeley, writes about the classical goals in human-imitative AI, and reflects on how in the current hubbub over the AI revolution it is easy to forget that these goals haven’t yet been achieved.Read More