The 2001 paper was awarded for “foundational work initiating a long and fruitful line of work in approximately revenue-optimal auction design in prior free settings”.Read More
SURE summer program to promote diversity in STEM a great success
Seventy-four percent of surveyed undergraduates in Columbia-Amazon program say it exceeded or far exceeded expectations.Read More

Announcing TensorFlow’s Kaggle Challenge to Help Protect Coral Reefs
Posted by Megha Malpani & Tim Davis, Google Product Managers
We are excited to announce a TensorFlow-sponsored Kaggle challenge to locate and identify harmful crown-of-thorns starfish (COTS), as part of a broader partnership between the Commonwealth Scientific and Industrial Research Organization (CSIRO) and Google, to help protect coral reefs everywhere.
Coral reefs are some of the most diverse and important ecosystems in the world – both for marine life and society more broadly. Not only are healthy reefs critical to fisheries and food security, they provide countless additional benefits: protecting coastlines from storm surge, supporting tourism-based economies and sustainable livelihoods, and pushing forward drug discovery research.
Reefs around the world face a number of rising threats, most notably climate change, pollution, and overfishing. In the past 30 years alone, there have been dramatic losses in coral cover and habitat in the Great Barrier Reef (GBR), with other reefs experiencing similar declines. In Australia, outbreaks of the coral-eating COTS have been shown to cause major coral loss. These outbreaks can strip a reef of 90% of its coral tissue. While COTS naturally exist in the Indo-Pacific ocean, overfishing and excess run-off nutrients have led to massive outbreaks that are devastating already vulnerable coral communities.
Controlling COTS populations is critical to reducing coral mortality from outbreaks. Google has teamed up with CSIRO to supercharge efforts in monitoring COTS using artificial intelligence. This is just the beginning of a much deeper collaboration and we, along with the Great Barrier Reef Foundation, are extremely excited to invite you, our global ML community, to help protect the world’s reefs.
We are challenging the Kaggle community to build the most accurate and performant (in terms of runtime and memory usage) crown-of-thorns starfish object detection models for image sequences. For this challenge, we are offering $150,000 in prizes to the best solutions.
We have two tiers of prizes – the first, in standard Kaggle fashion, for the most accurate models. Since we will be deploying these models on the edge, we are offering an additional prize for the most performant models (that fall in the top 10% of the accuracy leaderboard). We are looking for creative ideas on how to maximize performance while working effectively with underwater image sequences. We intend to ultimately bring the most innovative ideas together in a single model that we deploy on the Great Barrier Reef. We plan to open-source the winning model for other scientific organizations and agencies around the world to use.
This is an amazing opportunity to have a real impact protecting coral reefs everywhere! The competition is now live, so please join the challenge today and get started with this notebook. We look forward to seeing what you come up with, good luck!
Acknowledgements: Thanks to everyone whose hard work made this collaboration possible!
Google: Martin Wicke, Kemal El Moujahid, Sarah Sirajudddin, Scott Riddle, Glenn Cameron, Addison Howard, Will Cukierski, Sohier Dane, Ryan Holbrook, Khanh LeViet, Sachin Joglekar, Tei Jeong, Rachel Stiegler, Daniel Formoso, Tom Small, Ana Nieto, Arun Venkatesan
CSIRO: Jiajun Liu, Brano Kusy, Ross Marchant, David Ahmedt, Lachlan Tychsen-Smith, Joey Crosswell, Geoffrey Carlin, Russ Babcock

Predicting Text Selections with Federated Learning
Posted by Florian Hartmann, Software Engineer, Google Research
Smart Text Selection, launched in 2017 as part of Android O, is one of Android’s most frequently used features, helping users select, copy, and use text easily and quickly by predicting the desired word or set of words around a user’s tap, and automatically expanding the selection appropriately. Through this feature, selections are automatically expanded, and for selections with defined classification types, e.g., addresses and phone numbers, users are offered an app with which to open the selection, saving users even more time.
Today we describe how we have improved the performance of Smart Text Selection by using federated learning to train the neural network model on user interactions responsibly while preserving user privacy. This work, which is part of Android’s new Private Compute Core secure environment, enabled us to improve the model’s selection accuracy by up to 20% on some types of entities.
Server-Side Proxy Data for Entity Selections
Smart Text Selection, which is the same technology behind Smart Linkify, does not predict arbitrary selections, but focuses on well-defined entities, such as addresses or phone numbers, and tries to predict the selection bounds for those categories. In the absence of multi-word entities, the model is trained to only select a single word in order to minimize the frequency of making multi-word selections in error.
The Smart Text Selection feature was originally trained using proxy data sourced from web pages to which schema.org annotations had been applied. These entities were then embedded in a selection of random text, and the model was trained to select just the entity, without spilling over into the random text surrounding it.
While this approach of training on schema.org-annotations worked, it had several limitations. The data was quite different from text that we expect users see on-device. For example, websites with schema.org annotations typically have entities with more proper formatting than what users might type on their phones. In addition, the text samples in which the entities were embedded for training were random and did not reflect realistic context on-device.
On-Device Feedback Signal for Federated Learning
With this new launch, the model no longer uses proxy data for span prediction, but is instead trained on-device on real interactions using federated learning. This is a training approach for machine learning models in which a central server coordinates model training that is split among many devices, while the raw data used stays on the local device. A standard federated learning training process works as follows: The server starts by initializing the model. Then, an iterative process begins in which (a) devices get sampled, (b) selected devices improve the model using their local data, and (c) then send back only the improved model, not the data used for training. The server then averages the updates it received to create the model that is sent out in the next iteration.
For Smart Text Selection, each time a user taps to select text and corrects the model’s suggestion, Android gets precise feedback for what selection span the model should have predicted. In order to preserve user privacy, the selections are temporarily kept on the device, without being visible server-side, and are then used to improve the model by applying federated learning techniques. This technique has the advantage of training the model on the same kind of data that it sees during inference.
Federated Learning & Privacy
One of the advantages of the federated learning approach is that it enables user privacy, because raw data is not exposed to a server. Instead, the server only receives updated model weights. Still, to protect against various threats, we explored ways to protect the on-device data, securely aggregate gradients, and reduce the risk of model memorization.
The on-device code for training Federated Smart Text Selection models is part of Android’s Private Compute Core secure environment, which makes it particularly well situated to securely handle user data. This is because the training environment in Private Compute Core is isolated from the network and data egress is only allowed when federated and other privacy-preserving techniques are applied. In addition to network isolation, data in Private Compute Core is protected by policies that restrict how it can be used, thus protecting from malicious code that may have found its way onto the device.
To aggregate model updates produced by the on-device training code, we use Secure Aggregation, a cryptographic protocol that allows servers to compute the mean update for federated learning model training without reading the updates provided by individual devices. In addition to being individually protected by Secure Aggregation, the updates are also protected by transport encryption, creating two layers of defense against attackers on the network.
Finally, we looked into model memorization. In principle, it is possible for characteristics of the training data to be encoded in the updates sent to the server, survive the aggregation process, and end up being memorized by the global model. This could make it possible for an attacker to attempt to reconstruct the training data from the model. We used methods from Secret Sharer, an analysis technique that quantifies to what degree a model unintentionally memorizes its training data, to empirically verify that the model was not memorizing sensitive information. Further, we employed data masking techniques to prevent certain kinds of sensitive data from ever being seen by the model
In combination, these techniques help ensure that Federated Smart Text Selection is trained in a way that preserves user privacy.
Achieving Superior Model Quality
Initial attempts to train the model using federated learning were unsuccessful. The loss did not converge and predictions were essentially random. Debugging the training process was difficult, because the training data was on-device and not centrally collected, and so, it could not be examined or verified. In fact, in such a case, it’s not even possible to determine if the data looks as expected, which is often the first step in debugging machine learning pipelines.
To overcome this challenge, we carefully designed high-level metrics that gave us an understanding of how the model behaved during training. Such metrics included the number of training examples, selection accuracy, and recall and precision metrics for each entity type. These metrics are collected during federated training via federated analytics, a similar process as the collection of the model weights. Through these metrics and many analyses, we were able to better understand which aspects of the system worked well and where bugs could exist.
After fixing these bugs and making additional improvements, such as implementing on-device filters for data, using better federated optimization methods and applying more robust gradient aggregators, the model trained nicely.
Results
Using this new federated approach, we were able to significantly improve Smart Text Selection models, with the degree depending on the language being used. Typical improvements ranged between 5% and 7% for multi-word selection accuracy, with no drop in single-word performance. The accuracy of correctly selecting addresses (the most complex type of entity supported) increased by between 8% and 20%, again, depending on the language being used. These improvements lead to millions of additional selections being automatically expanded for users every day.
Internationalization
An additional advantage of this federated learning approach for Smart Text Selection is its ability to scale to additional languages. Server-side training required manual tweaking of the proxy data for each language in order to make it more similar to on-device data. While this only works to some degree, it takes a tremendous amount of effort for each additional language.
The federated learning pipeline, however, trains on user interactions, without the need for such manual adjustments. Once the model achieved good results for English, we applied the same pipeline to Japanese and saw even greater improvements, without needing to tune the system specifically for Japanese selections.
We hope that this new federated approach lets us scale Smart Text Selection to many more languages. Ideally this will also work without manual tuning of the system, making it possible to support even low-resource languages.
Conclusion
We developed a federated way of learning to predict text selections based on user interactions, resulting in much improved Smart Text Selection models deployed to Android users. This approach required the use of federated learning, since it works without collecting user data on the server. Additionally, we used many state-of-the-art privacy approaches, such as Android’s new Private Compute Core, Secure Aggregation and the Secret Sharer method. The results show that privacy does not have to be a limiting factor when training models. Instead, we managed to obtain a significantly better model, while ensuring that users’ data stays private.
Acknowledgements
Many people contributed to this work. We would like to thank Lukas Zilka, Asela Gunawardana, Silvano Bonacina, Seth Welna, Tony Mak, Chang Li, Abodunrinwa Toki, Sergey Volnov, Matt Sharifi, Abhanshu Sharma, Eugenio Marchiori, Jacek Jurewicz, Nicholas Carlini, Jordan McClead, Sophia Kovaleva, Evelyn Kao, Tom Hume, Alex Ingerman, Brendan McMahan, Fei Zheng, Zachary Charles, Sean Augenstein, Zachary Garrett, Stefan Dierauf, David Petrou, Vishwath Mohan, Hunter King, Emily Glanz, Hubert Eichner, Krzysztof Ostrowski, Jakub Konecny, Shanshan Wu, Janel Thamkul, Elizabeth Kemp, and everyone else involved in the project.

In MIT visit, Dropbox CEO Drew Houston ’05 explores the accelerated shift to distributed work
When the cloud storage firm Dropbox decided to shut down its offices with the outbreak of the Covid-19 pandemic, co-founder and CEO Drew Houston ’05 had to send the company’s nearly 3,000 employees home and tell them they were not coming back to work anytime soon. “It felt like I was announcing a snow day or something.”
In the early days of the pandemic, Houston says that Dropbox reacted as many others did to ensure that employees were safe and customers were taken care of. “It’s surreal, there’s no playbook for running a global company in a pandemic over Zoom. For a lot of it we were just taking it as we go.”
Houston talked about his experience leading Dropbox through a public health crisis and how Covid-19 has accelerated a shift to distributed work in a fireside chat on Oct. 14 with Dan Huttenlocher, dean of the MIT Stephen A. Schwarzman College of Computing.
During the discussion, Houston also spoke about his $10 million gift to MIT, which will endow the first shared professorship between the MIT Schwarzman College of Computing and the MIT Sloan School of Management, as well as provide a catalyst startup fund for the college.
“The goal is to find ways to unlock more of our brainpower through a multidisciplinary approach between computing and management,” says Houston. “It’s often at the intersection of these disciplines where you can bring people together from different perspectives, where you can have really big unlocks. I think academia has a huge role to play [here], and I think MIT is super well-positioned to lead. So, I want to do anything I can to help with that.”
Virtual first
While the abrupt swing to remote work was unexpected, Houston says it was pretty clear that the entire way of working as we knew it was going to change indefinitely for knowledge workers. “There’s a silver lining in every crisis,” says Houston, noting that people have been using Dropbox for years to work more flexibly so it made sense for the company to lean in and become early adopters of a distributed work paradigm in which employees work in different physical locations.
Dropbox proceeded to redesign the work experience throughout the company, unveiling a “virtual first” working model in October 2020 in which remote work is the primary experience for all employees. Individual work spaces went by the wayside and offices located in areas with a high concentration of employees were converted into convening and collaborative spaces called Dropbox Studios for in-person work with teammates.
“There’s a lot we could say about Covid, but for me, the most significant thing is that we’ll look back at 2020 as the year we shifted permanently from working out of offices to primarily working out of screens. It’s a transition that’s been underway for a while, but Covid completely finished the swing,” says Houston.
Designing for the future workplace
Houston says the pandemic also prompted Dropbox to reevaluate its product line and begin thinking of ways to make improvements. “We’ve had this whole new way of working sort of forced on us. No one designed it; it just happened. Even tools like Zoom, Slack, and Dropbox were designed in and for the old world.”
Undergoing that process helped Dropbox gain clarity on where they could add value and led to the realization that they needed to get back to their roots. “In a lot of ways, what people need today in principle is the same thing they needed in the beginning — one place for all their stuff,” says Houston.
Dropbox reoriented its product roadmap to refocus efforts from syncing files to organizing cloud content. The company is focused on building toward this new direction with the release of new automation features that users can easily implement to better organize their uploaded content and find it quickly. Dropbox also recently announced the acquisition of Command E, a universal search and productivity company, to help accelerate its efforts in this space.
Houston views Dropbox as still evolving and sees many opportunities ahead in this new era of distributed work. “We need to design better tools and smarter systems. It’s not just the individual parts, but how they’re woven together.” He’s surprised by how little intelligence is actually integrated into current systems and believes that rapid advances in AI and machine learning will soon lead to a new generation of smart tools that will ultimately reshape the nature of work — “in the same way that we had a new generation of cloud tools revolutionize how we work and had all these advantages that we couldn’t imagine not having now.”
Founding roots
Houston famously turned his frustration with carrying USB drives and emailing files to himself into a demo for what became Dropbox.
After graduating from MIT in 2005 with a bachelor’s degree in electrical engineering and computer science, he teamed up with fellow classmate Arash Ferdowsi to found Dropbox in 2007 and led the company’s growth from a simple idea to a service used by 700 million people around the world today.
Houston credits MIT for preparing him well for his entrepreneurial journey, recalling that what surprised him most about his student experience was how much he learned outside the classroom. At the event, he stressed the importance of developing both sides of the brain to a select group of computer science and management students who were in attendance, and a broader live stream audience. “One thing you learn about starting a company is that the hardest problems are usually not technical problems; they’re people problems.” He says that he didn’t realize it at the time, but some of his first lessons in management were gained by taking on responsibilities in his fraternity and in various student organizations that evoked a sense of being “on the hook.”
As CEO, Houston has had a chance to look behind the curtain at how things happen and has come to appreciate that problems don’t solve themselves. While individual people can make a huge difference, he explains that many of the challenges the world faces right now are inherently multidisciplinary ones, which sparked his interest in the MIT Schwarzman College of Computing.
He says that the mindset embodied by the college to connect computing with other disciplines resonated and inspired him to initiate his biggest philanthropic effort to date sooner rather than later because “we don’t have that much time to address these problems.”
Finding critical information during disasters
Lise St. Denis, a research scientist at the University of Colorado, says social media can be useful for responders. Now she’s helping them separate truly useful info from the noise.Read More
Decisiveness in Imitation Learning for Robots
Posted by Pete Florence, Research Scientist and Corey Lynch, Research Engineer, Robotics at Google
Despite considerable progress in robot learning over the past several years, some policies for robotic agents can still struggle to decisively choose actions when trying to imitate precise or complex behaviors. Consider a task in which a robot tries to slide a block across a table to precisely position it into a slot. There are many possible ways to solve this task, each requiring precise movements and corrections. The robot must commit to just one of these options, but must also be capable of changing plans each time the block ends up sliding farther than expected. Although one might expect such a task to be easy, that is often not the case for modern learning-based robots, which often learn behavior that expert observers describe as indecisive or imprecise.
| Example of a baseline explicit behavior cloning model struggling on a task where the robot needs to slide a block across a table and then precisely insert it into a fixture. |
To encourage robots to be more decisive, researchers often utilize a discretized action space, which forces the robot to choose option A or option B, without oscillating between options. For example, discretization was a key element of our recent Transporter Networks architecture, and is also inherent in many notable achievements by game-playing agents, such as AlphaGo, AlphaStar, and OpenAI’s Dota bot. But discretization brings its own limitations — for robots that operate in the spatially continuous real world, there are at least two downsides to discretization: (i) it limits precision, and (ii) it triggers the curse of dimensionality, since considering discretizations along many different dimensions can dramatically increase memory and compute requirements. Related to this, in 3D computer vision much recent progress has been powered by continuous, rather than discretized, representations.
With the goal of learning decisive policies without the drawbacks of discretization, today we announce our open source implementation of Implicit Behavioral Cloning (Implicit BC), which is a new, simple approach to imitation learning and was presented last week at CoRL 2021. We found that Implicit BC achieves strong results on both simulated benchmark tasks and on real-world robotic tasks that demand precise and decisive behavior. This includes achieving state-of-the-art (SOTA) results on human-expert tasks from our team’s recent benchmark for offline reinforcement learning, D4RL. On six out of seven of these tasks, Implicit BC outperforms the best previous method for offline RL, Conservative Q Learning. Interestingly, Implicit BC achieves these results without requiring any reward information, i.e., it can use relatively simple supervised learning rather than more-complex reinforcement learning.
Implicit Behavioral Cloning
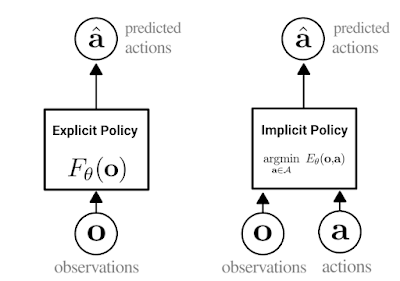
Our approach is a type of behavior cloning, which is arguably the simplest way for robots to learn new skills from demonstrations. In behavior cloning, an agent learns how to mimic an expert’s behavior using standard supervised learning. Traditionally, behavior cloning involves training an explicit neural network (shown below, left), which takes in observations and outputs expert actions.
The key idea behind Implicit BC is to instead train a neural network to take in both observations and actions, and output a single number that is low for expert actions and high for non-expert actions (below, right), turning behavioral cloning into an energy-based modeling problem. After training, the Implicit BC policy generates actions by finding the action input that has the lowest score for a given observation.
|
| Depiction of the difference between explicit (left) and implicit (right) policies. In the implicit policy, the “argmin” means the action that, when paired with a particular observation, minimizes the value of the energy function. |
To train Implicit BC models, we use an InfoNCE loss, which trains the network to output low energy for expert actions in the dataset, and high energy for all others (see below). It is interesting to note that this idea of using models that take in both observations and actions is common in reinforcement learning, but not so in supervised policy learning.
| Animation of how implicit models can fit discontinuities — in this case, training an implicit model to fit a step (Heaviside) function. Left: 2D plot fitting the black (X) training points — the colors represent the values of the energies (blue is low, brown is high). Middle: 3D plot of the energy model during training. Right: Training loss curve. |
Once trained, we find that implicit models are particularly good at precisely modeling discontinuities (above) on which prior explicit models struggle (as in the first figure of this post), resulting in policies that are newly capable of switching decisively between different behaviors.
But why do conventional explicit models struggle? Modern neural networks almost always use continuous activation functions — for example, Tensorflow, Jax, and PyTorch all only ship with continuous activation functions. In attempting to fit discontinuous data, explicit networks built with these activation functions cannot represent discontinuities, so must draw continuous curves between data points. A key aspect of implicit models is that they gain the ability to represent sharp discontinuities, even though the network itself is composed only of continuous layers.
We also establish theoretical foundations for this aspect, specifically a notion of universal approximation. This proves the class of functions that implicit neural networks can represent, which can help justify and guide future research.
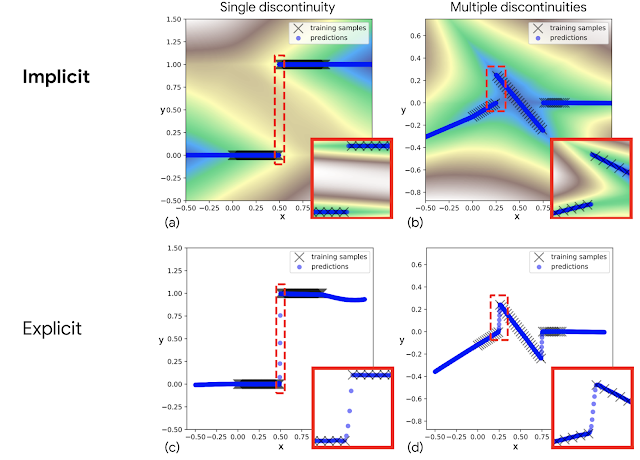 |
| Examples of fitting discontinuous functions, for implicit models (top) compared to explicit models (bottom). The red highlighted insets show that implicit models represent discontinuities (a) and (b) while the explicit models must draw continuous lines (c) and (d) in between the discontinuities. |
One challenge faced by our initial attempts at this approach was “high action dimensionality”, which means that a robot must decide how to coordinate many motors all at the same time. To scale to high action dimensionality, we use either autoregressive models or Langevin dynamics.
Highlights
In our experiments, we found Implicit BC does particularly well in the real world, including an order of magnitude (10x) better on the 1mm-precision slide-then-insert task compared to a baseline explicit BC model. On this task the implicit model does several consecutive precise adjustments (below) before sliding the block into place. This task demands multiple elements of decisiveness: there are many different possible solutions due to the symmetry of the block and the arbitrary ordering of push maneuvers, and the robot needs to discontinuously decide when the block has been pushed far “enough” before switching to slide it in a different direction. This is in contrast to the indecisiveness that is often associated with continuous-controlled robots.
| Example task of sliding a block across a table and precisely inserting it into a slot. These are autonomous behaviors of our Implicit BC policies, using only images (from the shown camera) as input. |
| A diverse set of different strategies for accomplishing this task. These are autonomous behaviors from our Implicit BC policies, using only images as input. |
In another challenging task, the robot needs to sort blocks by color, which presents a large number of possible solutions due to the arbitrary ordering of sorting. On this task the explicit models are customarily indecisive, while implicit models perform considerably better.
| Comparison of implicit (left) and explicit (right) BC models on a challenging continuous multi-item sorting task. (4x speed) |
In our testing, implicit BC models can also exhibit robust reactive behavior, even when we try to interfere with the robot, despite the model never seeing human hands.
| Robust behavior of the implicit BC model despite interfering with the robot. |
Overall, we find that Implicit BC policies can achieve strong results compared to state of the art offline reinforcement learning methods across several different task domains. These results include tasks that, challengingly, have either a low number of demonstrations (as few as 19), high observation dimensionality with image-based observations, and/or high action dimensionality up to 30 — which is a large number of actuators to have on a robot.
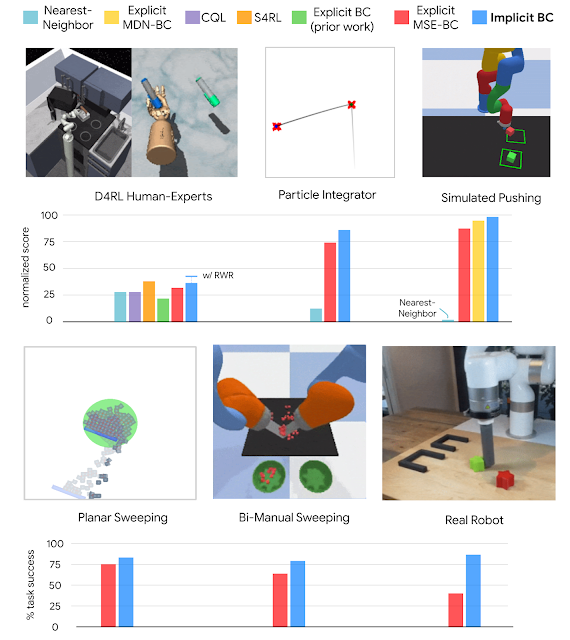 |
| Policy learning results of Implicit BC compared to baselines across several domains. |
Conclusion
Despite its limitations, behavioral cloning with supervised learning remains one of the simplest ways for robots to learn from examples of human behaviors. As we showed here, replacing explicit policies with implicit policies when doing behavioral cloning allows robots to overcome the “struggle of decisiveness”, enabling them to imitate much more complex and precise behaviors. While the focus of our results here was on robot learning, the ability of implicit functions to model sharp discontinuities and multimodal labels may have broader interest in other application domains of machine learning as well.
Acknowledgements
Pete and Corey summarized research performed together with other co-authors: Andy Zeng, Oscar Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, and Jonathan Tompson. The authors would also like to thank Vikas Sindwhani for project direction advice; Steve Xu, Robert Baruch, Arnab Bose for robot software infrastructure; Jake Varley, Alexa Greenberg for ML infrastructure; and Kamyar Ghasemipour, Jon Barron, Eric Jang, Stephen Tu, Sumeet Singh, Jean-Jacques Slotine, Anirudha Majumdar, Vincent Vanhoucke for helpful feedback and discussions.
Design’s new frontier
In the 1960s, the advent of computer-aided design (CAD) sparked a revolution in design. For his PhD thesis in 1963, MIT Professor Ivan Sutherland developed Sketchpad, a game-changing software program that enabled users to draw, move, and resize shapes on a computer. Over the course of the next few decades, CAD software reshaped how everything from consumer products to buildings and airplanes were designed.
“CAD was part of the first wave in computing in design. The ability of researchers and practitioners to represent and model designs using computers was a major breakthrough and still is one of the biggest outcomes of design research, in my opinion,” says Maria Yang, Gail E. Kendall Professor and director of MIT’s Ideation Lab.
Innovations in 3D printing during the 1980s and 1990s expanded CAD’s capabilities beyond traditional injection molding and casting methods, providing designers even more flexibility. Designers could sketch, ideate, and develop prototypes or models faster and more efficiently. Meanwhile, with the push of a button, software like that developed by Professor Emeritus David Gossard of MIT’s CAD Lab could solve equations simultaneously to produce a new geometry on the fly.
In recent years, mechanical engineers have expanded the computing tools they use to ideate, design, and prototype. More sophisticated algorithms and the explosion of machine learning and artificial intelligence technologies have sparked a second revolution in design engineering.
Researchers and faculty at MIT’s Department of Mechanical Engineering are utilizing these technologies to re-imagine how the products, systems, and infrastructures we use are designed. These researchers are at the forefront of the new frontier in design.
Computational design
Faez Ahmed wants to reinvent the wheel, or at least the bicycle wheel. He and his team at MIT’s Design Computation & Digital Engineering Lab (DeCoDE) use an artificial intelligence-driven design method that can generate entirely novel and improved designs for a range of products — including the traditional bicycle. They create advanced computational methods to blend human-driven design with simulation-based design.
“The focus of our DeCoDE lab is computational design. We are looking at how we can create machine learning and AI algorithms to help us discover new designs that are optimized based on specific performance parameters,” says Ahmed, an assistant professor of mechanical engineering at MIT.
For their work using AI-driven design for bicycles, Ahmed and his collaborator Professor Daniel Frey wanted to make it easier to design customizable bicycles, and by extension, encourage more people to use bicycles over transportation methods that emit greenhouse gases.
To start, the group gathered a dataset of 4,500 bicycle designs. Using this massive dataset, they tested the limits of what machine learning could do. First, they developed algorithms to group bicycles that looked similar together and explore the design space. They then created machine learning models that could successfully predict what components are key in identifying a bicycle style, such as a road bike versus a mountain bike.
Once the algorithms were good enough at identifying bicycle designs and parts, the team proposed novel machine learning tools that could use this data to create a unique and creative design for a bicycle based on certain performance parameters and rider dimensions.
Ahmed used a generative adversarial network — or GAN — as the basis of this model. GAN models utilize neural networks that can create new designs based on vast amounts of data. However, using GAN models alone would result in homogeneous designs that lack novelty and can’t be assessed in terms of performance. To address these issues in design problems, Ahmed has developed a new method which he calls “PaDGAN,” performance augmented diverse GAN.
“When we apply this type of model, what we see is that we can get large improvements in the diversity, quality, as well as novelty of the designs,” Ahmed explains.
Using this approach, Ahmed’s team developed an open-source computational design tool for bicycles freely available on their lab website. They hope to further develop a set of generalizable tools that can be used across industries and products.
Longer term, Ahmed has his sights set on loftier goals. He hopes the computational design tools he develops could lead to “design democratization,” putting more power in the hands of the end user.
“With these algorithms, you can have more individualization where the algorithm assists a customer in understanding their needs and helps them create a product that satisfies their exact requirements,” he adds.
Using algorithms to democratize the design process is a goal shared by Stefanie Mueller, an associate professor in electrical engineering and computer science and mechanical engineering.
Personal fabrication
Platforms like Instagram give users the freedom to instantly edit their photographs or videos using filters. In one click, users can alter the palette, tone, and brightness of their content by applying filters that range from bold colors to sepia-toned or black-and-white. Mueller, X-Window Consortium Career Development Professor, wants to bring this concept of the Instagram filter to the physical world.
“We want to explore how digital capabilities can be applied to tangible objects. Our goal is to bring reprogrammable appearance to the physical world,” explains Mueller, director of the HCI Engineering Group based out of MIT’s Computer Science and Artificial Intelligence Laboratory.
Mueller’s team utilizes a combination of smart materials, optics, and computation to advance personal fabrication technologies that would allow end users to alter the design and appearance of the products they own. They tested this concept in a project they dubbed “Photo-Chromeleon.”
First, a mix of photochromic cyan, magenta, and yellow dies are airbrushed onto an object — in this instance, a 3D sculpture of a chameleon. Using software they developed, the team sketches the exact color pattern they want to achieve on the object itself. An ultraviolet light shines on the object to activate the dyes.
To actually create the physical pattern on the object, Mueller has developed an optimization algorithm to use alongside a normal office projector outfitted with red, green, and blue LED lights. These lights shine on specific pixels on the object for a given period of time to physically change the makeup of the photochromic pigments.
“This fancy algorithm tells us exactly how long we have to shine the red, green, and blue light on every single pixel of an object to get the exact pattern we’ve programmed in our software,” says Mueller.
Giving this freedom to the end user enables limitless possibilities. Mueller’s team has applied this technology to iPhone cases, shoes, and even cars. In the case of shoes, Mueller envisions a shoebox embedded with UV and LED light projectors. Users could put their shoes in the box overnight and the next day have a pair of shoes in a completely new pattern.
Mueller wants to expand her personal fabrication methods to the clothes we wear. Rather than utilize the light projection technique developed in the PhotoChromeleon project, her team is exploring the possibility of weaving LEDs directly into clothing fibers, allowing people to change their shirt’s appearance as they wear it. These personal fabrication technologies could completely alter consumer habits.
“It’s very interesting for me to think about how these computational techniques will change product design on a high level,” adds Mueller. “In the future, a consumer could buy a blank iPhone case and update the design on a weekly or daily basis.”
Computational fluid dynamics and participatory design
Another team of mechanical engineers, including Sili Deng, the Brit (1961) & Alex (1949) d’Arbeloff Career Development Professor, are developing a different kind of design tool that could have a large impact on individuals in low- and middle-income countries across the world.
As Deng walked down the hallway of Building 1 on MIT’s campus, a monitor playing a video caught her eye. The video featured work done by mechanical engineers and MIT D-Lab on developing cleaner burning briquettes for cookstoves in Uganda. Deng immediately knew she wanted to get involved.
“As a combustion scientist, I’ve always wanted to work on such a tangible real-world problem, but the field of combustion tends to focus more heavily on the academic side of things,” explains Deng.
After reaching out to colleagues in MIT D-Lab, Deng joined a collaborative effort to develop a new cookstove design tool for the 3 billion people across the world who burn solid fuels to cook and heat their homes. These stoves often emit soot and carbon monoxide, leading not only to millions of deaths each year, but also worsening the world’s greenhouse gas emission problem.
The team is taking a three-pronged approach to developing this solution, using a combination of participatory design, physical modeling, and experimental validation to create a tool that will lead to the production of high-performing, low-cost energy products.
Deng and her team in the Deng Energy and Nanotechnology Group use physics-based modeling for the combustion and emission process in cookstoves.
“My team is focused on computational fluid dynamics. We use computational and numerical studies to understand the flow field where the fuel is burned and releases heat,” says Deng.
These flow mechanics are crucial to understanding how to minimize heat loss and make cookstoves more efficient, as well as learning how dangerous pollutants are formed and released in the process.
Using computational methods, Deng’s team performs three-dimensional simulations of the complex chemistry and transport coupling at play in the combustion and emission processes. They then use these simulations to build a combustion model for how fuel is burned and a pollution model that predicts carbon monoxide emissions.
Deng’s models are used by a group led by Daniel Sweeney in MIT D-Lab to test the experimental validation in prototypes of stoves. Finally, Professor Maria Yang uses participatory design methods to integrate user feedback, ensuring the design tool can actually be used by people across the world.
The end goal for this collaborative team is to not only provide local manufacturers with a prototype they could produce themselves, but to also provide them with a tool that can tweak the design based on local needs and available materials.
Deng sees wide-ranging applications for the computational fluid dynamics her team is developing.
“We see an opportunity to use physics-based modeling, augmented with a machine learning approach, to come up with chemical models for practical fuels that help us better understand combustion. Therefore, we can design new methods to minimize carbon emissions,” she adds.
While Deng is utilizing simulations and machine learning at the molecular level to improve designs, others are taking a more macro approach.
Designing intelligent systems
When it comes to intelligent design, Navid Azizan thinks big. He hopes to help create future intelligent systems that are capable of making decisions autonomously by using the enormous amounts of data emerging from the physical world. From smart robots and autonomous vehicles to smart power grids and smart cities, Azizan focuses on the analysis, design, and control of intelligent systems.
Achieving such massive feats takes a truly interdisciplinary approach that draws upon various fields such as machine learning, dynamical systems, control, optimization, statistics, and network science, among others.
“Developing intelligent systems is a multifaceted problem, and it really requires a confluence of disciplines,” says Azizan, assistant professor of mechanical engineering with a dual appointment in MIT’s Institute for Data, Systems, and Society (IDSS). “To create such systems, we need to go beyond standard approaches to machine learning, such as those commonly used in computer vision, and devise algorithms that can enable safe, efficient, real-time decision-making for physical systems.”
For robot control to work in the complex dynamic environments that arise in the real world, real-time adaptation is key. If, for example, an autonomous vehicle is going to drive in icy conditions or a drone is operating in windy conditions, they need to be able to adapt to their new environment quickly.
To address this challenge, Azizan and his collaborators at MIT and Stanford University have developed a new algorithm that combines adaptive control, a powerful methodology from control theory, with meta learning, a new machine learning paradigm.
“This ‘control-oriented’ learning approach outperforms the existing ‘regression-oriented’ methods, which are mostly focused on just fitting the data, by a wide margin,” says Azizan.
Another critical aspect of deploying machine learning algorithms in physical systems that Azizan and his team hope to address is safety. Deep neural networks are a crucial part of autonomous systems. They are used for interpreting complex visual inputs and making data-driven predictions of future behavior in real time. However, Azizan urges caution.
“These deep neural networks are only as good as their training data, and their predictions can often be untrustworthy in scenarios not covered by their training data,” he says. Making decisions based on such untrustworthy predictions could lead to fatal accidents in autonomous vehicles or other safety-critical systems.
To avoid these potentially catastrophic events, Azizan proposes that it is imperative to equip neural networks with a measure of their uncertainty. When the uncertainty is high, they can then be switched to a “safe policy.”
In pursuit of this goal, Azizan and his collaborators have developed a new algorithm known as SCOD — Sketching Curvature of Out-of-Distribution Detection. This framework could be embedded within any deep neural network to equip them with a measure of their uncertainty.
“This algorithm is model-agnostic and can be applied to neural networks used in various kinds of autonomous systems, whether it’s drones, vehicles, or robots,” says Azizan.
Azizan hopes to continue working on algorithms for even larger-scale systems. He and his team are designing efficient algorithms to better control supply and demand in smart energy grids. According to Azizan, even if we create the most efficient solar panels and batteries, we can never achieve a sustainable grid powered by renewable resources without the right control mechanisms.
Mechanical engineers like Ahmed, Mueller, Deng, and Azizan serve as the key to realizing the next revolution of computing in design.
“MechE is in a unique position at the intersection of the computational and physical worlds,” Azizan says. “Mechanical engineers build a bridge between theoretical, algorithmic tools and real, physical world applications.”
Sophisticated computational tools, coupled with the ground truth mechanical engineers have in the physical world, could unlock limitless possibilities for design engineering, well beyond what could have been imagined in those early days of CAD.
Amazon releases dataset to help detect counterfactual phrases
Identifying descriptions of events that did not take place in product reviews improves product retrieval results.Read More